Abstract
Apolipoprotein B (APOB) is a key structural component of atherogenic lipoproteins and one of the principal genes implicated in familial hypercholesterolemia (FH). However, APOB genetic variation remains poorly characterized in Latin American and admixed populations. In this study, we performed a descriptive analysis of APOB variants in 60 Ecuadorian mestizo patients with inherited cardiac conditions using next-generation sequencing (NGS) and genetic ancestry inference. A total of 227 APOB variants were identified, the majority of which were classified as benign (n = 220) or likely benign (n = 3) according to ACMG criteria, while three variants were classified as variants of uncertain significance (VUS). The most frequently observed variants included rs1042034, rs679899, rs676210, and rs1367117. Comparative allele-frequency analyses using ALFA and PAGE Latin American reference datasets demonstrated that the APOB variant frequencies observed in the cohort were comparable to those reported in other Latin American populations, reflecting the admixed genetic background of Ecuadorian mestizos, predominantly of Native American and European ancestry. No pathogenic APOB variants were detected. Although lipid measurements were not available and genotype–phenotype associations could not be assessed, this study provides the first comprehensive overview of APOB variation in Ecuadorian mestizo individuals. These findings expand population-specific genomic data for an underrepresented group and underscore the importance of regional reference datasets for accurate variant interpretation in admixed populations.
1. Introduction
APOB is a critical structural and functional component of atherogenic lipoproteins, including very low-density lipoproteins (VLDL), intermediate-density lipoproteins (IDL), and low-density lipoprotein (LDL) [1]. It serves as the sole apolipoprotein in LDL and functions as the ligand for LDL receptor (LDLR), mediating hepatic clearance of LDL particles [2]. Variants that impair this interaction can disrupt LDL uptake, whereas truncating APOB mutations reduce VLDL assembly and may lead to hypocholesterolemia [1,3]. For instance, pathogenic APOB variants associated with LDLR-binding defects, such as the well-characterized p.Arg3527Gln mutation, have been described primarily in European and Asian populations [2,4].
Familial hypercholesterolemia (FH) is an inherited disorder of lipid metabolism, characterized by markedly elevated plasma low-density lipoprotein cholesterol (LDL-C) levels and a significantly increased risk of premature atherosclerotic cardiovascular disease (ASCVD) [5,6,7,8]. Pathogenic APOB variants represent one of the three primary causes of autosomal dominant FH, alongside mutations in LDLR and PCSK9 [3]. Approximately 5–10% of genetically confirmed FH cases are attributed to APOB mutations [5]. However, most APOB variants identified to date are benign or of uncertain significance, and their functional impact often remains unknown.
While most studies on FH have focused on identifying single pathogenic variants with large effects, the role of multiple low-impact or benign variants in modifying the disease phenotype is being increasingly recognized [9,10]. In individuals without clearly identifiable pathogenic variants, hypercholesterolemia may result from the cumulative effect of multiple common single nucleotide polymorphisms (SNPs), each exerting a modest influence on LDL-C levels. These polygenic risk scores (PRS) not only provide a potential alternative explanation for hypercholesterolemia but also may serve as phenotype modifiers in those with monogenic FH [11]. Moreover, PRS may help explain the biochemical heterogeneity observed among patients carrying the same monogenic variant, as the presence of multiple common variants can either exacerbate or attenuate the clinical expression of FH [12,13]. Although PRS is not currently considered a diagnostic tool and its utility may vary across populations, it represents a valuable approach for elucidating the genetic architecture and phenotypic variability of hypercholesterolemia [12].
Although FH and APOB variants have been studied in populations of European or Asian descent, Latin American populations remain markedly underrepresented in genomic and clinical research [14,15]. This lack of representation limits the interpretation of genetic variants, hinders the development of population-specific reference datasets, and may contribute to disparities in diagnosis, treatment efficacy, and risk assessment [14,15,16]. Furthermore, highly admixed groups, including Ecuadorian Mestizos, which have a mixture of Native American, European, and African contributions, are especially affected, as allele frequencies and variant classifications derived from non-admixed populations may not accurately reflect their genetic architecture [17].
Given that APOB variation is understudied in Latin America, and considering the admixed genetic composition of Ecuadorian populations, population-specific allele characterization is essential for accurate genomic interpretation. Thus, this study represents the first comprehensive characterization of APOB variants in Ecuadorian Mestizo individuals. The goal of this study is to describe the spectrum of APOB variants identified in Ecuadorian mestizo patients with inherited cardiac conditions, by integrating Next-Generation Sequencing with genetic ancestry analysis and describe potential implications for variant interpretation in underrepresented populations.
2. Materials and Methods
2.1. Study Population
The present study involved the analysis of the APOB gene in sixty Ecuadorian mestizo patients diagnosed with an inherited cardiac condition, including hypertrophic cardiomyopathy, long QT syndrome, atrial flutter, atrioventricular block, cardiac arrhythmias, Brugada syndrome, systolic murmur, arrhythmogenic cardiomyopathy, Ebstein anomaly, and Wolff-Parkinson-White syndrome. The ages ranged from 9 days to 70 years old. This cohort included patients derived from the electrophysiological unit from a third-level Ecuadorian hospital (Quito–Ecuador). The individuals must meet the following inclusion criteria: self-reported Ecuadorian mestizo ethnicity and confirmed or suspected hereditary cardiac disorder based on clinical evaluation Lipid profiles, including LDL-C measurements, were not available.
2.2. Sampling, DNA Extraction and Quantification
A peripheral blood sample from each individual was collected in EDTA tubes, following the signing of the informed consent. DNA extraction was carried out with the PureLink Genomic DNA Mini Kit, starting from 200 uL of the blood sample according to the manufacturer’s instructions [18]. The DNA quality and quantity was measured by fluorometric method (Qubit) through Broad Range dsDNA Assay (Thermo Fisher Scientific, Waltham, MA, USA) following the manufacturer’s protocol [19].
2.3. Next Generation Sequencing
NGS was performed using the TruSight Cardio Kit (Illumina, San Diego, CA, USA), which covers 174 genes associated with 17 inherited cardiac diseases including FH, according to the manufacturer’s protocol [20]. After library preparation, this was diluted and denatured to 10 pM and combined with denatured PhiX (12.5 pM) control to form a final volume of 600 µL, which was loaded into a v2 300 cycle Miseq cartridge, and run at the Illumina Miseq Next Generation Sequencer (Illumina, San Diego, CA, USA) (315 cycles), according to the manufacturer’s instructions [21,22].
2.4. Variant Calling and American College of Medical Genetics and Genomics (ACMG) Interpretation
For genomic data, the FASTQ file generated at BaseSpace (Illumina, San Diego, CA, USA) was analyzed in the Dragen Enrichment (v. 3.10.4) software to align it against reference genome sequence (GRCh38), which allowed the identification of genomic variants like SNPs, insertions, deletions, and structural variations (variant calling). After variant calling, the Q30 quality of all variants were analyzed to remove false positives and keep high-confidence variants. Next, the Variant Interpreter (Illumina, San Diego, CA, USA, v2.17) software was used to annotate the APOB variants and to convert to the nomenclature recommended by the Human Genome Variation Society (HGVS).
