1. Introduction
Accelerated testing consists of subjecting a product or material to a high stress that shortens its life or hastens the degradation of its performance. Stress can refer to different accelerating variables, such as temperature, humidity, pressure, etc. The main reasons to perform over-stress testing is to estimate the life expectancy of the product under normal conditions (at lower or null stress levels) [
1], i.e., to obtain the parameters of the distribution of the time-to-failure for usual conditions through the observed failure times. Generally, there is some information available (based on physical/chemical theory or previous experience with similar tests) that can be used to explain the existing relationship between the accelerating variables and the failure mechanism and that can be used to identify a model and justify the extrapolation [
2]. The Accelerated Failure Time (AFT) model provides a natural formulation of the effects of covariates on the response variable. The aim of AFT models is to study how the survival function is directly affected by the explanatory variables, rather than the hazard function in the commonly used proportional hazards models. Unlike proportional hazards models, AFT models are mostly fully parametric, which facilitates their interpretation measuring the effect of the corresponding covariate on the survival time. Estimating the failure time distribution of the long-term performance of a product or material is particularly important in the field of manufacturing to demonstrate product or material reliability [
3,
4,
5,
6], although AFT models are also used for analyzing clinical trial data [
7,
8,
9] and genomic studies [
10,
11].
One of the most widely used methods to accelerate a failure mechanism is to modify the temperature at which it is used. Products and materials can be tested at temperatures above (or below) their normal use temperature so that defects or failure modes that may appear in the distant future at normal use temperatures can be detected in short times. The typical failure mode is dependent on migration/diffusion or chemical degradation (resulting in eventual weakening and failure). These types of failures are typically found in electronic components, but can also occur in other types of products or materials such as adhesives, batteries, etc. More on the effects of temperature on short-time failures can be found in [
12,
13,
14].
As important as it is to observe failures in a short period of time to extrapolate survival time in usual conditions, it is important to optimally select the points of stress in which the observations shall be taken; that is, to select the points of stress efficiently so that they provide as much information as possible about the failure process. Meeker [
15] and Meeker and Nelson [
16] obtained the optimal tests that minimized the asymptotic variance of the maximum likelihood estimator of the
pth percentile at design stress. Bai and Chung [
17] studied optimal designs for tests in which two levels of stress were constantly applied and the failed items were replaced. In this paper, the accelerated failure process was described making use of Arrhenius and Eyring equations. AFT models are introduced in
Section 2, and D-optimal designs when the acceleration factor is temperature are calculated in
Section 3.
As expected, as is common in AFT models with single stress and type I censoring [
18], the statistically optimal plan has only two stress levels. These optimal two-level plans are not always practical [
19], and there has been extensive research on “compromise design plans” ([
20,
21,
22,
23], to name a few). Meeker [
15] proposed several compromise plans and concluded that the best plan has three equally spaced test stresses, and between 10% and 20% of the samples are taken at the middle stress level, as collected in Chen et al. [
18]. This developed into the so-called “4:2:1 plan”, proposed by Meeker and Hahn [
24] and still widely used. A new alternative compromise plan is presented in
Section 4, combining different optimal designs. A numerical example, showing the comparisons between the most commonly used designs and the proposed mixture of designs, is presented in
Section 5.
1.1. Design of Experiments Background
Let
T represent the response variable time-to-event, assumed to be a random variable from a parametric distribution with vector of parameters
. The response
T is observed under certain experimental conditions represented by
, where the vector of covariates,
, is chosen from a compact design space
. An approximate design,
, is a collection of
n different support points,
, and weights,
, defining a discrete probability on
. The Fisher Information Matrix (FIM) captures the information given by a design
. Loosely speaking, it describes the amount of information about an unknown parameter provided by the data. The FIM is defined as:
where
is the log-likelihood function for experimental conditions
. The inverse of the FIM,
, for independent observations, is proportional to the asymptotic covariance matrix of the maximum likelihood estimate of
. Optimal designs aim to minimize the covariance matrix, i.e., maximize a function
of the information matrix, called the optimality criterion.
1.1.1. D-Optimal Designs
The most popular criterion is D-optimality. For non-linear models, the FIM (and thus the optimal designs) are dependent on the model parameters. Therefore, to obtain locally optimal designs’ initial (also called nominal) values,
are needed. For a given
, D-optimality maximizes the determinant of the FIM, i.e., it minimizes the volume of the confidence ellipsoid of estimators of the parameters of the model [
25].
