Abstract
Identifying item–trait relationships is a core task in multidimensional item response theory (MIRT). Common empirical approaches include exploratory item factor analysis (EIFA) with rotations, the expectation maximization-based regularization (EML1) algorithm, and the expectation model selection (EMS) algorithm. While these methods typically assume multivariate normality of latent traits, empirical data often deviate from this assumption. This study evaluates the robustness of EIFA, EML1, and EMS, when latent traits violate normality assumptions. Using the independent generator transform, we generate latent variables under varying levels of skewness, excess kurtosis, numbers of non-normal dimensions, and inter-factor correlations. We then assess the performance of each method in terms of the F1-score for identifying item–trait relationships and mean squared error (MSE) of parameter estimations. The results indicate that non-normality leads to a reduction in F1-score and an increase in MSE generally. For F1-score, EMS performs best with small samples (e.g., ), whereas EIFA with rotations yields the highest F1-score in larger samples. In terms of estimation accuracy, EMS and EML1 generally yield lower MSEs than EIFA. The effects of non-normality are also demonstrated by applying these methods to a real data set from the Depression, Anxiety, and Stress Scale.
Keywords:
MIRT models; EIFA; rotation; expectation maximization-based L1 regularization; expectation model selection algorithm; non-normality; latent trait MSC:
62H25; 62P15
1. Introduction
In psychological and educational testing, dichotomous and polytomous items are widely used to assess individuals’ latent traits or abilities. When multiple latent dimensions are involved, a central task is to identify the underlying relationships between items and latent traits. Traditionally, such relationships are determined a priori by domain experts based on their knowledge of item content and construct definitions. However, the correct specification of item–trait associations is critical, not only for accurate model calibration but also for valid individual assessment. Misclassification of these associations can result in serious model misfit and flawed diagnostic interpretations. Therefore, an important question is to empirically estimate the underlying item–trait relationships from the data. In this paper, we consider this question within the framework of MIRT models.
More specifically, each subject is characterized by a random latent trait vector in a MIRT model. The probability of a correct response to item j is modeled as where and are the discrimination and difficulty parameters, respectively. Essentially, the detection of item–trait relationships corresponds to the identification of the nonzero elements of .
There are three primary approaches for empirically estimating the underlying relationships between items and latent traits. A commonly used approach is exploratory item factor analysis (EIFA). It estimates all parameters (under location and scale constraints on the latent traits), applies an analytic rotation, and then imposes a cutoff on the rotated discrimination matrix to obtain a simpler, interpretable structure with some zero elements [1,2,3]. As an alternative, regularized methods are proposed [4,5,6]. These methods impose an penalty on the log-likelihood, shrinking small discrimination parameters toward zero. The performance of -regularized methods depends critically on the choice of regularization parameters, which are typically selected by minimizing the Bayesian Information Criterion (BIC; [7]). To avoid the selection of regularization parameters, Xu et al. [8] develops the expectation model selection (EMS) and Shang et al. [9] proposes generalized EMS algorithms. Both algorithms directly minimize BIC to explore item–trait relationships. Further methodological details are provided in Section 2.
It should be noted that most of preceding methods assume that latent traits in Equation (1) follow a multivariate normal distribution. Empirical evidence, however, shows that this assumption is often unrealistic. In clinical assessments, many respondents report no symptoms, creating strong floor effects and non-normal latent traits [10]. Likewise, in psychiatric research, latent variables reflecting psychological disorders are typically positively skewed, as most individuals show low pathology and only a few show severe levels [11]. Similarly, psychological constructs such as depression, pain, and gambling often display non-normal distribution characteristics in the general population [12]. Even when the population distribution is normal, non-random sampling techniques can induce non-normality in the sampled latent traits [13]. For example, when analyzing test scores solely from honors program students, one may obtain a negatively skewed ability distribution.
Many studies investigate the impact of non-normal latent traits on parameter estimation in item response theory (IRT) models. Stone [14] reports that estimation bias increases as latent traits deviate from normality. Finch and Edwards [15] further demonstrates that severe skewness can still distort discrimination parameters even when the sample size is large. Related findings appear in MIRT models. Svetina et al. [16] shows that skewed latent traits reduce the accuracy of discrimination estimates, particularly under complex loading structures and higher inter-factor correlations. Wang et al. [17] extends this investigation to polytomous data under the multidimensional graded response model (MGRM), showing that full-information maximum likelihood reduces bias more effectively than weighted least squares. More recently, McClure and Jacobucci [18] evaluates the Metropolis–Hastings Robbins–Monro algorithm in high-dimensional MGRM models and observes increasing discrimination bias as dimensionality and factor correlations rise. Collectively, these studies underscore that violations of normality substantially reduce parameter recovery accuracy.
While confirmatory item factor analysis under non-normality is widely studied, the robustness of methods for identifying item–trait relationships remains underexplored. This study evaluates the performance of EIFA with rotations, the -regularized method, and the EMS algorithm in recovering item–trait structures when latent traits deviate from normality. To conduct this investigation, a method for generating latent variables with controlled deviations from normality is required. A commonly used technique is the Vale–Maurelli (VM) transformation [19], which allows specification of skewness, kurtosis, and a target correlation matrix. However, prior studies show that the VM method often produces biased or unstable estimates of skewness and kurtosis [20], and its dependence structure is closely related to the multivariate normal copula [21]. To generate stronger forms of multivariate non-normality, Foldnes and Olsson [22] proposes the independent generator (IG) transform, which creates non-normal data through linear combinations of independent generator variables. The resulting distributions have a genuinely non-normal copula, and empirical studies indicate that the IG transform produces more pronounced departures from normality than the VM method [22]. Thus, this study employs the IG transform to simulate latent variables under varying levels of skewness, excess kurtosis, numbers of non-normal latent dimensions, and inter-factor correlations, following Svetina et al. [16], Wang et al. [17], and McClure and Jacobucci [18]. We then evaluate each method’s performance using the F1-score for recovering item–trait relationships and the mean squared error (MSE) for parameter estimation. These results provide practical guidance for identifying the item–trait relationships under non-normal latent distributions.
The rest of the article is organized as follows. In Section 2, we first review three methods (EIFA with rotations, EML1, and EMS) within the multidimensional 2-parameter logistic (M2PL) model framework. In Section 3, we describe the IG transform and generate two types of non-normal latent trait distributions. We then conduct two simulations to compare the robustness of the methods for identifying item–trait relationships under non-normality in Section 4. In Section 5, we analyze a real data set. Finally, we summarize the key findings and outline directions for future research.
2. Methods for Identifying the Item–Trait Relationships in the M2PL Model
2.1. The M2PL Model
We focus on the M2PL model, one of the most widely used MIRT models. For subject and item , let be the binary response from subject i to item j and be the response matrix. The item response function for subject i on item j is given by
The latent traits , for , are assumed to be independent and identically distributed, following a K-dimensional normal distribution , where is the covariance matrix with unit variances. Conditional on , item responses are locally independent. Under these assumptions, the marginal log-likelihood is
where is the density of .
2.2. Exploratory Item Factor Analysis with Rotations
EIFA estimates the discrimination parameters and difficulties by maximizing the log-likelihood function (2) under the assumption that is the identity matrix. A rotation matrix is then applied to obtain a simpler structure, yielding a rotated discrimination matrix with some elements close to zero. There are two broad classes of rotation in EIFA: orthogonal and oblique. Orthogonal rotations assume that the latent traits remain uncorrelated, while oblique rotations allow for correlations among traits. In this study, we apply oblique rotations, including Quartimin [23], Geomin [24], and Infomax [3]. Each employs distinct criteria to achieve a simple and interpretable factor structure while accommodating inter-trait correlations. To facilitate interpretation, small discrimination parameters are often thresholded to zero.
