
The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval

 ,
,  , , ,
, , ,  , ,
, ,  and
and
Abstract
1. Introduction
2. Related Work
3. The VISIONE Video Search Tool
- query by keywords: the user can specify keywords including scenes, places or concepts (e.g., outdoor, building, sport) to search for video scenes;
- query by object location: the user can draw on a canvas some simple diagrams to specify the objects that appear in a target scene and their spatial locations;
- query by color location: the user can specify some colors present in a target scene and their spatial locations (similarly to object location above);
- query by visual example: an image can be used as a query to retrieve video scenes that are visually similar to it.
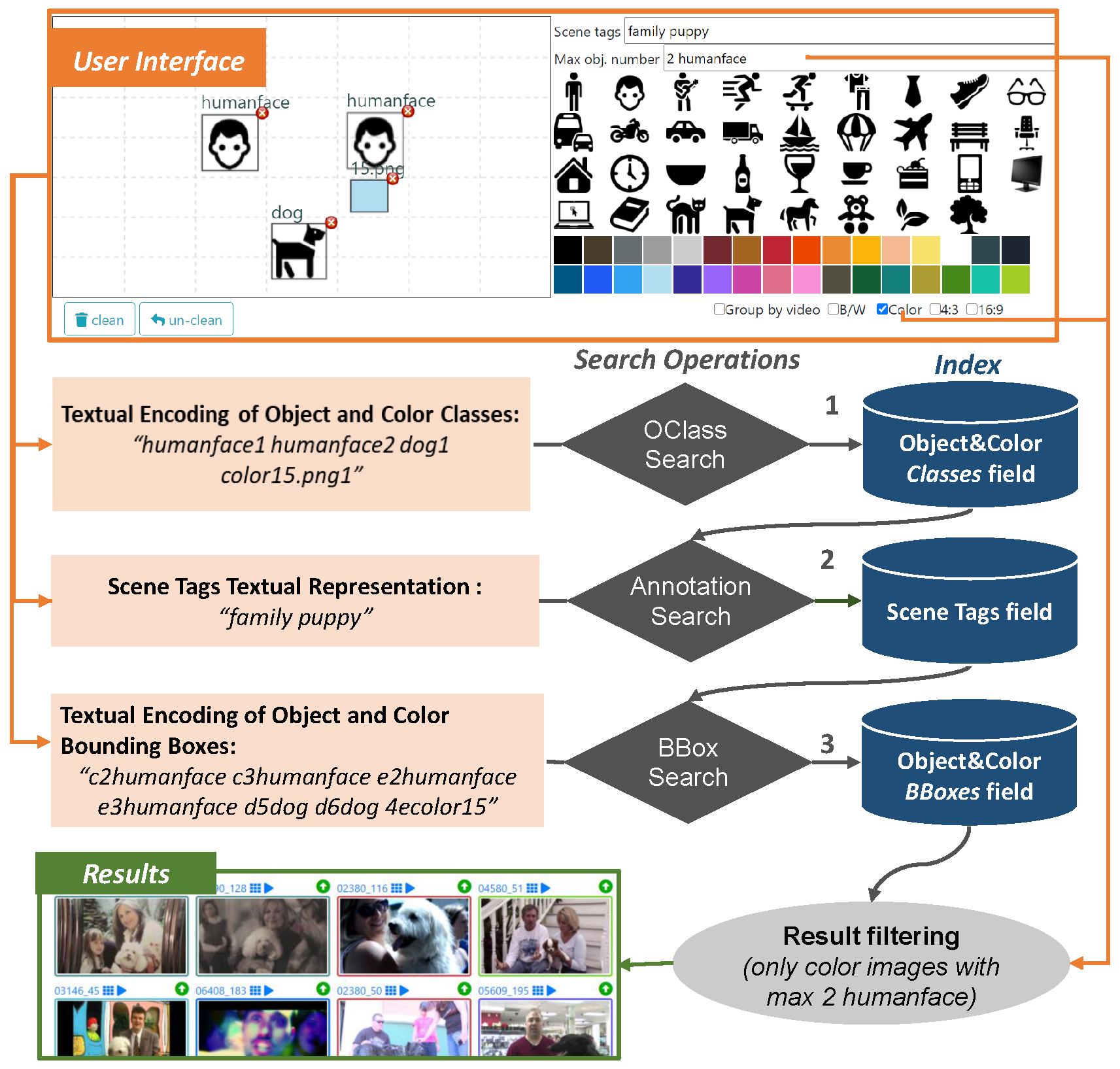
3.1. The User Interface
- a text box, named “Scene tags”, where the user can type keywords describing the target scene (e.g., “park sunset tree walk”);
- a color palette and an object palette that can be used to easily drag & drop a desired color or object on the canvas (see below);
- a canvas, where the user can sketch objects and colors that appear in the target scene simply by drawing bounding-boxes that approximately indicate the positions of the desired objects and colors (both selected from the palettes above) in the scene;
- a text box, named “Max obj. number”, where the user can specify the maximum number of instances of the objects appearing in the target scene (e.g.,: two glasses);
- two checkboxes where the user can filter the type of keyframes to be retrieved (B/W or color images, 4:3 or 16:9 aspect ratio).
