Abstract
We propose a robust procedure to estimate the conditional mode of a univariate outcome O given a Hilbertian explanatory variable I, under the assumption that follow a single-index structure. The estimator is constructed using the M-estimator for the conditional density, and we establish its complete convergence. We discuss the estimator’s advantages in addressing challenges within functional data analysis, particularly robustness and reliability. We then evaluate both the performance and practical implementation of our method via Monte Carlo simulations. Furthermore, we carry out an empirical study to showcase the improved reliability and robustness of this estimator compared to conventional approaches. In particular, our methodology is applied to predict fuel quality based on spectrometry data, illustrating its strong potential in real-world scenarios.
Keywords:
functional data; functional M-regression; robust estimator; modal regression; kernel smoothing; conditional quantile; additive model; single-index model MSC:
62G08; 62G10; 62G35; 62G07; 62G32; 62G30; 62H12
1. Introduction
In typical regression analyses, one aims to identify a possible relationship between the variables by finding a function that minimizes the mean squared error criterion. It is well established that this minimizer corresponds to the regression function
where is a bounded measurable function. A substantial body of work has been devoted to the nonparametric estimation of this function, utilizing an array of smoothing techniques, such as kernel methods, spline smoothing, local polynomials, and orthogonal expansions, to capture the potentially complex structure of the relationship between O and I. For comprehensive discussions on theoretical developments and practical applications in both independent and dependent settings, readers are referred to [1,2,3,4,5,6,7,8].
Under the classic setting where , the conditional expectation is commonly estimated via least-squares regression (or robust/weighted variants) to summarize how the response O depends on the covariate I. However, such a mean-based framework can be unsuitable for data characterized by strong skewness, multiple modes, or the presence of outliers. For instance, in domains such as economics (e.g., wages, prices, and expenditures) or nutrition (e.g., energy intake), the arithmetic mean may be a poor representation of the central tendency. As a concrete illustration, consider the following conditional density function:
Here, the conditional mean is
implying that the usual regression function is constant and thus unhelpful for prediction purposes in this scenario.
Mode regression (MR) emerges as a compelling alternative when the conditional density exhibits heavy tails, significant skewness, or multiple local modes. Unlike mean regression, which can be heavily influenced by outliers or fail to capture multimodal structures, MR focuses on estimating the most frequent (modal) values of Y given X. The advantages of MR over classical mean-based approaches in such circumstances were first observed by [9] and further emphasized by [10]. For detailed reviews and methodological extensions, see [11,12,13].
Building on these ideas, the present work focuses on mode estimation within a functional single index (FSI) framework, offering new insights and methodologies for robustly capturing the salient features of complex data distributions.
The FSI framework is widely adopted because it enhances nonparametric estimation through the projection of the functional input onto a principal direction. This approach combines the interpretability of a linear model with the flexibility of a nonparametric procedure, achieved by applying a suitable link function. Although there is a substantial body of research on single-index models in finite-dimensional settings (see [14,15] for early investigations and [16,17,18] for more recent advances), the extension to functional data was first introduced by [19,20], who proposed a kernel-based estimator for conditional expectation under an FSI assumption. Quantile regression under an FSI model was discussed in [21], where both the unknown link function and the slope were estimated using a B-spline method. A compact single functional index model with a specific coefficient function was examined in [22], whereas [18] addressed nonparametric models tied to the conditional distribution in the FSI setting. Multi-index scenarios under functional inputs are considered in [23], with established asymptotic properties for kernel-smoothing methods when estimating unknown parameters. Additional works relevant to nonparametric conditional density estimation with Hilbertian regressors in an FSI framework can be found in [24,25]. In [26], the estimation of a functional single-index regression model is addressed under the setting where responses may be randomly missing, and the data follow a strongly mixing time series structure. Under general conditions, the proposed estimator is shown to achieve a uniform, almost complete convergence rate, and its asymptotic normality is also established. In [27], a robust nonparametric estimation procedure is introduced for regression functions using a kernel-based approach. The covariates are i.i.d. functional data linked to a single-index model, and the methodology accommodates censored observations. In [28], a robust estimator grounded in Huber’s loss function is proposed for a functional single-index model with a parameter of fixed dimension. This work further extends to high-dimensional settings by developing a robust estimator of the unknown parameter, achieved through an adaptive lasso penalty. An extensive overview of functional semiparametric modeling is provided in [29,30,31,32].
A second focus of this contribution concerns conditional mode functions, which were introduced in functional statistics by [33]. Since that foundational work, a considerable number of studies have analyzed the interplay between functional predictors and a scalar response. For instance, ref. [34] explored functional M-regression, ref. [35] investigated functional linear local regression, and [36] dealt with relative error functional regression. Within this general framework, the nonparametric conditional mode has attracted growing attention. Seminal work by [37] established the asymptotic distribution of a kernel-based modal regression estimator under independent and identically distributed observations, later generalized to dependent samples in [38]. The complete consistency of the kernel-based modal regression estimator for spatio-functional data was studied by [39], who also demonstrated consistency in [40]. A distribution-free version of the modal regression estimator for ergodic functional time series, accommodating missing-at-random (MAR) data in the response, was introduced by [41], who proved its almost sure consistency. Additionally, ref. [42] analyzed a local linear estimator for modal regression and derived its asymptotic distribution. For recent advances in FSI modeling, see [43,44,45,46], among others.
1.1. Contribution
In contrast to previous research, this study offers a novel strategy that merges modal and quantile regression. Instead of relying on the usual definition of the conditional mode as the point that maximizes the conditional density, we redefine the conditional mode by minimizing the derivative of the conditional quantile. This perspective establishes a direct link between modal regression and quantile regression, providing a robust alternative for estimating the mode function. Our estimator is developed under the functional single-index (FSI) framework, which integrates robust estimation with single-index modeling to improve both robustness and efficiency. It is well recognized that using the FSI approach enhances convergence by projecting the functional predictor onto its principal direction. A major theoretical contribution of this work is the derivation of complete consistency for the proposed estimator, with explicit convergence rates provided. In addition, we examine how selecting the functional index influences efficiency. Finally, an empirical analysis illustrates the method’s straightforward implementation and compares its performance against standard estimators from earlier research.
1.2. Organization of the Paper
The paper is structured as follows. In the next section, we present the underlying model together with the robust modal regression estimator. In Section 3, we demonstrate that this estimator achieves complete consistency, subject to certain mild conditions that relate to the functional space of the model and the nature of the data. Section 4 explores the performance of the estimator on both synthetic and real datasets. In particular, for the real-data application, we illustrate how to determine the chemical composition of fuel by examining the spectrometry curves of the processed energy product. Some concluding observations are provided in Section 5. Finally, in order to maintain a clear narrative and foster a deeper comprehension of our proofs, all the detailed mathematical developments are postponed to Section 6.
