
Eigenvalue Estimates via Pseudospectra †

Abstract
1. Introduction
2. Eigenvalues via Pseudospectra
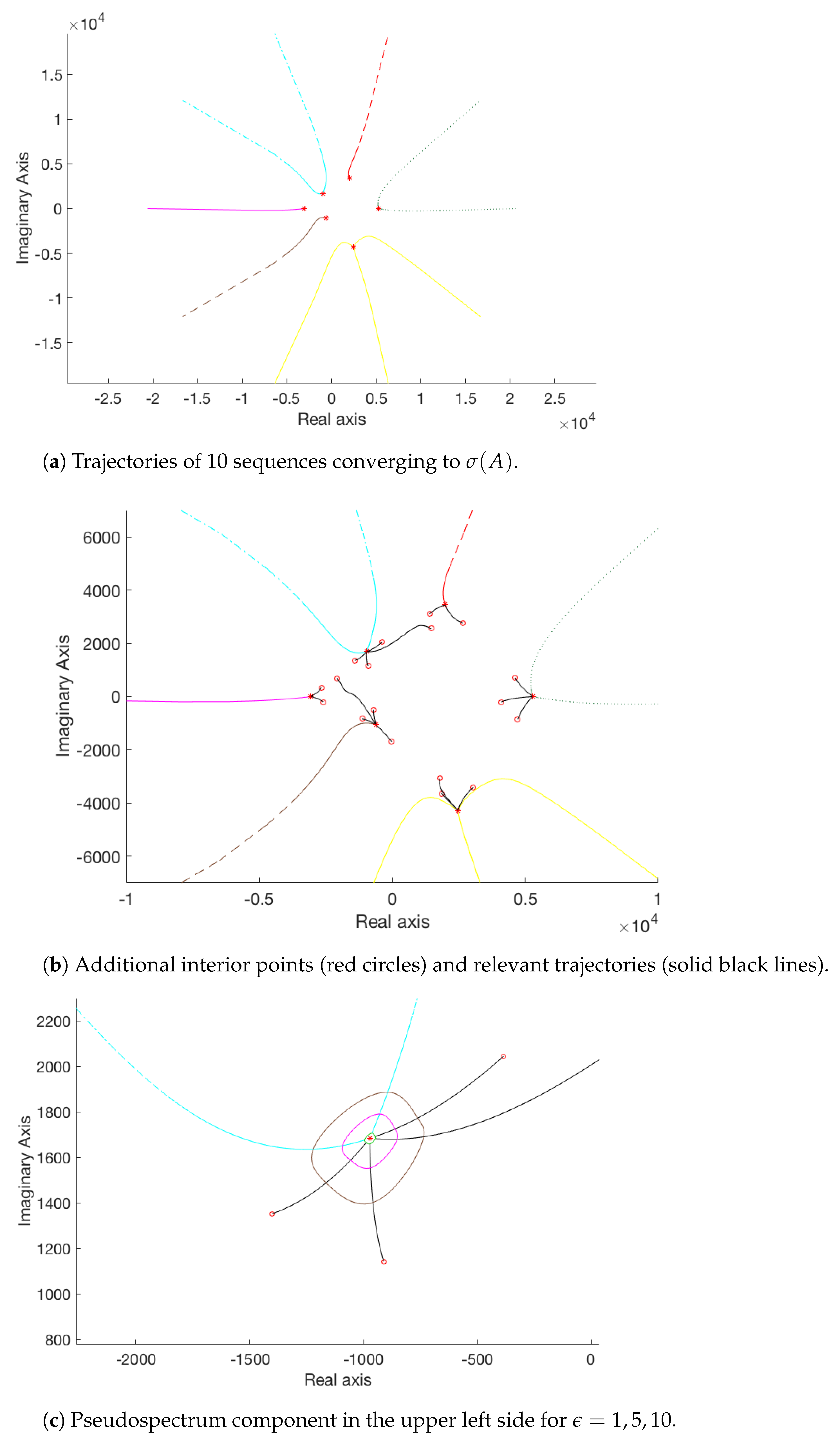
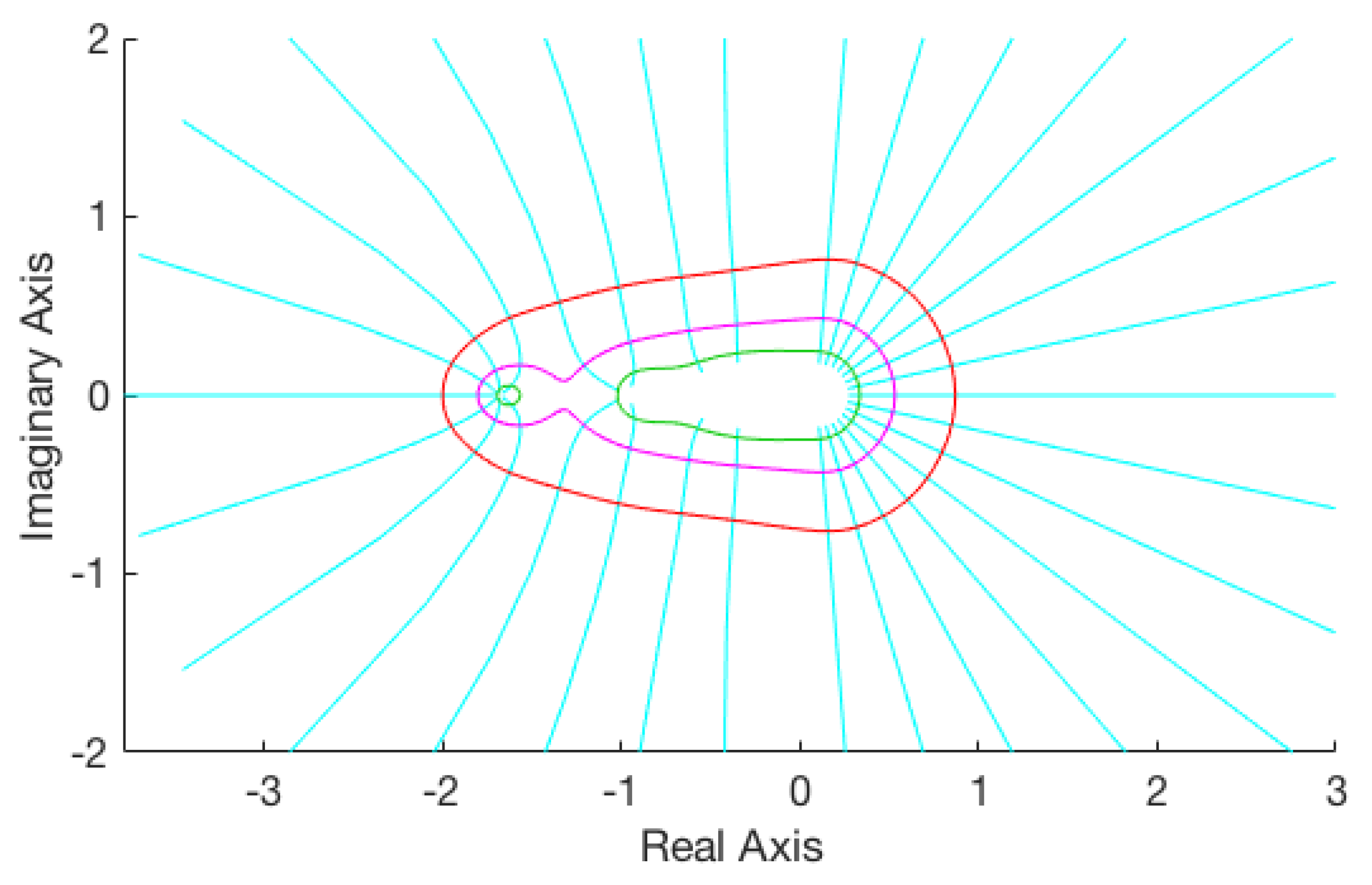
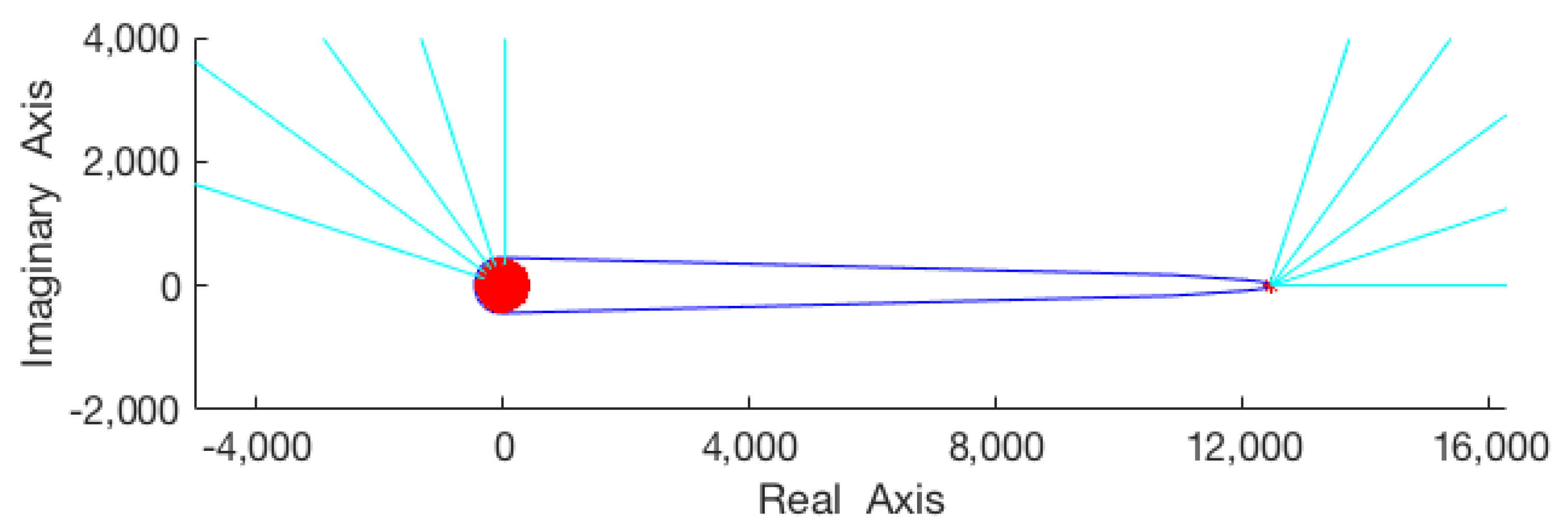
2.1. Numerical Experiments
2.1.1. Pseudospectrum Computation
- Select a tuple of initial points encircling the spectrum; for instance, these can be chosen on the circle .
- Construct eigenvalue approximating sequences (), as in (2). If () are such that , the length of each sequence is determined, so that for all , where is some prefixed parameter value. In other words, indicates the tolerance with which the approached by the constructed sequences eigenvalues should be approximated and corresponds to the minimum parameter for which pseudospectra will be computed.
- Classify the sequences into distinct clusters, according to the proximity of their final terms. This step may be performed using a k-means clustering algorithm, using a suitable criterion to evaluate the optimal number of groups.
- Compute
- If necessary, repeat the procedure for t additional points between the centroids of the detected clusters, constructing additional sequences, so that
- Detect boundary points of for any choice of parameters along the polygonal chains formed by the total of constructed sequences of points by interpolation.