3.2. System Architecture Overview
- an image annotation engine, to extract scene tags (see Section 4.1);
- state-of-the-art object detectors, like YOLO [53], to identify and localize objects in the video keyframes (see Section 4.2);
- spatial colors histograms, to identify dominant colors and their locations (see Section 4.2);
- the R-MAC deep visual descriptors, to support the Similarity Search functionality (see Section 4.3).
- Scene Tags, containing automatically associated tags;
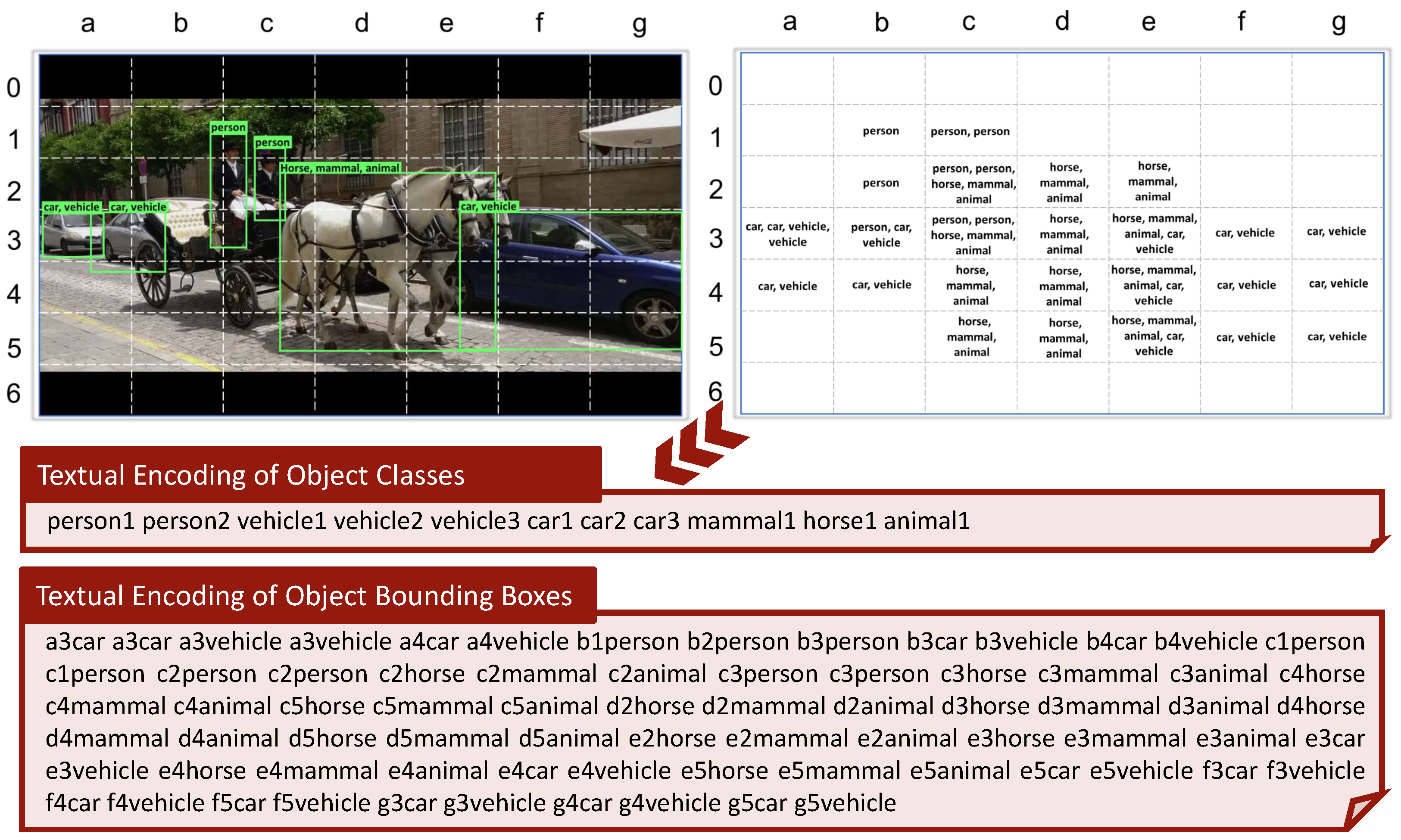
- Object&Color BBoxes, containing text encoding of colors and objects locations;
- Object&Color Classes, containing global information on objects and colors in the keyframe;
- Visual Features, containing text encoding of extracted visual features.
- Annotation Search, search for keyframes associated with specified annotations;
- BBox Search, search for keyframes having specific spatial relationships among objects/colors;
- OClass Search, search for keyframes containing specified objects/colors;
- Similarity Search, search for keyframes visually similar to a query image.
4. Indexing and Searching Implementation
4.1. Image Annotation
Annotation Search
4.2. Objects and Colors
4.2.1. Objects
4.2.2. Colors
Object and Color Location Search
4.3. Deep Visual Features
Similarity Search
4.4. Overview of the Search Process
5. Evaluation
5.1. Experiment Design and Evaluation Methodology
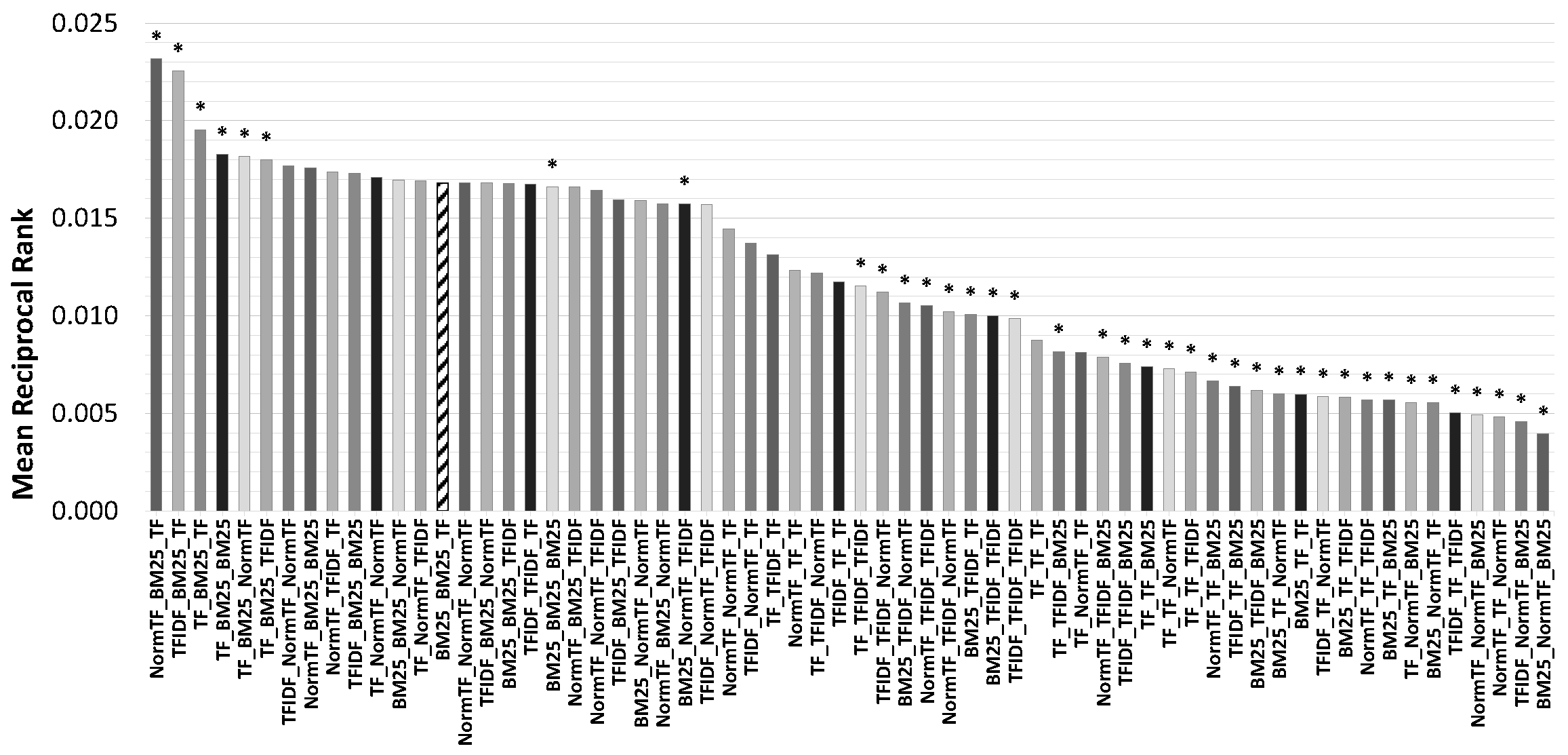
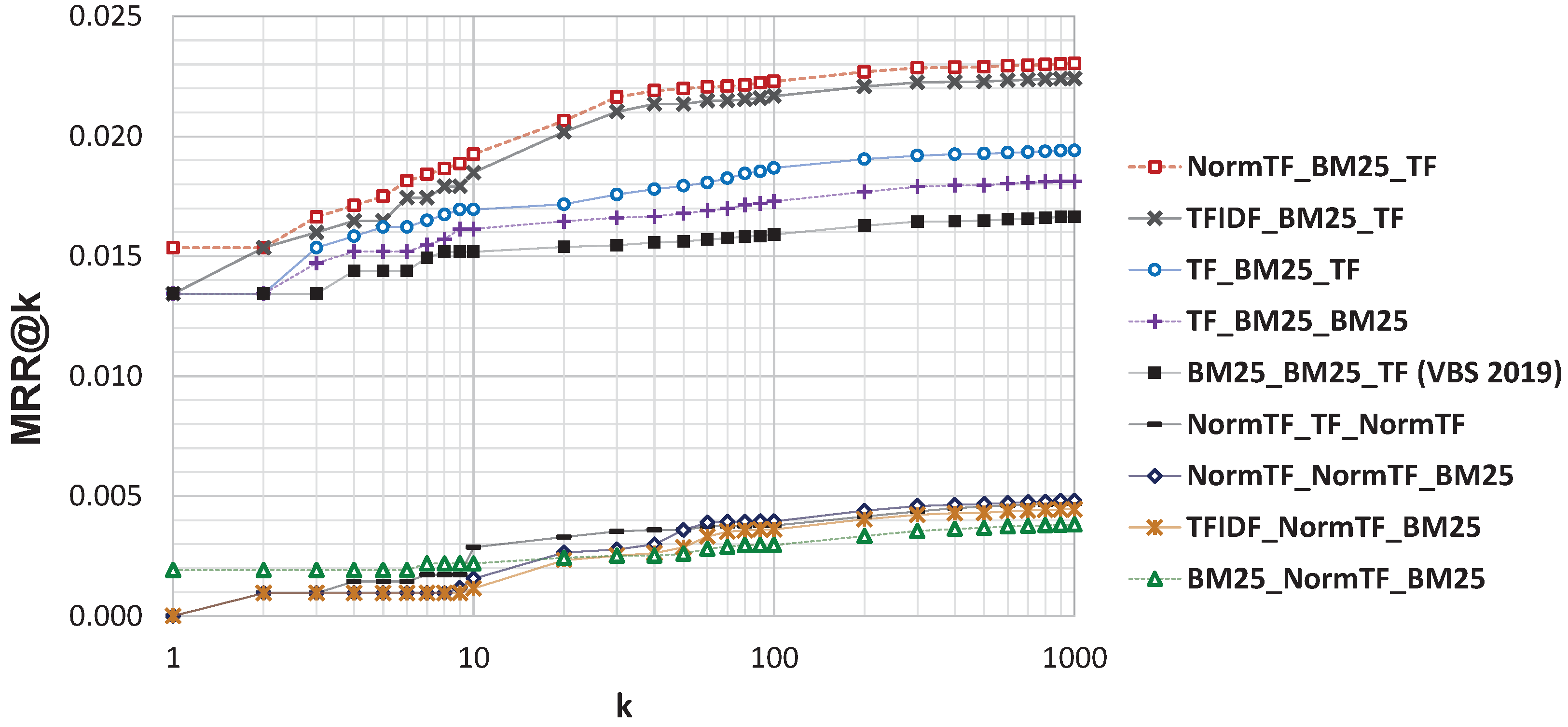
- BM25: Lucene’s implementation of the well-known similarity function BM25 introduced in [64];
- TFIDF: Lucene’s implementation of the weighing scheme known as Term Frequency-Inverse Document Frequency introduced in [65];
- TF: implementation of dot product similarity over the frequency terms vector;
- NormTF: implementation of cosine similarity (the normalized dot product of the two weight vectors) over the frequency terms vectors.
Evaluation Metrics
- as the rank of the image in the ranked results returned by our system after executing the query q
