Abstract
The usefulness of (probability) distributions in the field of biomedical science cannot be underestimated. Hence, several distributions have been used in this field to perform statistical analyses and make inferences. In this study, we develop the arctan power (AP) distribution and illustrate its application using biomedical data. The distribution is flexible in the sense that its probability density function exhibits characteristics such as left-skewedness, right-skewedness, and J and reversed-J shapes. The characteristic of the corresponding hazard rate function also suggests that the distribution is capable of modeling data with monotonic and non-monotonic failure rates. A bivariate extension of the AP distribution is also created to model the interdependence of two random variables or pairs of data. The application reveals that the AP distribution provides a better fit to the biomedical data than other existing distributions. The parameters of the distribution can also be fairly accurately estimated using a Bayesian approach, which is also elaborated. To end the study, the quantile and modal regression models based on the AP distribution provided better fits to the biomedical data than other existing regression models.
1. Introduction
Parametric statistical techniques have been used in biomedical studies to conduct analyses and draw conclusions. These parametric analyses, however, are constrained by some assumptions about (probability) distributions. Thus, the task of selecting an appropriate distribution for such analyses is incredibly essential. In addition, it is nontrivial, as the use of an incorrect distribution will result in misleading inferences. Knowing which distribution to use in biomedical modeling has become increasingly important as it is used to develop new parametric regression models for modeling the relationship between endogenous variables and a set of exogenous variables. These new regression models often provide a good fit with minimal loss of information compared to the existing ones. This has triggered new interest in developing regression models using extended or modified forms of existing distributions.
Among the distributions used for developing the regression models, those that are defined on the unit interval have received much attention due to the small loss of information they offer in modeling data on this interval. Some of these distributions include the unit folded normal distribution [1], bounded truncated Cauchy power exponential distribution [2], unit exponentiated Fréchet distribution [3], log XLindley (LXL) distribution [4], unit Chen distribution [5], unit Burr XII distribution (UBXII) [6], unit generalized half-normal distribution [7], unit Burr III (UBIII) distribution [8], unit Lindley distribution [9], unit Gompertz distribution [10], unit improved second degree Lindley (UISDL) distribution [11], unit Weibull distribution [12], and exponentiated Topp–Leone distribution [13].
Despite the existence of these distributions, it is worth noting that the behavior of humans or organisms is nondeterministic, and a single distribution cannot be selected in all situations to describe or model these traits. Therefore, we develop a new distribution called the arctan power (AP) distribution for modeling data on the unit interval based on the following motivations:
- Develop a flexible unit distribution that is able to model data that are left-skewed, right-skewed, symmetric, J, and reversed-J shapes.
- Develop a unit distribution capable of modeling data with increasing, bathtub, and modified upside-down bathtub hazard rate functions (HRFs).
- Develop quantile regression for modeling response variables that are skewed or contain extreme values.
- Develop modal regression for modeling response variables that are asymmetric or heavy-tailed.
The article is organized into eight sections. Section 2 describes the development of the AP distribution. Section 3 presents their statistical properties. Section 4 shows the construction of a possible bivariate extension of the AP distribution. Nine frequentist approaches to estimating the involved parameters are proposed in Section 5. The frequentist and Bayesian univariate applications of the distribution are given in Section 6. Section 7 is devoted to the quantile and modal regressions based on the AP distribution and their applications. The conclusion of the study is presented in Section 8.
2. Development of AP Distribution
Suppose that a random variable, , follows the arctan uniform (AU) distribution. Then, according to [14], the cumulative distribution function (CDF) and probability density function (PDF) of are, respectively, given by
and
The proposed AP distribution is obtained using the power transformation . The motivations for introducing the power parameter, , are to improve the tail properties of the new distribution, making it capable of handling both monotonic and non-monotonic HRFs. Other researchers have used the power transformation approach to modify existing continuous distributions. See, for instance, [15,16,17]. Hence, using standard mathematical developments, the CDF of is obtained as
The PDF and HRF are, respectively, given by
and
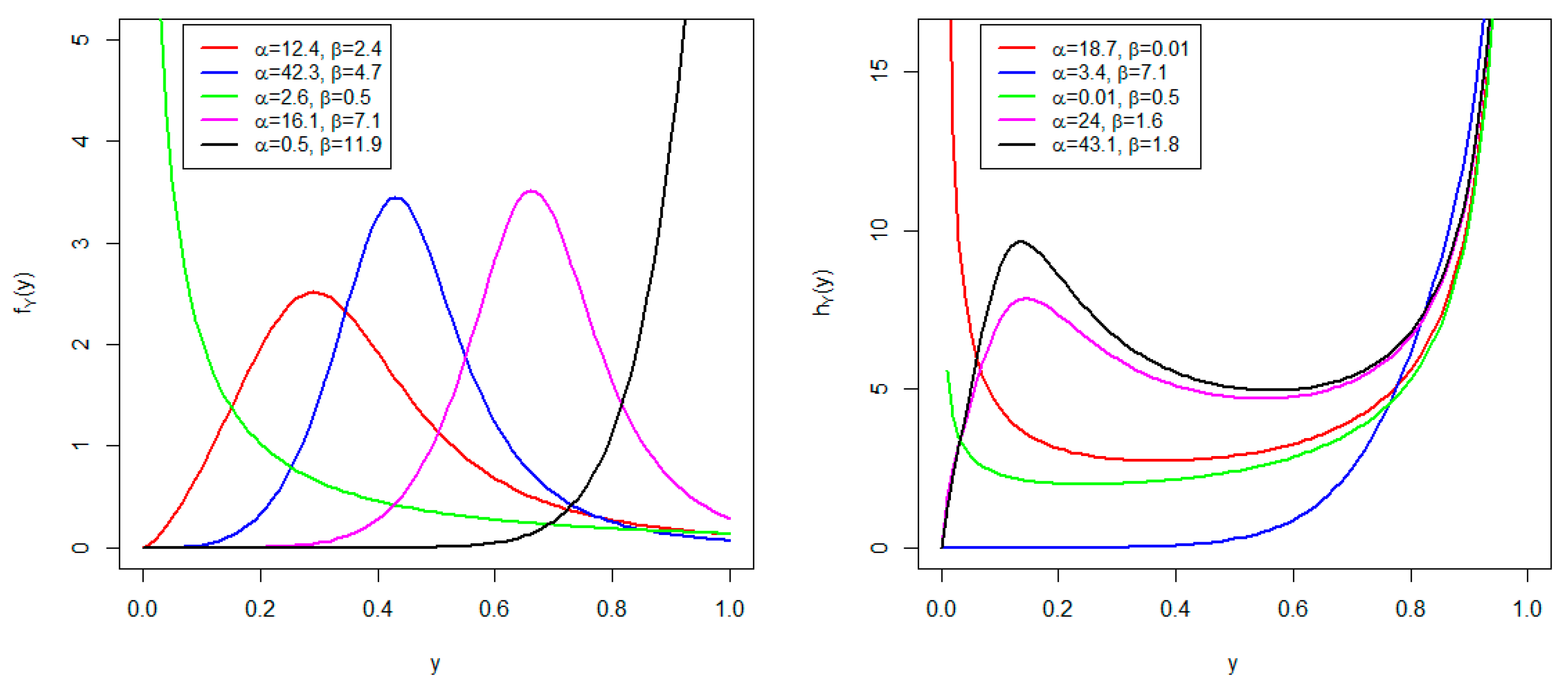
Basically, when , the PDF of the AP distribution reduces to the one of the power distribution. As and , the PDF of the AP distribution reduces to the one of the standard uniform distribution. Furthermore, when , the PDF of the AP distribution reduces to the one of the AU distribution.
The expanded form of the PDF is often useful when deriving the statistical properties of the distribution. Thus, using the arctangent function expansion indicated as follows: (see [18]) and , the CDF of can be expressed as
Differentiating the expanded form of the CDF in Equation (6), the corresponding PDF is given by
The PDF and HRF plots are shown in Figure 1 for some given parameter values. In it, the PDF exhibits left-skewed, right-skewed, J, and reversed-J shapes. This makes the AP distribution superior to the AU distribution, which exhibits only J shapes. On this side, the HRF displays increasing, bathtub, and modified upside-down bathtub shapes.
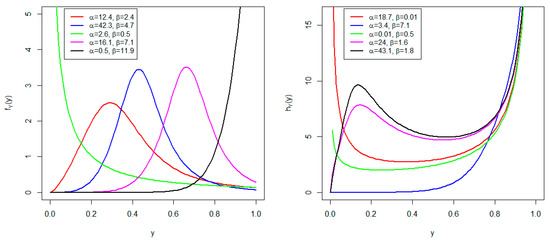
Figure 1.
PDF (left) and HRF (right) plots.
3. Some Statistical Properties
In this section, some statistical properties of the AP distribution are presented.
3.1. Mode
The mode of a distribution is a useful measure of central tendency. It can be used as it for data measured on the nominal, ordinal, interval, or ratio scale. The AP distribution has a unique mode when , and it is expressed in the result below.
Proposition 1.
The mode of the AP distribution is given by
Proof.
To establish this expression, it is essential to locate the critical point(s) of the PDF. A critical point of the PDF is a point of the PDF, or equivalently, the logarithm of the PDF, where its derivative is zero or infinity. Taking the logarithm of the PDF and differentiating, we have
Equating the derivative to zero and simplifying yields the mode. This completes the proof. □
3.2. Quantile Function
The quantile function can be used to generate random observations from the AP distribution and to compute shape-related metrics like skewness and kurtosis.
Proposition 2.
The quantile function of the AP distribution is given by
Proof.
The quantile function is the solution of the following nonlinear equation: for all . After some simplifications, letting in the CDF and equating the CDF to yields the quantile function. This completes the proof. □
It is important to note that the quantile function of the AP distribution is uniquely determined with simple trigonometric and power functions.
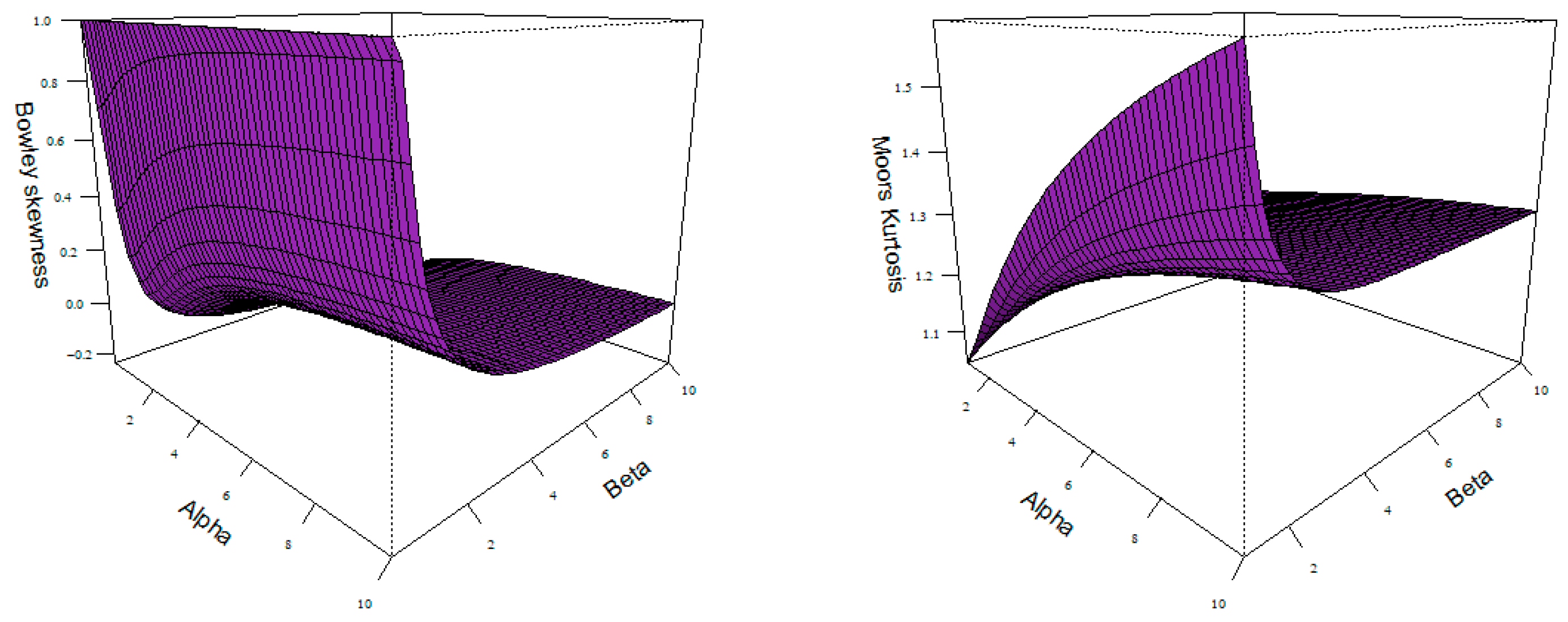
The median , first quartile , and upper quartile are obtained, respectively, by substituting 0.5, 0.25, and 0.75 into the quantile function. The Bowley’s (BS) measure of skewness and the Moors’ (MK) measure of kurtosis can then be calculated using the quantiles. They are, respectively, given by
and
The plots of the Bowley’s coefficient of skewness and Moor’s coefficient of kurtosis are displayed in Figure 2. Both the skewness and kurtosis are affected by changes in the values of the parameters. From this figure, we can observe that the AP distribution can be left-skewed or right-skewed.
