
Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries



Abstract
1. Introduction
2. Literature Review
3. Methodology
3.1. Model Composition and Settings
3.2. Methods for Minimal Appropriate Index Composition
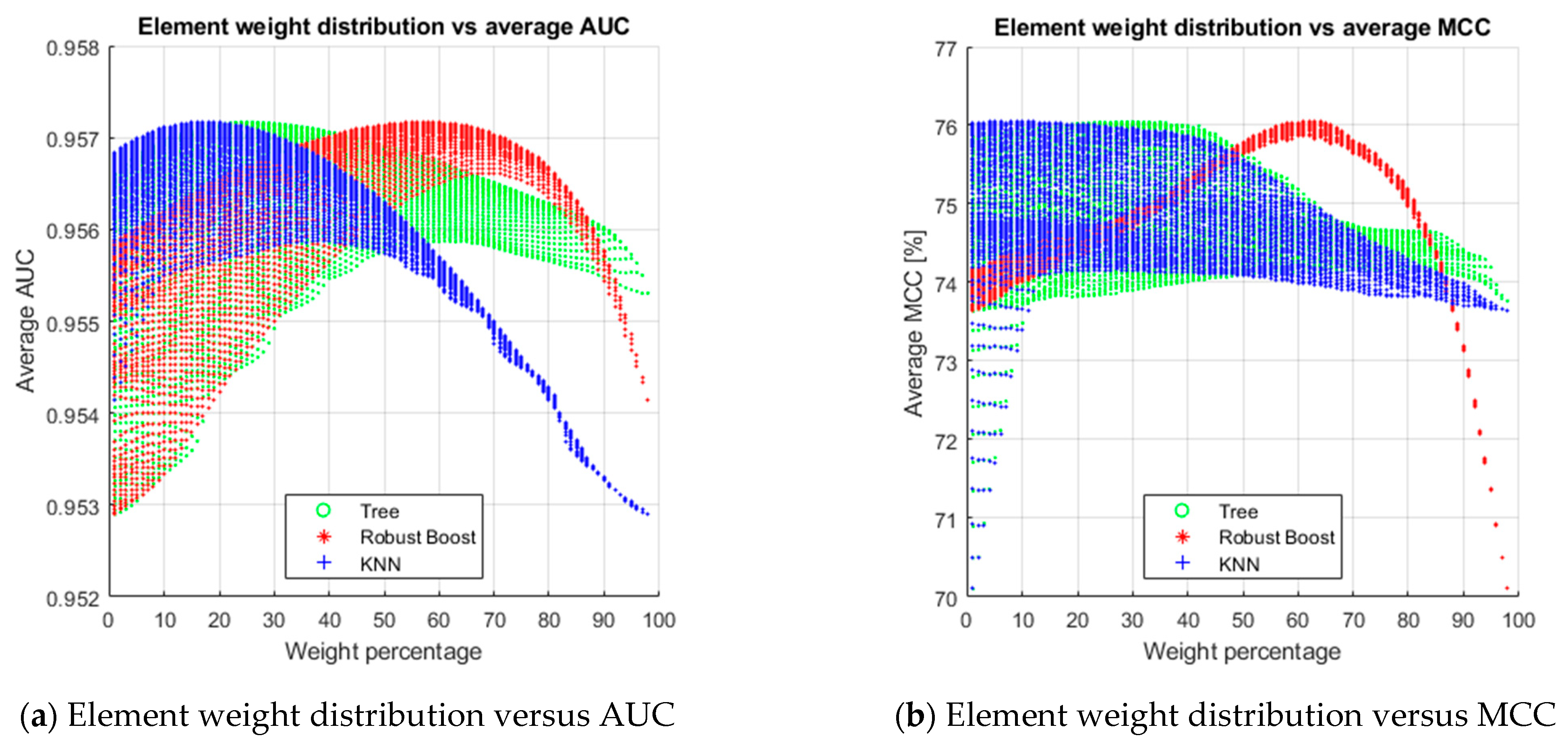
3.3. Optimal Weights and Threshold Setting
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving Financial Bankruptcy Prediction in a Highly Imbalanced Class Distribution Using Oversampling and Ensemble Learning: A Case from the Spanish Market. Prog. Artif. Intell. 2020, 9, 31–53. [Google Scholar] [CrossRef]
- Kim, S.Y.; Upneja, A. Majority Voting Ensemble with a Decision Trees for Business Failure Prediction during Economic Downturns. J. Innov. Knowl. 2021, 6, 112–123. [Google Scholar] [CrossRef]
- Hsieh, N.-C.; Hung, L.-P. A Data Driven Ensemble Classifier for Credit Scoring Analysis. Expert Syst. Appl. 2010, 37, 534–545. [Google Scholar] [CrossRef]
- Valentini, G.; Masulli, F. Ensembles of Learning Machines. In Italian Workshop on Neural Nets 2002 May 30; Marinaro, M., Tagliaferri, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 3–20. [Google Scholar]
- De Bock, K.W.; Coussement, K.; Lessmann, S. Cost-Sensitive Business Failure Prediction When Misclassification Costs Are Uncertain: A Heterogeneous Ensemble Selection Approach. Eur. J. Oper. Res. 2020, 285, 612–630. [Google Scholar] [CrossRef]
- Liu, J.; Wu, C. Hybridizing Kernel-Based Fuzzy c-Means with Hierarchical Selective Neural Network Ensemble Model for Business Failure Prediction. J. Forecast. 2019, 38, 92–105. [Google Scholar] [CrossRef]
- Ekinci, A.; Erdal, H.İ. Forecasting Bank Failure: Base Learners, Ensembles and Hybrid Ensembles. Comput. Econ. 2017, 49, 677–686. [Google Scholar] [CrossRef]
- du Jardin, P. Failure Pattern-Based Ensembles Applied to Bankruptcy Forecasting. Decis. Support Syst. 2018, 107, 64–77. [Google Scholar] [CrossRef]
- FitzPatrick, P.J. A Comparison of the Ratios of Successful Industrial Enterprises with Those of Failed Companies. Certif. Public Account. 1932, 6, 727–731. [Google Scholar]
- Merwin, C.L. Financing Small Corporations in Five Manufacturing Industries, 1926–1936; NBER Books; National Bureau of Economic Research, Inc.: New York, NY, USA, 1942. [Google Scholar]
- Ramser, J.R.; Foster, L.O. A Demonstration of Ratio Analysis; Bulletin; Bureau of Business Research, University of Illinois: Urbana, IL, USA, 1931. [Google Scholar]
- Smith, R.F.; Winakor, A.H. Changes in the Financial Structure of Unsuccessful Industrial Corporations; Bureau of Business Research. Bulletin; University of Illinois (Urbana-Champaign campus): Champaign, IL, USA, 1935. [Google Scholar]
- Beaver, W.H. Financial Ratios As Predictors of Failure. J. Account. Res. 1966, 4, 71–111. [Google Scholar] [CrossRef]
- Altman, E.I. Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Blum, M. Failing Company Discriminant Analysis. J. Account. Res. 1974, 12, 1–25. [Google Scholar] [CrossRef]
- Deakin, E.B. A Discriminant Analysis of Predictors of Business Failure. J. Account. Res. 1972, 10, 167–179. [Google Scholar] [CrossRef]
- Moyer, R.C. Forecasting Financial Failure: A Re-Examination. Financ. Manag. 1977, 6, 11–17. [Google Scholar] [CrossRef]
- Ohlson, J.A. Financial Ratios and the Probabilistic Prediction of Bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef]
