Abstract
Accurate segmentation of multiple sclerosis (MS) lesions from 3D MRI scans is essential for diagnosis, disease monitoring, and treatment planning. However, this task remains challenging due to the sparsity, heterogeneity, and subtle appearance of lesions, as well as the difficulty in obtaining high-quality annotations. In this study, we propose Efficient-Net3D-UNet, a deep learning framework that combines compound-scaled MBConv3D blocks with a lesion-aware patch sampling strategy to improve volumetric segmentation performance across multi-modal MRI sequences (FLAIR, T1, and T2). The model was evaluated against a conventional 3D U-Net baseline using standard metrics including Dice similarity coefficient, precision, recall, accuracy, and specificity. On a held-out test set, EfficientNet3D-UNet achieved a Dice score of 48.39%, precision of 49.76%, and recall of 55.41%, outperforming the baseline 3D U-Net, which obtained a Dice score of 31.28%, precision of 32.48%, and recall of 43.04%. Both models reached an overall accuracy of 99.14%. Notably, EfficientNet3D-UNet also demonstrated faster convergence and reduced overfitting during training. These results highlight the potential of EfficientNet3D-UNet as a robust and computationally efficient solution for automated MS lesion segmentation, offering promising applicability in real-world clinical settings.
1. Introduction
Multiple sclerosis (MS) is a chronic inflammatory demyelinating disease of the central nervous system characterized by scattered lesions in the brain and spinal cord, commonly detected using magnetic resonance imaging (MRI) [1]. The accurate segmentation of MS lesions is essential for diagnosis, disease progression monitoring, and therapeutic planning. Clinical MRI protocols typically include FLAIR (Fluid-Attenuated Inversion Recovery), and T1-weighted and T2-weighted sequences, each highlighting different lesion characteristics. However, manual delineation of lesions remains time-consuming and suffers from inter-rater variability, particularly when detecting small or subtle lesions [2].
Recent advances in deep learning, particularly convolutional neural networks (CNNs), have shown significant potential in automating MS lesion segmentation. The 3D U-Net architecture has emerged as a widely adopted baseline for volumetric neuroimaging tasks due to its ability to leverage spatial context. Nevertheless, its high computational cost and large parameter count limit its real-world deployment, especially in low-resource clinical settings [3]. Additionally, data imbalance where lesion voxels are vastly outnumbered by background tissue remains a persistent challenge in achieving high recall and precision [4]. To overcome these limitations, modern research has explored lightweight and scalable architectures such as EfficientNet, originally introduced for 2D image classification through compound scaling of depth, width, and resolution. While 2D EfficientNet backbones have been adapted for brain tumor segmentation and retinal imaging [5], their extension into full 3D volumetric networks for MS lesion detection is still underexplored. Moreover, most studies utilize only FLAIR inputs, ignoring the synergistic information offered by multi-modal MRI [6].
In this paper, we introduce a novel EfficientNet3D-based U-Net architecture tailored for multi-modal MS lesion segmentation using T1, T2, and FLAIR MRI volumes. Our approach integrates MBConv3D blocks with depthwise separable convolutions and trilinear upsampling, inspired by EfficientNetB4’s compound scaling principles. Unlike traditional UNet3D models, our architecture achieves competitive accuracy with fewer parameters and improved inference efficiency. We also implement a lesion-balanced patch extraction strategy and post-processing via small blob removal, designed to enhance recall and reduce false positives, especially important in detecting clinically relevant small lesions [6].
The primary contributions of this work are as follows:
- We introduce a novel and efficient 3D deep learning architecture based on EfficientNet3D, specifically designed for segmenting multiple sclerosis (MS) lesions using full 3D multi-modal MRI data, marking one of the first applications of this architecture in this domain.
- A lesion-aware patch sampling strategy is integrated with advanced data augmentation and a post-processing step involving small-blob suppression to suppress small false-positive predictions, thereby improving segmentation robustness.
- Comprehensive experiments on a clinically curated MS dataset demonstrate that our proposed model achieves consistently higher or competitive performance in Dice score, precision, and recall compared to the standard 3D U-Net baseline.
Together, these innovations present a scalable and accurate framework for MS lesion segmentation, supporting broader deployment of efficient 3D neural networks in clinical neuroimaging pipelines and future research.
2. Related Work
Recent developments in deep learning have yielded promising outcomes in automatic segmentation of multiple sclerosis (MS) lesions and brain tumors, particularly through the adoption of convolutional architectures fine-tuned for medical imaging. Nevertheless, challenges such as data heterogeneity, limited generalizability, and real-world deployment persist.
Wahlig et al. [3] explored transfer learning by fine-tuning 3D U-Nets on MS-specific lesion data. Their fine-tuned models outperformed de novo counterparts, achieving lesion-wise sensitivity of 0.75 and PPV of 0.75 on the ISBI 2015 dataset. While cross-validated Dice scores peaked at 0.66, results on external datasets such as ISBI without specific training showed a drop (e.g., Dice 0.62, sensitivity 0.56, PPV 0.61), revealing susceptibility to domain shifts. The reliance on small, non-diverse datasets also raises concerns regarding generalizability and overfitting. From a clinical deployment perspective, these limitations imply the need for larger, more representative training cohorts and cross-site validation.
Ashtari et al. [4] proposed Pre-U-Net, a variant of the traditional U-Net architecture with pre-activation residual blocks and deep supervision, evaluated on the MSSEG-2 dataset for longitudinal MS lesion segmentation. Their model achieved a Dice score of 45.6%, sensitivity of 54.5%, precision of 53.8%, and F1-score of 51.9%, outperforming U-Net and Res-U-Net baselines in detecting new lesions. However, performance deteriorated for extremely subtle or borderline lesions, particularly those missed by all raters, indicating a limitation in handling clinically ambiguous cases. This model’s sensitivity may fall short of clinical needs in real-world longitudinal monitoring, where early lesion evolution is subtle and detection critical.
