1. Introduction
Healthcare providers rely on patient feedback to improve the patient experience and enhance satisfaction, as it is one of the core indicators used to measure the quality of service and success of healthcare providers. One of the traditional ways to collect patient feedback is through surveys; however, the results are sometimes skewed towards indicating high satisfaction levels. This issue results from patients’ unwillingness to criticize healthcare services and is partially due to the design of the surveys. Therefore, using methods that allow patients to describe their experiences of healthcare services from their own perspective typically gives a more realistic view [
1]. Social media platforms (e.g., Twitter and Google Maps) could be valuable information sources, as patients tend to freely express their feelings and opinions about healthcare services, including their feedback on the healthcare provider, doctors, treatment, prices, and appointments.
AlMuhaideb et al. [
2] collected a dataset comprising patient experiences in Arabic from the Twitter platform and conducted sentiment analysis using a deep learning model. However, sentiments were analyzed with respect to the healthcare service as a whole, which cannot accurately reflect the specific aspects mentioned by the patient, mainly as a tweet can express different opinions towards different aspects. Aspect-based sentiment analysis is an effective tool for identifying the aspects discussed in a given text and determining the opinions or sentiments of these identified aspects. Therefore, the results obtained from aspect-based sentiment analysis are helpful for both patients in choosing healthcare providers and healthcare providers in enhancing the patient experience. Despite the crucial need for such advanced analyses, only a few studies have explored the use of aspect-based sentiment analysis in the healthcare domain, especially with respect to the Arabic literature. Therefore, in the study reported herein, the authors seek to classify sentiments on a more fine-grained level through the use of aspect-based sentiment analysis, which aims to extract the aspects and their related polarities from the patient experience, thus providing a comprehensive view of the strengths and weaknesses of the provided healthcare service and enabling the healthcare provider to make targeted improvements.
The task of aspect-based sentiment analysis can be divided into four sub-tasks [
3]: aspect term extraction, aspect term polarity, aspect category detection, and aspect category polarity. Aspect term extraction is the task of identifying all aspect terms present in a given text. Aspect term polarity is the task of determining the polarity of each aspect term presented in a given text, assuming that the present aspect terms are provided. Aspect category detection is the task of identifying the aspect categories discussed in a given text from a pre-defined list of aspect categories. Aspect category polarity is the task of determining the polarity of each discussed category in a given text. This work focuses on two aspect-based sentiment analysis sub-tasks—namely, aspect category detection and aspect category polarity—which involve identifying the aspect categories discussed in a given text from a pre-defined list of aspect categories and determining the polarity of each. The word detection in this context implies recognizing the presence of a label. As the text may include more than one aspect category, this problem can be considered a multi-label classification problem.
The authors aimed to answer the following research questions: (1) What are patients’ attitudes towards different aspects of the healthcare services provided in Saudi Arabia? (2) How accurate are shallow machine learning classifiers using BERT as word embeddings in the aspect category detection and polarity sub-tasks? (3) How well do generative models (i.e., GPT-4) perform in aspect-based sentiment analysis, compared with BERT-based models?
In summary, the anticipated contributions of the manuscript are as follows:
Introduction of a Novel Arabic Patient Experience Dataset: The study introduces a Google Maps-based dataset of Arabic patient reviews on healthcare providers in Saudi Arabia (i.e., Hospital Experiences Arabic Reviews; HEAR) and annotates the HoPE-SA dataset for aspect detection and polarity tasks.
Comparative Study of BERT-based Models with Machine Learning Classifiers: The study evaluates fine-tuned BERT models with traditional classifiers (Support Vector Machine (SVM) [
4], Random Forest (RF) [
5], and neural networks [
6]) for aspect-based sentiment analysis.
Performance Analysis of Joint and Two-Stage Models: The study compares joint and two-stage models, as well as GPT-4, revealing that the joint model significantly outperforms the two-stage approach and slightly surpasses GPT-4 in aspect detection and sentiment polarity tasks.
The rest of this paper is organized as follows:
Section 2 presents the related work in the field of aspect-based sentiment analysis.
Section 3 provides a detailed description of the process of collecting, annotating, and analyzing Arabic tweets and reviews with respect to several aspects. The results and findings are presented and discussed in
Section 5 and
Section 6, and the paper is concluded in
Section 7.
2. Related Work
2.1. Classical Machine Learning Approaches
Alassaf et al. [
7] adopted classical machine learning methods for aspect-based sentiment analysis, for which they collected Arabic tweets related to the education sector in Saudi Arabia to perform aspect-based sentiment analysis. They used the Term Frequency–Inverse Document Frequency (TF-IDF) feature extraction method, a hybrid feature selection method consisting of one-way ANOVA based on F-values and regularization, and a Support Vector Machine (SVM) [
4] for the classification task. The use of a hybrid feature selection method enhanced the model’s performance and its ability to overcome the high-dimensionality problem in text classification. However, the dataset used in this study was limited to one university in Saudi Arabia. Almasaud et al. [
8] created an Arabic multi-aspect and multi-sentiment dataset of Google Maps restaurant reviews. They used four machine learning models: Naïve Bayes (NB), Support Vector Classification (SVC), linear SVC, and Stochastic Gradient Descent (SGD) [
9]. The best results were achieved by the SVC and linear SVC models. The machine learning-based approaches in the mentioned studies relied on hand-crafted features, which are surpassed by the state-of-the-art automatic feature extraction empowered by deep learning methods.
2.2. Convolutional and Recurrent Neural Network Approaches
For aspect term-related tasks, Al-Smadi et al. [
10] proposed two models based on Long Short-Term Memory (LSTM) [
11] to solve Arabic aspect term extraction and polarity separately. The aspect extraction model consists of three layers: an embedding layer using Word2vec [
12] and FastText [
13], a Bidirectional Long Short-Term Memory (BiLSTM) layer, and a Conditional Random Fields (CRFs) [
14] layer. Meanwhile, the sentiment polarity model consists of LSTM, attention, and Softmax layers. They evaluated the proposed model on the Arabic Hotel Reviews dataset part of the SemEval 2016 Task 5 dataset. The results showed that using FastText character embeddings yielded better results, compared to Word2vec word embeddings. In contrast, Kuppusamy et al. [
15] proposed a hybrid deep learning model that jointly tackles the aspect term extraction and polarity tasks by concatenating Convolutional Neural Networks (CNNs) [
16] and BiLSTM models. Han et al. [
17] utilized Bidirectional Gated Recurrent Units (BiGRUs) to perform aspect term polarity assessment for drug reviews. They proposed a pre-training and multi-task learning model based on double BiGRU and a dataset called SentiDrugs. The proposed model is divided into an embedding layer, double BiGRU layer, attention layer, and Softmax layer. They constructed the SentiDrugs dataset by randomly selecting 4200 reviews shorter than 200 words on the effectiveness and side effects from Druglib.com. The results showed that the proposed model outperformed the baseline methods, including LSTM and BiGRU.
For aspect category-related tasks, Sivakumar et al. [
18] proposed the use of an LSTM with a fuzzy logic model to classify consumer review sentences under various aspects with four different labels, namely, highly negative, negative, positive, and highly positive. Initially, the dataset was grouped according to geographical location. The proposed model was trained and tested separately for every dataset, based on country. Records from only the most recent three years were considered for training and testing the developed system. Thus, the current trends can also be considered for making decisions on input customer reviews. Word embedding using Continuous Bag of Words (CBOW) [
12] was used to extract aspects from sentences. The sentiment score was generated using an LSTM, following which the score was passed to the fuzzy logic system for classification into one of four categories. Gao et al. [
19] constructed a hybrid model consisting of a CNN and a BiGRU for Chinese aspect category detection and polarity. The use of BiGRU, along with a CNN, alleviated the vanishing gradient problem and enhanced the model’s ability to learn sequence information.
Al-Dabet et al. [
20] proposed two deep learning models to address the Arabic aspect category detection and polarity tasks separately. The aspect category detection model is decomposed into independent binary classifiers, each trained on a single aspect category. It consists of a CNN and a stacked independent LSTM [
21]. The aspect category polarity model consists of five primary modules: an input module (skip-gram for character level and CBOW for word level), a stacked bidirectional independent LSTM module, a position-weighting mechanism module, a multiple attention mechanism module, and an output module. They conducted experiments on the Arabic Hotel Reviews dataset, part of the SemEval 2016 Task 5 dataset, and the results demonstrated that the proposed models outperformed the baseline and other models, with the first model achieving an F1 measure of 58.08%, and the second model achieving an accuracy measure of 87.31%.
2.3. Transformer-Based Approaches
For aspect term-related tasks, Apostol et al. [
22] proposed a heterogeneous ensemble model to solve English aspect-based sentiment analysis in terms of two sub-tasks: aspect term extraction and aspect term polarity. The proposed model consists of a linear model, BiLSTM, CNN-BiLSTM, and pre-trained and fine-tuned Bidirectional Embedding Representations from Transformers (BERT) [
23] and Bidirectional and Auto-Regressive Transformers (BART) [
24] as word embeddings. They evaluated the proposed model on the SemEval 2016 Task 5 Restaurants dataset and the Multi-Aspect Multi Sentiment dataset. The accuracies for the task of aspect term extraction were 99.96% and 99.95% for the two datasets, respectively. For the aspect term polarity task, the accuracies were 99.74% and 99.87% for the two datasets, respectively. To solve the problem of aspect detection and sentiment classification jointly, Rani et al. [
25] proposed a multi-task learning-based dual BiLSTM model for aspect-based sentiment analysis of drug reviews. The first layer of the proposed model includes contextual embeddings initialized using BERT, and aspect-specific representations are generated by multi-head self-attention to emphasize different parts of the input sequence. The second layer of the model consists of a dual BiLSTM—one for the BERT embeddings and the other for aspect-specific representations. The final layer of the model is the Softmax layer for the classification task.
