1. Introduction
Advances in enabling technologies, both software and hardware, have encouraged a widespread proliferation of social robots in several application domains, including education, therapy, services, entertainment, and arts [
1,
2,
3,
4,
5]. In all applications, the capacity of social robots to sensibly interact with humans is critical [
6,
7,
8].
In general, the interaction of a social robot with a human is driven by a mathematical model implemented in software. The interest here is in “intelligence models” in the following sense. First, a “model” here is defined as “a mathematical description of a world aspect”; second, “intelligence” here is defined as “a capacity for both learning and generalization, including non-numerical data as well as explanations as described next.
Conventional models typically regard the (physical) world; therefore, they are developed in the Euclidean space R
N, based on real numbers stemming from sensor measurements [
9]. However, when humans are involved, in addition to sensory data during their interaction with one another, humans also employ non-numerical data, such as spoken words/language, symbols, concepts, rules, moral principles, and others. Therefore, for a seamless interaction with humans, social robots are required to also cope with non-numerical data. Another requirement, in the European Union, is the observance of the General Data Protection Regulation (GDPR); hence, anonymous data are preferable during data processing [
10]. Due to the personalized character of social robot-human interaction, it is preferable to induce a model from personal data by machine-learning techniques, rather than develop a model based on “first principles”.
Learning and generalization here are considered as necessary, but not sufficient, conditions for intelligence. For instance, conventional steepest-descent methods pursue learning by optimizing an energy-type “objective function”; moreover, they pursue generalization by interpolation and/or extrapolation. However, conventional models typically operate as black-boxes that carry out number-crunching and fall short of providing with common sense explanations. In addition, the latter models cannot manipulate non-numerical data (e.g., symbols or data structures). In the aforementioned context, the long-term interest here is in a simple abductive classifier model toward inducing world representations that are not merely descriptive, but also explanatory [
11].
A mathematical approach for modeling has been proposed recently, based on the fact that popular data domains are partially (lattice) ordered; for instance, the Cartesian product R
N, hyperboxes in R
N, Boolean algebras, measure spaces, decision trees, and distribution functions are partially (lattice) ordered. In conclusion, the Lattice Computing (LC) information processing paradigm has been proposed as “an evolving collection of tools and methodologies that process lattice ordered data per se including logic values, numbers, sets, symbols, graphs, etc.” [
9,
12,
13,
14,
15,
16,
17]. Different authors have recently correlated the emergence of lattice theory with the proliferation of computers [
18]. In the context of LC, decision-making instruments have been introduced such as metric distances, as well as fuzzy order functions; moreover, effective LC models have been proposed [
12,
19,
20,
21].
Since information granules are partially ordered [
20], Granular Computing [
22] can be subsumed in Lattice Computing. Note that mathematical Lattice Theory or, equivalently, Order Theory, is the common instrument for analysis regarding LC, fuzzy systems [
23], formal concept analysis and rough sets approximations [
24], and other.
Previous LC classifiers have engaged non-numerical data including, lattice-ordered gender symbols, and events in a probability space, as well as structured data, namely graphs. However, the latter (graphs) have been used as instruments for ad hoc feature extraction of vectors [
25]. In other words, a graph in previous LC works has been used only once, for data preprocessing. Similarly, different authors have recently employed an interesting hierarchic and/or a linguistic descriptor approach for extracting vectors of features regarding face recognition problems [
26,
27].
This work considers three social robot-human interaction related problems regarding visual pattern recognition of (1) head orientation, in order to quantify the engagement/attention of a human, (2) facial expressions, in order to adjust behavior according to a human’s emotional state, and (3) human faces, in order to address a human personally. In fact, this work focuses on the GbC classifier itself, rather than on human-robot interaction applications. The latter application is a topic for future work.
The motivation of this work is the solution of specific research problems, as explained subsequently. A social robot-human interaction calls for decision-making based on multimodal data semantics. However, most of the state-of-the-art models are developed strictly in the Euclidean space R
N, thus ignoring other types of data per se, such as structured data. On the other hand, LC based models have the capacity to rigorously fuse multimodal data per se, based on the fact that, first, popular data types are lattice-ordered and, second, the Cartesian product of mathematical lattices is also a lattice; in particular, this preliminary work considers trees data structures for classification. Furthermore, state-of-the-art models, such as deep learning neural networks, typically require huge training data sets, whereas, the proposed techniques here can be used with orders of magnitude fewer training data. In addition, state-of-the-art methods such as deep learning often cannot explain their answers, whereas the proposed method can explain its answers by granular rules induced from tree data structure. In a similar vein, note that image recognition systems have been reported lately in the context of fuzzy logic that can explain their decisions using type-2 fuzzy sets, fuzzy relations, and fuzzy IF-THEN rules [
28]. Nevertheless, state-of-the-art methods typically call for a different feature extraction per classification problem, whereas the proposed method here engages the same features in three different classification problems. Finally, state-of-the-art methods often do not typically retain the anonymity of the human subjects, especially when they process images, whereas the proposed method extracts facial landmark features in a data preprocessing step and thereafter, i.e., during data processing such as training, it retains the anonymity of the human subjects.
The proposed classification techniques apply fairly “expensive” real world data. Therefore, they differ from alternative machine (deep) learning techniques, such as generative adversarial networks (GANs) [
29], which massively generate new data with the same statistics as the training set. The proposed techniques also differ from probabilistic graphical models, such as the variational autoencoders (VAEs) [
30], in that the latter use graphs to optimally estimate probability distributions of vector data, whereas GbC here processes graph (tree) data per se.
The novelties of this work include, first, a unifying, anonymous representation of a human face for face recognition; second, the introduction of the Granule-based-Classifier (GbC) parametric model that processes trees data structures; third, the induction of granular rules, involving tree data structures, toward an explainable artificial intelligence (AI); and fourth, the far-reaching potential of pursuing creativeness by machines based on a lattice order isomorphism.
This work is organized as follows:
Section 2 outlines the mathematical background.
Section 3 presents computational considerations.
Section 4 describes the Granule-based-Classifier (GbC).
Section 5 demonstrates computational experiments and results. Finally,
Section 6 discusses comparatively the reported results; furthermore, it describes potential future work extensions.
2. Mathematical Background
Useful mathematical lattice theory definitions and instruments have been presented elsewhere [
23,
31,
32]. This section customizes the aforementioned instruments to a specific lattice, as explained in the following.
