
A Square-Root Factor-Based Multi-Population Extension of the Mortality Laws


Abstract
1. Introduction
2. Mortality Laws: Motivation
3. The Model
3.1. Mortality Intensity and Information
3.2. Stochastic Mortality Laws
- Gompertz’s law:In this case, , while .
- First Makeham law:In this case, , while .
- Second Makeham law:In this case, , while .
- Thiele’s law:In this case, , while .
3.3. The State Process Vector
3.4. Survival Probabilities
4. The State-Space Form of the Model
- it captures the dependence of the conditional variance on the current value of the state;
- it puts a non-negativity constraint on the value of the state process.
4.1. Description of the Quasi-Linear Kalman Filter Algorithm
- 1.
- Given a certain parameter set , the filter is initialized using the unconditional mean and variance of the state-process vector,
- 2.
- For each time step t, the state process vector and its variance covariance matrix are updated:where , denotes an M-dimensional identity matrix,, and is the state-process conditional variance/covariance matrix. Notice that such variance/covariance matrix depends on , differently relative to the standard Gaussian case.
- 3.
- The estimates are initialized asand then updated after each observation , setting a floor to the value of the estimated mean to zero:where the measurement error prediction and the Kalman gain are respectively:Note that and are scalars and is a N-dimensional column vector.
- 4.
- Finally, when , we setand we compute
- 5.
- Using these last expressions for and we can compute the log-likelihood function:which has to be maximized to obtain the optimal parameter set.
4.2. Log-Likelihood Maximisation