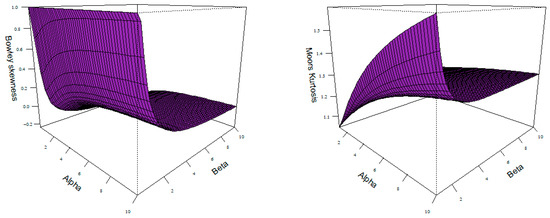
Figure 2.
Skewness (left) and Kurtosis (right) plots.
3.3. Moments and Generating Function
The moments are useful for estimating measures of central tendency, dispersion, and shapes. The generating functions can be used to estimate the moments, if they exist in the mathematical sense.
Proposition 3.
For , the raw moment of an AP random variable is given by
Proof.
The raw moment by definition is given by . Thus, we obtain
After some algebraic simplifications, the raw moment of the AP random variable is obtained. This completes the proof. □
The incomplete moment is very useful when computing measures of inequalities, such as the Lorenz and Bonferroni curves.
Proposition 4.
For , the incomplete moment of an AP random variable is given by
Proof.
By definition, . Hence, substituting the expanded PDF into the definition and simplifying it completes the proof. □
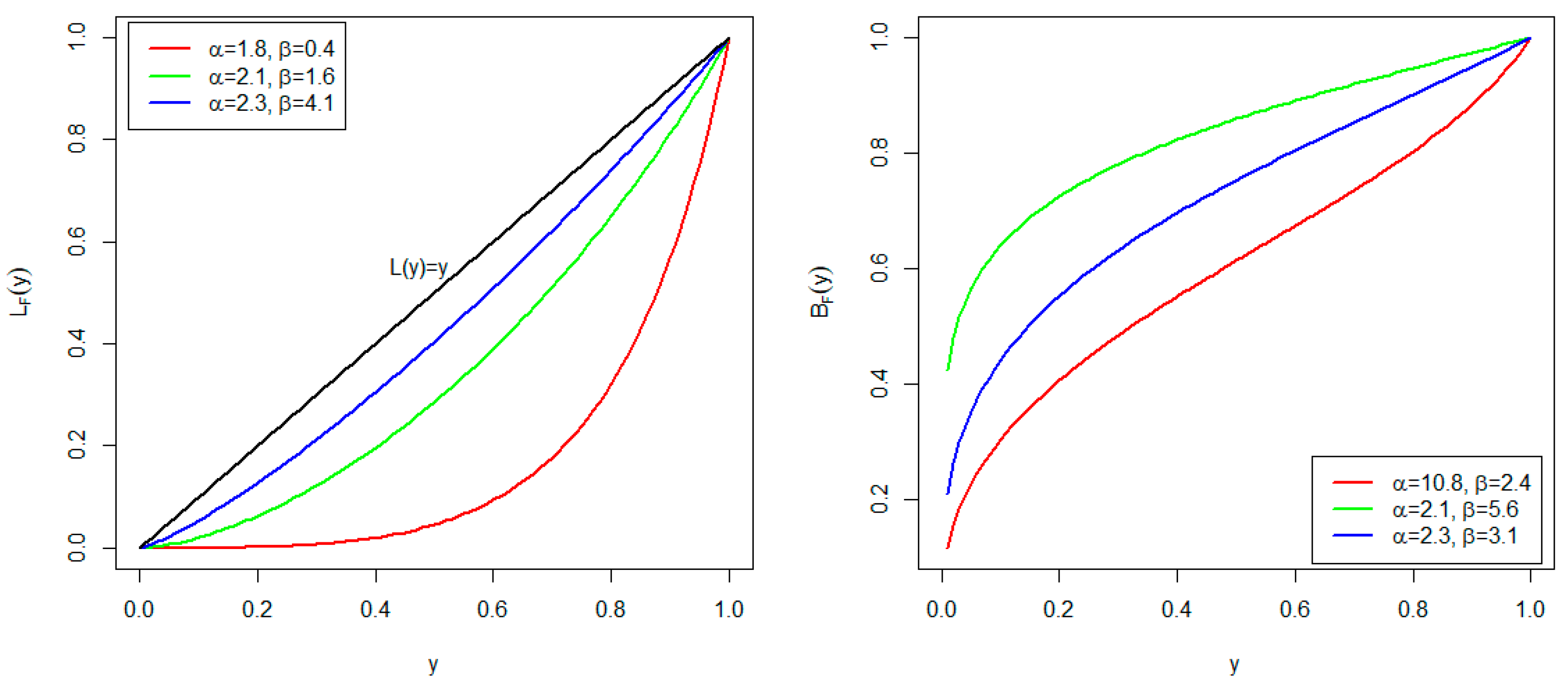
The Lorenz and Bonferroni curves are obtained, respectively, as
and
where is the mean.
Figure 3 displays the plots of the Lorenz and Bonferroni curves of the AP distribution for some selected parameter values. For the Lorenz curve, when , the minimal point of inequality is obtained. When , the so-called equidistributional line for the Bonferroni curve is obtained.
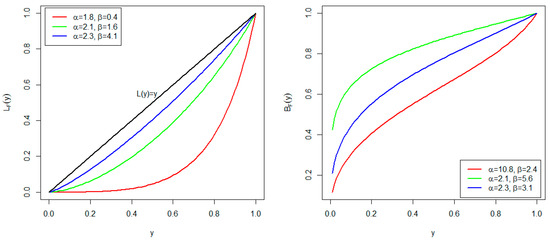
Figure 3.
Plots of Lorenz curve (left) and Bonferroni curve (right).
When non-central moments of a random variable exist, they can be found using the moment-generating function (MGF).
Proposition 5.
For , the MGF of an AP random variable is given by
Proof.
Using the definition and applying the Taylor series expansion, we get
Hence, substituting the non-central moment completes the proof. □
3.4. Order Statistics
Order statistics are very useful in extreme value analysis. They can be used to determine the behavior of the minimum and maximum value. Consider the order statistics from the AP distribution. Then, the PDF of is
where the factor constant is given by
Using the standard binomial expansion, we can express this PDF as
Hence, we obtain
The minimum () and maximum () order statistics can serve to investigate the minimum and maximum failure time of a system, respectively. The PDF of is given by
and the PDF of is
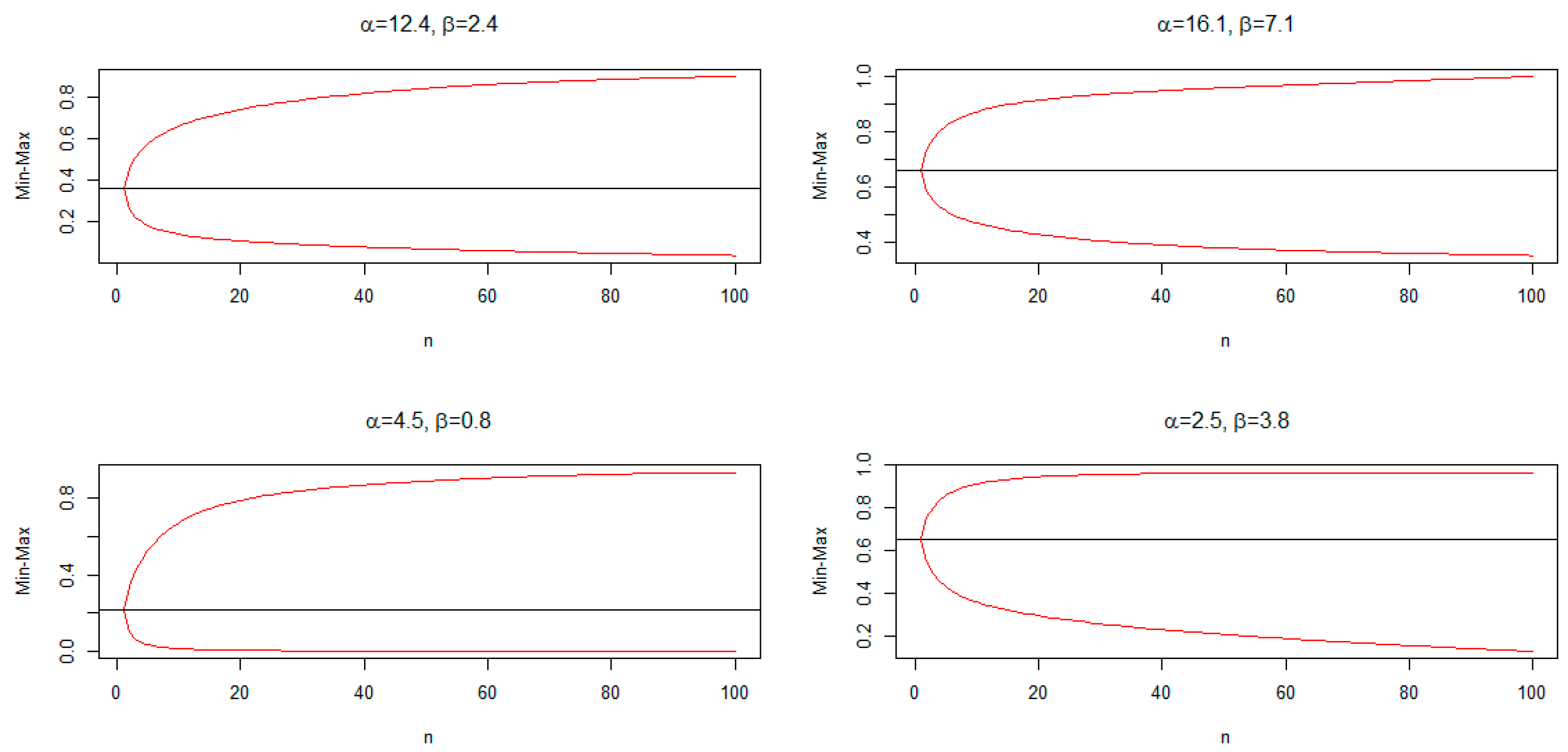
The minimum and maximum (min-max) plot of the order statistics can be used to describe whether the distribution is symmetrical or skewed. The min-max plots depend on and . The min-max plots for some chosen parameter values for the AP distribution are shown in Figure 4. This figure reveals that the AP distribution can be right-skewed, left-skewed, or symmetric.