The D-optimal design has equal weights when the number of support points is the same as the number of parameters of the model,
. From the General Equivalence Theorem (GET) [
26], a design
is D-optimal if and only if:
Moreover, equality is reached at the support points of the design. is known as the sensitivity function.
Let
represent the actual values of the parameters, which give an optimal design
. Then, how good a design
is can be studied by calculating its efficiency when compared to
. The D-efficiency is computed as:
If the design has D-efficiency p and N experiments are performed under it, the same accuracy in the estimations can be reached by performing experiments under the optimal design .
The efficiency function (
3) can also be used to check the robustness of a design by considering different sets of values to be the true parameters and computing the efficiency of the
D-optimal design with respect to the design obtained for the new set of parameters.
1.1.2. c-Optimal Designs
c-optimality aims to minimize the variance of the estimator of a linear combination of the unknown parameters . c-optimal designs are commonly used when the main objective is to estimate a specific parameter, i.e., when c is chosen to be the m-dimensional euclidean vector , the criterion leads to the best design for the estimation of the parameter , and thus, the corresponding c-optimal design minimizes the variance of the estimator of . This is done by minimizing the element of .
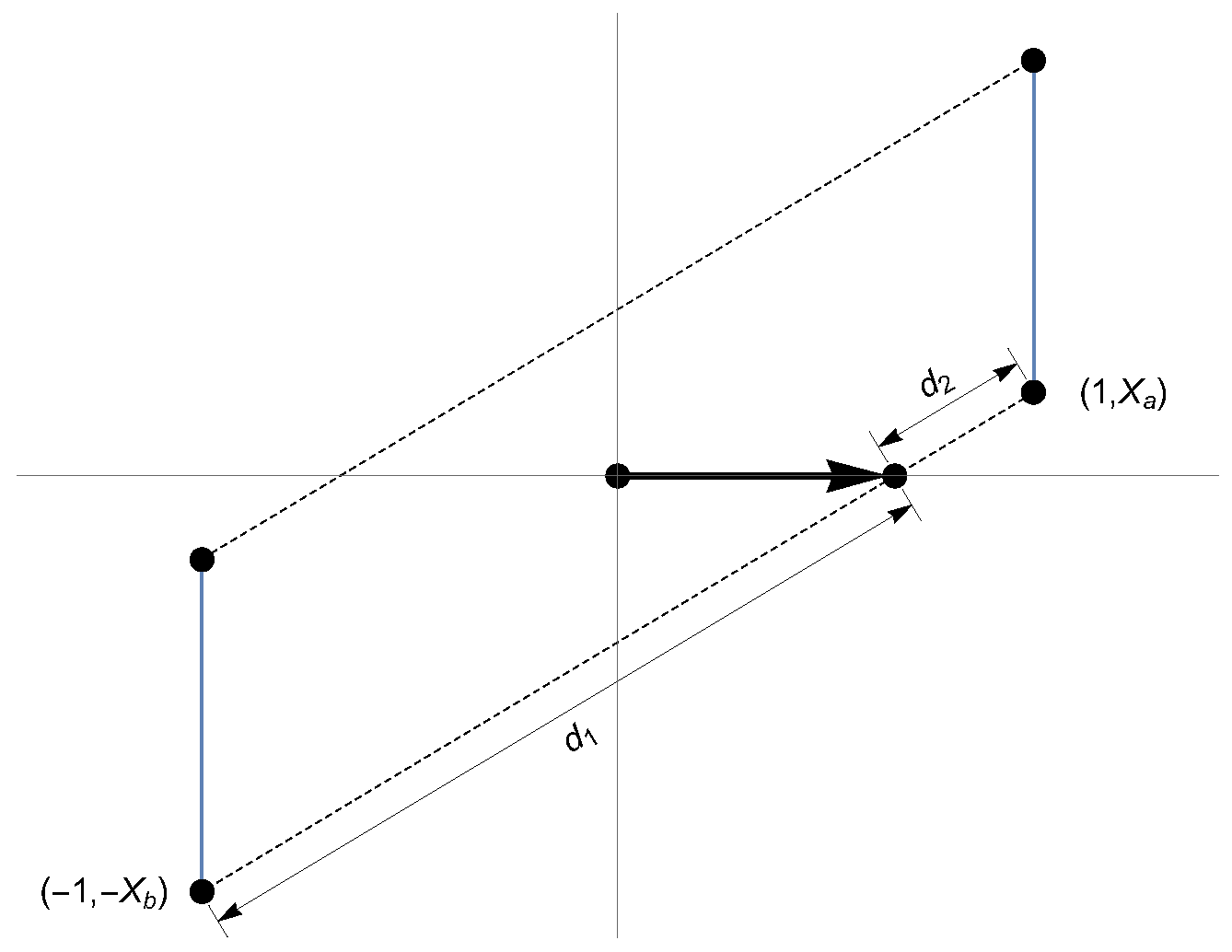
Elfving’s method is a well-known geometric procedure to obtain c-optimal designs [
27]. While the method is particularly useful for two-dimensional models, its complexity increases in higher dimensions. López-Fidalgo and Rodríguez-Díaz [
28] proposed a computational procedure for finding c-optimal designs that does not require the graphical construction of Elfving’s approach.