- as the rank of the first correct result in the ranked result list for the query q.
5.2. Results
- about 200 queries involved the execution of a Similarity Search, a video summary or a filtering, whose results are independent of the rankers used in the three search operations considered in our analysis;
- the search result sets of about 800 queries do not contain any correct result due to the lack of alignment between the text associated with the query and the text associated with images relevant to the target video. For those cases, the system is not able to display the relevant images in the result set regardless of the ranker used. In fact, the effect of using a specific ranker only affects the ordering of the results and not the actual selection of them.
5.3. Efficiency and Scalability Issues
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rossetto, L.; Gasser, R.; Lokoc, J.; Bailer, W.; Schoeffmann, K.; Muenzer, B.; Soucek, T.; Nguyen, P.A.; Bolettieri, P.; Leibetseder, A.; et al. Interactive Video Retrieval in the Age of Deep Learning - Detailed Evaluation of VBS 2019. IEEE Trans. Multimed. 2020, 23, 243–256. [Google Scholar] [CrossRef]
- Cobârzan, C.; Schoeffmann, K.; Bailer, W.; Hürst, W.; Blažek, A.; Lokoč, J.; Vrochidis, S.; Barthel, K.U.; Rossetto, L. Interactive video search tools: A detailed analysis of the video browser showdown 2015. Multimed. Tools Appl. 2017, 76, 5539–5571. [Google Scholar] [CrossRef]
- Lokoč, J.; Bailer, W.; Schoeffmann, K.; Muenzer, B.; Awad, G. On influential trends in interactive video retrieval: Video Browser Showdown 2015–2017. IEEE Trans. Multimed. 2018, 20, 3361–3376. [Google Scholar] [CrossRef]
- Berns, F.; Rossetto, L.; Schoeffmann, K.; Beecks, C.; Awad, G. V3C1 Dataset: An Evaluation of Content Characteristics. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 334–338. [Google Scholar] [CrossRef]
