
Long-Term Retrospective Predicted Concentration of PM2.5 in Upper Northern Thailand Using Machine Learning Models

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
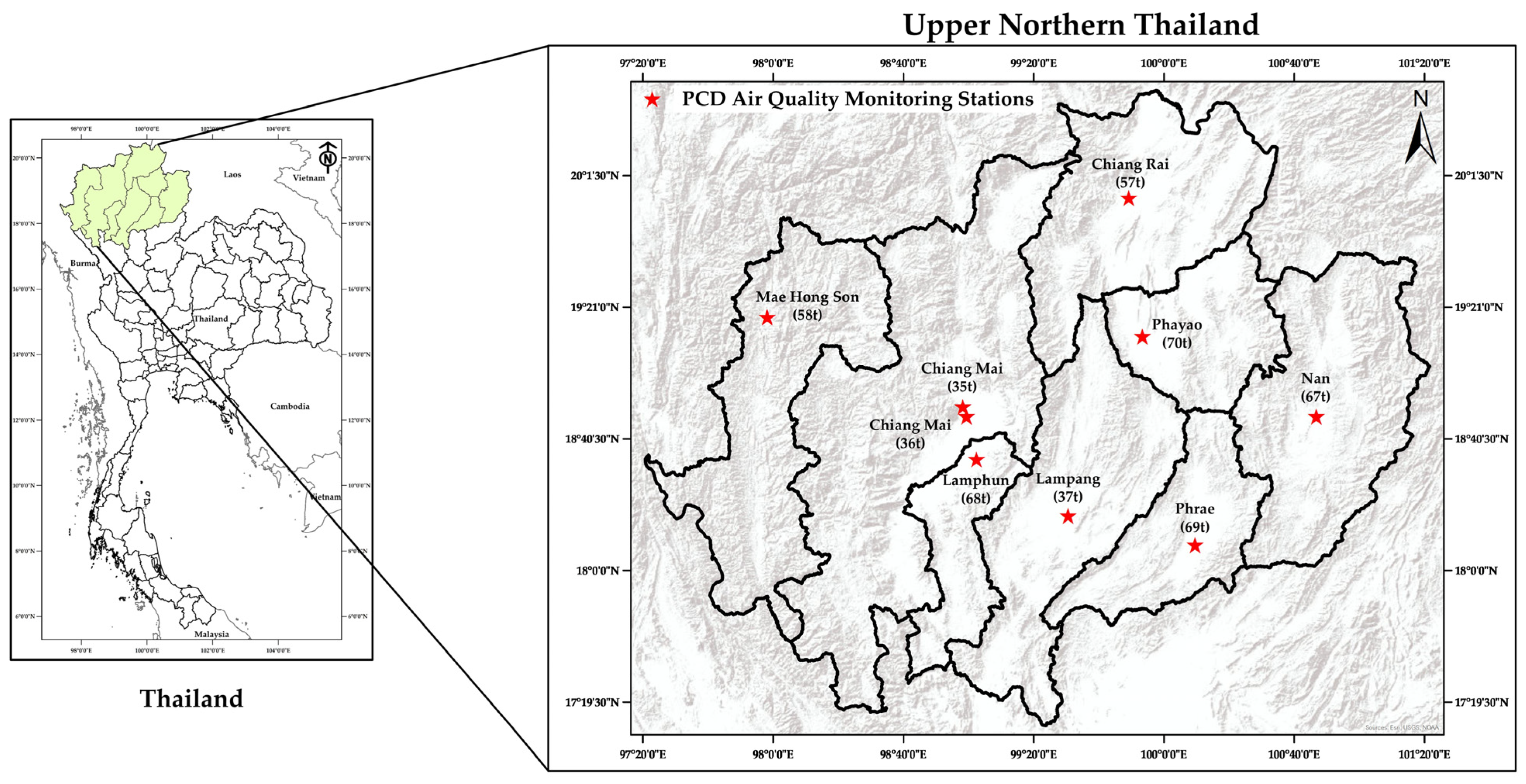
2.1. Descriptions of the Data
2.2. Predictive Model
2.3. Model Validation
2.4. Prediction Evaluation Visual Check
3. Results
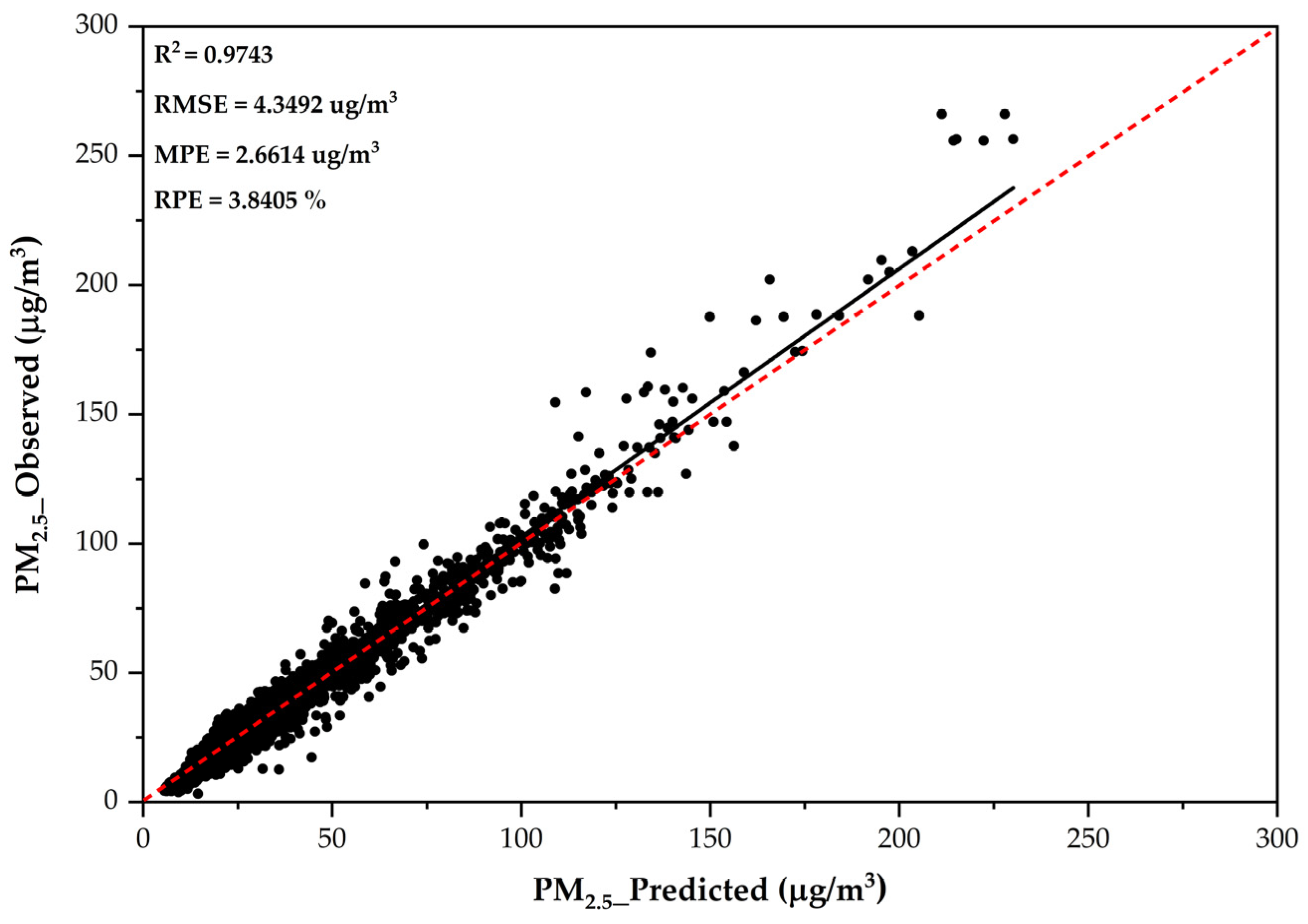
3.1. Performance of RF Model with Different Features
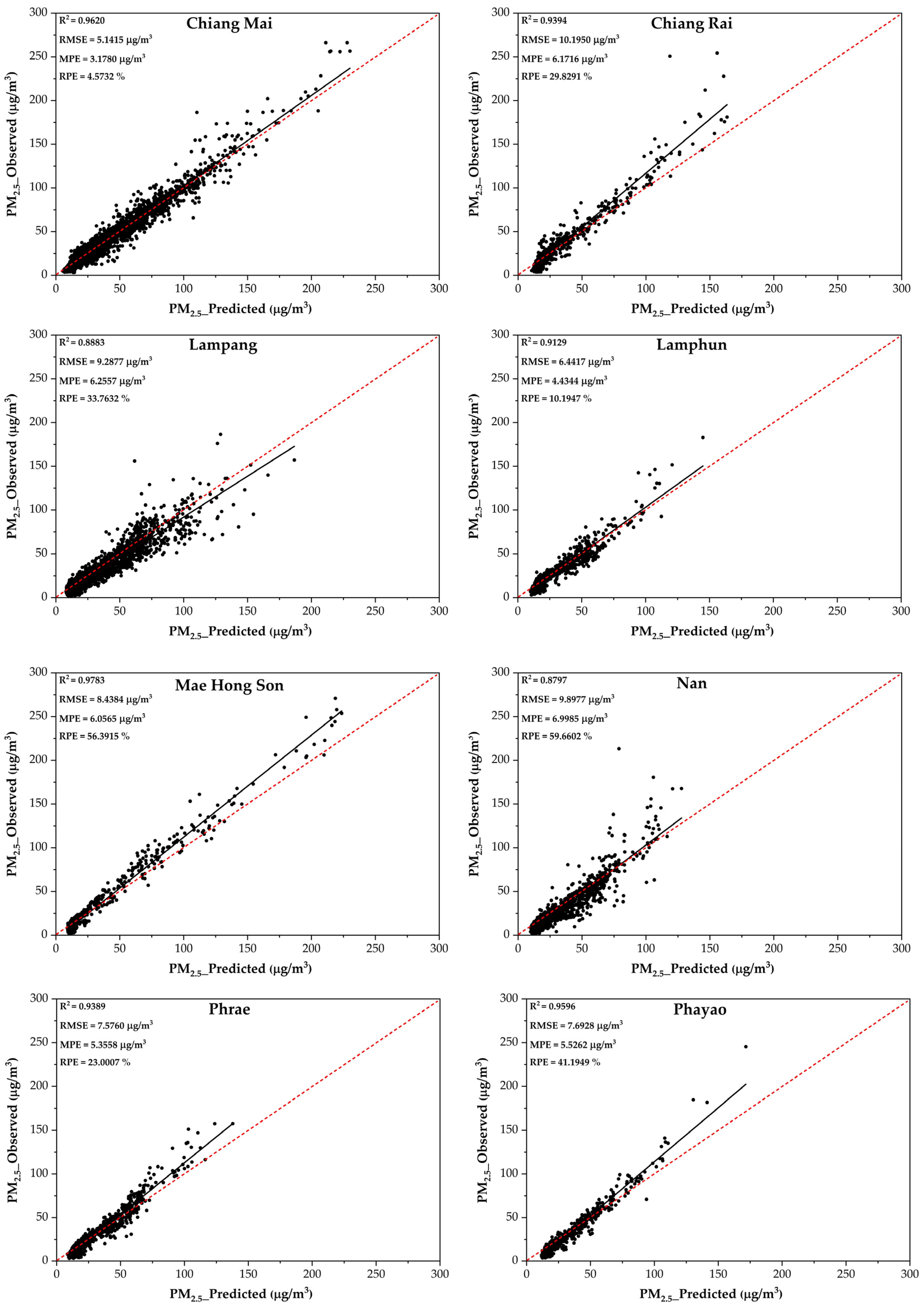
3.2. Performance of RF During PM2.5 Prediction in Eight Provinces in Upper Northern Thailand
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANNs | Artificial neural networks |
| COPD | Chronic obstructive pulmonary disease |
| CVDs | Cardiovascular diseases |
| DT | Decision tree |
