Abstract
This work focuses on the development of a Lyapunov-based economic model predictive control (LEMPC) scheme that utilizes recurrent neural networks (RNNs) with an online update to optimize the economic benefits of switched non-linear systems subject to a prescribed switching schedule. We first develop an initial offline-learning RNN using historical operational data, and then update RNNs with real-time data to improve model prediction accuracy. The generalized error bounds for RNNs updated online with independent and identically distributed (i.i.d.) and non-i.i.d. data samples are derived, respectively. Subsequently, by incorporating online updating RNNs within LEMPC, probabilistic closed-loop stability, and economic optimality are achieved simultaneously for switched non-linear systems accounting for the RNN generalized error bound. A chemical process example with scheduled mode transitions is used to demonstrate that the closed-loop economic performance under LEMPC can be improved using an online update of RNNs.
1. Introduction
An economic model predictive control (EMPC) that addresses economic considerations within process control has attracted considerable attention in the control community over recent decades. Model predictive control (MPC) is applied in a wide variety of applications due to its ability to handle hard constraints on system states and manipulated inputs. The key idea of MPC is to compute an optimal input sequence using state feedback at the current sampling instant, and only the first input is fed to the system. Typically, a quadratic cost function is used in tracking MPC schemes to penalize the deviation of predicted system states and manipulated inputs from their steady-state values over a finite prediction horizon, such that the system is driven to its desired steady-state by minimizing the quadratic cost function. Unlike the steady-state operation of conventional tracking MPC schemes, EMPC generally uses a non-quadratic objective function to operate in a dynamic fashion (off steady-state) by optimizing process economics. Many research works have been developed to address closed-loop stability, economic optimization considerations, and model uncertainty for non-linear systems under EMPC (e.g., [1,2,3,4,5,6]).
Since, in real life, dynamical processes often involve mode transitions that may arise due to various reasons (e.g., actuator/sensor faults, feedback changes, and changes in environmental factors), it gives rise to an important research subject of switched systems. A class of systems with multiple switching modes is termed switched systems, whose active mode is determined by a switching signal. Switch systems have wide applications in engineering practice (e.g., mobile robots [7], electrical circuits [8], and flight control [9]). Control and optimization of switched systems have been extensively explored using methods in terms of Lyapunov stability theory [10,11], dwell-time [12,13], and linear matrix inequality [14]. In [15], a Lyapunov-based MPC framework was presented to stabilize switched non-linear systems that execute mode transitions at the prescribed switching times. Following this direction, in [16], a Lyapunov-based EMPC method was proposed to address the stabilization and economic optimality of switched non-linear systems subject to a prescribed switching schedule.
An accurate process model is a key requirement for achieving the desired control performance under EMPC. To this end, the above EMPC schemes often assume that the process model with the desired prediction accuracy can be obtained using first-principles modeling approaches. However, capturing the non-linear dynamics of complex and large-scale systems based on first-principles modeling approaches can be cumbersome and inaccurate when the physio-chemical phenomena of the system are not well-understood. Machine learning (ML) algorithms have shown great success in a variety of application domains in recent years, e.g., the resolving-power domination number of probabilistic neural networks was investigated in [17], and Gaussian process models were used to capture the dynamics of non-linear processes with unknown dynamics in [18] and with time-varying dynamics in [19]. As a powerful black box modeling tool among various ML algorithms, RNNs have achieved astonishing results in ML-based control for non-linear systems since they can approximate non-linear dynamics based on time-series data [20,21,22]. In [23], an RNN model was constructed offline to predict future states for EMPC that optimize economic benefits for non-linear systems while maintaining closed-loop stability. However, since ML models are generally trained offline to model non-linear systems under normal operation (i.e., without model uncertainty) using historical operational data, the resulting offline-trained ML models may not well approximate real-time non-linear dynamics subject to model uncertainty. Therefore, the presence of model uncertainty could result in degradation of the control performance of real-world non-linear processes under ML-based EMPC with offline-trained ML models. In [24], online learning with event-triggered and error-triggered mechanisms was applied to update ML models based on real-time data to learn model uncertainty, thus improving the control performance of non-linear systems subject to model uncertainty under ML-based EMPC.
Many works have been developed to integrate online learning models with a control design for non-linear processes (e.g., [25,26,27,28]). Although online learning models have shown their effectiveness in improving the prediction accuracy and control performance of non-linear processes, characterizing their generalization performance on the unseen testing set remains a critical challenge for real-time implementation of online ML-based controllers in practice. The generalized error bound is widely used to evaluate how an ML model developed using the training set can generalize well to the unseen testing set. The generalized error bound for online ML models has been developed in [29,30,31] by assuming that the online learner receives a data sequence generated in an i.i.d. manner. Certain efforts have been made in [32,33] to remove the i.i.d. assumption on training data points, for which the generalized error bound for online ML models updated with a set of non-i.i.d. data points has been derived. In our previous work, the generalized error bounds for RNNs updated online using i.i.d. and non-i.i.d. data points were established in [34,35], respectively, and the error bounds were utilized to derive closed-loop stability properties for switched non-linear systems without and with process disturbances under online updating RNN-based MPC. However, at this stage, it remains unclear how online learning RNNs can be integrated with EMPC to optimize economic benefits for switched non-linear systems while maintaining closed-loop stability.
To fill this research gap, this work aims to incorporate online learning RNNs into LEMPC to address closed-loop stability and economic optimality for switched non-linear systems operating under scheduled mode transitions. Specifically, the notation, class of switched non-linear systems, and the developments of RNNs are presented in Section 2. The generalized error bounds for RNNs updated online using i.i.d. and non-i.i.d. training data points are derived in Section 3. In Section 4, an LEMPC scheme that integrates online updating RNNs is proposed for switched non-linear systems involving process disturbances, under which probabilistic closed-loop stability is proved based on the RNN generalized error bound. In Section 5, a non-linear chemical process example with scheduled mode transitions is presented to demonstrate the efficacy of the proposed LEMPC scheme.
2. Preliminaries
2.1. Notation
The operators and are used to represent the Frobenius norm of a matrix and the Euclidean norm of a vector, respectively. The function belongs to class if is continuously differentiable. We use the operator to represent set subtraction, i.e., . The continuous function belongs to class if it satisfies and increases strictly in its domain. and and are used to denote the expected value of a random variable X and the probability of a event A occurring, respectively. Let and be two sequences, we will write provided that .
2.2. Class of Switched Non-Linear Systems
In this work, a class of switched non-linear systems described by the following first-order ordinary differential equations (ODEs) is considered.
where , , and denote the vectors of system states, control inputs, and disturbances, respectively. The control input constraint is given by , where the set defines the vectors of the minimum value and the maximum value for the input constraint (i.e., ). The disturbance vector is subject to the constraint . The switching function takes a value in . The number of switching modes is denoted by p. Throughout this manuscript, the notations and are used to represent the time at which the k-th mode (i.e., ) of Equation (1) is switched out and in, respectively. Therefore, the state-space model of Equation (1) is denoted by with when the system operates under mode k for . For all , , , and are assumed to be sufficiently smooth functions of dimensions , , and , respectively. Additionally, for all , we assume that and the initial time is zero, indicating that the origin is a steady-state of Equation (1) without disturbances (i.e., the nominal system). All states are assumed to be measurable at each sampling instant , where is the sampling period, , and is assumed to be a positive integer denoting the total number of sampling periods within , ).
