Abstract
In this article, a structural modification of the Kumaraswamy distribution yields a new two-parameter distribution defined on , called the modified Kumaraswamy distribution. It has the advantages of being (i) original in its definition, mixing logarithmic, power and ratio functions, (ii) flexible from the modeling viewpoint, with rare functional capabilities for a bounded distribution—in particular, N-shapes are observed for both the probability density and hazard rate functions—and (iii) a solid alternative to its parental Kumaraswamy distribution in the first-order stochastic sense. Some statistical features, such as the moments and quantile function, are represented in closed form. The Lambert function and incomplete beta function are involved in this regard. The distributions of order statistics are also explored. Then, emphasis is put on the practice of the modified Kumaraswamy model in the context of data fitting. The well-known maximum likelihood approach is used to estimate the parameters, and a simulation study is conducted to examine the performance of this approach. In order to demonstrate the applicability of the suggested model, two real data sets are considered. As a notable result, for the considered data sets, statistical benchmarks indicate that the new modeling strategy outperforms the Kumaraswamy model. The transmuted Kumaraswamy, beta, unit Rayleigh, Topp–Leone and power models are also outperformed.
Keywords:
Kumaraswamy distribution; logarithmic transformation; moments; quantile; real data applications MSC:
60E05; 62E15; 62F10
1. Introduction
The perfect modeling of random processes that one regularly observes in applied sciences remains in the order of utopia. Scientists and practitioners have already discussed a wide range of models for solving these challenges. When the processes take values in the interval , a primary statistical analysis can be performed with the standard beta and Kumaraswamy (Kw) models. Before going further, a retrospective on these models is necessary. First, they are derived from the beta and Kw distributions, respectively. The beta distribution is a continuous distribution with support on the interval and parameterized by two positive shape parameters, and . It is mathematically defined by the following cumulative distribution function (cdf):
where , for , and for . Naturally, the values of and influence the shape of the distribution. The corresponding probability density function (pdf) can be U-shaped, bell-shaped, monotonic (increasing or decreasing), or even straight lines. On the other hand, the corresponding hazard rate function (hrf) can be increasing with convex shapes, or U-shaped (see [1,2]). In a wide number of areas, the beta distribution is used to model the behavior of characteristics representing percentages and proportions. See, for example, the developments in [3].
In [4], the Kw distribution was introduced to complement the beta distribution. Thus, it is also a continuous distribution with support in and parameterized by two positive shape parameters, and . The Kw distribution is conceptually based on uniform order statistics, and it has extremely simple functions that do not rely on special functions. The cdf of the Kw distribution is given as follows:
where for , and for . The form of the functions related to this distribution is naturally influenced by the values of and . Its application domain is identical to that of the beta distribution. As a brief comparison, the Kw distribution is similar to the beta distribution, but it is much easier to work with thanks to the tractability of its functions. We refer the reader to [5] and the references therein for more information on this claim. As a fact, the beta and Kw models rarely achieve the goal of optimal performance in all cases. For these reasons, new models on the unit intervals have been proposed, derived from new distributions with support equal to . These distributions are more or less sophisticated in the analytical sense. Contemporary works on this topic can be found in [6,7,8,9,10,11,12,13,14,15,16,17,18,19].
In this article, we propose a new two-parameter unit distribution, called the modified Kumaraswamy (MKw) distribution. The considered cdf is such that, for , the following holds:
where denotes a certain analytical transformation that will be presented later. At this introductory step, some features of are listed below.
- Feature I.
- First of all, the transformation has an original form involving polynomial and logarithmic functions without additional parameters. Thanks to it, some functional capabilities of the Kw distribution are extended or modified, and can be more adapted in some practical situations. In particular, the pdf of the MKw distribution can be monotonic in a nearly angular way, “strongly” left- or right-skewed and of a leptokurtic nature, or N-shaped. To our knowledge, these properties are not observed for the pdf of the Kw distribution. On the other hand, the corresponding hrf presents a wide panel of non-monotonic shapes, including N-shapes, that the hrf of the Kw distribution does not possess. All these curvature differences give credit for a more in-depth investigation of the MKw distribution from the modeling viewpoint.
- Feature II.
- The transformation increases with respect to x. Thus, the intrinsic first-order stochastic dominance (FOS) properties of the Kw distribution can be transposed to the MKw distribution: for any and , we have for any .
- Feature III.
- The transformation satisfies the following inequality: for any . Thanks to it, the Kw and MKw distributions are involved in a simple FOS dominance result: for any . This means that the MKw distribution generates a two-parameter statistical model, which does not intersect with the Kw model in the cdf sense.
In fact, several mathematical interpretations of the MKw distribution are possible. For instance, the MKw distribution may be viewed as a special parametric weighted version of the Kw distribution. Additionally, it is deeply connected with the ratio power-logarithmic (RPL) distribution created by [20]. Thanks to this connection, some properties of the RPL distribution may be used to determine those of the MKw distribution, among other things. These diverse interpretations are detailed in the first part of the paper, along with some theoretical properties. These properties include detailed quantile and moment analyses, illustrated numerically and graphically for some selected values of and . The order statistics are also discussed. The second part is devoted to the modeling characteristics of the MKw distribution. The MKw model is considered, assuming that the parameters and are unknown, and may be estimated via available data. We examine the estimation of these parameters by the maximum likelihood method. We show the efficiency of the obtained estimates by the use of simulated data. Then, two different data sets are analyzed, and comparisons are made between the fits of the NKw, Kw, and beta models and four other referenced models of the literature. We show that the proposed MKw model outperforms the concurrence through the use of standard statistical benchmarks. The findings are illustrated by numerous graphics.
The organization of the paper is composed of the following section. Section 2 introduces the MKw distribution with full details, along with a functional analysis of the pdf and hrf. Section 3 is devoted to quantile analysis and moment analysis. The statistical inference on the parameters is considered in Section 4. Section 5 is devoted to applications. We end the paper with a concluding part in Section 6.
2. The Modified Kw Distribution
This section focuses on the MKw distribution and its basic functional features.
2.1. Primary Definition
The following mathematical result is at the basis of the MKw distribution.
Proposition 1.
Let and , and be the function defined on by
for , and for . Thus defined, has the required properties of a continuous cdf.
Proof.
First, it is clear that is continuous on . Let us examine its behavior at the particular points and . At the neighborhood of , by virtue of standard equivalence functions, we have the following:
and, at the neighborhood of , we have
Therefore, is continuous on , and on . By construction, we have and . Let us now prove that is increasing. By applying standard rules of differentiation, for , we obtain the following:
The famous logarithmic inequality for , with yields the following:
This inequality can be rearranged as . Therefore, the numerator in Equation (1) is negative. Since the denominator is also negative, we have , implying that is increasing. This concludes the proof of Proposition 1. □
To the best of our knowledge, the cdf presented in Proposition 1 is new in the literature. It defines a modified version of the Kw distribution, described as the MKw distribution, discussed in Section 1. Some mathematical interpretations of this distribution are important to understand why the term “modified” is employed here. This is developed in the next section.
2.2. Mathematical Interpretations
Thus, the cdf of the MKw distribution is defined by the following:
where for , and for , with and . Some mathematical interpretations of this cdf are given below.
- Interpretation 1.
- As sketched in Section 1, for , we can write the following:with . In this sense, the transformation modifies the mathematical structure of the cdf of the Kw distribution for different modeling perspectives.The following facts can be deduced from the well-known logarithmic inequality for when applied to :
- . This implies that is an increasing function with respect to x. Following this is the stochastic FOS property: for any and , we have for any .
- for any . This implies that for any . In other words, there is a direct FOS dominance of the MKw distribution over the Kw distribution.
At the neighborhood of , we have . This convergence is slow, compared to the polynomial convergence to 0. This asymptotic result plays an important role to understand the possible difference in the right skewness between the MKw and Kw distributions; without more investigation, from the statistical viewpoint, it is natural to think that the MKw model is more able to capture the slow right-decay of a phenomena that the Kw model. This will be confirmed later with a skewness analysis through quantile and moment methods, as well as practical data. - Interpretation 2.
- As a twin viewpoint, for , we can write the following:with . Thus, the weight function modulate the main polynomial term of the cdf of the Kw distribution. In this sense, the MKw distribution is a weighted version of the Kw distribution.
- Interpretation 3.
- There is a deep relationship between the MKw and RPL distributions. First, we recall that the RPL distribution is defined by the following logarithmic-power cdf:for and for . Then, for a random variable Y following the RPL distribution, the random variable follows the MKw distribution. Indeed, for , we have the following:By identification, the stated result is obtained. Thanks to the representation of X, some properties of the RPL distribution can be used to determine those of the MKw distribution.
Finally, because any random variable X defined on can be shifted to a bounded support of the form with , using the transformation , the MKw distribution can easily be extended to any bounded domain.
2.3. Functional Analysis
This part is devoted to a functional analysis of the main functions of the MKw distribution. To begin, we recall that the cdf of the MKw distribution is given by Equation (3). As any cdf, it is an increasing function. Some asymptotic results are now presented. In the neighborhood of , by virtue of standard equivalence functions at orders of 1 or 2, we have the following:
Thus, converges to 0 with a polynomial decay. In the neighborhood of , we have the following:
This implies that converges to 1 with a slow rate of convergence, due to the logarithmic term.
