Abstract
The weighted flexible Weibull distribution focuses on its unique point of flaunting a bathtub-shaped hazard rate, characterized by an initial increase followed by a drop over time. This property plays a major role in reliability analysis. In this paper, this distribution and its main properties are examined, and the parameters are estimated using several estimation methods. In addition, a simulation study is done for different sample sizes. The performance of the proposed model is illustrated through two real-world applications: component failure times and COVID-19 mortality. Moreover, the value-at-risk (VaR), tail value-at-risk (TVaR), peaks over a random threshold VaR (PORT-VaR), the mean of order P () analysis, and optimal order of P due to the true mean value can help identify and characterize critical events or outliers in failure events and COVID-19 death data across different counties. Finally, the PORT-VaR estimators are provided under a risk analysis for both applications.
1. Introduction
The Weibull distribution is a versatile model widely used in fields such as reliability engineering and survival analysis. However, it struggles to adequately fit data with bathtub-shaped or unimodal hazard rates. To address this limitation, several extensions and modifications have been proposed in the literature. Notable contributions include the works of [1,2,3,4,5,6], among others. More recently, the flexible Weibull (FW) distribution was introduced by [7]. Its cumulative distribution function (CDF) is defined as
and the corresponding probability density function (PDF) as
For and , the FW model is reduced to exponential distribution, demonstrating its role as a generalization of the Weibull distribution. Several extensions of the FW distribution have been developed, such as those provided by [7,8,9,10], and others. From the latter references, it is known that there does not exists a unique distribution suitable for modeling and analyzing all types of data. Thus, the goal of this study is to develop a generalization of the FW distribution, called the weighted flexible Weibull (WFW) distribution. The WFW model is based on a PDF derived from the upper record values of independent FW random variables. This approach has also been adapted by the Lindley distribution [11]. The WFW distribution could be considered in medical data analysis, especially in modeling unimodal and bimodal datasets related to COVID-19 events and cancer decease, as discussed in subsequent sections.
On the other hand, the PORT-VaR analysis plays a crucial role in identifying and characterizing critical events or outliers in failure events and COVID-19 death data across various counties [12]. In this study, PORT-VaR estimators are utilized to gain insight in risk analysis relative to the fields of engineering and medicine. In the context of engineering, the PORT-VaR analysis assists in pinpointing extreme failure events that exceed predetermined risk thresholds. By identifying these peaks over the random threshold, engineers can gain insights into potential weaknesses or vulnerabilities in systems, components, or processes. By applying PORT-VaR estimators to mortality data, healthcare professionals can identify countries with unusually high mortality rates compared to the expected threshold [13]. This analysis enables targeted interventions, resource allocation, and public health measures to mitigate the impact of the pandemic and prioritize healthcare resources effectively.
This study proposes several key contributions to actuarial risk modeling and statistical analysis, addressing critical gaps and introducing novel methodologies with broad applications. One of the primary contributions is the introduction of the WFW distribution, a versatile model with good performance in lifetime data analysis. Its properties (including cumulative and residual cumulative entropy), provide deeper insights into risk modeling. A simulation study confirms the consistency of the maximum likelihood estimators (MLEs), ensuring the reliability of parameter estimation. Furthermore, the study applies the WFW distribution to real-world datasets, including unimodal and COVID-19 case data, demonstrating its effectiveness in practical scenarios. A significant advancement in this work is the development of PORT-VaR estimators, specifically tailored for risk assessment in engineering and medical applications. These estimators provide a refined approach for identifying and quantifying extreme events, which is crucial for making informed decisions in high-risk environments. The study expands the discussion on PORT-VaR, emphasizing its practical significance in modern risk assessment and its potential to improve public health planning, engineering safety measures, and financial risk management. Our key findings go beyond a review of existing ideas and introduce several new aspects of actuarial risk assessment:
- This study is a pioneer in the use of weighted distributions in actuarial risk modeling, filling a critical research gap and providing a fresh perspective on risk evaluation.
