A Novel Ensemble Neuro-Fuzzy Model for Financial Time Series Forecasting

 , , and
, , and
Abstract
:1. Introduction
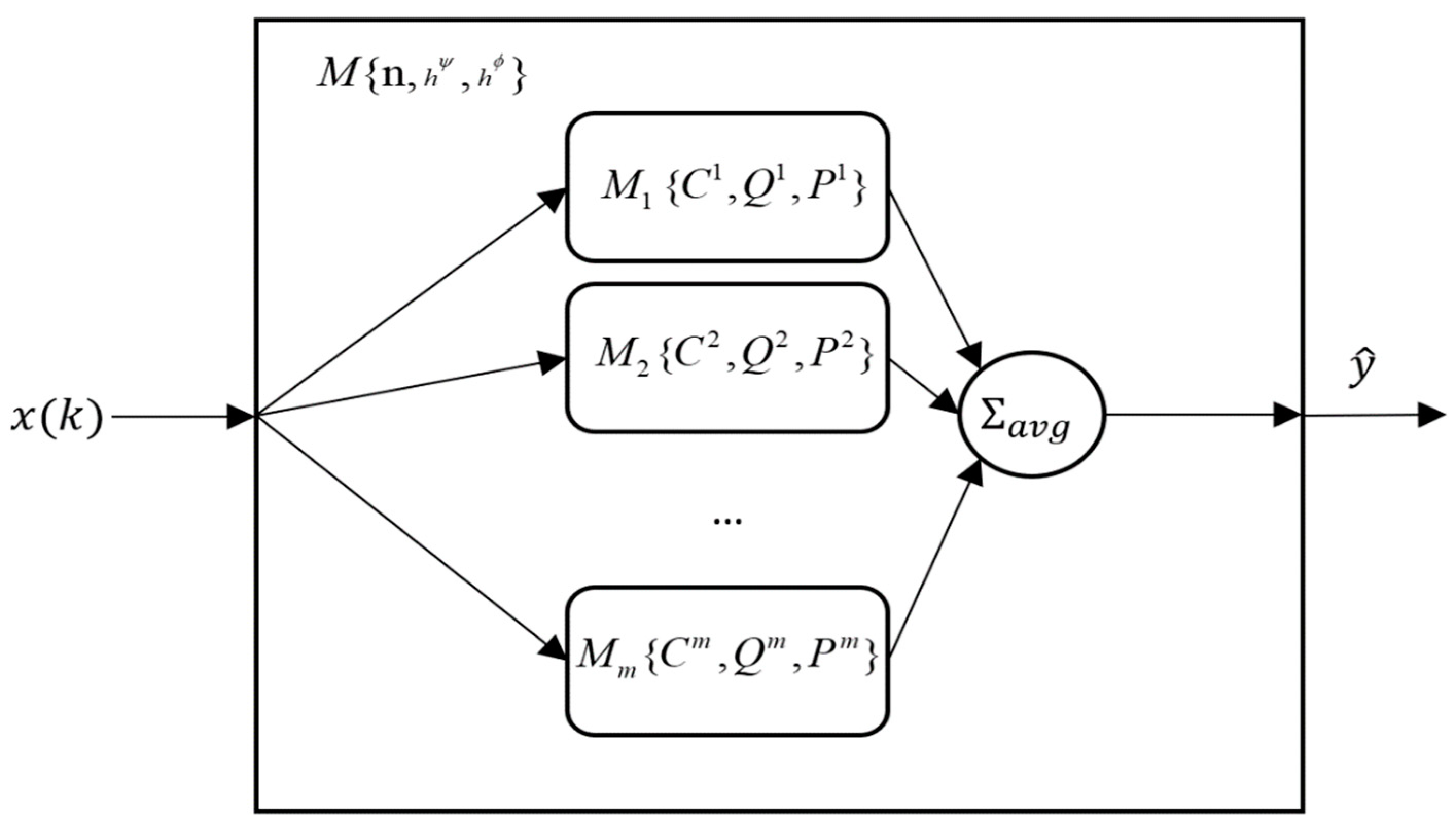
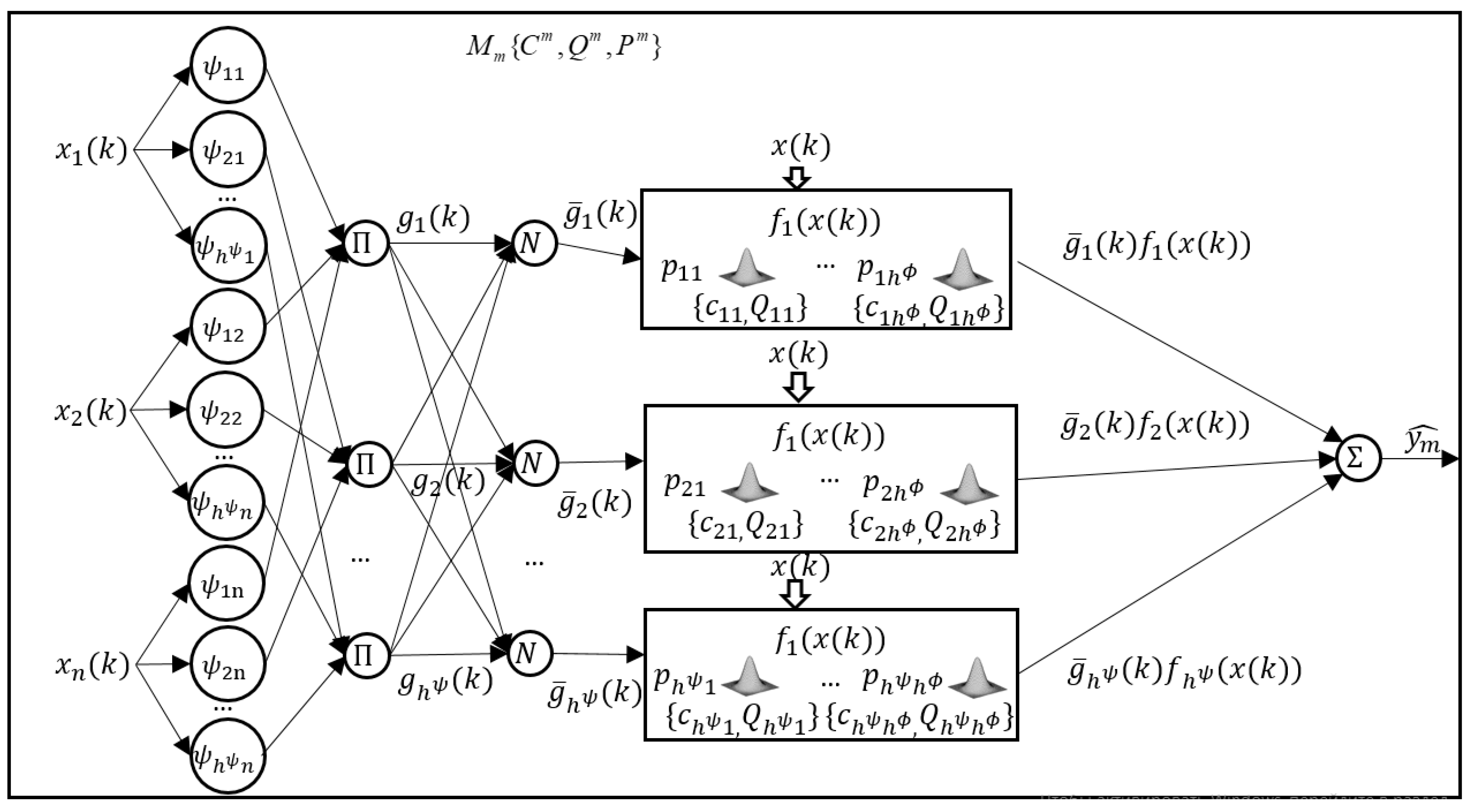
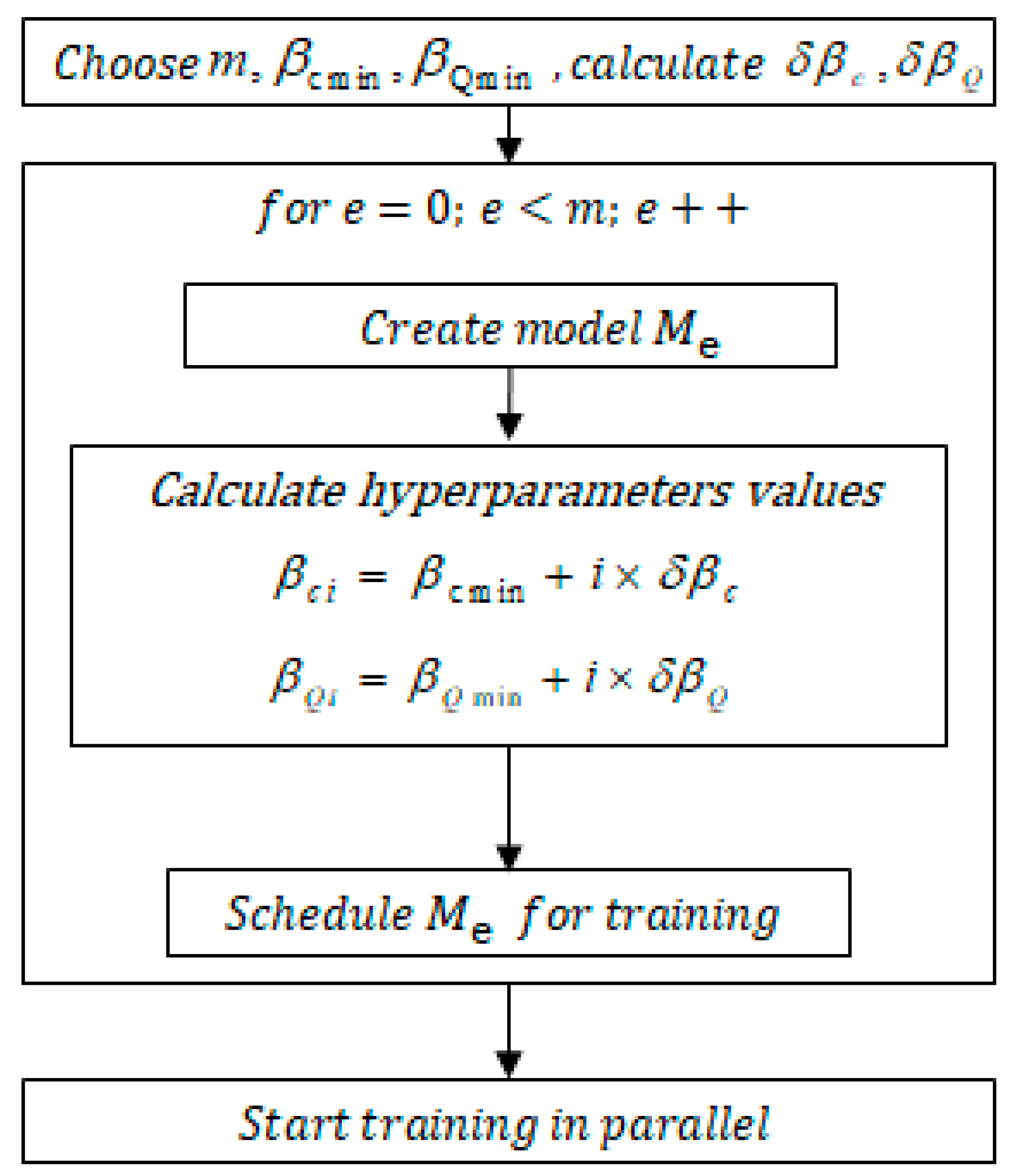