2.3. Expectation Maximization-Based Regularization Method
In MIRT models, identifying the item–trait relationship structure can be framed as a model selection problem with missing data. Specifically, the dependence of item responses on latent traits follows the framework of a generalized linear model, where the latent traits serve as unobserved covariates and the discrimination parameters act as regression coefficients. Identifying the nonzero entries in reveals the item’s associated traits. This forms a latent variable selection problem [4]. Each possible zero-nonzero configuration of the discrimination matrix defines a distinct candidate MIRT model, as it specifies a unique pattern of item–trait associations across all items. Selecting the optimal item–trait structure is thus equivalent to choosing the best model among candidate models. This is fundamentally a model selection problem with missing covariates. Exhaustively evaluating all candidate models is computationally infeasible, even for moderately sized assessments. To address this challenge, the -regularized methods [4,5,6] are proposed.
The -penalized estimator is defined as
where denotes the entry-wise norm of the matrix , and is a regularization parameter controlling the sparsity of . When , the estimator reduces to the marginal maximum likelihood estimator, yielding a dense discrimination matrix ; when , all entries shrink to zero (). Thus, choosing appropriately is crucial for recovering the true nonzero elements. Sun et al. [4] and Shang et al. [6] recommend selecting the regularization parameter by minimizing BIC. Recently, Robitzsch [25] proposes a smooth BIC approximation for regularized estimation. It is more efficient and matches or exceeds the performance of -regularized methods that select using BIC.
It should be noted that the M2PL model exhibits rotational indeterminacy. To ensure identifiability, additional constraints must be imposed on the item parameters. In this paper, we adopt the constraint proposed by Sun et al. [4], which assumes that each of the first K items is associated with only one latent trait separately, i.e., and for . In practice, the constraint should be determined according to prior knowledge of the items and the entire study. This identifiability constraint is adopted in subsequent studies, including Xu et al. [8], Shang et al. [6], Shang et al. [9], and Shang et al. [26].
To maximize (3), which involves an integral over the latent variable , Sun et al. [4] and Shang et al. [6] apply the expectation maximization (EM) algorithm [27]. The EM algorithm is widely used to handle latent variables by treating them as missing data. Accordingly, their approach is referred to as the EM-based regularization method (EML1).
2.4. Expectation Model Selection Algorithm
The aforementioned EML1 can produce sparse estimates of the discrimination parameter matrix. However, its effectiveness depends critically on the selection of an appropriate regularization parameter, which is typically determined by minimizing BIC. To bypass this tuning step, Xu et al. [8] directly minimize BIC using the EMS algorithm [28]. The EMS algorithm is a recently proposed method for model selection with missing data [28]. It extends the EM algorithm by iteratively updating both model structure and parameters to minimize information criteria.
For M2PL models, EMS simultaneously optimizes both the model structure (represented by an incidence matrix ) and its parameters to minimize the BIC for the observed data :
where is the -norm, representing the number of nonzero elements in . Specifically, the EMS algorithm alternates between the expectation step (E-step) and the model selection step (MS-step) until convergence. The E-step computes the conditional expectation of the BIC criterion for the complete data, known as the Q-function, for each candidate model. In the MS-step, the algorithm selects the optimal model by minimizing the Q function over all candidate models and then updates the model (i.e., ) with its parameter estimates (i.e., ). In practice, the selected optimal model is often a sparse M2PL model with many zero elements in , which tends to be close to the underlying true model. This adaptive model update improves the EMS algorithm’s performance in identifying the item–trait relationships. To ensure parameter identification, EMS adopts the same constraints as EML1.
Recent research further enhances the computational efficiency. Shang et al. [9] proposes the generalized EMS algorithm, which only requires a decrease in the Q function value during the MS-step. Shang et al. [26] computes the Q function approximately by Gauss–Hermite quadrature in the E-step.
3. Generation of Non-Normal Latent Variables
3.1. The IG Transform
In the independent generator (IG) transform framework proposed by Foldnes and Olsson [22], the non-normal latent trait vector is constructed as . Here, consists of mutually independent generator variables with zero mean and unit variance, and is the coefficient matrix (). The goal is to choose A and appropriate distributions for the such that the generated latent vector attains (a) a prespecified covariance matrix , and (b) prespecified marginal skewness and excess kurtosis (i.e., kurtosis minus 3) of .
To match the covariance structure, A is chosen such that . In practice, the square-root matrix of may be used or A may be constructed using a structural equation modeling formulation, as described in Foldnes and Olsson [22]. Because , the marginal skewness and excess kurtosis of each latent trait dimension satisfy
Given target and , these systems are solved to obtain the required and . When , the systems often have more unknowns than equations, allowing feasible solutions across a wide range of distributions.
Once feasible solutions are obtained, each generator can be simulated from any univariate distribution with mean 0, variance 1, and specified skewness and excess kurtosis (e.g., Fleishman polynomial or Pearson-type distributions). Then, we apply the transform to obtain latent trait samples. This procedure can be implemented using the rIG() function in the R package covsim [29].
As noted by Foldnes and Olsson [22], not all combinations of univariate skewness and excess kurtosis are feasible under the IG framework, even when the moment Equations (4) and (5) are algebraically solvable. Consequently, some target non-normality settings cannot be generated. As shown later, we encounter such infeasible combinations of skewness and excess kurtosis.
3.2. Two Types of Non-Normal Latent Traits
In this paper, we employ the IG transform to systematically simulate two types of latent variable distributions that vary in skewness, excess kurtosis, number of non-normal dimensions, and inter-factor correlations.
3.2.1. Type 1
We first fix the number of non-normal latent variable dimensions at K. All dimensions share the same skewness and excess kurtosis . To examine how varying degrees of non-normality in the latent traits affect the performance of identifying item–trait relationships, we consider combinations of skewness and excess kurtosis . These values span a realistic and interpretable range of latent trait shapes, from near-normal distributions to moderately skewed and heavy-tailed forms. Our selection is informed by prior work such as Curran et al. [30] and Wang et al. [17], who use and based on analyses of data from several community-based mental-health and substance-use studies. Note that the latent variables follow a normal distribution when both skewness and excess kurtosis are equal to zero. When the inter-factor correlation is 0.4, the combinations with or are infeasible, as noted in the subsection above. Attempts to generate these distributions using the rIG function in the covsim package produce errors, so these cases are excluded. This results in six feasible non-normal combinations.
Figure 1 presents the kernel density curves for the first dimension of four-dimensional non-normal latent variables generated under six different combinations. The densities are based on a sample of subjects with an inter-factor correlation of 0.4. From visual inspection, the combinations and represent two pronounced departures from normality. The former corresponds to a left-skewed distribution with moderate kurtosis, whereas the latter reflects a right-skewed distribution with heavier tails. Therefore, we select these two combinations for our simulation studies.
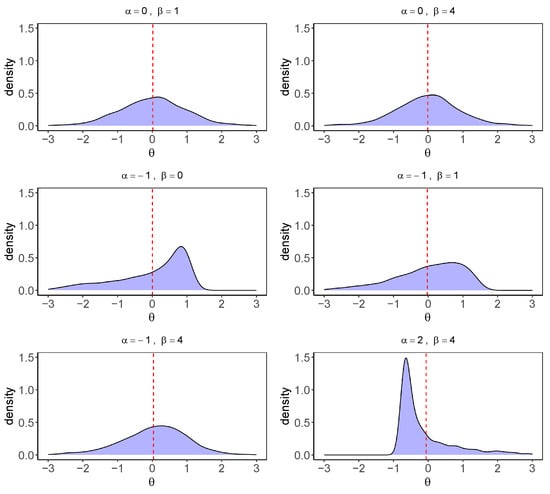
Figure 1.
Kernel density curves of six different degrees of non-normal latent variables.
