1. Introduction
In the modern world of finance and insurance, it is routine for investors, firms and companies to manage different financial/insurance assets in the hope of increasing their capital gain. The collection of such investments is known as a portfolio, and it is designed to match the investor’s preference. Different compositions of varying assets allow for a diversity of combinations that suit distinct appetites. For example, a bulge bracket investment bank such as J.P. Morgan is willing to undertake more risk to compensate for a larger return, in comparison to a retiree who is overseeing his retirement fund. However, despite an individual’s taste, investors face the challenge of balancing reward and risk, as a high reward investment is often tightly linked with high underlying risk, and thus the main goal of portfolio management is finding the optimal tradeoff between the two.
The mean-variance portfolio model, proposed by
Harry Markowitz (1968) serves as the keystone to portfolio theory. He formalized the problem of a rational, risk adverse investor that faces the tradeoff between reward and risk as proposed above. In such a scenario, reward and risk are defined as the expected return from the portfolio and its variance. There are problems with the implementation of the Markowitz model when the universe of assets is large. In this situation, the assets’ sample covariance matrix is not an efficient estimator of the assets’ true covariance matrix. Therefore, using the sample mean and covariance matrix in the mean-variance optimization procedure will result in an optimal return estimate different from reality. A fix for this problem is proposed in
Bai et al. (2009), by using the theory of the large-dimensional random matrix. Another reason for the poor performance of the optimal mean-variance portfolio is perhaps due to the symmetry of asset returns.
Low et al. (2016) shows that it is possible to enhance mean-variance portfolio selection by allowing for distributional asymmetries. Portfolio optimization under skewed returns is performed in several papers such as in
Low (2015);
Hu et al. (2010).
Under the mean-variance framework, various major portfolio theories have sprouted, and one of the major developments proposed by
Willian Sharpe (1966) is known as the Sharpe ratio. The Sharpe ratio is the most fundamental of performance measures, which are critical in the evaluation, management and trading of portfolios. Under the mean-variance portfolio framework, the Sharpe ratio compares the return of the portfolio with the risk-free interest rate, which serves as a significant benchmark, owing to the fact that if overall return of the portfolio ranks below the risk free rate, investors should put their capital in the money market and earn interest without bearing any risk. The Sharpe ratio is greatly incorporated as a modern investment strategy, and is highly appraised by investors. However, the Sharpe ratio only comprises and examines the first two moments of the return distribution, namely, the expected return and the variance in return, while distribution properties such as skewness and kurtosis, which measure asymmetry and thickness of the tail distribution at the third and fourth moments respectively, may profoundly impact the performance of the portfolio.
DeMiguel et al. (2009) compares the optimal mean-variance portfolio with the naive
portfolio. They found that the
rule performs better than the optimal mean-variance portfolio in terms of the Sharpe ratio, indicating that the gain from optimal diversification is higher when compared to the offset produced by estimation error.
The failure of the Sharpe ratio to address higher moments motivated
Keating and Shadwick (2002) to develop the Omega measure, which captures all moments of the return distribution, including the expected value and variance. The Omega measure serves as a universal performance measure as it can be applied to any portfolio that follows a well-defined return distribution.
Even though the Omega measure was developed over 10 years ago, little research has been done to address its compatibility with previous developments, namely, with distribution functions that only involve lower moments. This paper aims to explore and address the backward compatibility of the Omega measure. We consider a market (financial or insurance) encompassing several risks within a one period paradigm. The risks are first assumed to follow a jointly elliptical distribution. Under this framework, we prove that the Sharpe ratio and the Omega measure yield the same optimal portfolios. Next, Sharpe ratio portfolio optimization is explored. The quasi-concavity of the Sharpe ratio is employed to develop an active-set algorithm for markets banning short sales. The convergence of this algorithm is established and numerical results are presented. Moreover, we show that, in a model with asymmetric returns, the optimal Sharpe ratio portfolio fails to be optimal when Omega measure is considered.
The remainder of this paper is organized as follows: in
Section 2, we present the model.
Section 3 provides the Sharpe ratio and Omega measure equivalence within the class of elliptical distributions of returns. Portfolio optimization formulations are presented in
Section 4. Numerical analysis is performed in
Section 5, with numerical results displayed in
Section 6.
