Abstract
Background/Objectives: Healthcare-associated infections (HAIs), including sepsis, represent a major challenge in clinical practice owing to their impact on patient outcomes and healthcare systems. Large language models (LLMs) offer a potential solution by analyzing clinical documentation and providing guideline-based recommendations for infection management. This study aimed to evaluate the performance of LLMs in extracting and assessing clinical data for appropriateness in infection prevention and management practices of patients admitted to an infectious disease ward. Methods: This retrospective proof-of-concept study analyzed the clinical documentation of seven patients diagnosed with sepsis and admitted to the Infectious Disease Unit of San Bortolo Hospital, ULSS 8, in the Veneto region (Italy). The following five domains were assessed: antibiotic therapy, isolation measures, urinary catheter management, infusion line management, and pressure ulcer care. The records, written in Italian, were anonymized and paired with international guidelines to evaluate the ability of LLMs (ChatGPT-4o) to extract relevant data and determine appropriateness. Results: The model demonstrated strengths in antibiotic therapy, urinary catheter management, the accurate identification of indications, de-escalation timing, and removal protocols. However, errors occurred in isolation measures, with incorrect recommendations for contact precautions, and in pressure ulcer management, where non-existent lesions were identified. Conclusions: The findings underscore the potential of LLMs not merely as computational tools but also as valuable allies in advancing evidence-based practice and supporting healthcare professionals in delivering high-quality care.
1. Introduction
Infection control is one of the most critical challenges in modern healthcare systems and has significant implications for patient safety and quality of care. Healthcare-associated infections (HAIs), such as sepsis and device-related infections, are major contributors to morbidity and mortality and have considerable economic and social impacts. This issue is further exacerbated by an increase in antimicrobial resistance (AMR), which undermines the effectiveness of available treatments, making some infections difficult or even impossible to manage [1].
The World Health Organization (WHO) has identified antimicrobial resistance as one of the top ten threats to global public health. Each year, an estimated 700,000 deaths are attributed to infections caused by resistant microorganisms, with projections indicating that this number could increase to 10 million annually by 2050 if adequate interventions are not implemented [2]. Antimicrobial stewardship programs and infection control strategies are central to preventing and mitigating this growing crisis.
Managing infections in hospitalized patients requires a multidisciplinary approach. This includes early risk identification, evidence-based protocols, and the continuous monitoring of intervention outcomes [1]. Despite advancements in these areas, challenges remain, such as the heterogeneity of clinical data, incomplete documentation, and difficulties in integrating information for timely and personalized decision-making [3].
Advanced technologies, such as large language models (LLMs) powered by artificial intelligence (AI), are emerging as promising tools for improving the efficiency of infection management. An example is represented by a generative pre-trained transformer (GPT), an LLM that forms the basis for applications, such as ChatGPT, which enables users to interact with the model in real time. These systems have shown the ability to analyze large amounts of unstructured clinical data, including electronic health records, and provide recommendations that align with international guidelines [4]. Their application enables the rapid analysis of clinical documentation while supporting healthcare professionals in preventing HAIs and optimizing antimicrobial use [5].
The use of LLMs in infectious disease research has already shown promising results in areas, such as patient education for infection prevention and management [6,7], support for clinical decision-making [8], public health surveillance [9,10,11], and overall clinical management [12]. Regarding patient education, a study explored LLMs’ capability of preparing educational material about Helicobacter pylori infection with promising results [7]. On the other hand, in the context of LLM use for healthcare professional training and clinical decision-making support, another study evaluated the appropriateness of information regarding endocarditis prophylaxis for dental procedures, reporting an accuracy of 80% [8].
However, despite the transformative potential of these technologies, questions remain regarding their practical applications and ethical implications [13]. Ensuring the accuracy of the generated recommendations, addressing the need for human oversight, and mitigating biases in the underlying data are challenges that must be addressed to enable safe and effective adoption [14]. Integrating LLMs into healthcare supports clinical decision making, optimizes infection management strategies, and enhances guideline adherence. Nevertheless, the use of LLMs in healthcare represents a potential paradigm shift in infection management and prevention, contributing to improved clinical outcomes and enhanced patient safety.