Similarly, Chouikhi et al. [
26] utilized transfer learning for Arabic aspect-based sentiment analysis. They used an Arabic-based BERT stacked with a CRF layer. They used an annotation scheme that considers the aspect term and its polarity, and jointly solved the aspect term extraction and aspect term polarity. This model benefits from the characteristics of CRF, which can provide certain constraints on the output label that adhere to the labeling scheme. Furthermore, Li et al. [
27] formulated the problem of aspect term extraction and aspect term polarity as a sequence labeling problem and solved both tasks jointly. They used BERT as word embeddings along with four different models in the classification layer: a fully connected layer, Gated Recurrent Units (GRUs) [
28], a self-attention network, and a CRF. The results on the SemEval 2014 Task 4 dataset showed that the best results were achieved by GRU, with an F1-score of 61.12%.
Abdelgwad et al. [
29] explored the Arabic aspect term polarity as a sentence-pair problem. They proposed an Arabic BERT-based model with a linear classification layer. The model receives two sentences—the review sentence and the aspect terms—and the task is to determine the sentiments towards each aspect. Their results demonstrated that the proposed model achieved better results than many previous Arabic deep learning models through simply adding a linear layer on top of BERT. Fadel et al. [
30] proposed an Arabic aspect term extraction model using a stacked embeddings layer consisting of AraBERT [
31] and Flair [
32] embeddings, stacked Recurrent Neural Network (RNN)-based models [
33], and CRF layers. They employed two versions of the model using BiLSTM and BiGRU. The results indicated that the BiLSTM version of the model outperformed BiGRU.
For aspect category-related tasks, Chang et al. [
34] jointly tackled aspect category extraction and polarity, where they investigated customer satisfaction through aspect-level sentiment analysis and visual analytics. They collected flight reviews from Tripadvisor.com in order to measure the impact of COVID-19 on passenger travel sentiments in several aspects. They selected the top 12 airlines from Tripadvisor.com and collected their reviews from January 2016 to August 2020. They split the reviews into two groups: before and during the pandemic. They then classified the reviews based on the star ratings of eight aspect categories into negative (1–3) or positive (4–5). They used BERT followed by multi-head attention and a fully connected layer. The model achieved a 60% F1-score across the eight aspect categories. Meanwhile, Hoang et al. [
35] proposed three models for aspect category detection and aspect category polarity. The first model is the aspect category classifier, which predicts whether the aspect is related to the text. The second model is the sentiment classifier, which predicts the sentiment polarity of the text and aspect. The third is a combined model that takes the text and aspect as inputs and predicts the polarity if the aspect is related. All three proposed models used BERT and formulated the problem as sentence-pair classification. The results showed that the aspect classifier outperformed the combined classifier, whereas the combined classifier outperformed the sentiment analysis.
One of the challenges faced when conducting aspect-based sentiment analysis is the limited availability of labeled data points as highlighted by Shim et al. [
36], who proposed a label-efficient training scheme to overcome this challenge. For the construction of an auxiliary sentence, Sun et al. [
37] investigated four methods to construct an auxiliary sentence and transform aspect-based sentiment analysis into a sentence-pair classification task. They fine-tuned the pre-trained BERT model on an aspect-based sentiment analysis task with a classification layer and Softmax function. They evaluated the model on the SemEval 2014 Task 4 dataset, and the results showed that the BERT pair outperformed the single BERT model. Li et al. [
38] utilized two methods to construct an auxiliary sentence and used a gating mechanism with context-aware aspect embeddings to enhance and control the BERT representation for aspect-based sentiment analysis. The main idea of context-aware embeddings is to select highly correlated words from the context. The gating layer controls the propagation of sentiment features from the BERT representation with context-aware embeddings. The results showed that using context-aware embeddings enhances the model performance. Additionally, the use of the BERT pair outperformed the single BERT.
For aspect term and category-related tasks, Al-jarrah et al. [
39] performed Arabic aspect term extraction, aspect category detection, and aspect term polarity. They collected and annotated Arabic tweets about food delivery service reviews with different Arabic dialects for aspect-based sentiment analysis. They used two deep learning models (BiLSTM-CRF and LSTM), two transformer-based models (GigaBERT [
40] and AraBERT), and a classical machine learning model (SVM with TF-IDF) for feature extraction. The results demonstrated that the transformer-based models outperformed the other models, as AraBERT and GigaBERT have been pre-trained on a large amount of data, thus enhancing the learned language representation. Bensoltane et al. [
41] performed Arabic aspect term extraction and aspect category detection. For the aspect term extraction, they used four models: AraBERT with linear layer, AraBERT with CRF layer, AraBERT with BiLSTM and CRF, and AraBERT with BiGRU and CRF. They used two approaches based on the BERT model for aspect category detection, where the first approach uses a fine-tuned AraBERT model, while the second uses AraBERT as a word embedding with CNN model. For the fine-tuning approach, they explored single-sentence classification and sentence-pair classification. Their results showed that AraBERT with BiGRU and CRF outperformed the other three models in the aspect term extraction task. For aspect category detection, AraBERT fine-tuned with sentence-pair classification outperformed other models. Furthermore, their results revealed that fine-tuning is suitable in the case of limited available data. Moreover, this work focused on extracting and detecting terms and categories but did not analyze the polarity of these terms and categories.
2.4. Critical Analysis
Based on the above-mentioned studies—except for that of Shim et al. [
36], who performed English aspect category detection and polarity for healthcare-related program reviews—no study has explored the use of aspect-based sentiment analysis in the healthcare domain, especially in the context of the Arabic literature.
Based on those studies that explored the aspect term-related tasks, the studies that only involved the aspect term polarity task demonstrated that simply adding a linear layer on top of BERT enhanced the performance of the model. However, the studies that involved the aspect term extraction task showed that using models with more complex classification layers, such as LSTM, GRU, or CRF, yielded better results.
Based on the studies that explored the aspect category-related tasks, several works [
35,
36,
37,
38] have formulated the problem as a sentence-pair classification problem. Based on the studies of Sun et al. [
37] and Li et al. [
38], the present authors concluded that formulating the problem of aspect category detection and polarity as sentence-pair BERT outperforms single BERT when applied with the same settings. The superiority of sentence-pair BERT derives from the advantages of BERT in the sentence-pair classification task, given that it has been pre-trained on a masked language model and next-sentence prediction tasks. Additionally, constructing a dataset for sentence-pair classification expands the original dataset exponentially. As suggested by Al-jarrah et al. [
39] and Li et al. [
27], the transformer-based word embedding method, BERT, outperforms other frequency- and prediction-based word embedding methods, as it has been pre-trained on a large amount of data, enhancing the learned language representation, in addition to its ability to dynamically learn better contextual embeddings based on a given context. It is also worth mentioning that, except for ArabicBERT, GigaBERT, and AraBERT, no other BERT versions were utilized.
A notable deficiency in the existing literature can be observed with respect to aspect-based sentiment analysis, particularly in the context of the healthcare industry in the Arabic literature. Our review of 21 articles revealed that, aside from Shim et al. [
36], who addressed English aspect category detection and polarity for healthcare-related program reviews, no studies have specifically examined this topic in the Arabic literature. This study seeks to address this gap by offering insights and analyses that can enhance understanding and improve methodologies in this important area of research.
Table 1 presents a comparison of the retrieved literature in the context of aspect-based sentiment analysis.
3. Materials and Methods
3.1. Datasets
This work used the HoPE-SA [
2] dataset, which contains 12,400 patient experience-related Arabic tweets from 14 healthcare organizations in Saudi Arabia. Each tweet has been labeled, according to its sentiment, as positive or negative. In this work, in order to perform aspect-based sentiment analysis, we annotated the dataset for aspect category detection and aspect category polarity tasks.
3.1.1. Aspect Category Identification
The first step in annotating the dataset for aspect category detection and polarity tasks is to identify the healthcare aspects discussed in the dataset. In order to do so, we first used the list of the most frequent words in the HoPE-SA dataset.
Table 2 presents the top 20 most frequent words in the HoPE-SA dataset, with the potential categories in bold (words 6, 7, and 15).
However, the list of the most frequent words was not sufficient to identify the aspect categories, as one category may be discussed using many different terms (e.g., words 15, 16, 17, and 20). Thus, this work utilized GPT-4, through ChatGPT by OpenAI [
42] in order to find the most frequent aspects and identify more fine-grained categories. We used the ChatGPT API to send and receive prompts and responses. Inspired by [
43], the process started by prompt engineering to enable GPT-4 to assign aspects for each tweet.
Figure 1 shows the designed prompt for this task in few-shot settings [
43]. The input to the first example in the figure can be translated as follows:
“Sulaiman Al Habib Specialized Hospital, but unfortunately the appointments are very far away. I want an appointment and I’m trying, but there aren’t any available”. The second example tweet is translated as follows:
“Doctor Mohammed Shaker at Al Hammadi Hospital- Alsuwaidi (branch), has a lot of experience and is a very skilled artist with a light touch”. The resulting aspects were sorted according to their frequency and, based on the results, five healthcare categories were initially identified.
Medical staff;
Appointments;
Customer service;
Emergency services;
Pricing.
3.1.2. Pre-Labeling of HoPE-SA Dataset
After identifying the initial categories, this work also used GPT-4 for the aspect category polarity pre-labeling task. Initially, four classes were identified: positive, negative, neutral, and not mentioned. The latter refers to the aspect categories not discussed in the tweet.
Figure 2 shows the designed prompt for this task in few-shot settings.
The pre-labeling results are provided in
Table 3. These labels require human verification before being used for the training of aspect-based sentiment analysis models.
Additionally, the results showed that 173 instances were not classified into any of the initial categories. These instances were reviewed manually in the human verification stage, and mapped to one of the below cases:
Case 1: The instance was misclassified by GPT-4.
Case 2: The instance has no aspect discussed.
Case 3: The aspect discussed in the instance does not belong to any of the initial categories.
The fact that only 173 instances out of the total 12,400 instances remained unclassified suggests that the initially identified categories effectively encompassed the aspects discussed in the dataset.
Based on the pre-labeling results, some categories had few instances, which may affect the performance of the aspect-based sentiment analysis models. Thus, we collected more data as an extension to the HoPE-SA dataset.