3.2.2. Type 2
We first fix the total number of latent variables at K, which includes both normally and non-normally distributed dimensions. Following Svetina et al. [16] and Wang et al. [17], we simulate varying degrees of non-normality by altering the number of non-normal dimensions from 0 to K. For each non-normal latent variable, we fix , as this combination represents the greatest deviation from normality as observed in Figure 1.
For example, when , the number of non-normal dimensions varies as follows: zero dimensions (non0), the first dimension only (non1), the first two dimensions (non2), and all three dimensions (non3).
4. Simulation Studies
In this section, we compare the robustness of three methods: the improved EMS [26], the accelerated EML1 [6], and EIFA with three oblique rotations (Quartimin, Geomin, and Infomax). In EIFA, a sparse discrimination matrix is obtained by thresholding small discrimination parameter estimates to zero. Note that, selecting a suitable threshold for EIFA is important but nontrivial. In practice, discrimination parameters below 0.30 or 0.32 are often treated as negligible [31,32]. Following this convention, and in line with the specification in Shang et al. [9], we set 0.30 as the threshold in our study. All analyses are conducted using publicly accessible R codes hosted at https://github.com/xupf900/ (accessed on 24 November 2025). Simulations are run on a 64-bit Windows 10 system configured with an Intel(R) Xeon(R) Gold 5118 CPU (2.30 GHz) and 256 GB of RAM.
4.1. Simulation Design
In the simulations, we consider M2PL models with latent dimensions, while fixing the number of items at . The non-zero elements of the discrimination parameter matrices are independently drawn from a uniform distribution . The elements of the vectors are sampled from the standard normal distribution. The true parameter values for and under all scenarios are provided in Section S1 of the Supplementary File.
For the covariance matrix of latent traits, the diagonal elements are fixed at 1, and the off-diagonal elements are set to either 0.4 or 0.6 to represent moderate and higher correlations, respectively. Four sample size levels are considered. To simulate violations of the normality, we consider the following two settings:
- Simulation 1.
- Type 1 latent variable distributions are used, with and for , and for . The correlation is set to 0.4.
- Simulation 2.
- Type 2 latent variable distributions with are used for both and . The correlation is again set to 0.4.
Under each setting, we draw independent data sets and apply EMS, EML1, and EIFA with rotations to recover the discrimination parameter matrix. To resolve the issue of rotational indeterminacy, the same identification constraint is applied to EMS and EML1, but not to EIFA with rotations. Specifically, we fix a submatrix of the discrimination parameter matrix to be an identity matrix. For example, when , items 1, 10, and 19 are constrained to relate only to latent traits 1, 2, and 3, respectively. That is, the structure of is fixed to the identity matrix. Similarly, for , we fix accordingly.
4.2. Evaluation Metrics
This paper evaluates the simulation results using three structural recovery metrics: F1-score, true positive rate (TPR), and false positive rate (FPR). In addition, the mean squared error (MSE) is used to assess parameter estimation.
For each replication z, let , where denotes the estimate of . We define the following quantities (excluding entries fixed by identification constraints):
The precision, TPR (i.e., recall), and FPR for replication z are defined as
The F1-score, which provides a balanced summary of precision and recall, is computed as
for the zth replication.
The MSE measures the average of the squares of the errors and is calculated for each parameter as
where is the total number of replications. The MSE for each parameter in is computed analogously.
4.3. Results
4.3.1. Results for Simulation 1
This subsection presents results for simulation 1. Table 1 provides the mean and standard deviation (in parentheses) of the F1-score for all methods. From this table, EMS achieves the highest F1-score when the sample size is small () across all normal and non-normal conditions. However, its performance does not improve as N increases; in fact, the F1-score decreases slightly for larger samples, particularly when . This decline suggests that EMS may lack asymptotic consistency in recovering the item–trait relationships. In contrast, the performance of EML1 and EIFA with rotations improves steadily with N, indicating stronger large-sample consistency. For , EIFA with rotations consistently outperforms both EMS and EML1. The only exception occurs at with and , where EML1 achieves the highest F1-score. Among rotations, Quartimin, Geomin, and Infomax produce very similar results.

Table 1.
Mean and standard deviation of the F1-score of under simulation setting 1, where the correlation coefficient is 0.4.
Regarding the effect of non-normality, all methods show some degradation in F1-score relative to the normal case in most settings. Larger departures from normality generally lead to greater decreases in performance. This trend is particularly evident for the combination , where most methods achieve their lowest F1-scores. However, for and larger sample sizes ( and ), EIFA with rotations shows strong robustness and, in several instances, even benefits from moderate non-normality, achieving an F1-score of 1 in multiple conditions.
Figure 2 shows the boxplots of the MSEs of . Note that these boxplots are based on the element-wise values of defined in Equation (6). From Figure 2, EMS and EML1 show better estimation of than EIFA with rotations in most cases, especially when and . This may be because EMS and EML1 estimate by directly optimizing penalized likelihoods. In contrast, EIFA uses marginal maximum likelihood followed by rotation and thresholding. The extra cutoff step can introduce small distortions and reduce estimation accuracy. Note that while larger sample sizes generally reduce the MSE of , some non-normal conditions still yield higher MSEs than the normal cases, as shown in Figure 2. Figure 3 shows the boxplots of the MSEs of . Non-normality increases the MSE, and larger sample sizes do not noticeably reduce it. For , EMS gives the smallest MSE. But for , EIFA with rotations performs best. Thus, no method consistently dominates under non-normality. This may be because all three methods estimate directly through likelihood-based optimization.
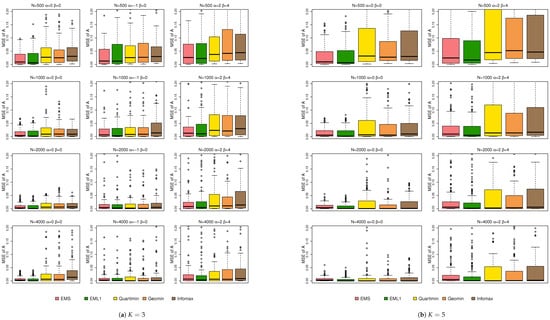
Figure 2.
Boxplots of the MSEs of under simulation 1.
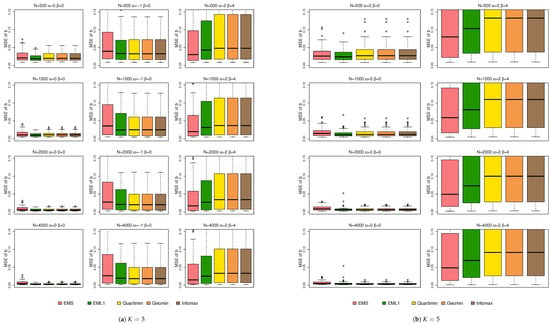
Figure 3.
Boxplots of the MSEs of under simulation 1.
4.3.2. Results for Simulation 2
This subsection presents results from simulation 2. Table 2 reports the mean of F1-scores (with standard deviations) for under simulation setting 2, where the inter-factor correlation is fixed at . A clear pattern emerges as the sample size increases. When , EMS achieves the highest F1-scores for both and . This is likely because its MS-step minimizes the expected BIC and tends to select a sparse discrimination matrix that is close to the true M2PL structure. The reduced model complexity improves structural recovery in small samples. However, as the sample size increases, the performance of EMS declines. In contrast, the F1-scores of EML1 and EIFA with rotations steadily increase with N. As a result, EML1 and EIFA with rotations outperform EMS for large N. This pattern implies that EML1 and EIFA with rotations exhibit better consistency properties than EMS.
Table 2.
Mean and standard deviation of the F1-score of under simulation 2.