| FIRMS | Fire Information for Resource Management System |
| ML | Machine learning |
| MLP | Multi-layer perceptron neural network |
| MLR | Multiple linear regression |
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| NASA | National Aeronautics and Space Administration |
| PCD | Pollution Control Department |
| PM2.5 | Particulate matter smaller than 2.5 microns |
| PM10 | Particulate matter smaller than 10 microns |
| RF | Random forests |
| SVM | Support vector machine |
| TEOM | Tapered element oscillating microbalance method |
References
- Chansuebsri, S.; Kraisitnitikul, P.; Wiriya, W.; Chantara, S. Fresh and aged PM2.5 and their ion composition in rural and urban atmospheres of Northern Thailand in relation to source identification. Chemosphere 2021, 286, 131803. [Google Scholar] [CrossRef]
- Kawichai, S.; Prapamontol, T.; Cao, F.; Song, W.; Zhang, Y. Source Identification of PM2.5 during a smoke haze period in Chiang Mai, Thailand, using stable carbon and nitrogen isotopes. Atmosphere 2022, 13, 1149. [Google Scholar] [CrossRef]
- Kawichai, S.; Prapamontol, T.; Cao, F.; Song, W.; Zhang, Y.L. Characteristics of carbonaceous species of PM2.5 in Chiang Mai city, Thailand. Aerosol Air Qual. Res. 2024, 24, 230269. [Google Scholar] [CrossRef]
- Song, W.; Hong, Y.; Zhang, Y.; Cao, F.; Rauber, M.; Santijitpakdee, T.; Kawichai, S.; Prapamontol, T.; Szidat, S.; Zhang, Y.L. Biomass burning greatly enhances the concentration of fine carbonaceous aerosols at an urban area in upper northern Thailand: Evidence from the radiocarbon-based source apportionment on size-resolved aerosols. J. Geophys. Res. Atmos. 2024, 129, e2023JD040692. [Google Scholar] [CrossRef]
- Huang, F.; Pan, B.; Wu, J.; Chen, E.; Chen, L. Relationship between exposure to PM2.5 and lung cancer incidence and mortality: A meta-analysis. Oncotarget 2017, 8, 43322–43331. [Google Scholar] [CrossRef]
- Department of Pollution Control. Manual Report: Air Quality Data Monitoring; Pollution Control Department: Bangkok, Thailand, 2024; Available online: https://www.pcd.go.th/wp-content/uploads/2021/03/pcdnew-2021-04-07_06-54-58_342183.pdf (accessed on 10 January 2025).
- Pollution Control Department. Air Quality and Noise. Available online: http://air4thai.pcd.go.th/webV3/#/Home (accessed on 10 January 2025).
