
IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques

Abstract
:1. Introduction
- Propose a new IoT framework based on machine learning techniques for the detection of COVID-19 by using breathing voice signals.
- Use mel-frequency cepstral coefficients (MFCCs) to extract the needed features from breathing voice signals and the naïve Bayes (NB) algorithm to classify whether the input voice signal is positive or negative.
- Evaluate the proposed work based on several of the most common evaluation measurements—accuracy, sensitivity, specificity, precision, F-Measure, and G-Mean.
- Compare the proposed NB algorithm against the SVM and RF algorithms in the detection of the COVID-19 by using breathing voice signals.
- Compare the performance of the proposed work, in terms of accuracy, with recent studies that used the same dataset.
2. Related Works
- The outcomes of most previous works are still not encouraging and require more enhancement regarding the accuracy rate.
- Most of the previous studies have been evaluated based on limited evaluation measurements.
3. Proposed Method
3.1. Database
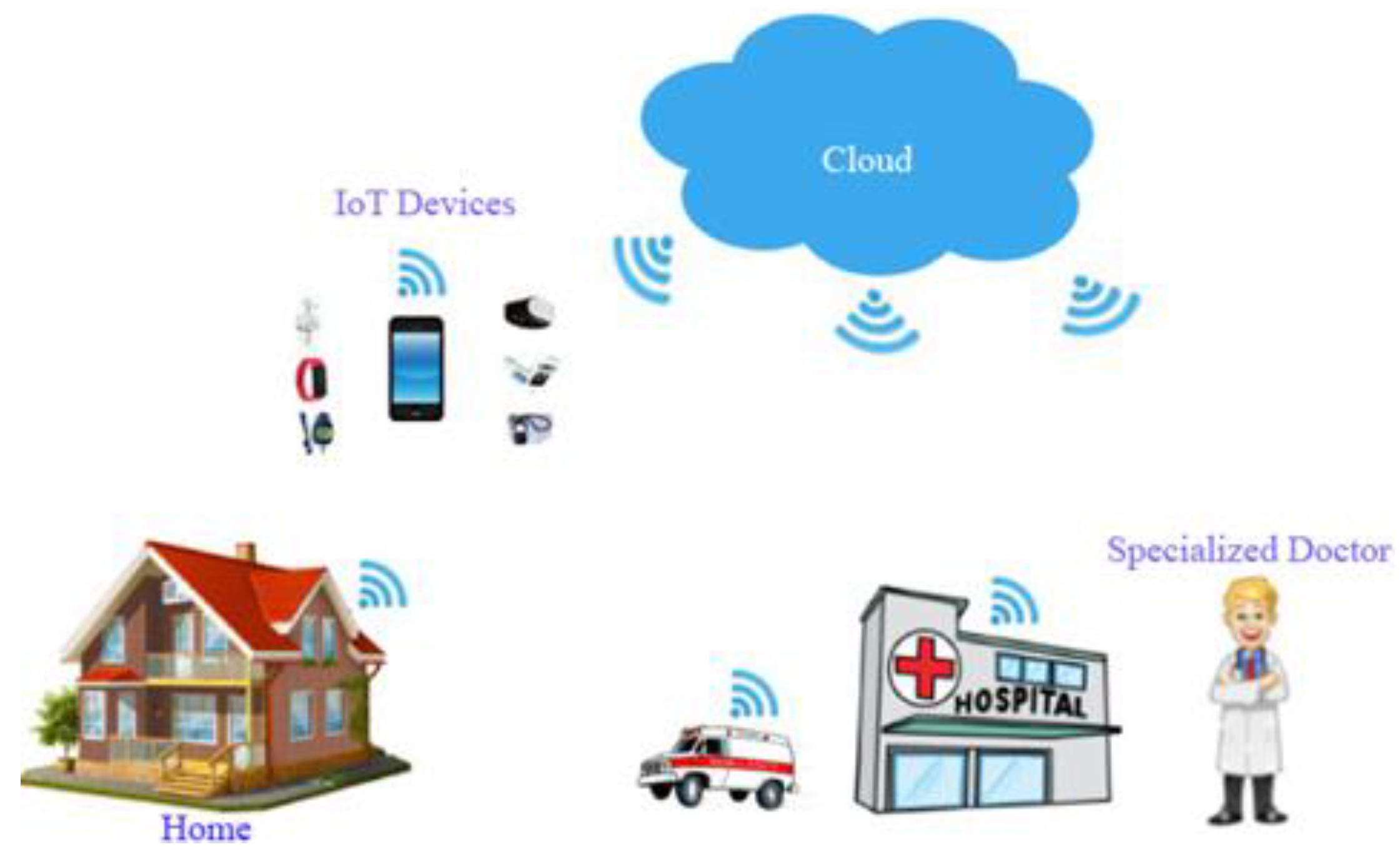
3.2. IoT Framework
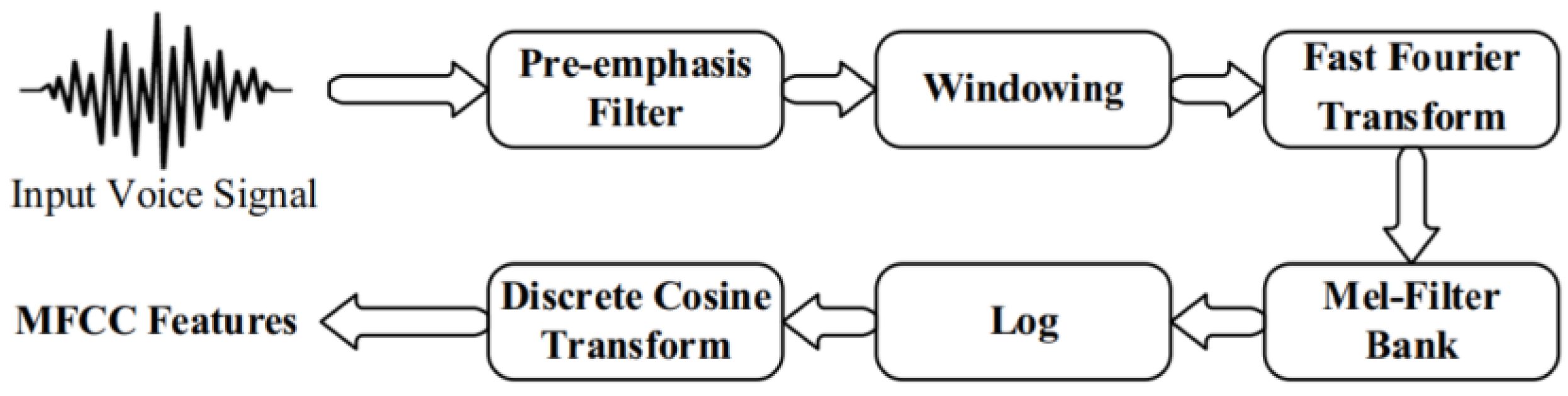
3.3. Feature Extraction
3.4. Classification
- ○
- P(c|x) is the posterior probability of class (c) given predictor (x).