Let us now focus our attention on the pdf and hrf of the MKw distribution. First, the pdf is given by the following:
and for . Because of its analytical complexity, this function is difficult to investigate using ordinary mathematical techniques (derivatives, …). We thus propose to study its asymptotic behaviors, then provide a graphical analysis to reveal its possible shapes. At the neighborhood of , with similar arguments as those used for the cdf, we have the following:
From this result, it comes that explodes to for , is equal to the constant for , and tends to 0 for . The values of are thus of particular importance for the limit points. At the neighborhood of , we have the following:
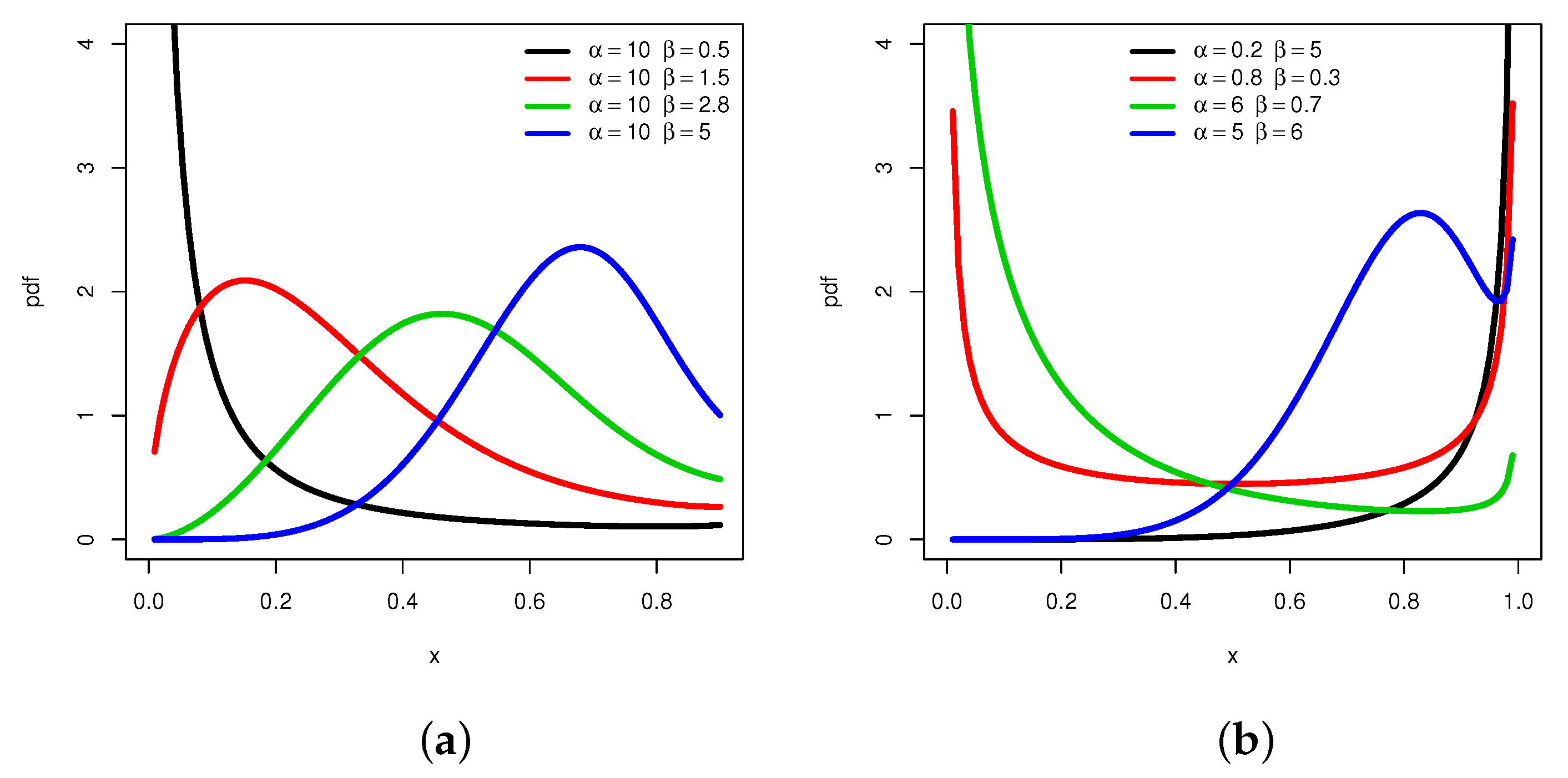
Thus, explodes to for all the values of and , more or less slowly. We complete this first approach by a graphical analysis. Figure 1 reveals a maximum of different shapes that possesses .
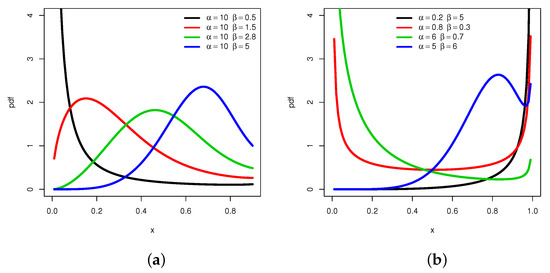
Figure 1.
Plots showing different shapes of the pdf of the MKw distribution: (a) decreasing and unimodal shapes and (b) U- and N-shapes.
From Figure 1, we remark that can be decreasing, unimodal with all the possible skewed directions, and also can be U- and N-shapes, which remains a rare property for a distribution supported on . In particular, the almost angular monotonicity, “strongly” left-or right-skewed and N shape properties are not immediate for the Kw distribution. To this first graphical analysis, we propose to show the versatility of via three-dimensional (3D) plots in Figure 2 and Figure 3, with moving for Figure 2, and moving for Figure 3.
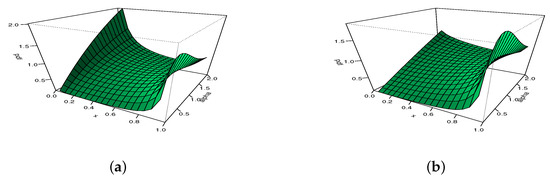
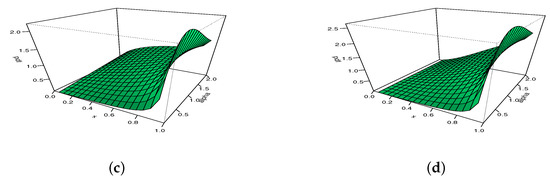
Figure 2.
The 3D plots of the pdf of the MKw distribution for with (a) , (b) , (c) , and (d) .
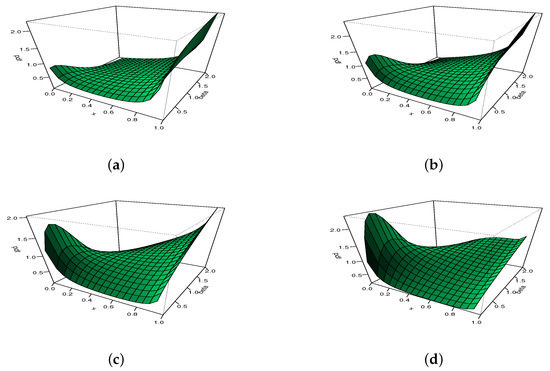
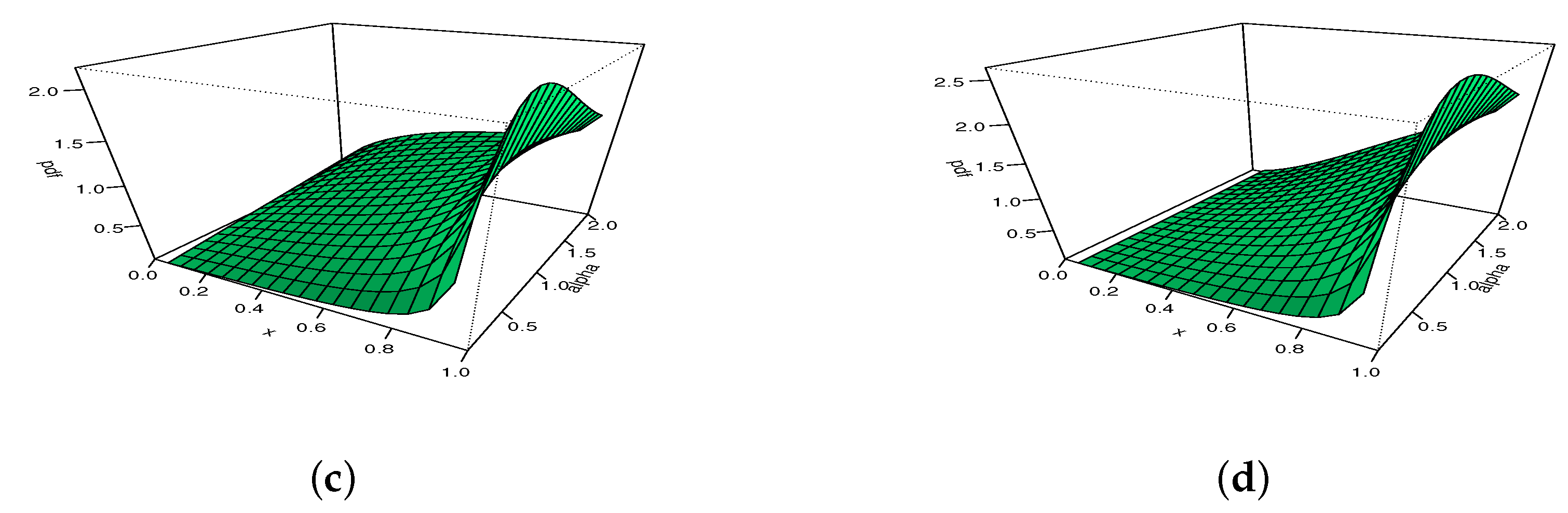
Figure 3.
The 3D plots of the pdf of the MKw distribution for with (a) , (b) , (c) , and (d) .
