

Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization †


Abstract
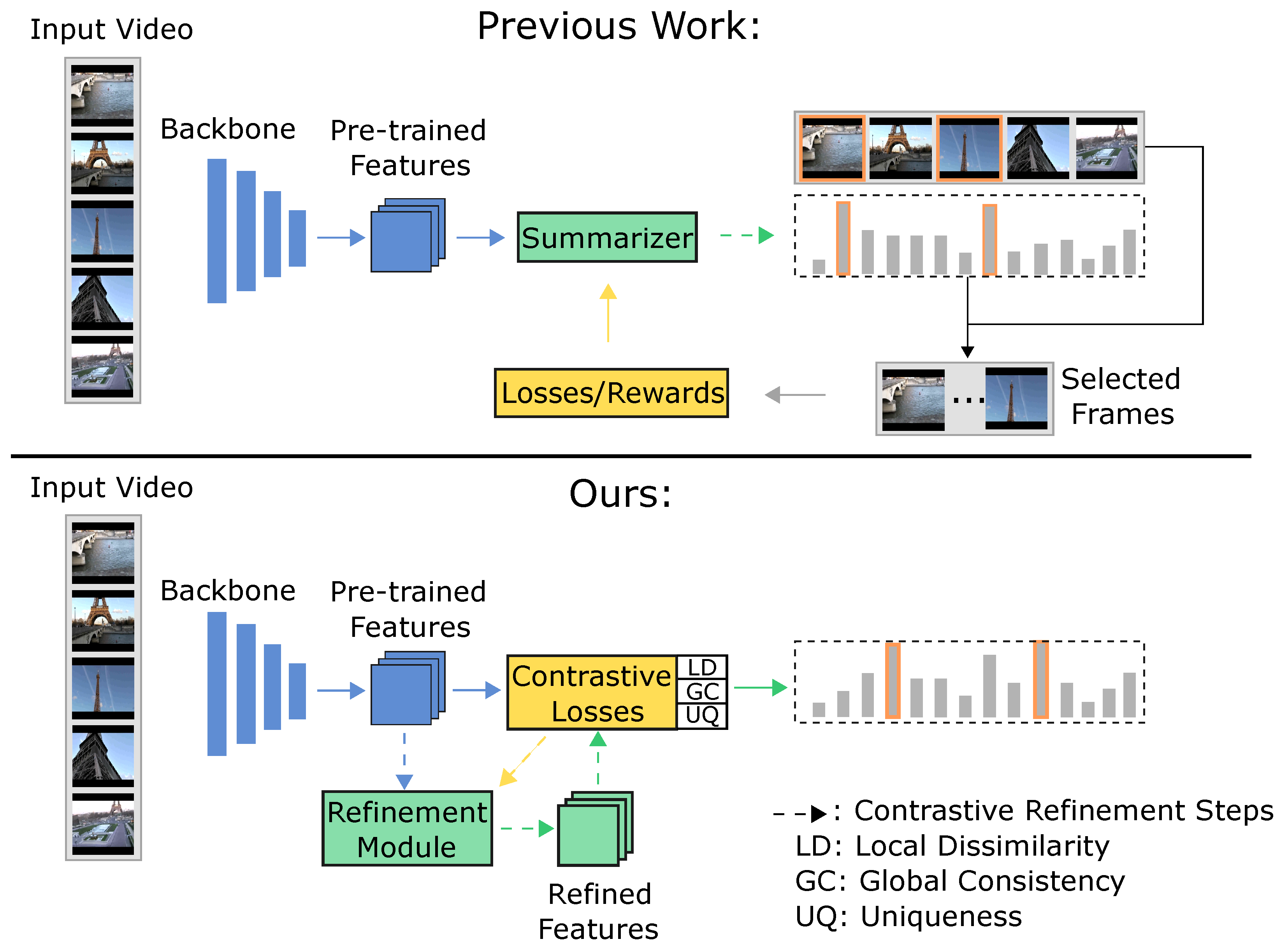
1. Introduction
2. Related Work
3. Preliminaries
3.1. Instance Discrimination via the InfoNCE Loss
3.2. Contrastive Learning via Alignment and Uniformity
4. Proposed Method
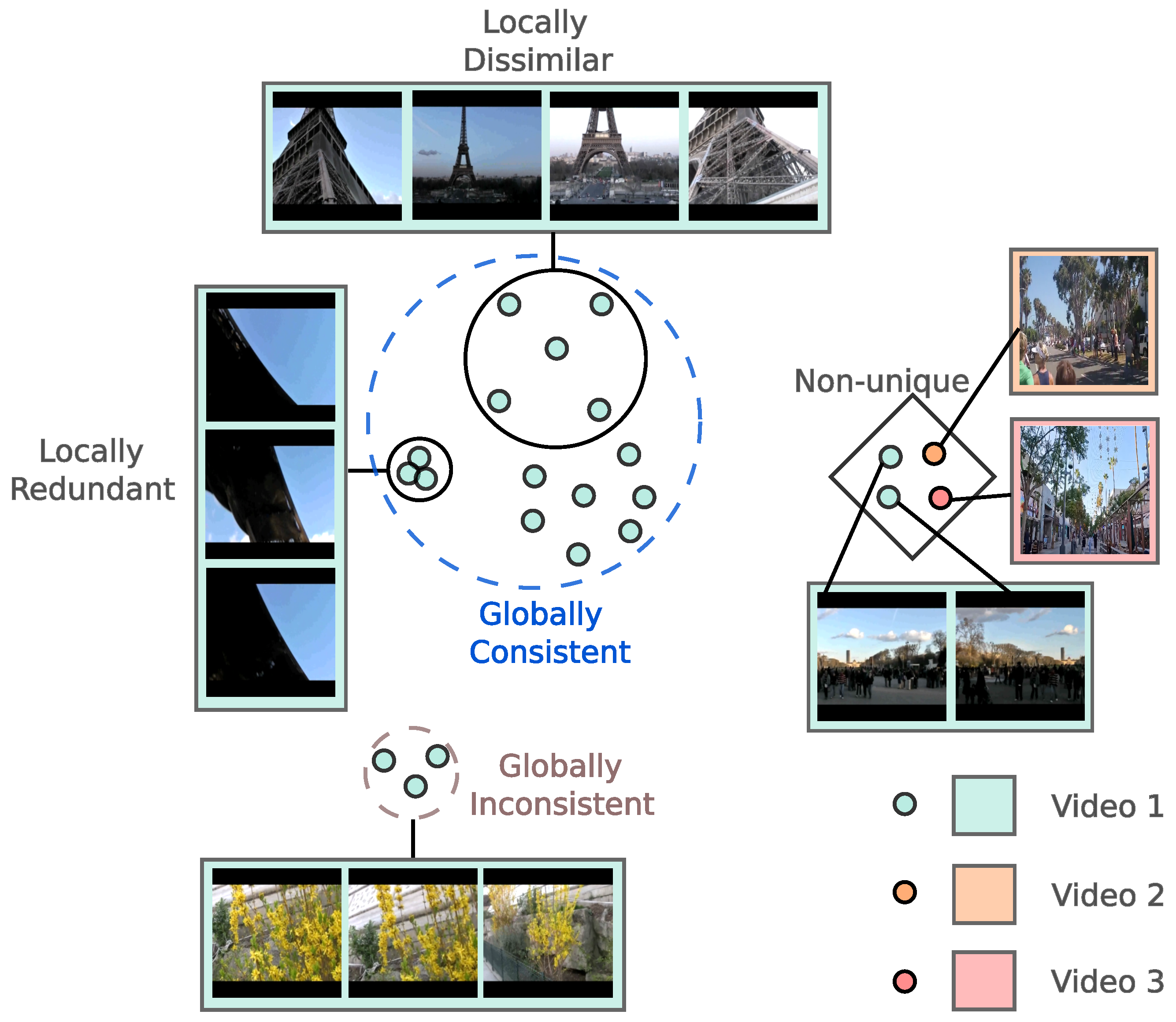
4.1. Local Dissimilarity
4.2. Global Consistency
4.3. Contrastive Refinement
4.4. The Uniqueness Filter
4.5. The Full Loss and Importance Scores
5. Experiments
5.1. Datasets and Settings
5.2. Evaluation Metrics
5.3. Summary Generation
5.4. Implementation Details
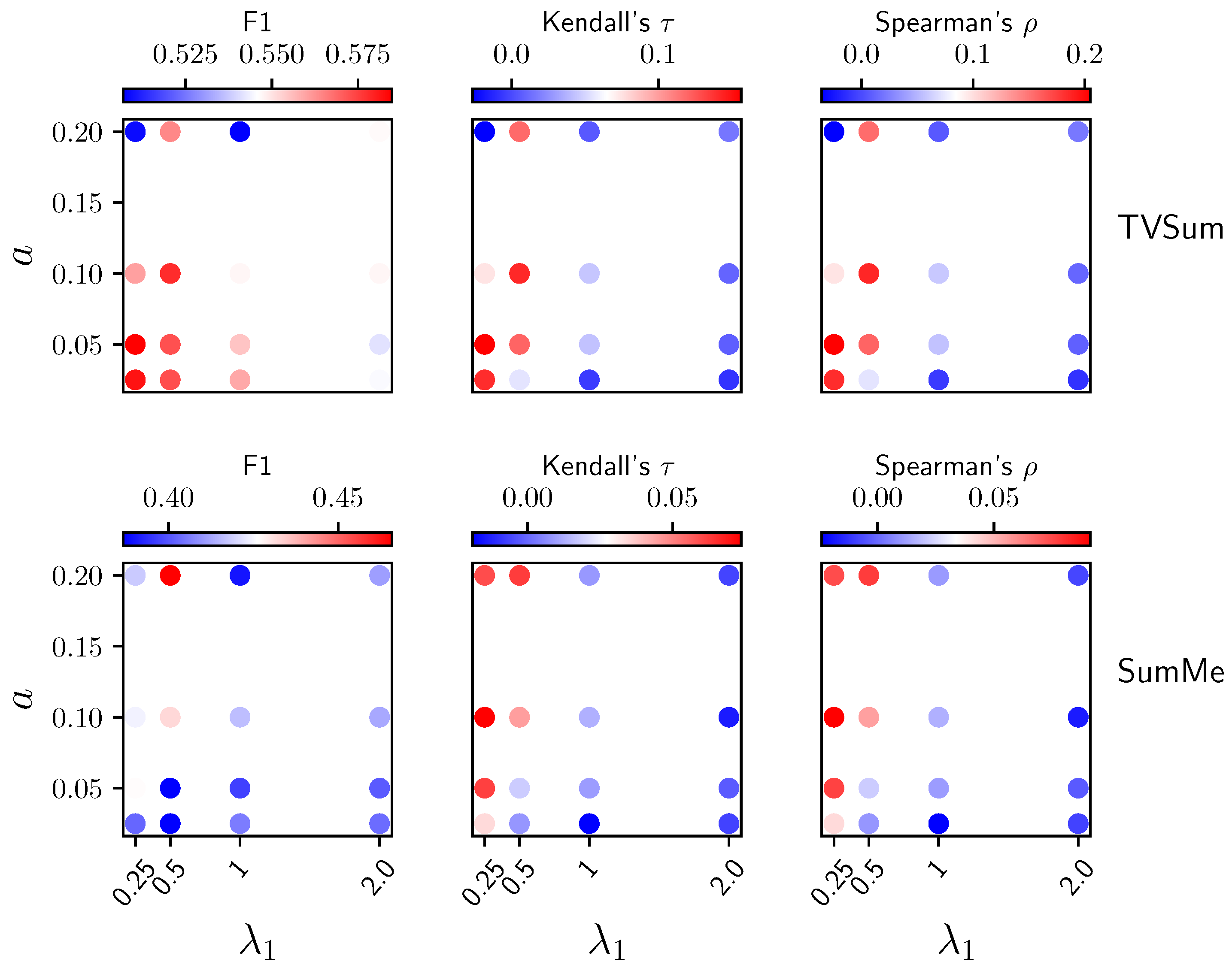
5.5. Quantitative Results
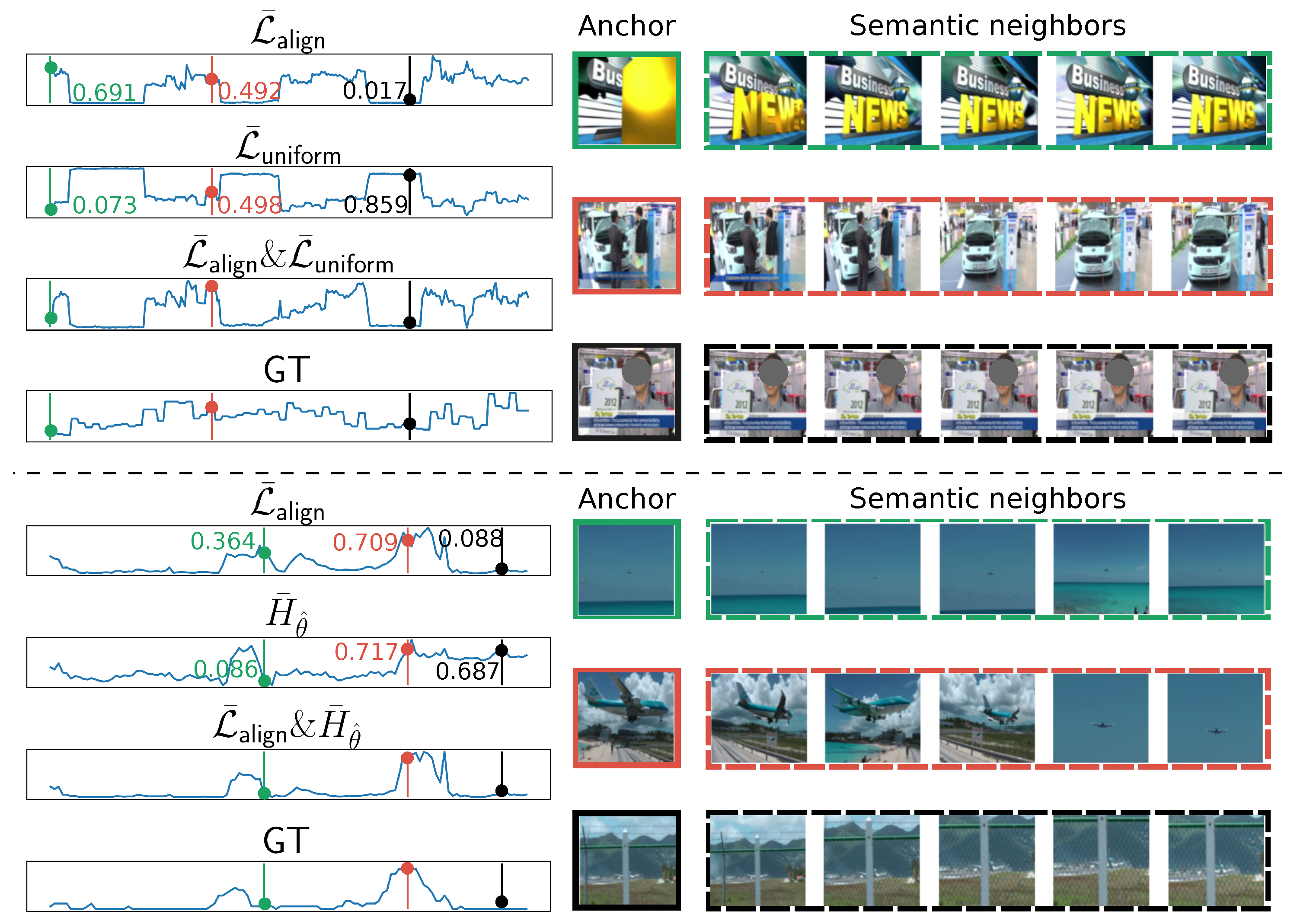
5.6. Qualitative Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Otani, M.; Song, Y.; Wang, Y. Video summarization overview. Found. Trends® Comput. Graph. Vis. 2022, 13, 284–335. [Google Scholar] [CrossRef]
- Zhang, K.; Chao, W.L.; Sha, F.; Grauman, K. Video summarization with long short-term memory. In Proceedings of the European Conference on Computer Vision, ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, K.; Grauman, K.; Sha, F. Retrospective encoders for video summarization. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fu, T.J.; Tai, S.H.; Chen, H.T. Attentive and adversarial learning for video summarization. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, WACV, Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Fajtl, J.; Sokeh, H.S.; Argyriou, V.; Monekosso, D.; Remagnino, P. Summarizing videos with attention. In Proceedings of the Asian Conference on Computer Vision, ACCV, Perth, Australia, 2–6 December 2018. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems, NeurIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial LSTM networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rochan, M.; Ye, L.; Wang, Y. Video summarization using fully convolutional sequence networks. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, Y.T.; Li, Y.J.; Yang, F.E.; Chen, S.F.; Wang, Y.C.F. Learning hierarchical self-attention for video summarization. In Proceedings of the IEEE International Conference on Image Processing, ICIP, Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3377–3381. [Google Scholar]
