Abstract
(1) Background: Most studies including health data have relied on reducing all variables to manifest scores, ignoring the latent nature of variables. Moreover, relying only on manifest variables is a limitation of longitudinal studies where identical measures cannot be collected at each time point. (2) Objective: This scoping review aims to identify latent variable statistical methods for longitudinal studies of multi-dimensional health and educational data investigating early health predictors of long-term educational outcomes and developmental trajectories that lead to better or worse than expected outcomes. (3) Eligibility criteria: We included peer-reviewed health and education journal articles, doctoral theses, and book chapters of longitudinal studies of children under 12 years of age that adopted latent variable, multivariate analysis of three or more waves of data. We only included full-text-available, English-written articles, without restriction on date of publication. (4) Sources of evidence: We searched five databases, Scopus, MEDLINE, PsycINFO, ERIC, and Web of Science, and identified 4836 publications for screening. (5) Results: After title, abstract, and full-text screening, nine studies were included in the review, reporting seven statistical methods. These methods were categorised into two groups—variable-oriented modelling and person-oriented modelling. (6) Conclusions: Variable-oriented modelling methods are useful for determining predictors of long-term educational outcomes. Person-oriented modelling methods are effective in detecting trajectories to better or worse than expected outcomes. (7) Registration: Open Science Framework.
1. Introduction
1.1. Rationale
In a longitudinal cohort, it is often of interest to examine early predictors and trajectories of outcomes, particularly in health and education domains. The analysis of data waves over a developmental period allows researchers to identify potential risk and protective factors that hinder or contribute to important outcomes. Many studies have investigated the identification of predictors of both health and educational outcomes (Dai et al., 2020; Harwell et al., 2017; S. W. Kim et al., 2019; Kulkarni et al., 2021; Matingwina, 2018; Mayer, 2020), but ignoring the latent nature of data is a limitation of many such studies. Relying only on manifest variables can be problematic in longitudinal studies where identical measures cannot be collected at each time point, which is common among longitudinal studies that look through infancy to adolescence and adulthood. In addition, methods that can detect mid-study changes (for example, environmental shifts) explaining why individuals deviate from trajectories predicted by their early conditions could generate insights not otherwise available. Hence, methods are needed that identify not just which conditions explain outcomes but also which factors contribute to changes in trajectory.
The selection of statistical method may greatly affect the interpretation of results and subsequence policy or clinical suggestions (Silberzahn et al., 2018). A variety of methods have been developed to analyse longitudinal data (Fitzmaurice et al., 2011; Frees, 2004; Hoffman, 2015; Singer & Willett, 2003; Y.-G. Wang et al., 2022). However, uncertainty remains around which method is most appropriate for different research scenarios. This uncertainty typically stems from the nature of data (e.g., manifest vs. latent, categorical vs. continuous), sample size, number of data collection waves, measurement frequency, the nature of missingness, the complexity of outcome variables (e.g., single or multiple), and model assumptions.
A search of systematic or scoping reviews concerning longitudinal statistical methods on Web of Science found most reviews were on specific health issues in medical studies (Cezard et al., 2021; Cosco et al., 2017; Lim et al., 2017; Majewska et al., 2019; Michael et al., 2024; Stanley et al., 2019; Stevens et al., 2021; Timman et al., 2004), but with little focus on educational studies (Hicks & Knollman, 2015). In Cosco et al.’s (2017) review, the most popular latent variable model to group similar participants in longitudinal patterns is growth mixture modelling. Other common latent variable methods reported in the reviews include latent class models (Cezard et al., 2021; Cosco et al., 2017; Lim et al., 2017; Majewska et al., 2019) and group-based modelling (Cezard et al., 2021; Cosco et al., 2017), while less frequently used methods include the Tobit model (Majewska et al., 2019). However, these reviews did not exclusively focus on latent variable methods, and they reported more non-latent than latent variable methods. Among latent variable methods, latent growth curve modelling (Bollen & Curran, 2006) is widely used to examine individual trajectories over time. In addition, the cross-lagged panel model (Lüdtke & Robitzsch, 2021) and the random intercept cross-lagged panel models (Hamaker et al., 2015) have also gained popularity for modelling reciprocal effects using longitudinal data, but they are typically applied in two constructs models. Therefore, we undertook this scoping review of statistical methods that adopt longitudinal, multivariate, latent variable design.
While there are many longitudinal cohort studies worldwide that may benefit from methods described in our review, one example that highlights the need for a comprehensive review of predictor and trajectory analysis methods is the Children with Hypoglycaemia and Their Later Development (CHYLD) study, which explored neonatal and early childhood factors contributing to early schooling outcomes (Shah et al., 2022). This longitudinal cohort study of children born at risk of neonatal hypoglycaemia (low glucose concentrations) includes psychological, environmental, and physiological data in three waves at ages 2, 4.5, and 9–10 years, with educational achievement outcomes at 9–10 years (McKinlay et al., 2015, 2017; Ansell et al., 2017; Shah et al., 2021, 2022). Previous analyses of this dataset applied conventional analysis of variance methods (i.e., “generalized linear models (maximum likelihood) with binomial, Poisson, or normal distributions and relevant link functions, as appropriate, adjusted for prespecified potential confounders (socioeconomic decile, sex, and primary risk factor for neonatal hypoglycaemia).” (Shah et al., 2022, p. 1161). They have relied on manifest scores (e.g., cognitive function, behaviour ratings), ignoring the latent nature of these variables. Modelling these variables as latent variables (e.g., the psychological factor) would enable tests of longitudinal measurement invariance across age given that different measurement instruments/scales were used at different ages in that data. By doing so, researchers may reveal novel insights that previous manifest-only analyses have overlooked.
1.2. Objective
The aim of this review was to identify appropriate latent variable statistical methods for studies that have complex and repeated waves of data about the intricate relationships between early health experiences and longer-term educational outcomes. We aimed to offer guidance for researchers facing similar analytical challenges in either disciplinary setting. Three research questions guided this review, as follows:
- Which latent variable statistical methods have been applied in longitudinal studies of multi-dimensional health and education data?
- Among those methods found, which methods are appropriate to identify predictors of long-term educational outcomes?
- Among those methods found, which methods are appropriate to detect trajectories or pathways over time that lead to better or worse than expected educational outcomes?
2. Methods
This scoping review was undertaken in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) (Tricco et al., 2018). The PRISMA checklist for this scoping review was provided (Supplementary S1). A protocol was prospectively registered with Open Science Framework on 3 May 2023 (https://osf.io/a89rq (accessed on 13 September 2023)).
2.1. Eligibility Criteria
The eligibility criteria are shown in Table 1.

Table 1.
Inclusion and exclusion criteria for studies.