All APOB variants were analyzed and classified according to ACMG guidelines [23]. The Franklin® variant interpretation platform (Genoox, Tel Aviv, Israel) was used for automated ACMG evaluation, followed by manual review when discrepancies were detected. Notably, this platform uses information retrieved from clinical databases, including ClinVar [18], and compiles the results of various in silico prediction software programs such as Revel, AlphaMissense, FATHMM, Mut Assesor, SIFT, MutationTaster, DANN, MetaLR, PrimateAI, and BayesDel. Lastly, Franklin® variant interpretation platform also includes the variant frequency based on information of the Genome Aggregation Database (gnomAD v3.1).
2.5. Genetic Ancestry Determination
Ancestry Informative Markers (AIMs), which include a collection of insertion/deletion (InDel) polymorphisms was used for ancestry determination, according to the protocol described by Zambrano et al. (2019) [17]. Fragment analysis and capillary electrophoresis were performed using a 3500 Genetic Analyzer from Applied Biosystems (Waltham, MA, USA).
The bioinformatics pipeline included ancestry inference analyses using STRUCTURE software v2.3.4, by comparing genotypic data from the 46 AIMS-InDels polymorphisms against populations of reference reported in the HGDP-CEPH panel (Africans, Europeans, and Native Americans; subset H952) [24,25,26]. An admixture model “Use population information to test for migrants”, with a burn-in length of 10,000, and 10,000 Markov Chain Monte Carlo (MCMC) iterations was used. The number of cluster (K) was evaluated from K = 1 to K = 3, and the results were visualized as triangular plots generated, using STRUCTURE, to illustrate individual ancestry proportions and population admixture patterns.
3. Results
3.1. Variant Detection in the APOB Gene
This study analyzed genetic variants in 60 Ecuadorian mestizo individuals diagnosed with hereditary cardiovascular disease using the TruSight Cardio Kit (Illumina) for targeted sequencing, resulting in a 20× coverage in 99% of the targeted APOB regions. A total of 227 APOB gene variants were identified across all samples, some of which were recurrent among different individuals. Figure 1 illustrates the number of variants identified in each exon of the APOB gene.
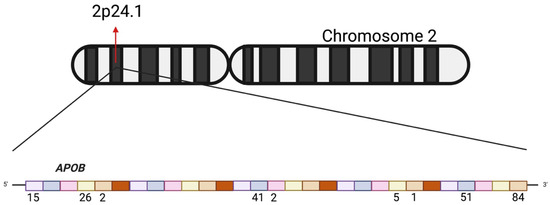
Figure 1.
Representation of the APOB gene on chromosome 2 (2p24.1). The upper panel shows the chromosomal localization of the gene. The lower panel illustrates the gene structure, where each colored block represents an exon. Numbers below the exons indicate the number of variants identified within each exon in the present study.
3.2. Variant Frequency in the Cohort
The most frequently identified benign variants in the cohort were rs1042034 (c.13013G>A), rs679899 (c.1853C>T), rs1367117 (c.293C>T), and rs13306194 (c.8216C>T). Among these, rs1042034 exhibited the highest frequency, with 54 occurrences across the analyzed samples. This was followed by rs679899, rs13306194, and rs1367117, all of which were recurrently detected in multiple individuals within the study population.
A total of 227 genetic variants were identified in the APOB gene. Of these, 220 were classified as benign, 3 as likely benign, and 4 as variants of uncertain significance (VUS) according to the ACMG guidelines (Figure 2). In addition to common variants, several low-frequency and benign variants were also identified in the APOB gene, each detected in a single individual. Among the benign variants, rs533617 (c.5768A>G), rs12713843 (c.3383G>A), rs72653077 (c.3427C>T), rs61736761 (c.3634C>A), and rs12713450 (c.13451C>T) were observed. Furthermore, three variants were classified as likely benign rs141225768 (c.4663A>G), rs72653098 (c.8912A>C), and rs142638069 (c.5110G>A). Additionally, three variants were categorized as VUS such as rs531341535 (c.3443T>A), rs539614975 (c.3379C>T), and rs769491475 (c.9871C>T). The detection of these rare variants emphasizes the genetic heterogeneity present in the Ecuadorian mestizo population. The use of a cardiovascular genetic panel enabled the detection of common and rare variants associated with familial hypercholesterolemia in the APOB gene in Ecuadorian Mestizo population.
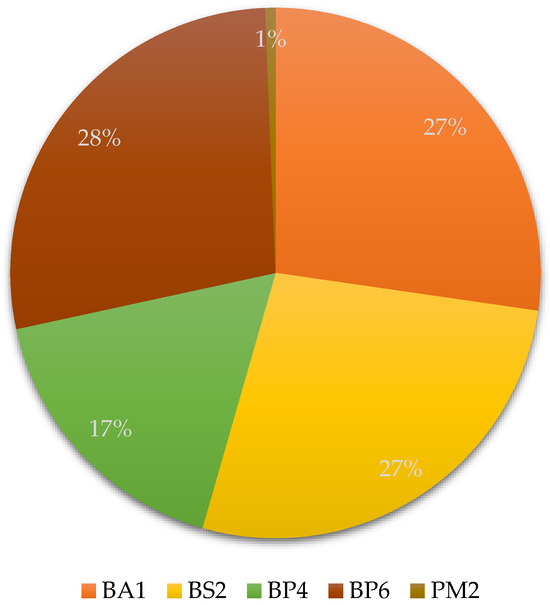
Figure 2.
Distribution of APOB variants according to ACMG evidence criteria. The pie chart illustrates the proportion of APOB gene variants identified in the study. Most variants were categorized as benign based on population frequency and computational data: BA1 (benign stand-alone), BS2 (benign strong), BP4 and BP6 (benign supporting). Only a minor fraction of variants exhibited PM2 (pathogenic moderate) evidence, indicating very low population frequency but insufficient data for definitive pathogenic classification.
3.3. Comparative Allele Frequencies with Population Databases
In addition to the variants classification, Table 1 lists all APOB variants identified in the cohort, including HGVS annotations, molecular consequences, zygosity, ACMG classifications with associated criteria. For each variant, the number of carriers and the corresponding cohort frequency are reported, providing a comprehensive overview of APOB genetic variation in this population.

Table 1.
Missense variants identified in the APOB gene in the study cohort.
Figure 3 compares the allele frequencies of APOB gene variants identified in our Ecuadorian patient cohort with those reported in ALFA, and PAGE population databases. Furthermore, Supplementary Table S1 summarizes missense variants identified in the cohort, indicating SNP identifiers, HGVS nomenclature, predicted consequences, ACMG classification and criteria, population allele frequencies (ALFA and PAGE), the number of carriers, and the corresponding variant frequencies within the study cohort.