In addition, we can see a systematic impact of non-normality from Table 2. As the number of non-normal latent dimensions increases, all methods exhibit a decline in F1-score, especially when . However, for large sample sizes, the negative effect of non-normality on EIFA with rotations is minimal. EIFA with rotations remains comparatively robust and continues to achieve F1-scores extremely close to 1. This robustness may stem from the consistency properties that EIFA with rotations enjoys under normality, which appear to extend favorably to mildly non-normal settings.
Figure 4 shows the boxplots of the MSEs of . From this figure, the MSE increases with the number of non-normal latent variables. Overall, EMS and EML1 outperform EIFA with rotations in terms of estimation accuracy. While a larger sample size helps reduce the MSE, it does not fully eliminate the adverse effects of non-normality. This behavior is consistent with the results observed in simulation 1. Figure 5 displays the boxplots of the MSEs of . From Figure 5, all methods perform similarly under normal conditions; yet, EMS and EML1 outperform EIFA with rotations in terms of estimation accuracy for most non-normal cases. Increasing the sample size significantly reduces the MSE of under both normal and non-normal conditions.
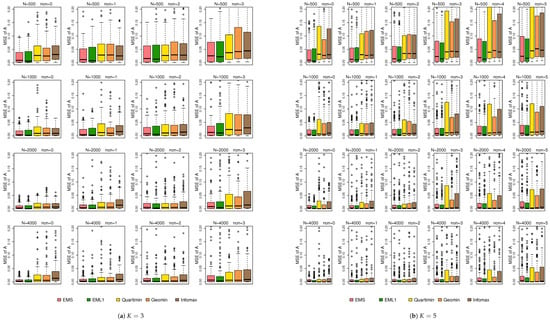
Figure 4.
Boxplots of the MSEs of under simulation 2.
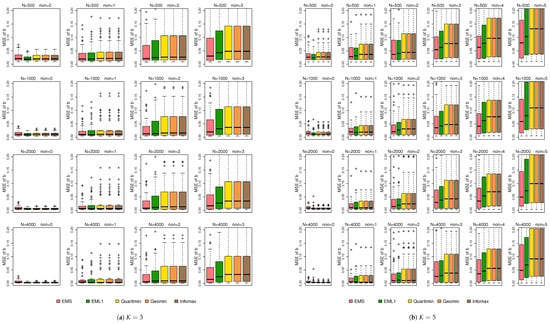
Figure 5.
Boxplots of the MSEs of under simulation 2.
4.4. Additional Simulation Results
As higher inter-factor correlations are common in psychological research, we conduct additional simulation studies using a stronger correlation of 0.6. As expected, this stronger correlation decreases the F1-scores and increases the MSEs. The comparative behaviors of EMS, EML1, and EIFA with rotations remain similar to those observed in simulations 1 and 2. Therefore, these results are moved to the Appendix A to save space in the main paper.
Moreover, we report additional simulation results in the Supplementary File, including the TPR and FPR for , the biases of and , the MSEs and biases of , and the CPU time. From the TPR and FPR results, we observe that when the sample size is large (), EMS attains a TPR close to 1 but also a non-negligible FPR. This leads to poorer F1-score in recovering item–trait relationships. The finding suggests that EMS may require stronger penalization on the likelihood, for example, by employing the extended Bayesian information criterion (EBIC). EBIC is commonly used in high-dimensional settings. Further empirical and theoretical work is needed to explore this direction.
Regarding the effect of skewness, higher skewness results in larger bias in the estimates of the difficulty parameters . In terms of computational cost, EML1 is the slowest method, likely because it must evaluate multiple regularization parameters in (3). EMS is also slower than EIFA with rotations, presumably due to its greater number of iterations. In future work, we plan to adopt the smooth approximation of BIC for regularized estimation proposed by Robitzsch [25] to improve computational efficiency.
5. Real Data Analysis
Psychological constructs such as depression, pain, and gambling are particularly likely to exhibit non-normal distributions in the general population [12]. To illustrate how such non-normal latent traits affect the performance in latent variable selection, we apply the EMS, EML1, and EIFA with rotations to analyze a real data set based on the Depression, Anxiety, and Stress Scale (42-item version, DASS-42) under the M2PL model. The DASS-42 data set, which contains responses from 5000 subjects to 42 items, is publicly available at https://osf.io/ykq2a/ (accessed on 8 May 2025). The items are reordered such that items 1–14, 15–28, and 29–42 correspond to the latent traits of depression (D), anxiety (A), and stress (S), respectively [33]. The full item content and measurement structure are presented in Table A2 in Appendix B. Responses are originally collected on a 4-point scale (0 = “Did not apply to me at all”; 1 = “Applied to me to some degree, or some of the time”; 2 = “Applied to me to a considerable degree, or a good part of time”; 3 = “Applied to me very much, or most of the time”). In our analysis, we dichotomize the responses by retaining 0 as 0 (symptom absence) and recoding categories 1–3 as 1 (symptom presence).
To verify the non-normality of the latent traits involved in this dataset, we compute factor scores by summarizing all responses for each individual on dimensions D, A, and S. As demonstrated in Figure 6 and Table 3, all three latent trait distributions exhibit substantial deviations from normality, thereby confirming the presence of non-normal latent traits in the DASS-42 data.
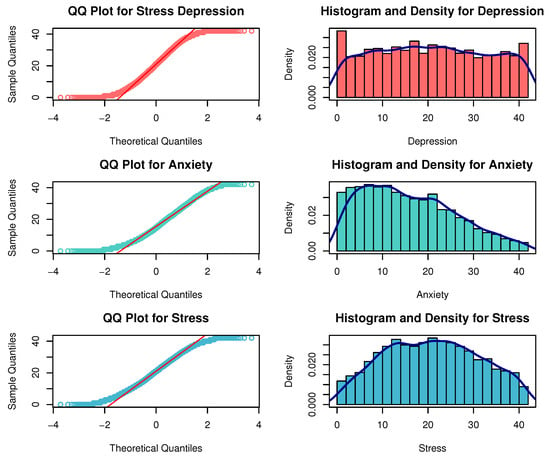
Figure 6.
QQ plots, histograms, and density curves for depression, anxiety, and stress.
Table 3.
Results of normality tests for depression, anxiety, and stress.
Next, we compare the performance of EMS, EML1, and EIFA with rotations in identifying the item–trait relationships in this dataset. To ensure identifiability, we designate one item for each trait based on the content of the items, similarly as Xu et al. [8]. Specifically, items 1, 15, and 29 are exclusively assigned to traits D, A, and S, respectively. The loading structures estimated by EMS, EML1, and EIFA with rotations are visualized as heatmaps in Figure 7. The estimated and are reported in Table A3, Table A4, Table A5, Table A6 and Table A7 in Appendix B, and are
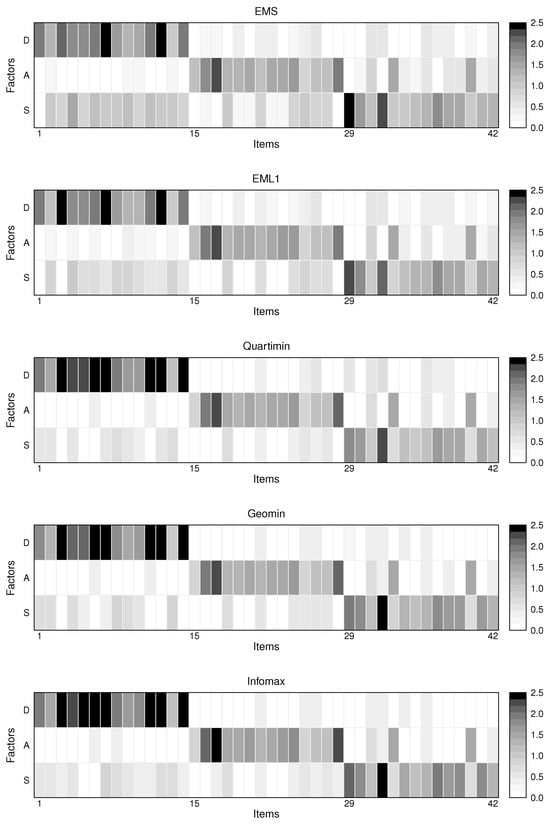
Figure 7.
