Abstract
Sequential recommendation systems face challenges in integrating local sequential patterns with global collaborative information. While Transformers capture long-term dependencies through self-attention, they suffer from quadratic complexity. State-space models offer linear efficiency but are constrained by Markovian assumptions that limit their ability to model direct inter-item relationships. This paper addresses the expressiveness limitations of selective state-space models in capturing collaborative signals. We propose MCARec, which integrates selective state spaces with a dedicated collaborative awareness module. The key components include: (1) a lightweight attention mechanism that explicitly models item co-occurrence and transition patterns, enabling direct pairwise relationship modeling beyond the sequential bottleneck; (2) context-aware adaptive gating that dynamically balances sequential and collaborative features based on input context; (3) a lightweight architecture that enhances representational capacity while maintaining computational efficiency. On MovieLens-1M, a dataset characterized by dense user interactions, MCARec achieves improvements of 3.89% in HR@10, 5.52% in NDCG@10, and 6.97% in MRR@10 over Mamba4Rec, and 9.19%, 12.09%, and 8.45% respectively over SASRec (all ). Performance gains correlate with interaction density: substantial improvements on dense datasets diminish on sparser Amazon datasets (2–6% over SASRec in most metrics), while showing mixed results compared to Mamba4Rec on sparse datasets, suggesting that the collaborative awareness mechanism is most effective when sufficient co-occurrence signals are available. This work provides the first systematic analysis of how Markovian constraints in state-space models limit collaborative information utilization in recommendations. MCARec demonstrates that augmenting state-space models with explicit collaborative modeling significantly improves recommendation accuracy in dense interaction scenarios, offering a complementary approach to pure sequential or pure attention-based methods.
1. Introduction
Sequential recommendation aims to predict users’ next interactions by modeling the temporal dynamics of their behavior histories [1]. Unlike static collaborative filtering, sequential methods must capture how user preferences evolve over time, making them essential for modern platforms where user interests shift rapidly [2,3].
Early approaches based on Markov chains [4], RNNs [5,6], and CNNs [7] model sequential transitions but struggle with long-range dependencies or computational efficiency. Transformer-based methods such as SASRec [8] and BERT4Rec [9] address this through self-attention, enabling direct pairwise modeling across all positions, but incur quadratic complexity with sequence length. Recently, selective state-space models (SSMs), particularly Mamba [10], have emerged as efficient alternatives that achieve linear complexity while maintaining strong sequential modeling capability [11,12]. Hybrid architectures such as Jamba [13] and MaTrRec [14] further explore combining Mamba with Transformer layers.
However, Mamba’s architecture presents a fundamental limitation for recommendation tasks. Its recurrent state update compresses all historical information into a fixed-size state vector, and each position’s output depends only on its local context and this compressed history. As a result, Mamba cannot directly compute relationships between arbitrary item pairs—a capability central to collaborative filtering.
This limitation matters because collaborative signals are fundamental to recommendation quality. Consider a scenario where users who purchase a phone case frequently also purchase screen protectors and charging cables. This co-occurrence pattern is independent of sequential proximity—the items may appear at varying positions across different user histories. Attention mechanisms capture such patterns through an explicit relationship matrix, but Mamba’s state-mediated information flow can only approximate them through lossy compression. Existing hybrid approaches [13,14] employ general-purpose attention layers without specifically targeting these collaborative relationships.
To address this, we propose MCARec, which augments a selective state-space encoder with a dedicated collaborative awareness (CA) module. The CA module employs lightweight single-layer attention to explicitly model item co-occurrence and transition patterns, while a context-aware adaptive gating mechanism dynamically balances sequential and collaborative features based on input context. This design preserves Mamba’s efficient sequential modeling while providing the direct pairwise relationship modeling that collaborative filtering requires.
Our main contributions are as follows:
- We analyze how the Markovian state bottleneck in selective SSMs limits collaborative information utilization, providing theoretical motivation for augmenting SSMs with explicit pairwise modeling.
- We propose MCARec, integrating a lightweight collaborative awareness module with context-aware adaptive gating into the Mamba architecture, where each layer combines sequential and collaborative modeling within a unified block design.
- We conduct extensive experiments demonstrating that MCARec achieves significant improvements on dense datasets (3–7% over Mamba4Rec, 6–14% over SASRec on ML-1M, ), with gains correlating with interaction density, providing practical guidance on when collaborative awareness mechanisms are most beneficial.
2. Preliminaries
2.1. Sequential Recommendation
Sequential recommendation systems predict users’ future preferences based on their interaction history. Let be the set of users and be the set of items. For user , the interaction sequence is ordered chronologically, and the goal is to predict .