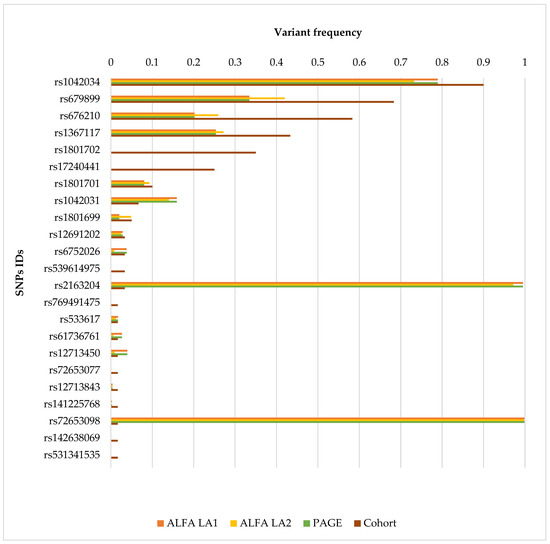
Figure 3.
Comparison of APOB Variant Allele Frequencies in Ecuadorian Patients and Reference Populations. The bar chart compares the allele frequencies of APOB gene variants identified in a cohort of Ecuadorian patients with suspected hereditary cardiac conditions against reference populations. Each bar corresponds to a specific single nucleotide polymorphism (SNP), identified by its SNP ID on the y-axis. The x-axis represents allele frequency values ranging from 0 to 1. Four data sources are shown per variant: ALFA Latin American 1 (LA1) (orange), ALFA Latin American 2 (LA2) (blue), PAGE database (green), and the study cohort (brown). This graphical representation allows for a direct visual comparison of variant frequencies between the Ecuadorian cohort and Latin American populations reported in public databases.
3.4. Genetic Ancestry Determination
Ancestry analysis of the Ecuadorian Mestizo cohort showed a mainly Native American genetic background (58.3%), followed by European (32.9%) and African (8.8%) components. Figure 4 illustrates that most individuals cluster along the Native American and European axis, with a minimal dispersion toward the African vertex. This pattern is consistent with the admixed genetic composition historically described in the Ecuadorian populations. The predominance of Native American ancestry could provide crucial information for interpreting allele frequency differences and may identify potential population-specific variants observed in the APOB gene.
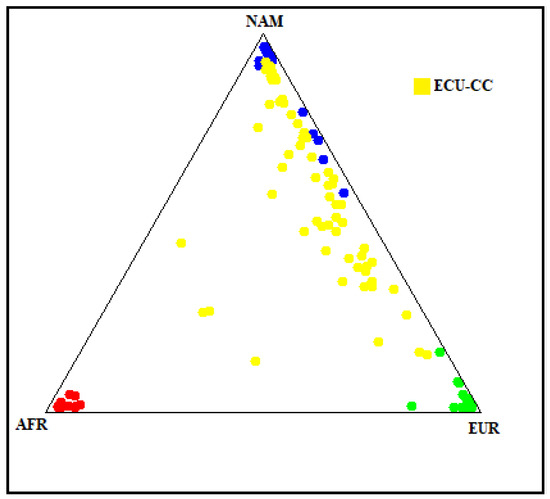
Figure 4.
Genetic ancestry composition of the Ecuadorian Mestizo cohort. The plot illustrates the genetic ancestry proportions of the study cohort (yellow dots, labeled ECU-CC) in comparison with reference populations of African (AFR, red), Native American (NAM, blue), and European (EUR, green) origin. Each point represents an individual’s ancestry component estimated from 46 AIMs polymorphisms.
4. Discussion
APOB mutations account for approximately 5–10% of all FH cases, which could potentially lead to a compromised cardiovascular health due to elevated levels of LDL-C [27]. These mutations typically occur within the LDL receptor-binding domain of apolipoprotein B-100, disrupting receptor interaction and leading to the accumulation of LDL-C in plasma [1,28]. However, many variants in APOB are located outside this functional region or have not been experimentally characterized, limiting their clinical interpretation [20,27,28].
A comprehensive study that compiled global APOB variant data up to November 2015 identified 97 distinct variants associated with FH. Of these, 83% were missense and 97% were single-nucleotide substitutions. Importantly, 80.4% lacked sufficient functional evidence and were classified as variants of uncertain significance (VUS) based on ACMG criteria. The geographical distribution of these variants was markedly skewed, with countries such as Portugal (40 variants), France (12), and Germany (9) reporting high mutational diversity, while no pathogenic APOB variants were documented in African populations. These findings underscore the underrepresentation of many regions, including Latin America, in genomic studies and highlight the need of population-specific research [20].
Ethnic and regional variability in APOB variation has been described in several populations. For instance, the Malaysian Health and Wellbeing Assessment reported frequencies of APOB pathogenic variants comparable to LDLR mutations [29], while other studies highlight inconsistencies in variant annotation and classification across databases [29,30]. These disparities further complicate variant interpretation, especially in admixed populations.
The ancestry composition of the patients included in the study provides noteworthy context for interpreting the APOB variants identified. The predominance of Native American ancestry (58.3%), together with European (32.9%) and African (8.8%) proportions, reflects the characteristic admixture of the Ecuadorian Mestizo population, which aligns with previously reported studies [17].
Consistent with global datasets, most APOB variants detected in our study were classified as benign according to ACMG criteria. The absence of pathogenic variants may be attributed to our cohort not being selected for hypercholesterolemia and the unavailability of lipid measurements (including LDL-C), preventing a direct genotype–phenotype correlation. Nonetheless, several recurrent benign variants identified in our cohort have been associated with lipid traits or cardiometabolic phenotypes in other populations. Examples include the rs2163204 (c.8353A>C) variant, which has been identified in risk haplotypes associated with hyperlipidemia and exists in linkage disequilibrium with other functional variants of the APOB gene (rs1042034, rs676210, and rs679899) [31]. Furthermore, thers1801702 (c.12809G>C) variant has also shown significant associations with elevated total cholesterol and LDL-C levels in Latin American populations. Specifically, individuals of Mayan ancestry carrying the G allele demonstrated higher lipid concentrations [32], a finding replicated in Caribbean Hispanics in Manhattan [33]. Although this variant has been classified as benign under monogenic disease criteria, its cumulative effect suggests an important functional role within the spectrum of polygenic hypercholesterolemia, especially in underrepresented population contexts [33,34].