- Rochan, M.; Wang, Y. Video summarization by learning from unpaired data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, K.; Qiao, Y.; Xiang, T. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In Proceedings of the Conference on Artificial Intelligence, AAAI, New Orleans, LA, USA, 26–28 March 2018. [Google Scholar]
- Jung, Y.; Cho, D.; Kim, D.; Woo, S.; Kweon, I.S. Discriminative feature learning for unsupervised video summarization. In Proceedings of the Conference on Artificial Intelligence, AAAI, Honolulu, HI, USA, 27–28 January 2019. [Google Scholar]
- Jung, Y.; Cho, D.; Woo, S.; Kweon, I.S. Global-and-Local Relative Position Embedding for Unsupervised Video Summarization. In Proceedings of the European Conference on Computer Vision, ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhou, J.; Wei, C.; Wang, H.; Shen, W.; Xie, C.; Yuille, A.; Kong, T. ibot: Image bert pre-training with online tokenizer. arXiv 2021, arXiv:2111.07832. [Google Scholar]
- Hamilton, M.; Zhang, Z.; Hariharan, B.; Snavely, N.; Freeman, W.T. Unsupervised Semantic Segmentation by Distilling Feature Correspondences. arXiv 2022, arXiv:2203.08414. [Google Scholar]
- Wang, X.; Girdhar, R.; Yu, S.X.; Misra, I. Cut and learn for unsupervised object detection and instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3124–3134. [Google Scholar]
- Zhuang, C.; Zhai, A.L.; Yamins, D. Local aggregation for unsupervised learning of visual embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the International Conference on Machine Learning, ICML, Virtual, 13–18 July 2020. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Pang, Z.; Nakashima, Y.; Otani, M.; Nagahara, H. Contrastive Losses Are Natural Criteria for Unsupervised Video Summarization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV, Waikoloa, HI, USA, 2–7 January 2023. [Google Scholar]
- Narasimhan, M.; Rohrbach, A.; Darrell, T. CLIP-It! language-guided video summarization. In Proceedings of the Annual Conference on Neural Information Processing Systems, NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- He, B.; Wang, J.; Qiu, J.; Bui, T.; Shrivastava, A.; Wang, Z. Align and attend: Multimodal summarization with dual contrastive losses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14867–14878. [Google Scholar]