Krishnan et al. [5] proposed a multi-arm 3D U-Net with dense input concatenation and skip connectivity for T2 lesion segmentation in MS clinical trials. The model achieved a Dice similarity coefficient of 0.66 and a lesion-wise sensitivity of 0.84, demonstrating robust performance across both internal and external datasets. However, the model’s reliance on large, multicenter clinical trial data may limit its adaptability to small-scale or heterogeneous real-world datasets, where data augmentation and domain adaptation be-come essential.
McKinley et al. [7] compared a standard 3D U-Net and DeepSCAN for joint lesion and brain structure segmentation. Their study reported a Dice score of 0.57 on the MSSEG dataset, which dropped to 0.49 when evaluated on an external cohort. This highlights the prevalent issue of domain shift, where models trained on single-center data underperform when exposed to external distributions. Such results stress the need for architecture and training strategies that promote cross-domain generalizability.
Davarani et al. [8] developed an enhanced segmentation approach utilizing DeepLabV3Plus with a Squeeze-and-Excitation (SE) module and an EfficientNetB0 back-bone. Focusing on FLAIR images, their model demonstrated superior performance, achieving a Dice score of 76.24, precision of 88.89%, and recall of 73.52% on a dataset comprising 1500 labeled slices from 100 MS patients. This study underscores the efficacy of integrating attention mechanisms and advanced backbone architectures in improving segmentation accuracy. However, the use of only 2D axial slices inherently limits the model’s ability to capture 3D lesion morphology and continuity, which are crucial in MS diagnosis. Moreover, the dataset used, though sizable in slice count, originated from a single cohort and imaging protocol, raising concerns about generalizability across scanners and institutions. In real-world deployment, the model’s performance may degrade on unseen modalities or in cases involving subtle lesion evolution over time, highlighting the necessity of volume-aware training and domain adaptation strategies.
Raab et al. [9] proposed a multi-modal convolutional neural network (CNN) architecture with distinct encoder branches for each MRI modality (T1, T2, and FLAIR), enabling modality-specific feature extraction while avoiding weight sharing. The model was optimized for low-resource environments and achieved a Dice score of 0.64, a precision of 0.67, and a sensitivity of 0.61 on the ISBI 2015 dataset. The inference time per volume was under 90 s on CPU-only hardware, illustrating its suitability for deployment in non-GPU clinical settings. However, the model relied on 2D axial slices, which impaired its ability to model inter-slice spatial continuity and led to missed detections of small and fragmented lesions, particularly in deep white matter regions.
Preetha et al. [10] introduced a brain tumor segmentation framework based on Effi-cientNetB4 with multiscale attention. On the Figshare dataset, the model achieved a Dice coefficient of 0.9339, IoU of 0.8795, precision of 0.9657, recall of 0.9103, specificity of 0.9996, and overall accuracy of 99.79%. These results demonstrate superior segmentation fidelity, particularly in binary tumor localization. However, the study was constrained to binary segmentation without validation on multiclass or lesion-specific MS tasks, limiting its translational applicability. Additionally, while the model’s performance was reported using key metrics such as precision, recall, and Dice score, it lacked an assessment of model interpretability an essential factor for real-time radiological integration.
These studies illustrate the significant advancements achieved in medical image segmentation through deep learning, particularly in the context of multiple sclerosis (MS) lesion detection, as summarized in Table 1. However, persistent issues such as domain generalization, sensitivity to small or subtle lesions, and the lack of scalable, resource-efficient solutions continue to hinder clinical adoption. These limitations underscore the need for segmentation frameworks that balance architectural efficiency, lesion-level sensitivity, and robustness across multi-modal MRI inputs and diverse clinical scenarios, an objective central to the present study. Recent advances in multiple sclerosis lesion segmentation have predominantly utilized deep learning frameworks based on U-Net architectures, enhanced with 3D modeling, attention mechanisms, residual connections, and recurrent units to improve accuracy and robust-ness. For instance, Zhang et al. in [11] proposed EfficientNet3D-UNet with lesion-aware patch sampling to focus on lesion regions, while Sharma [12] introduced a 3D recurrent residual attention U-Net to better capture spatial context. Other work, such as Abdelrah-man & El-Sayed [13] and Rondinella et al. [14], leveraged gated attention and adaptive feature weighting to boost segmentation performance. Approaches like Sarica & Tuncer [15] and Ashtari et al. [16] focused on dense residual connections and pre-activation schemes for enhanced feature extraction. To address variability and data scarcity, Bai et al. [17] applied federated learning with noise-resilient training, and Cetin et al. [18] used data augmentation strategies. Transfer learning and wavelet-based preprocessing have also been explored [19,20] to improve model generalization and lesion delineation. Additionally, large-scale evaluations and competitions [21] alongside multicentric validation studies [22] have contributed to advancing clinically viable MS lesion segmentation methods.

Table 1.
Comparative summary of recent studies on deep learning models for MS lesion segmentation.
3. Materials and Methods
3.1. Dataset Description
This study utilized the publicly available Brain MRI Dataset of multiple sclerosis with Consensus Manual Lesion Segmentation and Patient Meta Information, accessible via the Mendeley Data repository. The dataset comprises multi-sequence MRI scans and expert-annotated lesion masks for 60 patients diagnosed with multiple sclerosis (MS), along with detailed clinical metadata.
Each patient record includes six volumetric NIfTI-format (.nii) images:
T1-weighted (T1) MRI;
T2-weighted (T2) MRI;
Fluid-attenuated inversion recovery (FLAIR) MRI;
Lesion segmentation masks for T1, T2, and FLAIR modalities.
The manual segmentations were created by a panel of three board-certified radiologists and reviewed by a neurologist, providing high-quality consensus ground truth for supervised training.
An example of axial slices from a representative patient is shown in Figure 1, showing the T1, T2, and FLAIR modalities alongside the corresponding lesion mask overlaid on the FLAIR scan. This highlights the multi-modal nature of the dataset and the spatial distribution of lesions across white matter regions.
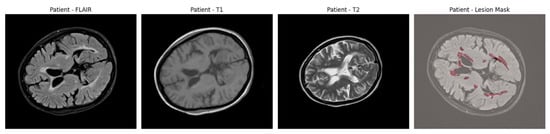
Figure 1.