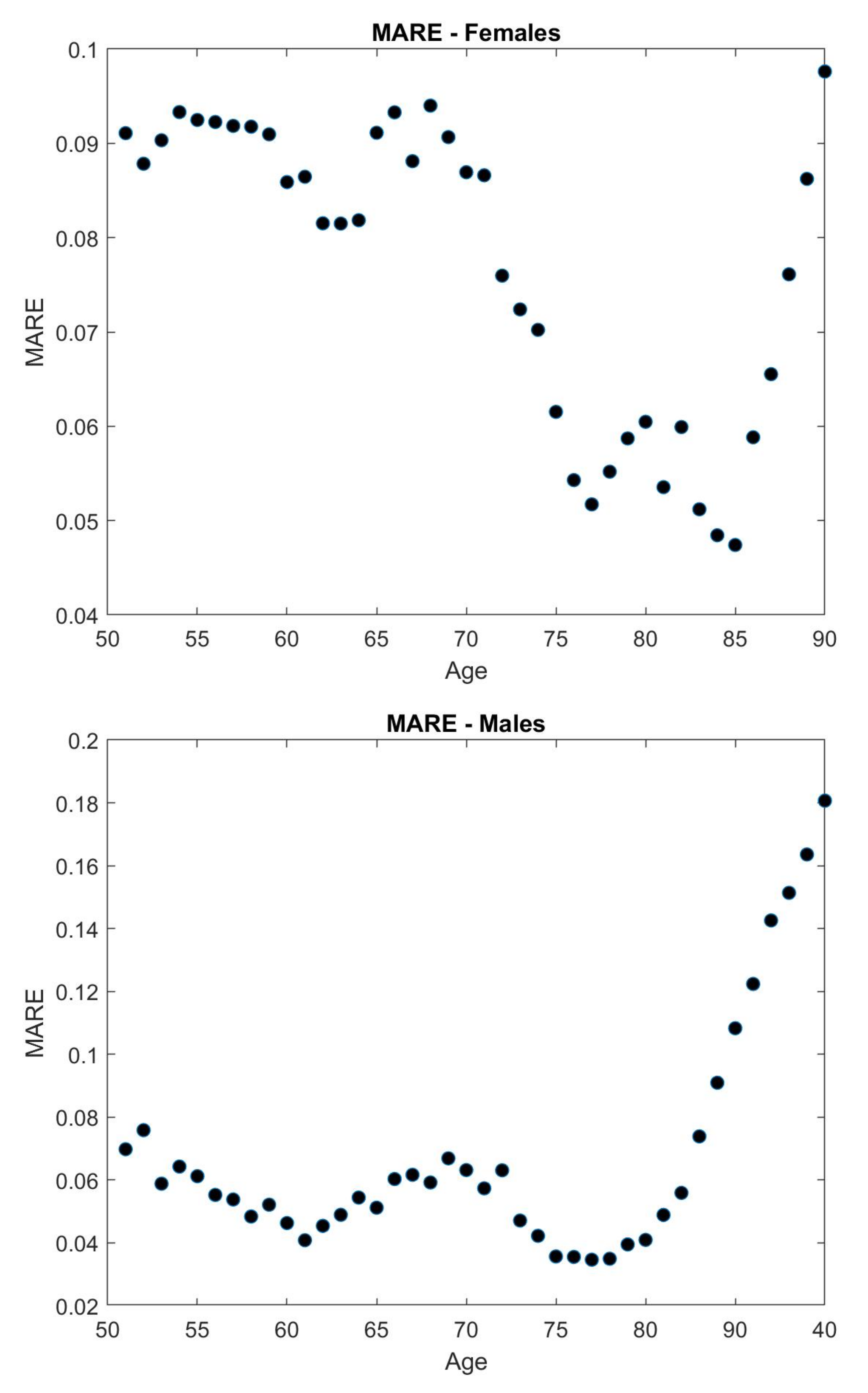
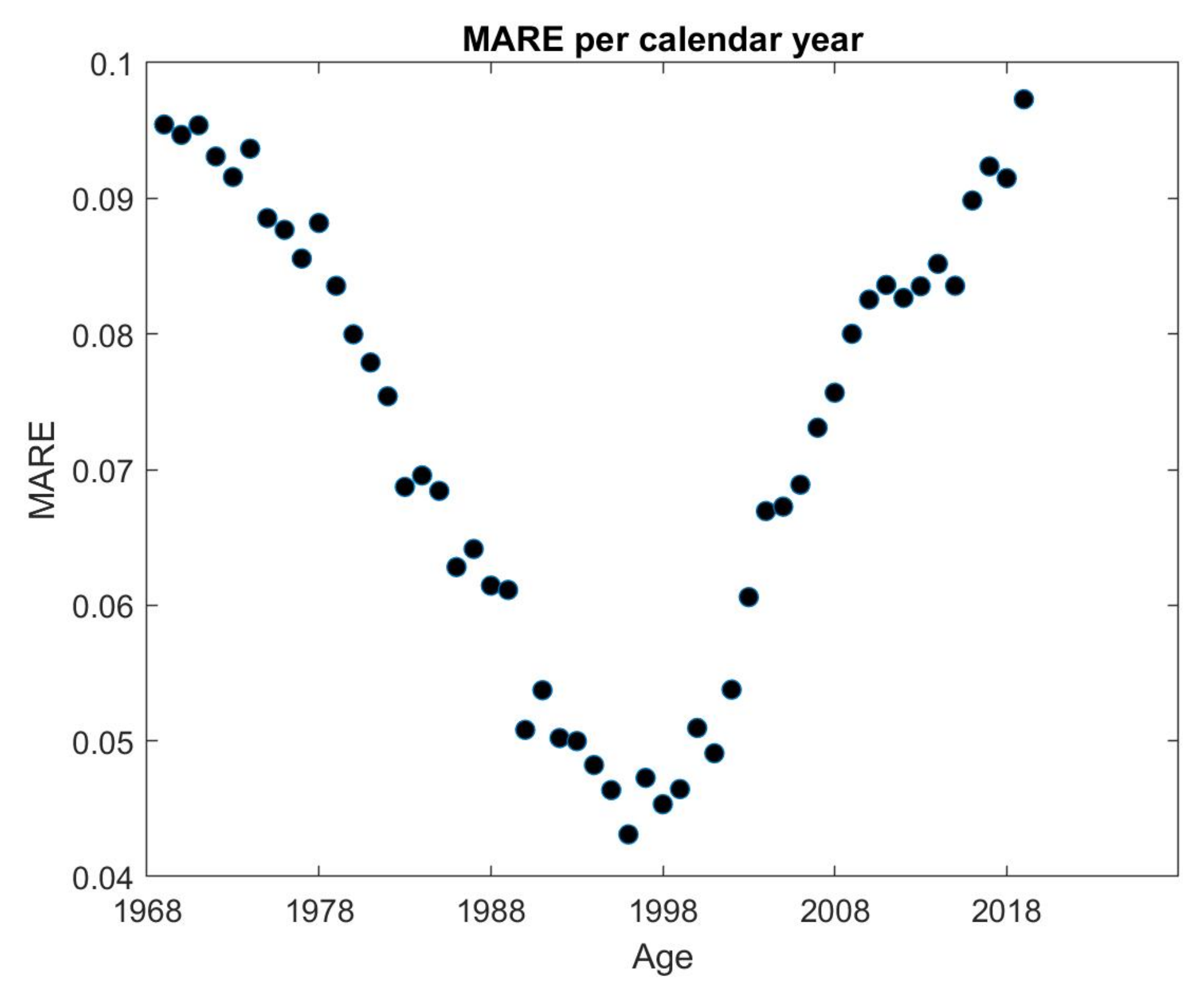
5. Results
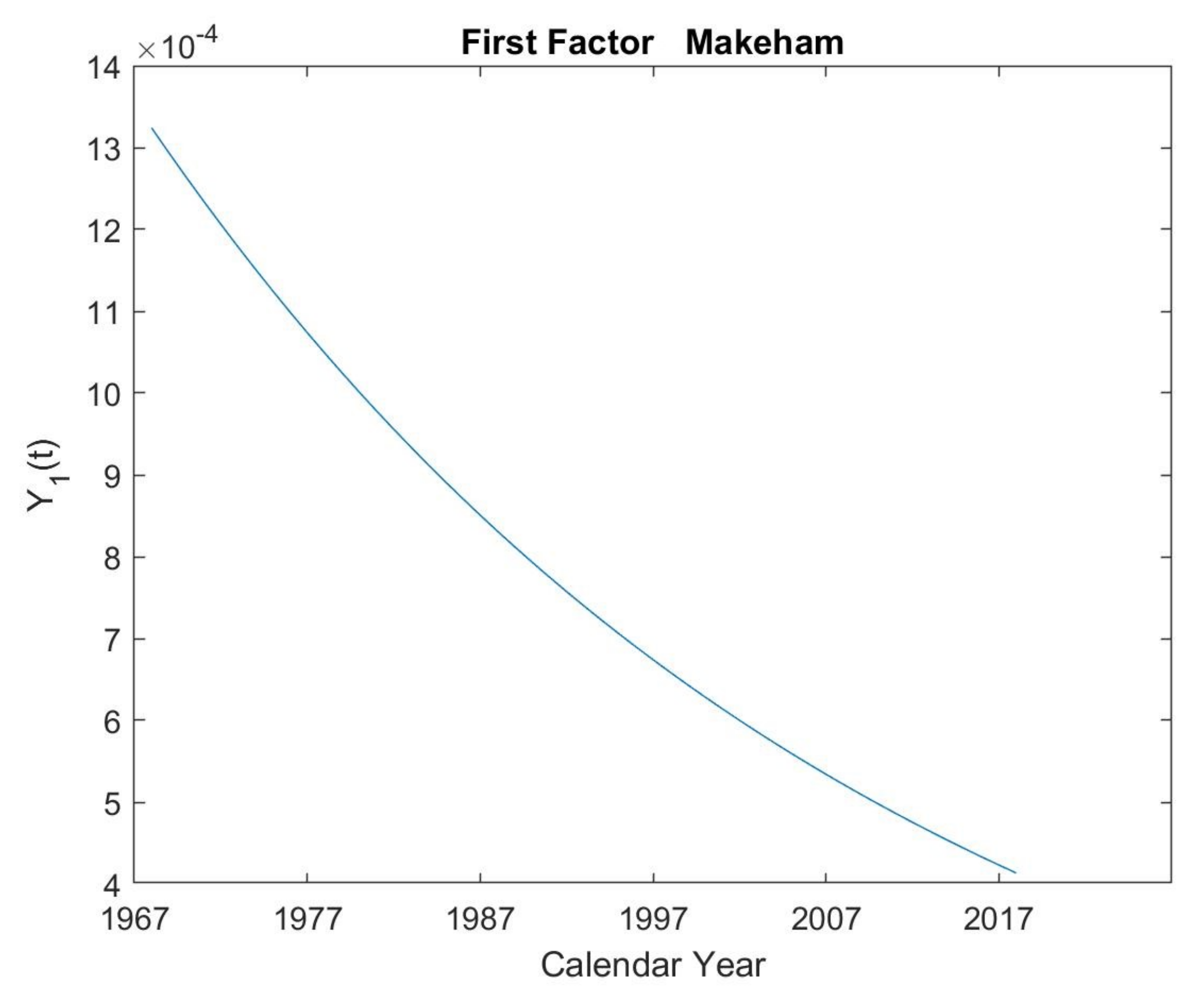
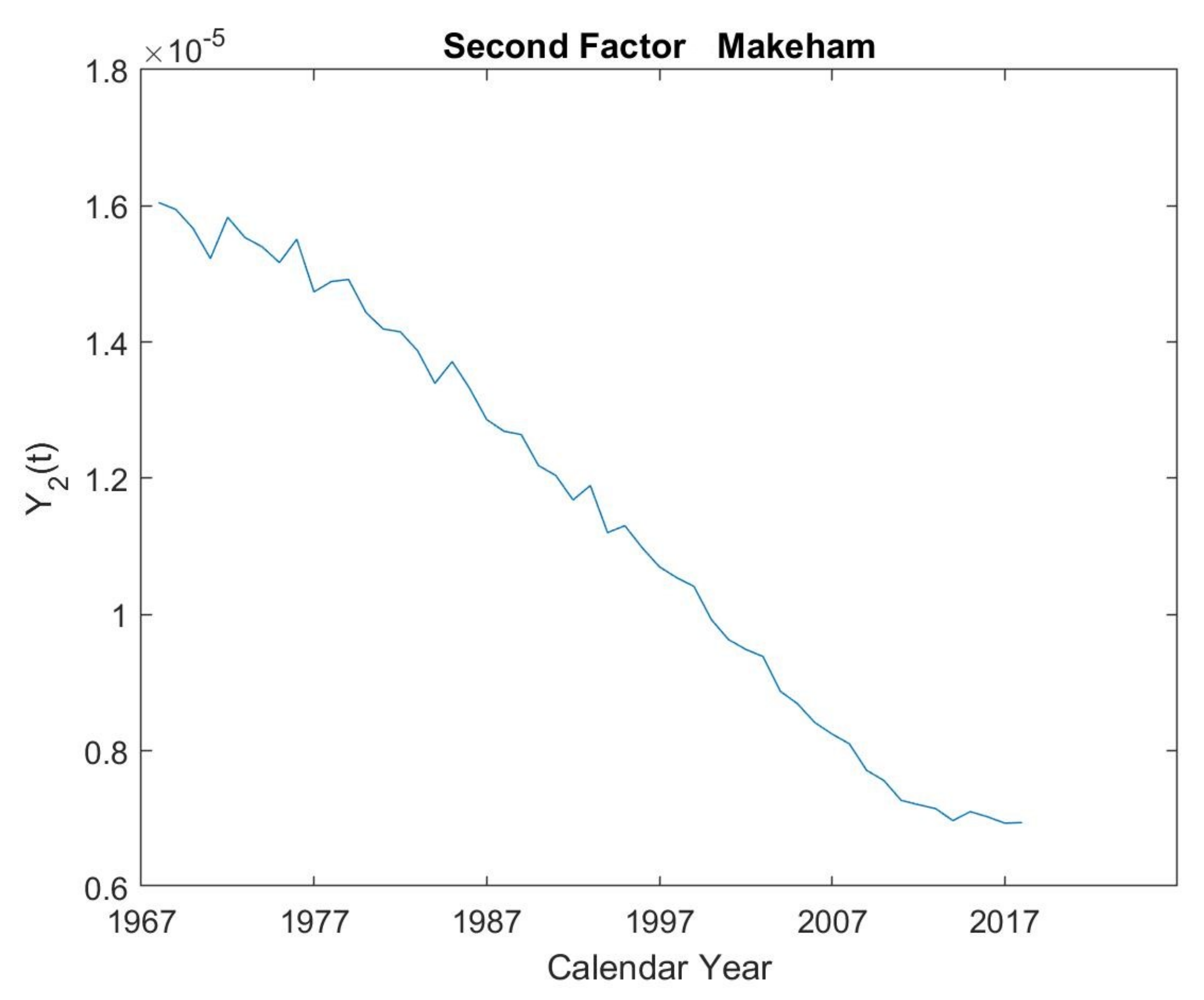
5.1. First Makeham’s Multi-Population Law
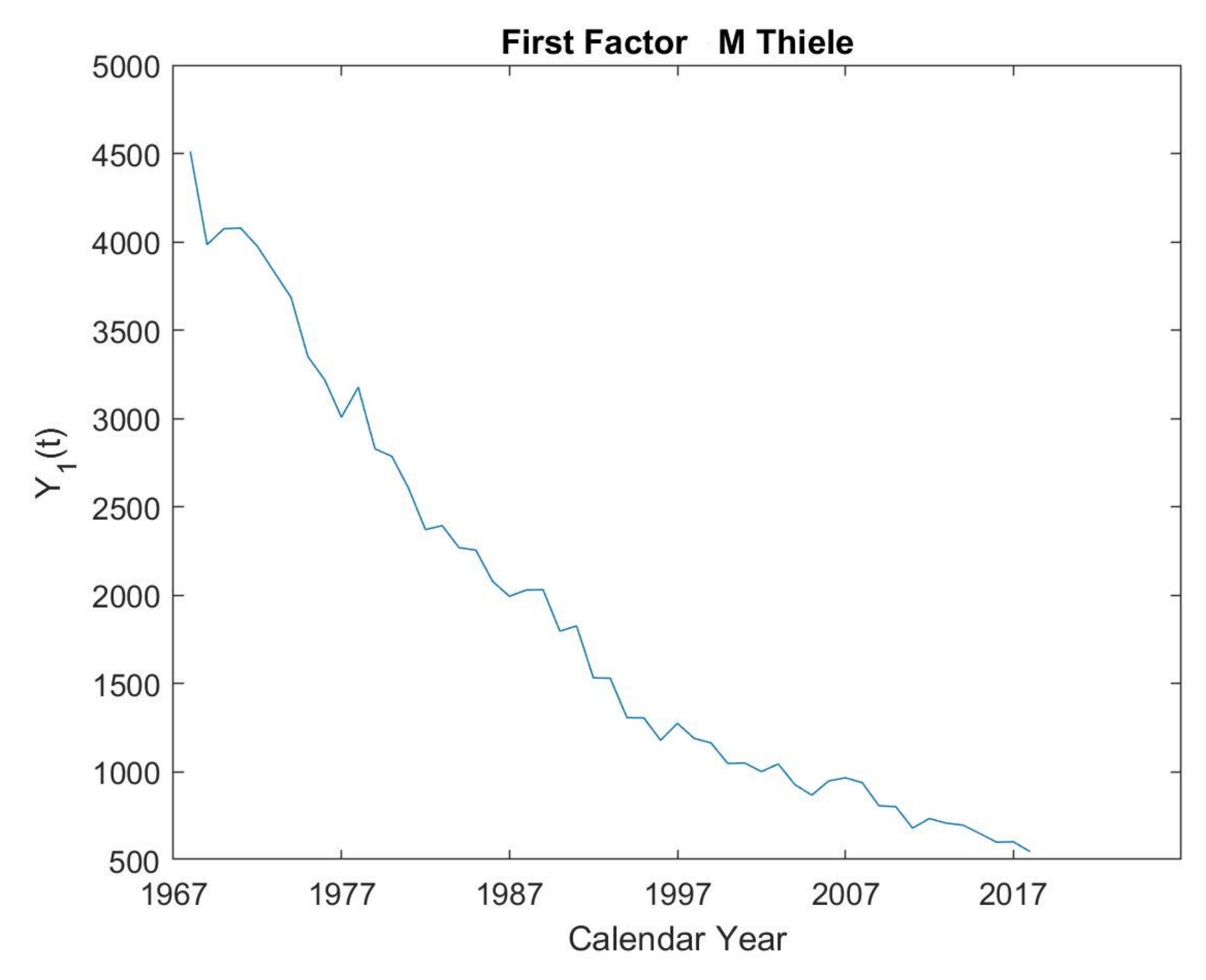
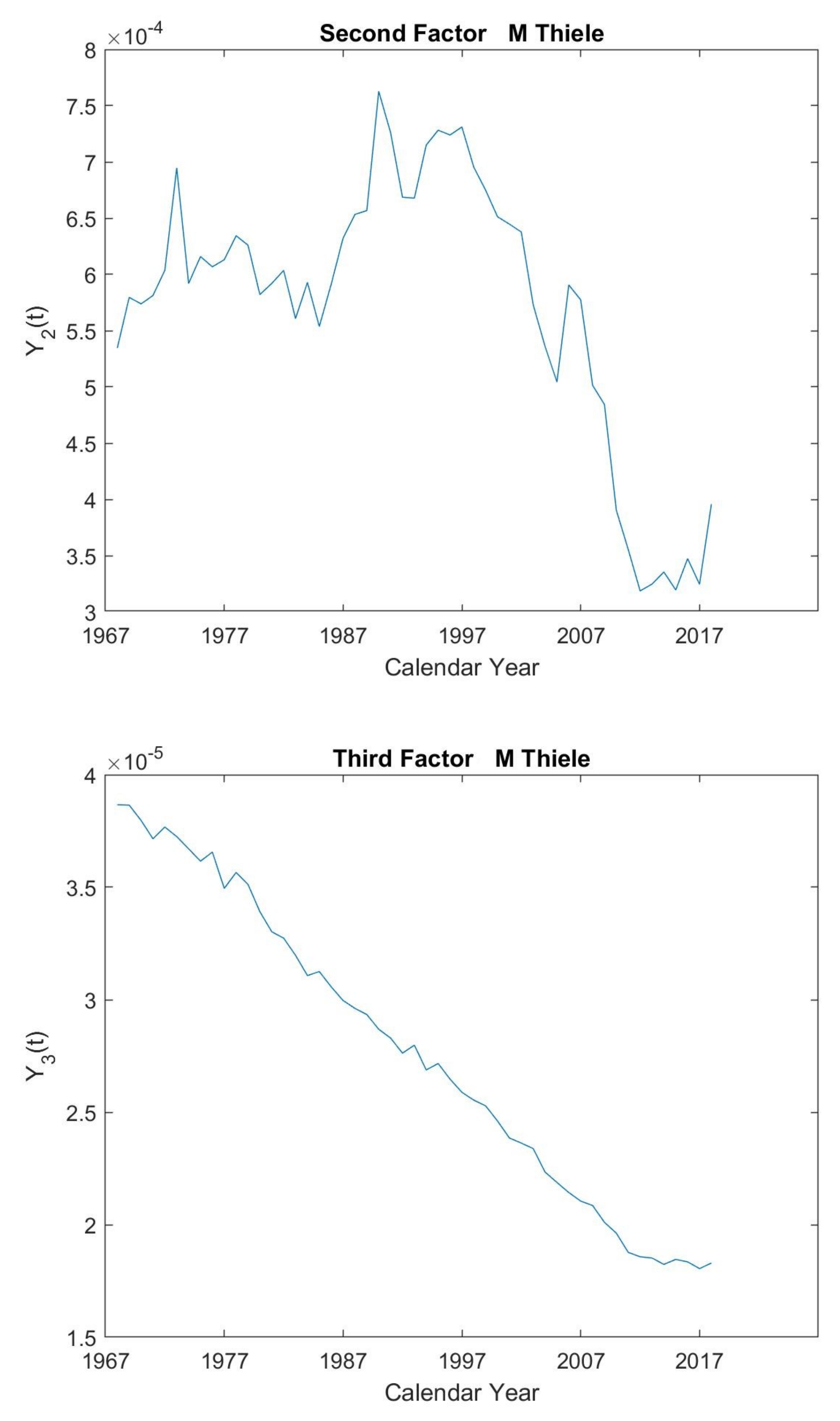
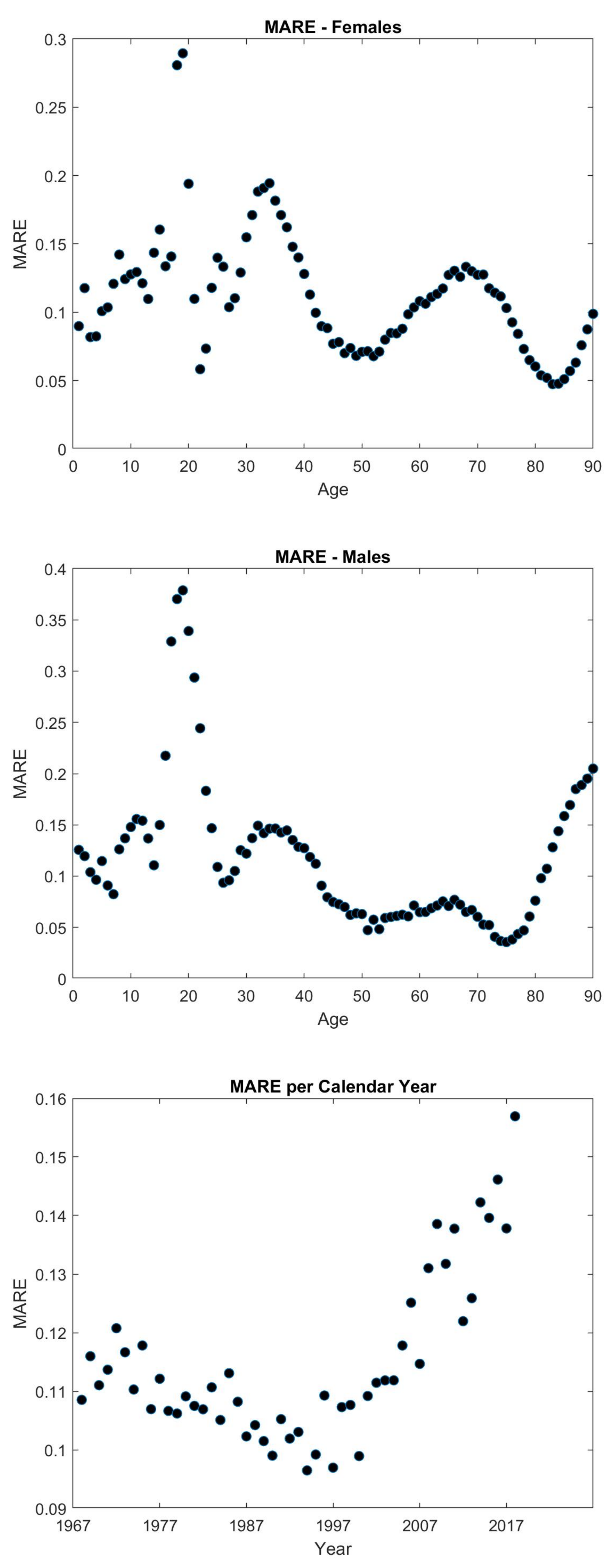
5.2. Modified Thiele’s Law
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schrager, D.F. Affine stochastic mortality. Insur. Math. Econom. 2006, 38, 81–97. [Google Scholar] [CrossRef]
- Jevtić, P.; Regis, L. A continuous-time stochastic model for the mortality surface of multiple populations. Insur. Math. Econom. 2019, 88, 181–195. [Google Scholar] [CrossRef]
- Jevtić, P.; Luciano, E.; Vigna, E. Mortality surface by means of continuous time cohort models. Insur. Math. Econom. 2013, 53, 122–133. [Google Scholar] [CrossRef]