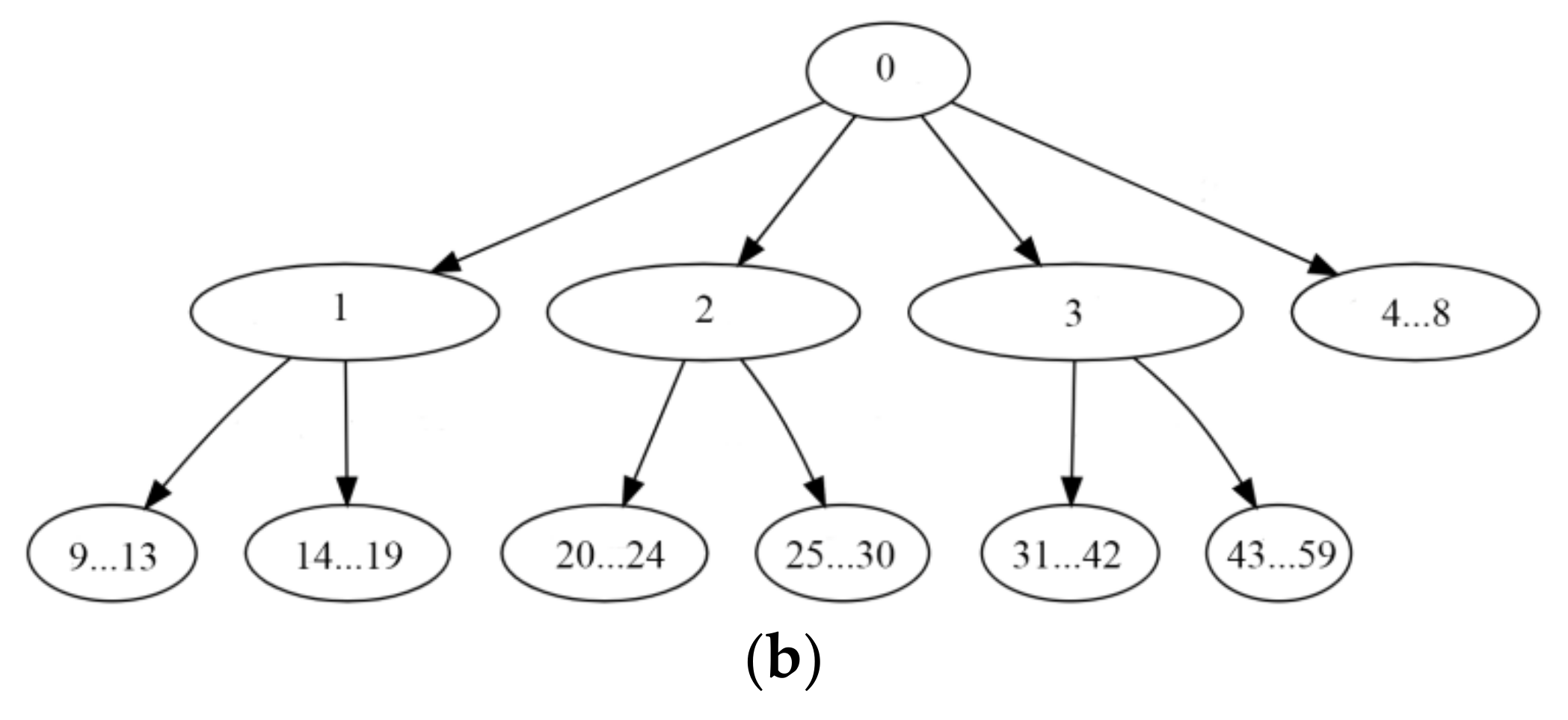
Consider a basic tree data structure, including a specific number
L + 1 of levels, as well as a specific number
Ni of nodes per level, where
i∈{0, …,
L}; moreover, let each parent-node have a specific number of children-nodes. For instance, for the tree in
Figure 1a, it is
L = 3,
N0 = 1,
N1 = 2,
N2 = 4, and
N3 = 8; the root node
n0 in
Figure 1a has 2 children-nodes; node
n1,1 has 1 child-node; node
n1,2 has 3 children-nodes, etc. Each node
ni,j is identified by two indices, namely a level number
i and an index number
j∈{1, …,
Ni}; alternatively, a (tree) node can be identified by a single cardinal integer number
k∈{1, …,
N}, where
N =
N0 + N1 + … + NL. A basic tree data structure gives rise to a set T of trees as described next.
Let each tree node nj be associated with a constituent lattice (Lj,⊑), j∈{0, …, N}. A specific tree instance emerges by attaching a specific lattice (Lj,⊑) element xj to node nj, j∈{0, …, N}. The interest here is in the set T of all tree instances—Note that all the trees in T have identical structure, and differ only in the lattice elements attached to their nodes.
Consider the Cartesian product lattice (P,⊑) = (L1 × … × LN,⊑), where, given that Px,Py∈P with Px = (x1, …, xN) and Py = (y1, …, yN), the corresponding lattice meet and join are defined as Px⊓Py = (x1, …, xN) ⊓ (y1, …, yN) = (x1⊓y1, …, xN⊓yN), and Px⊔Py = (x1, …, xN) ⊔ (y1, …, yN) = (x1⊔y1, …, xN⊔yN), respectively; moreover, (x1, …, xN) ⊑ (y1, …, yN) ⟺ x1⊑y1, …, xN⊑yN. Furthermore, consider the lattice (T,⊑) of trees defined as (order-)isomorphic with lattice (P,⊑). We remark that, on the one hand, the set T is convenient for interpretations, whereas, on the other hand, the set P lends itself to calculations. Next, a positive valuation function is defined constructively in lattice (T,⊑).
Consider a basic tree structure, e.g., the one in
Figure 1a, enhanced to a complete lattice by inserting a single node
O, namely the least element, at an additional level at the bottom of the lattice’s Hasse diagram, as shown in
Figure 1b. The corresponding greatest element
I is the tree root, i.e.,
I =
n0.
Let vj: Lj→R, j∈{1, …, M} be a positive valuation function defined on every constituent lattice (Lj,⊑), j∈{1, …, M}. Recall that (1) a positive valuation function in lattice (L1 × … × LM,⊑) which may be defined by v = v1 + … + vM, and (2) a positive valuation function in lattice (Lj,⊑), j∈{1, …, M} which may also be defined by λjvj (.), where λj > 0 is a real number multiplier.
