Abstract
In this paper, we investigate the CUSUM-type estimator of mean change-point models based on m-asymptotically almost negatively associated (m-AANA) sequences. The family of m-AANA sequences contains AANA, NA, m-NA, and independent sequences as special cases. Under some weak conditions, some convergence rates are obtained such as , and , where and . Our rates are better than the ones obtained by Kokoszka and Leipus (Stat. Probab. Lett., 1998, 40, 385–393). In order to illustrate our results, we do perform simulations based on m-AANA sequences. As important applications, we use the CUSUM-type estimator to do the change-point analysis based on three real data such as Quebec temperature, Nile flow, and stock returns for Tesla. Some potential applications to change-point models in finance and economics are also discussed in this paper.
MSC:
62F12; 62E20
1. Introduction
Change-point problems originally arose in the context of quality control, where one typically observes the output of a production line and would wish to signal deviation from an acceptable level while observing the data. The change-point problems may be changes of the mean, variance, and other parameters. Therefore, detecting a change-point and estimating its location are both very important in data processing, modeling, estimation, and inference. The cumulative sum (CUSUM) method is a popular method to solve this problem; see Csörgő and Horváth [1] and Shiryaev [2], and among others. In this paper, we consider the mean change-point models, which can be applied in many fields. For example, investors pay attention to the mean changes of the economic growth rate, consumption level, exchange rate, stock returns, and so on. Therefore, we consider the mean change-point models in this paper. For some , let . Here, denotes the largest integer not exceeding x. For , suppose the observations satisfy the model:
where mean parameter , change-amount , as well as change-point location are unknown and are mean zero random variables. In Model (1), the estimators of and based on the CUSUM method (see Kokoszka and Leipus [3]) are, respectively:
where:
and . Kokoszka and Leipus [3] used the Hájek–Rényi-type inequalities to obtain the convergence rate of CUSUM-type estimator . In this paper, we also study the consistency of estimator in (2) based on dependent sequences of . Now, let us recall some related definitions. Block et al. [4] introduced an important concept of negative associated (NA) random variables, which can be applied in reliability theory, percolation theory, and multivariate analysis.
Definition 1.
A finite family of random variables is said to be NA if for every pair of disjoint subsets A and B of 1, 2,…, n,
whenever f and g are coordinatewise nondecreasing and the covariance exists.
Motivated by the notion of NA random variables, Chandra and Ghosal [5] introduced the concept of asymptotically almost negatively associated (AANA) random variables.
Definition 2.
A sequence of random variables is called AANA if there exists a nonnegative sequence as such that:
for all , and for all coordinatewise nondecreasing continuous functions f and g whenever the variances exist. The sequence is said to be the mixing coefficients of .
Hu et al. [6] gave a natural extension of m-NA from NA random variables.
Definition 3.
Let be a fixed integer. A sequence of random variables is said to be m-NA if for any and any , such that for all , we have that are NA random variables.
Motivated by Hu et al. [6], Nam et al. [7] gave the concept of m-AANA.
Definition 4.
Let be a fixed integer. A sequence of random variables is said to be m-AANA if there exists a nonnegative sequence as such that:
for all , , and for all coordinatewise nondecreasing continuous functions f and g whenever the variances exist.
Nam et al. [7] obtained the maximal inequalities for m-AANA sequences and gave its applications to Hájek–Rényi-type inequalities and the strong law of large numbers. Ko [8] extended the results of Nam et al. [7] to the Hilbert space. The family of m-AANA sequences contains AANA (with ), NA, m-NA, and independent sequences as special cases. The notions of NA and AANA have received increasing attention recently. One can refer to [9,10,11,12,13,14,15], etc.
For the mean change-point model (1), Shi et al. [16] extended the results of Kokoszka and Leipus [3] to NA sequences and obtained the strong convergence rate for the estimator in (2). Since the m-AANA sequence is weaker than the NA sequence, we study the convergence rate for the estimator based on m-AANA sequences. For more research on the change-point models, we can refer to many works such as [1,17,18,19,20,21,22,23,24] and the references therein. In addition, many researchers have joined the study of change-point models in mathematical finance and econometrics. For example, Shiryaev [25] considered a Brownian motion with mean drift, depending on ,
where and are known constants (as a rule) and is the “disorder” time or change-point location, which can be either a random variable or simply an unknown parameter. Here, is a standard Brownian motion. Obviously, (4) is very important to study Black–Scholes models in finance and economics. For more stochastic models of asset pricing in finance based on change-points, we can refer to Shiryaev [25].
