1. Introduction
Many queueing systems are analysed for their dynamic and optimal control related to system access, resource allocation, changing service area characteristics and so on. Sets of computerised tools and procedures provide large data sets which can be useful to expand potential of classical optimisation methods. The paper deals with a known model of a multi-server queueing system with controllable allocation of customers between heterogeneous servers which are differentiated by their service and cost attributes. For the queueing system with two heterogeneous servers it has been shown in [
1] by using a dynamic programming approach that to minimise the mean sojourn time of customers in the system, the faster server must be always used and the customer has to be assigned to the slower server if and only if the number of customers in the queue exceeds the certain threshold level. Furthermore, this result was obtained independently in more simple form in [
2,
3]. In [
4], the author has analysed a multi-server version of such a system and confirmed a threshold nature of the optimal policy as well.
The problem of an optimal allocation of customers between heterogeneous servers in queueing systems with additional costs with the aim to minimise the long-run average cost per unit of time is notoriously more difficult. Some progress has been made after the appearance of a review paper [
5]. In [
6,
7], the authors studied a model with set-up costs using a hysteretic control rule, thereby stressing the algorithmic aspects of the optimal control structure. The same system has been discussed in [
8], where a direct method that provides a closed-form expression for the stationary occupancy distribution was proposed. In [
9,
10], the authors have used theoretical study and exhaustive numerical analysis to show that for some specified servers, ordering the optimal allocation policy which minimises the long-run average cost belongs to a set of structural policies. In other words, for the servers’ enumeration (
1), the allocation control policy denoted by
f can be defined through a sequence of threshold levels
. With respect to the defined policy, the server operating at highest rate should remain busy by non-empty queueing system. The
kth server (
) is used only if the first
servers are busy and the queue length reaches a threshold level
. In the general case, the optimal threshold levels can depend on states of slower server and formally the optimal policy
f is not of a pure threshold type. However, since the
kth threshold value may vary by at most one when the state of slower server changes and it has a weak effect on the average cost, such influence can be neglected. Hence the optimal allocation policy for multi-server heterogeneous queueing system can be treated as a threshold one.
Searching for the optimal values of
by direct minimising the average cost function can be expensive, especially when
K is large. To calculate the optimal threshold levels we can use a policy-iteration algorithm [
11,
12,
13] which constructs a sequence of improved policies that converges to optimal one. This algorithm is a fairly versatile tool for solving various optimisation problems. Unfortunately, as is usually the case in practice, this algorithm is not without some limitations, such as the difficulties associated with convergence when the traffic is close to loaded, limitation on the process dimension and, consequently, on the number of states. Thus, we would like to compensate for some of the weaknesses of this algorithm with other methods for calculating the optimal control policy. The contribution of this paper can be briefly described in two conceptual parts. In the first part, we propose a heuristic solution (HS) to obtain functional relationships for optimal thresholds based on a simple discrete approximation of the system’s behaviour. The second part is devoted to the alternative machine learning technique such as artificial neural networks (NN) [
14,
15,
16] which is used again for the estimation of the optimal threshold levels. The policy-iteration algorithm is used in the paper to generate the data sets needed both to verify the quality of the proposed optimal threshold estimation methods and to train the neural networks. We strongly believe that the trained neural network can be successfully used to calculate the optimal thresholds for those system parameters for which alternative numerical methods are difficult or impossible to use, for example, in heavy traffic case, or, in general, to reconstruct the areas of optimality without usage of time-expensive algorithms and procedures. There are some number of papers on prediction of the stochastic behaviour of queueing systems and networks using machine learning algorithms, see e.g., [
17,
18] and references therein. However, we unsuccessfully tried to find published works where heuristics and machine learning methods would be used to solve a similar optimisation problem for heterogeneous queueing systems and therefore we consider this paper relevant.
This paper is organised as follows. In
Section 2, we briefly discuss a mathematical model.
Section 3 introduces some heuristic choices for threshold levels that turn out to be nearly optimal.
Section 4 presents results when the trained neural network was ran on verification data of the policy-iteration algorithm.