- Blackburn, C.; Sherris, M. Consistent dynamic affine mortality models for longevity risk applications. Insur. Math. Econom. 2013, 53, 64–73. [Google Scholar] [CrossRef]
- De Rosa, C.; Luciano, E.; Regis, L. Geographical diversification and longevity risk mitigation in annuity portfolios. ASTIN Bull. J. IAA 2021, 51, 375–410. [Google Scholar] [CrossRef]
- Cox, J.C.; Ingersoll, J.E., Jr.; Ross, S.A. An intertemporal general equilibrium model of asset prices. Econometrica 1985, 53, 363–384. [Google Scholar] [CrossRef]
- Chen, R.R.; Scott, L. Multi-factor Cox-Ingersoll-Ross models of the term structure: Estimates and tests from a Kalman filter model. J. Real Estate Financ. Econ. 2003, 27, 143–172. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Pitacco, E.; Denuit, M.; Haberman, S. Modelling Longevity Dynamics for Pensions and Annuity Business; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Milevsky, M.A.; Promislow, S.D. Mortality Derivatives and the Option to Annuitise. Insur. Math. Econom. 2001, 29, 299–318. [Google Scholar] [CrossRef]
- Lando, D. On Cox processes and credit risky securities. Rev. Deriv. Res. 1998, 2, 99–120. [Google Scholar] [CrossRef]
- Duffie, D.; Pan, J.; Singleton, K. Transform analysis and asset pricing for affine jump-diffusions. Econometrica 2000, 68, 1343–1376. [Google Scholar] [CrossRef]
- Filipović, D. Term-Structure Models: A Graduate Course, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Duffie, D.; Kan, R. A yield-factor model of interest rates. Math. Financ. 1996, 6, 379–406. [Google Scholar] [CrossRef]