2.1.1. Markov Chain Methods
Early sequential recommendation systems used Markov Chain (MC) models [15] based on the assumption that the current state depends only on the previous state: . Factorized Personalized Markov Chains (FPMCs) [4] improved this by combining matrix factorization with Markov transitions, handling both personalization and sequential patterns. However, these methods are fundamentally limited by the first-order Markov assumption and cannot capture longer-range dependencies.
2.1.2. Recurrent Neural Network Methods
RNNs and their variants, such as LSTM [16] and GRU [17], capture temporal dependencies through recurrent hidden states. GRU4Rec [5] applies GRU to session-based recommendation, where the hidden state is updated at each time step through gating mechanisms:
where is the update gate and is the candidate hidden state. While RNNs handle longer dependencies than Markov models, they suffer from sequential computation bottlenecks and gradient degradation over long sequences.
2.1.3. Attention-Based Methods
Transformer-based methods [18] revolutionized sequential recommendation by enabling direct pairwise relationship modeling. SASRec [8,19] employs self-attention to compute relationships between all position pairs:
BERT4Rec [9,20] further advances the field with bidirectional encoding and masked pre-training. These methods achieve strong performance through parallel computation and explicit pairwise modeling, but incur quadratic complexity with sequence length L, creating challenges for long user histories. Attention-based approaches have been extensively studied for recommendation, and alternative efficient architectures such as LinRec [21] have also been explored. This trade-off between expressiveness and efficiency motivates exploring state-space models as an alternative paradigm.
2.2. State-Space Models
2.2.1. Traditional State-Space Models
Linear Time-Invariant (LTI) state-space models provide a powerful framework for characterizing dynamic systems, with applications in control theory, signal processing, and time series analysis.
The state-space model (SSM) maps input sequence to output sequence through latent state :
where , , and are learnable matrices. Here is the hidden state vector capturing system dynamics and memory, is the input vector, and is the observable output.
For discrete sequences, the model must be discretized with step size :
where and . After converting from continuous form to discrete form , the model can be computed as a linear recurrence, improving computational efficiency.
2.2.2. Structured State-Space Sequence Model (S4)
S4 [22] addresses computational inefficiencies of traditional state-space models through structured parameterization. By diagonalizing the state matrix, S4 reduces computational complexity while preserving expressive power.
The state matrix is parameterized as:
The continuous-time state evolution is:
Here is a low-rank factor matrix that captures essential data characteristics while reducing parameter space, and prevents overfitting by controlling the eigenvalue spectrum of matrix .
S4 structures the state matrix with HiPPO initialization [23] to improve long sequence modeling. S4’s key innovation is efficient parameterization that handles long-range dependencies with linear complexity. However, its fixed parameterization lacks adaptability for highly context-dependent sequential data.
2.2.3. Selective State-Space Model (Mamba)
Among recent SSM variants, S5 [24] simplifies the state-space layer design, and Mega [25] combines the moving average with gated attention. Building on S4, Mamba [10] introduces an input-dependent selection mechanism with a hardware-aware parallel algorithm. Unlike S4’s fixed parameterization, Mamba makes the SSM parameters functions of the input, enabling the model to selectively retain or discard information based on the current context. This selective mechanism significantly enhances the model’s ability to capture complex sequential patterns while maintaining computational efficiency.
The discretized state-space model in Mamba operates as follows:
where is the hidden state at time t, is the input, and is the output. The key innovation of Mamba is that the discretized state transition matrices and output projection are computed based on the input through learned transformations:
Here is a structured state matrix (initialized with HiPPO), is the discretization step size, and the discretization function converts continuous-time parameters to discrete-time parameters:
This input-dependent parameterization enables Mamba to dynamically adjust its state transitions based on context. When the input indicates important information, the model can increase to better retain it in the hidden state; conversely, for less relevant information, smaller values effectively filter it out. This selective mechanism allows Mamba to capture contextual information effectively, especially in long sequences, while maintaining linear computational complexity.
Recent theoretical work has rigorously analyzed the expressiveness and representational capacity of selective state-space models, providing foundations for understanding their advantages in sequence modeling [26]. These theoretical insights motivate exploring SSMs as efficient alternatives to attention mechanisms in sequential recommendation tasks.
As a linear-time sequence model, Mamba achieves Transformer-quality performance with better efficiency on long sequences. Recent theoretical work has established deep connections between Transformers and SSMs through structured state-space duality [27]. For comprehensive surveys on state-space models, we refer readers to [28,29]. Jamba [13] proposes a hybrid architecture that interleaves Mamba and attention layers for large language models, demonstrating improved throughput and efficiency while maintaining model quality. In the recommendation domain, MaTrRec [14] applies this hybrid paradigm by sequentially composing Mamba blocks for efficient sequence encoding followed by Transformer layers for representation refinement.