1.1.3. Filling Designs
Another commonly used approach is to use designs that cover the design space with a specific, pre-fixed, number of points, including both ends of the interval, and assign equal weights to all the support points. This type of design is denominated (space) filling designs or sequence designs. There are several ways in which the interval can be divided. Let
be the design interval, which has length
, and suppose
n points are wanted. The simplest form is to divide the interval into equal parts, where the distance between every pair of consecutive design points is
. These are known as uniform designs. Another kind of filling designs is parabolic designs, which offer the possibility to concentrate samples near a particular point of the interval. To compute a parabolic design, first, the interval
is divided by
n equally spaced points, which are projected into a parabola of curvature
k and then projected back, giving points
. The values of
k and
q regulate the dispersion of the points, while
v (
) controls where the concentrations of points occurs (−1: near
a, 0: center of the interval, 1: near
b). Then, the support points are calculated as
, with
and
. More details on the calculations of filling designs can be found in [
29] and their application in [
30].
2. Accelerated Failure Time Models
AFT models can be mathematically expressed making use of the survival function,
where the survival function under conditions
is represented by
S and
is the baseline survival function under usual conditions. The acceleration factor is
, which speeds up the effect of the survival time and depends on parameters
. Let
represent the survival time subject to conditions
x and
in usual conditions. Loosely speaking, the time-to-failure under conditions
x is equal to the time-to-failure in usual conditions divided by the acceleration factor, precisely
. Both
T and
follow the same distribution. Then:
that is, when
, then,
.
Taking logarithms:
with
and
. The expression
represents a random variable with a particular distribution and mean zero:
For each distribution of , there is a corresponding distribution for T, and vice versa.
The log-linear form of the model is:
This form is implemented in most software packages.
In the following sections, two types of acceleration factors related to chemical degradation of products are considered. The rate of the chemical reaction that produces the degradation increases with temperature, thus decreasing the survival time of the product/component (for example, the plastic cover of wires in an electric device). The popular Arrhenius and Eyring equations relating the reaction rate with temperature are described and studied in order to obtain the corresponding acceleration factors.
2.1. Arrhenius Relationship
Introduced by Arrhenius [
31] in his studies of the dissociation of electrolytes, it is broadly used to measure how the rate of a chemical reaction is affected by changes in temperature. The rate of a process in terms of the temperature,
, can be written:
where the parameters are independent of temperature. The frequency factor
is a constant, and
is the activation energy that represents the energy that a molecule must achieve in order to take part in the chemical reaction. This activation energy is a characteristic of the product or material, and it is measured in electron-volts. The information on
is generally available from previous experience, physical/chemical knowledge, handbooks, etc. For many consumer electronics products,
is roughly within some typical ranges.
Let
be the usual temperature of use of the material or product (in Kelvin degrees) and
the experimental temperature; the Arrhenius acceleration factor is:
In this case, the rate, , is inversely proportional to the expected failure time (as the velocity of the reaction increases, so does the degradation of the product, and thus, the expected failure time shortens). Therefore, .
The Arrhenius relationship does not apply to all temperature acceleration problems, but is widely and satisfactorily used in many applications [
2].