- Amato, G.; Bolettieri, P.; Carrara, F.; Debole, F.; Falchi, F.; Gennaro, C.; Vadicamo, L.; Vairo, C. VISIONE at VBS2019. In Lecture Notes in Computer Science, Proceedings of the MultiMedia Modeling, Thessaloniki, Greece, 8–11 January 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 591–596. [Google Scholar] [CrossRef]
- Hu, P.; Zhen, L.; Peng, D.; Liu, P. Scalable deep multimodal learning for cross-modal retrieval. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 635–644. [Google Scholar]
- Liu, Y.; Albanie, S.; Nagrani, A.; Zisserman, A. Use what you have: Video retrieval using representations from collaborative experts. arXiv 2019, arXiv:1907.13487. [Google Scholar]
- Mithun, N.C.; Li, J.; Metze, F.; Roy-Chowdhury, A.K. Learning joint embedding with multimodal cues for cross-modal video-text retrieval. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 19–27. [Google Scholar]
- Otani, M.; Nakashima, Y.; Rahtu, E.; Heikkilä, J.; Yokoya, N. Learning joint representations of videos and sentences with web image search. In European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 651–667. [Google Scholar]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10394–10403. [Google Scholar]
- Sclaroff, S.; La Cascia, M.; Sethi, S.; Taycher, L. Unifying textual and visual cues for content-based image retrieval on the world wide web. Comput. Vis. Image Underst. 1999, 75, 86–98. [Google Scholar] [CrossRef]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2121–2129. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying visual-semantic embeddings with multimodal neural language models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Karpathy, A.; Joulin, A.; Fei-Fei, L.F. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1889–1897. [Google Scholar]
- Dong, J.; Li, X.; Snoek, C.G. Word2visualvec: Image and video to sentence matching by visual feature prediction. arXiv 2016, arXiv:1604.06838. [Google Scholar]
- Miech, A.; Zhukov, D.; Alayrac, J.B.; Tapaswi, M.; Laptev, I.; Sivic, J. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2630–2640. [Google Scholar]
