
UnCanny: Exploiting Reversed Edge Detection as a Basis for Object Tracking in Video


Abstract
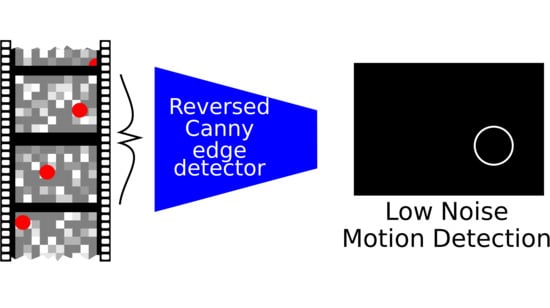
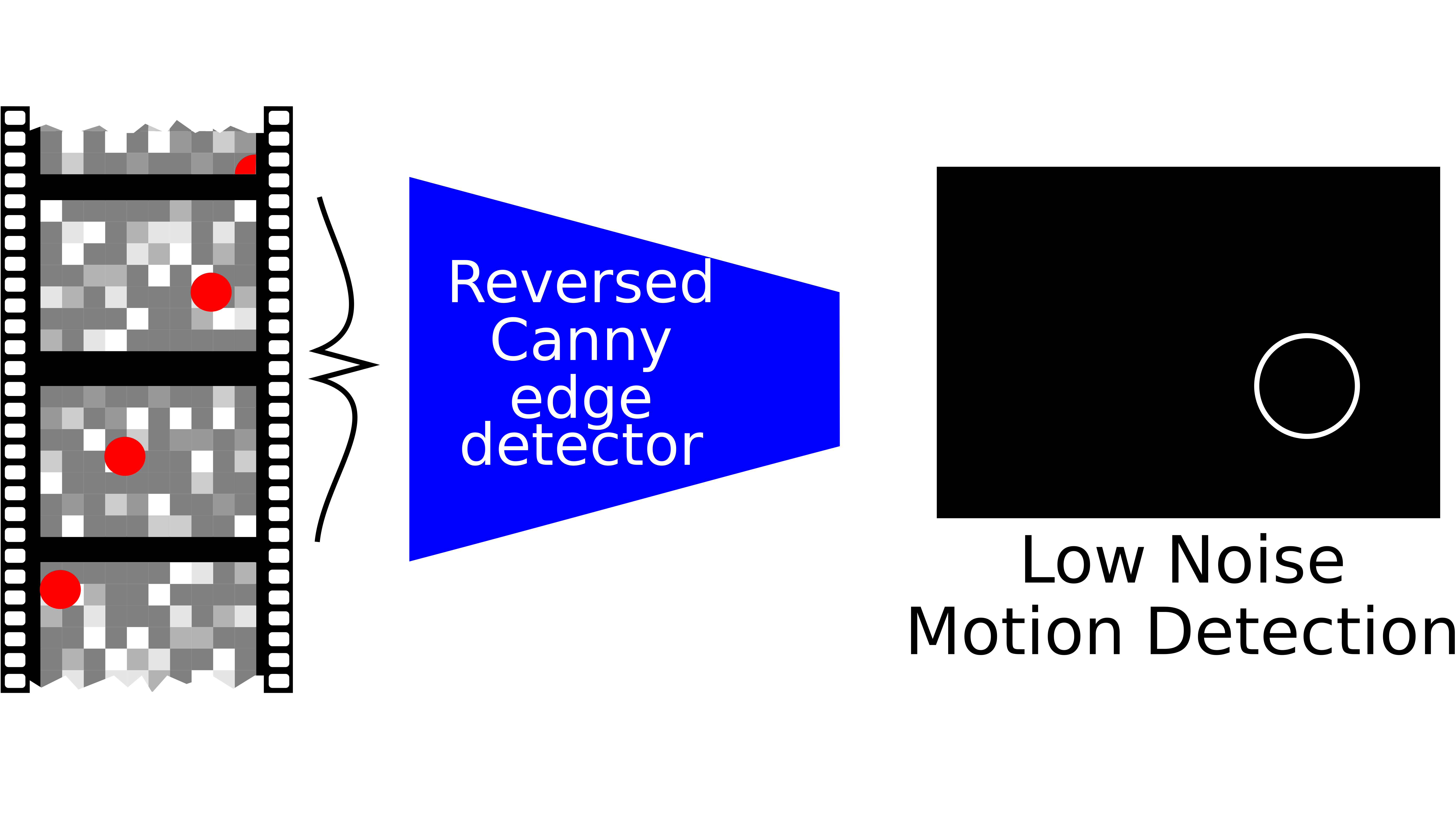{kind=link}
{kind=link}
{kind=link}
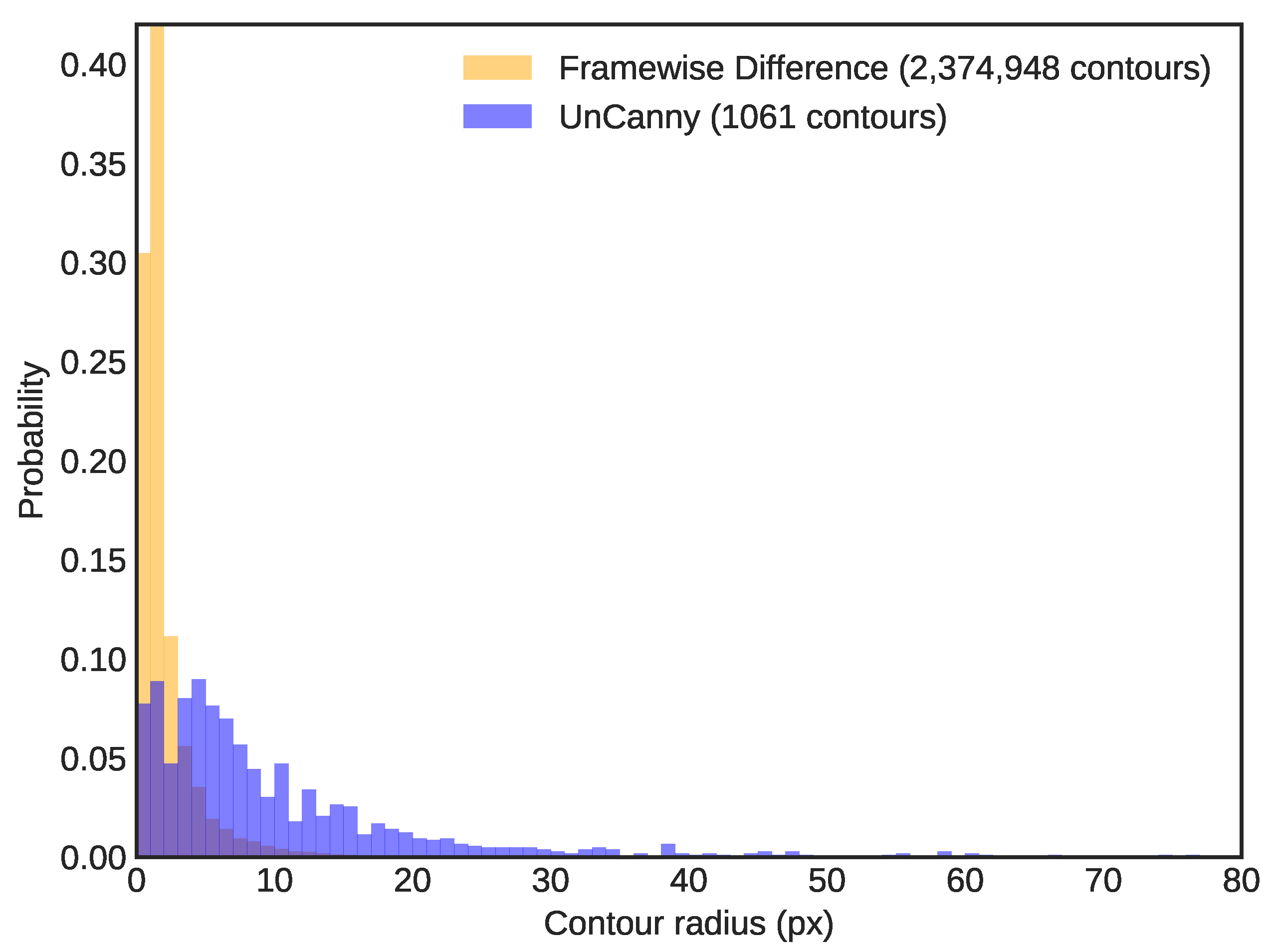{kind=link}
{kind=link}
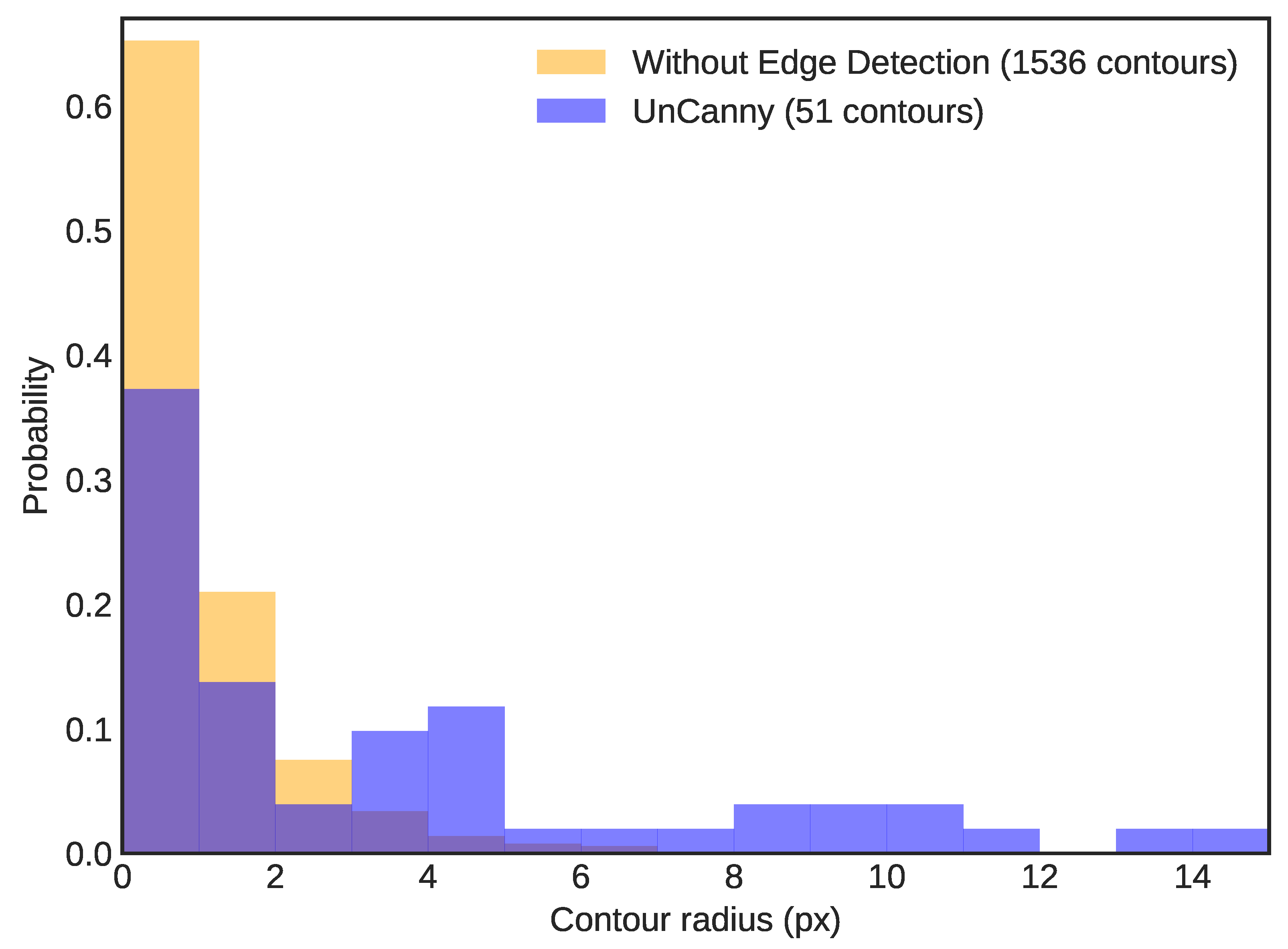{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Methods
UnCanny Filter
3. Results and Discussion
3.1. Stepwise UnCanny Application to Video Frames
3.2. Comparison to Raw Frame Differences
3.3. Edge Detection Necessity
3.4. Limitations and Shortcomings
3.5. Tracking Object Motion
3.6. Computational Efficiency
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Roberts, L.G. Machine Perception of Three-Dimensional Solids. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Sobel, I.; Feldman, G. A 3 × 3 Isotropic Gradient Operator for Image Processing; Stanford Artificial Intelligence Project (SAIL): Stanford, CA, USA, 1968. [Google Scholar]