- ○
- P(c) is the prior probability of class.
- ○
- P(x|c) is the likelihood which is the probability of the predictor given class.
- ○
- P(x) is the prior probability of the predictor.
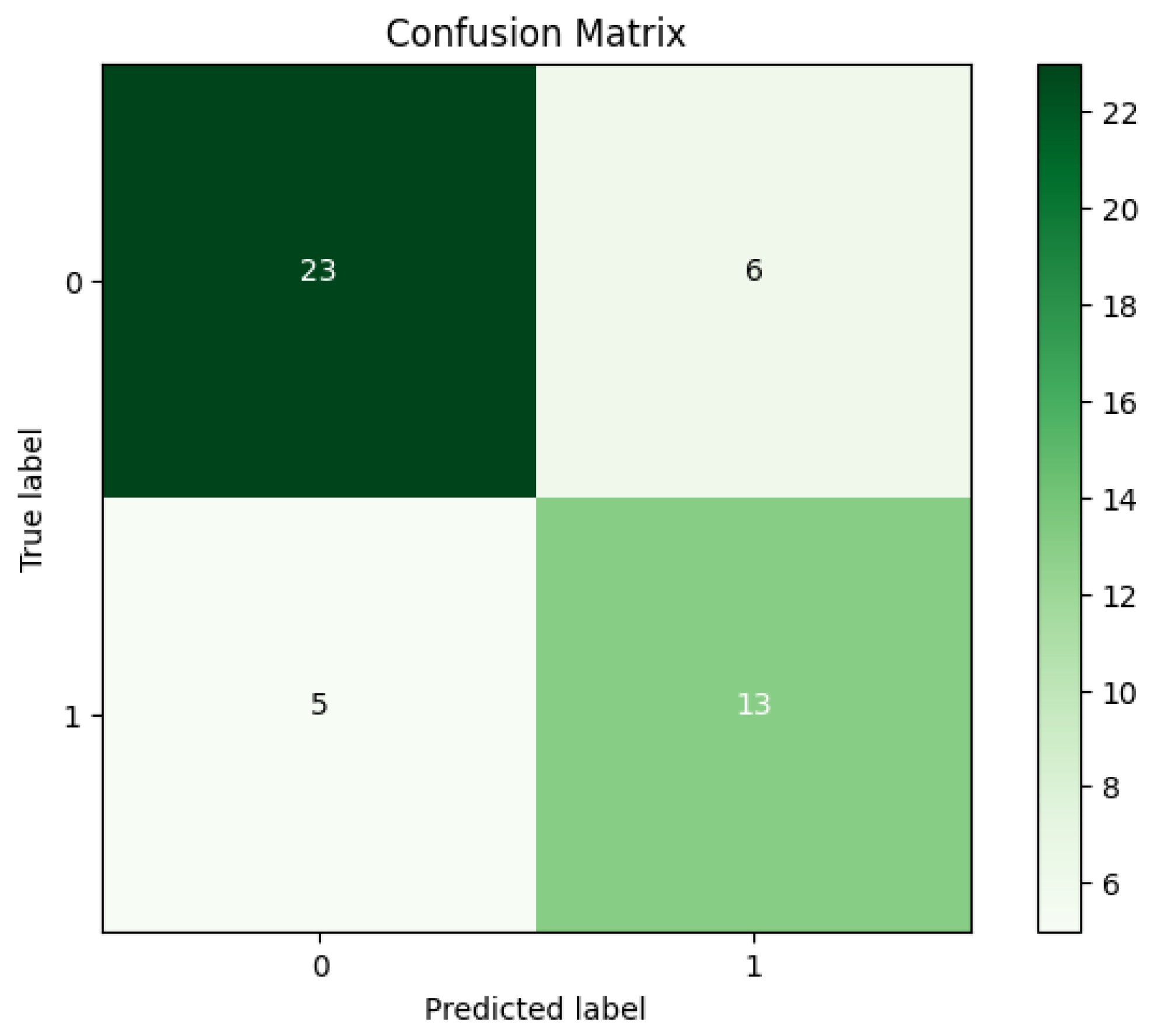
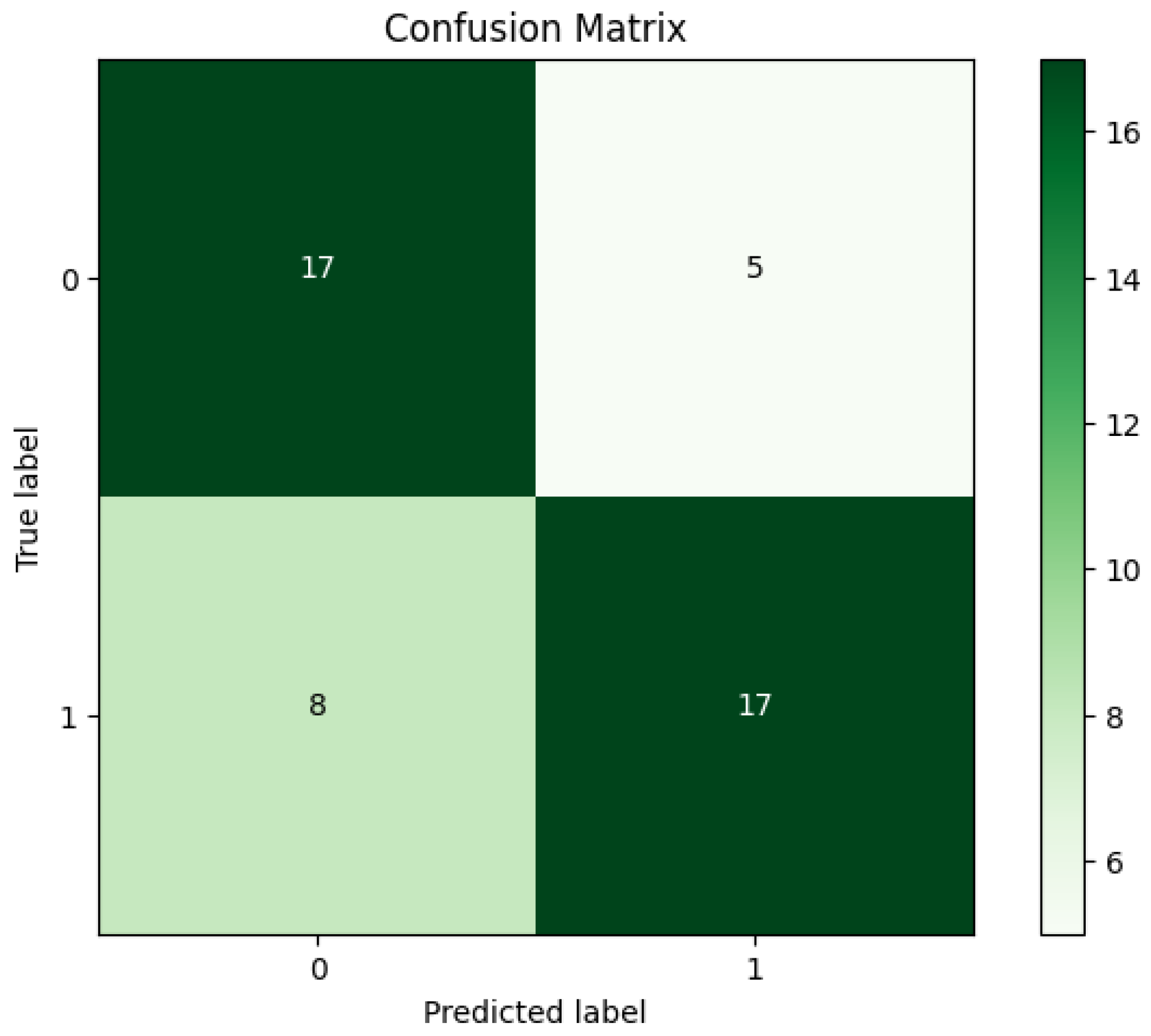
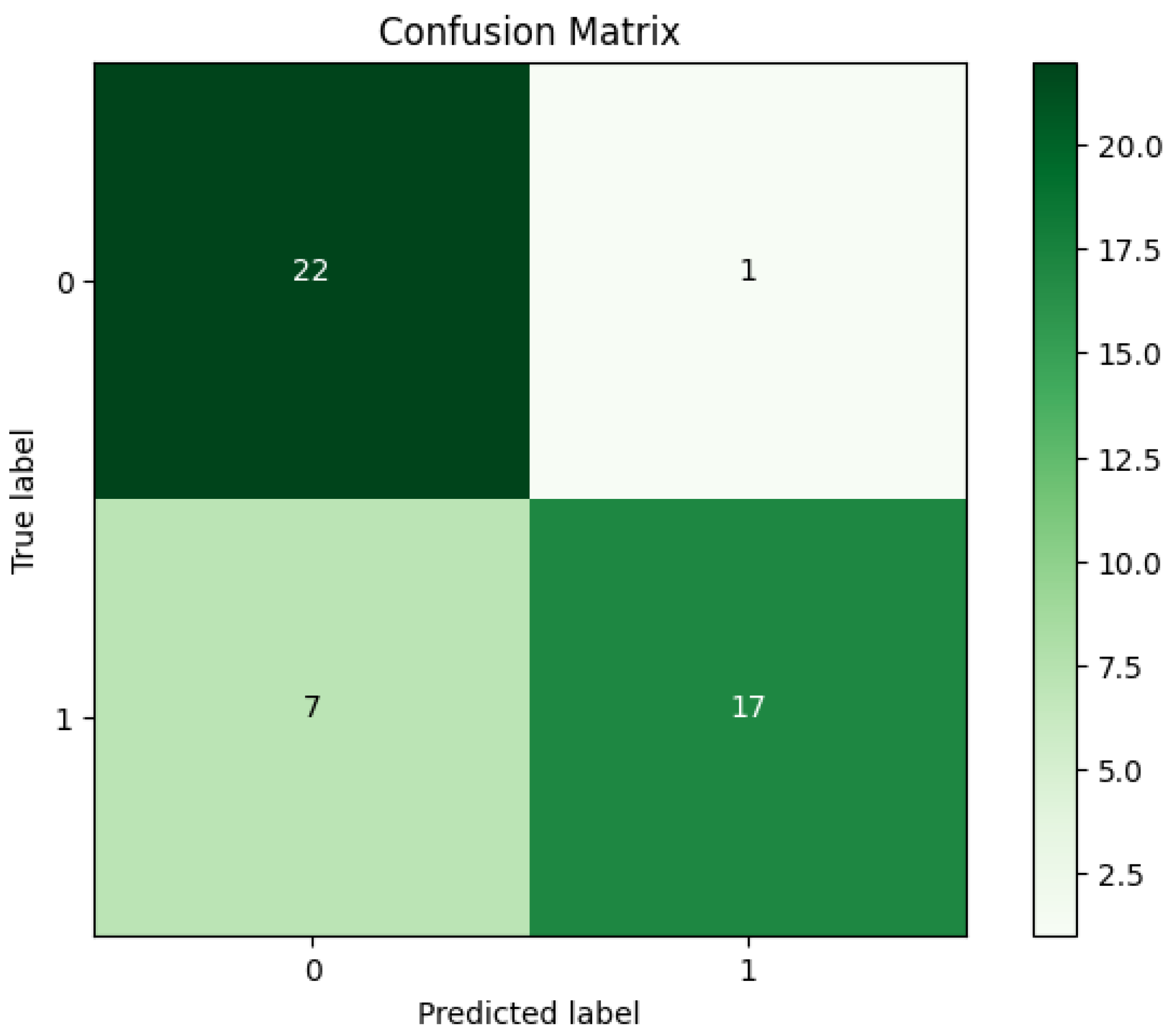
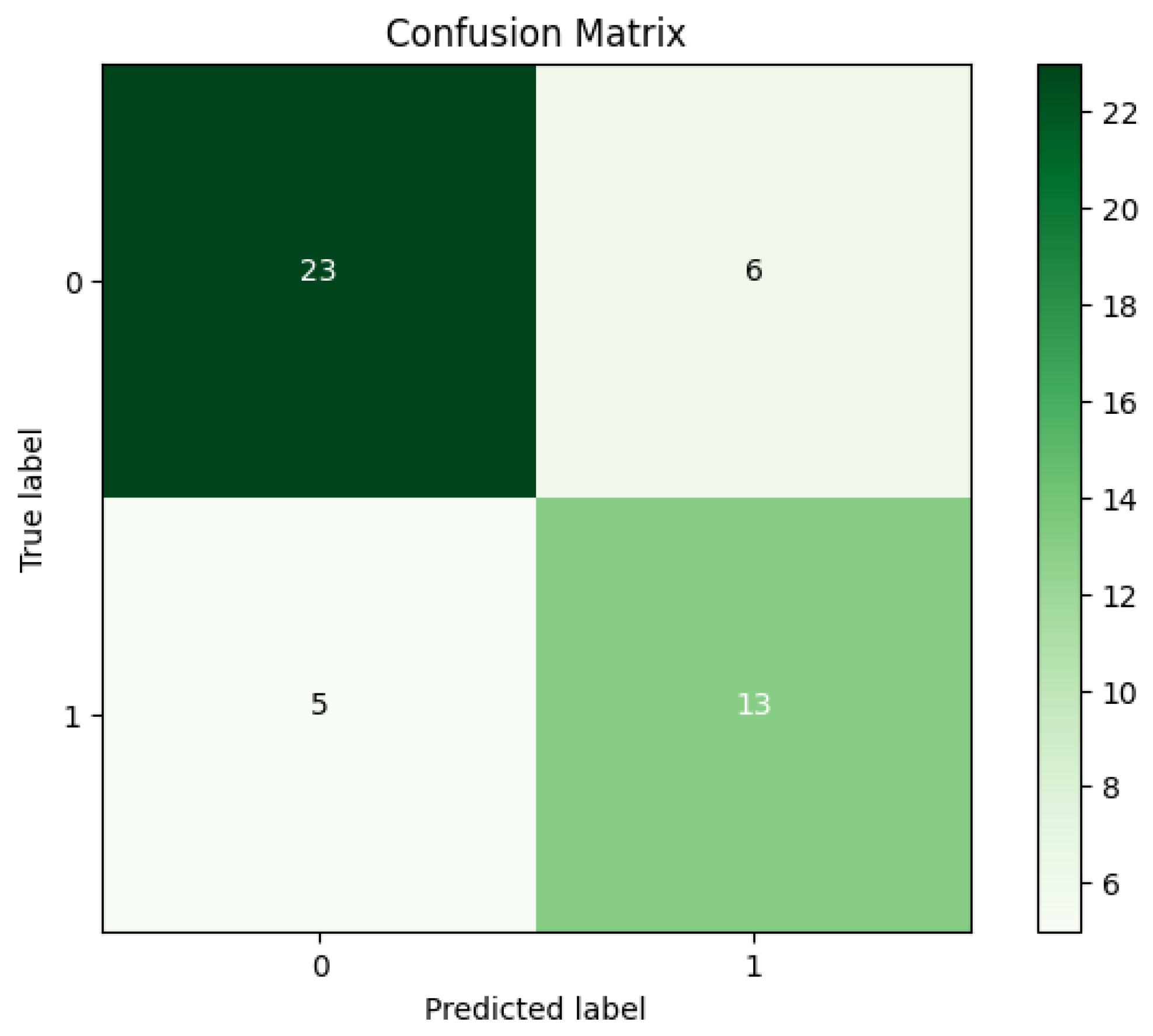
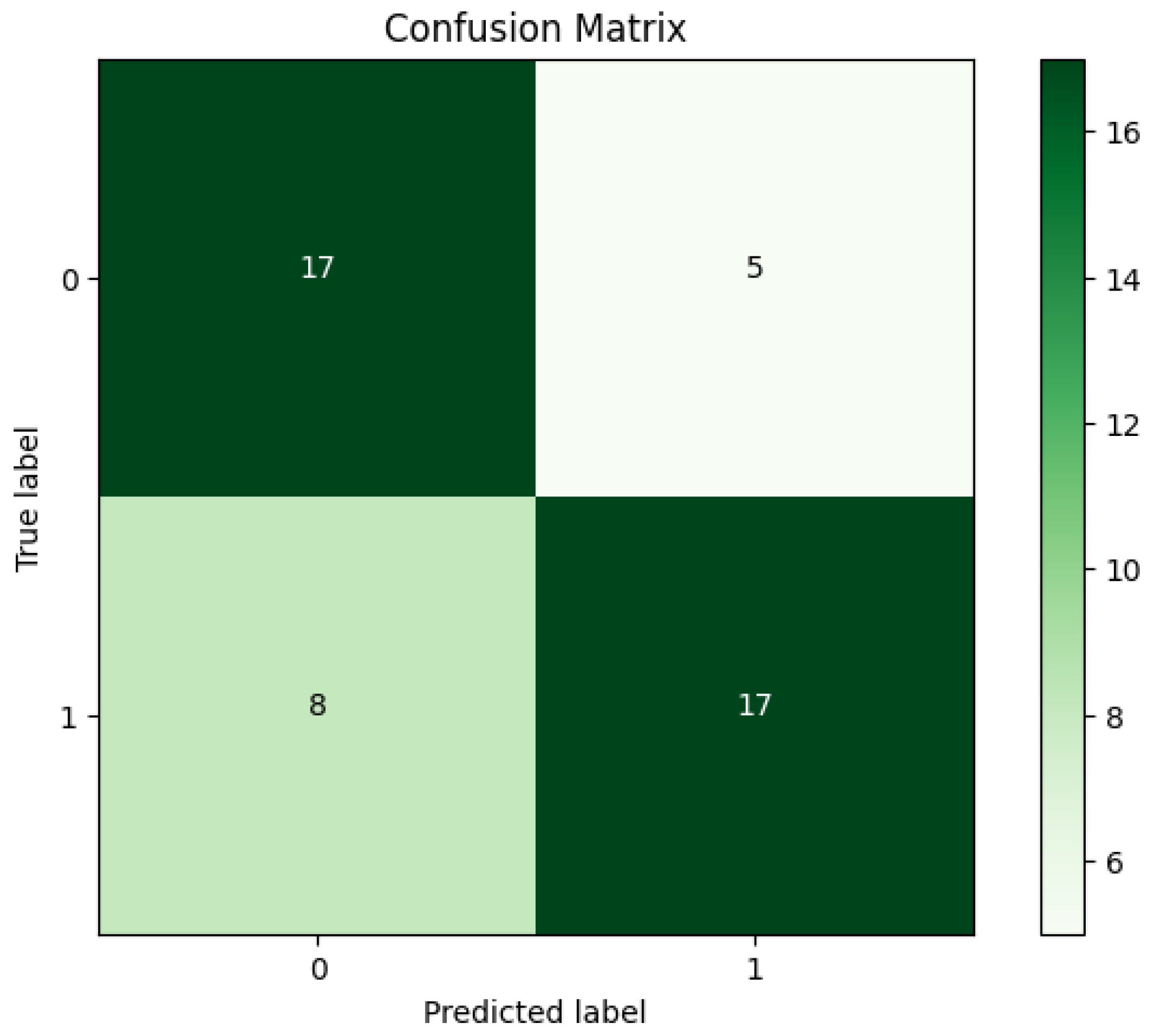
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Latif, S.; Qadir, J.; Qayyum, A.; Usama, M.; Younis, S. Speech technology for healthcare: Opportunities, challenges, and state of the art. IEEE Rev. Biomed. Eng. 2020, 14, 342–356. [Google Scholar] [CrossRef] [PubMed]
- Kanase, N.V.; Pangoankar, S.A.; Panat, A.R. A Robust Approach of Estimating Voice Disorder Due to Thyroid Disease. In Advances in Signal and Data Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 157–168. [Google Scholar]
- Pradhan, B.; Bhattacharyya, S.; Pal, K. IoT-based applications in healthcare devices. J. Healthc. Eng. 2021, 2021, 6632599. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Internet of Things: Device Capabilities, Architectures, Protocols, and Smart Applications in Healthcare Domain. IEEE Internet Things J. 2022, 10, 3611–3641. [Google Scholar] [CrossRef]
- Al-Dhief, F.T.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Salim, N.S.; Baki, M.M.; Albadr, M.A.A.; Mohammed, M.A. A survey of voice pathology surveillance systems based on internet of things and machine learning algorithms. IEEE Access 2020, 8, 64514–64533. [Google Scholar] [CrossRef]