Section 7 presents a model with asymmetric returns. The conclusion is summarized in
Section 8. The paper ends with an
Appendix A containing the proofs.
2. The Model
We have a market (financial or insurance) model that encompasses several instruments denoted
We consider a single period model from time
to
. For each instrument, let the arithmetic return be
and
We assume the return of the portfolio follows an
elliptically symmetric distribution. Then, the vector of means
and the
covariance matrix
exist, and we further assume that
is invertible. The density
if it exists, is
where
and
is called the
density generator or
shape of
R, and we write
where
is called the parametric part and
g is called the non-parametric part of the elliptical distribution. The characteristic function
of
R is
for some scalar function
, called the
characteristic generator. For background on the elliptically symmetric distribution, which is also called elliptically countered, see
Bingham and Kiesel (2002);
Fang et al. (1990).
The class of elliptical distributions, which have densities and defined mean and covariance is rich enough to contain several common distributions of asset returns: the multivariate normal distribution, the multivariate
t distribution, normal-variance mixture distributions, symmetric stable distributions, the symmetric generalized hyperbolic distribution, the symmetric variance-gamma distribution, and the multivariate exponential power family (and thus the Laplace distribution). One advantage of this class is that the non-parametric part
g “escapes the curse of dimensionality” (cf.
Bingham and Kiesel (2002)). This class is chosen to model the stock returns by
Bingham et al. (2003);
Chamberlain (1983);
Owen and Rabinovitch (1983).
Elliptical distributions are appealing for portfolio analysis, since it is a closed class under linear combinations. A portfolio at times
and
will, respectively, be
Let the arithmetic return of the portfolio be
The following Lemma gives the distribution of
Lemma 1. Letbe the proportion of the initial wealth invested in instrument i, and w be the vector with components . Then, R follows an elliptical distributionwhere Let us consider the Sharpe Ratio and Omega measure defined by the formal definitions.
Definition 1. The Sharpe ratio of a portfolio with return R is defined aswhere is the expected return of the portfolio, is the standard deviation of return, and is the risk-free interest rate. Definition 2. The Omega measure of a portfolio with return R is defined aswhere is the cumulative distribution function of the return distribution R, and L is an exogenously satisfied benchmark index. The intuition behind the Omega measure is simple; by selecting a benchmark L, which serves as a reference that our portfolio is aiming to beat, the Omega measure compares the area of the cumulative distribution function from the right of L to the area to the left of L. Under such a definition, the Omega measure encompasses the entire return distribution, therefore incorporating higher moment properties as discussed.
3. Sharpe Ratio and Omega Measure Equivalence
When holding a portfolio, an investor uses a performance measure such as the Sharpe ratio or the Omega measure to evaluate how well the portfolio is performing. Hence, it is a natural question to ask how one should distribute his wealth in order to maximize his portfolio under the Omega measure. The following theorem states that using the Sharpe ratio or the Omega measure to optimize portfolio performance leads to the same optimal portfolio within the class of elliptical distributions of returns.
Theorem 1. Recall that, under our framework, the portfolio return R is elliptically distributed . If we claim thatis equivalent to 4. Portfolio Optimization
Given Theorem 1, we are able to transform optimization problems of the Omega measure into optimization problems of the Sharpe ratio for elliptical distributions. Let
, the excess expected return above a selected benchmark index
L. With no restrictions on short selling, our optimization problem is as follows:
However, certain financial markets prohibit the act of short selling, especially during periods of financial upheaval. An example would be the U.S. securities market under the 2008 financial crisis, when the U.S. Securities and Exchange Commission prohibited the act of short selling to protect the integrity of the securities market. Hence, we are also interested in the following problem as well:
5. Numerical Analysis
The optimal solution to (
1) can be found directly as described in the following proposition.
Proposition 1. The optimal solution to (1) is , where . We require the following properties of the Sharpe ratio in developing an algorithm for solving (
2).
Proposition 2. The Sharpe ratio is a quasi-concave function and iff for some .
If
then our optimal solution for (
1) is also optimal for (
2), so let us assume that for (
2), our optimal solution
for any
c. By our assumption,
and the following theorem is applicable.
Theorem 2 (
Arrow and Enthroven (1961))
. Let be a differentiable quasi-concave function subject to non-negativity constraints. If and satisfies the KKT conditions with constants , then it is a global optimal solution. The KKT conditions for (
2), ignoring the equality constraint are as follows, where
.
