Abstract
Regression models in which the response variable has a compound distribution have applications in actuarial science. For example, the aggregate claim amount in a vehicle insurance portfolio can be modeled using a compound Poisson distribution. In this paper, we propose a regression model, wherein the response variable is assumed to have a compound Conway–Maxwell–Poisson (CMP) distribution. This distribution is a parsimonious two-parameter Poisson distribution that accounts for both over- and under-dispersed count data, making it more suitable for application in various fields. A two-part methodology in the framework of a generalized linear model is proposed to estimate the parameters. Additionally, a method to obtain the prediction interval of the response variable is developed. The workings of the proposed methodology are illustrated through simulated data. An application of the compound CMP regression model to real-life vehicle insurance claims data is presented.
1. Introduction
Compound regression models have applications in various research fields, including economics and finance. In economic consumer theory, for example, compound Poisson regression models are often used to examine the factors that account for the expenditures incurred by tourists during their stay at a location. The factors may include length of stay, type of holiday accommodations, age, occupation, socio-economic status of the tourist, etc. See Gómez-Déniz and Pérez-Rodríguez [1]. In actuarial risk theory, the aggregate claim amount incurred by the insurance company against the claims made by the policyholders is modeled using compound models. See Klugman et al. [2] and Bahnemann [3] for a detailed discussion on compound models, their distributional properties and applications in insurance claim modeling. Jørgensen and Paes De Souza [4] applied the compound Poisson regression model to determine the impact on the conditional mean of the aggregate claim amount caused by factors such as age and model of the vehicle, exposure, deductibles, etc., in the context of car insurance. In this paper, we propose a compound regression model using a two-parameter Poisson distribution. On this topic, some mathematical backgrounds are presented below in order to fix the notations. Let
denote the random sum, where the distributions of the random variables N and are assumed to be discrete and continuous, respectively. Moreover, s are assumed to be independent and identically distributed. Therefore, in the sequel, we refer to s as Y. Further, N and Y in general are assumed to be independent. The above-mentioned S is a compound random variable. Suppose represents the claim amounts on an insurance portfolio, N denotes the number of claims made, then S represents the aggregate claim amount. When N has a Poisson distribution, the distribution of S is known as the compound Poisson distribution. Though the Poisson distribution is often used in constructing compound distributions, it is not suitable for modeling over- or under-dispersed count data. As an alternative to the Poisson distribution, one can use a generalized Poisson distribution (Consul and Jain [5]) to model count data that are either over- or under-dispersed. Recently, Shmueli et al. [6] studied a two-parameter Poisson distribution developed by Conway and Maxwell [7] known as the Conway–Maxwell–Poisson (CMP) distribution. This is a two-parameter flexible generalization of the Poisson distribution that can model both over- and under-dispersed data and has the feature to include the Poisson, geometric and Bernoulli distributions as special cases. A detailed discussion on the properties of this distribution and its applications can be found in Sellers et al. [8]. Also, Sellers and Premeaux [9] contains a detailed review on CMP regression models. In the context of compound distributions, assuming the CMP and binomial distributions for N and Y in Equation (1), a discrete compound CMP-binomial distribution is developed by Saavithri et al. [10].
Considering the Poisson distribution as the counting distribution, compound Poisson regression models are available in the literature. See Frees et al. [11], Andersen and Bonat [12], and Delong et al. [13]. However, its applicability is limited to data with equi-dispersed counts. To allow for flexibility in the compound regression models in terms of accommodating dispersed counts, a counting distribution that can model both over- and under-dispersed data should be considered. This serves as motivation to use the CMP distribution as the counting distribution to build a compound regression model.
The goal of this work is to create a regression model for S using a CMP distribution for N. The present work is novel because of the distribution used for N and its convolution with the distribution of Y. The problem of obtaining prediction intervals for the response variable S is also addressed. The parameters of the compound regression model are estimated using the generalized linear model (GLM) approach in two cases. In the first case, we assume that data on S are available but not on N and Y. We assume data on both N and Y are available in the latter case. For this case, a two-part likelihood-based estimation procedure is developed within the framework of the GLM. A methodology to obtain the prediction interval (PI) for the response variable of the proposed compound regression model is developed.