2.2. Eyring Relationship
The Arrhenius model requires that the rate of a reaction increases monotonically with temperature. Eyring and Lin [
32] gave a physical theory that describes the effect that temperature has on a reaction rate, based on the Arrhenius relationship, which was discovered through empirical observation. Written in terms of a reaction rate, the Eyring relationship is:
The Eyring acceleration factor is:
The value of
m usually ranges between zero and one. It is important to be aware that the estimate of
depends strongly on the assumed value of
m when the data are limited [
2], and only with great amounts of data can the effects of
and
m be split. The Eyring relationship leads to better low-stress extrapolations when
m can be determined accurately on the basis of physical considerations.
4. New Compromise Design Plan
As mentioned in the Introduction, two-level optimal designs are not very useful in practice. Nelson and Hahn [
35,
36] used Monte Carlo simulations to conclude that test plans with at least three levels and the majority of samples taken at the lowest level are more robust than the optimal two-level plans. Later on, Nelson and Kielpinski [
21] suggested the use of compromise plans where the extra stress levels and their allocation are selected by the practitioner. Meeker [
15] showed that the three equally spaced levels’ plans (with equal allocations) and the optimal plans are less robust than the compromise plans. Later on, Meeker and Hahn [
24] proposed a compromise plan with three equally spaced levels and weights
at the lowest, middle, and highest stress levels, respectively. There have not been many changes since Meeker’s optimal compromise plan, which is widely used in engineering and used as a reference for most of the subsequent plans proposed [
18].
The proposed compromised design plan presented below builds on the idea of taking advantage of the known optimal designs for the Arrhenius and Eyring equations [
37,
38]. These designs are (in most cases) supported at two points as well: the upper extreme and one within the design interval. These optimal designs produce the best estimate for the activation energy (the
parameter). Moreover, the c-optimal design for the parameter
can be calculated in order to produce the best estimate of
. A mixture of the D-optimal design for the AFT model and these two designs optimizing each parameter respectively was proposed, based on the three-point compromise plan. Rather than the third point of the design being just the middle point, this can be taken from the designs corresponding to the acceleration factor equation. Moreover, the weights can be allocated depending on the most interesting parameter from the point of view of the practitioner.
4.1. D-Optimal Design for the Arrhenius Equation
For the Arrhenius Equation (
9), the D-optimal design is equally supported at two points in the design interval. If
and
11,605
, then:
otherwise,
. Then:
Details of the calculations can be found in Rodríguez-Aragón and López-Fidalgo [
37].
4.2. D-Optimal Design for the Eyring Equation
In the case of the Eyring Equation (
11), the D-optimal design is also supported at two points. Now, if
and
11,605
, then:
with
11,605
. Otherwise,
. Then:
Details of the calculations can be found in Rodríguez-Díaz and Santos-Martín [
38].
4.3. c-Optimal Design for the Parameter
The c-optimal design for the parameter
in the AFT model is:
Details of the computation can be found in
Appendix A. As
tends to zero (
tends to the normal use temperature), the first weight approaches one, and as the usual situation is having the extreme of the design interval close to
, the c1-optimal design can be approximated to the one-point design:
4.4. A New Mixture of Designs
In this paper, a combination of the three previous designs was proposed: let
represent the weight, which was assigned to the
design (
26), and
to the c1-optimal design, then a mixture of the designs could be:
where
represents the design for the Acceleration Factor,
or
, depending on the relationship chosen. The resulting mixture of the three designs is:
with
corresponding to the appropriate point:
or
.
It could also be considered to use only the two optimal designs for the acceleration factor and
:
and so, the resulting mixture of these two designs is:
5. Numerical Example
Liu and Tang [
39] proposed a Bayesian inference method to estimate the model parameters of a Device A being tested by accelerating its failure time by high temperatures. The data were presented in Hooper and Amster [
40] and also available in Meeker and Escobar [
20]. In their scheme, the testing units, which had a normal temperature of 283 K, were tested at three accelerated temperatures: 313 K, 333 K, and 353 K, and the number of failures within a censoring time of 5000 h was observed. They also assumed
to be known and fixed it at
, its maximum likelihood estimate. Their estimates of
for each of the used temperatures were, respectively, 7.48, 8.81, and 10.13. In this case, the engineering knowledge suggested
. In their design, they allocated
of the units to the lowest temperature,
to the second, and the final
to the highest temperature.
usual temperature of use ,
design interval ,
censoring time, ,
(mean of the three estimates in Liu and Tang [
39]),
,
energy of activation .
