Abstract
Generative recommendation systems based on Large Language Models leverage their reasoning capabilities to capture users’ latent interests. However, aligning continuous user behavioral embeddings with the discrete semantic space of LLMs remains a challenge. Direct alignment often leads to semantic mismatch and hallucination issues. Furthermore, existing methods typically rely on multi-stage training strategies to adapt to variations in feature distributions, thereby limiting training efficiency. To address the aforementioned issues, we propose SBT-Rec, a structured behavioral tokenization framework. Specifically, we first design a hierarchical discrete structure discovery module, utilizing a recursive residual quantization mechanism to decompose continuous behavioral vectors into discrete behavioral atoms to resolve modality discrepancies. Second, the multi-scale behavioral semantic reconstruction module reconstructs behavioral representations via residual superposition, thereby reducing data noise. Third, a residual-aware modality distribution aligner is introduced to transform behavioral features into input tokens compatible with the LLM via non-linear mapping. Finally, based on structured discrete representations, we propose a single-stage behavioral-semantic adaptive optimization strategy, achieving end-to-end parameter-efficient fine-tuning. Experiments on the MovieLens, LastFM, and Steam datasets demonstrate that SBT-Rec outperforms existing baseline models in terms of recommendation accuracy, training efficiency, and noise robustness.
1. Introduction
Generative recommendation systems leverage the reasoning capabilities of Large Language Models (LLMs) to capture users’ latent interests [1,2]. This paradigm shows significant potential in addressing the cold-start problem [3] and providing explainable recommendations [4,5]. Although current methods attempt to transform recommendation tasks into language generation tasks via instruction tuning [6,7], effectively fusing collaborative filtering signals inherent in traditional recommendation systems into LLMs without incurring high retraining costs remains a key research challenge in open-domain recommendation scenarios. Therefore, constructing a structured and efficient modality alignment framework that enables LLMs to accurately comprehend user behavioral sequences is a focus of current research.
A primary challenge in generative recommendation is effectively aligning continuous user behavioral embeddings with the discrete semantic space of LLMs while ensuring training stability. Recent studies have attempted to inject continuous vectors output by traditional recommenders directly into the input layer of LLMs to enhance performance [8,9]. However, this direct alignment approach has two major limitations:
- (1)
- Noise Sensitivity in Continuous Space Alignment : Continuous vectors generated by recommendation systems are typically dense and contain manifold distribution noise, whereas the input space of LLMs is a sparse and structured discrete symbolic space. Directly aligning these two vector spaces with distinct properties causes the model to be extremely sensitive to minor perturbations. When semantically outlier interactions appear in a user’s historical behavior—for instance, the abrupt appearance of the children’s cartoon Peppa Pig within a sequence of science fiction movies—minor shifts in the continuous vector space may be amplified by the LLM and erroneously decoded as semantic intent. This occurs because continuous mapping lacks explicit semantic boundaries and cannot function as a “low-pass filter” like discrete clustering to automatically filter out noise signals that do not belong to cluster centers, thereby leading to semantic hallucinations [10].
- (2)
- Non-stationarity of Training Paradigms and Convergence Latency: To alleviate modality alignment difficulties, existing state-of-the-art methods (such as LLaRA [11]) typically employ progressive curriculum learning strategies [12], gradually transitioning from pure text tasks to hybrid modality tasks. However, this strategy forces the model to continuously adapt to dynamically changing input distributions during training, leading to delayed convergence and limiting the model’s ability to reach the optimal solution within a single stage. In contrast, although traditional two-stage fine-tuning paradigms avoid distribution shift, they face risks of optimization fragmentation and catastrophic forgetting.
To address the aforementioned issues, this paper proposes a structured behavioral tokenization framework, termed SBT-Rec (Structured Behavioral Tokenization Framework for LLM-Based Sequential Recommendation). SBT-Rec comprises four main components: the Hierarchical Discrete Structure Discovery module (HDSD), the Multi-Scale Behavioral Semantic Reconstruction module (MBSR), the Residual-Aware Modality Distribution Aligner (RAM-Aligner), and the Single-Stage Behavioral-Semantic Adaptive Optimization strategy (SBS-AO). Specifically, the HDSD module utilizes a recursive residual quantization mechanism [13] to decompose continuous user behaviors into a series of discrete behavioral atoms with explicit semantic weights, separating noise from primary interests via clustering mechanisms to reduce modality discrepancy. The MBSR module utilizes multi-level residual superposition logic [14] to capture high-order behavioral information at different levels of semantic granularity, enhancing the noise resistance of representations. The RAM-Aligner projects discretized behavioral residuals into the semantic space of the LLM via a non-linear manifold mapping mechanism to resolve the distribution mismatch problem. Finally, leveraging the distributional stability of structured behavioral representations, the SBS-AO strategy synchronously optimizes the underlying codebooks and the upper-level mapping in a unified end-to-end training process, achieving parameter-efficient fine-tuning [15].
We conducted experiments on three diverse benchmark datasets: MovieLens, LastFM, and Steam. The results demonstrate that compared with existing baseline models, SBT-Rec exhibits superior performance in terms of recommendation accuracy and training efficiency. Furthermore, the study indicates that due to the constraints of the discretized structure, SBT-Rec shows strong robustness when facing noisy data. From the perspective of cognitive computing, SBT-Rec enhances the LLM’s understanding of the structure of user behavioral sequences by transforming continuous behaviors into discrete semantic atoms. This transformation from continuous signals to discrete symbols is key to bridging the modality gap and improving the reasoning capability of recommendation systems.
In summary, the contributions of this paper are as follows:
- We propose the SBT-Rec framework, a novel structured behavioral tokenization method that fundamentally bridges the modality gap between continuous behavioral embeddings and the discrete semantic space of Large Language Models through deep structural coupling and synergistic alignment.
- We innovatively introduce a hierarchical residual quantization mechanism to decompose noisy behavioral sequences into discrete behavioral atoms, which empirically acts as a conceptual semantic low-pass filter to mitigate input noise.
- To the best of our knowledge, we are pioneers in exploring discretized alignment for user behavior modality, addressing the challenges of training efficiency (e.g., slow convergence and multi-stage paradigm complexity) and stability in existing methods through a Single-Stage Synergistic Optimization strategy.
- We conducted extensive experiments and analyses on benchmark datasets to validate the effectiveness of SBT-Rec and its superior robustness against noise compared to existing state-of-the-art baseline models.
2. Related Work
In this section, we review related literature from two dimensions: sequential recommendation based on Large Language Models (LLMs) and vector quantization for behavioral modality alignment.
2.1. Sequential Recommendation Based on LLMs
Early LLM-based generative recommendations primarily transformed recommendation into language processing tasks [1,2,16]. For instance, Geng et al. [6] proposed a unified framework integrating sequential recommendation and explanation generation via personalized text templates. Subsequently, Bao et al. [7] further introduced the instruction tuning paradigm, demonstrating that constructing task-specific instruction data (e.g., “User likes A, likes B, will they like C?”) effectively aligns the general knowledge of LLMs with the preference patterns of recommendation systems, significantly boosting model performance in few-shot scenarios. Additionally, some works attempt to introduce cross-domain knowledge or external knowledge bases to assist LLMs in understanding cold-start and long-tail items [17,18].
