Abstract
The Aquila Optimizer (AO) is a novel and efficient optimization algorithm inspired by the hunting and searching behavior of Aquila. However, the AO faces limitations when tackling high-dimensional and complex optimization problems due to insufficient search capabilities and a tendency to prematurely converge to local optima, which restricts its overall performance. To address these challenges, this study proposes the Multi-Strategy Aquila Optimizer (MSAO) by integrating multiple enhancement techniques. Firstly, the MSAO introduces a random sub-dimension update mechanism, significantly enhancing its exploration capacity in high-dimensional spaces. Secondly, it incorporates memory strategy and dream-sharing strategy from the Dream Optimization Algorithm (DOA), thereby achieving a balance between global exploration and local exploitation. Additionally, the MSAO employs adaptive parameter and dynamic opposition-based learning to further refine the AO’s original update rules, making them more suitable for a multi-strategy collaborative framework. In the experiment, the MSAO outperform eight state-of-the-art algorithms, including CEC-winning and enhanced AO variants, achieving the best optimization results on 55%, 69%, 69%, and 72% of the benchmark functions, respectively, which demonstrates its outstanding performance. Furthermore, ablation experiments validate the independent contributions of each proposed strategy, and the application of MSAO to five engineering problems confirms its strong practical value and potential for broader adoption.
1. Introduction
Optimization problems, characterized by high nonlinearity, multimodality, and large-scale search spaces, have long posed significant challenges across scientific and engineering domains due to the proliferation of local optima. In practical applications, increasing complexity and dynamism demand algorithms with enhanced performance and adaptability. Consequently, the development of efficient and highly adaptable optimization algorithms has become a key to improving the efficiency of the system and the quality of decision making.
In recent years, metaheuristic algorithms have demonstrated unique advantages in handling complex large-scale problems by combining global exploration with local exploitation. They have been successfully applied in various domains, including computational intelligence and data mining [1,2,3,4,5,6], transportation [7], task planning [8], resource management [9,10], and UAV path planning [11,12]. (1) In computational intelligence and data mining, Manoharan et al. [1] introduced an enhanced weighted K-means Grey Wolf Optimizer to enhance clustering performance. Tang et al. [2] developed EDECO, an Enhanced Educational Competition Optimizer [13] that uses distribution-based replacement and dynamic distance balancing for efficient numerical optimization. Jia et al. [3] improved the Slime Mould Algorithm (SMA) [14] with Compound Mutation Strategy (CMS) and Restart Strategy (RS) for feature selection. Djaafar Zouache et al. [4] drew inspiration from quantum computing to combine the Firefly Algorithm (FA) [15] and Particle Swarm Optimization (PSO) [16] for feature selection tasks. (2) In transportation, Fang et al. [7] proposed the Discrete Wild Horse Optimizer (DWHO) to solve the Capacitated Vehicle Routing Problem (CVRP) [17]. (3) In task planning, Zhong et al. [8] proposed a novel Independent Success History Adaptation Competitive Differential Evolution (ISHACDE) algorithm to address functional optimization problems and Space Mission Trajectory Optimization (SMTO). (4) In resource management, Abd et al. [9] presented an improved White Shark Optimizer [18] to optimize hybrid photovoltaic, wind turbine, biomass and hydrogen storage systems. Zhang et al. [10] proposed MFSMA, a Multi-Strategy Slime Mould Algorithm, for optimal microgrid scheduling. (5) In UAV path planning, Xu et al. [11] introduced DBO-AWOA, an Adaptive Whale Optimization Algorithm that combines chaotic mapping, nonlinear convergence factors, adaptive inertia mechanisms, and dung beetle-inspired reproduction behaviors for 3D route planning. Liang et al. [12] developed the Improved Spider-Bee Optimizer (ISWO) for UAV 3D path planning.
In general, metaheuristic algorithms offer a rich toolkit to solve complex optimization challenges by emulating natural phenomena, animal behaviors, physical laws, and social processes. These algorithms fall into evolution-based, physics-based, swarm-based, and human-based categories [19].
Evolution-based algorithms draw inspiration from Darwin’s theory of natural selection and genetic inheritance. Prominent examples include the Genetic Algorithm (GA) [20], Differential Evolution (DE) [21], Genetic Programming (GP) [22], and Evolution Strategies (ES) [23]. Among these, the GA and DE are particularly popular due to their strong adaptability and straightforward implementation.
Physics-based algorithms are derived from various phenomena and principles in physics. Simulated Annealing (SA) [24] mimics the annealing process in solids to achieve global search, the Sine–Cosine Algorithm (SCA) [25] uses the periodic oscillations of trigonometric functions to balance exploration and exploitation, Young’s Double-Slit Experiment (YDSE) Optimizer [26] is inspired by the interference patterns observed in Young’s double-slit experiment, and the Sinh Cosh Optimizer (SCHO) [27] leverages the mathematical properties of hyperbolic sine and hyperbolic cosine functions to drive its exploration and exploitation mechanisms.
Human-behavior-based algorithms simulate educational or social activities to drive optimization. Teaching–Learning-Based Optimization (TLBO) [28] models the influence mechanism between teachers and learners, the Attraction–Repulsion Optimization Algorithm (AROA) [29] emulates the balance between attractive and repulsive forces observed in nature, using this mechanism as the basis for its search process, Differentiated Creative Search (DCS) [30] balances divergent and convergent thinking within a team-based framework, fostering a continuously learning and adaptive optimization environment, and the Football Team Training Algorithm (FTTA) [31] draws on the training routines and tactical drills of football teams to formulate its optimization strategy.
Swarm-based algorithms are inspired by collective foraging and collaboration behaviors in nature. Particle Swarm Optimization (PSO) [16] emulates bird flocking and foraging, the Whale Optimization Algorithm (WOA) [32] mimics the bubble net feeding strategy of humpback whales, the Grey Wolf Optimizer (GWO) [33] draws on the hierarchical pack hunting of grey wolves, and the Griffon Vulture Optimization Algorithm (GVOA) [34] models the collective intelligent foraging behavior of griffon and vulture species in nature.
Abualigah et al. [35] are the first to formalize the “high-altitude cruise and dive hunting” strategy of Aquila into a novel metaheuristic optimization algorithm, known as the Aquila Optimizer (AO). By alternating between global cruise and precise diving behaviors, the AO achieves rapid convergence while maintaining a simple and easy-to-implement structure. Its outstanding performance in numerous benchmark tests has made AO a research focal point and led to its widespread adoption for solving complex optimization problems. However, the AO exhibits several limitations: It tends to converge prematurely, becoming trapped in local optima and failing to sufficiently explore the global search space, which can result in suboptimal solutions. Its convergence speed in complex high-dimensional problems can be slow, requiring more iterations to reach the best results, and its scalability is limited, making it challenging to address large-scale optimization tasks with many variables and constraints [36]. To address these issues, researchers have proposed various improved variants of the AO in different optimization domains, including hybrids with other techniques and novel movement strategies. Compared to the original AO, these enhanced algorithms demonstrate superior adaptability and performance in a broader range of complex problems. Serdar Ekinci et al. [37] developed an enhanced AO algorithm (enAO) by innovatively integrating an improved Opposition-Based Learning (OBL) mechanism [38] with the Nelder–Mead (NM) simplex search method [39]. Kujur et al. [40] introduced a Chaotic Aquila Optimizer tailored for demand response scheduling in grid-connected residential microgrid (GCRMG) systems. Pashaei et al. [41] proposed a Mutated Binary Aquila Optimizer (MBAO) that incorporates a Time-Varying Mirrored S-shaped (TVMS) transfer function. Designed as a new wrapper-based gene selection method, MBAO aims to identify the optimal subset of informative genes. Inspired by the superior performance of the Arithmetic Optimization Algorithm (AOA) [42] and the Aquila Optimizer (AO), Zhang et al. [43] proposed a hybrid algorithm that integrates the strengths of both, denoted AOAAO.
Although various AO variants have addressed some of the shortcomings of the original AO, there are still issues that need to be resolved. Xiao et al. [44] introduced an enhanced hybrid metaheuristic, IHAOAVOA, which combines the strengths of the AO and the African Vultures Optimization Algorithm (AVOA) [45]. Although IHAOAVOA demonstrates marked improvements over both the AO and AVOA on various benchmark functions, its increased computational cost remains a potential drawback, and there is still room for performance gains on certain benchmark functions. To accelerate convergence, Wirma et al. [46] integrated chaotic mapping into the AO and employed a single-stage evolutionary strategy to balance exploration and exploitation. However, compared to other AO variants, this approach incurs additional computational overhead and memory usage for chaotic variables, resulting in higher CPU time and resource demands. Zhao et al. [47] developed a multiple-update mechanism employing heterogeneous strategies to accelerate the late-stage convergence of the AO and enhance its overall performance. However, this approach exhibits suboptimal results when applied to real-world engineering problems. Zhao et al. [48] simplified the Aquila Optimizer to enhance its convergence speed, introducing a simplified Aquila Optimizer (IAO). In benchmark functions, the IAO outperforms the original AO and other comparison algorithms. However, its performance remains suboptimal when applied to real-world engineering problems. This suggests that, although the AO algorithm and its variants have undergone continual refinement and perform excellently on benchmark functions, they still exhibit limitations: They often underperform on real-world engineering problems, and their performance on certain test functions leaves room for further improvement. Furthermore, we observe that many AO variants still exhibit performance bottlenecks when tackling high-dimensional optimization problems.
