Abstract
We will prove that when uniformly distributed random numbers are sorted by value, their successive differences are a exponentially distributed random variable Ex(λ). For a set of n random numbers, the parameters of mathematical expectation and standard deviation is λ = n−1. The theorem was verified on four series of 200 sets of 101 random numbers each. The first series was obtained on the basis of decimals of the constant e = 2.718281…, the second on the decimals of the constant π = 3.141592…, the third on a Pseudo Random Number generated from Excel function RAND, and the fourth series of True Random Number generated from atmospheric noise. The obtained results confirm the application of the derived theorem in practice.
1. Introduction
Random numbers generators are applicable in various areas, such as: Computer simulation, Monte-Carlo method, multiple integration, nonconvex global optimization, scientific computing, commercial finance, electronic gambling equipment (including on-line gambling), and other fields. The modern world ’exploits’ a huge amount of random numbers. Especially in the field of information security, which is based on the cryptography where encryption key randomness is essential [,], the quality of random numbers is directly related to the secure transmission of information [].
One of the basic functions of the human brain is the ability to generate random numbers [,]. There are significant differences in activities of particular brain centers during the processes of generating ordinal numbers and random numbers. The inability of a person to generate random numbers may indicate possible disorders. Furthermore, distinctions in brain functions while generating random numbers may significantly imply certain diseases: Dementia of the Alzheimer type, schizophrenia, multiple sclerosis, and Parkinson’s disease [,,,]. Nonetheless, the human brain as the natural source of random numbers does not represent a significant quantitative capacity. The ability to mimic natural entropy is obviously an extremely intellectual demand. However, materialized mental models with computers completely eliminate this deficit.
Random sequences are produced by two basic types of generators: The True or Physical Random Number Generator (TRNG) and the Pseudo-Random Number Generator (PRNG). True or physical random numbers are generated by a stochastic physical entropy source in the natural world, such as radioactive decay, thermal noise in resistors, the frequency jitter in an oscillator, single photon splitting on a beam-splitter, amplified spontaneous emissions, chaotic laser, and so on []. The natural source of TRNGs is number π [,]. TRNGs usually need some post-processing functions for producing random sequences in physical quantities. Everyday life requires converting physical quantities into digital ones. The generation of random numbers in total meets the demand []. The quality of a PRNG is defined as the randomness of its outputs, whereby high-quality, cryptographically strong PRNGs are practically indistinguishable from TRNG [].
Generating pseudo-random numbers by using computers is a fast and cheap way to provide substantial quantities. Pseudo-random numbers generated in that way must comply with the following criteria: A certain sequence length without repetition, uniformity, and resolution, etc., []. For generating pseudo-random numbers, a large number of PRNGs is used, as well as a large number of tests which must verify the randomness of generated numbers [,,,,,], i.e., quality of the random number generator. Diehard contains 12 tests, with confirmation that the generators that pass the three tests (GCD-greatest common divisor, The Gorilla Test, and The Birthday Spacings Test) seem to pass all the tests in the Diehard Battery of Tests []. TESTU01 offers three batteries of tests called ‘Small Crush’ (which consists of 10 tests), ‘Crush’ (60 tests), and ‘Big Crush’ (45 tests) []. The NIST battery contains 15 tests: The Frequency (Monobit) Test, The Discrete Fourier Transform (Spectral) Test, Maurer’s “Universal Statistical” Test, The Approximate Entropy Test, Cusums Test, etc., []. The reference distributions of tests are dominated by Normal, half-Normal, andχ2 distributions. In accordance with the CLT—Central Limit Theorem—, this outcome is partially expected. However, The Birthday Spacings Test from the Diehard Battery is asymptotically exponentially distributed. The first question is: Why does the Birthday Spacings Test have a hard-shell against the CLT attitude?
According to the de Moivre-Laplace theorem (the earliest version of CLT), the Binomial distribution of binary sequences (the original input string of zero and one to be tested) has a Normal distribution. Now, another question arises: If χ2 is the reference distribution in 10 of the 15 NIST tests, then why the Normal distribution not prevalent?
On the other hand, the Binomial distribution B(p, n) can be approximated by the Poisson distribution P(λ), np = λ. Exponential distribution with parameter λ is the basis of Poison’s processes with the identical parameter λ. Thus, the Binomial distribution of binary sequences can be approximated by an Exponential distribution, Ex(np).
