
Novel Light Convolutional Neural Network for COVID Detection with Watershed Based Region Growing Segmentation



Abstract
:1. Introduction
2. Related Work
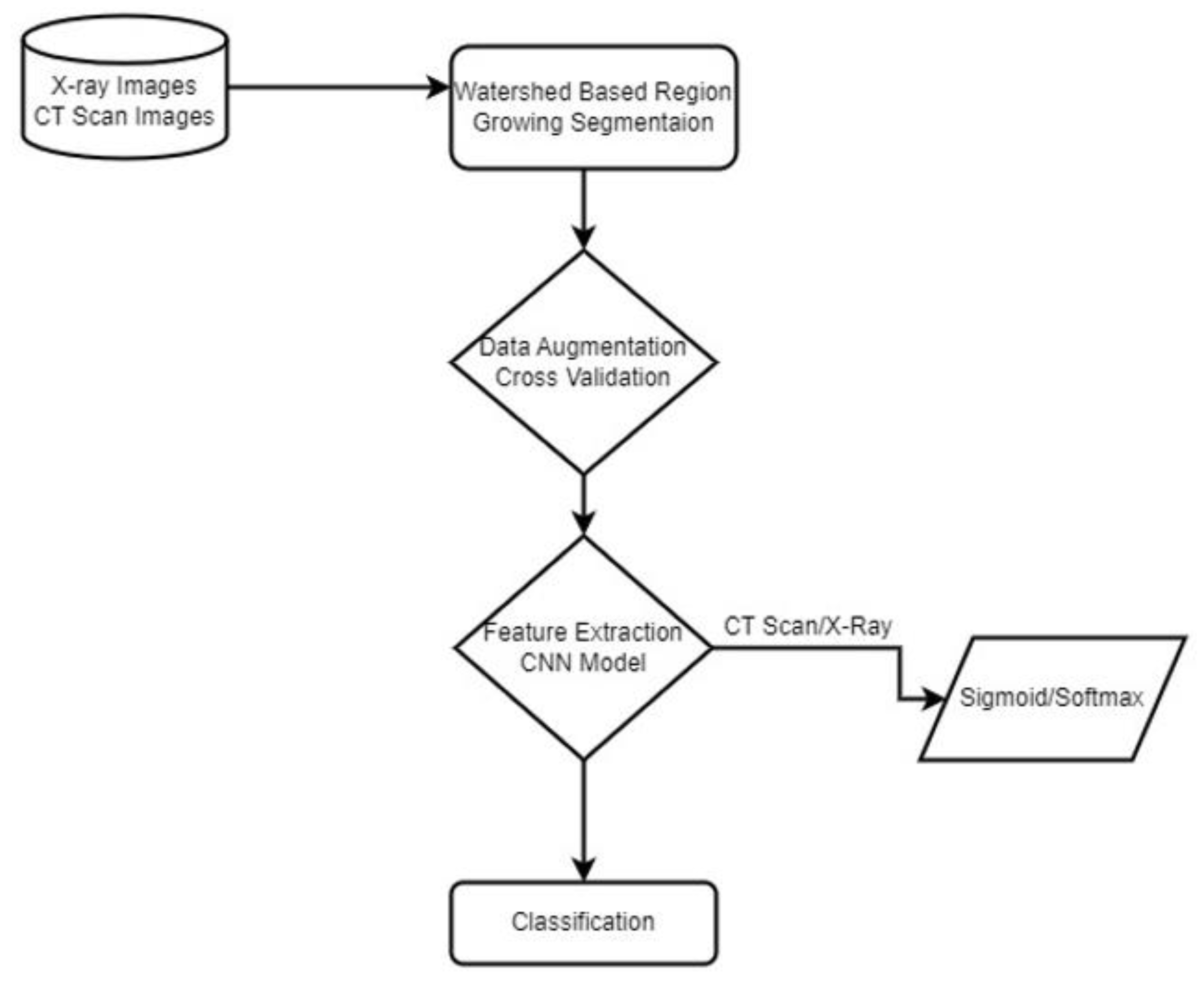
3. Materials and Method
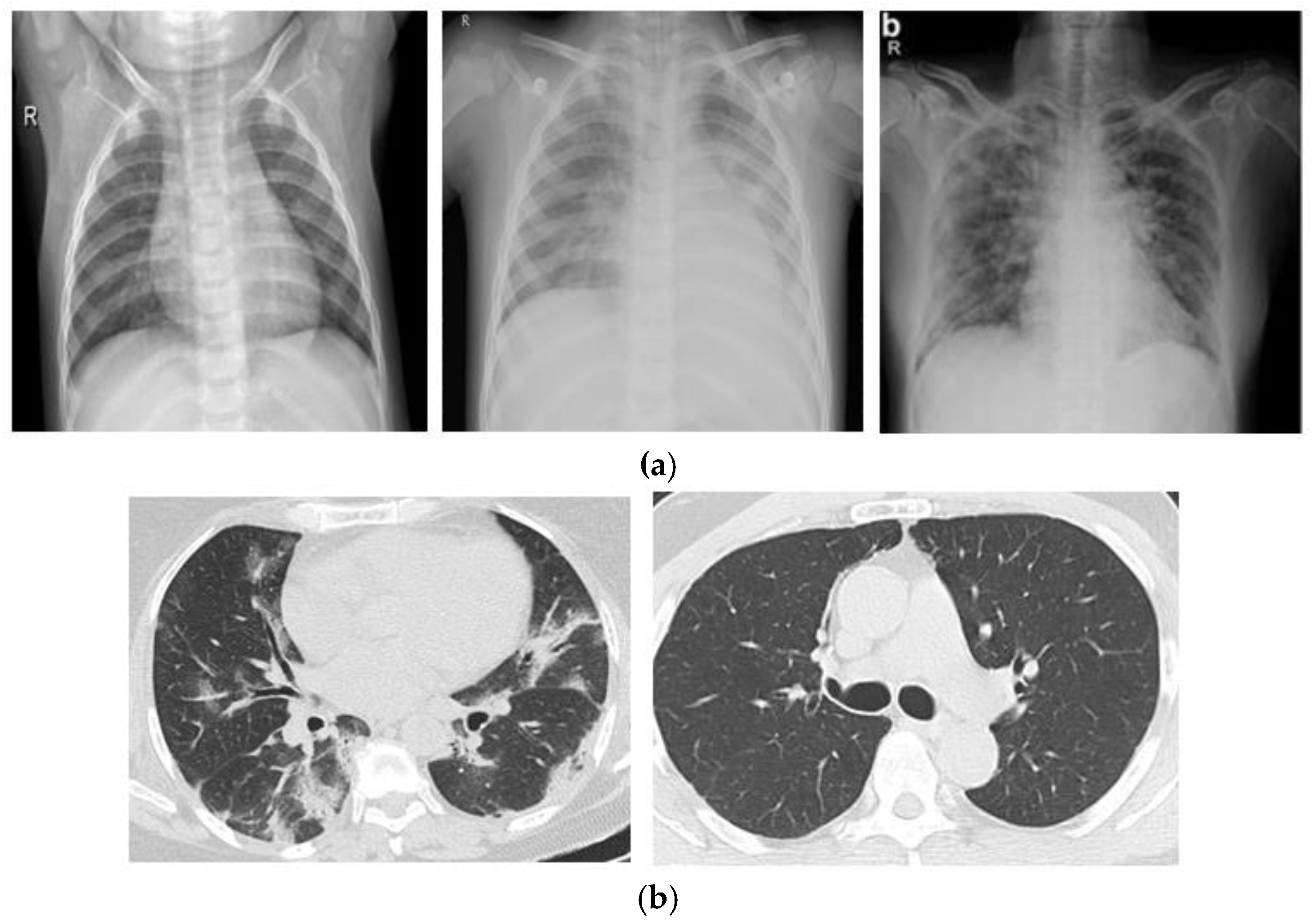
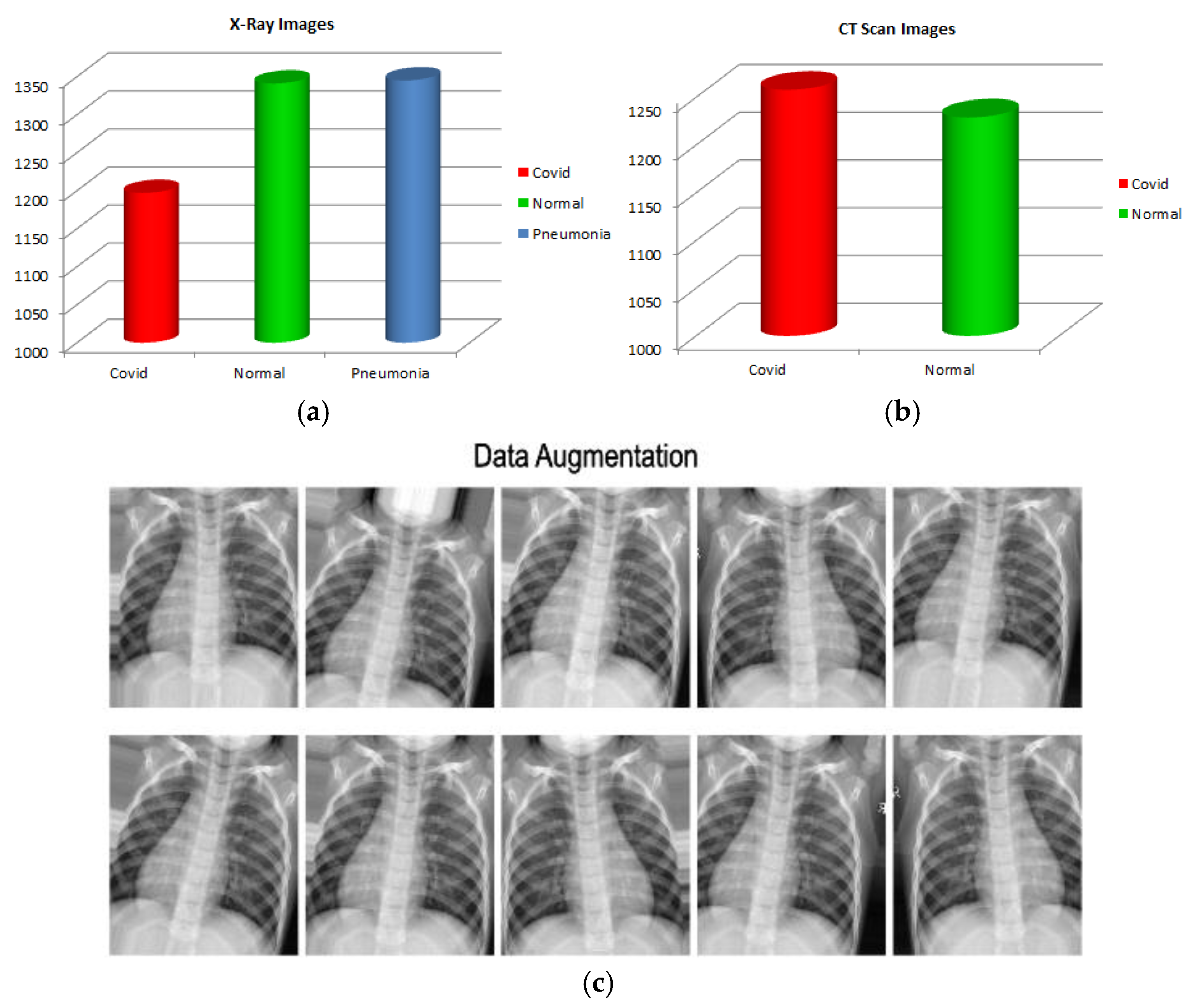
3.1. Dataset