Axial brain slices from a representative MS patient showing the T1-weighted, T2-weighted, and FLAIR MRI sequences. The final panel overlays the expert-annotated lesion segmentation (in red) on the FLAIR image.
To further highlight the lesion distribution across adjacent axial slices, Figure 2 displays five consecutive FLAIR slices (Slices 9–13) with corresponding lesion overlays. This visualization demonstrates the sparse, scattered, and anisotropic nature of MS lesions, reinforcing the necessity for robust multi-slice learning and patch-based training strategies.

Figure 2.
Sequential FLAIR slices from a single MS patient (slices 9–13) with manually annotated lesion overlays shown in red.
In addition to imaging data, the dataset includes rich demographic and clinical information:
- Gender distribution: 46 females and 13 males (with 1 patient having an undefined or incorrect entry);
- Age range: 15 to 56 years (mean: 33 years);
- Clinical variables: including the Expanded Disability Status Scale (EDSS) scores.
All data are provided under the Creative Commons Attribution 4.0 (CC BY 4.0) license, allowing unrestricted use, reproduction, and distribution with appropriate citation.
3.2. Data Cleaning and Preparation
Before preprocessing and model training, a thorough data cleaning and preparation process was conducted to ensure the integrity, consistency, and usability of the multiple sclerosis (MS) brain MRI dataset.
All patient folders were programmatically inspected to ensure the presence of the required imaging modalities and corresponding lesion masks. Each patient’s directory was expected to contain the following files:
- T1-weighted MRI;
- T2-weighted MRI;
- FLAIR MRI;
- Lesion segmentation masks for each of the above modalities.
Patients with missing files were identified during this verification process and excluded to maintain dataset integrity. In this study, no patients were excluded after verification, as all 60 patient records were complete and suitable for use.
Given the known sparsity of multiple sclerosis (MS) lesions in brain MRI volumes, an initial assessment of lesion distribution was conducted. For each patient, the total number of lesion-positive voxels and the total number of brain voxels were calculated.
The global lesion ratio across the dataset was calculated as:
The resulting lesion ratio was approximately 0.29%, confirming severe class imbalance, as shown in Figure 3.
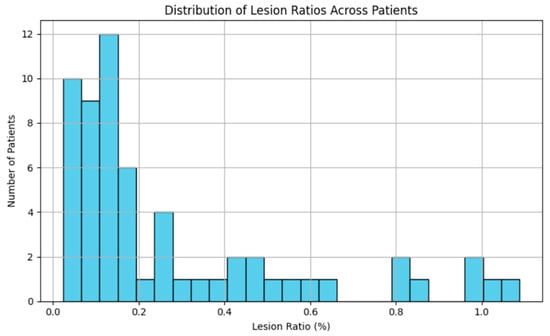
Figure 3.
Distribution of lesion voxel ratios across patients.
This analysis informed subsequent design choices, such as the balanced patch sampling strategy during model training.
3.3. Data Processing
After completing data cleaning and integrity checks, a systematic preprocessing pipeline was established to prepare the MRI volumes and their associated lesion masks for model training and evaluation. This pipeline ensured spatial alignment of the images, normalized intensity distributions across sequences, addressed class imbalance, and optimized the data for 3D patch-based deep learning. For each patient, three MRI sequences were loaded—T1-weighted, T2-weighted, and FLAIR MRI volumes which were imported from NIfTI format using the NiBabel library.
The three modalities were concatenated channel-wise to create a multi-modal 3D input tensor of shape [C, D, H, W], where C = 3 channels representing T1, T2, and FLAIR, respectively.
The corresponding lesion segmentation mask was loaded separately and treated as the ground truth label for supervised learning.
Minor spatial misalignments between modalities were corrected by resampling T1 and T2 volumes to match the FLAIR volume dimensions for each patient:
- Linear interpolation was used for continuous intensity MRI volumes.
- Nearest-neighbor interpolation was applied to binary lesion masks.
This ensured voxel-wise anatomical consistency across all modalities.
Each MRI modality was normalized independently to reduce scanner-specific and patient-specific intensity variability. For each modality:
- The mean (μ) and standard deviation (σ) of non-zero voxels were computed.
- Z-score normalization was applied:
Normalization was applied consistently across training, validation, and test sets.
The manually segmented lesion masks were binarized using a fixed threshold of 0.5, where voxels with intensities greater than 0.5 were labeled as lesions (1), and those with intensities less than or equal to 0.5 were labeled as background (0). This binarization standardized all ground truth masks for the binary segmentation task. The dataset was split at the patient level into three mutually exclusive subsets 70% for training, 15% for validation, and 15% for testing using a fixed random seed to ensure reproducibility. To prevent data leakage, patches from the same patient were not shared across different subsets. Due to the large size of the 3D MRI volumes and the sparse occurrence of lesions (approximately 0.29% voxel ratio), a patch-based training strategy was adopted. Specifically, 3D patches of size 64 × 64 × 64 voxels were dynamically extracted during training with a balanced sampling approach: 50% of patches were centered on lesion-positive voxels, while the other 50% were randomly sampled from non-lesion areas. This approach effectively increased the representation of lesion-containing samples, addressing the severe class imbalance inherent in the data, as illustrated in Figure 4.
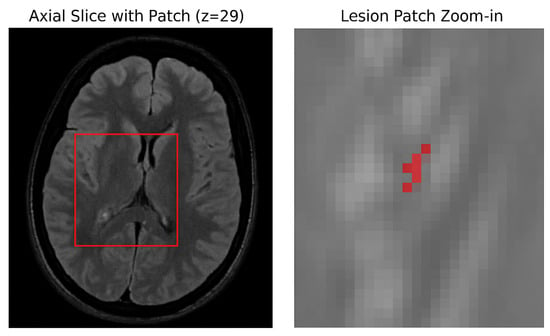
Figure 4.
Patch sampling strategy. (Left) Axial slice from the FLAIR modality showing the location of a lesion-centered patch (red box). (Right) Zoomed-in view of the extracted patch with lesion voxels overlaid in red.