To address the shortcomings of the AO and AO variants, this paper proposes MSAO, a multi-strategy enhanced variant designed to overcome the premature convergence to local optima and its degraded performance in high-dimensional search spaces. In summary, the MSAO introduces three key innovations: the incorporation of a random sub-dimension update mechanism to effectively decompose and explore high-dimensional search spaces; the integration of the memory strategy and dream-sharing mechanism of the DOA, allowing individuals to retain historical elite information, achieving a coordinated balance between global exploration and local exploitation; and the adoption of adaptive parameter control and dynamic opposition-based learning to refine the original AO’s update rules, thus accelerating convergence and improving solution precision. The main contributions of this work can be summarized as follows:
- A random sub-dimension update mechanism is incorporated to effectively decompose high-dimensional search spaces. The memory strategy and dream-sharing strategy from the DOA are fused to enable individual memory retention and inter-population information sharing, achieving a coordinated balance between global exploration and local exploitation.
- Adaptive parameter and dynamic opposition-based learning are integrated to further refine the original AO update rules within its multi-strategy framework.
- In the CEC2017 benchmark suite, the MSAO significantly outperforms the original AO and seven other state-of-the-art algorithms. Ablation studies confirm the independent contributions of each enhancement, and outstanding results in five real-world engineering optimization cases underscore the practical applicability.
2. Related Work
2.1. Overview of the Original AO
Abualigah et al. introduced the Aquila Optimizer (AO), a swarm-based algorithm inspired by the predatory behavior of Aquila raptors. Aquila employs four hunting modes: a high-altitude vertical dive for broad reconnaissance; level gliding at mid-altitudes for localized exploration; a low-altitude gradual descent to refine the search in promising zones; and ground-level stalking and capture using subtle perturbations to fine-tune local prey detection. Based on predation strategies, the AO divides the search process into five phases: initialization, expanded exploration, narrowed exploration, expanded exploitation, and narrowed exploitation. Phase transitions are governed by the iteration index t relative to the maximum T: When the current iteration , the algorithm prioritizes exploration; otherwise, it switches to the exploitation phase. This design ensures robust global search in early iterations and enhanced local search precision later, thereby achieving an effective balance between convergence speed and solution quality.
In all mathematical expressions of this algorithm, vector variables are shown in boldface. The symbol “×” denotes multiplication between scalars or between a scalar and a vector and the symbol “∗” denotes element-wise multiplication between vectors.
2.1.1. Initialization
The Aquila Optimizer employs a population-based search strategy. Initially, a set of candidate solutions X is randomly generated within the upper and lower bounds ( and ) [35]. During each iteration, the best solution identified so far is updated and regarded as the current global best.
where X denotes the set of current candidate solutions, which are randomly generated within the upper and lower bounds by Equation (2). represents the decision vector (position) of the ith solution, N is the total number of candidate solutions (population size), and indicates the dimensionality of the problem.
where rand denotes a random number in the interval [0,1], and and represent the lower and upper bounds of the jth decision variable, respectively.
2.1.2. Expanded Exploration
During the expanded exploration phase, the algorithm mimics Aquila’s broad search behavior during high-altitude vertical dives to perform a coarse scan of the entire search space. Its mathematical formulation is as follows [35].
where denotes the new solution generated by the expanded exploration strategy at iteration . is the best individual found so far. is the mean position of all individuals in the population at iteration t, defined as
where N denotes the size of the population.
2.1.3. Narrowed Exploration
In the narrowed exploration phase, the algorithm emulates Aquila’s short-range contour gliding around promising regions to perform fine-grained reconnaissance and encirclement of high-potential solution areas [35]. Its mathematical formulation is as follows [35].
where denotes the new solution generated in iteration by the narrowed exploration strategy. is an individual randomly selected from the population and the variables x and y define the spiral trajectory used during the search, as specified in Equation (6).
The parameter takes integer values from 1 to 20 to determine the fixed number of search cycles. U is a small constant set to 0.00565. is an integer that ranges from 1 to the dimensionality of the search space. is a small constant fixed at 0.005.
Furthermore, Equation (5) incorporates the Lévy flight distribution function , which is defined as follows:
where denotes the Lévy flight distribution function in a space of D. s = 0.1 is a constant. u and v are random numbers uniformly distributed in [0,1]. = 0.5 is the exponent parameter of the Lévy distribution, and is the scale parameter of the Lévy distribution.
2.1.4. Expanded Exploitation
In the expanded exploitation phase, Aquila emulates a low-altitude gradual descent behavior: Individuals progressively approach the target region and perform precise strikes through slow dive maneuvers, thereby intensifying the in-depth exploitation of high-quality solution areas [35]. Its mathematical formulation is as follows [35].
where denotes the new solution generated in iteration by the expanded exploitation strategy. and serve as fixed parameter settings to adjust the search behavior.
2.1.5. Narrowed Exploitation
In the narrowed exploitation phase, the algorithm emulates Aquila’s stalking and capture behavior to perform fine-grained localized encirclement of high-quality solution regions [35]. Its mathematical formulation is as follows [35].
where denotes the new solution generated in iteration by the narrowed exploitation strategy. The quality function and the adjustment functions and are defined as follows:
2.1.6. Algorithm Procedure
Algorithm 1 details the complete execution workflow of the AO algorithm.
The algorithm begins by randomly generating N individuals in the search space and initializing the iteration counter t = 1. Then, it evaluates the fitness of all individuals and logs the best global solution to guide subsequent position updates. It dynamically alternates among four behavioral strategies: during the first of iterations (exploration phase), High Soar with Vertical Stoop (Expanded Exploration, Equation (3)) for broad global sampling and Contour Flight with Short Glide (Narrowed Exploration, Equation (5)) to refine the search region; and in the final of the iterations (exploitation phase), Low Flight with Slow Descent (Expanded Exploitation, Equation (9)) for fine-grained local search around promising areas and Swoop and Grab Prey (Narrowed Exploitation, Equation (10)) to converge on and polish the best solutions. After each update, boundary handling ensures feasibility. If the termination criterion is met, the algorithm returns the final global best . Otherwise, t increases and the cycle repeats.
| Algorithm 1: Pseudo-code of AO |
 |
The two parameters used in this algorithm, 2/3 and 0.5, are adopted directly from the original AO literature [35] without modification. In particular, the parameter governs the transition point between the exploration and exploitation phases: When the current iteration , the algorithm prioritizes exploration. Otherwise, it switches to the exploitation phase. This design maintains robust global search in the early iterations and enhances local search precision in later stages, thereby balancing convergence speed and solution quality. The parameter 0.5 serves as a randomness threshold, allowing a 50% probability of switching between the two strategies, which ensures an even execution of exploration and exploitation.
2.2. Overview of the DOA
Since the MSAO draws on the Dream Optimization Algorithm (DOA), we provide a brief overview of the DOA. Lang et al. [49] introduced the DOA, inspired by the human dreaming process, which involves memory retention, forgetting, and the logical organization of ideas. These features parallel the cycle of exploration and exploitation in metaheuristic optimization. The DOA incorporates a forgetting and supplementation strategy that ensures a balance between broad search and focused refinement, and a dream-sharing strategy that helps the method overcome local traps.
As depicted in Figure 1, the DOA operates in two phases: exploration and exploitation. During the exploration phase, the algorithm divides the population into five subpopulations and applies the memory strategy to reset each subpopulation’s individuals to their current best position. Then, it employs the forgetting and supplementation strategy, which combines global and local search by selectively removing old solutions and introducing new ones. Additionally, the dream-sharing strategy is activated in this phase to enhance escape from local optima. In the exploitation phase, no further subpopulation partitioning occurs. The algorithm first applies the memory strategy to reset all individuals to the current best global position and then proceeds with the forgetting and supplementation strategy alone, omitting the dream-sharing strategy. In Section 3.4, we will provide a detailed comparison of the algorithmic workflows of the DOA and MSAO.
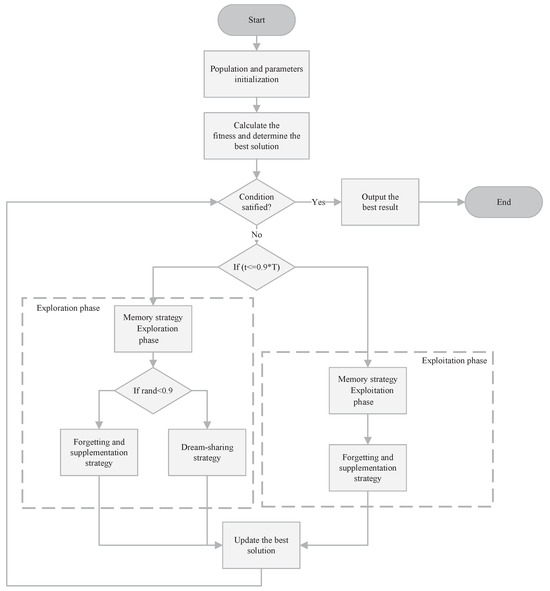
Figure 1.