An important property of a set of random numbers is a complete mutual independence of the previous and subsequent generated digits. Such a “longitudinal” lack of influence or unpredictability is the known property of exponential distribution (1):
described with memoryless properties (2):
In the class of random variables whose densities are positive at [0, ∞) and with an equal expectation, the highest differential entropy has an exact exponential distribution.
Wide use of exponential distribution has long been known in natural and technical processes [,,,,]. The recognition period of significance of exponential distribution corresponds with the occurrence of first tests of random numbers []. An analogy of the natural entropy and differential entropy of information theory points to potential of exponential distribution. Furthermore, if we adopt the difference between stochasticity and randomness [] or, respectively, TRNG/PRNG, then the application of Poisson processes in randomness testing, the essential relation between the Poisson and exponential distribution and the maximal differential entropy of exponential distribution, spontaneously forms an idea of the application of a memoryless characteristic (2) in the testing of random numbers. The next theorem proves the existence of these two stated ideas.
2. Exponential Distribution of the Successive Difference Between Random Numbers
Let us denote by Ti−1 the interval between two random adjacent events {ti−1, ti} in the stream of the independent events {t1, t2, t3, …, tn, tn+1} in which the event S has been realized by the random selection of intervals (Figure 1):

Figure 1.
Stream of the independent events ti, intervals Ti, and the independent choice of an interval T•.
Theorem 1.
If the random events {t1, t2, t3, …, tn, tn+1} are independent and uniformly distributed on the arbitrary interval, arranged so that ∀i∈[1, n], ti ≤ ti+1, then the intervals between the successive random events Ti−1 = (ti − ti−1) are such that ∀i∈[1, n], ti ≤ ti+1 has the exponential distribution with the values of mathematical expectation and standard deviation reciprocal to the number of random events n.
Proof.
The procedure of proving the Theorem will be derived by mathematical induction. For this purpose, we need to find the first, second, and third moment of the distribution of intervals between the successive random events Ti−1.
Let the distribution function and the density distribution of the random variable T be equal to F(T) if (T) = F′(T). We need to find the density f(T•) of the interval T, that is, the point S randomly distributed in the intervals A and B.
Random variables T and T•, do not have the same functions and density distributions, f(T) ≠ f(T•) and F(T) ≠ F(T•). The probability of an arbitrary choice of the interval from the point S is proportional to the length of the interval. In a greater number of repetitions, the point S will more often fall on the longer intervals than on the shorter ones. Therefore, we can conclude that the choice probability of the interval T• is higher than the average choice probability of the interval E(T) ≤ E(T•).
The density distribution of the event T• in the interval (ti−1, ti) is equal to f(T•)dT. If n intervals are defined, then the average number of intervals is equal to n⋅f(t)dt, and the average length of all intervals is equal to t⋅n⋅f(t)dt. If the average f(T) is equal to E(T), then the average length of all n intervals is equal to n⋅E(T). Probability f(T•)dT is approximately equal to the ratio between the sum of intervals with the length between ti−1 and ti and the total length of all intervals between the moments of the event appearance. This approximate equality is more accurate if the interval (ti−1, ti) is longer and the number of intervals greater. The density of the random variable T• is equal to (3) []:
In order to determine the mathematical expectation and variance of the random variable T• it is necessary to determine the characteristic function of the random variable T (4):
Since , the E(T) and V(T) of the random variable T are equal to (5):
The characteristic function of the random variable T• is equal to (6):
Since , it follows that (7):
So that the average value is equal to (8):
Since (9)
The variance of the random variable T• is (10):
If we divide the interval T•, whose event S has been implemented, into two intervals A and B, so that
| → | • The interval A is equal from the previous event ti−1 to the event S |
| → | • The interval B is equal from the event S to the following event ti. |
The density of the random variable B on the interval T• equals:
Due to stationarity, it applies (11):
Subintegral function is greater than zero only for values , so we get (12):
where F(T) is distribution function of the random variable T, i.e., . Thus, the density of a probability distribution for the rest of the variable B from the random point S to the next event is (13):
The characteristic function of the random variable B equals (14):
Using the partial integration, we get (15):
The mathematical expectation of the random variable B equals (16):
Since for x = 0 we get the vagueness in the form of “0/0”, thus by applying L’Hopital’s rule we get (17) []:
Using the connection for variance of the random variable B, we get (18):
The same applies for the random variable A (19):
The density of distribution for the random variables A and B are identical. Provided that the characteristics of the uniform distribution of random events have not changed, the probability distributions T, A, and B are identical. From (17), (18), and (19) we get (20) and (21):
The uniformity requirement enables us to form a system of equations with the solutions (22):
When we introduce the obtained relationship from Equations (20) and (21), we get (23):
The expression for from (22) and (23) is (24):
By mathematical induction we establish for k = 1, k = 2 and k = 3. The basic conditions of the division of n intervals, from (6), imply mathematical expectation for k = 1 as (25):
From (22), it follows that for k = 2 (26):
From (24), it follows that for k = 3 (27):
Let us assume that for the integer k is fulfilled (28):
With the assumption for k, for (k+1) it follows (29):
This proves that for every integer ∀n∈N, it is valid (30):
The distribution of a random variable Ti is exponential because the ratio of moments of the exponential distribution is equal to . The condition results in the following: The variance and the standard deviation of the distribution of the random variable T is equal to (31):
These are the identifiable parameters of the exponential distribution (Figure 2).
