1. Introduction
Count data regression models arise in situations in which the variable of interest takes only non-negative integer values for each of the available observations. These values usually represent the number of times an event occurs in a fixed domain.
Cameron and Trivedi (
1998) and
Winkelmann (
2008) provide good overviews of standard count regression models. Typically, a Poisson distribution can be assumed when modeling the distribution of count citations. However, the Poisson model often underestimates the observed overdispersion (variance larger than the mean). This is because a single parameter is likely to be insufficient to describe the population under study, and because the population is usually heterogeneous. This population heterogeneity is unobserved, i.e., the population consists of several subpopulations; the general method to deal with this is to assume that the heterogeneity can be adequately described by some probability density function, say
, defined on the population of possible Poisson parameters
, and to consider the marginal distribution of the number of citations provided by
Mixed Poisson distributions are helpful in situations where count displays extra-Poisson variation. Applications of univariate models abound in areas such as insurance (
Willmot, 1987;
Gómez-Déniz & Calderín-Ojeda, 2018) and accident analysis (
Arbous & Kerrich, 1951), where specific models such as the negative-binomial (mixed Poisson-gamma), Poisson-inverse-Gaussian, Poisson-reciprocal inverse-Gaussian, and Poisson-lognormal distributions have been used. On the other hand, mixed Poisson regression models have been employed in areas such as insurance (
Dean et al., 1989), demography (
Brillinger, 1986), medicine (
Breslow, 1984;
Campbell et al., 1991), and engineering (
Engel, 1984). For a complete review of mixed Poisson distributions, see
Karlis and Xekalaki (
2005); for the Poisson and negative binomial regression models, see
Cameron and Trivedi (
1998),
Winkelmann (
2008) and
Hilbe (
2011), among others.
Nevertheless, the process be which papers accumulate citations may be divided into two parts: in the first stage, the paper has no citations, while the second part provides the intensity of the citations. After a paper has been cited for the first time, the contagious process of obtaining new citations is carried out, at most for the time following this first citation. Thus, a hurdle model for dealing separately with papers with citations and those with no citations is considered.
The hurdle model in bibliometrics and altmetrics represents a significant advance in understanding the citation process. Several studies and experts support this idea. For example, studies in biology, biochemistry, chemistry, and social sciences (
Didegah & Thelwall, 2013) as well as a study of permanent Italian researchers from different scientific fields (
Baccini et al., 2014) have found that the citation process can be modeled using a hurdle approach. In this model, the initial publication phase is characterized by low probability of citation, while the subsequent phase has higher probability.
The hurdle model has important implications for assessing research impact. It suggests that the initial publication phase is not necessarily indicative of the overall impact of a research paper; instead, the critical point at which citations begin can strongly influence the total number of citations. This is particularly relevant in the context of altmetrics, where initial engagement with a research paper can trigger subsequent mentions and other forms of online engagement (
Hodas & Lerman, 2014).
It is important to note that human behavior when deciding which works to cite is complex. The aim of this study is not to predict such behavior or to estimate citation counts, but rather to contribute knowledge regarding some of the variables involved. Over the past two decades, there has been a paradigm shift in how scientists disseminate their research findings. On one hand, they tend to publish in journals with high impact factor rankings; on the other, they increasingly favor open access and dissemination through channels that are closer to society, in addition to traditional academic outlets. The goal of this study is to provide insights into the effects of these new forms of scientific communication on research impact.
The remainder of this paper is organized as follows:
Section 2 focuses on reviewing the literature;
Section 3 describes the dataset and variables used in this work;
Section 4 is devoted to the specific distributional models employed to reach this work’s target; numerical results are provided in
Section 5; and conclusions are presented in the last
Section 6.
3. Data
3.1. Data Sources and Sample Description
In our empirical application, we explore research trends in Economics and Business by examining scientific articles. This analysis focuses on the publication period 2014–2021 and citation period 2014–2023 using data from The Lens, Scimago Journal Rank (based on Scopus data), Altmetric, and the Australian Business Deans Council.
We used the Field of Research (FoR) classification provided by The Lens as a classification system for determining the discipline. This system is also used by other bibliographic databases and is generated automatically using artificial intelligence. It is important to note that this AI-based classification has not yet been thoroughly validated and that its accuracy and consistency across different fields of research are uncertain. Nevertheless, we consider it to be suitable for the purposes of this study.
The analysis focused on journal articles as the document type, and was limited to the years 2014 to 2021; however, citation data were collected up to 2023 in order to include the two years following publication, as this is typically the period when citation counts peak. We acknowledge that including publications from this period may introduce a citation lag, particularly for more recent articles; however, our model includes time as an explanatory variable, enabling us to isolate and compare the effects of other variables in relation to the passage of time. This approach enables us to explicitly account for delays in the accumulation of citations, thereby reducing potential bias associated with newer publications.
The search criteria in The Lens were the following: Field of Study (Business OR Economics); Publication Date (2014-01-01 TO 2021-12-31); Publication Type (journal article); and Institution Country (Australia, Brazil, Canada, China, France, Germany, India, Indonesia, Italy, Japan, Netherlands, Republic of Korea, Russia, Spain, United Kingdom, United States).
The analysis focused on the sixteen countries with the highest production of articles in Business and Economics over the analyzed period. This selection was made in order to ensure a representative sample of articles in Economics and Business from the past decade. To allow for the accumulation of citations, the search was limited to articles published up to 2021.
The following article-level variables were obtained from The Lens database: publication year, ISSN, number of authors, funding, DOI, number of citations, open access, and open access type.
