Abstract
The aim of this work is to propose a proportional log survival model (PLSM) as a discrete alternative to the proportional hazards (PH) model. This paper presents the formulation of PLSM as well as the procedures for verifying its assumption. The parameters of the PLSM are inferred using the maximum likelihood method, and a simulation study was carried out to investigate the usual asymptotic properties of the estimators. The PLSM was illustrated using data on the survival time of leukemia patients, and it was shown to be a viable alternative for modeling discrete survival data in the presence of covariates.
Keywords:
discrete censored data; discrete Weibull distribution; proportional models; survival analysis MSC:
62N01
1. Introduction
The proportional hazards (PH) model [1] is one of the most popular regression models in survival analysis, whose main characteristic is that the covariates act multiplicatively on the hazard function, i.e., , which results in
In (1), is the baseline survival function, is a non-negative link function that takes the value 1 when its argument is zero (usually the exponential function), and is the vector of coefficients associated with the vector of covariates . Other models with a proportional structure have been proposed [2], including the proportional reversed hazard [3], the proportional odds survival model [4], the proportional mean residual life [5], the proportional vitalities [6], the proportional mean past lifetimes [7], and the proportional median residual lifetime [8].
Although the PH model is popular, it cannot be used when the survival times are discrete (grouped into intervals or intrinsically discrete) since the hazard function is limited in the unit interval.
Recently, discrete models with a proportional structure have been proposed, including the proportional odds hazard model (POHM) [9] and the discrete proportional odds survival model (POSM) [10]. The advantage of regression models with proportional structure is due to their easy interpretation (more specifically, the interpretation of its regression coefficients), which does not depend on the baseline probability distribution.
In this context, this work aims to formulate a new regression model for discrete time-to-event data with a proportional structure. More specifically, this work presents the formulation of the proportional log survival model (PLSM) for discrete data as an alternative to the POHM and POSM models. The main characteristic of the PLSM is that the covariates act multiplicatively on the logarithm of the survival function. Consequently, the survival function of the PSLM mimics the survival function of the PH model (1). Therefore, the PLSM can be considered as a discrete version of the PH model.
Inferences about the parameters of the PLSM will be presented, as well as the procedures for verification of the assumption of the model. The asymptotic properties of the estimators are evaluated using simulated data while considering the discrete Weibull [11] as the baseline distribution. In addition, the proposed model is illustrated using a dataset on the survival time of patients with acute myeloid leukemia (AML) [12].
2. Proportional Log Survival Model for Discrete Time-to-Event-Data
2.1. Model Formulation
Let T be a discrete random variable that assumes non-negative integer values. The proportional log survival model (PLSM) assumes that a vector of covariates acts multiplicatively on the logarithm of the survival function, i.e.,
which results in
In (2) and (3), is the baseline survival function of a discrete random variable, and ) is the vector of coefficients associated with the vector of covariates z. It is important to emphasize that the intercept does not appear in the linear predictor because the baseline survival function, , absorbs this constant term.
It is interesting to note that the survival function of the PLSM (3) mimics the survival function of the PH model (1). Therefore, the PLSM can be considered a discrete version of the PH model.
From (3), it follows that the probability and hazard functions of the PLSM are given, respectively, by the following:
and
where is the baseline survival function of the discrete random variable, ) is the vector of coefficients associated with the vector of covariates z and is the indicator function that assumes the value 1 if or the value 0 if .
2.2. Parameter Estimation
This section presents the procedures for obtaining the point and interval estimates of the PLSM parameters.
Let be a random sample of T∼ PLSM with its respective censoring indicators , where if is a failure time and if is a right-censored time and the covariates vector of individual i, . Here, represents the vector of parameters of the baseline distribution and is the vector of regression coefficients. Thus, the likelihood function of the PLSM is given by the following [13]:
Applying the logarithm to the likelihood function (6) results in the following:
where c is a constant that does not depend on and .
The score equation is given by the following:
Thus, the value that satisfies (8) is the maximum likelihood estimator of the PLSM, which, under appropriate regularity conditions, has, asymptotically, a multivariate normal distribution with mean and variance and covariance matrix given by the following:
The and the observed information matrix can be obtained numerically using computational optimization methods using the Newton-Raphson type algorithm, which provides an accurate numerical approximation for this matrix. From these results, it is possible to obtain asymptotic confidence intervals for the PLSM parameters.