2. Robust Estimator of Modal Regression in the FSI Structure
In this section, we introduce the FSI-mode estimator and provide a detailed examination of its conceptual alignment with the conditional quantile. Consider a pair of input–output random variables taking values in , where is an inner product space equipped with the inner product . Let be n independent and identically distributed samples from the same distribution as . In the framework of an FSI model, the dependence of O on I is described via a functional index , satisfying the following
Typically, to guarantee the identifiability of this FSI model, one assumes that the regression operator is differentiable and that is chosen so that , where is the first vector of an orthonormal basis of ; for instance, see [19]. As in the finite-dimensional case, the FSI approach is highly effective in mitigating the impact of the infinite-dimensional setting when constructing estimators.
Throughout what follows, we fix a point and consider a neighborhood of u. We assume that the conditional distribution function of O given , denoted by , is strictly increasing and that it has a continuous density with respect to the Lebesgue measure on . We define the SFI mode as the maximizer of this conditional density over a given compact set S:
In order to connect the mode function to the conditional quantile , which is known to be more robust, we use the relationship that, for any ,
where is the conditional quantile of order q given . It follows that the function satisfies the following:
with
Hence, a robust estimator of the FSI mode is given by
where
Here, and , respectively, denote estimators for the conditional quantile and its derivative. First, for , the derivative is estimated by
where is a sequence of positive real numbers. Second, the qth conditional quantile is defined as the solution in t of the following optimization problem:
with the loss function . Consequently, its robust estimator is obtained by solving
where
denotes a kernel function, and is a sequence of positive real numbers tending to zero as .
Our main objective is to derive the asymptotic properties of the estimator relative to the true mode . Under standard assumptions, which will be detailed in the next section, we establish convergence properties and asymptotic distributions for .
3. Main Results
We begin by introducing C and as generic positive constants. Additionally, we define . The following are essential conditions necessary for establishing the almost complete convergence (a.co.). Consider a sequence of real-valued random variables for . The sequence is said to converge almost completely (a.co.) to zero if, for any , the series
is finite. Moreover, the rate of this convergence is said to be of order (with ), denoted by , if there exists such that
By the Borel–Cantelli lemma, this implies almost surely, thus indicating that almost complete convergence entails both almost sure convergence and convergence in probability of the estimator for .
- (CO1)
- , where as .
- (CO2)
- The function belongs to the class , and satisfies the following Lipschitz condition:where represents a neighborhood of u.
- (CO3)
- is a function supported on , and there exist constants and C such that .
- (CO4)
- The smoothing parameters and satisfy .
These conditions, (CO1) through (CO4), are standard in the context of functional statistics under a distribution-free framework. Specifically, condition (CO1) plays a critical role in such data analyses, as the function can often be explicitly determined for various continuous processes [33].
Condition (CO2) is a regularity assumption designed to facilitate the exploration of the functional space associated with the model. This assumption significantly affects the bias term in the convergence rate of . Furthermore, conditions (CO3) and (CO4) pertain to the kernel function and the bandwidth parameters and . These technical requirements simplify the proof of the estimator ’s consistency.
It should be noted that these conditions are less restrictive than those used in earlier studies, such as those mentioned in [33]. Unlike traditional approaches that rely on two-kernel functions, our methodology estimates only a single kernel, which introduces significant simplifications.
The main asymptotic results derived from this study are summarized in the theorem below.
Theorem 1.
Under assumptions (CO1)–(CO4) and if we have the following:
4. Computational Study
4.1. Simulation Results
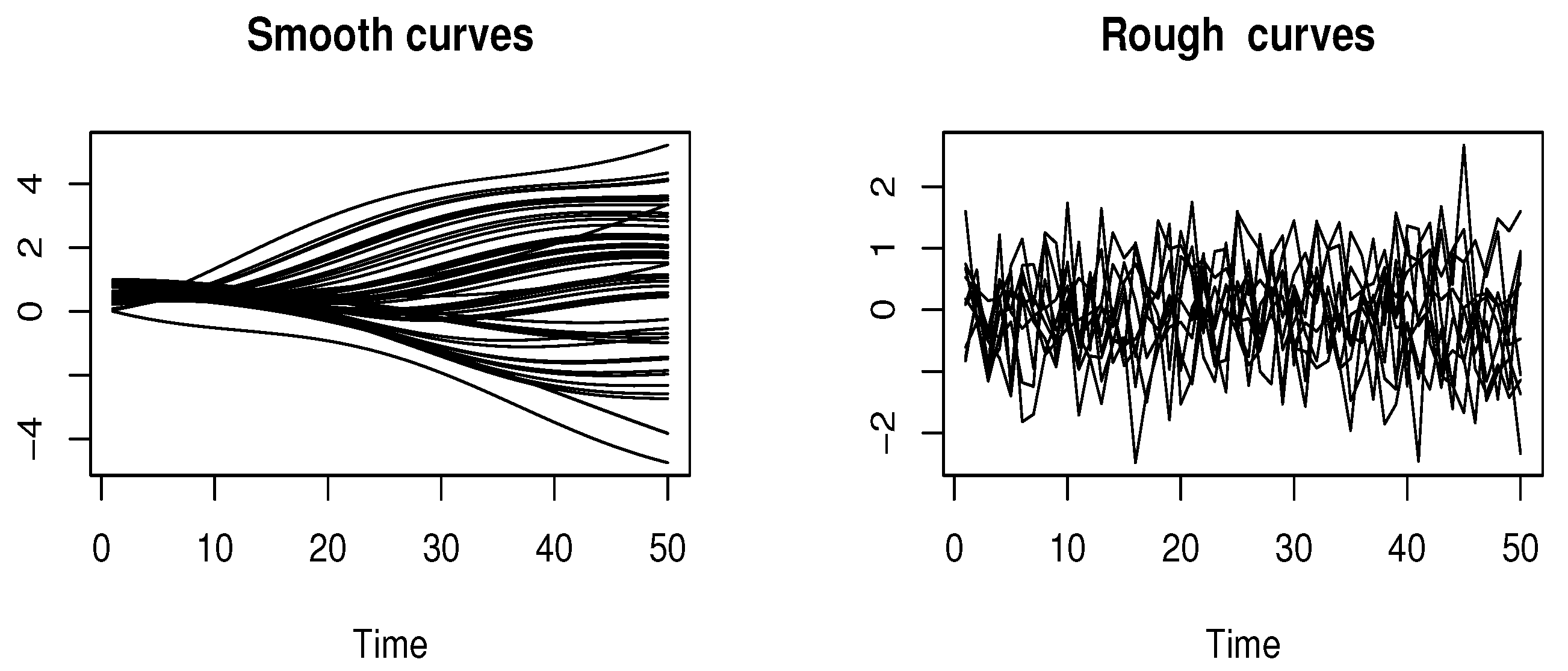
In this section, we present an empirical investigation to evaluate the practical usability of the constructed estimators. Specifically, our objective is to demonstrate the feasibility of employing various data-driven selection strategies to determine the functional index and smoothing parameters and . A key challenge in this analysis lies in constructing functional regressors in practice. To address this, we simulate data using two distinct types of curves: (i) smooth curves and (ii) rough curves. The generation of these curves is defined as follows:
where , , , and . The curves are discretized over a grid of 110 equidistant points in the interval . Examples of the resulting curves are visualized in Figure 1.