However, these approaches typically rely on sequential composition—processing inputs through Mamba layers first, then attention layers—which may not optimally integrate the two paradigms. Moreover, they lack explicit mechanisms for modeling collaborative relationships between items, which are fundamental to recommendation tasks. The attention mechanisms in these hybrid architectures are designed for general-purpose sequence modeling rather than specifically capturing item co-occurrence patterns, sequential transitions, and complementarity relationships that characterize collaborative filtering. Our work addresses these limitations by introducing a specialized collaborative awareness module with context-aware adaptive fusion tailored for sequential recommendation.
2.3. Theoretical Analysis and Motivation
2.3.1. Architecture of Mamba in Sequential Recommendation
To understand the potential and limitations of Mamba in sequential recommendation contexts, we examine its architectural components as implemented in Mamba4Rec. The Mamba block processes sequential information through a three-stage pipeline: local convolution, selective state-space modeling, and gated output projection.
The architecture begins with a 1D convolution of kernel size applied to the input sequence, enabling each position to aggregate information from its neighboring positions for capturing short-range dependencies. Following this, Mamba applies the selective state-space mechanism where SSM parameters are input-dependent. The hidden state evolves as follows:
where and are discretized state transition matrices, and is the output projection. The state dimension determines the capacity for encoding historical information beyond the local window. Finally, the SSM output is modulated through gating before projection, producing representations encoding both local context and compressed sequential history.
2.3.2. Limitations of Mamba in Sequential Recommendation
Having established the architecture, we now examine how these design choices create challenges for recommendation tasks. While Mamba excels at general sequence modeling, we argue that its architecture presents inherent limitations for sequential recommendation, where capturing collaborative item relationships is essential. These arise not from implementation details but from fundamental architectural choices prioritizing efficiency over explicit pairwise modeling.
Consider first the spatial extent of direct interactions. The 1D convolution provides direct interaction primarily within a window of size . For item pairs beyond this window, information must propagate through recurrent state updates. One might consider increasing , but this introduces a fundamental trade-off: larger kernels increase parameters and computation while still providing only bounded coverage. Regardless of the value chosen, the proportion of directly interacting pairs remains , diminishing as sequences lengthen. This reveals a structural constraint rather than a tunable parameter issue.
Beyond the convolution window, information traverses recurrent updates , encountering a second constraint: information compression. The state must compress all history into a fixed-size vector. While parameters and enable selective retention, the compression itself limits fine-grained relationship information. Increasing faces two constraints: maintaining efficiency requires (otherwise eliminating Mamba’s linear complexity advantage), and recurrent propagation means early information traverses multiple transitions, potentially degrading compared to direct connections.
Perhaps most fundamentally, Mamba produces position-wise outputs without computing explicit item-pair relationships. Each position computation depends on current input and compressed history, but never directly computes relationships between arbitrary positions i and j. In collaborative filtering, item co-occurrence patterns are central—items appearing together frequently exhibit collaborative affinity regardless of proximity. Attention mechanisms address this via explicit relationship matrix , where quantifies affinity between positions. Mamba lacks this architectural analog, a limitation that cannot be resolved through hyperparameter tuning but reflects fundamental differences in relationship modeling.
These characteristics are not inherent deficiencies across all domains—the compression and linear complexity enabling Mamba’s efficiency in language modeling become constraints specifically for recommendation, where explicit collaborative modeling is essential. Our collaborative awareness module thus complements Mamba’s sequential strengths while addressing these recommendation-specific limitations.
2.3.3. Motivation for Collaborative Awareness
This analysis motivates introducing a mechanism for explicit pairwise modeling while preserving Mamba’s efficient sequential processing. We augment Mamba’s recurrent compression with a lightweight attention mechanism providing direct pairwise connections:
where and are query and key projections of input . The attention matrix explicitly represents all item-pair relationships, with each entry quantifying collaborative affinity. Implementation details are provided in Section 3.3.2.
This design directly addresses the three constraints. Unlike convolution’s bounded window, attention enables any pair to interact directly regardless of distance, providing a global receptive field. Each position retains full d-dimensional representation, avoiding lossy compression. Most importantly, the attention matrix directly represents item-pair relationships, capturing collaborative patterns Mamba cannot explicitly model.
We employ a single attention layer rather than deep stacks typical of Transformers, reflecting our goal of complementing rather than replacing Mamba. The single layer provides sufficient capacity for pairwise relationship modeling while maintaining architectural efficiency.