Similar cases include the rs679899 variant, which population-level associations have suggested broader implications in LDL-C levels and chronic kidney disease in hypertensive patients [35,36,37,38]. More examples include the rs1042031 [34,39,40,41,42,43,44], rs533617 [45,46,47,48] rs17240441 [30,48,49,50], rs61736761 [17,51,52], rs1042034 [53,54,55,56], rs1367117 [57,58,59], rs6752026 [4,36,60,61,62,63,64], and rs676210 [65,66,67,68]. Although these associations are heterogeneous and often population-specific, they collectively illustrate that APOB variation may modulate lipid phenotypes within polygenic or context-dependent models. However, such mechanisms cannot be evaluated in the present study due to the lack of available lipid data and the heterogeneous clinical indications of the cohort.
Lastly, among the variants identified in our cohort, nine more missense variants were also identified: rs141225768, rs72653098, rs72653077, rs127113450, rs1801699, rs1801701, rs12713843, rs142638069, and rs12691202. According to ACMG criteria, these variants have been classified as benign, and likely benign; however, there is no evidence of the potential pathogenicity of the variants, as these substitutions may alter structural domains and could collectively influence the lipid phenotypes. Thus, further functional characterization is required to understand the impact of these changes.
Therefore, the characterization of benign variants should not be overlooked in the context of FH. Especially in underexplored populations, such as the Ecuadorian mestizo population, because these types of variants could exert a cumulative effect that contributes to the hyperlipidemic phenotype, even in the absence of classic pathogenic mutations. This context encourages us to rethink the functional significance of these variants within models of polygenic inheritance and underscores the necessity to adjust clinical and genetic algorithms to reflect more diverse and multifaceted situations [11,34,69].
Moreover, this scenario highlights the need for implementing more advanced genetic characterization strategies, including cascade testing, in silico prediction tools, and experimental validation [11]. By incorporating variants typically considered benign, which may have functional significance in complex inheritance models, this approach can significantly enhance the stratification of cardiovascular risk.
Notably, our study identified three VUS: rs539614975, rs769491475, and rs531341535. These subset of variants exhibit low allele frequencies across reference datasets, which could suggest their relevance as rare variants and potential clinical implications. The absence of these variants at high frequencies in healthy populations supports the hypothesis that they could be of pathogenic significance. Furthermore, the overall similarity between the cohort and ALFA/PAGE allele frequencies highlights the genetic representativeness of our study population within the broader Latin American context. These findings reinforce the utility of population-specific databases for interpreting genetic variants in admixed populations.
Although benign variants are traditionally assumed to have minimal functional impact, accumulating evidence suggests that multiple low-effect variants can collectively influence lipid traits and may contribute to polygenic hypercholesterolemia [70,71,72,73,74]. A variant deemed benign in one population may potentially contribute to disease susceptibility in specific genetic contexts. Furthermore, the accumulation of multiple benign variants, each with minimal effect on its own, can collectively reach a threshold where the combined genetic burden influences disease risk [73,74]. Given the admixed ancestry of Ecuadorians, the cumulative burden of benign variants may differ from that of other populations. However, without LDL-C data, this possibility remains hypothetical and should be addressed in future studies integrating polygenic scores, lipid measurements, and functional assays.
The present study has limitations. First, LDL-C and other lipid parameters were unavailable, preventing direct phenotype–genotype analyses and limiting clinical interpretation. Second, patients were not selected based on hypercholesterolemia, but rather on diverse hereditary cardiac disorders, which restricts comparisons to FH-oriented studies. Furthermore, the study lies in the lack of in vitro or in vivo functional analyses that would confirm the biological relevance of the identified benign variants, particularly those with indirect or contextual associations with lipid metabolism. Additionally, the clinical interpretation of variants in highly polymorphic genes such as APOB may be limited by the limited availability of representative databases for Latin American populations, which could have influenced the automated classification of some variants according to the ACMG criteria.
Lastly, the limited sample size, and the absence of segregation analyses and a healthy control group hinder the precise assessment of the statistical significance of allele frequencies within a larger epidemiological framework. Future research should consider integrating polygenic, transcriptomic, and epigenetic analyses, as well as cellular models, to assess the functional impact of the variants.
In conclusion, this study provides the first descriptive analysis of APOB variation in Ecuadorian mestizo individuals using next-generation sequencing and ancestry inference. Although no pathogenic APOB variants were identified, the dataset expands regional genomic knowledge and highlights the importance of population-specific allele frequencies for variant interpretation. The identification of rare VUS and the predominance of benign variants underscore the need for broader genomic research in Latin America, including functional and clinical studies, to better understand the implications of APOB variation in genetically admixed populations.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/jcdd13010036/s1: Supplementary Table S1: Missense Variants Identified in the Cohort.
Author Contributions
Conceptualization, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R. and A.K.Z.; Methodology, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R. and A.K.Z.; Formal Analysis, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R. and A.K.Z.; Investigation, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R., M.B.-F., N.D., A.C.-A. and A.K.Z.; Resources, J.L.L.-B. and R.I.-C.; Data Curation, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R. and A.K.Z.; Writing—Original Draft Preparation, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R. and A.K.Z.; Writing—Review and Editing, S.C.-U., V.A.R.-P., R.T.-T., E.P.-C., P.G.-R., M.B.-F., N.D., J.L.L.-B., R.I.-C., A.C.-A. and A.K.Z.; Supervision, A.K.Z.; Project Administration, A.K.Z.; Funding Acquisition, A.K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The present project was funded by Universidad UTE.
Institutional Review Board Statement
The present study was reviewed and approved by the Ethics Committee (Comité de Ética en Investigación en Seres Humanos, CEISH) from Universidad UTE (CEISH-2021-016). All participants provided written informed consent prior to inclusion.
Data Availability Statement
Variants have been presents in the article. However, due to the size of the information and the fact that some information will be part of other articles, data may be made available upon a considerable request.
Acknowledgments
The authors are grateful to Universidad UTE for their support.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abifadel, M.; Boileau, C. Genetic and Molecular Architecture of Familial Hypercholesterolemia. J. Intern. Med. 2023, 293, 144–165. [Google Scholar] [CrossRef]
- Alves, A.C.; Benito-Vicente, A.; Medeiros, A.M.; Reeves, K.; Martin, C.; Bourbon, M. Further Evidence of Novel APOB Mutations as a Cause of Familial Hypercholesterolaemia. Atherosclerosis 2018, 277, 448–456. [Google Scholar] [CrossRef]
- Di Taranto, M.D.; Giacobbe, C.; Fortunato, G. Familial Hypercholesterolemia: A Complex Genetic Disease with Variable Phenotypes. Eur. J. Med. Genet. 2020, 63, 103831. [Google Scholar] [CrossRef] [PubMed]
- Phan, L.; Jin, Y.; Zhang, H.; Qiang, W.; Shekhtman, E.; Shao, D.; Revoe, D.; Villamarin, R.; Ivanchenko, E.; Kimura, M.; et al. ALFA: Allele Frequency Aggregator; National Center for Biotechnology Information, U.S. National Library of Medicine: Bethesda, MD, USA, 2020; pp. 2–5.