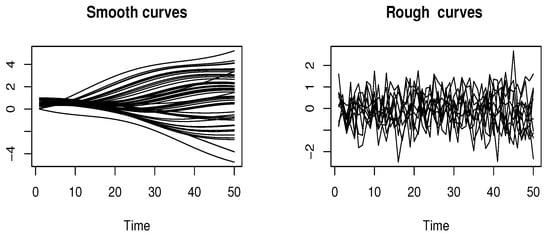
Figure 1.
Functional input variables: smooth curves (left) and rough curves (right).
To simulate the output variables O, we employ two semiparametric models:
where are independent realizations from a normal distribution . Here, the conditional mode of the model is linked to the distribution of the noise . For the purposes of this study, we generate O using the link function , and represents the first eigenfunction corresponding to the largest eigenvalue of the covariance operator associated with the process . In practical scenarios, the functional index is typically unknown, making its accurate estimation crucial for FSI structures. We explore two well-known approaches for estimating , both based on cross-validation principles: The functional index is selected by minimizing the cross-validation error:
The optimal index is chosen as follows:
where denotes the subset of candidate indices defined by the following:
Here, are basis functions obtained via Karhunen–Loève decomposition, and are calibration constants, typically chosen from . The second approach maximizes the pseudo-log-likelihood of the conditional density:
where
and represents the double-kernel estimator of the conditional density:
The smoothing parameter is also selected using the same optimization rules over the subsets , where represents a sequence of bandwidths indexed by k (e.g., ). The kernel used in this study is the quadratic kernel defined on , which aligns with the assumptions of the FSI model. To assess the performance, we compare the estimated mode with the true mode by computing the mean squared error (MSE):
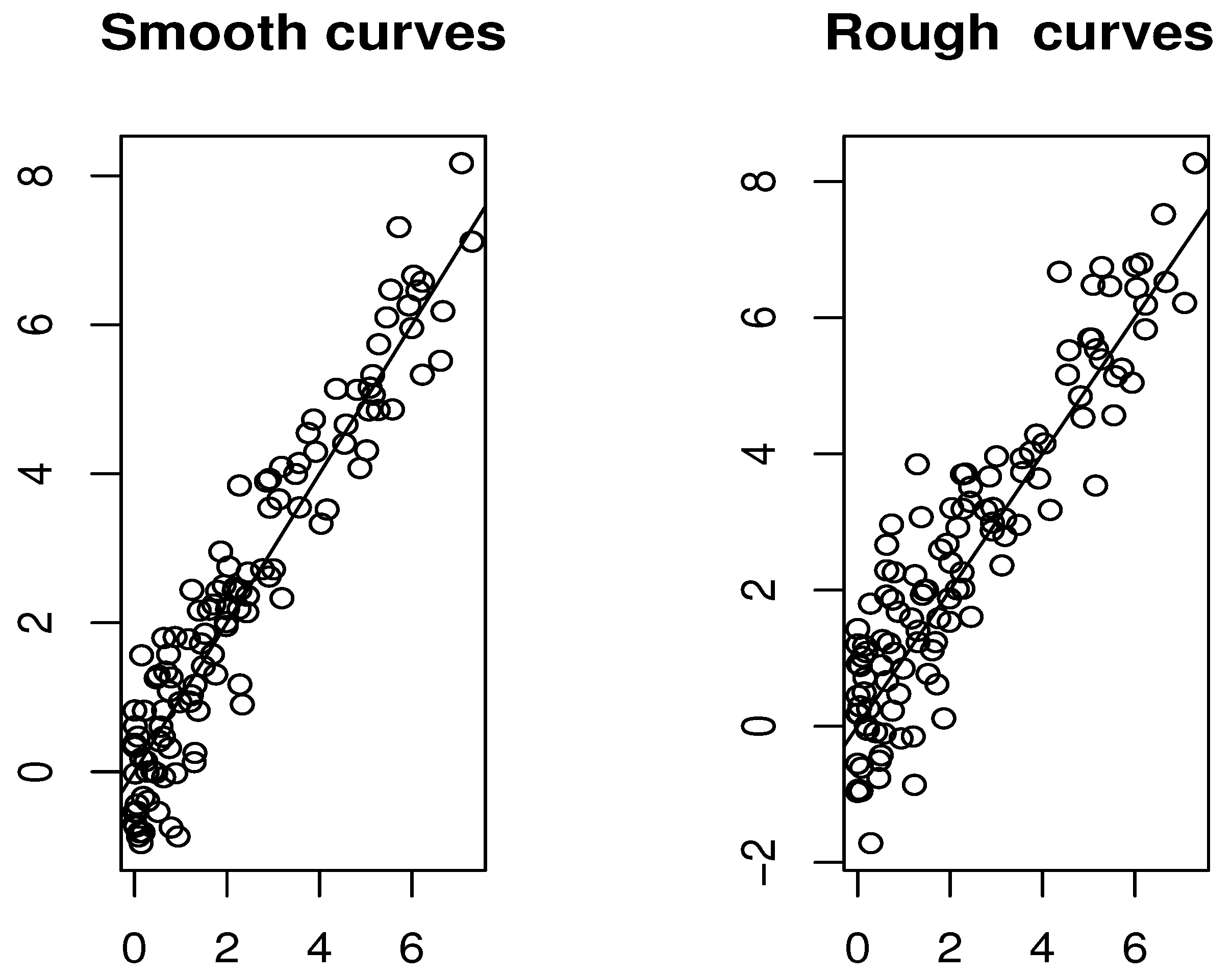
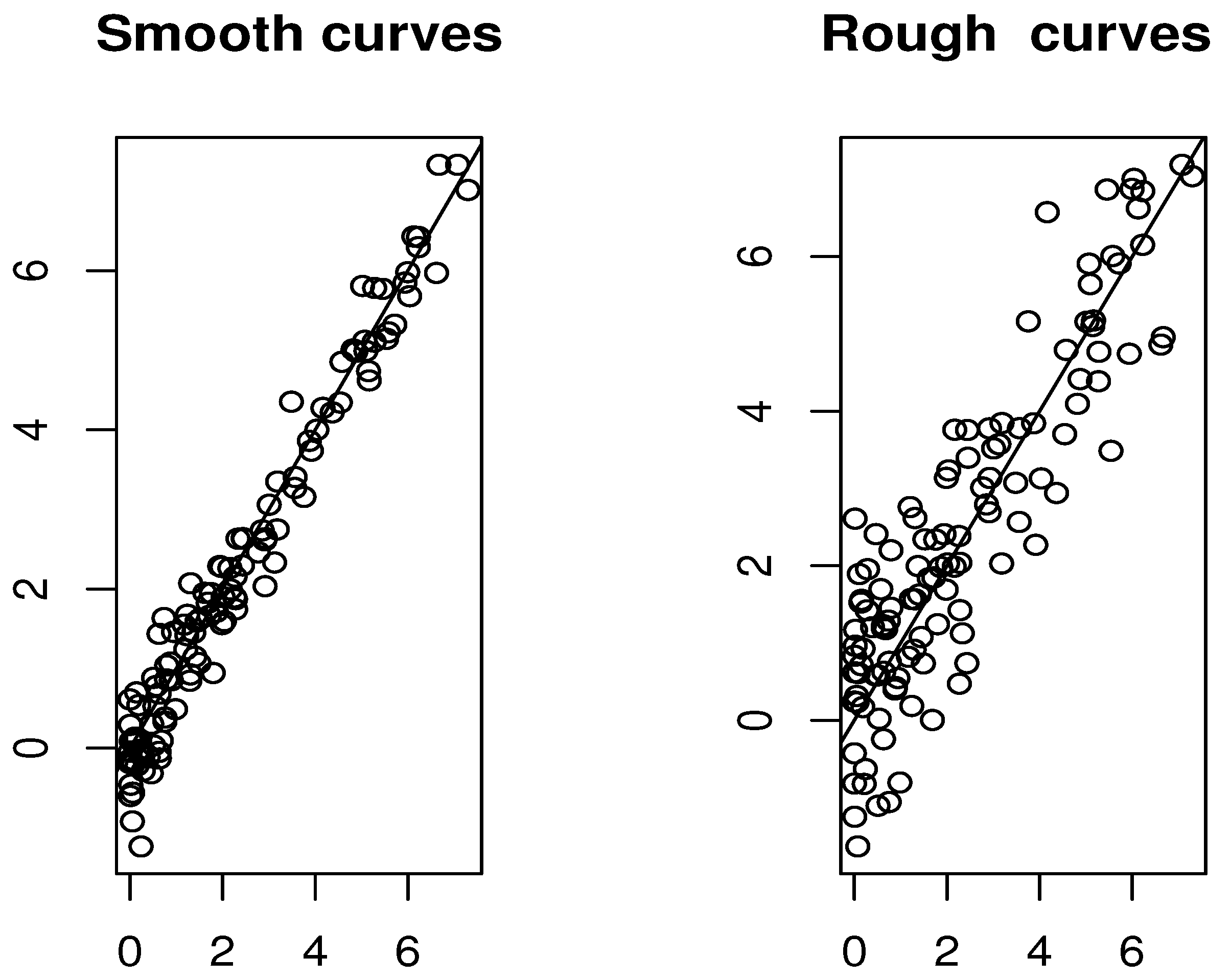
