1. Introduction
In an age where technology and its advancements redefine the boundaries of human–machine interactions, the launch of new technological tools, especially those with the potential to revolutionise communication, often elicits a spectrum of public reactions [
1]. Such reactions can offer crucial guidance for stakeholders involved in the development, implementation, and governance of such technologies, providing valuable insights into user acceptance, potential barriers, and opportunities for improvement [
2].
Recent studies (e.g., [
3,
4,
5]) have explored the application of data-driven and text mining approaches to extract information about public reactions from social media platforms (e.g., Twitter, now formally known as ‘X’), leveraging the wealth of public discourse surrounding emerging technologies. However, these works have predominantly focused on extracting sentiment polarity, which categorises responses as positive or negative. Although this binary approach provides a basic indication of adoption or acceptance, it fails to capture the nuanced emotional landscape surrounding technological adoption.
To overcome this limitation, this paper presents a comprehensive analysis to investigate the emotional landscape surrounding technology adoption. This approach goes beyond sentiment polarity, allowing specific emotions to be pinpointed, such as excitement, surprise, frustration, and others that users experience with the emergence of new technologies. This granular emotional analysis offers a more sophisticated understanding of public reactions, enabling more informed decision-making in the development and deployment of technology.
In recent years, artificial-intelligence-(AI)-powered technologies have been widely adopted in various fields, including health care, finance, transportation, and entertainment [
6], as well as being integral to our daily lives (e.g., virtual assistants, personalised recommendations, facial recognition). One of the most recent breakthroughs in AI research has been the emergence of large language models (LLMs) that are built on generative pre-trained transformers (GPTs) [
6]. In particular, OpenAI’s ChatGPT [
7] emerged as a groundbreaking innovation in the domain of conversational AI in November 2022. This AI-powered chatbot quickly gained widespread attention for its ability to engage in human-like conversations and its unprecedented capabilities in natural language processing, including answering questions, providing explanations, assisting with writing tasks, and even generating code. Given the advantages of ChatGPT over traditional chatbots, it attracted more than 1 million users in its first week after it was launched, surpassing adoption rates of other popular online platforms such as Netflix, Facebook, and Instagram [
4].
However, along with its rapid popularity, ChatGPT has prompted concerns about the broader implications of its use [
6]. Among these concerns is the potential for its exploitation for malicious purposes [
8], the possibility of the technology exacerbating preexisting societal biases by inadvertently reflecting biases from its training data, causing ChatGPT to produce biased responses [
9], and its ability to produce highly convincing fake text.
Given these two contrasting scenarios—on the one hand, the rapid adoption and widespread benefits of ChatGPT, and on the other, the concerns around its potential misuse and unintended societal impacts—it becomes crucial to explore how users emotionally respond to this technology. These varied reactions highlight the complexity of public sentiment toward AI systems. As such, in this paper, we focus on ChatGPT as a case study, aiming to capture and analyse the full spectrum of emotions expressed by users during its release to the public. By doing so, we ensure that we explore the emotional landscape in all its nuances, offering a deeper understanding of both the enthusiasm and apprehension surrounding its adoption and integration.
The main contributions of the work presented herein are as follows:
A deep exploration of the emotional responses of early technology adopters. This study goes beyond traditional sentiment analysis by categorising user responses into specific emotions. This approach pushes the boundaries of sentiment analysis, offering a more nuanced and fine-grained understanding than the conventional positive, negative, and neutral classifications.
A comprehensive analysis of key topics driving emotional responses among early technology adopters. By mapping user discussions to distinct emotional categories, this analysis uncovers the underlying reasons behind the emotions expressed. This offers valuable insights into the factors influencing both positive and negative reactions, providing a deeper understanding of user sentiment towards new technologies.
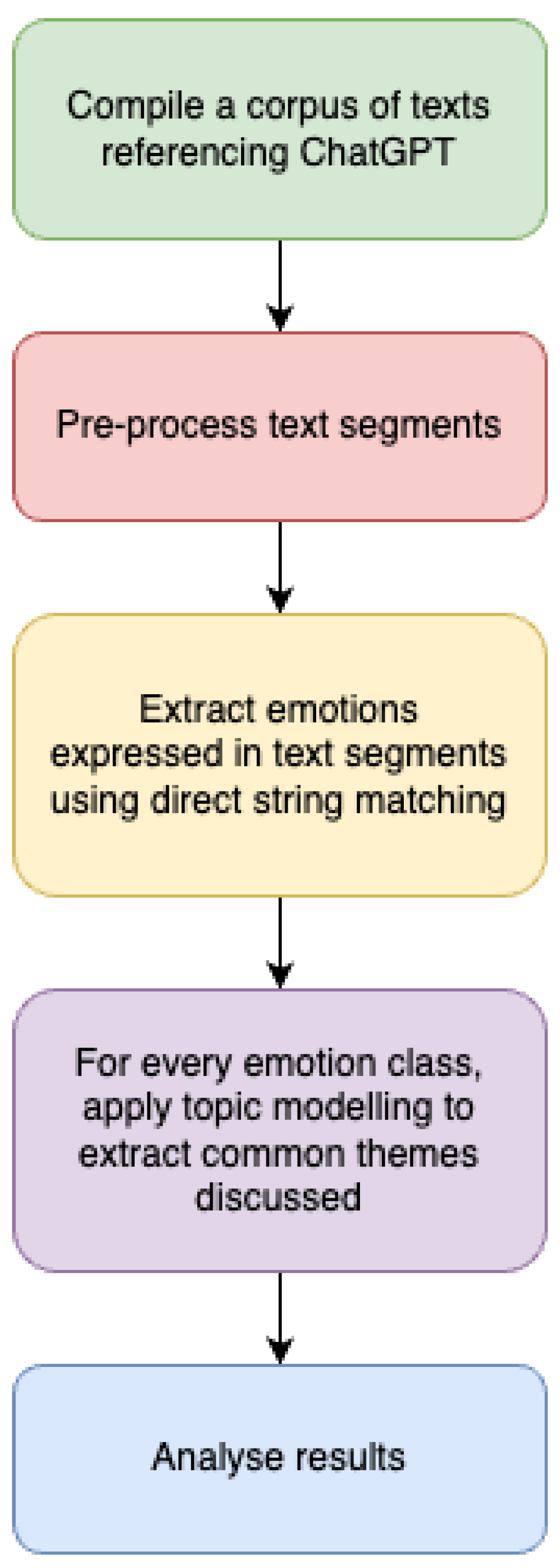
This study was designed as shown in
Figure 1: (1) compile a corpus of texts containing references to ChatGPT during its launch, (2) preprocess text responses using traditional natural language processing (NLP) techniques, (3) divide texts based on their publication date, (4) for each dataset in (3), automatically extract emotions expressed within text segments, (5) for each emotive category in (4), apply a topic modelling approach to automatically identify aspects discussed in text segments, and (6) visualise and analyse the results.
