Abstract
We develop a novel Steffensen-type iterative solver to solve nonlinear scalar equations without requiring derivatives. A two-parameter one-step scheme without memory is first introduced and analyzed. Its optimal quadratic convergence is then established. To enhance the convergence rate without additional functional evaluations, we extend the scheme by incorporating memory through adaptively updated accelerator parameters. These parameters are approximated by Newton interpolation polynomials constructed from previously computed values, yielding a derivative-free method with R-rate of convergence of approximately 3.56155. A dynamical system analysis based on attraction basins demonstrates enlarged convergence regions compared to Steffensen-type methods without memory. Numerical experiments further confirm the accuracy of the proposed scheme for solving nonlinear equations.
Keywords:
Steffensen method; derivative-free iteration; methods with memory; convergence analysis; interpolation-based acceleration; attraction basins MSC:
65H05; 65H99
1. Introduction
The numerical approximation of simple zeros of nonlinear scalar equations
is among the most fundamental problems in computational mathematics; see, for instance, [1,2]. Classical derivative-based procedures, such as Newton’s method, possess attractive local convergence properties, yet their success relies heavily on the availability and stability of derivative information [3]. In many practical models—especially those arising in applied physics, computational chemistry, engineering design, and matrix-oriented formulations—analytic derivatives may be unavailable or computationally expensive. This necessitates the development of derivative-free schemes with competitive convergence properties.
A useful parameterized modification of Steffensen’s scheme is introduced in [4], expressed as
wherein
denotes the first-order divided difference. While the original formula in [5] corresponds to , the introduction of a parameter still keeps the quadratic order of convergence and provides a family of derivative-free accelerators well-suited to nonlinear and matrix-oriented problems; cf. [6,7,8].
Following the classification of Traub [9], iterative processes may be grouped into two broad categories: methods without memory and methods with memory. Kung and Traub formulated in [10] a well-known optimality conjecture, stating that any derivative-free method without memory employing functional evaluations for every iterate can reach at most the convergence order . For , this implies the upper bound , which is attained by Steffensen-type procedures. Motivated by this limitation, the literature contains extensive developments of optimal and non-optimal methods without memory.
Iteration (1) realizes the optimal order under this conjecture. By contrast, methods with memory preserve the quantity of functional evaluations per iterate but introduce adaptive parameters that are updated dynamically from previously computed approximations. These parameters are typically constructed through interpolation formulas, divided differences of various orders, or rational/Padé-type local models. Because no additional evaluations are performed, the computational cost remains unchanged while the convergence order is increased, improving both asymptotic speed and the computational efficiency index [11].
The efficiency index, proposed in [12], is defined as
where denotes the (local) order of convergence, and denotes the quantity of functional evaluations for every iterate. For derivative-free methods, the enhancement of without increasing is particularly significant. In addition to efficiency, attraction basins provide a perspective on convergence, revealing the robustness of an iteration to initial guesses and identifying regions of stability or chaotic behavior; see [13].
In the root-finding literature, the order of convergence and the asymptotic error constant quantify the local speed of an iteration in a precise sense. If converges to a simple zero and , then the method has (Q-)order if there exists a finite nonzero constant C such that
In this relation, the exponent determines the rate at which the error contracts (larger means a higher-order, faster asymptotic contraction), while the constant C governs the asymptotic scale of the error reduction among methods of the same order. Accordingly, when comparing two methods with the same order, the one with a smaller asymptotic error constant typically achieves smaller errors with fewer iterations in the asymptotic regime. For methods with memory, the order is commonly expressed in the R-sense: there exists and a constant such that an error relation of the form (11) holds, that is, . In what follows, we use the term “order” (Q-order for memoryless methods and R-order for methods with memory) when referring to the exponent or r, and we reserve the phrase "asymptotic error constant" for the leading coefficient C or K.
To place our development in context, we recall several recent Steffensen-type contributions. A two-parameter derivative-free scheme without memory introduced in [14] reads
This method retains quadratic convergence while incorporating an additional free parameter .
A two-step method with memory presented in [15] illustrates the effect of incorporating adaptive parameters through Newton interpolant ():
requiring three function evaluations per iteration and achieving an R-order of convergence approximately .
A one-step method with memory is due to Džunić [16], who introduced adaptive parameters computed from Newton interpolation polynomials:
where denotes the Newton interpolation polynomial having degree k. The resulting R-order equals .
Derivative-free solvers thus remain indispensable in contexts where evaluating functional derivatives is impractical, as emphasized in [17]. In view of recent improvements in the literature [18,19], our aim is to construct a Steffensen-type procedure that simultaneously increases the local convergence rate as well as the index of efficiency, without any rise in the quantity of functional evaluations. Here, and throughout, "classical Steffensen-type" denotes the standard derivative-free schemes without memory based on first-order divided differences (including (1)) which are also old root-finding methods in this field. This terminology does not imply that the proposed variants with memory are “non-classical,” but only that they extend the classical framework by incorporating adaptive parameters without increasing the number of function evaluations.