- Fit closed spline curves passing through the respective sets of boundary points in for the various choices of to obtain sketches of the corresponding pseudospectra .
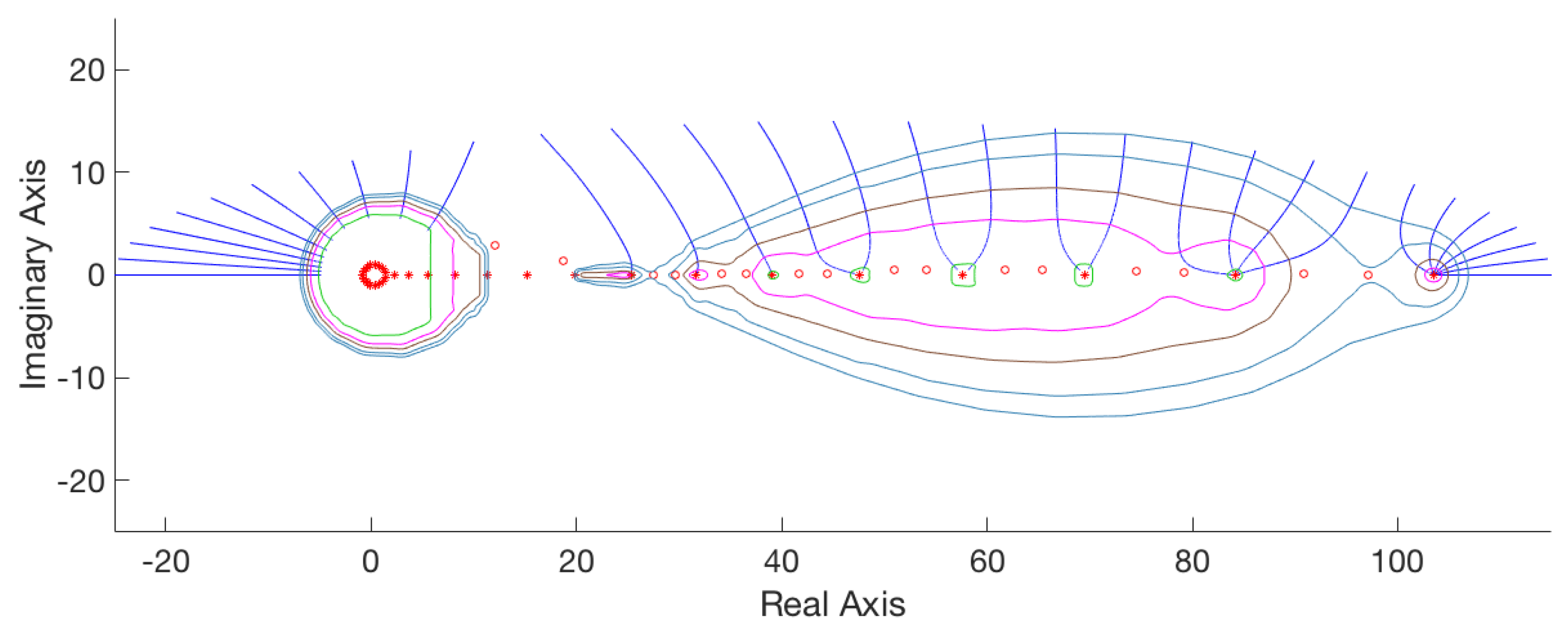
3. Matrix Polynomials
Numerical Experiments
4. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Landau, H.J. On Szegö’s eigenvalue distribution theorem and non–Hermitian kernels. J. Analyse Math. 1975, 28, 216–222. [Google Scholar] [CrossRef]
- Varah, J.M. On the separation of two matrices. SIAM J. Numer. Anal. 1979, 16, 216–222. [Google Scholar] [CrossRef]
- Wilkinson, J.H. Sensitivity of eigenvalues II. Utilitas Math. 1986, 30, 243–286. [Google Scholar]
- Demmel, W. A counterexample for two conjectures bout stability. IEEE Trans. Aut. Control 1987, 32, 340–342. [Google Scholar] [CrossRef]
- Trefethen, L.N. Approximation theory and numerical linear algebra. In Algorithms for Approximation, II (Shrivenham, 1988); Chapman & Hall: London, UK, 1990; pp. 336–360. [Google Scholar]
- Nachtigal, N.M.; Reddy, S.C.; Trefethen, L.N. How fast are nonsymmetric matrix iterations? SIAM J. Matrix. Anal. 1992, 13, 778–795. [Google Scholar] [CrossRef]
- Mosier, R.G. Root neighborhoods of a polynomial. Math. Comput. 1986, 47, 265–273. [Google Scholar] [CrossRef]
- Reddy, S.C.; Trefethen, L.N. Lax–stability of fully discrete spectral methods via stability regions and pseudo–eigenvalues. Comput. Methods Appl. Mech. Eng. 1990, 80, 147–164. [Google Scholar] [CrossRef]
- Higham, D.J.; Trefethen, L.N. Stiffness of ODEs. BIT Numer. Math. 1993, 33, 285–303. [Google Scholar] [CrossRef]
- Davies, E.; Simon, B. Eigenvalue estimates for non–normal matrices and the zeros of random orthogonal polynomials on the unit circle. J. Approx. Theory 2006, 141, 189–213. [Google Scholar] [CrossRef]
- Böttcher, A.; Grudsky, S.M. Spectral Properties of Banded Toeplitz Matrices; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2005. [Google Scholar]
- Van Dorsselaer, J.L.M. Pseudospectra for matrix pencils and stability of equilibria. BIT Numer. Math. 1997, 37, 833–845. [Google Scholar] [CrossRef]
- Lancaster, P.; Psarrakos, P. On the pseudospectra of matrix polynomials. SIAM J. Matrix Anal. Appl. 2005, 27, 115–129. [Google Scholar] [CrossRef][Green Version]