- Takahashi, Y.; Nitta, N.; Babaguchi, N. Video summarization for large sports video archives. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 1170–1173. [Google Scholar]
- Tjondronegoro, D.; Chen, Y.P.P.; Pham, B. Highlights for more complete sports video summarization. IEEE Multimed. 2004, 11, 22–37. [Google Scholar] [CrossRef]
- Li, B.; Pan, H.; Sezan, I. A general framework for sports video summarization with its application to soccer. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Proceedings. (ICASSP’03). IEEE: Piscataway, NJ, USA, 2003; Volumn 3, pp. III–169. [Google Scholar]
- Choudary, C.; Liu, T. Summarization of visual content in instructional videos. IEEE Trans. Multimed. 2007, 9, 1443–1455. [Google Scholar] [CrossRef]
- Liu, T.; Kender, J.R. Rule-based semantic summarization of instructional videos. In Proceedings of the Proceedings. International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; IEEE: Piscataway, NJ, USA, 2002; Volumn 1, p. I. [Google Scholar]
- Liu, T.; Choudary, C. Content extraction and summarization of instructional videos. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, Georgia, 8–11 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 149–152. [Google Scholar]
- Song, Y.; Vallmitjana, J.; Stent, A.; Jaimes, A. TVSum: Summarizing web videos using titles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sang, J.; Xu, C. Character-based movie summarization. In Proceedings of the 18th ACM international Conference on Multimedia, Firenze, Italy, 25–26 October 2010; pp. 855–858. [Google Scholar]
- Tsai, C.M.; Kang, L.W.; Lin, C.W.; Lin, W. Scene-based movie summarization via role-community networks. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1927–1940. [Google Scholar] [CrossRef]
- Gygli, M.; Grabner, H.; Riemenschneider, H.; Van Gool, L. Creating summaries from user videos. In Proceedings of the European Conference on Computer Vision, ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Zhao, B.; Li, X.; Lu, X. Hierarchical recurrent neural network for video summarization. In Proceedings of the ACM International Conference on Multimedia, ACM MM, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Zhao, B.; Li, X.; Lu, X. HSA-RNN: Hierarchical structure-adaptive RNN for video summarization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Feng, L.; Li, Z.; Kuang, Z.; Zhang, W. Extractive