For each mode , a stabilizing controller (e.g., the universal Sontag control law [36]) is assumed to exist in the sense that the origin of Equation (1) without disturbances is rendered exponentially stable. Following the construction method in [37], a level set of (denoted by , where for ) is used to represent the stability region of Equation (1) operating under mode k. Additionally, taking into account by the boundedness of , the smoothness assumed for , , and , and the continuous differentiable property of , positive constants are assumed to exist, such that the following inequalities hold for all , , :
2.3. Recurrent Neural Networks (RNN)
As opposed to the architecture of a traditional feedforward neural network in which signals are transmitted in only one direction, information in an RNN travels in both directions (i.e., forward and backward) due to the inclusion of recurrent loops as shown in Figure 1. This enables the feedback of signals associated with previous inputs back into the network, and fosters a temporal dynamic behavior that corresponds to the numerical techniques (e.g., the explicit Euler method) for solving an ODE. Therefore, the architecture of the RNN is especially suitable for modeling non-linear dynamic systems governed by ODEs.
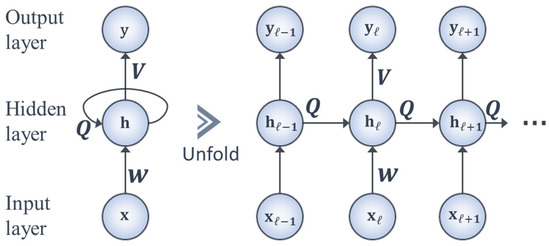
Figure 1.
A schematic of a recurrent neutral network and its unfolded structure.
In this work, we use a one-hidden-layer RNN described by the following form as a surrogate model for Equation (1):
where , , and , (T is the data sequences) and ( is the time length), are the RNN outputs, the RNN inputs, and the hidden states, respectively. The weight matrices , , and are associated with the output layer, the hidden layer, and the input layer, respectively. The non-linear activation functions and are associated with the output and the hidden layers, respectively. In this work, we follow the method in [37] to generate historical data for developing the initial offline-learning RNN. Specifically, numerous open-loop simulations are carried out for Equation (1) without disturbances operating under mode k with various conditions and , where is applied to the system of Equation (1) in a sample-and-hold fashion at each sampling step (i.e., holds for , , where is the sampling period). Subsequently, the initial RNN model is developed with open-loop simulation data to predict one sampling period forward using as RNN inputs. The RNN outputs are the predicted states within one sampling period (i.e., ) that contain all internal time steps of , where denotes the integration time step with a sufficiently small value used for solving the system of Equation (1) with numerical methods (e.g., the explicit Euler method). Without loss of generality, RNNs are developed under the following assumptions [38]:
Assumption 1.
An upper bound exists for the RNN inputs in the sense that for all , , where .
Assumption 2.
There are upper bounds for the weight matrices in the sense that , , and .
Assumption 3.
is a positive-homogeneous and 1-Lipschitz continuous activation function in the sense that for all , , where .
Let be the RNN model mapping the RNN input to the RNN output (), where denotes the hypothesis class. In this work, we use the mean squared error (MSE) as the loss function for the development of RNNs, where represents the true or labeled output vector. Since the training dataset for RNNs is generated for bounded states and inputs , there is an upper bound (denoted by ) for the RNN output and the true output , i.e., for , where . Therefore, the MSE loss function meets the local Lipschitz property in the sense that for all , the inequality is satisfied, where represents the local Lipschitz constant.
3. Online Learning of RNNs
Offline-trained RNNs are constructed based on historical data gathered from Equation (1) without disturbances, and may not be capable of capturing the dynamics of Equation (1) in real-time operation involving disturbances. Therefore, online learning is applied to update ML models to approximate the non-linear dynamics of Equation (1) with disturbances using real-time data. To integrate online ML models with EMPC for switched non-linear systems, ML models need to be developed with the desired predictive capacity on unseen testing data, which is commonly measured by generalized error bounds. In this section, the generalized error bounds for RNN models updated online using i.i.d. and non-i.i.d. training data points are developed, respectively.
3.1. Generalized Error of RNNs Updated Online with i.i.d. Training Data
We first consider a special case of switched non-linear systems, where the system dynamics of Equation (1) does not vary over time, and, thus, Equation (1) can be simplified to the following state-space model:
It is assumed that there exist multiple steady-states for the non-linear system of Equation (4) under the stabilizing controller , where and is a positive integer that represents the number of steady-states. When Equation (4) operates within the stability region around the steady-state , , , we define the system operating in mode k. In this section, we assume that historical data are only available for a portion of the stability region around . The initial RNN developed with the limited historical data around may not be capable of approximating the system dynamics of Equation (4) when the system operates in the stability region around another steady-state (e.g., , ). Therefore, it is essential to update the RNN models with improved prediction accuracy through online learning. In this case, online learning RNNs are developed using real-time process data that are drawn i.i.d. from the system of Equation (4).
We consider a sequence of data samples , …, drawn i.i.d. from the same distribution (e.g., the system of Equation (1)), where the online update of ML models takes place sequentially by processing these i.i.d. samples. Specifically, given an initial hypothesis , the online learner receives an instance and makes a prediction on the t-th round, where . Subsequently, the learner receives the true output , incurs the loss (e.g., the MSE loss), and then updates the ML model from to after processing . Therefore, the learner yields (i.e., a sequence of hypotheses) after T rounds. To simplify the notation, the loss is denoted by for any data sample , and we use the shorthand to represent (i.e., a sequence of data samples). In general, the goal of the online learner is to minimize the regret after the end of T rounds, which is defined as follows [32]:
where the first term denotes the cumulative loss of hypotheses , and the second term represents the minimum cumulative loss that is achieved by the best mode in the hypothesis class , where is defined by: . Note that we can only obtain in hindsight after the learner receives all the samples . Given a hypothesis h, its generalized error is defined as the expected loss at a new data point : .
The following lemma gives the generalized error bound for an ensemble hypothesis of ML models updated online using i.i.d. training set.