- Actuarial risk metrics are applied beyond traditional financial contexts to medical data, specifically for assessing COVID-19 risk and managing datasets with extreme values. This cross-disciplinary approach highlights the adaptability of actuarial methods in diverse fields.
- A new estimation techniques and a sequential sampling plan based on truncated life testing are introduced, enhancing the precision and efficiency of risk assessment models.
- While the original discussion on PORT-VaR is too general, we have now expanded on its significance and provided a more detailed analysis of its applicability in modern risk assessment scenarios.
2. The WFW Distribution
A random variable X follows the WFW distribution if its CDF and PDF, respectively, are defined as
and
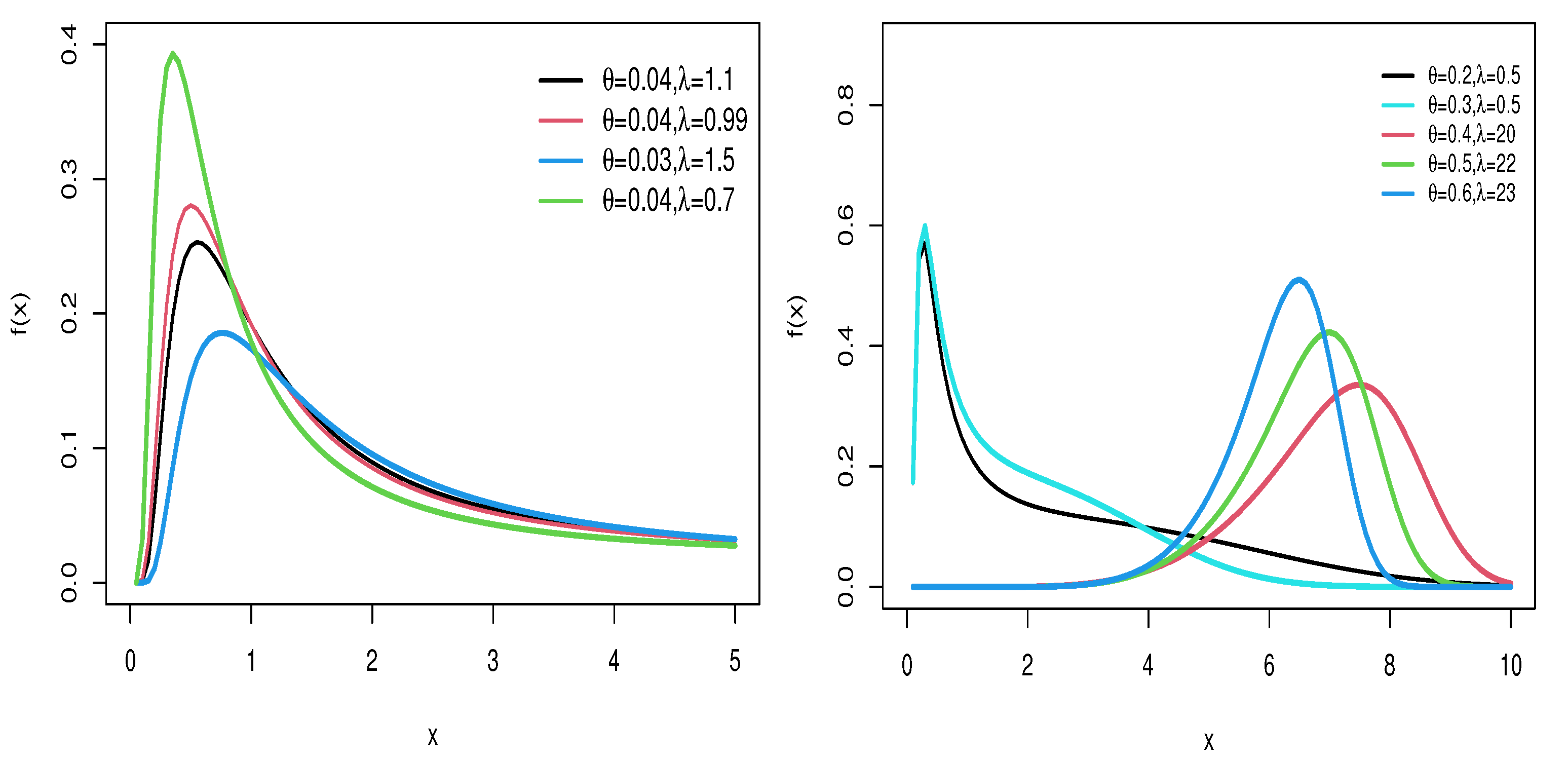
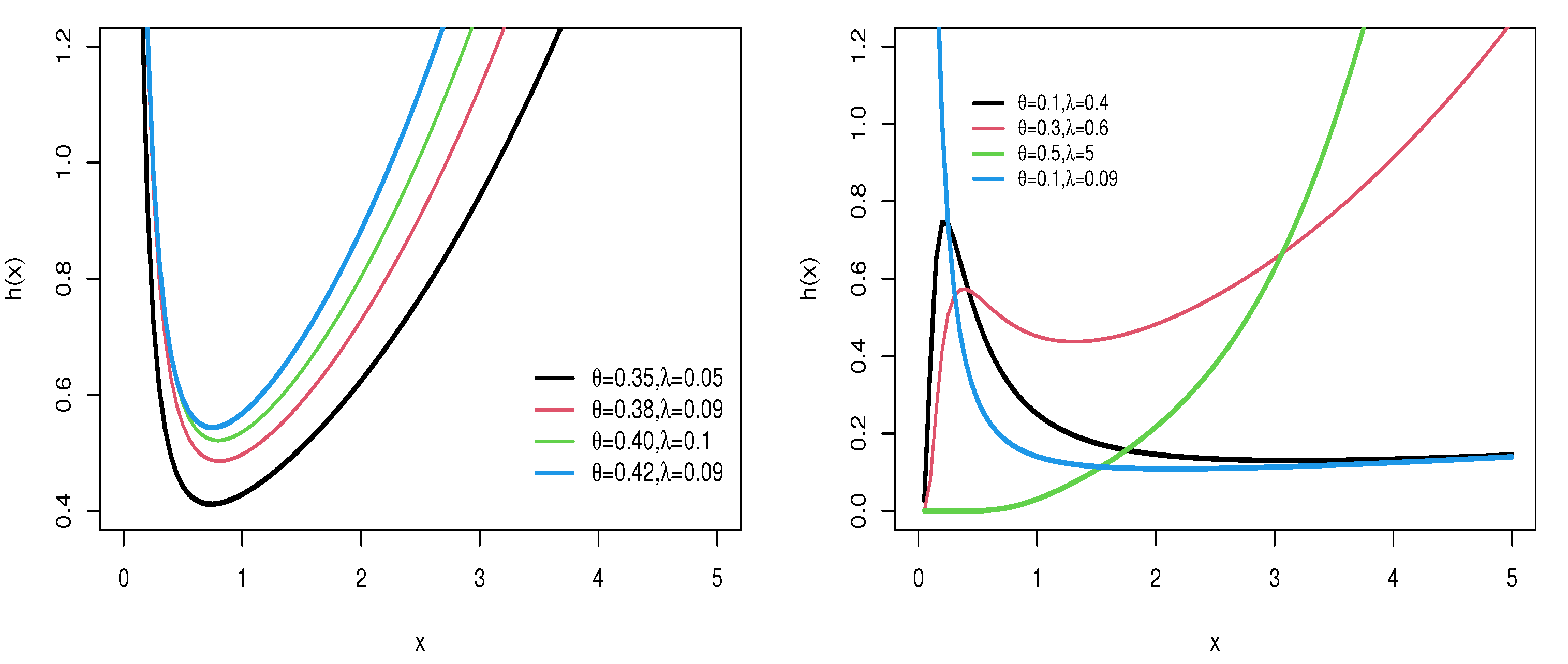
Figure 1 and Figure 2 provide visual representations of the density and hazard rate functions for varying parameter values. Figure 1 demonstrates that the density function can exhibit symmetrical, right-skewed, left-skewed, or even bimodal forms. On the other hand, Figure 2 shows that the hazard rate function can take on increasing, decreasing, or unimodal shapes depending on the parameter settings.
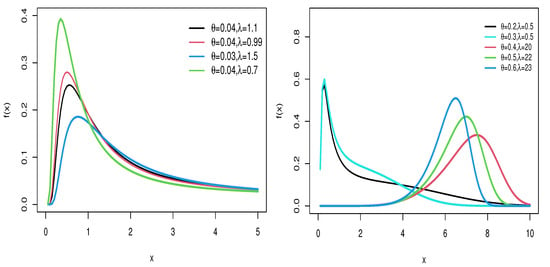
Figure 1.
PDF of WFW distribution for several parameter settings.
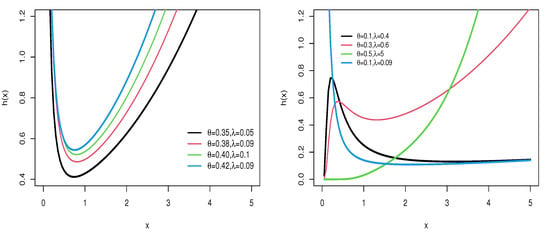
Figure 2.
HRF of WFW distribution for several parameter settings.
The reversed hazard rate function of the WFW distribution is obtained as follows:
The inverse of the hazard function for the WFW distribution exhibits a decreasing trend across different parameter values. The quantile function is a widely used tool in data analysis and probability, providing valuable information about the distribution of data and their observed values. Let be the quantile function of X. Then, by solving a quadratic equation, the quantile function (for ) is obtained:
3. Properties
3.1. Asymptotic Properties
Let X be a random variable with parameters and . The asymptotic behavior of the CDF, PDF, and HRF are given by
as . When , the asymptotic behavior of these functions for the WFW distribution is expressed as
3.2. Moments and Generating Function
Moments play crucial roles in identifying and quantifying various statistical characteristics, including detecting flattening and spacing, as well as assessing the coefficient of variation. In Table 1, the first four moments, standard deviation (SD), skewness (SK), and kurtosis (KR) are numerically computed. The rth moment of the WFW distribution can be determined using the following relationship [14]:

Table 1.
First four moments, standard deviation (SD), skewness (SK), and kurtosis (KR) for the WFW model.
Employing the outcomes from the study conducted by [15], it is evident that
Further, by using the result 3.471.9 of [16], the nth moment of the WFW distribution is
Then,
where and
The modified Bessel function of the first kind is
and denotes the gamma function. Similarly, the nth incomplete moment of X, say
is
Following Theorem 2 of [17], then
for , where
represents the lower incomplete gamma function.
3.3. Moment Generating Function
For a random variable X, the moment generating function (MGF) is given by
4. Entropy
4.1. Cumulative Entropy
Cumulative entropy serves as a measure for quantifying the uncertainty of a random variable. It is defined based on the CDF of the random variable X [18]. Then, the cumulative entropy is defined as:
By (1), the can be expressed as
Using the Taylor expansion, the cumulative entropy of the flexible Weibull weighted distribution is
Based on [14], it can be seen that
and
4.2. Cumulative Residual Entropy
Cumulative residual entropy [19,20] is a metric for measuring uncertainty in the time remaining until an event occurs. This concept considered the survival and hazard distributions and provides a better description of temporal unpredictability in events. The applications of cumulative residual entropy has been studied in various fields, including insurance and risk assessment [21]. For a random variable X, the cumulative residual entropy is given by
By using the equation above, the can be expanded as
Finally, based on [14], the can be expanded as
4.3. Rényi Entropy
For a random variable X, the Rényi entropy [22] is given by
Additional properties of Rényi entropy can be seen in [23]. Using (6), the term can be expressed as
where
Note that
Thus,
Based on Formula (3.471 9) of [16], can be simplified as
where
5. Estimation Methods
5.1. Maximum Likelihood Estimation Method
The parameters of the WFW distribution are estimated using the MLE method. Given a set of random samples, , following the WFW distribution, the likelihood function is derived. Using (2), the can be expressed as
By taking the natural logarithm, the log-likelihood function is obtained as
MLEs are numerically calculated using caret package [24] of R software [25].