An asymptotic confidence interval for the regression coefficient, , , is given by the following:
where is the maximum likelihood estimator of , is the quantile of a standard normal distribution, and is the variance estimate of obtained in (9).
Note that the confidence interval (10) is also valid for any parameter of a baseline distribution that has no restriction on its parametric space. For a parameter, , for which the parametric space is restricted, for example, to positive values or in the unit interval (0, 1), the confidence interval can be obtained using the log or the log-log transformations, respectively, i.e, or . In both cases, the values of are obtained via the delta method [14].
Thus, an asymptotic log type confidence interval for a positive parameter is given by
and an asymptotic log-log type confidence interval for a parameter , restricted in the unit interval (0, 1), is given by the following:
where is the maximum likelihood estimator of , is the quantile of a standard normal distribution, and is the variance estimate of obtained in (9).
2.3. Verification of the Proportional Log Survival Assumption
The proportionality assumption of the logarithm of the survival function can be verified in a similar way to that presented by [9,10] and which is described below. The proposed model (2) assumes that the logarithm of the survival function for two individuals is proportional.
Let T be a discrete random variable and a dichotomous covariate Z that assumes the values of 0 and 1. The PLSM assumes the following:
which results in
where is the survival function and is the proportionality constant that does not depend on t. Therefore, the relationship between and is a straight line with the angular coefficient, , equal to 1 and the linear coefficient , i.e.,
The assumption of proportional log survival can be verified graphically by fitting a simple regression line with an angular coefficient equal to one (). In this context, we can plot a graph of points formed by the coordinates (, ), and the proportionality will be confirmed if these points are close to this regression line.
Alternatively, the proportionality can be checked by plotting versus t or on the same graph (l = 0, 1). Under the assumption of proportionality (13), the two plots would be approximately parallel. Note that the distance between the two curves is the linear coefficient , which does not depend on t.
Although a graphical analysis is very informative, it may be interesting (or necessary) to make a decision based on a measure of evidence. Thus, when considering the relation (15), a hypothesis test can be considered.
Let , with , be the j-th distinct time observed (censored or uncensored), the verification can be conducted by testing the hypothesis of the angular coefficient of the straight line being different from one (). Thus, the hypotheses of interest are described by the following:
The statistical test of the hypothesis (16) is given by the following [9]:
where , and with and . Assuming the normality of , M follows a Student’s t distribution with degrees of freedom.
The procedures for the verification of the assumption of proportional log survival presented can be easily extended to categorical covariates with three or more levels by comparing each level of the covariate two-by-two. For numerical covariates, the same method can be adopted by categorizing the covariates to be tested.
2.4. Discrete Weibull Proportional Log Survival Model (PLSM-DW)
A discrete Weibull proportional log survival model is obtained by adopting Nakagawa and Osaki’s discrete Weibull distribution (DW) [11] as the baseline distribution. Thus, assuming that T∼ Discrete-Weibull(,q), and , the discrete Weibull proportional log survival model (PLSM-DW) is given by (3) with , i.e.,
Thus, according to (4) and (5), the probability and hazard functions of the PLSM-DW are given, respectively, by the following:
and
In particular, when , the DW distribution is reduced to the Geometric distribution (G) and, therefore, the PLSM-WD reduces to the Geometric proportional log survival model (PLSM-G).
In addition, any distribution of non-negative discrete variables can be adopted as the baseline distribution for the PLSM, such as the discrete log-logistic distribution [15], the exponentiated discrete Weibull distribution [16], the discrete Burr and Pareto distributions [17] and others [18,19].
3. Simulation Study
This section presents a simulation study to investigate whether the usual asymptotic properties of maximum likelihood estimators are present.
The study of the PLSM is conducted considering simulated data in R version 4.3.3 [20]. The simulations performed in this work consider in the model a dichotomous covariate, , generated from a Bernoulli distribution with a probability of success and a numerical covariate, , with a standard normal distribution. This simulation study considers the discrete Weibull (DW) distribution as the baseline distribution.
The survival times of the PLSM-DW are simulated by the inverse transformation method. Initially, continuous survival times are generated using the inverse of the survival function given by (3), with
where is the shape parameter and is the scale parameter of the continuous Weibull distribution. Note that, considering the parameters and q of the discrete Weibull distribution, the scale parameter, , of the corresponding continuous Weibull distribution is given by . Moreover, the shape parameter, , of the continuous Weibull distribution is the same as that of the discrete Weibull distribution.