Lemma 1
([34]). Given the training set drawn i.i.d. from the same distribution , the learner produces the hypotheses by processing the samples sequentially with the loss function that is convex in its first argument and satisfies . Let be a unit simplex, be a weight vector, and be the ensemble hypothesis. Then, with a probability no less than , the following inequalities are satisfied for any :
The generalized error bound for given by the right-hand side (RHS) of Equation (6) depends on the cumulative loss incurred by the online algorithm after T rounds (the second term) and an error function (the first term) with respect to some parameters , , and M that represent the weight vector, the confidence level, and the upper bound for , respectively. Additionally, Equation (7) is derived using online-to-batch conversion to establish an important connection between the generalized error in the batch setting and the regret of an online learning algorithm. In detail, the generalized error is bounded by two error functions based on T, , M, and , the cumulative loss of , and the average regret in T rounds. The average regret converges to zero if the online algorithm achieves a sub-linear regret bound (i.e., ), and the two error functions are known once the parameters of and are chosen. Finally, it is noted that the weight vector is a dominant factor that affects the calculation of the generalized error bound in Lemma 1. Therefore, to achieve a low generalized error, the weight vector for the hypotheses can be optimized by solving the optimization problem as follows [34]:
where the objective function is the cumulative loss of hypotheses , is an inequality constraint used for constraining the difference between the weight and , and denotes a hyperparameter predetermined by a validation procedure.
3.2. Generalized Error of RNNs Updated Online with Non-i.i.d. Training Set
We next consider the switched non-linear systems of Equation (1) subject to bounded disturbances and the system is switched between different modes with time-varying system dynamics. As a result, process data collected in real-time operation of the system of Equation (1) are non-i.i.d. samples. The notations and the training procedure of RNNs updated with non-i.i.d. training samples follow those in the i.i.d. case. The only difference is that (i.e., the new data point) in the non-i.i.d. setting is conditioned on the past samples , and thus, the generalized error of the hypothesis is defined as follows [33]:
The following lemma provides the generalized error bound for an ensemble hypothesis of ML models updated online using non-i.i.d. training set.
Lemma 2
([33]). Given the non-i.i.d. training set , the learner yields hypotheses by processing samples sequentially. Let the weight vector λ and the loss function be defined in Lemma 1, and be the ensemble hypothesis. Then, with probability no less than , the following inequalities are satisfied for any :
In contrast to the generalized error bound for ML models updated online using i.i.d. training set in Lemma 1, Lemma 2 contains the term in the non-i.i.d. case, which is used to quantify the divergence of the sample and target distributions, and is given by [33]:
Since the calculation of requires knowledge of the distribution of and we do not have access to at the end of the T-th round, the discrepancy needs to be estimated based on the given data samples. Based on the results of Theorem 2 in [39] and Lemma 7 in [33], showing that the discrepancy can be bounded using sequential Rademacher complexity, the following lemma presents the generalized error bound for ML models updated online using non-i.i.d. training set in terms of sequential Rademacher complexity.
Lemma 3
([35]). Given the non-i.i.d. training set , let be the ensemble hypothesis that is developed satisfying all the conditions in Lemma 2. Consider a family of loss functions defined by . For any , the following inequality is satisfied with probability no less than :
where denotes the empirical discrepancy, , and denotes the sequential Rademacher complexity of the function class .
It is noted that and can be computed and optimized based on the given data samples, and can be obtained once the weight vector is chosen. As a result, to calculate the generalized error bound of Equation (13), it remains to characterize the upper bound on . The definition of sequential Rademacher complexity is given below.
Definition 1.
(Sequential Rademacher complexity [33]). Let be a -valued, T-depth tree and be a class of functions mapping . The sequential Rademacher complexity of a function class on a -valued tree is given by:
where represents a set of Rademacher random variables drawn i.i.d. from and denotes .
Lemma 3 characterizes the generalized error bound for a broad class of online ML models. In the remainder of this section, we will develop the generalized error bound for the RNN model of Equation (3) updated online with non-i.i.d. training set drawn from the non-linear system of Equation (1). We consider the RNN hypothesis class that maps the first ℓ-time-step inputs to the ℓ-th output, , and a family of loss functions associated with is defined by Note that is a family of vector-valued functions since the RNN model of Equation (3) is developed to approximate the dynamics of the multiple-input and multiple-output non-linear system (i.e., Equation (1)). Following the results of Lemma 4 in [32], we have the following upper bound for :
where denotes a family of real-valued functions that corresponds to the j-th component of , , and represents the RNN output dimension. Subsequently, we develop the upper bound on following the proof techniques in [38] that peel off the weight matrices (i.e., V, W, and Q) and the activation functions (i.e., and ) layer by layer.
Lemma 4
([35]). Consider a family of real-valued functions that corresponds to the j-th component of the RNN hypothesis class , with weight matrices and activation functions that satisfy Assumptions 1–3. The following inequality is satisfied for the RNNs developed with the non-i.i.d. training set :
where .
Based on Equations (13), (15) and (16), the following theorem develops the generalized error bound for RNN models updated online using the non-i.i.d. training set.
Theorem 1
([35]). Let be the RNN hypothesis class that maps the first ℓ-time-step inputs to the ℓ-th output, , be the hypotheses from that are developed using the non-i.i.d. training set and meet all the conditions in Lemmas 2–4, and be the ensemble hypothesis. For any , the following inequality holds with probability no less than :
where .
The weight vector for the hypotheses developed with non-i.i.d. training set can be optimized as follows [35]:
Remark 1.
Compared to the optimization problem of Equation (8) for the i.i.d. case, the objective function of Equation (18) accounts for the empirical discrepancy term for non-i.i.d training set. Additionally, since the cost function of Equation (18) is based on the sample that is unavailable after the T-th round, Equation (18) includes an additional equality constraint that lets , and, therefore, (i.e., the last hypothesis) is discarded. This is consistent with the i.i.d. case where the ensemble hypothesis is developed using the hypotheses without . It should be noted that the initial hypothesis is also discarded for the ensemble hypothesis in the non-i.i.d. case, since is trained offline using historical data that cannot predict the system dynamics of Equation (1) well with disturbances. Therefore, the ensemble hypothesis h is derived using the hypotheses , that is, .
4. RNN-Based LEMPC of Switched Non-Linear Systems
In this section, we develop a framework that integrates online learning RNN models with Lyapunov-based EMPC (RNN-LEMPC) for switched non-linear systems. Specifically, for each switching mode , the closed-loop state of Equation (1) is maintained in the prescribed stability region while an economic cost function is maximized to obtain optimal economic performance for the system under RNN-LEMPC. Additionally, due to the switching behavior of Equation (1), an appropriate mode transition constraint is included in the RNN-LEMPC formulation to guarantee the success of scheduled mode transitions. Note that in this section, we will only discuss the case of RNNs updated online with non-i.i.d. training set for modeling Equation (1) involving process disturbances, since Equation (4) switched between different steady-states without disturbances (the i.i.d. case) is a special case of Equation (1) and the stability results derived in this section can be easily adapted to the i.i.d. case.