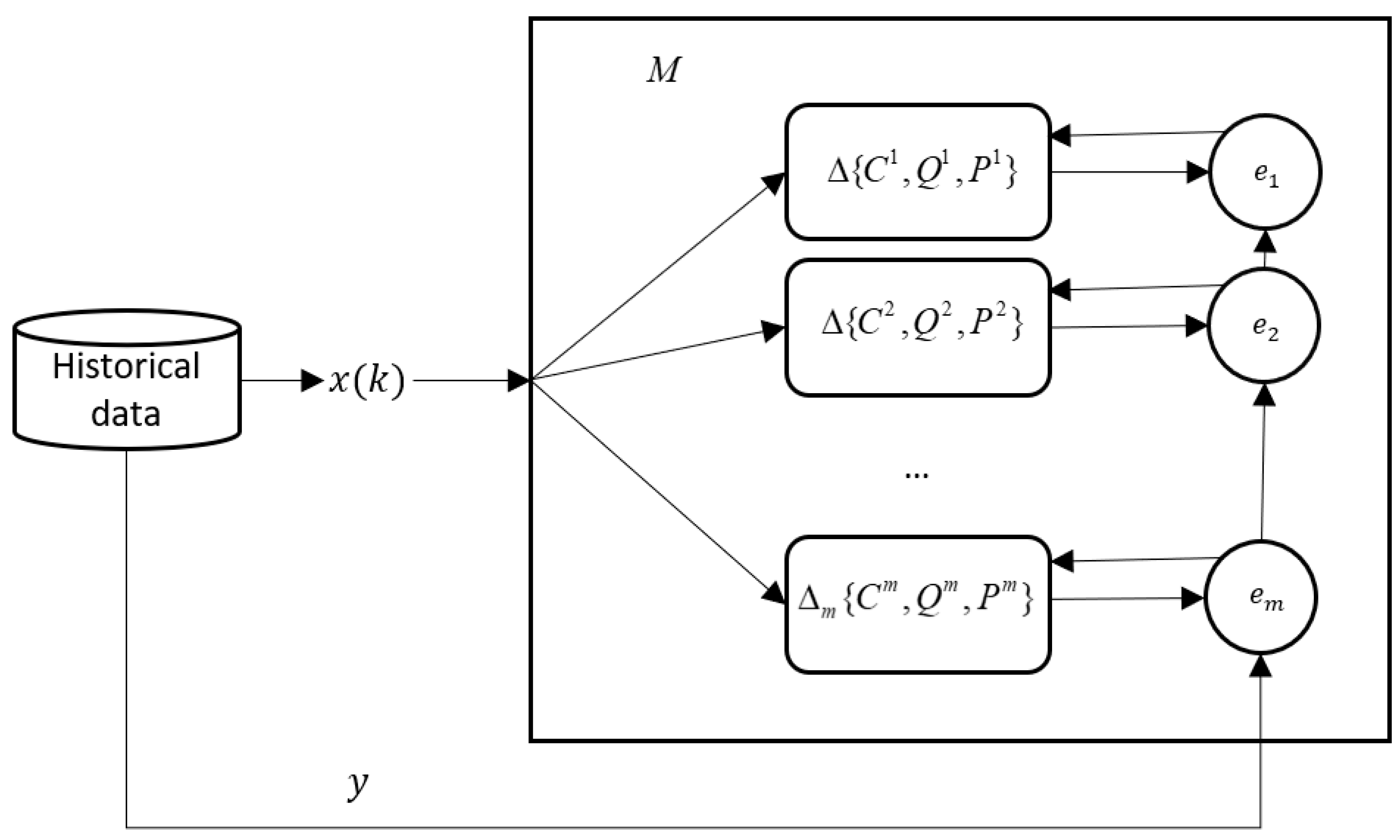
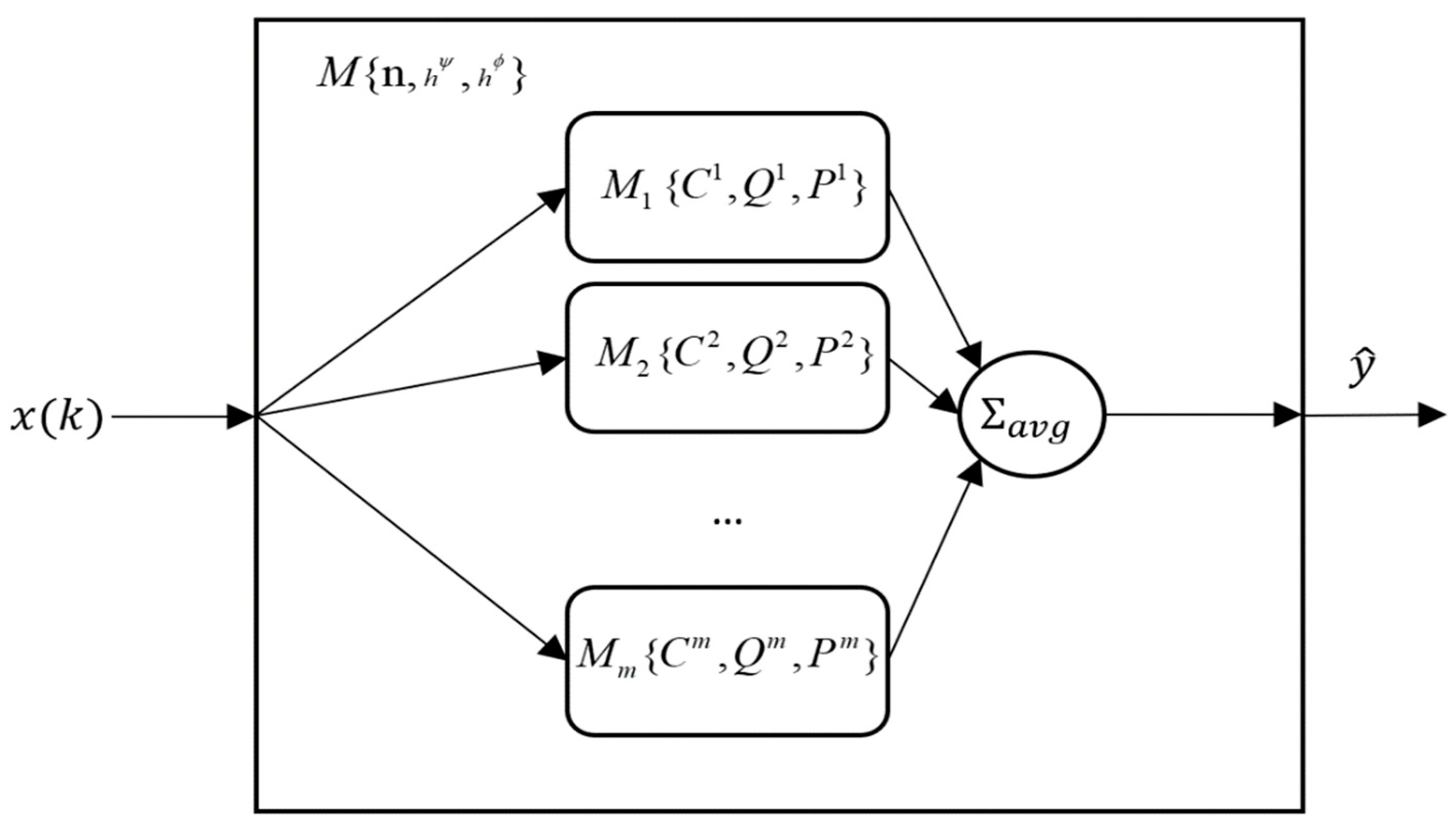
2. Proposed Model and Inference