- Alshamrani, M. IoT and artificial intelligence implementations for remote healthcare monitoring systems: A survey. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4687–4701. [Google Scholar] [CrossRef]
- He, R.; Liu, H.; Niu, Y.; Zhang, H.; Genin, G.M.; Xu, F. Flexible miniaturized sensor technologies for long-term physiological monitoring. npj Flex. Electron. 2022, 6, 20. [Google Scholar] [CrossRef]
- Vellela, S.S.; Balamanigandan, R.; Praveen, S.P. Strategic Survey on Security and Privacy Methods of Cloud Computing Environment. J. Next Gener. Technol. 2022, 2, 70–78. [Google Scholar]
- Baker, S.; Xiang, W. Artificial Intelligence of Things for Smarter Healthcare: A Survey of Advancements, Challenges, and Opportunities. IEEE Commun. Surv. Tutor. 2023, 25, 1261–1293. [Google Scholar] [CrossRef]
- Chavda, V.P.; Patel, K.; Patel, S.; Apostolopoulos, V. Artificial Intelligence and Machine Learning in Healthcare Sector. Bioinform. Tools Pharm. Drug Prod. Dev. 2023, 285–314. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T.; Omar, K.; Hamzah, F.A. Optimised genetic algorithm-extreme learning machine approach for automatic COVID-19 detection. PLoS ONE 2020, 15, e0242899. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; AL-Dhief, F.T. Spoken language identification based on optimised genetic algorithm–extreme learning machine approach. Int. J. Speech Technol. 2019, 22, 711–727. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Nazri, M.Z.A.; AL-Dhief, F.T. Grey wolf optimization-extreme learning machine for automatic spoken language identification. Multimed. Tools Appl. 2023, 82, 27165–27191. [Google Scholar] [CrossRef]