Next, the ISSNs were searched in the Scimago Journal Rank database to obtain the following variables at the journal level: foundation year (proxy for the year of inception in Scopus), SJR, best SJR quartile, and citations per document (3-year period).
Using the ISSNs, the Australian Business Deans Council journal quality list (
ABDC, 2022) was linked in order to obtain the expert rating and the Fields of Research (FoR) code at the journal level. In 2022, the expert rating process resulted in a total of 2680 journals receiving classifications, with the distribution from highest to lowest as follows: A* = 7% (199), A = 25% (653), B = 32% (855), and C = 36% (973). We required that every journal on the list fall within the relevant Australia and New Zealand Fields of Research (FoR) codes.
Aggregation into disciplines was carried out according to the following (code and FoR): Accounting and Finance (3501 accounting, auditing, and accountability; 3502 banking, finance, and investment), Applied Economics (3801 applied economics; 3802 econometrics), Business (3505 human resources and industrial relations; 3506 marketing; 3507 strategy, management, and organizational behaviour), Commercial (4801 commercial law; 3504 commercial services; 3599 other commerce, management, tourism, and services), Economic Theory (3803 economic theory; 3509 transportation, logistics, and supply chains), Statistics (4905 statistics), and Tourism (3508 tourism). The discipline of Statistics was used as a reference point for comparison within the regressions.
Finally, we queried the Altmetric.com database using the Digital Object Identifier (DOI) of each article to obtain a set of altmetric indicators at paper level. Specifically, we collected data on mentions in the news, on blogs, in policy documents and patents, on X (formerly Twitter) and Facebook, in Wikipedia citations, and on video platforms (e.g., YouTube), as well as the number of Mendeley readers. This information was retrieved using the Altmetric.com search interface, with the DOI serving as the primary search criterion to ensure precise matching between records. Using the DOI guarantees a high level of accuracy in data linkage, as it serves as a unique and persistent identifier for each publication. To enable disaggregated analysis of the effects of different types of online attention on citations, each altmetric variable was recorded as a raw count without weighting or composite scoring.
Data were downloaded and merged during the last two weeks of March 2024.
3.2. Variable Description
Table 1 describes the analyzed variables along with their coding in cases where it was necessary. In terms of access type definitions, closed access (also known as subscription access) refers to the traditional model in which scholarly articles are only available to readers through subscription or paywall barriers. Typically, articles are available only to subscribers or individuals affiliated with subscribing institutions, thereby limiting access to a wider audience. Gold OA, on the other hand, is the practice of publishing scholarly articles in fully open access journals where the articles are freely available to readers without subscription or paywall restrictions. These articles are usually published under a Creative Commons license, which allows them to be freely distributed. Authors may be charged an Article Processing Charge (APC) to cover publication costs.
Hybrid OA refers to the publication of individual articles in subscription-based journals, with the option for authors to pay a fee for open access to their articles. This model allows journals to retain subscription revenue while offering authors the choice of open access publication. Green OA involves the self-archiving or depositing of scholarly articles in repositories or platforms after publication in subscription-based journals. These articles become openly accessible through institutional repositories, subject-based repositories, or preprint servers, thereby extending access beyond the journal’s paywall. Finally, Bronze OA is the practice of making articles openly accessible on a publisher’s website without an explicit open license. Some publishers choose to make selected articles freely available within subscription-based journals or to designate specific journals or sections where articles are accessible without a subscription. In some cases, known as delayed open access, publishers may impose an embargo period during which articles remain behind a paywall, after which the articles become freely available.
Table 2 shows the descriptive statistics obtained for the dependent and explanatory variables associated with the filtered database. The large sample size of 43,190 observations provides a strong basis for regressions. In terms of the characteristics of the research articles in the sample, the average article has 27.3 citations with a median of 11, indicating a right-skewed distribution. The number of citations varies considerably, ranging from 0 to 2672. Over the analyzed period, closed access was predominant in Economics and Business, with 55% of the observations in the sample, compared to 45% of open access articles. Green OA is the most common type of open access (30%), followed by Hybrid (10%), Bronze (3%), and Gold (2%).
Regarding the author and disciplinary characteristics, articles have an average of 2.58 authors, with a median of 2 and a range of 1 to 47. Moreover, funding is reported in 21% of articles. Applied Economics (44%), Business (25%), Commerce (14%), and Accounting and Finance (10%) are the most common disciplines, while Economic Theory (3%), Tourism (2%), and Statistics (2%) are the least common.
In terms of the prestige and impact of the journal, the year of the journal’s foundation shows high diversity. The a median of 1985 along with a standard deviation of 22 years indicates high variability. The average Scimago Journal Rank (SJR) is 1.8, with a median of 1, showing that most journals have a relatively low score, although there are outliers with scores as high as 20. The median of the best SJR quartile is 1, which means that more than half of the analyzed articles were published in journals classified in the first quartile of one of the different subject categories assigned by the Scopus database. Furthermore, journals in the sample receive an average of 4.47 citations per article three years after publication, with a median of 3.38. Expert ratings vary in frequency, with the highest rating of level 4 occurring 17% of the time and serving as the base in the regressions. Among the other levels, level 1 (the lowest) is the least frequent at 10%, followed by level 2 at 30% and level 3 at 43%.
Regarding social impact and influence, mentions vary between sources; the number of news items per article has an average of 0.63, with a median of 0 and range of 319. Similar patterns are observed for the number of mentions in blogs (mean 0.18, median 0, range 37), policy documents (mean 0.44, median 0, range 104), and patents (mean 0.0025, median 0, range 12). The average number of social media mentions on X/Twitter is 8, with a median of 1 and a range of 16,317. Other social media sources are rare (Facebook: average 0.15, median 0, range 38; Wikipedia: average 0.07, median 0, range 30; videos: average 0.0046, median 0, range 25). However, readers of Mendeley, a scientific reference management software program, are more frequent (average 68, median 34, range 8668).