video summarizer with memory augmented neural networks. In Proceedings of the ACM International Conference on Multimedia, ACM MM, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Wang, J.; Wang, W.; Wang, Z.; Wang, L.; Feng, D.; Tan, T. Stacked memory network for video summarization. In Proceedings of the ACM International Conference on Multimedia, ACM MM, Nice, France, 21–25 October 2019. [Google Scholar]
- Casas, L.L.; Koblents, E. Video Summarization with LSTM and Deep Attention Models. In Proceedings of the International Conference on MultiMedia Modeling, MMM, Thessaloniki, Greece, 8–11 January 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 67–79. [Google Scholar]
- Ji, Z.; Xiong, K.; Pang, Y.; Li, X. Video summarization with attention-based encoder–decoder networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1709–1717. [Google Scholar] [CrossRef]
- Ji, Z.; Jiao, F.; Pang, Y.; Shao, L. Deep attentive and semantic preserving video summarization. Neurocomputing 2020, 405, 200–207. [Google Scholar] [CrossRef]
- Liu, Y.T.; Li, Y.J.; Wang, Y.C.F. Transforming multi-concept attention into video summarization. In Proceedings of the Asian Conference on Computer Vision, ACCV, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Lin, J.; Zhong, S.h. Bi-Directional Self-Attention with Relative Positional Encoding for Video Summarization. In Proceedings of the IEEE 32nd International Conference on Tools with Artificial Intelligence, ICTAI, Baltimore, MD, USA, 9–11 November 2020. [Google Scholar]
- Yuan, Y.; Li, H.; Wang, Q. Spatiotemporal modeling for video summarization using convolutional recurrent neural network. IEEE Access 2019, 7, 64676–64685. [Google Scholar] [CrossRef]
- Chu, W.T.; Liu, Y.H. Spatiotemporal Modeling and Label Distribution Learning for Video Summarization. In Proceedings of the IEEE 21st International Workshop on Multimedia Signal Processing, MMSP, Kuala Lumpur, Malaysia, 27–29 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Elfeki, M.; Borji, A. Video summarization via actionness ranking. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, WACV, Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Park, J.; Lee, J.; Kim, I.J.; Sohn, K. SumGraph: Video Summarization via Recursive Graph Modeling. In Proceedings of the European Conference on Computer Vision, ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Otani, M.; Nakashima, Y.; Rahtu, E.; Heikkilä, J.; Yokoya, N. Video summarization using deep semantic features. In Proceedings of the Asian Conference on Computer Vision, ACCV, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Chen, Y.; Tao, L.; Wang, X.; Yamasaki, T. Weakly supervised video summarization by hierarchical reinforcement learning. In Proceedings of the ACM MM Asia, Beijing, China, 16–18 December 2019. [Google Scholar]
- Li, Z.; Yang, L. Weakly Supervised Deep Reinforcement Learning for Video Summarization With Semantically Meaningful Reward. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, WACV, Waikoloa, HI, USA, 5–9 January 2021. [Google Scholar]
- He, X.; Hua, Y.; Song, T.; Zhang, Z.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Unsupervised video summarization with attentive conditional generative adversarial networks. In Proceedings of the ACM International Conference on Multimedia, ACM MM, Nice, France, 21–25 October 2019. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the European Conference on Computer Vision, ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, ICML, Virtual, 13–18 July 2020. [Google Scholar]
- Wang, F.; Liu, H. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, NeurIPS, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Nguyen, P.X.; Ramanan, D.; Fowlkes, C.C. Weakly-supervised action localization with background modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, D.; Jiang, T.; Wang, Y. Completeness modeling and context separation for weakly supervised temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lee, P.; Uh, Y.; Byun, H. Background suppression network for weakly-supervised temporal action localization. In Proceedings of the Conference on Artificial Intelligence, AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Lee, P.; Wang, J.; Lu, Y.; Byun, H. Weakly-supervised temporal action localization by uncertainty modeling. In Proceedings of the Conference on Artificial Intelligence, AAAI, Vancouver, BC, Canada, 2–9 February 2021. [Google Scholar]
- De Avila, S.E.F.; Lopes, A.P.B.; da Luz Jr, A.; de Albuquerque Araújo, A. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recognit. Lett. 2011, 32, 56–68. [Google Scholar] [CrossRef]