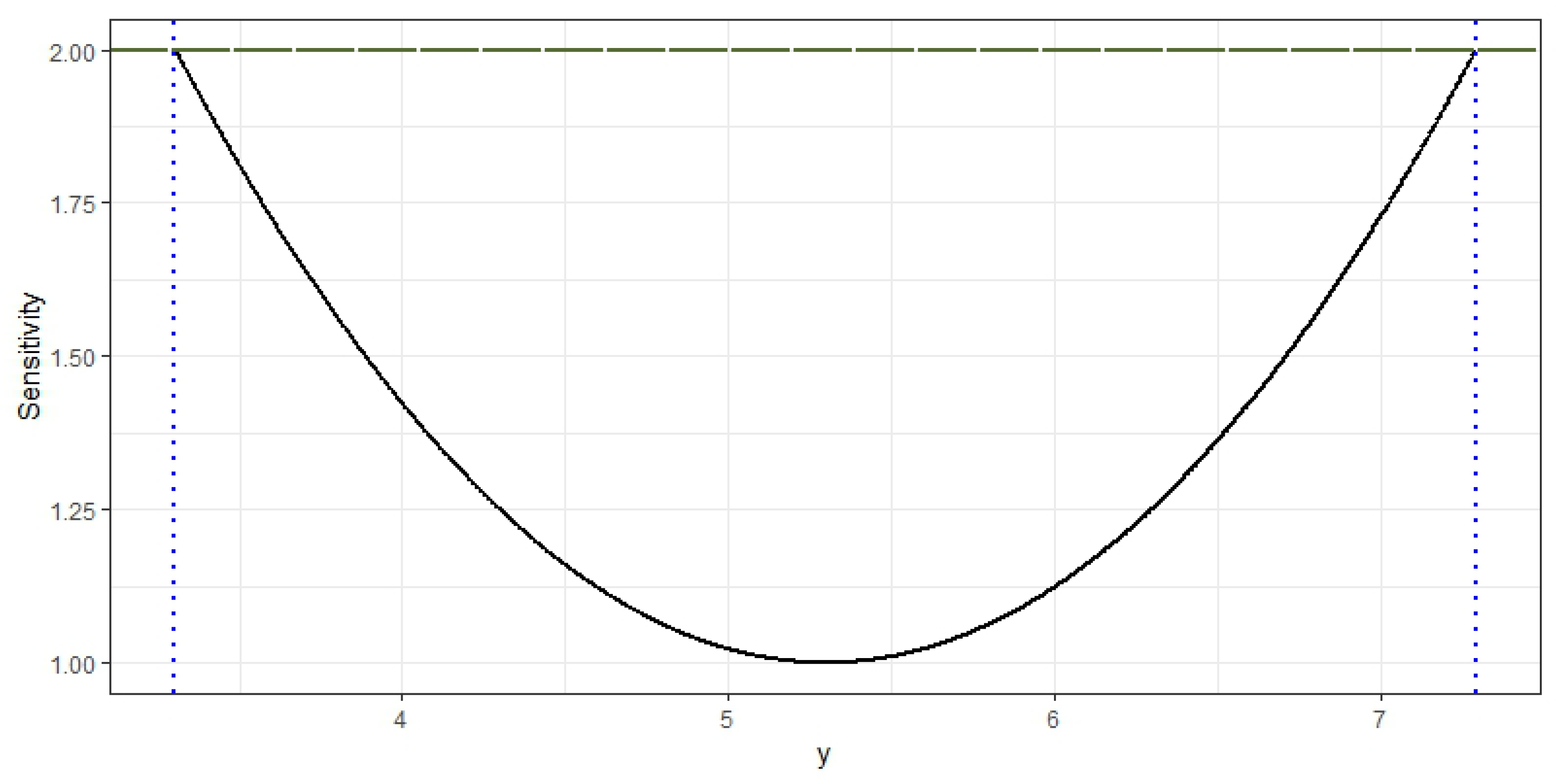
The D-optimal design for the AFT model is the equally weighted design supported at both extremes of the interval. The sensitivity Function (
2), shown in
Figure 2, remains smaller than two (the number of parameters) in the whole design space, and so, the obtained design is indeed D-optimal. Furthermore, the maxima are reached at the support points (i.e., the extremes of the interval). The three optimal designs are shown in
Table 1.