- Zmijewski, M.E. Methodological Issues Related to the Estimation of Financial Distress Prediction Models. J. Account. Res. 1984, 22, 59–82. [Google Scholar] [CrossRef]
- Jakubík, P.; Teplý, P. The JT Index as an Indicator of Financial Stability of Corporate Sector. Prague Econ. Pap. 2011, 20, 157–176. [Google Scholar] [CrossRef]
- Valecký, J.; Slivková, E. Microeconomic scoring model of Czech firms’ bankruptcy. Ekon. Rev. Cent. Eur. Rev. Econ. Issues 2012, 15, 15–26. [Google Scholar] [CrossRef]
- Karas, M.; Režňáková, M. A Parametric or Nonparametric Approach for Creating a New Bankruptcy Prediction Model: The Evidence from the Czech Republic. Int. J. Math. Models Methods Appl. Sci. 2014, 8, 214–223. [Google Scholar]
- Vochozka, M.; Straková, J.; Váchal, J. Model to Predict Survival of Transportation and Shipping Companies. Naše More 2015, 62, 109–113. [Google Scholar] [CrossRef]
- Hajdu, O.; Virág, M. A Hungarian Model for Predicting Financial Bankruptcy. Soc. Econ. Cent. East. Eur. 2001, 23, 28–46. [Google Scholar]
- Chrastinová, Z. Methods of Assessing Economic Creditworthiness and Predicting the Financial Situation of Agricultural Enterprises [Metódy Hodnotenia Ekonomickej Bonity a Predikcie Finančnej Situácie Poľnohospodárskych Podnikov]; VUEPP: Bratislava, Slovakia, 1998; ISBN 978-80-8058-022-3. [Google Scholar]
- Gurčík, Ľ. G-index—The financial situation prognosis method of agricultural enterprises. Agric. Econ. (Zemědělská Ekon.) 2012, 48, 373–378. [Google Scholar] [CrossRef]
- Hurtošová, J. Construction of a Rating Model, a Tool for Assessing the Creditworthiness of a Company [Konštrukcia Ratingového Modelu, Nástroja Hodnotenia Úverovej Spôsobilosti Podniku]. Bachelor’s Thesis, Economic University in Bratislava, Bratislava, Slovakia, 2009. [Google Scholar]
- Delina, R.; Packová, M. Validation of Predictive Bankruptcy Models in the Conditions of the Slovak Republic [Validácia Predikčných Bankrotových Modelov v Podmienkach SR]. Ekon. A Manag. 2013, 16, 101–112. [Google Scholar]
- Harumova, A.; Janisova, M. Rating Slovak Enterprises by Scoring Functions [Hodnotenie slovenských podnikov pomocou skóringovej funkcie]. Ekon. Časopis (J. Econ.) 2014, 62, 522–539. [Google Scholar]
- Gulka, M. Bankruptcy prediction model of commercial companies operating in the conditions of the Slovak Republic [Model predikcie úpadku obchodných spoločností podnikajúcich v podmienkach SR]. Forum Stat. Slovacum 2016, 12, 16–22. [Google Scholar]
- Jenčová, S.; Štefko, R.; Vašaničová, P. Scoring Model of the Financial Health of the Electrical Engineering Industry’s Non-Financial Corporations. Energies 2020, 13, 4364. [Google Scholar] [CrossRef]
- Svabova, L.; Michalkova, L.; Durica, M.; Nica, E. Business Failure Prediction for Slovak Small and Medium-Sized Companies. Sustainability 2020, 12, 4572. [Google Scholar] [CrossRef]
- Valaskova, K.; Durana, P.; Adamko, P.; Jaros, J. Financial Compass for Slovak Enterprises: Modeling Economic Stability of Agricultural Entities. J. Risk Financ. Manag. 2020, 13, 92. [Google Scholar] [CrossRef]
- Pisula, T. The Usage of Scoring Models to Evaluate the Risk of Bankruptcy on the Example of Companies from the Transport Sector. Sci. J. Rzesz. Univ. Technol. Ser. Manag. Mark. 2012, 19, 133–151. [Google Scholar] [CrossRef][Green Version]
- Balina, R.; Juszczyk, S. Forecasting Bankruptcy Risk of International Commercial Road Transport Companies. Int. J. Manag. Enterp. Dev. 2014, 13, 1–20. [Google Scholar] [CrossRef]