2.1.1. Participants
Studies were eligible if they reported analyses of data from children under 12 years of age. For mixed-age studies, eligibility required that at least 40% of participants were under 12 years, and for multi-wave studies, at least one time point had to include data from participants under 12 years. This age was chosen because in New Zealand, as in many countries, it is the age when many children transition from primary to secondary schooling. Educational influences and opportunities start to undergo significant changes. It is also the time when many children begin to experience significant developmental changes associated with puberty. This threshold was set to minimise potential confounding factors related to adolescence transitions.
2.1.2. Concept
We included multivariate, quantitative, longitudinal design studies. Although linear trends can be identified with two time points (resulting in a saturated model), longitudinal in our review was defined as three or more waves of data, as a minimum of three time points is generally necessary to identify linear trajectories and to evaluate model fit (Bollen & Curran, 2006). Studies could include measures of the same or different variables in multiple waves. Multivariate was defined as at least three outcome variables of interest in the statistical models. In addition, we included only studies with latent variables analysis design, and excluded studies that did not apply latent analysis of manifest variables. We included both methodological articles and application studies but excluded systematic reviews.
2.1.3. Context
We included studies in the fields of health and education that considered human data. Studies reporting analysis of non-human data (such as animals or plants) were excluded. Included studies were peer-reviewed journal articles, doctoral theses, or book chapters with full text available, written in English, with no restrictions on date of publication.
2.2. Information Sources and Search
We searched five databases, Scopus, MEDLINE, PsycINFO, ERIC, and Web of Science, from inception to July 2025. The search strategies were developed in consultation with an academic librarian. Key terms used in the search included variations of “statistical method*” (e.g., “statistical analysis”, “statistical model*”, “analytic* approach*”, “analytic* model*”), “multi-variate” (e.g., “multivariate”, “multidimension*”, “multi-construct*”, “multidomain*”), and “longitudinal study” (e.g., “longitudinal studies”, “multi-wave”, “repeated measurement*”). These keywords were applied across five databases, and detailed search strategies are provided in Supplementary S2. All final search results were saved to Zotero (Corporation for Digital Scholarship, 2006/2023) then uploaded into Covidence systematic review software (Veritas Health Innovation, Melbourne, Australia) (available at www.covidence.org (accessed on 12 May 2023)).
2.3. Selection of Sources of Evidence
Literature screening was conducted in the following two stages: (1) title and abstract and (2) full texts. The first reviewer (M.H.) carried out the title and abstract screening. Then, at the beginning of full texts screening, two rounds of inter-rater reliability tests were conducted to minimise evidence selection bias. In the first round, three reviewers (M.H., G.B., and J.H.) independently reviewed full texts of the same 30 randomly selected studies. The inter-rater agreement was poor (κ < 0.20) (Fleiss, 1971). To improve the consistency, all reviewers discussed the results and resolved disagreements to reach consensus before the second round. Disagreements were on whether to include mixed-age studies, whether to include studies with simulation data only, whether two-wave studies were considered longitudinal, whether imaging data of humans were considered human data, and whether certain analyses (e.g., cluster analysis) were considered latent variable analysis. In the second round, reviewers worked in pairs (M.H. and G.B., M.H. and J.H.). Each pair independently reviewed 25 randomly selected studies. This resulted in 95% (κ = 0.64) and 96% consensus (κ = 0.65), respectively. Disagreements were on whether doctoral theses were considered grey literature and whether to include review articles. These two rounds of inter-rater reliability tests and discussions increased understanding the subtleties of concept definitions among reviewers and led to refinement of the eligibility criteria. After that, the first reviewer (M.H.) reviewed all remaining studies, with any uncertain cases discussed with the second reviewer (G.B.) to reach a decision.
2.4. Data Charting
A data extraction table was jointly developed by all reviewers. Data were extracted from the included studies by the first reviewer and checked by the second reviewer. Data extracted included the context, country, data-related details (sample size, baseline age, number of time points, time intervals, follow-up time, and scale data types), the statistical methods used, and method-related details (handling missing data and software or package).
2.5. Synthesis of Results
We classified the identified methods into different groups based on similarities and differences in method assumptions. We also evaluated each statistical method on its suitability for the specific purposes set out in the objectives of review.
3. Results
3.1. Study Selection
Figure 1 shows the study selection process. Database searches produced 4836 results, which were uploaded into Covidence. A total of 960 duplicates were removed (936 automatically by Covidence and 24 manually). Of the remaining 3876 studies, 2045 were removed during the title and abstract level screening by the first reviewer (M.H.), leaving 1831 full-text studies to be assessed for eligibility. A further 1822 were removed during full-text screening by three reviewers (M.H., G.B., and J.H.). The most common reasons for exclusion were studies that did not include participants in the right age range (1132) and studies that did not involve latent variables analysis (518). The remaining nine studies were included for further data extraction.
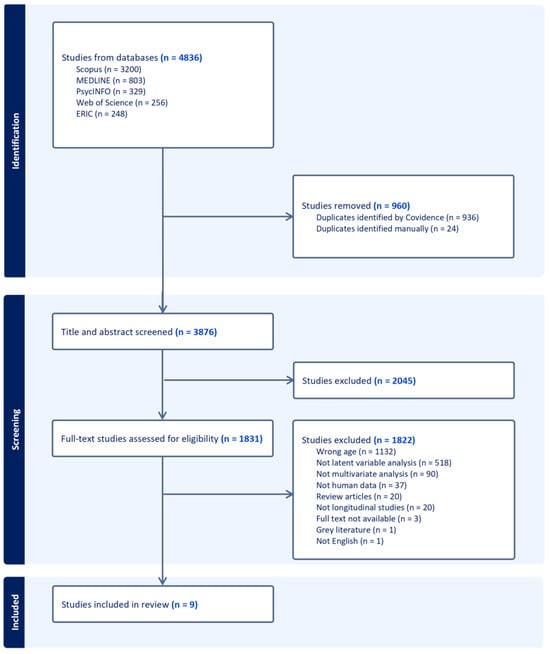
Figure 1.
PRISMA flowchart of the selection process.
3.2. Characteristics of Included Studies
We included nine studies reporting 10 data examples (Table 2). The studies were conducted in diverse countries, with the largest number (i.e., 5 out of 10) in the United States. Sample sizes ranged from 237 to 7507, and follow-up times ranged from 2 to 35 years. Most (6 out of 10) had three or four waves of data. The most common time interval between waves was 1 year (i.e., 6 out of 10), and the most commonly used software for data analysis was Mplus (L. K. Muthén & Muthén, 1998).
Table 2.
Characteristics of the included studies (sorted by publication year).