However, the aforementioned text-based methods mainly rely on item metadata such as titles and descriptions, often ignoring the implicit collaborative filtering signals embedded in user interaction histories [19,20]. To address this issue, researchers have begun exploring how to fuse behavioral representations from traditional recommendation models into LLMs. Liao et al. [11] proposed a hybrid prompting mechanism that projects ID embeddings generated by traditional sequential recommenders into the input space of the LLM, concatenating them with text tokens as input. Although Liao et al. [11] successfully introduce collaborative signals, their direct mapping of continuous vectors leads to distribution discrepancies between modalities. To alleviate this problem, they have to rely on a complex curriculum learning strategy: initially warming up with pure text and then gradually transitioning to hybrid modality training. This multi-stage training process not only increases computational overhead but also requires the model to adapt to dynamically changing input distributions, leading to non-stationarity in the training process and a potential risk of catastrophic forgetting.
Recently, advanced frameworks such as PLUM [21] have attempted to further unify user behaviors and text semantics to enhance reasoning capabilities. However, without explicit structural constraints during the modality mapping process, these continuous-space methods still face challenges in isolating collaborative noise from textual semantics. Meanwhile, multi-modal recommendation works such as Sassi et al. [22] attempt to encode non-text modalities like images and audio into continuous vectors for injection into LLMs. Directly mapping high-dimensional, dense continuous features to the sparse semantic space of LLMs often introduces manifold distribution noise, causing the LLM to generate semantic hallucinations [10,15]. Rajput et al. [23] and Hua et al. [24] have explored using soft prompt techniques to inject behavioral signals; however, their alignment effectiveness remains limited by the ambiguity of the continuous space when handling noisy interaction sequences.
Addressing the limitations of existing methods regarding multi-stage training complexity and continuous feature alignment noise, this paper proposes the structured HDSD and MBSR modules. By transforming the chaotic continuous behavioral space into structured discrete behavioral atoms, we provide the model with robust static semantic anchors. This enables the model to discard complex curriculum learning strategies and directly achieve efficient end-to-end single-stage fine-tuning.
2.2. Vector Quantization for Modality Alignment
Vector quantization aims to discretize continuous features into finite codebook indices and has been widely applied in recent years to bridge the modality gap between structured data and LLMs [13,25].
Pioneering the application of VQ techniques to item indexing tasks, generative retrieval works such as those by Hou et al. [26] and Rajput et al. [23] have significantly advanced the field of recommendation systems. Notably, by introducing the concept of Semantic IDs through RQ-VAE, Rajput et al. enabled LLMs to encode static item features into hierarchical discrete ID sequences. This allows LLMs to directly predict the next item’s semantic ID via generative retrieval, thereby avoiding the computational bottleneck of large scale candidate set ranking.
Further advancing this paradigm, Rajput et al. [23] comprehensively explored recommender systems with generative retrieval, proving the efficacy of generating item identifiers directly via LLMs. Building upon this, TokenRec [27] proposed a generalized discrete tokenization method for items to facilitate LLM comprehension. These works demonstrate that discretized representations possess natural advantages in adapting to the token-based reasoning mechanisms of LLMs.
However, while these closely related discrete-token approaches successfully map static item features into semantic IDs, they predominantly focus on the item side, leaving research on discretization alignment for dynamic user behavior sequences underexplored. Unlike static item features, user behavior implies interest manifolds that evolve over time and complex long-tail preferences; simple concatenation of tokenized item IDs fails to capture such high-order semantics [28]. Furthermore, some attempts to introduce hierarchical structures, such as Lee et al. [29] and Dehghani et al. [30], mostly rely on Straight-Through Estimators for gradient approximation, which are prone to training oscillation and feature representation instability when processing variable-length behavioral sequences.
To fill this gap, this paper proposes the structured HDSD module, migrating the residual quantization mechanism from “item indexing” to “behavioral alignment” tasks. Unlike TokenRec [27] and general generative retrieval methods [23] which generate static item tokens, our method dynamically decomposes evolving user behavioral sequences. This “coarse-to-fine” residual approximation strategy carries explicit physical meaning: the top-level codebook anchors the user’s mainstream interests, such as macro preferences for “Sci-Fi,” while bottom-level codebooks layer-wise refine residuals to accurately capture specific style preferences, such as micro “Cyberpunk” elements. This design not only ensures the richness of semantic representations but, more importantly, decouples the discovery of discrete structures from the semantic alignment process. This empirically promotes the distributional stability of input features in the early stages of training, thereby eliminating the gradient variance problem in end-to-end training and providing a solid theoretical foundation for the Single-Stage Behavioral-Semantic Adaptive Optimization strategy proposed in this paper.
3. Methodology
3.1. Overview
In this section, we first formally define the instruction-based sequential recommendation task based on Large Language Models (LLMs). Subsequently, we introduce the proposed SBT-Rec framework. This framework employs a structured behavioral tokenization mechanism to align the feature spaces of the recommendation model and the LLM. SBT-Rec comprises four core components: the Hierarchical Discrete Structure Discovery module (HDSD, see Section 3.2), the Multi-Scale Behavioral Semantic Reconstruction module (MBSR, see Section 3.3), the Residual-Aware Modality Distribution Aligner (RAM-Aligner, see Section 3.4), and the Single-Stage Behavioral-Semantic Adaptive Optimization strategy (SBS-AO, see Section 3.5).
For the sequential recommendation task, the objective is to model the evolution of user interests. Given a chronologically ordered user historical interaction sequence , where represents the item interacted with by the user at time step t, the sequential recommender learns user representations based on the historical sequence and predicts the next interaction item . In SBT-Rec, we transform this task into an instruction-based conditional text generation task, utilizing behavioral tokens to guide the LLM in generating the textual description of the target item.
Figure 1 illustrates the architecture of SBT-Rec. The process primarily involves two steps: "discretization" and "alignment" of behavioral features.
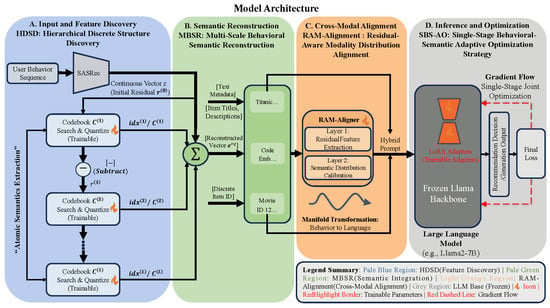
Figure 1.