The rest of the paper is organized as follows: The compound CMP regression model is given in Section 2. In Section 3, the estimation of the parameters of the proposed regression model using the GLM approach is discussed. Section 4 deals with the suggested methodology for obtaining the prediction intervals for the compound CMP regression model. A numerical illustration of the estimation procedure using simulated data and an application to real-life vehicle insurance claims data is presented in Section 5. The conclusion of the paper is given in Section 6.
2. Compound CMP Regression Model
The probability mass function (pmf) of the random variable N having the CMP distribution is given by
where is the normalizing constant. Some important remarks on this distribution are given below. The parameters and are the location and dispersion parameters, respectively. This pmf is not defined for and . The mean and variance of N are given by and , respectively. When , the CMP distribution reduces to the Poisson distribution. For , the distribution is under-dispersed, and for , it is over-dispersed.
Since the location parameter of the CMP distribution does not represent its mean, a mean reparameterized form of the distribution is used in building the compound regression model. The pmf of N under the mean-reparametrization is given by
where is the normalizing constant. When the distribution reduces to the Poisson distribution. For the distribution is under-dispersed, and for it is over-dispersed. See Ribeiro Jr et al. [14]. Here, corresponds to the mean of the distribution and . This approximation works reasonably well for or . The mean and variance of N are and , respectively.
Convolutions can be used to obtain the probability density function (pdf) of the random sum S defined in Equation (1). In Equation (1), implies . Let denote the probability mass at . Since S is not continuous at zero, the pdf of S is represented as a generalized pdf in terms of Dirac delta function as
where is the Dirac delta function such that Here, denotes the pmf of the CMP distribution defined in Equation (3), and denotes the pdf of the i-fold convolution of Y, whose distribution is assumed to be continuous with support in . Note that . In this paper, the distribution of Y is considered to be a mean reparameterized gamma distribution. Based on Jorgensen [15] (Chapter 3), the pdf of Y is given by
where denotes the mean of Y, denotes the dispersion parameter and denotes the gamma function. This form is taken for mathematical convenience and to accommodate asymmetry in the distribution of Y. For example, in the context of insurance claim modeling, the individual claim amounts are always positive and often right-skewed. Since the gamma distribution is closed under convolution, we obtain
The pdf of S defined in Equation (7) is called the compound CMP gamma pdf. For the random sum defined in Equation (1), we have
See, for instance, Bahnemann [3] (Chapter 4). Using Equation (8), the mean and variance of the compound CMP gamma distribution given in Equation (7) are obtained as
To build a compound regression model for S, let denote the design matrix where are the column vectors corresponding to the covariates and is the vector of . Following the GLM procedure given in De Jong et al. [16] (Chapter 5), the model is built by regressing S on X using the log-link function. This is because the log-link function guarantees that the expected value of the response variable is positive. Let denote the expected value of S. Then, the compound CMP gamma regression model is given by
where is a vector of regression parameters. In the context of modeling vehicle insurance claims data, S may denote the aggregate claim amount, and the covariates may denote the driver’s age, vehicle type, and so on. In the sequel, the method of estimating the regression parameters using the likelihood approach is discussed.
3. Parameter Estimation
Consider a sample of r observations on S. Let positive values in and zeros exist. Note that D can be assimilated to be random and , where . Therefore, the likelihood function L based on and is
where
Thus, the log-likelihood function l based on and is obtained as
Since and from Equation (9), we obtain . Let the elements of the design matrix X be with the row given by Replacing with and with in Equation (12), the log-likelihood function based on and becomes
The maximum likelihood (ML) estimates of the parameters in Equation (13) can be obtained by solving the () log-likelihood equations simultaneously. However, these equations are non-linear, and therefore closed-form solutions cannot be obtained. Hence, iterative algorithms based on numerical methods can be used to solve the equations to get the estimates for the parameters. Let denote the ML estimate of . By the asymptotic property of the ML estimators, for large r, the following distribution approximation holds:
where and denote the mean vector and the covariance matrix of , respectively. Using Equation (10), an estimate of the expected value of S given the covariates X can be obtained as
Assume that data on S are unavailable, but data on N and Y are. This can happen in such situations as, for example, when modeling the aggregate claim amount when one has data on the claim frequency (N) and the individual claim amounts (Y). Using N and Y, we can compute the value of S and then build the regression model using the method described above. However, it is computationally more challenging to compute the estimates due to the presence of an infinite sum in the log-likelihood function. To reduce the computational difficulty, we can use N and Y to build two separate regression models to obtain . Towards this, a two-part GLM methodology is proposed to estimate assuming N and Y to be (1) independent and (2) dependent.