3.1.3. Hospital Experiences Arabic Reviews (HEAR)
As an extension to the HoPE-SA dataset, we constructed an Arabic aspect-based sentiment analysis dataset of Google Maps reviews for the same 14 healthcare organizations in the HoPE-SA dataset. The newly constructed HEAR dataset contains 31,561 Arabic reviews extracted from Google Maps using outscraper.com, an online tool for scraping data. We named the dataset HEAR, which stands for Hospital Experiences Arabic Reviews.
We followed the same steps as for the pre-labeling of the HoPE-SA dataset in
Section 3.1.2. The pre-labeling results are detailed in
Table 4. As mentioned earlier, these labels required human verification before being used for the training of aspect-based sentiment analysis models.
The results indicated that 1992 instances were not classified into any of the initial categories. These instances were reviewed manually in the human verification stage and mapped to the three cases explained in
Section 3.1.2.
3.1.4. Dataset Annotation
To annotate the datasets, we recruited five annotators with Arabic as their mother tongue. We provided annotation guidelines to the annotators and assessed their understanding of the task by reviewing their annotations for ten reviews. The selection criteria for the annotators were as follows:
Arabic native speaker;
A minimum of 21 years old;
A minimum of a bachelor’s degree and/or professional certificates;
Passing the initial annotation assessment.
The annotators were told to reach out if they had any doubts about the task. Each annotator was given a subset of the dataset, and each review/tweet was annotated by at least two annotators; in the case of disagreement, a third annotator was assigned for the review/tweet.
3.1.5. Dataset Cleaning
The datasets were reviewed manually to remove duplicate records and identify records with conflicting sentiments towards the same aspect category. After eliminating duplicate records and conflicting sentiments, the large number of reviews in the HEAR dataset was reduced to 25,156 reviews, whereas the number of instances in the HoPE-SA dataset remained the same. For the HEAR dataset, we removed an extra 2152 reviews which were longer than 100 tokens, in order to reduce the computational complexity.
3.1.6. Exploratory Data Analysis (EDA)
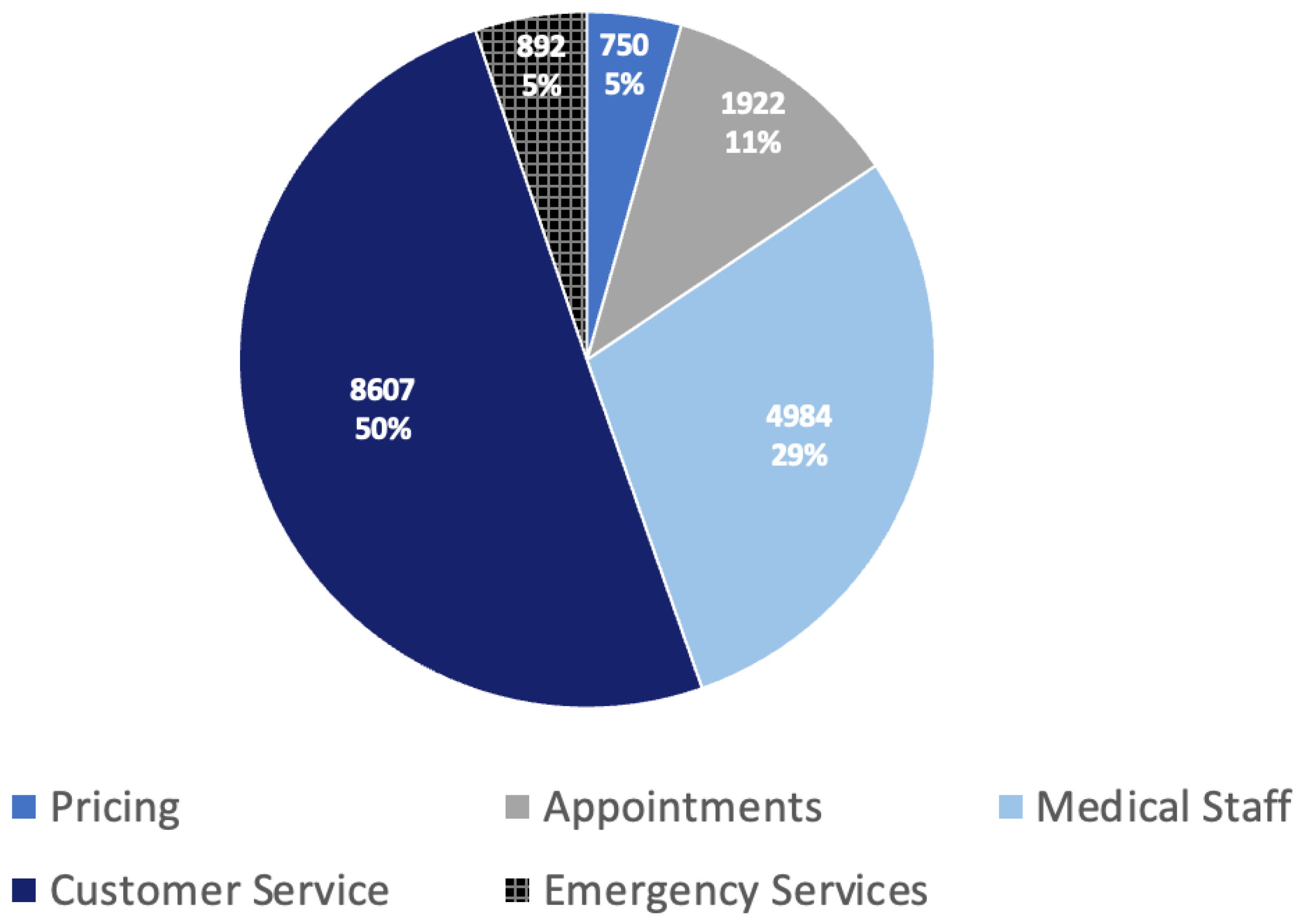
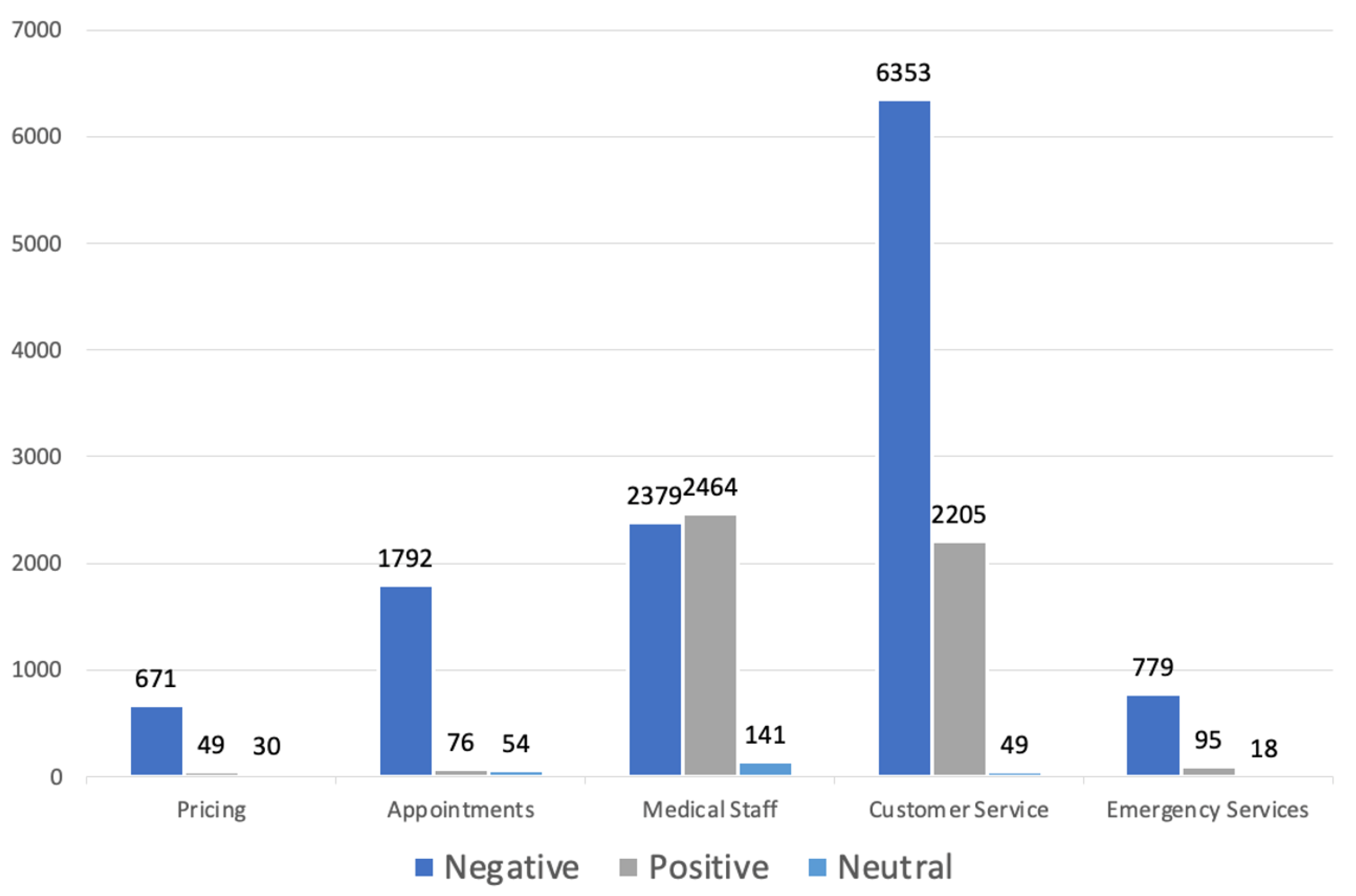
A total of 17,155 mentioned aspect categories were identified in the HoPE-SA dataset. This dataset contains a total of 4889 positive tweets, 11,974 negative tweets, and 292 neutral tweets, with a total of 4984 tweets in the medical staff category, 1922 in the appointments category, 8607 in the customer service category, 750 in the pricing category, and 892 in the emergency services category.
Table 5 provides further statistics on the HoPE-SA dataset.
Figure 3 shows the percentage of tweets in each aspect category, and
Figure 4 shows the percentage of tweets in each sentiment for each aspect category.
