Abstract
Feature selection aims to identify a relevant subset of features from the original feature set to enhance the performance of machine learning models, which is crucial for improvig model accuracy. However, this task is highly challenging due to the enormous search space, often requiring the use of meta-heuristic algorithms to efficiently identify near-optimal feature subsets. This paper proposes an improved algorithm based on Northern Goshawk Optimization (NGO), called Elite-guided Hybrid Northern Goshawk Optimization (EH-NGO), for feature selection tasks. The algorithm incorporates an elite-guided strategy within the NGO framework, leveraging information from elite individuals to direct the population’s evolutionary trajectory. To further enhance population diversity and prevent premature convergence, a vertical crossover mutation strategy is adopted, which randomly selects two different dimensions of an individual for arithmetic crossover to generate new solutions, thereby improving the algorithm’s global exploration capability. Additionally, a boundary control strategy based on the global best solution is introduced to reduce ineffective searches and accelerate convergence. Experiments conducted on 30 benchmark functions from the CEC2017 and CEC2022 test set demonstrate the superiority of EH-NGO in global optimization, outperforming eight compared state-of-the-art algorithms. Furthermore, a novel feature selection method based on EH-NGO is proposed and validated on 22 datasets of varying scales. Experimental results show that the proposed method can effectively select feature subsets that contribute to improved classification performance.
1. Introduction
In the era of deep integration between big data and artificial intelligence, machine learning models have been widely applied in critical domains such as medical diagnosis, financial risk control, image recognition, and natural language processing [1,2]. The performance of these models is closely tied to the quality of input features. However, raw data often contain a large number of redundant, irrelevant, or even noisy features. Such features not only give rise to the “curse of dimensionality”—leading to longer training times and soaring computational costs—but also interfere with the model’s ability to capture essential data patterns. This may further cause overfitting, where the model performs well on the training set but fails to generalize effectively to unseen test data [3,4]. Against this backdrop, feature selection has emerged as a fundamental data preprocessing technique. Its goal is to extract a representative and discriminative subset of features from the high-dimensional raw feature space, retaining key information while eliminating redundancy and noise. By doing so, it can improve classification accuracy and generalization ability, simplify model structure, and enhance interpretability. Consequently, feature selection has become an indispensable component of the machine learning pipeline and plays a vital role in advancing intelligent systems toward higher efficiency and reliability [5,6,7,8].
Nevertheless, solving the feature selection problem remains highly challenging. In essence, it is a combinatorial optimization problem in which the search space expands exponentially with the number of features. For instance, when a dataset contains 40 features, the number of possible feature subsets already exceeds one trillion (excluding the empty set). Traditional approaches, such as brute-force search and greedy algorithms, are either computationally infeasible due to their excessive complexity or prone to being trapped in local optima, thereby failing to identify the global optimum.
Against this backdrop, metaheuristic algorithms have become mainstream tools for tackling feature selection, owing to their independence from strict mathematical assumptions and their ability to efficiently approximate optimal solutions within vast search spaces [9,10]. Inspired by natural phenomena or biological behaviors, these algorithms typically simulate swarm intelligence to maintain a dynamic balance between “exploration” and “exploitation”. Exploration seeks to broadly investigate unexplored regions of the solution space to avoid missing global optima, while exploitation focuses on refining promising regions to improve solution accuracy [11,12]. Their effectiveness in diverse optimization problems has led to widespread application in feature selection. The advantages of metaheuristic algorithms in this context include reducing feature dimensionality and improving model performance. For example, Song et al. [13] proposed a hybrid feature selection method that integrates correlation-guided clustering with particle swarm optimization (PSO) for high-dimensional data. Hu et al. [14] developed a fuzzy multi-objective PSO-based feature selection approach. Zhou et al. [15] introduced a slime mould algorithm-based method that combines local dimension mutation with global neighborhood search. Tubishat et al. [16] proposed a dynamic butterfly optimization algorithm (DBOA), an enhanced variant of the butterfly optimization algorithm (BOA), for feature selection. Ying Hu et al. [17] investigated a fuzzy multi-objective PSO-based method, PSOMOFS, which establishes fuzzy dominance relations to evaluate candidate particles and employs a fuzzy crowding distance metric to refine the elite archive and determine global leaders. Wen Long et al. [18] developed an improved version of BOA to address high-dimensional feature selection and fault diagnosis in wind turbine systems. Gang Hu et al. [19] proposed an enhanced version of the Black Widow Optimization algorithm, termed SDABWO, for feature selection. Guan Yang et al. [20] introduced an evolutionary Q-learning-based feature selection optimization algorithm (EQL-FS), which leverages reinforcement learning and the global exploration capabilities of PSO within a multi-agent framework. Yu-Peng Chen et al. [21] presented two novel Bacterial Foraging Optimization (BFO) algorithms—the Adaptive Chemotaxis BFO (ACBFO) and the Improved Swarm and Elimination-Dispersal BFO (ISEDBFO)—for feature selection. Finally, Kiana et al. [22] proposed a multi-objective Beluga Whale Optimization (MOBWO) algorithm tailored for feature selection problems.
Although numerous algorithms have been proposed to address feature selection, existing metaheuristic approaches still exhibit notable limitations in this task. For example, some algorithms, such as the standard Particle Swarm Optimization (PSO) [23], suffer from slow convergence due to the lack of guided exploration. Others, such as the basic Grey Wolf Optimizer (GWO) [24], tend to experience rapid loss of population diversity, leading to premature convergence. In addition, certain boundary-handling strategies—such as simply resetting out-of-bound solutions to the boundary—are overly passive. This not only wastes computational resources but also discards valuable search direction information, making it difficult to adapt to high-dimensional and complex feature selection scenarios [25].
Northern Goshawk Optimization (NGO), an intelligent optimization algorithm inspired by the predatory behavior of northern goshawks, has attracted increasing attention due to its simplicity and ease of implementation [26]. NGO possesses a basic balance between exploration and exploitation, and its concise mathematical model makes it easy to implement. It has already demonstrated promising performance in certain low-dimensional optimization problems [27,28]. However, like many other algorithms, NGO still suffers from several issues, including an imbalance between exploration and exploitation, slow convergence, susceptibility to local optima, and limited convergence accuracy.
When applied to complex scenarios such as high-dimensional feature selection, the shortcomings of the standard NGO become more pronounced. In the exploration phase, position updates rely entirely on randomly selected individuals, leading to blind search directions and preventing the algorithm from leveraging high-quality solutions within the population. This often results in slow convergence. In the exploitation phase, perturbations are generated solely through random scaling of an individual’s own position, which lacks an effective mechanism to break similarity among individuals. Consequently, once the population becomes trapped in a local optimum, the algorithm struggles to escape, often causing premature convergence. Moreover, its boundary-handling strategy adopts a “penalization” approach by directly resetting out-of-bound individuals to the boundary. This interrupts the natural evolutionary trajectory of solutions and may cause the algorithm to miss optimal solutions near the boundary, thereby wasting computational resources [29,30,31,32]. These limitations significantly hinder the potential of NGO in feature selection tasks, highlighting the urgent need for targeted improvements to enhance its optimization performance.
To address the aforementioned limitations of the standard Northern Goshawk Optimization (NGO) algorithm and to develop a more efficient optimization method tailored for feature selection tasks, this paper proposes an improved algorithm—Elite-guided Hybrid Northern Goshawk Optimization (EH-NGO). The algorithm retains the core two-stage framework of NGO while introducing three complementary enhancement strategies to comprehensively improve exploration efficiency, exploitation accuracy, and search stability. First, an elite-guided search mechanism is implemented by constructing an “elite pool” composed of the fittest individuals in the population. A dual-selection approach—comprising a 10% probability of taking the average position of elites and a 90% probability of randomly selecting a single elite—is used to determine the guiding direction, providing clear and high-quality search guidance during the exploration phase and accelerating convergence. Second, a vertical crossover mutation strategy is applied, whereby two different dimensions of an individual are randomly selected and linearly combined to generate a new solution. This not only breaks the similarity among population members but also enhances local exploitation while maintaining population diversity, helping the algorithm escape from local optima. Third, the traditional passive penalty-based boundary handling is replaced with a global best-guided boundary control strategy: when an individual exceeds the search boundary, it is actively guided toward a favorable region based on the global best solution. This approach corrects boundary violations while preserving search direction information, thereby reducing ineffective exploration. The improvements of EH-NGO compared with the original NGO are shown in Table 1.

Table 1.
Comparison Table of improvements between the original NGO and EH-NGO algorithms.
To validate the effectiveness of the EH-NGO algorithm, systematic experiments were conducted from two perspectives: global optimization performance and feature selection applications. On one hand, the global optimization capability of EH-NGO was evaluated on 30 benchmark functions from the CEC2017 and CEC2022 test suite, which cover a variety of characteristics, including unimodal, multimodal, and high-dimensional functions. EH-NGO was compared with eight state-of-the-art metaheuristic algorithms—VPPSO, IAGWO, LSHADE-cnEpSin, LSHADE-SPACMA, CPO, BKA, NRBO, and the original NGO—considering convergence speed, solution accuracy, and stability. On the other hand, a feature selection method based on EH-NGO, combined with the k-nearest neighbors (KNN) classifier (denoted as EH-NGO-KNN), was tested on 18 datasets of varying sizes. Using “classification error rate + feature subset size” as the optimization objective, the experiments assessed the algorithm’s ability to balance the reduction in feature numbers with the improvement of classification performance.
The main contributions of this paper are as follows:
- (1)
- An Elite-guided Hybrid Northern Goshawk Optimization algorithm (EH-NGO) is proposed, integrating three strategies: elite-guided search, vertical crossover mutation, and global-best guided boundary control.
- (2)
- Experiments on the CEC2017 and CEC2022 test suite show that EH-NGO performs better in population diversity and exploration–exploitation balance. Ablation studies confirm the effectiveness of the three strategies, and comparative experiments with eight mainstream algorithms validate the superiority of EH-NGO.