The present study aimed to explore the ability of LLMs to evaluate the appropriateness of actions and prescriptions employed in the management and prevention of infections in patients hospitalized for sepsis in an infectious disease unit in the Veneto region.
2. Materials and Methods
This retrospective study employed anonymized records of patients admitted to the Infectious Disease Unit of San Bortolo Hospital, ULSS 8, Veneto region, Italy. The conversational implementation of the LLM GPT, ChatGPT (4o version), was employed to systematically analyze these records and provide recommendations based on evidence-based guidelines. For this study, we used a license-based version of ChatGPT, which ensured access to the most up-to-date version of the model and stability between sessions. ChatGPT was chosen because it is currently one of the most widely used and recognized LLMs in the biomedical literature. Its accessibility, generalizability, and increasing adoption in clinical research has made it a suitable choice for evaluating the feasibility of applying LLMs in real-world clinical documentation. A search on PubMed confirms this: the term ChatGPT returned 6000 results for the years 2024–2025 alone. In contrast, alternative chat-based models, such as DeepSeek, returned substantially fewer results, making their inclusion in our task both impractical and irrelevant regarding current adoption and visibility.
Specific queries were designed for each domain of interest to evaluate adherence to the guidelines. The analysis was performed sequentially, focusing on one domain at a time and covering the following aspects:
- Antibiotic Therapy: The appropriateness of administered antibiotic regimens was evaluated based on the type of infection and the provided guideline recommendations;
- Isolation Measures: The chosen isolation precautions (e.g., contact, airborne, and droplet) were assessed for compliance with the guidelines based on the patient’s clinical condition and type of infection;
- Pressure Ulcer Management: The dressing selection and frequency of dressing changes were analyzed according to the ulcer stage and relevant guidelines for patients with documented pressure ulcers;
- Urinary Catheter Management: The placement, maintenance, and removal or replacement of urinary catheters were evaluated to determine alignment with the guideline recommendations;
- Infusion Line Management: The placement, maintenance, and removal or replacement of infusion lines (e.g., central venous catheter (CVC), peripherally inserted central catheter (PICC)) were analyzed for adherence to clinical necessity and procedural guidelines.
Relevant clinical data were extracted from each patient’s medical record, including admission notes, discharge letters, clinical diaries, nursing diaries, and emergency department reports. The extracted information was cross-referenced with domain-specific guidelines provided by ChatGPT-4o.
ChatGPT-4o responses were structured as follows:
- Identification and categorization of key interventions (e.g., antibiotic type, isolation measures, and catheter use).
- Evaluation of the appropriateness of each intervention based on the guideline criteria.
- Justifications for each assessment, citing specific guideline recommendations.
The analyses were performed stepwise to ensure consistent evaluations across patients and domains. Figure 1 presents the workflow of the study.
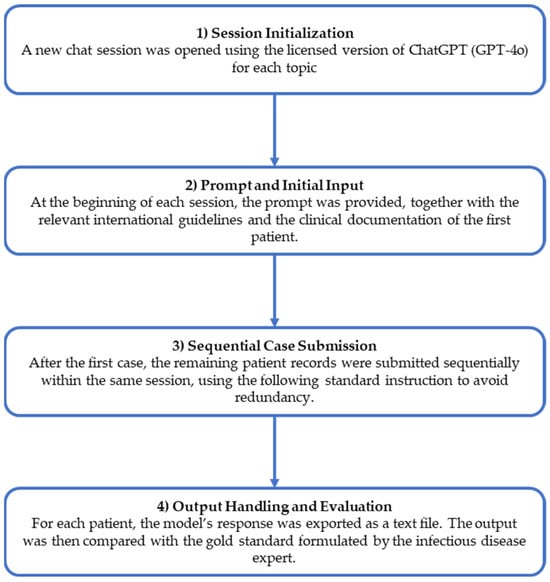
Figure 1.
Study workflow.