Whenever g is differentiable at u, the divided difference satisfies the well-known mean-value relation
establishing that acts as a discrete derivative. To see its approximation accuracy near a simple root of g, consider the Taylor expansions
Subtracting these expressions and dividing by yields the expansion
illustrating that the approximation error decays quadratically with respect to the distances of u and v from . In Steffensen-type schemes such as (1) and (3), the pair is taken as , where ; hence, the divided difference serves as an approximation of without requiring explicit differentiation.
In order to improve the performance of (1) or (3), it is natural to introduce acceleration parameters whose purpose is to reduce the truncation error in the associated error equation. Consider a general one-step Steffensen-type update of the form
where is a parameter (possibly depending on previously computed quantities). Let denote the error. Using the Taylor expansions and the divided difference expansion (7), one may write
where depends smoothly on , , , and the structure of . Substituting this expression into (8) produces the error recursion
If , then the linear term vanishes and the quadratic term dominates, yielding quadratic convergence. However, if the parameter is allowed to satisfy an approximation of the form
the linear coefficient in (9) still vanishes, but the quadratic coefficient becomes
By choosing suitably—or by approximating it via interpolation of earlier steps, as done in methods with memory—the quadratic term can be suppressed or reduced, thereby elevating the order of convergence from 2 to a value exceeding 3. This mechanism is the theoretical motivation behind the acceleration parameters used in (3), (4), and (5).
In methods with memory, is not a fixed number but an adaptively updated parameter, typically obtained by approximating higher-order information such as or similar ratios using interpolation polynomials built from stored points . Let denote an approximation of in (10) computed without additional evaluations. Then, the resulting parameter satisfies
and substituting it into (9) yields an error equation of the type
where is the R-order of convergence induced by the adaptive construction. Schemes such as (5) achieve through this mechanism. The central idea exploited later in this work is that such accelerator parameters may be approximated efficiently using Newton interpolation (or Padé-like formulas) without increasing the evaluation count of the basic Steffensen-type method. In addition, the authors in the works [20,21] solve nonlinear equation systems using arbitrary operators and functionals with certain conditions.
The present work introduces a one-step Steffensen-type method with memory that attains an R-order of convergence while maintaining exactly the same functional evaluation count as (1). Our construction begins with a two-parameter Steffensen-type method without memory and proceeds by embedding dynamically updated accelerator parameters obtained via Newton interpolation (or analogously via Padé-type local models [22]). The adaptive parameters elevate the R-order from 2 to approximately , matching the best-performing one-step derivative-free schemes with memory. Numerical and dynamical analysis of attraction basins demonstrates that the proposed method not only accelerates convergence but also enlarges convergence regions in the complex plane.
The convergence analysis provided in Section 2 is local; under the smoothness assumptions stated there and for initial guesses sufficiently close to the simple zero , the proposed methods converge with the proven orders. In addition, Section 3 offers a local dynamical assessment by studying basins of attraction in the complex plane, which provides information on convergence regions; such basin portraits are not a formal convergence theorem, but they do demonstrate enlarged convergence domains and fewer divergent initial conditions for the with-memory scheme in the tested families.
The structure of the article is as follows. In Section 2, we introduce a two-parameter Steffensen-type iterative method without memory and establish its quadratic convergence. Using interpolants constructed from previously computed iterates and function values, we then derive an enhanced family of methods with memory. In Section 3, the dynamical behavior of the new method is investigated through detailed attraction basin diagrams. Computational experiments in Section 4 confirm the good performance of the contributed approach relative to existing derivative-free solvers. Concluding remarks are provided in Section 5.
2. Developing a New Scheme
In this section, we construct a Steffensen-type method containing two free parameters, prove its quadratic convergence, and subsequently introduce a memory-based improvement by adaptively updating the parameters through Newton interpolation of appropriate degrees. Throughout the analysis, we assume that g is adequately smooth in a vicinity of its simple zero , though the resulting algorithm is derivative-free in implementation.
We begin by presenting a two-parameter modification of (1), written as
The structure of (12) reduces to (1) for , while the nonzero parameter p introduces an auxiliary correction term in the denominator. The goal is to retain second-order convergence while obtaining a formulation that can later be adapted to methods with memory. At iteration j, scheme (12) requires exactly two evaluations of g, namely and . Indeed, the divided difference is formed from the already computed pair , and the quantity introduces no additional evaluation. Hence, (12) is a derivative-free method with an evaluation count per iterate, and its quadratic order (as seen below) is optimal in the Kung–Traub sense for memoryless derivative-free iterations.
To establish the local behavior of (12), let and . Following standard notation, we write , . Taylor expansion of the function above gives the classical representation
Since , inserting (13) into this expression yields
The divided difference is expanded by substituting the Taylor expansions of and , producing
Using (15), we compute . Substitution of the expansions leads to
Finally, inserting (16) into the denominator of (12) and expanding the resulting fraction, we obtain the error equation
where + − This establishes the following convergence result.
Theorem 1.
Let α be a simple zero of g, i.e., and . Assume that on an open interval with . Then, there exists such that, for a suitable initial guess , the sequence generated by (12) is well defined and converges to α. Moreover, the convergence is quadratic.