3.2. Watershed Based Region Growing Segmentation
3.3. Data Augmentation
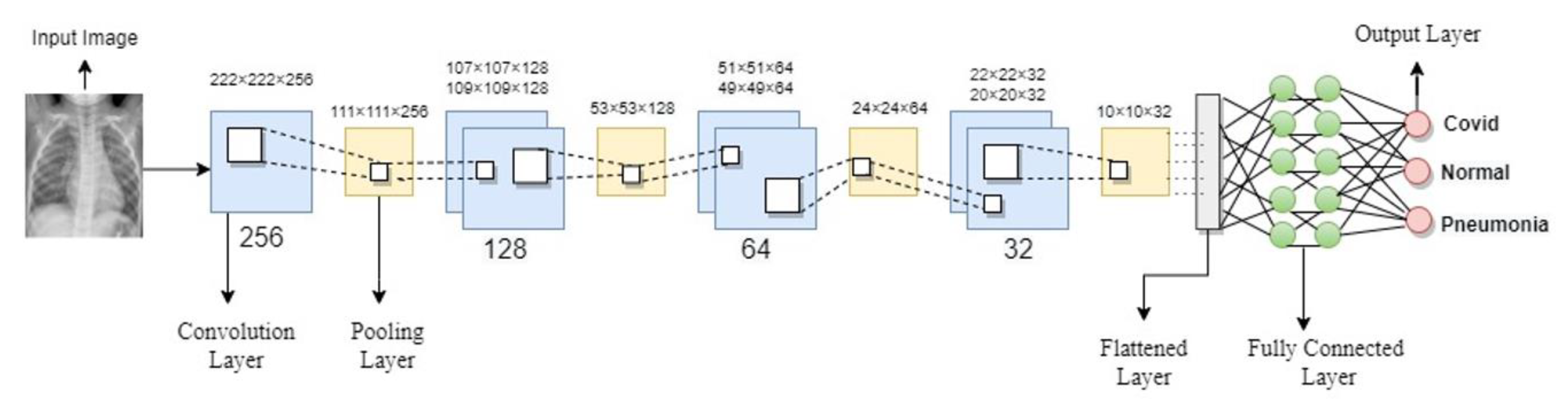
3.4. Convolutional Neural Network