3.3. Results of Included Studies
From the included studies, we found seven statistical methods (Table 3). Two studies applied latent growth curve modelling (LGM), two growth mixture models (GMM), and two latent transition analysis models (LTA). Each of the other studies adopted a different other method. Three studies identified mean changes in the whole population over time (Isiordia et al., 2017; Ju & Lee, 2018; Liu & Perera, 2023), and six studies investigated trajectories of different subgroups within the population (Ip et al., 2018; Katsantonis & Symonds, 2023; Nagin et al., 2018; Reboussin et al., 1998; Wildeboer et al., 2015; Yarnell et al., 2018).
Table 3.
Results of the included studies (sorted by statistical method).
3.4. Synthesis of Results
Based on the assumptions of each method, we grouped the seven methods into two categories—variable-oriented modelling and person-oriented modelling (Table 4). Variable-oriented modelling works on the assumption that people are at the average, while person-oriented modelling looks at the pattens of people within the variables. These two categories indicate that people are not forced to be at the average but allowed to vary within the range. Variable-oriented modelling methods assume population homogeneity and allow researchers to test the influence of variables (Bollen & Curran, 2006), making them suitable for the objective in Research Question 2—identifying predictors of long-term outcome. In contrast, person-oriented modelling methods reflect a person-centred, emergentist worldview drawn from developmental systems theory, assuming population heterogeneity through discrete latent classes, each following its own growth trajectory (B. O. Muthén, 2004). Thus, person-oriented modelling methods are suited to address objective in Research Question 3—detecting trajectories of subpopulation to differential outcomes.
Table 4.
Grouping of statistical methods from included studies.
Variable-oriented modelling includes LGM (Ju & Lee, 2018), factor of curves (FOCUS) (Isiordia et al., 2017), and piecewise linear growth curve models (Piecewise LGM) (Liu & Perera, 2023). LGM is a structural equation modelling (SEM) approach that estimates changes over time using two inter-correlated traits (i.e., the starting value or intercept and the change or slope rate) (Brown & Peterson, 2018). LGM can be used to understand group-level change, to explore individual changes, and to identify explanatory variables to predict individual changes (Bollen & Curran, 2006). FOCUS, introduced by McArdle (1988), extends the LGM approach to include higher-order common factors to capture the relations among the lower-order developmental trajectories. Piecewise LGM extends standard LGM by allowing the rate of change (growth/latent slope) to differ across phases separated by one or more knots (timepoints) (Liu & Perera, 2023). Grimm et al. (2016) referred a two-stage piecewise model as a bilinear spline growth model. Using this model, researchers were able to examine joint longitudinal processes. All three methods allow researchers to estimate between-person differences in within-person change in longitudinal studies.
Person-oriented modelling includes GMM, group-based multi-trajectory models (GBMT), hidden Markov models (HMM), and LTA. GMM relaxes the single population assumption of conventional growth modelling to allow for parameter differences across unobserved subpopulations (B. O. Muthén, 2004). GBMT is an extension of univariate group-based trajectory modelling (Nagin et al., 2018), which identifies groups of individuals following similar trajectories over time in terms of a single outcome. GBMT can be used to model multiple related trajectories for more than two outcomes simultaneously (Nagin et al., 2018). HMM is a probabilistic modelling technique that models a system as a Markov process with hidden or unobservable states (latent classes) (Ali & Bouguila, 2022). LTA extends HMM by modelling transitions between latent classes (states) over time. Compared to LGM, which assumes continuous change across an entire time period, LTA uses an autoregressive approach to describe discrete timepoint to timepoint change with transition probabilities (Nylund-Gibson et al., 2023).
4. Discussion
4.1. Summary
We included 9 studies out of 4836 health and education studies that used latent variable statistical methods to model three or more outcome variables simultaneously, with three or more waves of longitudinal data, conducted with children under 12 years of age. Seven methods were identified from the included studies and classified into two groups: (1) variable-oriented modelling (LGM, FOCUS, and Piecewise LGM) and (2) person-oriented modelling (GMM, LTA, HMM, and GBMT). In general, variable-oriented modelling methods seemed most suitable for determining predictors of long-term outcomes, while person-oriented modelling methods seemed best able to detect trajectories of differential outcomes. We discussed recommendations for analysts with different research purposes below.
4.2. Variable-Oriented Modelling: For Researchers Aiming to Find Predictors of Long-Term Outcomes
For analysts looking to understand how one construct influences another construct over time, or to predict in which situation a person will be in the future based on their start values, variable-oriented modelling methods can be used (LGM, FOCUS, and Piecewise LGM) that assume people are close to the average. All three methods are based on the SEM framework, so they share some similarities. They are robust against data limitations and able to handle complex longitudinal data. In contrast to LGM, FOCUS seems to have been used less often in previous studies, but it retains the same ability to model latent factors and structures as LGM (Martinez-Huertas & Ferrer, 2023; McArdle, 1988).
Consistent with SEM, these three methods can model manifest variables as indicators of latent constructs (e.g., standardised test scores and teacher ratings can be aggregated as a latent factor for academic performance). This latent factor approach reduces data dimensionality in a robust manner, making it easier to identify causal paths over time (Bollen, 2020). Hence, they allow for simultaneous modelling of multiple outcome variables and different types of scale data (including nominal, ordinal, and continuous data). Indeed, multiple correlated predictors can be modelled alongside multiple correlated dependencies, along with mediators and moderators. An advantage of Piecewise LGM is that growth at the earlier phase (pre-knot slope) can be specified to predict growth at the later phase (post-knot slope) (Cheong et al., 2003). The piecewise approach in a mediation model is optimal if researchers are interested in finding out the change point event or a developmental milestone (indicated by the estimated knot) in a longitudinal process (Liu & Perera, 2023).
Given the presence of different kinds of data, the SEM framework provides multiple estimators to adjust standard error estimates and test statistics. The use of maximum likelihood estimation allows LGM, FOCUS, and Piecewise LGM to analyse even highly kurtotic data (i.e., up to 7.00) (H.-Y. Kim, 2013). Other estimators exist to handle binary (e.g., asymptotic distribution free) and ordinal (e.g., diagonal weighted least squares) variables. This gives the methods great flexibility.
The methods are designed to model repeated measurements of three or more time points across multiple kinds of time windows; time gaps of more than 2 years are very manageable (Bollen & Curran, 2006; Isiordia et al., 2017; Martinez-Huertas & Ferrer, 2023). This permits tracking changes in data across both small and large time periods. Both LGM and FOCUS are capable of handling relatively small sample sizes of 300–400 (Kline, 2023; Taherian et al., 2021), which are typical in longitudinal cohort studies.