The flowchart of DOA.
3. The Proposed MSOA
This section presents the Multi-Strategy Aquila Optimizer (MSAO), developed to address the original AO’s limitations in convergence accuracy and its propensity to become trapped in local optima when solving high-dimensional optimization problems. To achieve this, we integrate several critical enhancements within the AO framework to markedly strengthen its global exploration and local exploitation capabilities. Each of these improvements will be described in detail in the following sections.
In all mathematical expressions of this algorithm, vector variables are shown in boldface. The symbol “×” denotes multiplication between scalars or between a scalar and a vector and the symbol “∗” denotes element-wise multiplication between vectors.
3.1. Exploration Phase
During the exploration phase, the MSAO implements a random sub-dimension update mechanism by partitioning the population into five subpopulations. Initially, the each positions of subpopulation positions are reinitialized to their best individual position from the previous iteration using the memory strategy. Then, for each subpopulation q (), dimensions are randomly selected from the set , denoted as , , …, . For each individual , only the components in these dimensions are updated according to the enhanced exploration rule, while all other dimensions remain unchanged. This procedure is applied sequentially across individuals, ensuring that all subpopulations collaboratively explore their respective subspaces within a single iteration, thus increasing global search diversity and accelerating convergence.
3.1.1. Memory Strategy
The memory strategy, originating from the DOA [49], is defined mathematically in Equation (12). For any individual in subpopulation q, its position at the beginning of iteration is reset to the best solution found by that subpopulation in iteration t.
where denotes the position of the ith individual in generation . represents the best individual in the qth subpopulation during generation t.
3.1.2. The Improved Expanded Exploration
To accelerate convergence and enhance solution accuracy, an adaptive convergence parameter is introduced during the expanded exploration phase. This parameter enables gradual decay in the early stages of iteration, facilitating broad global exploration [50]. As the iteration progresses, the decay rate increases, promoting faster convergence. In contrast, the original AO’s convergence parameter may lead to premature convergence. Based on this nonlinear factor, the improved update formula for the expanded exploration is presented in Equation (14).
where denotes the value of the ith individual in the jth dimension at iteration . represents the value of the best individual in group q in the jth dimension at iteration t. is the mean position of the population in the jth dimension at iteration t.
3.1.3. The Improved Narrowed Exploration
To better align the narrowed exploration with the multi-strategy framework, this study replaces the original random perturbation mechanism with a dynamic opposition-based learning strategy [51], thus more effectively guiding the algorithm’s exploration and exploitation in the search space. The control factor for this strategy is defined in Equation (15), the dynamic opposition-based learning formula is given in Equation (16), and the resulting improved narrowed exploration update rule is presented in Equation (17).
where denotes the position in the jth dimension at iteration t obtained by the dynamic opposition-based learning strategy.
3.1.4. Dream-Sharing Strategy
The dream-sharing strategy, derived from the DOA [49], enables each individual to randomly “borrow” positional information from other members of its subpopulation along selected dimensions, thereby enhancing the algorithm’s ability to escape local optima. This strategy is executed in parallel with the improved exploration update rules. Its mathematical formulation is given by
3.2. Exploitation Phase
During the exploitation phase, the MSAO continues to employ the random sub-dimension update mechanism without subpopulation partitioning. Specifically, the algorithm first reinitializes all individual positions to that of the best solution from the previous iteration using the memory strategy. It then updates the selected sub-dimensions of each individual according to the enhanced exploration update rule, while keeping the other dimensions unchanged, thereby preserving global alignment while enabling localized fine-grained exploitation.
3.2.1. Memory Strategy
During the exploitation phase, each individual has its position at the beginning of the iteration reset to the best global solution from iteration t. Its mathematical formulation is as follows [49].
where represents the best individual during generation t.
3.2.2. The Improved Expanded Exploitation
To accelerate iterations in high-dimensional settings, we streamline the expanded exploitation update strategy and introduce an adaptive parameter . This enhancement maintains a minimalist design of the parameter, while improving the numerical stability and high-dimensional handling [50]. The definition of is provided in Equation (20), and the refined expanded exploitation update rule is given in Equation (21).
3.2.3. The Improved Narrowed Exploitation
The update strategy for the narrowed exploitation phase remains largely unchanged, with the addition of a random sub-dimension update mechanism to enhance high-dimensional performance. Its mathematical formulation is as follows:
3.3. Parameters Setting
The remaining key parameter settings for the MSAO are as follows: The threshold for switching between the exploration and exploitation phases is critical to overall performance, and the default value of the original AO is unsuitable. Therefore, in subsequent experiments, we conduct a sensitivity analysis to identify the optimal threshold that maximizes the benefits of prior empirical knowledge. In this study, the phase switching parameter is set to 0.6. and denote the number of randomly selected sub-dimensions in the exploration and exploitation phases, respectively. Their calculation formulas are given in Equations (23) and (24).
The parameter u is used to balance the enhanced exploration update rule and the dream-sharing strategy during the exploration phase. If rand < u, the algorithm applies the forgetting-and-replenishment mechanism; otherwise, it executes the dream-sharing strategy. Following the empirical setting in the DOA, u is set to 0.9.
3.4. The Detail of MSAO
The pseudo-code for the proposed MSAO algorithm is presented in Algorithm 2, and its flowchart is illustrated in Figure 2.
| Algorithm 2: Pseudo-code of MSAO |
 |
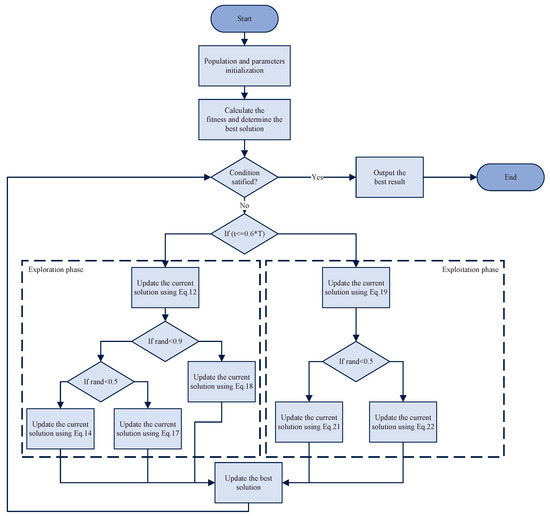
Figure 2.
The flowchart of MSAO.
The algorithm begins by randomly generating N individuals within the search space and evenly dividing them into five subpopulations to ensure initial diversity and enable parallel local searches. The iteration counter t is initialized to 1. The fitness of all individuals is then evaluated and the best global solution is recorded to guide the subsequent memory strategy and positional updates. During the first 60% of the iterations (exploration phase), the algorithm extracts the best solution of each subpopulation and applies the memory strategy to reset all individuals in that subpopulation to their best solution, thereby rapidly exploiting promising regions. Then, it randomly switches between the expanded exploration update strategy (Equation (14)) and the narrowed exploration update strategy (Equation (17)) to balance global and local search and activates the dream-sharing mechanism (Equation (18)) to enhance diversity through inter-information exchange between subpopulations. In the remaining 40% of the iterations (exploitation phase), the algorithm focuses on the best global solution , using the memory strategy (Equation (19)) to pull all individuals back into its neighborhood and fully utilize global information. It selects between the expanded exploitation update strategy (Equation (21)) and the narrowed exploitation update strategy (Equation (22)) based on a random probability, flexibly adjusting step sizes for a finer-grained local search. After position update, boundary handling ensures feasibility. If the termination criterion is met, the final best global solution is returned. Otherwise, t is incremented and the process repeats.
Figure 1 and Figure 2 illustrate that both the DOA and MSAO divide the algorithmic workflow into exploration and exploitation phases, with the MSAO adopting the DOA’s memory strategy and dream-sharing strategy to enhance performance. However, they differ markedly in their primary update procedures. The DOA relies primarily on the forgetting and supplementation strategy in both phases. In contrast, the MSAO adopts two distinct update rules in each phase. During the exploration phase, it utilizes Expanded Exploration and Narrowed Exploration, while in the exploitation phase, it applies Expanded Exploitation and Narrowed Exploitation. This richer set of phase-specific update mechanisms further enhances search efficiency and solution accuracy.
3.5. Complexity Analysis of MSAO
The time complexity of the MSAO is determined by the population size N, initialization, fitness evaluations and individual updates, the number of iterations T, and the dimensionality of the problem D. Initializing the population incurs complexity, whereas the fitness evaluation complexity depends on the specific problem and is not detailed here. Individual updates involve for position updates and for other per-generation operations. Hence, the overall time complexity of MSAO can be expressed as: .