We note that while the CA module employs attention with complexity per layer, this does not contradict our efficiency motivation. The cost concern with Transformer-based recommenders arises from stacking multiple attention layers (typically 2–6 in SASRec/BERT4Rec), each with multi-head computation and feed-forward sub-layers. Our CA module uses a single layer without multi-head decomposition, serving as a lightweight complement to the Mamba encoder. Empirical measurements confirm that MCARec’s total overhead remains moderate (see Table 1).

Table 1.
Efficiency comparison on ML-1M.
2.3.4. Adaptive Fusion Strategy
With both mechanisms in place, a natural question arises: how should we combine these complementary sources? Rather than fixed combination, we design adaptive fusion dynamically balancing sequential and collaborative information based on context:
where captures sequential patterns, captures pairwise relationships, and represents input-dependent fusion weights computed from concatenated representations. This enables flexible adaptation: when temporal patterns dominate (e.g., strong recency effects), the model emphasizes Mamba’s output; when co-occurrence relationships are more informative (e.g., complementary item exploration), it emphasizes collaborative awareness. The mechanism supports smooth interpolation with optimal balance learned from data.
Based on this analysis, we hypothesize that the collaborative awareness mechanism provides greater benefit when important relationships span distances beyond the convolution window and sufficient interaction data exists to learn meaningful patterns. Conversely, with sparse interactions or predominantly local patterns, benefits may be limited. These hypotheses are empirically examined in Section 4, where we observe substantial performance variations across datasets with different interaction densities.
3. MCARec
This section describes the core architecture of MCARec. Based on our theoretical analysis, we build an end-to-end framework that combines selective state spaces with adaptive collaborative awareness. The framework has four key modules: (1) a semantic embedding layer for item representations; (2) a selective state-space encoder for capturing temporal patterns; (3) a collaborative awareness module for modeling item relationships; (4) a context-aware dynamic fusion mechanism for integrating sequential and collaborative information.
3.1. Framework Overview
The overall architecture of MCARec is shown in Figure 1, with three core components: the item embedding layer, model layer, and prediction layer.
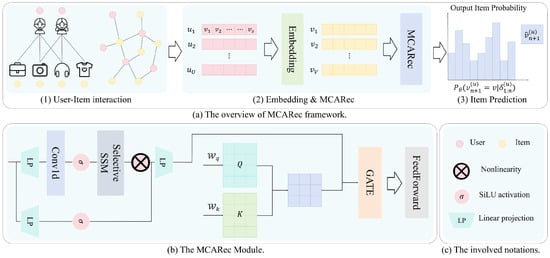
Figure 1.
Overall architecture of MCARec, showing the integration of the Mamba encoder, collaborative awareness module, and adaptive fusion mechanism.
3.2. Embedding Layer
Given item sequence , each item is mapped to a d-dimensional vector via a learnable embedding table. The embedding sequence is processed through layer normalization [30] and dropout [31] to produce the regularized input :
3.3. Model Layer
MCARec combines selective sequential modeling with collaborative awareness through three components. The selective state-space encoder captures temporal evolution patterns through Mamba’s selective mechanism, which adaptively retains and forgets historical information for efficient long sequence processing. The collaborative awareness module explicitly models global item-pair relationships through lightweight single-layer attention, capturing collaborative patterns that pure sequential models cannot access. The context-aware dynamic fusion mechanism learns joint representations of sequential and collaborative contexts, intelligently balancing these two information sources.
3.3.1. Mamba Encoder
The Mamba encoder applies the selective state-space model (Section 2.2.3) to process sequential item embeddings. For the normalized input sequence , the encoder processes each position through the input-dependent state transitions defined in Equations (10) and (11), where the generic input is instantiated as the item embedding at position t. The output sequence is collected and normalized to produce the sequential representations:
where is the hidden state carrying sequential information, and are input-dependent parameters computed as:
Here are learnable projection matrices, is a learnable parameter, and is the structured state matrix (HiPPO-initialized). The output sequence undergoes layer normalization for training stability.
The input-dependent mechanism allows the model to selectively emphasize important items while filtering noise. For instance, when processing a highly relevant item, larger values enable stronger retention in the hidden state ; conversely, for less relevant items, smaller values reduce their influence on subsequent predictions.
3.3.2. Collaborative Awareness Module
The collaborative awareness module implements the attention-based pairwise modeling described in Section 2.3.3. Operating on the normalized embeddings , the module computes collaborative relationships through three sequential phases.
First, it generates collaborative query and key representations:
Second, it computes the normalized collaborative attention matrix:
Finally, it generates collaborative-aware representations:
where are learnable projection matrices. The layer normalization ensures training stability and output scale consistency with the Mamba encoder. The single-layer design keeps the additional computation manageable for typical recommendation sequence lengths, contrasting with Transformer architectures that stack multiple attention layers.
