
Ternary Precursor Centrifuge Rolling Bearing Fault Diagnosis Based on Adaptive Sample Length Adjustment of 1DCNN-SeNet

Abstract
1. Introduction
- (1)
- Adaptive adjustment based on the cumulative variance explained ratio in the Principal Component Analysis (PCA) algorithm reduces the data to a uniform dimensionality, addressing the issue of uneven sample lengths. This ensures effective fault diagnosis on input signals of different lengths.
- (2)
- We propose a fault diagnosis method called 1DCNN-SeNet, which leverages 1DCNN to automatically extract local feature information from the data and then utilizes SeNet to adaptively adjust the importance of each channel. This approach significantly enhances diagnostic accuracy and demonstrates distinct advantages.
- (3)
- A comparative analysis between the proposed method and four classical algorithms demonstrates that the proposed method outperforms in adapting to complex fault scenarios in rolling bearing fault diagnosis tasks. The analysis of accuracy curves, loss curves, and confusion matrices confirms the effectiveness and generalization capability of the proposed algorithm.
2. Research Objectives and Methodology Theory
2.1. Research Objectives
2.2. Principal Component Analysis Algorithm
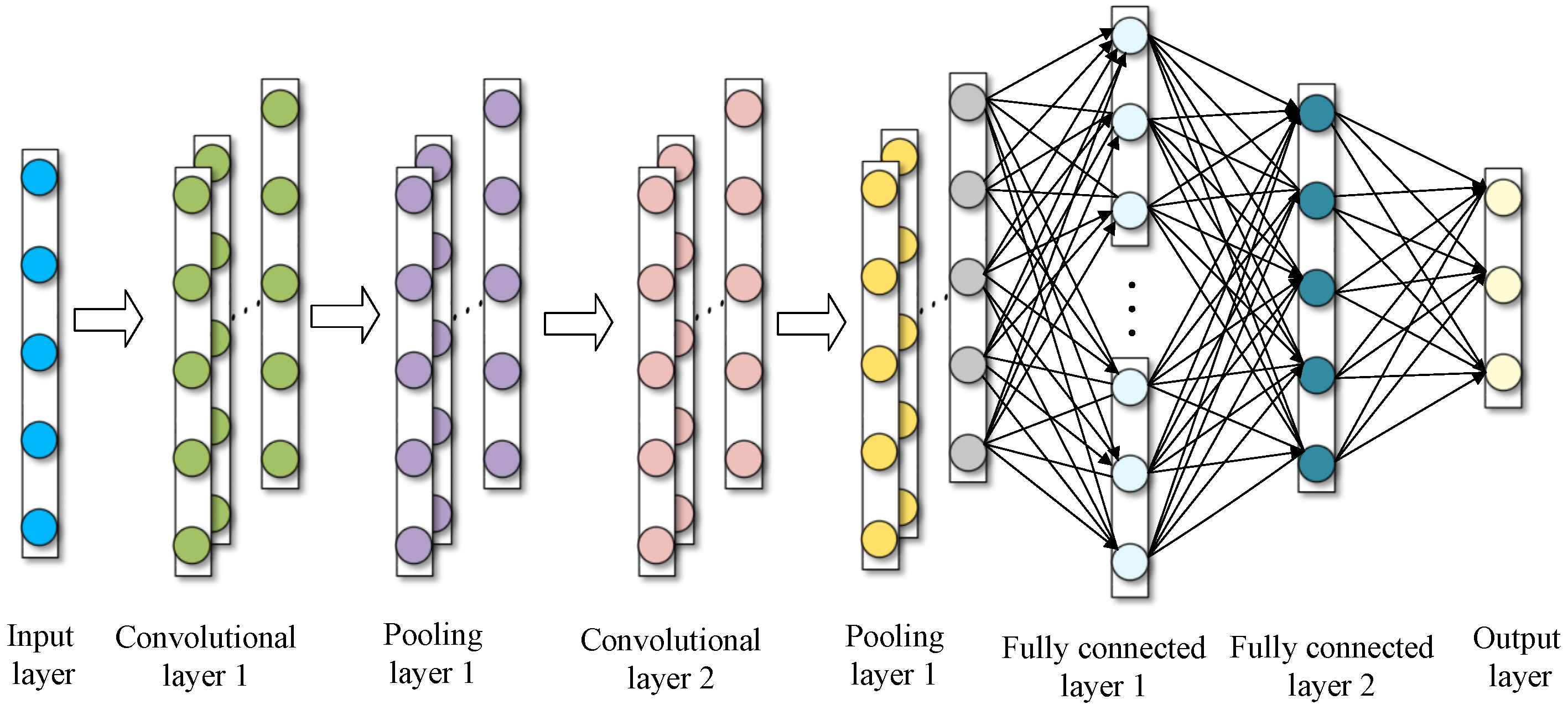
2.3. One-Dimensional Convolutional Neural Network