Schematic diagram of the overall architecture of the SBT-Rec framework. The framework consists of four core functional areas, corresponding to four processing stages of the data flow: (A) Feature Discovery (Pale Blue): The HDSD module receives continuous behavioral vectors encoded by SASRec and decomposes them into hierarchical discrete index sequences via a recursive residual quantization mechanism. (B) Semantic Reconstruction (Pale Green): The MBSR module retrieves basis vectors from multi-layer codebooks and performs residual superposition to synthesize denoised multi-scale behavioral representations, subsequently integrating them with textual metadata. (C) Cross-Modal Alignment (Light Orange): The RAM-Aligner projects reconstructed behavioral features onto the semantic manifold space of the Large Language Model via a two-layer non-linear mapping to generate behavioral tokens . (D) Inference and Optimization (Gray): Constructs a hybrid prompt containing behavioral tokens and textual instructions, which is fed into the frozen Llama2-7B backbone. Note: Red dashed lines indicate the gradient back-propagation path during the Single-Stage Behavioral-Semantic Adaptive Optimization (SBS-AO) process, indicating that LoRA adapters, the aligner, and underlying codebooks are updated synchronously under a unified objective.
First, the sequential recommender encodes the input sequence to generate feature vectors in a continuous space. Subsequently, the HDSD module utilizes a residual recursive quantization mechanism to decompose these vectors into discrete index sequences. This step transforms continuous features into structured behavioral atoms. Next, the MBSR module utilizes these indices to retrieve and accumulate basis vectors from the codebooks, generating behavioral representations containing multi-scale features. This approach preserves specific user preferences while reducing noise in the data.
To address the distribution discrepancy between behavioral vectors and the semantic space of the LLM, we employ the RAM-Aligner to map the reconstructed vectors to the input space of the LLM. This module converts behavioral features into continuous tokens via non-linear layers, enabling them to be directly processed by the LLM. Finally, the SBS-AO strategy employs a single-stage collaborative optimization policy to optimize model parameters, ensuring consistency between underlying behavioral features and high-level reasoning logic. Compared to multi-stage alignment methods, this framework leverages structured representations to improve convergence efficiency.
3.2. Hierarchical Discrete Structure Discovery Module (HDSD)
Feature vectors generated by traditional sequential recommenders reside in a high-dimensional continuous space, typically containing noise and lacking explicit semantic structure. The HDSD module employs a residual recursive quantization mechanism (detailed in Algorithm 1) to decompose into a set of discrete behavioral atoms with hierarchical attributes [13].
| Algorithm 1 Recursive Residual Quantization Process (HDSD) |
|
3.2.1. Hierarchical Codebook Definition
We define a set of discrete codebooks containing L layers:
where each layer of the codebook contains K learnable basis vectors, and represents a specific semantic center of that layer.
3.2.2. Residual Recursive Quantization Process
Given the raw behavioral vector generated by the sequential encoder (e.g., SASRec [20]):
The quantization process extracts features layer by layer. We define the initial residual as:
For each layer , HDSD performs two operations. First, a nearest neighbor search is conducted to find the basis vector index in the current layer codebook that is closest to the residual vector:
Second, a residual update is performed to calculate the remaining information after quantization, which is passed to the next layer for finer-grained feature extraction:
After L rounds of iteration, the original vector is transformed into a discrete index sequence . By finding the nearest codebook vectors, this process corrects minor perturbations in the original vector. Rather than a rigorous mathematical equivalence, conceptually, this process functions analogously to an empirical low-pass filter for semantic signals, preserving the main semantic structure (cluster centers) while empirically filtering out high-frequency noise (outlier deviations).
3.3. Multi-Scale Behavioral Semantic Reconstruction Module (MBSR)
The MBSR module bridges the discrete index sequence and the semantic space of the large model. It retrieves and reconstructs the behavioral representation from the codebooks based on the index sequence output by HDSD.
3.3.1. Semantic Synthesis Based on Residual Superposition
MBSR does not directly project the raw behavioral vector; instead, it performs a linear accumulation of basis vectors from the codebooks. For the index sequence , the reconstructed vector is calculated as follows:
This summation mechanism draws inspiration from the concept of residual networks [14]. It is a coarse-to-fine process: the first-layer vector determines the primary semantics, while vectors in subsequent layers act as residual corrections for details. This hierarchical superposition prevents gradient vanishing in deep layers and enables reconstruction from discrete symbols to dense vectors.
3.3.2. Multi-Scale Feature Fusion and Adaptive Denoising
The MBSR module balances the stability and dynamics of user interests. Through the aforementioned mechanism, the model utilizes the top-level codebook to determine macroscopic preferences and employs bottom-level residuals to capture microscopic corrections. Furthermore, since the reconstructed vector is synthesized from a finite number of basis vectors, this process acts as a denoising filter. It filters out random noise from the original output, ensuring that the signal fed into the LLM maintains a high signal-to-noise ratio.
3.4. Residual-Aware Modality Distribution Aligner (RAM-Aligner)
Although MBSR reconstructs behavioral semantics, a distribution discrepancy remains between the behavioral space and the semantic space of the LLM. The RAM-Aligner constructs a non-linear mapping function to achieve cross-modal alignment:
3.4.1. Definition of Cross-Modal Projection Manifold
We define the mapping between the behavioral representation and the LLM embedding space . The RAM-Aligner uses deep transformations to fit this mapping. We formalize the process as two consecutive transformations:
where extracts features from the quantized residuals, and calibrates the features to the target distribution.
3.4.2. Hierarchical Non-Linear Manifold Mapping
The alignment process is implemented via a Multi-Layer Perceptron (MLP). Since complex topological structural differences exist between the two spaces, a simple linear projection is insufficient for fitting. Therefore, we introduce the GeLU activation function during the feature extraction stage:
where is the GeLU function. GeLU enables the RAM-Aligner to map the discrete behavioral manifold into the continuous language manifold. Subsequently, a second linear projection maps the features to the target dimension , generating the final behavioral token :
Through this transformation, the model smooths the jumps in the quantization space, adapting it to the input distribution of the LLM.
3.4.3. Modality Alignment Objective
The objective of the RAM-Aligner is to minimize the KL divergence between the behavioral modality distribution and the language modality distribution . Although this is implicitly achieved through end-to-end supervision during training, we can formulate it as finding the optimal parameters :
This indicates that the RAM-Aligner serves as an adapter with distribution calibration capabilities. The generated behavioral tokens carry calibrated semantics and are integrated into the input sequence of the large model.
3.4.4. Hybrid Prompt Integration
Based on the aligned behavioral token , we construct the hybrid prompt input for the LLM. This prompt integrates textual semantics and behavioral semantics with the following logic:
where represents the textual embedding of task instructions and item metadata. This design ensures that the LLM simultaneously receives natural language instructions and behavioral signals during inference, thereby enhancing recommendation consistency.
3.5. Single-Stage Behavioral-Semantic Adaptive Optimization Strategy (SBS-AO)
To achieve modality alignment and reduce computational overhead, we propose a parameter-efficient Single-Stage Behavioral-Semantic Adaptive Optimization strategy (SBS-AO). Traditional alignment methods rely on multi-stage curriculum learning to mitigate modality discrepancies. This requires the model to adapt to dynamically changing feature distributions, leading to high computational costs. Conversely, utilizing the stable discrete representations provided by HDSD, SBT-Rec obtains stable semantic priors at the initialization stage. This allows us to construct a unified end-to-end optimization objective, synchronously updating the underlying codebooks and the upper-level mapping within a single stage. Specifically, SBS-AO allows the semantic supervision signal from the LLM to back-propagate, guiding codebook adjustments and thus ensuring the consistency of feature expression.