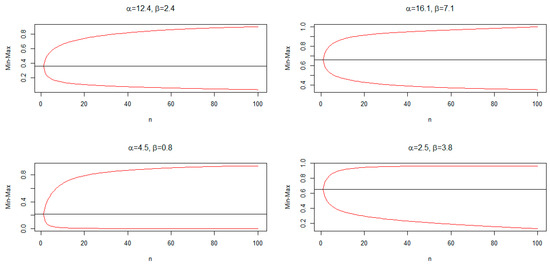
Figure 4.
Min-max plots for the AP distribution.
4. Bivariate AP Distribution
The development of bivariate distributions is very useful in the context of investigating the joint relationship between two random variables. For example, one may be interested in studying the relationship between the human development index and literacy rate of a country, the maternal mortality rate and literacy rate, or rainfall and temperature, among others. There are different methods of developing bivariate distributions. One way to do this is to use copula functions (see [19]). However, in this study, we follow the approach used by [20,21]. Let be a bivariate continuous random vector. The CDF of the bivariate AP (BAP) distribution with parameters , where , and , is given by
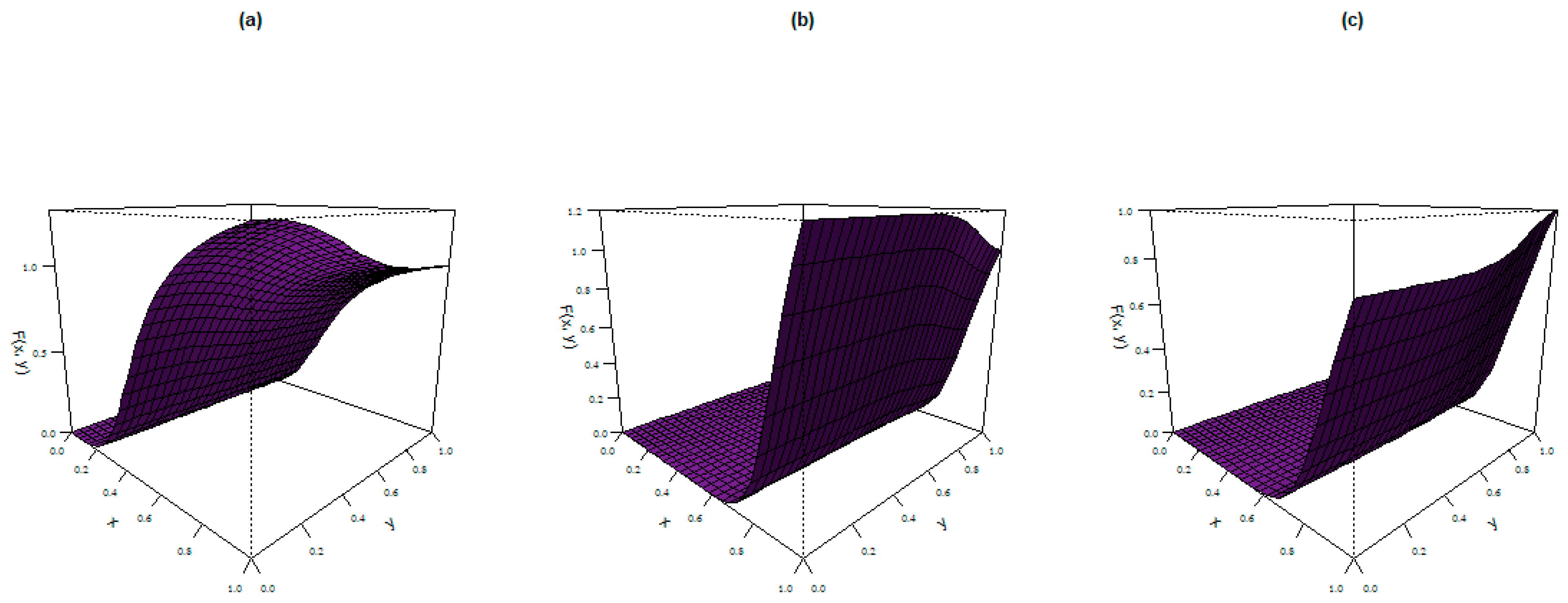
where . The plots of the CDF of the BAP distribution for the given parameter values are shown in Figure 5:
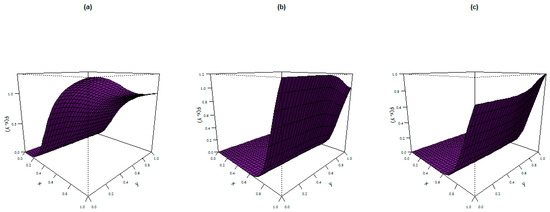
Figure 5.
CDF plots of the BAP distribution.
- (a)
- ,
- (b)
- and
- (c)
- .
These plots reveal different concave and convex shapes for the chosen parameter values.
The PDF of the BAP distribution is given by
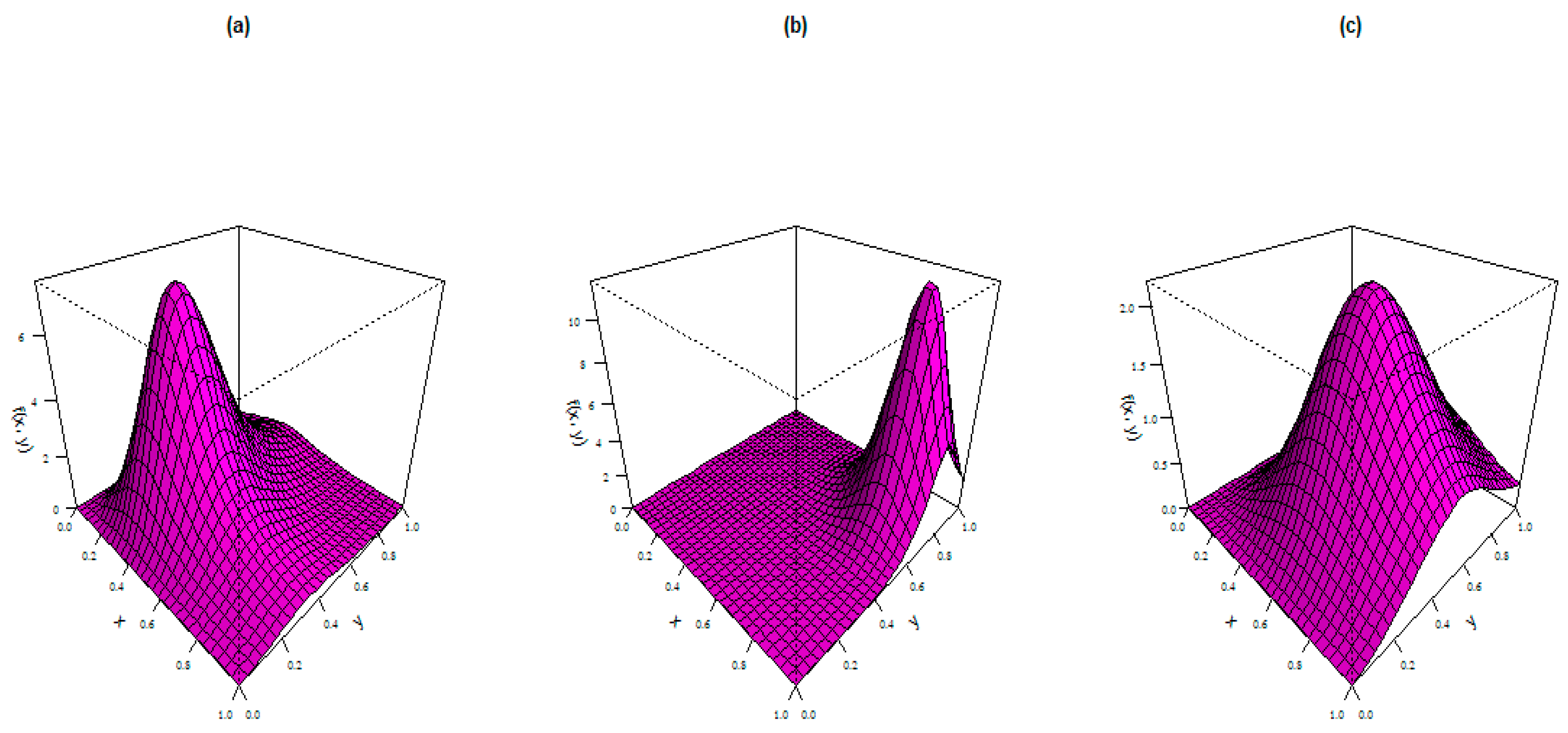
The PDF plots of the BAP distribution for the following selected parameter values are displayed in Figure 6:
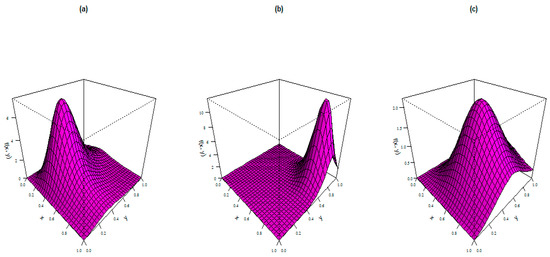
Figure 6.
PDF plots of the BAP distribution.
- (a)
- ,
- (b)
- and
- (c)
- .
These plots display left-skewed, right-skewed, and approximate symmetrical shapes.
5. Estimation Methods and Simulations
This section presents nine frequentist estimation procedures for estimating the parameters of the AP distribution. These are the maximum likelihood (ML) estimation, ordinary least squares (OLS), weighted least squares (WLS), Cramér–von Mises (CVM) estimation, Anderson–Darling (AD) estimation, percentile estimation (PE), and product spacing estimations.
5.1. Maximum Likelihood Estimation
Let be independent and identically random observations of sample size from the AP distribution. Suppose that is the vector of parameters; then, the total log-likelihood function is
The total likelihood function can be maximized directly with respect to the parameters and to obtain the ML estimates of the parameters. Alternatively, these estimates can be obtained by equating the score functions to zero and solving the resulting system of equations simultaneously. The score functions, obtained by differentiating Equation (16) with respect to the parameters, are given by
and
The score functions do not have a closed form, thus, the resulting system of equations are solved numerically to obtain the estimates and .
5.2. Ordinary and Weighted Least Squares Estimation
Consider an ordered random sample of size from the AP distribution; then, the OLS estimates, and , of the parameters are obtained by minimizing the function
with respect to the parameters and . The OLS estimates can also be obtained by numerically solving the nonlinear equations
where
and
The WLS estimates, and , of the parameters are obtained by minimizing the function
with respect to the parameters and . Alternatively, the WLS estimates are obtained by numerically solving the nonlinear equations
where are defined in Equations (21) and (22).
5.3. Cramér–Von Mises Estimation
Given that are the ordered observations of size from the AP distribution, the CVM estimates, and , of the parameters are obtained by minimizing the function
with respect to the parameters and . The CVM estimates can also be obtained by solving the nonlinear equation
where are given in Equations (21) and (22).
5.4. Anderson–Darling Estimation
Let be ordered observations of size from the AP distribution. The AD estimates, and , of the parameters of the AP distribution are obtained by minimizing the function
with respect to the parameters and .
5.5. Percentile Estimation
Let be ordered observations of size from the AP distribution, and . The percentile estimates, and , of the parameters of the AP distribution are obtained by minimizing the function
with respect to the parameters and .
5.6. Product Spacing Estimations
In this subsection, the maximum product spacing (MPS) and minimum spacing distance (MSD) estimation methods are discussed. The MPS estimation method is based on the Kullback–Leibler information measure. Let us consider the uniform spacing
where and . The MPS estimates, and , of the parameters are obtained by directly maximizing the logarithm of the geometric mean of the spacing given by
with respect to the parameters and .