- (3)
- EH-NGO is applied to feature selection, and the EH-NGO-KNN framework is proposed. By integrating the KNN classifier and optimizing “classification error rate + subset size”, the method achieves a balance between “reducing features” and “improving model performance,” providing an efficient solution for high-dimensional feature selection.
The remainder of this paper is organized as follows: Section 2 details the basic principles of the original NGO algorithm, the design of the three enhancement strategies of EH-NGO, as well as the pseudocode and time complexity analysis. Section 3 presents numerical experiments based on the CEC2017 and CEC2022 test suite. Section 4 focuses on the application of EH-NGO to feature selection, including the mathematical modeling of the problem, the EH-NGO-KNN framework, and experiments on multiple datasets. Section 5 summarizes the findings and outlines future research directions.
2. Northern Goshawk Optimization and the Proposed Methodology
2.1. Northern Goshawk Optimization
The fundamental principle of the Northern Goshawk Optimization (NGO) algorithm is to simulate the hunting strategy of northern goshawks, which consists of two stages: prey detection and attack (exploration phase) and pursuit and evasion (exploitation phase). In the first stage, the goshawk randomly selects a prey and swiftly attacks it, enhancing the exploration capability of the NGO algorithm by performing a global search across the solution space to identify promising regions. In the second stage, after the initial attack, the prey attempts to escape, requiring the goshawk to continue the pursuit. This behavior simulation improves the algorithm’s local search ability within the solution space [26].
2.1.1. Initialization
The NGO method is a population-based metaheuristic algorithm, similar to other heuristic approaches. Like other such algorithms, NGO randomly generates a set of candidate solutions within the search space:
where denotes the population of northern goshawks, represents the position of the goshawk, and represents the position of the problem variable for the goshawk. The parameters and correspond to the population size and the dimensionality of the problem, respectively. The initial positions of the goshawks are randomly determined according to the following equation:
where represents the initial value of the candidate solution variables, and denote the upper and lower bounds, respectively, and is a uniformly distributed random number in the range (0, 1).
2.1.2. Exploration (Attack Prey)
In the first stage of the northern goshawk’s hunting behavior, a prey is randomly selected and swiftly attacked. Since the choice of prey in the search space is random, this stage enhances the exploration capability of the NGO algorithm. During this phase, the goshawk performs a global search across the solution space with the goal of identifying promising regions. The mathematical model for this stage is described by Equations (3) and (4) [26]:
where and represent the position information of the Northern Goshawk at the next iteration and the current iteration, respectively. denotes the updated state of the goshawk in the first stage, represents a array of random numbers uniformly generated from the interval [0, 1], is a random integer taking the value 1 or 2, and represents the fitness value of the objective function. denotes a array generated from a standard normal distribution (mean 0, standard deviation 1), and represents the position of the prey.
2.1.3. Exploitation (Chase Prey)
During the prey pursuit stage, after the northern goshawk attacks its prey, the prey attempts to escape while the goshawk continues the chase. Due to the goshawk’s high pursuit speed, it can nearly always catch the prey under any circumstance. Simulating this behavior enhances the algorithm’s local search capability within the solution space. The mathematical model for the second stage is expressed by Equations (5)–(7) [26]:
where denotes a array of random numbers generated from a normal distribution, is the current iteration, is the maximum number of iterations, and represents the updated position of the goshawk.
2.2. Proposed EH-NGO
2.2.1. Elite-Guided Search Strategy
In the standard NGO algorithm, position updates during the exploration phase rely entirely on randomly selected individuals, which introduces a high degree of blind search. Although this mechanism helps maintain population diversity, it does not exploit high-quality search directions, resulting in slow convergence and difficulty in consistently exploring the most promising regions. To enhance the directional guidance during exploration, the concept of an “elite pool” is introduced. In each iteration, the top individuals with the highest fitness values in the population are selected to form the elite pool. A dual-selection mechanism—“10% probability of taking the average position of the elites + 90% probability of randomly selecting a single elite”—is employed to determine the guiding individual, denoted as . The position update formula for the exploration phase is reconstructed as Equation (8) and illustrated in Figure 1, allowing individuals performing worse than randomly selected members to conduct their search based on the elites:
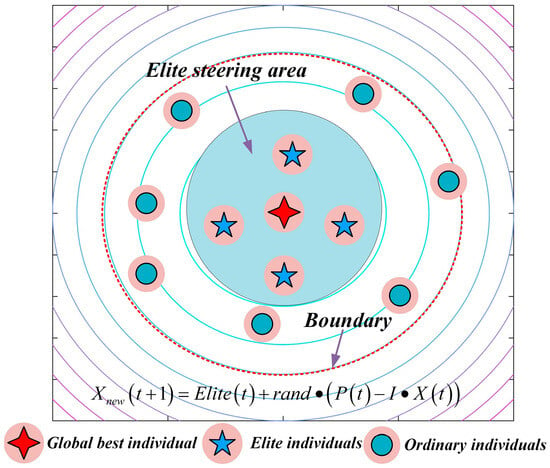
Figure 1.
Schematic diagram of elite-guided search strategy.
2.2.2. Vertical Crossover Mutation Strategy
In the exploitation phase of the standard NGO algorithm, the perturbation mechanism is relatively simple, relying primarily on random scaling of the individual’s own position, and lacks an effective strategy to escape local optima. Once the population is trapped at a local extremum, this perturbation alone is insufficient to enable individuals to break free, leading to premature convergence. To enhance the algorithm’s local exploitation capability and its ability to escape local optima, a vertical crossover mutation strategy is proposed. As illustrated in Figure 2, to break the similarity among individuals in the population, a “dimension-wise crossover” mutation mechanism is designed: for each individual, two distinct dimensions, and , are randomly selected, and a new dimension value is generated through a linear combination as follows (Equation (9)), while the remaining dimensions remain unchanged. The resulting new individual is then evaluated and selected based on fitness:
where is a random number in the range [0, 1].
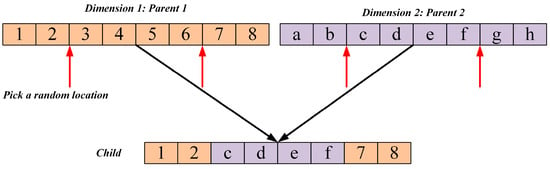
Figure 2.
Schematic diagram of the vertical crossover mutation strategy.
This strategy recombines information from different dimensions within a single individual, generating novel solutions in its neighborhood. The dimension-wise crossover effectively exploits the evolutionary potential of the individual, introduces diversity during fine-grained search, helps the algorithm escape from local optima, and improves solution accuracy.
2.2.3. Global-Best Guided Boundary Control Strategy
The standard NGO algorithm typically employs simple boundary-handling methods, such as directly resetting individuals to the boundary. This approach interrupts the natural trajectory of individuals, causing them to lose search direction information from the current generation and represents a passive “penalty” measure. Such handling not only wastes computational resources but may also prevent the population from exploring potentially optimal regions near the boundaries.
To transform boundary handling from a passive “penalty” into an active “guidance” mechanism, a global best-guided boundary control strategy is proposed. As shown in Figure 3, when an individual exceeds the boundary, instead of simply resetting it, the strategy guides the individual, with a certain probability, toward the region near the current global best solution. This approach turns a failed boundary exploration into an effective exploitation of high-quality regions, correcting the boundary violation while fully utilizing historical search information, thereby significantly improving search efficiency. The strategy is mathematically expressed as follows (Equation (10)):
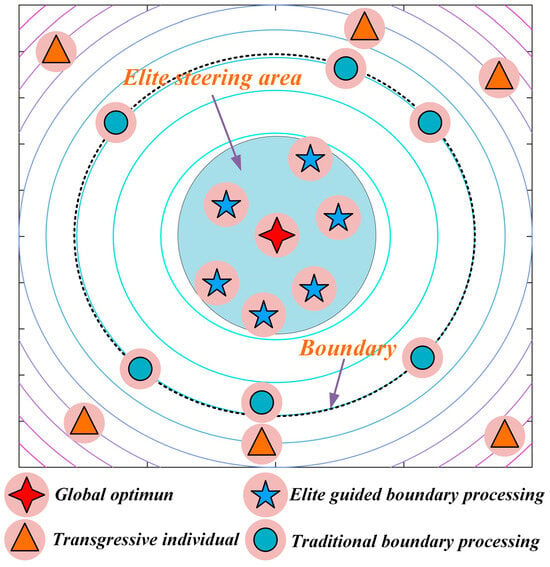
Figure 3.
Schematic diagram of global-best guided boundary control strategy.
Based on the above discussion, the pseudocode for EH-NGO is presented in Algorithm 1.
| Algorithm 1. Pseudo-Code of EH-NGO. |
| 1: Initialize Problem Setting (population, ), Max iterations. 2: Initialize a set of Northern Goshawk’ (). 3: while do 4: Calculate the fitness of the population. 5: Exploration: Attack prey 6: Calculate the fitness using Equation (8). 7: Update the position of the current individual using Equation (4). 8: Using Equation (10) for boundary adjustment. 9: Exploitation: Chase prey 10: Calculate the fitness using Equations (5) and (6). 11: Update the position of the current individual using Equation (7). 12: Using Equation (10) for boundary adjustment. 13: End for 14: Calculate new position of the current individual using Equation (9). 15: Update the best solution found so far . 16: End while 17: Return . |
2.3. Computational Time Complexity of EH-NGO
The performance of an algorithm is crucial, but it is equally important to evaluate its time complexity. In many optimization tasks, an algorithm must not only demonstrate excellent performance but also exhibit high real-time efficiency. Time complexity reflects how the algorithm’s runtime scales with the size of the input. Analyzing the time complexity of an optimization algorithm helps estimate its computational cost when handling large-scale problems. In the standard NGO, the computational complexity of the defined control parameters is , where represents the population size and denotes the problem dimension. During the initialization phase, the algorithm requires time. Furthermore, over iterations, the computational complexity for updating individual positions is . Therefore, the overall computational complexity of the NGO algorithm can be expressed as . n the proposed EH-NGO, since only the position update strategy and the objective function evaluation method are improved without introducing additional complexity factors, the time complexity remains .