3.1. Independent Compound Regression Model
Using Equation (9), we have . The proposed two-part GLM method is implemented by building two separate regression models, namely, the CMP regression model and the gamma regression model, for the means of N and Y, respectively. Given the data on and X, the estimated mean of S is computed as . Here, and are obtained by regressing N and Y separately on X. Using the log-link function, we have where and denote the set of regression parameters.
Let denote m observations on N. For each , let there be observations on Y denoted by . Let where
Let the design matrix X be of order with elements . Since the distribution of Y has positive support, zeros in if any, are not to be considered. The corresponding sample observation in and the observed covariate matrix X are not included when building the gamma regression model. Let q denote the number of observations for which and let . Following Garrido et al. [17], the distribution of is equivalent to for independently identically distributed . Using the pmf of N given in Equation (3) with , the corresponding log-likelihood function is given by
The ML estimates for the regression parameters are obtained by simultaneously solving the corresponding log-likelihood equations. Let denote the ML estimate of . Then the ML estimate of is obtained as . In similar lines, the ML estimate of , namely, , is obtained using the likelihood function corresponding to the conditional pdf of given . The conditional pdf is given by
Taking in Equation (15), the log-likelihood function is obtained as
The likelihood equations for and are, respectively, given by
and
Since Equations (17) and (18) are non-linear, iterative procedures can be used to solve them. As an alternate, one can use the in-built functions cmp() and glm(., family=“gamma”) available in R to obtain and . Using and , the ML estimate of the expected value of S, namely, , can be computed. By the asymptotic property of the ML estimators, we have
and
Here, and denote the mean vector and covariance matrix of , respectively. Similarly, and denote the mean vector and covariance matrix of , respectively. The standard errors of and are the square root of the diagonal elements of the corresponding covariance matrices. Since and do not have closed-form expressions, their standard errors can be obtained using the sample Hessian matrix. The sample Hessian matrices of and , namely, and , are given by and , respectively. Since the expressions of the standard errors of the parameters and contain the dispersion parameters and , respectively, they may be estimated using the following formulas:
and
where and are the estimated values of and , respectively, corresponding to the observation.
3.2. Dependent Compound Regression Model
Although independence between N and Y is commonly assumed in compound regression models, it is rarely observed in practice. For instance, in the framework of modeling the aggregate claim amounts, it is typical to observe that the claim amounts depend on the claim frequency as well. See, for example, the work of Garrido et al. [17]. As a result, N is included as a covariate in the regression model of . Let represent the regression parameter associated with N. Since S denotes a random sum, it can be written as . The GLM of S through the log-link function is given by Garrido et al. [17] as
where represents the derivative of the moment generating function of N with respect to . Taking N as CMP, is obtained as
Note that if , i.e., when N is independent of , , and thus the dependent compound regression model will coincide with the independent compound regression model. The pdf of S under dependent case is given by
where is indicated in Equation (15) with and . The corresponding log-likelihood function is
where corresponds to Equation (14). Let the ML estimates of and be denoted as and , where is obtained using Equation (17). The function corresponds to Equation (16) with replaced with . To obtain the estimates of and , the GLM of is used with the log-link function and is defined by . The corresponding likelihood equations of the regression parameters are
and
The dispersion parameter can be estimated using
where is the estimated value of corresponding to the observation. In addition, and can be obtained by solving Equations (21) and (22) through iterative algorithms. Thus, the estimate of is given by . Denote and its ML estimate as By the asymptotic property of the ML estimators, we have
Here, and denote the mean vector and covariance matrix of , respectively. The standard error of corresponds to the square root of the diagonal elements of the sample Hessian matrix, which is given by where is a matrix of order that denotes the design matrix which includes A is a diagonal matrix with positive elements of . Note that
4. Prediction Intervals
From the estimates of the regression parameters, we can obtain an estimate of the expected value of S for some fixed values of the covariates. Given the covariates, it is frequently useful to predict the actual value of S. In a regression setup, the actual value of S is related to its expected value as