4. Experimental Results and Analysis
In this experiment, the MSAO is evaluated on 29 benchmark functions of the CEC2017, excluding the unstable F2 function to ensure consistency of the result [52], detailed in Table 1. All benchmark functions are defined in the search space [−100, 100], and denotes the theoretical minimum value of each test function. To assess adaptability across problem scales, we conduct experiments in 10, 30, 50, and 100 dimensions, with a fixed population size of 30 and a maximum of 1000 iterations. Each configuration is independently run 30 times to evaluate reliability. The MSAO is compared with its five AO variants and six state-of-the-art metaheuristic algorithms: the original AO [35] and its enhanced variants LOBLAO [53], TEAO [54], SGAO [55], MMSIAO [56], and IAO [57]; the classic WOA [32] and HHO [58]; the novel AOO [59] and DOA [49]; and the CEC-winning LSHADE [60]. The algorithm parameters are set according to original sources or widely accepted values, detailed in Table 2, and all methods use the same population size and iteration count to ensure a fair and rigorous comparison.

Table 1.
Descriptions of CEC2017 benchmark test functions.
Table 2.
Setting parameters for contrast algorithms.
4.1. Sensitivity Analysis
This section presents a systematic sensitivity and performance evaluation of the phase-switching threshold between exploration and exploitation. This threshold critically determines the allocation of computational effort between early global search and later local refinement, affecting the convergence speed and final precision [61]. To investigate its impact on the MSAO’s performance, we test threshold values of 0.5, 0.6, 0.7, 0.8, and 0.9, corresponding to 50%, 60%, 70%, 80%, and 90% of the total iteration. The results are summarized in Table 3, with the best performing thresholds for each dimension highlighted in bold. The “w/t/l” stands for win/tie/loss. For example, the “2/6/21” in the first row and second column of the table indicates that with the phase-switch threshold set to 0.5 in the 10D CEC2017 tests, the algorithm outperformed all competitors on 2 functions, tied on six, and underperformed on 21 of the 29 benchmark functions.
Table 3.
Sensitivity analysis on CEC2017.
The data reveal that increasing the threshold from 0.5 to 0.6 yields a marked performance improvement, whereas further increases lead to degradation. Although both 0.6 and 0.7 perform well, 0.6 offers the most stable and overall superior performance across dimensions. Consequently, we set the phase switching threshold to 0.6 to achieve an optimal balance between the two phases.
4.2. Ablation Experiments
To validate the individual contributions of each enhancement in the MSAO, we conduct ablation experiments. The MSAO comprises three key components: the memory strategy combined with dream-sharing strategy, the random sub-dimension update mechanism, and the tailored update rules that leverage these mechanisms. We created multiple variants of the algorithm by selectively including or excluding each component to assess their respective impacts on performance and to examine their synergistic effects. The results show that omitting any single strategy degrades performance, highlighting that these three components work cooperatively to achieve the MSAO’s optimal performance. Table 4 summarizes the combinations of strategies for each variant, where “∘” indicates inclusion and “×” indicates exclusion of a given component.
Table 4.
Versions of various MSOAs.
Figure 3, Figure 4, Figure 5 and Figure 6 present heatmaps of Friedman test rankings for these variants. In these heatmaps, darker cells correspond to better average rankings and, thus, superior performance. In Figure 3 and Figure 4, the original AO shows the lightest cells, while each single-strategy variant exhibits darker cells, indicating performance improvements over the AO. Two-strategy combinations yield even darker cells, whereas the full three-strategy integration, the MSAO, shows the darkest cells, denoting the best performance. This shows that the three strategies synergize in more than an additive fashion, mutually reinforcing each other under the complex characteristics of different test functions to substantially enhance global exploration and local exploitation. Similar trends are observed when the dimensionality increases to 50 and 100, confirming that the strategy combination remains highly effective in high-dimensional settings. In summary, analysis of cell darkness (average Friedman rankings) leads to three conclusions: (1) Any single strategy surpasses the original AO, (2) multi-strategy fusion further elevates performance, and (3) the fully integrated three-strategy MSAO achieves the top results, validating the effectiveness of the multi-strategy cooperative optimization framework.
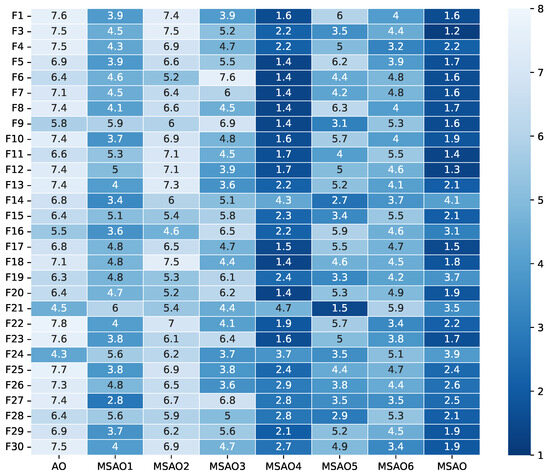
Figure 3.
Friedman test rankings for the ablation experiments on CEC2017 (10D).
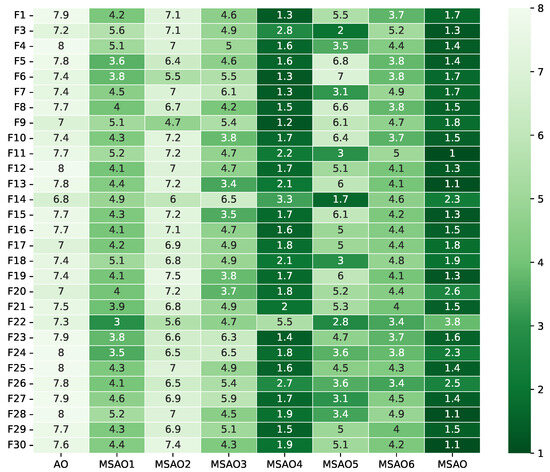
Figure 4.
Friedman test rankings for the ablation experiments on CEC2017 (30D).
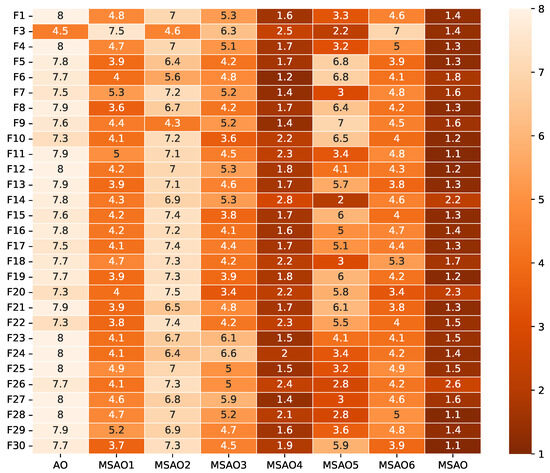
Figure 5.
Friedman test rankings for the ablation experiments on CEC2017 (50D).
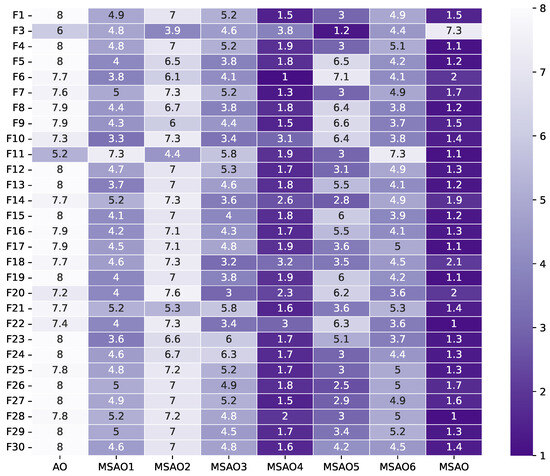
Figure 6.
Friedman test rankings for the ablation experiments on CEC2017 (100D).
4.3. Qualitative Analysis
To further validate the MSAO, we perform qualitative analyses on unimodal, simple multimodal, hybrid, and composition functions from the CEC2017. The results are shown in Figure 7.
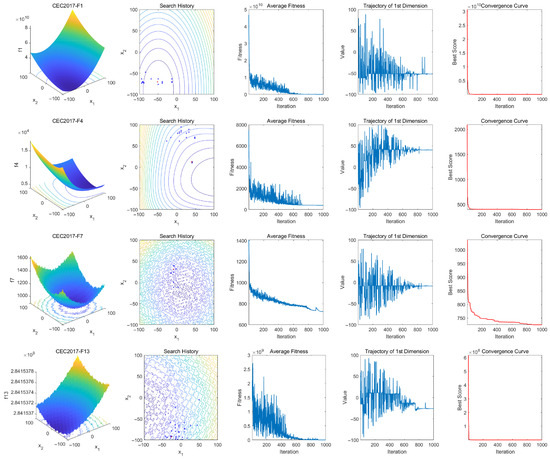
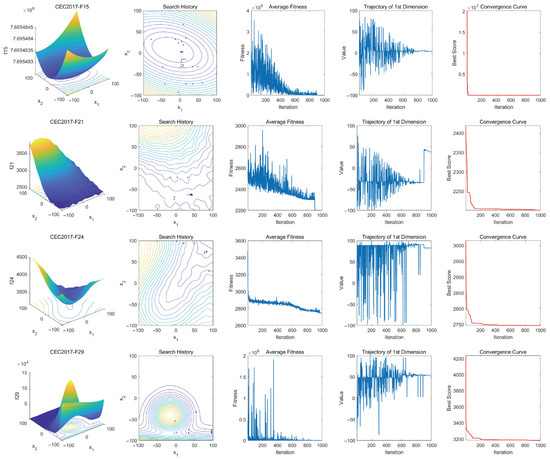
Figure 7.