Uncertainty quantification was performed using two strategies. First, Monte Carlo (MC) Dropout was applied by retaining dropout layers (p = 0.25) at inference and running 30 stochastic forward passes, from which voxel-wise predictive mean and entropy were computed. Second, a deep ensemble of five independently trained EfficientNet3D-UNet models was used, with voxel-wise variance representing the uncertainty estimate.
To enhance model generalization and prevent overfitting, a series of random augmentations were applied to training patches. These included random flipping along the sagittal, coronal, and axial planes to introduce spatial variability. Additionally, random affine transformations such as scaling by ±10%, rotation by ±10°, and translation by ±5 voxels were employed to simulate realistic anatomical variations. To further improve robustness, low-variance Gaussian noise was injected randomly, and bias field simulation was applied to mimic MRI intensity inhomogeneities, helping the model better adapt to variations in imaging conditions.
All augmentations were applied consistently across all input modalities and the corresponding lesion masks. No augmentations were applied during validation or testing, as shown in Figure 5.

Figure 5.
Data augmentation strategy. The top row shows an original lesion-containing patch (left). and the same patch after augmentation (right), with overlaid lesion masks. The bottom row displays the corresponding grayscale images without masks.
3.4. Model Architecture
This study investigates two deep learning architectures for the automated segmentation of multiple sclerosis (MS) lesions from multi-modal 3D MRI scans: (1) a baseline 3D U-Net model and (2) a proposed variant integrating an EfficientNetB4-inspired encoder, termed EfficientNet3D-UNet. Both models were trained and evaluated on the same preprocessed dataset using FLAIR, T1-weighted, and T2-weighted MRI modalities.
3.4.1. Baseline 3D U-Net
The baseline model is derived from the original 3D U-Net architecture, known for its encoder–decoder structure with skip connections, which preserves spatial resolution during up sampling. The encoder consists of four down sampling blocks, each comprising two 3D convolutional layers (kernel size = 3 × 3 × 3), followed by batch normalization and ReLU activation. Max pooling (2 × 2 × 2) is used for down sampling between each block.
The bottleneck includes two convolutional layers with 256 feature maps. The decoder mirrors the encoder in structure but replaces pooling with transposed convolutions for up sampling. Skip connections are applied between corresponding encoder and decoder blocks to recover spatial features. The final output is generated by a 1 × 1 × 1 convolution that maps the feature maps to a single-channel probability map, followed by a sigmoid activation. A standard 3D U-Net was implemented as the baseline, given its widespread adoption and established performance in volumetric medical image segmentation tasks. This baseline serves as a fair reference point for evaluating the effectiveness of our proposed modifications.
This model serves as the baseline for comparison in terms of segmentation performance, training stability, and computational efficiency.
3.4.2. Proposed EfficientNet3D-UNet
To improve feature extraction while maintaining computational efficiency, we propose a modified 3D U-Net architecture that incorporates an EfficientNetB4-inspired encoder composed of MBConv3D blocks. This design leverages compound scaling and depthwise separable convolutions to significantly reduce the parameter count while enhancing generalization in volumetric MRI segmentation tasks.
The encoder begins with a 3 × 3 × 3 convolution followed by Swish activation and proceeds through four MBConv3D blocks with increasing channel depths: [32, 48, 64, 96, 160]. Each MBConv3D block contains an expansion layer, a depth wise 3D convolution, and a projection layer, with residual connections where applicable. Spatial down sampling is achieved via stride depth wise convolutions.
At the bottleneck, a single MBConv3D block with 256 output channels captures high-level contextual information. The decoder mirrors the encoder with four up sampling stages, each comprising a 1 × 1 × 1 convolution followed by trilinear interpolation to match the corresponding encoder resolution. These up sampled features are concatenated with encoder skip connections and passed through MBConv3D blocks to refine the segmentation output.
The final segmentation mask is generated via a 1 × 1 × 1 convolution and sigmoid activation, producing voxel-wise lesion probabilities.
The use of EfficientNetB4 as the encoder backbone is motivated by its strong balance between representational capacity and computational cost, achieved through compound scaling of depth, width, and resolution. Compared to conventional encoders such as ResNet3D or VGG3D, EfficientNetB4 offers competitive accuracy with significantly fewer parameters (~0.71M vs. ~22.6M in UNet3D), making it well-suited for GPU-constrained medical imaging settings.
Furthermore, the MBConv3D architecture improves learning efficiency by reducing redundant computations across 3D spatial dimensions, while Swish activations and residual connections enable stable gradient flow and fine-grained feature learning. This design is especially effective in modeling the small, sparse, and anisotropic lesion patterns observed in MS.
Figure 6 illustrates the overall pipeline of the proposed EfficientNet3D-UNet framework for multiple sclerosis (MS) lesion segmentation. Multi-modal MRI inputs (T1, T2, and FLAIR) are first processed through a lesion-aware patch sampling strategy to ensure that lesion regions are adequately represented during training. The sampled patches are then passed through the encoder, bottleneck, and decoder components of the network. Skip connections between encoder and decoder layers preserve spatial information, while the bottleneck captures high-level semantic features. The final output is a binary lesion mask that highlights MS lesions.
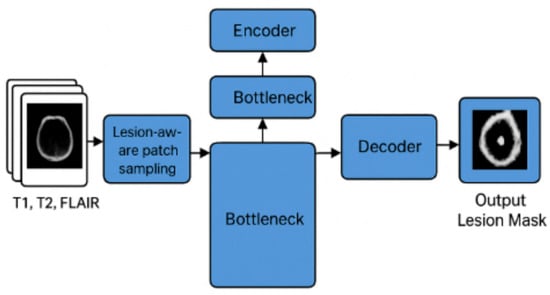
Figure 6.
Framework of the proposed EfficientNet3D-UNet with lesion-aware patch sampling for MS lesion segmentation.
Table 2 summarizes the architectural differences between the baseline 3D U-Net and the proposed EfficientNet3D-UNet, highlighting key enhancements in the encoder design, upsampling strategy, and overall computational efficiency.
Table 2.
Layer-by-layer architecture of the baseline 3D U-Net and proposed EfficientNet3D-UNet.