3.3. Associations Between Variables
Table 3 shows the Pearson correlation coefficients between the quantitative variables. The strongest positive correlation for the citation count is the dependent variable, which is observed with Mendeley readers (0.84). This indicates that papers with a higher number of Mendeley readers tend to have significantly more citations. Policy mentions also show a notable positive correlation (0.45), suggesting that research papers referenced in policy documents are more likely to be cited in academic papers. Blog mentions (0.30) and journal average citations (0.29) are moderately correlated with citation count, showing that papers in journals with a high average citation rate per document or mentioned in blogs receive more citations. Furthermore, the Scimago Journal Rank (SJR) has a positive correlation of 0.26 with the citation count, indicating that papers published in higher-ranked journals are more likely to be cited.
Other variables with notable positive correlations include news mentions (0.21), patent mentions (0.19), journal expert ratings (0.18), and Wikipedia mentions (0.18). Although these correlations are weaker compared to Mendeley readers or policy mentions, they still suggest some influence on citation counts. The year of publication shows a slight negative correlation with citation counts (−0.14), which is expected as older papers have more time to accumulate citations. In addition, the SJR best quartile has a negative correlation of −0.15, which is due to the coding, where quartile 1 corresponds to the top level and quartile 4 to the bottom level.
Several variables show little or no correlation with the citation count. These include funding (0.00), the foundation year of the journal (−0.01), video mentions (0.03), and number of authors (0.06).
Table 3 also shows several significant associations between the independent variables. The SJR is strongly correlated with the average citations in the journal (0.64), emphasizing that the most prestigious journals tend to publish articles that receive more citations in the three years after their publication. The other highest positive correlations are observed between expert rating and SJR (0.54) and between expert rating and journal average citations (0.41), reflecting that journals rated highly by experts are often highly positioned in the rankings of journals.
Another notable correlation is between news mentions and blog mentions (0.46), indicating that articles mentioned in the news are often discussed in blogs. Similarly, the correlation between blog mentions and policy mentions is notable (0.33), suggesting a link between online discussions and policies.
In addition, Mendeley readers show moderate positive correlations with several variables, including journal average citations (0.39), indicating that articles published in journals with higher citation rates tend to be saved by more readers. The correlation between Mendeley and peer review is weaker (0.16), but still suggests some relationship between peer review and the attention an article receives from the academic community.
The negative association between the best SJR quartile with expert rating and average citations is due to the coding, where quartile 1 corresponds to the top level and quartile 4 to the bottom level, as mentioned above.
In summary, the most influential factors associated with higher citation counts are Mendeley readers, policy mentions, blog mentions, journal average citations, and SJR. These variables should be included in any predictive model for research paper citations. On the other hand, the highest correlations among the independent variables highlight the interplay between peer review, journal rankings, and online mentions.
4. Specific Models
In (
1), if we allow
to be the gamma distribution with shape parameter
and scale parameter
,
, and
, then we have the following mixture (unconditional) distribution for the number of citations:
where
acts as a dispersion parameter and
as a
vector of exogenous or explanatory variables. Furthermore,
represents the Euler Gamma function. In this case, the random variable
Y has mean and variance provided by
respectively. It is usual to take
, i.e., we are assuming a log-linear specification in which
is a vector of regression parameters which has to be estimated. This parameterization of the negative binomial regression model has been considered by
Lawless (
1987),
Cameron and Trivedi (
1998), and
Hilbe (
2011), among others.
This model reduces to the Poisson distribution when
and to the geometric model when
. The log-likelihood function is shown in
Appendix A. Details about the normal equations obtained from (
A1) and second derivatives needed to obtain the variance–covariance matrix of the estimators can be found in
Lawless (
1987) and
Cameron and Trivedi (
1998).
Although in practice there are numerous statistical software programs that have implemented this model in their packages (R 4.4.0, Stata 18, Eviews 13, Matlab R2024a, and SAS 9.4M8), we have not made use of them but have instead programmed it in Mathematica, corroborating the results with additional programming in WinRats.
The normal equations obtained from (
A1) require the use of the digamma function
to estimate all the model parameters. This problem can be overcome by using Mathematica routines (see
Ruskeepaa, 2009) and RATS (see
Brooks, 2009), which work well with this special function. Other software such as Matlab, Stata, Eviews, and R can also be useful thanks to the incorporation of special packages to work with this model. In practice, given the difficulty sometimes encountered when estimating the index of dispersion
r, it is convenient to use the following approximation for the logarithm of the Euler gamma function:
Furthermore, the gamma function can be avoided by taking into account that , and consequently .
Distinction Between Cited and Uncited Articles
As pointed out previously, the process of citations of papers may be divided into two parts; in the first stage, the paper has no citations, while the second part provides the intensity of the citations. After a paper is cited for the first time, it accumulates new citations for at most the time since this first citation. Formally, we consider a hurdle model in order to deal separately with papers without citations and those with at least one citation. Thus, we consider a dichotomic variable that first differentiates documents with and without citations. In the former case, a separate process generates the number of citations. The hurdle count model represents a suitable distribution implying the assumption that the data come from two separate processes, with the simplest hurdle model setting the hurdle at zero. Specifically, the model we consider now is the hurdle model which sets the hurdle at zero with geometric distribution and with success probability at zero
and a negative binomial (such as in (
2)) for values larger than zero (see for instance
Mullahy, 1986;
Pohlmeier & Ulrich, 1995). Thus, we consider the model
where
,
(taken from (
2)) and
. As can be seen, we assume that the hurdle parameter is not constant for all observations but is modeled similarly to the mean parameter depending on the covariates. The first (hurdle) part of (
5) provides the probability of zero citations, while the second part governs the process once the hurdle has been passed with a truncated-at-zero probability distribution, which includes the probability of citations conditional on one citation.