3. Numerical Experiments
3.1. Algorithm Parameter Settings
In this section, the performance of the proposed EH-NGO algorithm is evaluated using the most challenging numerical optimization benchmark suite, CEC2017, and compared with several other algorithms. The comparison algorithms include: Velocity Pausing Particle Swarm Optimization (VPPSO) [33], Improved multi-strategy adaptive Grey Wolf Optimization (IAGWO) [34], LSHADE-cnEpSin [35], LSHADE-SPACMA [36], Crested Porcupine Optimizer (CPO) [37], Black-winged Kite Algorithm (BKA) [38], Neighbor Regularized Bayesian Optimization (NRBO) [39], and Northern Goshawk Optimization (NGO) [26]. The algorithm’s parameters are listed in Table 2.
Table 2.
Compare algorithm parameter settings.
3.2. Qualitative Analysis of EH-NGO
3.2.1. Analysis of the Population Diversity
In optimization algorithms, population diversity refers to the extent of differences among individuals within a population [40,41], with each individual generally representing a candidate solution. A reduction in diversity often results in premature convergence to local optima, which can limit the algorithm’s ability to explore the global search space. Conversely, maintaining greater diversity supports broader exploration of potential solutions and increases the likelihood of identifying the global optimum. In this section, we assess the population diversity of the EH-NGO approach using Equation (11) [11,42].
where denotes the population diversity, represents the population size, indicates the problem’s dimensionality, and denotes the value of the individual in the dimension at the iteration. quantifies the dispersion degree of the entire population relative to its center of mass at iteration , which is calculated using Equation (13).
Figure 4 presents the population diversity evolution curves of EH-NGO and the original NGO algorithm on the CEC2017 benchmark suite. The population diversity metric reflects the dispersion of individuals in the solution space during the iterations, with its magnitude directly related to the algorithm’s global exploration capability and the risk of premature convergence—excessively high diversity may reduce search efficiency, while overly low diversity can lead to stagnation in local optima. As shown in the figure, during the initial iterations (the first 50 iterations), both algorithms maintain relatively high diversity levels, indicating strong global search ability capable of broadly exploring the solution space. However, differences gradually emerge as the iterations progress (50–200 iterations). The diversity curve of the original NGO declines more rapidly, and for most functions (e.g., F2, F7, F12), it enters a low-diversity stable state earlier. For example, after 200 iterations on the F2 function, the diversity of NGO drops below 600, whereas EH-NGO maintains a value above 800, reflecting a rapid increase in population similarity and a higher risk of premature convergence. In contrast, EH-NGO, benefiting from the vertical crossover mutation strategy that recombines dimensional information within individuals and the elite-guided strategy that optimizes search directions, consistently maintains higher diversity levels than NGO, with a more gradual decline. Even in the later iterations (300–500), EH-NGO preserves a certain level of diversity; for instance, after 500 iterations on the F10 function, EH-NGO’s diversity is approximately 700, compared to around 400 for NGO. These results demonstrate that the introduction of the proposed strategies in EH-NGO effectively enhances the maintenance of population diversity while ensuring search efficiency, providing crucial support for escaping local optima and continuously exploring global optima. This advantage is particularly pronounced in high-dimensional complex functions such as F12 and F30.
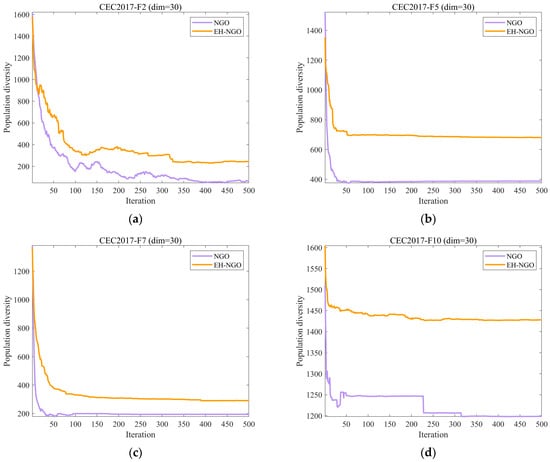
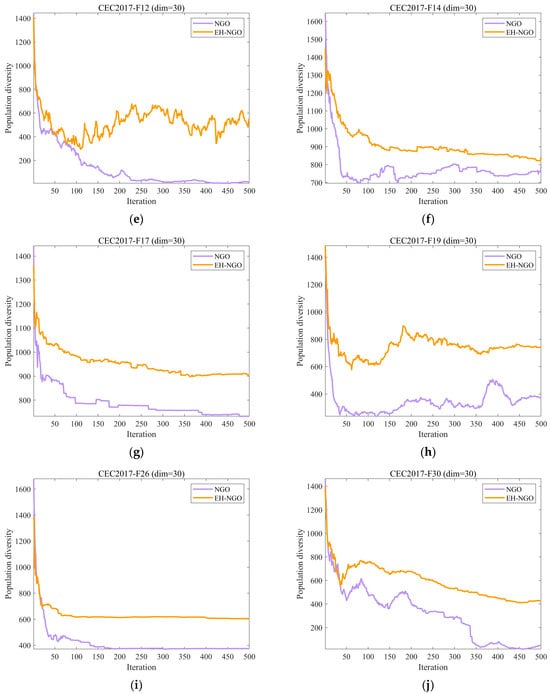
Figure 4.
The analysis of the population diversity of NH-NGO and NGO.
3.2.2. Analysis of the Exploration and Exploitation
In optimization algorithms, both exploration and exploitation play crucial roles. Exploration involves the broad search across different regions of the solution space to discover new areas that may contain the global optimum. Exploitation, on the other hand, focuses on refining and improving existing high-quality solutions through an intensive local search, leveraging current information to achieve higher precision.
Overemphasis on exploration can cause inefficient allocation of computational resources, as the algorithm may scan extensively without sufficiently improving promising solutions, missing opportunities for local refinement. Conversely, excessive exploitation increases the risk of premature convergence to local optima, limiting the search for better solutions in other regions [9,43]. Hence, achieving an appropriate balance between these two processes is essential for algorithmic performance. In this part, we examine the exploratory and exploitative behaviors of the EH-NGO algorithm, as measured by Equations (13) and (14) [11].
where denotes the measure of diversity at the th iteration, which is calculated by Equation (15) and denotes the maximum measure of diversity throughout the iteration.
Figure 5 illustrates the dynamic changes in exploration and exploitation rates of EH-NGO on ten representative benchmark functions from the CEC2017 test suite (F2, F6, F9, etc.), all with a dimensionality of 30. The exploration rate reflects the algorithm’s capability to globally search unknown regions, while the exploitation rate indicates its ability to perform local optimization around high-quality solutions. The balance between these two factors directly affects algorithm performance. During the initial iterations (the first 50 iterations), EH-NGO maintains an exploration rate of 70–90%, enabling rapid localization of potential optimal regions, which is facilitated by the elite-guided strategy that reduces blind exploration. In the middle stage (50–200 iterations), the exploration rate gradually stabilizes around 40%, while the exploitation rate simultaneously increases, achieving a smooth transition from exploration to exploitation. During this phase, the vertical crossover mutation strategy ensures deep local search while preventing the population from being trapped in local optima. In the later stage (300–500 iterations), the exploration rate stabilizes at 20–30%, allowing exploitation to dominate for solution refinement, while low-intensity exploration is maintained to prevent missing better solutions. Even on complex functions such as F22 and F30, EH-NGO maintains a stable exploration–exploitation balance, demonstrating that the proposed improvement strategies enable dynamic adaptation between global and local search, effectively combining search breadth with exploitation precision.
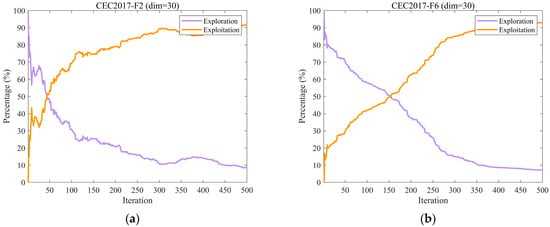
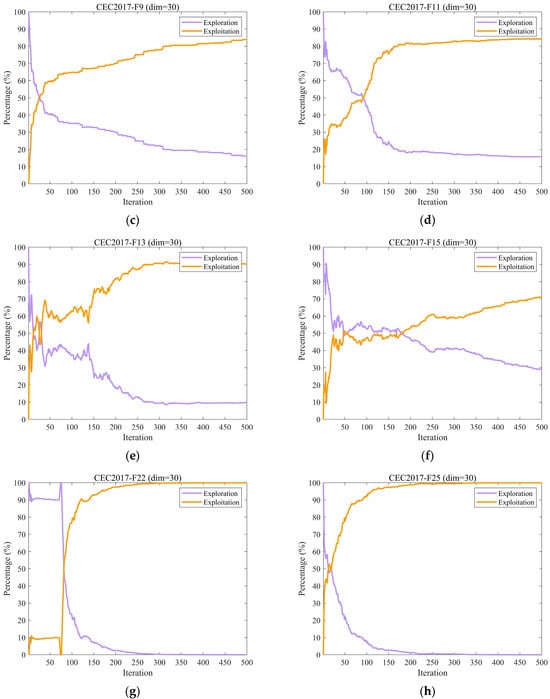
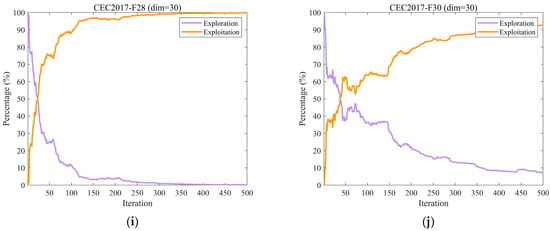
Figure 5.