Consider the sets
P and
W defined by
Let us permute the data so that
and let
be the covariance matrix of the instruments indexed by
P. Let
be the number of elements of
At optimality, the first
rows of (
3) will equal
with solution
Therefore, the optimal solution of (
2) is the optimal solution of (
1) for some unknown subset of instruments
P. For ease in what follows, we will always take
.
Our main objective then is to find the optimal set
P, after which the optimal solution can be found by solving a positive definite system of linear equations. We propose the use of the following active-set algorithm to solve (
2), which is inspired by Algorithm 16.3 in
Nocedal and Wright (2006).
| Algorithm 1: Sharpe Ratio active-set (SRAS) algorithm. |
| 1: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | loop |
| 8: | |
| 9: | |
| 10: | |
| 11: | if then |
| 12: | |
| 13: | if then |
| 14: | |
| 15: | quit |
| 16: | else |
| 17: | |
| 18: | |
| 19: | |
| 20: | |
| 21: | end if |
| 22: | else |
| 23: | |
| 24: | if then |
| 25: | |
| 26: | |
| 27: | |
| 28: | end if |
| 29: | |
| 30: | end if |
| 31: | |
| 32: | end loop |
We find the portfolio consisting of a single instrument that maximizes the Sharpe ratio to initialize the algorithm in lines 1–6. At iteration
i,
is set to maximize the Sharpe ratio, which in general is not feasible in (
2), in line 8. If the current feasible solution
, we check if
. If so, then
is the optimal solution to (
2), or else we remove the index of the minimum value of dual variables
from
to form
in lines 11–21. If
,
is set by moving in the direction of
from
while remaining feasible in (
2). If
, the index of the first blocking constraint
is added to
to create
in lines 22–30.
Theorem 3. The SRAS algorithm is convergent.
There is in fact a quadratic convex reformulation of this problem (see
Durand et al. (2012)), which has the following formulation under the mild condition that there exists at least one stock with
, where
is a free constant:
After solving, the
simply have to be normalized to sum to one to obtain the optimal solution. The choice of
z can affect solution quality, in particular when the number of instruments
n becomes large and the algorithm used to solve (
4) employs a stopping criteria of the form
. In practice, we have found that choosing
, ensuring the average value of elements of
equals 1, gives high quality solutions with virtually no optimality gap compared to the active-set algorithm, without having to alter default stopping criteria.
6. Numerical Results
A computational experiment was conducted where the SRAS algorithm was compared to Gurobi 7.0 using data derived from historical stock prices from two stock market indices. All computing was done using Matlab R2016a on a Windows 10 64-bit, AMD A8-7410 processor with 8 GB of RAM.
Six problems were used for testing. Historical stock prices of the Dow Jones Industrial Average and the S&P/ TSX 60 were used to calculate the expectation and covariance of instrument returns. For each index, the past year, two years and five years were used for estimation. This data was generated using the website
InvestSpy (2017). Results are presented in
Table 1 below. We observe that the mean computing time of SRAS is over an order of magnitude faster when compared to Gurobi.
7. Model with Skewness
We show numerically that the Omega measure is not equivalent to the Sharpe ratio for skewed distributions. Our estimation of Omega measure uses the following proposition.
Proposition 3. The Omega measure is equal to i.e., We consider the skew-normal distribution
Azzalini (2005), which is closed under affine transformation and has probability distribution function
where
and
are the standard normal probability distribution function and cumulative distribution function, respectively, with location paramter
, scale
and shape
.