3.5. Optimization
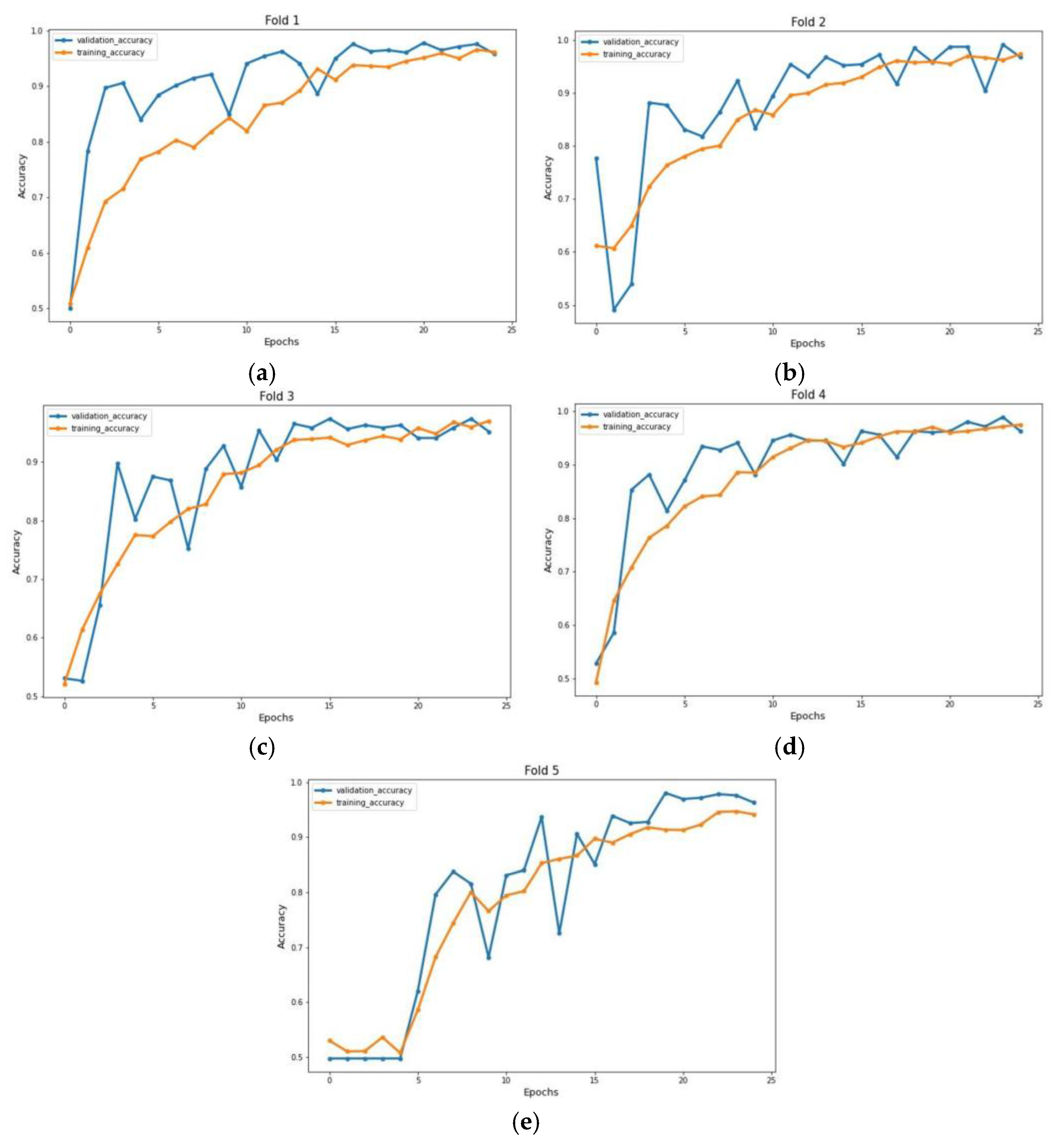
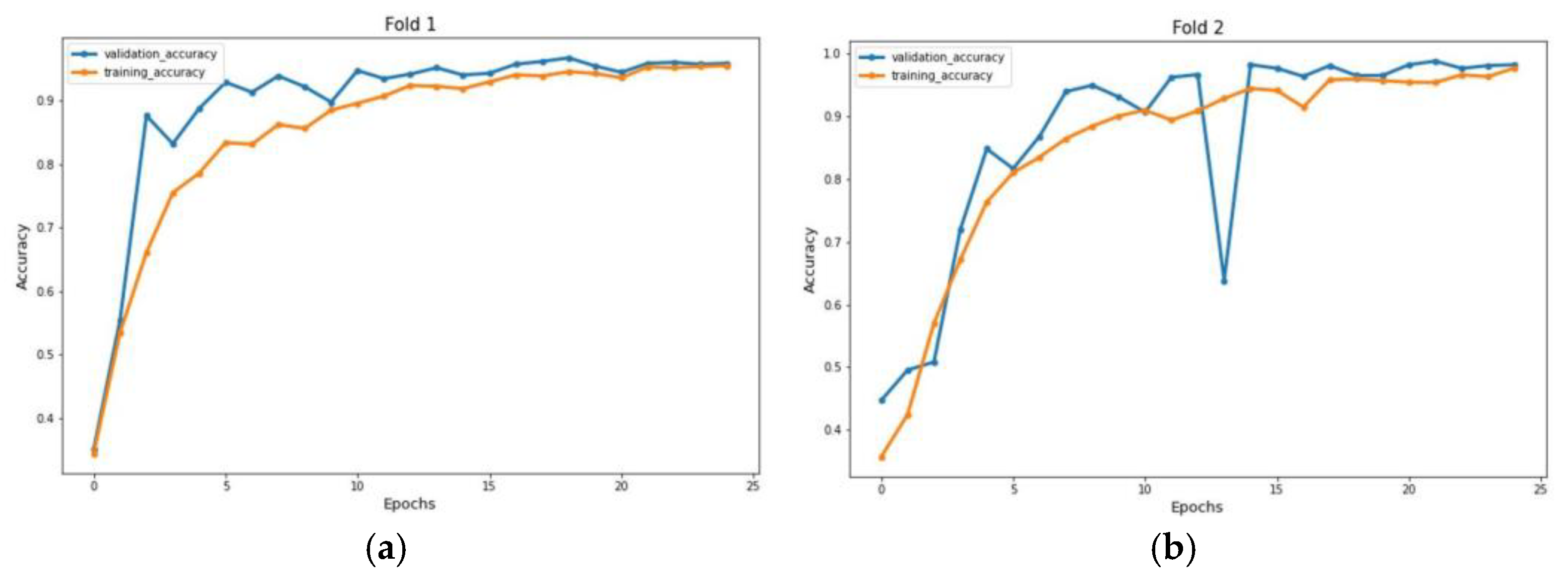
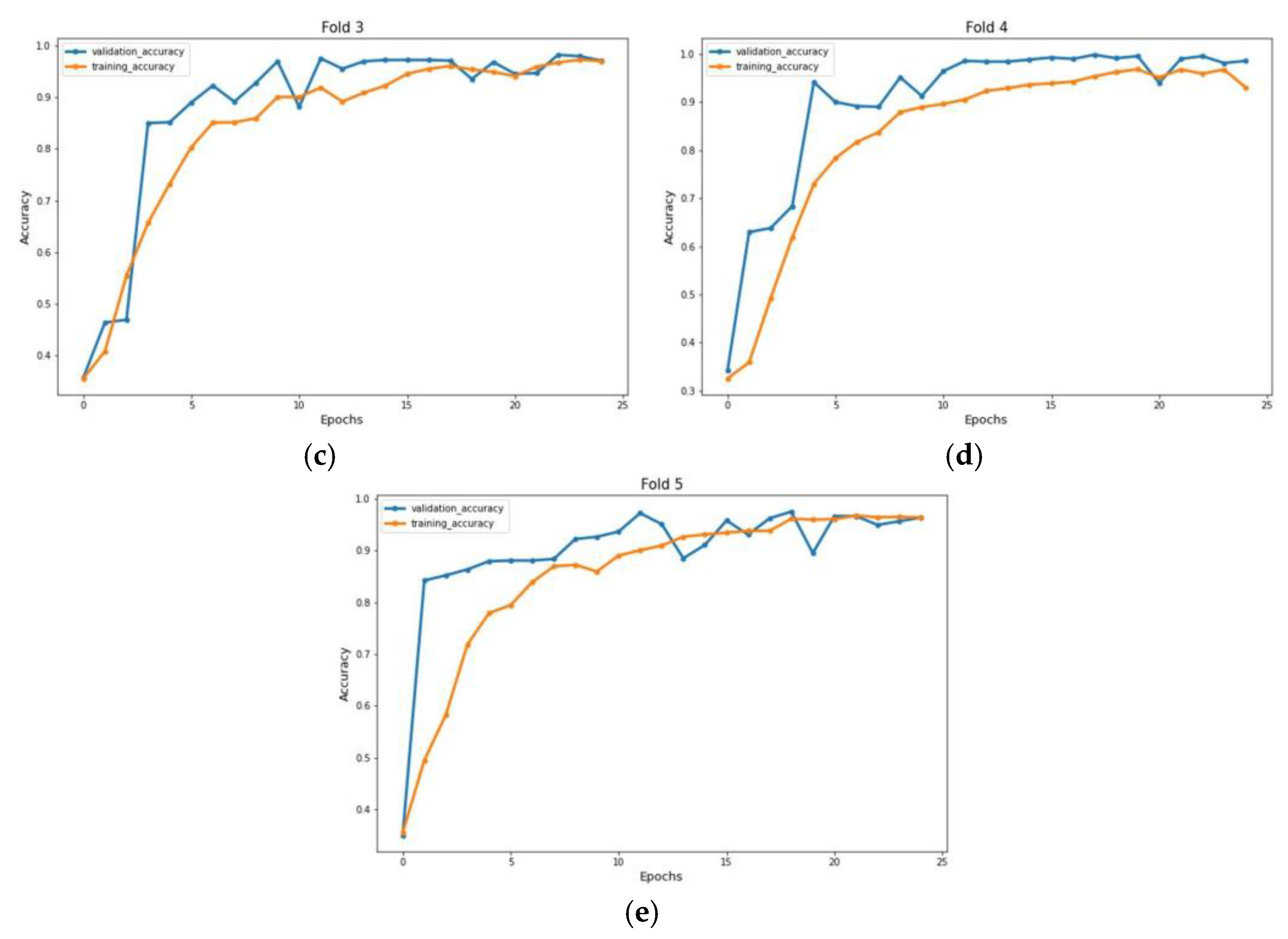
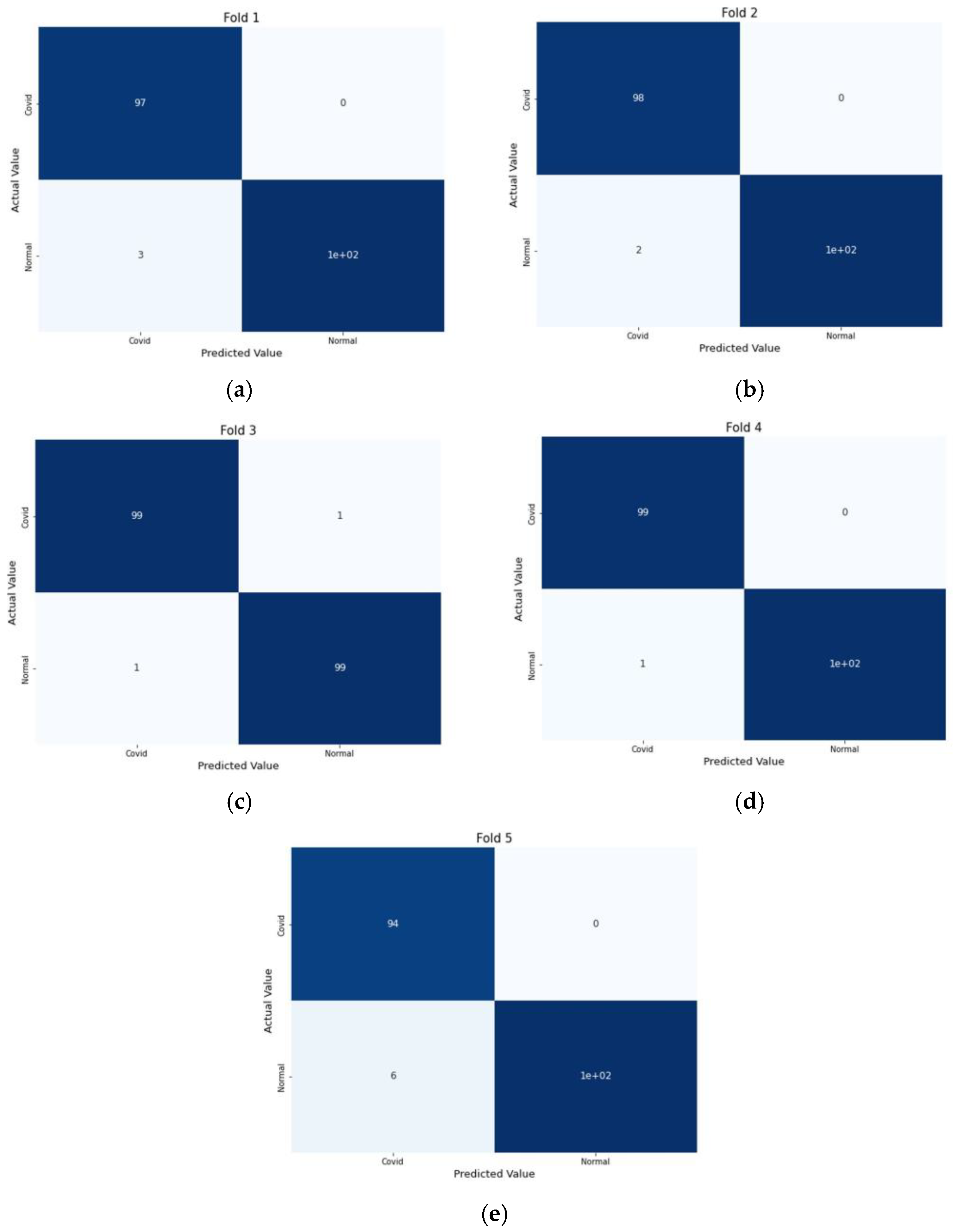
4. 5-Fold Cross Validation
5. Results and Discussion
6. Performance Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- NHS. Coronavirus (COVID-19) Symptoms in Adults. 2022. Available online: https://www.nhs.uk/conditions/coronavirus-covid-19/symptoms/main-symptoms/ (accessed on 7 July 2022).