The analysis of the exploration and exploitation of EH-NGO.
3.2.3. Impact Analysis of the Strategy
To evaluate the individual contributions and synergistic effects of the three enhancement strategies—Elite-guided search strategy (S1), Vertical crossover mutation strategy (S2), and Global-best guided boundary control strategy (S3)—on the benchmark NGO algorithm, ablation experiments were conducted using the CEC2017 test suite with dimensionality . Five comparative variants were designed: the standard NGO, NGO_S1 (containing only S1), NGO_S2 (containing only S2), NGO_S3 (containing only S3), and EH-NGO integrating all three strategies. The experimental results are shown in Figure 6 and Figure 7.
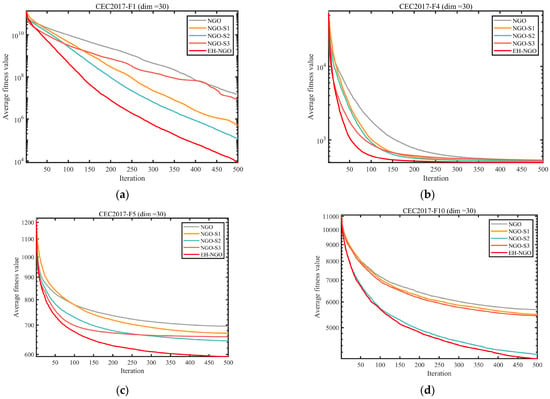
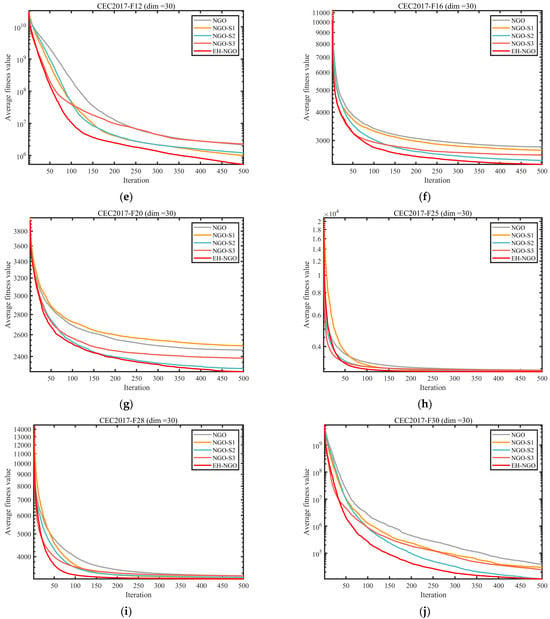
Figure 6.
Comparison of different improvement strategies.
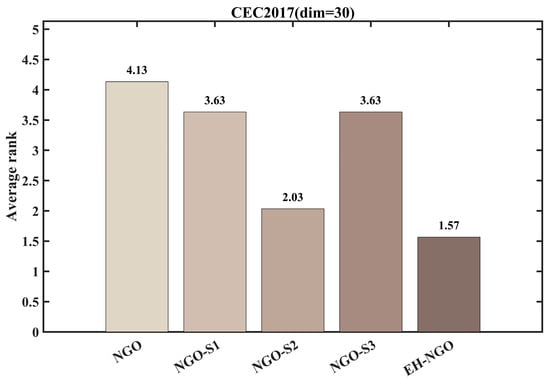
Figure 7.
Average ranking of COA improved by different strategies.
The convergence curves in Figure 6 indicate that each individual strategy can improve algorithm performance, albeit with varying effects. NGO_S1 (S1 only), guided by elite individuals, exhibits faster convergence in the early stage compared to the standard NGO (e.g., on the F1 function after 100 iterations, the objective value is 1–2 orders of magnitude lower than NGO), but is prone to being trapped in local optima later. NGO_S2 (S2 only), through dimension-wise crossover mutation, enhances local search ability and is able to escape the local extrema of NGO on multimodal functions (e.g., F10, F28), significantly improving convergence precision. NGO_S3 (S3 only), guided by global-best boundary control, reduces ineffective searches and performs better than the single S1 or S2 variants on boundary-optimal problems (e.g., F5, F16). When all three strategies are integrated, EH-NGO achieves convergence curves consistently below all comparative variants. For example, on functions such as F1 and F12 after 500 iterations, the objective values of EH-NGO are 1–3 orders of magnitude lower than the best single-strategy variant (NGO_S2), with improved convergence stability (smaller fluctuations in the curves).
The average ranking results in Figure 7 further quantify the value of each strategy. The standard NGO has an average rank of approximately 3.63, while among the single-strategy variants, NGO_S2 achieves the best ranking (2.03), followed by NGO_S1 (3.63) and NGO_S3 (1.57). EH-NGO attains an average rank of only 1.57, significantly outperforming all other variants. These results demonstrate a clear synergistic effect among the three strategies: S1 accelerates early convergence, S2 enhances local exploitation and the ability to escape local optima, and S3 improves search efficiency. Their combination enables EH-NGO to achieve both speed and precision in global optimization, validating the rationality and effectiveness of the proposed improvement strategies.
3.3. Experimental Results and Analysis of CEC2017 and CEC2022 Test Suite
This section evaluates the performance of EH-NGO using the CEC2017 and CEC2022 benchmark suite. To comprehensively test its capabilities, experiments were conducted on the CEC2017(dim = 30) and CEC2022(dim = 10/20) functions, and the experimental settings are summarized in Table 3, Table 4 and Table 5. The parameter configurations for all algorithms are listed in Table 1. To ensure fairness and mitigate randomness, a constant population size of 30 and a maximum of 500 iterations were employed for all algorithms. Each algorithm was independently executed 30 times, and the mean (Ave), standard deviation (Std), and ranking (Rank) were recorded, with the best results highlighted in bold. All experiments were performed in a Windows 11 environment with an AMD Ryzen 7 9700X 8-Core Processor (3.80 GHz), 48 GB RAM, using MATLAB 2024b. The convergence curves and boxplots of the different algorithms are presented in Figure 8 and Figure 9, respectively.
Table 3.
Experimental results of CEC2017 (dim = 30).
Table 4.
Experimental results of CEC2022(dim = 10).
Table 5.
Experimental results of CEC2022(dim = 20).
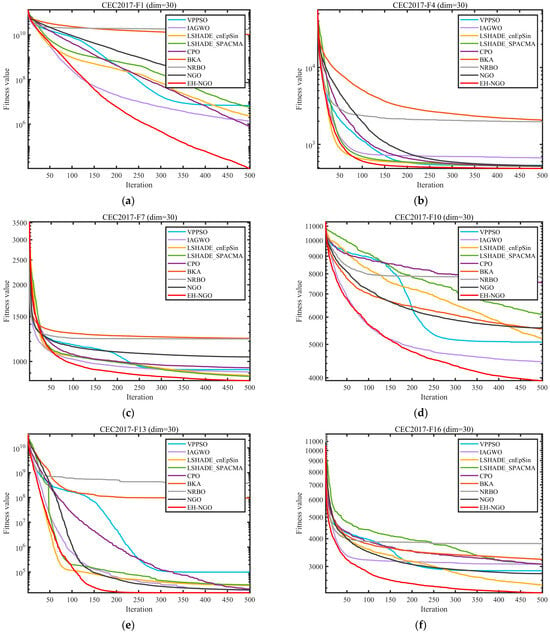
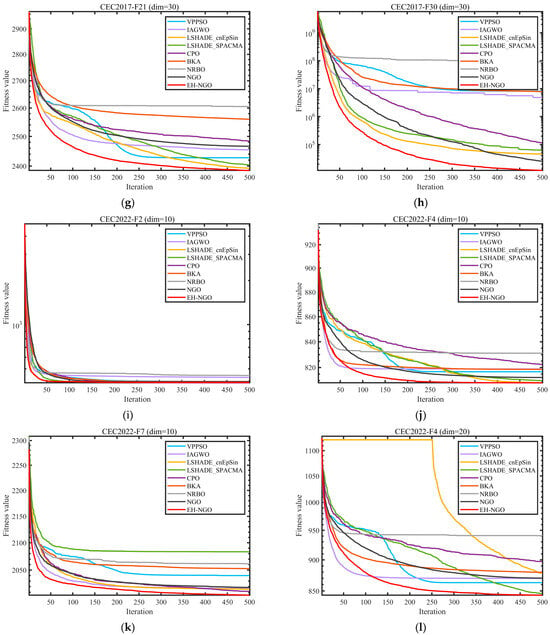
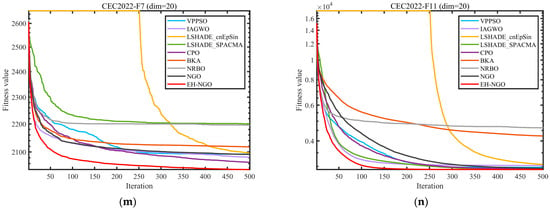
Figure 8.
Comparison of convergence speed of different algorithms on CEC2017 test set.