The hrf of the MKw distribution is given by the following:
and for . This function is difficult to explore using traditional mathematical tools, due to its analytical complexity. We proceed in the same manner as for . In the neighborhood of , we have the following:
As a result, explodes to for (and thus cannot be increasing), is equal to the constant for , and tends to 0 for . The values of are thus of particular importance for the limit points. In the neighborhood of , we obtain the following:
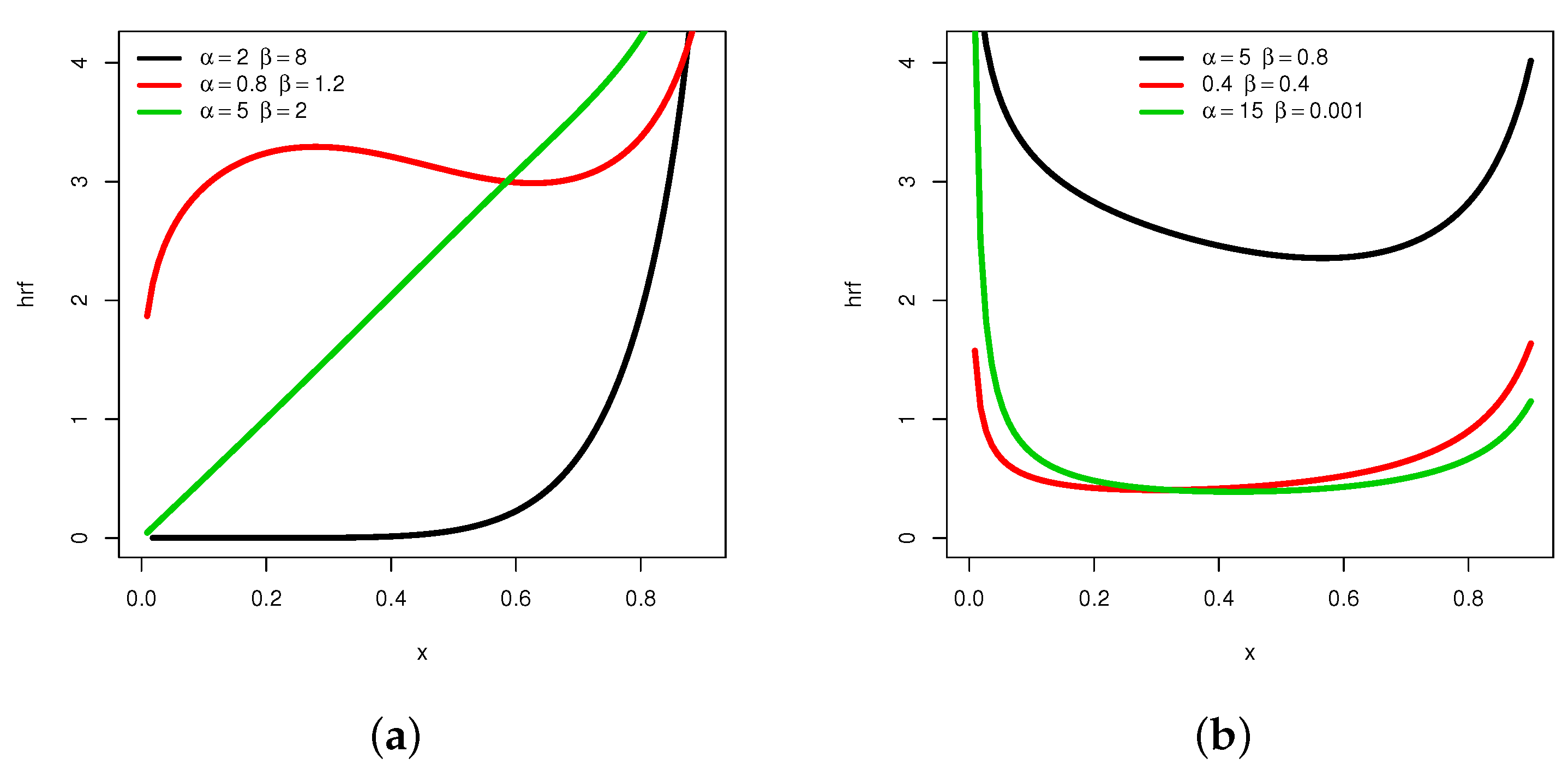
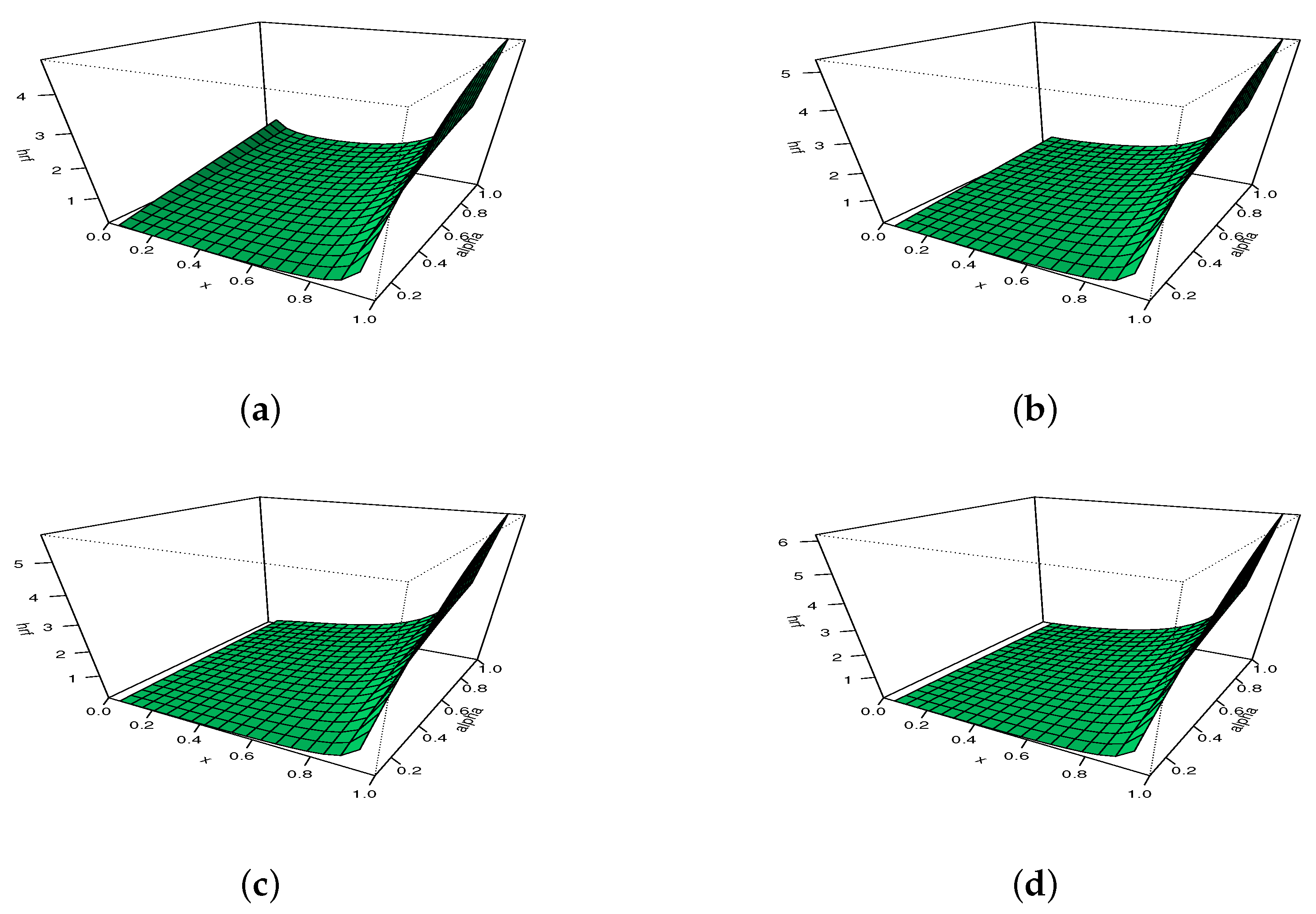
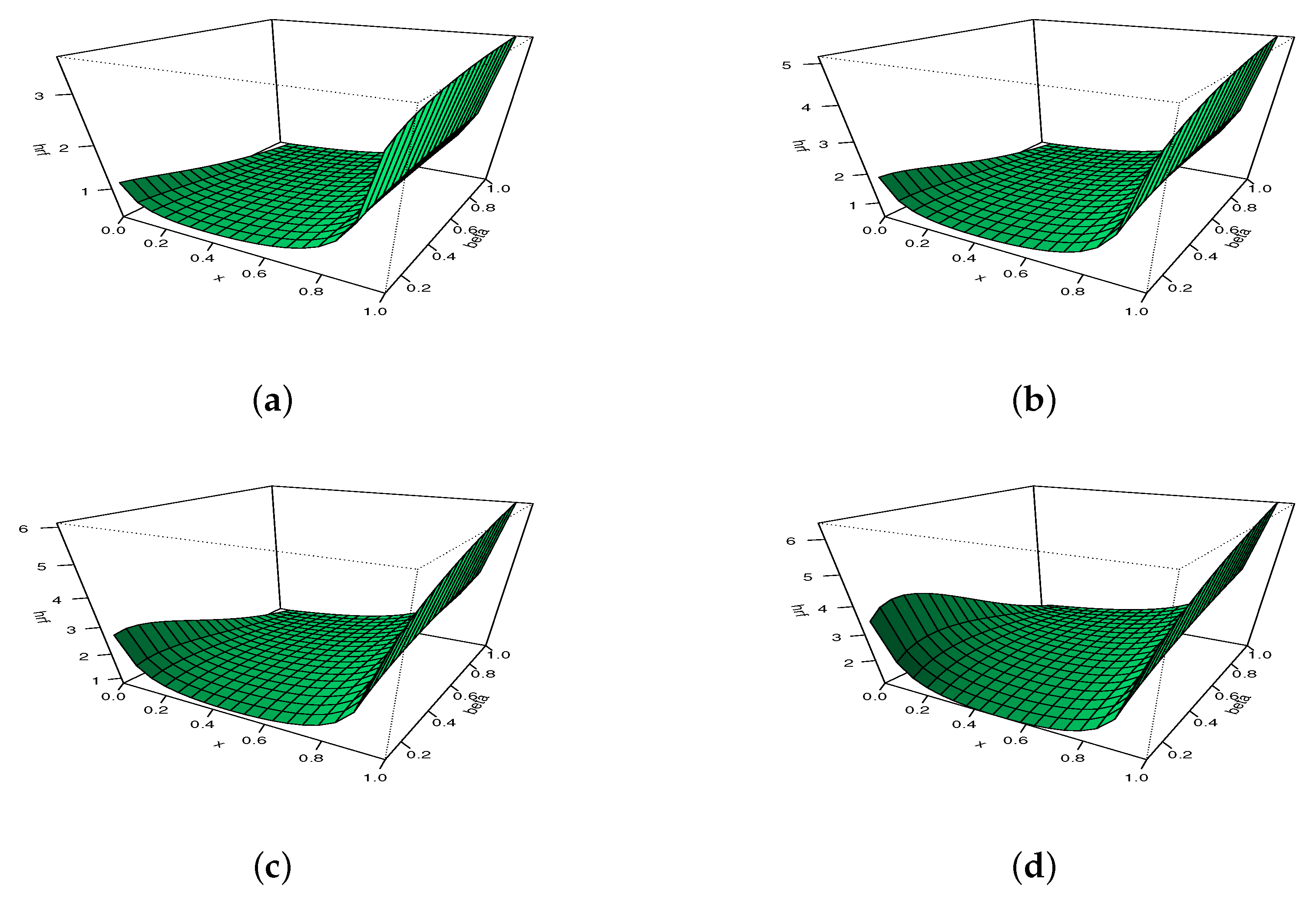
Hence, exploses to for all the values of and . A graphical analysis now completes these results, with a focus on the possible shapes of . The maximum number of distinct shapes of can be seen in Figure 4.