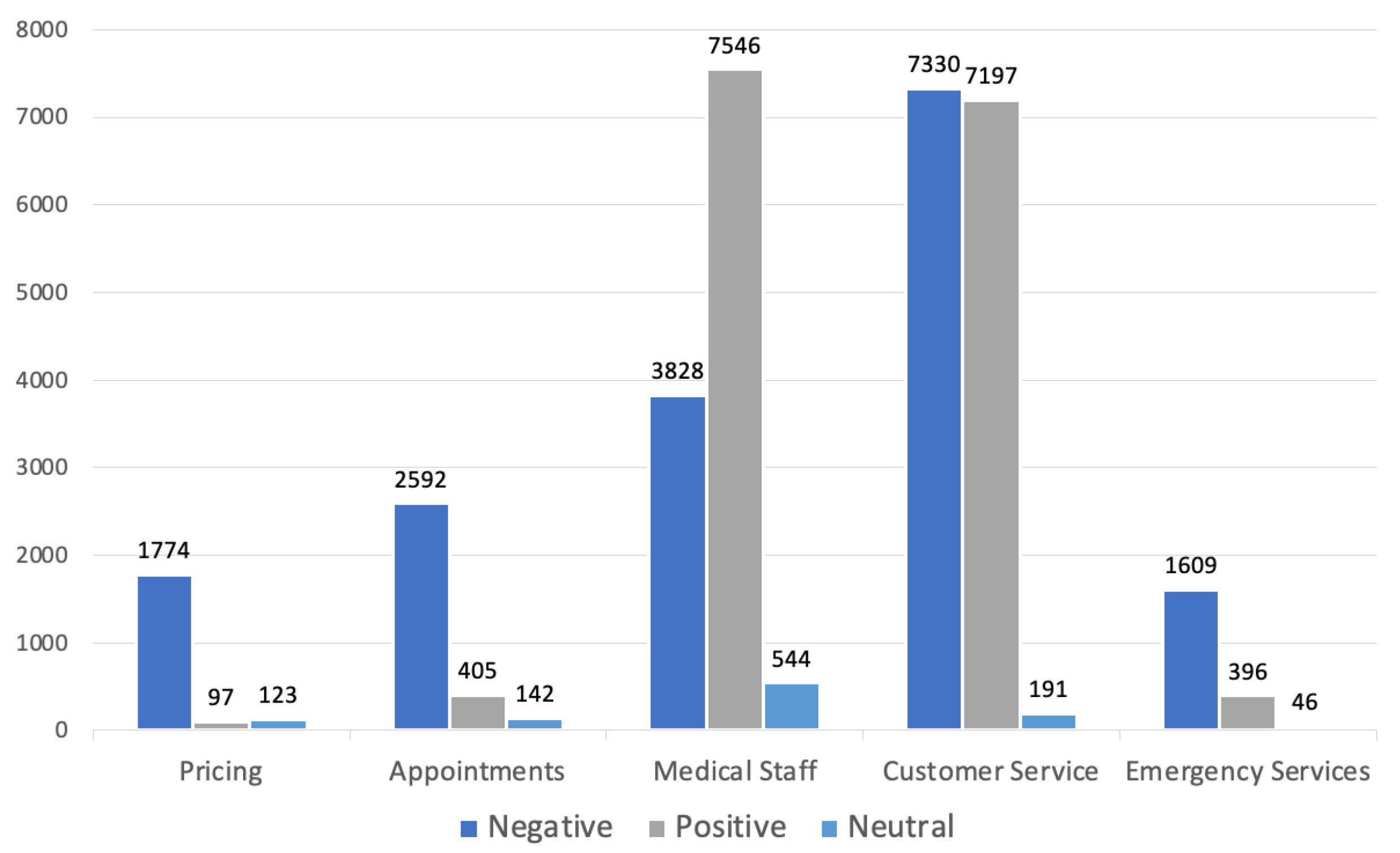
A total of 33,820 mentioned aspect categories were identified in the HEAR dataset. The dataset contains a total of 15,641 positive reviews, 17,133 negative reviews, and 1046 neutral reviews, with a total of 11,918 reviews in the medical staff category, 3139 in the appointments category, 14,718 in the customer service category, 1994 in the pricing category, and 2051 in the emergency services category.
Table 6 provides more statistics for the HEAR dataset.
Figure 5 shows the percentage of reviews in each aspect category, and
Figure 6 shows the percentage of reviews in each sentiment for each aspect category.
3.2. Dataset Pre-Processing
Several pre-processing techniques were implemented to eliminate noise, unify the reviews/tweets, and improve the learning process. We utilized steps similar to those detailed by Almuhaideb et al. [
2], who authored the HoPE-SA dataset. Regular expressions were employed to perform the following pre-processing steps:
After pre-processing, we tokenized the data using BERT’s WordPiece tokenizer, where we tokenized each review/tweet text to a length of 100 tokens. We added a special token [PAD] for reviews/tweets shorter than 100 tokens and, due to the associated computational complexity, we eliminated reviews longer than 100 tokens. We added the [CLS] token at the beginning and the [SEP] token at the end of each review/tweet text. In the sentence-pair models, we added another [SEP] token between the last token of the review/tweet text and the first token of the aspect category.
3.3. BERT-Based Models
This work proposes two BERT-based models; the first model solves the aspect category detection and aspect category polarity sub-tasks jointly, whereas the second model consists of two stages to solve the two sub-tasks separately.
3.3.1. Joint Model
This model jointly solves the aspect category detection and aspect category polarity sub-tasks as shown in
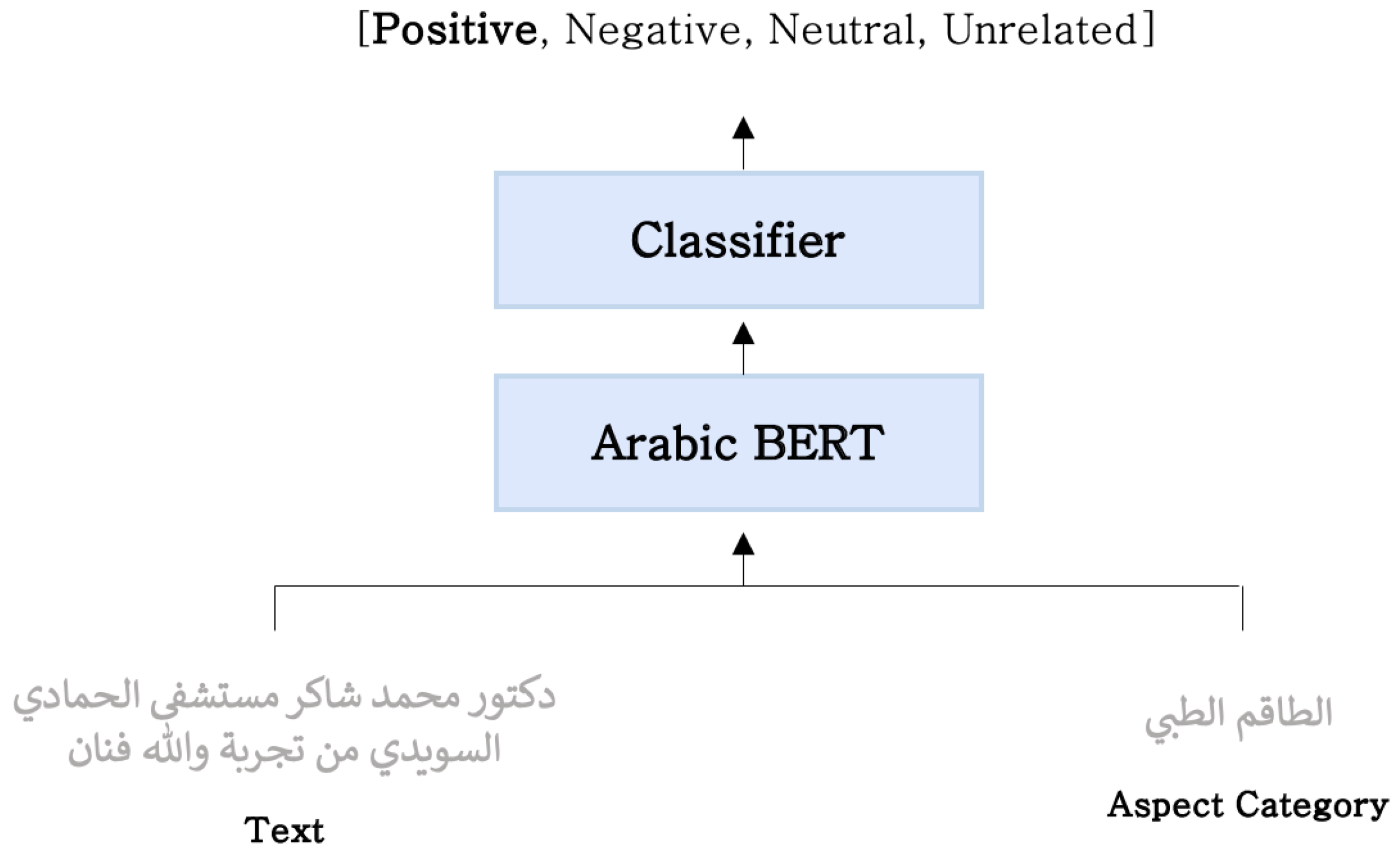
Figure 7. The model uses BERT as a word embedding stacked with three well-known machine learning classifiers for aspect-based sentiment analysis for patient experience. The problem of aspect category detection and aspect category polarity is formulated as a sentence-pair classification problem using BERT. As suggested in the literature, formulating the problem as a sentence-pair classification problem using BERT yields better results, when compared with single-sentence classification. As illustrated in
Figure 8, for a given text,
“Doctor Mohammed Shaker at Al Hammadi Hospital- Alsuwaidi (branch), has a lot of experience and is a very skilled artist”, and aspect category,
“The medical Staff”, the model will produce a sentiment polarity result. Thus, formulating the problems of aspect category detection and aspect category polarity as a sentence-pair classification problem allows the model to jointly solve these two sub-tasks.