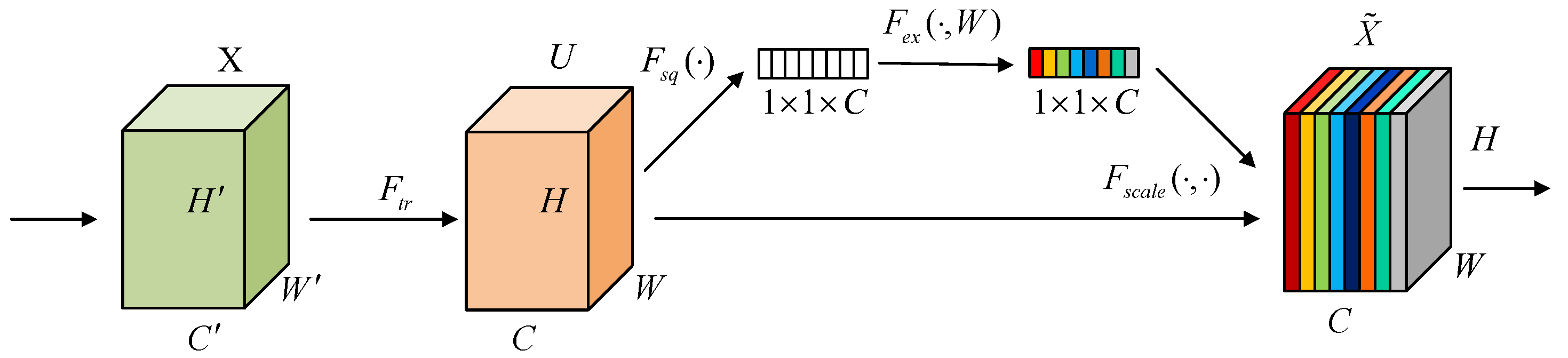
2.4. Squeeze-and-Excitation Network (SENet)
3. Experiment Validation and Result Analysis
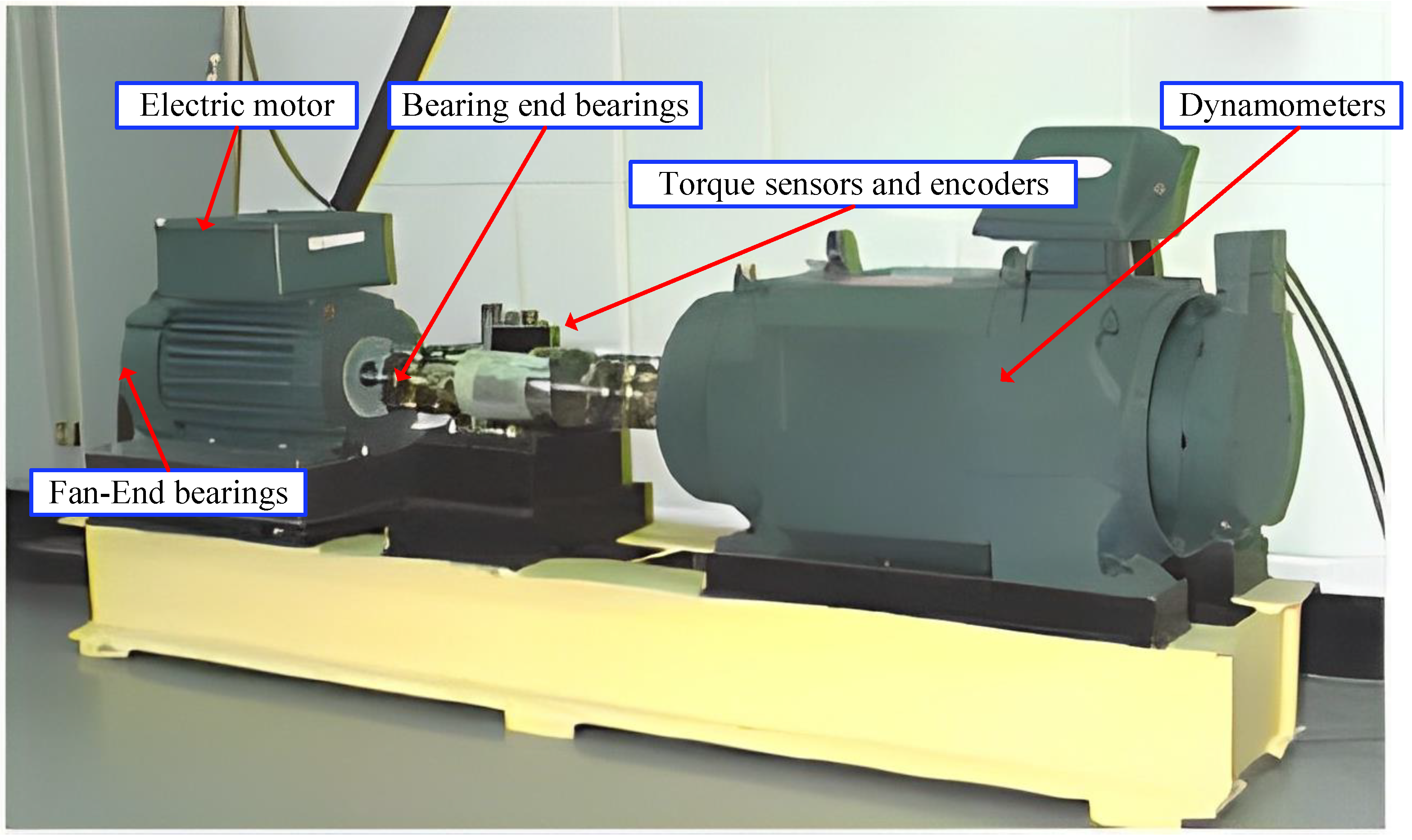
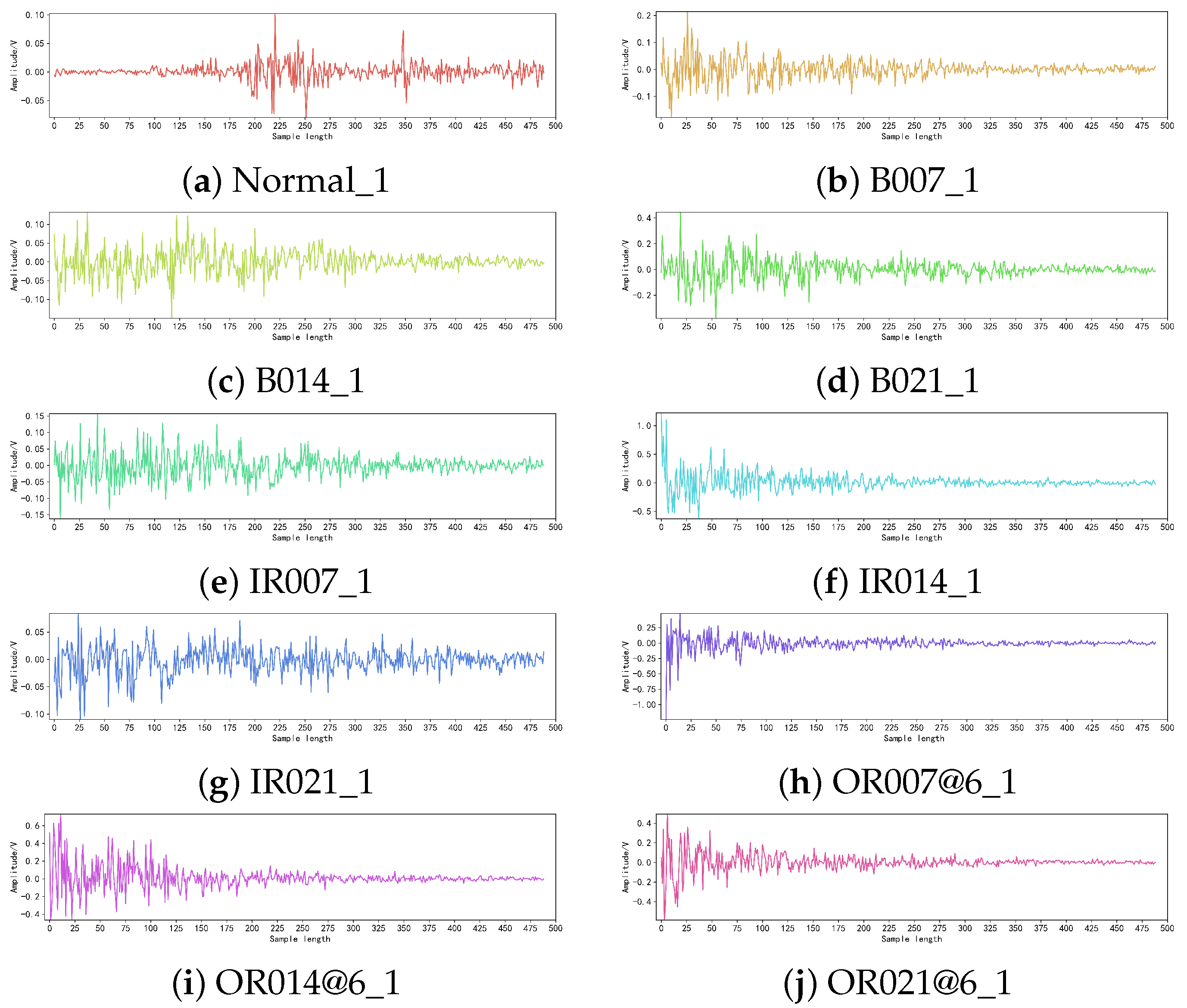
3.1. Description of Experimental Dataset
3.2. Data Normalization Process
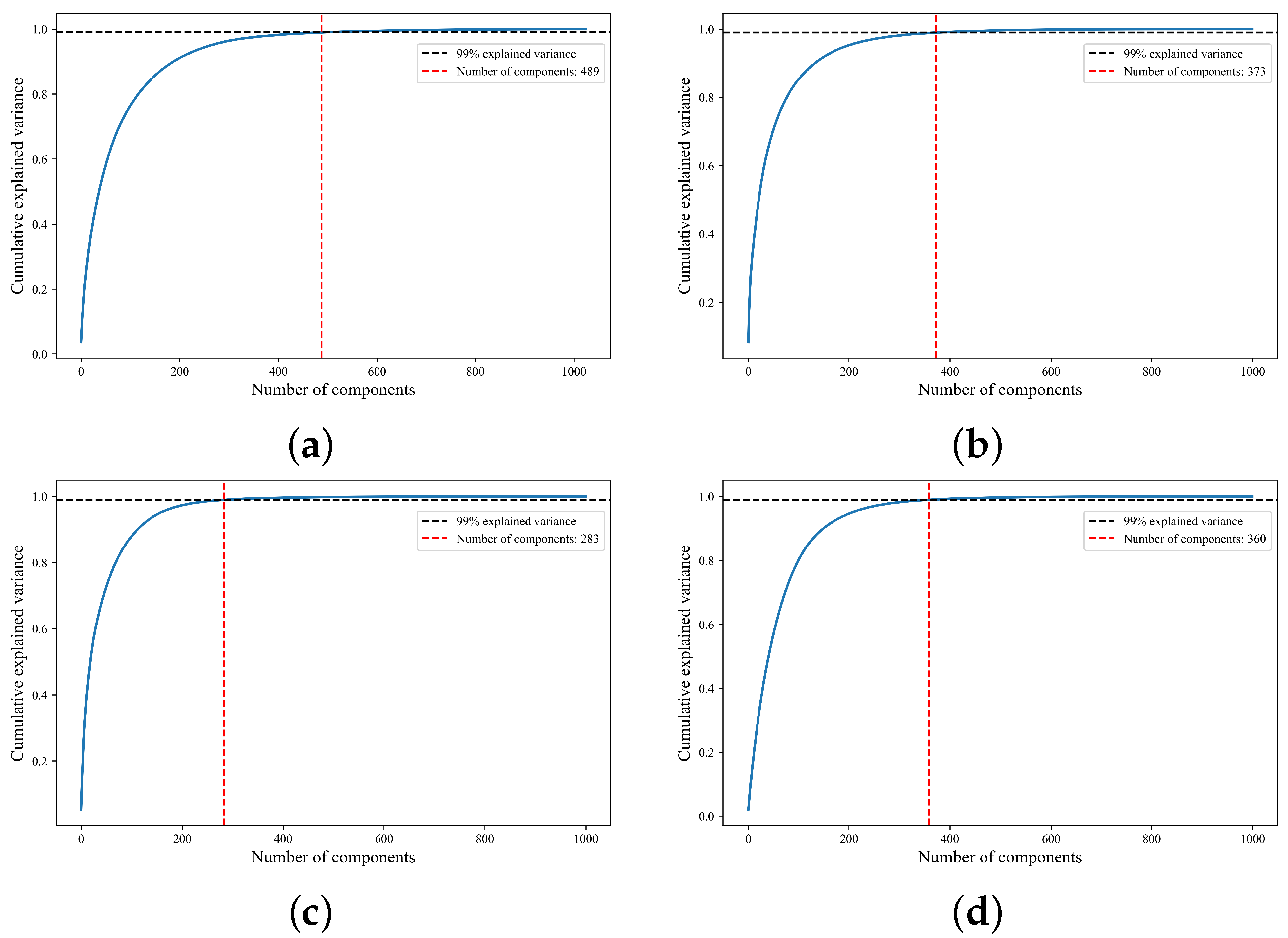
3.3. Adaptive Sample Length Selection
3.4. Correlation Analysis of Data after PCA Dimensionality Reduction
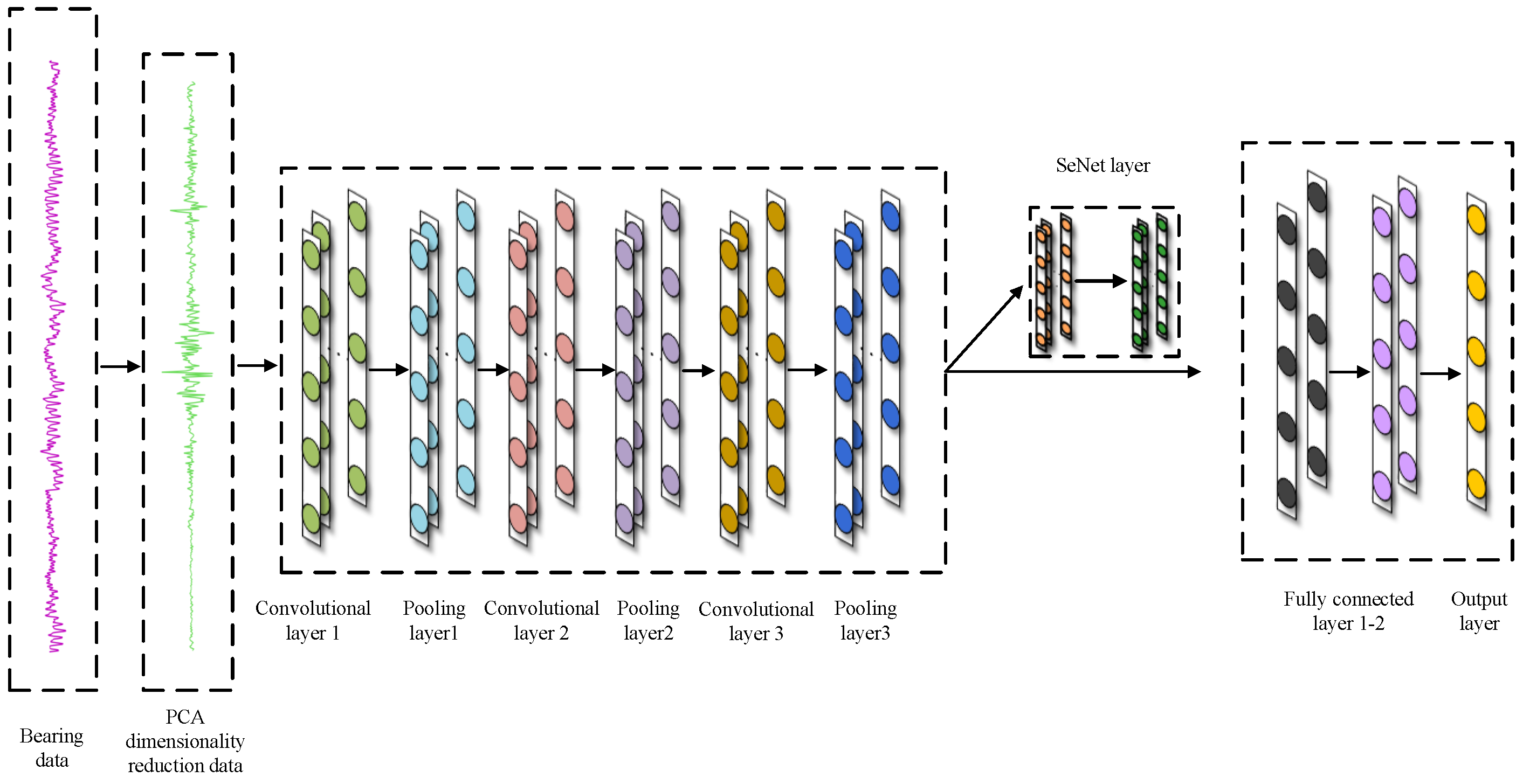