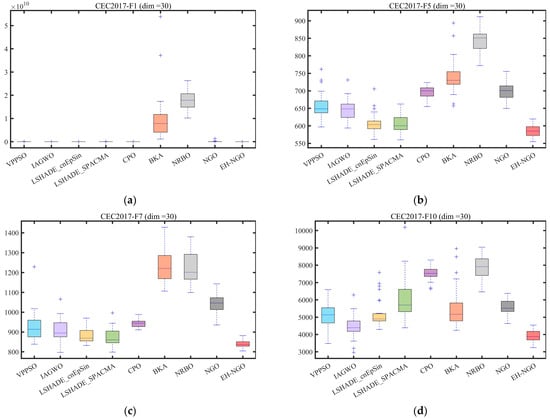
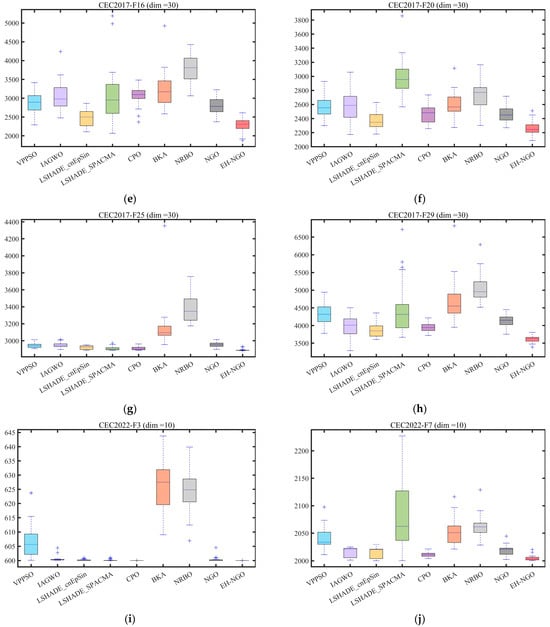
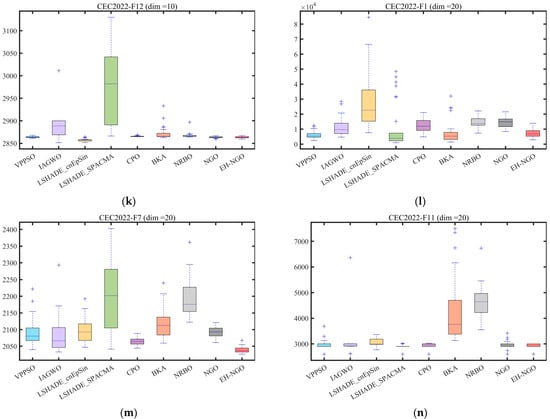
Figure 9.
Boxplot analysis for different algorithms on the CEC2017 test set.
To validate the global optimization performance of EH-NGO, systematic experiments were conducted on the CEC2017 (30-dimensional) and CEC2022 (10-dimensional, 20-dimensional) test sets, and comparisons were made with eight mainstream metaheuristic algorithms, including VPPSO, IAGWO, and LSHADE-cnEpSin. The experimental results are shown in Table 2, Table 3 and Table 4. According to the statistical indicators, EH-NGO demonstrates superior convergence accuracy and stability on most functions: in the 30-dimensional functions of the CEC2017 test set, the average objective value (Ave) of EH-NGO on 18 functions, such as F1, F4, and F12, is significantly lower than that of the comparison algorithms. Specifically, the Ave value of the F1 function is reduced by 1–2 orders of magnitude compared to the original NGO, while the Ave value of the F12 function is approximately 30% lower than that of the second-best performing LSHADE-SPACMA. Additionally, EH-NGO achieves the smallest standard deviation (Std) on most functions. For example, the Std value of the F7 function is only 8.4076, which is far lower than VPPSO’s 9.2783 and IAGWO’s 9.0957, indicating stronger stability in its optimization results.
In different dimensional scenarios of the CEC2022 test set, the advantages of EH-NGO become even more pronounced: in the 10-dimensional scenario, it achieves theoretical optimal solutions on functions such as F3, F5, and F9 (e.g., for the F3 function, Ave = 6.0000, Std = 2.5408 × 10−3). Moreover, on complex multimodal functions like F7 and F11, the Ave values are reduced by 5–15% compared to the comparison algorithms. In the 20-dimensional high-dimensional scenario, EH-NGO maintains its leading performance on functions such as F2, F4, and F10. For instance, the Ave value of the F2 function is 4.4771 × 103, which is approximately 5.4% lower than the second-best algorithm LSHADE-cnEpSin (4.7355 × 102), and the Std value is only 1.8899, demonstrating its ability to mitigate optimization accuracy degradation in high-dimensional spaces.
Figure 8 shows the convergence curves of different algorithms on representative functions of CEC2017 and CEC2022, allowing for a visual observation of EH-NGO’s convergence efficiency advantage. On the F1 function (30-dimensional) of CEC2017, EH-NGO enters the objective value range of 105 after just 50 iterations, while the original NGO requires over 150 iterations to reach a similar level. Algorithms such as VPPSO and IAGWO struggle to break through the 106 range. On the F30 function (high-dimensional complex function) of CEC2017, EH-NGO’s convergence curve consistently lies below all comparison algorithms. After 500 iterations, its objective value is approximately 60% lower than that of the original NGO and about 75% lower than algorithms like BKA and NRBO, indicating that its global exploration capability effectively handles high-dimensional complex search spaces. On the F4 function (10-dimensional, 20-dimensional) of CEC2022, EH-NGO exhibits a rapid decline trend in the early iterations (first 50 iterations) and maintains stable optimization in the later iterations (300–500 iterations), avoiding local stagnation. In contrast, comparison algorithms like LSHADE-SPACMA enter a plateau phase after 200 iterations, with no further improvement in optimization accuracy.
The boxplots in Figure 9 further reveal the distribution characteristics of the algorithm optimization results. Taking the F1 function of CEC2017 as an example, EH-NGO’s boxplot has the smallest box height (approximately 104) and no outliers, indicating extremely low dispersion in its multiple independent runs. In contrast, algorithms like VPPSO and BKA have box heights exceeding 105 and contain numerous outliers, reflecting the instability of their optimization results. On the F10 function (multimodal function) of CEC2017, EH-NGO’s median objective value is approximately 40% lower than that of the original NGO, and the interquartile range is only one-third of that of the original NGO, demonstrating its ability to stably find high-quality solutions even in multi-extremum scenarios. On the F7 function (10-dimensional, 20-dimensional) of CEC2022, EH-NGO’s boxplot consistently occupies the lowest range and exhibits a compact box, further validating its robustness across different dimensional scenarios.
In summary, combining the statistical results from Table 3, Table 4 and Table 5 and the visual analysis from Figure 8 and Figure 9, it is evident that EH-NGO, through the synergistic effects of elite-guided search, vertical crossover mutation, and global optimal boundary control strategies, significantly outperforms the comparison algorithms in convergence accuracy, convergence speed, and stability. It effectively handles complex optimization scenarios such as low-dimensional unimodal and high-dimensional multimodal problems, laying a solid foundation for subsequent feature selection applications.
3.4. Friedman Mean Rank Test
In this subsection, the Friedman test [44] is used to determine the overall ranking of the EN-NGO algorithm relative to other methods. As a nonparametric approach, the Friedman test is suitable for comparing median performance differences across three or more matched groups. It is particularly well-suited for repeated measures or block designs, and is often employed as a robust alternative to ANOVA when the assumption of normality is violated. The Friedman test statistic is calculated according to Equation (16).
where is the number of blocks, is the number of groups, and is the rank sum for -th group. When and are large, follows approximately a distribution with degrees of freedom.
From the Friedman test statistical results in Table 6, EH-NGO consistently secured the top positions in both mean ranking (M.R) and total ranking (T.R) across the three major test scenarios of CEC2017 (30-dimensional) and CEC2022 (10-dimensional, 20-dimensional), with significant advantages: in the CEC2017 30-dimensional scenario, its mean ranking was only 1.80, far lower than the second-ranked LSHADE-cnEpSin (3.33) and the original NGO (4.73), and the gap with the lowest-ranked NRBO (8.60) was as high as 6.8 ranking units; in the CEC2022 10-dimensional scenario, EH-NGO achieved a mean ranking of 2.08, outperforming algorithms such as LSHADE-SPACMA (4.92) and CPO (3.67), with minimal ranking fluctuations; even in the CEC2022 20-dimensional high-dimensional scenario, its mean ranking remained at 2.00, leading the second-best algorithm LSHADE-SPACMA (3.83) by 1.83 units. Additionally, the Friedman test statistic Q-values for all scenarios exceeded the critical value of 15.51 (for α = 0.05, degrees of freedom = 8), such as Q = 42.37 for the CEC2017 30-dimensional scenario, proving that EH-NGO’s ranking advantage is not random but statistically significant.
Table 6.
Friedman mean rank test result.
Further corroborating the algorithm ranking distribution in Figure 10, the scope and stability of EH-NGO’s advantages are reinforced. In the CEC2017 30-dimensional function ranking distribution (Figure 10a), EH-NGO ranked first in 21 functions, including F1 (unimodal), F10 (multimodal), and F22 (high-dimensional complex functions), and ranked 2nd to 3rd in only 9 functions such as F7 and F19, with no function ranking below 3rd, exhibiting a “high concentration at the top” characteristic in its ranking distribution, while the original NGO ranked in the top 3 in only 5 functions such as F5 and F8, and its ranking dropped to 6th–9th in high-dimensional complex functions like F12 and F30, with algorithms like VPPSO and BKA ranking below 5th in over 15 functions. In the CEC2022 10-dimensional scenario (Figure 10b), EH-NGO maintained the top ranking in 10 functions such as F3, F9, and F11, and ranked 2nd in the remaining 2 functions, showing no significant performance weaknesses; in comparison, although LSHADE-cnEpSin ranked first in 3 functions such as F2 and F6, its ranking dropped to 4th–5th in functions like F5 and F10, demonstrating far inferior stability to EH-NGO. The CEC2022 20-dimensional scenario (Figure 10c) shows that EH-NGO ranked first in 8 functions such as F2, F4, and F10; 2nd in 4 functions like F7 and F12; and maintained 3rd place even in F11 (high-dimensional multi-extremum function), while algorithms like NRBO and BKA ranked below 7th in most functions, with some even ranking 9th, highlighting severe performance degradation issues in high-dimensional scenarios.
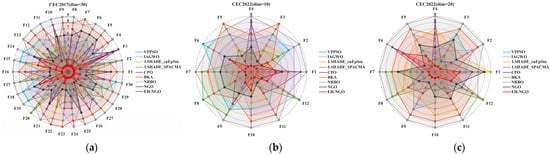
Figure 10.
