




Enhancing Object Detection for VIPs Using YOLOv4_Resnet101 and Text-to-Speech Conversion Model


Abstract
1. Introduction
2. Related Studies
2.1. Limitations of Previous Works
- Many of the earlier models are trained on limited datasets, therefore they are not adaptable well to different settings or circumstances. This restricts the models’ capacity to help VIPs navigate new settings or environments [10].
- The previously created models are frequently susceptible to changes in illumination, camera perspectives, and other external variables. Because of such limitations, those models are not always able to supply VIPs with trustworthy help in different real-world circumstances [5].
- Many earlier methods have poor processing rates, which make them unsuitable for real-time applications [26].
- Prior research could not have effectively considered the speech features of providing VIPs with object information. VIPs must obtain brief and clear audible input in order to fully comprehend the qualities and context of the object [27].
2.2. Novelty and Contributions
- This work focuses on ensuring real-time performance for object identification, enabling the quick and efficient processing of images. This is essential for VIPs because they need immediate information about their environment.
- To recognize objects in the user’s surroundings immediately, the system makes use of the extremely accurate and quick real-time object detection technology known as YOLOv4_Resnet101. This makes it possible for the system to give the user up-to-date information about their surroundings, which is essential for safe and independent travel.
- The proposed system uses state-of-the-art object detection and natural language processing methods to deliver instantaneous object detection and auditory feedback, enabling visually disabled people to freely navigate their environments.
- The incorporation of text-to-speech conversion technology within the system makes a substantial contribution. It enables visually impaired people to observe and comprehend the visual world through audible methods by converting the identified items into audible speech. This improves VIP accessibility and makes it possible for them to interact with their surroundings more successfully.
- The proposed model effectively detected and categorized objects in real-world contexts, reaching a remarkable accuracy of 96.34% on test images taken from the MS COCO dataset.
3. Proposed Work
3.1. Dataset and Pre-Processing
3.2. Data Augmentation
3.3. Object Detection Using YOLOv4
3.3.1. Workflow of YOLO
- Input processing: The input image is resized to a fixed size, such as 416 × 416 pixels, to ensure that the aspect ratio of objects in the image is preserved.
- Neural Network: In this step, the DCNN is deployed to make predictions about the presence and location of objects in an image. The DCNN is trained on a large dataset of annotated images to learn to recognize objects and predict their bounding boxes.
- Grid Cell Assignment: In this step, the image is divided into a grid of cells, where each cell is responsible for predicting the presence and location of objects in a specific region of the image. For each grid cell, YOLO predicts multiple bounding boxes, along with the class probabilities of the objects present in each box.
- Object Detection: These predictions are then filtered using non-maximal suppression to remove overlapping bounding boxes and obtain the final detection result. Finally, the resulting bounding boxes are drawn on the image, along with the class labels of the detected objects. The whole process is repeated for each frame in a video stream, allowing YOLO to perform real-time object detection.
3.3.2. Workflow of YOLOv4
- Backbone: The backbone of the Yolo is typically composed of a series of convolutional layers, which are used to extract high-level features from the input images. The convolutional layers apply a set of filters to the input, sliding them over the input to detect patterns and features at different spatial locations. In YOLOv4, the backbone of YOLOv3, called Darket-53, is replaced by CSPDarknet-53. Cross-stage partial connections (CSP) involve connecting different stages or blocks of the network through a shortcut connection, where a portion of the output from one stage is combined with the output from another stage. This technique improves information flow between the different stages of the network and enables better reuse of features learned at different levels of the network. This can help to improve the overall performance of the network, especially in tasks such as object detection and segmentation, where precise localization and feature reuse are important.