- Sobel, I. History and Definition of the So-Called “Sobel Operator”, More Appropriately Named the Sobel-Feldman Operator. 2014. Available online: https://www.researchgate.net/profile/Irwin-Sobel/publication/239398674_An_Isotropic_3x3_Image_Gradient_Operator/links/557e06f508aeea18b777c389/An-Isotropic-3x3-Image-Gradient-Operator.pdf (accessed on 20 February 2021).
- Marr, D.; Hildreth, E.; Brenner, S. Theory of Edge Detection. Proc. R. Soc. Lond. Ser. B Biol. 1980, 207, 187–217. [Google Scholar] [CrossRef]
- Haralick, R.M. Digital Step Edges from Zero Crossing of Second Directional Derivatives. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 58–68. [Google Scholar] [CrossRef] [PubMed]
- Sponton, H.; Cardelino, J. A Review of Classic Edge Detectors. Image Process. Line 2015, 5, 90–123. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Fan, S. An Improved CANNY Edge Detection Algorithm. In Proceedings of the 2009 Second International Workshop on Computer Science and Engineering, IWCSE’09, Qingdao, China, 28–30 October 2009; pp. 497–500. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man, Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S. Extracting Major Lines by Recruiting Zero-Threshold Canny Edge Links along Sobel Highlights. IEEE Signal Process. Lett. 2015, 22, 1689–1692. [Google Scholar] [CrossRef]
- Algethami, N.; Redfern, S. A Robust Tracking-by-Detection Algorithm Using Adaptive Accumulated Frame Differencing and Corner Features. J. Imaging 2020, 6, 25. [Google Scholar] [CrossRef]
- Kroeger, T.; Timofte, R.; Dai, D.; Van Gool, L. Fast Optical Flow Using Dense Inverse Search. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 471–488. [Google Scholar]
- Gunale, K.G.; Mukherji, P. Deep Learning with a Spatiotemporal Descriptor of Appearance and Motion Estimation for Video Anomaly Detection. J. Imaging 2018, 4, 79. [Google Scholar] [CrossRef]
- Singh, S.; Shekhar, C.; Vohra, A. Real-Time FPGA-Based Object Tracker with Automatic Pan-Tilt Features for Smart Video Surveillance Systems. J. Imaging 2017, 3, 18. [Google Scholar] [CrossRef]
- Honeycutt, W.T.; Heaston, A.V.; Kelly, J.F.; Bridge, E.S. LunAero: Automated “Smart” Hardware for Recording Video of Nocturnal Migration. HardwareX 2020, 7, e00106. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 3. Available online: https://www.drdobbs.com/open-source/the-opencv-library/184404319 (accessed on 20 February 2021).