For values of m between zero and one, varies from (m = 0, equivalent to the Arrhenius equation) to , so the points move slowly towards higher values. However, due to the closeness to the Arrhenius equation, we shall focus from now on on the designs using .
Mixtures of the three designs, calculated using (
34), were studied for different values of
and
.
Table 2 shows the weights of the support points
for different combinations of the designs with the determinants of the FIM shown in parentheses.
In Liu and Tang [
39], most of the observations were taken near the lower extreme of the interval, i.e., the temperature closer to the usual. Their three-point design had three equally spaced points, at temperatures 313 K, 333 K, and 353 K, with weights
,
, and
, which follows a similar idea as the “4:2:1 plan”.
It can be noted that the designs in
Table 3 have smaller values for the determinant of the FIM matrix (shown in brackets), which implies they are less efficient designs, according to the D-optimal criterion. In fact, taking, for example,
and
, their D-efficiency (
3) with respect to the mixture design,
, is
for Liu and Tang’s design and
for the 4:2:1 design.
Table 4 shows some filling designs for the AFT model. A parabolic design that concentrates points at the beginning of the interval was considered, to account for the concentration of points at lower temperatures. It can be seen that adding an extra support point (
) did not improve the design (in terms of D-optimality), but these filling designs are actually more efficient than the ones shown in
Table 3. The D-efficiency of Liu and Tang’s design, with respect to the three-point uniform and parabolic design presented, was
and
, respectively. The D-efficiency of the 4:2:1 design with respect to the uniform design was
and
with respect to the parabolic design. Taking again
and
as an example, the D-efficiency of the three-point filling designs with respect to the mixture design,
, was
for the uniform design and
for the parabolic design.
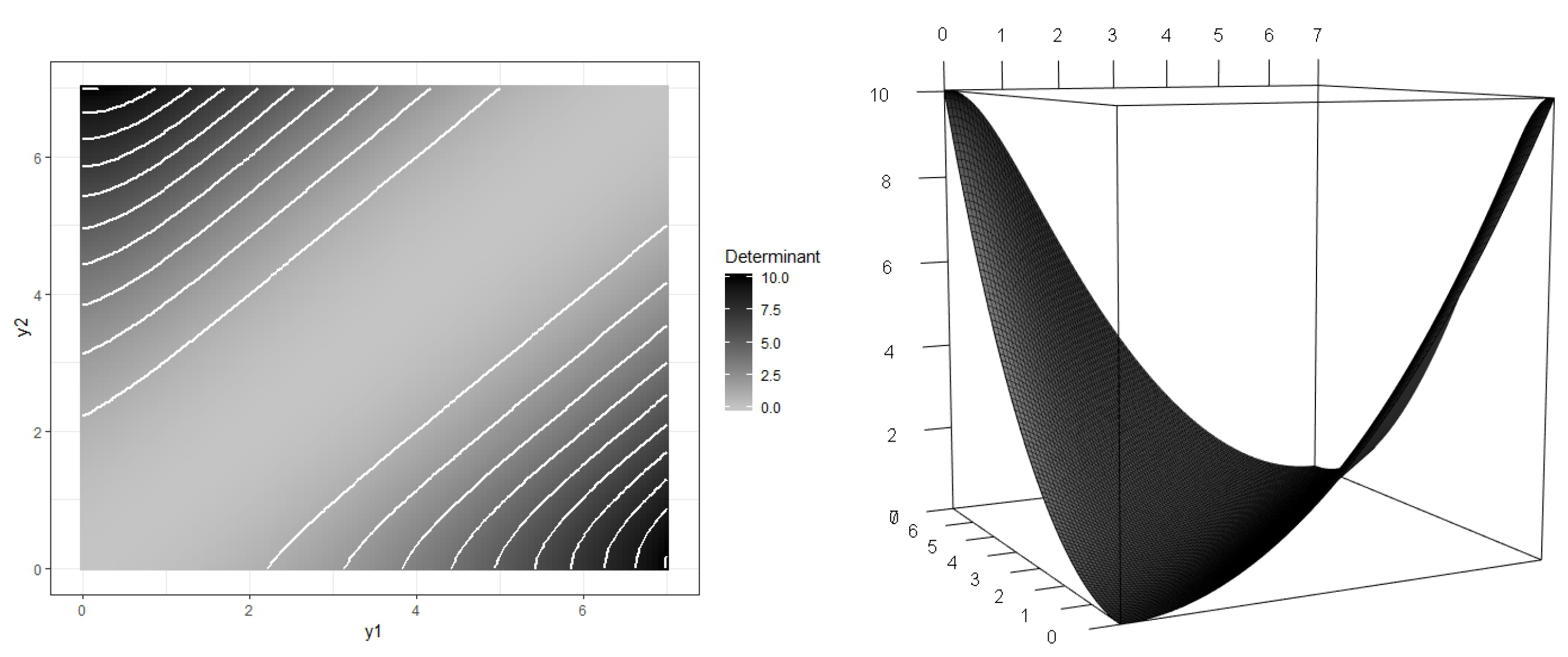
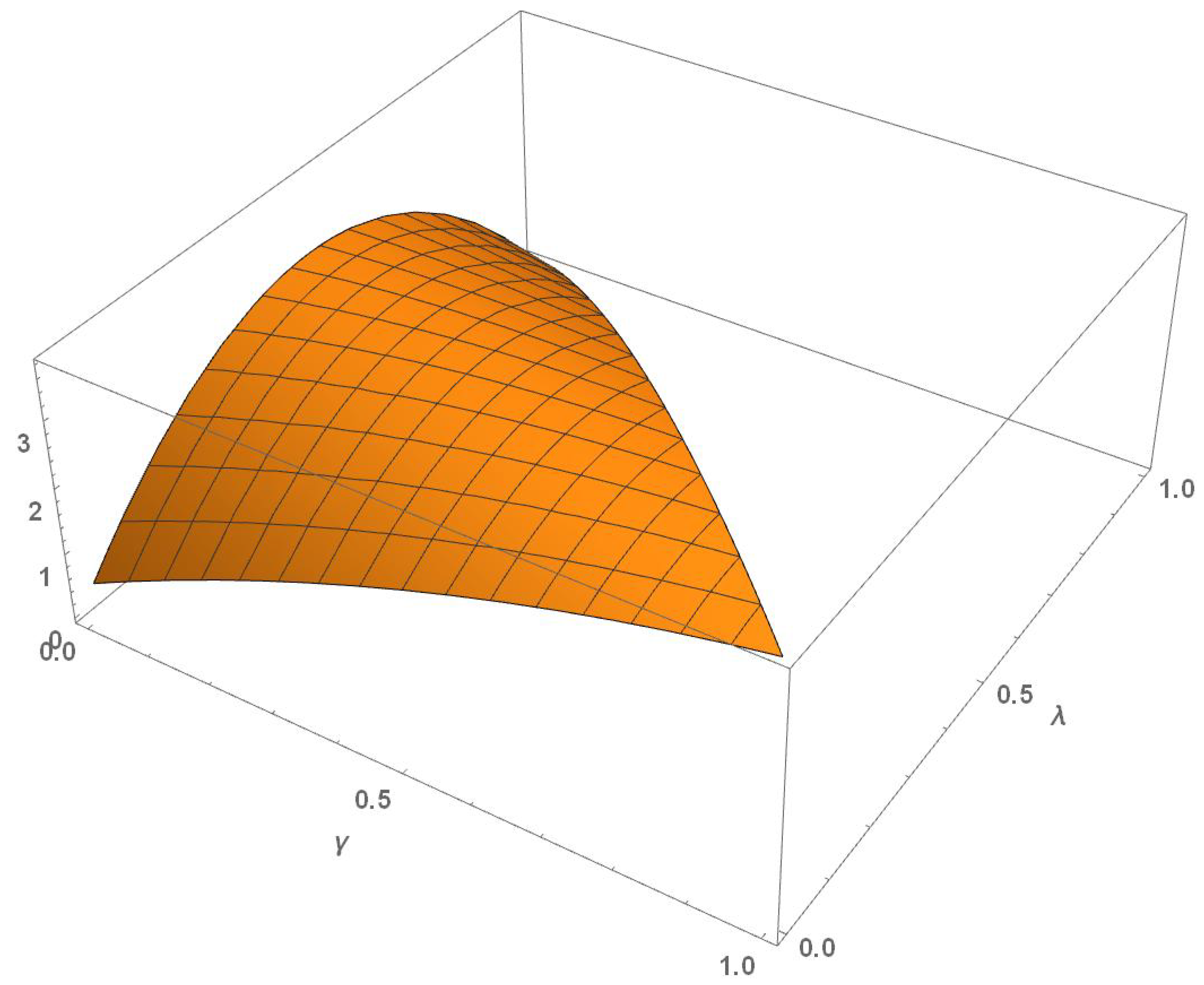
The determinant of the FIM of the mixture design
can be expressed as a function of
and
as:
which is shown in
Figure 3.