5.2. Least Squares Estimation Method
The least squares estimation (LSE) approach seeks optimal model parameters to minimize the sum of the square difference between the observed data points and those predicted by the model. For a model defined by and parameters and a distribution F, the LSE method defines the objective function:
where are ordered samples from the data and represents the value of the hypothetical distribution at .
5.3. Weighted Least Squares Estimation
In the weighted LSE method, the objective function is
where represents the ordered samples from the data, and denotes the value of the hypothetical distribution at .
5.4. Cramer–Von Mises Estimator
The Cramer–von Mises estimator (CME) is defined as
where represents the ordered samples from the data, and denotes the value of the hypothetical distribution at .
5.5. Anderson–Darling Estimator
The Anderson–Darling estimator (ADE) and right-tailed Anderson–Darling estimator (RTADE) are respectively defined as
where . In these equations, represents the samples from the data, and denotes the value of the hypothetical distribution at . The estimation of each parameter can therefore be obtained when the first partial derivative of the log-likelihood function for each of the parameters is taken, equated to zero, and solved simultaneously. Note that the solution cannot be obtained in closed form, but it can be obtained by solving numerically using the R software [25].
6. Simulations
In the study of the estimation and comparison of different estimation methods, several simulations were conducted to compare the methods for estimating the parameters and of the WFW distribution with generating Monte Carlo replicates for the WFW model based on Equation (3) with sample sizes . The simulations were performed under the following parameter settings: and . To assess the accuracy of the estimation methods, the Bias and MSE were calculated using the following equations:
This section discusses the assessment of estimating the and parameters and concerning bias and root mean square error MSE values. Furthermore, the analysis of bias was conducted. The bias value reflects the estimation method accuracy by averaging the possible deviation of estimates from the true parameter value. The MSE was used as well. This value sums up variance and bias for a deep comparison, where a smaller value is considered as a more accurate estimator. It can be seen in Table 2 that, when sample size n increases, the size of the bias decreases for all methods, which shows an improvement in accuracy. In this table, ADE and RTADE methods have a better performance of estimation than other methods. Also, the MLE method is more biased in smaller samples, but reduces its bias as the sample size increases. In Table 3, the value of MSE in all methods indicates the improvement of estimates in large samples sizes, where the RTADE method has the lowest values of MSE compared to other methods. Also, the MLE and CME methods have higher MSE in small samples, but both improve with increasing sample size. Based on the results, it is suggested to use ADE and RTADE methods to estimate model parameters, because in many cases these methods have lower bias and MSE values than other methods. Also, in small samples, WLSE can be a suitable option. The performance of the MLE method can improved with larger sample size.
Table 2.
Bias and RMSE of and for different sample sizes n.
Table 3.
MSE and Bias for and with n samples.
7. Risk Indicators
7.1. The Mean of Order P and Optimal Order of P
The analysis [26], formally defined by [27], is used to characterize the central tendency or average behavior of a dataset based on different orders of moments. The is calculated by raising each data point to the power of P (a positive integer) and then taking the average of these values. The optimal order of P in analysis refers to determining the most suitable value of P that provides meaningful insights into the dataset’s characteristics or distribution. The choice of P can influence the sensitivity of the analysis to different aspects of the dataset. This is usually done by calculating for different p values (e.g., ) to examine how much influence the dataset has on different moments.
7.2. The PORT-VaR Estimator
The PORT-VaR estimator is a statistical method used for risk analysis and extreme value modeling. This method is particularly useful for identifying and analyzing extreme events or peaks in a dataset that exceed a specified threshold, which is often determined based on a certain level of confidence or risk tolerance. The PORT-VaR estimator calculates the value-at-risk (VaR) associated with the chosen threshold. VaR represents the maximum potential loss that could occur within a given confidence interval (e.g., 95% or 99%) under normal market conditions. The PORT-VaR estimator is widely used in modeling and analyzing rare events or outliers, which may have significant implications for risk assessment and mitigation strategies. It helps in understanding the probability and severity of extreme events, thereby enabling organizations to prepare and respond effectively to potential risks; see [28] for more details.
The necessary steps to obtain the PORT-VaR estimator are as follows:
- Gather relevant data that capture extreme events or rare occurrences. Clean and preprocess the data to ensure quality and suitability for analysis.
- Choose an appropriate statistical model.
- Select a threshold above which extreme events are considered for analysis. This threshold is crucial and should be based on domain expertise and risk management goals.
- Identify all data points that exceed the chosen threshold to form the PORT subset.
- Estimate the VaR for each peak in the PORT subset, where VaR represents the maximum expected loss at a specified confidence level based on extreme value modeling.
- Analyze the distribution of PORT-VaR estimates to quantify the tail risk associated with extreme events. Assess the impact of these events on overall risk exposure.
- Utilize PORT-VaR results to inform risk management strategies, such as setting reserves, determining insurance premiums, or implementing risk mitigation measures.
8. Applications
This section presents and evaluates three different applications of the proposed model. Each application demonstrates the model’s effectiveness in capturing the underlying patterns within the data. Furthermore, we assess its performance by comparing it against other well-established distributions, highlighting its advantages and potential limitations in various scenarios. Through this comparative analysis, we aim to provide a comprehensive understanding of the model’s strengths and its applicability across different datasets, such as the exponentiated Weibull (EW) [29], modified Weibull (MW) [30], beta Weibull (BW) [3], gamma flexible Weibull (GFW) [31], and Kumaraswamy Burr XII (KwBXII) [32]. The best-fitting model is identified based on the Cramer–von Mises statistic (), Anderson–Darling statistic (), Akaike information criterion (AIC), consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC), and Hannan–Quinn information criterion (HQIC). The MLEs, standard errors (SEs), and relevant statistics are computed using the AdequacyModel package [33] in R software [25].
8.1. Failure Times Dataset
The failure times of 50 components (measured per 1000 h) are given in [34], as follows: 0.036, 0.058, 0.061, 0.074, 0.078, 0.086, 0.102, 0.103, 0.114, 0.116, 0.148, 0.183, 0.192, 0.254, 0.262, 0.379, 0.381, 0.538, 0.570, 0.574, 0.590, 0.618, 0.645, 0.961, 1.228, 1.600, 2.006, 2.054, 2.804, 3.058, 3.076, 3.147, 3.625, 3.704, 3.931, 4.073, 4.393, 4.534, 4.893, 6.274, 6.816, 7.896, 7.904, 8.022, 9.337, 10.940, 11.020, 13.880, 14.730, 15.080. These failure time datasets are used to analyze the failure behavior of components, fit probabilistic models for reliability analysis, and predict the lifespan of components. Table 4 shows the MLEs and their respective standard errors (SEs) for the parameters of different models fitted to the failure time data. From this table, parameter estimates from the WFW model are shown to have relatively small standard error estimates, indicating a good fit for the model to the actual data. On the other hand, estimates from models like MW, EW, and BW result in higher standard errors, suggesting a potential compromise in parameter estimation accuracy. More goodness-of-fit statistics (the measurements are considered test statistics, both and ) and model selection criteria (AIC, CAIC, BIC, and HQIC) are summarized in Table 5. Smaller values for these metrics are reflective of a better model fit. As can be seen, the WFW model has the lowest results on all criteria, proving its superiority over competing models. In particular, the value of AIC is equal to 192.294 in the WFW model, and this value is lower than that of the other models, demonstrating that the WFW model is more accurate in generalizing the data. The WWF model aligns the closest with the blue circles (empirical distribution), supporting the goodness of the WFW model in terms of fitting to the real failure time data. Thus, the results of this study support the ability of the WFW model to adequately analyze and predict actual real failure time data.
Table 4.
MLEs and their respective SEs of fitted models for failure time dataset.
Table 5.
Evaluation metrics for the models applied to failure time dataset.