2.1. Prompt Implementation
Specific prompts were designed and provided to ChatGPT-4o for each evaluation domain to standardize the analysis. Prompts were structured to guide the model in extracting relevant clinical details and assessing adherence to evidence-based guidelines. Each prompt was tailored to address key areas, such as antibiotic therapy, infusion line management, urinary catheter management, isolation precautions, and pressure ulcer care. The prompts aimed to ensure clarity, minimize ambiguity, and align the model’s responses with the clinical context.
To avoid redundancy and contextual interference between tasks, we initiated a new chat session for each clinical domain (e.g., antibiotic therapy, urinary catheter management, etc.) The model was given a structured prompt in each session, followed by task-specific international guidelines, and then each patient’s anonymized clinical record. This stepwise approach optimized the model’s focus on the task and minimized unintended carryover effects from previous prompts. Prompts are presented in the Supplementary Materials.
2.2. Reference Guidelines and Gold Standard Development
ChatGPT-4o was provided with a comprehensive set of internationally recognized guidelines to ensure its recommendations adhered to evidence-based standards. The Surviving Sepsis Campaign guidelines provide critical frameworks for the early recognition and management of sepsis and septic shock [15,16]. Guidelines addressing the prevention of central line-associated bloodstream infections [17] and the latest infusion therapy standards [18] were included for infusion line management. Urinary device management was guided by recommendations to prevent catheter-associated tract infections [19,20]. Isolation precautions were evaluated using well-established infection control protocols to prevent the transmission of infectious agents [21,22]. Pressure ulcer management adheres to guidelines from the European Pressure Ulcer Advisory Panel, which provides detailed protocols for selecting appropriate dressings and replacement intervals based on ulcer stage [23]. Antimicrobial stewardship practices were evaluated using institutional program recommendations designed to optimize antibiotic use and reduce antimicrobial resistance [24].
An expert in infectious diseases first extracted the information that ChatGPT-4o was tasked with, such as details about antibiotic therapy, pressure ulcers, infusion lines, isolation measures, and urinary catheters. This process established the gold standard for evaluating ChatGPT-4o’s performance. Subsequently, the expert evaluated the appropriateness of the extracted information against the same guideline documents provided to ChatGPT-4o.
2.3. Study Population
To be included in the study, records must adhere to the following:
- Pertain to patients admitted to the Infectious Disease Unit with a documented sepsis or septic state diagnosis, had access to the emergency department before hospitalization, and were discharged from the same unit without being transferred to other units during their hospital stay.
- Be complete and include the following:
- Emergency department report;
- Admission notes;
- Nursing and medical diaries;
- Discharge letters.
3. Results
This proof-of-concept study involved seven patients’ records. All the patients were diagnosed with sepsis according to the inclusion criteria. Table 1 provides an overview of the patient’s demographic and clinical characteristics, including primary symptoms at admission, relevant medical history, and discharge diagnoses for each patient included in the analysis.

Table 1.
Clinical characteristics of patients.
3.1. Antibiotic Therapy
Antibiotic therapy was assessed for appropriateness based on the clinical presentation and microbiological findings. According to the gold standard, in all seven cases, the initiation of empiric therapy was aligned with the guideline recommendations. Adjustments were made following culture results, with timely de-escalation to narrower-spectrum agents, when appropriate. For example, piperacillin/tazobactam was effectively used in cases of abdominal sepsis, followed by a transition to oral therapy as patients stabilized (Table 2). The LLM correctly identified all the antibiotic therapies administered and evaluated their appropriateness based on the guidelines provided. The assessments were accurate and consistent across all cases (no errors were detected in the antibiotic therapy extraction and appropriateness evaluation).
Table 2.
Analysis of antibiotic therapy. For each patient, the progressive numbers in the antibiotic therapy columns (actual and extracted using ChatGPT) indicate the sequence of multiple antibiotic therapies if more than one was administered.
3.2. Isolation Measures
Isolation measures were implemented according to the type of infection and the transmission mode. Only standard precautions were needed for all patients because none indicated additional isolation measures.