- Fairoozy, R.H.; Futema, M.; Vakili, R.; Abbaszadegan, M.R.; Hosseini, S.; Aminzadeh, M.; Zaeri, H.; Mobini, M.; Humphries, S.E.; Sahebkar, A. The Genetic Spectrum of Familial Hypercholesterolemia (FH) in the Iranian Population. Sci. Rep. 2017, 7, 17087. [Google Scholar] [CrossRef] [PubMed]
- Huijgen, R.; Stork, A.D.M.; Defesche, J.C.; Peter, J.; Alonso, R.; Cuevas, A.; Kastelein, J.J.P.; Duran, M.; Stroes, E.S.G. Extreme Xanthomatosis in Patients with Both Familial Hypercholesterolemia and Cerebrotendinous Xanthomatosis. Clin. Genet. 2012, 81, 24–28. [Google Scholar] [CrossRef] [PubMed]
- Tada, H.; Kawashiri, M.A.; Nomura, A.; Teramoto, R.; Hosomichi, K.; Nohara, A.; Inazu, A.; Mabuchi, H.; Tajima, A.; Yamagishi, M. Oligogenic Familial Hypercholesterolemia, LDL Cholesterol, and Coronary Artery Disease. J. Clin. Lipidol. 2018, 12, 1436–1444. [Google Scholar] [CrossRef]
- Alieva, A.; Di Costanzo, A.; Gazzotti, M.; Reutova, O.; Usova, E.; Bakaleiko, V.; Arca, M.; D’Erasmo, L.; Pellegatta, F.; Galimberti, F.; et al. Genetic Heterogeneity of Familial Hypercholesterolaemia in Two Populations from Two Different Countries. Eur. J. Intern. Med. 2024, 123, 65–71. [Google Scholar] [CrossRef]
- Vanhoye, X.; Bardel, C.; Rimbert, A.; Moulin, P.; Rollat-Farnier, P.A.; Muntaner, M.; Marmontel, O.; Dumont, S.; Charrière, S.; Cornélis, F.; et al. A New 165-SNP Low-Density Lipoprotein Cholesterol Polygenic Risk Score Based on next Generation Sequencing Outperforms Previously Published Scores in Routine Diagnostics of Familial Hypercholesterolemia. Transl. Res. 2023, 255, 119–127. [Google Scholar] [CrossRef]
- Futema, M.; Shah, S.; Cooper, J.A.; Li, K.; Whittall, R.A.; Sharifi, M.; Goldberg, O.; Drogari, E.; Mollaki, V.; Wiegman, A.; et al. Refinement of Variant Selection for the LDL Cholesterol Genetic Risk Score in the Diagnosis of the Polygenic Form of Clinical Familial Hypercholesterolemia and Replication in Samples from 6 Countries. Clin. Chem. 2015, 61, 231–238. [Google Scholar] [CrossRef]
- Di Taranto, M.D.; Fortunato, G. Genetic Heterogeneity of Familial Hypercholesterolemia: Repercussions for Molecular Diagnosis. Int. J. Mol. Sci. 2023, 24, 3224. [Google Scholar] [CrossRef]
- Ayoub, A.; McHugh, J.; Hayward, J.; Rafi, I.; Qureshi, N. Polygenic Risk Scores: Improving the Prediction of Future Disease or Added Complexity? Br. J. Gen. Pract. 2022, 72, 396. [Google Scholar] [CrossRef]
- Cupido, A.J.; Tromp, T.R.; Hovingh, G.K. The Clinical Applicability of Polygenic Risk Scores for LDL-Cholesterol: Considerations, Current Evidence and Future Perspectives. Curr. Opin. Lipidol. 2021, 32, 112. [Google Scholar] [CrossRef]
- Garza, M.A.; Li, Y.; Fryer, C.S.; Assini-Meytin, L.C.; Ghebrendrias, S.; Puga, C.C.; Butler lll, J.; Quinn, S.C.; Thomas, S.B. Bridging the Gap: Understanding Latino Willingness to Participate in Public Health and Clinical Trials Research across Diverse Subgroups. Contemp. Clin. Trials Commun. 2025, 44, 101440. [Google Scholar] [CrossRef]
- Ramirez, A.G.; Chalela, P. Equitable Representation of Latinos in Clinical Research Is Needed to Achieve Health Equity in Cancer Care. JCO Oncol. Pract. 2022, 18, e797. [Google Scholar] [CrossRef] [PubMed]
- Mohan, S.V.; Freedman, J. A Review of the Evolving Landscape of Inclusive Research and Improved Clinical Trial Access. Clin. Pharmacol. Ther. 2023, 113, 518–527. [Google Scholar] [CrossRef] [PubMed]
- Zambrano, A.K.; Gaviria, A.; Cobos-Navarrete, S.; Gruezo, C.; Rodríguez-Pollit, C.; Armendáriz-Castillo, I.; García-Cárdenas, J.M.; Guerrero, S.; López-Cortés, A.; Leone, P.E.; et al. The Three-Hybrid Genetic Composition of an Ecuadorian Population Using AIMs-InDels Compared with Autosomes, Mitochondrial DNA and Y Chromosome Data. Sci. Rep. 2019, 9, 9247. [Google Scholar] [CrossRef]
- Thermo Fisher Scientific PureLink® Genomic DNA Kits For Purification of Genomic DNA. Available online: https://documents.thermofisher.com/TFS-Assets/LSG/manuals/purelink_genomic_man.pdf (accessed on 15 June 2025).
- Thermo Fisher Scientific User Guide: Qubit DsDNA BR Assay Kits. Available online: https://documents.thermofisher.com/TFS-Assets/LSG/manuals/Qubit_dsDNA_BR_Assay_UG.pdf (accessed on 15 June 2025).
- Chora, J.R.; Medeiros, A.M.; Alves, A.C.; Bourbon, M. Analysis of Publicly Available LDLR, APOB, and PCSK9 Variants Associated with Familial Hypercholesterolemia: Application of ACMG Guidelines and Implications for Familial Hypercholesterolemia Diagnosis. Genet. Med. 2018, 20, 591–598. [Google Scholar] [CrossRef]
- Illumina TruSight® Cardio Sequencing Kit Reference Guide. Available online: https://support.illumina.com/content/dam/illumina-support/documents/documentation/chemistry_documentation/samplepreps_trusight/trusight-cardio/trusight-cardio-sequencing-kit-reference-guide-15063774-01.pdf (accessed on 15 June 2025).
- Illumina Denature and Dilute Libraries for the MiSeq System. Available online: https://support-docs.illumina.com/IN/MiSeq_DnD/Content/MiSeq/DnD-MiSeq.htm?protocol=standard (accessed on 15 June 2025).