8.2. COVID-19 Mortality Dataset
The dataset includes the number of COVID-19 deaths recorded across 83 counties in Illinois, United States, up to December 2021. The reported number of deaths are as follows: 169, 13, 28, 91, 13, 107, 4, 41, 31, 89, 46, 57, 108, 146, 35, 30, 32, 156, 38, 52, 21, 113, 73, 59, 130, 93, 10, 40, 101, 25, 36, 16, 15, 95, 90, 101, 21, 150, 57, 32, 34, 127, 184, 38, 69, 115, 78, 121, 165, 24, 53, 58, 72, 15, 38, 108, 85, 104, 39, 110, 82, 16, 58, 7, 15, 7, 107, 67, 74, 14, 8, 56, 29, 124, 52, 19, 72, 30, 66, 34, 196, 201, 98. This dataset can be found at: https://data.world/associatedpress/johns-hopkins-coronavirus-case-tracker (accessed on 16 February 2025).
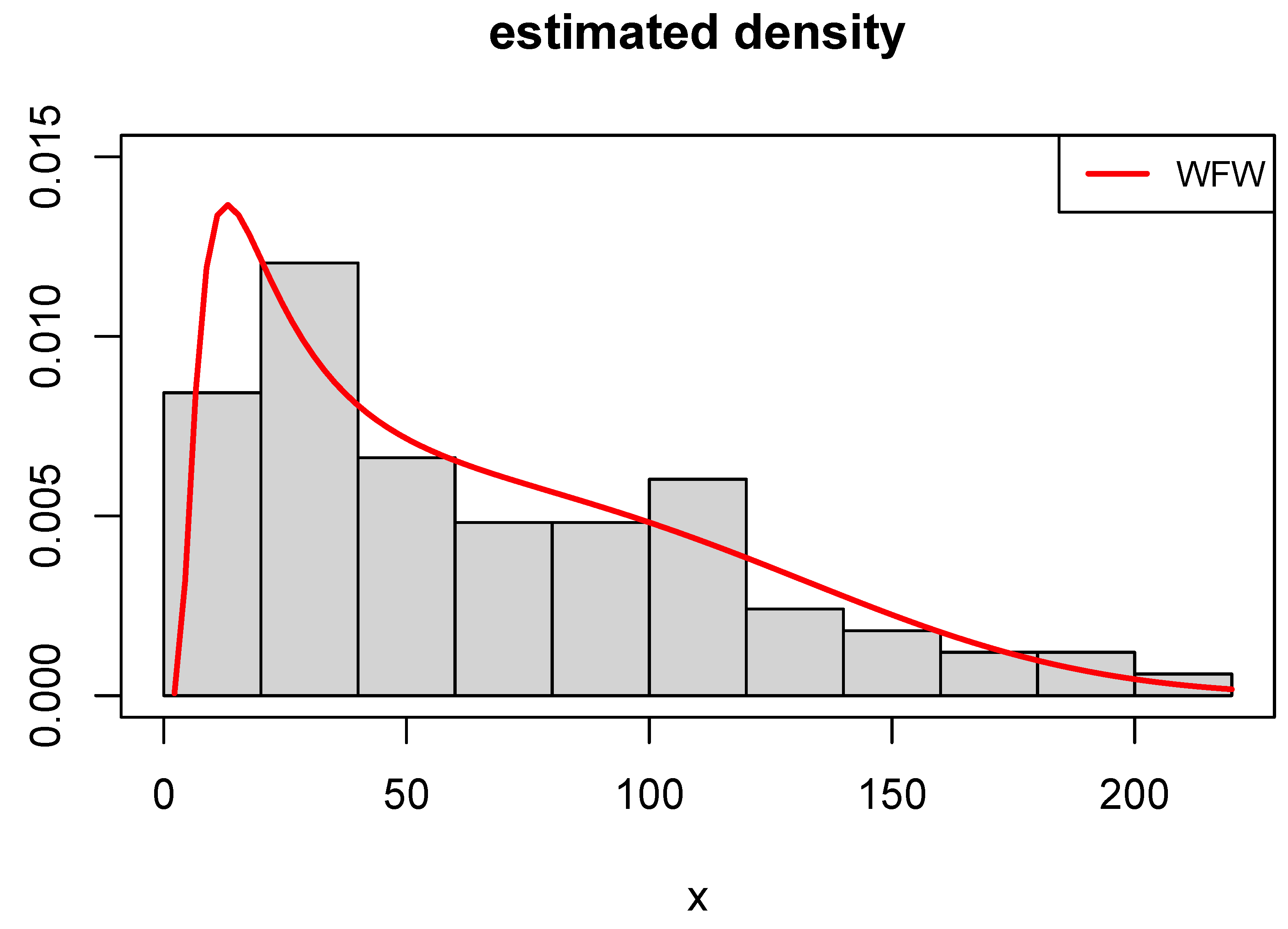
The obtained results regarding MLEs and their associated SEs are presented in Table 6. The results indicate that the WFW, GFW, and FW models yield precise parameter estimates with relatively low SEs, while other models exhibit higher SEs. Table 7 reports the values of various model selection criteria, showing that the WFW model consistently achieves the lowest values. Consequently, it is identified as the most suitable model for the data. Figure 3 illustrates the estimated density functions for the top-performing models. Among them, the WFW model demonstrates the closest agreement with the empirical histogram, underscoring its suitability for modeling the observed data.
Table 6.
Findings from the fitted models to COVID-19 mortality dataset.
Table 7.
Adequacy measures for the fitted models for COVID-19 mortality dataset.
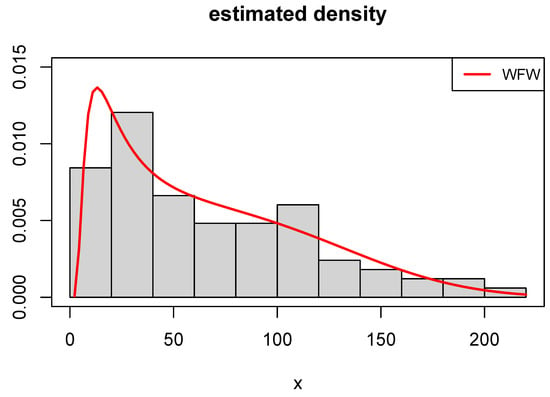
Figure 3.
Fitted WFW density to COVID-19 mortality dataset.
8.3. COVID-19 Times Dataset
The dataset of reported COVID-19 cases, introduced by [35], comprises 30 recorded observations representing the spread of the disease over a specific time interval. These observations offer valuable insights into infection trends and patterns, facilitating a thorough analysis of the disease’s progression and predictive modeling. These observations are as follows: 14.918, 10.656, 12.274, 10.289, 10.832, 7.099, 5.928, 13.211, 7.968, 7.584, 5.555, 6.027, 4.097, 3.611, 4.960, 7.498, 6.940, 5.307, 5.048, 2.857, 2.254, 5.431, 4.462, 3.883, 3.461, 3.647, 1.974, 1.273, 1.416, and 4.235. For more details, see [35]. This dataset requires appropriate statistical modeling techniques to capture their underlying patterns effectively. Therefore, to evaluate the ability of various distribution models to describe the observed trends, different statistical models are fitted to the dataset (see Table 8). The fitting results are presented in the following sections. Based on the low values of AIC, BIC, and HQIC, the WFW model emerges as the best option for describing this dataset (see Table 9). The FW and EW models also demonstrate a good performance, while the KwW model provides the weakest fit. Therefore, the WFW model is recommended for analyzing the COVID-19 times dataset.
Table 8.
Estimates of the fitted models for COVID-19 times data.
Table 9.
Adequacy measures for of the fitted models for COVID-19 times dataset.
9. Assessments and Risk Analysis Under Real Data
The PORT-VaR estimator helps in identifying and analyzing extreme events or outliers in COVID-19 data. Peaks over a specified VaR threshold may represent unusual or critical situations, such as sudden spikes in infection rates, hospitalizations, or other medical metrics related to COVID-19 [13,36,37]. Below, three subsections are presented: the first focuses on assessments and the optimal order of P based on the true mean value (TMV), the second examines the PORT-VaR estimator under failure time data, and the third explores the PORT-VaR estimator in the context of medical data.