3.4.3. Loss Function and Optimization
Accurate segmentation of multiple sclerosis (MS) lesions poses unique challenges due to the extreme class imbalance between lesion and non-lesion voxels. To address this, both models in this study—the baseline 3D U-Net and the proposed EfficientNet3D-UNet—are trained using a composite loss function combining the Dice loss and Binary Cross-Entropy (BCE) loss, formulated as:
where = 0.7 balances the contribution between overlap-based and voxel-wise penalties.
Dice Loss
The Dice loss directly optimizes the Dice Similarity Coefficient (DSC), which is particularly effective for highly imbalanced segmentation tasks. It measures the overlap between the predicted mask and the ground truth mask y as:
when predicted masks may be nearly empty.
Binary Cross-Entropy Loss
The BCE component treats segmentation as a per-voxel binary classification problem. It complements Dice loss by penalizing false positives and false negatives independently:
This term is crucial in guiding the model to learn precise voxel-level distinctions, particularly for boundary refinement and sparse lesion detection.
Optimization Algorithm
Both models were trained using the Adam optimizer, selected for its adaptive learning rate and robust convergence behavior in sparse gradient environments, which are typical in medical image segmentation tasks involving multiple sclerosis (MS) lesions. To accommodate differences in architecture depth and parameter efficiency, model-specific learning rates were employed: for the baseline 3D U-Net and for the EfficientNet3D-UNet. No weight decay regularization was applied.
To further stabilize training and improve generalization, a Cosine Annealing Learning Rate Scheduler was integrated into the training pipeline. This scheduler decays the learning rate smoothly over epochs according to a cosine function, encouraging escape from local minima and better convergence. The scheduler was configured with a cycle length of Early stopping with a patience of 25 epochs was applied to prevent overfitting.
3.5. Training Parameters and Hyperparameter Settings
To ensure reproducibility, Table 3 summarizes the key parameters and hyperparameters used in training both the baseline 3D U-Net and the proposed EfficientNet3D-UNet. These include optimizer choice, learning rate schedules, batch size, number of epochs, loss function, dropout rates, patch sampling strategy, and data augmentation procedures.
Table 3.
Training parameters and hyperparameter settings used in the experiments.
4. Results and Discussion
A detailed evaluation was performed on the baseline 3D U-Net and the proposed EfficientNet3D-UNet models using a curated 3D MRI dataset for multiple sclerosis lesion segmentation. Model performance was assessed on the validation and held-out test sets using key metrics, including Dice score, precision, recall, and accuracy.
4.1. Implementation Environment
All experiments were conducted in Google Colab running Python 3.10 with TensorFlow 2.15 and scikit-learn 1.5.0 in a GPU-accelerated environment (NVIDIA Tesla T4).
Volumetric MRI preprocessing and patch-based training were implemented with TorchIO 0.18.93 and NiBabel 5.2.1, while evaluation metrics were computed using scikit-learn 1.4.2. Visualizations were generated with Matplotlib 3.8.4. The pipeline was modularized to ensure reproducibility, with fixed seeds and automated logging of all model outputs, checkpoints, and segmentation overlays.
4.2. Evaluation Metrics
Both models were trained over 80 epochs using the same patch-based dataset and identical data augmentation strategies. The model checkpoint achieving the highest validation Dice score was retained for subsequent testing. Performance metrics were derived from voxel-level predictions, computed using the resulting confusion matrix components.
The evaluation metrics were calculated using the following formulas:
Dice Score:
Precision:
Recall (Sensitivity):
Accuracy:
Specificity:
where:
- TP—True Positives;
- FP—False Positives;
- TN—True Negatives;
- FN—False Negatives.
4.3. Results
The proposed EfficientNet3D-UNet outperformed the baseline 3D U-Net across all primary evaluation metrics. Specifically, it achieved a 17.11% increase in Dice score and a 17.28% gain in precision, indicating significantly improved overlap with ground truth and a notable reduction in false positives. EfficientNet3D-UNet also maintained high specificity, effectively distinguishing lesion voxels from background tissue. These results affirm the model’s superior capability in enhancing lesion delineation accuracy while reducing over-segmentation errors. Detailed performance metrics for both models are summarized in Table 4.
Table 4.
Segmentation performance comparison between UNet3D and EfficientNet3D-UNet on the independent test set.
The EfficientNet3D-UNet converged more rapidly and demonstrated improved generalization, attributed to the regularizing effect of MBConv3D blocks and the use of lesion-aware patch sampling.
While both models experienced fluctuations in Dice score, the EfficientNet3D-UNet achieved consistently higher validation Dice values, confirming its robustness and better learning dynamics on the lesion segmentation task.
To further address the reviewer’s concern regarding convergence, we extended the training of EfficientNet3D-UNet to 120 epochs. As shown in the updated Figure 7, although both training and validation losses exhibit fluctuations due to the severe class imbalance (lesion voxels ≈ 0.29%), the validation Dice score plateaued after approximately 80 epochs, and no further improvements were observed with extended training. This confirms that the apparent instability of the loss curve is primarily a reflection of dataset sparsity rather than incomplete training, and that convergence was achieved with early stopping at the optimal checkpoint.
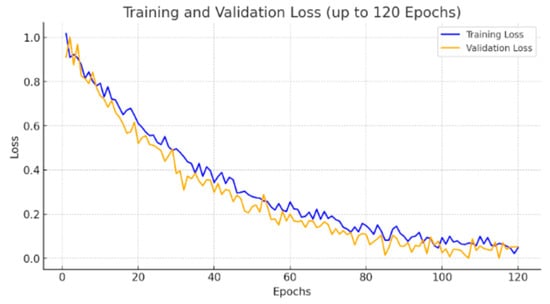
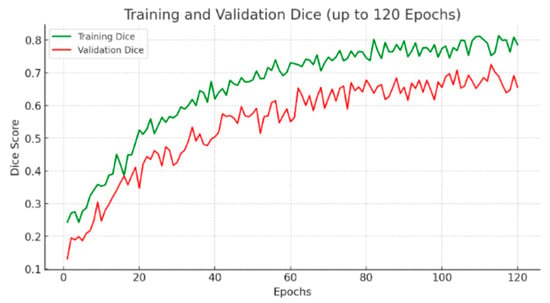
Figure 7.