Proof.
From (17), we observe that the leading term in the error satisfies
with for generic parameter values. Thus, the iteration is of quadratic order. No derivatives of the function appear in the computational steps, and the smoothness assumption is solely required to derive the theoretical error. The method is therefore derivative-free and optimal in the Kung–Traub sense for two functional evaluations. □
The method (12) therefore achieves second-order convergence using only two functional evaluations per iteration, matching the optimal bound for derivative-free, memoryless methods with evaluations. To exceed quadratic convergence, one must either increase the functional evaluations or incorporate memory; see [23,24] for further discussions. We pursue the latter approach now.
The key observation from the error Equation (17) is that superquadratic convergence occurs if the parameters satisfy
since these values eliminate the quadratic term in (17). In practice, however, , , and are unknown. Thus, the goal becomes to construct asymptotically correct approximations and computed recursively from stored values without requiring additional evaluations.
We impose the adaptive forms
and choose , , with the approximations generated by Newton interpolation polynomials based on already computed points. This leads naturally to the following memory-based method:
Use one startup step of the fixed-parameter scheme (12) (or (1) as a special case) with prescribed (,) to compute (and ), then start the memory updates for using (19).
The merit of (19) lies in its ability to enhance the asymptotic convergence order without increasing the number of function evaluations per iteration. The improved performance stems from employing interpolation polynomials of degrees two and three, whose derivatives approximate and curvature-related quantities. In practice, one may use built-in interpolation procedures to compute and without forming the polynomials analytically.
The interpolation mechanism generalizes naturally: increasing the degree of the interpolation by two at each memory update yields higher R-orders approaching, but never exceeding, the theoretical limit of four. This leads to the general family
We now provide the R-order of the scheme (19).
Theorem 2.
Take into consideration similar assumptions as in Theorem 1. Then, the Steffensen-type scheme with memory (19) attains an R-order of convergence equal to 3.56155.
Proof.
Let be the simple zero of g and define the error sequences
We emphasize that the error sequences in this theorem are local quantities, defined for iterates sufficiently close to the simple root . Moreover, in the proof we use solely to denote the R-order exponent describing the auxiliary sequence relative to (see (22)); this exponent should not be confused with the parameter p appearing in the memoryless scheme (12) (which becomes in (19)). Since the subsequent relations imply (see (33)–(35)), it follows that whenever ; in particular, values such as are not compatible with the asymptotics induced by (19). We assume that the sequence converges to with R-order and that the auxiliary sequence satisfies an R-type relation with exponent (with respect to ) in the sense of (22):
and
as . Here, “∼” denotes asymptotic equivalence up to a nonzero constant factor. From (21), shifting the index by one gives as , hence
Applying the same relation to yields , and therefore
Iterating this argument produces for any fixed as . In particular,
Similarly, (22) implies
in particular,
On the other hand, the structure of the method with memory (19) yields the following asymptotic relations (see the detailed expansions derived after (19)):
and, for the self-accelerating parameters,
where , are nonzero constants depending on derivatives of g at . We first use (25) and (27) to obtain an exponent relation for and r. Combining (25) and (27) gives
Using (24) and (23), we have
Hence,
for some nonzero constant . On the other hand, from (22) and (23), we also have , for some . Equating the exponents of in these two asymptotic representations of , we obtain
Next, we use (26), (27), and (28) to obtain a second relation between r and . From (26), we have
Combining (27) and (28), we deduce
Using (24) again, this gives
for some nonzero constant . Therefore, from (26),
for some constant . Using (23), we have , so that
Substituting this into (31) yields
for some constant . On the other hand, from the definition of the R-order r in (21) and the backward relation (23), we also have
for some nonzero constant . Equating the exponents of in the two asymptotic representations of , we obtain
We are thus led to the system of algebraic equations
with unknowns and . From (33), we obtain
so that
Substituting (35) into (34) gives = . Rewriting, . Multiplying both sides by and simplifying, we obtain the quadratic equation
The positive solution of (36) is
which is precisely the claimed R-order of the sequence generated by (19). This completes the proof. □
Theorem 2 establishes local convergence of (19) with R-order under the standard smoothness and proximity assumptions near a simple root. In the root-finding sense, (19) is also stable with respect to small perturbations in the self-accelerating parameters and generated by interpolation, because such perturbations are of higher asymptotic order than the leading error term and therefore do not alter the R-order. Global behavior is not claimed as a theorem; instead, it is assessed numerically in Section 3 through basins of attraction, which provide empirical evidence of enlarged convergence regions for the memory-based scheme.
The value in Theorem 2 is the R-order attained by a one-step derivative-free scheme with memory constructed from divided differences and interpolation-based parameter updates without increasing the per-iterate evaluation count beyond that of (1). This R-order is consistent with other well-known one-step with-memory Steffensen-type approaches based on similar interpolation mechanisms (e.g., the order reported for (5)). We do not claim that is the highest possible among all Steffensen-type variants in the literature; rather, the contribution is that (19) attains this high R-order within a simple one-step framework while preserving the evaluation count of (1).