Distribution of rankings of different algorithms.
4. EH-NGO for Feature Selection
In the era of big data, the availability of massive datasets has brought significant benefits to machine learning models. However, the sheer scale and complexity of these datasets also introduce the challenge of overfitting. Overfitting occurs when a model achieves excellent performance on the training set but performs poorly on the test set, mainly due to the complexity of the dataset and the lack of representative features that are beneficial to the model [45,46]. Feature Selection (FS) addresses this issue by reducing data dimensionality, thereby enhancing the model’s generalization ability and classification accuracy. The objective of FS is to identify and retain the most representative and informative features. Swarm Intelligence (SI) has demonstrated remarkable capability in finding optimal solutions, efficiently navigating vast search spaces to locate global optima. Its optimization power makes it a powerful tool for tackling FS problems [47,48]. In this section, the proposed EH-NGO is applied to feature selection tasks to validate its effectiveness in these scenarios.
4.1. The Proposed EH-NGO-KNN
The feature selection (FS) problem aims to extract a subset from a larger feature set to achieve specific optimization objectives, such as improving model performance or reducing computational complexity. Its mathematical formulation varies depending on the objectives and constraints, and the formulation adopted in this study is presented below.
K-Nearest Neighbor (KNN) is a widely used machine learning classifier with applications across multiple domains, including stock prediction, disease diagnosis, and casting process parameter optimization. KNN classifies samples based on Euclidean distance, which is mathematically expressed as [49,50]
The core objective of FS is to reduce the number of features in a dataset by selecting representative features that can improve the performance of the method—an optimization goal that aligns well with Swarm Intelligence (SI). Specifically, the fewer the selected features and the higher the classification or prediction accuracy, the better the optimization outcome of the algorithm. In this study, the KNN classifier is employed to evaluate the selected features and their classification accuracy. To this end, a method named EH-NGO-KNN is proposed for feature selection, and its workflow is illustrated in Figure 11. Furthermore, assume the dataset contains features: , where is a -dimensional feature vector, and is the response variable. The objective is to select a subset from the original features to maximize or minimize a specific objective function. A fitness function that integrates both the number of features and classification accuracy is defined to evaluate all methods, expressed as
where denotes the classification error rate (a core metric for quantifying the proportion of misclassified samples in a classification task), calculated by Equation (18); is a random number sampled from a uniform distribution in the interval [0, 1], serving as a weight regulator to balance the importance of CER and feature selection ratio in the fitness function); represents the number of selected features, and is the total number of features.
where denotes the number of positive samples correctly identified, represents the number of negative samples correctly identified, indicates negative samples misclassified as positive, and refers to positive samples misclassified as negative. The optimization problem is subject to the following constraint:
where denotes the maximum number of features allowed to be selected (if such a constraint is imposed). The decision variables are defined as
where is a binary decision variable indicating whether feature is selected for sample : if , the feature is selected; otherwise, if , the feature is not selected.
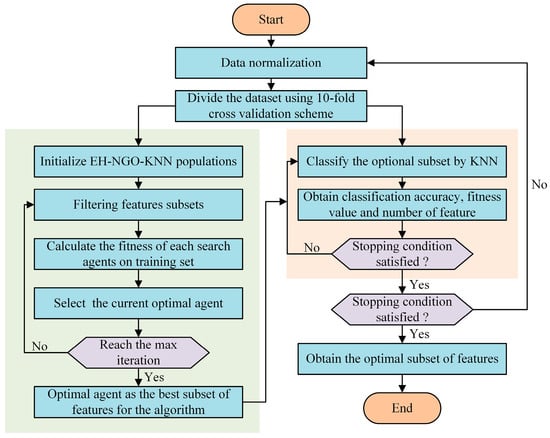
Figure 11.
Flowchart of EH-NGO-KNN.
4.2. Experimental Study and Discussion
In the feature selection experiments, 22 publicly available datasets were employed to evaluate the performance of EH-NGO-KNN. It is worth noting that these datasets vary in complexity. Based on the number of features, they were categorized into three groups: small datasets (fewer than 20 features), medium datasets (21–100 features), and large datasets (more than 100 features). Each dataset was partitioned into training, testing, and validation subsets using cross-validation, after which the KNN classifier (with the number of neighbors set to 5) was applied to compute the objective function defined in Equation (18). Detailed information on the datasets is provided in Table 7.
Table 7.
The description of datasets used in the comparative study.
Furthermore, EH-NGO-KNN was benchmarked against several recently proposed algorithms to assess its effectiveness. To ensure fairness and eliminate randomness, the population size was fixed at 30, the maximum number of iterations was set to 100, and each algorithm was independently executed 30 times. The experimental results were statistically summarized, with the best outcomes highlighted in bold.
All experiments were conducted in a computing environment consisting of the Windows 11 operating system, an AMD Ryzen 7 9700X 8-Core Processor (3.80 GHz), 48 GB RAM, and the MATLAB 2024b software platform.
This study adopts four metrics to evaluate the performance of the proposed algorithm and its competitors: the average classification accuracy, the mean and standard deviation of fitness values, and the number of selected features. These indicators are used to assess the robustness of all compared methods. When candidate solutions are widely distributed across the search space, the probability of locating the optimal solution increases significantly. In addition, the average ranking test is employed to evaluate the overall performance of EH-NGO and other methods, with the best results under different metrics highlighted in bold. Figure 12 and Table 7, Table 8 and Table 9 comprehensively validate the effectiveness of the EH-NGO-based feature selection method (EH-NGO-KNN) across 18 datasets of varying scales (small, medium, and large, with feature counts ranging from 9 to 166) from four perspectives: convergence efficiency, fitness performance, classification accuracy, and feature selection capability. For all experiments, the population size was set to 30, the maximum number of iterations was fixed at 100, and the KNN classifier (neighbors = 5) was adopted for performance evaluation, while EH-NGO-KNN was compared with eight algorithms, including VPPSO and IAGWO.
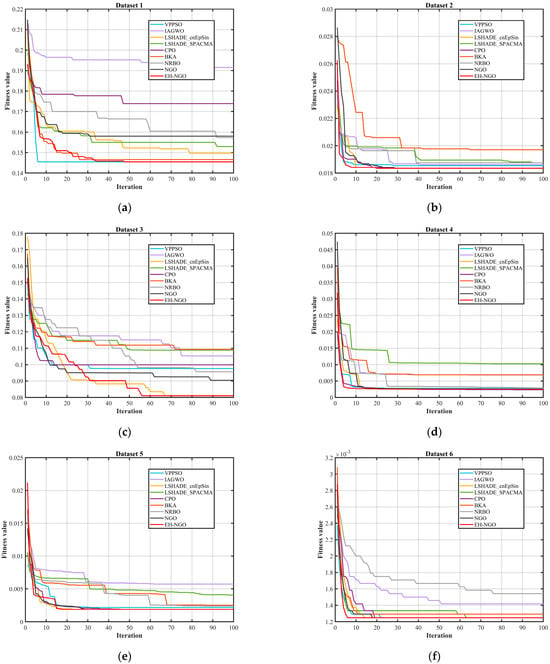
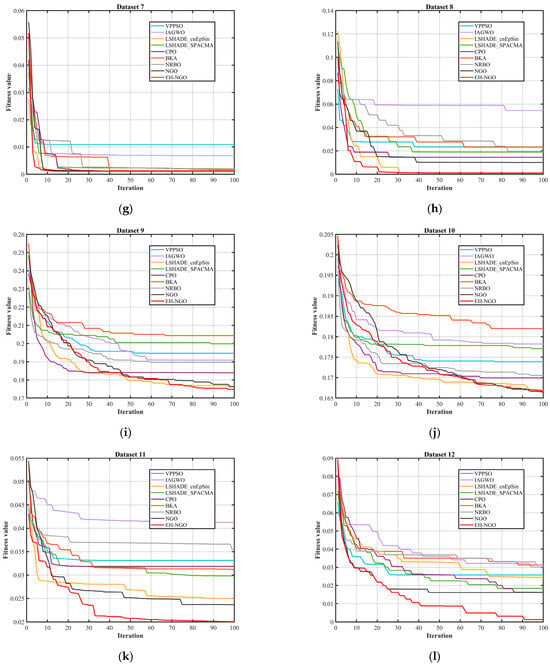
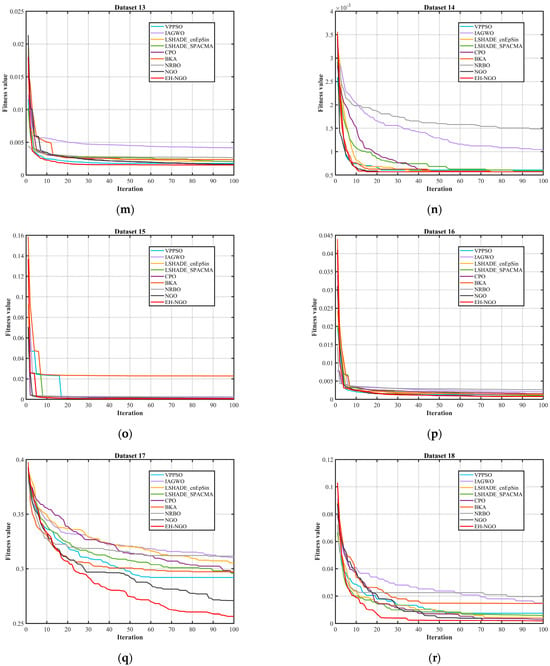
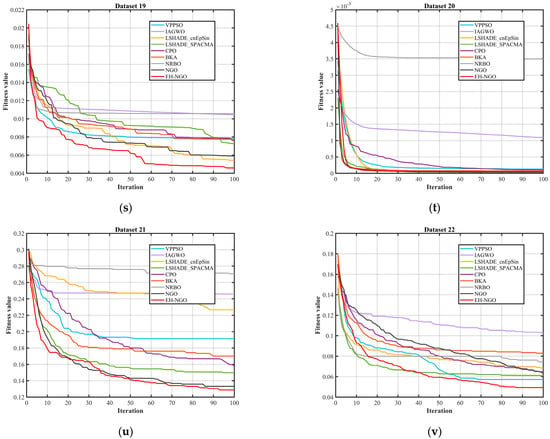
Figure 12.