- WHO. WHO Coronavirus (COVID-19) Dashboard. 2022. Available online: https://covid19.who.int/ (accessed on 7 July 2022).
- CDC. Center of Disease Control and Prevention: Covid-19 Testing. 2021. Available online: https://www.cdc.gov/coronavirus/2019-ncov/symptoms-testing/testing.html (accessed on 9 July 2022).
- Aslan, M.F.; Sabanci, K.; Durdu, A.; Unlersen, M.F. COVID-19 diagnosis using state-of-the-art CNN architecture features and Bayesian Optimization. Comput. Biol. Med. 2022, 142, 105244. [Google Scholar] [CrossRef] [PubMed]
- Gour, M.; Jain, S. Uncertainty-aware convolutional neural network for COVID-19 X-ray images classification. Comput. Biol. Med. 2022, 140, 105047. [Google Scholar] [CrossRef] [PubMed]
- Sarki, R.; Ahmed, K.; Wang, H.; Zhang, Y.; Wang, K. Automated detection of COVID-19 through convolutional neural network using chest X-ray images. PLoS ONE 2022, 17, e0262052. [Google Scholar] [CrossRef]
- Loey, M.; El-Sappagh, S.; Mirjalili, S. Bayesian-based optimized deep learning model to detect COVID-19 patients using chest X-ray image data. Comput. Biol. Med. 2022, 142, 105213. [Google Scholar] [CrossRef] [PubMed]
- Bassi, P.R.A.S.; Attux, R. A deep convolutional neural network for COVID-19 detection using chest X-rays. Res. Biomed. Eng. 2022, 38, 139–148. [Google Scholar] [CrossRef]
- Absar, N.; Mamur, B.; Mahmud, A.; Bin Emran, T.; Khandaker, M.U.; Faruque, M.; Osman, H.; Elzaki, A.; Elkhader, B.A. Development of a computer-aided tool for detection of COVID-19 pneumonia from CXR images using machine learning algorithm. J. Radiat. Res. Appl. Sci. 2022, 15, 32–43. [Google Scholar] [CrossRef]
- Aftab, M.; Amin, R.; Koundal, D.; Aldabbas, H.; Alouffi, B.; Iqbal, Z. Classification of COVID-19 and Influenza Patients Using Deep Learning. Contrast Media Mol. Imaging 2022, 2022, 8549707. [Google Scholar] [CrossRef]
- Muralidharan, N.; Gupta, S.; Prusty, M.R.; Tripathy, R.K. Detection of COVID19 from X-ray images using multiscale Deep Convolutional Neural Network. Appl. Soft Comput. 2022, 119, 108610. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Nahiduzzaman, M. Complex features extraction with deep learning model for the detection of COVID19 from CT scan images using ensemble based machine learning approach. Expert Syst. Appl. 2022, 195, 116554. [Google Scholar] [CrossRef]
- Kogilavani, S.V.; Prabhu, J.; Sandhiya, R.; Kumar, M.S.; Subramaniam, U.; Karthick, A.; Muhibbullah, M.; Imam, S.B.S. COVID-19 Detection Based on Lung Ct Scan Using Deep Learning Techniques. Comput. Math. Methods Med. 2022, 2022, 7672196. [Google Scholar] [CrossRef] [PubMed]
- Huang, M.-L.; Liao, Y.-C. A lightweight CNN-based network on COVID-19 detection using X-ray and CT images. Comput. Biol. Med. 2022, 146, 105604. [Google Scholar] [CrossRef] [PubMed]
- Baghdadi, N.A.; Malki, A.; Abdelaliem, S.F.; Balaha, H.M.; Badawy, M.; Elhosseini, M. An automated diagnosis and classification of COVID-19 from chest CT images using a transfer learning-based convolutional neural network. Comput. Biol. Med. 2022, 144, 105383. [Google Scholar] [CrossRef] [PubMed]