- Pisula, T.; Mentel, G.; Brożyna, J. Non-Statistical Methods of Analysing of Bankruptcy Risk. Folia Oeconomica Stetin. 2015, 15, 7–21. [Google Scholar] [CrossRef]
- Brozyna, J.; Mentel, G.; Pisula, T. Statistical Methods of the Banrkuptcy Prediction in the Logistic Sector in Poland and Slovakia. Transform. Bus. Econ. 2016, 15, 93–114. [Google Scholar]
- Noga, T.; Adamowicz, K. Forecasting Bankruptcy in the Wood Industry. Eur. J. Wood Wood Prod. 2021, 79, 735–743. [Google Scholar] [CrossRef]
- Prusak, B. Review of Research into Enterprise Bankruptcy Prediction in Selected Central and Eastern European Countries. Int. J. Financ. Stud. 2018, 6, 60. [Google Scholar] [CrossRef]
- Durica, M.; Frnda, J.; Svabova, L. Decision Tree Based Model of Business Failure Prediction for Polish Companies. Oeconomia Copernicana 2019, 10, 453–469. [Google Scholar] [CrossRef]
- Mihalovič, M. Performance Comparison of Multiple Discriminant Analysis and Logit Models in Bankruptcy Prediction. Econ. Sociol. 2016, 9, 101–118. [Google Scholar] [CrossRef]
- Kovacova, M.; Kliestik, T. Logit and Probit Application for the Prediction of Bankruptcy in Slovak Companies. Equilibrium. Q. J. Econ. Econ. Policy 2017, 12, 775–791. [Google Scholar] [CrossRef]
- Virág, M.; Kristóf, T. Neural Networks in Bankruptcy Prediction—A Comparative Study on the Basis of the First Hungarian Bankruptcy Model. Acta Oeconomica 2005, 55, 403–426. [Google Scholar] [CrossRef]
- Nyitrai, T.; Virag, M. The Effects of Handling Outliers on the Performance of Bankruptcy Prediction Models. Socio-Econ. Plan. Sci. 2019, 67, 34–42. [Google Scholar] [CrossRef]
- Štefko, R.; Horváthová, J.; Mokrišová, M. Bankruptcy Prediction with the Use of Data Envelopment Analysis: An Empirical Study of Slovak Businesses. J. Risk Financ. Manag. 2020, 13, 212. [Google Scholar] [CrossRef]
- Musa, H. Default Prediction Modelling for Small Enterprises: Case Slovakia. In Proceedings of the 34th International-Business-Information-Management-Association (IBIMA) Conference, Madrid, Spain, 13 November 2019; pp. 6342–6355. [Google Scholar]
- Tumpach, M.; Surovicova, A.; Juhaszova, Z.; Marci, A.; Kubascikova, Z. Prediction of the Bankruptcy of Slovak Companies Using Neural Networks with SMOTE. Ekon. Časopis (J. Econ.) 2020, 68, 1021–1039. [Google Scholar] [CrossRef]
- Neumaier, I.; Neumaierová, I. Try to calculate your index IN95. Terno 1995, 5, 7–10. [Google Scholar]
- Kalouda, F.; Vaníček, T. Alternative Bankruptcy Models—First Results. In European Financial Systems 2013: Proceedings of the 10th International Scientific Conference, Telč, Czech Republic, 10–11 June 2013; Masaryk University: Brno, Czech Republic, 2013; pp. 164–168. [Google Scholar]
- Karas, M.; Reznakova, M. Predicting the Bankruptcy of Construction Companies: A CART-Based Model. Eng. Econ. 2017, 28, 145–154. [Google Scholar] [CrossRef]
- Kubickova, D.; Skrivackova, E.; Hoffreiterova, K. Comparison of Prediction Ability of Bankruptcy Models in Conditions of the Czech Republic. In Double-Blind Peer-Reviewed, Proceedings of the International Scientific Conference Hradec Economic Days 2016; Hradec Králové, Czech Republic, 2-3 February 2016; Jedlicka, P., Ed.; University of Hradec Králové: Hradec Králové, Czech Republic, 2016; Volume 6, pp. 464–474. [Google Scholar]
- Hołda, A. Prognozowanie Bankructwa Jednostki w Warunkach Gospodarki Polskiej z Wykorzystaniem Funkcji Dyskryminacyjnej ZH. Rachunkowość 2001, 5, 306–310. [Google Scholar]