2. Mathematical Model
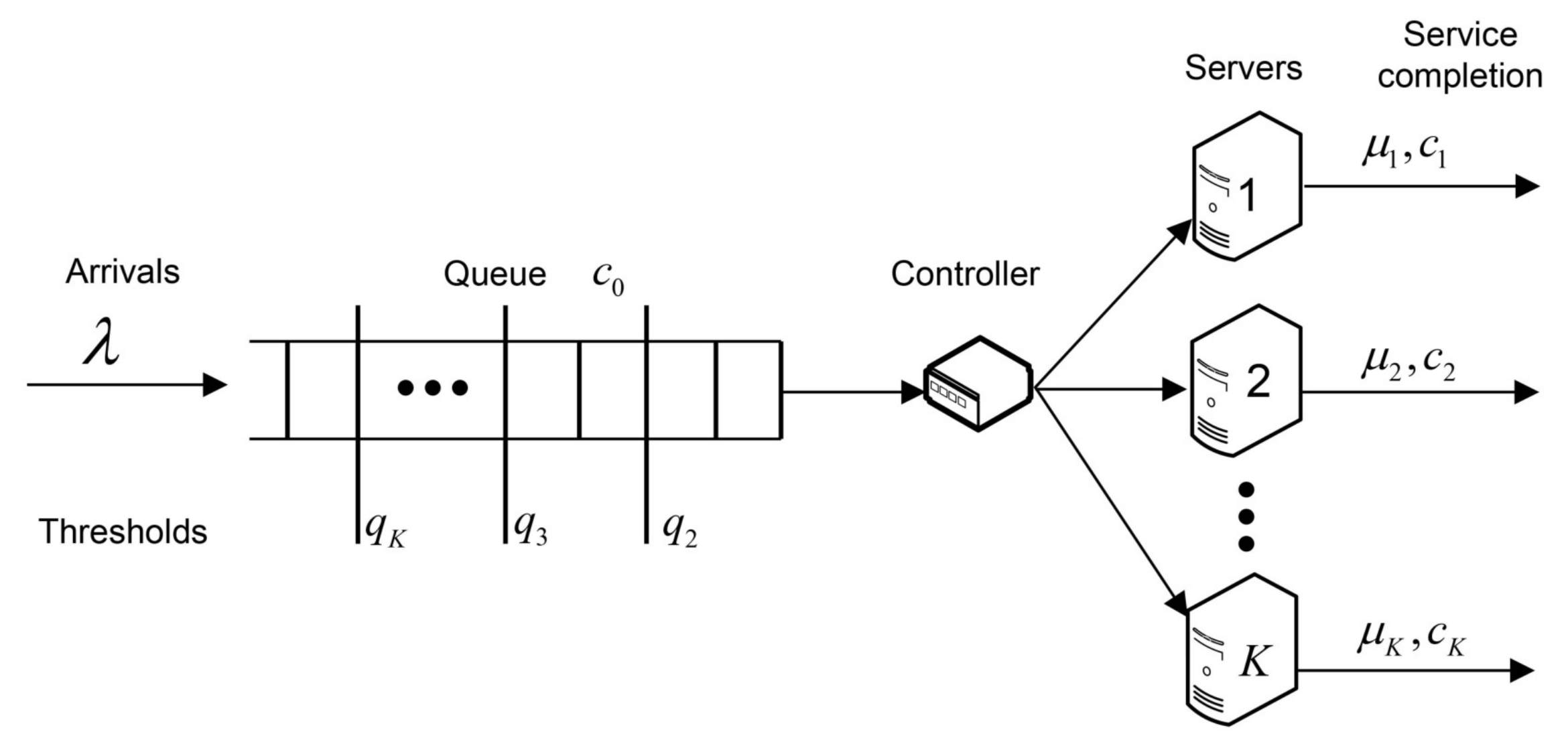
We summarise briefly the model under study. The queueing system is of the type
with infinite-capacity buffer and
K heterogeneous servers. This system is shown schematically in
Figure 1. The Poisson arrival stream has a rate
and the exponential distribution of the service time at server
j has a rate
. We assume that the service in the system is without preemption, when customer in service cannot change the server. The random variables of the inter-arrival times and the service times of the servers are assumed to be independent. An additional cost structure is introduced, consisting of the operating cost
per unit of time of service on server
j and the holding cost
of waiting in the queue. Assume that the servers are enumerated in a way
where
stands for the mean operating cost per customer for the
jth server.