4.1. Lyapunov-Based Control Using RNN Models
To simplify the closed-loop stability analysis for the system of Equation (1) under RNN-LEMPC, we represent the RNN model of Equation (3) in the following continuous-time state-space form:
where denotes the RNN state vector and represents the control input vector. For each mode , a stabilizing control law is assumed to exist in the sense that the origin of the RNN of Equation (19) is rendered exponentially stable. This stabilizability assumption indicates that there is a control Lyapunov function belonging to class such that the following inequalities are satisfied for all states x in :
where denotes an open neighborhood around the origin, , , are positive constants. Similarly to the construction procedure of the stability region for Equation (1) without disturbances, the stability region for the RNN model of Equation (19) operating under mode k with is characterized as a level set of as follows: , where for . Historical data are assumed to be available for Equation (1) without disturbances operating under each mode , and, thus, the initial RNN can be constructed offline using the corresponding historical data to approximate the nominal system dynamics for each mode, respectively. Subsequently, and for the initial RNN model can be characterized accordingly. Note that although the online update of RNNs is carried out using real-time data in this work, and will not be updated accordingly due to the excessive computational burden of real-time characterization of and for online learning RNNs. Therefore, and designed using the initial RNN remain unchanged at all times, and we will demonstrate that closed-loop stability for Equation (1) in terms of the boundedness of the state within the stability region is achieved in probability under LEMPC using online learning RNNs.
4.2. Lyapunov-Based EMPC Using RNN Models
Before we proceed to the closed-loop stability analysis for the system of Equation (1) under RNN-LEMPC, we need the following propositions that guarantee closed-loop stability of the system of Equation (1) under the controller . Specifically, Proposition 1 derives an upper bound for the state error between the RNN predicted state of Equation (19) and the actual state of Equation (1) taking into account bounded disturbances and model mismatch.
Proposition 1
([40]). Consider the RNN model of Equation (19) and the system of Equation (1) operating in mode k with the same initial condition , , and . There exist a function belonging to class and a positive constant κ such that for all , the following inequalities hold with probability no less than :
where denotes an upper bound for the model mismatch between the initial RNN model of Equation (19) and the system of Equation (1) without disturbances (i.e., ). The formulation of can be derived using the generalized error bound for offline-trained RNNs (see [38] for details).
Remark 2.
Since the initial RNN can capture the nominal system dynamics only, Equation (21a) is derived by taking (i.e., the worst-case scenario) into consideration. However, in this work, RNNs are iteratively updated using real-time data to capture non-linear dynamics of Equation (1) subject to bounded disturbances, such that the modeling error between the online learning RNN models of Equation (19) and the system of Equation (1) is bounded by the modeling error bound with probability no less than , i.e., . Based on the generalized error bound for RNNs updated online with non-i.i.d. training set (i.e., is given by the RHS of Equation (17)), the finite difference method can be used to approximate the modeling error bound . Note that the inequality holds with probability no less than if the MSE loss function is utilized in this work. Similarly to the derivation of Equation (21a), the following inequality holds with probability no less than :
Proposition 2 below demonstrates that if the initial RNN is trained to model the nominal system well (i.e., is sufficiently small), the closed-loop state of Equation (1) can be driven towards the origin and bounded in the stability region at all times under applied to the system of Equation (1) in a sample-and-hold fashion.
Proposition 2
([40]). Consider Equation (1) operating in mode k with , , under that is applied in a sample-and-hold fashion and meets the conditions of Equation (20). If the modeling error between the initial RNN model and the system of Equation (1) without disturbances can be bounded by , and there exist , , and , , such that the following inequality is satisfied:
where for satisfying , , then, with probability no less than , the following inequality holds for and :
The following proposition ensures that under , the closed-loop state can be driven to the stability region of mode f when the system of Equation (1) is switched to the subsequent mode f from the current mode k at the prescribed switching time.
Proposition 3
([34]). Consider Equation (1) operating in mode k for , with , and under satisfying the conditions in Proposition 1 and Proposition 2. Given and for some , if there exist positive real numbers , Δ, , and , such that
then .
The RNN-LEMPC scheme that optimizes economic benefits while maintaining closed-loop stability for Equation (1) is represented by the optimization problem as follows:
where and represent the predicted state trajectory and the class of piecewise constant functions with sampling period , and is used to evaluate the impact of (i.e., ) on the Lyapunov function value based on Equation (21b). At the current sampling time step , the optimization problem of Equation (26) is solved by maximizing the economic cost function of Equation (26a) over a shrinking prediction horizon for , ) and taking into account the constraints of Equations (26b)–(26g). In detail, Equation (26b) represents the prediction model that utilizes the initial RNN at the beginning and then is iteratively updated using real-time data. This prediction model is utilized to forecast future states for given obtained from the state measurement in Equation (26c). The constraint of Equation (26d) is incorporated to bound the control inputs for . Additionally, by designing as a subset of (i.e., ), the constraints of Equations (26e) and (26f) are designed to ensure that the predicted state moves toward and remains inside at all times, and it will be demonstrated in Theorem 2 that the actual state of Equation (1) is maintained in . Finally, Equation (26g) is the mode transition constraint used to drive the state to at .
It should be pointed out that when the prediction model (i.e., Equation (26b)) is updated online, all the terms in the RNN-LEMPC of Equation (26) associated with the Lyapunov function (i.e., Equation (26e), the LHS of Equation (26f), and Equation (26g)) use the latest RNN model except that the RHS of Equation (26f) utilizes the initial RNN at all times. Since the results of Propositions 1–3 are established under constructed using the initial RNN, the constraints of Equations (26e)–(26g) under may not hold due to the model inconsistency. Therefore, Equation (26) may not be guaranteed to be feasible once the prediction model is updated. To remedy this, the controller will be utilized for the next sampling period to stabilize the system of Equation (1) as a backup controller in the case of infeasibility of Equation (26) for some sampling steps. Finally, we develop the following theorem to guarantee that the closed-loop state of Equation (1) is maintained in at all times and is driven into at the switching moment under the RNN-LEMPC of Equation (26) with updating RNN models.
Theorem 2.
Consider the system of Equation (1) with under the RNN-LEMPC of Equation (26) using as the backup controller when Equation (26) is infeasible. Let , , , , satisfy
where is defined in Equation (21a) for the initial RNN and Equation (22) for online updating RNNs, respectively. For some , if and all the conditions in Propositions 1–3 are satisfied, and the online updating RNNs are developed, such that (i.e., the modeling error constraint) is met, then for each sampling step, with probability no less than , the state of Equation (1) is bounded in for and is driven to at .
Proof.
The proof consists of two parts. We first consider the case where the optimization problem of Equation (26) is infeasible and the control law is applied. In this case, it is demonstrated in Propositions 1–3 that the controller is able to guarantee the boundedness of the state within and the success of the scheduled model transitions for the non-linear system of Equation (1).