- Kutyłowska, M. Application of Regression Tress for Prediction of Water Conduits Failure Rate. E3S Web Conf. 2017, 22, 00097. [Google Scholar] [CrossRef]
- Pawełek, B. Prediction of Company Bankruptcy in the Context of Changes. In Proceedings of the 11th Professor Aleksander Zelias International Conference on Modelling and Forecasting of Socio-Economic Phenomena: Conference Proceedings, Zakopane, Poland, 9–12 May 2017; pp. 290–299. [Google Scholar]
- Vrbka, J. Altman Model for Prediction of Financial Health within Polish Enterprises. In Proceedings of the Abstracts & Proceedings of INTCESS 2020—7th International Conference on Education and Social Sciences, Dubai, UAE, 20–22 January 2020; pp. 1198–1205. [Google Scholar]
- Pociecha, J.; Pawełek, B.; Baryła, M.; Augustyn, S. Classification Models as Tools of Bankruptcy Prediction—Polish Experience. In Classification, (Big) Data Analysis and Statistical Learning; Mola, F., Conversano, C., Vichi, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 163–172. [Google Scholar]
- Herman, S. Industry Specifics of Joint-Stock Companies in Poland and Their Bankruptcy Prediction. In Proceedings of the 11th Professor Aleksander Zelias International Conference on Modelling and Forecasting of Socio-Economic Phenomena: Conference Proceedings, Zakopane, Poland, 9–12 May 2017; pp. 93–102. [Google Scholar]
- Jabeur, S.B.; Gharib, C.; Mefteh-Wali, S.; Arfi, W.B. CatBoost Model and Artificial Intelligence Techniques for Corporate Failure Prediction. Technol. Forecast. Soc. Chang. 2021, 166, 120658. [Google Scholar] [CrossRef]
- Wang, L.; Wu, C. Business Failure Prediction Based on Two-Stage Selective Ensemble with Manifold Learning Algorithm and Kernel-Based Fuzzy Self-Organizing Map. Knowl. Based Syst. 2017, 121, 99–110. [Google Scholar] [CrossRef]
- Alfaro Cortés, E.; Gámez Martínez, M.; García Rubio, N. Multiclass Corporate Failure Prediction by Adaboost.M1. Int. Adv. Econ. Res. 2007, 13, 301–312. [Google Scholar] [CrossRef]
- Ravi, V.; Kurniawan, H.; Thai, P.N.K.; Kumar, P.R. Soft Computing System for Bank Performance Prediction. Appl. Soft Comput. 2008, 8, 305–315. [Google Scholar] [CrossRef]
- Geng, R.; Bose, I.; Chen, X. Prediction of Financial Distress: An Empirical Study of Listed Chinese Companies Using Data Mining. Eur. J. Oper. Res. 2015, 241, 236–247. [Google Scholar] [CrossRef]
- Chandra, D.K.; Ravi, V.; Bose, I. Failure Prediction of Dotcom Companies Using Hybrid Intelligent Techniques. Expert Syst. Appl. 2009, 36, 4830–4837. [Google Scholar] [CrossRef]
- Huang, C.; Yang, Q.; Du, M.; Yang, D. Financial Distress Prediction Using SVM Ensemble Based on Earnings Manipulation and Fuzzy Integral. Intell. Data Anal. 2017, 21, 617–636. [Google Scholar] [CrossRef]
- Xu, W.; Fu, H.; Pan, Y. A Novel Soft Ensemble Model for Financial Distress Prediction with Different Sample Sizes. Math. Probl. Eng. 2019, 2019, e3085247. [Google Scholar] [CrossRef]
- Liang, D.; Tsai, C.-F.; Lu, H.-Y. (Richard); Chang, L.-S. Combining Corporate Governance Indicators with Stacking Ensembles for Financial Distress Prediction. J. Bus. Res. 2020, 120, 137–146. [Google Scholar] [CrossRef]
- Bureau van Dijk/Moody’s Analytics Amadeus Database. Available online: https://amadeus.bvdinfo.com/version-2021517/home.serv?product=AmadeusNeo (accessed on 14 June 2021).
