
Advancements in Medical Radiology Through Multimodal Machine Learning: A Comprehensive Overview

 ,
, 
 ,
,  and
and
Abstract

1. Introduction
- ❖ Examining how integrating medical imaging (X-ray, MRI, CT) and non-imaging (text, ECG, EHR) data improves diagnostic precision, addressing the shortcomings of single-modality machine learning approaches.
- ❖ Investigating cutting-edge multimodal machine learning approaches, including modality fusion, representation learning, and cross-modality translation, to enhance medical diagnosis and treatment.
- ❖ Identifying obstacles in implementing multimodal AI, underscoring prospective research possibilities, and emphasizing the need for sophisticated, multimodal diagnostic systems in healthcare.
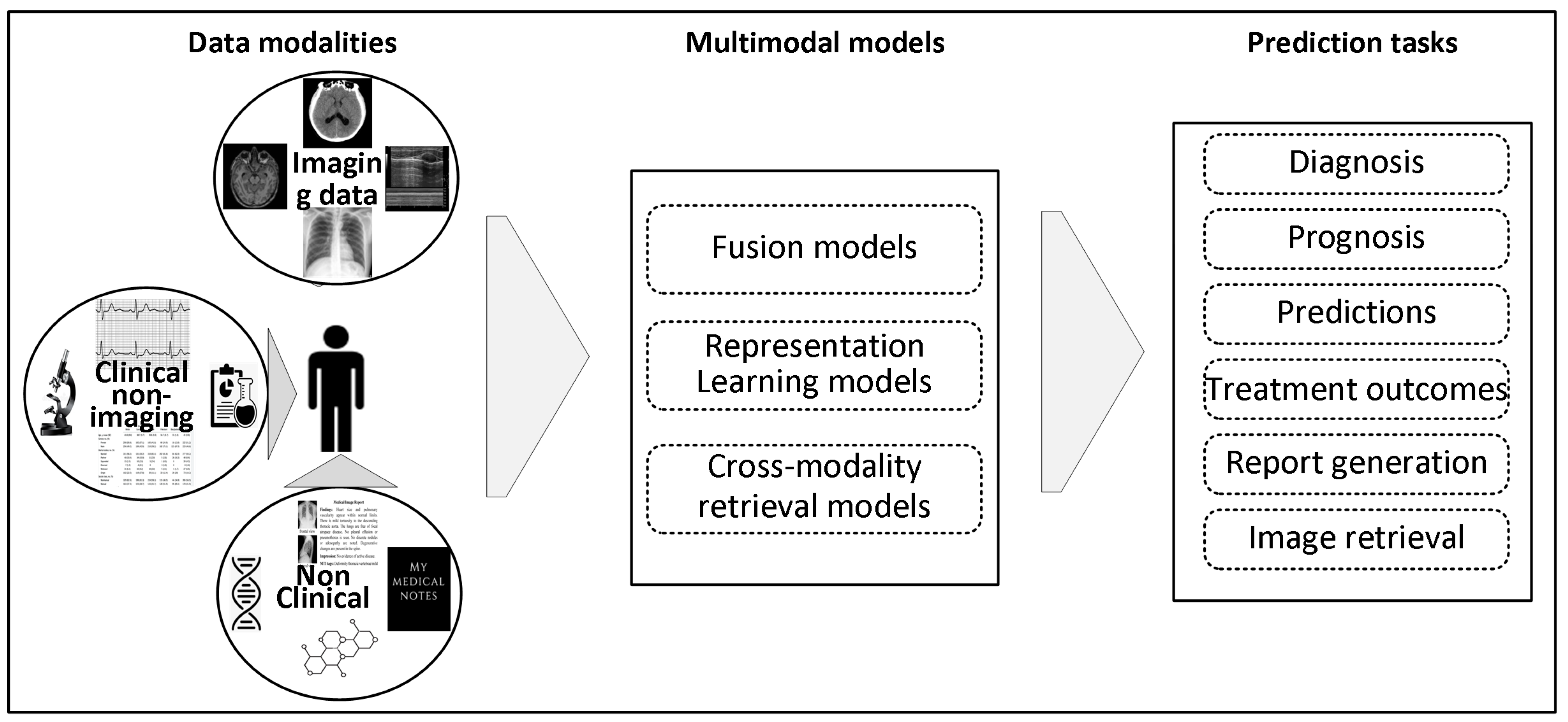
2. Data Modalities
2.1. Medical Image Data
2.1.1. Medical X-Ray
2.1.2. Computed Tomography
2.1.3. Magnetic Resonance Imaging (MRI)
2.1.4. Nuclear Medicine Imaging
2.1.5. Ultrasonography
2.2. Non-Imaging Data
2.2.1. Text Data
2.2.2. Structured Data (Time Series and Discrete Data)
3. Preliminaries
3.1. Data Modalities-Based Classification
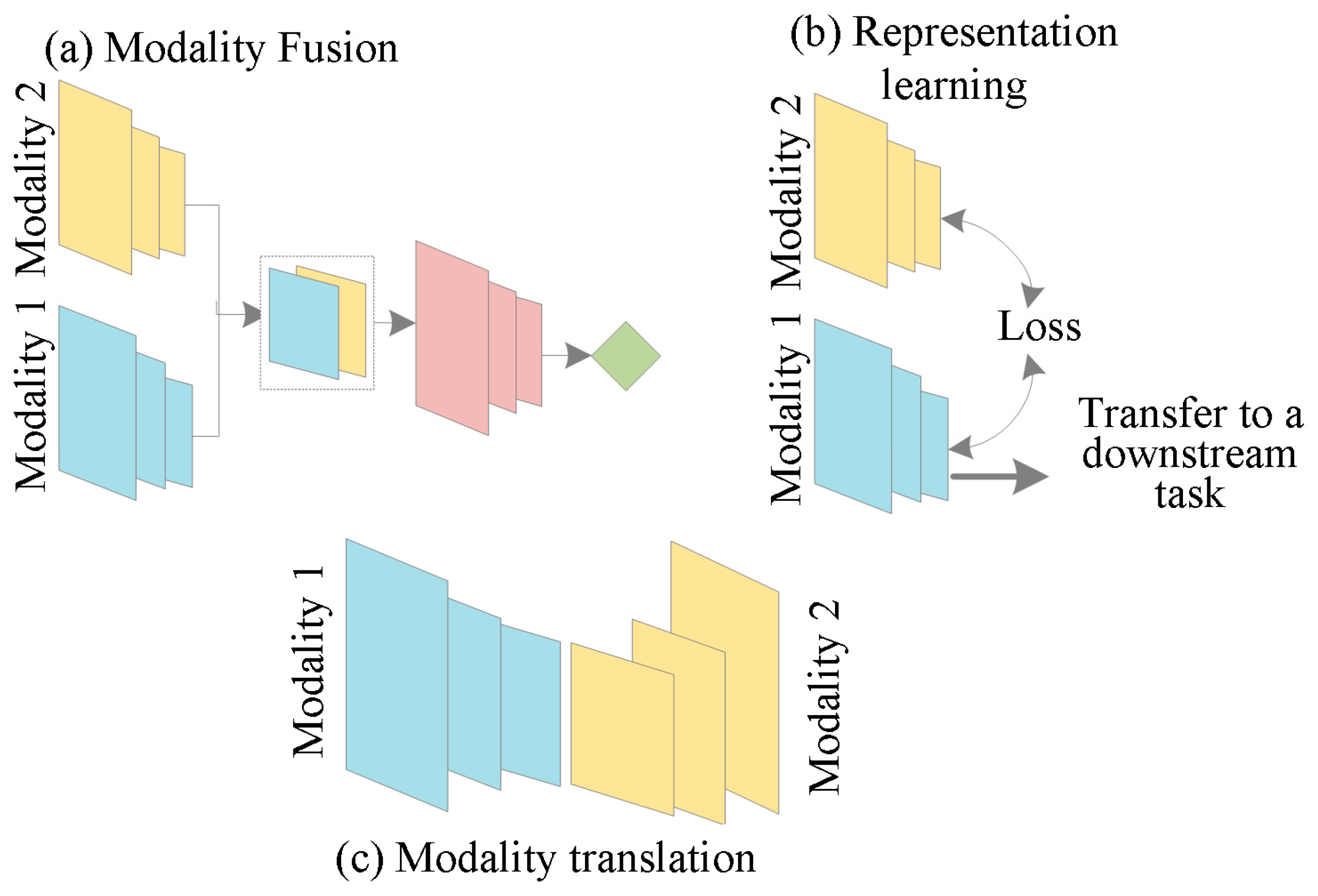
3.2. Methodology-Based Classification
3.2.1. Modality Fusion
3.2.2. Representation Learning
3.2.3. Cross-Modality Retrieval
3.2.4. Databases
3.3. Target Readers
3.4. Study Selection
4. Multimodal Machine Learning in Radiology
4.1. Combination of Medical Imaging with Text Data for Diagnostic Precision
4.1.1. Fusion
4.1.2. Representation Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Framework | Dataset | Image Modality | Text Modality | Fusion/Representation | Metric | MM Performance |
|---|---|---|---|---|---|---|---|
| [66] | TieNet | ChestX-ray14 | CXR | Text reports | Joint fusion | AUC | 0.989 |
| [71] | VisualBERT LXMERT UNITER PixelBERT | MIMIC-CXR | CXR | Text reports | Joint fusion | AUC AUC AUC AUC | 0.987 0.984 0.986 0.974 |
| [76] | MIFTP | MIMIC-CXR | CXR | Text reports | Joint fusion | Micro AUROC accuracy | 0.706 0.915 |
| [77] | CBP-MMFN DHP-MMFN | IU-X-ray | CXR | Text reports | Joint fusion | AUROC accuracy, AUROC accuracy | 0.987 0.988 0.984 0.972 |
| [78] | ResNet50 BERT | MIMIC-CXR | CXR | Text reports | Early fusion Late fusion | Accuracy Accuracy | 0.942 0.914 |
| [79] | Medical X-VL | MIMIC-CXR | CXR | Text reports | Joint fusion | AUC F1 score | 0.855 0.516 |
| [80] | DRSCL | Private | CT | Text reports | Joint fusion | Accuracy F1 score | 0.901 0.903 |
| [81] | Resnet, BERT | MIMIC-CXR | CXR | Text reports | Ranking-based | Macro-F1 | 0.51 |
| [83] | ConVIRT | CheXpert | CXR | Text reports | Contrastive | AUC AUC Accuracy AUC | 0.927 0.881 0.924 0.890 |
| [48] | GLoRIA | CheXpert, RSNA Pneumonia, SIIM Pneumothorax1 | CXR | Text reports | Contrastive | AUC AUC Dice | 0.881 0.886 0.634 |
| [84] | LoVT | MIMIC-CXR RSNA | CXR | Text reports | Contrastive | mAP fROC Dice Dice | 0.181 0.621 0.512 0.441 |
| [85] | UWOX | NIH14-CXR, MIMIC-CXR | CXR | Text reports | Masked (Word, Patch) prediction | AUC | 0.763 |
| [82] | CMITM, ViT-B/16 | MIMIC-CXR NIH-CXR CheXpert RSNA | CXR | Text reports | Contrastive, masked autoencoding | AUC AUC AUC accuracy | 0.860 0.892 0.934 0.953 |
4.1.3. Cross-Modality Retrieval
| Reference | Framework | Dataset | Text Modality | Image Modality | Metric | MM Performance |
|---|---|---|---|---|---|---|
| [114] | BERT, Vision transformer | VQA-RAD, SLAKE, ImageCLEF 2019 | Medical questions | Radiology scans | ACC | 0.785 0.835 0.833 |
| [112] | BERT Vision transformer | VQA-RAD, SLACK, ImageCLEF 2019 | Clinical questions | Radiology scans | ACC | 0.803 0.856 0.791 |
| [110] | SAN/BAN, MMQ, LSTM | VQA-RAD PathVQA | Clinical questions | Radiology scans | ACC | 0.488 0.670 |
| [113] | QCR, MEVF, CLIP | VQA-RAD SLAKE | Clinical questions | Radiology scans | ACC | 0.801 0.721 |
| [111] | LSTM, CNN | VQA-RAD | Clinical questions | Radiology scans | ACC | 0.732 |
| [109] | CPRD, BAN, LSTM, SLAKE | VQA-RAD | Clinical questions | Radiology scans | ACC | 0.678 |
| [104] | CNN, transformer | VQA-RAD ImageCLEF (2018, 2019) | Clinical questions | Radiology scans | BLEU ACC ACC | 0.162 0.654 0.727 |
| [115] | GRU, CDAE, MAML | PathVQA VQA-RAD | Clinical questions | Radiology scans | ACC | 0.504 0.733 |
| [108] | MFB, BERT, CNN | ImageCLEF 2019 | Clinical questions | Radiology scans | ACC, AUC-ROC AUC-PRC | 0.636 0.800 0.618 |
| [96] | BAN, BERT, CNN | VQA-RAD | Clinical questions | Radiology scans | Accuracy | 0.804 |
4.1.4. Specific Datasets Used in This Domain
4.1.5. Author’s Insights
4.2. Combination of Medical Imaging with Structured Data for Diagnostic Precision
4.2.1. Fusion
4.2.2. Representation Learning
4.2.3. Cross-Modality Retrieval
4.2.4. Datasets
4.2.5. Author’s Insights
5. Discussion
5.1. Trends in MMDL
5.2. Limitations
5.3. Future Research
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Smith, J. Science and Technology for Development; Bloomsbury publishing: London, UK, 2009. [Google Scholar]
- Carbonell, J.G.; Michalski, R.S.; Mitchell, T.M. An overview of machine learning. In Machine Learning; Springer: Cham, Switzerland, 1983; pp. 3–23. [Google Scholar]