The survival times are generated according to a non-informative right censoring mechanism. The times until censorship are generated independently of the survival time and according to an exponential distribution. Finally, the generated continuous survival times are discretized considering their integer part, that is, the largest integer smaller than or equal to the generated value.
The simulation study is performed by considering two scenarios, which differ in the behavior of the hazard function (varying parameter). The parameters of the two proposed scenarios are shown in Table 1.

Table 1.
Scenarios adopted in the simulations.
For each scenario shown in Table 1, the mean estimates, the mean square error (MSE), and the coverage probability (CP) of the estimators are obtained from 1000 Monte Carlo replicates, given sample sizes of n = 30, 50, 100, 250, and 500 and censoring percentages equal to 0%, 10%, and 30%. The PC’s are obtained from the 50% confidence intervals, as suggested by [21]. The adoption of this level of significance in the probability of coverage (instead of the 95% usually adopted) has the advantage of obtaining a measure whose comparison is symmetrical. In fact, a CP = 0.98 can be considered a more significant deviation from 0.95 than CP = 0.92.
The results referring to the estimates of , , and for 0% censoring are presented in Figure 1, Figure 2, Figure 3 and Figure 4, respectively.
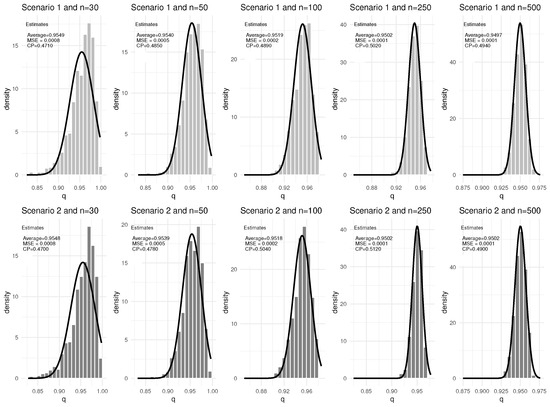
Figure 1.
Results from 1000 Monte Carlo replications for the parameter q separated by scenario and sample size with the respective estimated normal curves for 0% censoring.
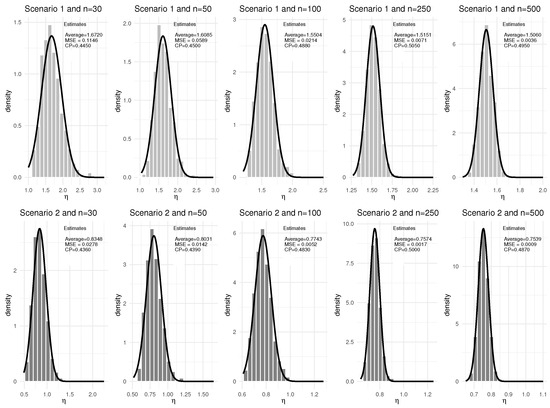
Figure 2.
Results from 1000 Monte Carlo replications for the parameter separated by scenario and sample size with the respective estimated normal curves for 0% censoring.
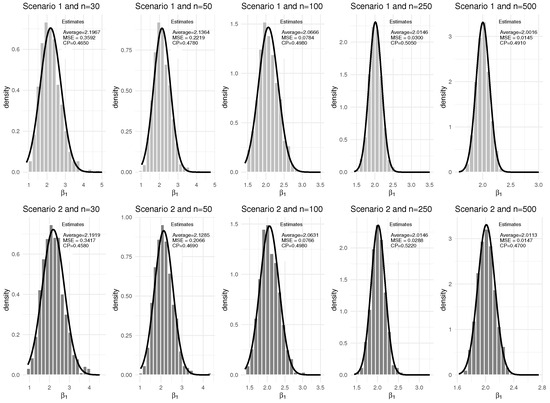
Figure 3.
Results from 1000 Monte Carlo replications for the parameter separated by scenario and sample size with the respective estimated normal curves for 0% censoring.
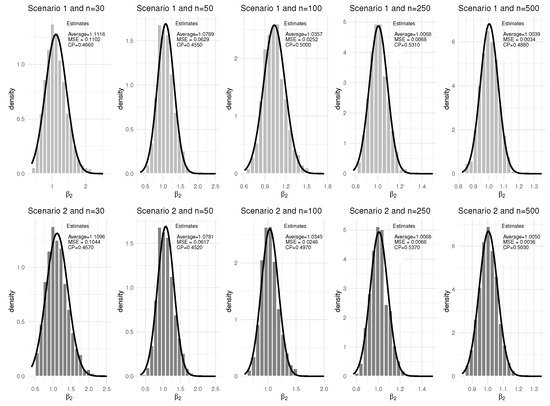
Figure 4.