- Neck: Following the backbone, the neck module acts as a link between the high-resolution characteristics of the backbone and the next detection layers. The backbone extracts feature from the input image, while the detection head predicts bounding boxes, abjectness scores, and class probabilities based on those features. The neck in YOLOv4 consists of three different components: the SPP (Spatial Pyramid Pooling) module, the PAN (Path Aggregation Network) module, and the SAM (Spatial Attention Module) module. The SPP module performs max-pooling at different levels of the feature map to capture context information at different scales. The PAN module is designed to aggregate features from different scales and resolutions, which can help improve the accuracy of object detection. The SAM module is a form of attention mechanism that helps the network focus on important features while suppressing irrelevant information.
- Head: The head module is responsible for producing the final predictions for object detection. It uses the feature maps from the neck module and adds additional convolutional layers, commonly followed by fully connected layers, to predict the bounding box coordinates, class probabilities, and other pertinent details for each grid cell. The head module often uses anchor boxes or previous boxes to help in predicting bounding box locations and sizes.
3.3.3. Modifications
- Architecture modifications:
- 2.
- Training modifications:
3.4. Model Training
3.5. Text-to-Speech Conversion
4. Results and Discussions
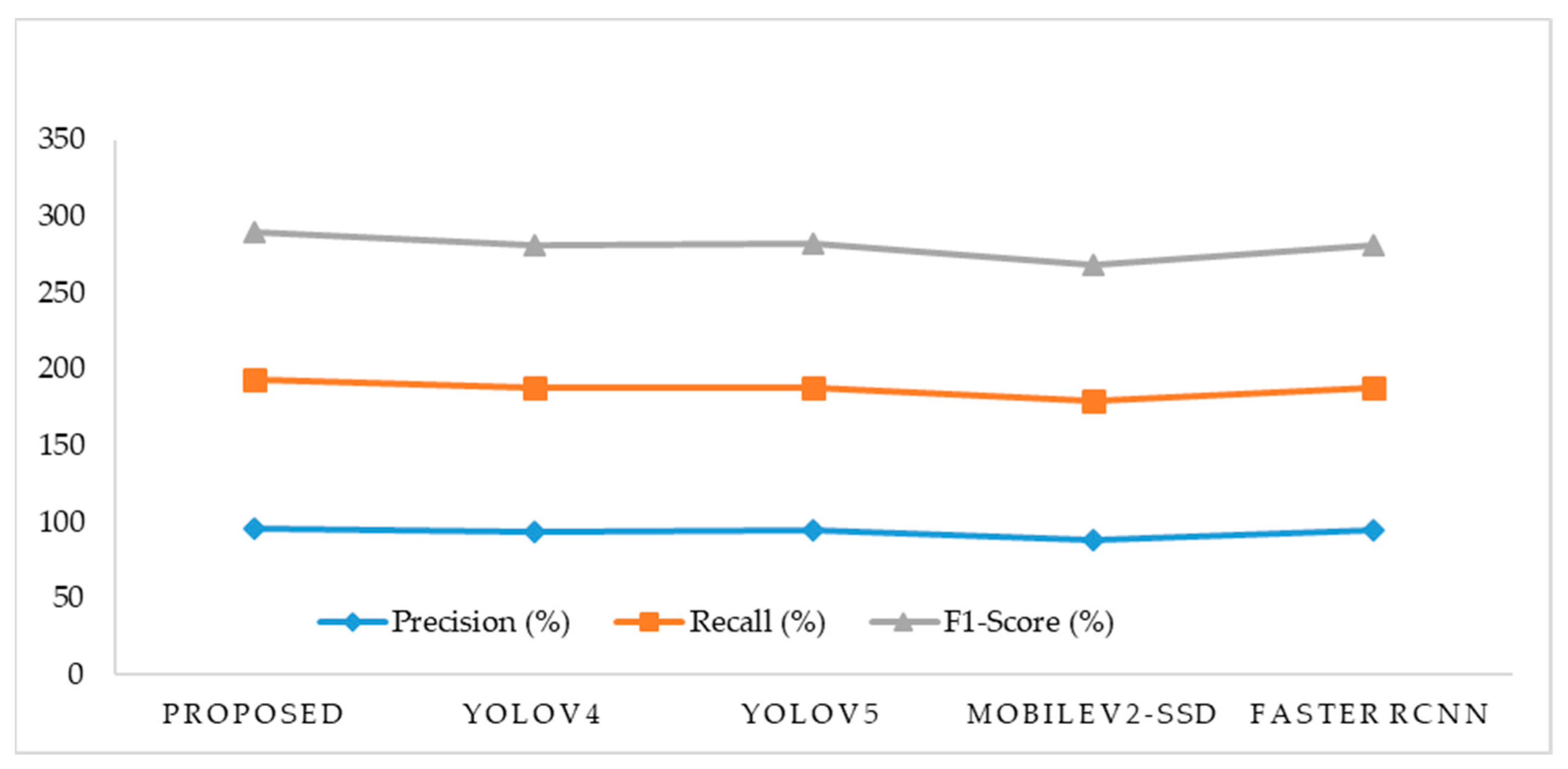
4.1. Comparison with the Related Frameworks
4.2. Comparison with State-of-the-Art Works
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kuriakose, B.; Shrestha, R.; Sandnes, F.E. DeepNAVI: A deep learning based smartphone navigation assistant for people with visual impairments. Expert Syst. Appl. 2023, 212, 118720. [Google Scholar] [CrossRef]
- Khan, G.; Tariq, Z.; Khan, M.U.G. Multi-Person Tracking Based on Faster R-CNN and Deep Appearance Features; Intechopen: London, UK, 2019. [Google Scholar] [CrossRef]
- Tambe, P.M.; Khade, R.; Shinde, A.; Ahire, A.; Murkute, N. Third eye: Object recognition and tracking system to assist visually impaired people. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 218, 1–5. [Google Scholar]
- Rathi, M.; Sahu, S.; Goel, A.; Gupta, P. Personalized Health Framework for Visually Impaired. Informatica 2022, 46. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance. Sensors 2017, 17, 2473. [Google Scholar] [CrossRef] [PubMed]