The MSD estimates, and , of the parameters of the AP distribution are obtained my minimizing the function
where represents an appropriate distance. Several choices of exist. However, in this study, we employ the absolute and absolute-logarithm distances. Hence, the minimum spacing absolute distance (MSAD) and minimum spacing absolute-logarithm (MSALD) estimates of the parameters are obtained by minimizing the functions
and
where and .
5.7. Monte Carlo Simulation
In this section, we conduct Monte Carlo simulation studies to investigate how the various estimation techniques perform with regards to estimating the parameter of the AP distribution. The exercise is carried out with two sets of parameter values, which are and . The simulation experiments are repeated times using the sample sizes and . The average estimates (AE), average absolute bias (AB), and root mean square error (RMSE) of the parameters are estimated and reported in Table 1 and Table 2. We observe that as the sample size increases, the AE of the parameters approaches the true parameter values. Furthermore, the ABs and RMSEs of the parameters decrease as the sample size increases for all the estimation methods used. Thus, the various estimation methods produce consistent estimates for the parameters of the AP distribution. However, none of the estimation methods proves to be superior to the others.

Table 1.
AE, AB, and RMSE for and .
Table 2.
AE, AB, and RMSE for and .
6. Empirical Application
In this section, we present frequentist and Bayesian applications of the AP distribution using biomedical data.
6.1. Frequentist Application
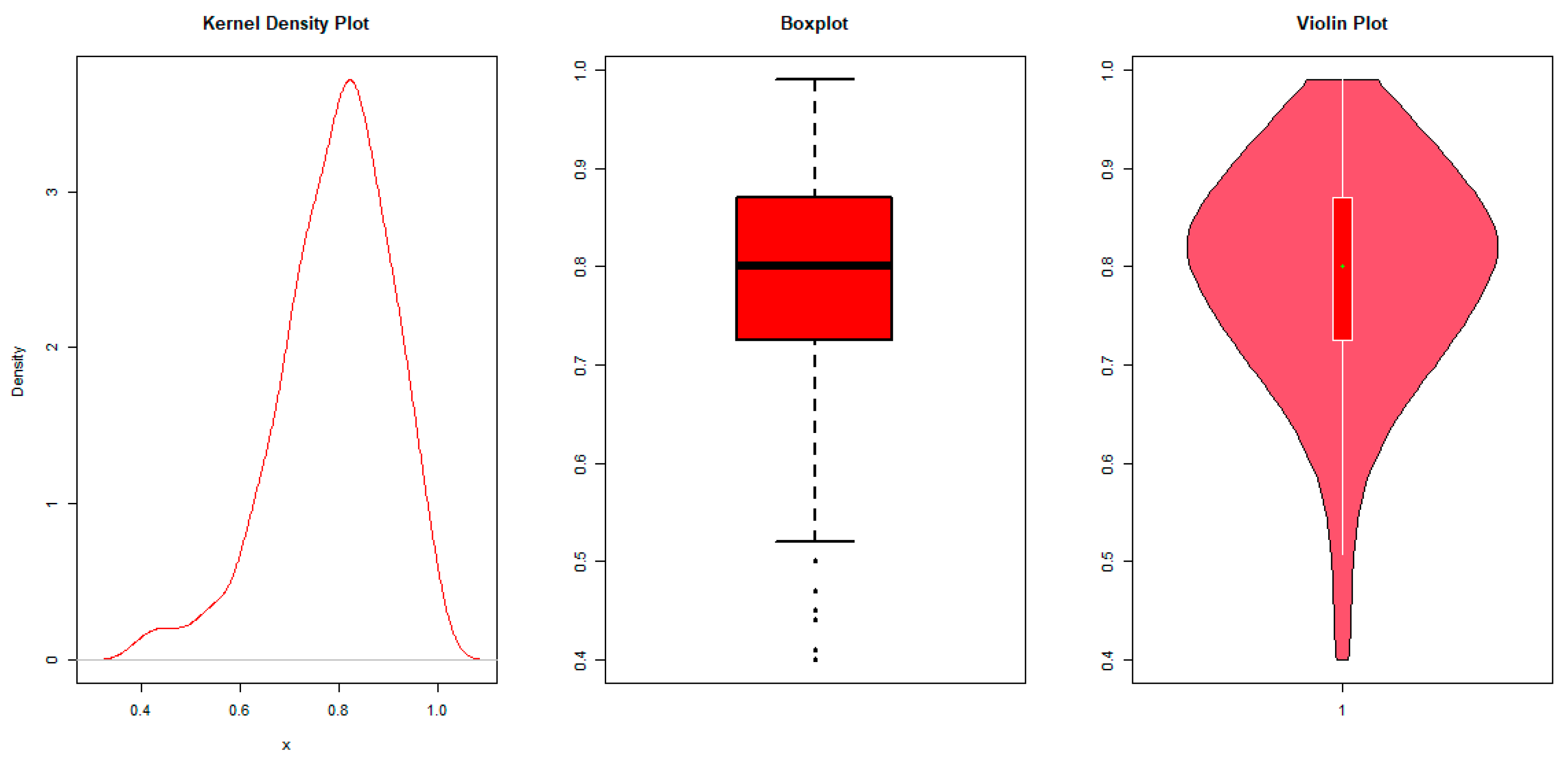
In this subsection, the univariate application of the AP distribution is illustrated using the ML estimation approach. The illustration is done using data on the recovery rates for viable CD34+ cells of 239 patients who agreed to an autologous peripheral blood stem cell (PBSC) transplant after myeloablative doses of chemotherapy between the years 2003 and 2008 at the Edmonton Hematopoietic Stem Cell Lab in the Cross Cancer Institute-Alberta Health Services. The data can be found in the simplexreg package developed by [22]. Ref. [6] recently fitted the unit Burr XII (UBXII) distribution to improve the recovery rates for viable CD34+ cells. The AP distribution is fitted to the recovery rates in this study, and its performance is compared to the AU distribution [14], unit power Weibull (UPW) distribution [23], log-XLindley (LXL) distribution [4], unit Lindley (UL) distribution [9], unit improved second degree Lindley (UISDL) distribution [11], bounded Marshall–Olkin extended exponential (BMOEE) distribution [24], unit Burr III (UBIII) distribution [8], unit Gompertz (UG) distribution [10], unit Weibull (UW) distribution [12], exponentiated Topp–Leone (ETL) distribution [13], Kumaraswamy distribution [25], and beta distribution. The performances of the distributions are compared using the log-likelihood (), Akaike information criterion (AIC), AIC difference (DAIC), Bayesian information criterion (BIC), Anderson–Darling (AD) test, Cramér–von Mises (CVM) test, and Kolmogorov–Smirnov (KS) test. The distribution with the highest value of and lowest values of AIC, BIC, AD, CVM, and KS is considered to be the best. The DAIC is computed as , where is the number of distributions under comparison. The best distribution satisfies . If , then the difference in performance between the two models is significant. Before fitting the models to the recovery rate for viable CD34+ cells, we explore their characteristics. From the kernel density, boxplot, and violin plots shown in Figure 7, we observe that the recovery rate for viable CD34+ cells is left-skewed. Hence, a distribution capable of modeling left-skewed data is required, which is the case for the AP distribution.
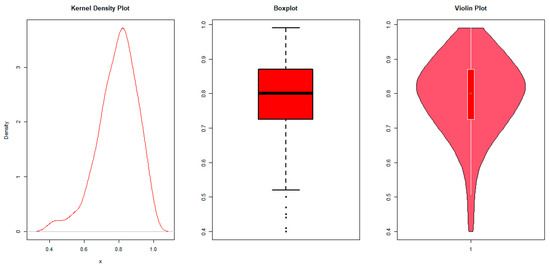
Figure 7.
Kernel density, boxplot, and violin plots.
Table 3 presents the ML estimates of the parameters with their respective standard errors in brackets. The AP distribution appears to be the best model since it has the highest log-likelihood values and the smallest values for the AIC, BIC, AD, CVM, and KS. The p-values of the AD, CVM, and KS tests are given in parentheses. The p-values also indicate that the AP distribution is the best. Furthermore, looking at the DAIC values, the AP distribution significantly performs better than the other fitted distributions. Comparing the goodness-of-fit statistics of the AP and AU distributions, it can be concluded that the induction of the new parameter has greatly improved the performance of the AP distribution, making it superior to the AU distribution.
Table 3.
Parameter estimates, standard errors, goodness-of-fit tests.
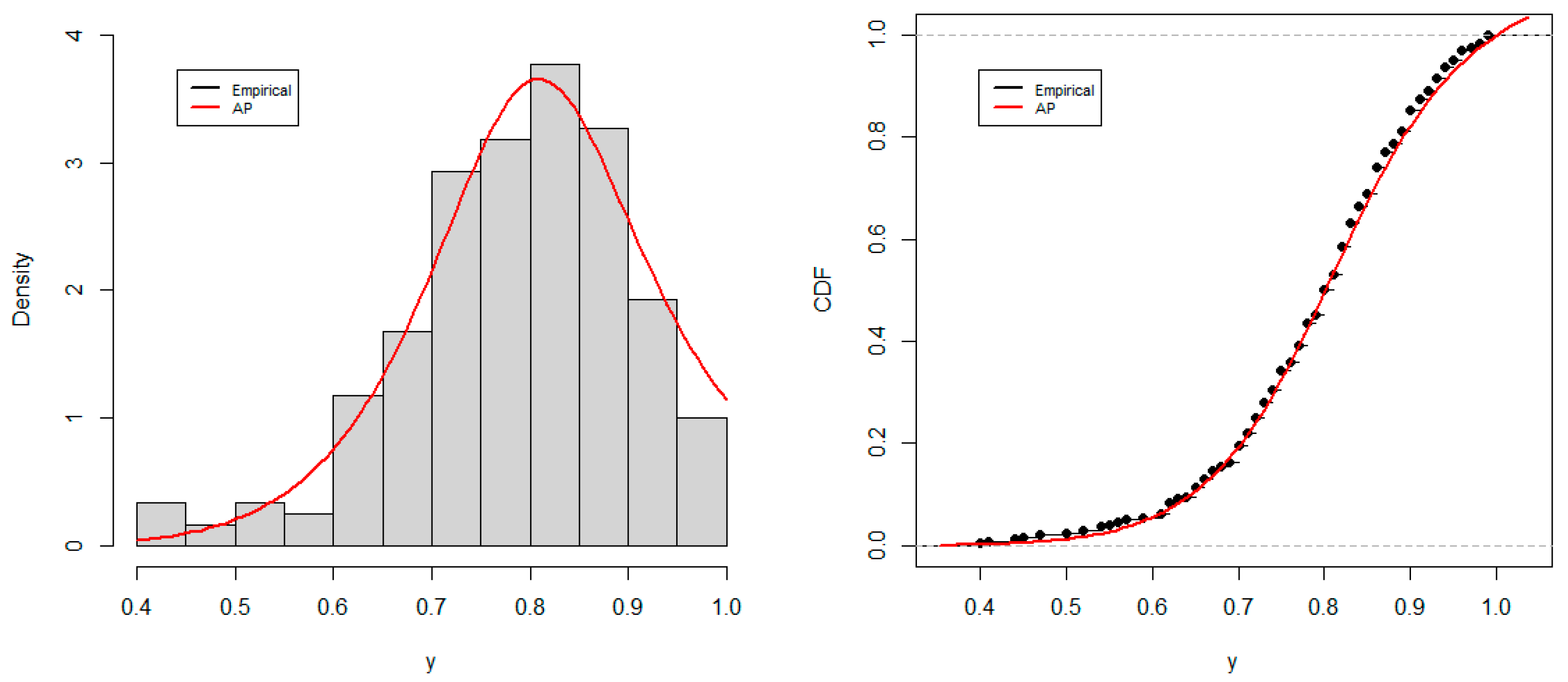
Figure 8 displays the histogram of the data and the estimated PDF of the AP distribution on the one hand and the empirical CDF and the estimated CDF of the AP distribution on the other hand, using the estimates of the parameter. This figure suggests that the AP distribution provides good fit to the data.