The rest of this paper is organized as follows. Section 2 presents some convergence rates of (for example, , and ). Section 3 provides some simulations to check the results obtained in this paper. As important applications, three real data examples are provided to do the mean change-point analysis in Section 4. The conclusions and further research are discussed in Section 5. Lastly, the main proofs are presented in Section 6.
2. Main Results
First, some assumptions are listed as follows.
Assumption 1.
For some , let be a mean zero sequence of m-AANA random variables with and the mixing coefficient sequence satisfy .
Assumption 2.
For and , denote:
Let:
Then, we obtain the convergence rate of in Theorem 1.
Theorem 1.
Let and Assumptions 1 and 2 be satisfied. Then, for any given ,
As an application of Theorem 1, we have Corollary 1.
Corollary 1.
Let . If in Theorem 1, then for any given ,
Remark 1.
In the mean change-point model (1), if and is an independent and identically distributed sequence of random variables with and , then, by Corollary 1, it has:
which was obtained by (1.5) of Kokoszka and Leipus [3]. In addition, Kokoszka and Leipus [3] considered the sequence satisfying the following dependent condition:
uniformly in , , where . Denote:
Let:
Then, Kokoszka and Leipus [3] obtained that:
(see Corollary 1.1 of [3]). Obviously, our rate (6) is better than that of (9). Thus, our Theorem 1 extends Theorem 1.1 and Corollary 1.1 of [3] to the case of the m-AANA sequence. On the other hand, one can take or in (6) (or (9)), provided (or ) as . Furthermore, let and be an NA sequence. Shi et al. [16] obtained a strong convergence rate , a.s. for any satisfying and . Our convergence rates are weaker than Shi et al. [16]; however, our m-AANA sequence is weaker than the NA sequence, and our change-amount can go to zero or infinity.
3. Simulations
In the mean change-point model (1), we assume that there exists a mean change point location such that:
where satisfy:
where , , is an identity matrix, and is:
and . It is easy to verify that is a m-AANA sequence with and mixing coefficients . For simplicity, we take , , , , and in (10)–(12) to do the simulation with 10000 replications. For the sample , Figure 1 shows the box plots of with different (for example, ) and (for example, ), where is defined by (2).
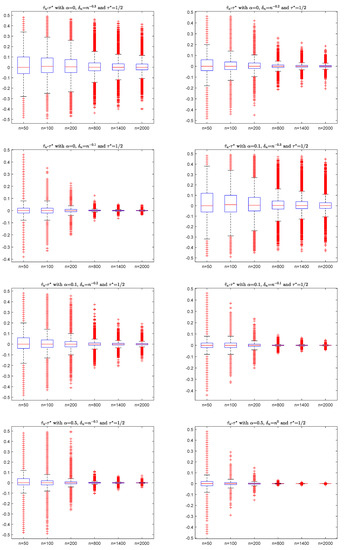
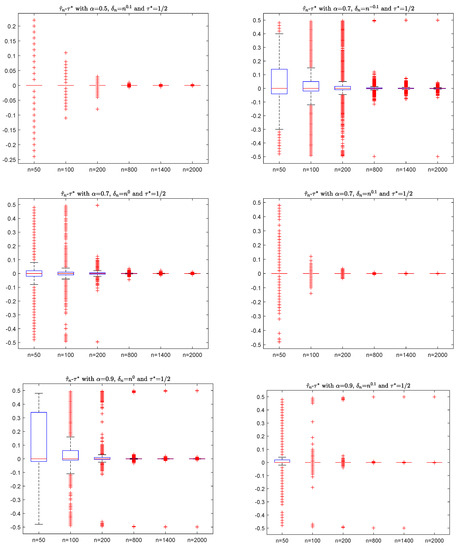
Figure 1.
The box plots of with different and .
In Figure 1, the y-axis is the value of , and the x-axis is the sample n. By the box plots in Figure 1, the differences of go to zero as sample n increases, which agrees with the consistency of (6) in Theorem 1. It has a similar performance if we take different values , so the details are omitted here.
4. Real Data Examples
In this section, we use the CUSUM-type estimator in (2) to do the mean change-point analysis with three real datasets. The first dataset is for the monthly mean temperature of Quebec in Canada from 1944 to 2008. The data can be found at http://climate.weather.gc.ca. For simplicity, we take the data of monthly mean temperatures for June and October, which contain 76 observations denoted by and , , respectively. Let if and if . Figure 2 shows the plot graph of , , where the y-axis is the value of temperature and the x-axis is the sample n.