- Tang, J.; Liu, G.; Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEE/CAA J. Autom. Sin. 2021, 8, 1627–1643. [Google Scholar] [CrossRef]
- McDonald, R.J.; Schwartz, K.M.; Eckel, L.J.; Diehn, F.E.; Hunt, C.H.; Bartholmai, B.J.; Erickson, B.J.; Kallmes, D.F. The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload. Acad. Radiol. 2015, 22, 1191–1198. [Google Scholar] [CrossRef]
- Piccialli, F.; Di Somma, V.; Giampaolo, F.; Cuomo, S.; Fortino, G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Shamshirband, S.; Fathi, M.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 2021, 113, 103627. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhu, H.; Wang, S.-H.; Zhang, Y.-D. A review of deep learning on medical image analysis. Mob. Netw. Appl. 2021, 26, 351–380. [Google Scholar] [CrossRef]
- Krittanawong, C.; Johnson, K.W.; Rosenson, R.S.; Wang, Z.; Aydar, M.; Baber, U.; Min, J.K.; Tang, W.W.; Halperin, J.L.; Narayan, S.M. Deep learning for cardiovascular medicine: A practical primer. Eur. Heart J. 2019, 40, 2058–2073. [Google Scholar] [CrossRef]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep learning for chest X-ray analysis: A survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Cui, C.; Yang, H.; Wang, Y.; Zhao, S.; Asad, Z.; Coburn, L.A.; Wilson, K.T.; Landman, B.A.; Huo, Y. Deep multimodal fusion of image and non-image data in disease diagnosis and prognosis: A review. Prog. Biomed. Eng. 2023, 5, 022001. [Google Scholar] [CrossRef]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A survey on deep learning for multimodal data fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef]
- Behrad, F.; Abadeh, M.S. An overview of deep learning methods for multimodal medical data mining. Expert Syst. Appl. 2022, 200, 117006. [Google Scholar]
- Xu, Z.; So, D.R.; Dai, A.M. Mufasa: Multimodal fusion architecture search for electronic health records. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Huang, S.-C.; Pareek, A.; Seyyedi, S.; Banerjee, I.; Lungren, M.P. Fusion of medical imaging and electronic health records using deep learning: A systematic review and implementation guidelines. NPJ Digit. Med. 2020, 3, 136. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.-C.; Pareek, A.; Zamanian, R.; Banerjee, I.; Lungren, M.P. Multimodal fusion with deep neural networks for leveraging CT imaging and electronic health record: A case-study in pulmonary embolism detection. Sci. Rep. 2020, 10, 22147. [Google Scholar]
- Stahlschmidt, S.R.; Ulfenborg, B.; Synnergren, J. Multimodal deep learning for biomedical data fusion: A review. Brief. Bioinform. 2022, 23, bbab569. [Google Scholar] [CrossRef] [PubMed]
- Ayesha, S.; Hanif, M.K.; Talib, R. Performance enhancement of predictive analytics for health informatics using dimensionality reduction techniques and fusion frameworks. IEEE Access 2021, 10, 753–769. [Google Scholar] [CrossRef]
- Acosta, J.N.; Falcone, G.J.; Rajpurkar, P.; Topol, E.J. Multimodal biomedical AI. Nat. Med. 2022, 28, 1773–1784. [Google Scholar]
- Lipkova, J.; Chen, R.J.; Chen, B.; Lu, M.Y.; Barbieri, M.; Shao, D.; Vaidya, A.J.; Chen, C.; Zhuang, L.; Williamson, D.F. Artificial intelligence for multimodal data integration in oncology. Cancer Cell 2022, 40, 1095–1110. [Google Scholar]
- Amal, S.; Safarnejad, L.; Omiye, J.A.; Ghanzouri, I.; Cabot, J.H.; Ross, E.G. Use of multi-modal data and machine learning to improve cardiovascular disease care. Front. Cardiovasc. Med. 2022, 9, 840262. [Google Scholar] [CrossRef]
- Kline, A.; Wang, H.; Li, Y.; Dennis, S.; Hutch, M.; Xu, Z.; Wang, F.; Cheng, F.; Luo, Y. Multimodal machine learning in precision health: A scoping review. Npj Digit. Med. 2022, 5, 171. [Google Scholar] [CrossRef]
- Wójcik, M.A. Foundation models in healthcare: Opportunities, biases and regulatory prospects in europe. In International Conference on Electronic Government and the Information Systems Perspective; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef]
- Fei, N.; Lu, Z.; Gao, Y.; Yang, G.; Huo, Y.; Wen, J.; Lu, H.; Song, R.; Gao, X.; Xiang, T. Towards artificial general intelligence via a multimodal foundation model. Nat. Commun. 2022, 13, 3094. [Google Scholar] [CrossRef] [PubMed]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. PeerJ Comput. Sci. 2022, 8, e1045. [Google Scholar] [PubMed]
- Duvieusart, B.; Krones, F.; Parsons, G.; Tarassenko, L.; Papież, B.W.; Mahdi, A. Multimodal cardiomegaly classification with image-derived digital biomarkers. In Annual Conference on Medical Image Understanding and Analysis; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Bidgood Jr, W.D.; Horii, S.C.; Prior, F.W.; Van Syckle, D.E. Understanding and using DICOM, the data interchange standard for biomedical imaging. J. Am. Med. Inform. Assoc. 1997, 4, 199–212. [Google Scholar] [PubMed]
- Poldrack, R.A.; Gorgolewski, K.J.; Varoquaux, G. Computational and informatic advances for reproducible data analysis in neuroimaging. Annu. Rev. Biomed. Data Sci. 2019, 2, 119–138. [Google Scholar]