Subsequently, we prove that when there is a feasible solution (i.e., the optimal control action) for the RNN-LEMPC of Equation (26) with online updating RNN models, closed-loop stability for Equation (1) holds as well under . In detail, if , the predicted state stays in following the constraint of Equation (26e). Then, it follows from Proposition 1 that with probability no less than , the actual state of Equation (1) for , ) can be bounded as follows:
Since , we obtain if Equation (27) holds, indicating that for all , ) with probability no less than . Following the proof technique in [40], if , the time derivative of of Equation (1) for can be bounded as using Equation (2). Note that for any , Equation (26f) is activated such that we can further bound with probability no less than as follows:
where the first inequality of Equation (29) is obtained under the constraints of Equations (26f) and (20c). The second inequality of Equation (29) follows from Equation (20b) and the inequality for online updating RNNs. Using Equation (20a) for any state , it follows that the last inequality of Equation (29) holds. Therefore, with probability no less than , the following inequality for holds:
Due to and , the second inequality of Equation (30) is derived. Therefore, it is demonstrated in Equation (30) that holds if the constraint of Equation (23) in Proposition 2 is met. This implies that for any , the value of decreases for with probability no less than under , and, thus, the closed-loop state of Equation (1) can enter into within finite sampling steps for a certain probability. Additionally, using Equation (21b) and , the value of can be bounded with probability no less than as follows:
According to Equation (31), we have if Equation (26g) is met, which indicates that at , the closed-loop state can be driven into in probability.
Therefore, closed-loop stability can be achieved for the system of Equation (1) in probability regardless of the feasibility of Equation (26). This completes the proof of Theorem 2. □
Remark 3.
The RNN-LEMPC of Equation (26) demonstrates that if the state measurement at is in the region , the economic cost function is maximized within ; if , the predicted state is driven towards . Additionally, it has been proven in Theorem 2 that the actual state of Equation (1) is bounded in the stability region if is maintained in . Therefore, the region is a “safe" operating region in which the RNN-LEMPC of Equation (26) can maximize economic benefits while maintaining the boundedness of the state within . It is noted from Equation (27) that the relation between and is determined by , which is the upper bound on within one sampling period Δ. As discussed in Remark 2, online learning RNNs are capable of modeling Equation (1) involving disturbances while the initial RNN can capture the nominal system dynamics only. This implies that compared to the initial model, online learning RNNs may better approximate Equation (1) such that the state error is smaller, and, thus, a larger may be chosen for RNN-LEMPC with online updating RNNs. Therefore, while we use the controller characterized using the initial offline-trained RNN as a backup controller to stabilize Equation (1) when RNN-LEMPC is infeasible, the online update of RNNs is performed to improve the closed-loop economic performance of Equation (1), which will be illustrated using a non-linear chemical process in the next section.
5. Application to a Chemical Process Example
In this section, a chemical process example is used to illustrate the efficacy of the proposed LEMPC scheme using RNN models updated online. Specifically, a non-isothermal continuous stirred tank reactor (CSTR) is considered, in which a reactant A is transformed into a product B () via a second-order, irreversible, and exothermic reaction. The CSTR is required to switch between two modes consisting of two available inlet streams with different inlet concentrations and inlet temperatures for the pure reactant A, where . Additionally, a heating jacket with the heat rate Q is furnished in the CSTR to supply or remove heat for the reactor. At mode , the CSTR dynamic model is described by the following ordinary differential equations:
where is the concentration of the reactant A and T is the reactor temperature. A detailed description of the chemical reaction and the process parameters in Equation (32) can be found in [24]. The process parameter values of the CSTR used in the closed-loop simulations are given in Table 1.

Table 1.
Parameter values of the CSTR.
For each mode, a steady-state is considered for the CSTR under (i.e., the steady-state input values). In this example, two manipulated inputs are the heat input rate Q and the inlet concentration , which are denoted by and in their deviation variable forms, respectively. The manipulated inputs are bounded by kJ/h and for both modes. The input and state vectors in deviation form for the CSTR of Equation (32) are represented by and , respectively, such that the equilibrium point of the CSTR for each mode is at the origin of the steady-space. It is desired to operate the CSTR in (i.e., the stability region) around while maximizing the production rate of B given by:
The explicit Euler method with a sufficiently small integration time step of is applied to numerically solve the CSTR dynamic model of Equation (32). Additionally, the non-linear optimization problem of Equation (26) is solved by PyIpopt [41] with a sampling period of .
5.1. The CSTR Switched between Two Modes with Bounded Disturbances
We first consider the CSTR subject to the following disturbances. (1) The upstream disturbance results in the variation of the feed flow rate F in a way that F is time varying and is subject to the constraint: . (2) The catalyst deactivation is considered during process operation; this results in a gradual reduction in the pre-exponential factor that is constrained by: . Additionally, the control Lyapunov functions for both modes are designed using the quadratic form of with for . As discussed in Section 2.3, we follow the development method of RNN models in [37] to construct two initial RNNs to model the nominal CSTR system (i.e., the values of F and are taken in Table 1 at all times) operating in two modes using historical data gathered from the entire operating region, respectively. Specifically, the RNN models are trained using Keras, where a hidden recurrent layer of 16 neurons is utilized for both initial RNNs, with as the activation function, MSE as the loss function, and Adam as the optimizer. Based on the two initial RNNs, the stability region and a subset for the CSTR at mode can be characterized accordingly. In this example, and are chosen to be 368 and 280 for mode 1, and and are chosen to be 228 and 170, respectively. Since the CSTR involves disturbances during process operation, we follow the update strategy in [34] to improve RNN models online to capture the uncertain CSTR system involving bounded disturbances. Specifically, the online update of RNNs is carried out based on the most recent real-time data collected from a fixed time interval (e.g., five sampling periods) and the previous RNN model. The new RNN is utilized to predicate state evolution in LEMPC only if the modeling error constraint in Theorem 2 is met; otherwise, we will discard the new RNN model and use the previous RNN model as the prediction model in LEMPC.
We carry out the closed-loop simulations for the CSTR subject to bounded disturbances and with scheduled mode transitions under RNN-LEMPC as follows. Specifically, the CSTR operates under mode 1 for h) and the mode transition takes place at h, after which the CSTR operates under mode 2 for h, . The value of F changes to 2.5 m/h and 5.5 m/h, and reduces to , , at h and h, respectively. Starting from an initial condition = (1.95 kmol/m 402 K), the simulation results for the uncertain CSTR system with process disturbances under the LEMPC with the initial offline-learning RNNs and the online updating RNNs are displayed in Figure 2, Figure 3 and Figure 4. In detail, it is observed from Figure 2a that under the LEMPC using the initial RNN at all times, the closed-loop state is bounded in and (i.e., the stability regions) for both modes, and is driven from the initial condition outside of into at the switching moment. However, the state trajectories under the initial RNNs show considerable oscillations near the boundaries of and for both modes, while those under the online updating RNNs stay smoothly at the boundaries of and with much smaller oscillations, as shown in Figure 2b. Additionally, Figure 3 shows the comparisons of the Lyapunov function value under the LEMPC using the initial and online updating RNN models for both modes, respectively. It is shown in Figure 3 that both and under the initial RNNs show persistent oscillations around and , respectively, while those under the online updating RNNs show oscillations within finite sampling steps and ultimately converge to and after several rounds of online updates of RNNs, respectively. This implies that the contractive constraint of Equation (26f) under the LEMPC using the initial RNNs is activated frequently, since the Lyapunov function value exceeds and for both modes frequently, while the contractive constraint remains inactive after finite sampling steps under the online updating RNNs. Figure 4 depicts the state profiles (i.e., and T) and the input profiles (i.e., and Q) in the original state space. Specifically, it is observed from Figure 4a that under the online updating RNNs, the LEMPC drives the states and T to the optimal operating points that maximize the production rate of B for both modes. However, the state exhibits sustained oscillations under the LEMPC using the initial RNNs. Similarly, it is shown in Figure 4b that the LEMPC using the online updating RNNs shows smoother manipulated input profiles (fewer oscillations) compared to that using the initial RNNs. The above simulation results demonstrate that the initial RNNs trained with historical data cannot predict well the uncertain CSTR system in the presence of process disturbances, which results in sustained oscillations in the state trajectories, the evolution of Lyapunov function value , and the state and input profiles. These oscillations can be effectively mitigated after a more accurate RNN model that approximates the uncertain CSTR system dynamics is derived through an online update of RNNs.