The controller has full information about the system’s state and, based on this information, can make control actions on the system at the decision epochs when certain state transitions occur, following the prescription of the policy f. In our case, the controller selects the control action at the time when a new customer enters the system and at the service completion times, if the queue is not empty. When a new customer arrives, it joins the queue and at the same time, the controller sends another customer from the head of the queue to one of the idle servers or leaves it in the queue. At the service completion, the customer leaves the corresponding server, and at the same time the controller takes the next customer from the head of the queue, if it is not empty, and dispatches it to one of idle servers or can leave it in the queue as well. The service completion in the system without waiting customers does not require the controller to perform any control action.
The fact that the optimal policy for the problem of minimising the long-run average cost per unit of time belongs to a set of threshold-based policies for the multi-server heterogeneous queueing systems with costs were proved first in [
10] and further conformed for systems with heterogeneous groups of servers in [
19]. The corresponding optimal thresholds can in the general case depend on the states of slower servers. However, according to obtained numerical results in [
9], we can neglect the weak influence of the slower servers’ states on the optimal allocation policy for the faster servers. This phenomena was discussed additionally in Example 2. Therefore, we may assume that the optimal policy belongs to the class of a pure threshold policy when the use of a certain server depends solely on the number of waiting customers in the queue. Specifically, for the system under study, such a policy is defined by the following sequence of threshold levels:
The policy prescribes the use of the k fastest servers whenever the number of customers waiting in the queue satisfies the condition .
To calculate optimal thresholds we need to formulate the introduced optimisation problem in terms of a Markov decision process. This process is based on a
-dimensional continuous-time Markov chain
with an infinitesimal matrix
which depends on the policy
f. Here the component
stands for the number of waiting customers at time
t and
The state space of the process operating under some policy f is , where the notations and are used respectively for the queue length and for the state of jth server in state .
The possible server states are partitioned as follows:
The sets
and
denote the sets of idle and busy servers in state
, respectively. The set of control actions
a is
. If
, the controller allocates a customer to the queue. Otherwise, if
, the controller instructs a customer to occupy the server with a number
a. In addition, we can define the subsets
of admissible actions in state
x The policy
f specifies the choice of a control action at any decision epoch and the infinitesimal matrix
of the Markov-chain (
3) has then the following elements,
where
is defined as
-dimensional unit vector with each element equal to zero except the
jth position (
).
We will search for the optimal control policy among the set of stationary Markov policies
f that guarantee ergodicity of the Markov chain
. The corresponding stability condition is obviously defined as
. It follows from the fact, that if number of customers exceeds a threshold
, then the queueing systems behaves like a
queue with an arrival rate
and total service rate
. As it is known, see e.g., [
13], the ergodic Markov chain with costs implies the equality of the long-run average cost per unit of time for the policy
f and the corresponding assemble average, that can be written in the form
where
is an immediate cost in state
. The cost function
is given by
This function describes the total average cost up to time
t given the initial state is
x and
is a stationary state distribution for the policy
f. The policy
is said to be optimal when for
defined in (
4) we evaluate
To evaluate optimal threshold levels and optimised value for the mean average cost per unit of time the policy-iteration Algorithm 1 is used. This algorithm constructs a sequence of improved policies until the average cost optimal is reached. It consists of three main steps: value evaluation, policy improvement and threshold evaluation. The Value evaluation is based on solving, for a given policy
f, a system of linear equations
| Algorithm 1 Policy-iteration algorithm |
- 1:
procedurePIA() - 2:
▹ Initial policy - 3:
- 4:
▹ Value evaluation - 5:
for do - 6:
- 7:
end for - 8:
- 9:
if then return - 10:
else , go to step 4 - 11:
end if - 12:
- 13:
end procedure
|
For the dynamic-programming value function
, which indicates a transition effect of an initial state
x to the total average cost and satisfies the following asymptotic relation,
In order to make the system (
6) solvable, one of the values
must be set to zero, e.g., for
we set
. Since in our case
, the first equation of the system (
6) is of the form
. In the policy improvement step a new policy
is calculated by minimising the value function
for any state
and any admissible control action
. The algorithm converges if the policies
f and
on neighbouring iterations are equal. In the threshold evaluation we calculate the optimal thresholds
,
, based on optimal policy
f. As an initial policy we select the policy which prescribes in any state the usage of a server
j with the minimal value of the mean operating cost
per customer. More detailed information on deriving the dynamic programming equations for the heterogeneous queueing system and calculating the corresponding optimal allocation control policy can be found in [
9]. For existence of an optimal stationary policy and convergence of the policy-iteration algorithm we refer to [
12,
20,
21,
22].