- AL-Dhief, F.T.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Sabri, N.; Baki, M.M.; Albadr, M.A.A.; Abbas, A.F.; Hussein, Y.M.; Mohammed, M.A. Voice Pathology Detection Using Machine Learning Technique. In Proceedings of the 2020 IEEE 5th International Symposium on Telecommunication Technologies (ISTT), Shah Alam, Malaysia, 9–11 November 2020; IEEE: New York, NY, USA, 2020; pp. 99–104. [Google Scholar]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Khanapi Abd Ghani, M.; Maashi, M.S.; Garcia-Zapirain, B.; Oleagordia, I.; Alhakami, H.; Al-Dhief, F.T. Voice Pathology Detection and Classification Using Convolutional Neural Network Model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Mostafa, S.A.; Obaid, O.I.; Zeebaree, S.R.; Abd Ghani, M.K.; Mustapha, A.; Fudzee, M.F.M.; Jubair, M.A.; Hassan, M.H.; Ismail, A.; et al. An anti-spam detection model for emails of multi-natural language. J. Southwest Jiaotong Univ. 2019, 54. [Google Scholar] [CrossRef]
- Abbas, A.F.; Sheikh, U.U.; AL-Dhief, F.T.; Mohd, M.N.H. A Comprehensive Review of Vehicle Detection Using Computer Vision. Submitt. TELKOMNIKA Telecommun. Comput. Electron. Control J. 2020, 19, 838–850. [Google Scholar] [CrossRef]
- Salam, M.A.; Taha, S.; Ramadan, M. COVID-19 detection using federated machine learning. PLoS ONE 2021, 16, e0252573. [Google Scholar]
- Radhika, P.; Nair, R.A.; Veena, G. A comparative study of lung cancer detection using machine learning algorithms. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar]