- England, N.; Improvement, N. Diagnostic Imaging Dataset Statistical Release; Department of Health: London, UK, 2016; Volume 421. [Google Scholar]
- Heiliger, L.; Sekuboyina, A.; Menze, B.; Egger, J.; Kleesiek, J. Beyond medical imaging-a review of multimodal deep learning in radiology. TechRxiv 2022, 19103432. [Google Scholar]
- Buzug, T.M. Computed tomography. In Springer Handbook of Medical Technology; Springer: Cham, Switzerland, 2011; pp. 311–342. [Google Scholar]
- Goldman, L.W. Principles of CT and CT technology. J. Nucl. Med. Technol. 2007, 35, 115–128. [Google Scholar]
- Hashemi, R.; Bradley, W.; Lisanti, C. Basic principles of MRI. MRI Basics 2010, 16. [Google Scholar]
- Stadler, A.; Schima, W.; Ba-Ssalamah, A.; Kettenbach, J.; Eisenhuber, E. Artifacts in body MR imaging: Their appearance and how to eliminate them. Eur. Radiol. 2007, 17, 1242–1255. [Google Scholar]
- Guermazi, A.; Roemer, F.W.; Haugen, I.K.; Crema, M.D.; Hayashi, D. MRI-based semiquantitative scoring of joint pathology in osteoarthritis. Nat. Rev. Rheumatol. 2013, 9, 236–251. [Google Scholar]
- Israel, O.; Pellet, O.; Biassoni, L.; De Palma, D.; Estrada-Lobato, E.; Gnanasegaran, G.; Kuwert, T.; La Fougère, C.; Mariani, G.; Massalha, S. Two decades of SPECT/CT–the coming of age of a technology: An updated review of literature evidence. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 1990–2012. [Google Scholar] [CrossRef] [PubMed]
- Dwivedi, S.; Goel, T.; Tanveer, M.; Murugan, R.; Sharma, R. Multimodal fusion-based deep learning network for effective diagnosis of Alzheimer’s disease. IEEE Multimed. 2022, 29, 45–55. [Google Scholar] [CrossRef]
- Merz, E.; Abramowicz, J.S. 3D/4D ultrasound in prenatal diagnosis: Is it time for routine use? Clin. Obstet. Gynecol. 2012, 55, 336–351. [Google Scholar] [CrossRef] [PubMed]
- Woo, J. A short history of the development of ultrasound in obstetrics and gynecology. Hist. Ultrasound Obstet. Gynecol. 2002, 3, 1–25. [Google Scholar]
- Brattain, L.J.; Telfer, B.A.; Dhyani, M.; Grajo, J.R.; Samir, A.E. Machine learning for medical ultrasound: Status, methods, and future opportunities. Abdom. Radiol. 2018, 43, 786–799. [Google Scholar] [CrossRef]
- Karaoğlu, O.; Bilge, H.Ş.; Uluer, I. Removal of speckle noises from ultrasound images using five different deep learning networks. Eng. Sci. Technol. Int. J. 2022, 29, 101030. [Google Scholar] [CrossRef]
- Spasic, I.; Nenadic, G. Clinical text data in machine learning: Systematic review. JMIR Med. Inform. 2020, 8, e17984. [Google Scholar] [CrossRef]
- Mustafa, A.; Rahimi Azghadi, M. Automated machine learning for healthcare and clinical notes analysis. Computers 2021, 10, 24. [Google Scholar] [CrossRef]
- Li, Q.; Spooner, S.A.; Kaiser, M.; Lingren, N.; Robbins, J.; Lingren, T.; Tang, H.; Solti, I.; Ni, Y. An end-to-end hybrid algorithm for automated medication discrepancy detection. BMC Med. Inform. Decis. Mak. 2015, 15, 37. [Google Scholar] [CrossRef]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. Mimic-iv. PhysioNet. 2020. pp. 49–55. Available online: https://physionet.org/content/mimiciv/1.0/ (accessed on 23 August 2021).
- Huang, S.-C.; Shen, L.; Lungren, M.P.; Yeung, S. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Casey, A.; Davidson, E.; Poon, M.; Dong, H.; Duma, D.; Grivas, A.; Grover, C.; Suárez-Paniagua, V.; Tobin, R.; Whiteley, W. A systematic review of natural language processing applied to radiology reports. BMC Med. Inform. Decis. Mak. 2021, 21, 179. [Google Scholar] [CrossRef]
- Sheikhalishahi, S.; Miotto, R.; Dudley, J.T.; Lavelli, A.; Rinaldi, F.; Osmani, V. Natural language processing of clinical notes on chronic diseases: Systematic review. JMIR Med. Inform. 2019, 7, e12239. [Google Scholar] [CrossRef] [PubMed]
- Locke, S.; Bashall, A.; Al-Adely, S.; Moore, J.; Wilson, A.; Kitchen, G.B. Natural language processing in medicine: A review. Trends Anaesth. Crit. Care 2021, 38, 4–9. [Google Scholar] [CrossRef]
- Chen, Y.; Lasko, T.A.; Mei, Q.; Denny, J.C.; Xu, H. A study of active learning methods for named entity recognition in clinical text. J. Biomed. Inform. 2015, 58, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Walonoski, J.; Kramer, M.; Nichols, J.; Quina, A.; Moesel, C.; Hall, D.; Duffett, C.; Dube, K.; Gallagher, T.; McLachlan, S. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. J. Am. Med. Inform. Assoc. 2018, 25, 230–238. [Google Scholar] [CrossRef]
- Nageotte, M.P. Fetal heart rate monitoring. In Seminars in Fetal and Neonatal Medicine; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Czosnyka, M.; Pickard, J.D. Monitoring and interpretation of intracranial pressure. J. Neurol. Neurosurg. Psychiatry 2004, 75, 813–821. [Google Scholar] [CrossRef]
- Nicolò, A.; Massaroni, C.; Schena, E.; Sacchetti, M. The importance of respiratory rate monitoring: From healthcare to sport and exercise. Sensors 2020, 20, 6396. [Google Scholar] [CrossRef]
- Luks, A.M.; Swenson, E.R. Pulse oximetry for monitoring patients with COVID-19 at home. Potential pitfalls and practical guidance. Ann. Am. Thorac. Soc. 2020, 17, 1040–1046. [Google Scholar] [CrossRef]