The remainder of this paper is structured as follows:
Section 2 presents the related work.
Section 3 discusses the collection of texts used to support the experiments herein and the techniques used to prepare the data for such experiments.
Section 4 and
Section 5 discuss aspect-based emotive analysis and how it was applied to the datasets.
Section 6 presents and discusses the results.
Section 7 concludes the paper; finally,
Section 8 discusses future work.
2. Related Work
Studies investigating technological adoption have traditionally employed various methodological approaches, ranging from theoretical frameworks to qualitative and quantitative analyses. Theoretical models like the Technology Acceptance Model (TAM) and Unified Theory of Acceptance and Use of Technology (UTAUT) have been instrumental in understanding factors influencing technology uptake by examining perceived usefulness and ease of use [
10,
11].
While early research predominantly used survey-based and interview methodologies, recent studies have turned to text mining approaches to automatically analyse and help understand the factors influencing consumer adoption or rejection of emerging technologies from a large landscape of adopters [
3]. These approaches offer advantages in processing large volumes of user-generated content, particularly from social media platforms. Most recently, Williams et al. [
3] introduce a scalable and automated framework designed to monitor the potential adoption or rejection of emerging technologies by analysing social media discourse. They compiled a substantial corpus of social media texts referencing new technologies and applied text mining techniques to extract sentiments related to various technological aspects. Powered by sentiment analysis, they hypothesised that positive sentiments correlate with a higher likelihood of acceptance of technology, while negative sentiments indicate potential rejection. To validate this hypothesis, a ground truth analysis was performed comparing the automated sentiment extraction results with human annotations. The findings demonstrated that the automated approach effectively captures sentiments comparable to human evaluations, providing valuable information on user behaviours, emerging demands, and uncertainties surrounding new technologies.
Others have applied sentiment analysis across diverse technological domains. Kwarteng et al. [
5] investigated consumer perceptions of autonomous vehicles through Twitter data, while Efuwape et al. [
12] examined digital collaborative tool adoption using sentiment analysis. Hizam et al. [
13] also explored technology adoption behaviours by analysing social media content, focusing on factors like perceived utility and social impact. Mardjo and Choksuchat [
14] and Caviggioli et al. [
15] used sentiment analysis to examine public perceptions of Bitcoin, aiming to forecast market behaviour and understand adopter reactions.
While existing research employs sentiment analysis to understand technology adoption patterns, such approaches that focus solely on sentiment polarity (positive/negative) provide limited insights into the nuanced factors driving adoption reactions and decisions. Basic sentiment analysis fails to capture the true nuances behind the specific aspects of technology that users embrace or reject, leaving a critical gap in our understanding of adoption behaviours. In this case, studies such as Lee and Kang [
16] apply topic modelling to analyse technology and innovation management research, identifying key themes and trends over two decades. Their study highlights a shift from traditional management theories to data-driven, empirical research, with growing interest in technology adoption, patent analysis, and social network analysis. Similarly, Cobelli and Blasi [
17] produce a similar topic modelling and bibliometric analysis to understand the evolution of technological innovation adoption in the healthcare industry. However, these works focus on academic discourse, lacking insight into public perception, emotional responses, and real-world adoption barriers.
This study presents a comprehensive framework for emotional landscape analysis, addressing the limitations of previous research by integrating emotional analysis with topic modelling. By leveraging text mining techniques on large-scale social media corpora, the research moves beyond polarised sentiment analysis to extract nuanced emotional reactions, such as excitement, fear, surprise, and frustration, providing deeper insights into technological acceptance and long-term societal impacts. This approach has significant implications for technology developers and policymakers, enabling them to optimise product features, address adoption concerns, and align innovation strategies with user expectations. Unlike other research that primarily serves academia and policy, this case study offers an adaptable methodology for analysing technology adoption across various domains. By combining emotion extraction with topic modelling, the research bridges the gap between technology development and public perception, supporting more informed decision-making in innovation strategy, deployment, and governance.
3. Text Corpus
To assess the public sentiment of early ChatGPT adopters, in this paper, social media data was collated, specifically from Twitter, a social networking service that enables users to send and read tweets, text messages consisting of up to 280 characters. Recent shifts in Twitter’s data collection policies, under the platform’s rebranded identity as ‘X’, have significantly impacted the social media platform’s data accessibility for research purposes. In response to these data accessibility limitations, other rich and well-established resources in the data science community, such as Kaggle (
https://www.kaggle.com, accessed on 5 May 2024), host an array of relevant datasets, including compilations of Twitter conversations.
To gather relevant data for this study, a comprehensive search was conducted on Kaggle using specific keywords related to the research focus. The search criteria included datasets of tweets that had been collected using references to ‘ChatGPT,’ ‘GPT3,’ ‘GPT4,’ and ‘OpenAI.’ This targeted approach allowed us to identify and compile a rich corpus of Twitter conversations specifically centred around ChatGPT and related AI technologies. By leveraging these pre-collected datasets, we were able to circumvent the challenges posed by Twitter’s new data policies while still accessing a robust and relevant sample of public discourse on the topic.
Table 1 reports the distribution of tweets across each dataset. Most datasets were collected using Twitter’s API, typically by targeting specific keywords or hashtags related to ChatGPT. However, in many cases, the detailed methodology behind data collection is not fully documented, which can hinder reproducibility and transparency. Additionally, none of the datasets explicitly filter tweets by region or age group. Although this broad approach enables the capture of a wide range of opinions, it can also introduce bias, particularly the over-representation of English-speaking users or individuals from regions with greater Twitter usage.