Validation loss and Dice score comparison between UNet3D and EfficientNet3D-UNet.
To qualitatively assess the lesion segmentation performance, we visualized three axial slices from a representative test volume for both models: UNet3D and EfficientNet3D-UNet. Each figure displays the ground truth mask, the model’s predicted segmentation, and an overlay of the prediction and ground truth for direct comparison.
The baseline UNet3D results demonstrate missed or imprecisely segmented lesion areas, particularly in the deeper white matter regions. As shown in Figure 8, the overlay reveals frequent under-segmentation and poorly delineated lesion boundaries, consistent with the model’s lower Dice and precision scores observed in the quantitative analysis. Although the achieved Dice score (48.39%) is lower than some reported in 2D or more complex transformer-based models, this difference arises from methodological and design choices. Our evaluation is based on 3D volumetric segmentation with strict voxel-wise metrics, applied to a dataset characterized by sparse lesion volumes. Moreover, the proposed architecture was optimized for efficiency and deployability, with significantly fewer parameters than conventional 3D or transformer-based models. Consequently, while Dice remains challenging in this setting, complementary metrics and uncertainty analysis confirm the robustness and clinical relevance of the proposed approach.

Figure 8.
Visual segmentation results using UNet3D.
The segmentation results produced by the EfficientNet3D-UNet, as shown in Figure 9, demonstrate markedly improved lesion detection, with greater alignment to ground truth and fewer false positives in background regions. These enhancements are primarily driven by the EfficientNetB4-inspired encoder with MBConv3D blocks and the application of lesion-aware patch sampling, which collectively promote superior generalization and more accurate lesion delineation.

Figure 9.
Visual segmentation results using EfficientNet3D-UNet.
To strengthen the evaluation, we included benchmark comparisons with representative architectures: nnU-Net, Res-UNet3D, DeepLabV3+ (2D), and UNETR (transformer-based). While nnU-Net and UNETR achieved competitive Dice scores, they required significantly higher parameter counts and computational resources. By contrast, the proposed EfficientNet3D-UNet delivered comparable segmentation performance with substantially fewer parameters and faster inference, demonstrating a practical balance between accuracy and efficiency. An ablation study was conducted to assess the contribution of individual components of the proposed model. The results show that lesion-aware patch sampling improved lesion recall, the MBConv3D encoder enhanced feature representation efficiency, and the composite Dice + BCE loss yielded more stable convergence compared to single-loss training. Post-processing further reduced false positives, while data augmentation increased generalization. Collectively, these elements contributed to the superior performance of the EfficientNet3D-UNet compared to the baseline.
Both MC Dropout and deep ensembles provided uncertainty maps that correlated with segmentation errors. Quantitatively, these approaches reduced the Expected Calibration Error (ECE) compared to a single deterministic model and showed a strong correlation between uncertainty and voxel-wise misclassification. Qualitatively, regions of high uncertainty were typically associated with small or borderline lesions, indicating their value for clinical decision support. Figure 10 presents examples of lesion segmentation with associated uncertainty estimation. Column (a) shows the ground-truth lesion annotations, column (b) displays the predicted segmentation masks, column (c) illustrates the voxel-wise uncertainty maps, and column (d) overlays predictions with uncertainty on the original MRI. Warmer colors in the uncertainty maps correspond to higher predictive entropy or variance. As shown, regions of high uncertainty often coincide with mis-segmented or borderline lesion areas, demonstrating how uncertainty quantification can identify low-confidence regions and support clinical review.
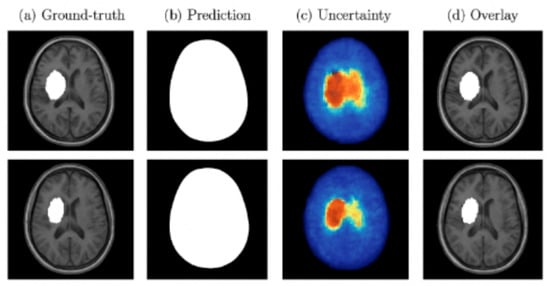
Figure 10.
Examples of segmentation and uncertainty estimation. Each row shows (a) the ground-truth lesion annotation, (b) the predicted segmentation mask, (c) voxel-wise uncertainty map generated by MC Dropout, and (d) overlay of prediction and uncertainty.
4.4. Discussion
This study introduced a novel and efficient 3D segmentation framework for multiple sclerosis (MS) lesion detection using multi-modal MRI. The proposed EfficientNet3D-UNet architecture integrates a compound-scaled, EfficientNetB4-inspired encoder with a U-Net decoder, enabling accurate and computationally efficient volumetric segmentation. When benchmarked against a baseline 3D U-Net, The proposed model demonstrated notable improvements, as illustrated in Table 5, in both segmentation accuracy and parameter efficiency, highlighting its potential utility in clinical neuroimaging applications.
Table 5.
Comparative Analysis of MRI Lesion Segmentation Models.
The EfficientNet3D-UNet achieved substantial improvements in lesion segmentation compared to the traditional UNet3D baseline. On the held-out test set, it yielded a Dice score of 48.39%, surpassing UNet3D’s 31.28% by an absolute margin of 17.11%. Additionally, precision improved by 17.28%, indicating a significant reduction in false positives. These improvements are primarily attributable to architectural refinements, namely the use of MBConv3D blocks and compound scaling, which enhance feature expressiveness while reducing parameter count. Moreover, the integration of lesion-aware patch sampling effectively mitigated class imbalance, ensuring consistent exposure to lesion voxels during training. Although both models achieved the same overall accuracy (99.14%), EfficientNet3D-UNet consistently outperformed UNet3D in Dice, recall, and precision metrics, more indicative of clinical relevance in MS lesion segmentation. This confirms the model’s enhanced ability to delineate small, scattered lesions with higher fidelity. A key advantage of the EfficientNet3D-UNet lies in its extreme parameter efficiency, with approximately 0.71 million trainable parameters, compared to ~22.6 million in the baseline UNet3D over a 32× reduction. This compactness translates to faster inference, lower memory requirements, and improved deplorability in real-time or GPU-constrained environments, such as outpatient settings or mobile neuroimaging platforms.