9.1. Assessments and Optimal Order of P
Following [27], selecting the optimal order of P is crucial for assessments, as it balances capturing sufficient detail in risk profiles with avoiding overfitting or excessive complexity. Empirical and statistical analyses are employed to determine the ideal P, ensuring accurate representation of the underlying risk distribution. This process enhances robust risk evaluation and decision-making. Statistical tools like distributions enable quantitative risk assessment, hazard identification, and effective mitigation strategies, empowering stakeholders to allocate resources efficiently and build resilience against uncertainties. Table 10 provides the assessment, including the TMV, MSE, and Bias under , and some different parameter values. Based on the results presented in Table 10 (the first scenario) for assessments under different orders () and with specific parameter values () and a dataset size of , it is seen that the TMVs for across all orders () remain stable around 1.001314, confirming a consistent estimate of the dataset’s true mean. The identical MSE values (0.9983274) indicate that prediction errors remain constant across different P orders, reflecting moderate deviation from the TMV. Similarly, the consistent bias values (0.9991634) suggest a systematic underestimation of the TMV. The stability of TMV, MSE, and bias across varying P orders highlights the robustness of , ensuring reliable mean estimation and prediction accuracy despite changes in model parameters and dataset size. Based on the results presented in Table 10 for the second scenario, assessments are conducted under different orders () with specific parameter values () and a dataset size of . The TMVs for across all orders remain stable at approximately 0.9973669, confirming consistent mean estimation. Additionally, identical MSE values (0.9947407) indicate a uniform level of prediction error across different P orders. Similarly, the bias values (0.9973669) consistently show a slight underestimation of the TMV. The stability of TMV, MSE, and bias across varying P orders highlights the robustness of , ensuring reliable mean estimation with predictable error levels regardless of parameter settings and dataset size. Across all parameter combinations and orders of P, the TMV estimates derived from assessments remain relatively stable and close to the expected value, indicating the robustness of the method in estimating central tendencies within the dataset, with means stability of the TMV. The MSE and bias values also exhibit consistency across different orders of P and parameter settings. This suggests that while there is a predictable level of MSE and bias in the estimates, these metrics remain relatively invariant to changes in the order of P and specific parameter values, which means a consistent MSE and consistent bias. The consistent performance of across varied conditions underscores its reliability as a statistical tool for risk analysis. Despite potential variations in dataset characteristics or model parameters, consistently provides estimates that capture meaningful aspects of risk distributions.
Table 10.
assessment under and .
9.2. VaR, TVaR and PORT-VaR Estimators for Extreme Failure Times
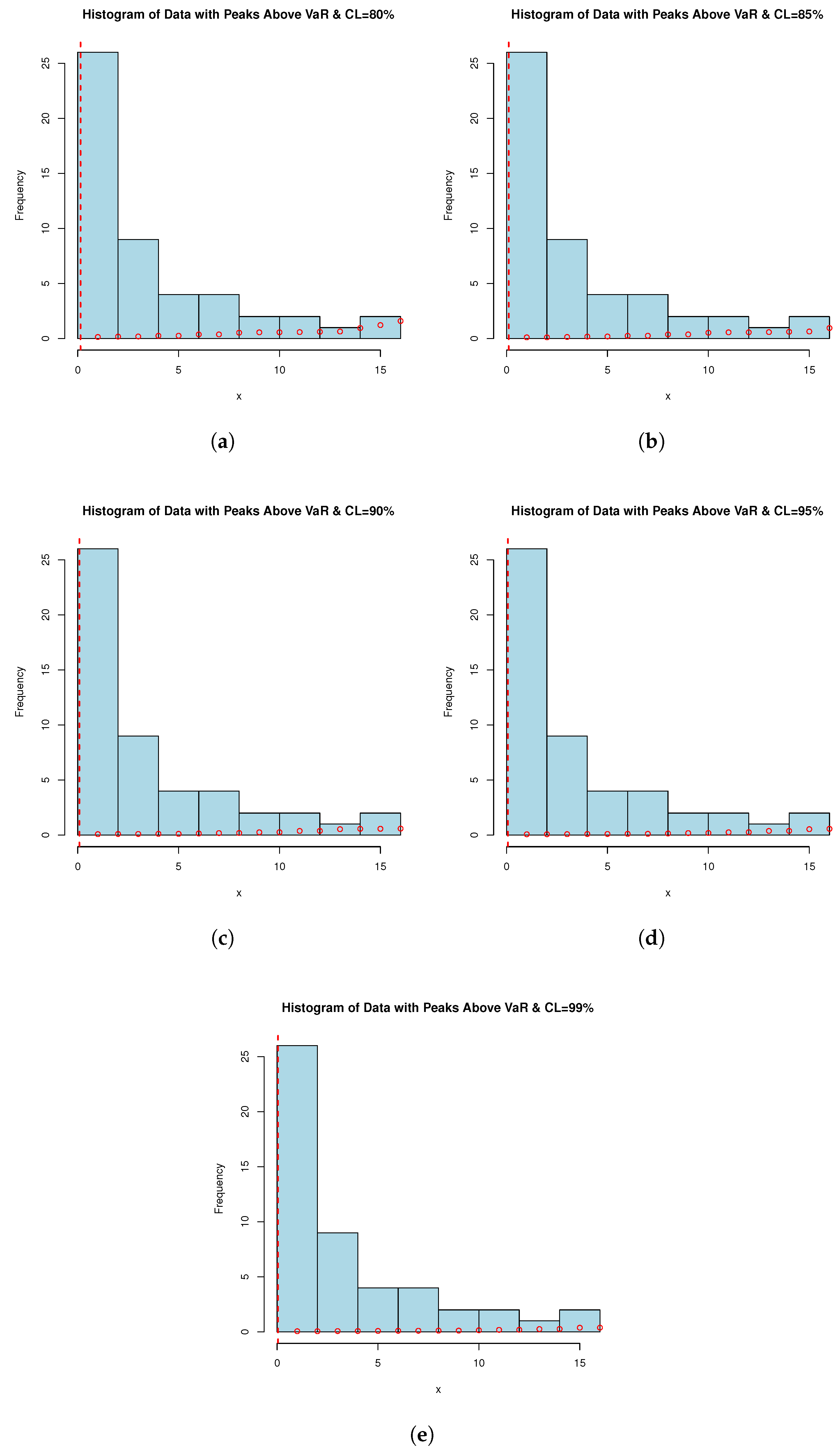
Failure time datasets often represent the occurrence of critical events such as equipment failures, system breakdowns, or component malfunctions. By applying the PORT-VaR estimator, analysts can identify and quantify extreme failure events that exceed a specified risk threshold. This information is crucial for understanding the reliability profile of systems or components. PORT-VaR analysis allows for a deeper assessment of the risk and uncertainty associated with failure times. By setting a threshold based on the desired confidence level (e.g., 95% or 99%), researchers can evaluate the probability of experiencing extreme failures beyond this threshold. This insight helps in assessing the overall risk exposure and potential consequences of critical failures. In this subsection, the PORT-VaR analysis is presented under failure times data. A summary of the analysis results obtained at different confidence levels (CLs: 80%, 85%, 90%, 95%, and 99%) is presented in Table 11. The trend shows that, as CL increases, the inferences of PORT volume decreases. This trend characterizes a shift towards a safer risk assessment method, one that relies on a higher range to incorporate only the most extreme data present in the sample. This relationship is critical for risk tolerance measurement and risk management design when risk exposure is acceptable. Also, Figure 4 shows the PORT-VaR analysis for extreme failure times. Based on Table 11, as the CL increases, the number of identified PORTs generally decreases, reflecting stricter risk thresholds. Lower CLs (e.g., 80% and 85%) yield higher extreme event counts, indicating a greater prevalence of significant failure time events relative to the VaR threshold. The statistical distribution (Min, Median, Mean, Max) highlights variability in severity and frequency, offering key insights into the risk profile of failure times. These findings inform risk assessment and response strategies, helping identify areas requiring targeted interventions and resource allocation to mitigate elevated mortality risks. Understanding the distribution of extreme failure events across CLs aids in quantifying risk exposure, prioritizing mitigation efforts, and optimizing reliability and maintenance practices. Decision-makers can leverage these insights to allocate resources efficiently, implement targeted interventions, and enhance system resilience against extreme failures. Notably, as CL increases, the number of PORTs rises monotonically, while VaR and TVaR decrease, indicating that more extreme failure events are captured at higher CLs, though their severity declines over time. Managing risk based on VaR alone suggests that an 80–85% CL may be overly conservative, while 99% could underestimate extreme failure impacts. A balanced choice (e.g., 90–95%) might be optimal. However, at 99% CL, the number of exceedances doubles, meaning organizations must prepare for more frequent small-to-moderate failures rather than rare, catastrophic events.