- Al-Dhief, F.T.; Baki, M.M.; Latiff, N.M.A.A.; Malik, N.N.N.A.; Salim, N.S.; Albader, M.A.A.; Mahyuddin, N.M.; Mohammed, M.A. Voice pathology detection and classification by adopting online sequential extreme learning machine. IEEE Access 2021, 9, 77293–77306. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Ayob, M.; Tiun, S.; AL-Dhief, F.T.; Arram, A.; Khalaf, S. Breast cancer diagnosis using the fast learning network algorithm. Front. Oncol. 2023, 13, 1150840. [Google Scholar] [CrossRef]
- Mujumdar, A.; Vaidehi, V. Diabetes prediction using machine learning algorithms. Procedia Comput. Sci. 2019, 165, 292–299. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Ayob, M.; Tiun, S.; Al-Dhief, F.T.; Hasan, M.K. Gray wolf optimization-extreme learning machine approach for diabetic retinopathy detection. Front. Public Health 2022, 10, 925901. [Google Scholar] [CrossRef]
- Atlam, M.; Torkey, H.; El-Fishawy, N.; Salem, H. Coronavirus disease 2019 (COVID-19): Survival analysis using deep learning and Cox regression model. Pattern Anal. Appl. 2021, 24, 993–1005. [Google Scholar] [CrossRef] [PubMed]
- Asghar, N.; Mumtaz, H.; Syed, A.A.; Eqbal, F.; Maharjan, R.; Bamboria, A.; Shrehta, M. Safety, efficacy, and immunogenicity of COVID-19 vaccines; a systematic review. Immunol. Med. 2022, 45, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Azarpazhooh, M.R.; Morovatdar, N.; Avan, A.; Phan, T.G.; Divani, A.A.; Yassi, N.; Stranges, S.; Silver, B.; Biller, J.; Belasi, M.T.; et al. COVID-19 pandemic and burden of non-communicable diseases: An ecological study on data of 185 countries. J. Stroke Cerebrovasc. Dis. 2020, 29, 105089. [Google Scholar] [CrossRef] [PubMed]