- Armitage, L.C.; Davidson, S.; Mahdi, A.; Harford, M.; McManus, R.; Farmer, A.; Watkinson, P.; Tarassenko, L. Diagnosing hypertension in primary care: A retrospective cohort study to investigate the importance of night-time blood pressure assessment. Br. J. Gen. Pract. 2023, 73, e16–e23. [Google Scholar] [CrossRef]
- Walker, B.; Krones, F.; Kiskin, I.; Parsons, G.; Lyons, T.; Mahdi, A. Dual Bayesian ResNet: A deep learning approach to heart murmur detection. In Proceedings of the 2022 Computing in Cardiology (CinC), Tampere, Finland, 4–7 September 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Ceccarelli, F.; Mahmoud, M. Multimodal temporal machine learning for Bipolar Disorder and Depression Recognition. Pattern Anal. Appl. 2022, 25, 493–504. [Google Scholar] [CrossRef]
- Salekin, M.S.; Zamzmi, G.; Goldgof, D.; Kasturi, R.; Ho, T.; Sun, Y. Multimodal spatio-temporal deep learning approach for neonatal postoperative pain assessment. Comput. Biol. Med. 2021, 129, 104150. [Google Scholar] [CrossRef]
- Grant, D.; Papież, B.W.; Parsons, G.; Tarassenko, L.; Mahdi, A. Deep learning classification of cardiomegaly using combined imaging and non-imaging ICU data. In Proceedings of the Medical Image Understanding and Analysis: 25th Annual Conference, MIUA 2021, Oxford, UK, 12–14 July 2021; Proceedings 25. Springer: Cham, Switzerland, 2021. [Google Scholar]
- Xu, M.; Ouyang, L.; Gao, Y.; Chen, Y.; Yu, T.; Li, Q.; Sun, K.; Bao, F.S.; Safarnejad, L.; Wen, J. Accurately differentiating COVID-19, other viral infection, and healthy individuals using multimodal features via late fusion learning. medRxiv 2020. [Google Scholar] [CrossRef]
- Samak, Z.A.; Clatworthy, P.; Mirmehdi, M. Prediction of thrombectomy functional outcomes using multimodal data. In Annual Conference on Medical Image Understanding and Analysis; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, J.; Wang, Y.; Zu, C.; Yu, B.; Wang, L.; Zhou, L. Medical Imaging Based Diagnosis Through Machine Learning and Data Analysis. In Advances in Artificial Intelligence, Computation, and Data Science: For Medicine and Life Science; Springer: Cham, Switzerland, 2021; pp. 179–225. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Summers, R.M. Tienet: Text-image embedding network for common thorax disease classification and reporting in chest x-rays. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hochreiter, S. Long Short-Term Memory; Neural Computation MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Wang, H.; Luo, Y. A comparison of pre-trained vision-and-language models for multimodal representation learning across medical images and reports. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Huang, Z.; Zeng, Z.; Liu, B.; Fu, D.; Fu, J. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv 2020, arXiv:2004.00849. [Google Scholar]
- Chen, Y.-C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Learning universal image-text representations. arXiv 2019, arXiv:1909.11740. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. Visualbert: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Alsentzer, E.; JMurphy, R.; Boag, W.; Weng, W.-H.; Jin, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zeng, J.; Niu, K.; Lu, Y.; Pei, S.; Zhou, Y.; Guo, Z. MIFTP: A Multimodal Multi-Level Independent Fusion Framework with Improved Twin Pyramid for Multilabel Chest X-Ray Image Classification. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Shetty, S.; Mahale, A. Multimodal medical tensor fusion network-based DL framework for abnormality prediction from the radiology CXRs and clinical text reports. Multimed. Tools Appl. 2023, 82, 44431–44478. [Google Scholar] [CrossRef]
- Upadhya, J.; Poudel, K.; Ranganathan, J. Advancing Medical Image Diagnostics through Multi-Modal Fusion: Insights from MIMIC Chest X-Ray Dataset Analysis. In Proceedings of the 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), Mt Pleasant, MI, USA, 13–14 April 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Park, S.; Lee, E.S.; Shin, K.S.; Lee, J.E.; Ye, J.C. Self-supervised multi-modal training from uncurated images and reports enables monitoring AI in radiology. Med. Image Anal. 2024, 91, 103021. [Google Scholar] [CrossRef]
- Deng, S.; Zhang, X.; Jiang, S. A diagnostic report supervised deep learning model training strategy for diagnosis of COVID-19. Pattern Recognit. 2024, 149, 110232. [Google Scholar] [CrossRef]
- Chauhan, G.; Liao, R.; Wells, W.; Andreas, J.; Wang, X.; Berkowitz, S.; Horng, S.; Szolovits, P.; Golland, P. Joint modeling of chest radiographs and radiology reports for pulmonary edema assessment. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part II 23. Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, Y.; Jiang, H.; Miura, Y.; Manning, C.D.; Langlotz, C.P. Contrastive learning of medical visual representations from paired images and text. In Machine Learning for Healthcare Conference; PMLR: Cambridge, MA, USA, 2022. [Google Scholar]