Heatmaps of the loading matrices estimated by EMS, EML1, and EIFA with rotations for the DASS-42 data set.
It can be seen that the estimated correlations among the latent traits are relatively high, with those obtained by EIFA with rotations evidently exceeding those produced by EMS and EML1. This suggests that the constructs are interconnected and mutually influential, even though each DASS-42 item is originally designed to measure a single psychological construct (D, A, or S). In other words, the constructs are not entirely distinct but partially overlapping in their manifestations. For example, items 27 and 33 are found to be associated with both anxiety and stress.
While the designed item–trait relationships serve as the benchmark, it is important to acknowledge that multiple psychological constructs may interact when subjects respond to items. Comparing the estimated loading structures with the benchmark, the F1-scores of EMS, EML1, and EIFA with rotations (Quartimin, Geomin, and Infomax) are 0.582, 0.609, 0.724, 0.724, and 0.706, respectively. Although EIFA with rotations achieves the highest F1-scores and produce the sparsest loading structures, none of the methods attains high accuracy in identifying item–trait relationships under conditions of stronger inter-factor correlations and non-normal latent trait distributions. These findings from the DASS-42 data analysis are consistent with our simulation results.
6. Discussion
This study evaluates the robustness of EMS, EML1, and EIFA with rotations for identifying item–trait relationships under non-normal latent distributions in MIRT models. Our simulation results suggest the following. For identifying item–trait relationships, EMS is preferable for small samples, whereas EIFA with rotations performs better for large samples. For estimation accuracy, EMS and EML1 generally outperform EIFA with rotations. EMS likely achieves higher accuracy because it directly optimizes a penalized likelihood, while EIFA relies on thresholding small loadings, which can reduce precision. A potential improvement is to apply marginal maximum likelihood estimation after thresholding to enhance estimation accuracy.
The simulation results align closely with previous IRT research. Consistent with Svetina et al. [16] and McClure and Jacobucci [18], we also find that higher inter-factor correlations significantly exacerbate the adverse effects of non-normality. When the correlation increases to 0.6, the impact of non-normality on parameter estimation becomes notably stronger than when the correlation is 0.4. Furthermore, consistent with Finch and Edwards [15], McClure and Jacobucci [18], and Wall et al. [34], a large sample size helps reduce, but does not eliminate, estimation errors. These errors remain larger than those under normality, especially when the number of latent traits is five.
To address violations of normality, more robust methods are needed. One direction is to allow flexible latent trait distributions, such as semi-nonparametric forms [35], multivariate skew-normal models [36], or centered skew-t distributions [37]. We plan to extend EMS and EML1 to these distributional frameworks in future work. Another direction is limited-information estimation based on tetrachoric or polychoric correlations. These methods avoid full multivariate integration and depend only on low-order summary statistics, making them faster and less sensitive to distributional assumptions. Inspired by Huang [38], which uses penalized least squares for ordinal structural equation modeling, we will explore regularized limited-information estimation for MIRT.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math13233858/s1.
Author Contributions
Conceptualization, P.-F.X., X.L., L.S., Q.-Z.Z., N.S. and Y.L.; methodology, P.-F.X. and X.L.; software, P.-F.X., X.L. and L.S.; validation, P.-F.X. and X.L.; formal analysis, P.-F.X., X.L. and Y.L.; investigation, P.-F.X. and X.L.; resources, P.-F.X. and Y.L.; data curation, P.-F.X. and X.L.; writing—original draft preparation, P.-F.X., X.L. and Y.L.; writing—review and editing, P.-F.X., X.L., L.S., Q.-Z.Z., N.S. and Y.L.; visualization, X.L.; supervision, P.-F.X. and Y.L.; project administration, P.-F.X. and Y.L.; funding acquisition, P.-F.X. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Ping-Feng Xu was supported by the National Social Science Fund of China (No. 23BTJ062).
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Simulation Study for Cases with Higher Correlations
In this appendix, we conduct simulation studies with a higher correlation fixed at 0.6. The non-normal latent trait data are designed as follows:
- Simulation 3.
- A Type 1 latent variable distribution with parameters and is used, and the correlation is fixed at 0.6.
In simulation 3, we do not include other combinations for or any combinations for , as these cases are either infeasible under the IG framework or do not depart substantially from normality.
Simulation studies are conducted similarly as in Section 4. Table A1 reports the corresponding mean of F1-scores (with standard deviations) for . As expected, these F1-scores are noticeably lower than those observed in simulation 1 where the correlation is 0.4. Other patterns remain largely consistent with the previous subsections. For example, EMS performs best when , whereas EML1 and EIFA with rotations achieve the highest accuracy for and 4000. In most settings, non-normality continues to reduce the performance of all methods.
Table A1.
Mean and standard deviation of the F1-score of under simulation 3.
Table A1.
Mean and standard deviation of the F1-score of under simulation 3.
| K = 3 | |||||||||||
| N = 500 | N = 1000 | N = 2000 | N = 4000 | ||||||||
| (0,0) | (2,4) | (0,0) | (2,4) | (0,0) | (2,4) | (0,0) | (2,4) | ||||
| EMS | 0.946 | 0.872 | 0.955 | 0.896 | 0.927 | 0.873 | 0.878 | 0.834 | |||
| (0.027) | (0.046) | (0.023) | (0.033) | (0.028) | (0.026) | (0.033) | (0.023) | ||||
| EML1 | 0.923 | 0.844 | 0.963 | 0.888 | 0.986 | 0.914 | 0.996 | 0.924 | |||
| (0.030) | (0.071) | (0.021) | (0.035) | (0.014) | (0.022) | (0.007) | (0.018) | ||||
| Quartimin | 0.925 | 0.854 | 0.966 | 0.916 | 0.985 | 0.955 | 0.979 | 0.989 | |||
| (0.031) | (0.083) | (0.058) | (0.080) | (0.058) | (0.096) | (0.074) | (0.028) | ||||
| Geomin | 0.921 | 0.828 | 0.965 | 0.910 | 0.983 | 0.950 | 0.978 | 0.988 | |||
| (0.035) | (0.092) | (0.063) | (0.084) | (0.062) | (0.100) | (0.077) | (0.030) | ||||
| Infomax | 0.918 | 0.853 | 0.960 | 0.919 | 0.983 | 0.953 | 0.980 | 0.977 | |||
| (0.031) | (0.057) | (0.056) | (0.055) | (0.054) | (0.060) | (0.071) | (0.027) | ||||
Note: The bold formatting is used to highlight the best results.
Figure A1 presents the boxplots of the MSEs for and . The figure shows that non-normality leads to a clear increase in MSE, and this negative effect cannot be eliminated simply by increasing the sample size. Under the non-normal case , EMS achieves slightly higher estimation accuracy than EIFA with rotations, particularly when and 2000.

Figure A1.
Boxplots of the MSEs of and under simulation 3.
Appendix B. DASS-42 Items and Estimated Parameters in Real Data Analysis
In this appendix, we present the full item content and measurement structure in Table A2, and provide the estimated discrimination parameters and difficulty parameters by EMS, EML1, and EIFA with rotations (Quartimin, Geomin, and Infomax) in Table A3, Table A4, Table A5, Table A6 and Table A7, respectively.
Table A2.
DASS-42 items.
Table A2.