3.5.1. Learning Objective Function
In SBT-Rec, sequential recommendation is reformulated as a conditional text generation task. Given the input containing the behavioral token and the target description y, the model is optimized by minimizing the negative log-likelihood loss:
where is the token at step t. is the complete parameter set, where represents the frozen LLM parameters and represents the updateable parameters. This formulation ensures that the generation process is jointly driven by semantic knowledge and task instructions [31]. During the inference phase, we employ a beam search strategy to generate text sequences, and the generated item titles are subsequently mapped back to the item space to provide the final Top-N recommendations.
3.5.2. Joint Parameter Space Definition
To capture the association from low-level features to high-level reasoning, SBS-AO defines a joint parameter space:
This realizes joint optimization across three dimensions: first, semantic anchor adaptation, where the underlying codebooks fine-tune their positions based on feedback; second, modality alignment calibration, reducing distribution distance by optimizing the RAM-Aligner parameters ; and finally, inference logic fine-tuning, utilizing LoRA matrices and to adjust attention weights to adapt to the recommendation logic [15].
4. Experimental Setup
This section introduces the experimental design for evaluating the SBT-Rec framework. More details regarding the experimental design and evaluation protocol can be found in Appendix A. We experimentally verify the effectiveness of the HDSD module and the SBS-AO strategy in terms of recommendation accuracy and cross-modal alignment efficiency.
4.1. Research Questions
To evaluate model performance, this study aims to answer the following five questions:
- 1.
- RQ1: Overall Recommendation Performance. How does SBT-Rec perform on benchmark datasets compared to traditional sequential recommendation models and existing LLM recommendation frameworks?
- 2.
- RQ2: Ablation Study. What are the contributions of the four core components of SBT-Rec (HDSD, MBSR, RAM-Aligner, and SBS-AO) to the overall performance?
- 3.
- RQ3: Hierarchical Quantization Analysis. How do the number of quantization layers L and the codebook size K in the HDSD module affect the model’s ability to represent user behaviors?
- 4.
- RQ4: Training Efficiency and Stability. How does the single-stage collaborative optimization strategy of SBT-Rec perform compared to the multi-stage training of LLaRA or other methods?
- 5.
- RQ5: Case Study. Can SBT-Rec generate logically consistent and accurate recommendation results in complex or noisy interaction scenarios?
4.2. Datasets
We conduct experiments on three real-world sequential recommendation benchmark datasets: MovieLens, LastFM, and Steam.
- MovieLens [32]: Contains user rating records for movies and movie metadata (e.g., titles, genres).
- LastFM [33]: Records user interaction history with music artists and social tag information.
- Steam [20]: A widely adopted dataset containing users’ historical interactions with video games and corresponding game metadata.
Following standard settings, we sort interaction sequences by timestamp and split them into training, validation, and test sets in a ratio of 8:1:1. We retain the most recent 10 interactions in the sequence as historical input and pad shorter sequences.
4.3. Baselines for Comparison
We compare SBT-Rec with the following two categories of baseline models:
4.3.1. Traditional Sequential Recommendation Models
- GRU4Rec: Utilizes Recurrent Neural Networks to capture short-term patterns in user behavioral sequences.
- Caser [34]: Captures high-order sequence features via convolutional operations.
- SASRec [20]: Based on self-attention mechanisms, capable of effectively modeling users’ long-term dependencies. Note: SASRec is also utilized as the shared foundational feature encoder for both SBT-Rec and the baseline LLaRA. Including it as a standalone baseline provides a controlled reference to isolate the performance gains derived specifically from modality alignment strategies.
4.3.2. LLM-Based Recommendation Models
- Llama2-7B: An open-source Large Language Model used as the base recommender after fine-tuning.
- GPT-4: An advanced commercial language model evaluated for its zero-shot/few-shot recommendation capabilities.
- MoRec [22]: A recommendation model that integrates multi-modal features of items to enhance semantic understanding.
- TALLRec [7]: An instruction tuning-based method that aligns large models to recommendation tasks.
- LLaRA [11]: The primary baseline for comparison, which similarly utilizes SASRec as its feature encoder, but aligns collaborative signals with the text space via continuous hybrid prompting and adopts a multi-stage curriculum learning strategy.
4.4. Evaluation Metrics
Following common protocols in the field of LLM-based sequential recommendation, we adopt HitRatio@1 (HR@1) and ValidRatio as the primary evaluation metrics. HR@1 measures the model’s accuracy in identifying the correct item from a candidate set containing 20 randomly selected non-interacted items and 1 target item. ValidRatio quantifies the proportion of valid responses in the model output—that is, responses where items are located within the predefined candidate set—reflecting the rigor of the model’s instruction following. For traditional baseline models, we select the candidate item with the highest predicted probability as the final recommendation result.
4.5. Implementation Details
SBT-Rec is implemented based on Python 3.8 and PyTorch Lightning 1.8.6, selecting Llama2-7B as the base model. We employ LoRA technology for parameter-efficient fine-tuning. All experiments are conducted on a single Nvidia A100 GPU. The optimizer used is Adam, with a cosine annealing strategy for the learning rate. In the HDSD module, we predefine hierarchical codebooks containing L layers, each of size K, to achieve the mapping from continuous space to discrete space.
5. Results and Discussion
This section provides a comprehensive analysis of the performance of the SBT-Rec framework through extensive experiments on the MovieLens, LastFM, and Steam datasets, validating the effectiveness of each core module in sequential recommendation tasks.
5.1. Overall Performance Comparison (RQ1)
Table 1 presents the overall performance comparison between SBT-Rec and existing mainstream baseline models on the MovieLens, LastFM, and Steam datasets.

Table 1.
Overall performance comparison of SBT-Rec with existing mainstream baseline models on LastFM, MovieLens, and Steam datasets. Bold values indicate the best-performing model in each column, and the “Imp.%” column shows the relative performance improvement. The statistical significance of the pairwise differences between SBT-Rec and the best baseline is determined by a paired t-test (* indicates ).
As shown in Table 1, SBT-Rec outperforms existing state-of-the-art models across all evaluation metrics on all three benchmark datasets. Specifically, regarding the key metric HitRatio@1, SBT-Rec achieves a performance improvement of 14.30% on the MovieLens dataset, 8.90% on the LastFM dataset, and 4.08% on the Steam dataset compared to the primary baseline, LLaRA [11]. To ensure absolute fairness and transparency, we adopted the exact same dataset splits and evaluation protocols as LLaRA. Therefore, baseline results (including GPT-4) are cited from LLaRA to ensure a standardized comparison and avoid potential prompting bias.
This significant performance gain is mainly attributed to the structured alignment strategy adopted by SBT-Rec. Unlike LLaRA, which relies on continuous space alignment, the HDSD module transforms continuous behavioral embeddings into discrete tokens with explicit semantic hierarchies. This mechanism effectively filters noise in high-dimensional spaces, thereby reducing the difficulty for the LLM to comprehend complex user behavioral patterns. Furthermore, the ValidRatio of SBT-Rec consistently remains above 96%, indicating that after fine-tuning with the Single-Stage Behavioral-Semantic Adaptive Optimization strategy, the model can precisely follow task constraints and generate valid candidate responses. To ensure the robustness of our empirical claims, we conducted 5 independent runs for SBT-Rec using different random initialization seeds. A paired Student’s t-test confirmed that the performance improvements in SBT-Rec over the best baseline (LLaRA) are statistically significant ().