3.5. The Adaptive Sample Length-Adjusted 1DCNN-SeNet Diagnostic Model
3.6. Analysis of Experimental Results
3.6.1. Model Training
3.6.2. Model Testing
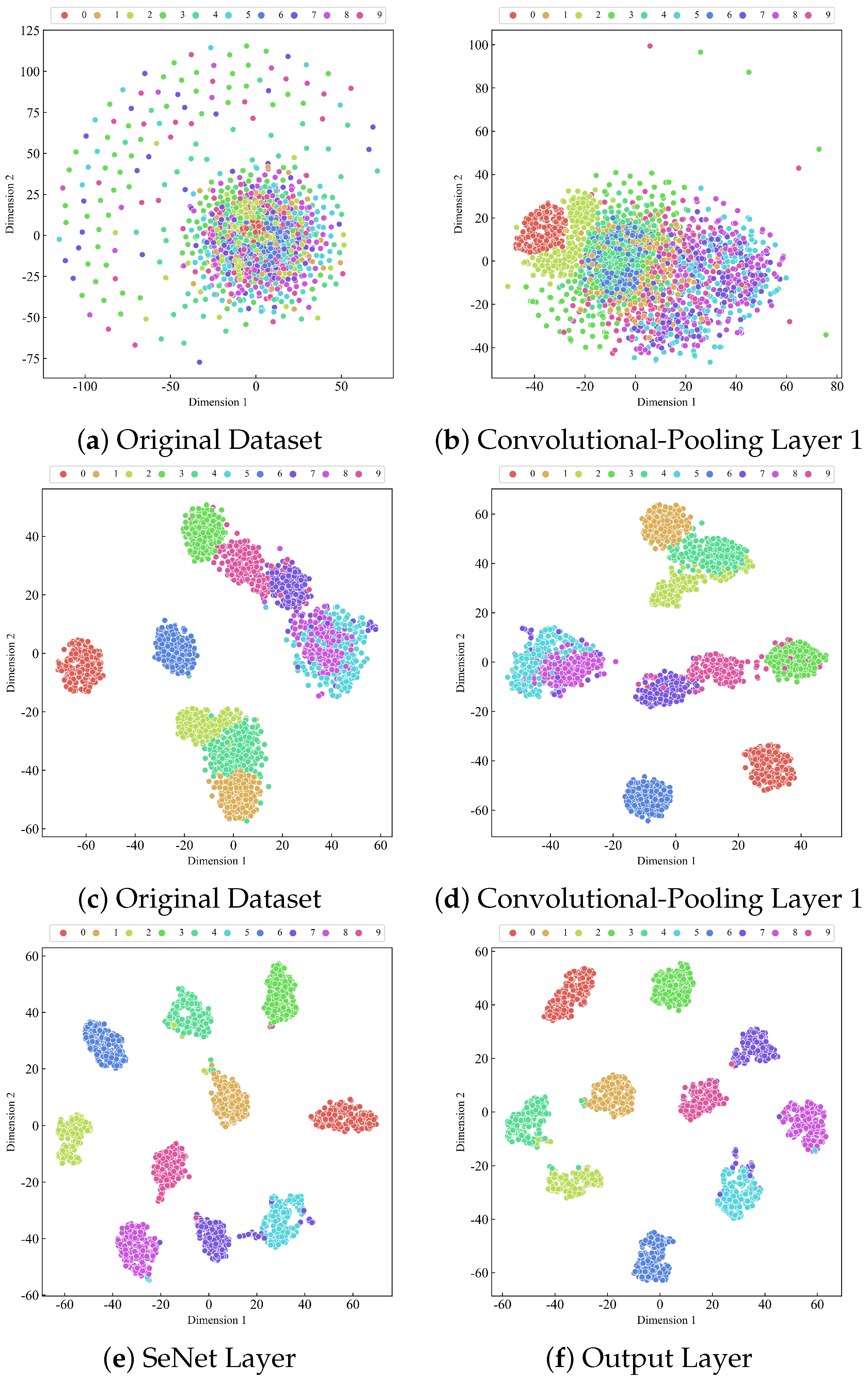
3.6.3. t-SNE Visualization Analysis
4. Summary
- (1)
- This paper utilizes a PCA algorithm to adaptively adjust the uneven sample lengths, ensuring effective fault diagnosis on samples of different lengths based on the actual length of the input signal.