Figure 9 shows an example of the model input
“Excellent care and highly specialized excellent doctors, the hospital cleanliness is excellent and the location is close. The staff is very courteous in their dealings. We ask Allah to make them always rescuers for the patients with merciful hearts, O Lord”, with the expected output.
We fine-tuned five Arabic versions of BERT, namely, MARBERT [
44], ArabicBERT [
45], QARiB [
46], CAMeLBERT [
47], and AraBERT. The reasons for selecting these five versions of BERT are as follows:
We used three well-known machine learning classifiers—namely, neural networks, SVM, and Random Forest (RF) [
5]—in order to compare their performance in aspect-based sentiment analysis for patient experience.
The joint model is designed as a sentence-pair classification approach, which requires constructing the dataset in the sentence-pair format. We generated the possible combinations of review/tweet sentences and the aspect categories. Applying this construction method, the resulting dataset comprised pairs of review/tweet sentences and aspect categories with multi-class labels: ‘0’, ‘1’, ‘2’, ‘3’. The label ‘0’ means that the corresponding review/tweet sentence has a negative sentiment towards the paired aspect category, the label ‘1’ means that the corresponding review/tweet sentence has a positive sentiment towards the paired aspect category, the label ‘2’ means that the corresponding review/tweet sentence has a neutral sentiment towards the paired aspect category, and the label ‘3’ means that the corresponding review/tweet sentence does not mention the paired aspect category.
Table 7 provides an illustration of the constructed sentence-pair dataset.
The training of the joint model consisted of two stages: the first stage was fine-tuning, and the second stage was classification. We split the dataset into 60% for training, 20% for validation, and 20% for testing. In the fine-tuning stage, the five Arabic versions of BERT were fine-tuned using a fully connected layer on the training and validation sets. The hidden layer size of the fully connected layer was 50, and the following parameters were set: the Adaptive Moment Estimation with Decoupled Weight Decay (AdamW) optimizer, a learning rate of , a cross-entropy loss function, and two epochs of training with batch size equal to 32. In the classification stage, the embeddings produced from the fine-tuned BERT were fed to the three machine learning classifiers for training. We used the [CLS] vector as an input to the classification models. Due to limited computational power, we took a stratified sample representing 50% of the training set to train the classification models. After fine-tuning and training the models, we evaluated their performance on the test set.
3.3.2. Two-Stage Model
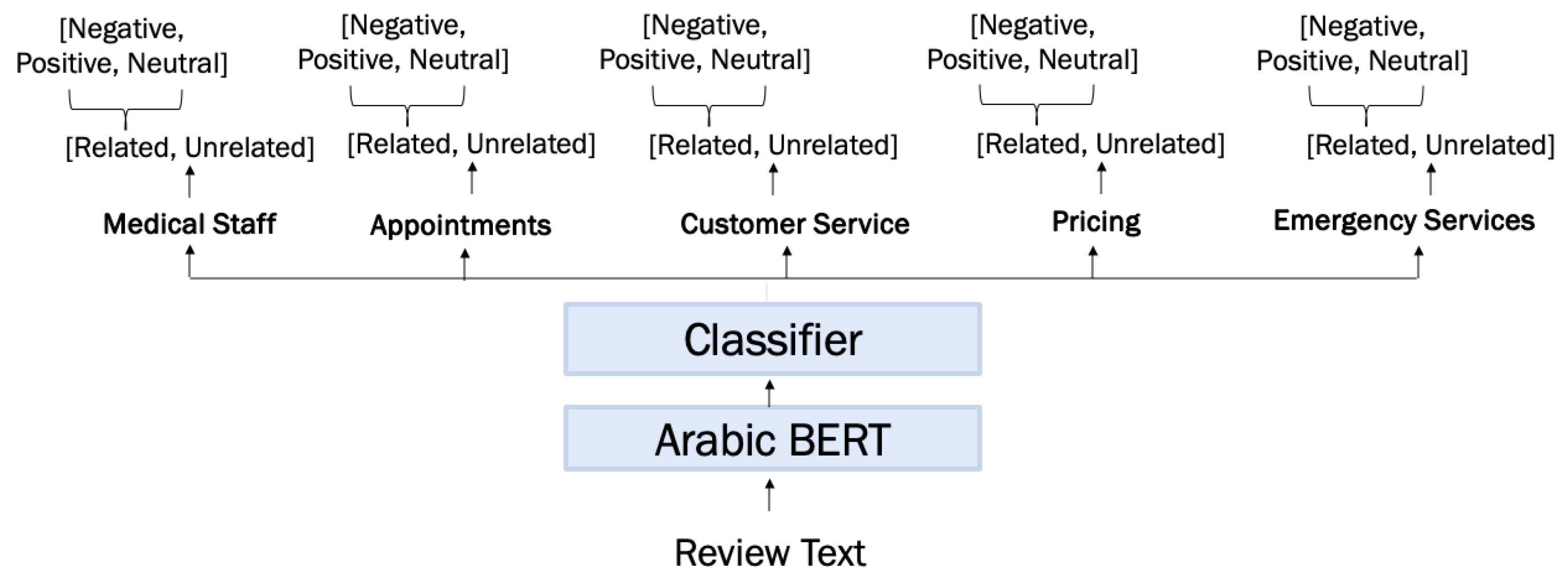
This model solves the aspect category detection and aspect category polarity as two sub-tasks using two sub-models. The first sub-model is a multi-label model that solves the aspect category detection problem using BERT followed by a fully connected layer. A certain threshold must be set to identify the detected aspect categories; in this way, the aspect categories below the threshold are labeled as unrelated, and the aspect categories above the threshold are considered related and fed to the second sub-model. The second sub-model is a multi-class model that solves the aspect category polarity problem as a sentence-pair classification problem using BERT followed by a fully connected layer.
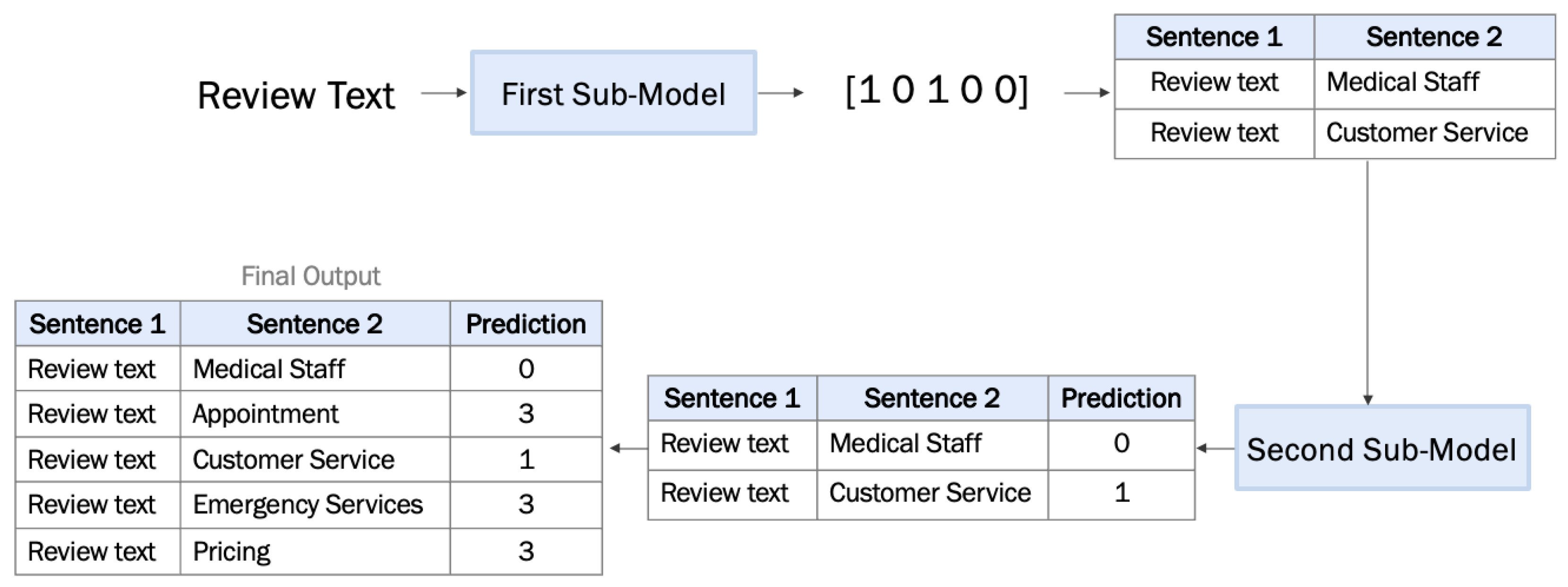
Figure 10 provides an illustrative example that demonstrates the flow of the two-stage model, including the input and output of each sub-model, as outlined below:
The first sub-model is a multi-label classification model that takes a review text as an input and produces five probabilities for the five aspect categories. In this example, the threshold is equal to 0.4 and, therefore, three of the five aspect categories are detected and fed to the second sub-model to determine their polarities. The other two aspect categories are not detected and so are labeled as unrelated.
The second sub-model is a multi-class classification model that takes the review text as input along with each detected aspect category and determines the sentiment (i.e., as negative, positive, or neutral). The three sentiments in this example represent the polarities predicted by the second sub-model for the three detected aspect categories.
The value of the threshold hyper-parameter was set experimentally. Additionally, a comparative analysis was performed using the five Arabic versions of BERT discussed earlier.
The aspect category detection sub-model is a multi-label classification model that utilizes single-sentence BERT followed by a fully connected layer with a sigmoid activation function to detect one or more of the defined aspect categories. As the model is a single-sentence classification model, the dataset is constructed as the review/tweet text and its corresponding label in the form of multi one-hot encoding. The negative, positive, and neutral labels are transformed to the label ‘1’ to represent the mentioned category, while the not mentioned label is transformed to the label ‘0’.