- Pan, Y.; Mei, T.; Yao, T.; Li, H.; Rui, Y. Jointly modeling embedding and translation to bridge video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4594–4602. [Google Scholar]
- Xu, R.; Xiong, C.; Chen, W.; Corso, J.J. Jointly Modeling Deep Video and Compositional Text to Bridge Vision and Language in a Unified Framework. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 5, p. 6. [Google Scholar]
- La Cascia, M.; Ardizzone, E. Jacob: Just a content-based query system for video databases. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 1216–1219. [Google Scholar]
- Marques, O.; Furht, B. Content-Based Image and Video Retrieval; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002; Volume 21. [Google Scholar]
- Patel, B.; Meshram, B. Content based video retrieval systems. arXiv 2012, arXiv:1205.1641. [Google Scholar] [CrossRef]
- Faloutsos, C.; Barber, R.; Flickner, M.; Hafner, J.; Niblack, W.; Petkovic, D.; Equitz, W. Efficient and effective querying by image content. J. Intell. Inf. Syst. 1994, 3, 231–262. [Google Scholar] [CrossRef]
- Schoeffmann, K. Video Browser Showdown 2012–2019: A Review. In Proceedings of the 2019 International Conference on Content-Based Multimedia Indexing (CBMI), Dublin, Ireland, 4–6 September 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Lokoč, J.; Kovalčík, G.; Münzer, B.; Schöffmann, K.; Bailer, W.; Gasser, R.; Vrochidis, S.; Nguyen, P.A.; Rujikietgumjorn, S.; Barthel, K.U. Interactive Search or Sequential Browsing? A Detailed Analysis of the Video Browser Showdown 2018. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15. [Google Scholar] [CrossRef]
- Lokoč, J.; Kovalčík, G.; Souček, T. Revisiting SIRET Video Retrieval Tool. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 419–424. [Google Scholar] [CrossRef]
- Rossetto, L.; Amiri Parian, M.; Gasser, R.; Giangreco, I.; Heller, S.; Schuldt, H. Deep Learning-Based Concept Detection in vitrivr. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 616–621. [Google Scholar] [CrossRef]