- (2)
- The 1DCNN network effectively captures the local temporal features of the bearing signal, while the SeNet network adaptsively learns the importance of features from each channel, automatically selecting and enhancing the features most helpful for bearing fault diagnosis. The combination of the two enables a more comprehensive capture of fault features in the bearing signal, thereby improving the accuracy and generalization capability of fault diagnosis.
- (3)
- Comparative analysis with four classical fault diagnosis algorithms demonstrates the significant advantages of the proposed model in bearing fault diagnosis tasks. It exhibits better adaptability to complex fault scenarios and different datasets, thus proving the effectiveness and superiority of the proposed algorithm.
- (4)
- Based on the research conducted in this paper, future endeavors could involve expanding the dataset to include a wider range of fault types and larger-scale real bearing fault data. This expansion would facilitate more comprehensive fault diagnosis and allow for deeper performance evaluation and comparative analysis of model algorithms. Additionally, it would be beneficial to seek engineering practical cases and apply the established models in real-world scenarios to validate their effectiveness.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pattnayak, M.R.; Ganai, P.; Pandey, R.K.; Dutt, J.K.; Fillon, M. An overview and assessment on aerodynamic journal bearings with important findings and scope for explorations. Tribol. Int. 2022, 174, 107778. [Google Scholar] [CrossRef]
- Peng, B.; Bi, Y.; Xue, B.; Zhang, M.; Wan, S. A Survey on Fault Diagnosis of Rolling Bearings. Algorithms 2022, 15, 347. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, Y.; Guo, F.; Karimi, H.R.; Dong, H.; Xuan, Q. A New Interpretable Learning Method for Fault Diagnosis of Rolling Bearings. IEEE Trans. Instrum. Meas. 2020, 70, 1–10. [Google Scholar] [CrossRef]
- Mikić, D.; Desnica, E.; Kiss, I.; Mikić, V. Reliability Analysis of Rolling Ball Bearings Considering the Bearing Radial Clearance and Operating Temperature. Adv. Eng. Lett. 2022, 1, 16–22. [Google Scholar] [CrossRef]
- Kim, T.; Han, J. Comparison of the Dynamic Behavior and Lubrication Characteristics of a Reciprocating Compressor Crankshaft in Both Finite and Short Bearing Models©. Tribol. Trans. 2004, 47, 61–69. [Google Scholar] [CrossRef]
- Vasić, M.; Stojanović, B.; Blagojević, M. Fault Analysis of Gearboxes in Open Pit Mine. Appl. Eng. Lett. 2020, 5, 50–61. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, X.; Li, Y.; Xu, J. Hybrid Multimodal Feature Fusion with Multi-Sensor for Bearing Fault Diagnosis. Sensors 2024, 24, 1792. [Google Scholar] [CrossRef]
- Feng, A.; Xu, G.; Chen, C.; Liu, B.; Wei, Y.; Pan, X. Surface characteristics and wear resistance of GCr15 bearing steel by cryogenic treatment-laser peening. Appl. Phys. 2022, 128, 921. [Google Scholar] [CrossRef]
- Ashwini, K.; Rudraswamy, S.B. Automated inspection system for automobile bearing seals. Mater. Today Proc. 2020, 46, 4709–4715. [Google Scholar] [CrossRef]
- Baart, P.; Lugt, P.M.; Prakash, B. On the Normal Stress Effect in Grease-Lubricated Bearing Seals. Tribol. Trans. 2020, 57, 939–943. [Google Scholar] [CrossRef]
- Wang, D.; Tsui, K.; Qin, Y. Optimization of segmentation fragments in empirical wavelet transform and its applications to extracting industrial bearing fault features. Measurement 2019, 133, 328–340. [Google Scholar] [CrossRef]
- Sun, W.; An Yang, G.; Chen, Q.; Palazoglu, A.; Feng, K. Fault diagnosis of rolling bearing based on wavelet transform and envelope spectrum correlation. J. Vib. Control 2013, 19, 924–941. [Google Scholar] [CrossRef]
- Zhang, H.; He, Q. Tacholess bearing fault detection based on adaptive impulse extraction in the time domain under fluctuant speed. Meas. Sci. Technol. 2020, 31, 074004. [Google Scholar] [CrossRef]
- Li, G.; Wen, C.; Huang, G.; Chen, Y. Error tolerance based support vector machine for regression. Neurocomputing 2011, 74, 771–782. [Google Scholar] [CrossRef]
- Rostami, S.; Toghraie, D.; Shabani, B.; Sina, N.; Barnoon, P. Measurement of the thermal conductivity of MWCNT-CuO/water hybrid nanofluid using artificial neural networks (ANNs). J. Therm. Anal. Calorim. 2020, 2, 1097–1105. [Google Scholar] [CrossRef]