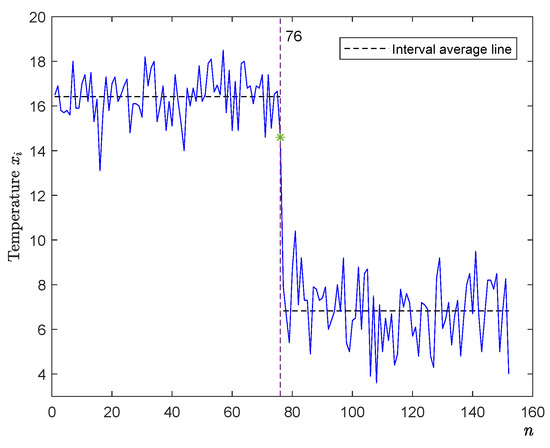
Figure 2.
The plot graph of monthly mean temperatures based on June and October data.
Obviously, the mean temperature of June is different from that of October, so the change-point location is 76 (or ). Now, we use the CUSUM-type estimator to detect , i.e., is defined by:
where and:
Table 1 shows the values of with different values such as .

Table 1.
The values of based on the temperature data.
By Table 1, the estimator with different successfully detects the true change-point location .
Second, we also use estimator to detect a time series of the annual flow of the Nile River at Aswan from 1871 to 1970 (see, for example, Zeileis et al. [26]). It measures annual discharge at Aswan in m3 and is depicted in Figure 3 (there are 100 observations denoted by , ). In Figure 3, the y-axis is the annual flow of the Nile River , and the x-axis is the sample n.
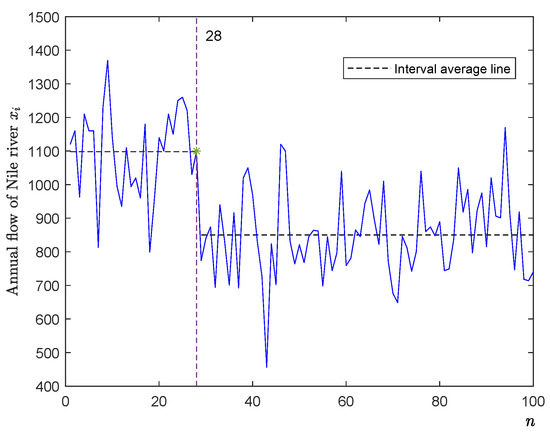
Figure 3.
The plot graph of the annual flow of the Nile River from 1871 to 1970.
Table 2.
The values of based on the Nile River data.
By Table 2, we get a change-point location of 28 or equivalently the year 1898 (see Figure 3). On the other hand, Zeileis et al. [26] and Gao et al. [27] respectively used F-statistics and CUSUM statistics to detected the same change-point location of 28. It is well known that Aswan dam was built in 1898. It significantly changes the annual flow of the river Nile.
Lastly, we do the change-point analysis of returns based on a financial time series. Let be the closing prices of Tesla stock. Therefore, the return is defined as . Figure 4 shows 138 daily returns on the prices of Tesla stock from 1 August 2016 to 13 February 2017. In Figure 4, the y-axis is the i-th return , and the x-axis is the sample n. The data were downloaded from Yahoo Finance. Tesla announced on 22 November 2016 that it had completed the acquisition of SolarCity. It seams that the mean returns changed after that time of 22 November 2016 (the observation is 80). Therefore, we perform the test for this change-point of mean returns.
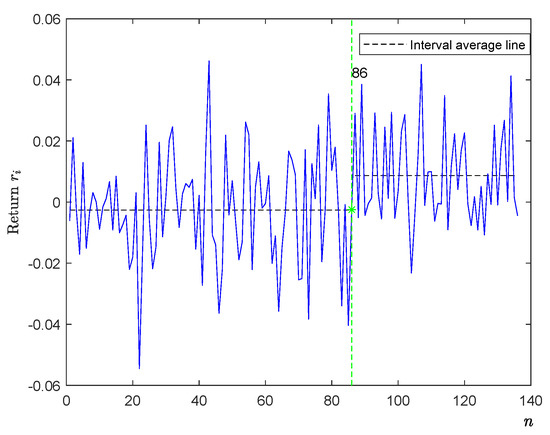
Figure 4.
The plot graph of the mean returns of Tesla stock from 2016 to 2017.
Similar to Kokoszka and Leipus’s CUSUM estimator defined by (2), for any given , Antoch et al. [17] investigated the following CUSUM estimator of defined as:
where:
and . Therefore, we use these CUSUM-type estimators by (13) and by (14) to detect the change-point location , where , . With the different , the values of and are presented in Table 3.