- Kratochvíl, M.; Veselý, P.; Mejzlík, F.; Lokoč, J. SOM-Hunter: Video Browsing with Relevance-to-SOM Feedback Loop. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 790–795. [Google Scholar] [CrossRef]
- Lokoč, J.; Kovalčík, G.; Souček, T. VIRET at Video Browser Showdown 2020. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 784–789. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Li, X.; Xu, C.; Yang, G.; Chen, Z.; Dong, J. W2VV++ Fully Deep Learning for Ad-hoc Video Search. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1786–1794. [Google Scholar]
- Sauter, L.; Amiri Parian, M.; Gasser, R.; Heller, S.; Rossetto, L.; Schuldt, H. Combining Boolean and Multimedia Retrieval in vitrivr for Large-Scale Video Search. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 760–765. [Google Scholar] [CrossRef]
- Rossetto, L.; Gasser, R.; Schuldt, H. Query by Semantic Sketch. arXiv 2019, arXiv:1909.12526. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Chang, E.Y.; Goh, K.; Sychay, G.; Wu, G. CBSA: Content-based soft annotation for multimodal image retrieval using Bayes point machines. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 26–38. [Google Scholar] [CrossRef]
- Carneiro, G.; Chan, A.; Moreno, P.; Vasconcelos, N. Supervised Learning of Semantic Classes for Image Annotation and Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 394–410. [Google Scholar] [CrossRef] [PubMed]
- Barnard, K.; Forsyth, D. Learning the semantics of words and pictures. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume II, pp. 408–415. [Google Scholar] [CrossRef]
- Li, X.; Uricchio, T.; Ballan, L.; Bertini, M.; Snoek, C.G.M.; Bimbo, A.D. Socializing the Semantic Gap: A Comparative Survey on Image Tag Assignment, Refinement, and Retrieval. ACM Comput. Surv. 2016, 49. [Google Scholar] [CrossRef]
- Pellegrin, L.; Escalante, H.J.; Montes, M.; González, F. Local and global approaches for unsupervised image annotation. Multimed. Tools Appl. 2016, 76, 16389–16414. [Google Scholar] [CrossRef]