Results from 1000 Monte Carlo replications for the parameter separated by scenario and sample size with the respective estimated normal curves for 0% censoring.
Analyzing the results of the Figure 1, Figure 2, Figure 3 and Figure 4, it can be seen that the simulations showed that the mean estimates of the parameters studied were close to their true values. The MSEs were close to zero even for smaller sample sizes, and as the sample size becomes larger, the results of the respective analyses converge to their true values, regardless of whether the estimator refers to the baseline distribution (q and ) or to the estimators related to the covariates ( and ). The CP’s remained close to the stipulated degree of confidence regardless of the parameter and sample size (the biggest difference is for the parameter in Scenario 2 with sample size equal to 30 and 0% censoring). In addition, it can be inferred that the estimators are asymptotically unbiased. Furthermore, since the increase in sample size leads to lower MSE estimates (lower variance of the estimator), it can be inferred that the estimators are consistent and, from what has been shown, the estimators are asymptotically normal.
The entire evaluation to this point was carried out in the absence of censoring. Therefore, considering the same scenarios and sample sizes, Table 2 shows the estimates (mean of the parameter estimates, MSE, and CP) considering censoring percentages of 0%, 10%, and 30%. These estimates are based on the result of 1000 Monte Carlo replications.
Table 2.
Average estimates, MSE, and coverage probability (CP) for the PLSM-DW parameters considering the simulation scenarios and different sample sizes and censoring percentages.
It can be seen that the results in the presence of censoring are similar to that of the estimators in the absence of censoring, a fact corroborated by the estimates shown in Table 2. Considering the situation with more censoring, i.e., a larger sample size (n = 500) and a higher censoring percentage (30%), the biggest difference between the estimate and the true value of the parameter is 2.000 − 1.9775 = 0.0225 and the largest value of the MSE is 0.01980 (both referring to parameter in Scenario 1), and the largest difference between the CP and the adopted degree of confidence is 0.5000 − 0.4580 = 0.0420 (referring to parameter in Scenario 1).
Based on the results of the simulations and the similarity of the results in the absence and presence of censoring, the asymptotic normality of the estimators was met. Therefore, the construction of confidence intervals approximated by a Normal distribution for the parameters of the baseline distribution, as well as for the parameters associated with the covariates, is valid and can be used for interval estimation of the model parameters. As a result, hypothesis tests approximated by a Normal distribution to check the significance of the covariate can also be used in applications.
4. Application
This section presents an application of the PLSM-WD to a dataset obtained from the book [12] and refers to the survival time in weeks of 30 patients with acute myeloid leukemia (AML). The database presents two possible prognostic factors (age and cellularity status). However, similarly to [10], this illustration only considers the covariate age in a dichotomous form:
The application data are presented in Table 3.
Table 3.
Survival time of 30 AML patients.
The data in Table 3 were adjusted by the discrete Weibull proportional log survival model (PLSM-DW). Initially, the assumption of the PLSM-WD was verified, observing the proportionality between the levels of the covariate age. The graphs , , and and the p-value of hypothesis test (16) are presented in Figure 5.
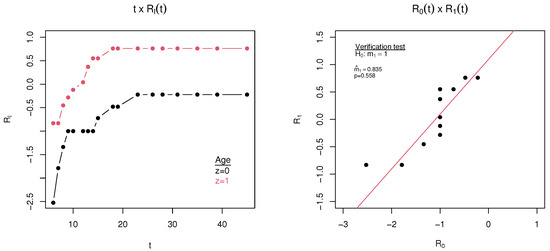
Figure 5.
Verification of assumption of proportional log survival for the covariate age.
Through the results of the test presented in Figure 5 it is noted that the assumption of proportional log survival was not rejected (considering a significance level of 5%). The graph corroborates such a statement since the points formed by the coordinates are close to the adjusted regression line. In addition, the graph , , also confirms the statement that the proportional log survival assumption is valid since the log-log values of the survival function of the different categories are approximately parallel to each other.
The parameter estimates for the PLSM-WD, taking into account the age covariate, are presented in Table 4.
Table 4.