- Shadi, S.; Hadi, S.; Nazari, M.; Hardt, W. Outdoor Navigation for Visually Impaired Based on Deep Learning. 2019. Volume 2514, pp. 97–406. Available online: https://ceur-ws.org/Vol-2514/paper102.pdf (accessed on 2 June 2023).
- Deepa, R.; Tamilselvan, E.; Abrar, E.; Sampath, S. Comparison of yolo, ssd, faster rcnn for real time tennis ball tracking for action decision networks. In Proceedings of the International Conference on Advances in Computing and Communication Engineering (ICACCE), IEEE, Sathyamangalam, India, 4–6 April 2019; pp. 1–4. [Google Scholar]
- Kim, J.; Sung, J.Y.; Park, S. Comparison of Faster-RCNN, YOLO, and SSD for real-time vehicle type recognition. In Proceedings of the IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020; pp. 1–4. [Google Scholar]
- Abdul-Ameer, H.S.; Hassan, H.J.; Abdullah, S.H. Development smart eyeglasses for visually impaired people based on you only look once. Telkomnika Telecommun. Comput. Electron. Control 2022, 20, 109–117. [Google Scholar] [CrossRef]
- Wong, Y.; Lai, J.; Ranjit, S.; Syafeeza, A.; Hamid, N. Convolutional neural network for object detection system for blind people. J. Telecommun. Electron. Comput. Eng. 2019, 11, 1–6. [Google Scholar]
- Suman, S.; Mishra, S.; Sahoo, K.S.; Nayyar, A. Vision Navigator: A Smart and Intelligent Obstacle Recognition Model for Visually Impaired Users. Mob. Inf. Syst. 2022, 2022, 9715891. [Google Scholar] [CrossRef]
- Ashiq, F.; Asif, M.; Bin Ahmad, M.; Zafar, S.; Masood, K.; Mahmood, T.; Mahmood, M.T.; Lee, I.H. CNN-Based Object Recognition and Tracking System to Assist Visually Impaired People. IEEE Access 2022, 10, 14819–14834. [Google Scholar] [CrossRef]
- Shamsollahi, D.; Moselhi, O.; Khorasani, K. A Timely Object Recognition Method for Construction using the Mask R-CNN Architecture. In Proceedings of the International Symposium on Automation and Robotics in Construction, Dubai, United Arab Emirates, 2–4 November 2021; pp. 372–378. [Google Scholar] [CrossRef]
- Rachburee, N.; Punlumjeak, W. An assistive model of obstacle detection based on deep learning: YOLOv3 for visually impaired people. Int. J. Electr. Comput. Eng. 2021, 11, 3434–3442. [Google Scholar] [CrossRef]
- Adeyanju, I.A.; Azeez, M.A.; Bello, O.; Badmus, T.A.; Oyediran, M. Development of a Convolutional Neural Network-Based Object Recognition System for Uncovered Gutters and Bollards. ABUAD J. Eng. Res. Dev. 2022, 5, 147–154. [Google Scholar]
- Rahman, M.M.; Manik, M.M.H.; Islam, M.M.; Mahmud, S.; Kim, J.-H. An Automated System to Limit COVID-19 Using Facial Mask Detection in Smart City Network. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Mbunge, E.; Simelane, S.; Fashoto, S.G.; Akinnuwesi, B.; Metfula, A.S. Application of deep learning and machine learning models to detect COVID-19 face masks—A review. Sustain. Oper. Comput. 2021, 2, 235–245. [Google Scholar] [CrossRef]