5.2. Ablation Study (RQ2)
To dissect the contribution of each model component, we constructed four variants for comparative experiments (see Figure 2):
- w/o HDSD: Removes the HDSD module, linearly mapping continuous vectors directly to the LLM.
- w/o MBSR: Removes the MBSR module, utilizing only a single-layer index to generate behavioral representations.
- w/o RAM-Aligner: Removes the RAM-Aligner, using a linear projection layer instead.
- w/o SBS-AO: Removes the SBS-AO strategy, employing progressive curriculum learning for training.
Specifically, the results in Figure 2 isolate the orthogonal contributions of the core components across two distinct evaluation dimensions: recommendation accuracy (HR@1) and instruction-following robustness (Valid Ratio). First, the MBSR module primarily drives recommendation accuracy. Removing this module (w/o MBSR) leads to a significant drop in HR@1. This result confirms the existence of obvious modality discrepancies when directly mapping continuous features. Without discretization, high-frequency noise in continuous vectors interferes with the semantic parsing of the LLM. Structured discrete behavioral atoms are a key prerequisite for achieving efficient cross-modal alignment. Additionally, the hierarchical structure of the HDSD module significantly enhances representation capability. Compared to single-layer quantization (w/o HDSD), the three-layer residual structure boosts HR@1 by 6.6%, suggesting that multi-scale codebooks can more comprehensively cover user intents through coarse-grained anchoring and fine-grained refinement.

Figure 2.
Performance contribution analysis of SBT-Rec and its ablation variants on the MovieLens dataset. The plot uses a dual-axis coordinate system to show the impact of different modules on overall performance: the left Y-axis (blue bar chart) represents recommendation accuracy (HR@1), and the right Y-axis (red line chart) represents robustness of instruction following (Valid Ratio). The horizontal axis lists the full model and four variants with specific components removed: (1) w/o SBS-AO (using curriculum learning strategy); (2) w/o HDSD (using only single-layer quantization); (3) w/o RAM (using linear projection instead of non-linear alignment); (4) w/o MBSR (directly using SASRec continuous output). Note: The significant drop in the red line reveals the critical role of RAM-Aligner in maintaining alignment with the LLM semantic space, while the height difference in the blue bars quantifies the contribution of each module to recommendation accuracy.
Figure 2.
Performance contribution analysis of SBT-Rec and its ablation variants on the MovieLens dataset. The plot uses a dual-axis coordinate system to show the impact of different modules on overall performance: the left Y-axis (blue bar chart) represents recommendation accuracy (HR@1), and the right Y-axis (red line chart) represents robustness of instruction following (Valid Ratio). The horizontal axis lists the full model and four variants with specific components removed: (1) w/o SBS-AO (using curriculum learning strategy); (2) w/o HDSD (using only single-layer quantization); (3) w/o RAM (using linear projection instead of non-linear alignment); (4) w/o MBSR (directly using SASRec continuous output). Note: The significant drop in the red line reveals the critical role of RAM-Aligner in maintaining alignment with the LLM semantic space, while the height difference in the blue bars quantifies the contribution of each module to recommendation accuracy.

Conversely, the RAM-Aligner serves an orthogonal role by ensuring cross-modal instruction-following capability. When using a naive linear projection (w/o RAM-Aligner), although the model retains a certain level of accuracy, the Valid Ratio drops precipitously to 0.916. This indicates that simple linear mapping struggles to handle manifold distribution discrepancies across modalities, leading to instruction drift. The RAM-Aligner calibrates the semantic distribution through non-linear transformations, ensuring the canonicalization of generated results.
Figure 3 further visualizes the feature distributions to provide a visual quantitative analysis of semantic interpretability. As shown in Figure 3a, when the RAM-Aligner is removed, the behavioral modality and semantic modality exhibit a state of distribution separation. As shown in Figure 3b, the full model successfully maps and fuses behavioral features into the LLM semantic space, achieving effective manifold alignment. This geometric overlap quantitatively demonstrates that the discrete behavioral atoms carry meaningful and interpretable semantics compatible with the LLM.
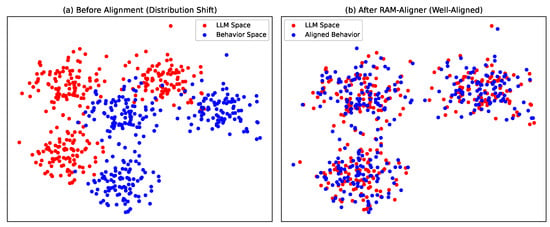
Figure 3.
Comparison of t-SNE visualizations of feature distributions for behavioral modalities and LLM semantic modalities. This visualization is based on 1000 interaction samples randomly drawn from the test set. (a) Unaligned State: Shows the feature distribution after removing RAM-Aligner, where behavioral embeddings (blue data points) and LLM semantic embeddings (red data points) exhibit significant spatial isolation, intuitively confirming the existence of a “modality gap.” (b) Aligned State: Shows the feature distribution of the full SBT-Rec model, where behavioral features are successfully mapped and tightly interwoven within the LLM semantic clusters. This overlap in geometric distribution indicates that RAM-Aligner effectively calibrates the manifold differences between heterogeneous modalities, making behavioral signals compatible with the large model’s semantic space.
Finally, the SBS-AO strategy demonstrates superior training stability. Compared to the variant using the curriculum learning strategy (w/o SBS-AO), the Single-Stage Behavioral-Semantic Adaptive Optimization strategy leverages the stable discrete priors provided by HDSD, avoiding distribution drift issues and achieving a better convergence solution under a unified gradient flow.
5.3. In-Depth Analysis of Hierarchical Quantization Mechanism (RQ3)
Based on the MovieLens dataset, we conducted an in-depth analysis of the impact of the number of quantization layers L and the codebook size K in the HDSD module on model performance.
Impact of Quantization Layers L: As shown in Figure 4b, as the number of layers increases from 1 to 3, model performance shows an upward trend, peaking at 0.505 when . This trend suggests that a single quantization layer struggles to fully cover complex behavioral semantics, while introducing a hierarchical residual structure can activate a coarse-to-fine representation mechanism, enhancing the model’s ability to capture long-tail interests. However, when the number of layers increases to , model performance declines slightly (0.484), which may be due to increased model complexity leading to overfitting given limited data. Therefore, we determine as the optimal structural depth.
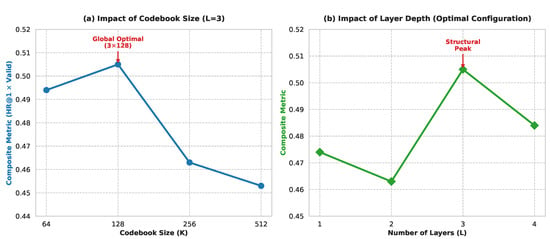
Figure 4.