Additionally, we present plots comparing the estimated and true modes for both smooth and rough cases.
In addition, we report the of different situations in the following table.
The results presented in Figure 2 and Figure 3 and Table 1 illustrate that the selection of both the functional index and the smoothing parameter plays a crucial role in determining the accuracy of the estimation. It is evident that the criterion defined in (7) performs exceptionally well in both the rough and smooth cases. Conversely, the rule described in (8) appears to be particularly well-suited for scenarios involving smoother data. Overall, the FSI-estimator proves to be computationally efficient, with multiple strategies available for parameter selection in its construction. Each of these selection methods delivers reliable and computationally efficient outcomes.
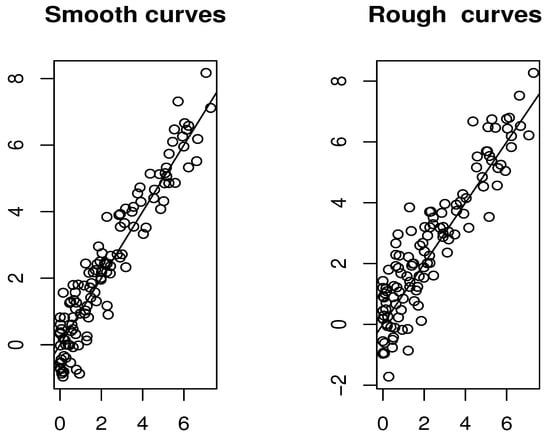
Figure 2.
Comparison of the prediction results using the cross-validation (7) rule.
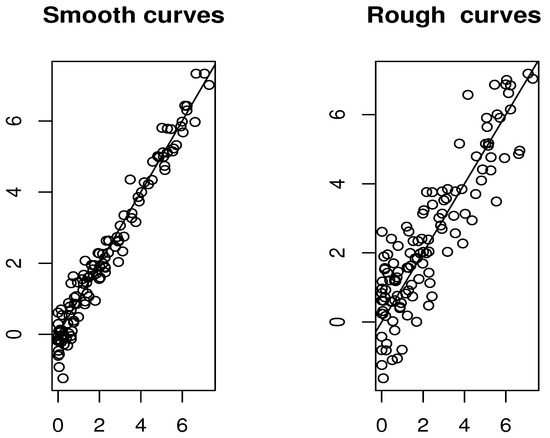
Figure 3.
Comparison of the prediction results using the cross-validation (8) rule.

Table 1.
MSE of the estimators.
4.2. Real Data Application
In this section, we demonstrate how our proposed model can be utilized for prediction tasks. As an illustrative example, we investigate the chemical composition of yogurt, with particular emphasis on forecasting its riboflavin content. Riboflavin plays a pivotal role in various metabolic processes, including the breakdown of fatty acids and amino acids, and is crucial for maintaining the integrity of skin, eyesight, and mucous membranes. Consequently, riboflavin levels are often used as an indicator of yogurt quality.