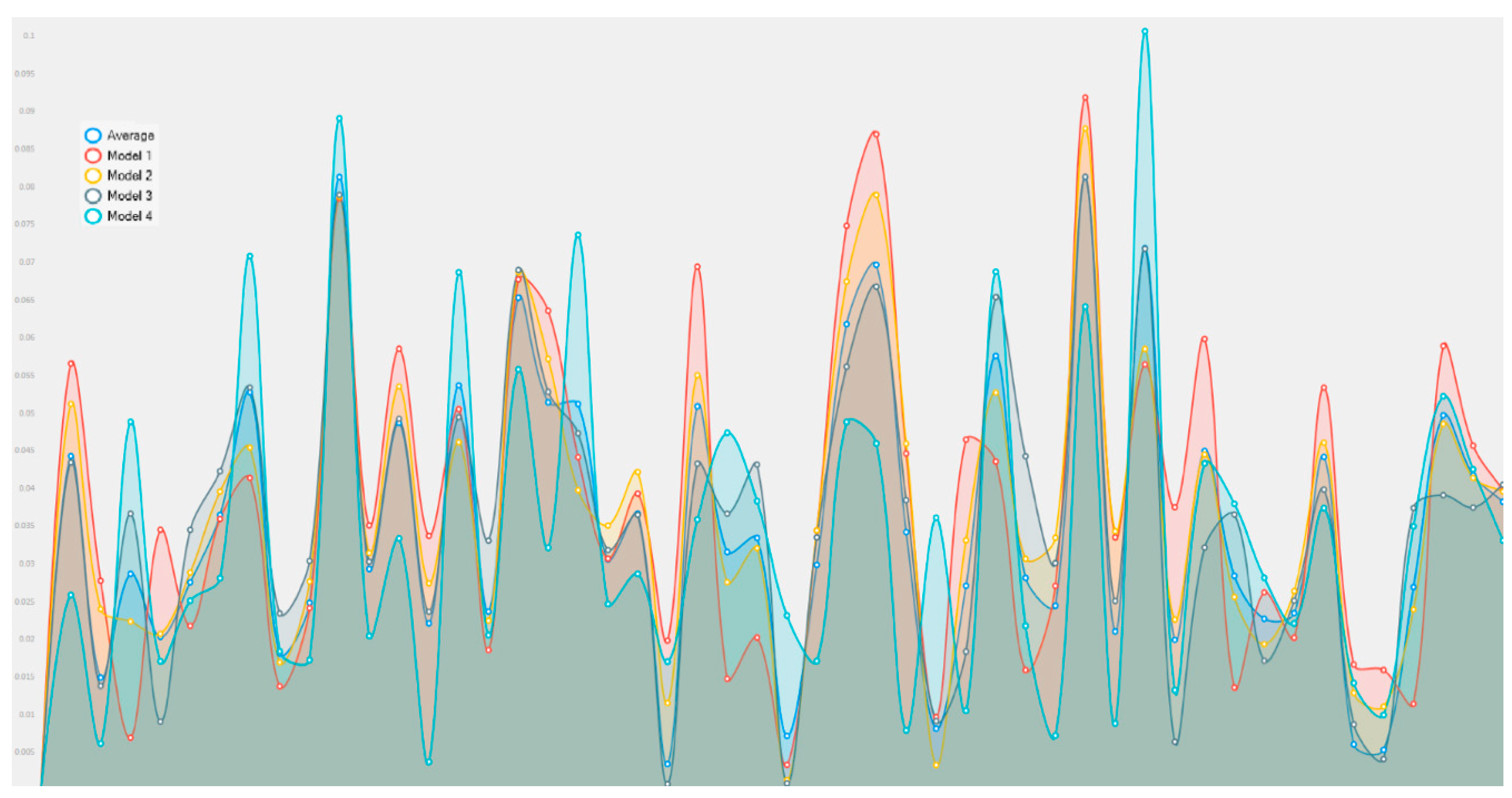
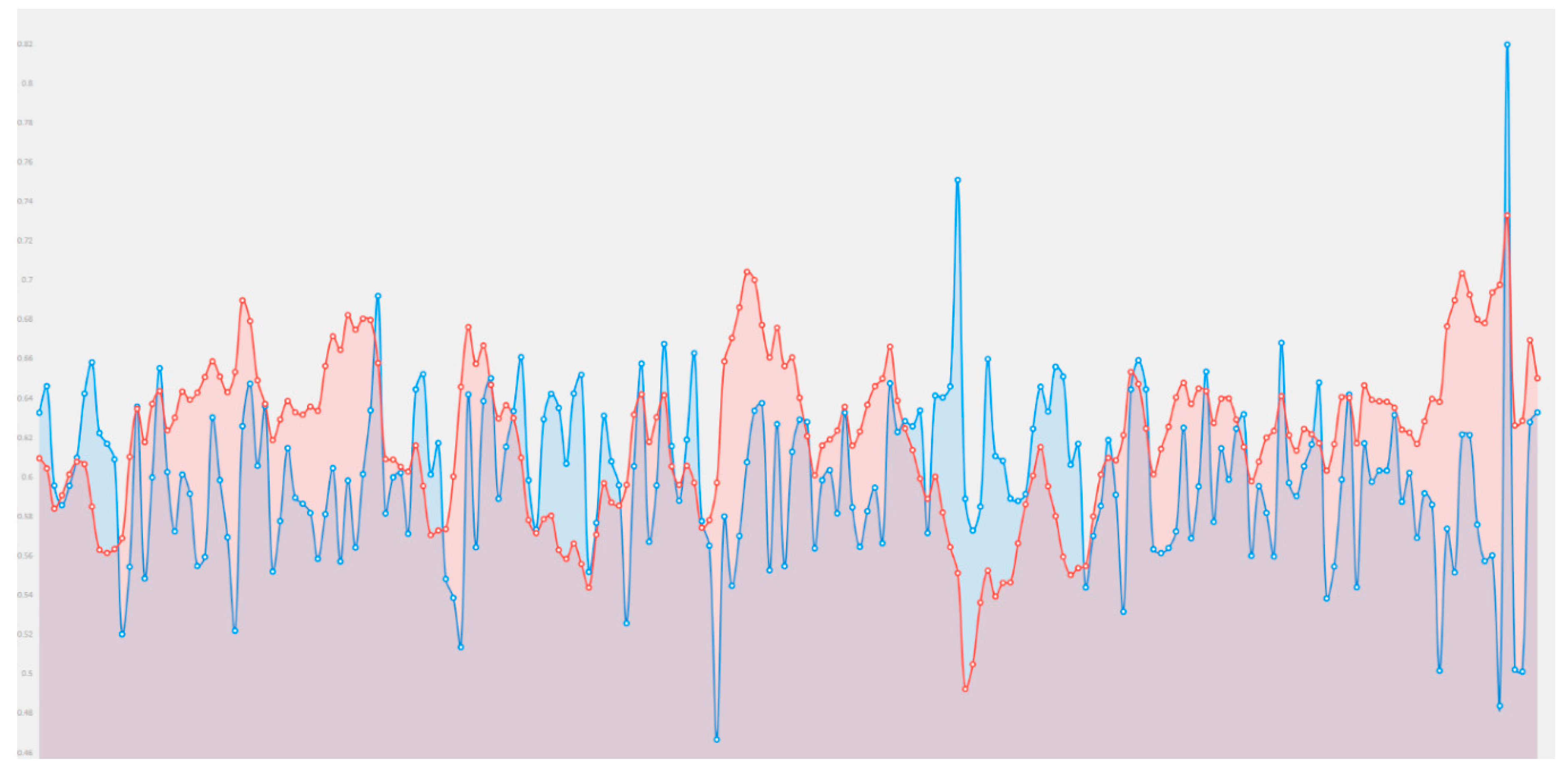
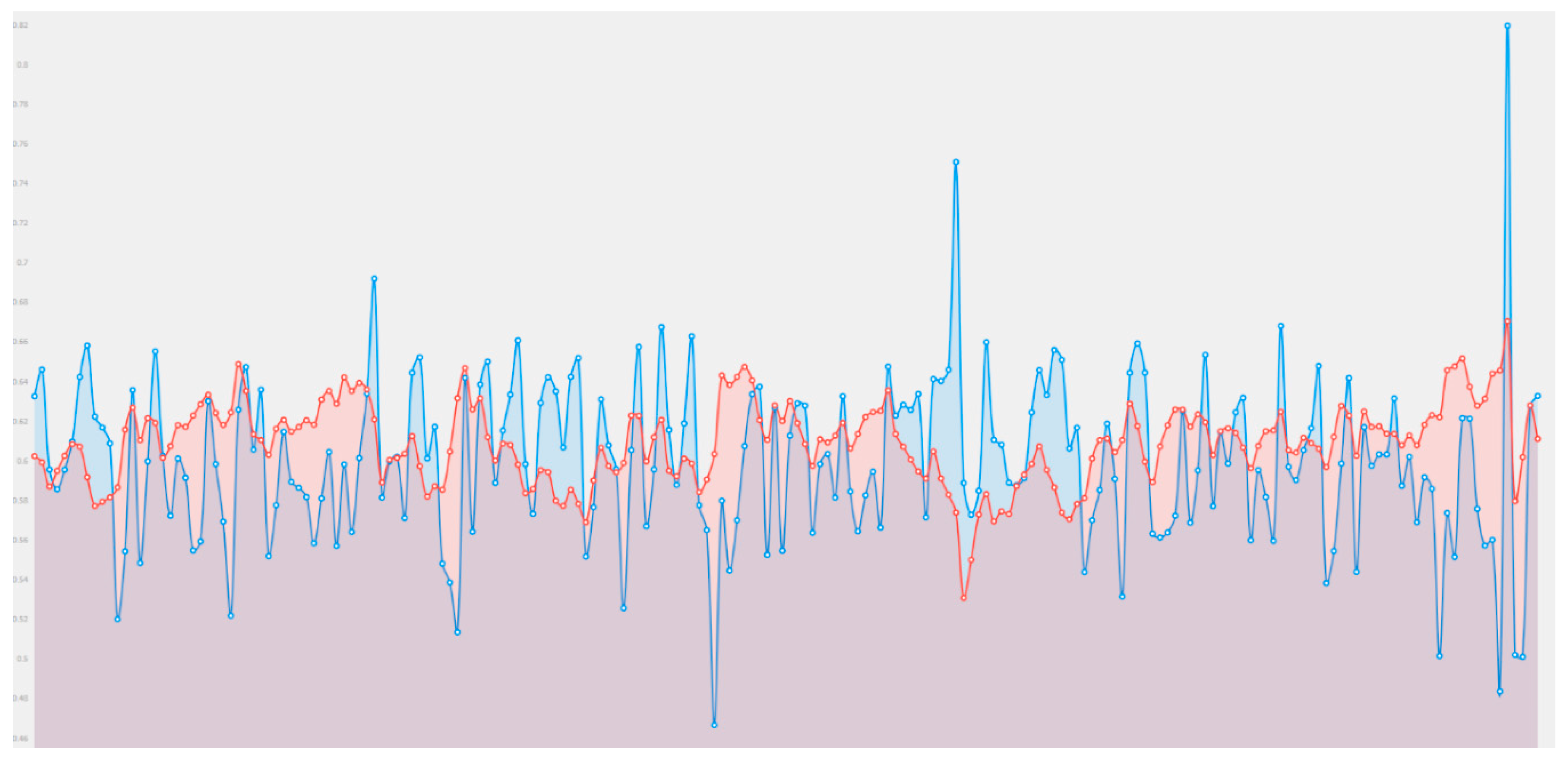
3. Experimental Results
- -
- Cisco stock with 6329 records.
- -
- Alcoa stock with 2528 records.
- -
- American Express stock with 2528 records.
- -
- Disney stock with 2528 records.
- -
- -
- Support vector machines with sequential minimal optimization.