Given a basic tree structure, a positive valuation function
V: T→R can be defined constructively (bottom up), as explained subsequently. Let
np be a parent-node with children-nodes
nc,
c∈{1, …,
C}. Let
vp and
vc,
c∈{1, …,
C} be positive valuation functions defined locally on the tree nodes, respectively. If
np is a tree leaf node, at level
L, then
V (.) is defined as
V =
vp—For the least element
O, it is defined as
V (
O) = 0; otherwise,
V (.) is defined as
vp +
kp (
v1 + … +
vC) in the Cartesian product lattice (L = L
p × L
1 × … × L
C,⊑), where
kp > 0. In conclusion, the positive valuation function on the greatest element
I is defined as the positive valuation function of the whole tree. A concrete example is shown in
Section 3.
We remark that, instead of attaching a single lattice element to a basic tree node, a lattice interval may be attached. In the latter case, a forest or, equivalently, grove of individual trees instances is defined in T.
The above mathematical instruments are customized further, as detailed in the following section.
4. The Granule-Based-Classifier (GbC)
The previous sections have detailed a structured human face representation by a tree data structure in lattice (T,⊑). In the following, Algorithm 1 describes a machine-learning scheme with a capacity to induce knowledge from tree data structures in the form of granular rules for classification.
| Algorithm 1. GbC: Granule-based-Classifier (training phase)
|
| 0: Set a threshold size ΔT = Δ0; |
| 1: Set a (small) size step δ; |
| 2: Randomly partition the training data in each class in clusters, such that the lattice-join of all the data in a cluster has size less than ΔT; |
3: If two granules in different classes overlap then
Abolish both (overlapping) granules into the training data they were induced from;
Set ΔT ← ΔT − δ;
Goto 2;
else
End the training phase. |
The basic idea behind GbC for training (i.e., Algorithm 1) is that, in the beginning, Algorithm 1 computes uniform granules, in the sense that all the data within a uniform granule belong to the same class of a user-defined maximum threshold size, ΔT = Δ0. If granules in different classes overlap, then, to avoid potential contradictions, overlapping granules are abolished; next, GbC resumes training on the data that induced overlapping granules, using a smaller threshold size ΔT ← ΔT − δ. The latter procedure repeats until (smaller) uniform granules are computed. Consequently, the computational complexity of Algorithm 1 (i.e., GbC training) is computed as follows. Given that the number of the training data is N, it takes time O (N × N) to compute all different sets of information granules. Then, for each set of information granules, it takes time O (N × N) to test possible overlaps between granules. The latter computations repeat O (Δ0/δ) times. Therefore, the computational complexity of Algorithm 1 (i.e., GbC training) is O (N4Δ0/δ).
As soon as the training data have been replaced by (uniform) granules, the corresponding class label is attached to each granule. In the aforementioned manner, pairs (
g,
l) emerge, where
g is a granule, and
l is its label. A pair (
g,
l) is interpreted as the rule “if
g then
l”, symbolically
g→
l. Decision-making, i.e., classification, is carried out by assigning a testing datum to a granule based on either a lattice metric distance (27
D) or a lattice fuzzy order function (σ). In conclusion, the corresponding “winner” granule label is assigned to the testing datum as Algorithm 2 shows.
| Algorithm 2. GbC: Granule-based-Classifier (testing phase) |
0: Let (gi, ci), i∈{1, ..., Μ} be all the pairs of labeled granules, where gi is a granule and ci is its corresponding label
Let g0 be an input granule to be classified |
| 1. Calculate |
| 2. Define the class of g0 as c0 = cj |
Apparently, the computational complexity of Algorithm 2 (i.e., GbC testing) is O (NrNs), where Nr and is Ns is the number of the training and testing data, respectively.
Recall that the representation of a granule by a lattice interval induced from all the training data in a granule involves two types of FLR generalization, namely Type I Generalization and Type II Generalization [
23]; more specifically, Type I Generalization refers to inclusion of points in a granule without explicit evidence, whereas Type II Generalization means decision-making beyond a granule.
The GbC scheme is potentially applicable on any lattice data domain including, in particular, the lattice (T,⊑) of tree data structures described in
Section 2. Two basic versions of GbC have been considered here, namely
GbCvector and
GbCtree, as subsequently explained. More specifically, for
k1 =
k2 =
k3 = 1 in Equation (1), no tree structure is considered in the calculations; therefore, the corresponding classifier is called GbCvector. Otherwise, if at least one of
k1 or
k2 or
k3 is different than 1, then a tree structure is considered in the calculations; therefore, the corresponding classifier is called GbCtree.
As a result of inducing trees in step-1 of Algorithm 1, a tree data structure in
Figure 3b may represent a forest or, equivalently, a grove, that is a set of trees, instead of representing a single (individual) tree. We remark that a grove of trees is also called interval-tree, whereas an individual tree is a trivial interval-tree. Differences of the GbC with other decision-tree classifiers are summarized next.
The tree data structure in Algorithm 1 is constant as shown in
Figure 3, whereas the data induced tree data structures of alternative decision-tree classifiers are not constant [
37]. Note that GbC induces the contents of its tree nodes instead. Furthermore, the forests of trees that GbC considers are granules/neighborhoods of individual trees, whereas forests of trees in the literature typically consist of individual trees without considering any neighborhood of trees whatsoever [
38].
The following section demonstrates applications of GbC.
5. Computational Experiments and Results
Recall that the motivation of this work is social robot–human interaction applications; in particular, the focus here is on machine vision applications. In particular, it turns out that during social robot–human interaction, the robot needs to keep (1) quantifying the engagement/attention of the human it interacts with, (2) modifying its behavior according to a human’s emotions—the latter is directly associated with facial expressions, and (3) personally addressing the human it interacts with. Hence, this section deals with three discrete pattern recognition problems, in a unifying manner, in the sense that the same representation of a human face is used in all three problems. Instead of developing an intelligence model based on “first principles”, a machine-learning model is assumed here that may induce explanatory knowledge (i.e., rules) from real world data; more specifically, a GbC scheme is used. The latter has the advantage of processing structured data per se as detailed next.