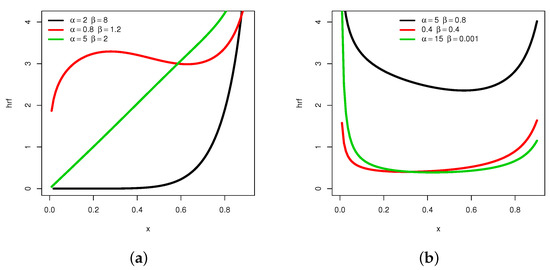
Figure 4.
Plots showing different shapes of the hrf of the MKw distribution: (a) increasing, convex, constant and N-shapes, and (b) U-shapes.
From Figure 4, it is clear that can be increasing with various convex properties, and can be non-monotonic with N- or U- shapes. Again, these remain as rare features for a distribution supported on . For instance, the hrf of the Kw distribution does not possess an N shape.
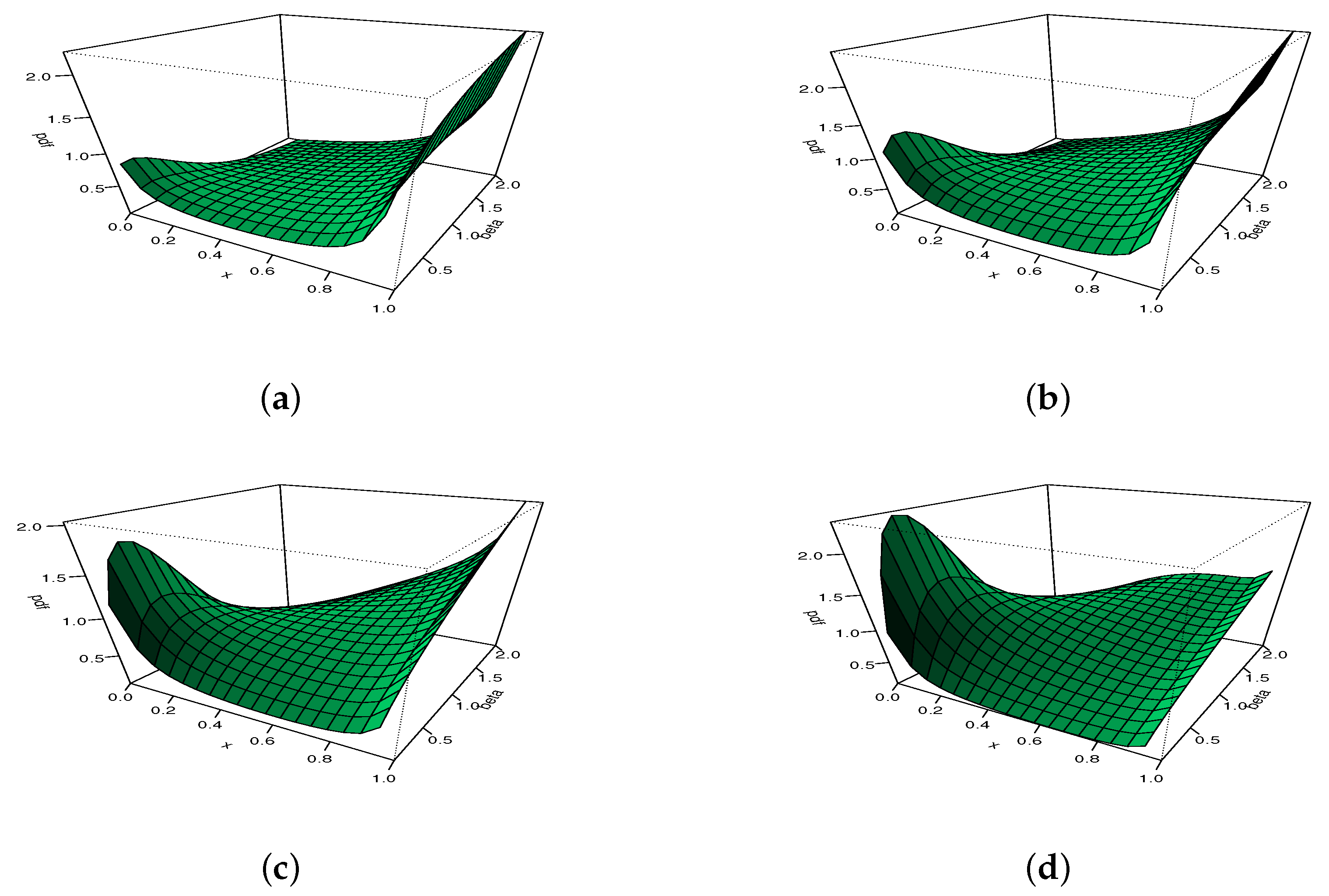
To illustrate the adaptability of , we propose to use 3D plots in Figure 5 and Figure 6, with moving for Figure 5 and moving for Figure 6.
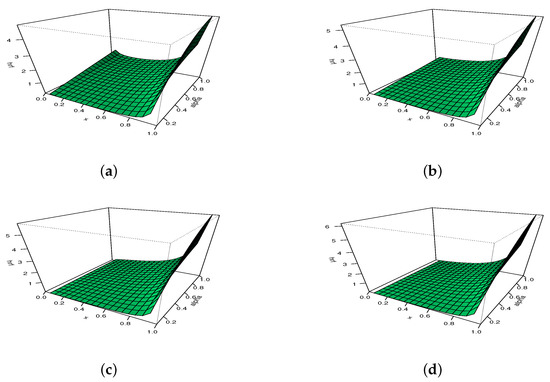
Figure 5.
The 3D plots of the hrf of the MKw distribution for with (a) , (b) , (c) , and (d) .
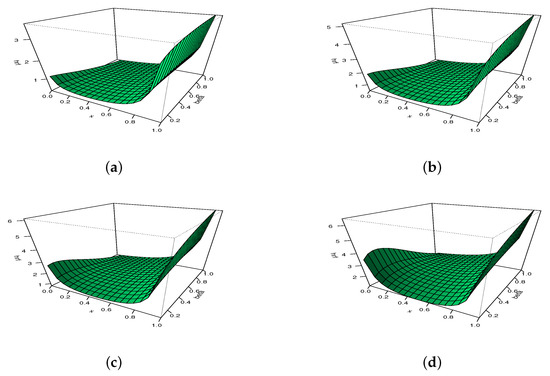
Figure 6.
The 3D plots of the hrf of the MKw distribution for with (a) , (b) , (c) , and (d) .
3. Mathematical Analysis
The MKw distribution is now mathematically treated, with emphasis on the quantile and moment features.
3.1. Quantile Analysis
The fact that the cdf of the KMw distribution is invertible is one of its most notable features. The quantile function (qf) can be expressed in closed form in terms of the principal branch of the Lambert function, as described in the next proposition. We may refer to [21] for further details on the Lambert function.
Proposition 2.
The qf of the MKw distribution is defined by the following:
where denotes the principal branch of the Lambert function.
Proof.
The qf is defined by . Therefore, we can determine it by solving the following nonlinear equation: with respect to y. We proceed as follows:
We obtain the expected result. □
The expression of the qf is essential to determine the main quartle of the MKw distribution, such as the median defined by the following:
Similarly, the first and third quartiles of the MKw distribution are given by and . The octiles of the MKw distribution are given by , , , and . These special quantile values can serve as the main tool to describe the skewness and kurtosis of the distribution. For instance, we can measure the skewness via the quantile coefficient of Bowley defined by the following:
On the other hand, we can measure the kurtosis by the quantile coefficient of Moors defined by the following:
The sign of QS indicates the skewness of the MKw distribution: if , the distribution is right-skewed; if , the distribution is left-skewed; and if QS approaches 0, the distribution is nearly symmetric. Concerning the coefficient of Moors, we can compare it to the value of , which corresponds to the quantile coefficient of Moors associated with the standard normal distribution. As a result, if , the distribution is platykurtic; if , the distribution is leptokurtic; and if QK approaches , the distribution is mesokurtic.