PLSM-DW parameter estimates.
Through the estimates in Table 4, an interpretation can be obtained regarding the odds of survival for the different categories of the age covariate. Since represents the ratio of the log survival of the different groups, constant over time, assuming the group of patients that is 50 years or older (). In this context, the log survival of a patient who is 50 years or older is times the log survival of patients younger than 50 years. This result implies that the survival of a patient who is 50 years or older is lower than the survival of a patient who is less than 50 years old (since the logarithm of the survival function is negative).
For diagnostic analysis of the model, by way of comparison, a discrete Weibull proportional odds hazard model (POHM-WD) presented by [9] and a discrete Weibull proportional odds survival model (POSM-WD) presented by [10] were fitted taking into account the data in Table 3.
The survival functions of the POHM-WD and POSM-WD are, respectively, given by the following:
and
where and are, respectively, the hazard and survival functions of DW distribution.
In addition, the maximum errors of the survival function estimates were calculated for the three models considered (Table 5). This error, , is based on the maximum difference between the survival estimates of the models, , and the empirical Kaplan–Meier (KM) estimates [22]. The maximum error is defined as follows [23]:
Table 5.
Maximum errors from model estimation (AML data).
Figure 6 shows the fits of the PLSM-DW, POHM-WD and POSM-WD.
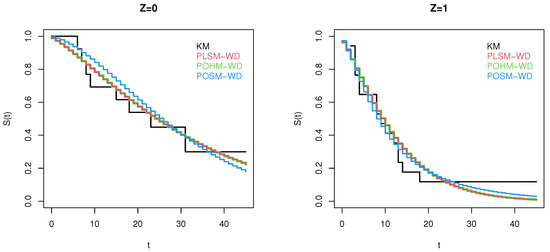
Figure 6.
Models fit to leukemia data by level of the age covariate.
Note that, through Table 5 and Figure 6, the three models designed for discrete time-to-event data (PLSM-DW, POHM-DW and POSM-DW) presented a good fit to the data, with the estimates of the survival function of these models always being close to the empirical estimates. It is interesting to note that the PLSM-WD and POHM-WD estimates were practically the same. However, even though the results were similar, the PLSM has the advantage of having a simple closed-form equation for the survival function, which is not the case in the POHM.
5. Conclusions
The aim of this work was to propose a proportional log survival model (PLSM) as an alternative to the proportional odds hazard model [9] and proportional odds survival model [10]. The PLSM is equivalent to the proportional hazards (PH) model when the variable is continuous, but this equivalence does not apply in cases where the variable is discrete. Thus, the PLSM can be seen as a discrete alternative to the PH model.
This paper presented the formulation of the PLSM, as well as the procedures for verifying its assumption. Although the PLSM can be applied to any discrete distribution as a baseline distribution, this work focused on the discrete Weibull distribution (WD), resulting in the discrete Weibull proportional log survival model (PLSM-DW). The parameters of the PLSM-DW were inferred using the maximum likelihood method, and computational optimization methods were applied to obtain the estimates.
A simulation study was carried out using R version 4.3.3 to evaluate the bias, the mean square error of the estimates, and the coverage probability of the proposed asymptotic confidence intervals. These simulations are considered two scenarios. The results showed that the estimators were consistent and asymptotically normal.
The PLSM-DW was illustrated using data on the survival time of patients with leukemia and showed a good fit for the application data, demonstrating that it is a viable alternative for modeling discrete survival data.
For future works, new studies could be conducted to verify the behavior of the PLSM with different discrete baseline distributions and other censoring mechanisms, such as left and interval censoring, as well as the inclusion of time-dependent covariates.