Table 8 provides an illustration of the constructed single-sentence dataset, where the mentioned aspect categories (i.e., medical staff and customer service) are indicated by ‘1’, while the other aspect categories (including pricing, appointments, and emergency services) are indicated by ‘0’ to represent the not mentioned class. The training of the aspect category detection sub-model involved fine-tuning the five Arabic versions of BERT using a fully connected layer on the training and validation sets. We used the [CLS] vector as an input to the fully connected layer. The hidden layer size of the fully connected layer was 50, and the following parameters were set: the AdamW optimizer, a learning rate of
, a binary cross-entropy with logits loss function, and two epochs of training with batch size equal to 32. The training of the aspect category polarity sub-model involved fine-tuning the five Arabic versions of BERT using a fully connected layer on the training and validation sets. We used the [CLS] vector as an input to the fully connected layer. The hidden layer size of the fully connected layer was 50, and the following parameters were set: the AdamW optimizer, a learning rate of
, a cross-entropy loss function, and two epochs of training with batch size equal to 32.
The aspect category polarity sub-model is a multi-class classification model that utilizes sentence-pair BERT followed by a fully connected layer with a Softmax activation function to classify review/tweet text and aspect category pairs with respect to the corresponding sentiment. To construct the dataset for the aspect category polarity sub-model, we followed the same construction method as for the joint model. The only difference was that the labels for this model were ‘0’, ‘1’, and ‘2’, where the label ’0’ means that the corresponding review/tweet sentence has a negative sentiment towards the paired aspect category, the label ‘1’ means that the corresponding review/tweet sentence has a positive sentiment towards the paired aspect category, and the label ‘2’ means that the corresponding review/tweet sentence has a neutral sentiment towards the paired aspect category. We eliminated label ‘3’, which represents the not mentioned aspects, as the task of detecting aspects was performed previously by the aspect category detection sub-model, while the objective of this sub-model was to determine the polarity with respect to each detected aspect.
Table 9 provides an illustration of the constructed sentence-pair dataset.
We needed to evaluate the performance of the two-stage model in a similar manner to the joint model in order to effectively compare their performance. Therefore, during the evaluation, as illustrated in
Figure 11, we fed the review/tweet sentences to the aspect category detection sub-model and produced the predicted outputs in the form of multi one-hot encoding. We transformed the predicted output into the form of a review/tweet sentence and aspect category pair for the detected aspect categories, and fed the transformed data to the aspect category polarity sub-model. The prediction of the aspect category polarity sub-model was then combined with the undetected aspect categories (i.e., those with label = ‘3’).
3.4. Generative Model
This work also evaluated the performance of a generative model (i.e., GPT-4) for aspect category detection and aspect category polarity tasks. As mentioned earlier, GPT-4 was utilized for the pre-labeling of the datasets. These pre-labeled datasets were then subjected to human verification. However, these pre-labels were considered GPT-4 predictions and were used to evaluate the performance of GPT-4 in terms of aspect-based sentiment analysis for patient experience in few-shot settings.
4. Implementation Details and Evaluation Measures
BERT-based models were selected for our study due to their exceptional performance in various NLP tasks, including sentiment analysis. Their ability to effectively capture contextual information and the availability of pre-trained models tailored to the Arabic language made them particularly suitable for our research objectives. We also incorporated traditional machine learning classifiers as baseline models. These classifiers offer advantages such as simplicity and potentially quicker inference times in specific contexts, providing a valuable point of comparison for our findings. Random Forest (RF) [
5] is an ensemble learning technique that combines multiple decision trees for improved prediction accuracy. Each tree is trained on a randomly sampled subset of the data, and predictions are aggregated through averaging for regression or voting for classification. Based on the bagging principle, RF fosters diversity among trees, reducing variance and enhancing generalization performance. Support Vector Machine (SVM) is both a straightforward and effective method. Nguyen et al. [
48] demonstrated that SVM can achieve high performance levels, even when compared with deep learning models and BERT variants. Therefore, we included SVM in our analysis of classical machine learning algorithms, as it is a widely used and proven competitive algorithm in prior research. Artificial Neural Networks (ANNs) [
6] were used as a computational method to learn and predict intricate relationships within the dataset.
While alternative models, including Recurrent Neural Network (RNN)-based architectures and other transformer models such as T5 [
49] and BART [