To realise the policy-iteration algorithm we convert the
-dimensional state space
of the Markov decision process to a one-dimensional equivalent state space. Let
be a one-to-one mapping of the vector state
to a value from
which is of the form
A new state after transition involving the addition or removal of customer in some state
, in a one-dimensional state space is calculated by
Further in the algorithm, an infinite buffer system must be approximated by an equivalent system where the number of waiting places is finite but at the same time is sufficiently large. As a truncation criterion, we use the loss probability which should not exceed some small value .
Remark 1. If the buffer size is W, the number of states isIn case the number of waiting customers is getting larger as the level , all servers must be occupied and the system dynamics is the same as in a classical queue with arrival rate λ and service rate . The stationary state probabilities for the states x where the component satisfy the following difference equationwhich has a solution in a geometric form, , . For details and theoretical substantiation see, e.g., [23]. Note that the value of included in this formula can be estimated by a heuristic solution (9). Then the truncation parameter W of the buffer size can be evaluated from the following constraint for the loss probabilitywhere . After simple algebra, it implies Example 1. Consider the system with and . All other parameters take the following values| j | 0 | 1 | 2 | 3 | 4 | 5 |
| 1 | 5 | 4 | 3 | 2 | 1 |
| - | 20 | 8 | 4 | 3 | 1 |
| - | 0.25 | 0.50 | 0.75 | 0.67 | 1.00 |
The truncation parameter W of the buffer size is chosen at value 80 which for guarantees that . Here was calculated by (9). In a control table, we summarise the functions which specify the control actions at time of arrivals to a certain state x:| System State | Queue Length |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ... |
| (0,*,*,*,*) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| (1,0,*,*,*) | 0 | 0 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| (1,1,0,*,*) | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| (1,1,1,0,*) | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| (1,1,1,1,0) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 5 | 5 |
| (1,1,1,1,1) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Threshold levels , , can be evaluated by comparing the optimal actions for . In this example the optimal policy is defined here through a sequence of threshold levels and . The bold and underline format in a control table is used to label the change of the control action in a certain system state.
In the next example we give some arguments that allow us to work further only with the threshold-based control policies.
Example 2. Consider the system with servers. The aim of this example consists in the following: With respect to the system states and the assignment to the second server can in general depend not only on the number of customers in the queue but also on the state of the third server. In this example it is optimal to make an assignment in state x but not in state y. We solve optimisation problem for the following parameters:
, , and ,
, , and .
The of optimal solution for the first and second group of system parameters are represented in Table 1 and Table 2, respectively. We notice that for most parameter values the optimal decision can be made independently of the states of the slower servers. However, it is interesting to consider the reasons for such possible dependence. It is evident that in our optimisation problem, the optimal policy assigns a customer to the fastest free server in states for which this would not be optimal if there were no arrivals. This is because the system should be ready for possible arrivals, which, if they occur, will wish to see a less congested system.
Consider now the system with three servers in the states and , where . Let us consider the case of potential service completion at the second server, taking into account a large number q of accompanied arrivals. Because of large q, it is optimal to occupy all accessible idle servers. The states mentioned above become and . Thus, the difference of value functions measures the advantage that will be obtained in the case of the assignment to the second processor . The events of service completion on the second server provide the incentive to make an assignment to the second server. However, if the two initial states are and , the measure of advantage if service completion takes place is . Since we expect that the value function is convex in q, it is plausible that the incentive to make an assignment to the second server is greater in state than in . Numerical examples proposed in Table 3 confirm our expectations. The further numerical examples show that the threshold levels have a very weak dependence of slower servers’ states. According to our observations, the optimal threshold may vary by at most 1 when the state of a slower server changes.