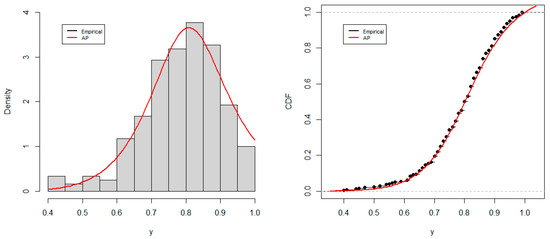
Figure 8.
Histogram and estimated PDF (left), and empirical CDF and estimated CDF (right).
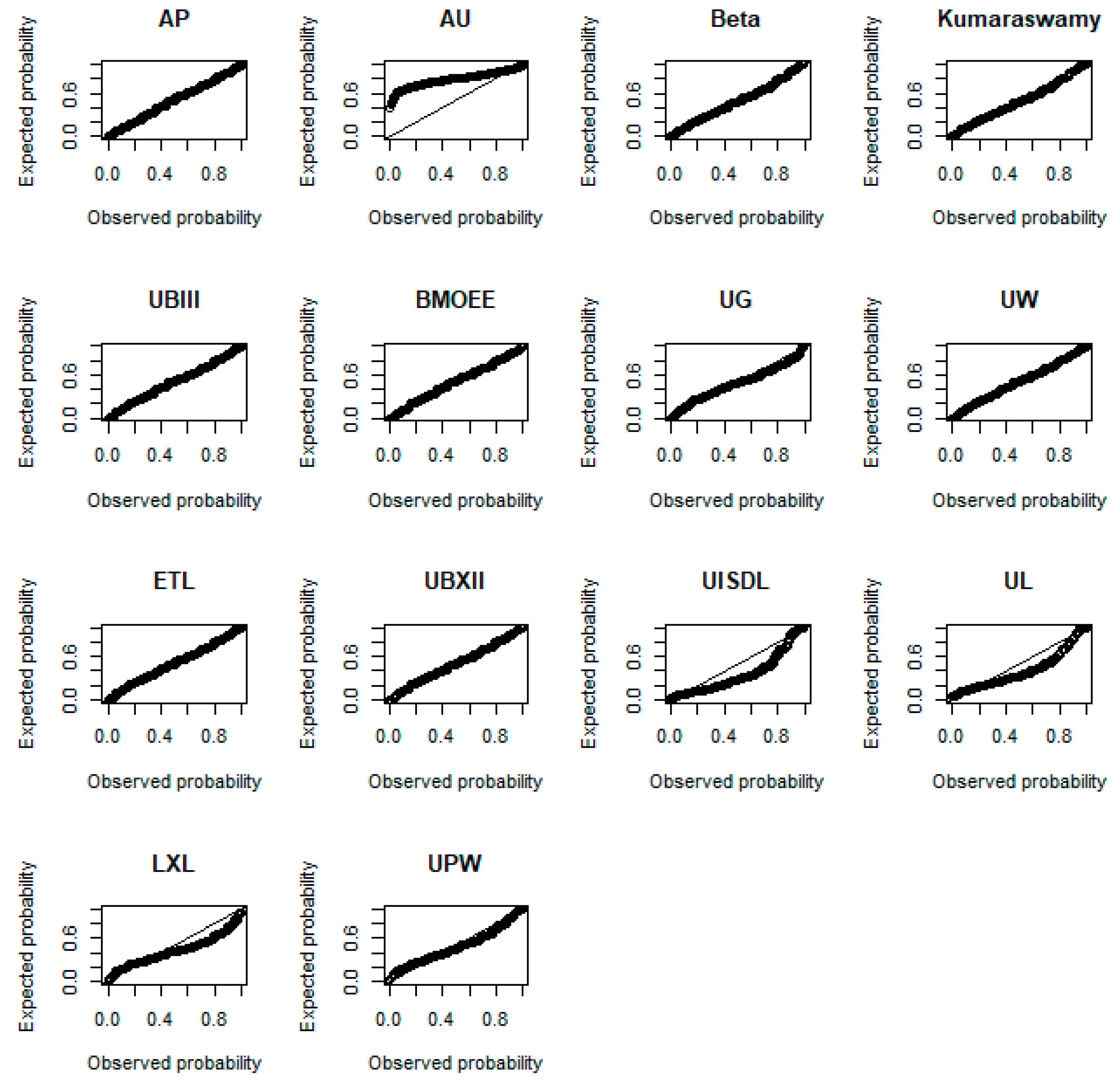
Figure 9 displays the probability-probability (P-P) plots of the fitted distributions. This figure suggests that the AP distribution provides a good fit to the data as its expected and observed probabilities cluster along the diagonal line.
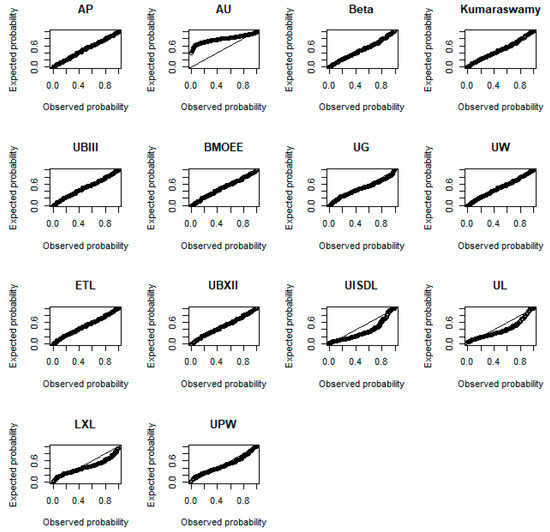
Figure 9.
P-P plots of the fitted distributions.
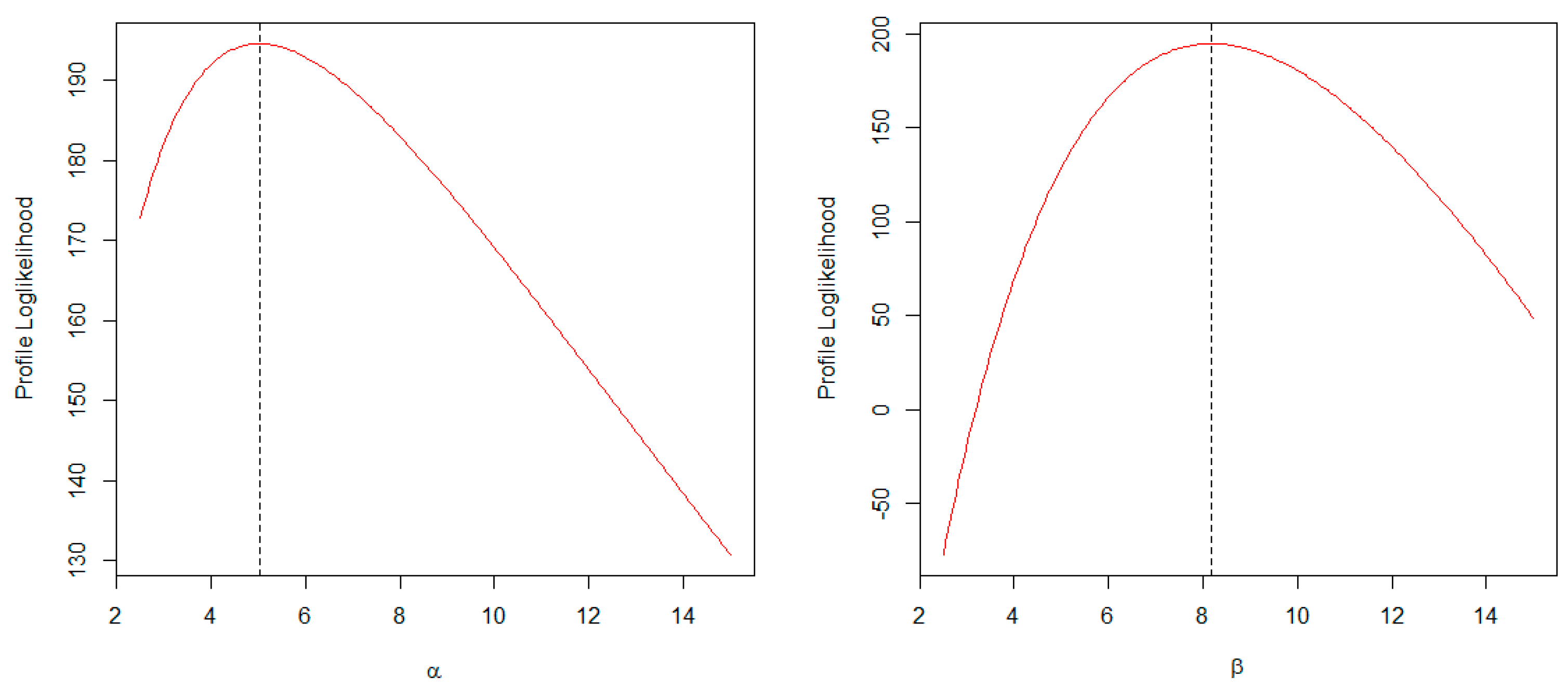
The profile log-likelihood plots of the estimated parameters of the AP distribution are shown in Figure 10. These plots suggest that the ML estimates of the parameters are unique and denote the true maxima.
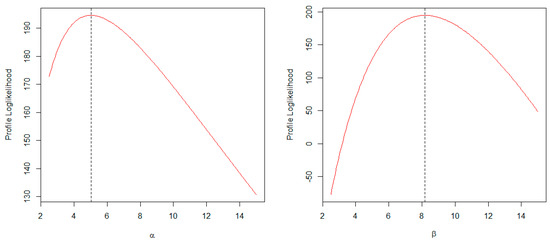
Figure 10.
Profile log-likelihood plots of the estimated parameters of the AP distribution.
6.2. Bayesian Application
In this subsection, we demonstrate how to use the Bayesian approach to estimate the parameters of the AP distribution. To proceed, we need to first establish the prior distributions for the parameters, as it is very essential in Bayesian estimation. In this study, we use the non-informative gamma distribution as the prior distribution. Numerous studies have recommended the use of this approach (see [26,27]). Thus, the prior distributions of the parameters are
and
The joint PDF of the prior distributions of the parameters is given by
The joint posterior PDF is therefore given by
where is the likelihood function of the AP distribution. The joint posterior PDF is not analytically tractable; hence, we employ the Markov Chain Monte Carlo (MCMC) approach to obtain samples from which features of the marginal distributions can be inferred. The following hyperparameter values are considered for the analysis. The analysis is performed using the R2jags package in R (see [28]) and the data described in Section 6.1. We use three parallel chains, each with 40,000 iterations and a burn-in of 5000. Hence, posterior sample of size 7000 and thinning interval 5 is used in the analysis. Table 4 presents the mean estimate, Monte Carlo standard error (SE), posterior standard deviation (SD), and other numerical summaries of the posterior distribution. From the results, the MCMC algorithm has converged because the potential reduction scale factor () is approximately 1 and the effective sample size (neff) is greater than 400. The estimated deviance information criterion (DIC) is . It can be observed that the Bayesian estimates and ML estimates of the parameters are quite close.
Table 4.
Posterior summaries of the parameters of the AP distribution.