In multiple waves of cohort studies, there is usually an increasing presence of unplanned missing data. The included studies using all three methods used full information maximum likelihood (FIML) to handle missing data. Under a missing at random assumption, both FIML and multiple imputation by chained equations (MICE) are widely used within the SEM framework and can produce unbiased estimates (McArdle & Nesselroade, 2014). It is important to note that multiple imputation are often preferred over FIML (Yucel, 2008), especially when normality assumption is violated or when the model is misspecified (Yuan, 2009). Additionally, Savalei and Bentler (2009) proposed a two-stage approach to handle missing data, which incorporates auxiliary variables to improve estimation. The two-stage approach is more stable than FIML when the sample size is small. In contrast, when person-oriented modelling (e.g., GMM) is used, multiple imputation becomes more complex, and FIML within the mixture modelling framework is commonly used.
In developmental studies, age-appropriate measures are used to estimate a common construct, such as cognitive ability. An important feature of latent factor modelling is that those different indicators can be construed as manifestations of the same underlying construct. Hence, LGM allows different manifest indicators in each data wave to represent the common construct of interest over time. Thus, the robustness of LGM to different indicators at different times is achieved by ensuring indicators are modelled as representing the same underlying construct (McArdle, 2009). Piecewise LGM retains this advantage, while it additionally permits different linear change rates across different phases (Cheong et al., 2003). Consequently, the bias or lack of bias in estimates in LGM depend on factors such as correct model specification, sample size, and estimation methods (Bollen & Curran, 2006; Curran et al., 2010). Although the literature on FOCUS’s robustness to missing data and its ability to produce unbiased estimates is insufficient, its basis in SEM suggests similar performance to that of LGM.
Fortunately, both LGM and FOCUS can be conducted through free software (e.g., R’s lavaan package) (Rosseel, 2012) and Piecewise LGM through R’s OpenMx package (Boker et al., 2025). All three methods also can be performed through commercial software Mplus (L. K. Muthén & Muthén, 1998). These software packages have been widely employed in published studies over the past decade.
4.3. Person-Oriented Modelling: For Researchers Aiming to Identify Differential Trajectories
For analysts looking to understand how people are different within a construct over time, or to detect the trajectories of subgroups leading to better or worse than expected outcomes, person-oriented modelling methods can be used (GMM, LTA, HMM, and GBMT). While variable-oriented approaches seek to identify factors contributing to individual differences on the population’s mean trajectory of development, the person-oriented approaches aim at differentiating group membership and understanding how groups respond differently to events that could change a trajectory (Nagin, 2005). Thus, person-oriented approaches provide a valuable framework for identifying factors that lead to unexpected paths. There are likely to be as many as seven possible trajectories over time; those that never change (e.g., always low, middle, or high), those that change consistently in upward or downward direction, and those that move in both directions over time (e.g., up then down or down then up).
With so many possible trajectories, it is likely that overall sample size will have an impact on reliably detecting such trajectories. Thus, a significant concern with person-oriented modelling is the overall sample size being evaluated. This has an impact on the number of trajectory groups being formed and their cell size. In relatively small samples, the approach can create very small trajectory groups as a consequence of random data fluctuations. Consistent with conventional interpretations of the central limit theorem (King et al., 2018), it is generally recommended to exclude a trajectory group smaller than 30 individuals (Nagin et al., 2024). For GMM, the smallest recommended total sample size is 200 (S.-Y. Kim, 2012), although this may sometimes vary depending on the model complexity, number of groups, percentages of missing data, and group separation (S.-Y. Kim, 2014). Similarly, for GMBT, a total sample size of at least 200 is generally sufficient to stabilize the number of trajectory groups identified, ensuring consistent results as sample size increases beyond this threshold (Sampson et al., 2004). The optimal number of groups is the fewest groups needed to represent distinct trajectory groups of the research interest (Nagin et al., 2024). However, no clear consensus exists for the sample size requirement for HMM and LTA (Nylund-Gibson et al., 2023). For LTA, Nylund-Gibson & Choi (2018) suggested a minimum of 300 while Baldwin (2015) suggested 500 or more. Thus, LTA may not be capable of handling relatively small sample sizes of 300–400. Conversely, HMM is applicable to sample sizes in this range (Song et al., 2017), but larger sample size may be required when modelling more latent states and observations to ensure reliable results (Zucchini et al., 2016).
When data are missing at random, all four methods (GMM, GBMT, HMM, and LTA) are generally robust to missing data when techniques such as FIML or expectation maximisation (EM) are applied (Collins & Lanza, 2010; Enders, 2022; Lee & Harring, 2023; Mody et al., 2021; Song et al., 2017). GMM can produce unbiased estimates of standard error, though biased standard error may occur with complex models and small sample size (Bauer & Curran, 2003). GBMT may underestimate standard errors due to the uncertainty in trajectory group assignments when using maximum likelihood estimation alone (Nagin, 2005; Nagin et al., 2018). However, this limitation can be mitigated through bootstrapping to enhance the robustness of standard error estimates (Nagin et al., 2024). For HMM, parameter estimates can be consistent and asymptotically normal under certain regularity conditions, but such conditions are often violated (Zucchini et al., 2016). The sample size has to be very large so that the asymptotic theory of maximum likelihood can apply. Consequently, it is possible that biased standard error estimates occur with a sample size of 300–400.
Regarding flexibility, GBMT can accommodate different outcome measures at different times by using appropriate statistical distributions (e.g., normal, binary or Poisson) (Nagin, 2005; Nagin et al., 2018). However, standardisation or normalisation of outcomes is necessary to ensure robustness when scales differ significantly. HMM can handle repeated measurement with a time interval of more than two years (Song et al., 2017). Its extensions, such as hidden Markov latent variable models, are particularly suitable for longitudinal data involving potentially different outcome measures at different times (Song et al., 2017). LTA, applicable to repeated measurements of three time points (Morin et al., 2021), is similarly robust to different outcome measures, because it does not require consistent measurement across different time points (Nylund-Gibson et al., 2023).
The most widely used software for GMM and LTA includes Mplus (L. K. Muthén & Muthén, 1998) and Latent Gold (Vermunt & Magidson, 2005). Commercial software includes SAS and Stata versions for GBMT (Jones, 2023) and MATLAB-based tools (Wake Forest School of Medicine, 2020). Free software or package options, such as R’s lcmm package for GMM (Proust-Lima et al., 2017), R’s depmixS4 package (Visser & Speekenbrink, 2010) for HMM, and R’s LMest (Bartolucci et al., 2017) and OpenMx (Boker et al., 2025) packages for LTA, offer accessible alternatives for researchers.