The mean and variance of this hurdle distribution are provided by
respectively, which are needed to compute the Pearson residuals, among other things.
A logit-link
, is now assumed to connect the covariates with the parameter
, where
is a new vector of regression parameters to be estimated. Both
and
may be influenced by different characteristics and variables. For this reason, the explanatory variables used to model them may not be the same. Finally, the log-likelihood is shown in the
Appendix A (see expression (
A2)). Because the parameters for the two pieces are different (then separable), the maximization may be carried out separately for each part.
The marginal effect reflects the variation of the conditional mean of citations due to a one-unit change in the
jth covariate, allowing us to obtain the mean of citations according to information contained in some explanatory variables. For the log-link, we have
meaning that we can interpret
as the proportional change in the mean of citations per unit change in
. For a dummy variable taking 0 and 1 values, it is well known that the estimator
(
) is the relative impact of the covariate
j on the expected count. This is the same for the logit-link; nevertheless, for the logit-link and a continuous variable, the effect on the number of citations due to a one-unit change in the covariate is provided by
.
5. Results
5.1. Homogeneous Models
We begin by fitting the random variable number of citations using Poisson (P), Negative Binomial (NB), and Hurdle Negative Binomial (HNB) distributions without including covariates. The resulting Akaike Information Criterion (AIC) value (
, where
ℓ is the loglikelihood value and
p is the number of parameters) is 2,297,340, 367,121 and 364,897 for P, NB, and HNB distributions, respectively. For this measure, the smaller the AIC, the better the model (see
Akaike, 1974). The estimated
and
parameters for P and NB is the mean of the number of citations (27.3193), while the estimated index of dispersion
r is 1.61933 for the NB distribution and 2.42694 for the HNB distribution. In this case, the
parameter results in
and the
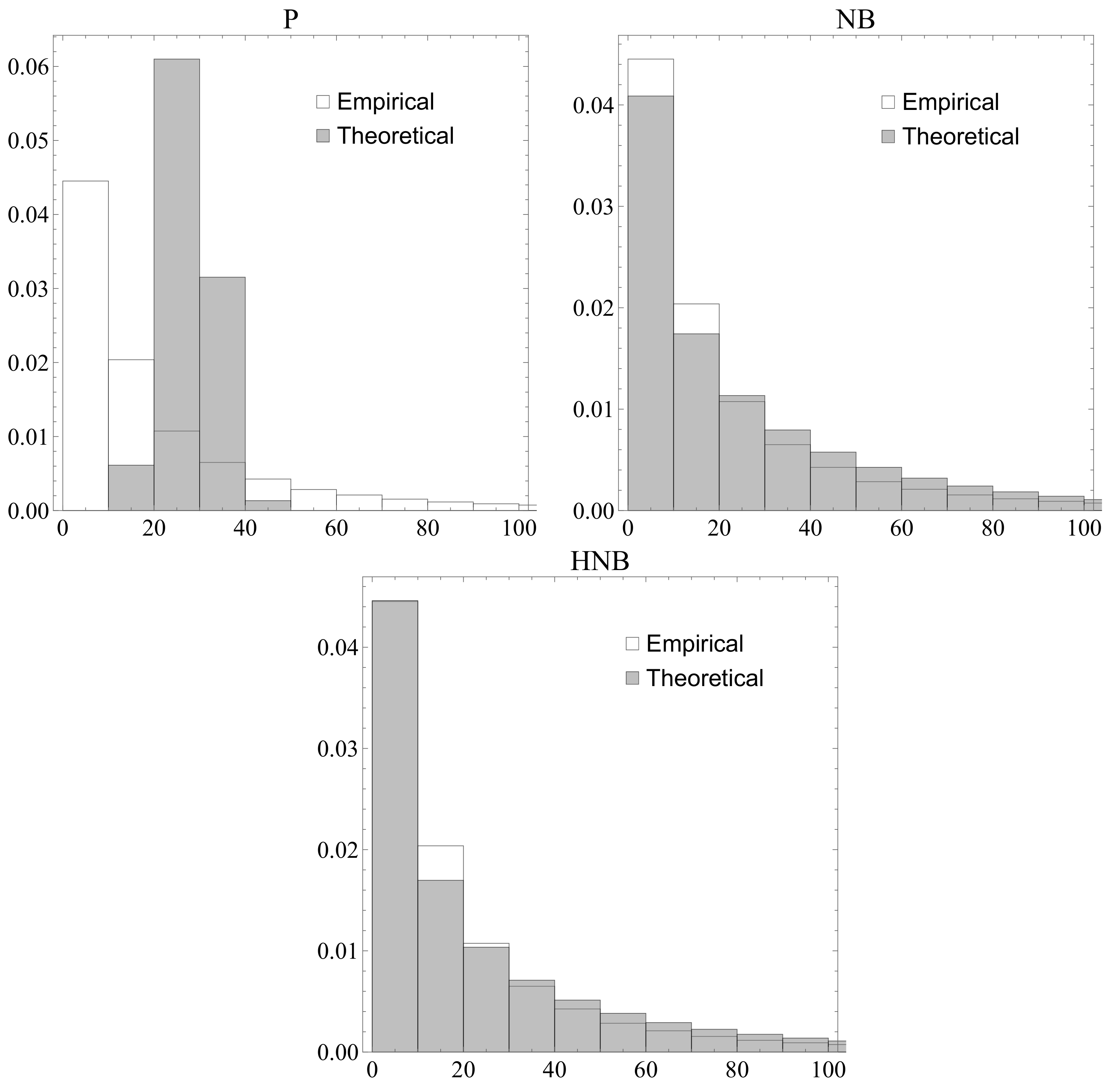
parameter results in 0.0552. The results were significant for all of these. As expected, the NB distribution provides a better fit than the P distribution, and the HNB is better than the NB distribution.