- Müller, P.; Kaissis, G.; Zou, C.; Rueckert, D. Joint learning of localized representations from medical images and reports. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Wang, X.; Xu, Z.; Tam, L.; Yang, D.; Xu, D. Self-supervised image-text pre-training with mixed data in chest x-rays. arXiv 2021, arXiv:2103.16022. [Google Scholar]
- Chen, C.; Zhong, A.; Wu, D.; Luo, J.; Li, Q. Contrastive masked image-text modeling for medical visual representation learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2023. [Google Scholar]
- Boag, W.; Hsu, T.-M.H.; McDermott, M.; Berner, G.; Alesentzer, E.; Szolovits, P. Baselines for chest x-ray report generation. In Machine Learning for Health Workshop; PMLR: Cambridge, MA, USA, 2020. [Google Scholar]
- Liu, G.; Hsu, T.-M.H.; McDermott, M.; Boag, W.; Weng, W.-H.; Szolovits, P.; Ghassemi, M. Clinically accurate chest x-ray report generation. In Machine Learning for Healthcare Conference; PMLR: Cambridge, MA, USA, 2019. [Google Scholar]
- Zhang, Y.; Wang, X.; Xu, Z.; Yu, Q.; Yuille, A.; Xu, D. When radiology report generation meets knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Chen, Z.; Song, Y.; Chang, T.-H.; Wan, X. Generating radiology reports via memory-driven transformer. arXiv 2020, arXiv:2010.16056. [Google Scholar]
- Chen, W.; Pan, H.; Zhang, K.; Du, X.; Cui, Q. VMEKNet: Visual Memory and External Knowledge Based Network for Medical Report Generation. In Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2022. [Google Scholar]
- You, D.; Liu, F.; Ge, S.; Xie, X.; Zhang, J.; Wu, X. Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part III 24. Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Liu, F.; You, C.; Wu, X.; Ge, S.; Sun, X. Auto-encoding knowledge graph for unsupervised medical report generation. Adv. Neural Inf. Process. Syst. 2021, 34, 16266–16279. [Google Scholar]
- Li, C.Y.; Liang, X.; Hu, Z.; Xing, E.P. Knowledge-driven encode, retrieve, paraphrase for medical image report generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Syeda-Mahmood, T.; Wong, K.C.; Gur, Y.; Wu, J.T.; Jadhav, A.; Kashyap, S.; Karargyris, A.; Pillai, A.; Sharma, A.; Syed, A.B. Chest x-ray report generation through fine-grained label learning. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part II 23. Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Endo, M.; Krishnan, R.; Krishna, V.; Ng, A.Y.; Rajpurkar, P. Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model. In Machine Learning for Health; PMLR: Cambridge, MA, USA, 2021. [Google Scholar]
- Tanwani, A.K.; Barral, J.; Freedman, D. Repsnet: Combining vision with language for automated medical reports. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Miura, Y.; Zhang, Y.; Tsai, E.B.; Langlotz, C.P.; Jurafsky, D. Improving factual completeness and consistency of image-to-text radiology report generation. arXiv 2020, arXiv:2010.10042. [Google Scholar]
- Delbrouck, J.-B.; Chambon, P.; Bluethgen, C.; Tsai, E.; Almusa, O.; Langlotz, C.P. Improving the factual correctness of radiology report generation with semantic rewards. arXiv 2022, arXiv:2210.12186. [Google Scholar]
- Wang, X.; Li, Y.; Wang, F.; Wang, S.; Li, C.; Jiang, B. R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation. arXiv 2024, arXiv:2408.09743. [Google Scholar]
- Rodin, I.; Fedulova, I.; Shelmanov, A.; Dylov, D.V. Multitask and multimodal neural network model for interpretable analysis of x-ray images. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Ben Abacha, A.; Sarrouti, M.; Demner-Fushman, D.; Hasan, S.A.; Müller, H. Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain. In Proceedings of the CLEF 2021 Conference and Labs of the Evaluation Forum-Working Notes, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Ben Abacha, A.; Hasan, S.A.; Datla, V.V.; Demner-Fushman, D.; Müller, H. Vqa-med: Overview of the medical visual question answering task at imageclef 2019. In Proceedings of the CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes, Bucharest, Romania, 9–12 September 2019. [Google Scholar]
- Hasan, S.A.; Ling, Y.; Farri, O.; Liu, J.; Müller, H.; Lungren, M. Overview of imageclef 2018 medical domain visual question answering task. In Proceedings of the CLEF 2018 Working Notes, Avignon, France, 10–14 September 2018. [Google Scholar]
- Liu, S.; Zhang, X.; Zhou, X.; Yang, J. BPI-MVQA: A bi-branch model for medical visual question answering. BMC Med. Imaging 2022, 22, 79. [Google Scholar] [CrossRef]
- Kenton, J.D.M.-W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; p. 2. [Google Scholar]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5947–5959. [Google Scholar] [CrossRef]
- Sharma, D.; Purushotham, S.; Reddy, C.K. MedFuseNet: An attention-based multimodal deep learning model for visual question answering in the medical domain. Sci. Rep. 2021, 11, 19826. [Google Scholar] [CrossRef]
- Chen, Z.; Li, G.; Wan, X. Align, reason and learn: Enhancing medical vision-and-language pre-training with knowledge. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022. [Google Scholar]