- Richards, S.; Aziz, N.; Bale, S.; Bick, D.; Das, S.; Gastier-Foster, J.; Grody, W.W.; Hegde, M.; Lyon, E.; Spector, E.; et al. Standards and Guidelines for the Interpretation of Sequence Variants: A Joint Consensus Recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet. Med. 2015, 17, 405. [Google Scholar] [CrossRef]
- Landrum, M.J.; Lee, J.M.; Riley, G.R.; Jang, W.; Rubinstein, W.S.; Church, D.M.; Maglott, D.R. ClinVar: Public Archive of Relationships among Sequence Variation and Human Phenotype. Nucleic Acids Res. 2014, 42, D980–D985. [Google Scholar] [CrossRef] [PubMed]
- Pereira, R.; Phillips, C.; Pinto, N.; Santos, C.; dos Santos, S.E.B.; Amorim, A.; Carracedo, Á.; Gusmão, L. Straightforward Inference of Ancestry and Admixture Proportions through Ancestry-Informative Insertion Deletion Multiplexing. PLoS ONE 2012, 7, e29684. [Google Scholar] [CrossRef]
- Rosenberg, N.A. Standardized Subsets of the HGDP-CEPH Human Genome Diversity Cell Line Panel, Accounting for Atypical and Duplicated Samples and Pairs of Close Relatives. Ann. Hum. Genet. 2006, 70, 841–847. [Google Scholar] [CrossRef]
- Vaezi, Z.; Amini, A. Familial Hypercholesterolemia; StatPearls: Orlando, FL, USA, 2022. [Google Scholar]
- Sturm, A.C.; Knowles, J.W.; Gidding, S.S.; Ahmad, Z.S.; Ahmed, C.D.; Ballantyne, C.M.; Baum, S.J.; Bourbon, M.; Carrié, A.; Cuchel, M.; et al. Clinical Genetic Testing for Familial Hypercholesterolemia: JACC Scientific Expert Panel. J. Am. Coll. Cardiol. 2018, 72, 662–680. [Google Scholar] [CrossRef] [PubMed]
- Razman, A.Z.; Chua, Y.A.; Mohd Kasim, N.A.; Al-Khateeb, A.; Sheikh Abdul Kadir, S.H.; Jusoh, S.A.; Nawawi, H. Genetic Spectrum of Familial Hypercholesterolaemia in the Malaysian Community: Identification of Pathogenic Gene Variants Using Targeted Next-Generation Sequencing. Int. J. Mol. Sci. 2022, 23, 14971. [Google Scholar] [CrossRef]
- Niu, C.; Luo, Z.; Yu, L.; Yang, Y.; Chen, Y.; Luo, X.; Lai, F.; Song, Y. Associations of the APOB Rs693 and Rs17240441 Polymorphisms with Plasma APOB and Lipid Levels: A Meta-Analysis. Lipids Health Dis. 2017, 16, 166. [Google Scholar] [CrossRef] [PubMed]
- Yoon, H.Y.; Song, T.J.; Yee, J.; Park, J.; Gwak, H.S. Association between Genetic Polymorphisms and Bleeding in Patients on Direct Oral Anticoagulants. Pharmaceutics 2022, 14, 1889. [Google Scholar] [CrossRef]
- Sánchez-Pozos, K.; Ortíz-López, M.G.; Peña-Espinoza, B.I.; de los Ángeles Granados-Silvestre, M.; Jiménez-Jacinto, V.; Verleyen, J.; Tekola-Ayele, F.; Sanchez-Flores, A.; Menjivar, M. Whole-Exome Sequencing in Maya Indigenous Families: Variant in PPP1R3A Is Associated with Type 2 Diabetes. Mol. Genet. Genom. 2018, 293, 1205–1216. [Google Scholar] [CrossRef]
- Liao, Y.-C.; Lin, H.-F.; Rundek, T.; Cheng, R.; Hsi, E.; Sacco, R.L.; Juo, S.-H.H. Multiple Genetic Determinants of Plasma Lipid Levels in Caribbean Hispanics. Clin. Biochem. 2008, 41, 306–312. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Dron, J.S.; Ban, M.R.; Robinson, J.F.; McIntyre, A.D.; Alazzam, M.; Zhao, P.J.; Dilliott, A.A.; Cao, H.; Huff, M.W.; et al. Polygenic Versus Monogenic Causes of Hypercholesterolemia Ascertained Clinically. Arterioscler. Thromb. Vasc. Biol. 2016, 36, 2439–2445. [Google Scholar] [CrossRef]
- Gu, Q.L.; Han, Y.; Lan, Y.M.; Li, Y.; Kou, W.; Zhou, Y.S.; Hai, X.J.; Yan, B.; Ci, C.H. Association between Polymorphisms in the APOB Gene and Hyperlipidemia in the Chinese Yugur Population. Braz. J. Med. Biol. Res. 2017, 50, e6613. [Google Scholar] [CrossRef]
- Hayat, M.; Kerr, R.; Bentley, A.R.; Rotimi, C.N.; Raal, F.J.; Ramsay, M. Genetic Associations between Serum Low LDL-Cholesterol Levels and Variants in LDLR, APOB, PCSK9 and LDLRAP1 in African Populations. PLoS ONE 2020, 15, e0229098. [Google Scholar] [CrossRef]
- Long, T.; Lu, S.; Li, H.; Lin, R.; Qin, Y.; Li, L.; Chen, L.; Zhang, L.; Lv, Y.; Liang, D.; et al. Association of APOB and LIPC Polymorphisms with Type 2 Diabetes in Chinese Han Population. Gene 2018, 672, 150–155. [Google Scholar] [CrossRef]
- Yoshida, T.; Kato, K.; Yokoi, K.; Watanabe, S.; Metoki, N.; Satoh, K.; Aoyagi, Y.; Nishigaki, Y.; Nozawa, Y.; Yamada, Y. Association of Candidate Gene Polymorphisms with Chronic Kidney Disease in Japanese Individuals with Hypertension. Hypertens. Res. 2009, 32, 411–418. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Y.; Qu, H.; Hou, M.; Cao, W.; Ma, Z.; Wang, H. Associations of Polymorphisms of Rs693 and Rs1042031 in Apolipoprotein B Gene with Risk of Breast Cancer in Chinese. Jpn. J. Clin. Oncol. 2013, 43, 362–368. [Google Scholar] [CrossRef] [PubMed]
- Abaj, F.; Koohdani, F. Macronutrient Intake Modulates Impact of EcoRI Polymorphism of ApoB Gene on Lipid Profile and Inflammatory Markers in Patients with Type 2 Diabetes. Sci. Rep. 2022, 12, 10504. [Google Scholar] [CrossRef]
- Zafar, M.; Malik, I.R.; Mirza, M.R.; Awan, F.R.; Nawrocki, A.; Hussain, M.; Khan, H.N.; Abbas, S.; Choudhary, M.I.; Larsen, M.R. Mass-Spectrometric Analysis of APOB Polymorphism Rs1042031 (G/T) and Its Influence on Serum Proteome of Coronary Artery Disease Patients: Genetic-Derived Proteomics Consequences. Mol. Cell. Biochem. 2024, 479, 1349–1361. [Google Scholar] [CrossRef] [PubMed]