- Tisseur, F.; Higham, N.J. Structured pseudospectra for polynomial eigenvalue problems with applications. SIAM J. Matrix Anal. Appl. 2001, 23, 187–208. [Google Scholar] [CrossRef]
- Trefethen, L.N.; Embree, M. Spectra and Pseudospectra: The Behavior of Nonnormal Matrices and Operators; Princeton University Press: Princeton, NJ, USA, 2005. [Google Scholar]
- Brühl, M. A curve tracing algorithm for computing the pseudospectrum. BIT 1996, 36, 441–454. [Google Scholar] [CrossRef]
- Sun, J.-G. A note on simple non–zero singular values. J. Comput. Math. 1988, 62, 235–267. [Google Scholar]
- Kokiopoulou, E.; Bekas, C.; Gallopoulos, E. Computing smallest singular triples with implicitly restarted Lanczos biorthogonalization. Appl. Num. Math. 2005, 49, 39–61. [Google Scholar] [CrossRef]
- Bekas, C.; Gallopoulos, E. Cobra: Parallel path following for computing the matrix pseudospectrum. Parallel Comput. 2001, 27, 1879–1896. [Google Scholar] [CrossRef]
- Bekas, C.; Gallopoulos, E. Parallel computation of pseudospectra by fast descent. Parallel Comput. 2002, 28, 223–242. [Google Scholar] [CrossRef]
- Trefethen, L.N. Computation of pseudospectra. Acta Numer. 1999, 9, 247–295. [Google Scholar] [CrossRef]
- Duff, I.S.; Grimes, R.G.; Lewis, J.G. Sparse matrix test problems. ACM Trans. Math. Softw. 1989, 15, 1–14. [Google Scholar] [CrossRef]
- Kolotilina, L.Y. Lower bounds for the Perron root of a nonnegative matrix. Linear Algebra Appl. 1993, 180, 133–151. [Google Scholar] [CrossRef][Green Version]
- Liu, S.L. Bounds for the greater characteristic root of a nonnegative matrix. Linear Algebra Appl. 1996, 239, 151–160. [Google Scholar] [CrossRef]
- Duan, X.; Zhou, B. Sharp bounds on the spectral radius of a nonnegative matrix. Linear Algebra Appl. 2013, 439, 2961–2970. [Google Scholar] [CrossRef]
- Xing, R.; Zhou, B. Sharp bounds on the spectral radius of nonnegative matrices. Linear Algebra Appl. 2014, 449, 194–209. [Google Scholar] [CrossRef]
- Liao, P. Bounds for the Perron root of nonnegative matrices and spectral radius of iteration matrices. Linear Algebra Appl. 2017, 530, 253–265. [Google Scholar] [CrossRef]