- Song, X.; Wei, W.; Zhou, J.; Ji, G.; Hussain, G.; Xiao, M.; Geng, G.S. Bayesian-Optimized Hybrid Kernel SVM for Rolling Bearing Fault Diagnosis. Sensors 2023, 23, 5137. [Google Scholar] [CrossRef] [PubMed]
- Yanting, A.; Jiaoyue, G.; Fei, C.; Jing, T.; Fengling, Z. Fusion information entropy method of rolling bearing fault diagnosis based on n-dimensional characteristic parameter distance. Mech. Syst. Signal Process. 2017, 88, 123–136. [Google Scholar]
- Saxena, A.; Saad, A. Evolving an artificial neural network classifier for condition monitoring of rotating mechanical systems. Appl. Soft Comput. 2007, 7, 441–454. [Google Scholar] [CrossRef]
- Liu, X.; Bo, L.; Luo, H. Bearing faults diagnostics based on hybrid LS-SVM and EMD method. Measurement 2015, 59, 145–166. [Google Scholar] [CrossRef]
- Zhao, M.; Lin, J.; Xu, X.; Li, X. Multi-Fault Detection of Rolling Element Bearings under Harsh Working Condition Using IMF-Based Adaptive Envelope Order Analysis. Sensors 2014, 14, 20320–20346. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA–DBN framework. Neural Comput. Appl. 2019, 32, 10773–10781. [Google Scholar] [CrossRef]
- Lei, C.; Xia, B.; Xue, L.; Jiao, M. Zhang Huqiang.Rolling bearing fault diagnosis method based on MTF-CNN. J. Vib. Shock 2022, 9, 41. [Google Scholar]
- Dong, S.; Li, Y.; Liang, T.; Zhao, X.; Hu, X.; Pei, X.; Zhu, P. Fault Diagnosis Method of Rolling Bearing Based on CNN-BiLSTM Under Variable Working Conditions. J. Vib. Meas. Diagn. 2022, 42, 1009–1016+1040. [Google Scholar] [CrossRef]
- Li, K.; He, S.; Su, L.; Gu, J.; Su, W.; Lu, L. Full Vector Autogram Based Fault Diagnosis Method for Rolling Bearing. J. Vib. Meas. Diagn. 2023, 43, 298–303+410. [Google Scholar] [CrossRef]
- Lu, F.; Tong, Q.; Feng, Z.; Wan, Q.; An, G.; Li, Y.; Wang, M.; Cao, J.; Guo, T. Explainable 1DCNN with demodulated frequency features method for fault diagnosis of rolling bearing under time-varying speed conditions. Meas. Sci. Technol. 2022, 33, 095022. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Afjal, M.I.; Hossain, M.A. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 2021, 42, 286–321. [Google Scholar] [CrossRef]
- Wang, T.; Xu, H.; Han, J.; Elbouchikhi, E.; Benbouzid, M.E.H. Cascaded H-Bridge Multilevel Inverter System Fault Diagnosis Using a PCA and Multiclass Relevance Vector Machine Approach. IEEE Trans. Power Electron. 2015, 30, 7006–7018. [Google Scholar] [CrossRef]
- Jia, G.W.; Zhang, X.; Wang, X.; Zhang, X.; Huang, N. A spindle thermal error modeling based on 1DCNN-GRU-Attention architecture under controlled ambient temperature and active cooling. Int. J. Adv. Manuf. Technol. 2023, 127, 1525–1539. [Google Scholar] [CrossRef]
- Li, B.; Lu, Z.; Jin, X.; Zhao, L. Tool wear prediction in milling CFRP with different fiber orientations based on multi-channel 1DCNN-LSTM. J. Intell. Manuf. 2023, 1–20. [Google Scholar] [CrossRef]
- Huang, J.; Ren, L.; Zhou, X.; Yan, K. An Improved Neural Network Based on SENet for Sleep Stage Classification. IEEE J. Biomed. Health Inform. 2022, 26, 4948–4956. [Google Scholar] [CrossRef]
- Xu, Y.; Jiang, X. Short-term power load forecasting based on BiGRU-Attention-SENet model. Energy Sources Part Recover. Util. Environ. Eff. 2022, 44, 973–985. [Google Scholar] [CrossRef]
- Aditya, A.; Zhou, L.; Vachhani, H.; Chandrasekaran, D.; Mago, V.K. Collision Detection: An Improved Deep Learning Approach Using SENet and ResNext. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Virtual, 17–20 October 2021; pp. 2075–2082. [Google Scholar]
- Yoo, Y.; Jo, H.; Ban, S. Lite and Efficient Deep Learning Model for Bearing Fault Diagnosis Using the CWRU Dataset. Sensors 2023, 23, 3157. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Tan, W.; Zhao, L.; Luo, H.; Zhou, Z.; Zhang, Y.; Bi, R.; Zhao, L. A Comprehensive Evaluation of 45 Pomegranate (Punica Granatum L.) Cultivars Based on Principal Component Analysis and Cluster Analysis. Int. J. Fruit Sci. 2023, 23, 135–150. [Google Scholar] [CrossRef]