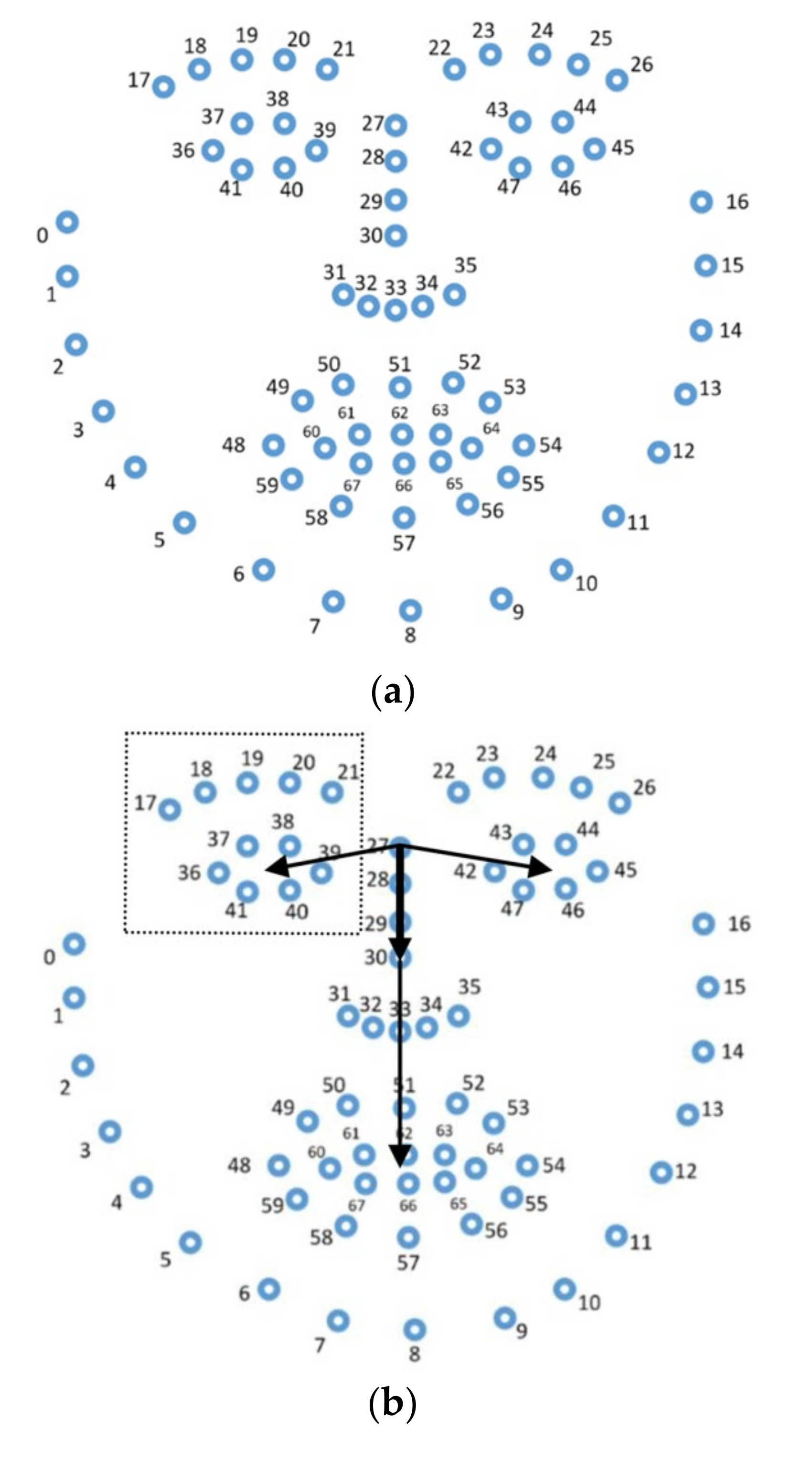
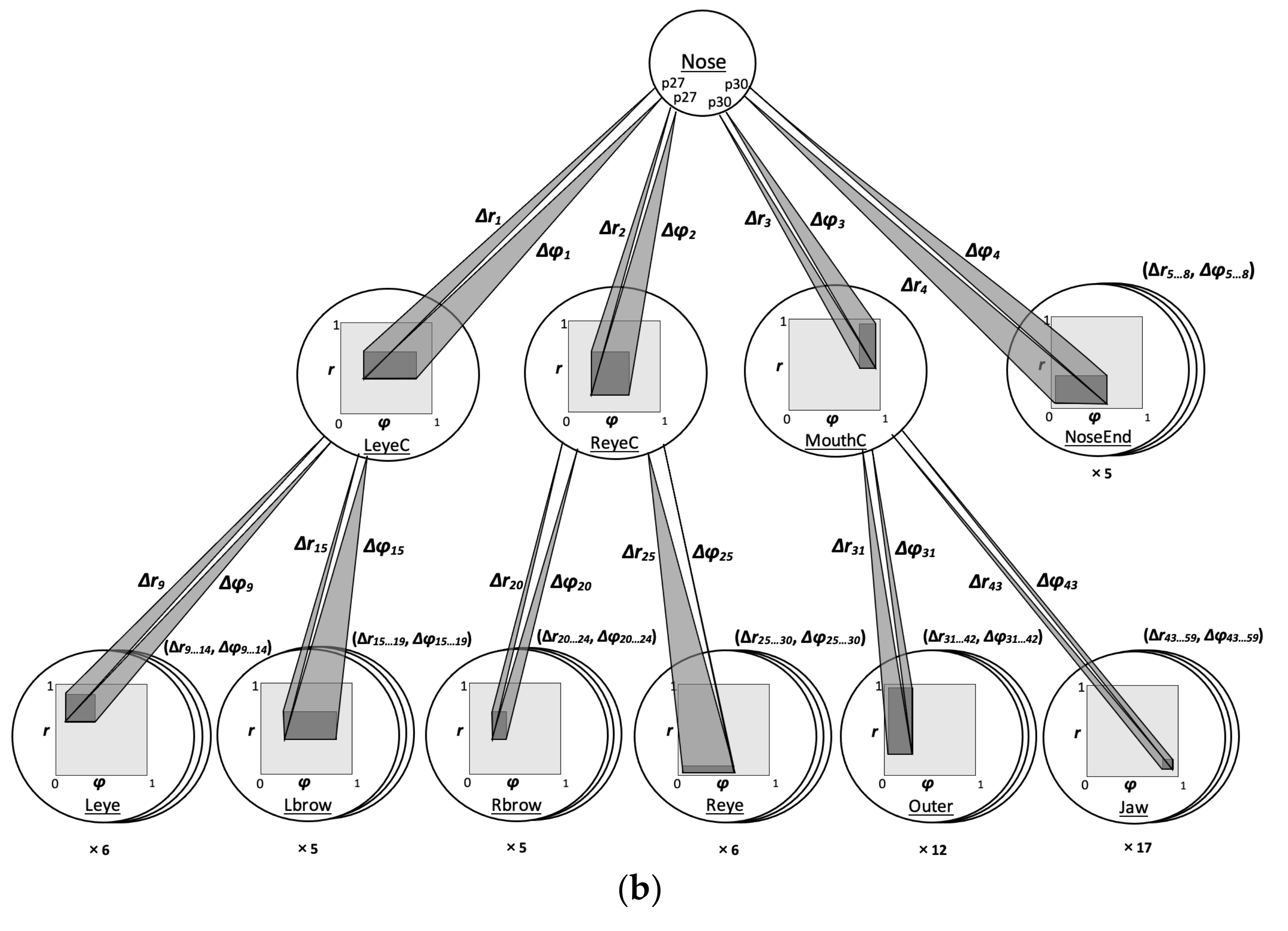
A tree data structure was induced from a single camera frame, as explained in
Section 3.1, including 59 primary and secondary nodes each of whom stores a pair (
r,
φ) of polar vector coordinates. In particular, a tree data structure stored a pair ([
r,
r], [
φ,
φ]) of trivial intervals, where both values
r and
φ were normalized over the interval [0, 1], such that 0 corresponds to the minimum, whereas 1 corresponds to the maximum over all the corresponding feature values. Regarding the data processing time, it took clearly less than 1 s overall to compute the image’s tree data structure representation in
Figure 3.
Two types of positive valuation functions were employed exclusively per node including, first, linear functions:
where
j∈{1, …,
N = 59}, for both variables
r and
φ and, second, sigmoid functions:
where
j∈{1, …,
N = 59}, for both variables
r and
φ. In addition, the following function
θ (
x) was used:
for both variables
r and
φ, always.
Equation (5) was used with c1 = … = c8 = 1/C, c9 = … = c19 = k1/C, c20 = …= c30 = k2/C, and c31 = … = c59 = k3/C, where C = 8 + 11k1 + 11k2 + 29k3 and k1, k2, k3 are the coefficients in Equation (1).
To optimize classification performance, a typical genetic algorithm was employed with a population of 500 individuals for 50 generations. First, for the linear Equation (6), it was λ
j∈[0.01,10],
j∈{1, …,
N = 59} for both variables
r and
φ. Second, for the sigmoid Equation (7), it was
Aj∈[0.1,20], λ
j∈[0.01,10] and μ
j∈[−50,50],
j∈{1, …,
N = 59} for both variables,
r and
φ. Furthermore, for both linear and sigmoid positive valuation functions, it was
kj∈[0.1,50],
j∈{1,2,3} in Equation (1) for both variables
r and
φ.
Figure 4 displays the genetic algorithm chromosome for linear positive valuation functions. Unless otherwise stated, the experiments below used a standard ten-fold cross-validation.
5.1. Head Orientation Recognition Experiments
A human’s head orientation is important toward quantifying the human’s engagement/attention during interaction with a robot [