Sensitivity analysis of key hyperparameter configurations in the HDSD module on overall model performance. To simultaneously evaluate recommendation accuracy and robustness of instruction following, the vertical axis uses a Composite Metric, defined as . (a) Impact of Codebook Size: Shows performance variations with different codebook sizes K under a fixed number of layers . The curve exhibits a significant inverted U-shaped trend, indicating that an overly small codebook limits semantic expression, while an overly large codebook leads to encoding sparsity issues. (b) Impact of Quantization Depth: Shows the performance trajectory for the number of recursive residual quantization layers L. The structural peak observed at confirms that an appropriate hierarchical depth balances feature granularity and the risk of model overfitting, establishing as the optimal structural configuration for the current data scale.
Impact of Codebook Size K: As shown in Figure 4a, performance exhibits a trend of rising and then falling as K increases. At , the smaller codebook capacity limits semantic richness, leading to underfitting. When K increases to 128, the model reaches a global optimum. As K further increases to 256 and 512, performance declines. Analysis suggests that an overly large codebook leads to encoding sparsity, where some discrete tokens fail to receive sufficient gradient updates, thereby affecting the mapping effectiveness of the RAM-Aligner. Therefore, this study selects as the optimal configuration.
5.4. Training Efficiency and Convergence Analysis (RQ4)
We compared SBT-Rec with two mainstream training paradigms—LLaRA (Progressive Curriculum Learning) and Two-Stage Fine-Tuning—in terms of convergence stability and computational efficiency.
Figure 5 illustrates the evolution trajectory of the composite metric () for each model during training. The Two-Stage paradigm (gray bars) shows a clear performance retraction at the beginning of the second stage after the first stage ends. This confirms that physically fragmented training stages may disrupt the alignment already established by the model, leading to a certain degree of forgetting. The curriculum learning paradigm (pink bars), while avoiding performance retraction, exhibits a slower convergence speed. This is because the model needs to continuously adapt to the distribution drift from pure text to hybrid modalities. SBT-Rec (blue bars) demonstrates rapid convergence. Benefiting from the stable discrete priors provided by HDSD, the model does not need to undergo a distribution adaptation period, maintaining high performance from the early stages of training and converging steadily. Compared to the multi-stage curriculum learning paradigm of baselines, our single-stage approach bypasses the heavy overhead of maintaining multiple training pipelines. While we do not focus on hardware-level execution metrics (e.g., FLOPs or GPU memory usage), experimental results indicate that the Single-Stage Behavioral-Semantic Adaptive Optimization strategy significantly improves overall training efficiency by accelerating convergence and reducing paradigm complexity. Notably, the “distributional stability” discussed here is an empirical intuition based on convergence observations, rather than a formal theoretical guarantee.
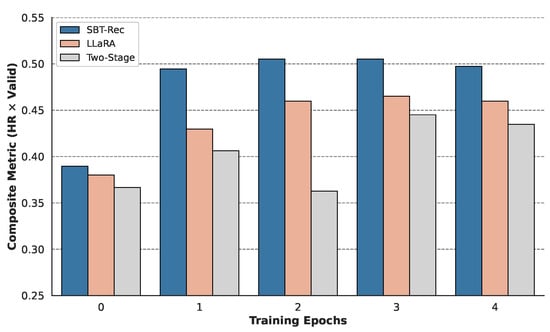
Figure 5.
Comparative analysis of model convergence efficiency and stability under different training paradigms. The vertical axis shows the evolution trajectory of the composite performance metric (calculated as ) over training epochs. (1) SBT-Rec (Blue): Benefiting from the stability of discrete priors, it exhibits immediate convergence characteristics without a warm-up period and maintains a lead throughout the process. (2) LLaRA (Pink): Shows a slower performance ramp-up rate due to the need to adapt to distribution shifts in curriculum learning. (3) Two-Stage (Gray): A significant performance retraction is observed at the phase transition point (Epoch 2), intuitively confirming the parameter optimization fragmentation problem caused by staged training.
5.5. Case Study (RQ5)
Table 2 presents a comparison of recommendation results between SBT-Rec and baseline models under three representative MovieLens interaction scenarios.
Table 2.
Qualitative case study and reasoning analysis under complex interaction scenarios. Selected samples illustrate model performance across three distinct challenges: noise interference (Case 1), fine-grained stylistic preference (Case 2), and dynamic intent shifting (Case 3). Red highlighted text within the interaction context denotes noise injections or pivotal intent turning points. The comparison demonstrates how SBT-Rec leverages hierarchical discrete structures—specifically global anchoring and residual refinement—to overcome recency and popularity biases observed in baselines (SASRec and LLaRA), thereby generating recommendations that are semantically consistent with the Ground Truth.
In the first case, the user’s history is dominated by a series of Hard Sci-Fi movies but ends with an abrupt interaction with a children’s cartoon (Peppa Pig). Both SASRec and LLaRA are trapped by the inherent recency bias of sequential models, erroneously recommending similar cartoons like Toy Story 4 and Frozen II, failing to identify this interaction as noise. In contrast, SBT-Rec successfully recommends Ad Astra, which aligns with the user’s long-term interest. This is mainly attributed to the hierarchical design of the HDSD module, where the top-level codebook firmly anchors the global semantics to the theme of space exploration, thereby effectively filtering out the bottom-level outlier noise during encoding, demonstrating the model’s robustness in complex interaction environments.
In the second case, although all models identified the broad “Action/Sci-Fi” category, only SBT-Rec generated Alita: Battle Angel, which aligns with the user’s unique “Cyberpunk” aesthetic (e.g., The Matrix, Ghost in the Shell). Baseline models were clearly distracted by the widely popular movie Avengers watched recently, falling into the trap of popularity bias and recommending mainstream Marvel movies. This result indicates that the Multi-Scale Behavioral Semantic Reconstruction (MBSR) mechanism in SBT-Rec can utilize bottom-level discrete atoms as “semantic hooks” to precisely capture subtle stylistic features such as “dystopian” aesthetics that are often smoothed out in continuous embedding spaces, thereby resisting the influence of mainstream distractors.
In the third case, the user’s interest shifted significantly recently, moving from a long period of “Romance” to “Action/Crime” (triggered by John Wick). SASRec was still dominated by long-term historical inertia and recommended La La Land, while LLaRA likely hallucinated due to overfitting on the rich textual descriptions of the early history, recommending an incorrect romance movie. However, SBT-Rec accurately predicted the action movie Taken of the same genre. By comparing the second and third cases, we find that SBT-Rec possesses a unique dynamic adjustment capability: it utilizes high-level structures to maintain the user’s long-term profile while leveraging bottom-level residual connections to quickly adapt to immediate interest changes. This semantic coherence confirms that the RAM-Aligner plays a key role in aligning the LLM’s reasoning logic with the user’s evolving intent. Furthermore, these cases provide strong qualitative evidence for the semantic interpretability of the learned behavioral atoms: top-level atoms effectively anchor macroscopic intents (e.g., broad genres), while bottom-level residuals precisely capture fine-grained, interpretable aesthetics (e.g., stylistic sub-genres).