- Muiya, P.; Wakil, S.; Al-Najai, M.; Meyer, B.F.; Al-Mohanna, F.; Alshahid, M.; Dzimiri, N. Identification of Loci Conferring Risk for Premature CAD and Heterozygous Familial Hyperlipidemia in the LDLR, APOB and PCSK9 Genes. Int. J. Diabetes Mellit. 2009, 1, 16–21. [Google Scholar] [CrossRef]
- Knoblauch, H.; Bauerfeind, A.; Toliat, M.R.; Becker, C.; Luganskaja, T.; Günther, U.P.; Rohde, K.; Schuster, H.; Junghans, C.; Luft, F.C.; et al. Haplotypes and SNPs in 13 Lipid-Relevant Genes Explain Most of the Genetic Variance in High-Density Lipoprotein and Low-Density Lipoprotein Cholesterol. Hum. Mol. Genet. 2004, 13, 993–1004. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Boekholdt, S.M.; Peters, R.J.G.; Fountoulaki, K.; Kastelein, J.J.P.; Sijbrands, E.J.G. Molecular Variation at the Apolipoprotein B Gene Locus in Relation to Lipids and Cardiovascular Disease: A Systematic Meta-Analysis. Hum. Genet. 2003, 113, 417–425. [Google Scholar] [CrossRef]
- Nuglozeh, E.; Fazaludeen, M.F.; Deshpande, S.; Warille, A.A.; Kürşat, M.K.; Kürşatşahin, K. Growth Hormone Receptor and PCSK9 Define a New Paradigm in the Initiation and Development of Chronic Kidney Disease as Revealed by Exome Sequencing on Illumina Platform. Eur. J. Med. Health Sci. 2024, 6, 1–9. [Google Scholar] [CrossRef]
- Abdul Murad, N.A.; Mohammad Noor, Y.; Zam, Z.Z.; Sulaiman, S.A.; Chow, Y.P.; Abdullah, N.; Ahmad, N.; Ismail, N.; Abdul Jalal, N.; Kamaruddin, M.A.; et al. Hypercholesterolemia in the Malaysian Cohort Participants: Genetic and Non-Genetic Risk Factors. Genes 2023, 14, 721. [Google Scholar] [CrossRef]
- Khlebus, E.; Kutsenko, V.; Meshkov, A.; Ershova, A.; Kiseleva, A.; Shevtsov, A.; Shcherbakova, N.; Zharikova, A.; Lankin, V.; Tikhaze, A.; et al. Multiple Rare and Common Variants in APOB Gene Locus Associated with Oxidatively Modified Low-Density Lipoprotein Levels. PLoS ONE 2019, 14, e0217620. [Google Scholar] [CrossRef]
- Colima Fausto, A.G.; Topete, J.; González García, J.R.; Hernández Flores, T.d.J.; Rodríguez Preciado, S.Y.; Magaña Torres, M.T. Effect of APOB Gene Polymorphisms on Body Mass Index, Blood Pressure, and Total Cholesterol Levels: A Cross-Sectional Study in Mexican Population. Medicine 2022, 101, e30457. [Google Scholar] [CrossRef]
- Vimaleswaran, K.S.; Minihane, A.M.; Li, Y.; Gill, R.; Lovegrove, J.A.; Williams, C.M.; Jackson, K.G. The APOB Insertion/Deletion Polymorphism (Rs17240441) Influences Postprandial Lipaemia in Healthy Adults. Nutr. Metab. 2015, 12, 7. [Google Scholar] [CrossRef]
- Matsunaga, A.; Nagashima, M.; Yamagishi, H.; Saku, K. Variants of Lipid-Related Genes in Adult Japanese Patients with Severe Hypertriglyceridemia. J. Atheroscler. Thromb. 2020, 27, 1264–1277. [Google Scholar] [CrossRef] [PubMed]
- Elbitar, S.; Susan-Resiga, D.; Ghaleb, Y.; El Khoury, P.; Peloso, G.; Stitziel, N.; Rabès, J.P.; Carreau, V.; Hamelin, J.; Ben-Djoudi-Ouadda, A.; et al. New Sequencing Technologies Help Revealing Unexpected Mutations in Autosomal Dominant Hypercholesterolemia. Sci. Rep. 2018, 8, 1943. [Google Scholar] [CrossRef]
- Alnouri, F.; Al-Allaf, F.A.; Athar, M.; Abduljaleel, Z.; Alabdullah, M.; Alammari, D.; Alanazi, M.; Alkaf, F.; Allehyani, A.; Alotaiby, M.A.; et al. Xanthomas Can Be Misdiagnosed and Mistreated in Homozygous Familial Hypercholesterolemia Patients: A Call for Increased Awareness Among Dermatologists and Health Care Practitioners. Glob. Heart 2020, 15, 19. [Google Scholar] [CrossRef] [PubMed]
- Akhtar, A.; Babar, M.E.; Awan, A.R.; Tayyab, M.; Shehzad, W.; Imran, M. A Genetic Variant (S4338N) in Apolipoprotein B Gene in Hypercholesterolemic Families from Pakistan. Pak. J. Zool. 2016, 48, 1423–1429. [Google Scholar]
- Zhou, Y.; Mägi, R.; Milani, L.; Lauschke, V.M. Global Genetic Diversity of Human Apolipoproteins and Effects on Cardiovascular Disease Risk. J. Lipid Res. 2018, 59, 1987–2000. [Google Scholar] [CrossRef] [PubMed]
- Teslovich, T.M.; Musunuru, K.; Smith, A.V.; Edmondson, A.C.; Stylianou, I.M.; Koseki, M.; Pirruccello, J.P.; Ripatti, S.; Chasman, D.I.; Willer, C.J.; et al. Biological, Clinical, and Population Relevance of 95 Loci for Blood Lipids. Nature 2010, 466, 707. [Google Scholar] [CrossRef]
- Aceves-Ramírez, M.; Valle, Y.; Casillas-Muñoz, F.; Martínez-Fernández, D.E.; Parra-Reyna, B.; López-Moreno, V.A.; Flores-Salinas, H.E.; Valdés-Alvarado, E.; Muñoz-Valle, J.F.; García-Garduño, T.; et al. Analysis of the APOB Gene and Apolipoprotein B Serum Levels in a Mexican Population with Acute Coronary Syndrome: Association with the Single Nucleotide Variants Rs1469513, Rs673548, Rs676210, and Rs1042034. Genet. Res. 2022, 2022, 4901090. [Google Scholar] [CrossRef]
- Sharifi, M.; Futema, M.; Nair, D.; Humphries, S.E. Polygenic Hypercholesterolemia and Cardiovascular Disease Risk. Curr. Cardiol. Rep. 2019, 21, 43. [Google Scholar] [CrossRef] [PubMed]