ChatGPT attempted to extract the isolation measures applied to each patient and evaluated their appropriateness based on the clinical context and guidelines. However, inaccuracies were observed in both the extraction and evaluation processes. Specifically, the model frequently misinterpreted the clinical context and incorrectly extracted the precautions applied in five out of seven cases (it identified contact precautions, even though only standard precautions were needed and applied). In only two cases, ChatGPT-4o correctly identified and evaluated the use of standard precautions (Table 3).
Table 3.
Analysis of isolation measures.
“Standard” refers to general infection prevention practices that apply to all patients, including the hygiene of the hospital environment, hand hygiene, the use of personal protective equipment (PPE), safe handling and disposal of sharps, and basic principles of asepsis. The label “Contact (additional),” as extracted from ChatGPT-4o, refers to specific precautions implemented in case of suspected or confirmed infections that are spread by direct or indirect contact with the patient or the patient’s environment (e.g., use of dedicated or disposable equipment, wearing gowns and gloves before entering the room, and discarding them before leaving the room). This error likely stemmed from misinterpreting the guidelines, leading to overgeneralizing recommendations for microorganisms that did not warrant additional precautions beyond standard measures.
3.3. Urinary Catheter Management
According to the gold standard, three of seven patients required urinary catheterization. In all cases, the use was justified by clinical indications, such as acute urinary retention or sepsis-related monitoring. Catheters were promptly removed once necessary. The remaining four patients were appropriately managed without catheterization (Table 4). The model accurately identified catheter placement and removal practices and evaluated all actions as appropriate based on guideline recommendations. Its performance in this domain strongly aligned with best practices, with no errors recorded in the data extraction and appropriateness evaluation.
Table 4.
Urinary catheter management analysis.
3.4. Infusion Line Management
Infusion line management was evaluated for all seven patients, focusing on the appropriateness of line placement, maintenance, and removal (Table 5).
Table 5.
Infusion line management analysis.
According to the gold standard, the placement of lines was deemed appropriate in all cases, with maintenance and removal practices aligned with evidence-based guidelines to ensure optimal patient safety and infection control. The LLM extracted and evaluated the infusion line details but encountered some inaccuracies. ChatGPT incorrectly extracted information indicating that a CVC had been placed in two patients treated with PVC. Likely, the abbreviation “CV” (used in the documentation to indicate “urinary catheter”, in Italian “catetere vescicale”) was coded as “CVC”. As a result, the assessment of the appropriateness of infusion line management in these two cases was also inaccurate.
3.5. Pressure Ulcer Management
None of the seven patients had documented pressure ulcers requiring specific care (Table 6).
Table 6.
Analysis of pressure ulcer management.
However, the model erroneously reported pressure ulcers in two of the seven patients without documented lesions. The cause of this error remains unclear but may be linked to ambiguous or poorly structured text in clinical or nursing records. Nevertheless, the model correctly applied the guidelines for erroneously reported pressure ulcers, selecting appropriate dressings and management practices based on ulcer staging. This suggests that while extraction errors occurred, the model demonstrated competence in aligning its recommendations with evidence-based standards for the identified scenarios.
4. Discussion
This proof-of-concept study aimed to evaluate the performance of LLMs in supporting the management and prevention of infections by analyzing clinical documentation and providing recommendations based on evidence-based guidelines.
There are already examples in the literature demonstrating the use of LLMs in infectious diseases, both from a public health perspective [10,11] and a more clinical standpoint [12], with promising results. To our knowledge, no previous study has evaluated the ability of LLMs to assess the appropriateness of the actions and prescriptions used in the management and prevention of healthcare-associated infections. A previous study analyzed the accuracy of responses generated by LLMs regarding infective endocarditis prophylaxis in the context of dental procedures [8]. Although GPT demonstrated significantly superior performance to the other models tested, the study was not based on real-world clinical data.
Our study contributes to a growing body of evidence. The analysis demonstrated the model’s ability to extract information from clinical documentation and assess its appropriateness according to the guidelines provided, highlighting its potential as a support tool for infection management. The model demonstrated strong potential for generating accurate and clinically relevant outputs across multiple domains. Its use in antibiotic therapy and urinary catheter management is particularly noteworthy.