3.3.3. Adaptive Gating Fusion
To dynamically fuse Mamba features and collaborative features , we design an adaptive gating mechanism. First, concatenate the two feature sets:
Then apply the gating mechanism with a residual connection:
Here and are learnable parameters, and the gating value g dynamically adjusts based on current context. The residual connection from the block input preserves representations from the preceding layer and stabilizes training. For a single-layer configuration, ; for stacked layers, is the output of the previous MCARec layer.
3.3.4. Feed-Forward Layer
The fused representation is further refined through a standard position-wise feed-forward network with residual connection:
where and are learnable parameters. The intermediate layer expands the feature dimension by a factor of 4, and GELU [32] activation provides smooth non-linearity.
3.4. Prediction Layer
The prediction layer extracts the representation at the last valid position from the fused output sequence to compute prediction probabilities:
where is the final representation encoding both sequential and collaborative information through the adaptive fusion mechanism, and is the full item embedding matrix. The result is a probability distribution over the entire item catalog , indicating the likelihood of each item being the user’s next selection.
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
We conducted experiments on three well-established real-world datasets. MovieLens-1M [33] is a benchmark dataset with approximately one million movie ratings from 6040 users on 3416 movies. This dataset is widely used in sequential recommendation research due to its rich temporal interaction patterns and dense user-item interactions. Amazon-Beauty and Amazon-Video-Games [34] are domain-specific datasets from the Amazon review corpus, containing product reviews and ratings from the “Beauty” and “Video Games” categories respectively. These datasets represent different user behavior patterns across product domains and are characterized by sparser interactions compared to MovieLens-1M.
For each user, we created chronological interaction sequences by sorting records by timestamps. Following standard protocols [8,9], we retained only users and items with at least 5 interactions to mitigate cold-start issues and ensure sufficient training signals. Table 2 shows the dataset statistics after preprocessing.
Table 2.
Dataset statistics after preprocessing.
The datasets exhibit substantial differences in interaction density. MovieLens-1M has an average sequence length of 165.5 items per user, providing rich collaborative signals. In contrast, the Amazon datasets have average sequence lengths of only 8–9 items, resulting in much sparser collaborative information. This variation allows us to evaluate how MCARec performs across different data density regimes.
4.1.2. Baselines
We compared MCARec against several state-of-the-art sequential recommendation approaches. Traditional methods include BPR-MF [35], a classic matrix factorization approach with Bayesian personalized ranking optimization. RNN-based models include GRU4Rec [5] and NARM [36], which use recurrent neural networks to capture sequential dependencies. Transformer-based models include SASRec [8] and BERT4Rec [9], which employ self-attention mechanisms to model complex item relationships and bidirectional contexts. Linear Recurrent Unit-based models [37] include LRURec [38] for efficient sequential modeling. Mamba-based models include Mamba4Rec [11], which incorporates state-space models for capturing long-range dependencies, and MaTrRec [14], which combines Mamba and Transformer to balance performance on both long and short interaction sequences.
4.1.3. Evaluation Metrics
We used multiple ranking-based evaluation metrics with different cut-off thresholds. Hit Ratio (HR@K) measures the percentage of test cases where the ground truth item appears in the top-K recommendation list. Normalized Discounted Cumulative Gain (NDCG@K) evaluates ranking quality by assigning higher importance to correctly recommended items appearing earlier. Mean Reciprocal Rank (MRR@K) calculates the average of reciprocal ranks of ground truth items in recommendation lists. We report results with K = 10 and K = 20, yielding six metrics: HR@10, NDCG@10, MRR@10, HR@20, NDCG@20, and MRR@20.
4.1.4. Implementation Details
MCARec uses a single model layer with an Adam optimizer [39] and a 0.001 learning rate. We used a batch size of 512 for training and 1024 for evaluation, with an embedding dimension of 64 for all models. We applied dataset-specific dropout regularization: 0.4 for the Amazon datasets and 0.2 for MovieLens-1M. The maximum sequence length was 200 for MovieLens-1M and 50 for the Amazon datasets. The Mamba block parameters included an SSM state expansion factor of 32, a kernel size of 4 for 1D convolution, and a block expansion factor of 2. All experiments were run on NVIDIA GeForce GTX 1080 Ti GPUs following RecBole [40] framework conventions. For statistical validation, all experiments on ML-1M were repeated 5 times with random seeds {2020, 2021, 2022, 2023, 2024}. All hyperparameters were systematically tuned via grid search on validation sets, and the reported configurations represent optimal settings, ensuring fair comparison across all methods. For fair comparison, Mamba4Rec, MaTrRec, and MCARec all used a single model layer. SASRec, BERT4Rec, and LRURec followed their default configurations of two layers.