All datasets are publicly available on Kaggle, making them accessible for further research and comparative analysis. To mitigate potential biases and enhance the robustness of the study, researchers are encouraged to consider data augmentation by incorporating datasets from more diverse sources or languages. If metadata such as user location or language preferences is available, it should be analysed to evaluate and correct for regional imbalances.
Following the concatenation of each dataset, using Python’s regular expression package, RegEx (version 2020.9.27), retweets were removed by identifying text that began with the standard Twitter retweet syntax (RT @username:), which typically signifies a reposted tweet. By filtering out such entries using a regular expression pattern (e.g., RT @), the dataset retains only original content posted each day. This helps reduce redundancy and the disproportionate influence of highly retweeted content. Duplicate tweets collected each day according to their posted timestamp were then removed. The remaining dataset contained a total of 5,262,428 tweets. The dataset spans between 30 November 2022 and 14 May 2023 (167 days), with 20 March 2023 reporting the most tweets (9171) and 23 April 2023 reporting the fewest (54).
The data preparation and analysis in this study were conducted using Python (version 3.7.2). For text preprocessing, the following traditional NLP techniques were applied:
Converting text to lowercase.
Removing additional white spacing, mentioned usernames, hashtags, URLs, punctuation, digits, and emojis using Python’s regular expression package, RegEx (version 2020.9.27).
Tokenising text using Python’s natural language package, Natural Language Toolkit (NLTK) (version 3.4.1).
Removing stop words (e.g., this, are, and a) as part of the NLTK package.
Stemming tokens using the Porter Stemmer as part of the NLTK package.
The keywords (i.e., ‘ChatGPT’, ‘GPT3’, ‘GPT4’, and ‘OpenAI’) used to search for tweets were removed, as their presence may disproportionately influence future topic modelling results. Such terms may dominate the text due to their frequency and centrality, not necessarily because they reflect the true variety of subtopics within the data. By removing them, topic distributions have a stronger likelihood of emerging based on semantic context rather than being skewed by the repetitive presence of such words. Furthermore, this practice supports a more unbiased exploration of the content landscape, uncovering hidden or less obvious themes such as sentiment, application domains, concerns, or trends related to ChatGPT, rather than reaffirming its mention.
4. Extracting Emotions from Text
Extracting emotions from text presents a significant challenge in natural language processing, primarily due to the lack of consensus on which terms should be classified as being emotive [
28]. This ambiguity has led to the development of various emotional classification schemes, each structuring emotion categories differently. Such schemes range from Ekman’s [
29] six basic emotions to more complex models like Plutchik’s [
30] wheel of emotions, illustrating the diverse approaches to emotion categorisation in text analysis.
Among the advancements in emotive text analysis, emotive hierarchies (e.g., [
31,
32,
33]) have emerged as a powerful tool for capturing the complexity of human emotions expressed in text. Emotive hierarchies are structured frameworks that organise emotions into multiple levels, typically starting with broad sentiment categories (such as positive or negative) and progressively narrowing down to more specific emotional states such as happiness, sadness, love, and anger [
28]. At the most granular level, such emotions are further refined into nuanced states that align with their overarching polarities, such as optimism (a form of happiness), misery (a form of sadness), and passion (a form of love).
Such hierarchies offer several advantages over traditional binary or categorical emotion classification methods. Firstly, they provide a more granular representation of emotions, allowing for the detection of subtle nuances in emotional expression. Secondly, the hierarchical structure reflects the natural relationship between emotions, capturing how certain emotions are related or can co-occur. This approach enables researchers and practitioners to analyse text at various levels of emotional specificity, from general sentiment to precise emotional states, thereby offering a more comprehensive understanding of the affective content in textual data.
Inspired by Williams et al. [
34], who investigate and compare the utility of different emotional classification schemes from both a machine and human perspective, in this paper, WordNet-Affect [
35] was employed. Building upon the foundation of WordNet, a comprehensive lexical database for the English language that organises nouns, verbs, adjectives, and adverbs into interconnected sets of synonyms called synsets [
36], WordNet-Affect was developed as a specialised lexical model to classify both direct (e.g., joy, sad, happy) and indirect (e.g., pleasure, hurt, sorry) expressions of affect. Since its creation, it has become a valuable lexical resource, supporting numerous natural language processing studies, particularly in the field of sentiment analysis (e.g., [
34,
37,
38]).
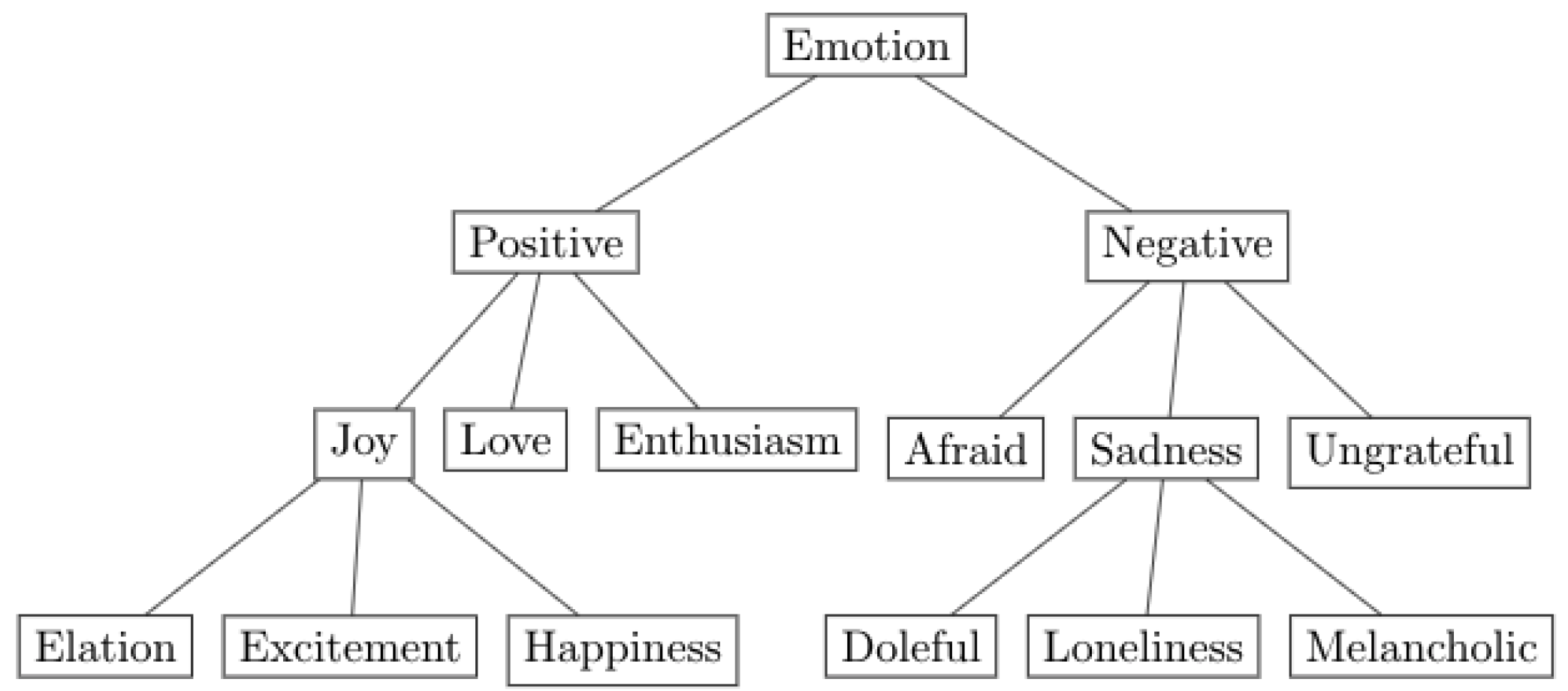
Figure 2 shows an excerpt from the WordNet-Affect hierarchy. The local version of the lexicon used in this paper consists of 1532 emotion terms, including all derivational and inflectional forms of the 798 word senses originally found in WordNet-Affect.