where is the error term. Since is unobserved, it is not possible to predict the actual S. In contrast, the prediction interval is a constructed interval that contains the predicted value of actual S. In this section, a method for calculating the PI for S is proposed. Let denote the response given the covariate . Thus, we have , where (say). Assuming we get, . Additionally, we have . Hence, the PI for is given by , such that
where . Here, and correspond, respectively, to the lower and upper percentiles of the distribution of , which is the compound CMP gamma distribution with mean and variance . Since depends on we proceed as below to obtain an expression for . To begin, consider
Using the Taylor series expansion of at , we have
Thus, we have
and
In a similar manner, we obtain
An estimate of namely, can be obtained by dividing the residual sum of squares (RSS) of the compound CMP regression model by . Using and we obtain . However, obtaining the values of and from Equation (23) is not easy since the cumulative distribution function of the compound CMP gamma distribution is not invertible. One may use bootstrap procedures to identify and . We propose below a heuristic method to obtain the PI using the two-part GLM methodology given in the previous section.
The PI for is obtained using the PIs of and , where and . Note that is obtained from the GLM of N on X and is obtained using the GLM of on X. Denoting and we have, and . Proceeding along similar lines for obtaining the PI for , the PIs for and can be obtained, respectively, as and , such that
and
where Since has a mean reparameterized CMP distribution given in Equation (3), and are respectively, the lower and upper percentiles of the CMP distribution with mean and dispersion parameter , where . Likewise, and correspond respectively, to the lower and upper percentiles of the mean reparameterized gamma distribution given in Equation (15) with mean and dispersion parameter where . Supposing and are not known, the corresponding sample Hessian matrices can be used to compute and . The values of of the CMP and gamma regression models can be obtained by dividing the RSS of the corresponding regression models by and , where h denotes the number of regression parameters in the model.
The PI for given can be constructed using the PIs of and . By virtue of equality a trivial PI for given can be taken to be . When N is large, it may be useful to know the PI for . For example, in modeling aggregate claim amounts from insurance data, the company may want to know the PI for the aggregate claim amount for high claim frequencies so that enough funds can be maintained. In this case, the PI for given can be defined as . This definition of PI is used in the remaining part.
5. Numerical Illustration
5.1. Simulation Study
This section provides a numerical illustration of how to compute the PI for S using simulated data for the independent and dependent compound regression models. To generate random samples from the CMP and gamma regression models with a single covariate , generated from a standard normal distribution, the following steps are implemented:
- Generate , from the CMP distribution given in Equation (3) with mean by fixing and . Obtain .
- For each generate from the gamma distribution given in Equation (5) with mean by fixing and where for the independent compound regression model and for the dependent compound regression model. Compute and obtain .
For simulation, the values of the regression parameters are taken as and . The dispersion parameter of the gamma distribution is set to 1.5. To accommodate over-, equi- and under-dispersion in three choices of the dispersion parameter namely, and , are considered. The CMP and gamma GLMs are fitted to the generated and values, using their respective log-link functions for both the independent and dependent compound regression models. All the computations are carried out in R (version 4.1.1). The cmp() function in cmpreg package (Ribeiro Jr [18]) and the glm() function are used to carry out the CMP and gamma regression, respectively. To compute the value of in the dependent compound regression model, the com.expectation() function in compoisson package is employed. qcom() function in the compoisson package is used to determine the quantile values from the CMP distribution and the function qgammaAlt() in the EnvStats package is used to determine quantile values from the gamma distribution. For the above choices of the parameters, the PI for S is obtained for the independent and dependent compound regression models under three choices of sample size (m), namely, and 100. The actual S observations, denoted by , are computed by .
The proportion of lying within its PI is presented in Table 1 for the various choices of m and . Additionally, the plots of the corresponding prediction bands are displayed in Table 2 and Table 3. From Table 1, it can be observed that, for the choices of the covariate and coefficients considered, the proportion is large for in the independent compound regression model and for in the dependent compound regression model.