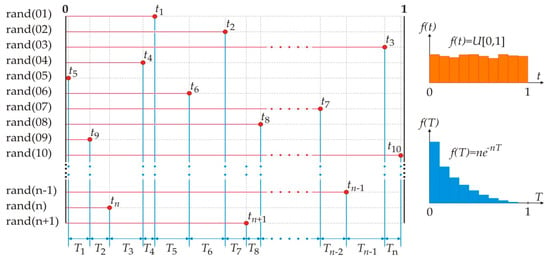
Figure 2.
Fundamental concept is based on the theorem proof.
Random events {t1, t2, t3, …, tn, tn+1} are independent. Distribution interval {T1, T2, …, Tn} between successive values of the random events {t1, t2, t3, …, tn, tn+1} is exponential. Independence of random events {t1, t2, t3, …, tn, tn+1} comes directly from (2)—the memoryless of the exponential distribution.
3. Application of Theorem
Pursuant to the theorem proof, successive differences {T1, T2, …, Tn} of n independent random numbers {t1, t2, t3, …, tn, tn+1} have an exponential distribution with mathematical expectation and function of distribution density (32):
Four series of random numbers were prepared for testing. The first series is formed by successive decimals of the constant e = 2.718281…, the second series is formed by successive decimals of the constant π = 3.141592… The third series of Pseudo Random Numbers, PRNG was generated from Microsoft Excel’s RAND function. The fourth series of True Random Numbers, TRNG was generated from atmospheric noise []. Table 1 contains a series of these numbers.

Table 1.
Series of random numbers.
Numbers are formed by taking five consecutive decimals. For example, from constant “e” the first random number is 0.271828, the second random number is 0.718281, the third random number is 0.182818, the fourth random number is 0.828182, etc. Through this process, 300 random numbers in series “e” were formed. The first set consists of numbers beginning with the first to the 101st decimal, the second set consists of numbers starting from the 2nd to 102nd decimals, the third set consists of numbers from the 3rd to 103rd decimals, etc. The 200th set consists of numbers starting from the 200th to the 300th decimal. The sets are formed by translating the decimal. Each subsequent set is obtained by ejecting the first number from the previous set and introducing the next decimal from the series, which enables successive testing of the decimal points.
Table 2 gives an example of the formation of the first six and last two sets of 101 random numbers derived from consecutive decimals of constant e. In total, 200 such sets e(i), i∈[1, 200] with 101 random numbers were formed.
Table 2.
Two hundred sets of random numbers e(i), i∈[1, 200].
The resulting sets are then sorted by value. Table 3 gives an example of sorting the first six and last two sets with 101 random numbers derived from consecutive decimals of a constant ↓[e(i)], i∈[1, 200], which are shown in the previous Table 2.
Table 3.
Sorted random numbers ↓[e(i)], i∈[1, 200].
In each sorted set ↓[e(i)], i∈[1, 200] with 101 random numbers 100 successive differences are formed Δ↓[e(i)], i∈[1, 200]. An example of consecutive differences in the first six and last two sets is given in Table 4.
Table 4.
Consecutive differences of sorted random numbers Δ↓[e(i)], i∈[1, 200].
Based on the theorem, the exponential distributions of a set Δ↓[e(i)], i∈[1, 200] of random numbers are verified by a χ2 test.