DASS-42 items.
| 1 | I felt downhearted and blue. |
| 2 | I felt sad and depressed. |
| 3 | I could see nothing in the future to be hopeful about. |
| 4 | I felt that I had nothing to look forward to. |
| 5 | I felt that life was meaningless. |
| 6 | I felt that life wasn’t worthwhile. |
| 7 | I felt I was pretty worthless. |
| 8 | I felt I wasn’t worth much as a person. |
| 9 | I felt that I had lost interest in just about everything. |
| 10 | I was unable to become enthusiastic about anything. |
| 11 | I couldn’t seem to experience any positive feeling at all. |
| 12 | I couldn’t seem to get any enjoyment out of the things I did. |
| 13 | I just couldn’t seem to get going. |
| 14 | I found it difficult to work up the initiative to do things. |
| 15 | I was aware of the action of my heart in the absence of physical exertion |
| (e.g., sense of heart rate increase, heart missing a beat). | |
| 16 | I perspired noticeably (e.g., hands sweaty) in the absence of high temperatures or physical exertion. |
| 17 | I was aware of dryness of my mouth. |
| 18 | I experienced breathing difficulty |
| (e.g., excessively rapid breathing, breathlessness in the absence of physical exertion). | |
| 19 | I had difficulty in swallowing. |
| 20 | I had a feeling of shakiness (e.g., legs going to give way). |
| 21 | I experienced trembling (e.g., in the hands). |
| 22 | I was worried about situations in which I might panic and make a fool of myself. |
| 23 | I found myself in situations which made me so anxious I was most relieved when they ended. |
| 24 | I feared that I would be “thrown” by some trivial but unfamiliar task. |
| 25 | I felt I was close to panic. |
| 26 | I felt terrified. |
| 27 | I felt scared without any good reason. |
| 28 | I had a feeling of faintness. |
| 29 | I found it hard to wind down. |
| 30 | I found it hard to calm down after something upset me. |
| 31 | I found it difficult to relax. |
| 32 | I felt that I was using a lot of nervous energy. |
| 33 | I was in a state of nervous tension. |
| 34 | I found myself getting upset rather easily. |
| 35 | I found myself getting upset by quite trivial things. |
| 36 | I found myself getting agitated. |
| 37 | I tended to over-react to situations. |
| 38 | I found that I was very irritable. |
| 39 | I felt that I was rather touchy. |
| 40 | I was intolerant of anything that kept me from getting on with what I was doing. |
| 41 | I found myself getting impatient when I was delayed in any way |
| (e.g., lifts, traffic lights, being kept waiting). | |
| 42 | I found it difficult to tolerate interruptions to what I was doing. |
Table A3.
The elements of and by EMS for the DASS-42 data set.
Table A3.
The elements of and by EMS for the DASS-42 data set.
| 1 | 1.941 | 1.310 | 22 | 0.330 | 1.440 | 0.213 | −1.134 | ||
| 2 | 1.284 | 0.254 | 1.080 | 2.145 | 23 | 1.484 | 0.245 | 0.687 | |
| 3 | 2.141 | 0.848 | 1.781 | 24 | 0.281 | 1.566 | 0.906 | 1.050 | |
| 4 | 1.837 | 1.463 | 3.293 | 25 | 0.325 | 0.792 | 0.967 | 1.509 | |
| 5 | 1.816 | 0.911 | 2.096 | 26 | 0.487 | 1.134 | 0.859 | 1.109 | |
| 6 | 1.941 | 1.182 | 2.264 | 27 | 1.106 | 0.887 | 1.949 | ||
| 7 | 2.502 | 1.046 | 1.302 | 28 | 1.987 | 0.145 | 0.259 | ||
| 8 | 1.673 | 1.082 | 2.114 | 29 | 2.355 | 2.877 | |||
| 9 | 1.386 | 0.242 | 1.213 | 2.554 | 30 | 0.223 | 1.660 | 1.993 | |
| 10 | 1.450 | 0.195 | 0.872 | 1.837 | 31 | 0.566 | 0.876 | 1.170 | 2.044 |
| 11 | 1.953 | 1.156 | 2.342 | 32 | 0.565 | 2.289 | 3.234 | ||
| 12 | 2.454 | 1.009 | 1.365 | 33 | 1.512 | 1.079 | 1.872 | ||
| 13 | 1.002 | 0.193 | 1.008 | 2.535 | 34 | 0.328 | 1.015 | 1.634 | |
| 14 | 1.960 | 0.825 | 1.501 | 35 | 0.184 | 1.158 | 1.535 | ||
| 15 | 1.119 | 0.626 | 36 | 0.525 | 0.576 | 1.308 | 1.651 | ||
| 16 | 0.220 | 1.836 | 0.295 | 0.063 | 37 | 0.443 | 1.826 | 2.442 | |
| 17 | 0.265 | 2.319 | −0.038 | 38 | 0.328 | 0.520 | 1.538 | 2.488 | |
| 18 | 1.263 | 0.960 | 2.317 | 39 | 0.462 | 1.427 | 1.867 | ||
| 19 | 0.356 | 1.301 | 0.296 | −0.235 | 40 | 0.248 | 1.497 | 0.957 | 1.885 |
| 20 | 1.403 | 0.261 | 0.003 | 41 | 0.132 | 0.339 | 1.379 | 1.514 | |
| 21 | 0.414 | 1.197 | 0.903 | 1.149 | 42 | 0.361 | 0.546 | 1.293 | 1.887 |
Table A4.
The elements of and by EML1 for the DASS-42 data set.
Table A4.
The elements of and by EML1 for the DASS-42 data set.
| 1 | 1.877 | 1.518 | 22 | 0.258 | 1.556 | −0.945 | |||
| 2 | 1.208 | 0.271 | 0.875 | 2.375 | 23 | 1.578 | 0.846 | ||
| 3 | 2.378 | 2.070 | 24 | 0.229 | 1.620 | 0.697 | 1.319 | ||
| 4 | 1.824 | 0.277 | 0.945 | 3.589 | 25 | 0.322 | 0.823 | 0.788 | 1.714 |
| 5 | 1.778 | 0.653 | 2.351 | 26 | 0.477 | 1.198 | 0.640 | 1.367 | |
| 6 | 1.926 | 0.287 | 0.637 | 2.578 | 27 | 1.147 | 0.727 | 2.139 | |
| 7 | 2.385 | 0.567 | 1.589 | 28 | 1.963 | 0.447 | |||
| 8 | 1.600 | 0.886 | 2.372 | 29 | 2.293 | 3.103 | |||
| 9 | 1.313 | 0.347 | 0.889 | 2.784 | 30 | 1.760 | 2.189 | ||
| 10 | 1.347 | 0.205 | 0.685 | 2.051 | 31 | 0.513 | 0.801 | 1.081 | 2.294 |
| 11 | 1.927 | 0.273 | 0.613 | 2.637 | 32 | 0.499 | 2.108 | 3.420 | |
| 12 | 2.379 | 0.533 | 1.659 | 33 | 1.503 | 0.912 | 2.107 | ||
| 13 | 0.965 | 0.201 | 0.846 | 2.744 | 34 | −0.191 | 0.311 | 1.120 | 1.784 |
| 14 | 1.944 | 0.473 | 1.763 | 35 | 1.258 | 1.682 | |||
| 15 | 1.098 | 0.727 | 36 | 0.456 | 0.532 | 1.274 | 1.913 | ||
| 16 | 0.154 | 2.004 | 0.287 | 37 | 0.388 | 1.749 | 2.661 | ||
| 17 | 2.291 | 0.186 | 38 | 0.309 | 0.454 | 1.493 | 2.744 | ||
| 18 | 1.290 | 0.791 | 2.519 | 39 | 0.355 | 1.446 | 2.067 | ||
| 19 | 0.316 | 1.406 | 0.075 | −0.046 | 40 | 0.194 | 1.495 | 0.808 | 2.136 |
| 20 | 1.548 | 0.163 | 41 | 0.277 | 1.467 | 1.721 | |||
| 21 | 0.374 | 1.245 | 0.698 | 1.397 | 42 | 0.281 | 0.499 | 1.277 | 2.119 |
Table A5.