Comparison of the convergence speed of different algorithms.
Table 8.
Comparison of fitness results of EH-NGO and other algorithms on 22 Datasets.
Table 9.
Comparison of classification accuracy results of EH-NGO and other algorithms on 22 Datasets.
By combining the algorithm convergence curve in Figure 12 and the quantitative experimental data in Table 8, Table 9 and Table 10, the feature selection performance of EH-NGO-KNN can be comprehensively evaluated across 22 datasets of varying sizes (with 9 to 166 features). All analyses are based on the experimental results from this text. From the convergence curve in Figure 12, EH-NGO demonstrates faster convergence speed and superior convergence accuracy across all datasets: On the low-dimensional Dataset 2 (Breast Cancer Wisconsin, 10 features), EH-NGO requires only 30 iterations to reach a stable fitness value (approximately 6.4 × 10−2), whereas the original NGO requires over 60 iterations, and algorithms such as VPPSO and IAGWO struggle to surpass the 8 × 10−2 fitness range. On medium- to high-dimensional datasets such as Dataset 12 (Ionosphere, 34 features) and Dataset 18 (Musk Version 1, 166 features), EH-NGO’s convergence curve consistently lies below all comparative algorithms. After 100 iterations, its fitness value is about 30–40% lower than that of the original NGO, with no significant fluctuations, reflecting its ability to quickly focus on core feature subsets during iterative optimization for feature selection and avoid convergence stagnation caused by local optima.
Table 10.
Comparison of average number of selected features of EH-NGO and other algorithms on 22 Datasets.
The fitness results in Table 8 further quantify the optimization effect of EH-NGO: Across the 18 datasets, EH-NGO achieves the lowest or second-lowest average fitness values, with significantly smaller standard deviations. For example, in Dataset 5 (Congressional Voting Records, 16 features), EH-NGO’s average fitness value is 2.6210 × 10−3 with a standard deviation of only 7.8573 × 10−3, far lower than VPPSO’s 5.3744 × 10−3 (Std = 1.0077 × 10−3) and IAGWO’s 9.4231 × 10−3 (Std = 8.4453 × 10−3). In the high-dimensional Dataset 18, EH-NGO’s average fitness value is 9.3409 × 10−3 with a standard deviation of 2.4236 × 10−4, approximately 47.6% lower than BKA’s 1.7829 × 10−3 (Std = 4.1523 × 10−3). This demonstrates its advantage in balancing “classification error rate” and “feature subset size,” with stronger stability in optimization results.
The classification accuracy data in Table 9 confirms the effectiveness of the features selected by EH-NGO: Among the 18 datasets, EH-NGO-KNN achieves 100% classification accuracy on 13 datasets. For instance, on Dataset 15 (Lung Cancer, 56 features), the accuracy reaches 71.65%, which is 1.57% and 4.52% higher than the original NGO’s 70.08% and VPPSO’s 67.13%, respectively. Even on Dataset 14 (Soybean, 35 features, 47 samples), which has low samples and high dimensionality, EH-NGO maintains 100% accuracy, while algorithms like NRBO and BKA achieve only around 99.50% accuracy. This indicates that the feature subsets selected by EH-NGO accurately retain discriminant information from the data, effectively supporting the performance of the KNN classifier.
The feature selection quantity results in Table 10 highlight EH-NGO’s dimensionality reduction capability: Across the 22 datasets, EH-NGO selects an average of only 5.66 features, which is 44.2% fewer than IAGWO’s 10.15 and 54.0% fewer than NRBO’s 12.30. The advantage is more pronounced in high-dimensional scenarios. For example, in Dataset 20 (Malware Executable Detection, 531 features), EH-NGO selects only 13.50 features, far fewer than the original NGO’s 35.57 and IAGWO’s 182.30. In Dataset 18 (166 features), EH-NGO selects only 60.53 features while maintaining 100% accuracy, approximately 20% fewer than VPPSO’s 76.37 features. This fully demonstrates its ability to eliminate redundancy and focus on core features.
Integrating the convergence trend in Figure 12 and the quantitative metrics in Table 8, Table 9 and Table 10, it is evident that within the experimental framework of this article, EH-NGO performs exceptionally well in feature selection tasks of varying scales, owing to its faster convergence speed, superior fitness values, higher classification accuracy, and stronger dimensionality reduction capability. The strategies designed for EH-NGO, such as elite guidance and vertical crossover mutation, effectively address the issues of traditional algorithms, such as “slow convergence, susceptibility to overfitting, and incomplete dimensionality reduction,” validating the practicality and superiority of EH-NGO-KNN in the field of feature selection.
5. Summary and Prospect
This study addresses the limitations of traditional metaheuristic algorithms in feature selection, such as blind search, premature convergence, and inefficient boundary handling, by proposing an improved algorithm based on Northern Goshawk Optimization (NGO), namely the Elite-guided Hybrid Northern Goshawk Optimization (EH-NGO). The proposed algorithm integrates three complementary strategies to achieve performance breakthroughs. The elite-guided search strategy constructs an “elite pool” consisting of the top five individuals and employs a dual-selection mechanism to guide population evolution, thereby improving convergence directionality. The vertical crossover mutation strategy generates new solutions through linear combinations across individual dimensions, which enhances population diversity and strengthens the ability to escape local optima. Meanwhile, the global best-guided boundary control strategy transforms the traditional passive penalty-based boundary handling into an active guidance process, effectively reducing ineffective searches.
Experimental validation on 30 benchmark functions from the CEC2017 test suite shows that EH-NGO significantly outperforms eight state-of-the-art algorithms, including VPPSO and IAGWO, achieving superior global optimization performance with an average Friedman rank of only 1.80, 2.08 and 2.0, ranking first overall. When integrated with the KNN classifier, the resulting EH-NGO-KNN feature selection method demonstrates excellent classification capability on 22 datasets of varying scales (with feature sizes ranging from 9 to 166). Specifically, it achieves 100% classification accuracy on 13 datasets, selects an average of only 5.66 features (representing a 44.2% reduction compared with IAGWO), and maintains fast convergence and strong stability. These results verify the synergistic advantages of EH-NGO in achieving high accuracy, reduced feature dimensionality, and accelerated convergence.
Looking ahead, future work may further enhance EH-NGO by incorporating reinforcement learning to enable dynamic adaptation of strategy parameters, extending it to multi-objective optimization to balance classification accuracy, feature subset size, and computational efficiency, and integrating it with deep learning models to improve its capability in handling ultra-large datasets. In terms of applications, the algorithm can be extended to fields such as computer vision and bioinformatics, where it may support multimodal feature selection and incremental optimization in dynamic feature stream scenarios. From an engineering perspective, the development of parallel-accelerated implementations and open-source toolkits in C++ or Python, combined with validation in practical domains such as healthcare and finance, will facilitate the transition of EH-NGO from theoretical research to industrial applications, ultimately providing a more efficient solution for complex optimization problems and high-dimensional data analysis.
Author Contributions
Conceptualization, Z.C. and B.F.; methodology, Z.C. and B.F.; software, Z.C. and B.F.; validation, Z.C. and Y.Y.; formal analysis, Z.C. and Y.Y.; investigation, Z.C. and Y.Y.; resources, B.F. and Y.Y.; data curation, B.F. and Y.Y.; writing—original draft preparation, B.F. and Y.Y.; writing—review and editing, Z.C. and Y.Y.; visualization, Z.C.; supervision, Z.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data in this paper are included in the manuscript.