4.2. Overall Performance
Table 3 presents a comprehensive comparison of recommendation performance across three datasets with distinct interaction characteristics. The results reveal a clear correlation between interaction density and the effectiveness of collaborative awareness mechanisms.
Table 3.
Recommendation performance comparison. The best results are in bold, and the second-best are underlined.
On MovieLens-1M, characterized by dense interactions with an average sequence length of 165.5 items, MCARec achieves substantial improvements over all baselines. Compared to Mamba4Rec, MCARec achieves 3.89% improvement in HR@10, 5.52% in NDCG@10, and 6.97% in MRR@10. These improvements are more pronounced relative to SASRec: 9.19% in HR@10, 12.09% in NDCG@10, and 8.45% in MRR@10. The larger gains in ranking-sensitive metrics (MRR) compared to hit-based metrics (HR) suggest that the collaborative awareness module particularly helps in distinguishing between relevant items and placing ground-truth items higher in rankings. These improvements can be attributed to the collaborative awareness module’s ability to capture rich co-occurrence patterns present in dense interaction data. With an average of 165 interactions per user, sufficient signal exists for learning meaningful item-pair relationships that complement the sequential patterns captured by Mamba. All improvements on ML-1M are statistically significant (, paired t-test over 5 runs with seeds 2020–2024).
MCARec also outperforms MaTrRec, a recent 2024 hybrid architecture that combines Mamba and Transformer layers, across all six metrics on ML-1M. This suggests that our design—dedicated collaborative awareness with adaptive gating—may be more effective for recommendation tasks than general-purpose Mamba-Transformer composition, particularly when capturing item co-occurrence patterns is important.
On the Amazon-Beauty and Amazon-Video-Games datasets, characterized by sparse interactions (average sequence lengths of 8–9 items), MCARec shows mixed results. While hit-based metrics at larger cutoffs improve modestly (e.g., 2.46% in HR@20 on Beauty, 3.84% in NDCG@10 on Video-Games over SASRec), MRR metrics decline on both datasets (e.g., −7.19% MRR@10 on Beauty, −13.93% MRR@10 on Video-Games).
We attribute this divergent behavior to the interaction between the CA module and data sparsity. The CA module introduces additional parameters for query and key projections that require sufficient co-occurrence observations to learn meaningful patterns. In sparse settings, attention weights may distribute nearly uniformly due to an insufficient discriminative signal, effectively adding noise. This noise particularly affects MRR, which is sensitive to the exact rank of the top-1 prediction, while HR at larger cutoffs is more tolerant since it only requires the ground-truth item to appear within the top-K list. The adaptive gating partially mitigates this—as evidenced by preserved HR improvements—but cannot fully compensate when collaborative signals are too sparse. This suggests that the CA module would benefit from regularization strategies (e.g., attention dropout or sparse attention constraints) in sparse scenarios, which we identify as a topic for future work.
4.3. Efficiency Analysis
Table 1 reports empirical efficiency on ML-1M, measured on a single NVIDIA GeForce GTX 1080 Ti GPU (11 GB). All models use identical training configuration to ensure fair comparison.
MCARec introduces moderate overhead compared to Mamba4Rec (1.43× in GPU memory, 1.26× in training time, and 1.36× in inference time), primarily due to the attention computation in the CA module. Notably, MCARec remains substantially more efficient than SASRec (1.86× faster training, 52.2% less GPU memory), and is comparable to MaTrRec while using less GPU memory (1.76 GB vs. 1.98 GB). These results confirm that the CA module adds bounded overhead in exchange for significant performance gains.
4.4. Ablation Study
To understand the contribution of individual components in MCARec, we conduct ablation studies on the ML-1M dataset. The default architecture uses a single model layer (L = 1). We introduce each variant and analyze its impact. The results are summarized in Table 4.
Table 4.
Ablation analysis on ML-1M. Bold scores indicate better performance than the default version (L = 1).
- Remove CA: This removes the collaborative awareness module, reducing the model to a pure Mamba encoder with gating and FFN.
- Remove Gate: This replaces the adaptive gating mechanism with simple addition of Mamba and CA features.
- Remove FFN: This removes the feed-forward network after the fusion layer.
- L = 2: This stacks two MCARec layers to examine the effect of depth.
Both the CA module and FFN contribute substantially to overall performance. Removing CA causes 3.93% degradation in HR@10, 5.29% in NDCG@10, and 6.45% in MRR@10. The CA module is particularly impactful on ranking-sensitive metrics, confirming that explicit collaborative modeling improves the model’s ability to rank ground-truth items higher. Removing FFN yields comparable degradation (3.50% in HR@10, 5.08% in NDCG@10, 5.91% in MRR@10), indicating that non-linear feature refinement is equally important for the fused representations. The gating mechanism shows a smaller but consistent contribution (1.49% in HR@10, 2.33% in NDCG@10, 3.16% in MRR@10), confirming its role as an effective fusion strategy rather than a primary performance driver.