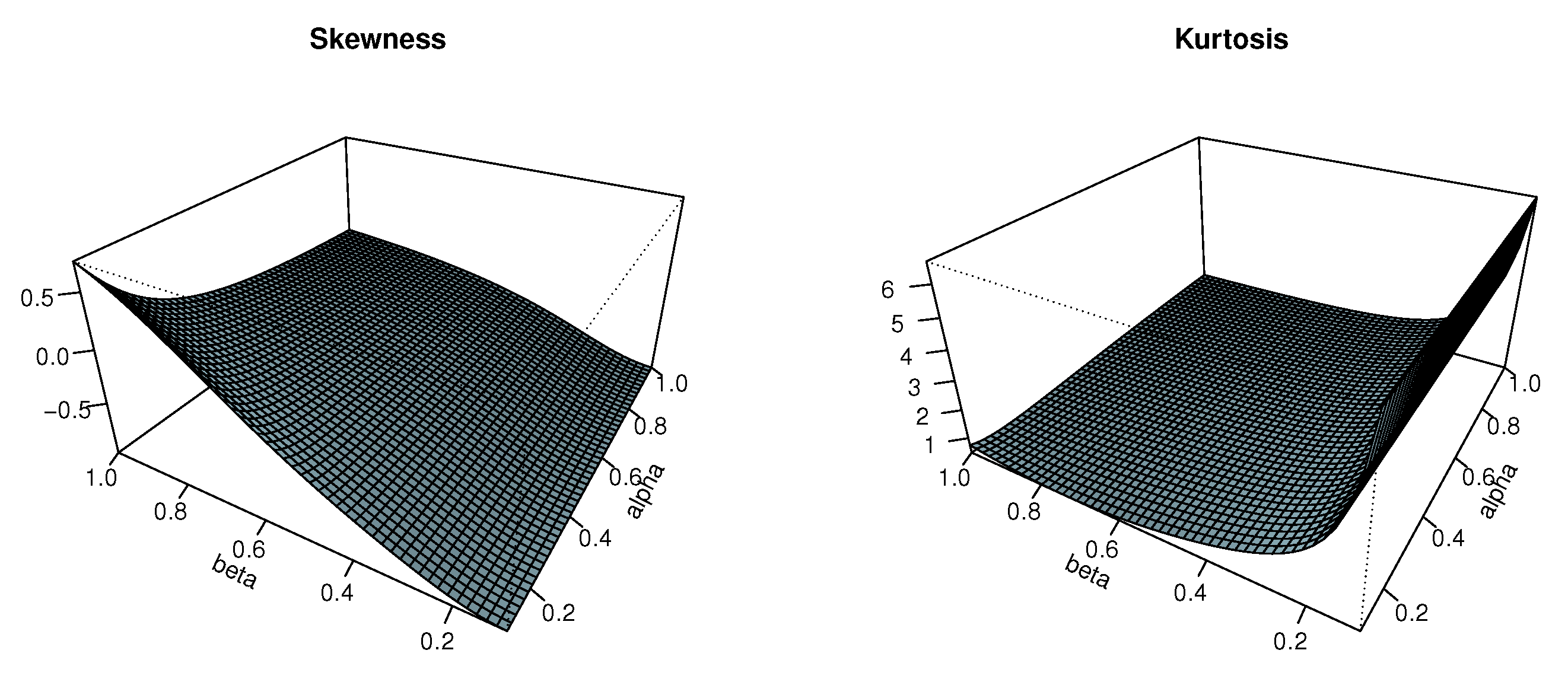
The 3D plots for QS and QK for varying and are displayed in Figure 7.
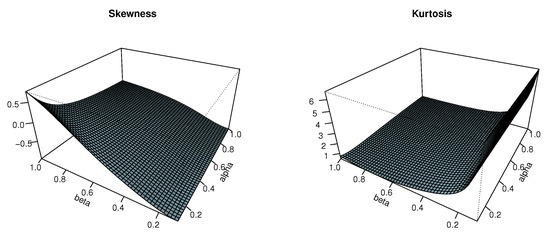
Figure 7.
The 3D plots of QS and QK for .
From Figure 7, we see that the behavior of the quantile coefficients of skewness and kurtosis is consistent with what was determined in Figure 1, Figure 2 and Figure 3: the MKw distribution exhibits all sorts of skewness since QS might be positive, almost equal to 0, or positive. Furthermore, the fact that QK can be less than, nearly equal to, or larger than demonstrates that all kurtosis levels are attained.
In addition, the expression of the qf is particularly useful for simulations. Indeed, pseudo-random data from the MKw distribution may be easily computer-generated using the inverse transform approach. Since the Lambert function is accessible in computer systems such as Maple, MATLAB and R, this approach is quite feasible. Further details on the above quantile analysis can be found in [22].
3.2. Moment Analysis
This section is devoted to the moment properties of the MKw distribution, beginning with the raw moments. Hereafter, we designate by X a random variable with the MKw distribution.
3.2.1. Raw Moments
For any integer r, the rth raw moment of X can be expressed in an integral form as follows:
This integral can be implemented in any mathematical software, and can be calculated numerically for given values of and . Some mathematical developments of this integral are proposed in the next proposition.
Proposition 3.
Two representations of the rth moment of X are given below.
- Representation 1.
- We can express in terms of the beta function as the following:where , with and .
- Representation 2.
- We can express as the following series expansion:
Proof.
Let us prove the two representations in turn.
- Representation 1.
- First, by an integration by part, we have the following:wherewith for . Owing to the Leibnitz integral rule and the change of variables , we have the following:Since for , upon integration with respect to , we obtain the following:
- Representation 2.
- We recall that, in the distribution sense, X can be written as , where Y follows the RPL distribution. Hence, for any positive integer r, the general binomial theorem yields the following infinite series representation:This expansion is valid almost everywhere; the event is of probability zero. Now, let us present a known result (see [20] (Proposition 6)). We obviously have , and, for any integer , the kth raw moment of Y is obtained as the following:Therefore, based on Equation (6) and the linearity of the expectation operator, we have the following:The stated result is obtained.
The proof of Proposition 3 ends. □
By arranging the raw moments in a suitable manner, we can determine the standard central, dispersion, skewness, and kurtosis measures of X. These measures include the mean given by , the variance obtained through the Koenig–Huygens formula, , the moment coefficient of skewness defined by
and the moment coefficient of kurtosis given by the following:
The interpretation of the moment skewness and kurtosis is similar to those of the quantile moment and kurtosis. The only difference is that, for the kurtosis, the benchmark value of the moment coefficient of kurtosis is 3 instead of for the quantile coefficient of kurtosis.
In addition, we can consider the coefficient of variation obtained as and the index of dispersion given as . Table 1 shows the numerical values of , , , , Var, MS, MK, CV and ID for a random variable X following the MKw distribution with and varying values of , while Table 2 does the same with and varying .

Table 1.
Numerical values of moment measures for a random variable X following the MKw distribution with and varying .
Table 2.
Numerical values of moment measures for a random variable X following the MKw distribution with and varying .
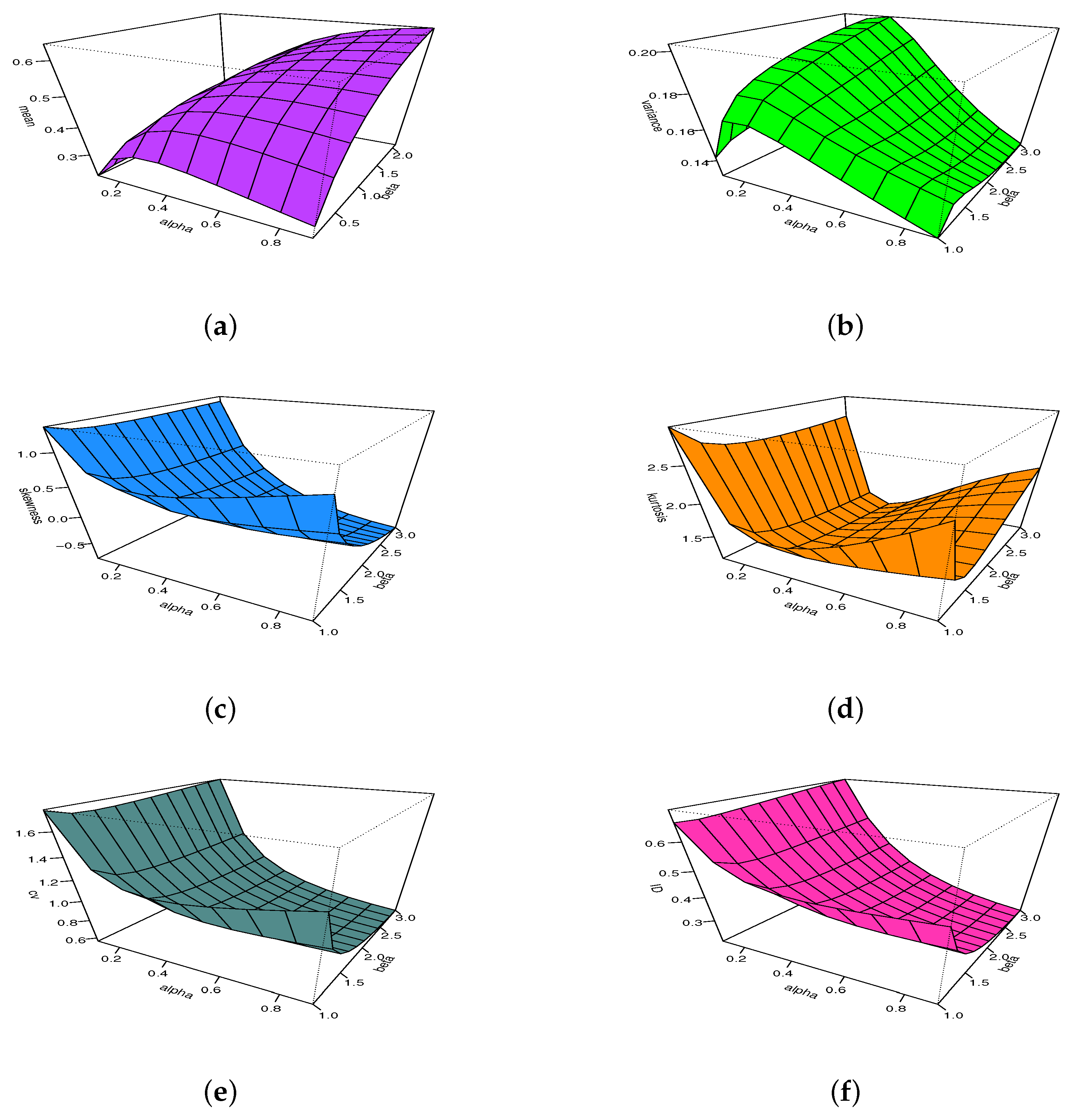
From both Table 1 and Table 2, we observe that the mean is monotonic with respect to and , which is not the case for the variance. Furthermore, wide variations of values are seen for the mean, whereas the variance remains relatively stable and small. The behavior of the moment coefficients of skewness and kurtosis are consistent with what is concluded in Figure 1, Figure 2 and Figure 3, as well as with the use of quantile coefficients of skewness and kurtosis; because MK can be positive, nearly equal to 0 or positive, the MKw distribution has all types of skewness. Moreover, since MK can be lower, almost equal or greater than 3, it indicates that all the kurtosis states are reached. In addition, we see a strong versatility in the numerical values of CV and ID.