6. Conclusions
This paper addresses the challenges of semantic ambiguity and modality gaps inherent in traditional recommendation models within continuous embedding spaces by proposing the SBT-Rec framework. The core contribution of this study lies in the introduction of a hierarchical discrete representation paradigm: through the HDSD and MBSR modules, we reconstruct continuous user behavioral sequences into discrete behavioral atoms with explicit semantic hierarchies, and achieve efficient alignment with the LLM semantic manifold in conjunction with the RAM-Aligner. Furthermore, the SBS-AO strategy, built upon discrete semantic priors, realizes end-to-end single-stage collaborative optimization, thereby enhancing training efficiency.
Experiments on three real-world datasets validate the effectiveness of SBT-Rec. The model not only outperforms the baseline LLaRA in recommendation accuracy but also demonstrates advantages in rapid convergence and denoising robustness. While SBT-Rec demonstrates strong overall performance, it is important to delineate its optimal application scenarios to improve its positioning within the literature. Compared to pure instruction-tuning and continuous hybrid prompting approaches, SBT-Rec is highly preferable in scenarios characterized by rich but noisy user behavioral histories, where its discrete semantic filter effectively isolates stable interests from outlier interactions. However, in extreme cold-start scenarios where users have zero or very few historical interactions, the advantages of hierarchical sequence quantization are inherently diminished. In such cases, pure text-based instruction-tuning approaches might be more straightforward and sufficiently effective, as they directly leverage the LLM’s zero-shot textual reasoning capabilities without requiring complex sequence modeling.
Future work will focus on expanding the applicability boundaries of SBT-Rec, such as introducing multi-modal information to enrich the semantic dimensions of behavioral atoms, and exploring the scalability of this architecture on larger-scale models.
Author Contributions
Conceptualization, L.C. and H.C.; methodology, L.C. and Y.M.; software, G.L.; validation, L.C. and Y.M.; formal analysis, L.C.; investigation, L.C.; resources, H.C.; data curation, G.L.; writing—original draft preparation, L.C.; writing—review and editing, Y.M. and H.C.; visualization, L.C.; supervision, H.C.; project administration, H.C.; funding acquisition, H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. The MovieLens dataset can be found here https://grouplens.org/datasets/movielens/ (accessed on 2 March 2026). The LastFM dataset used in this study corresponds to the HetRec 2011 version, which is available at https://grouplens.org/datasets/hetrec-2011/ (accessed on 2 March 2026).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Experimental Design and Evaluation Details
Appendix A.1. Dataset Descriptions
To evaluate the generalization capability of SBT-Rec, we conducted experiments on three real-world recommendation benchmark datasets:
- LastFM [33]: This is a music dataset commonly used in recommendation system research, containing historical user interaction records with artists, user demographics, artist names, and related social tags. Since this dataset contains long and highly diverse user behavioral sequences, it is particularly suitable for evaluating the model’s ability to capture the evolution of complex user interests and handle rich meta-information.
- MovieLens [32]: This is a widely used benchmark dataset in the field of recommendation systems, containing user ratings for movies and movie metadata. The diversity of this data helps in understanding model performance when processing different types of content (e.g., plot summaries, cast information, genres), while its long-term span allows us to test the model’s adaptability over time. This study used the standard version to verify the scalability and robustness of SBT-Rec under different data densities.
- Steam [20]: This dataset encompasses rich interaction logs between users and video games on the Steam platform. Compared to movies and music, video game interactions exhibit distinct consumption patterns and sequential dependencies, providing a rigorous testbed to verify the domain adaptability and robust generalizability of the SBT-Rec framework.
Appendix A.2. Baseline Model Details
We compared SBT-Rec with multiple categories of representative models, divided into Traditional Sequential Recommendation Models and LLM-based Recommendation Methods:
- Traditional Sequential Recommendation Models:
- GRU4Rec: Uses gating mechanisms within Recurrent Neural Networks and is capable of effectively modeling short-term user interests.
- Caser [34]: Explores local sequential patterns and dependencies by performing 2D convolutional operations on embedding matrices.
- SASRec [20]: Pioneered the introduction of self-attention mechanisms into recommendation systems and has been proven highly effective in capturing long-term interest evolution.
- LLM-based Models:
- Llama2-7B: An open-source language model released by Meta. We fine-tuned the 7B version to explore how pre-trained language models can adapt to specific recommendation tasks via standard fine-tuning.
- GPT-4: OpenAI’s advanced language model. As noted in Section 5.1, to ensure a strictly fair comparison and avoid prompt-engineering bias, the performance metrics for GPT-4 (evaluated via API calls using a sequential history prompt template) are directly cited from the LLaRA benchmark under identical data splits.
- MoRec [22]: Utilizes pre-trained modality encoders to capture item-specific features (such as text or images), improving recommendation accuracy through multi-modal integration.
- TALLRec [7]: Guides the LLM via domain-specific instruction tuning. It undergoes secondary training on large-scale recommendation corpora to align the model with user intents.
- LLaRA [11]: A state-of-the-art baseline model that uses a “hybrid prompting” method to align collaborative signals with the text space. Importantly, to ensure a fair comparison, LLaRA shares the exact same SASRec sequential encoder configuration as SBT-Rec. This model typically employs a curriculum learning strategy to bridge the modality gap.
Appendix A.3. Implementation and Training Protocol
- Hardware and Software Environment: Experiments for traditional sequential baselines were conducted on a single Nvidia A40 GPU. To meet the computational demands of the Large Language Model backbone, the SBT-Rec framework was implemented and trained on a single Nvidia A100 GPU. All experiments were based on Python 3.8 and PyTorch Lightning 1.8.6 to ensure code modularity and experimental reproducibility.
- Optimization Strategy: Unlike existing methods (such as LLaRA [11]) that rely on multi-stage training or curriculum learning, SBT-Rec adopts the Single-Stage Behavioral-Semantic Adaptive Optimization (SBS-AO) strategy. We set a unified learning rate scheduler and used the Adam optimizer. The training process is end-to-end:
- –
- The codebooks in the HDSD module, parameters of the RAM-Aligner, and LoRA adapters [15] in the LLM backbone are updated synchronously.
- –
- To preserve pre-trained knowledge, the backbone parameters of the LLM (except for LoRA modules) remain frozen.
This strategy significantly improves training efficiency and ensures the consistency of feature alignment.
Appendix A.4. Evaluation Protocol Details
- Candidate Set Construction: For each user sequence in the test set, we constructed a candidate set containing the ground-truth next item and 20 randomly sampled negative items. While traditional recommender systems often rank the entire item pool, doing so in LLM-based generative recommenders incurs severe computational bottlenecks during autoregressive decoding across massive vocabularies. Therefore, this 1:20 setting is deliberately adopted to align with mainstream LLM recommendation benchmarking protocols [7,11], ensuring an optimal balance between evaluation efficiency and fairness.
- Evaluation Metrics: HitRatio@1 Measures whether the model predicts the true item in the candidate set as the highest probability item. For LLM-based recommenders, we parse the generated text to identify the predicted item. ValidRatio Quantifies the proportion of valid responses generated by the LLM. A response is considered valid if the generated item title belongs to the predefined candidate set. This metric evaluates the model’s ability to follow instructions and avoid hallucinations.