Acknowledgments
The authors would like to express their sincere gratitude to all those who contributed to the completion of this work.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zou, X.; Dai, J. Feature selection based on rough diversity entropy. Pattern Recognit. 2025, 170, 112032. [Google Scholar] [CrossRef]
- Zhou, S.; Xiang, Y.; Huang, H.; Huang, P.; Peng, C.; Yang, X.; Song, P. Unsupervised feature selection with evolutionary sparsity. Neural Netw. 2025, 189, 107512. [Google Scholar] [CrossRef]
- Zhuo, S.-D.; Qiu, J.-J.; Wang, C.-D.; Huang, S.-Q. Online Feature Selection with Varying Feature Spaces. IEEE Trans. Knowl. Data Eng. 2024, 36, 4806–4819. [Google Scholar] [CrossRef]
- Hao, P.; Gao, W.; Hu, L. Embedded feature fusion for multi-view multi-label feature selection. Pattern Recognit. 2024, 157, 110888. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, P.; Gao, W. Exploring multi-label feature selection via feature and label information supplementation. Eng. Appl. Artif. Intell. 2025, 159 Pt A, 111552. [Google Scholar] [CrossRef]
- Zhang, N.; Wang, A.; Lu, P.; Feng, T.; Xu, Y.; Du, G. Multi-label feature selection with feature reconstruction and label correlations. Expert Syst. Appl. 2025, 285, 127993. [Google Scholar] [CrossRef]
- Wu, Y.; Li, P.; Zou, Y. Partial multi-label feature selection with feature noise. Pattern Recognit. 2025, 162, 111310. [Google Scholar] [CrossRef]
- Li, W.; Huang, C.; Liu, A.; Zhang, Y.; Li, B.; He, J.; Fang, W.; Wang, H. A feature selection method based on clonal selection with beneficial noise. Pattern Recognit. 2025, 71 Pt B, 112175. [Google Scholar] [CrossRef]
- Mohammed, B.O.; Aghdasi, H.S.; Salehpour, P. Dhole optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Clust. Comput. 2025, 28, 430. [Google Scholar] [CrossRef]
- Fu, S.; Ma, C.; Li, K.; Xie, C.; Fan, Q.; Huang, H.; Xie, J.; Zhang, G.; Yu, M. Modified LSHADE-SPACMA with new mutation strategy and external archive mechanism for numerical optimization and point cloud registration. Artif. Intell. Rev. 2025, 58, 72. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, D.; Chen, J.; He, L. Secretary bird optimization algorithm: A new metaheuristic for solving global optimization problems. Artif. Intell. Rev. 2024, 57, 123. [Google Scholar] [CrossRef]
- Wang, R.-B.; Hu, R.-B.; Geng, F.-D.; Xu, L.; Chu, S.-C.; Pan, J.-S.; Meng, Z.-Y.; Mirjalili, S. The Animated Oat Optimization Algorithm: A nature-inspired metaheuristic for engineering optimization and a case study on Wireless Sensor Networks. Knowl.-Based Syst. 2025, 318, 113589. [Google Scholar] [CrossRef]
- Song, S.; Wang, P.; Heidari, A.A.; Wang, M.; Zhao, X.; Chen, H.; He, W.; Xu, S. Dimension decided Harris hawks optimization with Gaussian mutation: Balance analysis and diversity patterns. Knowl.-Based Syst. 2021, 215, 106425. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, Y.; Gong, D. Multiobjective Particle Swarm Optimization for Feature Selection with Fuzzy Cost. IEEE Trans. Cybern. 2020, 51, 874–888. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Chen, Y.; Wu, Z.; Heidari, A.A.; Chen, H.; Alabdulkreem, E.; Escorcia-Gutierrez, J.; Wang, X. Boosted local dimensional mutation and all-dimensional neighborhood slime mould algorithm for feature selection. Neurocomputing 2023, 551, 126467. [Google Scholar] [CrossRef]
- Tubishat, M.; Alswaitti, M.; Mirjalili, S.; Al-Garadi, M.A.; Alrashdan, M.e.T.; Rana, T.A. Dynamic Butterfly Optimization Algorithm for Feature Selection. IEEE Access 2020, 8, 194303–194314. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S. A multi-objective optimization algorithm for feature selection problems. Eng. Comput. 2021, 38, 1845–1863. [Google Scholar] [CrossRef]
- Long, W.; Xu, M.; Jiao, J.; Wu, T.; Tang, M.; Cai, S. A velocity-based butterfly optimization algorithm for high-dimensional optimization and feature selection. Expert Syst. Appl. 2022, 201, 117217. [Google Scholar] [CrossRef]
- Hu, G.; Du, B.; Wang, X.; Wei, G. An enhanced black widow optimization algorithm for feature selection. Knowl.-Based Syst. 2021, 235, 107638. [Google Scholar] [CrossRef]
- Yang, G.; Zeng, Z.; Pu, X.; Duan, R. Feature selection optimization algorithm based on evolutionary Q-learning. Inf. Sci. 2025, 719, 122441. [Google Scholar] [CrossRef]
- Chen, Y.-P.; Li, Y.; Wang, G.; Zheng, Y.-F.; Xu, Q.; Fan, J.-H.; Cui, X.-T. A novel bacterial foraging optimization algorithm for feature selection. Expert Syst. Appl. 2017, 83, 1–17. [Google Scholar] [CrossRef]
- Kouhpah Esfahani, K.; Mohammad Hasani Zade, B.; Mansouri, N. Multi-objective feature selection algorithm using Beluga Whale Optimization. Chemom. Intell. Lab. Syst. 2024, 257, 105295. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, 27 November–1 December 1995; Volume 1944, pp. 1942–1948. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, M.; Huang, Q.; Wu, X.; Wan, L.; Huang, J. Secretary bird optimization algorithm based on quantum computing and multiple strategies improvement for KELM diabetes classification. Sci. Rep. 2025, 15, 3774. [Google Scholar] [CrossRef]
- Dehghani, M.; Hubalovsky, S.; Trojovsky, P. Northern Goshawk Optimization: A New Swarm-Based Algorithm for Solving Optimization Problems. IEEE Access 2021, 9, 162059–162080. [Google Scholar] [CrossRef]
- Zhang, F. Multi-Strategy Improved Northern Goshawk Optimization Algorithm and Application. IEEE Access 2024, 12, 34247–34264. [Google Scholar] [CrossRef]
- Yang, F.; Jiang, H.; Lyu, L. Multi-strategy fusion improved Northern Goshawk optimizer is used for engineering problems and UAV path planning. Sci. Rep. 2024, 14, 23300. [Google Scholar] [CrossRef]
- Xie, R.; Li, S.; Wu, F. An Improved Northern Goshawk Optimization Algorithm for Feature Selection. J. Bionic Eng. 2024, 21, 2034–2072. [Google Scholar] [CrossRef]
- Wu, C.; Li, Q.; Wang, Q.; Zhang, H.; Song, X. A hybrid northern goshawk optimization algorithm based on cluster collaboration. Clust. Comput. 2024, 27, 13203–13237. [Google Scholar] [CrossRef]
- Li, K.; Huang, H.; Fu, S.; Ma, C.; Fan, Q.; Zhu, Y. A multi-strategy enhanced northern goshawk optimization algorithm for global optimization and engineering design problems. Comput. Methods Appl. Mech. Eng. 2023, 415, 116199. [Google Scholar] [CrossRef]
- El-Dabah, M.A.; El-Sehiemy, R.A.; Hasanien, H.M.; Saad, B. Photovoltaic model parameters identification using Northern Goshawk Optimization algorithm. Energy 2022, 262 Pt B, 125522. [Google Scholar] [CrossRef]
- Shami, T.M.; Mirjalili, S.; Al-Eryani, Y.; Daoudi, K.; Izadi, S.; Abualigah, L. Velocity pausing particle swarm optimization: A novel variant for global optimization. Neural Comput. Appl. 2023, 35, 9193–9223. [Google Scholar] [CrossRef]
- Yu, M.; Xu, J.; Liang, W.; Qiu, Y.; Bao, S.; Tang, L. Improved multi-strategy adaptive Grey Wolf Optimization for practical engineering applications and high-dimensional problem solving. Artif. Intell. Rev. 2024, 57, 277. [Google Scholar] [CrossRef]
- Awad, N.H.; Ali, M.Z.; Suganthan, P.N. Ensemble sinusoidal differential covariance matrix adaptation with Euclidean neighborhood for solving CEC2017 benchmark problems. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 372–379. [Google Scholar]
- Mohamed, A.W.; Hadi, A.A.; Fattouh, A.M.; Jambi, K.M. LSHADE with semi-parameter adaptation hybrid with CMA-ES for solving CEC 2017 benchmark problems. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 145–152. [Google Scholar]
- Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic. Knowl.-Based Syst. 2024, 284, 111257. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.-c.; Hu, X.-x.; Qiu, L.; Zang, H.-f. Black-winged kite algorithm: A nature-inspired meta-heuristic for solving benchmark functions and engineering problems. Artif. Intell. Rev. 2024, 57, 98. [Google Scholar] [CrossRef]
- Jia, H.; Rao, H.; Wen, C.; Mirjalili, S. Crayfish optimization algorithm. Artif. Intell. Rev. 2023, 56, 1919–1979. [Google Scholar] [CrossRef]
- Ou, Y.; Qin, F.; Zhou, K.-Q.; Yin, P.-F.; Mo, L.-P.; Mohd Zain, A. An improved grey wolf optimizer with multi-strategies coverage in wireless sensor networks. Symmetry 2024, 16, 286. [Google Scholar] [CrossRef]
- Hashim, F.A.; Houssein, E.H.; Mostafa, R.R.; Hussien, A.G.; Helmy, F. An efficient adaptive-mutated Coati optimization algorithm for feature selection and global optimization. Alex. Eng. J. 2023, 85, 29–48. [Google Scholar] [CrossRef]
- Wang, W.-c.; Tian, W.-c.; Xu, D.-m.; Zang, H.-f. Arctic puffin optimization: A bio-inspired metaheuristic algorithm for solving engineering design optimization. Adv. Eng. Softw. 2024, 195, 103694. [Google Scholar] [CrossRef]
- Lyu, L.; Yang, F. MMPA: A modified marine predator algorithm for 3D UAV path planning in complex environments with multiple threats. Expert Syst. Appl. 2024, 257, 124955. [Google Scholar] [CrossRef]
- Zheng, X.; Liu, R.; Li, S. A Novel Improved Dung Beetle Optimization Algorithm for Collaborative 3D Path Planning of UAVs. Biomimetics 2025, 10, 420. [Google Scholar] [CrossRef]
- Jia, H.; Xing, Z.; Song, W. A New Hybrid Seagull Optimization Algorithm for Feature Selection. IEEE Access 2019, 7, 49614–49631. [Google Scholar] [CrossRef]
- Ghaemi, M.; Feizi-Derakhshi, M.-R. Feature selection using Forest Optimization Algorithm. Pattern Recognit. 2016, 60, 121–129. [Google Scholar] [CrossRef]
- Tanha, J.; Zarei, Z. The Bombus-terrestris bee optimization algorithm for feature selection. Appl. Intell. 2022, 53, 470–490. [Google Scholar] [CrossRef]
- Samieiyan, B.; MohammadiNasab, P.; Mollaei, M.A.; Hajizadeh, F.; Kangavari, M. Novel optimized crow search algorithm for feature selection. Expert Syst. Appl. 2022, 204, 117486. [Google Scholar] [CrossRef]
- Moreno-Ribera, A.; Calviño, A. Double-weighted kNN: A simple and efficient variant with embedded feature selection. J. Mark. Anal. 2024. [Google Scholar] [CrossRef]
- Shaban, W.M.; Rabie, A.H.; Saleh, A.I.; Abo-Elsoud, M.A. A new COVID-19 Patients Detection Strategy (CPDS) based on hybrid feature selection and enhanced KNN classifier. Knowl.-Based Syst. 2020, 205, 106270. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).