Table 1.
Proportion of S lying in its respective PIs.
Table 2.
Prediction bands of independent compound regression model for over-, equi- and under-dispersed data.
Table 3.
Prediction bands of dependent compound regression model for over-, equi- and under-dispersed data.
5.2. Real-Life Application
In this section, the proposed two-part methodology to obtain the PI for the compound CMP gamma regression is applied to real-life vehicle insurance claims data. The dataset pertains to the average damage claims for privately owned and insured vehicles in Britain in the year 1975. See Dutang and Charpentier [19]. It consists of 128 observations on five variables, namely, the owner’s age (), car age (), model (), number of claims (N) and average claim amount () in pounds. The variable consists of eight categories of age group; the variable , four categories of car age; and the variable , four categories of model. The aggregate claim amount (S) for each observation is obtained by multiplying the average claim amount by the number of claims. A dispersion test on N, performed using the function dispersiontest() available in R under AER package, resulted in a dispersion index of and a p-value of 2.091 , indicating that N is over-dispersed. Similarly, the Kolmogorov–Smirnov test on yielded a p-value of to assess the goodness-of-fit of the gamma distribution. As a result, the CMP distribution can be used to model N, whereas the gamma distribution can be used to model . To implement the proposed estimation methodology and validate its performance, of the observations are randomly chosen as training data and the rest as test data. The observations in the training data are used to fit the independent and dependent compound regression models. The owner’s age, car age and car model are the considered covariates in the model. The in-built functions cmp() function in cmpreg package and the glm() function are used to obtain the estimates of CMP and gamma regression models, respectively. The estimates of the regression parameters, their corresponding p-values (in parenthesis) and the AIC values are given in Table 4. Using the AIC values for the CMP and gamma regression models, the combined AIC values for the compound regression models are obtained as and , respectively. For each observation in the test data, the PI for S is computed using the estimates of the fitted model. The corresponding prediction band of the independent and dependent compound regression model is displayed in Figure 1. From this figure, it can be noted that some observations do not fall within the prediction band. One reason for this is that these observations have large claim frequencies when compared with the other observations, and the corresponding limits of the PI based on the CMP regression are also large. As a result, the limits of the PI of such observations deviate from their observed values. The proportion of observed S in the test data lying within its PI is found to be and for the independent and dependent compound regression models, respectively. Based on the combined AIC values and the proportions, it can be inferred that the dependent compound regression model provides a relatively better fit for modeling the aggregate claim amount.
Table 4.
Parameter estimates, p-values and AIC for the CMP and gamma regression models for the real-life data.
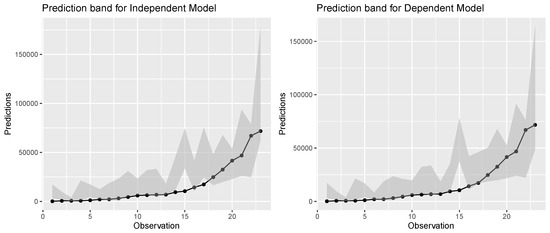
Figure 1.
Prediction band for the test data under independent model and dependent model.
6. Conclusions
The Poisson distribution is generally used in compound regression models as the counting distribution. In practice, the Poisson distribution’s equi-dispersion assumption is frequently violated. The methodology presented in this paper provided a way to handle non-equi-dispersed count data in the context of compound regression models by using the CMP distribution. The proposed compound regression model can be used when the count data are over- or under-dispersed. The estimation of the parameters was carried out using a two-part GLM approach for the independent and dependent compound regression models. This approach is less complex and provides separate estimates for the count and the continuous distribution involved in the model. Since, in practice, knowledge of the actual value of the response variable rather than its predicted value is more useful, a methodology to obtain the prediction interval of the response variable was proposed. An application of the two-part GLM method to real-life data revealed that the dependent compound regression model performs relatively better than the independent compound regression model. Thus, in practice, one can start with the dependent compound regression model and look for the significance of the count variable in the model. If the count variable is found to be not significant, then the independent compound regression model can be used. To conclude, the proposed compound CMP regression model could be an alternative to modeling a compound random variable when the count data are not equi-dispersed.