Table 11.
PORT-VaR analysis for extreme failure times.
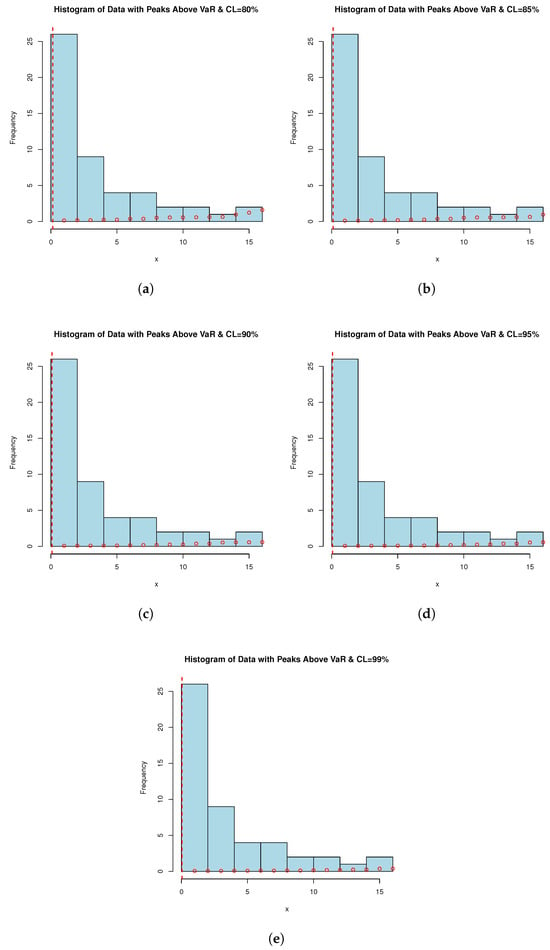
Figure 4.
PORT-VaR analysis for extreme failure times. Each histogram is related to a confidence level (CL) of (a) 80%, (b) 85%, (c) 90%, (d) 95%, and (e) 99%.
9.3. VaR, TVaR, and PORT-VaR Estimators for Extreme COVID-19 Deaths
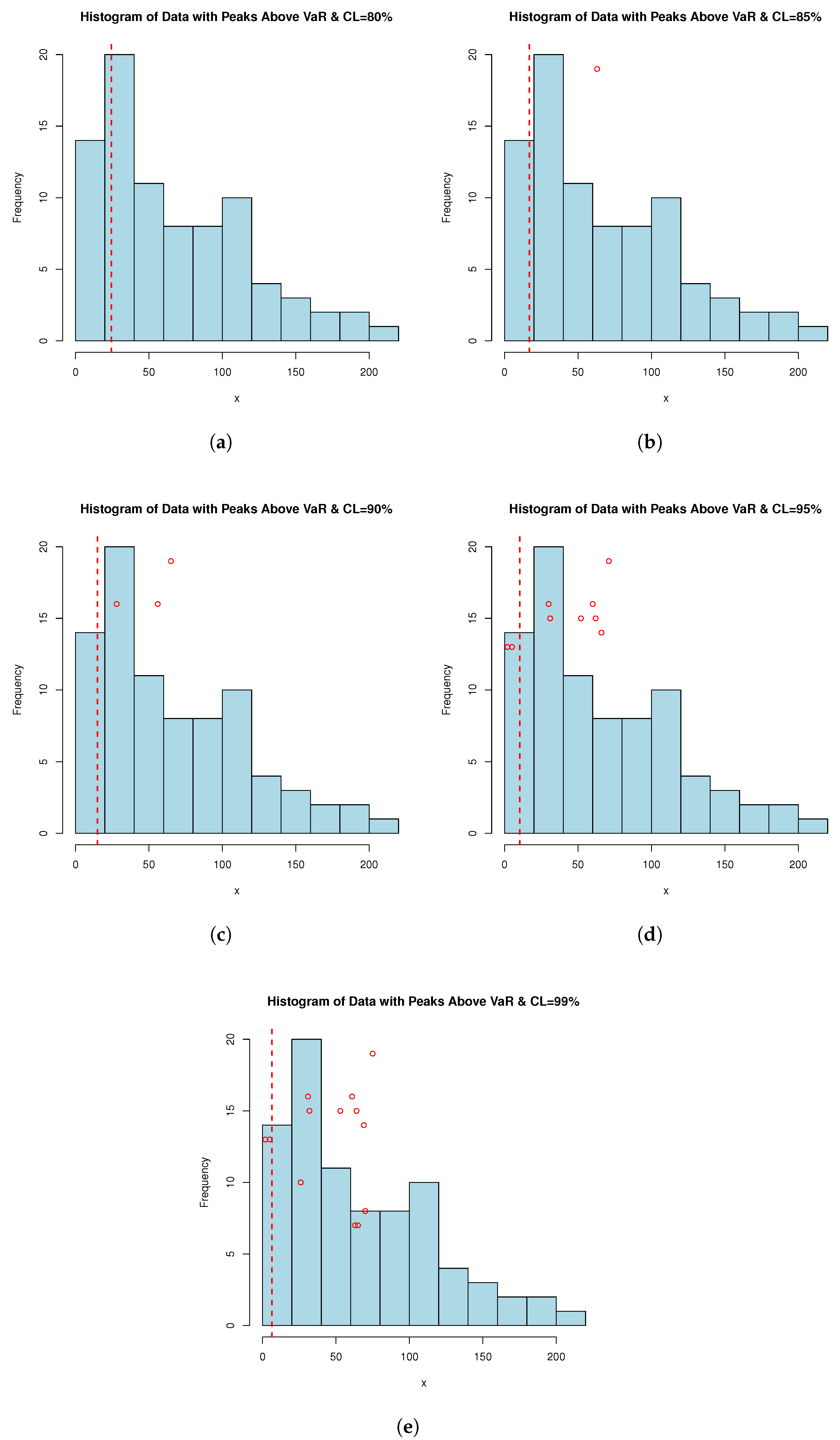
Analyzing PORT-VaR can aid in optimizing resource allocation within the medical sector. Identification of peaks over the VaR threshold allows for the focused allocation of healthcare resources, such as medical supplies, personnel, and hospital beds, to areas experiencing the highest levels of risk or demand during the pandemic. Insights from the PORT-VaR estimator can enhance decision-making processes and preparedness efforts. Healthcare facilities and public health authorities can use this information to develop robust contingency plans, allocate budgets effectively, and implement targeted interventions to address the emerging challenges highlighted by the peaks in COVID-19 data; for more applications, see [38,39]. According to [28], effective public health responses rely on timely and accurate data analysis. The PORT-VaR approach offers a quantitative framework to monitor and respond to evolving COVID-19 trends. It enables proactive measures to contain outbreaks, implement targeted vaccination campaigns, and mitigate the impact of unforeseen events. PORT-VaR analysis contributes to evidence-based research and policy development in the medical sector. Insights gained from studying peaks over the VaR threshold can inform the design of public health policies, clinical guidelines, and research priorities aimed at combating the COVID-19 pandemic. For this purpose, Table 12 is presented; it provides the PORT-VaR analysis under COVID-19 data. Table 12 provides valuable insights into the distribution and characteristics of extreme events (PORTs), identified using the VaR estimator under different confidence levels. These findings have practical implications for risk assessment, decision-making, and resource allocation in the context of COVID-19 dataset analysis and pandemic response efforts, where minimum (Min.) refers to the smallest PORT value observed above the VaR threshold and maximum (Max.) refers to the largest PORT value observed above the VaR threshold. However, the mean column refers to the average value of the PORT distribution, indicating the central tendency of extreme events. Finally, median refers to the middle value of the PORT distribution, separating the higher and lower halves of the data. Moreover, Figure 5 shows the PORT-VaR analysis for extreme COVID-19 deaths.