24], were considered, they were ultimately excluded from our comparison, primarily based on concerns regarding computational cost and the risk of vanishing gradient issues associated with RNNs.
We utilized Google Colaboratory (Colab) [
50] to build the training and testing environments, using a Colab Tensor Processing Unit (TPU) v2. All the implementations were carried out using Python 3.10.12 and PyTorch 2.5.0 [
51] as a deep learning framework.
For the joint model, we conducted 15 different experiments using the five versions of Arabic BERT and the three classifiers (SVM, RF, and neural networks). The SVM utilized a linear kernel and a regularization parameter of 1.0. For RF, 100 trees were utilized with a Gini impurity criterion. As for the neural network, the size of the hidden layer was 50, and the Adaptive Moment Estimation (Adam) [
52] optimizer was used with a learning rate of 0.001 and a cross-entropy loss function. For the two-stage model, we experimented nine values for the threshold hyper-parameter.
In terms of evaluation measures, the performance of the models was assessed using standard classification metrics, including accuracy, precision, recall, and F1-score. In addition to quantitative measures, confusion matrices and ROC curves were also used for performance comparison of the models. In multi-class classification tasks, where the model must distinguish between more than two classes, performance was evaluated using the average accuracy per class:
where
I is the number of classes,
and
represent the number of true positives and true negatives, respectively, and
and
represent the number of false positives and false negatives.
To assess the precision, recall, and F1-score across all classes, different averaging methods can be used. Macro-averaging computes the unweighted average of these metrics for each class:
Meanwhile, micro-averaging aggregates the
TP,
FP,
FN, and
TN counts across all classes before calculating the metrics:
Weighted-averaging accounts for class imbalances by weighting each class’s metric by the number of instances in that class.
In multi-label classification, where each instance may belong to multiple classes, performance can be evaluated using the subset accuracy (exact match ratio), which considers a prediction correct only if all the predicted labels for an instance match the true labels:
where
n is the number of instances,
is the set of predicted labels, and
is the set of true labels for instance
i.
The Hamming loss offers a less stringent measure by calculating the fraction of incorrect labels:
5. Results
5.1. Joint Model
The results obtained by the SVM, RF, and neural networks with the five versions of Arabic BERT are reported in
Table 10,
Table 11 and
Table 12, respectively, with the best scores shown in bold.
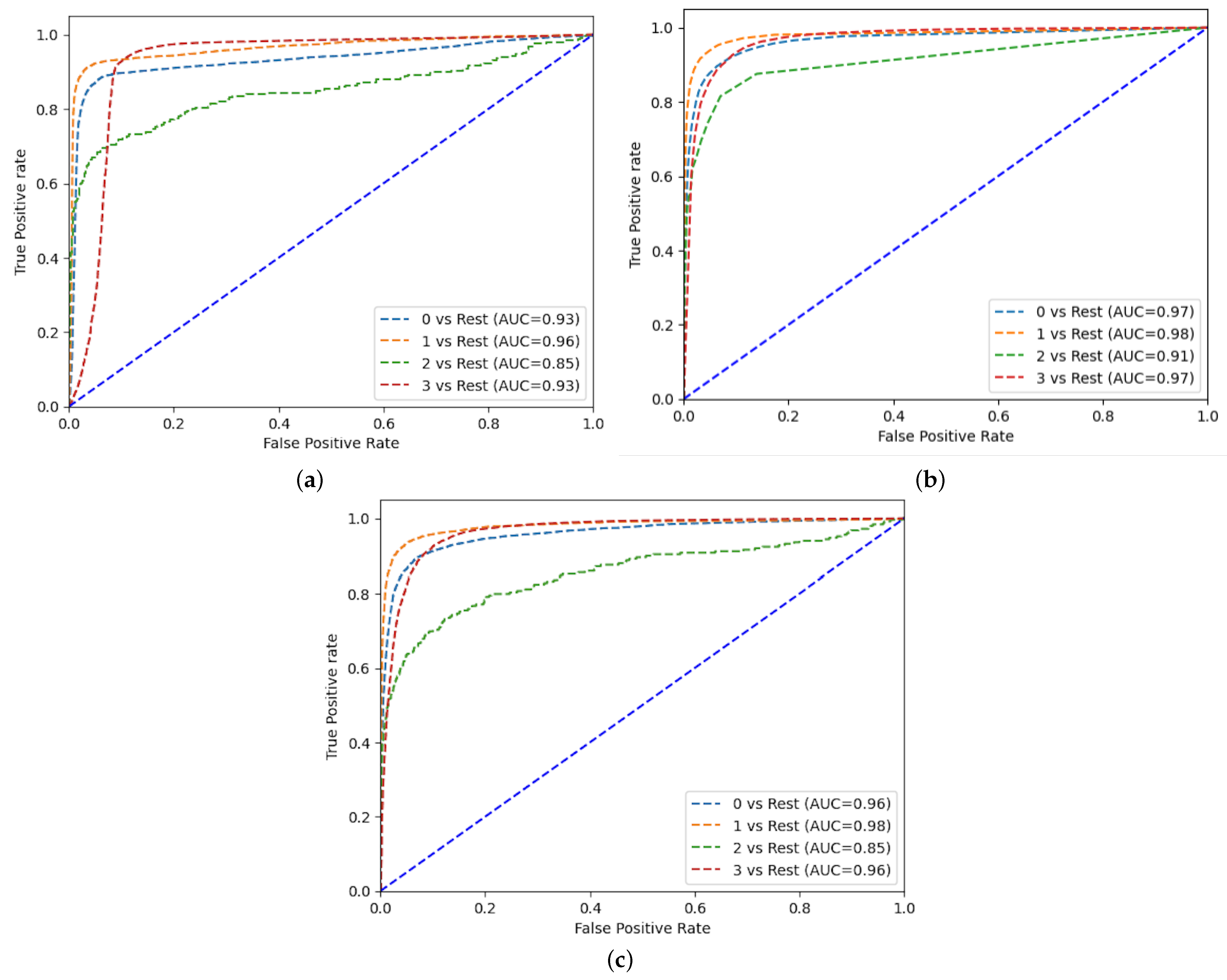
Figure 12 shows the ROC curves of the three classifiers with the MARBERT model, and
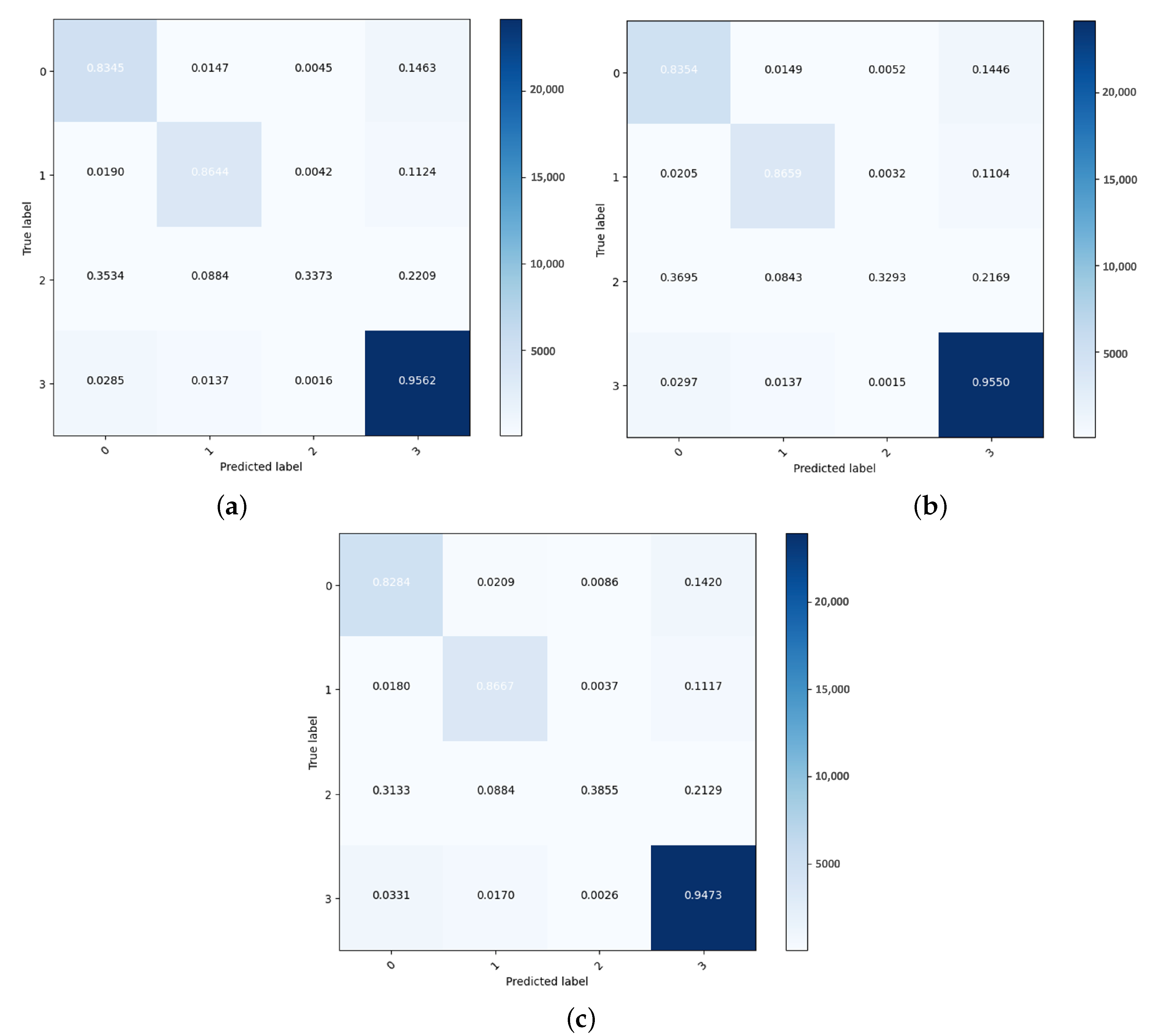
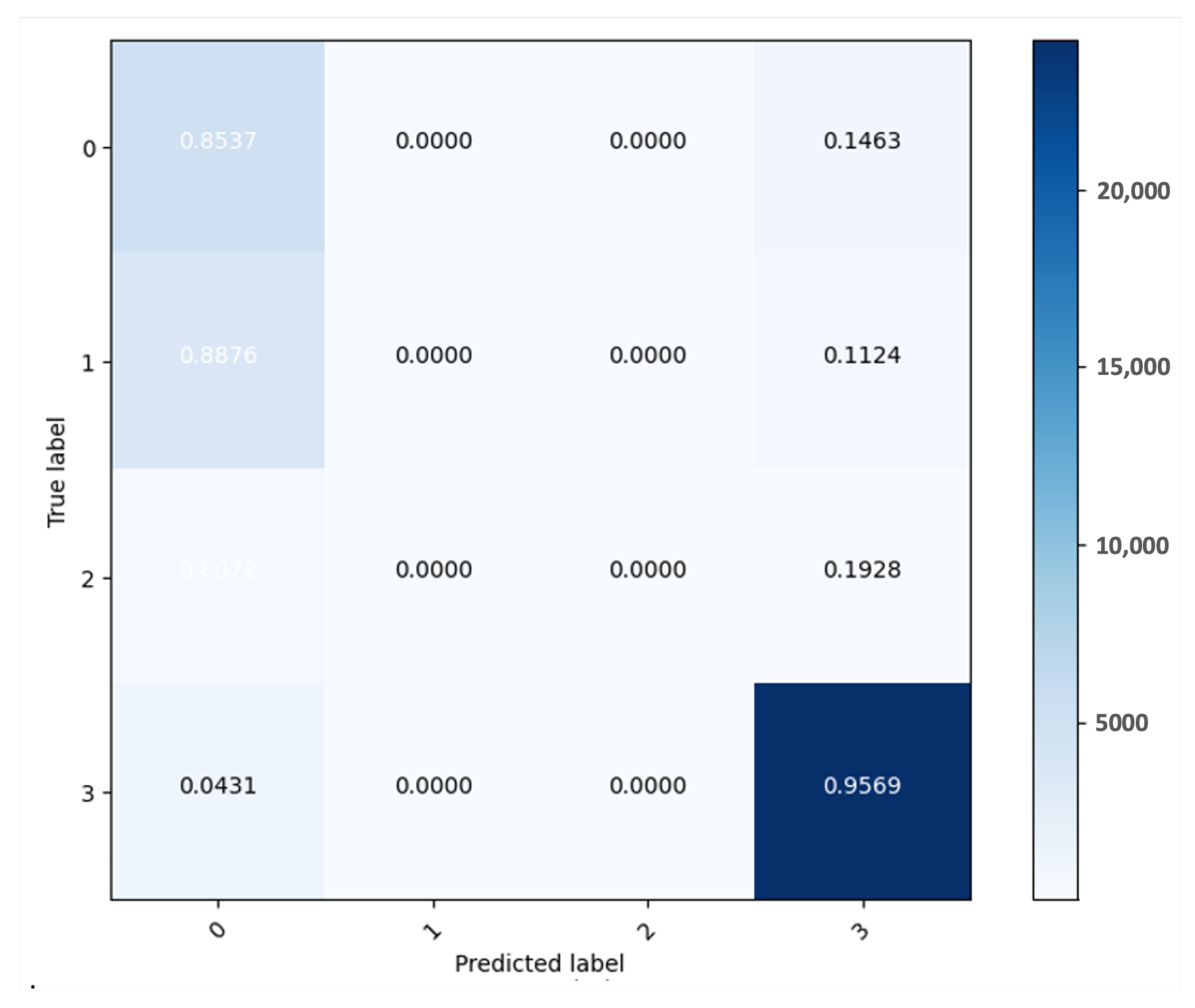
Figure 13 shows the confusion matrices for the three classifiers with the MARBERT model.
5.2. Two-Stage Model
The results obtained by the two-stage model using MARBERT with different values of the threshold parameter are reported in
Table 13, showing the best scores in bold.
The results obtained by the two-stage model with the five versions of Arabic BERT and the best threshold value based on weighted F1-score are reported in
Table 14, with the best scores shown in bold.
Figure 14 shows the confusion matrix for the two-stage model with the QARiB model.
5.2.1. Aspect Category Detection Sub-Model
This subsection provides the results of the aspect category detection sub-model, where we evaluate the performance of the sub-model in the aspect category detection sub-task.
Table 15 provides the results for the aspect category detection sub-model with the five versions of Arabic BERT and the best threshold value based on the weighted F1-score, with the best scores shown in bold.
5.2.2. Aspect Category Polarity Sub-Model
This subsection provides the results for the aspect category polarity sub-model, where we evaluate the performance of the sub-model in the aspect category polarity sub-task.
Table 16 provides the results of the aspect category polarity sub-model with the five versions of Arabic BERT, with the best scores shown in bold.
5.3. Generative Model
Regarding the generative model, we evaluated the performance of GPT-4 in the aspect category detection and aspect category polarity tasks. The results obtained by GPT-4 in few-shot settings are reported in
Table 17.
Figure 15 shows the confusion matrix for GPT-4.
6. Discussion
The first contribution of this work is the introduction of a Google Maps-based dataset; namely, an Arabic patient experience review dataset related to healthcare providers within Saudi Arabia, which is annotated with respect to several healthcare aspects and different sentiment polarities. In addition, we annotated the HoPE-SA dataset for the aspect category detection and aspect category polarity tasks. One of the objectives of this work was to analyze patient experiences in Saudi Arabia concerning several healthcare aspects. Based on the annotation of both datasets and from the statistical analysis performed on these datasets, the most-discussed aspect was customer service, followed by medical staff. In general, there was a higher rate of negative sentiments towards healthcare aspects than other sentiments.