Qualitative analysis of MSOA on CEC2017.
Four visualization metrics are used to intuitively assess performance: search history, average fitness curve, first-dimensional trajectory, and the convergence curve of the best candidate solution. In the search history plots, red dots denote global optima and blue dots indicate the best solution found at each iteration. These polts show that the MSAO explores effectively, using its memory strategy for rapid convergence, demonstrating strong global exploration and local development capabilities. The average fitness curve exhibits a pronounced steep decline in the early phase, indicating that the population, leveraging the memory strategy, dream-sharing strategy, and enhanced position-update mechanisms, rapidly escapes local optima and converges efficiently. In the mid-to-late stages, the curve levels off, demonstrating that the population has locked onto a global or near-global optimum region and, aided by the random sub-dimension update mechanism and refined update rules, performs fine-grained local searches to produce high-quality solutions. The first-dimension trajectory illustrates position oscillations: The initial rapid oscillations reflect the random sub-dimension update mechanism swiftly identifying the global optimum region, and subsequent reduced oscillations indicate the fine-tuned search. The convergence curves confirm that the MSAO quickly reduces fitness values early on and stabilizes at high-quality solutions, further validating its efficient performance.
4.4. Performance Analysis of MSAO and AO’s Variants in CEC2017
In this section, we compare the MSAO against five AO variants on the CEC2017 to verify the MSAO’s performance. Table 5, Table 6, Table 7 and Table 8 summarize the results for 10D, 30D, 50D, and 100D.
Table 5.
Experimental results of MSAO and AO variants on CEC2017 (10D).
Table 6.
Experimental results of MSAO and AO variants on CEC2017 (30D).
Table 7.
Experimental results of MSAO and AO variants on CEC2017 (50D).
Table 8.
Experimental results of MSAO and AO variants on CEC2017 (100D).
Across the four dimensions (10D, 30D, 50D, and 100D), the MSAO achieves the lowest average fitness on most of the benchmark functions: 25 (86%) in 10D, 22 (76%) in 30D, 23 (79%) in 50D, and 28 (97%) in 100D. Furthermore, the MSAO’s average rankings consistently rank first at 1.34, 1.28, 1.34, and 1.03 in these dimensions, followed by the LOBLAO (average rankings consistently rank second at 2.34, 2.41, 2.48, and 2.17 in these dimensions) and the TEAO (average rankings consistently rank third at 3.41, 3.72, 3.48, and 3.48 in these dimensions). Given their strong performance and status as recent AO’s variants, the LOBLAO and TEAO will serve as representative AO variants for comparative evaluation in subsequent experiments. Furthermore, the MSAO exhibits lower standard deviations in all dimensions, indicating a more stable convergence. In summary, the MSAO not only achieves superior average fitness across most test functions but also demonstrates higher stability, outperforming current state-of-the-art AO variants.
4.5. Performance Analysis of MSAO in CEC2017
In this section, we provide a comprehensive analysis of the MSAO’s performance compared to eight leading optimization algorithms in the CEC2017 benchmark suite. Table 9, Table 10, Table 11 and Table 12 summarize results for 10D, 30D, 50D, and 100D problems. Figure 8 shows the convergence curves and Figure 9 shows the box plots [62].
Table 9.
Experimental results of MSAO and other algorithms on CEC2017 (10D).
Table 10.
Experimental results of MSAO and other algorithms on CEC2017 (30D).
Table 11.
Experimental results of MSAO and other algorithms on CEC2017 (50D).
Table 12.
Experimental results of MSAO and other algorithms on CEC2017 (100D).
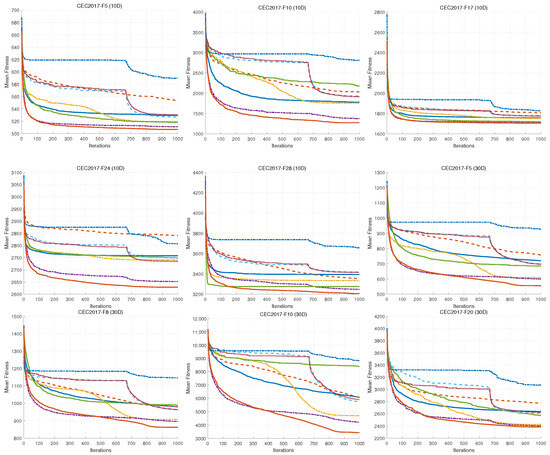
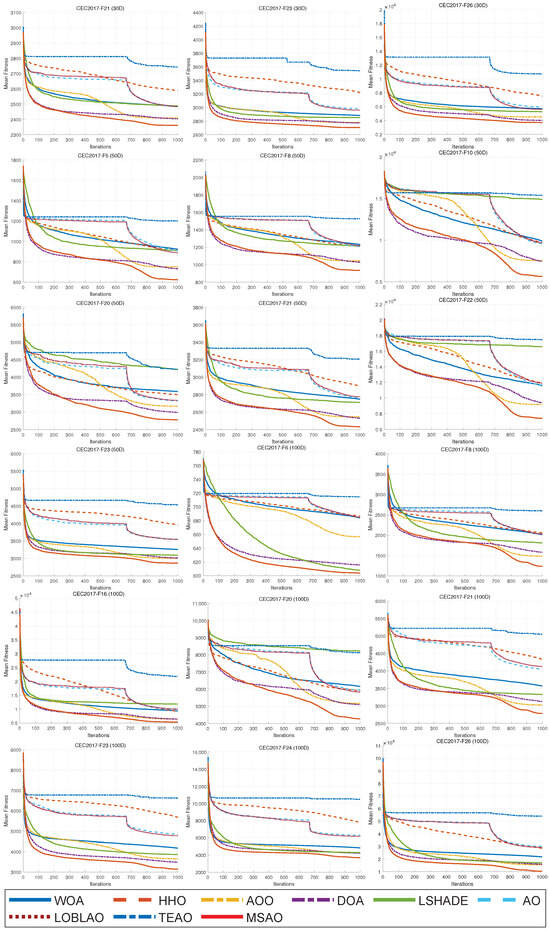
Figure 8.
Convergence curves of different algorithms on CEC2017.
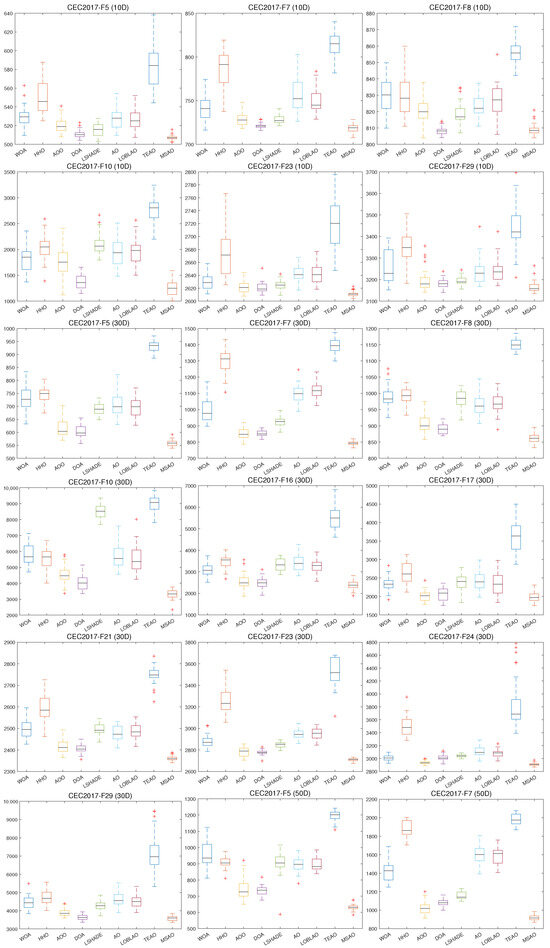
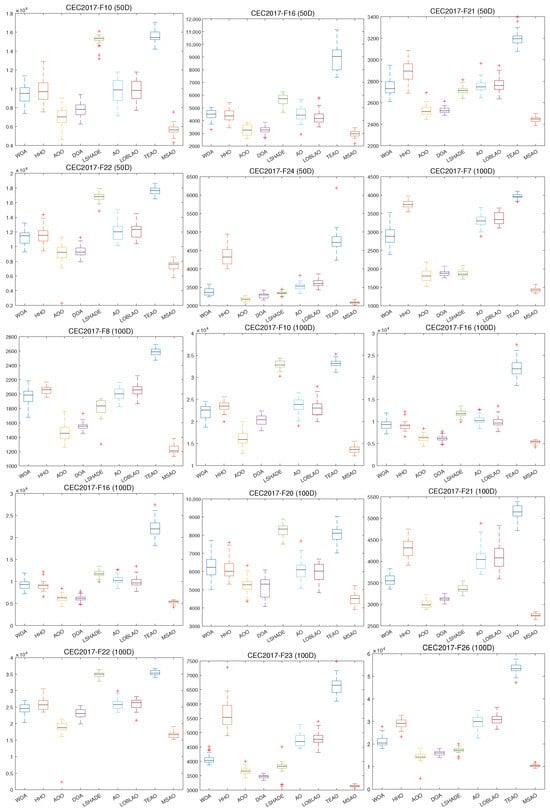
Figure 9.