39]. The estimation of head orientation was dealt with here as a classification problem, as follows.
Data were recorded in the HUMAIN-Lab, including snapshots of a human head in various head poses. Nine basic orientations (i.e., classes) of interest were considered, namely Upper Left, Up, Upper Right, Left, Front, Right, Lower Left, Down, and Lower Right. The resolution of the class “Front” was increased by considering three sub-classes, namely “Front Left”, “Front”, and “Front Right”, as shown in
Figure 5.
On the one hand, the training data included 100 image frames for each one of the 11 head orientations of
Figure 5. All the training data were acquired at distance 40 cm, under normal light. On the other hand, the testing data included 100 image frames for each one of the 9 basic head orientations for four different environmental conditions; in particular, all four combinations were considered of a subject distance from the camera at either 40 cm or 100 cm, under lighting conditions considered either normal or dim, corresponding to minimum light output (lumens) of 1600 and 90, respectively. In conclusion, one testing experiment was carried out for each one of the aforementioned four environmental conditions.
Training/testing data frames, where a face was fully detected by the OpenFace library, were considered exclusively. Each training/testing image was converted to its corresponding (trivial) tree representation, as described in
Section 3.1, including 59 features, i.e.,
N = 59. Then, a GbC scheme was applied.
In this experiment interval-trees were computed of the maximum possible size, Δ. Hence, 11 interval-trees prototypes were computed; that is, one prototype per data cluster, respectively. For instance,
Figure 6a displays a trivial-tree, whereas
Figure 6b displays an interval-tree. Recall from
Section 4 that an interval-tree
T, together with the label
l attached to it, is interpreted as a granular rule “if
T then
l”, symbolically
T→
l, where the label
l is an element of the set {Upper Left, Up, Upper Right, Left, Front, Right, Lower Left, Down, Lower Right}.