Figure 1 shows the empirical and fitted histograms of the number of citations obtained by the model based on the P, NB, and HNB distributions. From the graph shown in this figure, it is evident that the fit provided by the NB distribution is much better, especially for the tail of the data and for the zero value, which is particularly the case when the HNB distribution is considered.
Thus, in the following we concentrate our attention on the negative binomial model.
5.2. Models with Covariates
Table 4 summarizes the negative binomial regression model, for which it can be seen that many of the coefficients are statistically significant. After this, we estimate the hurdle model, for which the results are shown in Table 6. Not all covariates are statistically significant for the hurdle parameter, with different signs in many cases compared to the case in which the dependent variable takes a value larger than zero. Thus, including this model seems to significantly affect the dependent variable under investigation. TO make for a more parsimonious model, we have removed the variables that are not statistically significant; the new estimation results are shown in Table 7.
Table 5 shows the Incidence Rate Ratio (IRR) results along with their standard errors and confidence intervals for various categorical variables related to access type, discipline, and journal expert rating. These variables were analyzed to determine their impact on the likelihood of an article being cited. In terms of accessibility, the table shows that most open access modalities have a statistically significant higher incidence rate compared to closed articles, suggesting a citation advantage for open access. Concretely, Green OA articles have a 13.9% higher citation rate compared to closed articles, which is statistically significant. Hybrid OA articles have a 7.9% higher citation rate, also statistically significant. Bronze OA articles see a 5.9% higher citation rate, again statistically significant. Finally, Gold OA articles have a 6% higher citation rate; however, the confidence interval includes 1, suggesting that this result may not be statistically significant.
The table compares the incidence rates for different academic disciplines, using Statistics as the base category. All disciplines are statistically significant, indicating that they are more likely to be cited than Statistics. The disciplines with the highest positive effects are Accounting and Finance with a 42.5% higher incidence rate, followed by Applied Economics with a 36.8% higher incidence rate and Economic Theory with a 36% higher incidence rate. Tourism and Commerce also have higher incidence rates, with 28.4% and 28.3%, respectively. Articles in the Business category have a 24.9% higher incidence rate.
The table also examines the effect of journal prestige on the incidence rate using expert ratings from 1 to 4, with 4 being the highest tier. The results show that articles in journals with the lowest expert rating have a statistically significant 26.5% lower incidence rate compared to articles in the highest-rated journals. This suggests that high-impact journals are more selective and publish fewer but more impactful articles, potentially influencing citation practices. Intermediate expert ratings (2 and 3) also show lower incidence rates; however, the confidence intervals suggest potential problems with statistical significance.
In summary,
Table 5 highlights the positive impact of open access on the likelihood of an article being cited. Certain disciplines have higher incidence rates, such as Accounting and Finance, Applied Economics, and Economic Theory, which may reflect their broader impact. These results also suggest that high-impact journals are more selective, publishing fewer but more impactful articles, which may influence citation practices.
The results of the hurdle negative binomial regression model are summarized in
Table 6. This model is divided into two parts: the positive counts component (negative binomial part) and the zero counts component (hurdle part). The estimates provide insights into which factors are associated with higher or lower citation counts as well as the likelihood of an article having zero citations.
Younger publications tend to receive fewer citations (estimate = −0.14, ) and are more likely to have zero citations (0.13, ). Articles with Green OA are positively associated with citation counts (0.12, ) and are less likely to have zero citations (−0.28, ). Similarly, Hybrid OA is positively associated with citation counts (0.06, ) Conversely, while Bronze OA is positively associated with citation counts (0.13, ), it also increases the likelihood of zero citations (0.72, ).
The number of authors positively influences the citation count (estimate = 0.04, ) and reduces the likelihood of zero citations (−0.12, ). Articles with funding also see a positive impact on citation count (0.08, ) and a reduced likelihood of zero citations (−0.39, ). Several disciplines show significant associations with citation counts. Business (−0.27, ), Tourism (−0.20, ), Commercial (−0.19, ), and Applied Economics (−0.16, ) are negatively associated with citation counts when compared with Statistics.
The journal prestige and impact categories include several variables indicating the journal’s reputation and the impact of an average article in that journal. Lower expert ratings are associated with fewer citations, with a rating of 1 showing the strongest negative association (estimate = −0.26, ) and increasing the likelihood of zero citations (0.42, ). SJR positively affects citation counts (0.006, ). The SJR best quartile is negatively associated with citation counts (−0.25, ) but positively influences the likelihood of zero citations (0.18, ). Note that a higher quartile represents a worse position in the ranking, as the top quartile is coded as 1 while the bottom quartile is coded as 4. The journal’s average citations positively affects citation counts (0.03, ) but also positively influences the likelihood of zero citations (0.05, ).