4.4. Limitations
The first limitation of this review is that it does not include possible AI or machine learning methods applied in health and education. The predictive analytical capabilities of emerging AI technologies would enable identifying potential outcomes and trends not easily captured without such algorithms (Olawade et al., 2023; J. Wang & Li, 2024). Application of AI and machine learning techniques within longitudinal studies may discover new insights into complex health and education trajectories. Exclusion of AI and machine learning may potentially limit the applicability of our findings to contexts that increasingly rely on big data analytics.
Further, potential publication bias exits. By restricting our search to Scopus, MEDLINE, PsycINFO, ERIC, and Web of Science, we may have excluded methods reported in more comprehensive AI based databases (e.g., Dimensions.ai) (Stahlschmidt & Stephen, 2020). Related, there is a limitation because of our choice to restrict publications to English only. Excluding non-English publication could bias our review toward methods popular in English-speaking research communities, where studies using certain statistical methods are more likely to be published and therefore overrepresented in the review. We also excluded studies of children older than 12 years of age, to avoid possible confounding due to the substantial educational and pubertal changes expected after this age. Thus, findings may be less applicable to other age groups.
While we identify seven latent variable methods, the review did not find any articles on the cross-lagged panel model (CLPM) or random-intercept cross-lagged panel model (RI-CLPM) that had three or more constructs. These methods are widespread but are most often specified for bivariate outcome constructs, which explains why few CLPM and RI-CLPM studies met our inclusion criteria. Technically, the cross-lagged panel model can be extended to model three or more variables. However, this increases the number of paths and variables to estimate and often requires a larger sample size. Moreover, Lucas (2023) showed that CLPM often underestimates the actual cross-lagged effects and produces spurious cross-lagged effects when they do not exist, because it fails to account for stable trait-level variance. Increasing model complexity may make the model even more vulnerable. Future research could explore the feasibility of extending the bivariate cross-lagged panel model to one that involves more than two constructs.
In addition, conclusions in our review were drawn from a small number of included studies, with only 1–2 research examples per method. Although we supplemented these findings with a discussion of studies from the broader literature, the small evidence base may limit the generalisability of our findings. Future work could seek to include broader search and identify methods from a larger body of research.
4.5. Conclusions
This review identified nine studies employing seven latent variable analytical methods to model three or more outcome variables in longitudinal health and education data involving children under 12 years of age. The results suggest variable-oriented modelling (e.g., LGM) is the most effective for identifying predictors of long-term outcomes and person-oriented modelling (e.g., GMM) for detecting change trajectories. However, without investigating the recent AI and machine learning advancements and more comprehensive databases, we may have overlooked relevant methodologies. Future research should explore these emerging technologies to enhance understanding of child development trajectories in health and education.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/ejihpe15090173/s1, Supplementary S1: Preferred Reporting Items for Systematic reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) checklist; Supplementary S2: Search strategies of the five databases.
Author Contributions
Conceptualization, G.T.L.B. and J.E.H.; methodology, M.H., G.T.L.B., and J.E.H.; formal analysis, M.H.; investigation, M.H.; resources, J.E.H.; data curation, M.H.; writing—original draft preparation, M.H.; writing—review and editing, M.H., G.T.L.B., and J.E.H.; supervision, G.T.L.B. and J.E.H.; project administration, G.T.L.B.; funding acquisition, M.H. All authors have read and agreed to the published version of the manuscript.
Funding
The first author is funded by the China Scholarship Council (CSC), grant number 202208250033. The funder had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We would like to thank a research librarian for her assistance in developing the search strategy for this review.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | artificial intelligence |
| CHYLD | Children with Hypoglycaemia and Their Later Development |
| CLPM | cross-lagged panel model |
| EM | expectation maximisation |
| FIML | full information maximum likelihood |
| FOCUS | factor of curves |
| GMM | growth mixture models |
| GBMT | group-based multi-trajectory model |
| HMM | hidden Markov model |
| LGM | latent growth curve modelling |
| LTA | latent transition analysis models |
| MICE | multiple imputation by chained equations |
| Piecewise LGM | piecewise linear growth curve models |
| PRISMA-ScR | Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews |
| RI-CLPM | random-intercept cross-lagged panel model |
| SEM | structural equation modelling |
References
- Ali, S., & Bouguila, N. (2022). A road map to hidden Markov models and a review of its application in occupancy estimation. In N. Bouguila, W. Fan, & M. Amayri (Eds.), Hidden Markov models and applications (pp. 1–32). Springer International Publishing. [Google Scholar] [CrossRef]
- Ansell, J. M., Wouldes, T. A., Harding, J. E., & on behalf of the CHYLD Study group. (2017). Executive function assessment in New Zealand 2-year olds born at risk of neonatal hypoglycemia. PLoS ONE, 12(11), e0188158. [Google Scholar] [CrossRef]
- Baldwin, E. E. (2015). A Monte Carlo simulation study examining statistical power in latent transition analysis [Ph.D. thesis, University of California]. Available online: https://www.proquest.com/docview/1725906968/abstract/FC68243492A04E89PQ/1 (accessed on 20 June 2024).
- Bartolucci, F., Pandolfi, S., & Pennoni, F. (2017). LMest: An R package for latent Markov models for longitudinal categorical data. Journal of Statistical Software, 81, 1–38. [Google Scholar] [CrossRef]
- Bauer, D. J., & Curran, P. J. (2003). Distributional assumptions of growth mixture models: Implications for overextraction of latent trajectory classes. Psychological Methods, 8(3), 338–363. [Google Scholar] [CrossRef]
- Boker, S. M., Neale, M. C., Maes, H. H., Wilde, M. J., Spiegel, M., Brick, T. R., Estabrook, R., Bates, T. C., Mehta, P., von Oertzen, T., Gore, R. J., Hunter, M. D., Hackett, D. C., Karch, J., Brandmaier, A. M., Pritikin, J. N., Zahery, M., Kirkpatrick, R. M., Wang, Y., … Niesen, J. (2025). OpenMX: Extended structural equation modelling (Version 2.22.7) [Computer software]. Available online: https://cran.r-project.org/web/packages/OpenMx/index.html (accessed on 11 August 2025).