- Raol, J.R. Multi-Sensor Data Fusion with MATLAB®; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Duan, J.C.; Simonato, J.G. Estimating and testing exponential-affine term structure models by Kalman filter. Rev. Quant. Financ. Account. 1999, 13, 111–135. [Google Scholar] [CrossRef]
- Koopman, S.J.; Durbin, J. Fast filtering and smoothing for multivariate state space models. J. Time Ser. Anal. 2000, 21, 281–296. [Google Scholar] [CrossRef]
- Kitagawa, G. Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. J. Comput. Graph. Stat. 1996, 5, 1–25. [Google Scholar] [CrossRef]
- De Rossi, G. Maximum likelihood estimation of the Cox–Ingersoll–Ross model using particle filters. Comput. Econ. 2010, 36, 1–16. [Google Scholar] [CrossRef]
- Jong, F.d. Time series and cross-section information in affine term-structure models. J. Bus. Econ. Stat. 2000, 18, 300–314. [Google Scholar] [CrossRef][Green Version]
- Chen, R.R.; Scott, L. Maximum likelihood estimation for a multifactor equilibrium model of the term structure of interest rates. J. Fixed Income 1993, 3, 14–31. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximized Log-Likelihood | 22,409 | Number of Parameters | 9 | ||
|---|---|---|---|---|---|
| Optimal Parameters | |||||
| Common | Males | Females | |||
| Parameter | Value | Parameter | Value | Parameter | Value |
| 0.1153 | 0.0944 | ||||
| 0.0109 | |||||
| 0.0014 | |||||
| s | 0.1076 | ||||
| Maximized log-Likelihood | 65,464 | Number of Parameters | 20 | ||
|---|---|---|---|---|---|
| Optimal Parameters | |||||
| Common | Males | Females | |||
| Parameter | Value | Parameter | Value | Parameter | Value |
| 14.4989 | |||||
| 15.8046 | 15.0810 | ||||
| 0.0048 | 0.0229 | ||||
| 88.2853 | 23.1866 | ||||
| 0.0944 | 0.1016 | ||||
| 88.8547 | |||||
| s | 0.1496 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jevtić, P.; Regis, L. A Square-Root Factor-Based Multi-Population Extension of the Mortality Laws. Mathematics 2021, 9, 2402. https://doi.org/10.3390/math9192402
Jevtić P, Regis L. A Square-Root Factor-Based Multi-Population Extension of the Mortality Laws. Mathematics. 2021; 9(19):2402. https://doi.org/10.3390/math9192402
Chicago/Turabian StyleJevtić, Petar, and Luca Regis. 2021. "A Square-Root Factor-Based Multi-Population Extension of the Mortality Laws" Mathematics 9, no. 19: 2402. https://doi.org/10.3390/math9192402
APA StyleJevtić, P., & Regis, L. (2021). A Square-Root Factor-Based Multi-Population Extension of the Mortality Laws. Mathematics, 9(19), 2402. https://doi.org/10.3390/math9192402