In the influence and social impact categories, mentions in news items, blogs, policies, patents, and other platforms show mixed effects on citation counts. News mentions positively influence citation counts (estimate = 0.004, ) and decrease the likelihood of zero citations (−0.15, ). Blog mentions also positively influence citation counts (0.06, ). Policy mentions significantly reduce the likelihood of zero citations (−0.96, ) and positively influence citation counts (0.06, ). However, patent mentions negatively influence citation counts (−0.11, ).
Social media mentions have different effects on citation counts. Mentions on X/Twitter positively influence citation counts, although with a limited effect (estimate = 0.0001, ), and decrease the likelihood of zero citations (−0.027, ). On the other hand, Facebook and video mentions negatively influence citation counts (−0.015 and −0.047 respectively, ). Wikipedia mentions also positively influence citation counts (0.027, ). Finally, Mendeley readers have a positive association with citation counts (0.007, ) and a significant negative association with the likelihood of zero citations (−0.117, ).
Overall, these results highlight (
Table 7) the complex factors that influence the citation patterns of academic articles. Access type, publication age, discipline, collaboration, journal prestige, and social impact metrics all play significant roles in determining the citation outcomes of scholarly work.
5.3. Model Assessment
Various model fit statistics and residuals are readily available in the statistical literature. In regression studies, it is common to examine the Pearson residuals. These are provided by
, where
and
are respectively provided by (
3) and (
4) for the negative binomial model and (
6) and (
7) for the hurdle model, then comparing the regression coefficients to the estimated ones. The Pearson residuals can also be used to compute the Pearson goodness-of-fit statistic, provided by
, which in our case results in 45,018.60 and 43,523 for the negative binomial and hurdle models, respectively. These value are near to
(
) and 43,128 (
) for the two estimated models, where
k is the number of parameters in the model. For the restricted model, the Pearson goodness-of-fit statistic is 43,543.80, which is close to
,
. This indicates that the model is specified correctly, making it better than the hurdle model.
The Pearson residuals are often skewed for non-normal data, making the residual plots more challenging to interpret. Therefore, other quantifications of the discrepancy between observed and fitted values have been suggested in the literature. In this regard, another choice in residual analysis is to use the signed square root of the contribution to the deviance goodness-of-fit statistic (i.e., deviance residuals). This is provided by
(see
Cameron & Trivedi, 1998, p. 141), where sgn is the function that returns the argument’s sign (plus or minus), the
term is the log-likelihood value when the mean of the conditional distribution for the
i-th individual is the individual’s actual score of the response variable, and the
term is the log-likelihood when the conditional mean is plugged into the log-likelihood. Usually, the deviance divided by its degree of freedom is examined by taking into account that a value much greater than 1 indicates a poorly fitting model. The deviance is provided by
. The statistics
for the NB fitted model with covariates indicate a good result. Here,
denotes the degree of freedom. Because the HNB model is not a generalized linear model, it is impossible to compute this statistic. The NB model’s expression for deviance is displayed in (
A3) in the
Appendix A.
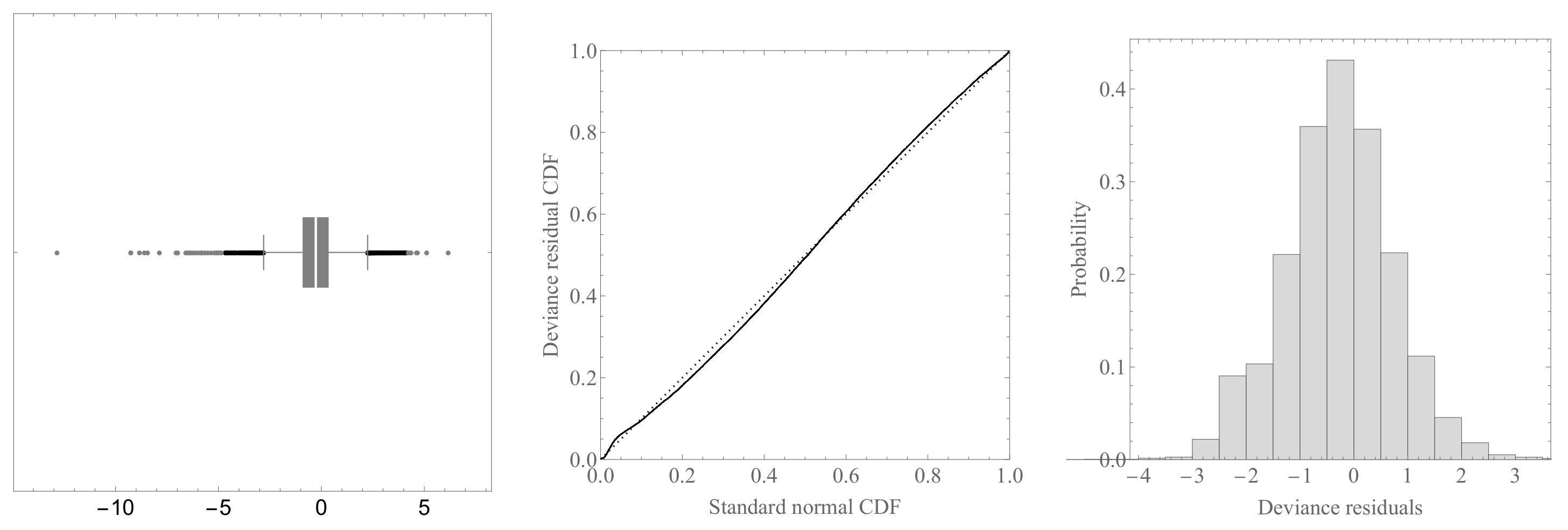
We now illustrate some diagnostic plots based on the Pearson residuals and deviance residuals. The box-and-whisker chart (left panel), probability plot, and histogram of the deviance residuals based on the NB regression model are shown in
Figure 2. All of the plots indicate reasonable behavior of the residuals, indicating that the deviance residuals are normally distributed to a reasonable approximation, resulting in normal plots that are rather linear.