- Bollen, K. A. (2020). Structural equations with latent variables. J. Wiley. [Google Scholar]
- Bollen, K. A., & Curran, P. J. (2006). Latent curve models: A structural equation perspective. Wiley-Interscience. [Google Scholar] [CrossRef]
- Brown, G. T. L., & Peterson, E. (2018). Evaluating repeated diary study responses: Latent curve modeling: Vol. SAGE research methods cases part 2. SAGE Publications, Ltd. [Google Scholar] [CrossRef]
- Cezard, G., McHale, C. T., Sullivan, F., Bowles, J. K. F., & Keenan, K. (2021). Studying trajectories of multimorbidity: A systematic scoping review of longitudinal approaches and evidence. BMJ Open, 11(11), e048485. [Google Scholar] [CrossRef] [PubMed]
- Cheong, J., MacKinnon, D. P., & Khoo, S. T. (2003). Investigation of mediational processes using parallel process latent growth curve modeling. Structural Equation Modeling: A Multidisciplinary Journal, 10(2), 238–262. [Google Scholar] [CrossRef]
- Collins, L. M., & Lanza, S. T. (2010). Latent class and latent transition analysis: With applications in the social behavioral, and health sciences. Wiley. [Google Scholar]
- Corporation for Digital Scholarship. (2023). Zotero (Version 6.0.26) [Computer software]. (Original work published 2006). Available online: https://www.zotero.org/ (accessed on 12 May 2023).
- Cosco, T. D., Kaushal, A., Hardy, R., Richards, M., Kuh, D., & Stafford, M. (2017). Operationalising resilience in longitudinal studies: A systematic review of methodological approaches. Journal of Epidemiology and Community Health, 71(1), 98. [Google Scholar] [CrossRef] [PubMed]
- Curran, P. J., Obeidat, K., & Losardo, D. (2010). Twelve frequently asked questions about growth curve modeling. Journal of Cognition and Development, 11(2), 121–136. [Google Scholar] [CrossRef] [PubMed]
- Dai, D. W. T., Wouldes, T. A., Brown, G. T. L., Tottman, A. C., Alsweiler, J. M., Gamble, G. D., & Harding, J. E. (2020). Relationships between intelligence, executive function and academic achievement in children born very preterm. Early Human Development, 148, 105122. [Google Scholar] [CrossRef]
- Enders, C. K. (2022). Applied missing data analysis, second edition (2nd ed.). Guilford Press. [Google Scholar]
- Fitzmaurice, G. M., Laird, N. M., & Ware, J. H. (2011). Applied longitudinal analysis (2nd ed). Wiley. [Google Scholar]
- Fleiss, J. L. (1971). Measuring nominal scale agreement among many raters. Psychological Bulletin, 76(5), 378–382. [Google Scholar] [CrossRef]
- Frees, E. W. (2004). Longitudinal and panel data: Analysis and applications in the social sciences. Cambridge University Press. [Google Scholar]
- Grimm, K. J., Ram, N., & Estabrook, R. (2016). Growth modeling: Structural equation and multilevel modeling approaches. Guilford Publications. [Google Scholar]
- Hamaker, E. L., Kuiper, R. M., & Grasman, R. P. P. P. (2015). A critique of the cross-lagged panel model. Psychological Methods, 20(1), 102–116. [Google Scholar] [CrossRef]
- Harwell, M., Maeda, Y., Bishop, K., & Xie, A. (2017). The surprisingly modest relationship between SES and educational achievement. The Journal of Experimental Education, 85(2), 197–214. [Google Scholar] [CrossRef]
- Hicks, T. A., & Knollman, G. A. (2015). Secondary analysis of national longitudinal transition study 2 data: A statistical review. Career Development and Transition for Exceptional Individuals, 38(3), 182–190. [Google Scholar] [CrossRef]
- Hoffman, L. (2015). Longitudinal analysis: Modeling within-person fluctuation and change (1st ed.). Routledge, Taylor & Francis Group. [Google Scholar]
- Ip, E. H., Marshall, S. A., Arcury, T. A., Suerken, C. K., Trejo, G., Skelton, J. A., & Quandt, S. A. (2018). Child feeding style and dietary outcomes in a cohort of latino farmworker families. Journal of the Academy of Nutrition and Dietetics, 118(7), 1208–1219. [Google Scholar] [CrossRef] [PubMed]
- Isiordia, M., Conger, R., Robins, R. W., & Ferrer, E. (2017). Using the factor of curves model to evaluate associations among multiple family constructs over time. Journal of Family Psychology: JFP: Journal of the Division of Family Psychology of the American Psychological Association (Division 43), 31(8), 1017–1028. [Google Scholar] [CrossRef]
- Jones, B. L. (2023). Traj: Group-based modeling of longitudinal data. Available online: https://www.andrew.cmu.edu/user/bjones/index.htm (accessed on 10 December 2024).
- Ju, S., & Lee, Y. (2018). Developmental trajectories and longitudinal mediation effects of self-esteem, peer attachment, child maltreatment and depression on early adolescents. Child Abuse & Neglect, 76, 353–363. [Google Scholar] [CrossRef] [PubMed]
- Katsantonis, I., & Symonds, J. E. (2023). Population heterogeneity in developmental trajectories of internalising and externalising mental health symptoms in childhood: Differential effects of parenting styles. Epidemiology and Psychiatric Sciences, 32, e16. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.-Y. (2013). Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis. Restorative Dentistry & Endodontics, 38(1), 52–54. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.-Y. (2012). Sample size requirements in single- and multiphase growth mixture models: A Monte Carlo simulation study. Structural Equation Modeling: A Multidisciplinary Journal, 19(3), 457–476. [Google Scholar] [CrossRef]
- Kim, S.-Y. (2014). Determining the number of latent classes in single- and multiphase growth mixture models. Structural Equation Modeling: A Multidisciplinary Journal, 21(2), 263–279. [Google Scholar] [CrossRef]
- Kim, S. W., Cho, H., & Kim, L. Y. (2019). Socioeconomic status and academic outcomes in developing countries: A meta-analysis. Review of Educational Research, 89(6), 875–916. [Google Scholar] [CrossRef]
- King, B. M., Rosopa, P. J., & Minium, E. W. (2018). Statistical reasoning in the behavioral sciences (7th ed.). Wiley. [Google Scholar]
- Kline, R. B. (2023). Principles and practice of structural equation modeling (5th ed.). Guilford Publications. [Google Scholar]
- Kulkarni, T., Sullivan, A. L., & Kim, J. (2021). Externalizing behavior problems and low academic achievement: Does a causal relation exist? Educational Psychology Review, 33(3), 915–936. [Google Scholar] [CrossRef]