- Adamko, P.; Klieštik, T.; Kováčová, M. An GLM Model for Prediction of Crisis in Slovak Companies. In Proceedings of the Conference Proceedings of the 2nd International Scientific Conference—EMAN 2018—Economics and Management: How to Cope with Disrupted Times, Ljubljana, Slovenia, 22 March 2018; pp. 223–228. [Google Scholar]
- Kliestik, T.; Vrbka, J.; Rowland, Z. Bankruptcy Prediction in Visegrad Group Countries Using Multiple Discriminant Analysis. Equilibrium. Q. J. Econ. Econ. Policy 2018, 13, 569–593. [Google Scholar] [CrossRef]
- Du, X.; Li, W.; Ruan, S.; Li, L. CUS-Heterogeneous Ensemble-Based Financial Distress Prediction for Imbalanced Dataset with Ensemble Feature Selection. Appl. Soft Comput. 2020, 97, 106758. [Google Scholar] [CrossRef]
- Adamko, P.; Kliestik, T. Proposal for a Bankruptcy Prediction Model with Modified Definition of Bankruptcy for Slovak Companies. In Proceedings of the 2nd Multidisciplinary Conference: Conference Book, Madrid, Spain, 2–4 November 2016; Yargı Yayınevi, Ankara, Turkey: Madrid, Spain, 2016; p. 7. [Google Scholar]
- Bradley, A.P. The Use of the Area under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Pintelas, P.E. Combining Bagging and Boosting. World Acad. Sci. Eng. Technol. Int. J. Math. Comput. Sci. 2007, 1, 372–381. [Google Scholar]
- Lahmiri, S.; Bekiros, S.; Giakoumelou, A.; Bezzina, F. Performance Assessment of Ensemble Learning Systems in Financial Data Classification. Intell. Syst. Account. Financ. Manag. 2020, 27, 3–9. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Leong, L. Analyzing Big Data with Decision Trees. Available online: https://scholarworks.sjsu.edu/etd_projects/366/ (accessed on 23 May 2021).
- Freund, Y. A More Robust Boosting Algorithm. arXiv 2009, arXiv:0905.2138. [Google Scholar]
- Long, P.M.; Servedio, R.A. Random Classification Noise Defeats All Convex Potential Boosters. Mach. Learn. 2010, 78, 287–304. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Klieštik, T.; Klieštiková, J.; Kováčová, M.; Švábová, L.; Valášková, K.; Vochozka, M.; Oláh, J. Prediction of Financial Health of Business Entities in Transition Economies; Addleton Academic Publishers: New York, NY, USA, 2018; ISBN 978-1-942585-39-8. [Google Scholar]
- Sivasankar, E.; Selvi, C.; Mahalakshmi, S. Rough Set-Based Feature Selection for Credit Risk Prediction Using Weight-Adjusted Boosting Ensemble Method. Soft Comput. 2020, 24, 3975–3988. [Google Scholar] [CrossRef]
- Adamko, P.; Siekelova, A. An Ensemble Model for Prediction of Crisis in Slovak Companies. In Proceedings of the 17th International Scientific Conference Globalization and Its Socio-Economic Consequences: Proceedings, Rajecke Teplice, Slovakia, 4–5 October 2017; pp. 1–7. [Google Scholar]
- Pisula, T. An Ensemble Classifier-Based Scoring Model for Predicting Bankruptcy of Polish Companies in the Podkarpackie Voivodeship. J. Risk Financ. Manag. 2020, 13, 37. [Google Scholar] [CrossRef]
- Chow, J.C.K. Analysis of Financial Credit Risk Using Machine. Learning. Dissertation, Thesis, Aston University, Birmingham, UK, 2017. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Kovacova, M.; Kliestik, T.; Valaskova, K.; Durana, P.; Juhaszova, Z. Systematic Review of Variables Applied in Bankruptcy Prediction Models of Visegrad Group Countries. Oeconomia Copernic. 2019, 10, 743–772. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Date of Publishing | Data | V4 Country | Sector | Non-Failed Companies | Failed Companies | Sample | Method | AUC (%) |
|---|---|---|---|---|---|---|---|---|---|
| Jakubik and Teply [20] | 2011 | 1993–2005 | CR | non-financial | 606 | 151 | 757 | LR | n/a |
| Valecky and Slivkova [21] | 2012 | 2008 | CR | all | 200 | 200 | 400 | LR | 86.25 |
| Karas and Reznakova [22] | 2014 | 2010–2013 | CR | manufacturing | 2.346 | 610 | 2.956 | DA | 93.91 |