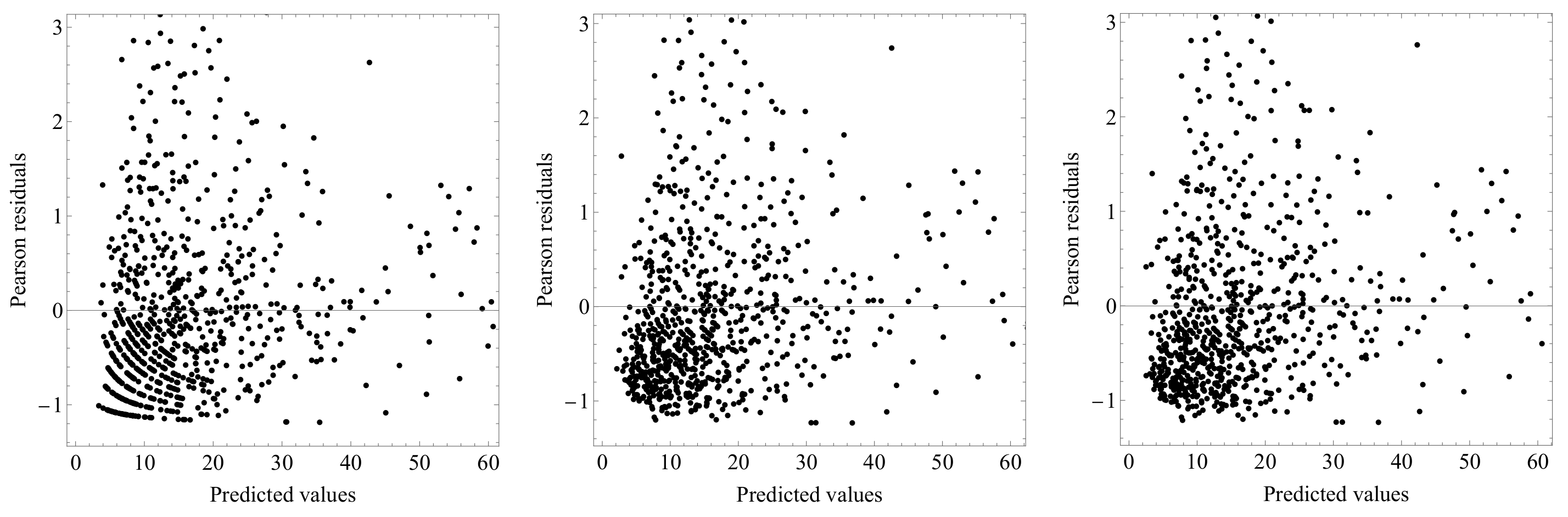
The standardized Pearson residuals plotted against the predicted values for the NB, HNB, and restricted HNB models are provided in
Figure 3. These plots reveal that no suspicious patterns are apparent.
6. Conclusions
Forecasting future citations and evaluating the quality of an article can be a valuable tool for research assessment, particularly for nations and organizations seeking to gauge their research achievements. Traditional research assessments often rely on citation metrics, expert reviews, and journal-level data; however, recent studies suggest that incorporating a broader range of variables can enhance prediction accuracy. Identifying factors that predict the citation impact and quality of journal articles is crucial for improving scientific research and supporting research evaluation. This study aims to bridge the gap by examining the relationships between document features and extra-documentary factors such as altmetric attention scores and downloads to predict citation impact.
Unlike traditional approaches which rely solely on Poisson or negative binomial models to analyze citation data, our framework explicitly distinguishes between the probability of receiving no citations and the frequency with which citations occur. This enables a more nuanced understanding of the factors influencing the visibility and impact of academic publications. Furthermore, by integrating altmetric indicators and multiple forms of open access, our study sheds new light on how contemporary dissemination practices beyond conventional journal metrics can shape citation outcomes.
This study aims to understand the factors influencing the citation counts of research papers in Economics and Business using a suitable regression model. The substantial variation in citation counts, where the sample variance exceeds the sample mean, necessitates moving beyond the classical Poisson regression model to a negative binomial regression model. This approach allows the variance to be a function of its predicted value. Furthermore, the citation process can be divided into two stages: papers with no citations and those with citations. This can help to model the observed attraction effect in citation counts after the first citation occurs. To address this, we employ a hurdle model to separately analyze the likelihood of having zero citations and the intensity of citations for papers that have already been cited.
Our dataset comprised 43,190 research papers from 2014–2021 sourced from The Lens database, with citation counts and social attention scores obtained from the Altmetric database. The results of the hurdle negative binomial regression model reveal that Green OA articles are positively correlated with higher citation counts and a reduced likelihood of zero citations, highlighting a clear citation advantage for articles in open access repositories. Conversely, Bronze OA articles, while also positively associated with citation counts, exhibit an increased likelihood of zero citations, indicating some complexity in their citation dynamics. Hybrid OA articles similarly show a positive association with citation counts.
A paper’s number of authors positively influences citation counts and decreases the likelihood of zero citations, reflecting the collaborative nature of impactful research. Funded articles also see a positive impact on citation counts and are less likely to have zero citations, suggesting that funding may enhance research quality and visibility.