- Lee, D. Y., & Harring, J. R. (2023). Handling missing data in growth mixture models. Journal of Educational and Behavioral Statistics, 48(3), 320–348. [Google Scholar] [CrossRef]
- Lim, L. S. H., Pullenayegum, E., Moineddin, R., Gladman, D. D., Silverman, E. D., & Feldman, B. M. (2017). Methods for analyzing observational longitudinal prognosis studies for rheumatic diseases: A review & worked example using a clinic-based cohort of juvenile dermatomyositis patients. Pediatric Rheumatology, 15(1), 18. [Google Scholar] [CrossRef]
- Liu, J., & Perera, R. A. (2023). Assessing mediational processes using piecewise linear growth curve models with individual measurement occasions. Behavior Research Methods, 55(6), 3218–3240. [Google Scholar] [CrossRef]
- Lucas, R. E. (2023). Why the cross-lagged panel model is almost never the right choice. Advances in Methods and Practices in Psychological Science, 6(1), 25152459231158378. [Google Scholar] [CrossRef]
- Lüdtke, O., & Robitzsch, A. (2021). A critique of the random intercept cross-lagged panel model. PsyArXiv. [Google Scholar] [CrossRef]
- Majewska, R., Jabłońska, K., Młynarczyk, D., Briere, J. B., Bowrin, K., & Millier, A. (2019). PNS322 Review of methodological approaches to analyse longitudinal utility data. Value in Health, 22, S818. [Google Scholar] [CrossRef]
- Martinez-Huertas, J. A., & Ferrer, E. (2023). Mixed-effects models with crossed random effects for multivariate longitudinal data. Structural Equation Modeling, 30(1), 105–122. [Google Scholar] [CrossRef]
- Matingwina, T. (2018). Health, academic achievement and school-based interventions. In B. Bernal-Morales (Ed.), Health and academic achievement. IntechOpen. [Google Scholar] [CrossRef]
- Mayer, R. E. (2020). Intelligence and achievement. In R. J. Sternberg (Ed.), The Cambridge Handbook of Intelligence (2nd ed., pp. 1048–1060). Cambridge University Press. [Google Scholar] [CrossRef]
- McArdle, J. J. (1988). Dynamic but structural equation modeling of repeated measures data. In J. R. Nesselroade, & R. B. Cattell (Eds.), Handbook of multivariate experimental psychology (pp. 561–614). Springer. [Google Scholar] [CrossRef]
- McArdle, J. J. (2009). Latent variable modeling of differences and changes with longitudinal data. Annual Review of Psychology, 60(1), 577–605. [Google Scholar] [CrossRef] [PubMed]
- McArdle, J. J., & Nesselroade, J. R. (2014). Longitudinal data analysis using structural equation models. American Psychological Association. Available online: https://psycnet.apa.org/record/2014-09354-000 (accessed on 19 June 2024).
- McKinlay, C. J. D., Alsweiler, J. M., Ansell, J. M., Anstice, N. S., Chase, J. G., Gamble, G. D., Harris, D. L., Jacobs, R. J., Jiang, Y., Paudel, N., Signal, M., Thompson, B., Wouldes, T. A., Yu, T.-Y., & Harding, J. E. (2015). Neonatal glycemia and neurodevelopmental outcomes at 2 years. The New England Journal of Medicine, 373(16), 1507–1518. [Google Scholar] [CrossRef]
- McKinlay, C. J. D., Alsweiler, J. M., Anstice, N. S., Burakevych, N., Chakraborty, A., Chase, J. G., Gamble, G. D., Harris, D. L., Jacobs, R. J., Jiang, Y., Paudel, N., San Diego, R. J., Thompson, B., Wouldes, T. A., & Harding, J. E. (2017). Association of neonatal glycemia with neurodevelopmental outcomes at 4.5 years. JAMA Pediatrics, 171(10), 972–983. [Google Scholar] [CrossRef]
- Michael, Y. L., Senerat, A. M., Buxbaum, C., Ezeanyagu, U., Hughes, T. M., Hayden, K. M., Langmuir, J., Besser, L. M., Sánchez, B., & Hirsch, J. A. (2024). Systematic review of longitudinal evidence and methodologies for research on neighborhood characteristics and brain health. Public Health Reviews, 45, 1606677. [Google Scholar] [CrossRef]
- Mody, A., Tram, K. H., Glidden, D. V., Eshun-Wilson, I., Sikombe, K., Mehrotra, M., Pry, J. M., & Geng, E. H. (2021). Novel longitudinal methods for assessing retention in care: A synthetic review. Current HIV/AIDS Reports, 18(4), 299–308. [Google Scholar] [CrossRef]
- Morin, A. J. S., Gallagher, D. G., Meyer, J. P., Litalien, D., & Clark, P. F. (2021). Investigating the dimensionality and stability of union commitment profiles over a 10-year period: A latent transition analysis. ILR Review, 74(1), 224–254. [Google Scholar] [CrossRef]
- Muthén, B. O. (2004). Latent variable analysis: Growth mixture modeling and related techniques for longitudinal data. In D. E. Kaplan (Ed.), The Sage handbook of quantitative methodology for the social sciences (pp. 345–368). Sage. [Google Scholar]
- Muthén, L. K., & Muthén, B. O. (1998). Mplus user’s guide (8th ed.). Muthén & Muthén. [Google Scholar]
- Nagin, D. S. (2005). Group-based modeling of development (1st ed.). Harvard University Press. [Google Scholar] [CrossRef]
- Nagin, D. S., Jones, B. L., & Elmer, J. (2024). Recent advances in group-based trajectory modeling for clinical research. Annual Review of Clinical Psychology, 20(1), 285–305. [Google Scholar] [CrossRef] [PubMed]
- Nagin, D. S., Jones, B. L., Passos, V. L., & Tremblay, R. E. (2018). Group-based multi-trajectory modeling. Statistical Methods in Medical Research, 27(7), 2015–2023. [Google Scholar] [CrossRef] [PubMed]
- Nylund-Gibson, K., & Choi, A. Y. (2018). Ten frequently asked questions about latent class analysis. Translational Issues in Psychological Science, 4(4), 440–461. [Google Scholar] [CrossRef]
- Nylund-Gibson, K., Garber, A. C., Carter, D. B., Chan, M., Arch, D. A. N., Simon, O., Whaling, K., Tartt, E., & Lawrie, S. I. (2023). Ten frequently asked questions about latent transition analysis. Psychological Methods, 28(2), 284–300. [Google Scholar] [CrossRef]
- Olawade, D. B., Wada, O. J., David-Olawade, A. C., Kunonga, E., Abaire, O., & Ling, J. (2023). Using artificial intelligence to improve public health: A narrative review. Frontiers in Public Health, 11, 1196397. [Google Scholar] [CrossRef]
- Proust-Lima, C., Philipps, V., & Liquet, B. (2017). Estimation of extended mixed models using latent classes and latent processes: The R package lcmm. Journal of Statistical Software, 78, 1–56. [Google Scholar] [CrossRef]