Table 2 shows the distribution of emotions across the seven levels of WordNet-Affect’s hierarchical structure, as well as examples of emotions at each level.
To automatically extract a breadth of emotions, a direct string matching approach was applied to automatically extract emotive terms from WordNet-Affect present in tweets.
Table 3 reports examples of tweets mapped to emotions. More specifically, a total of 4,206,691 tweets (79.9% of the original dataset) did not contain emotion and, therefore, were omitted from the dataset. A total of 1,055,737 tweets (20.1% of the original dataset) contained an expression that could be mapped to emotions from the WordNet-Affect lexicon, with 207,928 of those tweets containing one emotion. For the 847,809 tweets containing more than one emotion, they were represented in multiple emotion categories. This ensures that the complex and multifaceted emotional expressions found in the tweets are accurately captured and reflected in the analysis, allowing for a more nuanced understanding of the emotions conveyed in the dataset.
However, it is important to acknowledge that relying solely on a lexicon-based, string-matching technique may introduce limitations. The informal, creative, and evolving nature of social media language means that many emotional expressions, particularly those conveyed through slang, sarcasm, or implied sentiment, may not be captured, potentially resulting in false negatives or misclassification. A lexicon-based approach may be validated or complemented with machine learning classifiers fine-tuned for emotion detection, which may be equipped to handle contextual nuances and linguistic variation.
To analyse emotions more effectively, fewer emotive categories are needed. In this case, WordNet-Affect’s hierarchical structure can be leveraged, where emotive terms can be traced back to their ancestral emotion within the second level of the hierarchy. For example, in
Figure 2, “Happiness” and “Excitement” can be categorised as “Joy”, and “Doleful” and “Loneliness” can be categorised as “Sadness”. This categorisation approach resulted in 33 distinct emotion groups.
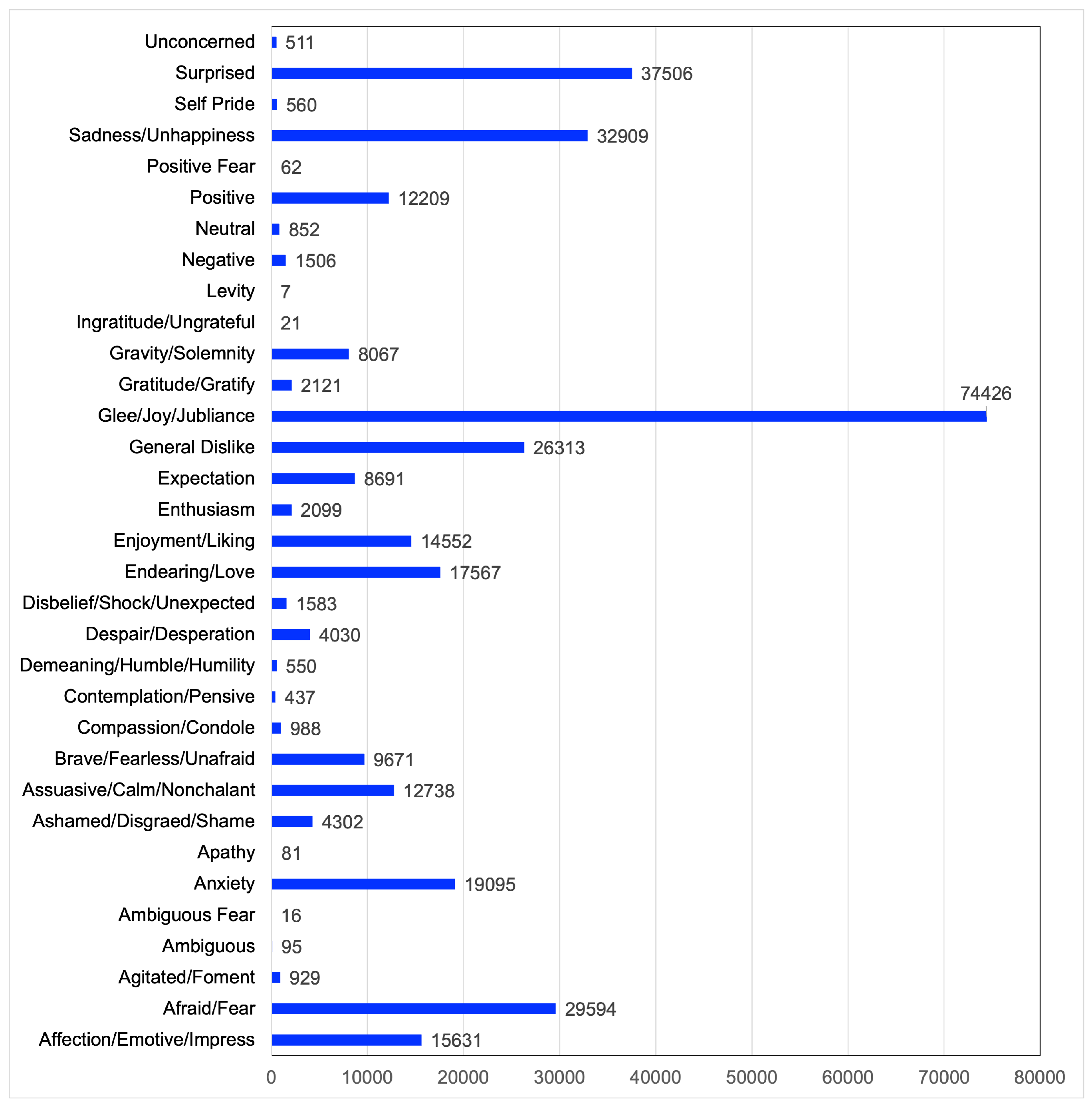
Figure 3 reports the emotion categories as well as the distribution of tweets across them.