Box plot of different algorithms on CEC2017.
In 10D and 30D (Table 9 and Table 10), the MSAO achieves the best average fitness ranking in 16 (55%) and 20 (69%) of the 29 benchmark functions, respectively. Specifically, for unimodal functions (F1–F3), the MSAO ranked first in F1 in 10D and in F3 in 30D. For simple multimodal functions (F4–F10), it dominated with a win rate of 86% in 10D, which slightly decreased to 57% in 30D. For hybrid functions (F11–F20), its win rate increases from 30% in 10D to 90% in 30D. For composition functions (F21–F30), the MSAO achieved 60% wins in 10D and 70% in 30D. For more than half of low-dimensional problems, the MSAO not only finds lower objective values than all competing algorithms but also maintains consistency with smaller standard deviations, demonstrating its exceptional ability to quickly and reliably locate high-quality solutions in low-dimensional search spaces. In 50D and 100D in higher dimensions (Table 11 and Table 12), the MSAO achieves the best average fitness in 20 (69%) and 21 (72%) of the 29 benchmark functions, respectively. In 50D, the MSAO ranks first on F5, F6, F7, F8, and F10 (71%) in the simple multimodal functions. For hybrid functions (F11 – F20), it takes the top spot in F12, F13, F15, F16, F17, F18, F19, and F20 (80%). In composition functions (F21–F30), the MSAO wins in F21, F22, F23, F24, F26, F29, and F30(70%). Although it does not claim first place in the unimodal functions F1 and F3, it secures second on F1. In 100D, the win rates remain 71% in simple multimodal and 70% in composition functions, while hybrid functions rise to 90%. This outstanding result in high dimensions, in which it wins nearly two thirds of all test functions, demonstrates that the integration of three strategies significantly enhances global search capability in high dimensions. Moreover, the MSAO shows lower standard deviations than the original AO and other competitors in these experiments, confirming its exceptional stability and robustness in high dimensional optimization problems.
As shown in Figure 8, the MSAO’s convergence curves in 10D, 30D, 50D, and 100D exhibit markedly steeper declines, faster convergence speeds, and lower fitness values than its counterparts. In the initial phase, the MSAO’s rapid descent is based on its memory strategy. By retaining and leveraging elite solutions from previous iterations, the algorithm quickly targets high-potential regions and avoids aimless exploration. Concurrently, the random sub-dimension update mechanism breaks free from full-dimensional search constraints, maintaining robust global exploration in high-dimensional landscapes and enabling rapid escape from local optima. In the mid-to-late stages, the MSAO’s curve levels off with significantly reduced oscillations compared to other methods, indicating that near convergence, its refined update rules, such as adaptive parameter control and dynamic opposition learning, effectively shrink step sizes for precise local exploitation, thus securing superior solutions and preventing premature convergence. In Figure 9, boxes are generally lower, narrower, and more concentrated, further confirming their superiority in consistency and stability of the results.
In summary, the MSAO not only significantly outperforms the original AO and other algorithms on low-dimensional optimization problems but also demonstrates exceptional performance and robustness in high-dimensional optimization problems. The experiments confirm that the memory strategy combined with dream-sharing strategy, the random sub-dimension update mechanism, and the tailored update rules that leverage these mechanisms effectively address the limitations of the original AO in high-dimensional search, offering an efficient and reliable solution for complex, large-scale optimization challenges.
4.6. Nonparametric Test Analysis
In this section, we perform nonparametric statistical analyses [63] (Wilcoxon rank sum test and Friedman test) to compare the performance of the MSAO against other algorithms. Table 13, Table 14, Table 15 and Table 16 present the results of the Wilcoxon test in various dimensional settings, showing statistically significant differences compared to the original AO and other competing algorithms (p < 0.05). The statistics of “wins/ties/losses” (w/t/l) overwhelmingly favor the MSAO, which generally achieves 27 to 29 wins (93% to 100%) against eight competing algorithms in 29 benchmark functions; even its lowest win count is 16 (55%), with only 0 to 7 ties and, at most, three losses, further corroborating its superior performance in most benchmark functions. Table 17, Table 18, Table 19 and Table 20 report the Friedman test results, showing that the MSAO’s average ranking mainly ranges from 1.4 to 2.4, while the runner-up LSHADE’s ranking mainly ranges from 2.7 to 4.4. Nonparametric statistical analyses confirm that the MSAO delivers outstanding optimization capability under the selected test conditions.
Table 13.
Wilcoxon rank sum test of MSOA and other algorithms on CEC2017 (10D).
Table 14.
Wilcoxon rank sum test of MSOA and other algorithms on CEC2017 (30D).
Table 15.
Wilcoxon rank sum test of MSOA and other algorithms on CEC2017 (50D).
Table 16.
Wilcoxon rank sum test of MSOA and other algorithms on CEC2017 (100D).
Table 17.
Friedman test rank test of MSOA and other algorithms on CEC2017 (10D).
Table 18.
Friedman test rank test of MSOA and other algorithms on CEC2017 (30D).
Table 19.
Friedman test rank test of MSOA and other algorithms on CEC2017 (50D).
Table 20.
Friedman test rank test of MSOA and other algorithms on CEC2017 (100D).
4.7. Engineering Optimization Experiments
To further assess the practical applicability of the MSOA, we compare it with other algorithms on five representative engineering design problems: the tension/compression spring design problem [64], pressure vessel design problem [65], three-bar truss design problem [64], welded beam design problem [66], and speed reducer design problem [67]. These engineering design problems have been widely adopted as benchmarks for evaluating optimization algorithms [68,69,70]. Each engineering design problem comprises an objective function to be minimized (typically weight or cost), subject to several nonlinear constraints. A smaller objective value indicates a better design and, consequently, corresponds to a better rank. Through comprehensive testing and the performance evaluation of these real-world engineering cases, the exceptional performance of the MSAO in engineering optimization is validated. The results are presented in Table 21, Table 22, Table 23, Table 24 and Table 25.
Table 21.
Optimization results for tension/compression spring design problem.
Table 22.
Optimization results for pressure vessel design problem.
Table 23.
Optimization results for three-bar truss design problem.
Table 24.
Optimization results for welded beam design problem.
Table 25.
Optimization results for speed reducer design problem.
4.7.1. Tension/Compression Spring Design Problem
The tension/compression spring design problem aims to minimize the weight of the spring. It involves four nonlinear constraints and three design variables: the wire diameter , mean coil diameter , and number of active coils . The mathematical model is defined as follows:
Table 21 presents the optimization results for the tension/compression spring design problem. The MSAO achieves the best optimal value of 0.012671 for the tension/compression spring design problem, ranking first. It is closely followed by LSHADE (0.012681, second place) and the AOO (0.012721, third place), with all three algorithms showing strong search capabilities for this problem. In contrast, the original AO (0.015784, eighth place), LOBLAO (0.015593, seventh place), and TEAO (0.015830, ninth place) perform poorly, primarily because they struggle to balance the three design variables while satisfying four nonlinear strength and deformation constraints. Although the DOA (0.014085, sixth place) and HHO (0.013924, fifth place) show improvements over them, they still fall short of the MSAO’s performance.
4.7.2. Pressure Vessel Design Problem
The pressure vessel design problem aims to minimize the total manufacturing cost, which comprises welding, material, and forming expenses. The problem involves four constraints and four design variables: shell thickness , head thickness , inner radius , and vessel length excluding heads . The mathematical model is defined as follows:
Table 22 presents the optimization results for the pressure vessel design problem, in which the MSAO achieves the best optimal value of 5821.851, ranking first. It is followed by LSHADE (5848.727, second place) and the AOO (5892.490, third place). In contrast, the WOA (5950.671, fourth place), LOBLAO (6282.705, fifth place), and TEAO (6307.177, sixth place) demonstrate reasonable search capability, but still exhibit shortcomings and underperform overall. The HHO (6755.636, seventh place) and DOA (7209.205, eighth place) adopt conservative boundary handling, leading to suboptimal design variables. The original AO performs the worst (7644.994, ninth place), struggling to finely optimize material thickness and dimensional requirements within the feasible region.
4.7.3. Three-Bar Truss Design Problem
The three-bar truss design problem, originating in civil engineering, features a complex feasible region defined by stress constraints. The primary objective is to minimize the total weight of the truss members, subject to three nonlinear inequality constraints based on member stresses, resulting in a linear objective function optimization. The mathematical formulation is as follows:
Table 23 presents the optimization results for the three-bar truss design problem, in which the MSAO achieves the best optimal value of 263.8958 for the three-bar truss design problem, ranking first. LSHADE (263.8972, second place) and the AOO (263.8972, third) follow closely. Mid-level performers include the WOA (263.8973, fourth place), DOA (263.8998, fifth place), and TEAO (263.9626, sixth place), which yield similar results but exhibit slightly less precision in exploring the constraint compared to the top three. The HHO (263.9721, seventh place), AO (264.0865, eighth place), and LOBLAO (264.2021, ninth place) demonstrate higher optimal values due to less refined adjustments near the stress limit constraints.