To better understand the role of the Newton interpolation polynomials in the construction of the parameters and in (19), we now present explicit formulas and asymptotic expansions for and , followed by a stability analysis with respect to perturbations in and , and finally a remark on local well-posedness of the scheme.
We first consider the quadratic Newton interpolant used in the definition of , see e.g., [25]. Let the nodes be chosen as
and denote the corresponding function values by
The quadratic Newton interpolation polynomial passing through these three points can be written as
where
Differentiating (37) with respect to o gives
so that, in particular,
By Taylor expanding g about and using the standard divided-difference expansions, one obtains
for a constant depending on derivatives of g at . The key point is that the first-order error term of relative to is of order , which is a product of previous errors; hence, it tends to zero faster than each individual error, a cornerstone for methods with memory. Recalling that in (19), we set , we may write
Using the standard series expansion , we obtain
Hence
which justifies the structure of (27) and shows how the memory through leads to a small factor of size .
We now turn to the cubic interpolant that appears in the definition of . Let the nodes be , , , , with corresponding values , , , . The cubic Newton interpolation polynomial through these four points is given by
Differentiating once yields
while the second derivative is
In particular, evaluating at gives
Using higher-order Taylor expansions of g around , it follows that
where depends on and . In scheme (19), the parameter is chosen as , so that
Recalling that , we have . Hence,
so that, up to a nonzero multiplicative constant,
which corresponds to the structure of (28). Combining (43) and (51) with the error Equation (26) explains why the error factor is asymptotically proportional to multiplied by , ultimately leading to the improved R-order in Theorem 2.
We now examine the stability of the scheme (19) with respect to perturbations in and . Assume that the ideal (unattainable) choices satisfy , , and suppose the actual parameters used by the algorithm can be written as
where and are perturbations stemming from the interpolation process and therefore depend on previous errors. We assume that, asymptotically, these perturbations satisfy
Inserting (52) into the general error Equation (17) and exploiting the ideal cancellation that would occur for , , we obtain
for some constants depending on derivatives of g at . Using (53) and the fact that , we have
and similarly for . Thus, the perturbation terms in (54) are of order at least , whereas the leading term behaves like . Since for the positive root we have , the perturbation terms are of strictly higher order than the principal term. Therefore, the R-order of convergence is not affected by these perturbations, and the method is stable with respect to the interpolation-induced errors in and .
Finally, we address the local well-posedness of the method, i.e., the fact that all denominators involved remain nonzero for iterates sufficiently close to the simple root . We state this as a lemma.
Lemma 1.
Assume that in a neighborhood of a simple zero α and that . Then, there exists a neighborhood U of α such that, if and the iterates generated by (19) remain in U, the following hold for all sufficiently large j:
for any fixed in the family (20). In particular, the iterations (19) and (20) are well defined in U.
Proof.
Here denotes a lower bound for on a neighborhood of (guaranteed by continuity and ); it is unrelated to the number of functional evaluations per iteration. Since , continuity of implies that there exists a neighborhood U of and a constant such that
for all . From the expansion (40), we have
so for j sufficiently large and , it follows that . An analogous argument, using continuity of the higher-order divided differences and the fact that as , shows the existence of such that for all , . Regarding the denominator , note that the ideal parameter choices yield cancellation of the quadratic term but not of the denominator itself. From the expansions (15) and (16), along with the asymptotic behavior (42) and (49), we obtain
so that
as . Thus, for all sufficiently large j with , one has
This ensures that none of the denominators vanish, and hence the schemes (19) and (20) are locally well-defined. □
3. Basin of Attractions
The local convergence analysis in Section 2 provides information about the behavior of the proposed schemes when the initial approximation lies adequately near to a simple root. This leads naturally to the study of attraction basins and the associated dynamical systems generated by the iterative schemes; see more concrete discussions in [26].
Let be a nonlinear function, and let denote the iteration function corresponding to a one-step method without memory, so that the iteration can be written as
In the case of the basic Steffensen-type method (12) with fixed parameters and p, the iteration function takes the form
which is a rational function of z whenever g is a polynomial. A point satisfying is a fixed point of . Simple zeros of g are fixed points of , since implies . More generally, other fixed points may appear, including spurious or extraneous ones not satisfying , [27].
For a given root of g, the basin of attraction of with respect to the iteration (55) is defined as
where denotes the j-fold composition of . The union of all such basins over all attracting fixed points partitions the complex plane (modulo the Julia set) into regions of convergence. The boundary of is contained in the Julia set associated with , which is typically a complicated fractal set even for simple rational maps.
The local dynamical nature of a fixed point of is characterized by the multiplier . The fixed point is attracting if , repelling if , and indifferent if . For methods designed to approximate simple roots of g, one typically has , which implies quadratic or higher-order convergence and a nonempty open basin of attraction .
We remark that the iteration map in (56) is a rational function of z only when g is a polynomial. For general nonlinear functions g, the map is still well defined but may no longer be rational; nevertheless, the dynamical interpretation through fixed points and attraction basins remains valid [28].