- -
- Restricted Boltzmann machines as an example of a stochastic neural network. We also used a resilient backpropagation learning algorithm for their learning.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rajab, S.; Sharma, V. A review on the applications of neuro-fuzzy systems in business. Artif. Intell. Rev. 2018, 49, 481–510. [Google Scholar] [CrossRef]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Billah, M.; Waheed, S.; Hanifa, A. Stock market prediction using an improved training algorithm of neural network. In Proceedings of the 2nd International Conference on Electrical, Computer & Telecommunication Engineering (ICECTE), Rajshahi, Bangladesh, 8–10 December 2016. [Google Scholar] [CrossRef]
- Esfahanipour, A.; Aghamiri, W. Adapted Neuro-Fuzzy Inference System on indirect approach TSK fuzzy rule base for stock market analysis. Expert Syst. Appl. 2010, 37, 4742–4748. [Google Scholar] [CrossRef]
- Rajab, S.; Sharma, V. An interpretable neuro-fuzzy approach to stock price forecasting. Soft Comput. 2017. [Google Scholar] [CrossRef]
- García, F.; Guijarro, F.; Oliver, J.; Tamošiūnienė, R. Hybrid fuzzy neural network to predict price direction in the German DAX-30 index. Technol. Econ. Dev. Econ. 2018, 24, 2161–2178. [Google Scholar] [CrossRef]
- Hadavandi, E.; Shavandi, H.; Ghanbari, A. Integration of genetic fuzzy systems and artificial neural networks for stock price forecasting. Knowl.-Based Syst. 2010, 23, 800–808. [Google Scholar] [CrossRef]
- Chiu, D.-Y.; Chen, P.-J. Dynamically exploring internal mechanism of stock market by fuzzy-based support vector machines with high dimension input space and genetic algorithm. Expert Syst. Appl. 2009, 36, 1240–1248. [Google Scholar] [CrossRef]
- González, J.A.; Solís, J.F.; Huacuja, H.J.; Barbosa, J.J.; Rangel, R.A. Fuzzy GA-SVR for Mexican Stock Exchange’s Financial Time Series Forecast with Online Parameter Tuning. Int. J. Combin. Optim. Probl. Inform. 2019, 10, 40–50. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.; Pliss, I.; Vynokurova, O. Adaptive wavelet-neuro-fuzzy network in the forecasting and emulation tasks. Int. J. Inf. Theory Appl. 2008, 15, 47–55. [Google Scholar]
- Chandar, S.K. Fusion model of wavelet transform and adaptive neuro fuzzy inference system for stock market prediction. J. Ambient Intell. Humaniz. Comput. 2019, 1–9. [Google Scholar] [CrossRef]
- Parida, A.K.; Bisoi, R.; Dash, P.K.; Mishra, S. Times Series Forecasting using Chebyshev Functions based Locally Recurrent neuro-Fuzzy Information System. Int. J. Comput. Intell. Syst. 2017, 10, 375. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Valavanis, K.P. Forecasting stock market short-term trends using a neuro-fuzzy based methodology. Expert Syst. Appl. 2009, 36, 10696–10707. [Google Scholar] [CrossRef]
- Cai, Q.; Zhang, D.; Zheng, W.; Leung, S.C. A new fuzzy time series forecasting model combined with ant colony optimization and auto-regression. Knowledge-Based Syst. 2015, 74, 61–68. [Google Scholar] [CrossRef]
- Lee, R.S. Chaotic Type-2 Transient-Fuzzy Deep Neuro-Oscillatory Network (CT2TFDNN) for Worldwide Financial Prediction. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Pulido, M.; Melin, P. Optimization of Ensemble Neural Networks with Type-1 and Type-2 Fuzzy Integration for Prediction of the Taiwan Stock Exchange. In Recent Developments and the New Direction in Soft-Computing Foundations and Applications; Springer: Cham, Switzerland, 2018; pp. 151–164. [Google Scholar]
- Bhattacharya, D.; Konar, A. Self-adaptive type-1/type-2 hybrid fuzzy reasoning techniques for two-factored stock index time-series prediction. Soft Comput. 2017, 22, 6229–6246. [Google Scholar] [CrossRef]
- Vlasenko, A.; Vynokurova, O.; Vlasenko, N.; Peleshko, M. A Hybrid Neuro-Fuzzy Model for Stock Market Time-Series Prediction. In Proceedings of the IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018. [Google Scholar] [CrossRef]
- Vlasenko, A.; Vlasenko, N.; Vynokurova, O.; Bodyanskiy, Y. An Enhancement of a Learning Procedure in Neuro-Fuzzy Model. In Proceedings of the IEEE First International Conference on System Analysis & Intelligent Computing (SAIC), Kyiv, Ukraine, 8–12 October 2018. [Google Scholar] [CrossRef]
- Vlasenko, A.; Vlasenko, N.; Vynokurova, O.; Peleshko, D. A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction. Data 2018, 3, 62. [Google Scholar] [CrossRef]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.-R. Efficient BackProp. Neural Netw. Tricks Trade 2012, 9–48. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Wiesler, S.; Richard, A.; Schluter, R.; Ney, H. A critical evaluation of stochastic algorithms for convex optimization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013. [Google Scholar] [CrossRef]
- Tsay, R.S. Analysis of Financial Time Series; Wiley Series in Probability and Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Monthly Log Returns of IBM Stock and the S&P 500 Index Dataset. Available online: https://faculty.chicagobooth.edu/ruey.tsay/teaching/fts/m-ibmspln.dat (accessed on 1 September 2018).