To better illustrate the emotion detection process and its contextual grounding,
Table 3 presents a series of tweets annotated with both their original emotion (as derived from the WordNet-Affect lexicon) and a more generalised emotional category. These examples serve to demonstrate how emotions were identified and interpreted within the discourse around ChatGPT. The first tweet reflects anxiety surrounding AI’s impact on academia, specifically regarding the rapid deployment of AI-detection tools and their perceived limitations. The emotion “worried” was mapped to the broader category “Anxiety” to capture this collective unease about educational integrity. The second tweet highlights a user comparison between two AI outputs, where the author notes a “sad practical answer” from ChatGPT. This sentiment is directly identified as “Sad” and categorised under “Sadness/Unhappiness”, showing how user expectations of AI outputs can evoke emotional disappointment. In the third example, the user expresses affection toward ChatGPT while humorously questioning their own intelligence. The phrase “I love ChatGPT” is associated with the original emotion “Love”, which was generalised as “Endearing/Love” to encapsulate both appreciation and a self-deprecating tone. Finally, the fourth tweet conveys enthusiasm about ChatGPT’s potential in retail, portraying optimism and forward-looking excitement. The original term “Excited” was generalised to “Glee/Joy/Jubliance”, reflecting broader positive anticipation in commercial contexts.
5. Extracting Topics from Emotive Texts
Following the extraction of emotions from tweets, to add an additional layer of analysis, topic modelling is integrated into the framework. This allows us to contextualise the emotional responses about the specific topics being discussed, providing a richer, more comprehensive view of public sentiment and the factors influencing the adoption of AI technologies like ChatGPT.
Topic modelling serves as a crucial technique to uncover latent semantic structures—commonly referred to as “topics”—from large text corpora [
39,
40]. It has been successfully applied in domains ranging from online social networks [
41,
42] to healthcare [
43] and mental health [
44].
There are various methods by which texts can be distributed into topics. Such methods vary in complexity, the representation of text segments taken as the model’s input, their computational speed, and their performance. However, such approaches often yield topics as collections of isolated words, which can lack clarity and semantic coherence. While these word lists suggest key themes, they may not fully capture the context or relationship between terms, making it challenging to interpret the exact meaning of the topics or their relevance to user discussions.
In this case, to ensure high interpretability and consistency, we adopted the enhanced topic modelling pipeline proposed by Williams et al. [
40], which is accompanied by publicly available and reproducible code. This pipeline builds on the Latent Dirichlet Allocation (LDA) algorithm and includes preprocessing, topic generation, and a post-processing stage designed to convert token lists into more semantically coherent topic descriptions. For example, instead of keywords like ‘AI,’ ‘job,’ and ‘disruption,’ the method produces descriptors such as “concerns about AI-driven job disruption,” offering clearer insights into public narratives. For more detail as to how such topic representations are generated, see [
40].
The preprocessing steps include:
Topic modelling is performed using the ‘LatentDirichletAllocation’ class from Scikit-learn [
45], following the same configuration as the original implementation in [
40]. The LDA model was applied in a plug-and-play fashion using the default hyperparameters:
number of topics = 10,
random state = 10
compute perplexity ever n iterations = −1
No manual specification of alpha or beta (i.e., doc_topic_prior and topic_word_prior left as default)
The choice to fix the number of topics at ten across all emotional categories per day was based on maintaining consistency with the original methodology, rather than conducting dataset-specific optimisation (e.g., via coherence or perplexity-based tuning). While perplexity is a commonly used metric for assessing topic model performance, it has been shown to not always align with human interpretability [
46]. Given the focus on cross-category comparison and practical interpretability, a stable and comparable topic structure was prioritised over per-category optimisation. It is also worth noting that multiple runs were not conducted to assess topic stability, as the goal of this step was not model tuning but to support the downstream emotion–topic alignment in line with the original reproducible framework.
Overall, this enhanced topic modelling approach offers an efficient and consistent method for extracting interpretable themes from large-scale social media text, supporting a more nuanced understanding of emotional discourse around ChatGPT and similar technologies.
To ensure consistency and comparability across emotion categories, a fixed topic count strategy was adopted. Specifically, for each of the 33 emotional categories described in
Section 4, topic modelling was applied to extract ten topics per day from the corresponding tweets.