All these comments are illustrated graphically in Figure 8 via 3D plots with varying and .
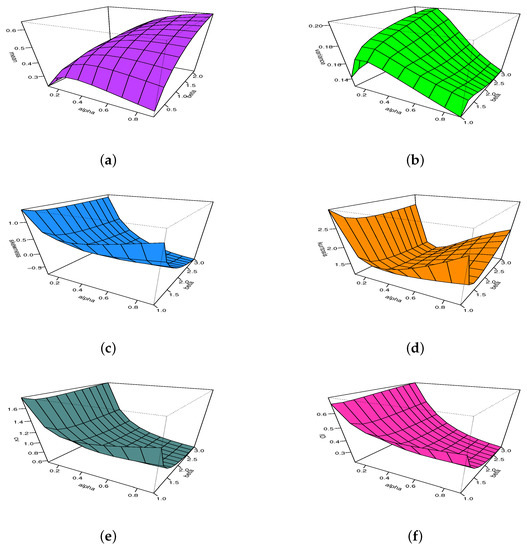
Figure 8.
The 3D plots of the (a) mean, (b) variance, (c) moment skewness, (d) moment kurtosis, (e) coefficient of variation and (f) index of dispersion for the MKw distribution for and .
In the next part, we complete this moment analysis with the expression of the mean log moments, and the incomplete moments of X.
3.2.2. Other Kinds of Moments
The mean logarithm of X can be expressed in an integral form as follows:
This kind of moment appears in some estimation methods, and entropy. It has the advantage of having values in , as opposed to , which has values in . This can be of interest for the construction of regression models, among other things. The integral defining may be determined numerically for given values of and and can be implemented in any mathematical software. In the following result, the mean logarithm of X is stated as a series expansion.
Proposition 4.
The mean logarithm of X is the following:
Proof.
For this proof, we adopt the setting used in the proof of Representation 2 of Proposition 3. By using the relationship between the MKw and RPL distributions, and the logarithmic series expansion, we obtain the following:
The desired expansion is proved. □
Now, let and be the random variable equal to X if , and 0 otherwise. Then, the rth incomplete moment of X truncated at y can be expressed as the following:
The incomplete moments are involved in a lot of probabilistic measures and functions, such as various mean deviations, residual life-type functions and curves. The integral defining may be determined numerically for given values of and and can be implemented in any scientific software. The following proposition proposes a mathematical development of this integral.
Proposition 5.
Two representations of the rth incomplete moment of X truncated at y are given below.
- Representation 1.
- We can express in terms of the incomplete beta function as the following:where , with , and .
- Representation 2.
- We can express as the following series expansion:where , .
Proof.
Let us prove the two representations in turn.
- Representation 1.
- First, by an integration by part, we obtain the following:wherewith for . By applying the Leibnitz integral rule and the change of variables , we obtain the following:Since for , upon integration with respect to , we obtain the following:
- Representation 2.
- To begin, let us introduce a known result (see [20] (Proposition 9)). The kth incomplete moment of a random variable Y with the RPL distribution at y with is given by the following:Hence, by using Equation (6), we have the following:The stated result is obtained.
The proof of Proposition 5 ends. □
The remainder of the work is devoted to the creation of a new data analysis paradigm based on the MKw model.
3.3. Order Statistics
In this section, we cover the fundamentals of the order statistics of the MKw distribution. Let n be a positive integer and be independent and identically distributed random variables following the MKw distribution. We consider the random variables defined as the ordered versions of , such that . Then, for any , the pdf of is given as the following:
That is, in an expanded form, we have the following:
and for . In particular, if we focus on the two extreme order statistics, the pdf of is given by
and for , and the pdf of is given by the following:
and for . Moment analysis is possible using these formulas. However, due to the functional complexity of the pdfs, numerical evaluations appear to necessitate the employment of computer mathematical tools.
4. Statistical Inference
The parameters and of the MKw distribution are now considered to be unknown and must be calculated using data. As a result, the MKw model is examined.
4.1. Estimation Method
The maximum likelihood (MLL) technique is well adapted for this purpose. The specifics of this estimation strategy are outlined below.
Let symbolize the n values lying into that are predicted to be seen from a random variable X with the MKw distribution and unknown parameters and . Then, the log-likelihood function for and is formulated as the following:
The MLL estimates (MLLEs) of and , denoted by and , are defined by the following:
These MLLEs fulfill the partial derivative equations listed below: , and , where
and
where and . Due to the intricacy of these partial derivatives, it is difficult to derive closed-form equations for and . Computational methods can be used to obtain precise numerical solutions. With the MMLEs, we can estimate all the functions of the MKw model by insertion. In particular, and may be naturally estimated by and , respectively.
A two-dimensional normal distribution with the mean and matrix of covariance could be used to identify the asymptotic distribution of the random version of . To be more specific, the matrix of covariance is given by , where the following holds:
The matrix can be computed quantitatively using mathematical techniques. We can establish estimated confidence intervals (CoIs) for and at a particular level, such as with . The associated lower bounds (CoI-LBs) and upper bounds (CoI-UBs) of such intervals remain traditional; if we keep our eyes on the unknown parameter , these interval bounds are provided by CoI-LB and CoI-UB , where is defined by , with Z a random variable having the standard Gaussian distribution, and is a term that relates to the standard error (SEr) of , determined by the square root of the first diagonal element of . For more theoretical and practical achievements of the MLLEs, see [23].
4.2. Simulation
Here, we perform simulation work to measure the behavior of the constructed MLLEs. In this situation, we employ the R program, which was created by [24]. The following steps are taken into consideration:
- We apply the inverse transform approach to produce 10,000 random samples with values . That is, for any , the value is computed as , where is a value generated from the uniform distribution on .
- Six different sample sizes are taken into account: , 50, 100, 200, 500, and 1000.
- Throughout the vector of parameters , we consider seven possible configurations.
- For the examined configurations, the average MLLEs, mean square errors (MSErs), CoI-LBs, CoI-UBs, and length (CoI-LEN) of the CoIs are computed at two distinct levels (90% and 95%).
- Table 3, Table 4, Table 5, Table 6, Table 7, Table 8 and Table 9 show the outcomes that were achieved.
Table 3. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.5, = 0.5) of the MKw model.
Table 4. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.5, = 1.2) of the MKw model.
Table 5. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 1.2, = 0.5) of the MKw model.
Table 6. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.8, = 0.5) of the MKw model.
Table 7. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.8, = 0.8) of the MKw model.
Table 8. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.5, = 1.5) of the MKw model.
Table 9. Numerical values of the MLLEs, MSErs, CoI-LBs, CoI-UBs, and CoI-LENs for ( = 0.5, = 2.0) of the MKw model.
From the tables above, we see that the values of MLLEs are near to the values of the parameters provided in the settings as n rises. Furthermore, when n rises, the MSEr and CoI-LEN values fall, as one would anticipate.
5. Application
It is critical to demonstrate how the MKw model may be used in practice. This is the aim of this section.
5.1. Method
In the coming applications, the fits of the MKw model are compared with those of some competitive models, such as the transmuted Kumaraswamy (TKw), Kumaraswamy (Kw), beta (B), unit Rayleigh (UR), Topp–Leone (Topp), and Power models. The TKw model has three parameters, whereas the other models have two parameters only. These models are defined through their cdfs in Table 10.
Table 10.
Competent models with the MKw model.
In order to compare these models, we consider well-referenced statistical measures, namely the Cramér–Von Mises (W), Anderson–Darling (A), Kolmogorov–Smirnov (KS), and Akaike information criterion (AIC) based on the minus maximal likelihood value, denoted by . The best model is the one with the smallest values of these statistics and criteria. We refer to [26] for more information on the usage and underlying meaning of the measures W, A, KS and AIC. In addition, we extract the p-value associated with the KS test. The best model is the one with the largest p-value.
As for the simulated part, the results are obtained using the R software, and two real data sets are considered.
5.2. Maximum Flood Level Data Set
The first data set comes from [27] and contains environmental data. It refers to 20 observations of the Susquehanna River’s greatest flood level (measured in millions of cubic feet per second) in Harrisburg, Pennsylvania. The data are 0.26, 0.27, 0.30, 0.32, 0.32, 0.34, 0.38, 0.38, 0.39, 0.40, 0.41, 0.42, 0.42, 0.42, 0.45, 0.48, 0.49, 0.61, 0.65, 0.74. A histogram analysis reveals that the data are unimodal and right skewed, with a small left-skewed tail. Theoretically, in view of the shape ability of the related pdf, the MKw model is able to fit these data.
Following our methodology, we first determine the MLLEs and the related SEs of the considered models in Table 11.
Table 11.
MLLEs and SEs of the models for the maximum flood level data set.
From Table 11, if we focus on the MKw model, we see that and . By using these estimates, we derive function estimates for the pdf and cdf of the MKw model through the substitution method; and may be naturally estimated by and , respectively.
The models are compared via our statistical benchmarks in Table 12.
Table 12.
Values of , AIC, W, A, KS and (KS p-value) of the models for the maximum flood level data set.