- Otani, M.; Nakashima, Y.; Rahtu, E.; Heikkila, J. Rethinking the evaluation of video summaries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kendall, M.G. The treatment of ties in ranking problems. Biometrika 1945, 33, 239–251. [Google Scholar] [CrossRef] [PubMed]
- Beyer, W.H. Standard Probability and Statistics: Tables and Formulae; CRC Press: Boca Raton, FL, USA, 1991. [Google Scholar]
- Potapov, D.; Douze, M.; Harchaoui, Z.; Schmid, C. Category-specific video summarization. In Proceedings of the European Conference on Computer Vision, ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Saquil, Y.; Chen, D.; He, Y.; Li, C.; Yang, Y.L. Multiple Pairwise Ranking Networks for Personalized Video Summarization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Heads | Optimizer | LR | Weight Decay | Batch Size | Epoch | Dropout | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard | 4 | 1 | 128 | 64 | 512 | Adam | 0.0001 | 0.0001 | 32 (TVSum) 8 (SumMe) | 40 | 0 |
| YT8M | 4 | 8 | 128 | 64 | 512 | Adam | 0.0001 | 0.0005 | 128 | 40 | 0 |
| TVSum | SumMe | |||
|---|---|---|---|---|
| Human baseline [74] | 0.1755 | 0.2019 | 0.1796 | 0.1863 |
| Supervised | ||||
| VASNet [5,74] | 0.1690 | 0.2221 | 0.0224 | 0.0255 |
| dppLSTM [2,69] | 0.0298 | 0.0385 | −0.0256 | −0.0311 |
| SumGraph [48] | 0.094 | 0.138 | - | - |
| Multi-ranker [74] | 0.1758 | 0.2301 | 0.0108 | 0.0137 |
| Clip-It † [23] | 0.108 | 0.147 | - | |
| † [24] | 0.137 | 0.165 | 0.108 | 0.129 |
| Unsupervised | ||||
| DR-DSN60 [12,69] | 0.0169 | 0.0227 | 0.0433 | 0.0501 |
| DR-DSN2000 [12,74] | 0.1516 | 0.198 | −0.0159 | −0.0218 |
| SUM-FCNunsup [9,74] | 0.0107 | 0.0142 | 0.0080 | 0.0096 |
| SUM-GAN [8,74] | −0.0535 | −0.0701 | −0.0095 | −0.0122 |
| CSNet + GL + RPE [14] | 0.070 | 0.091 | - | - |
| Training-free | ||||
| 0.1055 | 0.1389 | 0.0960 | 0.1173 | |
| & | 0.1345 | 0.1776 | 0.0819 | 0.1001 |
| Contrastively refined | ||||
| 0.1002 | 0.1321 | 0.0942 | 0.1151 | |
| & | 0.1231 | 0.1625 | 0.0689 | 0.0842 |
| & | 0.1388 | 0.1827 | 0.0585 | 0.0715 |
| & & | 0.1609 | 0.2118 | 0.0358 | 0.0437 |
| TVSum | SumMe | |||||
|---|---|---|---|---|---|---|
| C | A | T | C | A | T | |
| Unsupervised | ||||||
| DR-DSN60 [12] | 57.6 | 58.4 | 57.8 | 41.4 | 42.8 | 42.4 |