However, specific errors highlight the model’s limitations when applied to specific scenarios. It frequently recommends contact precautions in isolation measures even when standard precautions are sufficient. This error likely resulted from an incorrect application of guideline recommendations for the identified microorganism, as the specific characteristics of the case did not warrant such measures. A notable issue emerged in the analysis of infusion line management. The model probably incorrectly interpreted the abbreviation “CV” (used to indicate urinary catheter in the documentation language) as “CVC” (central venous catheter), leading to references to non-existent cases. Furthermore, the model reported ulcers not documented in patient records for pressure ulcer management. The cause of this error remains unclear but may be due to challenges in processing ambiguous or poorly structured input data. Such discrepancies highlight the necessity of human oversight to validate AI-generated outputs and ensure reliability in clinical decision-making.
Using clinical documentation written in a language other than English poses an additional challenge for ChatGPT-4o. Although the model is pre-trained to operate in a multilingual environment, its primary training source is English, which remains the dominant language for the biomedical literature and for performing tasks, such as information extraction, classification, and synthesis. Nevertheless, the model performed excellently when processing input in a different language, except for a few selected cases that appeared to be associated with using acronyms. These findings underscore the importance of optimizing AI tools for multilingual environments, particularly in healthcare settings, where accuracy in understanding language-specific terms is crucial. Furthermore, the small sample size, dictated by strict inclusion and exclusion criteria, limited the diversity and complexity of the cases analyzed. As this is a proof-of-concept study, further research must include a broader range of cases and clinical scenarios. That said, the limited number of cases is consistent with the study’s exploratory nature aimed at testing the feasibility of the approach. Working with a smaller, more uniform dataset allowed us to focus on specific challenges, such as the model’s difficulty in interpreting language-specific abbreviations, which are often not directly transferable from English. However, future studies should prioritize the expansion of the dataset to validate the generalizability of the results in different clinical settings and patient profiles.
5. Conclusions
This study explored the ability of LLMs (ChatGPT-4o) to extract clinical information and evaluate the appropriateness of patient management based on complex and unstructured documentation. Despite the limited number of cases, the results suggest that LLMs can provide valuable support for interpreting clinical narratives, with promising performance in data extraction and clinical reasoning tasks.
By offering structured insights and enhancing the assessment of complex documentation, LLMs can bridge gaps in clinical workflows, ultimately promoting informed and timely decisions. Clearly, the present study should be considered a proof of concept given the small number of cases included in the analysis. Further research is needed to better analyze the number of cases to understand ChatGPT’s capabilities in such complex tasks and to explore its integration into real-world clinical settings.
However, these preliminary findings underscore the potential of LLMs not merely as computational tools but also as valuable allies in advancing evidence-based practice and supporting healthcare professionals in delivering high-quality care.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/healthcare13080879/s1, Prompts provided to ChatGPT.
Author Contributions
Conceptualization, D.G.; data curation, G.B. and C.A.M.P.; formal analysis, G.L.; investigation, A.G; supervision, V.M.; writing—original draft, G.L. and A.G.; writing—review and editing, G.B., C.A.M.P., V.M. and D.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were not required since the study was retrospective and used anonymized data.
Informed Consent Statement
Patient consent was waived because this retrospective, proof-of-concept analysis posed minimal risk to participants, relied on data originally collected for standard care, and used fully de-identified patient information. All records were anonymized before analysis to ensure confidentiality and prevent potential disclosures.
Data Availability Statement
The authors will make the raw data supporting this article’s conclusions available upon request.