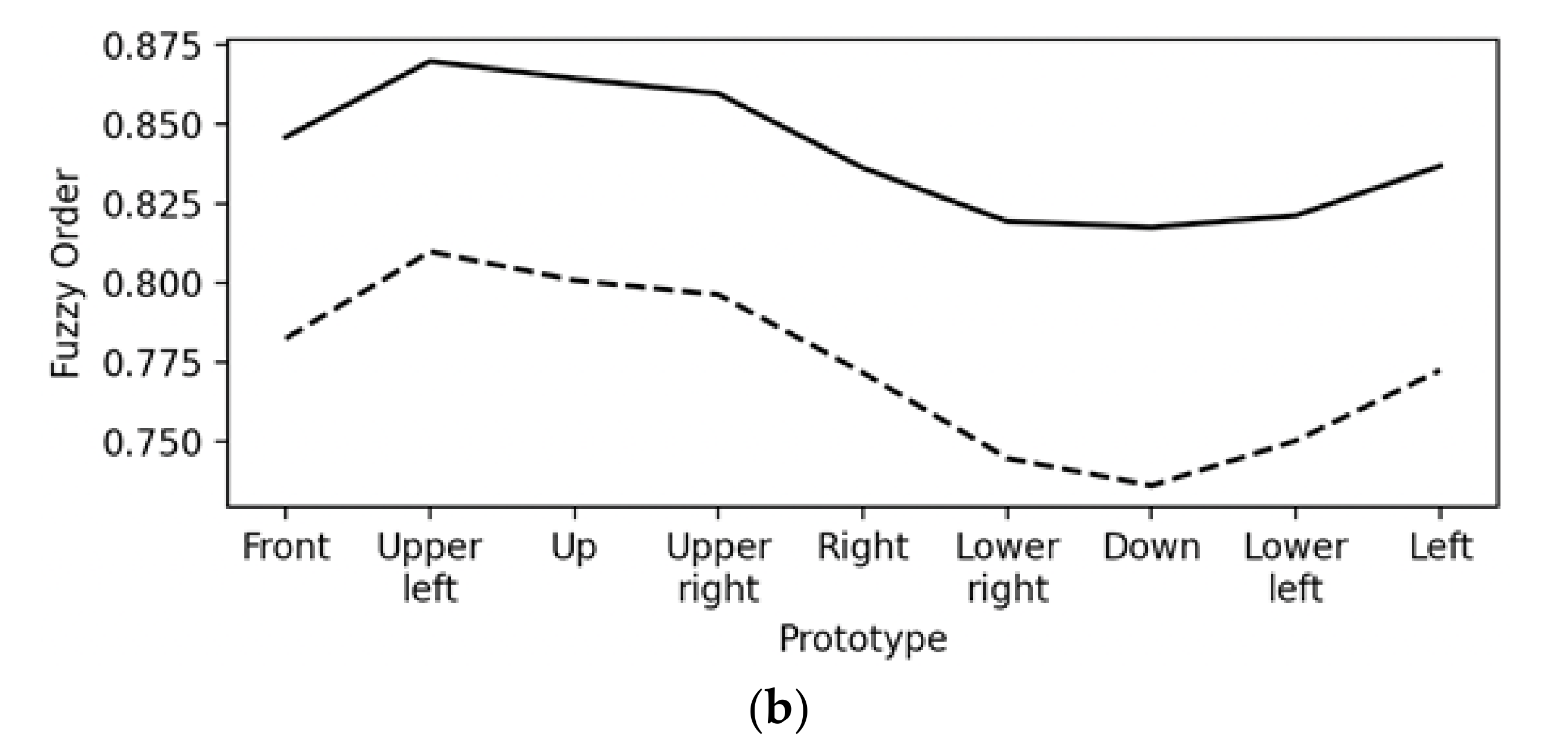
Figure 7a demonstrates how the values of the metric distance function Equation (2) change; similarly,
Figure 7b demonstrates how the values of fuzzy order function Equation (3), as well as Equation (4), both change for an arbitrary frame, namely
fL, of the class “Upper Left” versus all class prototypes.
Figure 7a confirms, as expected, that the frame
fL is nearest to the class prototype “Upper Left”; similarly,
Figure 7b confirms, also as expected, that the frame
fL is mostly similar to the class prototype “Upper Left”. Note that Equation (3) results in larger values than Equation (4), since partly overlapping trees result in smaller values for Equation (4) than they do for Equation (3).
A preliminary work [
34] has considered (1) 11 prototypes, (2) normalized r and
φ values over the interval [0,1], (3) the r and
φ separately, and (4) the functions
v (
x) =
x and
θ (
x) =
−x. For comparison reasons, the corresponding results are repeated, in a different format, in
Table 1. In particular, a generic geometrical classification scheme has employed as inputs the 68 facial landmarks (points) of
Figure 2a. The results in
Table 1 show that the GbCvector can be clearly superior to a generic geometrical classification scheme.
Next, the
r and
φ were considered concatenated; all other considerations were kept the same. The corresponding classification results are shown in
Table 2.
Next, in addition to the latter consideration, the function
θ (
x) = 1 −
x was employed by implementing the
complement coding technique motivated from models of brain neurons. The corresponding classification results are shown in
Table 3.
Next, in addition to the latter consideration, the functions
vk (
x) =
λkx, k∈{1, …, 59} were used optimized. The corresponding classification results are shown in
Table 4.
Finally, in addition to the latter consideration, the GbCtree scheme was used; furthermore, the coefficients
k1,
k2,
k3 (for
r) and
k4,
k5,
k6 (for
φ) were optimized. The corresponding head pose classification results are shown in
Table 5.
The results of this experiment are discussed comparatively in
Section 6.
5.2. Facial Expression Recognition Experiments
Human facial expressions are important as they are closely associated with emotions. This is essential information for a sensible social robot-human interaction. Therefore, this application regarded facial expression recognition. More specifically, the Extended Cohn-Kanade (CK+) benchmark dataset was employed, including 327 image sequences partitioned in seven discrete emotion labeled classes, namely, anger, contempt, disgust, fear, happiness, sadness, and surprise [
40,
41].
An individual image sequence consists of 10 to 60 (image) frames, where a frame is typically a 640 × 490 or 640 × 480 array of pixels; each of the latter stored either an 8-bit gray scale or a 24-bit color value. One of the frames per image sequence, typically the last one, was characterized in the database as “peak (of emotional intensity)”. The latter is the only image used here from its corresponding image sequence in the experiments below. Similar to before, an image was represented by a trivial-tree.
In this application, only facial landmarks points involved in facial expressions were considered (
Figure 2a). The selection of the aforementioned facial landmarks was based on the Facial Action Coding System (FACS), as well as the Action Units (AU) of the facial expressions for emotions [
42,
43], as shown in
Table 6. In particular, the first two columns of
Table 6 associate an emotion with AUs whose name is shown in the third column; furthermore, the fourth column displays the corresponding landmark points selected by an expert. In conclusion, in addition to left/right eye and mouth centers from
Figure 2a, the following 22 landmarks points have been selected: 31, 33, 35 (from NoseEnd), 17, 19, 21, 36, 39 (from the left eye/brow), 22, 24, 26, 42, 45 (from the right eye/brow), 48, 51, 54, 57, 60, 62, 64, 66 (from the inner/outer mouth), and 8 (from the Jaw). Hence, a reduced tree resulted compared to that of
Figure 3; moreover, Equations (1) and (5) were simplified accordingly. Note that a couple of empty sets appear in the fourth column of
Table 6 since, for two AUs, there were no landmark points among the 68 facial landmark points; more specifically, there were no landmarks for either AU 6 nor AU 14 in
Table 6. In conclusion, the resulted tree representation consisted of 25 nodes, i.e.,
N = 25. Hence, the data employed for classification here were reduced from 640 × 490 = 313,600 real numbers per image down to 25 × 2 = 50 real numbers per tree, that is, orders of magnitude fewer real numbers.