Stacking two MCARec layers (L = 2) yields further improvements over the single-layer default across all metrics (2.79% in HR@10, 2.75% in NDCG@10, 2.69% in MRR@10). This demonstrates that the collaborative awareness mechanism benefits from deeper feature extraction, though the single-layer configuration already achieves competitive performance.
A potential concern is whether MCARec’s improvements stem from the architectural design or simply from increased parameter count. MCARec introduces 307,776 parameters compared to Mamba4Rec’s 290,944, an increase of only 16,832 parameters (5.79%). To disentangle the effect of architecture from parameter count, we examine the ablation results: removing the CA module eliminates only parameters (2.66% of total) while retaining the gating and FFN modules with their substantially larger parameter budgets, yet causes 3.93% HR@10 and 6.45% MRR@10 degradation. Conversely, removing FFN eliminates far more parameters () but causes comparable degradation (3.50% and 5.91%). This asymmetry between parameter reduction and performance impact demonstrates that the CA module’s collaborative modeling function, not its parameter count, drives the improvement.
5. Conclusions
This paper proposes MCARec, which integrates selective state-space models with collaborative awareness mechanisms for sequential recommendation. We identify the expressiveness limitations of pure state-space models stemming from their Markovian information flow, and demonstrate how explicit collaborative modeling can address these limitations.
MCARec makes three key contributions. First, we provide a theoretical analysis explaining how the sequential state bottleneck in Mamba prevents direct modeling of item-pair relationships. Second, we design a collaborative awareness module with adaptive gating that effectively combines sequential and collaborative information sources. Third, we conduct extensive empirical validation revealing the relationship between interaction density and model effectiveness.
Extensive experiments validate our approach. On MovieLens-1M, MCARec achieves 3.89–6.97% improvements over Mamba4Rec and 8.45–12.09% over SASRec in all metrics. Ablation studies confirm that the collaborative awareness module and feed-forward network are the primary drivers of improvements. Importantly, performance gains correlate with data density: substantial improvements on dense datasets diminish on sparser Amazon datasets, confirming our hypothesis that collaborative awareness mechanisms require sufficient co-occurrence signals to be effective.
Based on our findings, MCARec is particularly well-suited for platforms with established user bases and dense interaction histories, such as video streaming services or mature e-commerce platforms. Conversely, for cold-start scenarios with limited interaction data or platforms with sparse user engagement, pure sequential models may be more appropriate as they avoid attempting to extract collaborative patterns from insufficient data.
MCARec has several limitations. First, it introduces additional computational cost through attention computation. Second, the collaborative awareness mechanism is less effective on sparse datasets where co-occurrence signals are insufficient. Third, like other collaborative methods, MCARec may exhibit popularity bias, favoring frequently occurring items.
Future work could explore sparse attention mechanisms to reduce computational cost for longer sequences, hybrid approaches that adaptively switch between collaborative and content-based signals based on data density, debiasing techniques to address popularity bias, and investigation of how collaborative awareness patterns learned by the model correlate with item semantics.
Author Contributions
All authors contributed equally to the conceptualization, methodology, implementation, experimentation, analysis, and writing of this manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC) under Grant Nos. 61004012, 62173008, 62371013, 61873007, and U24A20267.
Data Availability Statement
The datasets used in this study are publicly available. MovieLens-1M is available at https://grouplens.org/datasets/movielens/1m/ (accessed on 13 January 2026). The Amazon datasets are available at https://jmcauley.ucsd.edu/data/amazon/ (accessed on 13 January 2026).