| SUM-FCNunsup [9] | 52.7 | - | - | 41.5 | - | 39.5 |
| SUM-GAN [8] | 51.7 | 59.5 | - | 39.1 | 43.4 | - |
| UnpairedVSN [11] | 55.6 | - | 55.7 | 47.5 | - | 41.6 |
| CSNet [13] | 58.8 | 59 | 59.2 | 51.3 | 52.1 | 45.1 |
| CSNet + GL + RPE [14] | 59.1 | - | - | 50.2 | - | - |
| SumGraphunsup [48] | 59.3 | 61.2 | 57.6 | 49.8 | 52.1 | 47 |
| Training-free | ||||||
| 56.4 | 56.4 | 54.6 | 43.5 | 43.5 | 39.4 | |
| & | 58.4 | 58.4 | 56.8 | 47.2 | 46.07 | 41.7 |
| Contrastively refined | ||||||
| 54.6 | 55.1 | 53 | 46.8 | 47.1 | 41.5 | |
| & | 58.8 | 59.9 | 57.4 | 46.7 | 48.4 | 41.1 |
| & | 53.8 | 56 | 54.3 | 45.2 | 45 | 45.3 |
| & & | 59.5 | 59.9 | 59.7 | 46.8 | 45.5 | 43.9 |
| TVSum | SumMe | |||||
|---|---|---|---|---|---|---|
| F1 | F1 | |||||
| Unsupervised | ||||||
| DR-DSN [12] | 51.6 | 0.0594 | 0.0788 | 39.8 | −0.0142 | −0.0176 |
| Training-free | ||||||
| 55.9 | 0.0595 | 0.0779 | 45.5 | 0.1000 | 0.1237 | |
| & | 56.7 | 0.0680 | 0.0899 | 42.9 | 0.0531 | 0.0649 |
| Contrastively refined | ||||||
| 56.2 | 0.0911 | 0.1196 | 46.6 | 0.0776 | 0.0960 | |
| & | 57.3 | 0.1130 | 0.1490 | 40.9 | 0.0153 | 0.0190 |
| & | 58.1 | 0.1230 | 0.1612 | 48.7 | 0.0780 | 0.0964 |
| & & | 59.4 | 0.1563 | 0.2048 | 43.2 | 0.0449 | 0.0553 |
| TVSum | SumMe | |||||
|---|---|---|---|---|---|---|
| F1 | F1 | |||||
| DR-DSN [12] | 51.6 | 0.0594 | 0.0788 | 39.8 | −0.0142 | −0.0176 |
| 2L2H | 58.0 | 0.1492 | 0.1953 | 42.9 | 0.0689 | 0.0850 |
| 2L4H | 58.1 | 0.1445 | 0.1894 | 42.8 | 0.0644 | 0.0794 |
| 2L8H | 58.8 | 0.1535 | 0.2011 | 44.0 | 0.0584 | 0.0722 |
| 4L2H | 57.4 | 0.1498 | 0.1963 | 45.3 | 0.0627 | 0.0776 |
| 4L4H | 58.3 | 0.1534 | 0.2009 | 43.1 | 0.0640 | 0.0790 |
| 4L8H | 58.5 | 0.1564 | 0.2050 | 42.7 | 0.0618 | 0.0765 |
| TVSum | SumMe | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| & | & | |||||||||||
| F1 | F1 | F1 | F1 | |||||||||
| Supervised (2D) | ||||||||||||
| VGG19 [75] | 50.62 | 0.0745 | 0.0971 | 55.91 | 0.1119 | 0.1473 | 45.16 | 0.0929 | 0.1151 | 43.28 | 0.0899 | 0.1114 |
| GoogleNet [54] | 54.67 | 0.0985 | 0.1285 | 57.09 | 0.1296 | 0.1699 | 41.89 | 0.0832 | 0.1031 | 40.97 | 0.0750 | 0.0929 |
| InceptionV3 [73] | 55.02 | 0.1093 | 0.1434 | 55.63 | 0.0819 | 0.1082 | 42.71 | 0.0878 | 0.1087 | 42.30 | 0.0688 | 0.0851 |
| ResNet50 [76] | 51.19 | 0.0806 | 0.1051 | 55.19 | 0.1073 | 0.1410 | 42.30 | 0.0868 | 0.1076 | 43.86 | 0.0737 | 0.0914 |