Table 7 displays the experimental results using both classifiers GbCtree and GbCvector with a linear Equation (6) positive valuation function, whereas
Table 8 displays experimental results using both classifiers GbCtree and GbCvector with a sigmoid Equation (7) positive valuation function.
Table 7 and
Table 8 display the classification results both before (within parentheses) and after parameter optimization. It must be noted that
Table 7 and
Table 8 display results by two different sigma-join functions σ
⊔ (.,.), computed by Equations (3) and (5), respectively, as well as by two different sigma-meet functions σ
⊓ (.,.), computed by Equations (4) and (5), respectively.
In both
Table 7 and
Table 8, on the one hand, when the distance
D (..) was used, the best classification resulted in a zero tree size, i.e., when each training datum was represented by a trivial-tree; on the other hand, when a fuzzy order function was used, then the best classification results were obtained for 5 interval-trees prototypes per class.
Figure 8, for example, displays one rule induced from data of the class “happiness”. Note that the rule consists of 25 pairs of intervals; each interval corresponds to normalized polar, i.e., radial and angular, coordinates. It is clear that a pair of intervals defines an annulus (ring) sector. For clarity,
Figure 9a displays only a pair of annulus sectors, namely the annulus sectors 21 and 23 underlined in
Figure 8, on a human face in the class “happiness”. Likewise,
Figure 9b displays the corresponding pair of annulus sectors of another rule, induced from data in the class “anger”.
An annulus (ring) sector identifies a granule of primary/secondary feature vectors. For instance,
Figure 9a, as well as
Figure 9b, displays a pair of annulus sectors, that is, part of a rule that recognizes a facial expression either “happiness” or “anger”, respectively. Note that the aforementioned annulus sectors were computed by the lattice-join of the “outer mouth left” and “outer mouth right” secondary feature vectors in the corresponding granule. In particular,
Figure 9a shows that both “happiness” prototypes are longer, wider, and have an upward inclination, whereas
Figure 9b shows that both “anger” prototypes are shorter, narrower, and nearly horizontal.
Figure 9 confirms that, as expected, from
Table 6, AUs participate per facial expression “happiness” and “anger” regarding lip movement. Regarding “happiness”, there is a widening of the lip corners (AU6—Cheek Raiser), as well as a raising of the cheeks (AU12—Lip Corner Puller), whereas for “anger”, there is a lip tightening action (AU23—Lip Tightener). The latter is interpreted as explainable artificial intelligence (AI), enabled by the fact that AU information is retained in the proposed tree data representation all along during data processing.
The effectiveness of the 22 aforementioned selected features, corresponding to AUs associated with specific emotions, was tested by running additional experiments using all the 59 features considered in
Section 3.1. In all cases, the GbCtree was employed due to its superior performance compared to GbCvector. In far more experiments, the employment of the 59 features produced results 3 to 5 percentage points less than the results shown in
Table 7 and
Table 8, whereas in the remaining experiments, the employment of the 59 features produced results comparable to the ones shown in
Table 7 and
Table 8.
The results of this experiment are discussed comparatively in
Section 6.
5.3. Face Recognition Experiments
Human face recognition is important in addressing a human personally during social robot–human interaction. In this application, the ORL benchmark dataset [
44] was considered, which includes 10 images of 40 different subjects. The images were acquired under slight lighting variations, and with different facial expressions, as well as varying facial details (e.g., glasses/no-glasses). All the images are taken against a dark uniform background, with the subjects in an upright/front position. The size of each image is 92 × 112 pixels with 8-bit grey levels per pixel. The tree data structure of
Figure 3b was used and included 59 features, i.e.,
N = 59.
Table 9 displays experimental results using both classifiers GbCtree and GbCvector with a linear Equation (6) positive valuation function, whereas
Table 10 displays experimental results, using both classifiers GbCtree and GbCvector with a sigmoid Equation (7) positive valuation function. Both
Table 9 and
Table 10 display the classification results after as well as before (within parentheses) parameter optimization. It is noted that
Table 9 and
Table 10 display results by two different sigma-join functions computed by Equations (3) and (5), respectively, as well as by two different sigma-meet functions, computed by Equations (4) and (5), respectively.
In both
Table 9 and
Table 10, when either the distance
D (..) or a fuzzy order, either σ
⊔ (.,.) or σ
⊓ (.,.), was used, the best classification resulted in a zero tree size, i.e., when each training datum was represented by a trivial-tree.
The results of this experiment are discussed comparatively in
Section 6.
6. Discussion and Future Work
This work has introduced the Granule-based-Classifier (GbC) parametric model. Discussion of the results as well as potential future work is presented next.
6.1. Discussion
The GbC was applied here on a mathematical lattice of tree data structures, each one of whom represented a human face, thus retaining geometrical topology semantics. In conclusion, the GbC here was applied to three different classification problems regarding recognition of (1) Head Orientation, (2) Facial Expressions, and (3) Human Faces. The same (tree data structure) representation was used in all aforementioned problems with the following results.
First, in the Head Orientation recognition problem, the GbCvector performed, in general, clearly better than a conventional classification scheme, as shown in
Table 1. Furthermore,
Table 2,
Table 3 and
Table 4 have demonstrated that considering incrementally (a) concatenated vectors
r and
φ, (b) the complement coding technique, and (c) optimized linear positive valuation functions, the classification accuracy progressively increased. GbCtree performance versus GbCvector performance is discussed below. Note that the proposed, structural human head representation has advantages compared to alternative methods [
45], in that the proposed representation can also be used for additional recognition tasks, as subsequently explained.