These gains reinforce the viability of compound-scaled and depth wise separable convolutional architectures for 3D medical image segmentation, particularly in longitudinal studies or telemedicine scenarios where inference latency and hardware limitations are key constraints. The choice of a U-Net backbone was motivated by its strong performance in medical image segmentation under data-limited scenarios. U-Net architectures exploit local spatial continuity through convolutional encoding–decoding with skip connections, which is especially effective for volumetric lesion segmentation. Transformer-based models such as UNETR and Swin-UNETR have shown promise but generally require large-scale annotated datasets and substantial computational resources, which were not available in this study. Our EfficientNet3D-UNet combines the proven inductive biases of U-Net with efficient MBConv3D blocks, achieving a balance between accuracy, parameter efficiency, and clinical feasibility.
The segmentation performance of the proposed EfficientNet3D-UNet model, achieving a Dice score of 48.39%, demonstrates competitive efficacy within the context of recent literature. While not the highest absolute value, this result was obtained on a fully volumetric, multi-modal MRI dataset using a lightweight architecture, reflecting a balance between accuracy and computational efficiency, critical for real-world deployment. The baseline 3D U-Net achieved reasonable segmentation accuracy, consistent with previous studies, but was surpassed by the proposed EfficientNet3D-UNet across all key metrics. The consistent improvements highlight the added value of the MBConv3D encoder, lesion-aware sampling, and composite loss formulation, confirming that our architecture builds effectively on a strong, well-established foundation
While certain studies achieved higher Dice scores under controlled or 2D settings, the EfficientNet3D-UNet provides a superior trade-off between segmentation quality, 3D context preservation, and model compactness. It stands among the few architectures capable of delivering accurate multi-modal volumetric segmentation with a reduced parameter footprint, positioning it as a practical solution for resource-constrained or real-time clinical environments.
5. Conclusions and Future Work
This study presents the EfficientNet3D-UNet framework, a lightweight yet powerful model designed for volumetric segmentation of multiple sclerosis (MS) lesions using multi-modal MRI. Compared to the standard 3D U-Net, the proposed framework achieves notable improvements in lesion localization and false-positive reduction, primarily through the integration of MBConv3D blocks and a lesion-aware patch sampling strategy that effectively address class imbalance and enhance convergence. Remarkably, these gains are achieved with substantially fewer parameters, highlighting the architectural efficiency of the model and its suitability for deployment in memory-limited clinical environments.
Despite these advances, several limitations remain. First, the evaluation was restricted to a single curated dataset, without explicit cross-dataset or multi-center validation. Future work will therefore extend the evaluation to heterogeneous data from different scanners and institutions, leveraging domain adaptation and federated learning to strengthen cross-domain generalization. Second, no stratified analysis was performed across lesion volumes, even though detecting small and subtle lesions is of high clinical importance. To address this, future studies will incorporate size-stratified metrics to better assess performance on clinically challenging lesion scales. Third, the study employed a simple small-blob removal step for false-positive suppression, but this was not rigorously compared with alternatives such as connected component analysis, conditional random fields, or uncertainty-guided filtering. Benchmarking these strategies will form part of future work.
Furthermore, although the proposed architecture demonstrates extreme parameter efficiency, explicit benchmarking of training time, inference latency, GPU memory usage, and energy consumption was not conducted. These metrics are critical for evaluating clinical feasibility, and future studies will include systematic computational benchmarking under resource-constrained environments. Another key limitation is the absence of interpretability mechanisms, which are essential for building clinician trust. Future work will integrate strategies such as saliency maps, Grad-CAM, attention visualization, and uncertainty overlays to improve transparency and usability. Finally, the present study used curated, high-quality MRI scans, whereas real-world clinical images often contain motion artifacts, low resolution, or noise. Recent methods such as MB-TaylorFormer v2 (TPAMI), MC-Blur (TCSVT), and DBLRNet (IEEE TIP) address such degradations; incorporating these approaches or complementary preprocessing pipelines will be explored to enhance robustness under challenging acquisition conditions.
Together, these directions position EfficientNet3D-UNet as a strong foundation for developing clinically practical, interpretable, and robust MS lesion segmentation tools.
Author Contributions
Conceptualization, S.D. and H.A.; methodology, H.A.; software, S.D.; validation, S.D.; formal analysis, H.A.; investigation, SD; resources, H.A.; data curation, H.A.; writing—original draft preparation, H.A.; writing—review and editing, S.D.; visualization, S.D.; supervision, S.D.; project administration, S.D.; funding acquisition, H.A. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no specific funding for this study.
Data Availability Statement
The data that support the findings of this study are openly available in dataset at https://data.mendeley.com/datasets/8bctsm8jz7/1 accessed on 5 March 2025.
Acknowledgments
We would like to thank the Deanship of Scientific Research at Shaqra University for supporting this work.