The data needed either to verify the heuristic solution or for training and verification of the neural network was generated by a policy-iteration algorithm in form of the list
Example 3. Some elements of the list S for the queueing system are
4. Artificial Neural Networks
Artificial Neural Networks (NN) belong to a set of supervised machine learning methods. It is most popular in different applied problems including data classification, pattern recognition, regression, clustering and time series forecasting. Here we show that the NN can give even more positive results compared to the HS that indicates the possibility to use it for predicting the structural control policies.
The data set
S (
8) is used to explore predictions for the optimal threshold levels through the NN. The multilayer neural network is used for the data classification. It can be formally defined as a function
, which maps an input vector
of dimension
to an estimate output
of the class number
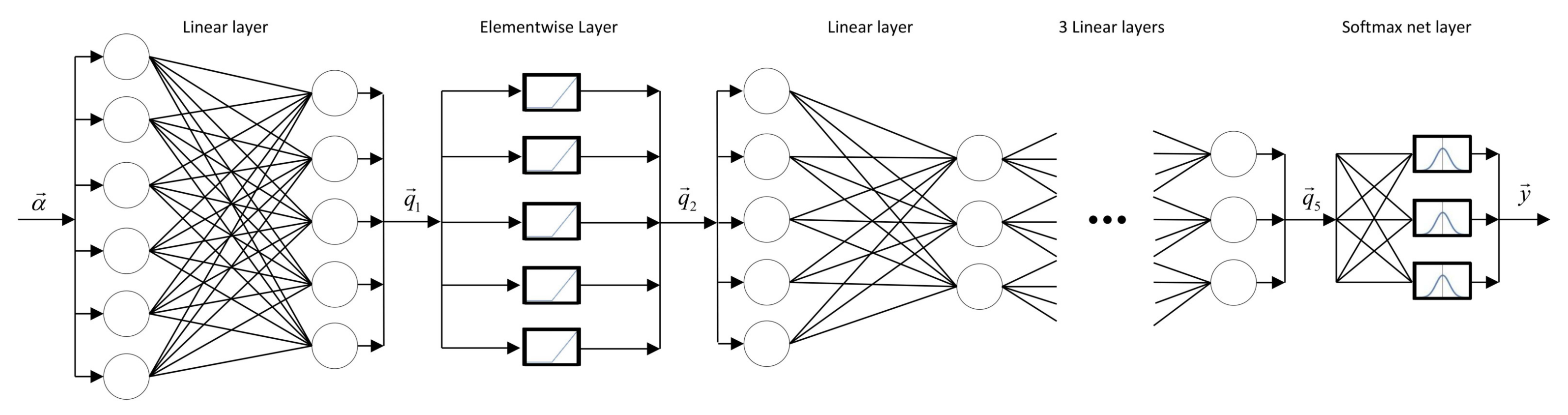
. The network is decomposed into 6 layers as illustrated in
Figure 4, each of which represents a different function mapping vectors to vectors. The successive layers are: a linear layer with an output vector of size
k, a nonlinear elementwise activation layer, other three linear layers with output vectors of size
k and a nonlinear normalisation layer.
The first layer is an affine transformation
where
is the output vector,
is the weight matrix,
is the bias vector. The rows in
are interpreted as features that are relevant for differentiating between corresponding classes. Consequently,
is a projection of the input
onto these features. The second layer is an elementwise activation layer which is defined by the nonlinear function
setting negative entries of
to zero and uses only positive entries. The next three layers are other affine transformations,
where
,
, and
,
. The last layer is the normalisation layer
, whose componentwise is of the form
The last layer normalises the output vector with the aim to get the values between 0 and 1. The output can be treated as a probability distribution vector, where the Nth element represents the likelihood that belongs to class N.
We use 70% of the same data
S which was not used to verify the quality of the HS in a training phase of the NN and the rest of
S—as validation data. We train a multilayer (6-layer) NN using an adaptive moment estimation method [
24] and the neural network toolbox in
Mathematica© of the Wolfram Research. Then we verify the approximated function
which should be accurate enough to be used to predict new output from verification data. The algorithm was ran many times on samples and networks with different sizes. In all cases the results were quite positive and indicate the potential of machine learning methodology for optimisation problems in the queueing theory.