| Vochodzka, Strakova and Vachal [23] | 2015 | 2003–2012 | CR | transport | n/a | n/a | 12.930 | LR | 91.75 |
| Hajdu and Virag [24] | 2001 | 1991 | HU | all | 77 | 77 | 154 | NN, LR, DA | n/a |
| Chrastinova [25] | 1998 | n/a | SK | agricultural | n/a | n/a | 1.123 | MDA | n/a |
| Gurcik [26] | 2002 | n/a | SK | agricultural | n/a | n/a | 60 | MDA | n/a |
| Hurtosova [27] | 2009 | 2004–2006 | SK | all | 333 | 94 | 427 | LR | n/a |
| Delina and Packova [28] | 2013 | 1993–2007 | SK | all | 1.457 | 103 | 1.560 | LR | n/a |
| Harumova and Janisova [29] | 2014 | 2008–2011 | SK | all | n/a | n/a | 11.253 | LR | n/a |
| Gulka [30] | 2016 | 2012–2014 | SK | all | 120.252 | 602 | 120.854 | LR | 80.81 |
| Jencova, Stefko and Vasanicova [31] | 2020 | 2017 | SK | electrical engineering | n/a | n/a | 1.000 | LR | 95.35 |
| Svabova, Michalkova, Durica and Nica [32] | 2020 | 2016–2018 | SK | all | 66.155 | 9.497 | 75.652 | DA, LR | 93.40 |
| Valaskova, Durana, Adamko and Jaros [33] | 2020 | 2016–2018 | SK | agricultural | n/a | n/a | 3.329 | MDA | 86.30 |
| Pisula [34] | 2012 | 2004–2012 | PL | transport | 150 | 55 | 205 | LR | 94.80 |
| Balina and Juszczyk [35] | 2014 | 2007–2010 | PL | transport | 40 | 20 | 60 | DA, LR, NN | n/a |
| Pisula, Mentel and Brozyna [36] | 2015 | n/a | PL | transport | 24 | 23 | 47 | MLP, SVM | 94.70 |
| Brozyna, Mentel and Pisula [37] | 2016 | 1997–2003 | Pl SK | transport | 23 | 24 | 47 | CART, LR, MLP, k-NN | 95.00 |
| Noga and Adamowicz [38] | 2021 | n/a | PL | wood | 36 | 36 | 72 | DA | 89.00 |
| Country | The Year 2017 | The Year 2018 | ||||||
|---|---|---|---|---|---|---|---|---|
| Number | % | Number | % | |||||
| Non-Failed | Failed | Non-Failed | Failed | Non-Failed | Failed | Non-Failed | Failed | |
| SK | 122,946 | 32,178 | 79.26 | 20.74 | 122,846 | 32,278 | 79.19 | 20.81 |
| CZ | 76,634 | 20,845 | 78.62 | 21.38 | 76,633 | 20,846 | 78.61 | 21.39 |
| PL | 59,780 | 8,487 | 87.57 | 12.43 | 59,579 | 8,688 | 87.27 | 12.73 |
| HU | 298,713 | 47,999 | 86.16 | 13.84 | 299,189 | 47,523 | 86.29 | 13.71 |
| Total | 558,073 | 109,509 | 83.60 | 16.40 | 558,247 | 109,335 | 83.62 | 16.38% |
| Financial Variables | Number |
|---|---|
| current assets/current liabilities | 11 |
| current liabilities/total assets (or total liabilities) | 10 |
| working capital/total assets, cash/total assets, total debt/total assets | 9 |
| current assets/total assets | 8 |
| current assets/total sales | 7 |
| cash/current liabilities, sales/total assets, value added/total sales | 5 |
| accounts payable/total sales, current liabilities/total sales, EBITDA/total assets, inventory/total sales, EBIT/shareholder funds, quick assets/current liabilities, retained earnings/total assets, shareholder funds/total assets | 4 |
| cash flow/shareholder funds, cash/current assets, EBIT/total assets, EBIT/value added, EBITDA/permanent equity, EBITDA/total sales, financial expenses/EBITDA, financial expenses/net income, financial expenses/total assets, financial expenses/value added, fixed assets/total assets, EBT/total assets, long-term debt/total assets, net cash flows from financing activities per share, net income/shareholder funds, net income/total sales, net profit/average fixed assets, cash/current liabilities, receivables/total sales, EAT/total assets, shareholder funds/permanent equity, total debt/equity | 3 |
| № | ID | Type | Financial Variable | Formula |
|---|---|---|---|---|
| 1 | X01 | Activity | asset turnover ratio | sales/total assets |
| 2 | X16 | Activity | current assets to sales ratio | current assets/sales |
| 3 | X18 | Activity | inventory to sales ratio | inventories/sales |
| 4 | X32 | Activity | net assets turnover ratio | net sales/total assets |
| 5 | X38 | Activity | total liabilities to sales ratio | total liabilities/sales |
| 6 | X06 | Leverage | debt to EBITDA ratio | total liabilities/EBITDA |