6. Results and Discussion
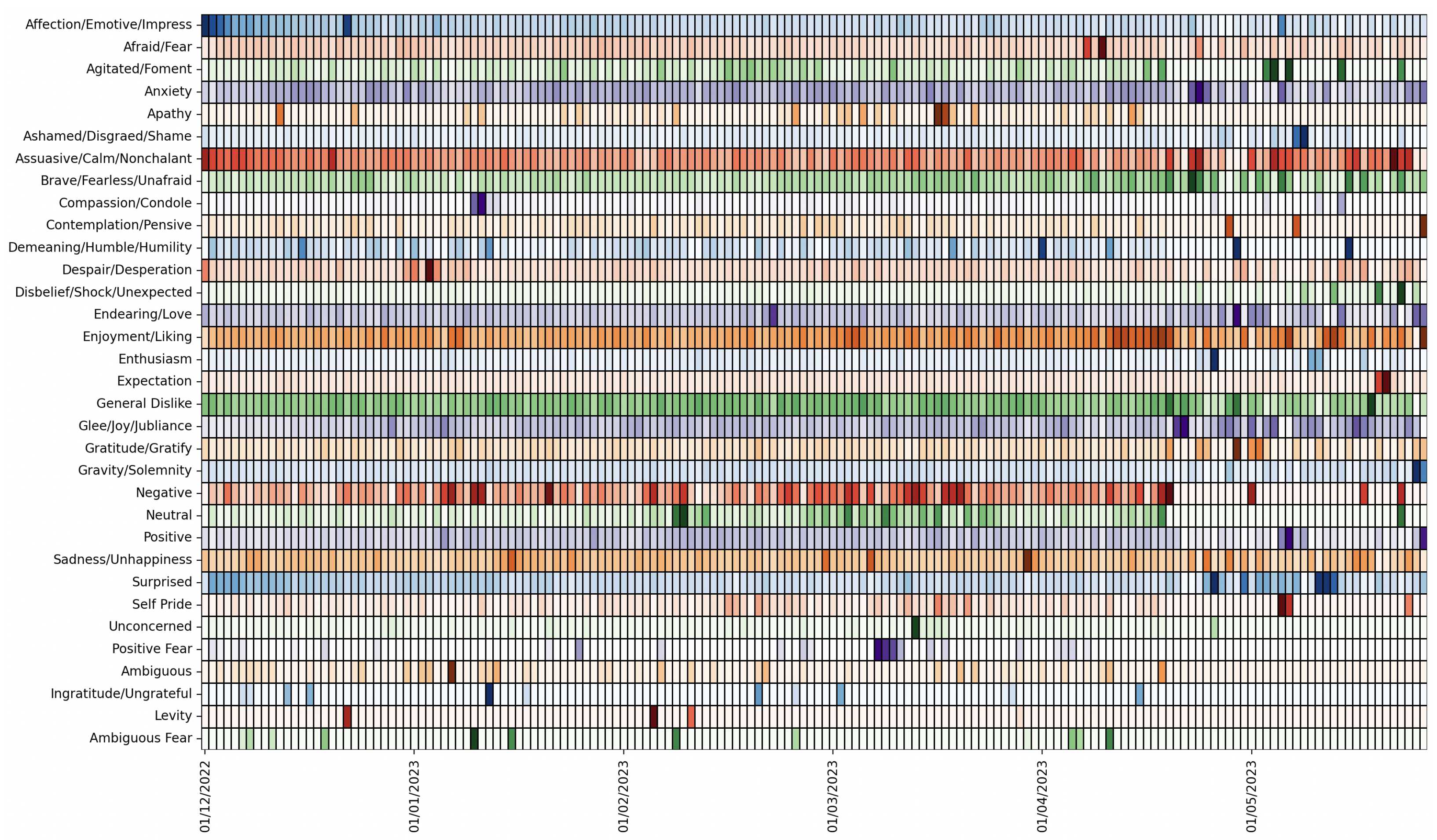
The chronological analysis depicted in
Figure 4 underscores the shift in emotional sentiment towards ChatGPT over time. Each row represents a unique generalised emotional category (e.g., Affection/Emotive/Impress, Endearing/Love, Sadness/Unhappiness), while each column represents a single day from December 2022 to May 2023. The values are normalised per day, such that the total number of emotion-tagged tweets on any given day sums to 1. This normalisation enables direct comparison across days, regardless of tweet volume. Although colours are used solely to differentiate emotion categories (i.e., no specific colour-to-emotion mapping exists), darker shades within each row indicate a higher relative proportion of that emotion on that day. For example, a darker cell in the “Anxiety” row on a given date signifies that anxiety-related tweets made up a larger share of total emotional tweets that day. This visualisation facilitates the identification of key emotional spikes or transitions in public discourse surrounding ChatGPT.
The heatmap allows emotional sentiments across different periods to be contrasted and compared, offering insights into the public’s evolving perceptions and attitudes. For example, the “Surprised” and “Enjoyment/Liking” categories initially follow a consistent pattern where a high volume of tweets about ChatGPT were shared but showed a marked increase in volume a few days post-launch, coinciding with the period when users began interacting with ChatGPT. This increase may capture users’ reactions to experiencing ChatGPT’s capabilities firsthand, which perhaps exceeded expectations or revealed the unforeseen abilities of the AI, prompting a heightened collective response of surprise and satisfaction in the discourse.
Similarly, the “Anxiety” category displayed a consistently significant emotional reaction throughout the timeline. However, this sustained intensity likely reflects the public’s apprehensions surrounding the launch of ChatGPT. Given the transformative potential of such AI technology, it is plausible that discussions were tinged with concern over its implications for privacy, employment, and the broader societal impact, leading to heightened expressions of anxiety across the observed period. This aligns with Moore’s [
47] adopter categories, where early adopters engage with the innovation enthusiastically while the early and late majority remain hesitant due to perceived risks.
Other emotional categories, such as “Afraid/Fear” and “Agitated/Foment,” displayed a generally lower volume of tweets over the timeline. However, a noticeable increase in tweet volume occurred a few days after the release of ChatGPT. This increase could potentially be attributed to users’ initial apprehension and heightened emotional responses as they began to grapple with the AI’s capabilities and implications, confronting the tangible reality of this advanced technology’s role in their digital lives. Such sentiments reflect the resistance typically found among laggards in the technology adoption lifecycle, who are more risk-averse and cautious about adopting new innovations [
48].