- Rofail, D.; McGale, N.; Podolanczuk, A.J.; Rams, A.; Przydzial, K.; Sivapalasingam, S.; Mastey, V.; Marquis, P. Patient experience of symptoms and impacts of COVID-19: A qualitative investigation with symptomatic outpatients. BMJ Open 2022, 12, e055989. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Chen, Z.; Nie, Y.; Ma, Y.; Guo, Q.; Dai, X. Identification of symptoms prognostic of COVID-19 severity: Multivariate data analysis of a case series in Henan Province. J. Med. Internet Res. 2020, 22, e19636. [Google Scholar] [CrossRef]
- Belkacem, A.N.; Ouhbi, S.; Lakas, A.; Benkhelifa, E.; Chen, C. End-to-end AI-based point-of-care diagnosis system for classifying respiratory illnesses and early detection of COVID-19: A theoretical framework. Front. Med. 2021, 8, 585578. [Google Scholar] [CrossRef]
- Bagad, P.; Dalmia, A.; Doshi, J.; Nagrani, A.; Bhamare, P.; Mahale, A.; Rane, S.; Agarwal, N.; Panicker, R. Cough against COVID: Evidence of COVID-19 signature in cough sounds. arXiv 2020, arXiv:2009.08790. [Google Scholar]
- Ritwik, K.V.S.; Kalluri, S.B.; Vijayasenan, D. COVID-19 patient detection from telephone quality speech data. arXiv 2020, arXiv:2011.04299. [Google Scholar]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring automatic diagnosis of COVID-19 from crowdsourced respiratory sound data. arXiv 2020, arXiv:2006.05919. [Google Scholar]
- Ritwik, K.V.S.; Kalluri, S.B.; Vijayasenan, D. COVID-19 Detection from Spectral Features on the DiCOVA Dataset. In Proceedings of the 22nd Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; pp. 936–940. Available online: https://pesquisa.bvsalud.org/global-literature-on-novel-coronavirus-2019-ncov/resource/pt/covidwho-1535020?lang=en (accessed on 20 December 2023).