Table 12.
PORT-VaR analysis for extreme COVID-19 deaths.
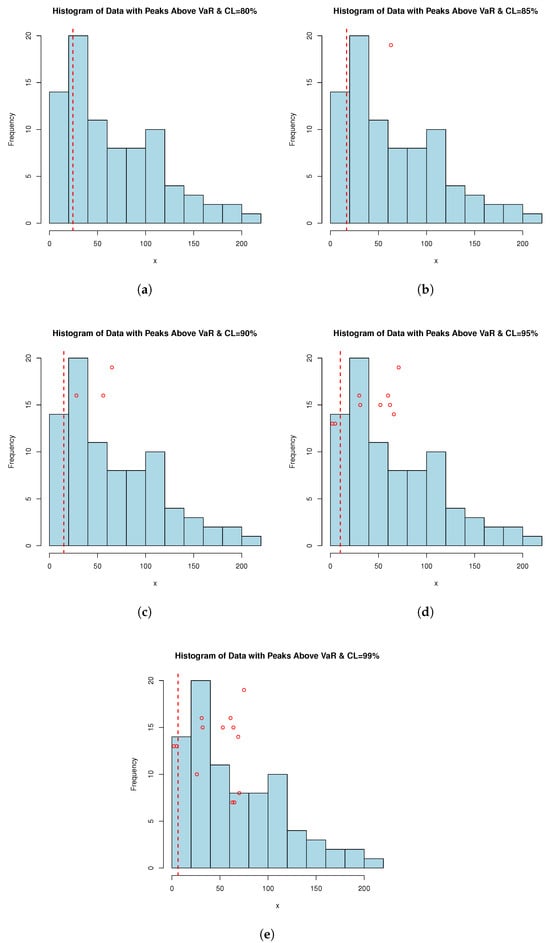
Figure 5.
PORT-VaR analysis for extreme COVID-19 deaths. Each histogram is related to a confidence level (CL) of (a) 80%, (b) 85%, (c) 90%, (d) 95%, and (e) 99%.
Table 12 presents the PORT-VaR analysis for COVID-19 data, where the PORT column indicates the count of extreme events exceeding the VaR threshold at different CLs. As CL increases, fewer extreme events are detected, reflecting stricter risk thresholds, while lower CLs (e.g., 80% and 85%) capture more frequent extreme events. Descriptive statistics of PORT values (Min., Median, Mean, Max.) highlight the severity and frequency of extreme cases. The analysis underscores the sensitivity of risk assessment to CL variations, aiding in resource allocation and pandemic response planning. Notably, as CL rises, PORT counts increase while VaR and TVaR decrease, suggesting that higher thresholds capture more extreme cases but reduce individual severity estimates. A CL of 90–95% may offer a balanced approach for policymakers, avoiding overly conservative or lenient risk assessments.
10. Conclusions and Limitations
This study introduces the weighted flexible Weibull distribution, and its main properties, including cumulative and residual cumulative entropy, are explored. A simulation study confirms the consistency of the MLEs for parameter estimation. Applications to real-world data, including failure times and COVID-19 datasets, demonstrate the model’s good competitive performance against other lifetime distributions. Additionally, peaks over a random threshold value-at-risk (PORT-VaR) estimators are developed for risk analysis in engineering and medicine. These estimators mark a significant advancement in quantitative risk assessment, offering tailored solutions for diverse challenges. The findings highlight the importance of PORT-VaR analysis in various fields, including public health and engineering, contributing to improved risk management strategies.
Future research could integrate advanced statistical techniques and predictive modeling to enhance the accuracy and robustness of PORT-VaR assessments. Comparative studies across different datasets and contexts could further refine their applicability for risk mitigation and decision-making in complex systems. The PORT-VaR analysis provides valuable insights for interdisciplinary risk analysis, addressing contemporary challenges across multiple domains. This study introduces several novel aspects of actuarial risk assessment, expanding beyond a review of existing concepts. It pioneers the use of weighted distributions in actuarial risk modeling, addressing a critical research gap and offering a fresh perspective on risk evaluation. Actuarial risk metrics are applied beyond traditional financial contexts to medical data, particularly in assessing COVID-19 risk and managing datasets with extreme values, highlighting the adaptability of actuarial methods across diverse fields. Additionally, a new estimation technique and a sequential sampling plan based on truncated life testing are introduced, enhancing the precision and efficiency of risk assessment models. Furthermore, the discussion on PORT-VaR has been expanded, offering a more detailed analysis of its significance and applicability in modern risk assessment scenarios. These contributions advance actuarial risk modeling methodologies and reinforce their relevance across multiple disciplines, supporting more robust and informed decision-making in risk management. The PORT-VaR analysis for COVID-19 data highlights the impact of CLs on risk assessment, with higher CLs detecting fewer extreme events due to stricter thresholds, while lower CLs capture more frequent occurrences. Descriptive statistics of PORT values provide insights into the severity and distribution of extreme cases, emphasizing the importance of selecting appropriate CLs for effective risk evaluation. The observed trend of increasing PORT counts alongside decreasing VaR and TVaR at higher CLs suggests that broader thresholds identify more extreme cases while moderating individual severity estimates. A CL range emerges as a balanced choice for policymakers, ensuring a comprehensive yet practical approach to pandemic response and resource allocation.
While this study introduces significant advancements in actuarial risk modeling and PORT-VaR analysis, several limitations should be acknowledged. First, the proposed weighted flexible Weibull distribution, though competitive, has been evaluated on a limited number of datasets. This model can be applied to broader real-world applications, including different domains and larger datasets, requires further validation. Second, the PORT-VaR estimators were developed and tested within specific contexts, such as engineering and medical risk analysis, but their performance in other industries remains unexplored. Additionally, the study assumes that extreme events follow particular statistical patterns, which may not always hold true in highly dynamic or unpredictable environments. Another limitation is that the study primarily relies on historical data, which may not fully account for evolving risk factors, policy changes, or unexpected future developments. While simulation studies confirm the consistency of estimation methods, real-world uncertainties could introduce biases or deviations not captured in the models. Finally, the selection of confidence levels (CLs) in PORT-VaR analysis is based on statistical reasoning and practical considerations, but the optimal choice may vary depending on specific risk tolerance levels and decision-making frameworks. Future works should address these limitations by expanding the application of the proposed methods to diverse datasets, exploring adaptive modeling approaches for evolving risks and refining PORT-VaR techniques to enhance robustness across various domains.
Author Contributions
Conceptualization, Z.R., M.A. (Morad Alizadeh), S.T. and M.A. (Mahmoud Afshari); methodology, Z.R., M.A. (Morad Alizadeh), M.A. (Mahmoud Afshari), S.T. and H.M.Y.; software, Z.R. and H.M.Y.; validation, J.E.C.-R. and H.M.Y.; formal analysis, Z.R., M.A. (Morad Alizadeh), M.A. (Mahmoud Afshari) and H.M.Y.; investigation, M.A. (Morad Alizadeh), M.A. (Mahmoud Afshari) and H.M.Y.; resources, J.E.C.-R., M.A. (Morad Alizadeh) and H.M.Y.; data curation, Z.R., M.A. (Mahmoud Afshari) and H.M.Y.; writing—original draft preparation, Z.R., M.A. (Morad Alizadeh), M.A. (Mahmoud Afshari) and H.M.Y.; writing—review and editing, J.E.C.-R. and H.M.Y.; visualization, Z.R. and H.M.Y.; supervision, J.E.C.-R. and H.M.Y.; project administration, M.A. (Morad Alizadeh); funding acquisition, J.E.C.-R., M.A. (Morad Alizadeh) and H.M.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Acknowledgments
The authors thank the editor and two anonymous referees for their helpful comments and suggestions.