For a given skewness
, let
where the sign of
is chosen as negative for left skewness and positive for right skewness. Given
,
and for a desired standard deviation,
and mean,
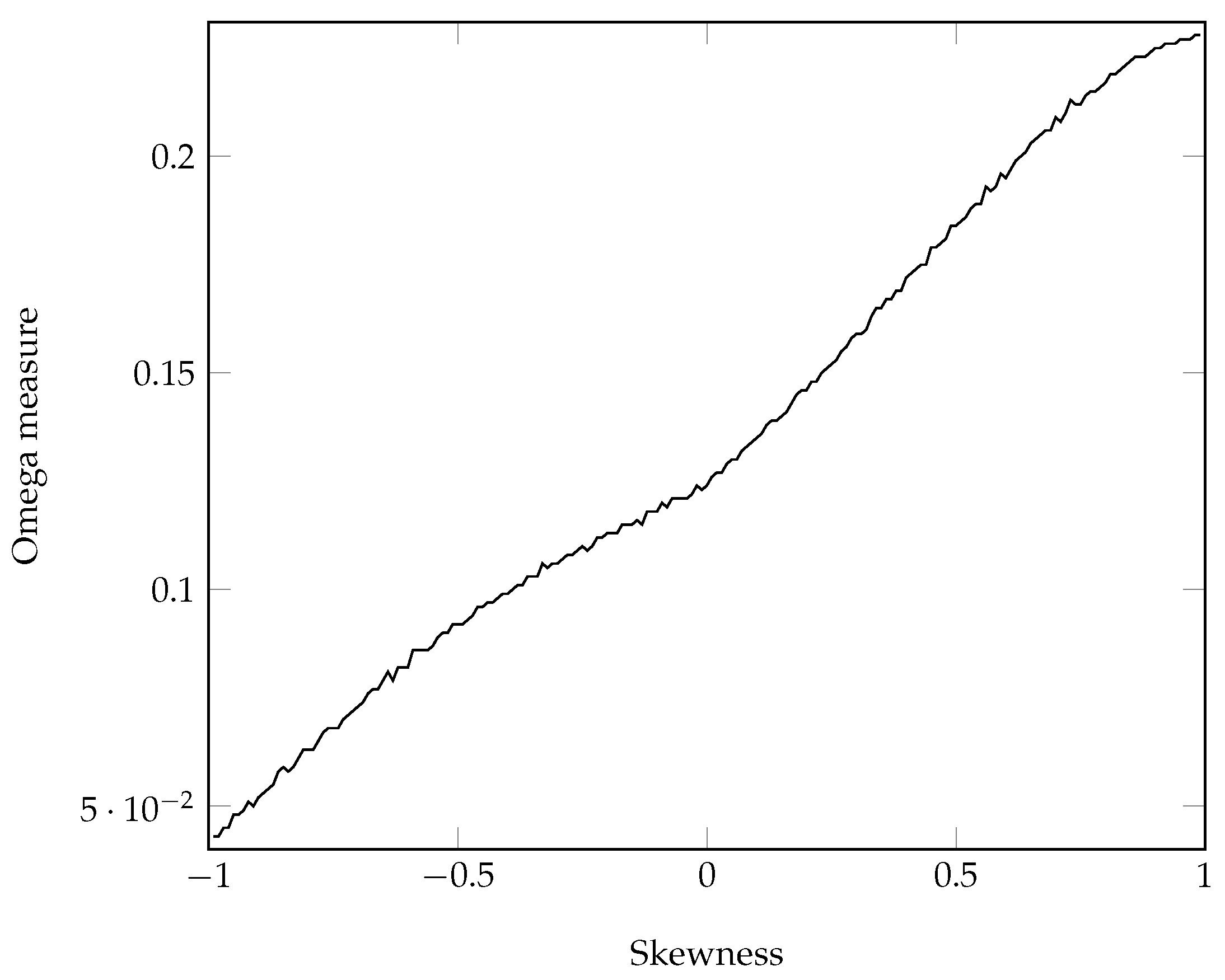
We plot the Omega measure for , and , with varying over the domain in increments of 0.01. Monte Carlo integration was used to estimate by taking 10 million samples of R and taking the mean of .
Under the Sharpe ratio, we are indifferent to all of the plotted portfolios, each having a Sharpe ratio , but under the Omega measure, taking into consideration higher moments, it is clear that we would prefer a portfolio with right skewness in this example.
8. Conclusions
In this paper, we have proved the equivalence of the Omega measure and the Sharpe ratio under jointly elliptical distributions of returns. The portfolio optimization of the Sharpe ratio with and without short sales was numerically analyzed. An active-set algorithm was presented for markets prohibiting short sales, with an improvement in average solution time of over an order of magnitude when compared to standard optimization techniques. Numerical experiments show that, when the return distributions are not symmetric, the Omega measure and the Sharpe ratio are not equivalent. Future research could be done to develop optimization methods for the Omega measure under more general distribution assumptions such as the skew-elliptical distribution.





{kind=link}