- Amato, G.; Falchi, F.; Gennaro, C.; Rabitti, F. Searching and annotating 100M Images with YFCC100M-HNfc6 and MI-File. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017; pp. 26:1–26:4. [Google Scholar] [CrossRef]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv 2013, arXiv:1310.1531. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; pp. 584–599. [Google Scholar] [CrossRef]
- Razavian, A.S.; Sullivan, J.; Carlsson, S.; Maki, A. Visual instance retrieval with deep convolutional networks. arXiv 2014, arXiv:1412.6574. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, IEEE Computer Society, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar] [CrossRef]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. End-to-End Learning of Deep Visual Representations for Image Retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef]
- Najva, N.; Bijoy, K.E. SIFT and tensor based object detection and classification in videos using deep neural networks. Procedia Comput. Sci. 2016, 93, 351–358. [Google Scholar] [CrossRef][Green Version]
- Anjum, A.; Abdullah, T.; Tariq, M.; Baltaci, Y.; Antonopoulos, N. Video stream analysis in clouds: An object detection and classification framework for high performance video analytics. IEEE Trans. Cloud Comput. 2016, 7, 1152–1167. [Google Scholar] [CrossRef]
- Yaseen, M.U.; Anjum, A.; Rana, O.; Hill, R. Cloud-based scalable object detection and classification in video streams. Future Gener. Comput. Syst. 2018, 80, 286–298. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, M.A.; Sharif, M.; Raza, M.; Sarfraz, M.M.; Afza, F. Object detection and classification: A joint selection and fusion strategy of deep convolutional neural network and SIFT point features. Multimed. Tools Appl. 2019, 78, 15751–15777. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3 on the Open Images Dataset. 2018. Available online: https://pjreddie.com/darknet/yolo/ (accessed on 28 February 2019).