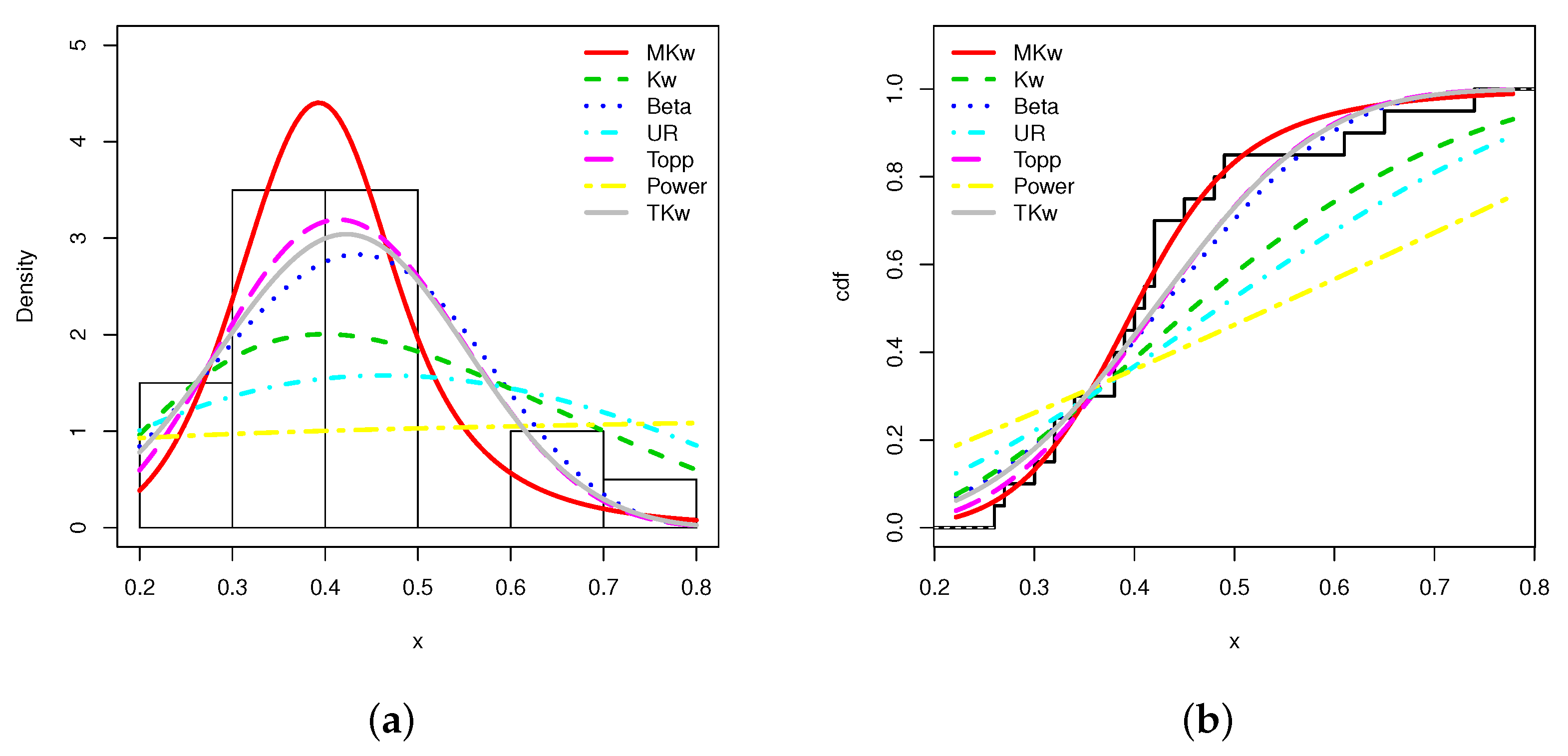
From Table 12, it is clear that the MKw model is the best, followed by the TKw model. Indeed, the MKw model has the smallest AIC, W, A, KS, and the largest p-values among all the considered models. We illustrate this claim through a graphical approach. Figure 9 plots the estimated pdfs and cdfs over the appropriate empirical objects.
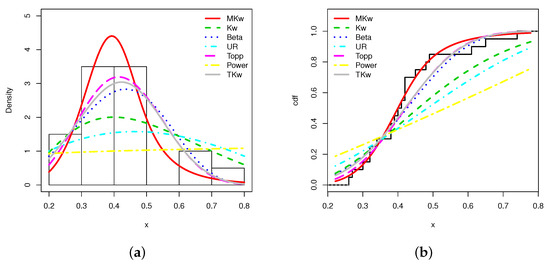
Figure 9.
Plots of the (a) estimated pdfs and (b) estimated cdfs over the appropriate statistical objects for the maximum flood level data set.
Based on Figure 9, we see that the fits of the MKw model are the best; the estimated pdf has well captured the form of the histogram, and well detected the lack of observations over the interval . Furthermore, the estimated cdf is very close to the scale shape of the empirical cdf.
5.3. Air Conditioning System Data Set
The second data set involves the failure times of an airplane’s air cooling system (in hours), as reported by [28]. The data are 23, 261, 87, 7, 120, 14, 62, 47, 225, 71, 246, 21, 42, 20, 5, 12, 120, 11, 3, 14, 71, 11, 14, 11, 16, 90, 1, 16, 52, 95. We perform a normalization operation on these data by dividing them by 265 to obtain data between 0 and 1. To put it another way, we work with the following data: 0.086792453, 0.984905660, 0.328301887, 0.026415094, 0.452830189, 0.052830189, 0.233962264, 0.177358491, 0.849056604, 0.267924528, 0.928301887, 0.079245283, 0.158490566, 0.075471698, 0.018867925, 0.045283019, 0.452830189, 0.041509434, 0.011320755, 0.052830189, 0.267924528, 0.041509434, 0.052830189, 0.041509434, 0.060377358, 0.339622642, 0.003773585, 0.060377358, 0.196226415, 0.358490566. A histogram analysis reveals that the data are decreasing and right skewed, with some data close to 1 that need to be considered. The MKw model can theoretically fit these data due to the shape ability of the corresponding pdf. Recently, these data were taken into account in [12] to illustrate the applicability of the UR model. By proceeding in the same way for the maximum flood level data set, we show that the MKw model is more appropriate for these data.
First, we determine the MLLEs and the related SEs of the considered models in Table 13.
Table 13.
MLLEs and SEs of the models for the air conditioning system data set.
Table 13 shows that and are the MLLEs for the MKw model. By using these estimates, we obtain the estimated pdf and cdf of the MKw model through the substitution method.
Table 14 gives the necessary values to compare the models.
Table 14.
Values of , AIC, W, A, KS and (KS p-value) of the models for the air conditioning system data set.
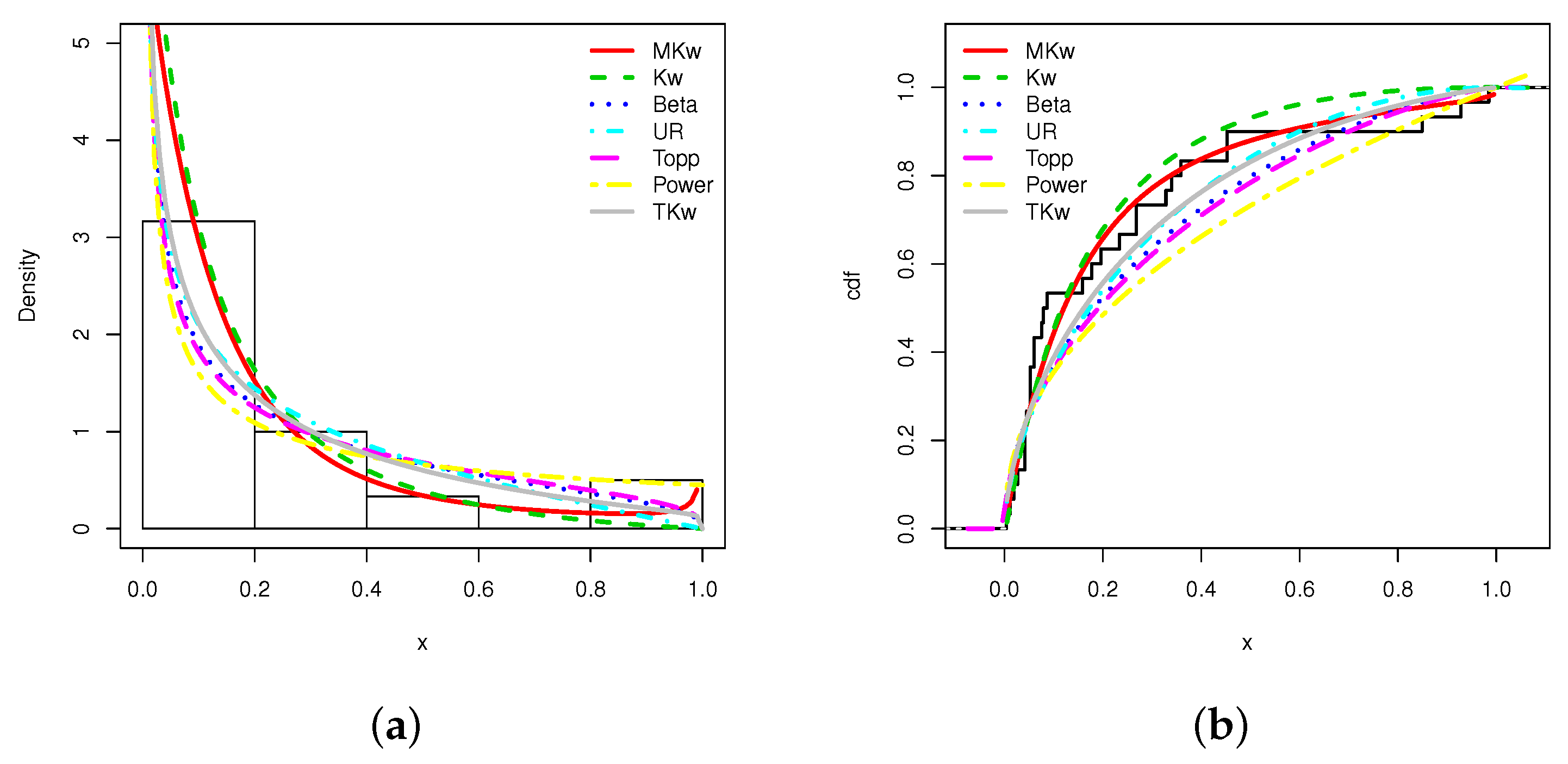
Table 14 clearly shows that the MKw model is the best; it has the more desirable AIC, W, A, KS, and p-values of all the models studied. We use a graphical way to demonstrate this assertion. The estimated pdfs and cdfs are plotted over the corresponding empirical objects in Figure 10.