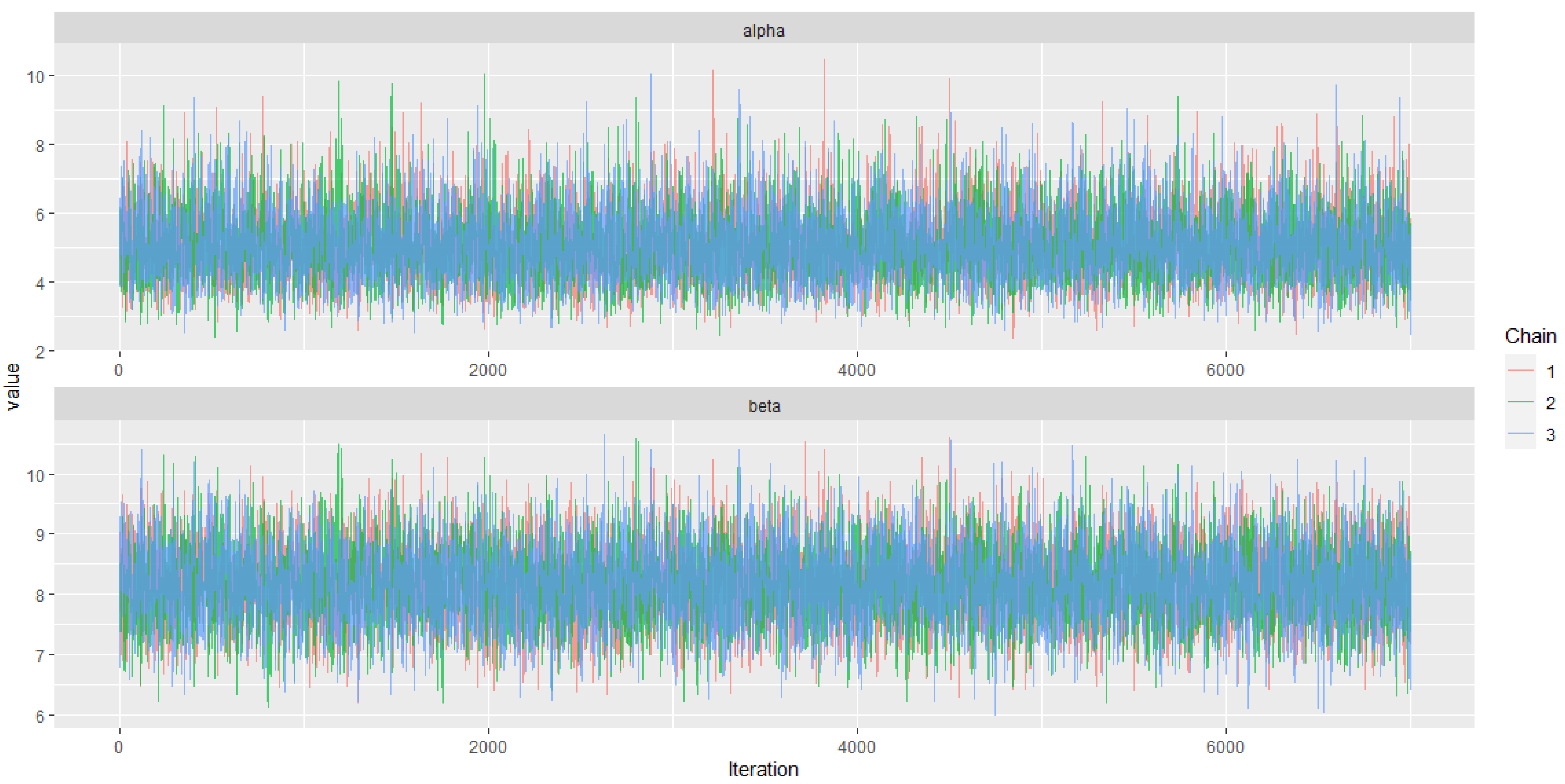
We investigate the convergence of the chains visually using the trace, ergodic mean, and autocorrelation plots. The trace plots shown in Figure 11 suggest a stationary pattern and thus convergence of the chains.
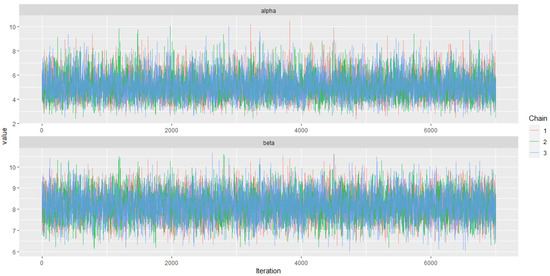
Figure 11.
The AP distribution posterior parameters trace plots.
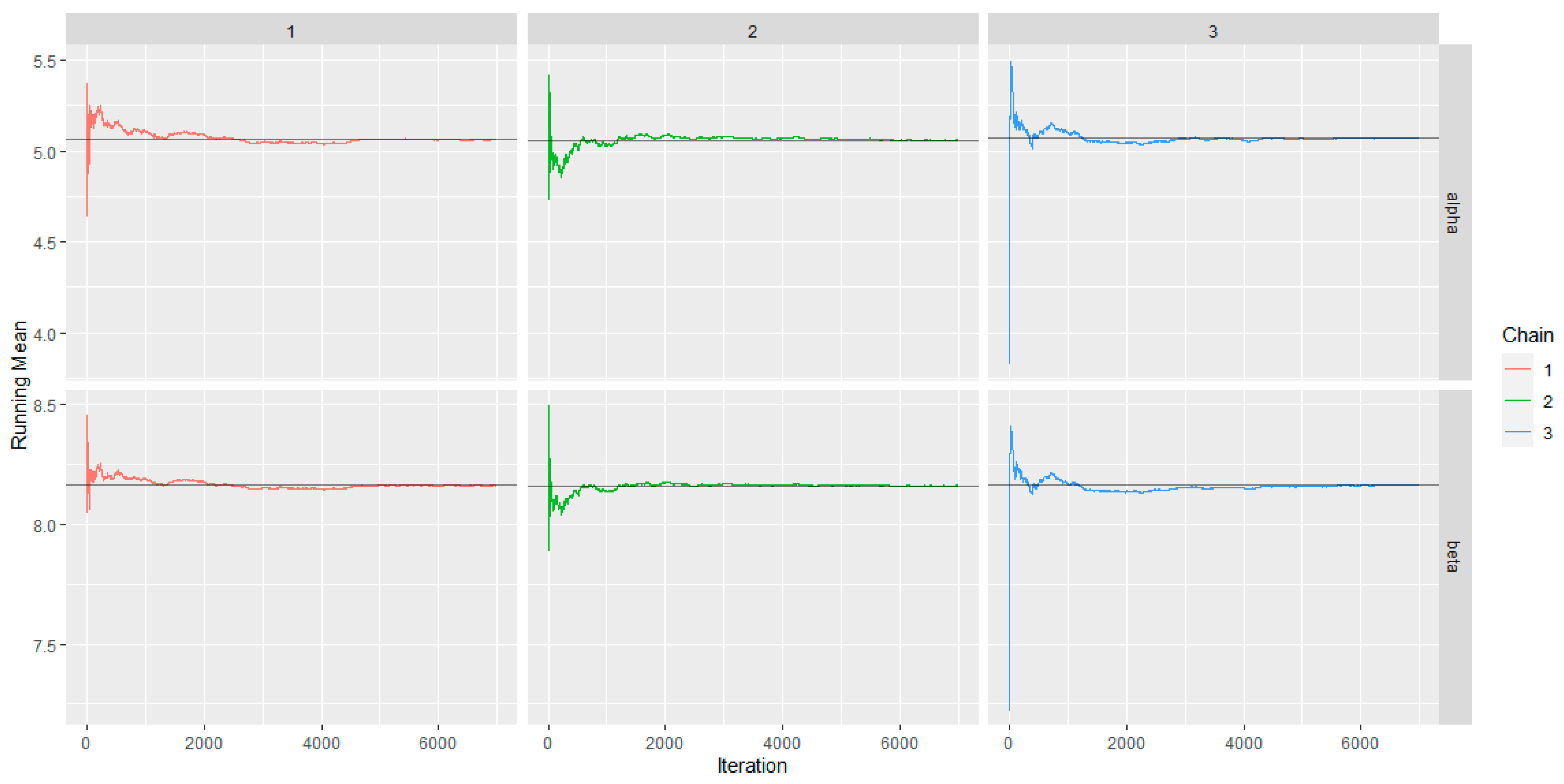
The ergodic mean plots (Figure 12) of the parameters clearly show that the chains have converged after 3000 iterations.
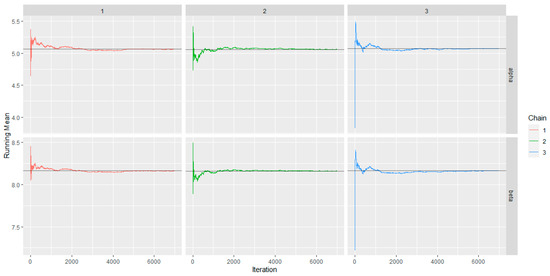
Figure 12.
The AP distribution posterior parameters ergodic mean plots.
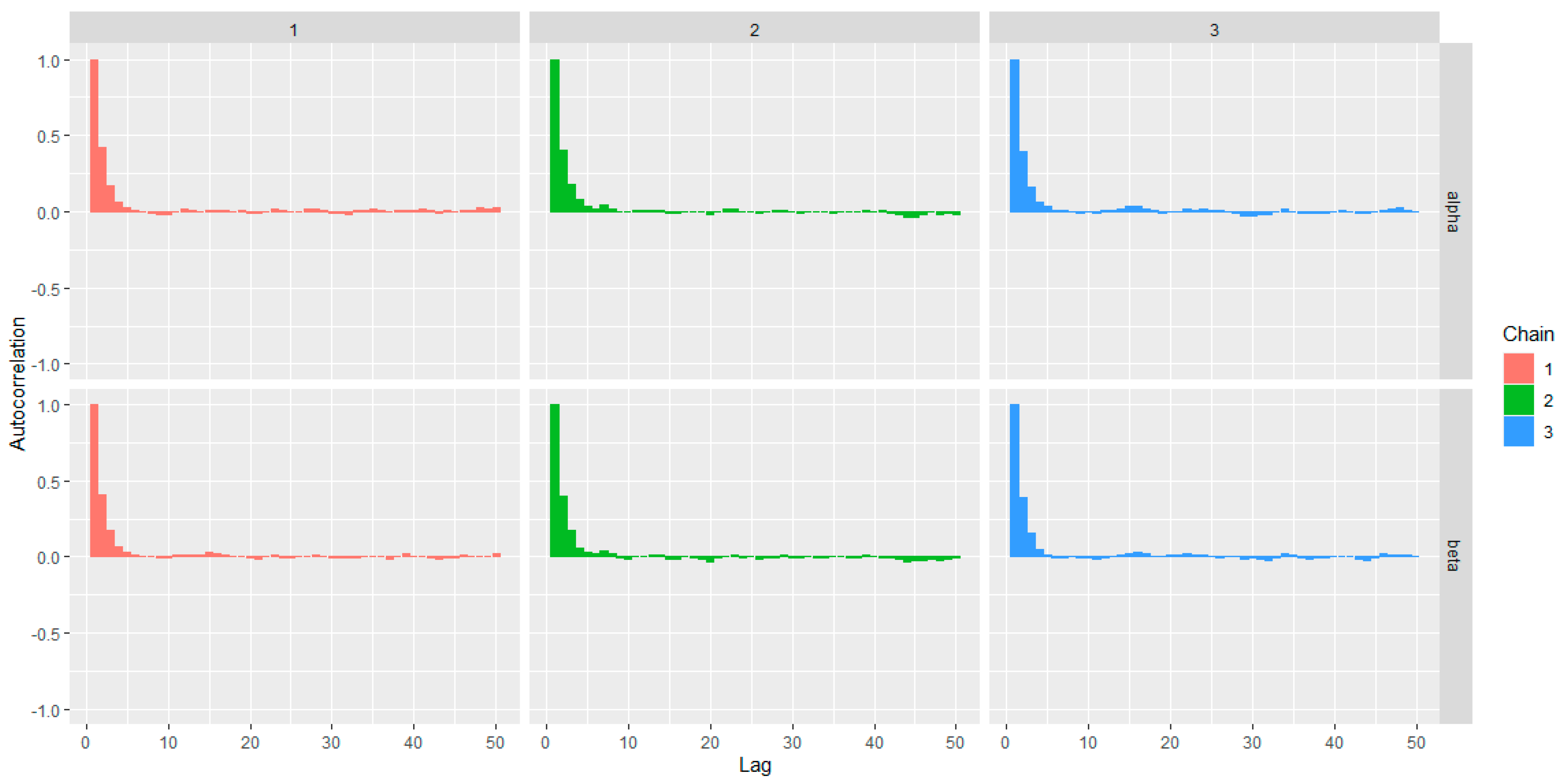
The rapid decay of the autocorrelation plots, as shown in Figure 13, suggests good mixing of the chains and the convergence of the MCMC algorithm.