4.7.4. Welded Beam Design Problem
The welded beam design problem aims to minimize the manufacturing cost of a welded beam. It features five constraints and four design variables that define the weld and beam geometry: weld thickness , beam height , beam length , and beam width . The mathematical formulation is as follows:
Table 24 presents the optimization results for the welded beam design problem, in which the MSAO achieves the lowest manufacturing cost of 1.692794 for the welded beam design problem, ranking first. It is followed by LSHADE (1.695725, second place) and the WOA (1.697121, third place). The AOO (1.826056, fourth place) demonstrates reasonable search capability, but still exhibits shortcomings and underperforms overall. The HHO (2.231482, fifth place) and LOBLAO (2.324208, sixth place) exhibit a similar problem, resulting in higher costs. The DOA (2.340397, seventh place) and AO (2.414442, eighth place) handle constraint boundaries conservatively, leading to suboptimal cost solutions. The TEAO performs worst (2.827475, ninth place), as its fixed parameter update rules struggle with the precise adjustments required in a complex, multi-constraint environment.
4.7.5. Speed Reducer Design Problem
The speed reducer design problem involves the structural optimization of a gearbox for a small aircraft engine. Its mathematical formulation is given by
Table 25 presents the optimization results for the speed reducer design problem, in which the MSAO achieves the best objective value of 2500.976, ranking first. It is followed by LSHADE (2592.060, second place) and the DOA (2995.152, third place), all demonstrating strong optimization capabilities. The WOA (2995.287, fourth), AOO (3000.988, fifth place), HHO (3025.564, sixth place), and TEAO (3047.838, seventh place) deliver similar performances, showcasing solid global search abilities but slightly lacking in fine-tuning under multiple geometric and stress constraints. The AO (3102.403, eighth place) and LOBLAO (3180.600, ninth place) perform comparatively worse.
5. Conclusions
This paper introduces a Multi-Strategy Aquila Optimizer (MSAO) that integrates a memory strategy and dream-sharing strategy, a random sub-dimension update mechanism, and enhanced position update rules to bolster performance on high-dimensional, complex optimization problems. First, the random sub-dimension update mechanism effectively decomposes the high-dimensional search space, significantly strengthening the algorithm’s ability to handle large-scale problems. Second, by combining the memory strategy and dream-sharing strategy from the DOA, individuals can both leverage past elite solutions and flexibly share information on each subpopulation, achieving an organic balance between global exploration and local exploitation. Finally, adaptive parameter control and dynamic opposition-based learning are employed to deeply refine the AO’s update rules, markedly accelerating convergence and improving solution precision. Compared with other AO variants, the MSAO achieves average rankings of 1.31 in the 10 dimension, 1.34 in the 30 dimension, 1.38 in the 50 dimension, and 1.45 in the 100 dimension. It is in the top ranking in each case, clearly demonstrating its superior performance over existing AO variants. Compared with other state-of-the-art algorithms, the MSAO delivered 16 (55%) and 20 (69%) best solutions out of 29 benchmark functions in the CEC2017 10D and 30D tests, respectively. When the dimensionality increases to 50D and 100D, the number of best solutions increases to 20 (69%) and 21 (72%). These results demonstrate that the MSAO’s three-strategy integration significantly enhances global search capability, effectively addressing the AO’s shortcomings in high-dimensional optimization. Ablation studies demonstrate the independent contributions of each module, thereby validating the effectiveness of each strategy. Across five real-world engineering design problems, the MSAO consistently achieved the top rank, demonstrating its superiority in engineering optimization and effectively addressing the shortcomings of existing AO variants in practical applications.
However, the performance in hybrid functions indicates that there is room for improvement. This limitation probably stems from the rigid division of the MSOA’s exploration and exploitation into two separate phases under a fixed threshold. In hybrid functions, subregions with diverse characteristics frequently overlap and cannot be addressed by inflexible phase transitions. As a result, if the algorithm becomes trapped in a local optimum in one region, it may shift phases too early or place undue emphasis on that area, thereby overlooking other promising regions of the search space. Future work will investigate a novel mechanism to more flexibly coordinate the exploration and exploitation phases, thereby overcoming this limitation, and focus on developing large-scale and multi-objective versions and applying the MSAO to path planning, image segmentation, data clustering, hyperparameter tuning, and wireless sensor network coverage to fully evaluate its generality and engineering value.
Author Contributions
Conceptualization, H.K. and Y.X.; methodology, H.K.; software, Z.G.; validation, H.K., Z.G. and X.Z.; formal analysis, H.K.; investigation, Z.G.; resources, H.K. and X.Z.; data curation, Y.X.; writing—original draft preparation, H.K. and Y.X.; writing—review and editing, H.K. and Y.X.; visualization, Y.X.; supervision, H.K.; project administration, H.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article. Further inquiries can be directed to the corresponding authors first.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Premkumar, M.; Sinha, G.; Ramasamy, M.D.; Sahu, S.; Subramanyam, C.B.; Sowmya, R.; Abualigah, L.; Derebew, B. Augmented weighted K-means grey wolf optimizer: An enhanced metaheuristic algorithm for data clustering problems. Sci. Rep. 2024, 14, 5434. [Google Scholar] [PubMed]
- Tang, W.; Shi, S.; Lu, Z.; Lin, M.; Cheng, H. EDECO: An Enhanced Educational Competition Optimizer for Numerical Optimization Problems. Biomimetics 2025, 10, 176. [Google Scholar] [CrossRef] [PubMed]
- Jia, H.; Zhang, W.; Zheng, R.; Wang, S.; Leng, X.; Cao, N. Ensemble mutation slime mould algorithm with restart mechanism for feature selection. Int. J. Intell. Syst. 2022, 37, 2335–2370. [Google Scholar] [CrossRef]
- Zouache, D.; Got, A.; Alarabiat, D.; Abualigah, L.; Talbi, E.G. A novel multi-objective wrapper-based feature selection method using quantum-inspired and swarm intelligence techniques. Multimed. Tools Appl. 2024, 83, 22811–22835. [Google Scholar] [CrossRef]
- Cui, C.; Zhen, Y.; Gong, S.; Zhang, C.; Liu, H.; Yin, Y. Dynamic prompt allocation and tuning for continual test-time adaptation. arXiv 2024, arXiv:2412.09308. [Google Scholar] [CrossRef]
- Cui, C.; Liu, Z.; Gong, S.; Zhu, L.; Zhang, C.; Liu, H. When Adversarial Training Meets Prompt Tuning: Adversarial Dual Prompt Tuning for Unsupervised Domain Adaptation. IEEE Trans. Image Process. 2025, 34, 1427–1440. [Google Scholar] [CrossRef]
- Fang, C.; Cai, Y.; Wu, Y. A discrete wild horse optimizer for capacitated vehicle routing problem. Sci. Rep. 2024, 14, 21277. [Google Scholar] [CrossRef]
- Zhong, R.; Hussien, A.G.; Zhang, S.; Xu, Y.; Yu, J. Space mission trajectory optimization via competitive differential evolution with independent success history adaptation. Appl. Soft Comput. 2025, 171, 112777. [Google Scholar] [CrossRef]
- Abd El-Sattar, H.; Kamel, S.; Elseify, M.A. A modified white shark optimizer for optimizing photovoltaic, wind turbines, biomass, and hydrogen storage hybrid systems. J. Energy Storage 2025, 113, 115655. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Y. Research on Microgrid Optimal Dispatching Based on a Multi-Strategy Optimization of Slime Mould Algorithm. Biomimetics 2024, 9, 138. [Google Scholar] [CrossRef]
- Xu, T.; Chen, C. DBO-AWOA: An Adaptive Whale Optimization Algorithm for Global Optimization and UAV 3D Path Planning. Sensors 2025, 25, 2336. [Google Scholar] [CrossRef] [PubMed]
- Liang, H.; Hu, W.; Wang, L.; Gong, K.; Qian, Y.; Li, L. An Improved Spider Wasp Optimizer for UAV Three-Dimensional Path Planning. Biomimetics 2024, 9, 765. [Google Scholar] [CrossRef] [PubMed]
- Lian, J.; Zhu, T.; Ma, L.; Wu, X.; Heidari, A.A.; Chen, Y.; Chen, H.; Hui, G. The educational competition optimizer. Int. J. Syst. Sci. 2024, 55, 3185–3222. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput.-Syst. Int. J. Escience 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Fister, I.; Fister, I., Jr.; Yang, X.S.; Brest, J. A comprehensive review of firefly algorithms. Swarm Evol. Comput. 2013, 13, 34–46. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Uchoa, E.; Pecin, D.; Pessoa, A.; Poggi, M.; Vidal, T.; Subramanian, A. New benchmark instances for the Capacitated Vehicle Routing Problem. Eur. J. Oper. Res. 2017, 257, 845–858. [Google Scholar] [CrossRef]