- Li, G.; Zhang, A.; Zhang, Q.; Wu, D.; Zhan, C. Pearson Correlation Coefficient-Based Performance Enhancement of Broad Learning System for Stock Price Prediction. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2413–2417. [Google Scholar] [CrossRef]
- Shin, H.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.J.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Taheri, M.; Ahmadilivani, M.H.; Jenihhin, M.; Daneshtalab, M.; Raik, J. APPRAISER: DNN Fault Resilience Analysis Employing Approximation Errors. In Proceedings of the 2023 26th International Symposium on Design and Diagnostics of Electronic Circuits and Systems (DDECS), Tallinn, Estonia, 3–5 May 2023; pp. 124–127. [Google Scholar]
- Borandag, E. Software Fault Prediction Using an RNN-Based Deep Learning Approach and Ensemble Machine Learning Techniques. Appl. Sci. 2023, 13, 1639. [Google Scholar] [CrossRef]
- Kang, Y.; Chen, G.; Pan, W.; Wei, X.; Wang, H.; He, Z. A dual-experience pool deep reinforcement learning method and its application in fault diagnosis of rolling bearing with unbalanced data. J. Mech. Sci. Technol. 2023, 37, 2715–2726. [Google Scholar] [CrossRef]
- Guo, J.; Wu, W.; Wang, C. A Novel Bearing Fault Diagnosis Method Based on the DLM-CNN Framework. In Proceedings of the 2023 38th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Hefei, China, 27–29 August 2023; pp. 370–374. [Google Scholar]
- Wu, G.; Ji, X.; Yang, G.; Jia, Y.; Cao, C. Signal-to-Image: Rolling Bearing Fault Diagnosis Using ResNet Family Deep-Learning Models. Processes 2023, 11, 1527. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, G.; Ouyang, Y.; Pi, X.; He, L.; Luo, J.; Yi, L.; Guo, Y. Fault Diagnosis of Oil-Immersed Transformer based on TSNE and IBASA-SVM. Recent Patents Mech. Eng. 2022, 15, 504–514. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data States | Data Symbols | Fault Diameter/Inches | Number of Samples/Units | Sample Length | Labels |
|---|---|---|---|---|---|
| Normal | Normal_1 | —— | 1000 | 1024 | 0 |
| Roller Fault | B007_1 | 0.007 | 1000 | 1024 | 1 |
| Roller Fault | B014_1 | 0.014 | 1000 | 1024 | 2 |
| Inner Race Fault | IR007_1 | 0.007 | 1000 | 1024 | 3 |
| Inner Race Fault | IR014_1 | 0.014 | 1000 | 1024 | 4 |
| Outer Race Fault | OR007@6_1 | 0.007 | 1000 | 1024 | 5 |
| Outer Race Fault | OR014@6_1 | 0.014 | 1000 | 1024 | 6 |
| Roller Fault | B021_1 | 0.021 | 1000 | 1004 | 7 |
| Inner Race Fault | IR021_1 | 0.021 | 1000 | 1014 | 8 |
| Outer Race Fault | OR021@6_1 | 0.021 | 1000 | 1034 | 9 |
| Network Layer | Number of Convolutional Kernels and Number of Neurons | Convolutional Kernel Size | Step | Output Size |
|---|---|---|---|---|
| Convolutional layer 1 | 32 | 1 × 3 | 1 × 1 | 32 × 489 |
| Pooling layer 1 | 32 | 1 × 2 | 1 × 2 | 32 × 244 |
| Convolutional layer 2 | 64 | 1 × 3 | 1 × 1 | 64 × 244 |
| Pooling layer 2 | 64 | 1 × 2 | 1 × 2 | 64 × 122 |
| Convolutional layer 3 | 128 | 1 × 3 | 1 × 1 | 128 ×122 |
| Pooling layer 3 | 128 | 1 × 2 | 1 × 2 | 128 × 61 |
| SeNet layer | - | - | - | 128 × 61 |
| Fully connected layer1 | 1000 | - | - | 1000 × 1 |
| Fully connected layer 2 | 100 | - | - | 100 ×1 |
| Output layer | 10 | - | - | 10 × 1 |
| Method | Average Accuracy % | Standard Deviation |
|---|---|---|
| CNN | 99.05 | 0.015 |
| DNN | 98.95 | 0.12 |
| RNN | 97.65 | 0.26 |
| ResNet18 | 97.40 | 0.135 |
| 1DCNN-SeNet | 99.30 | 0.009 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Sui, Z.; Ye, J.; Xu, J. Ternary Precursor Centrifuge Rolling Bearing Fault Diagnosis Based on Adaptive Sample Length Adjustment of 1DCNN-SeNet. Processes 2024, 12, 702. https://doi.org/10.3390/pr12040702
Xu F, Sui Z, Ye J, Xu J. Ternary Precursor Centrifuge Rolling Bearing Fault Diagnosis Based on Adaptive Sample Length Adjustment of 1DCNN-SeNet. Processes. 2024; 12(4):702. https://doi.org/10.3390/pr12040702
Chicago/Turabian StyleXu, Feng, Zhen Sui, Jiangang Ye, and Jianliang Xu. 2024. "Ternary Precursor Centrifuge Rolling Bearing Fault Diagnosis Based on Adaptive Sample Length Adjustment of 1DCNN-SeNet" Processes 12, no. 4: 702. https://doi.org/10.3390/pr12040702
APA StyleXu, F., Sui, Z., Ye, J., & Xu, J. (2024). Ternary Precursor Centrifuge Rolling Bearing Fault Diagnosis Based on Adaptive Sample Length Adjustment of 1DCNN-SeNet. Processes, 12(4), 702. https://doi.org/10.3390/pr12040702