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions that helped improve the quality of this paper. We also thank the developers of the RecBole framework for providing the experimental platform.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| SSM | State-Space Model |
| CA | Collaborative Awareness |
| FFN | Feed-Forward Network |
| HR | Hit Ratio |
| NDCG | Normalized Discounted Cumulative Gain |
| MRR | Mean Reciprocal Rank |
References
- Zhang, Y.; Fan, Y.; Sheng, T.; Wang, A. Temporal-aware and intent contrastive learning for sequential recommendation. Symmetry 2025, 17, 1634. [Google Scholar] [CrossRef]
- Peng, S.; Siet, S.; Ilkhomjon, S.; Kim, D.-Y.; Park, D.-S. Integration of deep reinforcement learning with collaborative filtering for movie recommendation systems. Appl. Sci. 2024, 14, 1155. [Google Scholar] [CrossRef]
- Peng, J.; Gong, J.; Zhou, C.; Zang, Q.; Fang, X.; Yang, K.; Yu, J. KGCFRec: Improving collaborative filtering recommendation with knowledge graph. Electronics 2024, 13, 1927. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 843–852. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; ACM: New York, NY, USA, 2018; pp. 565–573. [Google Scholar]
- Kang, W.-C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; IEEE: New York, NY, USA, 2018; pp. 197–206. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; ACM: New York, NY, USA, 2019; pp. 1441–1450. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. In Proceedings of the First Conference on Language Modeling, Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Liu, C.; Lin, J.; Wang, J.; Liu, H.; Caverlee, J. Mamba4Rec: Towards efficient sequential recommendation with selective state space models. arXiv 2024, arXiv:2403.03900. [Google Scholar] [CrossRef]
- Xiao, W.; Wang, H.; Zhou, Q.; Wang, Q. SS4Rec: Continuous-time sequential recommendation with state space models. arXiv 2025, arXiv:2502.08132. [Google Scholar]
- Lieber, O.; Lenz, B.; Bata, H.; Cohen, G.; Osin, J.; Dalmedigos, I.; Safahi, E.; Meirom, S.; Belinkov, Y.; Shalev-Shwartz, S.; et al. Jamba: A hybrid transformer-Mamba language model. arXiv 2024, arXiv:2403.19887. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, R.; Yang, Z. MaTrRec: Uniting Mamba and Transformer for sequential recommendation. arXiv 2024, arXiv:2407.19239. [Google Scholar]
- Norris, J.R. Markov Chains; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Su, Z.-A.; Zhang, J. Weight adjustment framework for self-attention sequential recommendation. Appl. Sci. 2024, 14, 3608. [Google Scholar] [CrossRef]
- Jang, D.; Lee, S.-K.; Li, Q. ITS-Rec: A sequential recommendation model using item textual information. Electronics 2025, 14, 1748. [Google Scholar] [CrossRef]
- Liu, L.; Cai, L.; Zhang, C.; Zhao, X.; Gao, J.; Wang, W.; Lv, Y.; Fan, W.; Wang, Y.; He, M.; et al. LinRec: Linear attention mechanism for long-term sequential recommender systems. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; ACM: New York, NY, USA, 2023; pp. 289–299. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. HiPPO: Recurrent memory with optimal polynomial projections. Adv. Neural Inf. Process. Syst. 2020, 33, 1474–1487. [Google Scholar]
- Smith, J.T.H.; Warrington, A.; Linderman, S.W. Simplified state space layers for sequence modeling. arXiv 2022, arXiv:2208.04933. [Google Scholar]
- Ma, X.; Zhou, C.; Kong, X.; He, J.; Gui, L.; Neubig, G.; May, J.; Zettlemoyer, L. MEGA: Moving average equipped gated attention. arXiv 2022, arXiv:2209.10655. [Google Scholar]
- Cirone, N.M.; Orvieto, A.; Walker, B.; Salvi, C.; Lyons, T. Theoretical foundations of deep selective state-space models. Adv. Neural Inf. Process. Syst. 2024, 37, 127226–127272. [Google Scholar]
- Dao, T.; Gu, A. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. arXiv 2024, arXiv:2405.21060. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Ding, Y.; Li, Y.; Wu, W.; Rong, Y.; Kong, W.; Huang, J.; Li, S.; Yang, H.; et al. State space model for new-generation network alternative to transformers: A survey. arXiv 2024, arXiv:2404.09516. [Google Scholar] [CrossRef]
- Patro, B.N.; Agneeswaran, V.S. Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. Eng. Appl. Artif. Intell. 2025, 159, 111279. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; ACM: New York, NY, USA, 2015; pp. 43–52. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar] [CrossRef]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; ACM: New York, NY, USA, 2017; pp. 1419–1428. [Google Scholar]
- Orvieto, A.; Smith, S.L.; Gu, A.; Fernando, A.; Gulcehre, C.; Pascanu, R.; De, S. Resurrecting recurrent neural networks for long sequences. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: New York, NY, USA, 2023; pp. 26670–26698. [Google Scholar]
- Yue, Z.; Wang, Y.; He, Z.; Zeng, H.; McAuley, J.; Wang, D. Linear recurrent units for sequential recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; ACM: New York, NY, USA, 2024; pp. 930–938. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhao, W.X.; Mu, S.; Hou, Y.; Lin, Z.; Chen, Y.; Pan, X.; Li, K.; Lu, Y.; Wang, H.; Tian, C.; et al. RecBole: Towards a unified, comprehensive and efficient framework for recommendation algorithms. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, 1–5 November 2021; ACM: New York, NY, USA, 2021; pp. 4653–4664. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.