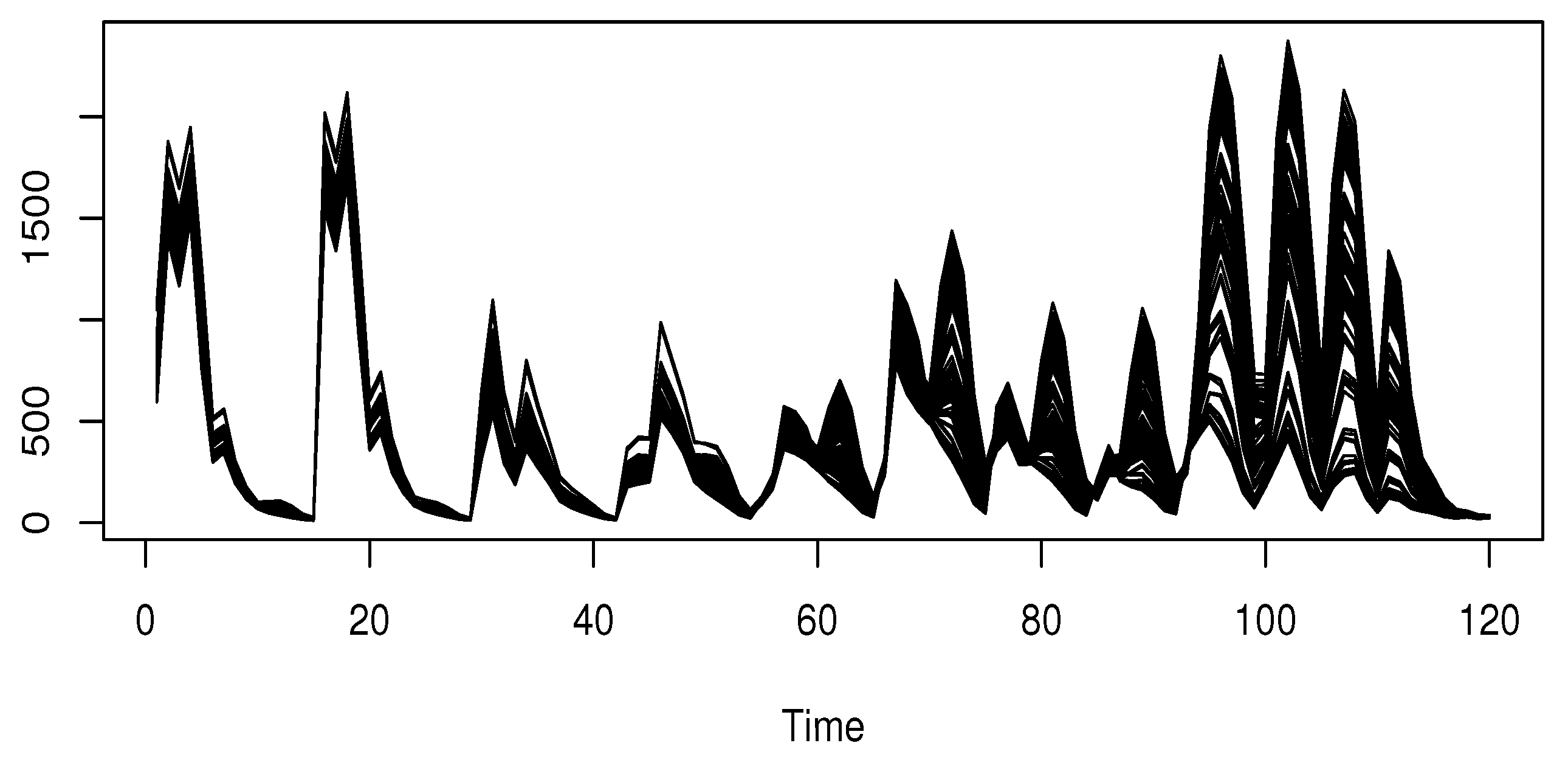
Although a similar type of analysis has been conducted previously (see [47]), our contribution introduces a functional single-index (FSI) approach that combines the near-infrared (NIR) spectral curves with a robust estimation procedure. The aim is to enhance predictive performance compared to traditional methods. The NIR data used in this study can be found at http://www.models.life.ku.dk/Yogurt (accessed on 20 September 2024). These spectral measurements were obtained using a BioView spectro-fluorometer, yielding absorbance profiles at 120 wave points between 270–550 nm and at wavelengths ranging from 310–590 nm. The dataset contains 115 spectral curves , as illustrated in Figure 4. Additional details regarding this dataset can be found in [48].
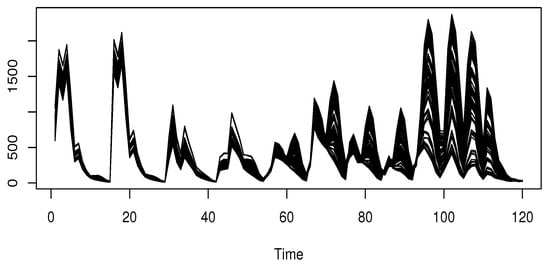
Figure 4.
Spectral curves of the yogurt dataset.
For the predictive comparison, we focus on three modal regression estimators: (FSI-robust), (FSI-standard), and (nonparametric-standard). They are defined by
where
All three estimators employ consistent parameter selection criteria, including the same kernel function and cross-validation strategy for choosing smoothing parameters. To evaluate predictive performance, the 115 available observations were randomly split into training (80 observations) and testing (35 observations) sets. The quality of each estimator was measured using the mean squared error (MSE):
where denotes the test set, and stands for one of the three estimators.