Author Contributions
J.M. has contributed to the conceptualization, methodology, mathematical derivation and simulation. V.S.V. and C.C. have contributed equally to mathematical derivation and original draft preparation. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gómez-Déniz, E.; Pérez-Rodríguez, J.V. Modelling distribution of aggregate expenditure on tourism. Econ. Model. 2019, 78, 293–308. [Google Scholar] [CrossRef]
- Klugman, S.A.; Panjer, H.H.; Willmot, G.E. Loss Models: From Data to Decisions; John Wiley & Sons: New York, NY, USA, 2012; Volume 715. [Google Scholar]
- Bahnemann, D. Distributions for Actuaries; Casualty Actuarial Society: Arlington, VA, USA, 2015; Volume 2. [Google Scholar]
- Jørgensen, B.; Paes De Souza, M.C. Fitting Tweedie’s compound Poisson model to insurance claims data. Scand. Actuar. J. 1994, 1994, 69–93. [Google Scholar] [CrossRef]
- Consul, P.C.; Jain, G.C. A generalization of the Poisson distribution. Technometrics 1973, 15, 791–799. [Google Scholar] [CrossRef]
- Shmueli, G.; Minka, T.P.; Kadane, J.B.; Borle, S.; Boatwright, P. A useful distribution for fitting discrete data: Revival of the Conway-Maxwell-Poisson distribution. J. R. Stat. Soc. Ser. (Appl. Stat.) 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. A queuing model with state dependent service rates. J. Ind. Eng. 1962, 12, 132–136. [Google Scholar]
- Sellers, K.F.; Borle, S.; Shmueli, G. The COM-Poisson model for count data: A survey of methods and applications. Appl. Stoch. Model. Bus. Ind. 2012, 28, 104–116. [Google Scholar] [CrossRef]
- Sellers, K.F.; Premeaux, B. Conway-Maxwell-Poisson regression models for dispersed count data. Wiley Interdiscip. Rev. Comput. Stat. 2021, 13, e1533. [Google Scholar] [CrossRef]
- Saavithri, V.; Priyadharshini, J.; Banu, Z.P. Compound COM-Poisson Distribution with Binomial Compounding Distribution. Available online: https://www.internationaljournalssrg.org/uploads/specialissuepdf/ICRMIT/2018/MTT/ICRMIT-P122.pdf (accessed on 15 January 2023).
- Frees, E.W.; Gao, J.; Rosenberg, M.A. Predicting the frequency and amount of health care expenditures. N. Am. Actuar. J. 2011, 15, 377–392. [Google Scholar] [CrossRef]
- Andersen, D.A.; Bonat, W.H. Double generalized linear compound Poisson models to insurance claims data. Electron. J. Appl. Stat. Anal. 2017, 10, 384–407. [Google Scholar]
- Delong, Ł; Lindholm, M.; Wüthrich, M.V. Making Tweedie’s compound Poisson model more accessible. Eur. Actuar. J. 2021, 11, 185–226. [Google Scholar] [CrossRef]
- Ribeiro, E.E., Jr.; Zeviani, W.M.; Bonat, W.H.; Demétrio, C.G.; Hinde, J. Reparametrization of COM-Poisson regression models with applications in the analysis of experimental data. Stat. Model. 2020, 20, 443–466. [Google Scholar] [CrossRef]
- Jorgensen, B. The Theory of Dispersion Models; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- De Jong, P.; Heller, G.Z. Generalized Linear Models for Insurance Data; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Garrido, J.; Genest, C.; Schulz, J. Generalized linear models for dependent frequency and severity of insurance claims. Insur. Math. Econ. 2016, 70, 205–215. [Google Scholar] [CrossRef]
- Ribeiro, E.E., Jr. Cmpreg: Reparametrized COM-Poisson Regression Models, R Package Version 0.0.1; Available online: https://rdrr.io/github/JrEduardo/cmpreg/ (accessed on 15 January 2023).
- Dutang, C.; Charpentier, A. CASdatasets: Insurance Datasets. 2019. R Package Version 1.0-11. Available online: http://cas.uqam.ca/ (accessed on 15 January 2023).



















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).