- Kanzow, C.; Yamashita, N.; Fukushima, M. Erratum to “Levenberg–Marquardt methods with strong local convergence properties for solving nonlinear equations with convex constraints. J. Comput. Appl. Math. 2005, 177, 241. [Google Scholar] [CrossRef]
- Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In Proceedings of the IEEE International Conference on Neural Networks, Rio, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Math.NET Numerics. Available online: https://numerics.mathdotnet.com (accessed on 1 July 2019).
- Souza, C.R. The Accord.NET Framework. Available online: http://accord-framework.net (accessed on 1 July 2019).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cisco | Normalized |
|---|---|
| −0.05382 | 0.50755 |
| 0.01827 | 0.63085 |
| −0.00909 | 0.58405 |
| 0.00909 | 0.61515 |
| −0.02752 | 0.55253 |
| −0.01878 | 0.56748 |
| 0.01878 | 0.63172 |
| 0.08895 | 0.75173 |
| −0.00855 | 0.58498 |
| 0.01702 | 0.62871 |
| Model | Cisco Stock Daily Log Returns | ||
|---|---|---|---|
| Execution Time (ms) | RMSE (%) | SMAPE (%) | |
| Proposed model , | 196 | 4.007 | 5.08246 |
| , | 279 | 4.007 | 5.09458 |
| , | 361 | 4.104 | 5.16344 |
| , | 417 | 4.058 | 5.14296 |
| Single model | 92 | 4.012 | 5.14493 |
| Bipolar Sigmoid Network Resilient BackProp | 307 | 4.022 | 5.14132 |
| Bipolar Sigmoid Network Levenberg-Marquart | 1377 | 4.054 | 5.16275 |
| Support Vector Machine | 10800 | 4.021 | 5.13844 |
| Restricted Boltzmann Machine | 210 | 4.018 | 5.14531 |
| Alcoa Stock Daily Log Returns | |||
| Execution time (ms) | RMSE (%) | SMAPE (%) | |
| Proposed model , | 60 | 9.017 | 15.299 |
| , | 77 | 9.032 | 15.385 |
| , | 102 | 9.452 | 16.025 |
| , | 145 | 9.578 | 16.245 |
| Single model | 27 | 9.111 | 15.377 |
| Bipolar Sigmoid Network Resilient BackProp | 192 | 9.894 | 16.667 |
| Bipolar Sigmoid Network Levenberg-Marquart | 472 | 9.896 | 16.711 |
| Support Vector Machine | 1136 | 9.910 | 16.634 |
| Restricted Boltzmann Machine | 72 | 9.889 | 16.663 |
| American Express Stock Daily Log Returns | |||
| Execution time (ms) | RMSE (%) | SMAPE (%) | |
| Proposed model , | 102 | 10.028 | 16.880 |
| , | 154 | 10.001 | 16.998 |
| , | 189 | 10.044 | 17.022 |
| , | 211 | 10.045 | 17.025 |
| Single model | 58 | 10.022 | 16.917 |
| Bipolar Sigmoid Network Resilient BackProp | 188 | 10.06 | 17.043 |
| Bipolar Sigmoid Network Levenberg-Marquart | 458 | 0.999 | 16.885 |
| Support Vector Machine | 1584 | 10.141 | 17.858 |
| Restricted Boltzmann Machine | 87 | 10.054 | 17.038 |
| Disney Stock Daily Log Returns | |||
| Execution time (ms) | RMSE (%) | SMAPE (%) | |
| Proposed model , | 41 | 8.90 | 12.908 |
| , | 52 | 8.902 | 12.952 |
| , | 102 | 8.997 | 12.984 |
| , | 145 | 9.009 | 12.989 |
| Single model | 27 | 8.960 | 12.983 |
| Bipolar Sigmoid Network Resilient BackProp | 166 | 8.991 | 12.953 |
| Bipolar Sigmoid Network Levenberg-Marquart | 468 | 9.024 | 12.985 |
| Support Vector Machine | 825 | 8.997 | 12.949 |
| Restricted Boltzmann Machine | 65 | 8.989 | 12.939 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlasenko, A.; Vlasenko, N.; Vynokurova, O.; Bodyanskiy, Y.; Peleshko, D. A Novel Ensemble Neuro-Fuzzy Model for Financial Time Series Forecasting. Data 2019, 4, 126. https://doi.org/10.3390/data4030126
Vlasenko A, Vlasenko N, Vynokurova O, Bodyanskiy Y, Peleshko D. A Novel Ensemble Neuro-Fuzzy Model for Financial Time Series Forecasting. Data. 2019; 4(3):126. https://doi.org/10.3390/data4030126
Chicago/Turabian StyleVlasenko, Alexander, Nataliia Vlasenko, Olena Vynokurova, Yevgeniy Bodyanskiy, and Dmytro Peleshko. 2019. "A Novel Ensemble Neuro-Fuzzy Model for Financial Time Series Forecasting" Data 4, no. 3: 126. https://doi.org/10.3390/data4030126
APA StyleVlasenko, A., Vlasenko, N., Vynokurova, O., Bodyanskiy, Y., & Peleshko, D. (2019). A Novel Ensemble Neuro-Fuzzy Model for Financial Time Series Forecasting. Data, 4(3), 126. https://doi.org/10.3390/data4030126