- Bhuvaneswari, A. An Ensemble Method for COVID-19 Positive Cases Detection using Machine Learning Algorithms. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–9. [Google Scholar]
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 detection in cough, breath and speech using deep transfer learning and bottleneck features. Comput. Biol. Med. 2022, 141, 105153. [Google Scholar] [CrossRef]
- Hamidi, M.; Zealouk, O.; Satori, H.; Laaidi, N.; Salek, A. COVID-19 assessment using HMM cough recognition system. Int. J. Inf. Technol. 2023, 15, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Pavel, I.; Ciocoiu, I.B. COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors 2023, 23, 4996. [Google Scholar] [CrossRef] [PubMed]
- Hassan, A.; Shahin, I.; Alsabek, M.B. COVID-19 detection system using recurrent neural networks. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics (CCCI), Sharjah, United Arab Emirates, 3–5 November 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Usman, M.; Gunjan, V.K.; Wajid, M.; Zubair, M. Speech as A Biomarker for COVID-19 detection using machine learning. Comput. Intell. Neurosci. 2022, 2022, 6093613. [Google Scholar] [CrossRef] [PubMed]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T.; Abdali, T.-A.N.; Abbas, A.F. Extreme learning machine for automatic language identification utilizing emotion speech data. In Proceedings of the 2021 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Kuala Lumpur, Malaysia, 12–13 June 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Alwateer, M.; Almars, A.M.; Areed, K.N.; Elhosseini, M.A.; Haikal, A.Y.; Badawy, M. Ambient healthcare approach with hybrid whale optimization algorithm and Naïve Bayes classifier. Sensors 2021, 21, 4579. [Google Scholar] [CrossRef] [PubMed]
- Albadr, M.A.A.; Tiun, S. Spoken language identification based on particle swarm optimisation–extreme learning machine approach. Circuits Syst. Signal Process. 2020, 39, 4596–4622. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Al-Dhief, F.T. Evaluation of machine translation systems and related procedures. ARPN J. Eng. Appl. Sci. 2018, 13, 3961–3972. [Google Scholar]
- Albadr, M.A.A.; Tiun, S.; Al-Dhief, F.T.; Sammour, M.A. Spoken language identification based on the enhanced self-adjusting extreme learning machine approach. PLoS ONE 2018, 13, e0194770. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; AL-Dhief, F.T.; Omar, K.; Maen, M.K. Speech emotion recognition using optimized genetic algorithm-extreme learning machine. Multimed. Tools Appl. 2022, 81, 23963–23989. [Google Scholar] [CrossRef]
- Albadra, M.A.A.; Tiuna, S. Extreme learning machine: A review. Int. J. Appl. Eng. Res. 2017, 12, 4610–4623. [Google Scholar]
- Chowdhury, M.E.; Ibtehaz, N.; Rahman, T.; Mekki, Y.M.S.; Qibalwey, Y.; Mahmud, S.; Ezeddin, M.; Zughaier, S.; Al-Maadeed, S.A.S. QUCoughScope: An artificially intelligent mobile application to detect asymptomatic COVID-19 patients using cough and breathing sounds. arXiv 2021, arXiv:2103.12063. [Google Scholar]