Since the computation is performed over a discrete grid, these values should be interpreted as mesh-dependent estimates whose accuracy increases with grid refinement. For methods with memory, such as (19), the iteration cannot be described by a scalar recurrence of the form (55). Instead, one must consider a higher-dimensional dynamical system. For instance, if the method uses and simultaneously, one can rewrite it as a map on ,
where is computed using both and . In such a setting, the root corresponds to a fixed point in . The basin of attraction in this case is a subset of defined by
For graphical representation in the complex plane, one typically restricts to a one-parameter family of initial pairs, for example, by fixing or by choosing a prescribed initialization rule, and then plotting the convergence behavior as a function of . Here, is the initial approximation, which is taken from the mesh points located for the discretization of the complex domain.
In the present context, the term "dynamical system" refers to the discrete-time iteration induced by a root-finding method: once an iteration function is defined, the sequence is generated by repeated composition , and the convergence behavior can be observed through fixed points, their stability, and the corresponding basins of attraction.
In order to compare the dynamical behavior of Steffensen-type methods with and without memory, we consider the polynomial family
whose simple roots are given by , . These roots lie on the unit circle and enjoy the rotational symmetry , , which implies that the basins of attraction of any reasonable root-finding method inherit rotational symmetry of order n. For a given iteration , each root is an attracting fixed point, and the dynamics are governed by how the complex plane is partitioned into the basins and the set of nonconvergent initial conditions.
In our numerical experiments, we fix a rectangular region
and define a uniform grid of initial points
with a prescribed mesh size (). For each grid point , the iteration scheme under consideration is applied up to a maximum number of steps . We declare convergence to a root if there exists an index such that
in which case, the point is assigned to the basin of . If no such j is found, or if the magnitude exceeds a certain large threshold (indicating divergence to infinity), then is classified as nonconvergent for that method [29].
The numerical goal of Section 3 is not to compute accurate approximations of the roots but to study the convergence behavior of the competing iterations as dynamical systems, namely (i) which root attracts a given initial point in the domain D, (ii) how large the corresponding attraction regions are (convergence radii and robustness), and (iii) how the memory mechanism modifies the set of nonconvergent (or slowly convergent) initial conditions. For this reason, the stopping rule (60) is employed as a classification threshold under a fixed iteration budget , rather than as a stringent accuracy certificate. In the test family , all roots are simple and are available in closed form, so the basin plots can be interpreted unambiguously as root-attraction classifications over a large set of initial conditions. The tolerance in (60) is chosen to balance two practical aspects that are intrinsic to basin computations on dense grids: first, it reliably separates convergent from divergent orbits within the fixed cap over the entire domain D; second, it avoids inflating the “nonconvergent” region by classifying as failures those initial points that are already attracted to a root but approach it more slowly and would require more than steps to satisfy a very stringent residual requirement. In other words, the basin study is intended to compare robustness and stability regions of the methods (especially the effect of memory), not to compare the final digits of accuracy. Finally, we stress that the basin computations use the same tolerance (60) and the same for every method, so the comparison is fair, and the observed enlargement of attraction basins for the with-memory scheme reflects improvements in stability rather than an artifact of inconsistent stopping rules.
The visual representation of attraction basins is obtained by assigning a distinct color to each root and a special color to the set of nonconvergent initial points. Furthermore, to encode information about the convergence speed within each basin, we employ a shading scheme: darker colors correspond to smaller iteration counts j required to satisfy (60), whereas lighter colors indicate larger iteration counts closer to the upper bound . Thus, the color intensity at a given starting point reflects the local efficiency of the iteration: darker regions correspond to fast convergence and lighter regions to slower convergence within the same basin.
The parameter is chosen as and when required for initialization, unless stated otherwise. This small positive value prevents premature numerical instabilities in the early stages of the memory-based schemes. All other free parameters are set to fixed values determined by the particular method under test (for instance, the choice of p in (12) or of and in (19)), unless adaptive updates are explicitly used by the with-memory algorithm.
The computation and plotting of attraction basins were implemented in Mathematica 13.3 [30], where each method is coded as a function that, given an initial point , iteratively produces the sequence and records the convergence behavior.
When comparing the Steffensen-type method without memory (12) to its memory-based counterpart (19), the dynamical portraits exhibit a clear qualitative difference. For methods without memory, the boundaries between basins are typically more intricate and interwoven, and a larger fraction of initial points in D either do not converge within iterations or diverge to infinity. In contrast, the with-memory method (19) exhibits larger homogeneous colored regions associated with each root, indicating enlarged basins of attraction. Moreover, the shading within these regions is generally darker, reflecting a reduced average number of iterations and thus faster convergence in a large portion of the domain.
From a dynamical systems perspective, in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6, the enlargement of attraction basins for methods with memory can be attributed to the improved local contraction properties induced by the adaptive parameters and . Near a simple root , the map in (58) has a Jacobian whose eigenvalues are closely related to the R-order of convergence: smaller eigenvalues in modulus correspond to a stronger local contraction, which in turn typically enlarges the region from which iterates are drawn toward the root.