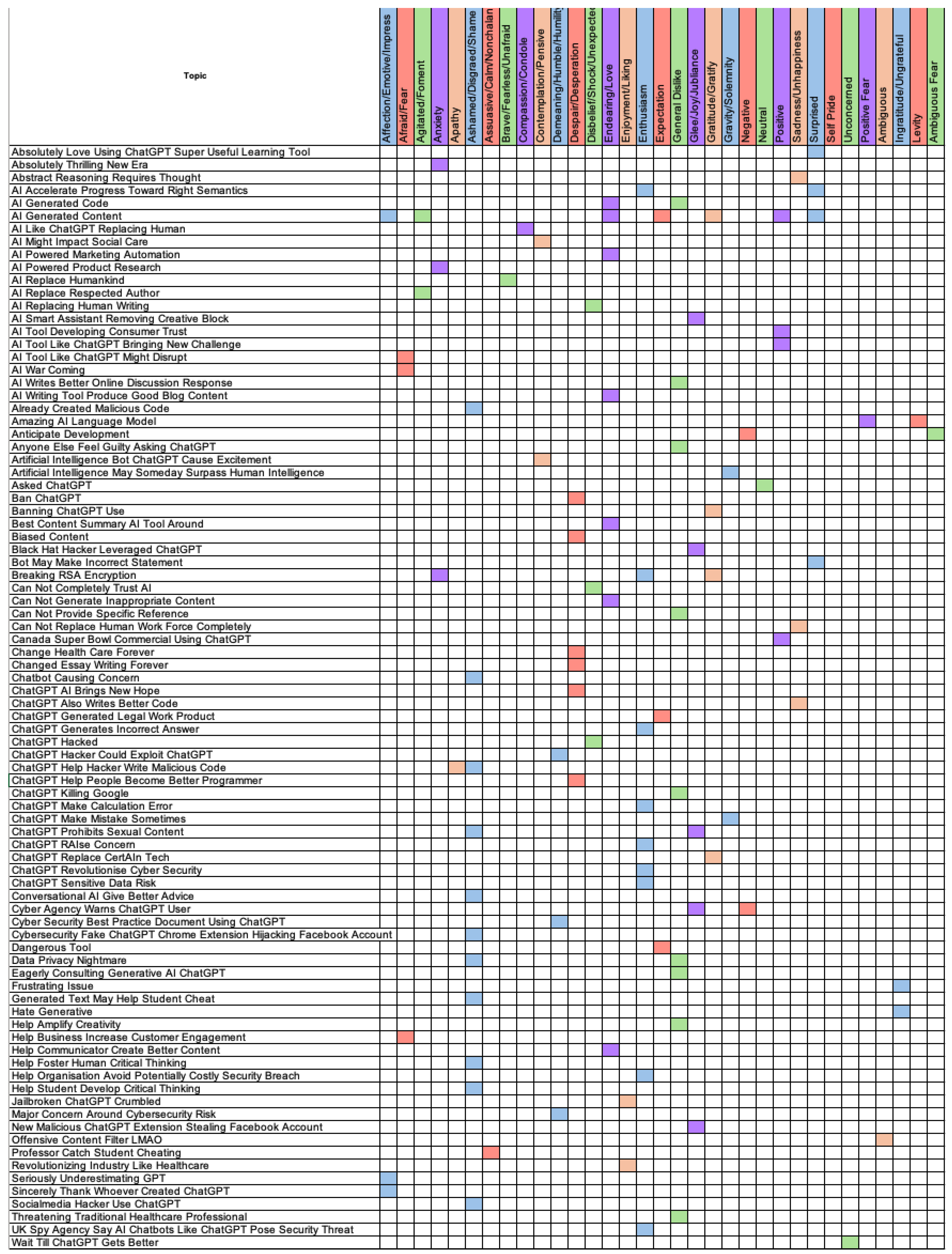
Figure 5 presents a matrix illustrating a subset of results following the extraction of topics (discussed in
Section 5), showing how specific emotional categories are distributed across identified topics. Each row corresponds to a distinct topic label, and each column represents one of the 33 emotional categories. A coloured cell indicates that a given emotion was detected in tweets associated with that topic. Colour hues are used only to visually distinguish between categories and do not represent intensity or frequency.
The analysis reveals a complex landscape of discourse. A diverse range of topics emerged, spanning from technological capabilities to ethical considerations and potential applications across multiple sectors, underscoring ChatGPT’s far-reaching implications. Positive emotional categories, such as “Endearing/Love” and “Affection/Emotive/Impress,” tied to topics like “AI Generated content” and “AI Writing Tool Produce Good Blog Content,” indicate strong user endorsement and satisfaction with ChatGPT’s creative and practical applications. These positive sentiments are likely to drive further adoption and integration of ChatGPT in various domains, as users see tangible benefits and improvements in their tasks. This pattern aligns with the early adopters and early majority in the adoption lifecycle, who embrace innovations that demonstrate clear advantages.
The highly polarised sentiment where the potential for AI to replace human roles is met with both apprehension and concern reflecting societal fears of job displacement and the ethical implications of AI advancement. It is also met with acceptance and excitement for the efficiency and innovation AI can bring, underscoring the dual nature of public perception. For example, the topics “AI Tool Like ChatGPT Might Disrupt”, “AI Writes Better Online Discussion Response”, and “Change Health Care Forever” were extracted from texts reflecting the emotional categories “Afraid/Fear”, “General Dislike”, and “Despair/Desperation”.
Whereas the topics “AI Replace Humankind”, “AI Tool Developing Consumer Trust”, and “Revolutionizing Industry Like Healthcare” were extracted from texts predominantly evoking the positive emotional categories “Brave/Fearless/Unafraid”, “Positive”, and “Enjoyment/Liking”, which denote the recognition of the practical benefits and enhancements that ChatGPT can bring to various professional fields, highlighting an optimistic outlook on AI’s role in enhancing productivity and skill development.
This duality highlights the need for careful management and communication from AI developers and policymakers to balance these concerns with the promising benefits, ensuring a transition that maximises positive outcomes while addressing and mitigating fears. The evolution of sentiment, as shown in the data, suggests that ChatGPT’s adoption trajectory follows Rogers’ [
48] stages of technology adoption, where initial scepticism gradually gives way to broader acceptance as users become more familiar with the technology’s capabilities and benefits.
The diverse emotional responses to ChatGPT-related topics reflect the complex landscape of AI adoption. While there is significant enthusiasm and positive anticipation about the capabilities and benefits of ChatGPT, there is also notable concern regarding its reliability, ethical implications, and security. This duality in sentiment underscores the need for ongoing dialogue, transparent practices, and continuous improvements in AI technologies. Ensuring that AI developments align with user expectations and address their concerns will be key to fostering a balanced and widespread adoption of AI tools like ChatGPT, ultimately progressing through the technology adoption lifecycle towards mainstream acceptance.