Second, in the Facial Expression recognition problem, the GbC performed up to nearly 85%. Note that alternative, state-of-the-art classifiers in image pattern recognition have reported performance up to 82% using an LBP scheme [
46]; furthermore, deep learning methods have reported higher classification accuracies, ranging from a mean of 91.80% up to 96.92% [
47], as well as from 91.64% up to 98.27% [
48]. Note that alternative image recognition methods had used orders of magnitude more data than GbC. In particular, they had used multiple consecutive image frames until an emotion reaches a peak, where a single image was represented by as many as 640 × 440 = 313,600 real numbers, whereas a GbC, from an image sequence used only a single image frame, represented only by 25 × 2 = 50 real numbers; the latter are the
x and
y coordinates of 25 facial landmark points.
Third, in the Human Face recognition problem the GbC performed up to 88.25%. Note that alternative, state-of-the-art classifiers in image pattern recognition have reported classification accuracies ranging from 93% up to 96% by ANFIS [
49], as well as from 92% up to 100% by a CNN deep learning scheme [
50]. Again, alternative image recognition methods typically used orders of magnitude more data than GbC did. In particular, they have used whole image frames, where a single image was represented by as many as 640 × 440 = 313,600 real numbers, whereas a GbC represented a single image frame by 59 × 2 = 118 real numbers; the latter are the
x and
y coordinates of 59 facial landmark points.
The clearly better classification performance of GbC in the Head Orientation recognition, compared to its performance in either Facial Expression- or Human Faces- recognition, was attributed to the fact that the proposed tree data structure represents geometrical topology semantics of a human face.
In the Facial Expression recognition, as well as in the Human Faces recognition problem, a deep learning scheme (i.e., CNN) had better classification accuracy. It is noteworthy that deep learning is employed in the OpenFace library to calculate the 68 facial landmarks (points) in a data preprocessing step. An advantage of the proposed GbC classification schemes is that they all use the same data preprocessing to result in the same human face representation, based on 68 facial landmarks (points), in three different pattern recognition tasks. Hence, both GbC training and testing in three different pattern recognition tasks is orders of magnitude faster than training and testing by task-specific deep learning schemes for the same tasks. Such a wide applicability of the proposed GbC with good classification resulting in three different tasks suggests that the proposed human face representation method is promising. Another advantage is that the proposed tree representation of a human face retains anonymity during data processing. Furthermore, a GbC classifier induces granular rules that can be used to explain its answers, whereas a deep learning classifier operates in a way that is similar to a black box that cannot explain its answers. Note that an information granule may represent a word; in the latter sense, the GbC computes with words. Moreover, the proposed representation is modular in the sense that other parts of a human body, e.g., the hands, the shoulders-torso etc., can be straightforward incorporated, as well as additional modalities. The latter are unique capacities of a GbC scheme that no deep learning scheme possesses. In addition, compared to alternative fuzzy systems for face recognition [
26,
27], the GbC can operate on structured (tree) data representations of a human face instead of operating solely on vectors of features. Furthermore, by its parameters, the GbC can carry out tunable generalization. Finally, the employment of a fuzzy order function explicitly engages logic/reasoning in decision-making.
In general, the computational experiments here have involved two GbCs schemes, namely GbCtree and GbCvector. In addition, they have involved one metric distance function D (.,.) as well as fuzzy order functions σ (.,.). The typically, better performance of σ (.,.) compared to D (.,.) was attributed to the rational definition of σ (.,.), by either Equation (3) or Equation (4). It turned out that σ⊔ (.,.) in Equation (3) performed clearly better than the convex fuzzy order with all σ⊔ (.,.) in Equation (5), as a positive valuation function defined on a whole interval-tree results in a holistic comparison of two interval-trees, whereas a positive valuation function, defined as the sum of positive valuation functions on individual tree nodes, results in a fragmented comparison of two interval-trees. Similarly, and for the same reason, σ⊓ (.,.) in Equation (4) performed better than the convex fuzzy order with all σ⊓ (.,.) in Equation (5). Finally, the better performance of a sigmoid positive valuation function compared to a linear one was attributed to the larger number of parameters a sigmoid has, as detailed below. Moreover, the (marginally) better classification accuracy of an optimized GbCtree, compared to an optimized GbCvector, was attributed to the employment of a tree data structure that retains geometrical topology semantics of a human face.
A GbC classifier has clearly performed better than random guess; therefore, GbC classifiers can result in a
strong classifier, in the sense of Probably Approximately Correct (PAC), by boosting techniques [
51]. In addition to boosting, an alternative instrument for improving classification performance is the number of parameters as explained next.
Good classification performance is often reported by computational intelligence models with a large number of parameters, e.g., deep learning [
52], or Type-2 fuzzy systems [
53]. Note that LC models, including the proposed GbC schemes, can introduce an arbitrary large number of parameters via parametric functions
v (.) and
θ (.) per constituent lattice. It is noteworthy that a sigmoid positive valuation function with 3 parameters, resulting in a total of either (3 × 59) × 2 = 354 parameters or (3 × 25) × 2 = 150 parameters, has performed clearly better than a linear positive valuation function with 1 parameter, resulting in a total of either (1 × 59) × 2 = 118 parameters or (1 × 25) × 2 = 50 parameters, in the facial expression recognition and the face recognition problems, respectively. Note that a typical deep learning model engages millions of parameters.
The above remarks encourage the engagement of boosting techniques, as well as the increase of the number of GbC parameters toward further increasing GbC classification accuracy, in a future work.
6.2. Future Work
Future work includes shorter-term plans, as well as longer-term plans. On the one hand, shorter-term plans regard mainly technical improvements of GbC such as, firstly, real-world applications of social robot-human interaction, including additional modalities beyond machine vision for face recognition; and secondly, a quest for improved sub-optimal solutions regarding parameter estimation, also considering more parameters per positive valuation function. On the other hand, longer-term plans include a far-reaching pursuit of “understanding”, “creativity” as well as “intention sharing” by machines. Note that future AI is expected to be creative [
54]; furthermore, proposed conditions for creativity include
metaphors [
55]. Different authors have explained how
analogy is the basis of metaphors [
56]. This work has demonstrated that a lattice-isomorphism can establish an analogy between two different lattice structures, possibly also toward “understanding” by machines, and “creativity” by machines as well as “intention sharing” of a machine with either another one or a human, as it will be pursued in a future work.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}