- Xie, L. Analysis of Commodity image recognition based on deep learning. In Proceedings of the 6th International Conference on Multimedia and Image Processing, Zhuhai, China, 8–10 January 2021; pp. 50–55. [Google Scholar]
- Wang, T.; Zheng, N.; Xin, J.; Ma, Z. Integrating Millimeter Wave Radar with a Monocular Vision Sensor for On-Road Obstacle Detection Applications. Sensors 2011, 11, 8992–9008. [Google Scholar] [CrossRef] [PubMed]
- Pouladzadeh, P.; Shirmohammadi, S. Mobile Multi-Food Recognition Using Deep Learning. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 13, 1–21. [Google Scholar] [CrossRef]
- Alahmadi, T.; Drew, S. Subjective evaluation of website accessibility and usability: A survey for people with sensory disabilities. In Proceedings of the 14th International Web for All Conference, Perth, Australia, 28 May–1 June 2017; pp. 1–4. [Google Scholar]
- Ivanov, R. An approach for developing indoor navigation systems for visually impaired people using Building Information Modeling. J. Ambient. Intell. Smart Environ. 2017, 9, 449–467. [Google Scholar] [CrossRef]
- Bhadani, A.K.; Sinha, A.J. A facemask detector using machine learning and image processing techniques. Eng. Sci. Technol. Int. J. 2020, 1–8. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Arora, A.; Grover, A.; Chugh, R.; Reka, S.S. Real Time Multi Object Detection for Blind Using Single Shot Multibox Detector. Wirel. Pers. Commun. 2019, 107, 651–661. [Google Scholar] [CrossRef]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An Evaluation of RetinaNet on Indoor Object Detection for Blind and Visually Impaired Persons Assistance Navigation. Neural Process Lett. 2020, 51, 2265–2279. [Google Scholar] [CrossRef]
- Alzahrani, N.; Al-Baity, H.H. Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation. Electronics 2023, 12, 541. [Google Scholar] [CrossRef]
- Lin, Y.T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13; pp. 740–755. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A.U. Object Detection through Modified YOLO Neural Network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| YOLOv4_Resnet101 | YOLOv4 with ResNet-101 as the backbone |
| Input-image (416, 416) | The size of input images provided for training |
| [(10, 13), (16, 30), (33, 23)] | Anchor Boxes are used for predicting bounding box coordinates. |
| kernel_size = (7, 7) | Filters size |
| Pool-size = (3 × 3), stride (2, 2) | Max pooling with a pool size of 3 × 3 and stride 2 is used |
| train_ratio = 0.8 | Training set |
| test_ratio = 0.2 | Testing set |