Table 3.
The values of and based on Tesla’s returns data.
By Table 3, the estimators and find the same change-point location of 86 (1 December 2016). Thus, the capital market recognized Tesla’s acquisition of SolarCity on 22 November of 2016, and the mean returns significantly changed from negative to positive after the time of 1 December 2016 (see Figure 4).
5. Conclusions
The CUSUM method is a popular method to detect the change-point. In this paper, we investigate the consistency of CUSUM-type estimator based on m-AANA sequences, which contain many dependent sequences such as NA, m-NA, and AANA sequences. Under the p-th moment () condition, we obtain a general consistency rate , where is defined by (6) and . By taking in Theorem 1, we obtain the convergence rates as:
Therefore, our Theorem 1 and Corollary 1 generalize the results of Kokoszka and Leipus [3]. In addition, in Theorem 1 can be taken as or , if as . Let and be any positive constant sequence satisfying and . Shi et al. [16] obtained a strong convergence rate , a.s. for the case of NA sequence. Our convergence rates are weaker than Shi et al. [16]; however, the m-AANA sequence is weaker than the NA sequence, and the change-amount can go to zero or infinity. In order to check our results, some simulations are shown in Figure 1, which agree with the consistency of Theorem 1. Lastly, three real dataset of Quebec temperature, Nile flow, and returns for Tesla in Section 4 are discussed to show that the CUSUM-type estimator defined by (13) can successfully detect the change-point location. In addition, it is interesting for scholars to study the strong convergence rate and limit distribution of CUSUM-type estimator based on the m-AANA sequence or other dependent sequences in future research. Furthermore, Shiryaev [25] discussed the stochastic disorder problems, which are known as the quickest detection problems. For example, Shiryaev [25] considered the Black–Scholes models with mean drift. Thus, we should pay attention to the applications of change-point models in mathematical finance and econometrics.
6. Proofs of the Main Results
For convenience, in the proofs, let be some positive constants that are independent of n and may have different values in different expressions.
Lemma 1.
(Theorem 3 of Nam et al. [7]). For some , let be an m-AANA sequence of zero mean random variables with mixing coefficients satisfying . Let be a nondecreasing sequence of positive numbers. Then, for any and any integer , we have:
where is a positive constant depending only on p.
Proof of Theorem 1.
Therefore, we have by (3.11) of Kokoszka and Leipus [3] that:
where . By (1) and (3), it is easy to see that:
By (5), (17), and (18), in order to prove (6), we have to prove that:
where is defined (5). On the one hand, for any , it follows from Lemma 1 with that:
where , , are positive constants independentof n. Consequently, by (18)–(20), we have:
On the other hand, it can be checked that:
Therefore, one can obtain analogously the same result that
Thus, the proof of (6) is completed. □
Proof of Corollary 1.
By taking in Theorem 1, one can immediately obtain Corollary 1. □
Author Contributions
Supervision W.Y.; software S.D. and X.D.; writing, original draft preparation, S.D., X.L., and W.Y. All authors read and agreed to the published version of the manuscript.
Funding
This work is supported by NNSF of China (11701004, 11801003), NSF of Anhui Province (2008085MA14, 1808085QA03, 1808085QA17), and Provincial Natural Science Research Project of Anhui Colleges (KJ2019A0006).