The elements of and by EIFA with Quartimin for the DASS-42 data set.
Table A5.
The elements of and by EIFA with Quartimin for the DASS-42 data set.
| 1 | 1.916 | 0.482 | 1.687 | 22 | 1.480 | −0.849 | |||
| 2 | 1.498 | 0.579 | 2.472 | 23 | 1.554 | 0.915 | |||
| 3 | 2.979 | 2.314 | 24 | 1.693 | 0.432 | 1.438 | |||
| 4 | 2.219 | 0.545 | 3.739 | 25 | 0.395 | 0.877 | 0.513 | 1.797 | |
| 5 | 2.279 | 2.509 | 26 | 0.517 | 1.198 | 0.382 | 1.445 | ||
| 6 | 2.584 | 0.389 | 2.780 | 27 | 1.182 | 0.496 | 2.224 | ||
| 7 | 3.609 | −0.529 | 1.978 | 28 | 2.093 | 0.536 | |||
| 8 | 1.958 | 0.648 | 2.502 | 29 | 0.473 | 1.830 | 3.256 | ||
| 9 | 1.637 | 0.599 | 2.905 | 30 | 1.574 | 2.270 | |||
| 10 | 1.690 | 0.441 | 2.173 | 31 | 0.527 | 0.707 | 0.996 | 2.405 | |
| 11 | 2.603 | 0.365 | 2.843 | 32 | 0.647 | 2.188 | 3.731 | ||
| 12 | 3.632 | −0.487 | 2.054 | 33 | 1.492 | 0.716 | 2.210 | ||
| 13 | 1.138 | 0.667 | 2.851 | 34 | 1.224 | 1.895 | |||
| 14 | 2.599 | 1.938 | 35 | 1.084 | 1.751 | ||||
| 15 | 0.880 | 0.778 | 36 | 0.481 | 0.471 | 1.199 | 2.044 | ||
| 16 | 1.957 | 0.378 | 37 | 0.425 | 1.686 | 2.817 | |||
| 17 | 2.323 | 0.286 | 38 | 0.326 | 0.391 | 1.465 | 2.924 | ||
| 18 | 1.442 | 0.637 | 2.674 | 39 | 1.548 | 2.232 | |||
| 19 | 1.349 | 0.034 | 40 | 1.510 | 0.649 | 2.252 | |||
| 20 | 1.535 | 0.238 | 41 | 1.511 | 1.852 | ||||
| 21 | 0.414 | 1.297 | 0.457 | 1.510 | 42 | 0.456 | 1.213 | 2.250 | |
Table A6.
The elements of and by EIFA with Geomin for the DASS-42 data set.
Table A6.
The elements of and by EIFA with Geomin for the DASS-42 data set.
| 1 | 1.786 | 0.656 | 1.687 | 22 | 1.451 | −0.849 | |||
| 2 | 1.378 | 0.741 | 2.472 | 23 | 1.528 | 0.915 | |||
| 3 | 2.848 | 2.314 | 24 | 1.638 | 0.540 | 1.438 | |||
| 4 | 2.067 | 0.754 | 3.739 | 25 | 0.329 | 0.833 | 0.614 | 1.797 | |
| 5 | 2.154 | 0.369 | 2.509 | 26 | 0.453 | 1.155 | 0.490 | 1.445 | |
| 6 | 2.467 | 0.390 | 2.780 | 27 | 1.132 | 0.582 | 2.224 | ||
| 7 | 3.476 | −0.316 | 1.978 | 28 | 2.067 | 0.536 | |||
| 8 | 1.813 | 0.838 | 2.502 | 29 | 0.303 | 2.029 | 3.256 | ||
| 9 | 1.508 | 0.773 | 2.905 | 30 | 1.720 | 2.270 | |||
| 10 | 1.573 | 0.601 | 2.173 | 31 | 0.416 | 0.640 | 1.145 | 2.405 | |
| 11 | 2.488 | 0.370 | 2.843 | 32 | 0.442 | −0.341 | 2.423 | 3.731 | |
| 12 | 3.495 | 2.054 | 33 | 1.424 | 0.828 | 2.210 | |||
| 13 | 1.029 | 0.810 | 2.851 | 34 | −0.354 | 1.323 | 1.895 | ||
| 14 | 2.490 | 1.938 | 35 | 1.190 | 1.751 | ||||
| 15 | 0.856 | 0.778 | 36 | 0.358 | 0.397 | 1.355 | 2.044 | ||
| 16 | 1.925 | 0.378 | 37 | 1.866 | 2.817 | ||||
| 17 | 2.295 | 0.286 | 38 | 0.304 | 1.632 | 2.924 | |||
| 18 | 1.380 | 0.730 | 2.674 | 39 | 1.693 | 2.232 | |||
| 19 | 1.323 | 0.034 | 40 | 1.446 | 0.764 | 2.252 | |||
| 20 | 1.508 | 0.238 | 41 | 1.656 | 1.852 | ||||
| 21 | 0.347 | 1.248 | 0.569 | 1.510 | 42 | 0.381 | 1.357 | 2.250 | |
Table A7.
The elements of and by EIFA with Infomax for the DASS-42 data set.
Table A7.
The elements of and by EIFA with Infomax for the DASS-42 data set.