- Sirignano, C.; Riccio, A.; Chianese, E.; Ni, H.; Zenker, K.; D’Onofrio, A.; Meijer, H.A.J.; Dusek, U. High contribution of biomass combustion to PM2.5 in the city centre of Naples (Italy). Atmosphere 2019, 10, 451. [Google Scholar] [CrossRef]
- Xu, G.; Jiao, L.; Zhao, S.; Cheng, J. Spatial and temporal variability of PM2.5 concentration in China. Wuhan Univ. J. Nat. Sci. 2016, 21, 358–368. [Google Scholar] [CrossRef]
- Zhuang, Y.; Chen, D.; Li, R.; Chen, Z.; Cai, J.; He, B.; Gao, B.; Cheng, N.; Huang, Y. Understanding the influence of crop residue burning on PM2.5 and PM10 concentrations in China from 2013 to 2017 using MODIS data. Int. J. Environ. Res. Public Health 2018, 15, 1504. [Google Scholar] [CrossRef]
- Geng, G.; Murray, N.L.; Tong, D.; Fu, J.S.; Hu, X.; Lee, P.; Meng, X.; Chang, H.H.; Liu, Y. Satellite-based daily PM2.5 estimates during fire seasons in Colorado. J. Geophys. Res. Atmos. 2018, 123, 8159–8171. [Google Scholar] [CrossRef]
- Lee, H.H.; Iraqui, O.; Gu, Y.; Yim, S.H.L.; Chulakadabba, A.; Tonks, A.Y.M.; Yang, Z.; Wang, C. Impacts of air pollutants from fire and non-fire emissions on the regional air quality in southeast asia. Atmos. Chem. Phys. 2018, 18, 6141–6156. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhao, C.; Kwan, M.P.; Cai, J.; Zhuang, Y.; Zhao, B.; Wang, X.; Chen, B.; Yang, J.; et al. Influence of meteorological conditions on PM2.5 concentrations across China: A review of methodology and mechanism. Environ. Int. 2020, 139, 105558. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Q.; Zhao, H.; Wang, L.; Tao, R. Variations in PM10, PM2.5 and PM1.0 in an urban area of the Sichuan basin and their relation to meteorological factors. Atmosphere 2015, 6, 150–163. [Google Scholar] [CrossRef]
- Suleiman, A.; Tight, M.R.; Quinn, A.D. Applying machine learning methods in managing urban concentrations of traffic-related particulate matter (PM10 and PM2.5). Atmos. Pollut. Res. 2019, 10, 134–144. [Google Scholar] [CrossRef]
- Zhang, G.; Rui, X.; Fan, Y. Critical review of methods to estimate PM2.5 concentrations within specified research region. ISPRS Int. J. Geo-Inf. 2018, 7, 368. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Chen, M.J.; Yang, P.H.; Hsieh, M.T.; Yeh, C.H.; Huang, C.H.; Yang, C.M.; Lin, G.M. Machine learning to relate PM2.5 and PM10 concentrations to outpatient visits for upper respiratory tract infections in Taiwan: A nationwide analysis. World J. Clin. Cases. 2018, 6, 200–206. [Google Scholar] [CrossRef]
- Gholizadeh, A.; Neshat, A.A.; Conti, G.O.; Ghaffari, H.R.; Aval, H.E.; Almodarresi, S.A.; Aval, M.Y.; Zuccarello, P.; Taghavi, M.; Mohammadi, A.; et al. PM2.5 concentration modeling and mapping in the urban areas. Model. Earth Syst. Environ. 2019, 5, 897–906. [Google Scholar] [CrossRef]
- Fire Information for Resource Management System. Available online: https://firms.modaps.eosdis.nasa.gov/active_fire (accessed on 24 October 2024).
- Hagan, M.; Demuth, H.; Beale, M. Neural Network Design; PWS Publishing: Boston, MA, USA, 1997. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Cont. Sig. Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Basak, D.; Pal, S.; Patranabis, D. Support vector regression. Neural Inf. Process. -Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Freedman, D. Statistical Models: Theory and Practice; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Tranmer, M.; Murphy, J.; Elliot, M.; Pampaka, M. Multiple Linear Regression, 2nd ed.; Cathie Marsh Institute Working Paper 2020–01; Cathie Marsh Institute for Social Research: Manchester, UK, 2020; Available online: https://hummedia.manchester.ac.uk/institutes/cmist/archive-publications/working-papers/2020/multiple-linear-regression.pdf (accessed on 10 January 2025).