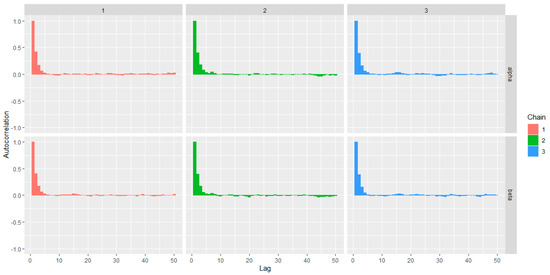
Figure 13.
The AP distribution posterior parameters autocorrelation plots.
7. Regression Models
In this section, the quantile and modal regression models are developed for investigating the relationship between a dependent variable and a set of independent variable (s).
7.1. Quantile Regression Model
When investigating the influence of covariates on a skewed, bounded response variable, the beta regression model cannot produce reliable results since it models the conditional mean of the response variable. This is because the mean is not an appropriate measure of central tendency when the data are skewed. Thus, a regression model that is not influenced by outliers is required. The quantile regression is appropriate when dealing with skewed response variables. In this subsection, the AP quantile regression model is developed. To this aim, we re-parameterize the PDF of the AP distribution in terms of its quantile function. Let , making the subject in the quantile function, and we have . Hence, the re-parametrized PDF in terms of the quantile function is given by
where and is the quantile parameter. Suppose that are random observations from the AP distribution and is non-random covariates. The AP quantile regression model is thus given by
where is the vector of coefficients of the covariates to be estimated, is the known vector of independent variables, and is an appropriate link function that relates the independent variables to the conditional quantile of the dependent variable. When , the median regression is obtained. Although different link functions exist for modeling bounded response variables, in this study, the logit link function is used due to the easy interpretation of the parameters. Hence, we have
The log-likelihood for estimating the parameters of the regression model is
Maximizing the log-likelihood function in Equation (34) with respect to the involved parameters gives the estimates of the parameters of the model. For more information on the development of parametric quantile regressions, we refer the readers to [2,3,6].
7.2. Modal Regression
When the response variable is heavy-tailed or asymmetric, modal regression is known to give a better fit than the conditional mean or median regression [29]. It is also established that the prediction intervals from modal regression possess a higher coverage probability than the mean-based prediction interval (see [29,30]). This subsection presents the modal-based regression using the AP distribution. Suppose that the transformation is one-to-one, where is the mode and is a precision/shape parameter. Then the PDF of the AP distribution can be re-parameterized in terms of the mode (see [29]). Let , then and the PDF of the AP distribution in terms of mode is given by
The modal regression is given by
where is the vector of unknown parameters to be estimated, are the known vector of covariates and is an appropriate link function that links the covariates to the conditional mode of the response variable. The logit link function is adopted since the mode of the AP distribution lies on (0, 1). Thus, we have
The log-likelihood for estimating the parameters of the model is given by
The estimates of the parameters of the modal regression are obtained by maximizing Equation (36) with respect to the involved parameters.
7.3. Residual Analysis
Investigating how well a model fits a given data set is very important. Hence, the adequacy of the model is often examined using the residuals from the fitted model. The Cox–Snell and randomized quantile residuals are used to assess the performance of the regression models in this study.
Thus, the Cox–Snell residuals (see [31]) are used to assess the adequacy of the regression models. The Cox–Snell residuals are defined as
where is the vector of the estimated parameters of the regression models. The Cox–Snell residuals are expected to be standard exponentially distributed if the models provide good fit to the data.
Assessing the randomized quantile residuals of the model is another alternative for examining the adequacy of the regression model. The randomized quantile residual is given by
where is the quantile of the standard normal distribution. If the regression model provides good fit to the data, the randomized quantile residuals are expected to follow the standard normal distribution (see [32]).
7.4. Monte Carlo Simulation for Regression Models
In this section, Monte Carlo simulation experiments are carried out to assess how the ML estimates perform with regards to estimating the parameters of the AP quantile and modal regressions. The simulations for the quantile regression are carried out using the conditional median. The conditional median in this case is the median of the response variable given the values of the covariates. The experiment is replicated 5000 times for each sample size , and . For the first scenario, the following parameter combinations are used for the quantile and modal regressions, respectively: and . In the second scenario, the parameter following combinations are used, respectively, for the quantile and modal regressions: and . The following regression structure with two covariates is employed during the simulation for both regression models:
The covariate, , is generated from a standard normal distribution and is from a distribution with four degrees of freedom. The covariates are held fixed during the simulation process. The observations for the response variable are generated using the inversion method for both the quantile and modal regressions. The performance of the estimation method is assessed using the average estimate (AE), absolute bias (AB), and root mean square error (RMSE). The results in Table 5 and Table 6 reveal that the AEs approach the true parameter values as the sample size increases. Furthermore, the ABs and RMSEs decrease as the sample size increases. Hence, the estimates of the parameters for both models are consistent based on the ML technique.
Table 5.
Simulation results for the first scenario.
Table 6.
Simulation results for the second scenario.
7.5. Application of Regression Models
The use of quantile and modal regressions is demonstrated in this subsection. The application of the quantile regression is illustrated via the conditional median regression by setting . The application of the models is illustrated by regressing the recovery rates for viable CD34+ cells of 239 patients described in Section 6 on the following covariates: gender (, 0 for female and 1 for male), chemotherapy (, 0 for receiving chemotherapy on a one-day protocol and 1 for a three-day protocol), and adjusted patient’s age (, that is the current age minus 40). Ref. [6] fitted the UBXII median regression with the following results: and . The authors showed that the UBXII median regression performs better than the Kumaraswamy median regression with the following results: and , and beta mean regression with the following results: and . The exploratory analysis in Section 6.1 suggests that the response variable is left-skewed or contains some extreme values. This is an indication that robust regression models are required for modeling the data, and thus our choice of using the median and modal regressions is appropriate. We adopt the following regression structure:
to model the data. Table 7 displays the estimates of the model parameters, standard errors, p-values, and information criteria. From the information criteria, the AP regressions (median and modal) perform better than the UBXII median, Kumaraswamy median, and beta mean regressions. Since , the AP regressions perform significantly better than the compared regressions. Comparing the AP median regression with the modal regression, it can be said that the AP median regression performs better than the modal regression. From Table 7, it can be seen that the parameter is not statistically significant at 5% level of significance. Hence, the variable gender has no significant effect on the recovery rate. The parameters and are statistically significant at the 5% level of significance. This implies that the recovery rate of older patients is higher than that of younger ones. Furthermore, the recovery rate of patients who receive chemotherapy on a three-day protocol is higher than that of those who receive chemotherapy on a one-day protocol.
Table 7.
Estimates, standard errors, and information criteria for the regression models.
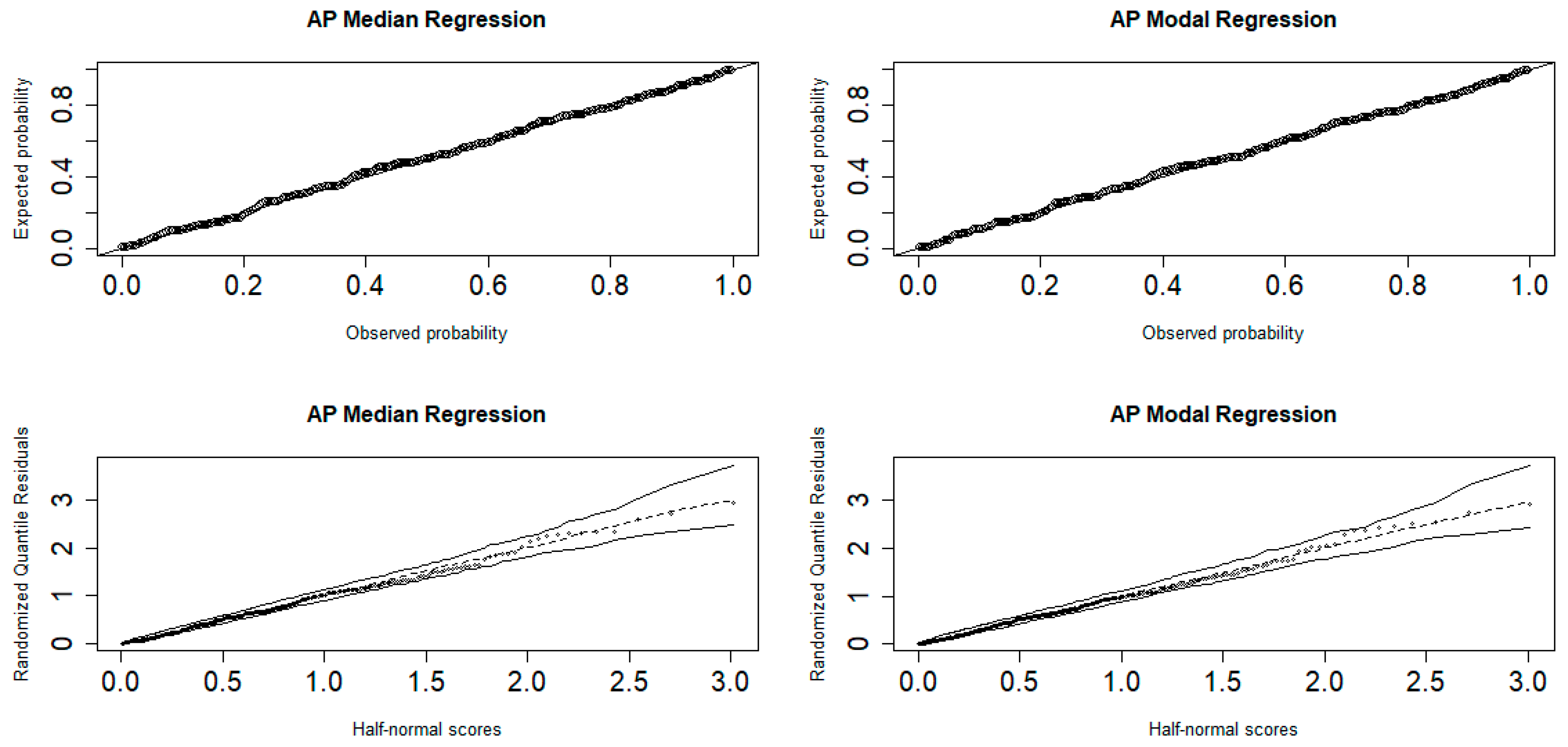
The adequacy of the fitted regression models is assessed by examining the residuals of the fitted models. The P-P plots and half-normal plots with simulated envelopes of the randomized quantile residuals in Figure 14 indicate that the models are adequate.