Figure 3 gives an example of verification of Δ↓[e(1)] with a significance threshold of p = 0.22811, i.e., of a set of random numbers Δ↓[e(199)] with a significance threshold of p = 0.57509. Verifications of the exponential distributions are given in Figure 3.
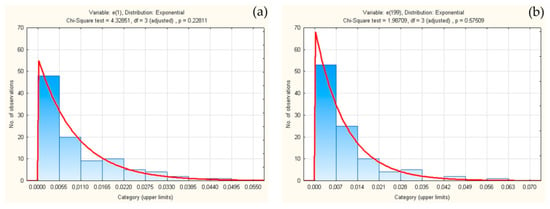
Figure 3.
Verifications of exponential distributions for sets Δ↓[e(1)] (a) and Δ↓[e(199)] (b).
Figure 4 shows verifications of exponential distributions of all 200 sets of random numbers obtained from the successive decimals of constant e. All verifications were performed by χ2 test, with a mandatory standard of 10 classes. The distribution of all 200 obtained significance thresholds is given in Figure 4. The distribution of all 200 obtained significance thresholds is given in Figure 4. From Figure 4 it is obvious that the verifications of the sets of random counts have periods of low verification. From Figure 4 it is obvious that the verifications of the sets of random counts have periods of low verification p < 0.05. These are the verifications (with the set index): p < 0.05. These are the verifications (with the set index): p157 = 0.03111, p158 = 0.00740, p159 = 0.00740, p160 = 0.00900, p161 = 0.02863, p162 = 0.01072, p163 = 0.01072, p164 = 0.01017, p165 = 0.02065, p169 = 0.03327, p170 = 0.03327, p172 = 0.03705, p180 = 0.03282, p181 = 0.02265, p182 = 0.03890, p183 = 0.04056, p184 = 0.02192, p185 = 0.03890, p186 = 0.03890, p187 = 0.03890, p189 = 0.00865, p191 = 0.03546 and p192 = 0.02889. Out of a total of 200 sets of random numbers obtained on the basis of decimals of constant e, 23 sets have a significance threshold less than 0.05.
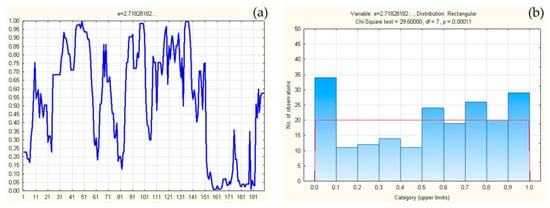
Figure 4.
Exponential distributions of all 200 sets Δ↓[e(i)] (a), verifications, and distribution of verifications (b).
By the same procedure, consecutive differences were formed in 200 sets of random numbers obtained on the basis of successive decimals of a constant π(i), PRNG(i), and TRNG(i), i∈[1, 200].Figure 5 shows the results of 200 verifications of exponential distributions obtained from differences Δ↓[π(i)], i∈[1, 200] formed on the basis of successive decimals of a constant π(i), previously sorted ↓[π(i)].
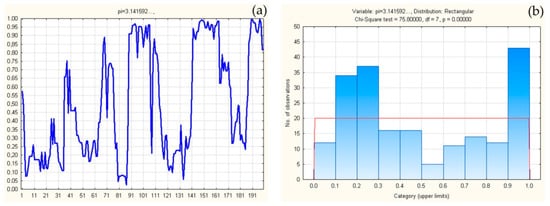
Figure 5.
Exponential distributions of all 200 sets Δ↓[π(i)] (a), verifications, and distribution of verifications (b).
All verifications were performed by χ2 test, according to the established standard of 10 classes. The distribution of all 200 obtained significance thresholds is given in Figure 5.
From Figure 5, it is obvious that the verifications of sets of random numbers are low verifications p < 0.05. These are the verifications (with the set index): p83 = 0.00809 < 0.05, p84 = 0.00809 < 0.05.
From a total of 200 sets of random numbers obtained based on the decimals of a constant π(i), i∈[1, 200], two sets have a significance threshold of less than 0.05.
Figure 6 shows the results of 200 verifications of exponential distributions obtained from differences Δ↓[PRNG(i)], i∈[1, 200], previously sorted ↓[PRNG(i)].