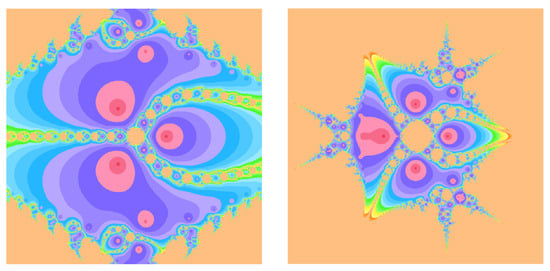
Figure 1.
Basin of attractions for (1) with on (left), (right).
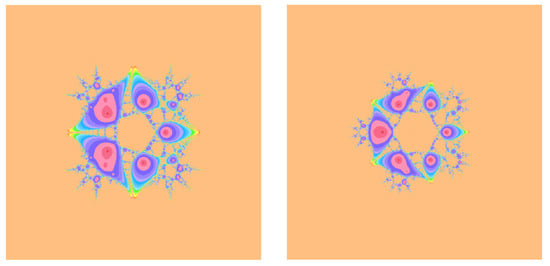
Figure 2.
Basin of attractions for (1) with on (left), (right).

Figure 3.
Basin of attractions for (12) with on (left), (right).
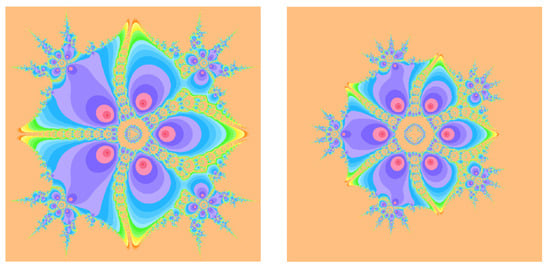
Figure 4.
Basin of attractions for (12) with on (left), (right).
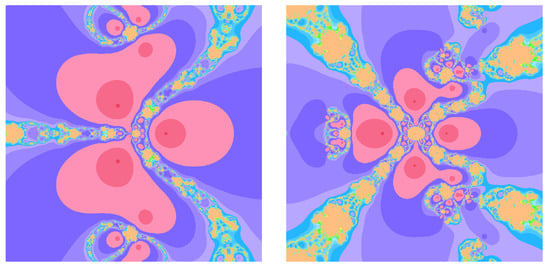
Figure 5.
Basin of attractions for (19) with on (left), (right).
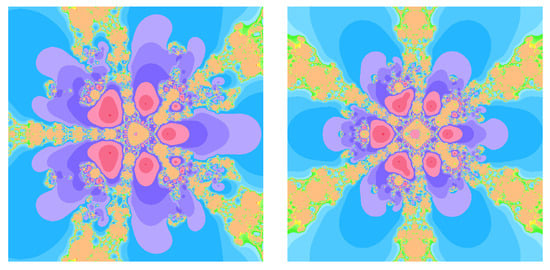
Figure 6.
Basin of attractions for (19) with on (left), (right).
4. Computational Results
Here, we present computational experiments that demonstrate the practical performance of the newly developed Steffensen-type schemes, both with and without memory. All computations were carried out using Mathematica 13.3 with 1500-digit floating-point precision to observe the asymptotic convergence behavior and to avoid premature rounding errors that may obscure the higher-order convergence phenomenon. The results presented here are entirely consistent with the theoretical analysis performed in Section 2 and Section 3, confirming the predicted R-orders, the enhanced convergence radii, and the dynamical robustness of the proposed methods.
To illustrate the advantages of the self-accelerating parameters and the memory mechanism, we consider the oscillatory test function
which is known to be challenging for many iterative solvers due to its rapidly oscillating nature and its combination of polynomial and transcendental components. The function has a simple root at , but the surrounding landscape contains multiple oscillatory extrema and steep curvature variations, making it a good benchmark for convergence speed and sensitivity to initial guesses.
To visualize the numerical behavior, the iterative trajectories are plotted in Figure 7, where the left frame shows convergence from a moderate initial approximation and the right frame illustrates robustness from a distant starting point. The parameters , , and the initial guess used for each scheme are explicitly stated in the figure captions. The simulations reveal that the method with memory not only converges more quickly but also maintains stable behavior in regions where the derivative-free method without memory struggles to converge or becomes sensitive to perturbations.
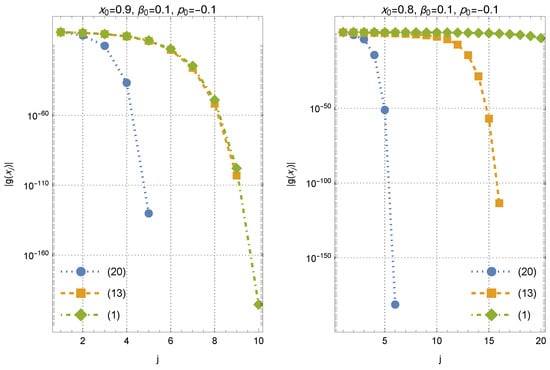
Figure 7.
Numerical convergence results for different values of the initial approximations.