- de Ville, B. Decision trees. WIREs Comp Stats. 2013, 5, 448–455. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- González, S.; García, S.; Del Ser, J.; Rokach, L.; Herrera, F. A practical tutorial on bagging and boosting based ensembles for machine learning: Algorithms, software tools, performance study, practical perspectives and opportunities. Inf. Fusion 2020, 64, 205–237. [Google Scholar] [CrossRef]
- Sun, Y.; Zeng, Q.; Geng, B.; Lin, X.; Sude, B.; Chen, L. Deep learning architecture for estimating hourly ground-level PM2.5 using satellite remote sensing. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1343–1347. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, S.; Jiao, L.; Taylor, M.; Zhang, B.; Xu, G.; Hou, H. Estimation of PM2.5 concentrations in China using a spatial back propagation neural network. Sci. Rep. 2019, 9, 13788. [Google Scholar] [CrossRef]
- Yun, E.; Tornero-Velez, R.; Purucker, S.; Chang, D.; Edginton, A. Evaluation of quantitative structure property relationship algorithms for predicting plasma protein binding in humans. Comput. Toxicol. 2020, 17, 100142. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Duin, R.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Chen, M.; Chen, Y.C.; Chou, T.Y.; Ning, F.S. PM2.5 Concentration prediction model: A CNN-RF ensemble framework. Int. J. Environ. Res. Public Health 2023, 20, 4077. [Google Scholar] [CrossRef]
- Vignesh, P.P.; Jiang, J.H.; Kishore, P. Predicting PM2.5 concentrations across USA using machine learning. Earth Space Sci. 2023, 10, e2023EA002911. [Google Scholar] [CrossRef]
- Amnuaylojaroen, T.; Kreasuwun, J. Investigation of fine and coarse particulate matter from burning areas in Chiang Mai, Thailand using the WRF/CALPUFF. Chiang Mai J. Sci. 2011, 39, 311–326. [Google Scholar]
- Punsompong, P.; Pani, S.; Wang, S.H.; Thao, P. Assessment of biomass-burning types and transport over Thailand and the associated health risks. Atmos. Environ. 2020, 247, 118176. [Google Scholar] [CrossRef]
- Suriyawong, P.; Chuetor, S.; Samae, H.; Piriyakarnsakul, S.; Amin, M.; Furuuchi, M.; Hata, M.; Inerb, M.; Phairuang, W. Airborne particulate matter from biomass burning in Thailand: Recent issues, challenges, and options. Heliyon 2023, 9, e14261. [Google Scholar] [CrossRef] [PubMed]
- Kliengchuay, W.; Meeyai, A.; Worakhunpiset, S.; Tantrakarnapa, K. Relationships between meteorological parameters and particulate matter in Mae Hong Son Province, Thailand. Int. J. Environ. Res. Public Health 2018, 15, 2801. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Xie, X.; Cai, J.; Danlu, C.; Gao, B.; He, B.; Cheng, N.; Xu, B. Understanding meteorological influences on PM2.5 concentrations across China: A temporal and spatial perspective. Atmos. Chem. Phys. 2018, 18, 5343–5358. [Google Scholar] [CrossRef]
- Chang, C.H.; Hsiao, Y.L.; Hwang, C. Evaluating spatial and temporal variations of aerosol optical depth and biomass burning over southeast asia based on satellite data products. Aerosol Air Qual. Res. 2015, 15, 2625–2640. [Google Scholar] [CrossRef]