| num_epoch = 300 | Number of epochs |
| num_iterations = 4000 | Number of iterations |
| lr = 1 × 10−4 | Learning rate |
| lr_decay_epoch = 50 | Every 50 epochs, the learning rate decays |
| batch_size = 32, 64 | Samples processed in a single forward and backward pass |
| Adam Optimizer | To optimize the parameters of the network |
| S. No. | Obstacle Category | Average Accuracy |
|---|---|---|
| 1 | Person | 99.03 |
| 2 | Car | 98.17 |
| 3 | Bus | 95.81 |
| 4 | Truck | 99.01 |
| 5 | M-Cycle | 93.00 |
| 6 | Cycle | 97.80 |
| 7 | Table | 95.80 |
| 8 | Desk | 98.90 |
| 9 | Chair | 93.17 |
| 10 | Bed | 92.76 |
| 11 | Tree | 97.55 |
| 12 | Animal | 96.87 |
| 13 | Pillar | 97.00 |
| 14 | Gutter | 87.00 |
| 15 | Fan | 96.73 |
| 16 | Refrigerator | 97.00 |
| 17 | mAP | 96.025 |
| Model | Inference Speed (FPS) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Proposed Model | 60–80 | 95.6 | 97.1 | 96.34 |
| YOLOv4 | 20–40 | 93.41 | 94.07 | 93.74 |
| YOLOv5 | 30–50 | 95 | 93 | 93.99 |
| MobileV2-SSD | 50–70 | 88.31 | 90.8 | 89.54 |
| Faster RCNN | 5–10 | 95 | 92.67 | 93.82 |
| Study | Year | Method | Dataset | Accuracy |
|---|---|---|---|---|
| Shadi et al. [5] | 2019 | DeepLabV3+ | Custom | 79% |
| Wong et al. [10] | 2019 | Edge Box- SSD | CIFAR | 73.7 |
| Ashiq, F. et al. [12] | 2022 | MobileNet | ImageNet | 83.3% |
| Suman, S. et al. [11] | 2022 | SSD-RNN | MS COCO | 95.06 |
| Adeyanju et al. [15] | 2022 | Custom CNN | Custom | 84% |
| Kuriakose et al. [1] | 2023 | Efficient Net | Custom | 87.8% |
| Proposed method | 2023 | YOLOv4_Resnet101 | MS COCO | 96.34% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alahmadi, T.J.; Rahman, A.U.; Alkahtani, H.K.; Kholidy, H. Enhancing Object Detection for VIPs Using YOLOv4_Resnet101 and Text-to-Speech Conversion Model. Multimodal Technol. Interact. 2023, 7, 77. https://doi.org/10.3390/mti7080077
Alahmadi TJ, Rahman AU, Alkahtani HK, Kholidy H. Enhancing Object Detection for VIPs Using YOLOv4_Resnet101 and Text-to-Speech Conversion Model. Multimodal Technologies and Interaction. 2023; 7(8):77. https://doi.org/10.3390/mti7080077
Chicago/Turabian StyleAlahmadi, Tahani Jaser, Atta Ur Rahman, Hend Khalid Alkahtani, and Hisham Kholidy. 2023. "Enhancing Object Detection for VIPs Using YOLOv4_Resnet101 and Text-to-Speech Conversion Model" Multimodal Technologies and Interaction 7, no. 8: 77. https://doi.org/10.3390/mti7080077
APA StyleAlahmadi, T. J., Rahman, A. U., Alkahtani, H. K., & Kholidy, H. (2023). Enhancing Object Detection for VIPs Using YOLOv4_Resnet101 and Text-to-Speech Conversion Model. Multimodal Technologies and Interaction, 7(8), 77. https://doi.org/10.3390/mti7080077