Author Contributions
Conceptualization, T.C.E.F., M.R.P.C. and E.Y.N.; methodology, T.C.E.F., M.R.P.C. and E.Y.N.; software, T.C.E.F., M.R.P.C. and E.Y.N.; validation, T.C.E.F., M.R.P.C. and E.Y.N.; formal analysis, T.C.E.F., M.R.P.C. and E.Y.N.; investigation, T.C.E.F., M.R.P.C. and E.Y.N.; resources, T.C.E.F. and E.Y.N.; data curation, T.C.E.F., M.R.P.C. and E.Y.N.; writing—original draft preparation, T.C.E.F., M.R.P.C. and E.Y.N.; writing—review and editing, T.C.E.F., M.R.P.C. and E.Y.N.; visualization, T.C.E.F., M.R.P.C. and E.Y.N.; supervision, E.Y.N.; project administration, E.Y.N.; funding acquisition, T.C.E.F. and E.Y.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brasil (CAPES)—Finance Code 001 and Fundação de Apoio à Pesquisa do Distrito Federal (FAPDF)—TOA 443/2022 and TOA 101/2024.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AML | acute myeloid leukemia |
| CI | confidence interval |
| CP | coverage probability |
| DW | discrete Weibull |
| KM | Kaplan–Meier |
| MSE | Mean squared error |
| PH | proportional hazard |
| PLSM | proportional log survival model |
| PLSM-DW | discrete Weibull proportional log survival model |
| POHM | Proportional odds hazard model |
| POHM-DW | discrete Weibull proportional odds hazard model |
| POSM-DW | discrete Weibull proportional odds survival model |
References
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B (Methodol.) 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Caroni, C. Regression models for lifetime data: An overview. Stats 2022, 5, 1294–1304. [Google Scholar] [CrossRef]
- Gupta, R.C.; Gupta, R.D. Proportional reversed hazard rate model and its applications. J. Stat. Plan. Inf. 2007, 137, 3525–3536. [Google Scholar] [CrossRef]
- Bennett, S. Analysis of survival data by the proportional odds model. Stat. Med. 1983, 2, 273–277. [Google Scholar] [CrossRef] [PubMed]
- Oakes, D.; Dasu, T. Inference for the proportional mean residual life model. Inst. Math. Stat. Lect. Notes 2003, 43, 105–116. [Google Scholar]
- Shrahili, M.; Albabtain, A.A.; Kayid, M.; Kaabi, Z. Stochastic aspects of proportional vitalities model. Mathematics 2020, 8, 1823. [Google Scholar] [CrossRef]
- Asadi, M.; Berred, A. Properties and estimation of the mean past lifetime. Statistics 2012, 46, 405–417. [Google Scholar] [CrossRef]
- Bandos, H. Regression on Median Residual Life Function for Censored Survival Data. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 2007. [Google Scholar]
- Vieira, M.G.; Cardial, M.R.P.; Matsushita, R.; Nakano, E.Y. Proportional odds hazard model for discrete time-to-event data. Axioms 2023, 12, 1102. [Google Scholar] [CrossRef]
- Cardial, M.R.P.; Cobre, J.; Nakano, E.Y. A discrete Weibull proportional odds survival model. J. Appl. Stat. 2025, 52, 429–447. [Google Scholar] [CrossRef] [PubMed]
- Nakagawa, T.; Osaki, S. The discrete Weibull distribution. IEEE Trans. Reliab. 1975, 24, 300–301. [Google Scholar] [CrossRef]
- Lee, E.T.; Wang, J. Statistical Methods for Survival Data Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Tutz, G.; Schmid, M. Modeling Discrete Time-to-Event Data; Springer: New York, NY, USA, 2016. [Google Scholar]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Para, B.A.; Jan, T.R. Discrete version of log-logistic distribution and its applications in genetics. Int. J. Mod. Math. Sci. 2016, 14, 407–422. [Google Scholar]
- Cardial, M.R.P.; Fachini-Gomes, J.B.; Nakano, E.Y. Exponentiated discrete Weibull distribution for censored data. Braz. J. Biom. 2020, 38, 35–56. [Google Scholar]
- Krishna, H.; Pundir, P.S. Discrete Burr and discrete Pareto distributions. Stat. Methodol. 2009, 6, 177–188. [Google Scholar] [CrossRef]
- Chakraborty, S. Generating discrete analogues of continuous probability distributions—A survey of methods and constructions. J. Stat. Distrib. Appl. 2015, 2, 1–30. [Google Scholar] [CrossRef]
- Jayakumar, K.; Babu, M.G. Discrete Weibull geometric distribution and its properties. Commun.-Stat.-Theory Methods 2018, 47, 1767–1783. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 20 January 2025).
- Brunello, G.H.V.; Nakano, E.Y. A Bayesian Measure of Model Accuracy. Entropy 2024, 26, 510. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1958, 53, 457–481. [Google Scholar] [CrossRef]
- Nakano, E.Y.; Carrasco, C.G. Uma avaliação do uso de um modelo contínuo na análise de dados discretos de sobrevivência. Trends Comput. Appl. Math. 2006, 7, 91–100. [Google Scholar] [CrossRef][Green Version]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).