Acknowledgments
During the preparation of this manuscript/study, the authors used ChatGPT-4o for the purposes of extracting and assessing clinical data for appropriateness in infection prevention and management practices of patients admitted to an infectious disease ward. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhao, W.; Guo, W.; Sun, P.; Yang, Y.; Ning, Y.; Liu, R.; Xu, Y.; Li, S.; Shang, L. Bedside Nurses’ Antimicrobial Stewardship Practice Scope and Competencies in Acute Hospital Settings: A Scoping Review. J. Clin. Nurs. 2023, 32, 6061–6088. [Google Scholar] [CrossRef] [PubMed]
- O’Neill, J. Tackling Drug-Resistant Infections Globally: Final Report and Recommendations; Wellcome Trust: London, UK, 2016. [Google Scholar]
- Van Bulck, L.; Moons, P. What If Your Patient Switches from Dr. Google to Dr. ChatGPT? A Vignette-Based Survey of the Trustworthiness, Value, and Danger of ChatGPT-Generated Responses to Health Questions. Eur. J. Cardiovasc. Nurs. 2024, 23, 95–98. [Google Scholar] [CrossRef]
- Balas, M.; Ing, E.B. Conversational AI Models for Ophthalmic Diagnosis: Comparison of ChatGPT and the Isabel Pro Differential Diagnosis Generator. JFO Open Ophthalmol. 2023, 1, 100005. [Google Scholar] [CrossRef]
- Saban, M.; Dubovi, I. A Comparative Vignette Study: Evaluating the Potential Role of a Generative AI Model in Enhancing Clinical Decision-Making in Nursing. J. Adv. Nurs. 2024, 80, 4750–4751. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Zhang, W.; Zhou, Q.; Zhang, Q.; Du, J.; Jin, Y.; Weng, X. Revolutionizing Patient Education with GPT-4o: A New Approach to Preventing Surgical Site Infections in Total Hip Arthroplasty. Int. J. Surg. 2025, 111, 1571–1575. [Google Scholar] [CrossRef] [PubMed]
- Zeng, S.; Kong, Q.; Wu, X.; Ma, T.; Wang, L.; Xu, L.; Kou, G.; Zhang, M.; Yang, X.; Zuo, X.; et al. Artificial Intelligence-Generated Patient Education Materials for Helicobacter Pylori Infection: A Comparative Analysis. Helicobacter 2024, 29, e13115. [Google Scholar] [CrossRef]
- Rewthamrongsris, P.; Burapacheep, J.; Trachoo, V.; Porntaveetus, T. Accuracy of Large Language Models for Infective Endocarditis Prophylaxis in Dental Procedures. Int. Dent. J. 2025, 75, 206–212. [Google Scholar] [CrossRef]
- Wiemken, T.L.; Carrico, R.M. Assisting the Infection Preventionist: Use of Artificial Intelligence for Health Care–Associated Infection Surveillance. Am. J. Infect. Control 2024, 52, 625–629. [Google Scholar] [CrossRef]
- Rizzo, A.; Mensa, E.; Giacomelli, A. The Future of Large Language Models in Fighting Emerging Outbreaks: Lights and Shadows. Lancet Microbe 2024, 5, 100954. [Google Scholar] [CrossRef]
- Kwok, K.O.; Huynh, T.; Wei, W.I.; Wong, S.Y.; Riley, S.; Tang, A. Utilizing Large Language Models in Infectious Disease Transmission Modelling for Public Health Preparedness. Comput. Struct. Biotechnol. J. 2024, 23, 3254–3257. [Google Scholar] [CrossRef]
- Omar, M.; Brin, D.; Glicksberg, B.; Klang, E. Utilizing Natural Language Processing and Large Language Models in the Diagnosis and Prediction of Infectious Diseases: A Systematic Review. Am. J. Infect. Control 2024, 52, 992–1001. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, I.S.; Link, K.E.; Daneshjou, R.; Cortés-Penfield, N. Black Box Warning: Large Language Models and the Future of Infectious Diseases Consultation. Clin. Infect. Dis. 2024, 78, 860–866. [Google Scholar] [CrossRef] [PubMed]