- Liu, B.; Zhan, L.-M.; Wu, X.-M. Contrastive pre-training and representation distillation for medical visual question answering based on radiology images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part II 24. Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Do, T.; Nguyen, B.X.; Tjiputra, E.; Tran, M.; Tran, Q.D.; Nguyen, A. Multiple meta-model quantifying for medical visual question answering. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part V 24. Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Eslami, S.; Meinel, C.; De Melo, G. Pubmedclip: How much does clip benefit visual question answering in the medical domain? In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023.
- Gong, H.; Chen, G.; Liu, S.; Yu, Y.; Li, G. Cross-modal self-attention with multi-task pre-training for medical visual question answering. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021. [Google Scholar]
- Chen, Z.; Du, Y.; Hu, J.; Liu, Y.; Li, G.; Wan, X.; Chang, T.-H. Multi-modal masked autoencoders for medical vision-and-language pre-training. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Pan, H.; He, S.; Zhang, K.; Qu, B.; Chen, C.; Shi, K. AMAM: An attention-based multimodal alignment model for medical visual question answering. Knowl. -Based Syst. 2022, 255, 109763. [Google Scholar] [CrossRef]
- Kim, K.; Na, Y.; Ye, S.-J.; Lee, J.; Ahn, S.S.; Park, J.E.; Kim, H. Controllable text-to-image synthesis for multi-modality MR images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024. [Google Scholar]
- Chen, W.; Wang, P.; Ren, H.; Sun, L.; Li, Q.; Yuan, Y.; Li, X. Medical Image Synthesis via Fine-Grained Image-Text Alignment and Anatomy-Pathology Prompting. arXiv 2024, arXiv:2403.06835. [Google Scholar]
- Maleki, D.; Tizhoosh, H.R. LILE: Look in-depth before looking elsewhere–a dual attention network using transformers for cross-modal information retrieval in histopathology archives. In International Conference on Medical Imaging with Deep Learning; PMLR: Cambridge, MA, USA, 2022. [Google Scholar]
- Liu, C.; Shah, A.; Bai, W.; Arcucci, R. Utilizing synthetic data for medical vision-language pre-training: Bypassing the need for real images. arXiv 2023, arXiv:2310.07027. [Google Scholar]
- Yang, X.; Gireesh, N.; Xing, E.; Xie, P. Xraygan: Consistency-preserving generation of x-ray images from radiology reports. arXiv 2020, arXiv:2006.10552. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.-Y.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a collection of radiology examinations for distribution and retrieval. J. Am. Med. Inform. Assoc. 2016, 23, 304–310. [Google Scholar] [CrossRef]
- Bustos, A.; Pertusa, A.; Salinas, J.-M.; De La Iglesia-Vaya, M. Padchest: A large chest x-ray image dataset with multi-label annotated reports. Med. Image Anal. 2020, 66, 101797. [Google Scholar] [CrossRef]
- Ionescu, B.; Müller, H.; Villegas, M.; García Seco de Herrera, A.; Eickhoff, C.; Andrearczyk, V.; Dicente Cid, Y.; Liauchuk, V.; Kovalev, V.; Hasan, S.A. Overview of ImageCLEF 2018: Challenges, datasets and evaluation. In Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction: 9th International Conference of the CLEF Association, CLEF 2018, Avignon, France, 10–14 September 2018; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Jain, S.; Agrawal, A.; Saporta, A.; Truong, S.Q.; Duong, D.N.; Bui, T.; Chambon, P.; Zhang, Y.; Lungren, M.P.; Ng, A.Y. Radgraph: Extracting clinical entities and relations from radiology reports. arXiv 2021, arXiv:2106.14463. [Google Scholar]
- Li, M.; Liu, R.; Wang, F.; Chang, X.; Liang, X. Auxiliary signal-guided knowledge encoder-decoder for medical report generation. World Wide Web 2023, 26, 253–270. [Google Scholar] [CrossRef]
- Liu, G.; Liao, Y.; Wang, F.; Zhang, B.; Zhang, L.; Liang, X.; Wan, X.; Li, S.; Li, Z.; Zhang, S. Medical-vlbert: Medical visual language bert for covid-19 ct report generation with alternate learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3786–3797. [Google Scholar] [PubMed]
- Feng, S.; Azzollini, D.; Kim, J.S.; Jin, C.-K.; Gordon, S.P.; Yeoh, J.; Kim, E.; Han, M.; Lee, A.; Patel, A. Curation of the candid-ptx dataset with free-text reports. Radiol. Artif. Intell. 2021, 3, e210136. [Google Scholar] [PubMed]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shih, G.; Wu, C.C.; Halabi, S.S.; Kohli, M.D.; Prevedello, L.M.; Cook, T.S.; Sharma, A.; Amorosa, J.K.; Arteaga, V.; Galperin-Aizenberg, M. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia. Radiol. Artif. Intell. 2019, 1, e180041. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.; Wang, L.L.; Mehta, S.; Bogin, B.; van Zuylen, M.; Parasa, S.; Singh, S.; Gardner, M.; Hajishirzi, H. Medicat: A dataset of medical images, captions, and textual references. arXiv 2020, arXiv:2010.06000. [Google Scholar]
- Pelka, O.; Koitka, S.; Rückert, J.; Nensa, F.; Friedrich, C.M. Radiology objects in context (roco): A multimodal image dataset. In Proceedings of the Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis: 7th Joint International Workshop, CVII-STENT 2018 and Third International Workshop, LABELS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16 September 2018; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Lau, J.J.; Gayen, S.; Ben Abacha, A.; Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 2018, 5, 180251. [Google Scholar]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. Pathvqa: 30000+ questions for medical visual question answering. arXiv 2020, arXiv:2003.10286. [Google Scholar]