- Dash, T.K.; Mishra, S.; Panda, G.; Satapathy, S.C. Detection of COVID-19 from speech signal using bio-inspired based cepstral features. Pattern Recognit. 2021, 117, 107999. [Google Scholar]
- Muguli, A.; Pinto, L.; Sharma, N.; Krishnan, P.; Ghosh, P.K.; Kumar, R.; Bhat, S.; Chetupalli, S.R.; Ganapathy, S.; Ramoji, S.; et al. DiCOVA Challenge: Dataset, task, and baseline system for COVID-19 diagnosis using acoustics. arXiv 2021, arXiv:2103.09148. [Google Scholar]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T. Particle Swarm Optimization-Based Extreme Learning Machine for COVID-19 Detection. Cogn. Comput. 2022, 1–16. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
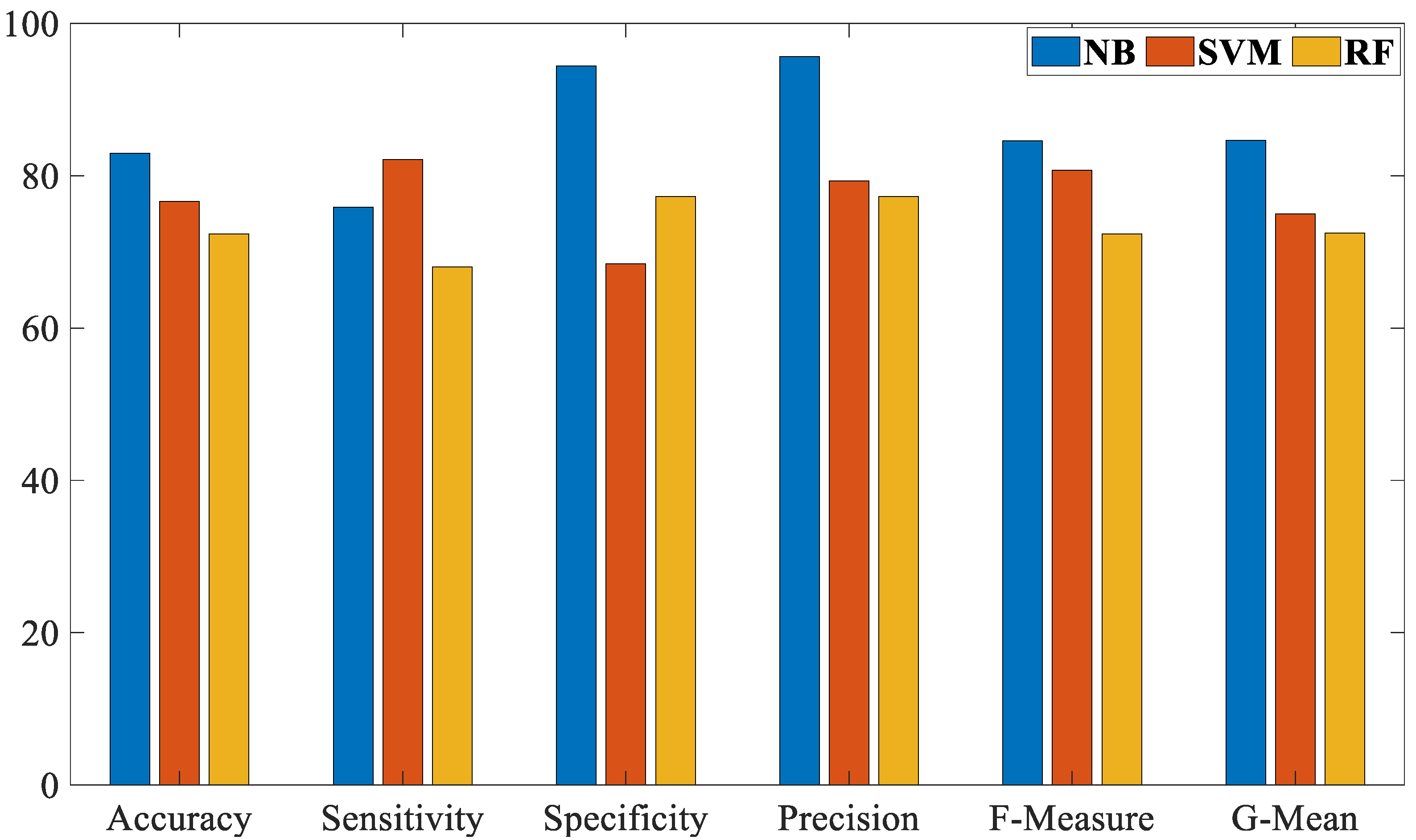{kind=link}
| Ref. | Modality/Parameters | Features Extraction | Classifier | Results |
|---|---|---|---|---|
| [30] | Cough | SRMSF | ResNet18 | 0.72 AUC |
| [31] | Speech | MFBF | SVM | 88.60% accuracy |
| [32] | Cough and breath | Several handcrafted features | LR | 80.00% accuracy using cough voice data and 69.00% accuracy using breath voice data |
| [33] | Vowel /i/, number counting, and deep breathing | harmonics, super-vectors, MFCC, and formats | SVM | 0.734 and 0.717 AUC for cross-validation and testing, respectively. |
| [34] | Speech | MFCC | K-NN | 92% accuracy |
| [35] | speech, breath, and cough | MFCC | Resnet50, CNN, and LSTM | The best AUC results were achieved by the Resnet50, where it obtained 0.98 (coughs), 0.94 (breaths), and 0.92 (speech). |
| [36] | cough | MFCC | GMM | Sensitivity ranging from 85.86% to 91.57%. |
| [37] | Cough | MFCC | BoW | 74.3% accuracy, 71.4% sensitivity, 75.4% F1-score, and 82.6% AUC. |
| [38] | Cough | SC, ZCR, and MFCC | LSTM | 99.30% precision |
| [39] | speech | STFT | DF | 73.17% accuracy |
| Acc | Sen | Spe | Pre | F-M | G-M |
|---|---|---|---|---|---|
| 82.97% | 75.86% | 94.44% | 95.65% | 84.61% | 84.64% |
| SVM Algorithm | |||||
|---|---|---|---|---|---|
| Acc | Sen | Spe | Pre | F-M | G-M |
| 76.60% | 82.14% | 68.42% | 79.31% | 80.70% | 74.97% |
| RF Algorithm | |||||
| Acc | Sen | Spe | Pre | F-M | G-M |
| 72.34% | 68.00% | 77.27% | 77.27% | 72.34% | 72.49% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Khaleefa, A.S.; Al-Musawi, G.F.K.; Saeed, T.J. IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques. Sci 2024, 6, 2. https://doi.org/10.3390/sci6010002
Al-Khaleefa AS, Al-Musawi GFK, Saeed TJ. IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques. Sci. 2024; 6(1):2. https://doi.org/10.3390/sci6010002
Chicago/Turabian StyleAl-Khaleefa, Ahmed Salih, Ghazwan Fouad Kadhim Al-Musawi, and Tahseen Jebur Saeed. 2024. "IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques" Sci 6, no. 1: 2. https://doi.org/10.3390/sci6010002
APA StyleAl-Khaleefa, A. S., Al-Musawi, G. F. K., & Saeed, T. J. (2024). IoT-Based Framework for COVID-19 Detection Using Machine Learning Techniques. Sci, 6(1), 2. https://doi.org/10.3390/sci6010002