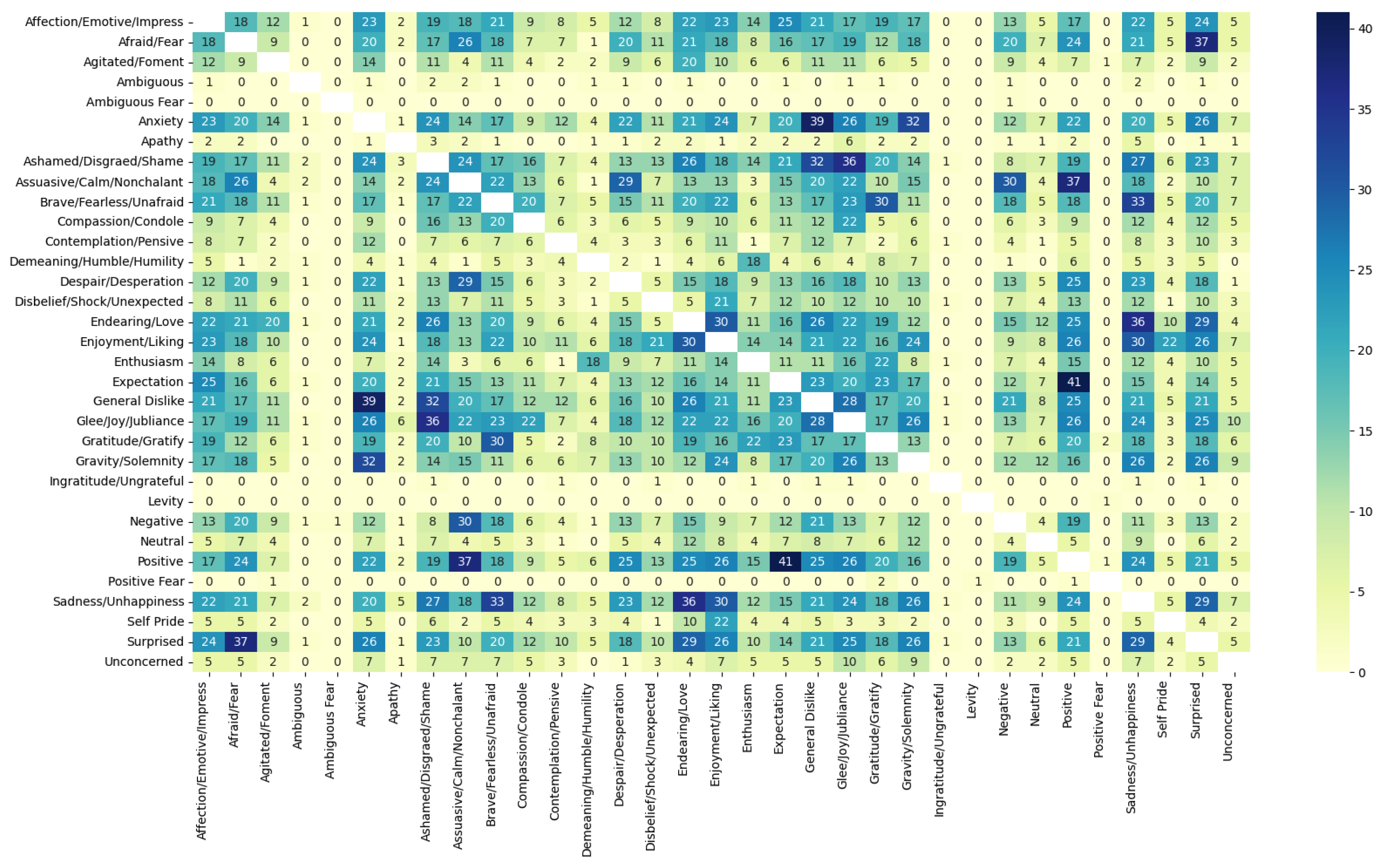
The emotion concurrence matrix, shown in
Figure 6, captures how often different emotional categories co-occur across various topics discussed in ChatGPT-related tweets. Each cell represents the number of topics in which a pair of emotions appear together, allowing us to explore patterns of emotional entanglement within thematic content. The diagonal values, representing self-co-occurrence (e.g., “Joy” with “Joy”), have been omitted for clarity, as they reflect how frequently each individual emotion appears across topics.
The emotion concurrence matrix reveals several notable patterns in how emotional categories co-occur in ChatGPT-related tweets. Emotions rarely appear in isolation; instead, they tend to cluster in meaningful ways, indicating the complex nature of public sentiment toward generative AI. Among the most frequent co-occurrences are those involving “General Dislike”, which appears prominently alongside “Anxiety” and “Ashamed/Disgraced/Shame,” which may reflect underlying societal discomfort or ethical unease surrounding AI use, particularly in sensitive domains like education or employment. Emotions such as “Assuasive/Calm/Nonchalant” and “Brave/Fearless/Unafraid” also show multiple connections, often appearing in contrastive contexts—tweets that balance optimism with caution or confidence with critique. Similarly, “Enjoyment/Liking” often co-occurs with “Endearing/Love” and “Surprised”, reflecting consistent patterns in positive affect when users express satisfaction or excitement about ChatGPT.
In contrast, several emotion categories demonstrate minimal co-occurrence with others. These include “Ambiguous Fear”, “Ingratitude/Ungrateful”, “Positive Fear”, and “Levity”, which may indicate their rarity in the dataset or challenges in detecting such nuanced sentiments using a lexicon-based approach. The relative isolation of these categories might also suggest that they tend to occur in more context-specific or subtle expressions that are not easily captured through surface-level keyword matching.
Overall, the results highlight clusters of emotion that align with broader sentiment dynamics—positive categories reinforcing each other in celebratory or promotional content and negative or anxiety-related emotions clustering around moments of uncertainty, fear, or disillusionment. These findings not only underscore the multidimensional emotional landscape surrounding ChatGPT but also point to the value of co-occurrence analysis in uncovering how emotional expressions are entangled in public discourse.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}