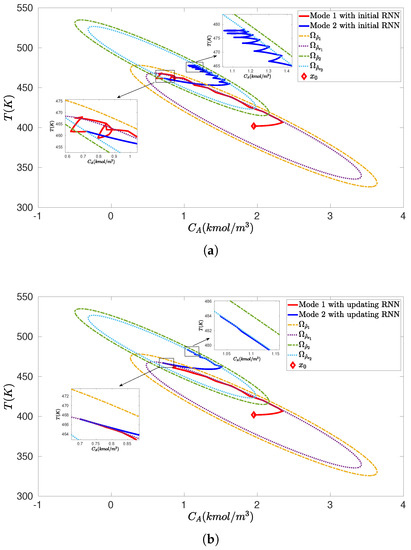
Figure 2.
Closed–loop state trajectories for the uncertain CSTR system operating in mode 1 for h) (red solid line) and switching to mode 2 at h (blue solid line) under the RNN-LEMPC of Equation (26), (a) using the initial offline-learning RNNs at all times, and (b) using the online updating RNNs, for the initial condition = (1.95 kmol/m 402 K) (marked as red diamond).
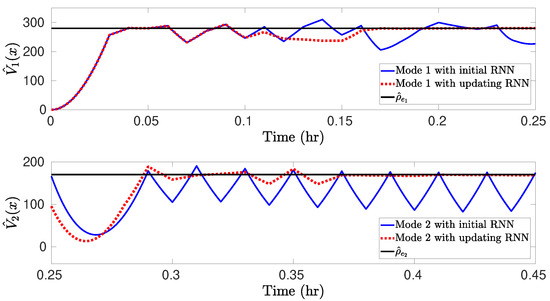
Figure 3.
Comparisons of for mode 1 and for mode 2 under the initial offline-learning and online updating RNN models.
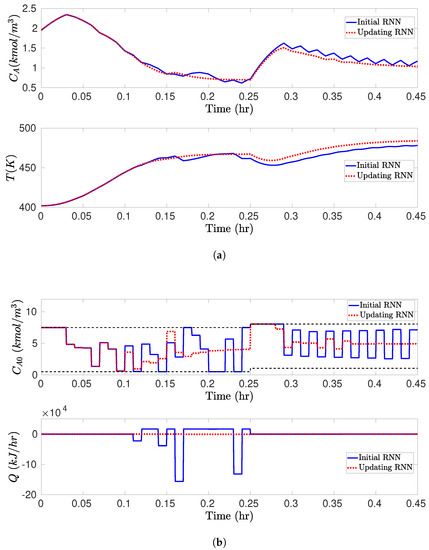
Figure 4.
(a) Closed-loop state ( and T) and (b) manipulated input ( and Q) profiles for the uncertain CSTR system operating in mode 1 for h) and switching to mode 2 at h under the RNN-LEMPC of Equation (26) using the initial offline-learning RNNs at all times (blue solid line), and using the online updating RNNs (red dashed line), for the initial condition = (1.95 kmol/m 402 K).
Finally, in the event that the system dynamics of the CSTR remains unchanged for the remaining operation time (i.e., no further mode transition and no process disturbances after ), an online update of RNNs will be deactivated and the final RNN model can be derived by solving Equation (18), and the CSTR will operate in mode 2 under the LEMPC using the final RNN model after . Specifically, when the CSTR operates in mode 2, the RNNs are updated online at for four times (the number of rounds ). We use the hypothesis and a sequence of hypotheses to denote the initial RNN and the four online updating RNNs for mode 2, respectively. To simplify the calculation of the empirical discrepancy of Equation (18), the hypothesis is considered to belong to a linear space (denoted by of the hypotheses in this example, that is . It is noted that each round of online learning represents five sampling periods in this example, and, thus, the RNN input for the next round consists of the system states and the control inputs for the current and the next four sampling steps, where and . Therefore, the loss between the RNN outputs predicted by the hypotheses and on (i.e., , ) can be obtained. The optimization problem of Equation (18) can be simplified to the following minimax optimization problem:
It is noted that exhaustive searches for the hypothesis are performed in the linear space , thereby converting the minimax optimization problem of Equation (34) into the minimization problem of the maximum of a set of objective functions, which can be efficiently solved using the MATLAB routine fminimax. By setting the hyperparameter , the optimization problem of Equation (34) is solved to calculate the optimal weight vector , yielding , , , where the weight is assigned to be zero following the constraints in Equation (34). Subsequently, the final RNN model h is derived using the ensemble of the hypotheses with the corresponding weights , that is , and the hypothesis is discarded due to its weight . It should be pointed out that when the system dynamics of the CSTR varies over time caused by further mode transitions and/or process disturbances at some future operation time, the final model h needs to be updated online again using real-time data if it does not perform well.
5.2. The CSTR Switched between Two Steady-States without Disturbances
We next consider a special switching case of the nominal CSTR system, as discussed in Section 3.1, where the CSTR operates in mode 1 defined in Section 5.1 at all times (i.e., for Equation (32)) and does not involve disturbances. In this case, two steady-states = (1.95 kmol/m, 402 K) and = (1.22 kmol/m, 438 K) for the CSTR are considered under = (4 kmol/m, 0 kJ/h). The CSTR is switched between two steady-states at the prescribed switching times while maximizing the economic costs of Equation (33) under RNN-LEMPC. The CSTR is said to operate in mode 1 or 2 when it operates in the stability region or around the steady-state or . For both modes, the control Lyapunov functions follow those in Section 5.1 with . In this section, it is assumed that historical operational data is only available for the CSTR operating in a portion of operating region (denoted by ) around the steady-state , where (marked as a rectangle in Figure 5). Based on this limited training dataset, an initial RNN is trained using the same method in Section 5.1. The stability region and a subset for mode 1 follow those in Section 5.1 with and , and the stability region with and a subset with are chosen for the CSTR at mode 2 in this section. In this example, since the initial RNN is developed with the dataset in around the steady-state of mode 1, we will operate the CSTR in mode 1 under LEMPC with the initial RNN at all times. However, when the CSTR operates in mode 2, we will update the RNN models online since the initial RNN lacks the dataset around the steady-state of mode 2. Specifically, starting from the initial RNN, the RNNs are updated online using the most recent real-time data (i.e., every five sampling periods for each round) and the previous RNN model.