| 1 | 1.986 | 0.462 | 1.687 | 22 | 1.558 | −0.849 | |||
| 2 | 1.518 | 0.584 | 2.472 | 23 | 1.653 | 0.915 | |||
| 3 | 3.189 | −0.314 | 2.314 | 24 | 1.747 | 0.417 | 1.438 | ||
| 4 | 2.289 | 0.509 | 3.739 | 25 | 0.323 | 0.869 | 0.534 | 1.797 | |
| 5 | 2.401 | 2.509 | 26 | 0.453 | 1.215 | 0.365 | 1.445 | ||
| 6 | 2.745 | 0.317 | 2.780 | 27 | 1.208 | 0.520 | 2.224 | ||
| 7 | 3.887 | −0.795 | 1.978 | 28 | 2.241 | −0.358 | 0.536 | ||
| 8 | 2.013 | −0.327 | 0.654 | 2.502 | 29 | 2.074 | 3.256 | ||
| 9 | 1.662 | 0.599 | 2.905 | 30 | 1.802 | 2.270 | |||
| 10 | 1.743 | 0.421 | 2.173 | 31 | 0.414 | 0.643 | 1.088 | 2.405 | |
| 11 | 2.770 | −0.336 | 2.843 | 32 | 0.443 | −0.450 | 2.487 | 3.731 | |
| 12 | 3.912 | −0.744 | 2.054 | 33 | 1.519 | 0.763 | 2.210 | ||
| 13 | 1.127 | 0.704 | 2.851 | 34 | −0.436 | 1.408 | 1.895 | ||
| 14 | 2.783 | −0.375 | 1.938 | 35 | 1.236 | 1.751 | |||
| 15 | 0.918 | 0.778 | 36 | 0.352 | 0.378 | 1.333 | 2.044 | ||
| 16 | 2.076 | 0.378 | 37 | 1.914 | 2.817 | ||||
| 17 | 2.483 | −0.422 | 0.286 | 38 | 1.649 | 2.924 | |||
| 18 | 1.479 | 0.680 | 2.674 | 39 | 1.768 | 2.232 | |||
| 19 | 1.415 | 0.034 | 40 | 1.538 | 0.679 | 2.252 | |||
| 20 | 1.631 | 0.238 | 41 | 1.726 | 1.852 | ||||
| 21 | 0.330 | 1.318 | 0.453 | 1.510 | 42 | 0.368 | 1.359 | 2.250 | |
References
- Bock, R.D.; Gibbons, R.; Muraki, E. Full-information item factor analysis. Appl. Psychol. Meas. 1988, 12, 261–280. [Google Scholar] [CrossRef]
- Cai, L. High-dimensional exploratory item factor analysis by a Metropolis–Hastings Robbins–Monro algorithm. Psychometrika 2010, 75, 33–57. [Google Scholar] [CrossRef]
- Browne, M.W. An overview of analytic rotation in exploratory factor analysis. Multivar. Behav. Res. 2001, 36, 111–150. [Google Scholar] [CrossRef]
- Sun, J.; Chen, Y.; Liu, J.; Ying, Z.; Xin, T. Latent variable selection for multidimensional item response theory models via L1 regularization. Psychometrika 2016, 81, 921–939. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Chen, Y. Computation for latent variable model estimation: A unified stochastic proximal framework. Psychometrika 2022, 87, 1473–1502. [Google Scholar] [CrossRef]
- Shang, L.; Xu, P.F.; Shan, N.; Tang, M.L.; Ho, G.T.S. Accelerating L1-penalized expectation maximization algorithm for latent variable selection in multidimensional two-parameter logistic models. PLoS ONE 2023, 18, e0279918. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Xu, P.F.; Shang, L.; Zheng, Q.Z.; Shan, N.; Tang, M.L. Latent variable selection in multidimensional item response theory models using the expectation model selection algorithm. Br. J. Math. Stat. Psychol. 2022, 75, 363–394. [Google Scholar] [CrossRef]
- Shang, L.; Zheng, Q.Z.; Xu, P.F.; Tang, M.L. A generalized expectation model selection algorithm for latent variable selection in multidimensional item response theory models. Stat. Comput. 2024, 34, 49. [Google Scholar] [CrossRef]
- Wall, M.M.; Park, J.Y.; Moustaki, I. IRT modeling in the presence of zero-inflation with application to psychiatric disorder severity. Appl. Psychol. Meas. 2015, 39, 583–597. [Google Scholar] [CrossRef] [PubMed]
- Woods, C.M.; Thissen, D. Item response theory with estimation of the latent population distribution using spline-based densities. Psychometrika 2006, 71, 281–301. [Google Scholar] [CrossRef]
- Preston, K.S.J.; Reise, S.P. Estimating the nominal response model under nonnormal conditions. Educ. Psychol. Meas. 2014, 74, 377–399. [Google Scholar] [CrossRef]
- Sass, D.A.; Schmitt, T.A.; Walker, C.M. Estimating non-normal latent trait distributions within item response theory using true and estimated item parameters. Appl. Meas. Educ. 2008, 21, 65–88. [Google Scholar] [CrossRef]
- Stone, C.A. Recovery of marginal maximum likelihood estimation in the two-parameter logistic model: An evaluation of MULTILOG. Appl. Psychol. Meas. 1992, 16, 1–16. [Google Scholar] [CrossRef]
- Finch, H.; Edwards, J.M. Rasch model parameter estimation in the presence of a nonnormal latent trait using a nonparametric Bayesian approach. Educ. Psychol. Meas. 2016, 76, 662–684. [Google Scholar] [CrossRef]
- Svetina, D.; Valdivia, A.; Underhill, S.; Dai, S.; Wang, X. Parameter recovery in multidimensional item response theory models under complexity and nonnormality. Appl. Psychol. Meas. 2017, 41, 530–544. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Su, S.; Weiss, D.J. Robustness of parameter estimation to assumptions of normality in the multidimensional graded response model. Multivar. Behav. Res. 2018, 53, 403–418. [Google Scholar] [CrossRef] [PubMed]
- McClure, K.; Jacobucci, R. Item parameter calibration in the multidimensional graded response model with high dimensional tests. PsyArXiv 2023. [Google Scholar] [CrossRef]
- Vale, C.D.; Maurelli, V.A. Simulating multivariate nonnormal distributions. Psychometrika 1983, 48, 465–471. [Google Scholar] [CrossRef]
- Astivia, O.L.O.; Zumbo, B.D. A cautionary note on the use of the Vale and Maurelli method to generate multivariate, nonnormal data for simulation purposes. Educ. Psychol. Meas. 2015, 75, 541–567. [Google Scholar] [CrossRef]
- Foldnes, N.; Grønneberg, S. How general is the Vale–Maurelli simulation approach? Psychometrika 2015, 80, 1066–1083. [Google Scholar] [CrossRef]
- Foldnes, N.; Olsson, U.H. A simple simulation technique for nonnormal data with prespecified skewness, kurtosis, and covariance matrix. Multivar. Behav. Res. 2016, 51, 207–219. [Google Scholar] [CrossRef]
- Carroll, J.B. An analytical solution for approximating simple structure in factor analysis. Psychometrika 1953, 18, 23–38. [Google Scholar] [CrossRef]
- Clarkson, D.B.; Jennrich, R.I. Quartic rotation criteria and algorithms. Psychometrika 1988, 53, 251–259. [Google Scholar] [CrossRef]
- Robitzsch, A. Smooth information criterion for regularized estimation of item response models. Algorithms 2024, 17, 153. [Google Scholar] [CrossRef]
- Shang, L.; Xu, P.F.; Shan, N.; Tang, M.L.; Zheng, Q.Z. The improved EMS algorithm for latent variable selection in M3PL model. Appl. Psychol. Meas. 2025, 49, 50–70. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Jiang, J.; Nguyen, T.; Rao, J.S. The E-MS algorithm: Model selection with incomplete data. J. Am. Stat. Assoc. 2015, 110, 1136–1147. [Google Scholar] [CrossRef]
- Grønneberg, S.; Foldnes, N.; Marcoulides, K.M. covsim: An R package for simulating non-normal data for structural equation models using copulas. J. Stat. Softw. 2022, 102, 1–45. [Google Scholar] [CrossRef]
- Curran, P.J.; West, S.G.; Finch, J.F. The robustness of test statistics to nonnormality and specification error in confirmatory factor analysis. Psychol. Methods 1996, 1, 16–29. [Google Scholar] [CrossRef]
- Hair, J.; Black, W.C.; Anderson, R.E. Multivariate Data Analysis, 7th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics; Allyn and Bacon: Boston, MA, USA, 2001. [Google Scholar]
- Lovibond, P.F.; Lovibond, S.H. The structure of negative emotional states: Comparison of the Depression Anxiety Stress Scales (DASS) with the Beck Depression and Anxiety Inventories. Behav. Res. Ther. 1995, 33, 335–343. [Google Scholar] [CrossRef] [PubMed]
- Wall, M.M.; Guo, J.; Amemiya, Y. Mixture factor analysis for approximating a nonnormally distributed continuous latent factor with continuous and dichotomous observed variables. Multivar. Behav. Res. 2012, 47, 276–313. [Google Scholar] [CrossRef] [PubMed]
- Monroe, S.L. Multidimensional Item Factor Analysis with Semi-Nonparametric Latent Densities. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2014. [Google Scholar]
- Padilla, J.L.; Azevedo, C.L.; Lachos, V.H. Multidimensional multiple group IRT models with skew normal latent trait distributions. J. Multivar. Anal. 2018, 167, 250–268. [Google Scholar] [CrossRef]
- Gómez, J.L.P. Bayesian Inference for Multidimensional Item Response Models Under Heavy Tail Skewed Latent Trait Distributions and Link Functions. Ph.D. Thesis, Universidade Estadual de Campinas, Campinas, Brazil, 2018. [Google Scholar]
- Huang, P.H. Penalized least squares for structural equation modeling with ordinal responses. Multivar. Behav. Res. 2022, 57, 279–297. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).