- Elsner, L.; Koltracht, I.; Neumann, M.; Xiao, D. On accuate computations of the Perron root. SIAM J. Matrix. Anal. 1993, 14, 456–467. [Google Scholar] [CrossRef]
- Lu, L. Perron complement and Perron root. Linear Algebra Appl. 2002, 341, 239–248. [Google Scholar] [CrossRef]
- Dembélé, D. A method for computing the Perron root for primitive matrices. Numer. Linear Algebra Appl. 2021, 28, e2340. [Google Scholar] [CrossRef]
- Fatouros, S.; Psarrakos, P. An improved grid method for the computation of the pseudospectra of matrix polynomials. Math. Comp. Model. 2009, 49, 55–65. [Google Scholar] [CrossRef][Green Version]
- Tisseur, F.; Meerbergen, K. The quadratic eigenvalue problem. SIAM Rev. 1997, 39, 383–406. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Iterations | Mean Rel. Error (Perron Root) | Mean Rel. Error (Other Eigenvalues) |
|---|---|---|
| 1 | 0.0011 | 0.4205 |
| 2 | 7.0082 | 0.1783 |
| 3 | 0.1030 | |
| 4 | 0.0680 | |
| 5 | 0.0483 |
| # of Initial Points | 10 | 15 | 30 |
|---|---|---|---|
| Iterations (initial points) | 11,206 | 18,455 | 35,159 |
| Iterations (additional points) | 16,116 | 14,872 | 11,883 |
| Iterations (total) | 27,322 | 33,327 | 47,042 |
| # of Iterations | Mean Rel. Error (Perron Root) | Mean Rel. Error (Intermediate Eigenvalues) | Mean Rel. Error (Leftmost Eigenvalues) |
|---|---|---|---|
| 1 | 0.0916 | 0.2795 | 11.0866 |
| 100 | 0.0373 | 0.1507 | 5.7968 |
| 200 | 0.0192 | 0.1206 | 5.3541 |
| 300 | 0.0103 | 0.1103 | 5.1174 |
| 400 | 0.0055 | 0.0956 | 4.9582 |
| 500 | 0.0029 | 0.0843 | 4.8652 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsouleas, G.; Panagakou, V.; Psarrakos, P. Eigenvalue Estimates via Pseudospectra. Mathematics 2021, 9, 1729. https://doi.org/10.3390/math9151729
Katsouleas G, Panagakou V, Psarrakos P. Eigenvalue Estimates via Pseudospectra. Mathematics. 2021; 9(15):1729. https://doi.org/10.3390/math9151729
Chicago/Turabian StyleKatsouleas, Georgios, Vasiliki Panagakou, and Panayiotis Psarrakos. 2021. "Eigenvalue Estimates via Pseudospectra" Mathematics 9, no. 15: 1729. https://doi.org/10.3390/math9151729
APA StyleKatsouleas, G., Panagakou, V., & Psarrakos, P. (2021). Eigenvalue Estimates via Pseudospectra. Mathematics, 9(15), 1729. https://doi.org/10.3390/math9151729