- Gennaro, C.; Amato, G.; Bolettieri, P.; Savino, P. An approach to content-based image retrieval based on the Lucene search engine library. In International Conference on Theory and Practice of Digital Libraries; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 55–66. [Google Scholar] [CrossRef]
- Amato, G.; Bolettieri, P.; Carrara, F.; Falchi, F.; Gennaro, C. Large-Scale Image Retrieval with Elasticsearch. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 925–928. [Google Scholar] [CrossRef]
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C.; Vadicamo, L. Large-scale instance-level image retrieval. Inf. Process. Manag. 2019, 102100. [Google Scholar] [CrossRef]
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C. Efficient Indexing of Regional Maximum Activations of Convolutions using Full-Text Search Engines. In Proceedings of the ACM International Conference on Multimedia Retrieval, ACM, Bucharest, Romania, 6–9 June 2017; pp. 420–423. [Google Scholar] [CrossRef]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The New Data in Multimedia Research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Miller, G. WordNet: An Electronic Lexical Database; Language, Speech, and Communication; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Amato, G.; Gennaro, C.; Savino, P. MI-File: Using inverted files for scalable approximate similarity search. Multimed. Tools Appl. 2012, 71, 1333–1362. [Google Scholar] [CrossRef]
- Truong, T.D.; Nguyen, V.T.; Tran, M.T.; Trieu, T.V.; Do, T.; Ngo, T.D.; Le, D.D. Video Search Based on Semantic Extraction and Locally Regional Object Proposal. In International Conference on Multimedia Modeling; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 451–456. [Google Scholar] [CrossRef]
- Rubner, Y.; Guibas, L.; Tomasi, C. The Earth Mover’s Distance, MultiDimensional Scaling, and Color-Based Image Retrieval. In Proceedings of the ARPA Image Understanding Workshop, New Orleans, LA, USA, 11–14 May 1997; Volume 661, p. 668. [Google Scholar]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Volume 48, pp. 2217–2225. [Google Scholar]
- Robertson, S.E.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.; Gatford, M. Okapi at TREC-3. In Proceedings of the Third Text REtrieval Conference, TREC 1994, Gaithersburg, MD, USA, 2–4 November 1994; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 1994; Volume 500–225, pp. 109–126. [Google Scholar]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Smucker, M.D.; Allan, J.; Carterette, B. A Comparison of Statistical Significance Tests for Information Retrieval Evaluation. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisboa, Portugal, 6–8 November 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 623–632. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NormTF-BM25-TF | 0.015 | 0.017 | 0.019 * | 0.022 * | 0.022 * | 0.023 * | 0.023 * |
| TFIDF-BM25-TF | 0.013 | 0.016 | 0.018 * | 0.021 * | 0.022 * | 0.022 * | 0.022 * |
| TF-BM25-TF | 0.013 | 0.016 | 0.017 | 0.018 * | 0.019 * | 0.019 * | 0.019 * |
| TF-BM25-BM25 | 0.013 | 0.015 | 0.016 | 0.017 | 0.017 * | 0.018 * | 0.018 * |
| TF-BM25-NormTF | 0.013 | 0.015 | 0.016 | 0.017 * | 0.017 * | 0.018 * | 0.018 * |
| BM25-BM25-TF (VBS 2019) | 0.013 | 0.014 | 0.015 | 0.016 | 0.016 | 0.016 | 0.017 |
| NormTF-TF-NormTF | 0.000 * | 0.001 * | 0.003 * | 0.004 * | 0.004 * | 0.005 * | 0.005 * |
| NormTF-NormTF-BM25 | 0.000 * | 0.001 * | 0.002 * | 0.004 * | 0.004 * | 0.005 * | 0.005 * |
| BM25-NormTF-BM25 | 0.002 * | 0.002 * | 0.002 * | 0.003 * | 0.003 * | 0.004 * | 0.004 * |
| TFIDF-NormTF-BM25 | 0.000 * | 0.001 * | 0.001 * | 0.003 * | 0.004 * | 0.004 * | 0.004 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amato, G.; Bolettieri, P.; Carrara, F.; Debole, F.; Falchi, F.; Gennaro, C.; Vadicamo, L.; Vairo, C. The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval. J. Imaging 2021, 7, 76. https://doi.org/10.3390/jimaging7050076
Amato G, Bolettieri P, Carrara F, Debole F, Falchi F, Gennaro C, Vadicamo L, Vairo C. The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval. Journal of Imaging. 2021; 7(5):76. https://doi.org/10.3390/jimaging7050076
Chicago/Turabian StyleAmato, Giuseppe, Paolo Bolettieri, Fabio Carrara, Franca Debole, Fabrizio Falchi, Claudio Gennaro, Lucia Vadicamo, and Claudio Vairo. 2021. "The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval" Journal of Imaging 7, no. 5: 76. https://doi.org/10.3390/jimaging7050076
APA StyleAmato, G., Bolettieri, P., Carrara, F., Debole, F., Falchi, F., Gennaro, C., Vadicamo, L., & Vairo, C. (2021). The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval. Journal of Imaging, 7(5), 76. https://doi.org/10.3390/jimaging7050076