- Reboussin, B. A., Reboussin, D. M., Liang, K.-Y., & Anthony, J. C. (1998). Latent transition modeling of progression of health-risk behavior. Multivariate Behavioral Research, 33(4), 457–478. [Google Scholar] [CrossRef]
- Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. [Google Scholar] [CrossRef]
- Sampson, R. J., Laub, J. H., & Eggleston, E. P. (2004). On the robustness and validity of groups. Journal of Quantitative Criminology, 20(1), 37–42. [Google Scholar] [CrossRef]
- Savalei, V., & Bentler, P. M. (2009). A two-stage approach to missing data: Theory and application to auxiliary variables. Structural Equation Modeling: A Multidisciplinary Journal, 16(3), 477–497. [Google Scholar] [CrossRef]
- Shah, R., Brown, G. T. L., Keegan, P., Harding, J. E., McKinlay, C. J. D., & CHYLD Study Group. (2021). School readiness screening and educational achievement at 9–10 years of age. Journal of Paediatrics and Child Health, 57(12), 1929–1935. [Google Scholar] [CrossRef] [PubMed]
- Shah, R., Dai, D. W. T., Alsweiler, J. M., Brown, G. T. L., Chase, J. G., Gamble, G. D., Harris, D. L., Keegan, P., Nivins, S., Wouldes, T. A., Thompson, B., Turuwhenua, J., Harding, J. E., McKinlay, C. J. D., & Children with Hypoglycaemia and Their Later Development (CHYLD) Study Team. (2022). Association of neonatal hypoglycemia with academic performance in mid-childhood. JAMA, 327(12), 1158–1170. [Google Scholar] [CrossRef] [PubMed]
- Silberzahn, R., Uhlmann, E. L., Martin, D. P., Anselmi, P., Aust, F., Awtrey, E., Bahník, Š., Bai, F., Bannard, C., Bonnier, E., Carlsson, R., Cheung, F., Christensen, G., Clay, R., Craig, M. A., Dalla Rosa, A., Dam, L., Evans, M. H., Flores Cervantes, I., … Nosek, B. A. (2018). Many analysts, one data set: Making transparent how variations in analytic choices affect results. Advances in Methods and Practices in Psychological Science, 1(3), 337–356. [Google Scholar] [CrossRef]
- Singer, J. D., & Willett, J. B. (2003). Applied longitudinal data analysis: Modeling change and event occurrence. Oxford University Press. [Google Scholar]
- Song, X., Xia, Y., & Zhu, H. (2017). Hidden Markov latent variable models with multivariate longitudinal data. Biometrics, 73(1), 313–323. [Google Scholar] [CrossRef]
- Stahlschmidt, S., & Stephen, D. (2020). Comparison of Web of Science, Scopus and Dimensions databases (KB Forschungspoolprojekt 2020). Available online: https://bibliometrie.info/downloads/DZHW-Comparison-DIM-SCP-WOS.PDF (accessed on 28 November 2024).
- Stanley, C. C., Kazembe, L. N., Mukaka, M., Otwombe, K. N., Buchwald, A. G., Hudgens, M. G., Mathanga, D. P., Laufer, M. K., & Chirwa, T. F. (2019). Systematic review of analytical methods applied to longitudinal studies of malaria. Malaria Journal, 18(1), 254. [Google Scholar] [CrossRef]
- Stevens, D., Lane, D. A., Harrison, S. L., Lip, G. Y. H., & Kolamunnage-Dona, R. (2021). Modelling of longitudinal data to predict cardiovascular disease risk: A methodological review. BMC Medical Research Methodology, 21(1), 283. [Google Scholar] [CrossRef]
- Taherian, T., Fazilatfar, A. M., & Mazdayasna, G. (2021). Joint growth trajectories of trait emotional intelligence subdomains among L2 language learners: Estimating a second-order factor-of-curves model with emotion perception. Frontiers in Psychology, 12, 720945. [Google Scholar] [CrossRef]
- Timman, R., Stijnen, T., & Tibben, A. (2004). Methodology in longitudinal studies on psychological effects of predictive DNA testing: A review. Journal of Medical Genetics, 41(7), e100. [Google Scholar] [CrossRef]
- Tricco, A. C., Lillie, E., Zarin, W., O’Brien, K. K., Colquhoun, H., Levac, D., Moher, D., Peters, M. D. J., Horsley, T., Weeks, L., Hempel, S., Akl, E. A., Chang, C., McGowan, J., Stewart, L., Hartling, L., Aldcroft, A., Wilson, M. G., Garritty, C., … Straus, S. E. (2018). PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Annals of Internal Medicine, 169(7), 467–473. [Google Scholar] [CrossRef]
- Vermunt, J. K., & Magidson, J. (2005). Latent GOLD 4.0 user’s guide. Statistical Innovations Inc. Available online: https://www.statisticalinnovations.com/wp-content/uploads/LGusersguide.pdf (accessed on 11 December 2024).
- Visser, I., & Speekenbrink, M. (2010). depmixs4: An R package for hidden Markov models. Journal of Statistical Software, 36(7). [Google Scholar] [CrossRef]
- Wake Forest School of Medicine. (2020, October 26). Dynamic Multichain Graphical Modeling Tool. Available online: http://dmgm.wfuhs.arane.us/ (accessed on 11 December 2024).
- Wang, J., & Li, J. (2024). Artificial intelligence empowering public health education: Prospects and challenges. Frontiers in Public Health, 12, 1389026. [Google Scholar] [CrossRef]
- Wang, Y.-G., Fu, L., & Paul, S. (2022). Analysis of longitudinal data with examples (1st ed., Vol. 1). CRC Press. [Google Scholar] [CrossRef]
- Wildeboer, A., Thijssen, S., van IJzendoorn, M. H., van der Ende, J., Jaddoe, V. W. V., Verhulst, F. C., Hofman, A., White, T., Tiemeier, H., & Bakermans-Kranenburg, M. J. (2015). Early childhood aggression trajectories: Associations with teacher-reported problem behaviour. International Journal of Behavioral Development, 39(3), 221–234. [Google Scholar] [CrossRef]
- Yarnell, L. M., Pasch, K. E., Perry, C. L., & Komro, K. A. (2018). Multiple risk behaviors among African American and Hispanic boys. Journal of Early Adolescence, 38(5), 681–713. [Google Scholar] [CrossRef]
- Yuan, K.-H. (2009). Normal distribution based pseudo ML for missing data: With applications to mean and covariance structure analysis. Journal of Multivariate Analysis, 100(9), 1900–1918. [Google Scholar] [CrossRef]
- Yucel, R. M. (2008). Multiple imputation inference for multivariate multilevel continuous data with ignorable non-response. Philosophical Transactions: Mathematical, Physical and Engineering Sciences, 366(1874), 2389–2403. [Google Scholar]
- Zucchini, W., MacDonald, I. L., & Langrock, R. (2016). Hidden Markov models for time series: An introduction using R (2nd ed.). Chapman and Hall/CRC. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the University Association of Education and Psychology. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).