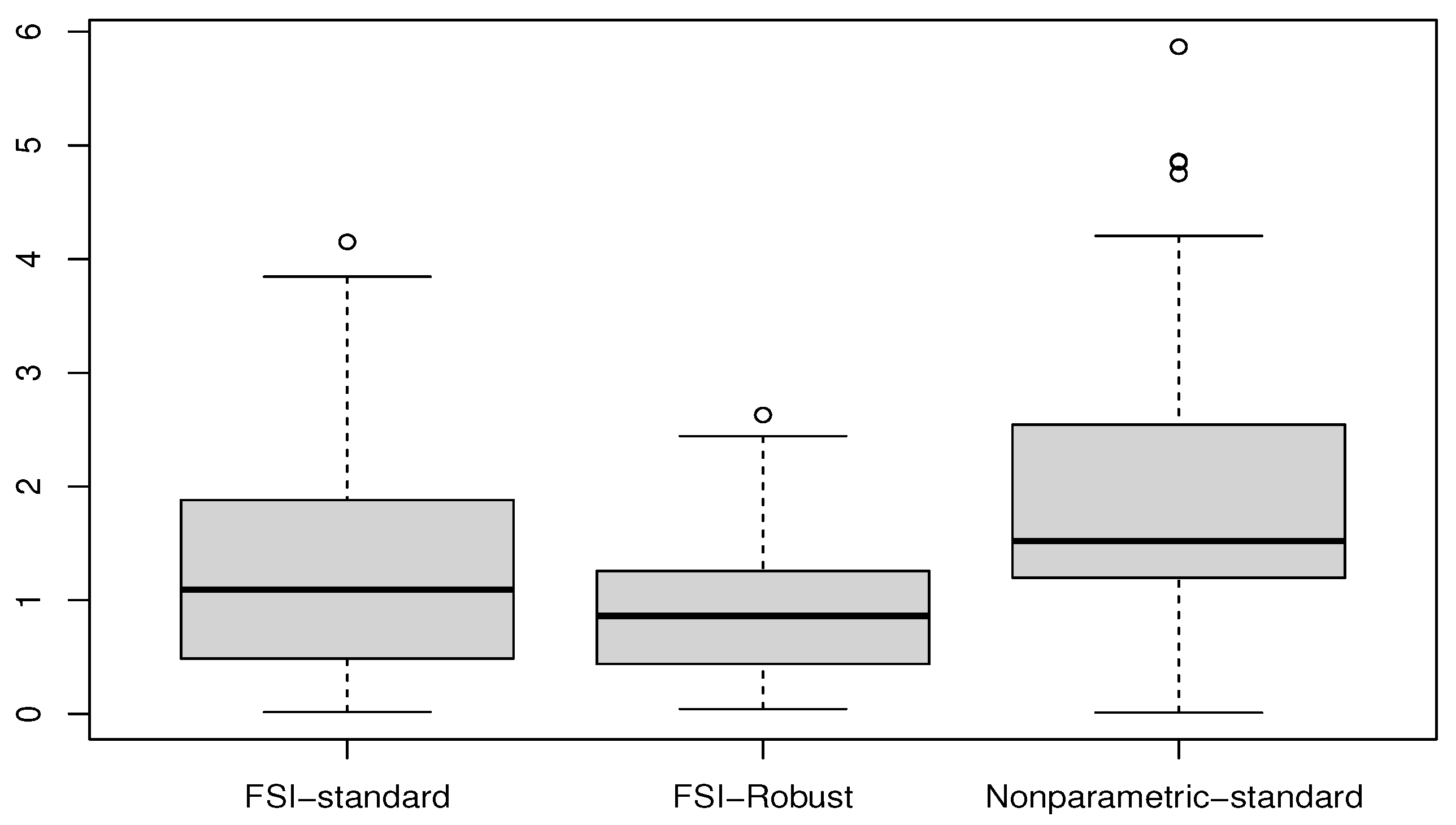
This splitting procedure was repeated 70 times to assess the stability and robustness of the predictions. Figure 5 provides a box plot of the MSE values, according to (9), for the three estimators across all runs.
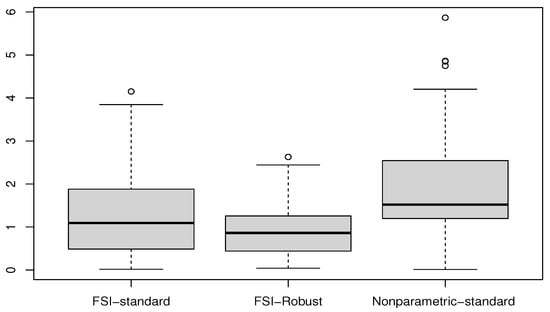
Figure 5.
Box plots of MSE values for the three predictors.
Overall, all estimators demonstrate strong performance; however, FSI-based methods exhibit a distinct advantage. This superiority is particularly evident in the interquartile range (IQR) presented in Figure 5, which highlights the greater consistency of . Specifically, the IQR for is approximately , which is notably smaller than those of and , respectively. These findings align with theoretical expectations, as the FSI framework, when integrated with a robust quantile-based approach, effectively mitigates the challenges posed by the high-dimensional nature of the functional regressor.
5. Conclusions and Prospects
In this work, we propose a robust methodology for estimating modal regression by exploiting the quantile function. We construct the estimator and establish its asymptotic properties through complete consistency. The functional structure is captured via a single-index smoothing algorithm, which is particularly effective for enhancing the precision of the estimator. Meanwhile, incorporating the quantile function bolsters the model’s robustness. Our asymptotic findings hold under general assumptions, thereby accommodating a broad class of functional data and/or continuous-time processes. Empirical evidence underscores both the simplicity of implementing the proposed estimator and its advantageous properties in terms of robustness and accuracy, especially when juxtaposed with alternative methods. Furthermore, the work presented here paves the way for various future research directions. As an illustration, exploring a local linear estimator for modal regression could prove promising, given that local linear approaches are well known for mitigating bias and thus advancing asymptotic performance. Another important yet unresolved question concerns the asymptotic normality of the robust estimator since its resolution would be pivotal for constructing confidence intervals and performing hypothesis testing.
One area not addressed in this paper concerns the optimal selection of smoothing parameters with the specific goal of minimizing the mean square error (MSE) of the proposed kernel estimators. This issue is highly pertinent within the broader domain of kernel-based nonparametric estimation and clearly merits a dedicated investigation. Although it is an integral component in refining our approach, we have opted to postpone a detailed analysis of smoothing parameter selection, potentially using cross-validation or other optimization strategies, to forthcoming work.
Moreover, there are numerous other directions for future research. For instance, one might consider linear or partially linear extensions of robust modal regression. Another more intricate avenue would involve accommodating censored data or functional time series, requiring a level of mathematical rigor that exceeds the scope of the present contribution.
A further question that naturally arises is how to extend our findings to other widely used nonparametric estimation techniques, such as wavelet-based estimators [49], delta sequence estimators [50], k-nearest neighbor (kNN) estimators, and various local linear estimators [51]. Given the versatility of these methods within functional data analysis, integrating the bias correction techniques introduced here could potentially enhance their performance in a variety of contexts.
6. The Mathematical Developments
In this section, we establish the main theoretical results of the paper. The proof of Theorem 1 relies on standard analytical arguments. In particular, we begin by writing the following:
Next, by applying a Taylor expansion, we obtain
Since is the minimizer of , it follows that
Moreover,
Combining (10)–(12) leads to
From the definition of and for sufficiently large n, we have
It follows that
Hence, Theorem 1 is implied by the following proposition.
Proposition 1.
Under the assumptions of Theorem 1, we have
In order to establish this proposition, we draw upon the lemmas presented below.
Lemma 1.
Suppose that is a sequence of real-valued random functions, each of which is monotonically decreasing in n, and let be a sequence of real-valued random variables satisfying
for some positive constants χ and M. Then, for any real sequence such that , it follows that
Proof of Lemma 1.
Let . We begin by noting that
Hence,
Since we have , the remaining task is to show that
To proceed, we use the fact that is a decreasing function, which allows us to write
Consequently, it will suffice to prove
For the first claimed result, we write
Thus,
Finally, let us select such that
Building on this choice and invoking conditions of the lemma, we thereby conclude that
Hence, the proof is complete. □
Proof of Proposition 1.