- Hasija, S.; Akash, P.; Hemanth, M.B.; Kumar, A.; Sharma, S. A novel approach for detection of COVID-19 and Pneumonia using only binary classification from chest CT-scans. Neurosci. Inform. 2022, 2, 100069. [Google Scholar] [CrossRef]
- Canayaz, M.; Şehribanoğlu, S.; Özdağ, R.; Demir, M. COVID-19 diagnosis on CT images with Bayes optimization-based deep neural networks and machine learning algorithms. Neural Comput. Appl. 2022, 34, 5349–5365. [Google Scholar] [CrossRef]
- Chowdhury, M.E.H.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al-Emadi, N.; et al. Can AI help in screening Viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Soares, E.; Angelov, P.; Biaso, S.; Froes, M.; Abe, D. SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification. medRxiv 2007, 2020.04.24.20078584. [Google Scholar]
- Teixeira, L.O.; Pereira, R.M.; Bertolini, D.; Oliveira, L.S.; Nanni, L.; Cavalcanti, G.D.C.; Costa, Y.M.G. Impact of Lung Segmentation on the Diagnosis and Explanation of COVID-19 in Chest X-ray Images. Sensors 2021, 21, 7116. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Fold | PPV | NPV | Accuracy |
|---|---|---|---|---|
| CT Scan | 1 | 0.97 | 1.0 | 98.5 |
| 2 | 0.98 | 1.0 | 99 | |
| 3 | 0.99 | 0.99 | 99 | |
| 4 | 0.99 | 1.0 | 99.5 | |
| 5 | 0.94 | 1.0 | 97 | |
| X-ray Images | 1 | 0.98 | 1.0 | 99.3 |
| 2 | 0.99 | 0.98 | 98.3 | |
| 3 | 0.98 | 0.99 | 98.6 | |
| 4 | 1.0 | 0.97 | 98.3 | |
| 5 | 1.0 | 0.99 | 99.3 |
| Previous Studies | Image Type | Methodologies | Accuracy |
|---|---|---|---|
| Muhammet Fatih et al. [4] | X-ray | DenseNet, SVM | 96.29% |
| Gour Mahesh et al. [5] | X-ray | UA-ConvNet | 98.02% |
| Rubina Sarki et al. [6] | X-ray | Vgg16, InceptionV3 | 93.7%, 87.5% |
| Mohamed Loey et al. [7] | X-ray | CNN, Bayesian Optimization | 96% |
| Nurul Absar et al. [9] | X-ray | SqueezeNet, SVM | 98.8% |
| Muralidharan Nehet et al. [11] | X-ray | EWT Filter, CNN | 96%, 97.17% |
| S. V. Kogilavani et al. [13] | CT-scan | Vgg16 | 97.68% |
| Mei-Ling Huang et al. [14] | CT-scan | LightefficentNetv2 | 98.33%,96.33% |
| Hasija Sanskar et al. [16] | CT-scan | Multiclassification, CNN | 98.38% |
| Proposed method without segmentation | X-ray | Scrateched CNN model | 93.7% |
| Proposed Model with segmentation | X-ray, CT-scan | Scratched CNN model | 98.8%,98.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, H.A.; Gong, X.; Bi, F.; Ali, R. Novel Light Convolutional Neural Network for COVID Detection with Watershed Based Region Growing Segmentation. J. Imaging 2023, 9, 42. https://doi.org/10.3390/jimaging9020042
Khan HA, Gong X, Bi F, Ali R. Novel Light Convolutional Neural Network for COVID Detection with Watershed Based Region Growing Segmentation. Journal of Imaging. 2023; 9(2):42. https://doi.org/10.3390/jimaging9020042
Chicago/Turabian StyleKhan, Hassan Ali, Xueqing Gong, Fenglin Bi, and Rashid Ali. 2023. "Novel Light Convolutional Neural Network for COVID Detection with Watershed Based Region Growing Segmentation" Journal of Imaging 9, no. 2: 42. https://doi.org/10.3390/jimaging9020042
APA StyleKhan, H. A., Gong, X., Bi, F., & Ali, R. (2023). Novel Light Convolutional Neural Network for COVID Detection with Watershed Based Region Growing Segmentation. Journal of Imaging, 9(2), 42. https://doi.org/10.3390/jimaging9020042