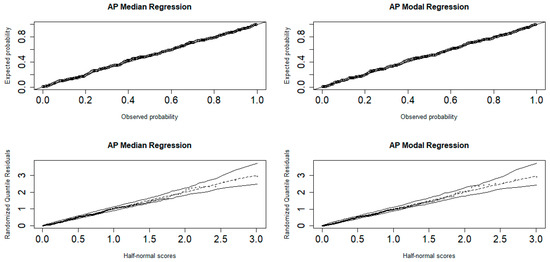
Figure 14.
P-P (top) and half-normal (bottom) plots of the randomized quantile residuals.
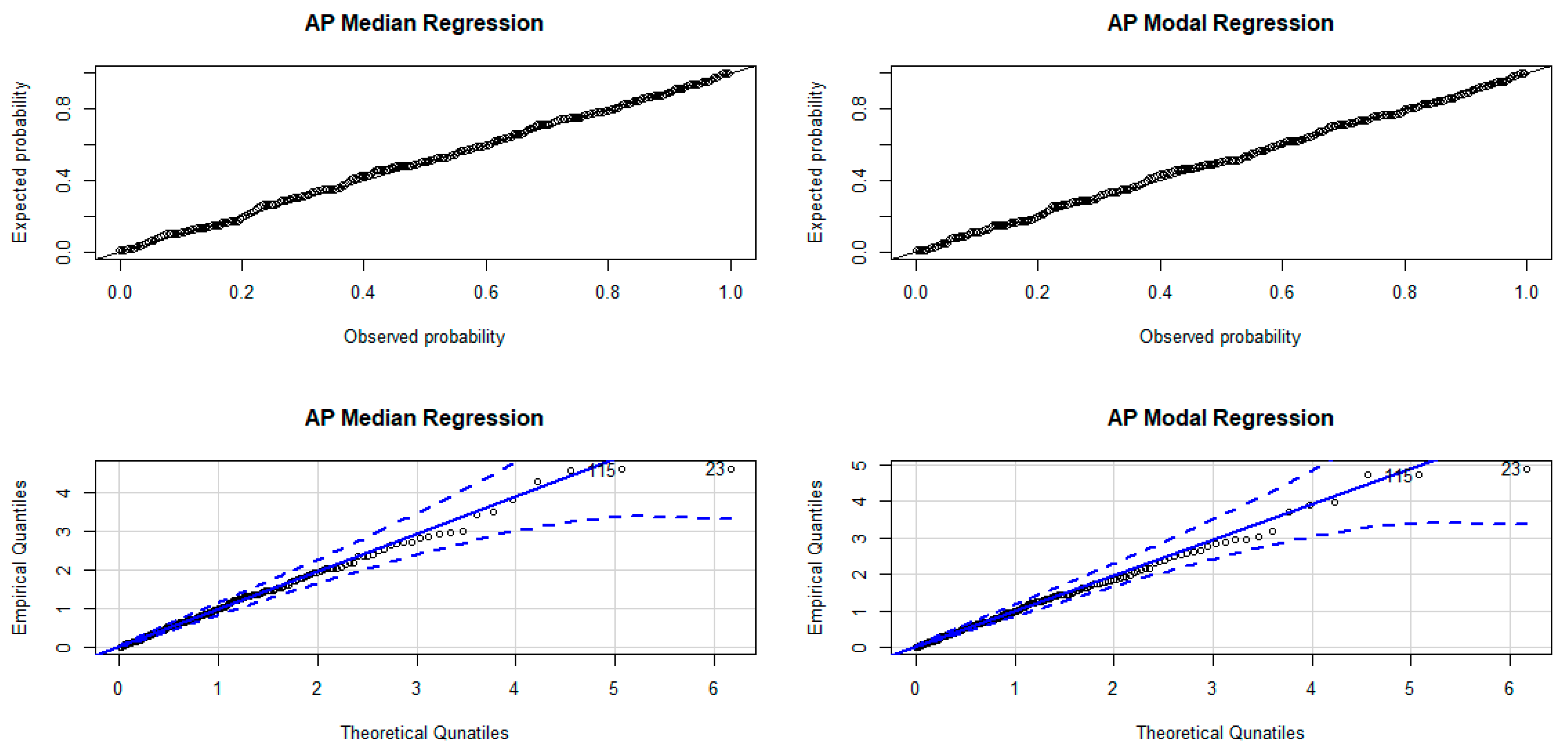
The P-P and quantile-quantile (Q-Q) plots with simulated envelopes of the Cox–Snell residuals shown in Figure 15 again affirm that the fitted models are adequate.
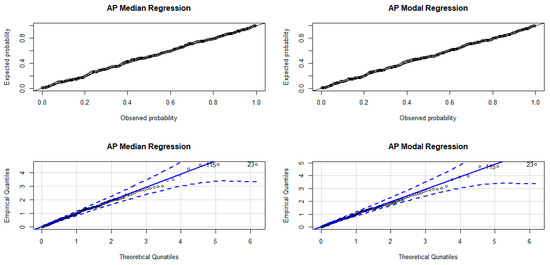
Figure 15.
P-P (top) and Q-Q (bottom) plots of the Cox–Snell residuals.
8. Conclusions
In this study, the AP distribution and its associated quantile and modal regressions were developed. The PDF of the AP distribution exhibits flexible shapes such as left-skewed, right-skewed, J, and reversed-J shapes. This makes the distribution a suitable candidate for fitting data with such characteristics. The corresponding HRF also suggests that the distribution is capable of fitting data with monotonic and non-monotonic failure rates. We explored the performance of nine frequentist estimation procedures for estimating the parameters of the distribution using Monte Carlo simulations, and the results revealed that most of the procedures are consistent with regards to estimating the parameters. A biomedical application of the distribution showed that the model provides a good fit to the data. A Bayesian illustration of how to apply the distribution showed that the approach is able to estimate the parameters of the distribution very well. The applications of the elaborated quantile and modal regressions demonstrated that the new regression models outperformed some existing regression models. The future perspective of this work is to demonstrate the Bayesian applications of the quantile and modal regressions.
Author Contributions
Conceptualization, S.N., A.G.A. and C.C.; Data curation, S.N., A.G.A. and C.C.; Methodology, S.N., A.G.A. and C.C.; Supervision, S.N. and C.C.; Validation, S.N. and C.C.; Visualization, S.N. and A.G.A.; Writing, S.N. and A.G.A.; Review and editing, S.N. and C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this study can be found in the simplexreg package of the R software developed by [22].
Acknowledgments
We express our sincere gratitude to the editor and reviewers whose constructive criticism improved the content of the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. The unit folded normal distribution: A new unit probability distribution with the estimation procedures, quantile regression modeling and educational attainment applications. J. Reliab. Stat. Stud. 2022, 15, 261–298. [Google Scholar] [CrossRef]
- Nasiru, S.; Abubakari, A.G.; Chesneau, C. New lifetime distribution for modeling data on the unit interval: Properties, application and quantile regression. Math. Comput. Appl. 2022, 27, 105. [Google Scholar] [CrossRef]
- Abubakari, A.G.; Luguterah, A.; Nasiru, S. Unit exponentiated Fréchet distribution: Actuarial measures, quantile regression and applications. J. Indian Soc. Probab. Stat. 2022, 23, 387–424. [Google Scholar] [CrossRef]
- Eliwa, M.S.; Ahsan-ul-Haq, M.; Al-Bossly, A.; El-Morshedy, M. Properties and estimation techniques with application to model data from SC16 and P3 algorithms. Math. Probl. Eng. 2022, 2022, 9289721. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Emrah, A.; Chesneau, C.; Yousof, H.M. On the unit-Chen distribution with associated quantile regression and applications. Math. Slovaca 2022, 72, 765–786. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C. On the unit Burr XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç. The unit generalized half normal distribution: A new bounded distribution with inference and application. UPB Sci. Bull. Ser. A 2020, 82, 133–140. [Google Scholar]
- Modi, K.; Gill, V. Unit Burr-III distribution with application. J. Stat. Manag. Syst. 2019, 23, 579–592. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2019, 35, 259–279. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Ghitany, M.E. The unit Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Pourdarvish, A.; Mirmostafaee, S.M.T.K.; Naderi, K. The exponentiated Topp-Leone distribution: Properties and application. J. Appl. Environ. Biol. Sci. 2015, 5, 251–256. [Google Scholar]
- Kharazmi, O.; Alizadeh, M.; Contreras-Reyes, J.E.; Haghbin, H. Arctan-based family of distributions: Properties, survival regression, Bayesian analysis and applications. Axioms 2022, 11, 399. [Google Scholar] [CrossRef]
- Al-Mofleh, H.; Afify, A.Z.; Ibrahim, N.A. A new extended two-parameter distribution: Properties, estimation methods and, applications in medicine and geology. Mathematics 2020, 8, 1578. [Google Scholar] [CrossRef]
- Iqbal, Z.; Tahir, M.M.; Riaz, N.; Ali, S.A.; Ahmad, M. Generalized inverted Kumaraswamy distribution: Properties and application. Open J. Stat. 2017, 7, 645–662. [Google Scholar] [CrossRef]
- Iqbal, Z.; Hasnain, S.A.; Salman, M.; Ahmad, M.; Hamedani, G.G. Generalized exponentiated moment exponential distribution. Pak. J. Stat. 2014, 30, 537–554. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Tables of Integrals, Series and Products, 7th ed.; Elsevier/Academic Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Sklar, A. Random variables, joint distribution functions and copulas. Kybernetika 1973, 9, 449–460. [Google Scholar]
- Elhassanein, A. On statistical properties of a new bivariate modified Lindley distribution with an application to financial data. Complexity 2022, 2022, 2328831. [Google Scholar] [CrossRef]
- Ganji, M.; Bevrani, H.; Hami, N. A new method for generating continuous bivariate families. J. Iran. Stat. Soc. 2018, 17, 109–129. [Google Scholar] [CrossRef]
- Zhang, P.; Qiu, Z.; Shi, C. Simplexreg: An R package for regression analysis of proportional data using the simplex distribution. J. Stat. Softw. 2016, 71, 1–21. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Shafiq, S.; Tahir, M.H.; Elhassanein, A.; Jamal, F.; Almutiry, W.; Elgarhy, M. Statistical analysis of COVID-19 data: Using a new univariate and bivariate statistical model. J. Funct. Spaces 2022, 2022, 2851352. [Google Scholar] [CrossRef]
- Ghosh, I.; Dey, S.; Kumar, D. Bounded M-O extended exponential distribution with applications. Stoch. Qual. Control. 2019, 34, 35–51. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A Generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Muse, A.H.; Chesneau, C.; Ngesa, O.; Mwalili, S. Flexible parametric accelerated hazard model: Simulation and application to censored lifetime data with crossing survival curves. Math. Comput. Appl. 2022, 27, 104. [Google Scholar] [CrossRef]
- Khan, S.A. Exponentiated Weibull regression for time-to-event data. Lifetime Data Anal. 2018, 24, 328–354. [Google Scholar] [CrossRef]
- Su, Y.S.; Yajima, M. R2jags: A Package for Running Jags from R. 2012. Available online: https://CRAN.R-project.org/package=R2jags (accessed on 21 December 2022).
- Menezes, A.F.B.; Mazucheli, J.; Chakraborty, S. A collection of parametric modal regression models for bounded data. J. Biopharm. Stat. 2021, 31, 490–506. [Google Scholar] [CrossRef]
- Yao, W.; Li, L. A new regression model. Scand. J. Stat. 2014, 41, 656–671. [Google Scholar] [CrossRef]
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. R. Stat. Soc. Ser. B 1968, 30, 248–275. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).