- Braik, M.; Hammouri, A.; Atwan, J.; Al-Betar, M.A.A.; Awadallah, M.A. White Shark Optimizer: A novel bio-inspired meta-heuristic algorithm for global optimization problems. Knowl.-Based Syst. 2022, 243, 108457. [Google Scholar] [CrossRef]
- Tomar, V.; Bansal, M.; Singh, P. Metaheuristic Algorithms for Optimization: A Brief Review. Eng. Proc. 2023, 59, 238. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Sarker, R.A.; Elsayed, S.M.; Ray, T. Differential evolution with dynamic parameters selection for optimization problems. IEEE Trans. Evol. Comput. 2013, 18, 689–707. [Google Scholar] [CrossRef]
- Fogel, D.B. Applying evolutionary programming to selected traveling salesman problems. Cybern. Syst. 1993, 24, 27–36. [Google Scholar] [CrossRef]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies–a comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: Bristol, UK, 2010. [Google Scholar]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Jameel, M.; Abouhawwash, M. Young’s double-slit experiment optimizer: A novel metaheuristic optimization algorithm for global and constraint optimization problems. Comput. Methods Appl. Mech. Eng. 2023, 403, 115652. [Google Scholar] [CrossRef]
- Bai, J.; Li, Y.; Zheng, M.; Khatir, S.; Benaissa, B.; Abualigah, L.; Wahab, M.A. A sinh cosh optimizer. Knowl.-Based Syst. 2023, 282, 111081. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Cymerys, K.; Oszust, M. Attraction–repulsion optimization algorithm for global optimization problems. Swarm Evol. Comput. 2024, 84, 101459. [Google Scholar] [CrossRef]
- Duankhan, P.; Sunat, K.; Chiewchanwattana, S.; Nasa-Ngium, P. The Differentiated Creative search (DCS): Leveraging Differentiated knowledge-acquisition and Creative realism to address complex optimization problems. Expert Syst. Appl. 2024, 252, 123734. [Google Scholar] [CrossRef]
- Tian, Z.; Gai, M. Football team training algorithm: A novel sport-inspired meta-heuristic optimization algorithm for global optimization. Expert Syst. Appl. 2024, 245, 123088. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Hasan, D.O.; Mohammed, H.M.; Abdul, Z.K. Griffon vultures optimization algorithm for solving optimization problems. Expert Syst. Appl. 2025, 276, 127206. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-Qaness, M.A.; Gandomi, A.H. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Sasmal, B.; Hussien, A.G.; Das, A.; Dhal, K.G. A comprehensive survey on aquila optimizer. Arch. Comput. Methods Eng. 2023, 30, 4449–4476. [Google Scholar] [CrossRef] [PubMed]
- Ekinci, S.; Izci, D.; Eker, E.; Abualigah, L. An effective control design approach based on novel enhanced aquila optimizer for automatic voltage regulator. Artif. Intell. Rev. 2023, 56, 1731–1762. [Google Scholar] [CrossRef]
- Gao, W.f.; Liu, S.y. A modified artificial bee colony algorithm. Comput. Oper. Res. 2012, 39, 687–697. [Google Scholar] [CrossRef]
- Schlipf, M.; Gygi, F. Optimization algorithm for the generation of ONCV pseudopotentials. Comput. Phys. Commun. 2015, 196, 36–44. [Google Scholar] [CrossRef]
- Kujur, S.; Dubey, H.M.; Salkuti, S.R. Demand Response Management of a Residential Microgrid Using Chaotic Aquila Optimization. Sustainability 2023, 15, 1484. [Google Scholar] [CrossRef]
- Pashaei, E. Mutation-based Binary Aquila optimizer for gene selection in cancer classification. Comput. Biol. Chem. 2022, 101, 107767. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Elaziz, M.A.; Gandomi, A.H. The Arithmetic Optimization Algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Yan, Y.X.; Zhao, J.; Gao, Z.M. AOAAO: The Hybrid Algorithm of Arithmetic Optimization Algorithm With Aquila Optimizer. IEEE Access 2022, 10, 10907–10933. [Google Scholar] [CrossRef]
- Xiao, Y.; Guo, Y.; Cui, H.; Wang, Y.; Li, J.; Zhang, Y. IHAOAVOA: An improved hybrid aquila optimizer and African vultures optimization algorithm for global optimization problems. Math. Biosci. Eng. 2022, 19, 10963–11017. [Google Scholar] [CrossRef] [PubMed]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Verma, M.; Sreejeth, M.; Singh, M.; Babu, T.S.; Alhelou, H.H. Chaotic mapping based advanced Aquila Optimizer with single stage evolutionary algorithm. IEEE Access 2022, 10, 89153–89169. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, Z.M. The heterogeneous Aquila optimization algorithm. Math. Biosci. Eng 2022, 19, 5867–5904. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, Z.M.; Chen, H.F. The simplified aquila optimization algorithm. IEEE Access 2022, 10, 22487–22515. [Google Scholar] [CrossRef]
- Lang, Y.; Gao, Y. Dream Optimization Algorithm (DOA): A novel metaheuristic optimization algorithm inspired by human dreams and its applications to real-world engineering problems. Comput. Methods Appl. Mech. Eng. 2025, 436, 117718. [Google Scholar] [CrossRef]
- Aleti, A.; Moser, I. A Systematic Literature Review of Adaptive Parameter Control Methods for Evolutionary Algorithms. ACM Comput. Surv. 2016, 49, 1–35. [Google Scholar] [CrossRef]
- Abdollahpour, A.; Rouhi, A.; Pira, E. An improved gazelle optimization algorithm using dynamic opposition-based learning and chaotic mapping combination for solving optimization problems. J. Supercomput. 2024, 80, 12813–12843. [Google Scholar] [CrossRef]
- Wu, G.; Mallipeddi, R.; Suganthan, P. Problem Definitions and Evaluation Criteria for the CEC 2017 Competition and Special Session on Constrained Single Objective Real-Parameter Optimization; Technical Report; Nanyang Technological University: Singapore, 2016; pp. 1–18. [Google Scholar]
- Abualigah, L.; Alomari, S.A.; Almomani, M.H.; Abu Zitar, R.; Migdady, H.; Saleem, K.; Smerat, A.; Snasel, V.; Gandomi, A.H. Enhanced aquila optimizer for global optimization and data clustering. Sci. Rep. 2025, 15, 13079. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, D.; Fu, S.; Chen, J.; He, L. Enhanced Aquila optimizer based on tent chaotic mapping and new rules. Sci. Rep. 2024, 14, 3013. [Google Scholar] [CrossRef]
- Zeng, L.; Li, M.; Shi, J.; Wang, S. Spiral Aquila Optimizer Based on Dynamic Gaussian Mutation: Applications in Global Optimization and Engineering. Neural Process. Lett. 2023, 55, 11653–11699. [Google Scholar] [CrossRef]
- Bao, T.; Zhao, J.; Liu, Y.; Guo, X.; Chen, T. Mixed Multi-Strategy Improved Aquila Optimizer and Its Application in Path Planning. Mathematics 2024, 12, 3818. [Google Scholar] [CrossRef]
- Gao, B.; Shi, Y.; Xu, F.; Xu, X. An Improved Aquila Optimizer Based on Search Control Factor and Mutations. Processes 2024, 10, 1451. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Wang, R.B.; Hu, R.B.; Geng, F.D.; Xu, L.; Chu, S.C.; Pan, J.S.; Meng, Z.Y.; Mirjalili, S. The Animated Oat Optimization Algorithm: A Nature-Inspired Metaheuristic for Engineering Optimization and a Case Study on Wireless Sensor Networks. Knowl.-Based Syst. 2025, 318, 113589. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Hoos, H.H. Automated algorithm configuration and parameter tuning. In Autonomous Search; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–71. [Google Scholar]
- McGill, R.; Tukey, J.W.; Larsen, W.A. Variations of box plots. Am. Stat. 1978, 32, 12–16. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Belegundu, A.D.; Arora, J.S. A study of mathematical programming methods for structural optimization. Part I: Theory. Int. J. Numer. Methods Eng. 1985, 21, 1583–1599. [Google Scholar] [CrossRef]
- Sandgren, E. Nonlinear integer and discrete programming in mechanical design. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering, Kissimmee, FL, USA, 25–28 September 1988; American Society of Mechanical Engineers: New York, NY, USA, 1988; Volume 26584, pp. 95–105. [Google Scholar]
- Ragsdell, K.M.; Phillips, D.T. Optimal design of a class of welded structures using geometric programming. J. Eng. Ind. 1976, 98, 1021–1025. [Google Scholar] [CrossRef]
- Chew, S.H.; Zheng, Q. Integral Global Optimization: Theory, Implementation and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 298. [Google Scholar]
- Yu, H.; Jia, H.; Zhou, J.; Hussien, A.G. Enhanced Aquila optimizer algorithm for global optimization and constrained engineering problems. Math. Biosci. Eng. 2022, 19, 14173–14211. [Google Scholar] [CrossRef]
- Eker, E. Development of Random Walks Strategy-Based Dandelion Optimizer and Its Application to Engineering Design Problems. IEEE Access 2025, 13, 56547–56575. [Google Scholar] [CrossRef]
- Bian, H.; Li, C.; Liu, Y.; Tong, Y.; Bing, S.; Chen, J.; Ren, Q.; Zhang, Z. Improved snow geese algorithm for engineering applications and clustering optimization. Sci. Rep. 2025, 15, 4506. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).