We begin by invoking Lemma 1 for the function
where
Under this framework, we derive the Bahadur representation of the quantile. Since , it remains to check that the conditions required by Lemma 1 are satisfied. In particular, we must show
and that there exist constants and such that
For (13), we derive
We also consider the expression
To analyze this, we apply Bernstein’s inequality to the random variables . By assumption, we have the following bounds:
These conditions allow us to establish the rate of convergence:
Next, we examine the expectation :
Combining these results, we deduce that
For (14), we have
and the bias term
In order to investigate (15), we begin by noting that
Hence, for every , let
We then decompose the following:
Because
we find
where
Clearly, , and
By using
we deduce
Next, we observe that
and consequently,
We now turn to
Notice that
with
Clearly, and
Hence, there exists such that
which completes the proof of (15). Concerning (16), we write
implying
Therefore,
Now, we use the Bahadur representation to state the uniform consistency of
So, all that remains is
For the sake of shortness, we only prove the second one. Indeed, we keep the notation of the first part and we use the compactness once again. Therefore,
Next, for each , define and consider the corresponding term as a function of and q. To simplify notation, set
Hence,
Therefore, it follows that
where
Since
we deduce
and
Similarly, we obtain
where
Because
we again conclude
and
To handle the final term, similarly define
where
Using Bernstein’s inequality, we note that
Hence, there exists such that
It follows that
Moreover, one can show
Thus, combining these bounds yields
which completes the proof of the proposition. □
Author Contributions
The authors contributed equally to this work. Formal analysis, F.A.A.; Validation, M.B.A. and Z.K.; Writing—review and editing, S.B. and A.L. All authors have read and agreed to the final version of the manuscript.
Funding
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R515), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia, and the Deanship of Scientific Research and Graduate Studies at King Khalid University through the Research Groups Program under grant number R.G.P. 1/163/45.
Data Availability Statement
The data used in this study are available through the following link: https://www.models.life.ku.dk/Yogurt (accessed on 20 September 2024).
Acknowledgments
The authors extend their sincere gratitude to the Editor-in-Chief, the Associate Editor, and the three referees for their invaluable feedback and for pointing out a number of oversights in the version initially submitted. Their insightful comments have greatly refined and focused the original work, resulting in a markedly improved presentation. The authors also thank and extend their appreciation to the funders of this work. This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R515), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia, and the Deanship of Scientific Research and Graduate Studies at King Khalid University through the Research Groups Program under grant number R.G.P. 1/163/45.
Conflicts of Interest
The authors declares no conflicts of interest.
References
- Györfi, L.; Härdle, W.; Sarda, P.; Vieu, P. Nonparametric Curve Estimation from Time Series; Lecture Notes in Statistics; Springer: Berlin, Germany, 1989; Volume 60, pp. viii+153. [Google Scholar] [CrossRef]
- Nadaraya, E.A. Nonparametric Estimation of Probability Densities and Regression Curves; Mathematics and its Applications (Soviet Series); Kluwer Academic Publishers Group: Dordrecht, The Netherlands, 1989; Volume 20, pp. x+213. [Google Scholar] [CrossRef]
- Wahba, G. Spline Models for Observational Data; CBMS-NSF Regional Conference Series in Applied Mathematics; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 1990; Volume 59, pp. xii+169. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; Monographs on Statistics and Applied Probability; Chapman and Hall, Ltd.: London, UK, 1995; Volume 60, pp. xii+212. [Google Scholar] [CrossRef]
- McQuarrie, A.D.R.; Tsai, C.L. Regression and Time Series Model Selection; World Scientific Publishing Co., Inc.: River Edge, NJ, USA, 1998; pp. xxii+455. [Google Scholar] [CrossRef]
- Eubank, R.L. Nonparametric Regression and Spline Smoothing, 2nd ed.; Statistics: Textbooks and Monographs; Marcel Dekker, Inc.: New York, NY, USA, 1999; Volume 157, pp. xii+338. [Google Scholar]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; Wiley Series in Probability and Statistics; Wiley-Interscience John Wiley & Sons: Hoboken, NJ, USA, 2002; pp. xiv+337. [Google Scholar] [CrossRef]
- Bouzebda, S.; Taachouche, N. Oracle inequalities and upper bounds for kernel conditional U-statistics estimators on manifolds and more general metric spaces associated with operators. Stochastics 2024, 96, 2135–2198. [Google Scholar] [CrossRef]
- Tarter, M.E.; Lock, M.D. Model-Free Curve Estimation; Monographs on Statistics and Applied Probability; Chapman & Hall: New York, NY, USA, 1993; Volume 56, pp. x+290. [Google Scholar]
- Chen, Y.C.; Genovese, C.R.; Tibshirani, R.J.; Wasserman, L. Nonparametric modal regression. Ann. Stat. 2016, 44, 489–514. [Google Scholar] [CrossRef]
- Chen, Y.C. Modal regression using kernel density estimation: A review. Wiley Interdiscip. Rev. Comput. Stat. 2018, 10, e1431. [Google Scholar] [CrossRef]
- Bouzebda, S.; Didi, S. Some asymptotic properties of kernel regression estimators of the mode for stationary and ergodic continuous time processes. Rev. Mat. Complut. 2021, 34, 811–852. [Google Scholar] [CrossRef] [PubMed]
- Collomb, G.; Härdle, W.; Hassani, S. A note on prediction via estimation of the conditional mode function. J. Stat. Plan. Inference 1987, 15, 227–236. [Google Scholar] [CrossRef]
- Härdle, W.; Hall, P.; Ichimura, H. Optimal smoothing in single-index models. Ann. Stat. 1993, 21, 157–178. [Google Scholar] [CrossRef]
- Stute, W.; Zhu, L.X. Nonparametric checks for single-index models. Ann. Stat. 2005, 33, 1048–1083. [Google Scholar] [CrossRef]
- Tang, Q.; Kong, L.; Rupper, D.; Karunamuni, R.J. Partial functional partially linear single-index models. Stat. Sin. 2021, 31, 107–133. [Google Scholar] [CrossRef]