- Liu, B.; Zhan, L.-M.; Xu, L.; Ma, L.; Yang, Y.; Wu, X.-M. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Huang, S.-C.; Kothari, T.; Banerjee, I.; Chute, C.; Ball, R.L.; Borus, N.; Huang, A.; Patel, B.N.; Rajpurkar, P.; Irvin, J. PENet—A scalable deep-learning model for automated diagnosis of pulmonary embolism using volumetric CT imaging. NPJ Digit. Med. 2020, 3, 61. [Google Scholar]
- Zhou, Y.; Huang, S.-C.; Fries, J.A.; Youssef, A.; Amrhein, T.J.; Chang, M.; Banerjee, I.; Rubin, D.; Xing, L.; Shah, N. Radfusion: Benchmarking performance and fairness for multimodal pulmonary embolism detection from ct and ehr. arXiv 2021, arXiv:2111.11665. [Google Scholar]
- Holste, G.; Partridge, S.C.; Rahbar, H.; Biswas, D.; Lee, C.I.; Alessio, A.M. End-to-end learning of fused image and non-image features for improved breast cancer classification from mri. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Sun, X.; Guo, W.; Shen, J. Toward attention-based learning to predict the risk of brain degeneration with multimodal medical data. Front. Neurosci. 2023, 16, 1043626. [Google Scholar]
- Ostertag, C.; Visani, M.; Urruty, T.; Beurton-Aimar, M. Long-term cognitive decline prediction based on multi-modal data using Multimodal3DSiameseNet: Transfer learning from Alzheimer’s disease to Parkinson’s disease. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 809–818. [Google Scholar]
- Ostertag, C.; Beurton-Aimar, M.; Visani, M.; Urruty, T.; Bertet, K. Predicting brain degeneration with a multimodal Siamese neural network. In Proceedings of the 2020 Tenth International Conference on Image Processing Theory, Tools and Applications (IPTA), Paris, France, 9–12 November 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Hou, G.; Jia, L.; Zhang, Y.; Wu, W.; Zhao, L.; Zhao, J.; Wang, L.; Qiang, Y. Deep learning approach for predicting lymph node metastasis in non-small cell lung cancer by fusing image–gene data. Eng. Appl. Artif. Intell. 2023, 122, 106140. [Google Scholar] [CrossRef]
- Cahan, N.; Klang, E.; Marom, E.M.; Soffer, S.; Barash, Y.; Burshtein, E.; Konen, E.; Greenspan, H. Multimodal fusion models for pulmonary embolism mortality prediction. Sci. Rep. 2023, 13, 7544. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Arik, S.Ö.; Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Cahan, N.; Marom, E.M.; Soffer, S.; Barash, Y.; Konen, E.; Klang, E.; Greenspan, H. Weakly supervised attention model for RV strain classification from volumetric CTPA scans. Comput. Methods Programs Biomed. 2022, 220, 106815. [Google Scholar] [CrossRef] [PubMed]
- Pölsterl, S.; Wolf, T.N.; Wachinger, C. Combining 3D image and tabular data via the dynamic affine feature map transform. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part V 24. Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Sousa, J.V.; Matos, P.; Silva, F.; Freitas, P.; Oliveira, H.P.; Pereira, T. Single Modality vs. Multimodality: What Works Best for Lung Cancer Screening? Sensors 2023, 23, 5597. [Google Scholar] [CrossRef]
- Duanmu, H.; Huang, P.B.; Brahmavar, S.; Lin, S.; Ren, T.; Kong, J.; Wang, F.; Duong, T.Q. Prediction of pathological complete response to neoadjuvant chemotherapy in breast cancer using deep learning with integrative imaging, molecular and demographic data. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part II 23. Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2020. [Google Scholar]
- Azizi, S.; Mustafa, B.; Ryan, F.; Beaver, Z.; Freyberg, J.; Deaton, J.; Loh, A.; Karthikesalingam, A.; Kornblith, S.; Chen, T. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Vu, Y.N.T.; Wang, R.; Balachandar, N.; Liu, C.; Ng, A.Y.; Rajpurkar, P. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation. In Machine Learning for Healthcare Conference; PMLR: Cambridge, MA, USA, 2021. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Shurrab, S.; Manzanares, A.G.; Shamout, F.E. Multimodal masked siamese network improves chest X-ray representation learning. Sci. Rep. 2024, 14, 22516. [Google Scholar] [CrossRef]
- Holland, R.; Leingang, O.; Bogunović, H.; Riedl, S.; Fritsche, L.; Prevost, T.; Scholl, H.P.; Schmidt-Erfurth, U.; Sivaprasad, S.; Lotery, A.J. Metadata-enhanced contrastive learning from retinal optical coherence tomography images. Med. Image Anal. 2024, 97, 103296. [Google Scholar] [CrossRef]
- Farooq, A.; Mishra, D.; Chaudhury, S. Survival Prediction in Lung Cancer through Multi-Modal Representation Learning. arXiv 2024, arXiv:2409.20179. [Google Scholar]
- Gorade, V.; Mittal, S.; Singhal, R. PaCL: Patient-aware contrastive learning through metadata refinement for generalized early disease diagnosis. Comput. Biol. Med. 2023, 167, 107569. [Google Scholar] [CrossRef]