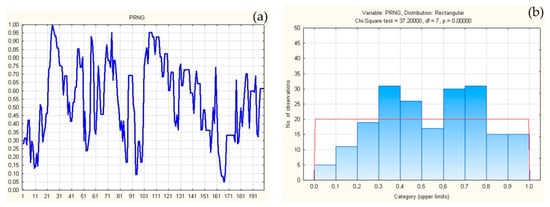
Figure 6.
Exponential distributions of all 200 sets Δ↓[PRNG(i)] (a), verifications, and distribution of verifications (b).
All verifications were performed by χ2 test, according to the established standard of 10 classes. The distribution of all 200 obtained significance thresholds is given in Figure 6.
From Figure 6 it is obvious that the verification of sets of random numbers has one low verification p < 0.05. This is the verification (with set index): p167 = 0.04777 < 0.05. Out of a total of i∈[1, 200], one set has a significance threshold of less than 0.05.
Figure 7 shows the results of 200 verifications of exponential distributions obtained from differences Δ↓[TRNG(i)], i∈[1, 200], previously sorted ↓[TRNG(i)].
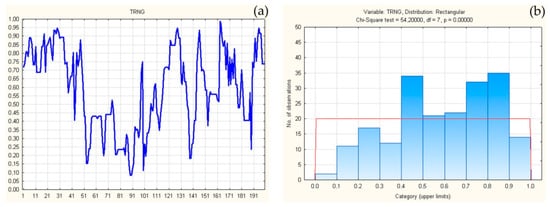
Figure 7.
Exponential distributions of all 200 sets Δ↓[TRNG(i)] (a), verifications, and distribution of verifications (b).
All verifications were performed by χ2 test, according to the established standard of 10 classes. The distribution of all 200 obtained significance thresholds is given in Figure 7.
All sets have a significant exponential distribution for the significance threshold pi > 0.05, i∈[1, 200].
4. Discussion and Conclusions
The procedure for the application of exponential distribution in the testing of sets of random numbers is as follows: The series of n generated random numbers needs to be sorted by value. Next, succcessive differences are calculated for random numbers sorted by value. The random variable of successive differences needs to have a significant exponential distribution. If the exponential distribution with parameters E(n−1, n−1) is not verified, the set of generated random numbers are dependent and cannot be used.
Although it is the basis of many probabilistic functions, in this particular case it was proven that the constant e cannot be applied as a transcendental source of random numbers. With the fact that it is a sequence of e2 purely-periodic with a period length of 40 [], the sensitivity of the theorem is indirectly confirmed. For random numbers obtained from consecutive decimals of constant π, a significant departure from a uniform distribution [] and randomness [] was found. For random numbers generated from successive decimals of a constant e over 11.50% of sets are not exponentially distributed with a significance threshold p = 0.05, and for constant π this condition is not fulfilled in 1% of sets. According to results from the Diehard Battery of Tests (monkey tests, GCD, birthday spacing’s tests, parking lot test, squeeze test, etc.) the first 109 digits of π and e all seem to pass the test very well [].
It should be noted here that the mean of the significance threshold of all 200 verifications for the number e was E(pe) = 0.526329 and was greater than the mean value of the significance threshold of all 200 verifications for the number π which was E(pπ) = 0.501486. The TRNG series did not meet the condition of exponential distribution in 0.5% (1 of 200), while the TRNG series fully met the condition of the theorem. The mean significance threshold of all 200 verifications for the PRNG series was E(pPRNG) = 0.543097. Although higher E(pe) and E(pπ), it was smaller than the mean significance threshold of 200 exponential distribution verification for TRNG sets-E(pTRNG) = 0.589363. In total, the TRNG series had all significant verifications in all 200 sets of random numbers and had the highest mean of verifications.
The results of the first tests and the comparative results confirm the validity of the theorem. The idea based on the entropy of the exponential distribution and its memoryless properties is expressed in the mutual independence between the generated random numbers. The test is natural because a stochastic function with the highest entropy, an exponential distribution, is introduced into the quality testing of a set of random numbers.
Certainly, the standard test of the uniform distribution U[0,1] of generated random numbers is also a stochastic test. However, the test of the exponential distribution of consecutive differences between generated random numbers, absorbs the test of uniform distribution. In the case of the non-uniform distribution of generated random numbers, a large number of small and big consecutive differences will appear in the set of generated random numbers, which will prevent the verification of the exponential distribution with a significant threshold. In the case of repeating the same decimals while generating random numbers, a large number of small differences with the same non-verification outcome also occur, etc.