The figure shows the residual histories for the test problem (61) using the three derivative-free iterations (1) (Equation , green diamonds), (12) (Equation , orange squares), and the proposed with-memory scheme (19) (Equation , blue circles). In each panel, the vertical axis reports the residual magnitude on a logarithmic scale versus the iteration index j. Left panel: Starting from the moderate initial approximation with and , all three schemes converge; however, the with-memory method produces a markedly steeper decay of , reaching a near-machine residual level within only a few iterations, whereas and require substantially more steps to attain comparable residual reductions. Right panel: For the more challenging initial approximation (with the same initialization , ), the with-memory scheme still converges rapidly, the two-parameter method without memory converges but much more slowly, and the classical Steffensen-type iteration exhibits stagnation (no visible residual decrease) over the displayed iteration range. Overall, the two panels illustrate that incorporating memory not only accelerates the asymptotic residual decay but also improves robustness with respect to the choice of the initial approximation.
This is consistent with the enlarged attraction basins documented in Section 3, which demonstrate that the interpolation-based parameter updates reinforce the stability properties of the scheme. The numerical experiments support the theoretical findings of Section 2 and Section 3 in two complementary ways. First, for the benchmark (61), the proposed memory-based scheme exhibits a faster residual decay and improved robustness with respect to the initial approximation when compared to the memoryless competitors. Second, the basin-of-attraction study in Section 3 indicates enlarged convergence regions and fewer nonconvergent initial conditions for the with-memory iteration on the tested polynomial families. These results provide evidence of improved efficiency and dynamical robustness.
Before ending this section, we evaluate the performance of the discussed schemes with some other recently proposed schemes [31] as follows ():
- Moser–Secant method:
- Moser–Kurchatov method:
We have chosen for the initial approximation . The results are provided in Table 1. The schemes (62) and (63) are useful for systems of nonlinear equations, but they are sensitive to the choice of as an approximation of the first derivative, and thus their convergence radii are lower than that of the Steffensen-type method with memory. Here, we have chosen and . Numerical results confirm the efficiency of (19).

Table 1.
Convergence comparisons for to solve (61).
5. Concluding Summary
In this work, we improved and analyzed a new Steffensen-type iterative scheme equipped with two free parameters and a memory-based acceleration mechanism. The derivative-free method without memory was shown to achieve optimal quadratic convergence, while its extension with memory attained an R-order of without requiring any additional functional evaluations. By employing Newton interpolation polynomials to approximate the self-accelerating parameters, the proposed scheme demonstrated improved local convergence behavior, enhanced efficiency index, and enlarged attraction basins. Numerical experiments and dynamical analyses confirmed that the new method performs efficiently.
Future research will focus on broadening the applicability of the proposed framework to systems of nonlinear equations and matrix equations. Some other scholars may study an alternative approximation tools, such as Padé-type rational interpolants or machine-learning-based parameter estimators for enhanced convergence.
Author Contributions
Conceptualization, S.W. and T.L.; Methodology, S.W. and C.L.; Software, C.L.; Validation, Z.Y.; Formal analysis, C.L.; Investigation, S.W. and C.L.; Resources, T.L.; Data curation, Z.Y.; Writing—original draft, S.W., C.L., and Z.Y.; Writing—review and editing, T.L.; Visualization, Z.Y.; Supervision, T.L.; Project administration, T.L.; Funding acquisition, T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research Project on Graduate Education and Teaching Reform of Hebei Province of China (YJG2024133), the Open Fund Project of Marine Ecological Restoration and Smart Ocean Engineering Research Center of Hebei Province (HBMESO2321), and the Technical Service Project of the Eighth Geological Brigade of the Hebei Bureau of Geology and Mineral Resources Exploration (KJ2025-029, KJ2025-037).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available because the research data are confidential.
Acknowledgments
We sincerely thank the two referees for their careful reading of the manuscript and for their constructive comments and suggestions, which have substantially improved the quality and clarity of the paper.
Conflicts of Interest
No conflicts of interest.