- Zhou, W.; Gao, J.; Harris, D.; Kew, H. Semi-parametric single-index predictive regression models with cointegrated regressors. J. Econ. 2024, 238, 105577. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, R.; Liu, Y.; Ding, H. Robust estimation for a general functional single index model via quantile regression. J. Korean Stat. Soc. 2022, 51, 1041–1070. [Google Scholar] [CrossRef]
- Ferraty, F.; Peuch, A.; Vieu, P. Modèle à indice fonctionnel simple. C. R. Math. 2003, 336, 1025–1028. [Google Scholar] [CrossRef]
- Ait-Saïdi, A.; Ferraty, F.; Kassa, R.; Vieu, P. Cross-validated estimations in the single-functional index model. Statistics 2008, 42, 475–494. [Google Scholar] [CrossRef]
- Jiang, Z.; Huang, Z.; Zhang, J. Functional single-index composite quantile regression. Metrika 2023, 86, 595–603. [Google Scholar] [CrossRef]
- Nie, Y.; Wang, L.; Cao, J. Estimating functional single index models with compact support. Environmetrics 2023, 34, e2784. [Google Scholar] [CrossRef]
- Chen, D.; Hall, P.; Müller, H.G. Single and multiple index functional regression models with nonparametric link. Ann. Stat. 2011, 39, 1720–1747. [Google Scholar] [CrossRef]
- Ling, N.; Xu, Q. Asymptotic normality of conditional density estimation in the single index model for functional time series data. Stat. Probab. Lett. 2012, 82, 2235–2243. [Google Scholar] [CrossRef]
- Attaoui, S. On the nonparametric conditional density and mode estimates in the single functional index model with strongly mixing data. Sankhya A 2014, 76, 356–378. [Google Scholar] [CrossRef]
- Ling, N.; Cheng, L.; Vieu, P.; Ding, H. Missing responses at random in functional single index model for time series data. Stat. Pap. 2022, 63, 665–692. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould Saïd, E. On the robust regression for a censored response data in the single functional index model. Commun. Stat. Theory Methods 2022, 51, 5162–5186. [Google Scholar] [CrossRef]
- Sun, Y.; Fang, X. Robust estimators of functional single index models for longitudinal data. Commun. Stat. Theory Methods 2024, 53, 6869–6890. [Google Scholar] [CrossRef]
- Han, Z.C.; Lin, J.G.; Zhao, Y.Y. Adaptive semiparametric estimation for single index models with jumps. Comput. Stat. Data Anal. 2020, 151, 107013. [Google Scholar] [CrossRef]
- Hao, M.; Liu, K.; Su, W.; Zhao, X. Semiparametric estimation for the functional additive hazards model. Can. J. Stat. 2024, 52, 755–782. [Google Scholar] [CrossRef]
- Kowal, D.R.; Canale, A. Semiparametric functional factor models with Bayesian rank selection. Bayesian Anal. 2023, 18, 1161–1189. [Google Scholar] [CrossRef]
- Elmezouar, Z.C.; Alshahrani, F.; Almanjahie, I.M.; Bouzebda, S.; Kaid, Z.; Laksaci, A. Strong consistency rate in functional single index expectile model for spatial data. AIMS Math. 2024, 9, 5550–5581. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis; Springer Series in Statistics; Springer: New York, NY, USA, 2006; pp. xx+258. [Google Scholar]
- Azzedine, N.; Laksaci, A.; Ould-Saïd, E. On robust nonparametric regression estimation for a functional regressor. Stat. Probab. Lett. 2008, 78, 3216–3221. [Google Scholar] [CrossRef]
- Barrientos-Marin, J.; Ferraty, F.; Vieu, P. Locally modelled regression and functional data. J. Nonparametr. Stat. 2010, 22, 617–632. [Google Scholar] [CrossRef]
- Demongeot, J.; Hamie, A.; Laksaci, A.; Rachdi, M. Relative-error prediction in nonparametric functional statistics: Theory and practice. J. Multivar. Anal. 2016, 146, 261–268. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Saïd, E. Asymptotic normality of a nonparametric estimator of the conditional mode function for functional data. J. Nonparametr. Stat. 2008, 20, 3–18. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould Saïd, E. Some asymptotic results of a non-parametric conditional mode estimator for functional time-series data. Stat. Neerl. 2010, 64, 171–201. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Laksaci, A. Propriétés asymptotiques d’un estimateur à noyau du mode conditionnel pour variable explicative fonctionnelle. Ann. l’ISUP 2007, 51, 27–42. [Google Scholar]
- Dabo-Niang, S.; Kaid, Z.; Laksaci, A. Asymptotic properties of the kernel estimate of spatial conditional mode when the regressor is functional. AStA Adv. Stat. Anal. 2015, 99, 131–160. [Google Scholar] [CrossRef]
- Ling, N.; Liu, Y.; Vieu, P. Conditional mode estimation for functional stationary ergodic data with responses missing at random. Statistics 2016, 50, 991–1013. [Google Scholar] [CrossRef]
- Bouanani, O.; Rahmani, S.; Laksaci, A.; Rachdi, M. Asymptotic normality of conditional mode estimation for functional dependent data. Indian J. Pure Appl. Math. 2020, 51, 465–481. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. Single index regression model for functional quasi-associated time series data. REVSTAT 2022, 20, 605–631. [Google Scholar]
- Mohammedi, M.; Bouzebda, S.; Laksaci, A.; Bouanani, O. Asymptotic normality of the k-NN single index regression estimator for functional weak dependence data. Commun. Stat. Theory Methods 2024, 53, 3143–3168. [Google Scholar] [CrossRef]
- Agua, B.M.; Bouzebda, S. Single index regression for locally stationary functional time series. AIMS Math. 2024, 9, 36202–36258. [Google Scholar] [CrossRef]
- Attaoui, S.; Bentata, B.; Bouzebda, S.; Laksaci, A. The strong consistency and asymptotic normality of the kernel estimator type in functional single index model in presence of censored data. AIMS Math. 2024, 9, 7340–7371. [Google Scholar] [CrossRef]
- Miquel Becker, E.; Christensen, J.; Frederiksen, C.; Haugaard, V. Front-Face Fluorescence Spectroscopy and Chemometrics in Analysis of Yogurt: Rapid Analysis of Riboflavin. J. Dairy Sci. 2003, 86, 2508–2515. [Google Scholar] [CrossRef]
- Christensen, J.; Becker, E.M.; Frederiksen, C. Fluorescence spectroscopy and PARAFAC in the analysis of yogurt. Chemom. Intell. Lab. Syst. 2005, 75, 201–208. [Google Scholar] [CrossRef]
- Didi, S.; Al Harby, A.; Bouzebda, S. Wavelet Density and Regression Estimators for Functional Stationary and Ergodic Data: Discrete Time. Mathematics 2022, 10, 3433. [Google Scholar] [CrossRef]
- Bouzebda, S.; Nezzal, A. Asymptotic properties of conditional U-statistics using delta sequences. Commun. Stat. Theory Methods 2024, 53, 4602–4657. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Wu, H.T. Local linear regression on manifolds and its geometric interpretation. J. Am. Stat. Assoc. 2013, 108, 1421–1434. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).