However, in the case of extremely large sets of generated random numbers, their consecutive differences converge to zero. According to the theorem and the parameters of the exponential distribution, the standard deviation of consecutive differences in large sets also converges to zero. This means that the proposed test has limitations, which need to be established. Despite this limitation, the proposed test can be applied for the primary selection of a series of generated random numbers. The estimated limit is based on the rare event standard [] for the exponential distribution parameter λ = 10−6, or 1,000,000 consecutive random decimals.
Author Contributions
Conceptualization, I.T., F.S. and Ž.S.; formal analysis, F.S. and M.S.; methodology, I.T.; supervision, M.S. and M.V.; validation, I.T. and M.V.; visualization, V.B. and J.M.-M.; writing—original draft, I.T. and J.M.-M.; writing—review & editing, V.B. and Ž.S.
Funding
This research received no external funding.
Acknowledgments
This paper is a contribution to the Ministry of Science and Technological Development of Serbia funded project TR 36012. The authors thank all the reviewers for their thoughtful reviews of our work and useful remarks. Also, the authors thank all the reviewers for their thoughtful reviews of our work and useful remarks.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gallager, R.G. Principles of Digital Communication, 1st ed.; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Ferguson, N.; Schneier, B.; Kohno, T. Cryptography Engineering: Design Principles and Practical Applications, 1st ed.; John Wiley & Sons: New York, NY, USA, 2010. [Google Scholar]
- Wang, J.; Liang, J.; Li, P.; Yang, L.; Wang, Y. All-optical random number generating using highly nonlinear fibers by numerical simulation. Opt. Commun. 2014, 321, 1–5. [Google Scholar] [CrossRef]
- Joppich, G.; Däuper, J.; Dengler, R.; Johannes, S.; Rodriguez-Fornells, A.; Münte, T.F. Brain potentials index executive functions during random number generation. Neurosci. Res. 2004, 49, 57–164. [Google Scholar] [CrossRef] [PubMed]
- Bains, W. Random number generation and creativity. Med. Hypotheses 2008, 70, 186–190. [Google Scholar] [CrossRef] [PubMed]
- Brugger, P.; Monsch, A.U.; Salmon, D.P.; Butters, N. Random number generation in dementia of the Alzheimer type: A test of frontal executive functions. Neuropsychologia 1996, 34, 97–103. [Google Scholar] [CrossRef]
- Koike, S.; Takizawa, R.; Nishimura, Y.; Marumo, K.; Kinou, M.; Kawakubo, Y.; Rogers, M.A.; Kasai, K. Association between severe dorsolateral prefrontal dysfunction during random number generation random number generation and earlier onset in schizophrenia. Clin. Neurophysiol. 2011, 122, 1533–1540. [Google Scholar] [CrossRef]
- Anzak, A.; Gaynor, L.; Beigi, M.; Foltynie, T.; Limousin, P.; Zrinzo, L.; Brown, P.; Jahanshahi, M. Subthalamic nucleus gamma oscillations mediate a switch from automatic to controlled processing: A study of random number generation in Parkinson’s disease. NeuroImage 2013, 64, 284–289. [Google Scholar] [CrossRef] [PubMed]
- Linnebank, M.; Brugger, P. Random number generation deficits in patients with multiple sclerosis: Characteristics and neural correlates. Cortex 2016, 82, 237–243. [Google Scholar]
- Yadolah, D. A Natural Random Number Generator. Int. Stat. Rev. 1996, 64, 329–344. [Google Scholar]
- Yadolah, D.; Melfi, G. Random numbergenerators and rare events in the continued fraction of π. J. Stat. Comput. Simul. 2005, 75, 189–197. [Google Scholar]
- Kanter, I.; Aviad, Y.; Reidler, I.; Cohen, E.; Rosenbluh, M. An optical ultrafast random bit generator. Nat. Photonics 2010, 4, 58–61. [Google Scholar] [CrossRef]
- Lucian, L. FPGA optimized cellular automaton random number generator. J. Parallel Distrib. Comput. 2018, 111, 251–259. [Google Scholar]