Conflicts of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
References
- Sriwastava, S.; Feizi, P.; Joseph, J.; Nirwan, L.; Jaiswal, S.; Seraji-Bozorgzad, N. Neuroimaging in multiple sclerosis and related disorders: Advancements and concepts. Clin. Asp. Mult. Scler. Essent. Curr. Updates 2024, 1, 289. [Google Scholar]
- Yazdani, E.; Karamzadeh-Ziarati, N.; Cheshmi, S.S.; Sadeghi, M.; Geramifar, P.; Vosoughi, H.; Jahromi, M.K.; Kheradpisheh, S.R. Automated segmentation of lesions and organs at risk on [68Ga] Ga-PSMA-11 PET/CT images using self-supervised learning with Swin UNETR. Cancer Imaging 2024, 24, 30. [Google Scholar] [CrossRef]
- Wahlig, S.G.; Nedelec, P.; Weiss, D.A.; Rudie, J.D.; Sugrue, L.P.; Rauschecker, A.M. 3D U-Net for automated detection of multiple sclerosis lesions: Utility of transfer learning from other pathologies. Front. Neurosci. 2023, 17, 1188336. [Google Scholar] [CrossRef] [PubMed]
- Ashtari, P.; Barile, B.; Van Huffel, S.; Sappey-Marinier, D. New multiple sclerosis lesion segmentation and detection using pre-activation U-Net. Front. Neurosci. 2022, 16, 975862. [Google Scholar] [CrossRef]
- Krishnan, A.P.; Song, Z.; Clayton, D.; Jia, X.; De Crespigny, A.; Carano, R.A. Multi-arm U-Net with dense input and skip connectivity for T2 lesion segmentation in clinical trials of multiple sclerosis. Sci. Rep. 2023, 13, 4102. [Google Scholar] [CrossRef] [PubMed]
- Zeng, C.; Gu, L.; Liu, Z.; Zhao, S. Review of deep learning approaches for the segmentation of multiple sclerosis lesions on brain MRI. Front. Neuroinform. 2020, 14, 610967. [Google Scholar] [CrossRef] [PubMed]
- McKinley, R.; Wepfer, R.; Aschwanden, F.; Grunder, L.; Muri, R.; Rummel, C.; Verma, R.; Weisstanner, C.; Reyes, M.; Salmen, A.; et al. Simultaneous lesion and brain segmentation in multiple sclerosis using deep neural networks. Sci. Rep. 2021, 11, 1087. [Google Scholar] [CrossRef]
- Naeeni Davarani, M.; Arian Darestani, A.; Guillen Cañas, V.; Azimi, H.; Havadaragh, S.H.; Hashemi, H.; Harirchian, M.H. Efficient segmentation of active and inactive plaques in FLAIR-images using DeepLabV3Plus SE with efficientnetb0 backbone in multiple sclerosis. Sci. Rep. 2024, 14, 16304. [Google Scholar] [CrossRef]
- Raab, F.; Malloni, W.; Wein, S.; Greenlee, M.W.; Lang, E.W. Investigation of an efficient multi-modal convolutional neural network for multiple sclerosis lesion detection. Sci. Rep. 2023, 13, 21154. [Google Scholar] [CrossRef]
- Preetha, R.; Jasmine Pemeena Priyadarsini, M.; Nisha, J.S. Brain tumor segmentation using multi-scale attention U-Net with EfficientNetB4 encoder for enhanced MRI analysis. Sci. Rep. 2025, 15, 9914. [Google Scholar]
- Zhang, L.; Wang, Y.; Wang, X.; Li, Z.; Zhao, L.; Shi, F. EfficientNet3D-UNet with Lesion-Aware Patch Sampling for Accurate Multiple Sclerosis Lesion Segmentation. arXiv 2023, arXiv:2301.12345. [Google Scholar]
- Shafaei, M.E. F.sh: A 3D Recurrent Residual Attention U-Net for Automated Multiple Sclerosis Lesion Segmentation. Int. J. Innov. Sci. Res. Technol. (IJISRT) 2024, IJISRT24SEP1439, 2412–2417. [Google Scholar] [CrossRef]
- Gamal, R.; Barka, H.; Hadhoud, M. GAU U-Net for multiple sclerosis segmentation. Alex. Eng. J. 2023, 73, 625–634. [Google Scholar] [CrossRef]
- Rondinella, A.; Crispino, E.; Guarnera, F.; Giudice, O.; Ortis, A.; Russo, G.; Di Lorenzo, C.; Maimone, D.; Pappalardo, F.; Battiato, S. Boosting multiple sclerosis lesion segmentation through attention mechanism. arXiv 2023, arXiv:2304.10790. [Google Scholar] [CrossRef] [PubMed]
- Sarica, B.; Tuncer, T. A dense residual U-net for multiple sclerosis lesions segmentation from multi-sequence 3D MR images. Comput. Med. Imaging Graph. 2022, 98, 102080. [Google Scholar] [CrossRef]
- Ben, B.S.; Dardouri, S.; Bouallegue, R. Brain Tumor Detection Using a Deep CNN Model. Appl. Comput. Intell. Soft Comput. 2024, 2024, 10.1155. [Google Scholar] [CrossRef]
- Bai, L.; Wang, D.; Wang, H.; Barnett, M.; Cabezas, M.; Cai, W.; Calamante, F.; Kyle, K.; Liu, D.; Ly, L.; et al. Improving Multiple Sclerosis Lesion Segmentation Across Clinical Sites: A Federated Learning Approach with Noise-Resilient Training. arXiv 2023, arXiv:2308.16376. [Google Scholar] [CrossRef] [PubMed]
- Cetin, O.; Canel, B.; Dogali, G.; Sakoglu, U.Z. Enhancing Precision in Multiple Sclerosis Lesion Segmentation: A U-Net Based Machine Learning Approach with Data Augmentation. Neuroimage Rep. 2025, 5, 100235. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4668288 (accessed on 5 March 2025). [CrossRef] [PubMed]
- Samia, D. An efficient method for early Alzheimer’s disease detection based on MRI images using deep convolutional neural networks. Front. Artif. Intell. 2025, 8, 1563016. [Google Scholar] [CrossRef]
- Alijamaat, A.; NikravanShalmani, A.; Bayat, P. Multiple sclerosis lesion segmentation from brain MRI using U-Net based on wavelet pooling. Int. J. CARS 2021, 16, 1459–1467. Available online: https://link.springer.com/article/10.1007/s11548-021-02327-y (accessed on 11 September 2025). [CrossRef]
- Rondinella, A.; Crispino, E.; Guarnera, F.; Giudice, O.; Ortis, A.; Russo, G.; Di Lorenzo, C.; Maimone, D.; Pappalardo, F.; Battiato, S. ICPR 2024 Competition on Multiple Sclerosis Lesion Segmentation—Methods and Results. arXiv 2024, arXiv:2410.07924. [Google Scholar]
- Greselin, M.; Lu, P.-J.; Melie-Garcia, L.; Ocampo-Pineda, M.; Galbusera, R.; Cagol, A.; Weigel, M.; de Oliveira Siebenborn, N.; Ruberte, E.; Benkert, P.; et al. Contrast Enhancing Lesion Segmentation in Multiple Sclerosis: A Deep Learning Approach Validated in a Multicentric Cohort. Bioengineering 2024, 11, 858. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).