| 7 | X10 | Leverage | debt ratio | total liabilities/total assets |
| 8 | X11 | Leverage | current assets to total assets ratio | current assets/total assets |
| 9 | X14 | Leverage | solvency ratio | cash flow/total liabilities |
| 10 | X15 | Leverage | short-term debt ratio | current liabilities/total assets |
| 11 | X21 | Leverage | long-term debt ratio | non-current liabilities/total assets |
| 12 | X02 | Liquidity | current ratio | current assets/current liabilities |
| 13 | X12 | Liquidity | cash to total assets ratio | cash and cash equivalents/total assets |
| 14 | X22 | Liquidity | cash ratio | cash and cash equivalents/current liabilities |
| 15 | X23 | Liquidity | operating cash flow ratio | cash flow/current liabilities |
| 16 | X26 | Liquidity | quick ratio | (current assets—stock)/current liabilities |
| 17 | X36 | Liquidity | net working capital | current assets—current liabilities |
| 18 | X04 | profitability | ROE (of EAT) | net income/shareholder’s equity |
| 19 | X05 | profitability | EBITDA margin | EBITDA/sales |
| 20 | X07 | profitability | ROA (of EAT) | net income/total assets |
| 21 | X09 | profitability | ROA (of EBIT) | EBIT/total assets |
| 22 | X13 | profitability | ROA (of cash-flow) | cash flow/total assets |
| 23 | X19 | profitability | free cash flow to sales ratio | cash flow/sales |
| 24 | X20 | profitability | net profit margin | net income/sales |
| 25 | X28 | profitability | ROE (of EBIT) | EBIT/shareholder’s equity |
| 26 | X31 | profitability | cash flow to operating revenue ratio | cash flow/EBIT |
| 27 | X35 | profitability | EBIT margin | EBIT/sales |
| Element | Parameter | Initial Setting | Notes | Examined |
|---|---|---|---|---|
| Global (all elements) | prior probabilities | Uniform | To set equal class probabilities. | No |
| RobustBoost | robust error goal | 0.05 | The main difference in comparison with other boosting algorithms. | Yes |
| number of weak learners | 100 | Default settings. | Yes | |
| score’s transformation | logit function | Original scores oscillate around zero, which is the default threshold. | No | |
| CART | split criterion | deviance | Also known as cross-entropy. | No |
| surrogate | On | Datasets with missing data. | No | |
| prune criterion | impurity | It is calculated via a setting in the split criterion, in this case, deviance. | No | |
| maximum number of splits | 20 | A smaller number could eliminate some of the weaker predictors. | Yes | |
| k-NN | search method | kd-tree | The number of dimensions is relatively small, and the number of entities is relevantly high. | No |
| number of neighbours | 30 | The low number can decrease the bias at the cost of variance, and many numbers can reduce a random noise effect at the cost of a less distinct boundary. | Yes | |
| distance | Cityblock | Manhattan distance was also used by Brozyna et al. [37]. | Yes |
| Procedure | Variables | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|---|
| Elimination | X02, X07, X10, X36 | 92.53 | 85.32 | 93.94 | 78.92 | 74.72 | 0.9543 |
| Growth | X02, X04, X07, X10, X20, X36 | 92.42 | 85.69 | 93.74 | 78.76 | 74.54 | 0.9552 |
| Procedure | Variables of k-NN Element | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|---|
| Elimination | X02, X07, X10, X36 | 87.24 | 80.39 | 88.59 | 67.40 | 60.95 | 0.9260 |
| Growth | X02, X04, X07, X10, X20, X36 | 86.17 | 60.14 | 91.28 | 58.80 | 50.52 | 0.9257 |
| The best variant | X07, X10 | 89.90 | 85.64 | 90.73 | 73.55 | 68.50 | 0.9420 |
| Process | Financial Variables | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|---|
| Elimination | X02, X07, X10, X36 | 92.44 | 85.64 | 93.78 | 78.82 | 74.61 | 0.9555 |
| Growth | X02, X04, X07, X10, X36 | 92.38 | 86.02 | 93.59 | 78.70 | 74.48 | 0.9560 |
| Model | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|
| Simple Voting | 92.69 | 88.07 | 93.59 | 79.78 | 75.86 | - |