- Fujii, T.M.d.M.; Norde, M.M.; Fisberg, R.M.; Marchioni, D.M.L.; Rogero, M.M. Lipid Metabolism Genetic Risk Score Interacts with the Brazilian Healthy Eating Index Revised and Its Components to Influence the Odds for Dyslipidemia in a Cross-Sectional Population-Based Survey in Brazil. Nutr. Health 2019, 25, 119–126. [Google Scholar] [CrossRef]
- Jurado-Camacho, P.A.; Cid-Soto, M.A.; Barajas-Olmos, F.; García-Ortíz, H.; Baca-Peynado, P.; Martínez-Hernández, A.; Centeno-Cruz, F.; Contreras-Cubas, C.; González-Villalpando, M.E.; Saldaña-Álvarez, Y.; et al. Exome Sequencing Data Analysis and a Case-Control Study in Mexican Population Reveals Lipid Trait Associations of New and Known Genetic Variants in Dyslipidemia-Associated Loci. Front. Genet. 2022, 13, 807381. [Google Scholar] [CrossRef]
- Rentzsch, P.; Witten, D.; Cooper, G.M.; Shendure, J.; Kircher, M. CADD: Predicting the Deleteriousness of Variants throughout the Human Genome. Nucleic Acids Res. 2019, 47, D886–D894. [Google Scholar] [CrossRef]
- Adzhubei, I.A.; Schmidt, S.; Peshkin, L.; Ramensky, V.E.; Gerasimova, A.; Bork, P.; Kondrashov, A.S.; Sunyaev, S.R. A Method and Server for Predicting Damaging Missense Mutations. Nat. Methods 2010, 7, 248–249. [Google Scholar] [CrossRef]
- Sim, N.; Kumar, P.; Hu, J.; Henikoff, S.; Schneider, G.; Ng, P.C. SIFT Web Server: Predicting Effects of Amino Acid Substitutions on Proteins. Nucleic Acids Res. 2012, 40, 452–457. [Google Scholar] [CrossRef] [PubMed]
- Marmontel, O.; Rollat-Farnier, P.A.; Wozny, A.S.; Charrière, S.; Vanhoye, X.; Simonet, T.; Chatron, N.; Collin-Chavagnac, D.; Nony, S.; Dumont, S.; et al. Development of a New Expanded Next-Generation Sequencing Panel for Genetic Diseases Involved in Dyslipidemia. Clin. Genet. 2020, 98, 589–594. [Google Scholar] [CrossRef]
- Pan-Lizcano, R.; Mariñas-Pardo, L.; Núñez, L.; Rebollal-Leal, F.; López-Vázquez, D.; Pereira, A.; Molina-Nieto, A.; Calviño, R.; Vázquez-Rodríguez, J.M.; Hermida-Prieto, M. Rare Variants in Genes of the Cholesterol Pathway Are Present in 60% of Patients with Acute Myocardial Infarction. Int. J. Mol. Sci. 2022, 23, 16127. [Google Scholar] [CrossRef]
- Abdulfattah, S.Y.; Al-Awadi, S.J. ApoB Gene Polymorphism (Rs676210) and Its Pharmacogenetics Impact on Atorvastatin Response among Iraqi Population with Coronary Artery Disease. J. Genet. Eng. Biotechnol. 2021, 19, 95. [Google Scholar] [CrossRef]
- Barbosa, E.J.L.; Glad, C.A.M.; Nilsson, A.G.; Nyström, H.F.; Götherström, G.; Svensson, P.A.; Vinotti, I.; Bengtsson, B.Å.; Nilsson, S.; Boguszewski, C.L.; et al. Genotypes Associated with Lipid Metabolism Contribute to Differences in Serum Lipid Profile of GH-Deficient Adults before and after GH Replacement Therapy. Eur. J. Endocrinol. 2012, 167, 353–362. [Google Scholar] [CrossRef] [PubMed]
- Chasman, D.I.; Paré, G.; Mora, S.; Hopewell, J.C.; Peloso, G. Forty-Three Loci Associated with Plasma Lipoprotein Size, Concentration, and Cholesterol Content in Genome-Wide Analysis. PLoS Genet. 2009, 5, 1000730. [Google Scholar] [CrossRef]
- Mäkelä, K.M.; Seppälä, I.; Hernesniemi, J.A.; Lyytikäinen, L.P.; Oksala, N.; Kleber, M.E.; Scharnagl, H.; Grammer, T.B.; Baumert, J.; Thorand, B.; et al. Genome-Wide Association Study Pinpoints a New Functional Apolipoprotein B Variant Influencing Oxidized Low-Density Lipoprotein Levels but Not Cardiovascular Events: AtheroRemo Consortium. Circ. Cardiovasc. Genet. 2013, 6, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Lamiquiz-Moneo, I.; Pérez-Ruiz, M.R.; Jarauta, E.; Tejedor, M.T.; Bea, A.M.; Mateo-Gallego, R.; Pérez-Calahorra, S.; Baila-Rueda, L.; Marco-Benedí, V.; de Castro-Orós, I.; et al. Single Nucleotide Variants Associated With Polygenic Hypercholesterolemia in Families Diagnosed Clinically With Familial Hypercholesterolemia. Rev. Española De Cardiol. Engl. Ed. 2018, 71, 351–356. [Google Scholar] [CrossRef]
- Lewis, C.M.; Vassos, E. Polygenic Risk Scores: From Research Tools to Clinical Instruments. Genome Med. 2020, 12, 44. [Google Scholar] [CrossRef] [PubMed]
- Phulka, J.S.; Ashraf, M.; Bajwa, B.K.; Pare, G.; Laksman, Z. Current State and Future of Polygenic Risk Scores in Cardiometabolic Disease: A Scoping Review. Circ. Genom. Precis. Med. 2023, 16, 286–313. [Google Scholar] [CrossRef]
- Choi, S.W.; Mak, T.S.H.; O’Reilly, P.F. A Guide to Performing Polygenic Risk Score Analyses. Nat. Protoc. 2020, 15, 2759. [Google Scholar] [CrossRef]
- Torkamani, A.; Wineinger, N.E.; Topol, E.J. The Personal and Clinical Utility of Polygenic Risk Scores. Nat. Rev. Genet. 2018, 19, 581–590. [Google Scholar] [CrossRef]
- Kachuri, L.; Chatterjee, N.; Hirbo, J.; Schaid, D.J.; Martin, I.; Kullo, I.J.; Kenny, E.E.; Pasaniuc, B.; Witte, J.S.; Tian, G. Principles and Methods for Transferring Polygenic Risk Scores across Global Populations Polygenic Risk Methods in Diverse Populations (PRIMED) Consortium Methods Working Group. Nat. Rev. Genet. 2023, 16, 19. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.