Acknowledgments
The authors are deeply grateful to the Editors and anonymous referees for their careful reading and insightful comments. The comments led to the significant improvement of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Csörgő, M.; Horváth, L. Limit Theorems in Change-Point Analysis; Wiley: Chichester, UK, 1997; pp. 170–181. [Google Scholar]
- Shiryaev, A. On stochastic models and optimal methods in the quickest detection problems. Theory Probab. Appl. 2009, 53, 385–401. [Google Scholar] [CrossRef]
- Kokoszka, P.; Leipus, R. Change-point in the mean of dependent observations. Stat. Probab. Lett. 1998, 40, 385–393. [Google Scholar] [CrossRef]
- Block, H.W.; Savits, T.H.; Shaked, M. Some concepts of negative dependence. Ann. Probab. 1982, 10, 765–772. [Google Scholar] [CrossRef]
- Chandra, T.K.; Ghosal, S. The strong law of large numbers for weighted averages under dependence assumptions. J. Theoret. Probab. 1996, 9, 797–809. [Google Scholar] [CrossRef]
- Hu, T.C.; Chiang, C.Y.; Taylor, R.L. On complete convergence for arrays of rowwise m-negatively associated random variables. Nonlinear Anal. 2009, 71, e1075–e1081. [Google Scholar] [CrossRef]
- Nam, T.; Hu, T.; Volodin, A. Maximal inequalities and strong law of large numbers for sequences of m-asymptotically almost negatively associated random variables. Commun. Stat. Theory Methods 2017, 46, 2696–2707. [Google Scholar] [CrossRef]
- Ko, M. Hájek-Rényi inequality for m-asymptotically almost negatively associated random vectors in Hilbert space and applications. J. Inequal. Appl. 2018, 2018, 80. [Google Scholar] [CrossRef]
- Bulinski, A.V.; Shaskin, A. Limit Theorems for Associated Random Fields and Related Systems; World Scientific: Singapore, 2007; pp. 1–20. [Google Scholar]
- Chen, P.; Hu, T.C.; Volodin, A. On complete convergence for arrays of row-wise negatively associated random variables. Theory Probab. Appl. 2008, 52, 323–328. [Google Scholar] [CrossRef]
- Yuan, D.M.; An, J. Rosenthal type inequalities for asymptotically almost negatively associated random variables and applications. Sci. China Ser. A 2009, 52, 1887–1904. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Wang, X.J.; Hu, S.H. Strong laws of large numbers for weighted sums of asymptotically almost negatively associated random variables. Rev. Real Acad. Cienc. Exactas Fis. Nat. Ser. A Mat. 2015, 109, 135–152. [Google Scholar] [CrossRef]
- Wu, Y.F.; Hu, T.C.; Volodin, A. Complete convergence and complete moment convergence for weighted sums of m-NA random variables. J. Inequal. Appl. 2015, 2015, 200. [Google Scholar] [CrossRef]
- Xi, M.M.; Deng, X.; Wang, X.J.; Cheng, Z.Y. Lp convergence and complete convergence for weighted sums of AANA random variables. Commun. Stat. Theory Methods 2018, 47, 5604–5613. [Google Scholar] [CrossRef]
- Ye, R.Y.; Liu, X.S.; Yu, Y.C. Pointwise optimality of wavelet density estimation for negatively associated biased sample. Mathematics 2020, 8, 176. [Google Scholar] [CrossRef]
- Shi, X.; Wu, Y.; Miao, B. Strong convergence rate of estimators of change point and its application. Comput. Stat. Data Anal. 2009, 53, 990–998. [Google Scholar] [CrossRef]
- Antoch, J.; Hušková, M.; Veraverbeke, N. Change-point problem and bootstrap. J. Nonparametr. Stat. 1995, 5, 123–144. [Google Scholar] [CrossRef]
- Lee, S.; Ha, J.; Na, O. The cusum test for parameter change in time series models. Scand. J. Stat. 2003, 30, 781–796. [Google Scholar] [CrossRef]
- Chen, J.; Gupta, A. Parametric Sstatistical Change Point Analysiswith Applications to Genetics Medicine and Finance, 2nd ed.; Birkhäuser: Boston, MA, USA, 2012; pp. 1–30. [Google Scholar]
- Horváth, L.; Hušková, M. Change-point detection in panel data. J. Time Ser. Anal. 2012, 33, 631–648. [Google Scholar] [CrossRef]
- Horváth, L.; Rice, G. Extensions of some classical methods in change point analysis. Test 2014, 23, 219–255. [Google Scholar] [CrossRef]
- Messer, M.; Albert, S.; Schneider, G. The multiple filter test for change point detection in time series. Metrika 2018, 81, 589–607. [Google Scholar] [CrossRef]
- Xu, M.; Wu, Y.; Jin, B. Detection of a change-point in variance by a weighted sum of powers of variances test. J. Appl. Stat. 2019, 46, 664–679. [Google Scholar] [CrossRef]
- Abbas, N.; Abujiya, M.A.R.; Riaz, M.; Mahmood, T. Cumulative sum chart modeled under the presence of outliers. Mathematics 2020, 8, 269. [Google Scholar] [CrossRef]
- Shiryaev, A. Stochastic Disorder Problems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 367–388. [Google Scholar]
- Zeileis, Z.; Kleiber, C.; Krämer, W.; Hornik, K. Testing and dating of structural changes in practice. Comput. Stat. Data Anal. 2003, 44, 109–123. [Google Scholar] [CrossRef]
- Gao, M.; Ding, S.S.; Wu, S.P.; Yang, W.Z. The asymptotic distribution of CUSUM estimator based on α-mixing sequences. Commun. Stat.-Simul. Comput. 2020. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).