- Niblack, W. An Introduction to Digital Image Processing; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1986. [Google Scholar]
- Zhang, T.Y.; Suen, C.Y. A Fast Parallel Algorithm for Thinning Digital Patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Andrews, L.C.; Phillips, R.L.; Hopen, C.Y.; Al-Habash, M.A. Theory of Optical Scintillation. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 1999, 16, 1417–1429. [Google Scholar] [CrossRef]
- Osborn, J.; Föhring, D.; Dhillon, V.S.; Wilson, R.W. Atmospheric Scintillation in Astronomical Photometry. Mon. Not. R. Astron. Soc. 2015, 452, 1707–1716. [Google Scholar] [CrossRef]
- Ace of Spades. Publicvideos November 2009 Batch, Part 1. 2009. Available online: http://archive.org/details/ace_200911_03 (accessed on 7 April 2021).
- Beach, J.; Beachfront Productions. Typewriter Close Up—Regular Speed (Free to Use HD Stock Video Footage). 2014. Available online: http://archive.org/details/TypewriterCloseUp-RegularSpeed (accessed on 7 April 2021).
- Vacavant, A.; Chateau, T.; Wilhelm, A.; Lequièvre, L. A Benchmark Dataset for Outdoor Foreground/Background Extraction. In Computer Vision—ACCV 2012 Workshops; Park, J.I., Kim, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 291–300. [Google Scholar]
- KaewTraKulPong, P.; Bowden, R. An Improved Adaptive Background Mixture Model for Real-Time Tracking with Shadow Detection. In Video-Based Surveillance Systems: Computer Vision and Distributed Processing; Remagnino, P., Jones, G.A., Paragios, N., Regazzoni, C.S., Eds.; Springer: Boston, MA, USA, 2002; pp. 135–144. [Google Scholar] [CrossRef]
- Zivkovic, Z. Improved Adaptive Gaussian Mixture Model for Background Subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26–26 August 2004; Volume 2, pp. 28–31. [Google Scholar] [CrossRef]
- Godbehere, A.B.; Matsukawa, A.; Goldberg, K. Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 4305–4312. [Google Scholar] [CrossRef]
- FatBudda. WW 2 Spitfire. 2006. Available online: http://archive.org/details/WW2Spitfire (accessed on 7 April 2021).
- Chabrier, S.; Laurent, H.; Rosenberger, C.; Emile, B. Comparative Study of Contour Detection Evaluation Criteria Based on Dissimilarity Measures. EURASIP J. Image Video Process. 2008, 2008, 693053. [Google Scholar] [CrossRef]
- Magnier, B.; Moradi, B. Shape Similarity Measurement for Known-Object Localization: A New Normalized Assessment. J. Imaging 2019, 5, 77. [Google Scholar] [CrossRef]
- Bensaid, A.M.; Hall, L.O.; Bezdek, J.C.; Clarke, L.P. Partially Supervised Clustering for Image Segmentation. Pattern Recognit. 1996, 29, 859–871. [Google Scholar] [CrossRef]
- Zhang, J.; Han, Y.; Tang, J.; Hu, Q.; Jiang, J. Semi-Supervised Image-to-Video Adaptation for Video Action Recognition. IEEE Trans. Cybern. 2017, 47, 960–973. [Google Scholar] [CrossRef] [PubMed]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Honeycutt, W.T.; Bridge, E.S. UnCanny: Exploiting Reversed Edge Detection as a Basis for Object Tracking in Video. J. Imaging 2021, 7, 77. https://doi.org/10.3390/jimaging7050077
Honeycutt WT, Bridge ES. UnCanny: Exploiting Reversed Edge Detection as a Basis for Object Tracking in Video. Journal of Imaging. 2021; 7(5):77. https://doi.org/10.3390/jimaging7050077
Chicago/Turabian StyleHoneycutt, Wesley T., and Eli S. Bridge. 2021. "UnCanny: Exploiting Reversed Edge Detection as a Basis for Object Tracking in Video" Journal of Imaging 7, no. 5: 77. https://doi.org/10.3390/jimaging7050077
APA StyleHoneycutt, W. T., & Bridge, E. S. (2021). UnCanny: Exploiting Reversed Edge Detection as a Basis for Object Tracking in Video. Journal of Imaging, 7(5), 77. https://doi.org/10.3390/jimaging7050077