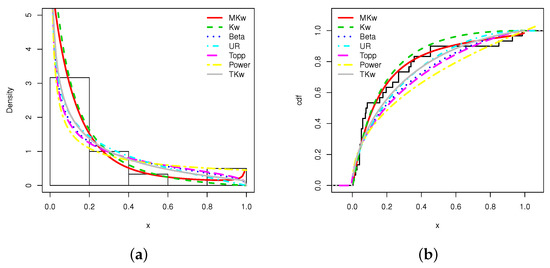
Figure 10.
Plots of the (a) estimated pdfs and (b) estimated cdfs over the appropriate statistical objects for the air conditioning system data set.
According to Figure 10, the MKw model fits best; the predicted pdf captures the form of the histogram quite well and has taken into account the values close to 1, contrary to the other models. Furthermore, the scale shape of the empirical cdf is extremely similar to the scale shape of the estimated cdf.
6. Conclusions
In this paper, a new distribution modifying the functional capabilities and mathematical structure of the Kumaraswamy distribution is proposed. We have called it the modified Kumaraswamy distribution. Evidence shows that it is more efficient than the Kumaraswamy distribution for the modeling of phenomena with data presenting a histogram that is monotonic in a nearly angular way, “strongly” left- or right-skewed, and of a leptokurtic nature, or N-shaped. On the stochastic plan, the modified Kumaraswamy distribution first order stochastic dominates the Kumaraswamy distribution. It is also deeply connected with the so-called ratio power-logarithmic distribution. In the first part, we have exhibited its main quantile and moment properties, with mathematical results, numerical tables, and graphics. These elements have offered the necessary comprehension of the distribution for further theoretical and practical purposes. In the statistical plan, an inferential methodology of the related model is developed. Then, two different data sets are analyzed with the proposed model, and other models of references: the Kumaraswamy, beta, unit Rayleigh, Topp–Leone and power models. The results are quite favorable to our modeling strategy. This study is thus encouraging for the use of the modified Kumaraswamy model for other statistical applications of importance in fields in full expansion, such as medicine, finance, biology, and environmental sciences. The development of likelihood inferential methods that take into account censored data, extensions to the multivariate case, incorporation of time series, spatial, and quantile regression structures in the modeling, and the development of influence diagnostic tools are some future research directions.
Author Contributions
Conceptualization, R.A.R.B., C.C., F.J., M.E., W.A. and A.A.A.; methodology, R.A.R.B., C.C., F.J., M.E., W.A. and A.A.A.; validation, R.A.R.B., C.C., F.J., M.E., W.A. and A.A.A.; writing—review and editing, R.A.R.B., C.C., F.J., M.E., W.A. and A.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Deanship of Scientific Research (DSR), King AbdulAziz University, Jeddah, under Grant No. FP-041-43.
Data Availability Statement
The corresponding author can provide the data sets utilized in this work upon reasonable request.
Acknowledgments
The authors thank the three reviewers for the deep and constructive comments on the first version of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gupta, P.L.; Gupta, R.C. The monotonicity of the reliability measures of the beta distribution. Appl. Math. Lett. 2000, 13, 5–9. [Google Scholar] [CrossRef] [Green Version]
- Ghitany, M.E. The monotonicity of the reliability measures of the beta distribution. Appl. Math. Lett. 2004, 17, 1277–1283. [Google Scholar] [CrossRef]
- Ferrari, S.L.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Jones, M.C. Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Khan, M.S.; King, R.; Hudson, I. Transmuted Kumaraswamy distribution. Stat. Transit. New Ser. 2016, 17, 1–28. [Google Scholar]
- Sharma, D.; Chakrabarty, T. On Size Biased Kumaraswamy Distribution. Statistics. Optim. Inf. Comput. 2016, 4, 252–264. [Google Scholar]
- Altun, E.; Hamedani, G.G. The log-xgamma distribution with inference and application. J. Soc. Fr. Stat. 2018, 159, 40–55. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Gündüz, S.; Korkmaz, M.Ç. A new unit distribution based on the unbounded Johnson distribution rule: The unit Johnson SU distribution. Pak. J. Stat. Oper. Res. 2020, 16, 471–490. [Google Scholar] [CrossRef]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat.-Theory Methods 2020, 50, 2306–2321. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Tahir, M.H.; Aqib, A.; Zubair, M.; Anam, S. Some new facts about the unit-Rayleigh distribution with applications. Mathematics 2020, 8, 1954. [Google Scholar] [CrossRef]
- Haq, M.A.; Hashmi, S.; Aidi, K.; Ramos, P.L.; Louzada, F. Unit modified Burr-III distribution: Estimation, characterizations and validation test. Ann. Data Sci. 2020. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. On the arcsecant hyperbolic normal distribution. Properties, quantile regression modeling and applications. Symmetry 2021, 13, 117. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 1–26. [Google Scholar] [CrossRef]
- Chesneau, C. A note on an extreme left skewed unit distribution: Theory, modelling and data fitting. Open Stat. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. Transmuted unit Rayleigh quantile regression model: Alternative to beta and Kumaraswamy quantile regression models. Univ. Politeh. Buchar. Sci. Bull.-Ser. A-Appl. Math. Phys. 2021, 83, 149–158. [Google Scholar]
- Figueroa-Zu, J.I.; Niklitschek-Soto, S.A.; Leiva, V.; Liu, S. Modeling heavy-tailed bounded data by the trapezoidal beta distribution with applications. REVSTAT-Stat. J. 2021. Revstat, to appear. Available online: https://www.ine.pt/revstat/pdf/ModelingBoundedDataWithHeavyTails.pdf (accessed on 4 November 2021).
- Bakouch, H.S.; Nik, A.S.; Asgharzadeh, A.; Salinas, H.S. A flexible probability model for proportion data: Unit-half-normal distribution, Communications in Statistics-Case Studies. Data Anal. Appl. 2021. [Google Scholar] [CrossRef]
- Chesneau, C. Study of a unit power-logarithmic distribution. Open J. Math. Sci. 2021, 5, 218–235. [Google Scholar] [CrossRef]
- Corless, R.M.; Gonnet, G.H.; Hare, D.E.G.; Jeffrey, D.J.; Knuth, D.E. On the Lambert W function. Adv. Comput. Math. 1996, 5, 329–359. [Google Scholar] [CrossRef]
- Gilchrist, W. Statistical Modelling with Quantile Functions; CRC Press: Abingdon, UK, 2000. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Brooks/Cole Publishing Company: Bel Air, CA, USA, 1990. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Konishi, S.; Kitagawa, G. Information Criteria and Statistical Modeling; Springer: New York, NY, USA, 2007. [Google Scholar]
- Dumonceaux, R.; Antle, C.E. Discrimination between the Log-Normal and the Weibull distributions. Technometrics 1973, 15, 923–926. [Google Scholar] [CrossRef]
- Linhart, H.; Zucchini, W. Model Selection; Wiley: New York, NY, USA, 1986. [Google Scholar]
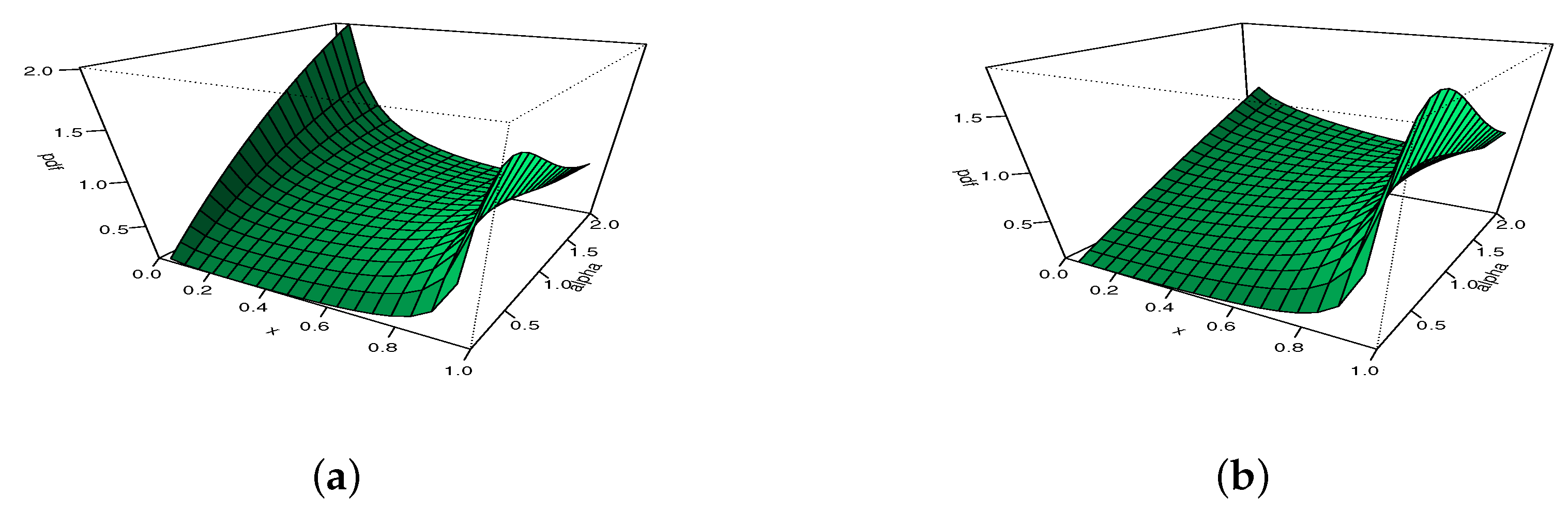
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).