Disciplinary differences are evident as well, indicating varying citation practices across study areas. Journal prestige significantly impacts citation counts, with lower expert ratings linked to fewer citations and a higher likelihood of zero citations. Furthermore, articles in journals with a higher SJR score and better quartile position tend to have higher citation rates, although the effect varies across quartiles.
Social and influential metrics also play a role in citation counts. News mentions and blog mentions positively influence citation counts and decrease the likelihood of zero citations, underscoring the importance of public and scholarly dissemination. Moreover, policy mentions significantly reduce the likelihood of zero citations and positively influence citation counts, reflecting the impact of policy relevance on academic recognition. However, patent mentions negatively influence citation counts, suggesting a different focus or recognition pattern in patent-referenced work.
Social media mentions exhibit varied effects. While mentions on X/Twitter positively influence citation counts and decrease the likelihood of zero citations, Facebook and video mentions negatively affect citation counts. Wikipedia mentions positively influence citation counts, while the number of Mendeley readers is positively associated with citation counts and significantly reduces the likelihood of zero citations, emphasizing the role of academic and public knowledge sources.
Overall, these results highlight the complex factors influencing citation patterns. Access type, publication age, discipline, collaboration, journal prestige, and social impact metrics all significantly determine citation outcomes. Our findings advocate for the promotion of open access and collaborative efforts to enhance the visibility and impact of scholarly work. This research provides important knowledge for academics, organizations, and policy makers aiming to understand and improve citation counts in scholarly research.
However, there are some considerations about the results and their generalization to other fields of research which must also be addressed. First, the field of Economics and Business has specific characteristics compared to other disciplines, making generalization to other fields complex. As pointed out by
Dorta-González and Gómez-Déniz (
2022), this field faces notable challenges of obsolescence compared to other disciplines, mainly due to its conservative publication practices and slower adoption of open access. Unlike the rapidly evolving natural and health sciences, where cutting-edge research is widely and rapidly disseminated, Economics and Business publishing often relies on traditional slower-moving channels. This inertia can delay the adoption of new methodologies and the integration of innovative findings, potentially hindering progress.
Citation concentration within Economics and Business also varies significantly across subject categories. For example, higher citation concentration indices as measured by the Gini and Pietra indices are observed in Statistics than in Management (
Gómez-Déniz & Dorta-González, 2024b). This disparity suggests that some disciplines receive disproportionately more citations than others. The elasticity, which measures the sensitivity of impact factors to changes in variables, further underlines the uniqueness of this field. The elasticity of impact factors with respect to the number of citations is higher in economics than in natural and health sciences such as biology and medicine. Conversely, the time elasticity of impact factors is lower in economics than in the hard sciences. This means that impact scores are more sensitive to changes in the number of citations but less sensitive to changes over time than those in natural and health sciences (
Gómez-Déniz & Dorta-González, 2024a).
These peculiarities suggest that caution should be exercised when attempting to generalize findings from economics and business to other fields. The conservative nature of publication practices, low prevalence of open access, varying citation concentrations, and distinctive elasticity measures highlight the unique landscape of research in the Economics and Business category. Such considerations are essential for an accurate interpretation of the impact and quality of research in this field.
Furthermore, our findings reveal systemic biases in citation dynamics that have critical implications for research practices in economics and business. The prominence of Journal Impact Factors (JIFs) and peer review ratings in predicting citation success may encourage researchers to prioritize conservative methodologies or topics that are considered ‘safer’ for high-status journals, which could lead to the homogenization of scholarship. Similarly, the outsized influence of collaboration and funding on citations raises equity concerns, as teams with more resources gain disproportionate visibility, potentially marginalizing innovative but underfunded work. The limited impact of altmetric mentions (e.g., in the news or on social media) further highlights how traditional citation metrics undervalue public engagement, thereby discouraging broader societal impact. These dynamics highlight the tension between citation-driven evaluation frameworks and the intellectual diversity that is essential for advancing economic research.
The results of this study have significant implications for researchers, institutions, and policymakers in the field of Economics and Business. By identifying the key factors influencing the likelihood of being cited and the intensity of citations, our findings can inform strategic decision-making regarding research dissemination. For instance, fostering collaboration and securing funding can support research production and enhance both its visibility and scholarly impact. In addition, the differentiated effects of various open access models suggest that if researchers and institutions aiming to increase their citation performance should carefully consider their publication and archiving strategies. These insights are particularly relevant in a context where citation metrics continue to play a central role in research evaluation and academic career progression.
In addition to its practical relevance, this study opens up new avenues for future research. The application of a two-stage modeling approach enables a more detailed understanding of citation dynamics, which could be extended to other disciplines or more specific subfields within economics. Furthermore, integrating altmetric data emphasizes the increasing importance of examining how new forms of digital visibility intersect with traditional scholarly impact. Future studies could examine the temporal dimensions of citation accumulation, field-specific effects, or the role of additional dissemination platforms. Overall, our findings contribute to a broader understanding of how scholarly communication practices are evolving and how they shape the recognition of academic work in an increasingly data-driven research environment.
Future research could benefit from a more nuanced examination of author collaboration and its impact on citations. While we used the number of authors as an indicator of collaboration the present study, we acknowledge that this measure may oversimplify the complex dynamics of teams. As one reviewer noted, large collaborations may involve diminishing returns or free-riding behavior, and an economic perspective could offer valuable insights into how incentives within research teams influence productivity and scholarly impact. Furthermore, future studies could examine whether the impact of collaboration varies across different subfields of economics and business. While our current dataset lacks the detailed information necessary for investigating these aspects, we recognize the importance of these observations and encourage further research in this area.






{kind=link}
{kind=link}
{kind=link}