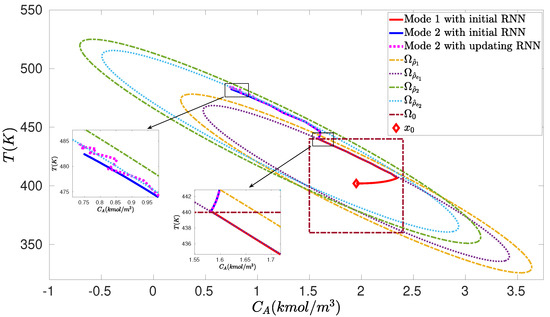
Figure 5.
Closed-loop state trajectories for the nominal CSTR system operating in mode 1 for using the initial offline-learning RNN (red solid line), and switching to mode 2 at using the initial RNN (blue solid line) and online updating RNNs (pink dashed line) under the RNN-LEMPC of Equation (26) with the initial condition (marked as red diamond).
The simulation results for the nominal CSTR system switched between two steady-states under the RNN-LEMPC of Equation (26) are presented in Figure 5 and Figure 6. Specifically, the CSTR starts from an initial condition and operates in mode 1 for under the LEMPC with the initial RNN constructed with the dataset in . Subsequently, the CSTR operates under mode 2 for (i.e., the remaining operation time) following a switching schedule from mode 1 to mode 2 at under LEMPC using the initial RNN and the online updating RNNs. Figure 5 shows that under the initial RNN, the state trajectory closely follows the boundary of for mode 1. This is consistent with the result in Figure 6a, which shows that the Lyapunov function value under the initial RNN converges to after . It should be mentioned that the initial RNN is constructed with the dataset gathered from a portion of the operating region around , and, thus, the LEMPC with the initial RNN performs well for the CSTR operating in mode 1. Additionally, it is observed in Figure 5 that under the initial RNN, there exists a gap between the closed-loop state trajectory and the boundary of for mode 2, while the closed-loop state trajectory under the online updating RNNs ultimately operates near the boundary of after exhibiting oscillations for some sampling steps. It is more apparent in Figure 6b that the Lyapunov function value under the initial RNN converges to a value of 340, while it converges to after under the online updating RNNs. The total economic benefits within the operating period are calculated (note that the first update of RNNs occurs at ), which yields 4.75 and 4.84 for the LEMPC with the initial RNN and the online RNNs, respectively. Therefore, the accumulative economic benefits during are improved by via online learning. Finally, the RNNs are updated online at six times () to generate a sequence of hypotheses . Based on the testing error for each hypothesis , Equation (8) is solved with the hyperparameter to calculate the optimal weights for the hypotheses , respectively, yielding , , , , , and . Subsequently, the final RNN model h is developed with , and the CSTR operates in mode 2 under the LEMPC with this final RNN model for the remaining operation time. However, when there is a further mode transition for the CSTR, the online update of RNNs is required to perform again if the final model does not predict well for the CSTR operating in the new mode.
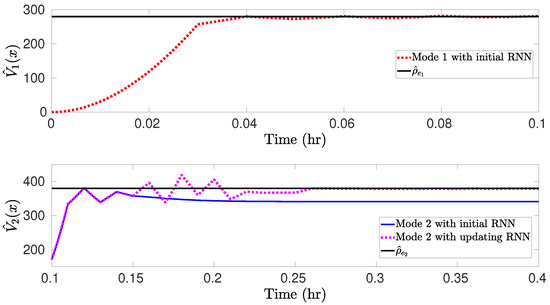
Figure 6.
Comparisons of for mode 1 using the initial offline-learning RNN (red dashed line), and for mode 2 using the initial RNN (blue solid line) and online updating RNNs (pink dashed line).
6. Conclusions
This work proposed an LEMPC scheme using online updating RNNs that can optimize the economic benefits of switched non-linear systems. The generalized error bounds for RNN models updated online in i.i.d. and non-i.i.d. settings were derived, respectively. Subsequently, the LEMPC that incorporates online learning RNNs was developed to maintain the closed-loop state within the prescribed stability region and maximize the economic benefits for the uncertain system involving bounded disturbances. A Lyapunov-based constraint was incorporated into the LEMPC formulation to ensure the success of scheduled mode transitions. Closed-loop stability for the uncertain non-linear system subject to bounded disturbances under LEMPC was proved in a probabilistic manner accounting for the generalized error bound. The proposed LEMPC scheme was applied to a chemical process example to demonstrate that economic optimality and closed-loop stability can be improved under the LEMPC using online RNNs compared to those using the initial RNNs at all times.
Author Contributions
C.H. developed the main results, performed the simulation studies and prepared the initial draft of the paper. S.C. contributed to the simulation studies in this manuscript. Z.W. developed the idea of RNN generalized error, oversaw all aspects of the research and revised this manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National University of Singapore Start-up Grant, Grant/Award Number: R279-000-656-731 and MOE AcRF Tier 1 FRC Grant, Grant/Award Number: CHBE-22-5367.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Angeli, D.; Amrit, R.; Rawlings, J.B. On average performance and stability of economic model predictive control. IEEE Trans. Autom. Control 2011, 57, 1615–1626. [Google Scholar] [CrossRef]
- Heidarinejad, M.; Liu, J.; Christofides, P.D. Economic model predictive control of nonlinear process systems using Lyapunov techniques. AIChE J. 2012, 58, 855–870. [Google Scholar] [CrossRef]
- Müller, M.A.; Angeli, D.; Allgöwer, F. Economic model predictive control with self-tuning terminal cost. Eur. J. Control 2013, 19, 408–416. [Google Scholar] [CrossRef]
- Ellis, M.; Durand, H.; Christofides, P.D. A tutorial review of economic model predictive control methods. J. Process Control 2014, 24, 1156–1178. [Google Scholar] [CrossRef]
- Dong, Z.; Angeli, D. Analysis of economic model predictive control with terminal penalty functions on generalized optimal regimes of operation. Int. J. Robust Nonlinear Control 2018, 28, 4790–4815. [Google Scholar] [CrossRef]
- Dong, Z.; Angeli, D. Homothetic tube-based robust economic mpc with integrated moving horizon estimation. IEEE Trans. Autom. Control 2020, 66, 64–75. [Google Scholar] [CrossRef]
- Lee, T.C.; Jiang, Z.P. Uniform asymptotic stability of nonlinear switched systems with an application to mobile robots. IEEE Trans. Autom. Control 2008, 53, 1235–1252. [Google Scholar] [CrossRef]
- Shen, H.; Xing, M.; Wu, Z.G.; Xu, S.; Cao, J. Multiobjective fault-tolerant control for fuzzy switched systems with persistent dwell time and its application in electric circuits. IEEE Trans. Fuzzy Syst. 2019, 28, 2335–2347. [Google Scholar] [CrossRef]