| Average Model | 92.80 | 87.91 | 93.76 | 80.01 | 76.12 | 0.9632 |
| Final Model | 94.25 | 81.25 | 96.80 | 82.24 | 78.82 | 0.9640 |
| Model | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|
| RobustBoost | 94.25 | 78.66 | 97.31 | 81.76 | 78.44 | 0.9634 |
| CART | 92.11 | 89.05 | 92.70 | 78.70 | 74.69 | 0.9598 |
| k-NN | 91.65 | 86.34 | 92.69 | 77.21 | 72.78 | 0.9588 |
| Simple Voting | 92.69 | 88.07 | 93.59 | 79.78 | 75.86 | - |
| Average Model | 92.80 | 87.91 | 93.76 | 80.01 | 76.12 | 0.9632 |
| Final Model | 94.25 | 81.25 | 96.80 | 82.24 | 78.82 | 0.9640 |
| Country | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|
| Slovakia | 92.27 | 79.57 | 95.60 | 81.07 | 76.24 | 0.9562 |
| Czechia | 93.99 | 84.81 | 96.49 | 85.79 | 82.00 | 0.9682 |
| Poland | 95.00 | 78.89 | 97.35 | 80.06 | 77.21 | 0.9626 |
| Hungary | 95.04 | 81.76 | 97.15 | 81.89 | 79.02 | 0.9650 |
| Visegrad group | 94.25 | 81.25 | 96.80 | 82.24 | 78.82 | 0.9640 |
| Model | Accuracy | Sensitivity | Specificity | F1Score | MCC | AUC |
|---|---|---|---|---|---|---|
| Zmijewski [19] | 84.56 | 93.09 | 82.89 | 66.38 | 61.62 | 0.9447 |
| Kliestik, Vrbka, and Rowland [69] | 71.34 | 92.72 | 67.15 | 51.45 | 44.80 | 0.9022 |
| Adamko, Kliestik, and Kovacova [68] | 86.52 | 90.94 | 85.66 | 68.85 | 63.94 | 0.9350 |
| Durica, Frnda, and Svabova [40] | 91.91 | 88.91 | 92.50 | 78.26 | 74.18 | 0.9531 |
| Final model | 94.25 | 81.25 | 96.80 | 82.24 | 78.82 | 0.9640 |
| Authors | Year | Country | Model | Formula/Methodology | Variables |
|---|---|---|---|---|---|
| Zmijewski [19] | 1984 | USA | probit | net income/total assets (X07), total liabilities/total assets (X10), current assets/current liabilities (X02) | |
| Kliestik, Vrbka, and Rowland [69] | 2018 | CZ HU PL SK | MDA | current assets/current liabilities (X02), net income/shareholder’s equity (X04), net income/total assets (X07), total liabilities/total assets (X10), current assets/total assets (X11), cash and cash equivalents/total assets (X12), current liabilities/total assets (X15), cash and cash equivalents/current liabilities (X22), return on assets (X27), return on equity (X28), profit margin (X35), dummy variabs: Czech Republic (CZ), Slovak Republic (SK) | |
| Adamko, Kliestik, and Kovacova * [68] | 2018 | SK | logit | current assets/total assets (X11), current liabilities/total assets (X15), EBIT/total assets (X09), total liabilities/total assets (X10), cash flow/total liabilities (X14) | |
| Durica, Frnda, and Svabova [40] | 2019 | PL | CART | Impurity function: Gini index Stop criterion for splitting: (Maximal depth: 5, Pure node, Minimal parent size: 100, Minimal leaf size: 50, Minimal purity improvement: 0.0001) | total liabilities/total assets (X10), EBIT/shareholder’s equity (X28), cash flow/total liabilities (X14) |
| Final model | 2021 | CZ HU PL SK | ensemble model | Ratios of elements: RobustBoost-to-CART-to-k-NN is 65-to-20-to-15, Threshold is 0.58 | current assets/current liabilities (X02), net income/shareholder´s equity (X04), net income/total assets (X07), total liabilities/total assets (X10), current assets—current liabilities (X36). |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pavlicko, M.; Durica, M.; Mazanec, J. Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries. Mathematics 2021, 9, 1886. https://doi.org/10.3390/math9161886
Pavlicko M, Durica M, Mazanec J. Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries. Mathematics. 2021; 9(16):1886. https://doi.org/10.3390/math9161886
Chicago/Turabian StylePavlicko, Michal, Marek Durica, and Jaroslav Mazanec. 2021. "Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries" Mathematics 9, no. 16: 1886. https://doi.org/10.3390/math9161886
APA StylePavlicko, M., Durica, M., & Mazanec, J. (2021). Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries. Mathematics, 9(16), 1886. https://doi.org/10.3390/math9161886