References
- Shil, S.; Nashine, H.K.; Soleymani, F. On an inversion-free algorithm for the nonlinear matrix problem . Int. J. Comput. Math. 2022, 99, 2555–2567. [Google Scholar] [CrossRef]
- Bini, D.A.; Iannazzo, B. Computational aspects of the geometric mean of two matrices a survey. Acta Sci. Math. 2024, 90, 349–389. [Google Scholar] [CrossRef]
- Dehdezi, E.K.; Karimi, S. A fast and efficient Newton-Shultz-type iterative method for computing inverse and Moore-Penrose inverse of tensors. J. Math. Model. 2021, 9, 645–664. [Google Scholar]
- Noda, T. The Steffensen iteration method for systems of nonlinear equations. Proc. Jpn. Acad. 1987, 63, 186–189. [Google Scholar] [CrossRef]
- Steffensen, J.F. Remarks on iteration. Skand. Aktuarietidskr. 1933, 16, 64–72. [Google Scholar] [CrossRef]
- Mehta, B.; Parida, P.K.; Nayak, S.K. Convergence analysis of higher order iterative methods in Riemannian manifold. Rend. Circ. Mat. Palermo II. Ser 2026, 75, 8. [Google Scholar] [CrossRef]
- Song, Y.; Soleymani, F.; Kumar, A. Finding the geometric mean for two Hermitian matrices by an efficient iteration method. Math. Methods Appl. Sci. 2025, 48, 7188–7196. [Google Scholar] [CrossRef]
- Zhang, K.; Soleymani, F.; Shateyi, S. On the construction of a two-step sixth-order scheme to find the Drazin generalized inverse. Axioms 2025, 14, 22. [Google Scholar] [CrossRef]
- Traub, J.F. Iterative Methods for the Solution of Equations; Prentice-Hall: New York, NY, USA, 1964. [Google Scholar]
- Kung, H.T.; Traub, J.F. Optimal order of one–point and multi–point iteration. J. ACM 1974, 21, 643–651. [Google Scholar] [CrossRef]
- Arora, H.; Cordero, A.; Torregrosa, J.R. On generalized one-step derivative-free iterative family for evaluating multiple roots. Iran. J. Numer. Anal. Optim. 2024, 14, 291–314. [Google Scholar]
- Ostrowski, A.M. Solution of Equations and Systems of Equations; Academic Press: New York, NY, USA, 1966. [Google Scholar]
- Torkashvand, V. A two-step method adaptive with memory with eighth-order for solving nonlinear equations and its dynamic. Comput. Methods Differ. Equ. 2022, 10, 1007–1026. [Google Scholar]
- Khaksar Haghani, F. A modified Steffensen’s method with memory for nonlinear equations. Int. J. Math. Model. Comput. 2015, 5, 41–48. [Google Scholar]
- Chicharro, F.I.; Cordero, A.; Garrido, N.; Torregrosa, J.R. Stability and applicability of iterative methods with memory. J. Math. Chem. 2019, 57, 1282–1300. [Google Scholar] [CrossRef]
- Džunić, J.; Petković, M.S. On generalized biparametric multipoint root finding methods with memory. J. Comput. Appl. Math. 2014, 255, 362–375. [Google Scholar] [CrossRef]
- Soleymani, F.; Vanani, S.K. A modified eighth-order derivative-free root solver. Thai. J. Math. 2012, 10, 541–549. [Google Scholar]
- Yilmaz, N. Introducing three new smoothing functions: Analysis on smoothing-Newton algorithms. J. Math. Model. 2024, 12, 463–479. [Google Scholar]
- Dehghani-Madiseh, M. A family of eight-order interval methods for computing rigorous bounds to the solution to nonlinear equations. Iran. J. Numer. Anal. Optim. 2023, 13, 102–120. [Google Scholar]
- Sreedeep, C.D.; Argyros, I.K.; Gopika Dinesh, K.C.; Shrestha, N.; Argyros, M. Convergence analysis of a power series based iterative method having seventh order of convergence. Mat. Stud. 2025, 64, 179–193. [Google Scholar] [CrossRef]
- George, S.; Grammont, M.M.L. Derivative-free convergence analysis for Steffensen-type schemes for nonlinear equations. Appl. Numer. Math. 2026, 223, 101–120. [Google Scholar] [CrossRef]
- Wang, X.; Guo, S. Dynamic analysis of a family of iterative methods with fifth-order convergence. Fractal Fract. 2025, 9, 783. [Google Scholar] [CrossRef]
- Ogbereyivwe, O.; Izevbizua, O. A three-free-parameter class of power series based iterative method for approximation of nonlinear equations solution. Iran. J. Numer. Anal. Optim. 2023, 13, 157–169. [Google Scholar]
- Soleymani, F. Some optimal iterative methods and their with memory variants. J. Egypt. Math. Soc. 2013, 21, 59–67. [Google Scholar] [CrossRef]
- Kiyoumarsi, F. On the construction of fast Steffensen–type iterative methods for nonlinear equations. Int. J. Comput. Meth. 2018, 15, 1850002. [Google Scholar] [CrossRef]
- Getz, C.; Helmstedt, J. Graphics with Mathematica Fractals, Julia Sets, Patterns and Natural Forms; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Zhu, J.; Li, Y.; Li, Y.; Liu, T.; Ma, Q. Fourth-order iterative algorithms for the simultaneous calculation of matrix square roots and their inverses. Mathematics 2025, 13, 3370. [Google Scholar] [CrossRef]
- Howk, C.L.; Hueso, J.L.; Martínez, E.; Teruel, C. A class of efficient high–order iterative methods with memory for nonlinear equations and their dynamics. Math. Meth. Appl. Sci. 2018, 41, 7263–7282. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Z.; Xie, W.; Qi, Y.; Liu, T. An accelerated sixth-order procedure to determine the matrix sign function computationally. Mathematics 2025, 13, 1080. [Google Scholar] [CrossRef]
- Mureşan, M. Introduction to Mathematica with Applications; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Argyros, I.K.; Shakhno, S.M.; Shunkin, Y.V. On an iterative Moser–Kurchatov method for solving systems of nonlinear equations. Mat. Stud. 2025, 63, 88–97. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.