- Jin, Y.; Fu, J.; Zhang, Y.; Jing, Y. Reliable control of a class of switched cascade nonlinear systems with its application to flight control. Nonlinear Anal. Hybrid Syst. 2014, 11, 11–21. [Google Scholar] [CrossRef]
- Branicky, M.S. Multiple Lyapunov functions and other analysis tools for switched and hybrid systems. IEEE Trans. Autom. Control 1998, 43, 475–482. [Google Scholar] [CrossRef]
- Aleksandrov, A.Y.; Chen, Y.; Platonov, A.V.; Zhang, L. Stability analysis for a class of switched nonlinear systems. Automatica 2011, 47, 2286–2291. [Google Scholar] [CrossRef]
- Hespanha, J.P.; Morse, A.S. Stability of switched systems with average dwell-time. In Proceedings of the 38th IEEE Conference on Decision and Control, Phoenix, AZ, USA, 7–10 December 1999; Volume 3, pp. 2655–2660. [Google Scholar]
- Xiang, W.; Xiao, J. Stabilization of switched continuous-time systems with all modes unstable via dwell time switching. Automatica 2014, 50, 940–945. [Google Scholar] [CrossRef]
- Nodozi, I.; Rahmani, M. LMI-based model predictive control for switched nonlinear systems. J. Process Control 2017, 59, 49–58. [Google Scholar] [CrossRef]
- Mhaskar, P.; El-Farra, N.H.; Christofides, P.D. Predictive control of switched nonlinear systems with scheduled mode transitions. IEEE Trans. Autom. Control 2005, 50, 1670–1680. [Google Scholar] [CrossRef]
- Heidarinejad, M.; Liu, J.; Christofides, P.D. Economic model predictive control of switched nonlinear systems. Syst. Control Lett. 2013, 62, 77–84. [Google Scholar] [CrossRef]
- Prabhu, S.; Deepa, S.; Arulperumjothi, M.; Susilowati, L.; Liu, J. Resolving-power domination number of probabilistic neural networks. J. Intell. Fuzzy Syst. 2022, 43, 6253–6263. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, T.; Li, S.; Qi, C.; Zhang, Y.; Wang, Y. Data-Driven Distributed Model Predictive Control of Continuous Nonlinear Systems with Gaussian Process. Ind. Eng. Chem. Res. 2022, 61, 18187–18202. [Google Scholar] [CrossRef]
- Zhang, T.; Li, S.; Zheng, Y. Implementable Stability Guaranteed Lyapunov-Based Data-Driven Model Predictive Control with Evolving Gaussian Process. Ind. Eng. Chem. Res. 2022, 61, 14681–14690. [Google Scholar] [CrossRef]
- Pan, Y.; Wang, J. Model predictive control of unknown nonlinear dynamical systems based on recurrent neural networks. IEEE Trans. Ind. Electron. 2011, 59, 3089–3101. [Google Scholar] [CrossRef]
- Xu, J.; Li, C.; He, X.; Huang, T. Recurrent neural network for solving model predictive control problem in application of four-tank benchmark. Neurocomputing 2016, 190, 172–178. [Google Scholar] [CrossRef]
- Shahnazari, H.; Mhaskar, P.; House, J.M.; Salsbury, T.I. Modeling and fault diagnosis design for HVAC systems using recurrent neural networks. Comput. Chem. Eng. 2019, 126, 189–203. [Google Scholar] [CrossRef]
- Wu, Z.; Christofides, P.D. Economic machine-learning-based predictive control of nonlinear systems. Mathematics 2019, 7, 494. [Google Scholar] [CrossRef]
- Wu, Z.; Rincon, D.; Christofides, P.D. Real-time adaptive machine-learning-based predictive control of nonlinear processes. Ind. Eng. Chem. Res. 2019, 59, 2275–2290. [Google Scholar] [CrossRef]
- Wagener, N.; Cheng, C.A.; Sacks, J.; Boots, B. An online learning approach to model predictive control. arXiv 2019, arXiv:1902.08967. [Google Scholar]
- Bieker, K.; Peitz, S.; Brunton, S.L.; Kutz, J.N.; Dellnitz, M. Deep model predictive control with online learning for complex physical systems. arXiv 2019, arXiv:1905.10094. [Google Scholar]
- Ning, C.; You, F. Online learning based risk-averse stochastic MPC of constrained linear uncertain systems. Automatica 2021, 125, 109402. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhao, T.; Wang, X.; Wu, Z. Online Learning-Based Predictive Control of Crystallization Processes under Batch-to-Batch Parametric Drift. AIChE J. 2022, 68, e17815. [Google Scholar] [CrossRef]
- Cesa-Bianchi, N.; Conconi, A.; Gentile, C. On the generalization ability of on-line learning algorithms. IEEE Trans. Inf. Theory 2004, 50, 2050–2057. [Google Scholar] [CrossRef]
- Cesa-Bianchi, N.; Gentile, C. Improved risk tail bounds for on-line algorithms. IEEE Trans. Inf. Theory 2008, 54, 386–390. [Google Scholar] [CrossRef]
- Kakade, S.M.; Tewari, A. On the generalization ability of online strongly convex programming algorithms. Adv. Neural Inf. Process. Syst. 2008, 21, 801–808. [Google Scholar]
- Rakhlin, A.; Sridharan, K.; Tewari, A. Online learning via sequential complexities. J. Mach. Learn. Res. 2015, 16, 155–186. [Google Scholar]
- Kuznetsov, V.; Mohri, M. Time series prediction and online learning. In Proceedings of the 29th Annual Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 1190–1213. [Google Scholar]
- Hu, C.; Cao, Y.; Wu, Z. Online Machine Learning Modeling and Predictive Control of Nonlinear Systems with Scheduled Mode Transitions. AIChE J. 2022, 69, e17882. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Z. Model Predictive Control of Switched Nonlinear Systems Using Online Machine Learning. submitted.
- Lin, Y.; Sontag, E.D. A universal formula for stabilization with bounded controls. Syst. Control Lett. 1991, 16, 393–397. [Google Scholar] [CrossRef]
- Wu, Z.; Tran, A.; Rincon, D.; Christofides, P.D. Machine learning-based predictive control of nonlinear processes. Part I: Theory. AIChE J. 2019, 65, e16729. [Google Scholar] [CrossRef]
- Wu, Z.; Rincon, D.; Gu, Q.; Christofides, P.D. Statistical Machine Learning in Model Predictive Control of Nonlinear Processes. Mathematics 2021, 9, 1912. [Google Scholar] [CrossRef]
- Kuznetsov, V.; Mohri, M. Discrepancy-based theory and algorithms for forecasting non-stationary time series. Ann. Math. Artif. Intell. 2020, 88, 367–399. [Google Scholar] [CrossRef]
- Wu, Z.; Alnajdi, A.; Gu, Q.; Christofides, P.D. Statistical machine-learning–based predictive control of uncertain nonlinear processes. AIChE J. 2022, 68, e17642. [Google Scholar] [CrossRef]
- Wächter, A.; Biegler, L.T. On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Math. Program. 2006, 106, 25–57. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).