| ResNet101 [76] | 51.75 | 0.0829 | 0.1081 | 54.88 | 0.1118 | 0.1469 | 42.32 | 0.0911 | 0.1130 | 44.39 | 0.0736 | 0.0913 |
| ViT-S-16 [77] | 53.48 | 0.0691 | 0.0903 | 56.15 | 0.1017 | 0.1332 | 40.30 | 0.0652 | 0.0808 | 40.88 | 0.0566 | 0.0701 |
| ViT-B-16 [77] | 52.85 | 0.0670 | 0.0873 | 56.15 | 0.0876 | 0.1152 | 42.10 | 0.0694 | 0.0860 | 41.65 | 0.0582 | 0.0723 |
| Swin-S [78] | 52.05 | 0.0825 | 0.1082 | 57.58 | 0.1120 | 0.1475 | 41.18 | 0.0880 | 0.1090 | 41.63 | 0.0825 | 0.1022 |
| Supervised (3D) | ||||||||||||
| R3D50 [79] | 52.09 | 0.0590 | 0.0766 | 53.35 | 0.0667 | 0.0869 | 37.40 | 0.0107 | 0.0138 | 41.03 | 0.0150 | 0.0190 |
| R3D101 [79] | 49.77 | 0.0561 | 0.0727 | 52.15 | 0.0644 | 0.0834 | 33.62 | 0.0173 | 0.0216 | 34.96 | 0.0212 | 0.0264 |
| Self-supervised (2D) | ||||||||||||
| MoCo [80] | 51.31 | 0.0797 | 0.1034 | 55.97 | 0.1062 | 0.1390 | 42.01 | 0.0768 | 0.0953 | 43.19 | 0.0711 | 0.0882 |
| DINO-S-16 [15] | 52.50 | 0.0970 | 0.1268 | 57.57 | 0.1200 | 0.1583 | 42.77 | 0.0848 | 0.1050 | 42.67 | 0.0737 | 0.0913 |
| DINO-B-16 [15] | 52.48 | 0.0893 | 0.1170 | 57.02 | 0.1147 | 0.1515 | 41.07 | 0.0861 | 0.1066 | 44.14 | 0.0679 | 0.0843 |
| BEiT-B-16 [81] | 49.64 | 0.1125 | 0.1468 | 56.34 | 0.1270 | 0.1665 | 36.91 | 0.0554 | 0.0686 | 38.48 | 0.0507 | 0.0629 |
| MAE-B-16 [82] | 50.40 | 0.0686 | 0.0892 | 54.58 | 0.1013 | 0.1327 | 40.32 | 0.0560 | 0.0695 | 39.46 | 0.0484 | 0.0601 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, Z.; Nakashima, Y.; Otani, M.; Nagahara, H. Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization. J. Imaging 2024, 10, 229. https://doi.org/10.3390/jimaging10090229
Pang Z, Nakashima Y, Otani M, Nagahara H. Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization. Journal of Imaging. 2024; 10(9):229. https://doi.org/10.3390/jimaging10090229
Chicago/Turabian StylePang, Zongshang, Yuta Nakashima, Mayu Otani, and Hajime Nagahara. 2024. "Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization" Journal of Imaging 10, no. 9: 229. https://doi.org/10.3390/jimaging10090229
APA StylePang, Z., Nakashima, Y., Otani, M., & Nagahara, H. (2024). Unleashing the Power of Contrastive Learning for Zero-Shot Video Summarization. Journal of Imaging, 10(9), 229. https://doi.org/10.3390/jimaging10090229