Conflicts of Interest
The authors declare that they have no known conflicting/competing interests that could have appeared to influence the work reported in this paper.
References
- Chen, Y.S.; Lai, S.B.; Wen, C.T. The influence of green innovation performance on corporate advantage in Taiwan. J. Bus. Ethics 2006, 67, 331–339. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- Famoye, F.; Lee, C.; Olumolade, O. The beta-Weibull distribution. J. Stat. Appl. 2005, 4, 121–136. [Google Scholar]
- Xie, M.; Tang, Y.; Goh, T.N. A modified Weibull extension with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 2002, 76, 279–285. [Google Scholar] [CrossRef]
- Xie, M.; Lai, C.D. Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 1996, 52, 87–93. [Google Scholar] [CrossRef]
- Mustafa, A.; El-Desouky, B.S.; AL-Garash, S. The Marshall-Olkin Flexible Weibull Extension Distribution. arXiv 2016, arXiv:1609.08997. [Google Scholar]
- Bebbington, M.; Lai, C.D.; Zitikis, R. A flexible Weibull extension. Reliab. Syst. Saf. 2007, 92, 719–726. [Google Scholar] [CrossRef]
- Mustafa, A.; El-Desouky, B.S.; Al-Garash, S. The exponentiated generalized flexible Weibull extension distribution. Fundam. J. Math. Math. Sci. 2016, 6, 75–98. [Google Scholar]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Zekri, A.R.N.; Youssef, A.S.E.D.; El-Desouky, E.D.; Ahmed, O.S.; Lotfy, M.M.; Nassar, A.A.M.; Bahnassey, A.A. Serum microRNA panels as potential biomarkers for early detection of hepatocellular carcinoma on top of HCV infection. Tumor Biol. 2016, 37, 12273–12286. [Google Scholar] [CrossRef]
- Alizadeh, M.; Afshari, M.; Cordeiro, G.M.; Ramaki, Z.; Contreras-Reyes, J.E.; Dirnik, F.; Yousof, H.M. A Weighted Lindley Claims Model with Applications to Extreme Historical Insurance Claims. Stats 2025, 8, 8. [Google Scholar] [CrossRef]
- Kharazmi, O.; Contreras-Reyes, J.E.; Balakrishnan, N. Optimal information, Jensen-RIG function and α-Onicescu’s correlation coefficient in terms of information generating functions. Phys. A 2023, 609, 128362. [Google Scholar] [CrossRef]
- Kuschel, K.; Carrasco, R.; Idrovo-Aguirre, B.J.; Duran, C.; Contreras-Reyes, J.E. Preparing Cities for Future Pandemics: Unraveling the influence of urban and housing variables on COVID-19 incidence in Santiago de Chile. Healthcare 2023, 11, 2259. [Google Scholar] [CrossRef] [PubMed]
- Zwillinger, D. Table of Integrals, Series, and Products; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Ferreira, A.A.; Cordeiro, G.M. The gamma flexible Weibull distribution: Properties and Applications. Span. J. Stat. 2023, 4, 55–71. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Chaudhry, M.A.; Zubair, S.M. Generalized incomplete gamma functions with applications. J. Comput. Appl. Math. 1994, 55, 99–124. [Google Scholar] [CrossRef]
- Di Crescenzo, A.; Longobardi, M. On cumulative entropies. J. Stat. Inference 2009, 139, 4072–4087. [Google Scholar] [CrossRef]
- Kharazmi, O.; Contreras-Reyes, J.E. Fractional cumulative residual inaccuracy information measure and its extensions with application to chaotic maps. Int. J. Bifurc. Chaos 2024, 34, 2450006. [Google Scholar] [CrossRef]
- Kharazmi, O.; Yalcin, F.; Contreras-Reyes, J.E. Cumulative residual Fisher information based on finite and infinite mixture models. Fluct. Noise Lett. 2025. [Google Scholar] [CrossRef]
- Psarrakos, G.; Toomaj, A. On the generalized cumulative residual entropy with applications in actuarial science. J. Comput. Appl. Math. 2017, 309, 186–199. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; University of California Press: Berkeley, CA, USA, 1961; Volume 4, pp. 547–562. [Google Scholar]
- Contreras-Reyes, J.E. Mutual information matrix based on Rényi entropy and application. Nonlinear Dyn. 2022, 110, 623–633. [Google Scholar] [CrossRef]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, R.C. Package ‘caret’. R J. 2020, 223, 48. [Google Scholar]
- R Core Team. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: http://www.R-project.org (accessed on 17 February 2025).
- Alizadeh, M.; Afshari, M.; Contreras-Reyes, J.E.; Mazarei, D.; Yousof, H.M. The Extended Gompertz Model: Applications, Mean of Order P Assessment and Statistical Threshold Risk Analysis Based on Extreme Stresses Data. IEEE Trans. Reliab. 2024. [Google Scholar] [CrossRef]
- Rice, J.A. Mathematical Statistics and Data Analysis; Thomson/Brooks/Cole: Belmont, CA, USA, 2007; Volume 371. [Google Scholar]
- Szubzda, F.; Chlebus, M. Comparison of Block Maxima and Peaks Over Threshold Value-at-Risk models for market risk in various economic conditions. Cent. Econ. J. 2019, 6, 70–85. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Lai, C.D.; Xie, M.; Murthy, D.N.P. A modified Weibull distribution. IEEE Trans. Reliab. 2003, 52, 33–37. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Vasconcelos, J.C.S.; dos Santos, D.P.; Ortega, E.M.; Sermarini, R.A. Three mixed-effects regression models using an extended Weibull with applications on games in differential and integral calculus. Braz. J. Probability Stat. 2022, 36, 751–770. [Google Scholar] [CrossRef]
- Paranaíba, P.F.; Ortega, E.M.; Cordeiro, G.M.; Pascoa, M.A.D. The Kumaraswamy Burr XII distribution: Theory and practice. J. Stat. Comput. Simul. 2013, 83, 2117–2143. [Google Scholar] [CrossRef]
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef]
- Murthy, D.P.; Xie, M.; Jiang, R. Weibull Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Ahmad, Z.; Almaspoor, Z.; Khan, F.; El-Morshedy, M. On predictive modeling using a new flexible Weibull distribution and machine learning approach: Analyzing the COVID-19 data. Mathematics 2022, 10, 1792. [Google Scholar] [CrossRef]
- Brown, A.; Williams, R. Equity implications of ride-hail travel during COVID-19 in California. Transp. Res. Rec. 2023, 2677, 1–14. [Google Scholar] [CrossRef]
- Mohamed, H.S.; Cordeiro, G.M.; Minkah, R.; Yousof, H.M.; Ibrahim, M. A size-of-loss model for the negatively skewed insurance claims data: Applications, risk analysis using different methods and statistical forecasting. J. Appl. Stat. 2024, 51, 348–369. [Google Scholar] [CrossRef] [PubMed]
- Golinelli, D.; Boetto, E.; Carullo, G.; Nuzzolese, A.G.; Landini, M.P.; Fantini, M.P. Adoption of digital technologies in health care during the COVID-19 pandemic: Systematic review of early scientific literature. J. Medical Internet Res. 2020, 22, e22280. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, E.B.; Souissi, M.N.; Baccar, A.; Bouri, A. CEO’s personal characteristics, ownership and investment cash flow sensitivity: Evidence from NYSE panel data firms. J. Econ. Financ. Adm. Sci. 2014, 19, 98–103. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).