- Haleem, A.; Javaid, M.; Singh, R.P. An Era of ChatGPT as a Significant Futuristic Support Tool: A Study on Features, Abilities, and Challenges. BenchCouncil Trans. Benchmarks Stand. Eval. 2022, 2, 100089. [Google Scholar] [CrossRef]
- Evans, L.; Rhodes, A.; Alhazzani, W.; Antonelli, M.; Coopersmith, C.M.; French, C.; Machado, F.R.; Mcintyre, L.; Ostermann, M.; Prescott, H.C.; et al. Surviving Sepsis Campaign: International Guidelines for Management of Sepsis and Septic Shock 2021. Crit. Care Med. 2021, 49, e1063–e1143. [Google Scholar] [CrossRef] [PubMed]
- Yealy, D.M.; Mohr, N.M.; Shapiro, N.I.; Venkatesh, A.; Jones, A.E.; Self, W.H. Early Care of Adults with Suspected Sepsis in the Emergency Department and Out-of-Hospital Environment: A Consensus-Based Task Force Report. Ann. Emerg. Med. 2021, 78, 1–19. [Google Scholar] [CrossRef]
- Buetti, N.; Marschall, J.; Drees, M.; Fakih, M.G.; Hadaway, L.; Maragakis, L.L.; Monsees, E.; Novosad, S.; O’Grady, N.P.; Rupp, M.E.; et al. Strategies to Prevent Central Line-Associated Bloodstream Infections in Acute-Care Hospitals: 2022 Update. Infect. Control Hosp. Epidemiol. 2022, 43, 553–569. [Google Scholar] [CrossRef]
- Nickel, B.; Gorski, L.; Kleidon, T.; Kyes, A.; DeVries, M.; Keogh, S.; Meyer, B.; Sarver, M.J.; Crickman, R.; Ong, J.; et al. Infusion Therapy Standards of Practice. J. Infus. Nurs. 2024, 47, S1–S285. [Google Scholar] [CrossRef]
- Patel, P.K.; Advani, S.D.; Kofman, A.D.; Lo, E.; Maragakis, L.L.; Pegues, D.A.; Pettis, A.M.; Saint, S.; Trautner, B.; Yokoe, D.S.; et al. Strategies to Prevent Catheter-Associated Urinary Tract Infections in Acute-Care Hospitals: 2022 Update. Infect. Control Hosp. Epidemiol. 2023, 44, 1209–1231. [Google Scholar] [CrossRef]
- Gould, C.V.; Umscheid, C.A.; Agarwal, R.K.; Kuntz, G.; Pegues, D.A.; Healthcare Infection Control Practices Advisory Committee. Guideline for Prevention of Catheter-Associated Urinary Tract Infections 2009. Infect. Control Hosp. Epidemiol. 2010, 31, 319–326. [Google Scholar] [CrossRef]
- Siegel, J.D.; Rhinehart, E.; Jackson, M.; Chiarello, L.; Healthcare Infection Control Practices Advisory Committee. 2007 Guideline for Isolation Precautions: Preventing Transmission of Infectious Agents in Health Care Settings. Am. J. Infect. Control 2007, 35, S65. [Google Scholar]
- Loveday, H.P.; Wilson, J.A.; Pratt, R.J.; Golsorkhi, M.; Tingle, A.; Bak, A.; Browne, J.; Prieto, J.; Wilcox, M. Epic3: National Evidence-Based Guidelines for Preventing Healthcare-Associated Infections in NHS Hospitals in England. J. Hosp. Infect. 2014, 86, S1–S70. [Google Scholar] [CrossRef] [PubMed]
- Haesler, E. Prevention and Treatment of Pressure Ulcers/Injuries: Clinical Practice Guideline: The International Guideline| Prevention and Treatment of Pressure Ulcers: Clinical Practice Guideline; Cambridge Media: Perth, Australia, 2019. [Google Scholar]
- Dellit, T.H.; Owens, R.C.; McGowan, J.E.; Gerding, D.N.; Weinstein, R.A.; Burke, J.P.; Huskins, W.C.; Paterson, D.L.; Fishman, N.O.; Carpenter, C.F.; et al. Infectious Diseases Society of America and the Society for Healthcare Epidemiology of America Guidelines for Developing an Institutional Program to Enhance Antimicrobial Stewardship. Clin. Infect. Dis. 2007, 44, 159–177. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).