- Dufumier, B.; Gori, P.; Victor, J.; Grigis, A.; Wessa, M.; Brambilla, P.; Favre, P.; Polosan, M.; Mcdonald, C.; Piguet, C.M. Contrastive learning with continuous proxy meta-data for 3D MRI classification. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part II 24. Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Qasim, A.B.; Ezhov, I.; Shit, S.; Schoppe, O.; Paetzold, J.C.; Sekuboyina, A.; Kofler, F.; Lipkova, J.; Li, H.; Menze, B. Red-GAN: Attacking class imbalance via conditioned generation. Yet another medical imaging perspective. In Medical Imaging with Deep Learning; PMLR: Cambridge, MA, USA, 2020. [Google Scholar]
- Štern, D.; Payer, C.; Urschler, M. Automated age estimation from MRI volumes of the hand. Med. Image Anal. 2019, 58, 101538. [Google Scholar] [CrossRef]
- Qu, H.; Zhou, M.; Yan, Z.; Wang, H.; Rustgi, V.K.; Zhang, S.; Gevaert, O.; Metaxas, D.N. Genetic mutation and biological pathway prediction based on whole slide images in breast carcinoma using deep learning. NPJ Precis. Oncol. 2021, 5, 87. [Google Scholar] [CrossRef] [PubMed]
- Di Martino, A.; O’connor, D.; Chen, B.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Balsters, J.H.; Baxter, L.; Beggiato, A.; Bernaerts, S. Enhancing studies of the connectome in autism using the autism brain imaging data exchange II. Sci. Data 2017, 4, 170010. [Google Scholar] [CrossRef] [PubMed]
- Littlejohns, T.J.; Holliday, J.; Gibson, L.M.; Garratt, S.; Oesingmann, N.; Alfaro-Almagro, F.; Bell, J.D.; Boultwood, C.; Collins, R.; Conroy, M.C. The UK Biobank imaging enhancement of 100,000 participants: Rationale, data collection, management and future directions. Nat. Commun. 2020, 11, 2624. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef]
- Di Martino, A.; Yan, C.-G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Kadra, A.; Lindauer, M.; Hutter, F.; Grabocka, J. Well-tuned simple nets excel on tabular datasets. Adv. Neural Inf. Process. Syst. 2021, 34, 23928–23941. [Google Scholar]


| Reference | Framework | Dataset | Image Modality | Structured Data Modality | Fusion Strategy | Metric | MM Performance |
|---|---|---|---|---|---|---|---|
| [17] | PENet, Elastic Net | Private | CT | EHR | Late fusion | AUC | 0.947 |
| [139] | PENet, Elastic Net | RadFusion | CT | EHR | Late fusion | AUC | 0.946 |
| [140] | ResNet-50, MLP | Private | MRI | EHR | Joint fusion | AUC | 0.898 |
| [141] | 3D ResNet-50, DenseNet | ADNI | MRI | EHR | Joint fusion | AUC | 0.859 0.899 |
| [142] | Multimodal 3D SiameseNet | PPMI | MRI | Clinical | Joint fusion | AUC | 0.81 |
| [144] | Inception-ResNet v2, MLP | NSCLC-Radiogenomics | CT | Clinical | Joint fusion | Accuracy AUC | 0.968, 0.963 |
| [145] | XGBoost, TabNet, SANet | Private | CT | Clinical | Joint fusion | AUC | 0.96 |
| [149] | CNN, DAFT | ADNI | MRI | Demographic Clinical | Joint fusion | Accuracy c-index | 0.622 0.748 |
| [28] | ResNet-50, XGBoost | MIMIC-CXR MIMIC-IV, JSRT | CXR | Demographic vital signs lab findings | Joint fusion | Accuracy F1 AUC | 0.812 0.859 0.810 |
| [150] | ResNet-18 + RF | NLST | CT | Clinical | Joint fusion | AUC | 0.8021 |
| [151] | CNN, NN | I-SPY-1 TRIAL | MRI | Demographic | Joint fusion | Accuracy AUC | 0.83 0.80 |
| Reference | Framework | Dataset | Image Modality | Structured Data Modality | Representation Strategy | Metric | MM Performance |
|---|---|---|---|---|---|---|---|
| [153] | SimCLR + MICLe | CheXpert | CXR | Metadata | Contrastive learning | Accuracy | 0.688 |
| [154] | MedAUG | CheXpert | CXR | Metadata | Contrastive learning | AUC | 0.906 |
| [157] | Masked Siamese Network (MSN) | MIMIC-CXR CheXpert | CXR | EHR | Non-contrastive learning | AUROC | 0.801 |
| [158] | BYOL, SimCLR | Southampton Moorfields | OCT | Metadata | Contrastive learning | AUC AUC | 0.85 0.88 |
| [159] | ViT, FCNet | NSCLC | CT, PET | Metadata | Contrastive learning | C-index | 0.756 |
| [160], | PaCL | NAH dataset | CXR | Metadata | Contrastive learning | mAUC | 0.836 |
| [161] | DenseNet | BHB dataset | MRI | Metadata | Contrastive learning | AUC | 0.7633 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haq, I.U.; Mhamed, M.; Al-Harbi, M.; Osman, H.; Hamd, Z.Y.; Liu, Z. Advancements in Medical Radiology Through Multimodal Machine Learning: A Comprehensive Overview. Bioengineering 2025, 12, 477. https://doi.org/10.3390/bioengineering12050477
Haq IU, Mhamed M, Al-Harbi M, Osman H, Hamd ZY, Liu Z. Advancements in Medical Radiology Through Multimodal Machine Learning: A Comprehensive Overview. Bioengineering. 2025; 12(5):477. https://doi.org/10.3390/bioengineering12050477
Chicago/Turabian StyleHaq, Imran Ul, Mustafa Mhamed, Mohammed Al-Harbi, Hamid Osman, Zuhal Y. Hamd, and Zhe Liu. 2025. "Advancements in Medical Radiology Through Multimodal Machine Learning: A Comprehensive Overview" Bioengineering 12, no. 5: 477. https://doi.org/10.3390/bioengineering12050477
APA StyleHaq, I. U., Mhamed, M., Al-Harbi, M., Osman, H., Hamd, Z. Y., & Liu, Z. (2025). Advancements in Medical Radiology Through Multimodal Machine Learning: A Comprehensive Overview. Bioengineering, 12(5), 477. https://doi.org/10.3390/bioengineering12050477