- Panneton, F.; L’Ecuyer, P. Resolution-stationary random number generators. Math. Comput. Simul. 2010, 80, 1096–1103. [Google Scholar] [CrossRef]
- Fleischer, K. Two tests of pseudo random number generators for independence and uniform distribution. J. Stat. Comput. Simul. 1995, 52, 311–322. [Google Scholar] [CrossRef]
- Geisseler, O.; Pflugshaupt, T.; Buchmann, A.; Bezzola, L.; Reuter, K.; Schuknecht, B.; Weller, D.; L’Ecuyer, P. Tests based on sum-functions of spacings for uniform random numbers. J. Stat. Comput. Simul. 1997, 59, 251–269. [Google Scholar]
- Tomassini, M.; Sipper, M.; Zolla, M.; Perrenoud, M. Generating high-quality random numbers in parallel by cellular automata. Future Gener. Comput. Syst. 1999, 16, 291–305. [Google Scholar] [CrossRef]
- Díaz, N.C.; Gil, A.V.; Vargas, M.J. Assessment of the suitability of different random number generators for Monte Carlo simulations in gamma-ray spectrometry. Appl. Radiat. Isot. 2010, 68, 469–473. [Google Scholar] [CrossRef] [PubMed]
- Van Bever, G. Simplicial bivariate tests for randomness. Stat. Probab. Lett. 2016, 112, 20–25. [Google Scholar] [CrossRef]
- Knuth, D. The Art of Computer Programming: Seminumerical Algorithms, 3rd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1997. [Google Scholar]
- Marsaglia, G.; Tsang, W. Some Difficult-to-pass Tests of Randomness. J. Stat. Softw. 2002, 7, 1–9. [Google Scholar] [CrossRef]
- McCullough, B.D. A Review of TestU01. J. Appl. Econ. 2006, 21, 677–682. [Google Scholar] [CrossRef]
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E.; Leigh, S.; Levenson, M.; Vangel, M.; Banks, D.; Heckert, A.; et al. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; National Institute of Standards and Technology; U.S. Department of Commerce: Washington, DC, USA, 2010.
- Steffensen, J.F. Some Recent Research in the Theory of Statistics and Actuarial Science; Cambridge University Press: Cambridge, UK, 1930. [Google Scholar]
- Kinzer, J.P. Application of The Theory of Probability to Problems of Highway Traffic, B.C.E. Doctoral Thesis, Polytechnic Institute of Brooklyn, New York, NY, USA, 1933. [Google Scholar]
- Teissier, F. Researches sur le vieillissement et sur les lios se mortalit. Ann. Phys. Biol. Phys. Chemestry 1934, 10, 237–264. [Google Scholar]
- Adams, W.F. Road Traffic Considered as a Random Series. J. Inst. Civ. Eng. 1936, 4, 121–130. [Google Scholar] [CrossRef]
- Weibull, W. The phenomenon of rupture in solids. Ingeniorsvetenskapsakademienshandlingar 1939, 153, 1–55. [Google Scholar]
- Kendall, M.G.; Smith, B.; Babington, B. Randomness and Random Sampling Numbers. J. R. Stat. Soc. 1938, 101, 147–166. [Google Scholar] [CrossRef]
- Kjos-Hanssen, B.; Taveneaux, A.; Thapen, N. How much randomness is needed for statistics? Ann. Pure Appl. Log. 2014, 165, 1470–1483. [Google Scholar] [CrossRef]
- Vukadinović, S. Queueing Systems; NaučnaKnjiga: Beograd, Serbia, 1988. [Google Scholar]
- Random Sequence Generator. Available online: https://www.random.org/sequences (accessed on 19 May 2019).
- Girstmair, K. Jacobi symbols and Euler′s number e. J. Number Theory 2014, 135, 155–166. [Google Scholar] [CrossRef]
- Khodabin, M. Some Wonderful Statistical Properties of Pi-number decimal digits. J. Math. Sci. Adv. Appl. 2011, 11, 69–77. [Google Scholar]
- Ganc, E.R. The Decimal Expansion of π Is Not Statistically Random. Exp. Math. 2014, 23, 99–104. [Google Scholar]
- Marsaglia, G. On the randomness of pi and other decimal expansions. InterStat: Statistics on the Internet, p. 17, October 2005. ISSN 1941-689X. Available online: http://interstat.statjournals.net/YEAR/2005/articles/ 0510005.pdf (accessed on 25 September 2019).
- Tanackov, I.; Jevtić, Ž.; Stojić, G.; Feta, S.; Ercegovac, P. Rare events queueing system. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 1–11. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).