The maximum value, 3.80482, was attained for and , that is without using in the mixture design. Nevertheless, the use of provides a way to “tune” the design according to the expertise of the practitioner when a higher weight at the lower extreme of the design interval seems convenient.
6. Discussion
AFT models were first introduced in engineering, but their use has become increasingly popular as an alternative to proportional hazard models, also in the medical field [
33]. As important as it is that accelerated test programs are planned and conducted by teams with good knowledge about the material/product, the typical use conditions, and the physical/chemical/mechanical aspects of the failure models, it is also important to take into account the statistical aspects of the design and analysis of reliability experiments [
2].
In this paper, the methodology to obtain optimal designs for an AFT model was presented. In particular, the details when assuming a log-normal distribution for the survival time and considering the case of known variance were shown. Optimal design uses different criteria related to the variance of the estimators to select observational points in which to obtain the best estimates of a model’s parameters. The most commonly used criterion, D-optimality, was considered. The D-optimal designs are supported at the extremes of the intervals, and although the two-point D-optimal design is better than a three-point design, a design in the boundaries of the interval may not always be useful. Moreover, these designs are not very robust [
19]. For these reasons, a new approach was presented, where the D-optimal design for the AFT model can be combined with the D-optimal design that produced the best estimates for the acceleration factor chosen (Arrhenius or Eyring) and the best design for estimating the parameter
, the expected value of the survival time under usual conditions (in logarithm scale). In the proposed mixture of designs, the experimenter can decide where to put the emphasis by selecting different values of
and
. The three-point mixture design proposed was studied in comparison to the design proposed by Liu and Tang [
39], the “4:2:1 plan” design plan, the use of which is widely extended, and different filling designs. The design proposed had a higher D-efficiency than the others. It can be thought that having a higher number of support points along the design interval would lead to better estimations of the parameters. Nonetheless, the four-point filling designs shown had lower efficiencies than the three-point ones.
As described by Meeker and Escobar [
20], accelerated tests should be designed, as much as possible, to minimize the amount of extrapolation required. This means that levels of accelerating variables that are too high may result in failure models that would never actually occur at the use levels of the accelerating models. For this reason, the approximation of the c-optimal design to the single point design at the lowest end of the design interval acts as a penalty to extreme temperature values. The mixture designs proposed in this paper seemed to be a good alternative to the compromise plans, improving them by choosing a support point in the interval that was optimal for the acceleration factor, rather than simply the middle point. Furthermore, the weights can be adjusted depending on the parameter in which the practitioner is more interested.
7. Conclusions and Future Work
This paper aimed to improve the traditionally used compromise design plans for AFT models. As previously mentioned, the two-level optimal design is not always practical, and there have not been many changes since the “4:2:1 plan”, broadly used in engineering, was introduced.
The presented mixture design proposed to select the middle point of the design to be taken from the designs corresponding to the acceleration factor equation. Furthermore, the weights can be allocated depending on the most interesting parameter from the point of view of the practitioner. It was shown that the proposed design performed better in terms of the D-efficiency. The participation of the c optimal design for the mean parameter in this mixture design is not essential, but can help the practitioner adjust the weights of the designs points from a convenient point of view.
Several extensions are being considered as future lines of research, including: sensitivity studies regarding the initial parameters; the choice of
m and/or other distributions; consideration of
m as an unknown parameter to be estimated (in this case, the dimensions of the information matrix would increase and, therefore, the difficulty of the computations); and similarly, considering
as an unknown parameter to be estimated. In the last case, the modification of the information matrix described in Pázman [
41] could be used. Furthermore, it may happen that the “controlled variable” (
) could not be completely fixed. In this case, extensions of
D-optimal designs can be used following the ideas of Pronzato [
42].


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}