- Statistical Validation: All newly reported metrics for SBT-Rec are the average of 5 independent runs initialized with different random seeds. Paired Student’s t-tests were conducted to verify that the performance gains observed over the cited baseline results are statistically significant at a confidence level of 95% ().
References
- Wu, L.; Zheng, Z.; Qiu, Z.; Wang, H.; Gu, H.; Shen, T.; Qin, C.; Zhu, C.; Zhu, H.; Liu, Q.; et al. A survey on large language models for recommendation. World Wide Web 2024, 27, 60. [Google Scholar] [CrossRef]
- Zhao, Z.; Fan, W.; Li, J.; Liu, Y.; Mei, X.; Wang, Y.; Wen, Z.; Wang, F.; Zhao, X.; Tang, J.; et al. Recommender systems in the era of large language models (llms). IEEE Trans. Knowl. Data Eng. 2024, 36, 6889–6907. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Hong, M.; Xia, Y.; Wang, Z.; Zhu, J.; Wang, Y.; Cai, S.; Yang, X.; Dai, Q.; Dong, Z.; Zhang, Z.; et al. EAGER-LLM: Enhancing large language models as recommenders through exogenous behavior-semantic integration. In ACM on Web Conference 2025; ACM: New York, NY, USA, 2025; pp. 2754–2762. [Google Scholar]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-term attention/memory priority model for session-based recommendation. In 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; ACM: New York, NY, USA, 2018; pp. 1831–1839. [Google Scholar]
- Geng, S.; Liu, S.; Fu, Z.; Ge, Y.; Zhang, Y. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In 16th ACM Conference on Recommender Systems; ACM: New York, NY, USA, 2022; pp. 299–315. [Google Scholar]
- Bao, K.; Zhang, J.; Zhang, Y.; Wang, W.; Feng, F.; He, X. TALLRec: An effective and efficient tuning framework to align large language model with recommendation. In 17th ACM Conference on Recommender Systems; ACM: New York, NY, USA, 2023; pp. 1007–1014. [Google Scholar]
- Liu, Q.; Chen, N.; Sakai, T.; Wu, X.M. Once: Boosting content-based recommendation with both open-and closed-source large language models. In 17th ACM International Conference on Web Search and Data Mining; ACM: New York, NY, USA, 2024; pp. 452–461. [Google Scholar]
- Harte, J.; Zorgdrager, W.; Louridas, P.; Katsifodimos, A.; Jannach, D.; Fragkoulis, M. Leveraging large language models for sequential recommendation. In 17th ACM Conference on Recommender Systems; ACM: New York, NY, USA, 2023; pp. 1096–1102. [Google Scholar]
- Yoon, S.e.; He, Z.; Echterhoff, J.; McAuley, J. Evaluating large language models as generative user simulators for conversational recommendation. In 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Volume 1: Long Papers; NAACL: Albuquerque, NM, USA, 2024; pp. 1490–1504. [Google Scholar]
- Liao, J.; Li, S.; Yang, Z.; Wu, J.; Yuan, Y.; Wang, X.; He, X. LLaRA: Large Language-Recommendation Assistant. In 47th International ACM SIGIR Conference on Research and Development in Information Retrieval; ACM: New York, NY, USA, 2024; pp. 1785–1795. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In 26th Annual International Conference on Machine Learning; ACM: New York, NY, USA, 2009; pp. 41–48. [Google Scholar]
- Zeghidour, N.; Luebs, A.; Omran, A.; Skoglund, J.; Tagliasacchi, M. Soundstream: An end-to-end neural audio codec. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 30, 495–507. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-rank adaptation of large language models. ICLR 2022, 1, 3. [Google Scholar]
- Zhang, S.; Dong, L.; Li, X.; Zhang, S.; Sun, X.; Wang, S.; Li, J.; Hu, R.; Zhang, T.; Wang, G.; et al. Instruction tuning for large language models: A survey. ACM Comput. Surv. 2026, 58, 1–36. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; ACM: New York, NY, USA, 2019; pp. 950–958. [Google Scholar]
- Yue, Z.; Rabhi, S.; Moreira, G.d.S.P.; Wang, D.; Oldridge, E. Llamarec: Two-stage recommendation using large language models for ranking. arXiv 2023, arXiv:2311.02089. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In 26th International Conference on World Wide Web (WWW); ACM: New York, NY, USA, 2017; pp. 173–182. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In 2018 IEEE International Conference on Data Mining (ICDM); IEEE: Piscataway, NJ, USA, 2018; pp. 197–206. [Google Scholar]
- He, R.; Heldt, L.; Hong, L.; Keshavan, R.; Mao, S.; Mehta, N.; Su, Z.; Tsai, A.; Wang, Y.; Wang, S.C.; et al. PLUM: Adapting Pre-trained Language Models for Industrial-Scale Generative Recommendations. arXiv 2025, arXiv:2510.07784. [Google Scholar]
- Sassi, I.B.; Yahia, S.B.; Liiv, I. MORec: At the crossroads of context-aware and multi-criteria decision making for online music recommendation. Expert Syst. Appl. 2021, 183, 115375. [Google Scholar] [CrossRef]
- Rajput, S.; Mehta, N.; Singh, A.; Hulikal Keshavan, R.; Vu, T.; Heldt, L.; Hong, L.; Tay, Y.; Tran, V.; Samost, J.; et al. Recommender systems with generative retrieval. Adv. Neural Inf. Process. Syst. 2023, 36, 10299–10315. [Google Scholar]
- Hua, W.; Xu, S.; Ge, Y.; Zhang, Y. How to index item ids for recommendation foundation models. In Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region; ACM: New York, NY, USA, 2023; pp. 195–204. [Google Scholar]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Hou, Y.; He, Z.; McAuley, J.; Zhao, W.X. Learning vector-quantized item representation for transferable sequential recommenders. In ACM Web Conference 2023; ACM: New York, NY, USA, 2023; pp. 1162–1171. [Google Scholar]
- Qu, H.; Fan, W.; Zhao, Z.; Li, Q. TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendations. IEEE Trans. Knowl. Data Eng. 2025, 37, 6216–6231. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In 28th ACM International Conference on Information and Knowledge Management; ACM: New York, NY, USA, 2019; pp. 1441–1450. [Google Scholar]
- Lee, K.; He, L.; Zettlemoyer, L. Higher-order coreference resolution with coarse-to-fine inference. In 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Volume 2 (Short Papers); NAACL: Albuquerque, NM, USA, 2018; pp. 687–692. [Google Scholar]
- Dehghani, M.; Gouws, S.; Vinyals, O.; Uszkoreit, J.; Kaiser, Ł. Universal transformers. arXiv 2018, arXiv:1807.03819. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. (TIIS) 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Cantador, I.; Brusilovsky, P.; Kuflik, T. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In 5th ACM Conference on Recommender Systems; ACM: New York, NY, USA, 2011; pp. 387–388. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In 11th ACM International Conference on Web Search and Data Mining; ACM: New York, NY, USA, 2018; pp. 565–573. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.