- Mohammadi, F.; Teiri, H.; Hajizadeh, Y.; Abdolahnejad, A.; Ebrahimi, A. Prediction of atmospheric PM2.5 level by machine learning techniques in Isfahan, Iran. Sci. Rep. 2024, 14, 2109. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| Methods | Prediction Performances | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 Features (Without SO2 and NO2) | 11 Features (Without SO2) | 12 Features | ||||||||||
| RMSE | R2 | MPE | RPE | RMSE | R2 | MPE | RPE | RMSE | R2 | MPE | RPE | |
| MLP (1 Hidden Layer) | 7.2287 | 0.9211 | 4.7944 | 23.88 | 7.2136 | 0.9214 | 4.8845 | 23.84 | 7.1802 | 0.9221 | 4.8121 | 23.73 |
| MLP (2 Hidden Layers) | 7.3328 | 0.9181 | 4.8184 | 24.24 | 7.3265 | 0.9189 | 4.8822 | 24.19 | 7.2367 | 0.9210 | 4.8854 | 23.91 |
| SVM (Linear Kernel) | 10.7402 | 0.8223 | 8.2057 | 35.51 | 11.1608 | 0.8111 | 8.4791 | 36.79 | 11.7684 | 0.7752 | 9.2530 | 38.99 |
| SVM (Polynomial Kernel) | 12.9420 | 0.7367 | 10.2391 | 42.70 | 12.5287 | 0.7602 | 9.8174 | 41.38 | 12.1642 | 0.7621 | 8.9826 | 40.08 |
| SVM (RBF Kernel) | 12.0770 | 0.7748 | 8.9261 | 39.91 | 12.6847 | 0.7539 | 9.6007 | 41.82 | 12.1247 | 0.7755 | 9.0067 | 40.01 |
| MLR | 7.7423 | 0.9103 | 5.2223 | 25.55 | 7.7415 | 0.9103 | 5.2270 | 25.55 | 7.7056 | 0.9111 | 5.2141 | 25.44 |
| DT | 9.0747 | 0.8762 | 5.8224 | 29.96 | 8.7843 | 0.8840 | 5.5989 | 29.01 | 8.9378 | 0.8800 | 5.6141 | 29.52 |
| RF | 6.8242 | 0.9306 | 4.3296 | 22.50 | 6.8234 | 0.9306 | 4.2499 | 22.49 | 6.7615 | 0.9318 | 4.1954 | 22.29 |
| Performances | 12 Features | 11 Features | p-Value | 10 Features | p-Value |
|---|---|---|---|---|---|
| Average RMSE | 6.7859 | 6.8110 | 0.8798 | 6.8216 | 0.9397 |
| Average R2 | 0.9313 | 0.9308 | 0.9397 | 0.9307 | 0.8798 |
| Average MPE | 4.3290 | 4.2533 | 0.2568 | 4.1944 | 0.3258 |
| Average RPE | 22.3740 | 22.4551 | 0.9397 | 22.4884 | 1.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kawichai, S.; Sripan, P.; Rerkasem, A.; Rerkasem, K.; Srisukkham, W. Long-Term Retrospective Predicted Concentration of PM2.5 in Upper Northern Thailand Using Machine Learning Models. Toxics 2025, 13, 170. https://doi.org/10.3390/toxics13030170
Kawichai S, Sripan P, Rerkasem A, Rerkasem K, Srisukkham W. Long-Term Retrospective Predicted Concentration of PM2.5 in Upper Northern Thailand Using Machine Learning Models. Toxics. 2025; 13(3):170. https://doi.org/10.3390/toxics13030170
Chicago/Turabian StyleKawichai, Sawaeng, Patumrat Sripan, Amaraporn Rerkasem, Kittipan Rerkasem, and Worawut Srisukkham. 2025. "Long-Term Retrospective Predicted Concentration of PM2.5 in Upper Northern Thailand Using Machine Learning Models" Toxics 13, no. 3: 170. https://doi.org/10.3390/toxics13030170
APA StyleKawichai, S., Sripan, P., Rerkasem, A., Rerkasem, K., & Srisukkham, W. (2025). Long-Term Retrospective Predicted Concentration of PM2.5 in Upper Northern Thailand Using Machine Learning Models. Toxics, 13(3), 170. https://doi.org/10.3390/toxics13030170