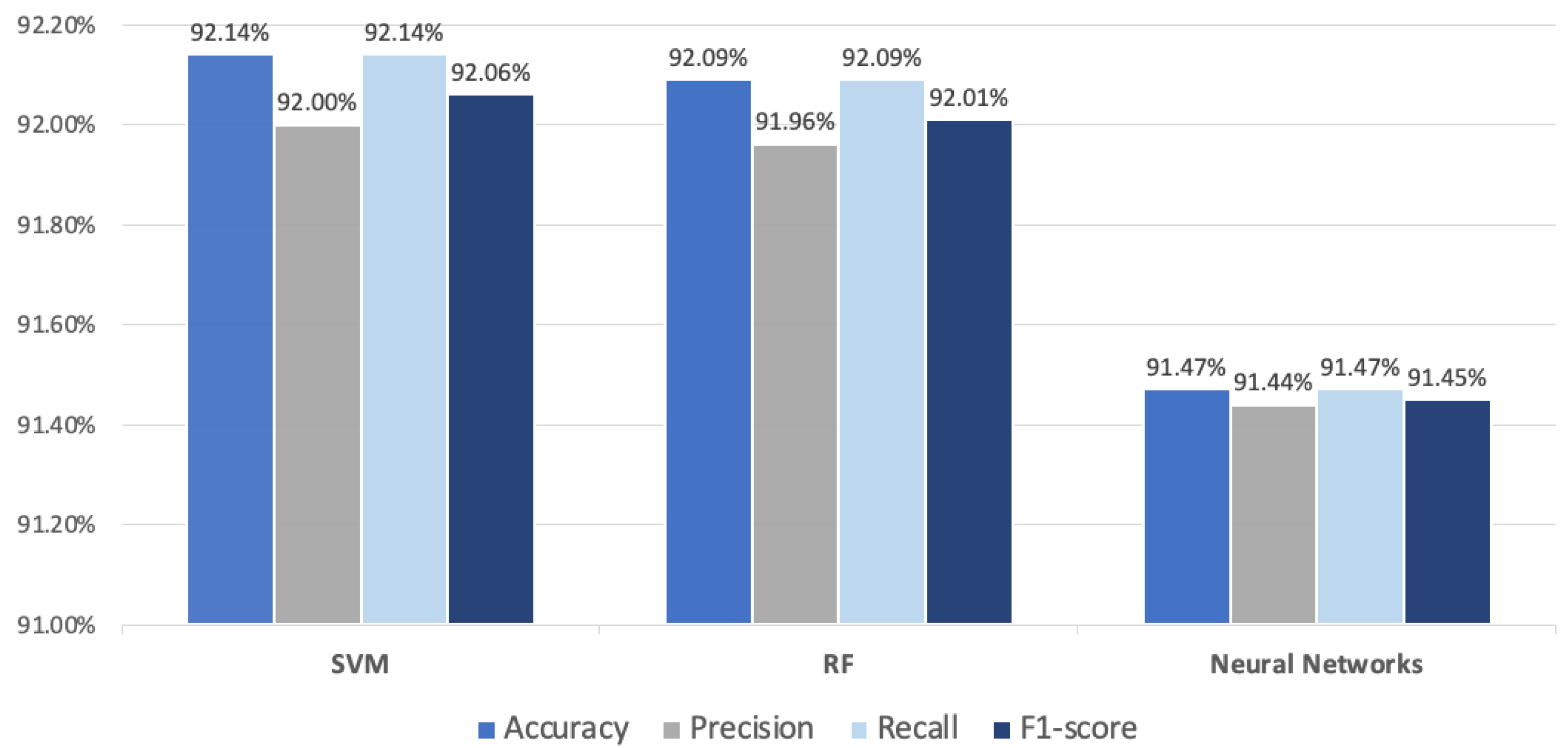
The second contribution of this work is a comparative study related to the use of fine-tuned BERT as word embedding with machine learning classifiers—namely, SVM, RF, and neural networks—for the tasks of aspect category detection and polarity. As illustrated in
Figure 16, the experimental results revealed that the RF and SVM classifiers outperformed the neural networks, which can be considered a baseline model, with all different versions of Arabic BERT. Moreover, the comparison between the five Arabic versions of BERT in the joint model indicated that the MARBERT-based models had superior performance among the five models with all three classifiers.
The experimental results comparing the joint model’s performance with the two-stage model indicated that the joint model surpassed the two-stage model in the aspect category detection and polarity tasks with a large margin of enhancement. We concluded that not only did the sentence-pair classification problem formulation contribute to its superior performance but also the joint model was fine-tuned using a larger amount of data, allowing it to learn a better language representation. The larger dataset utilized for fine-tuning significantly contributed to the superior performance of the joint model over the two-stage model. This underscores the critical role of the dataset size in model training and evaluation, as larger datasets typically provide more diverse and representative examples, thereby enhancing the model’s learning capacity and its ability to generalize to unseen data. In the two-stage model, the second sub-model was formulated as sentence-pair classification; however, it was fine-tuned on a smaller subset of the dataset, as it is only an aspect category polarity model and, thus, we eliminated the “not mentioned” class instances.
Experimental results comparing the performance of the generative model (i.e., GPT-4) with that of the BERT-based models revealed that the joint BERT-based model outperformed GPT-4 in the tasks of aspect category detection and aspect category polarity, although with a relatively small margin of enhancement. It is worth mentioning that the GPT-4 results were obtained in few-shot training settings. Therefore, its performance could be improved through the use of more training shots.
This study has several potential limitations. First, the training of the joint model was conducted using a two-stage approach, rather than an end-to-end approach, which might yield better results. Second, the reviews collected from Twitter and Google Maps may not represent the entire patient population. Certain demographics might be under-represented, which could lead to biased sentiment results. Additionally, the findings from this specific study may not be generalizable to other regions or healthcare contexts, limiting the applicability of the results. The third limitation involves the challenge associated with accurately identifying the relevant features and aspects from text data. Incomplete or incorrect extraction can result in misleading sentiment classifications, which is especially critical in healthcare, where nuanced opinions impact patient care and decision-making. We recognize that the effectiveness of aspect-based sentiment analysis depends on this accuracy, and that overlooking or misclassifying key elements may lead to erroneous results. This highlights the need for ongoing advancements in methodologies for aspect detection and feature extraction. Finally, we recognize that patient sentiment is not static, and can change over time due to various factors such as evolving treatment experiences and shifts in healthcare quality. Consequently, the analyzed reviews may capture sentiments that reflect a specific moment, rather than an ongoing patient experience. Acknowledging this temporal dimension is essential for a comprehensive understanding of sentiment dynamics in healthcare, and suggests opportunities for future research to explore longitudinal approaches to sentiment analysis.
Another challenge is that generic sentiment analysis, as evidenced in some existing research, often fails to capture the specificity and complexity of patient sentiments regarding particular aspects of healthcare. Through focusing on aspect-based sentiment analysis, we can better understand and represent the varied experiences and opinions of patients, leading to more accurate and actionable insights in the healthcare domain.
The findings of this study have significant implications for improving healthcare services. By linking specific feedback aspects (e.g., concerns about long wait times) to actionable solutions (e.g., optimizing scheduling systems and increasing staffing during peak hours), healthcare providers can enhance patient satisfaction and outcomes. Furthermore, incorporating patient feedback fosters a patient-centered approach, allowing providers to better meet the needs and preferences of individuals. Additionally, the study’s results can guide policy recommendations to address recurring issues and revise care protocols as necessary. These findings can assist healthcare providers in the Kingdom in prioritizing their improvement plans based on patient opinions, ultimately leading to significant enhancements in overall patient satisfaction.
7. Conclusions
Aspect-based sentiment analysis is a fine-grained analysis with the aim of extracting the aspects discussed in a text and their polarities. In the healthcare domain, utilizing such an advanced analysis provides a comprehensive view of the strengths and weaknesses of the provided healthcare service with respect to various aspects, which enables the healthcare provider to make targeted improvements. This study aimed to bridge the gap related to Arabic aspect-based sentiment analysis in the healthcare domain, annotate the HoPE-SA dataset, and introduce an annotated Arabic patient experience reviews dataset for aspect category detection and polarity tasks. The newly constructed HEAR dataset contains Arabic reviews related to patient experiences derived from Google Maps. In this work, we annotated the HoPE-SA and HEAR datasets with five aspect categories—namely, medical staff, appointments, customer service, emergency services, and pricing—along with four sentiment classes: negative, positive, neutral, and not mentioned.
In this work, a comparative study of different BERT-based models was conducted to investigate the performance of BERT in word embedding with machine learning classifiers, namely, neural networks, SVM, and RF. We fine-tuned five different Arabic pre-trained BERT models: MARBERT, ArabicBERT, AraBERT, QARiB, and CAMeLBERT. In addition, we evaluated the performance of GPT-4 using ChatGPT by OpenAI in terms of aspect-based sentiment analysis for patient experience. The experimental results demonstrate the superiority of the MARBERT model, when used with the SVM and RF classifiers, in capturing aspect-based sentiment.
The results show that the joint BERT-based model outperformed the two-stage model and GPT-4 in the aspect-based sentiment analysis task, with MARBERT achieving the highest accuracy at 92.14% and a weighted F1-score of 92.06% using the SVM classifier. The two-stage model with QARiB also showed strong performance, with an F1-score of 78.40%.
As future work, we may consider longer sentences using techniques such as sliding windows. We could also evaluate the proposed approaches in other aspect-based sentiment analysis tasks. In addition, it would be interesting to explore specifying the levels of sentiments or emotions instead of defining the sentiments as simply negative, positive, or neutral.
8. Ethical Considerations
The datasets utilized in this research were collected from public sources (i.e., Twitter and Google Maps) and only included the review text without any personal identifiers (e.g., account names). When utilizing data from social media platforms, ethical considerations are paramount. Users understandably express concerns regarding the privacy and confidentiality of their online information. Notably, data collected from the web for social good or public health purposes are often viewed as more acceptable in social media research by users [
53,
54]. While we recognize these concerns, it is important to note that all information used in this study was obtained for academic research purposes and was limited to publicly available posts that users chose not to keep private. The processing of these data in this research is in accordance with the Personal Data Protection Law [
55], which applies to any processing of personal data related to individuals that takes place in the Kingdom. The dataset annotation process was conducted with sensitive attention to cultural and linguistic nuances. The annotators were trained to follow specific guidelines, ensuring the consistent and respectful interpretation of sentiments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}