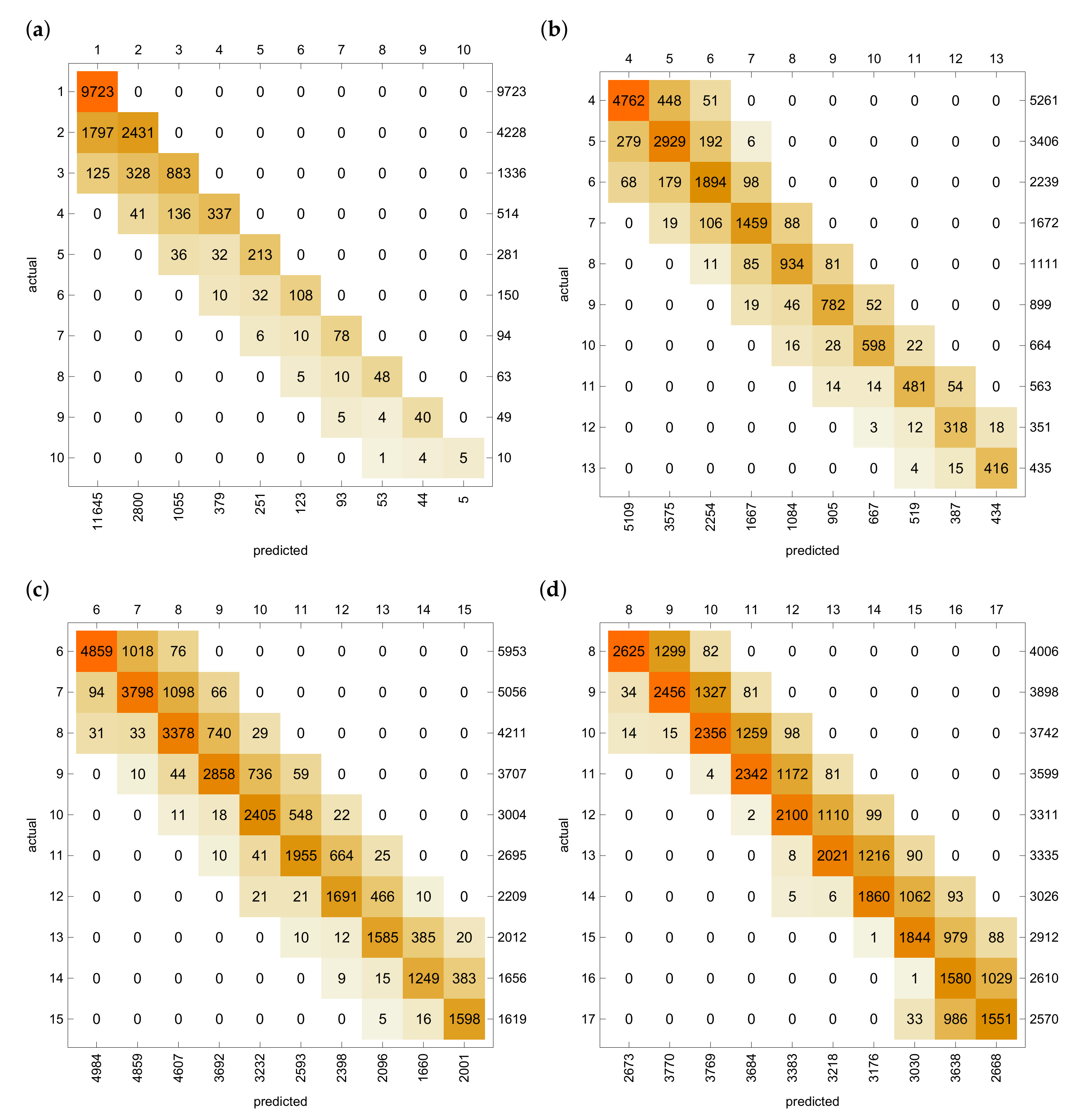
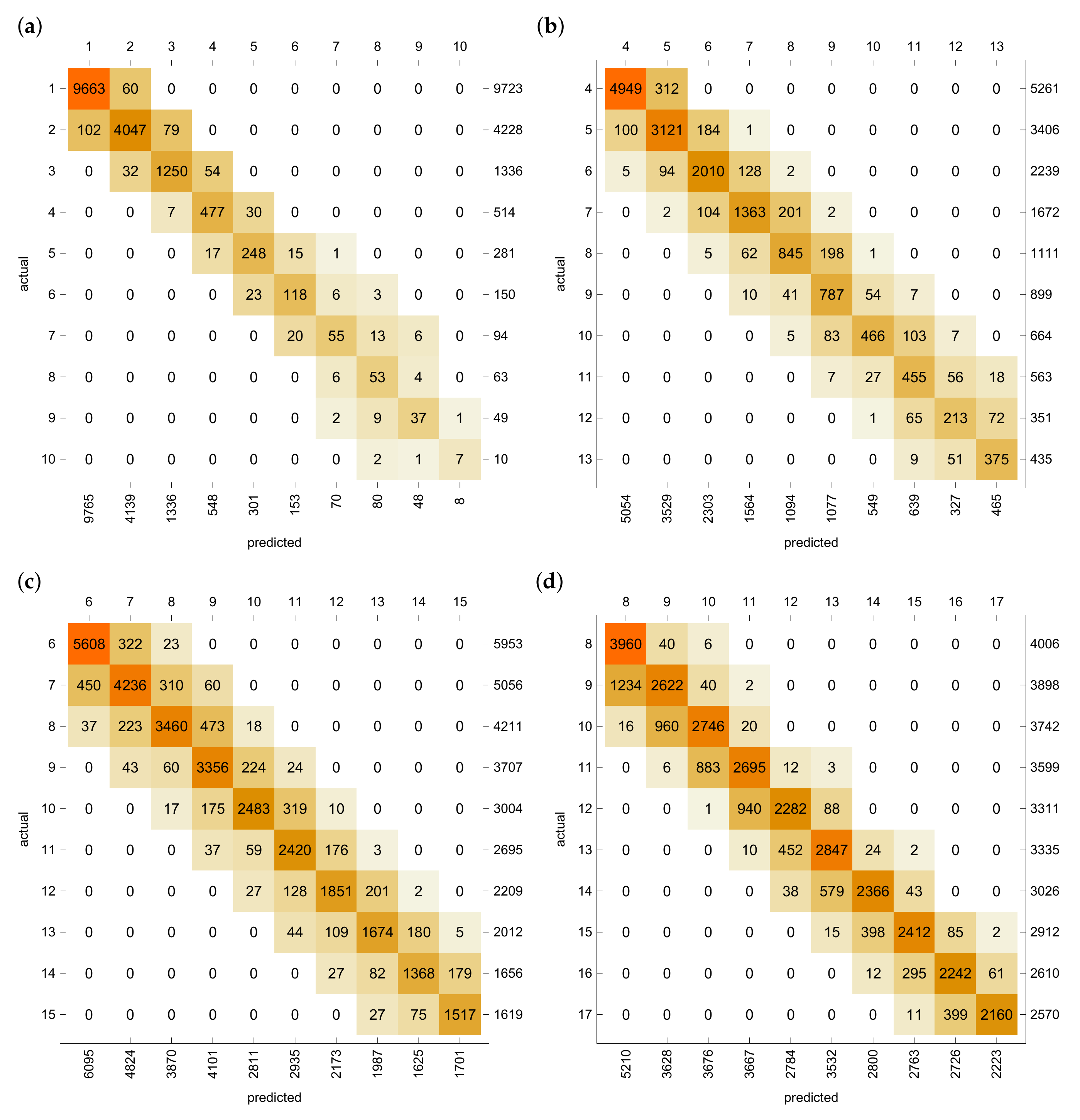
Example 5. The results of estimations of the optimal threshold values using the trained NN are summarised again in form of confusion matrices, as is shown in Figure 5. The overall accuracy of classification and accuracies for the values with deviations are given in Table 5. We can see that the NN methodology exhibits even more accurate estimations for the optimal thresholds if the results are compared with the corresponding HS. 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}