Abstract
A hybrid robust tracking-control design method is studied for linear stochastic systems in which the parameters of the reference system are unknown but inferred from discrete-time observations. First, the reference system parameters are estimated by the least-squares method, and a corresponding data-dependent augmented system is constructed. Second, a Riccati matrix inequality is established for these systems, and a state-feedback controller is designed to improve tracking performance. Third, to mitigate large tracking errors, an error-feedback control scheme is introduced to compensate for dynamic tracking deviations. These results yield a hybrid control framework that integrates data observation, state-feedback control, and error-feedback control to address the tracking problem more effectively. Two numerical examples and one practical example demonstrate the effectiveness of the proposed method.
MSC:
93E03
1. Introduction
With advancements in artificial intelligence and data-acquisition technology, data-driven control has become a prominent paradigm in control engineering [1]. Numerous important results have emerged. For instance, Shen et al. studied iterative learning control (ILC) for discrete-time linear systems without prior probability information on randomly varying iteration length [2]. The authors of Ref. [3] proposed a proportional–integral–derivative (PID) control scheme based on adaptive updating rules and data-driven techniques. In [4], bounded-input bounded-output stability, monotonic convergence of tracking-error dynamics, and internal stability of the full-form dynamic-linearization-based model-free adaptive control (MFAC) scheme were analyzed using the contraction mapping principle. The authors of [5] proposed a data-driven adaptive control method based on the incremental triangular dynamic-linearization data model. Recently, data-driven modeling methods have advanced rapidly, yielding notable results in several areas, including predictive control for switched linear systems [6], predictive control for a modular multilevel converter [7], optimal output tracking control [8], self-triggered control [9], and distributed predictive control [10].
The control technique is an effective method for enhancing robustness against exogenous disturbances [11] and has been widely applied in aerospace, robotics, and wireless communications [12,13,14,15]. Robust control theory has evolved over more than 40 years. The foundational works include [16,17], which introduce the frequency-domain and algebraic Riccati equation (ARE) methods, respectively, for linear deterministic systems. The linear matrix inequality (LMI) approach was later developed in [18]. For systems subject to random noise [19], stochastic differential equations have been adopted [20], and corresponding results have been extended to linear Itô systems [21]. control theories for nonlinear systems have also been established, such as those in [22] for deterministic settings and those in [23]. State-feedback control for affine stochastic Itô systems was studied in [24] using the completing-squares method. More recently, we proposed an control design method for general nonlinear discrete-time stochastic systems using the disintegration property of conditional expectation and convex functions [25]. Additional results on control can be found in [26,27,28] and the references therein.
Tracking-control design techniques are widely used in autonomous underwater vehicles (AUVs), unmanned surface vehicles, and unmanned aerial vehicles (UAVs). For example, Ref. [29] investigated trajectory-tracking control for underactuated autonomous underwater vehicles subject to input constraints and arbitrary attitude maneuvers. A delay-compensated control framework with prescribed performance guarantees was proposed in [30] for trajectory-tracking control of unmanned underwater vehicles (UUVs) subject to uncertain time-varying input delays. The distributed model-predictive control (MPC) framework in [31] was designed for tracking-control problems involving multiple unmanned aerial vehicles (UAVs) interconnected through a directed communication graph. To address size-related limitations in computing invariant sets and to simplify the offline model-predictive control (MPC) design, the authors of Ref. [32] developed an MPC technique based on implicit terminal components. Optimal adaptive fuzzy observer-based indirect reference tracking-control designs were investigated in [33] for uncertain SISO and MIMO nonlinear stochastic systems with nonlinear uncertain measurement functions and measurement noise.
This paper investigates a hybrid partial-data-driven robust tracking-control method for the following linear stochastic system to be controlled:
together with the unknown reference model:
where is the system state, is the reference trajectory, is the control input, and , and are the exogenous disturbances. The matrices , and of the system to be controlled are known, whereas the matrix of the reference system is unknown. Only some discrete-time observations of are available in . To reduce the tracking error, i.e., the distance between and , the control input must be properly designed.
A data-dependent augmented system is constructed, and state-feedback and error-feedback controllers are developed accordingly. The resulting hybrid partial-data-driven control design scheme comprises three stages: data observation, state-feedback control, and error-feedback control. In the first stage, information on is obtained, the reference system parameters are estimated, and the corresponding data-dependent augmented system is constructed, from which a state-feedback controller is derived. In the second stage, under the action of the state-feedback controller, the tracking error is reduced, although its magnitude remains relatively large because the control depends only on the system state and does not incorporate tracking-error values. In the third stage, an error-feedback controller is designed to further reduce the tracking error.
Compared with the method of [33], the proposed approach has two main innovations:
- Tracking errors are incorporated not only in the performance index but also directly in the control input through an error-feedback term.
- The control input is a hybrid partial-data-driven controller with a piecewise structure.
This paper is organized as follows: In Section 2, some results on control for linear stochastic systems are reviewed. In Section 3, the data-dependent augmented system is constructed, and the corresponding state-feedback control and error-feedback control design methods are studied by solving algebraic Riccati inequalities. In Section 4, the hybrid control scheme is proposed, which includes three stages, and the corresponding programming evolution is also provided. In Section 5, two numerical examples and one practical example are discussed to illustrate the effectiveness of the proposed method.
Notations: : the transpose of the matrix A; : the Euclidean norm of the vector ; : the trace of square matrix with ; : the norm of matrix defined by ; : the dimension of vector ; : the set of the n-order real symmetric matrix; : the set of the n-order positive definite matrix; : the matrix M is a positive definite (semi-definite) matrix; : the square root of a positive definite (semi-definite) matrix M; i.e., is a positive (semi-definite) matrix satisfying . : the norm of vector with weighted matrix M defined by , where .
2. Preliminaries
Let be a 1-dimensional standard Brownian motion in a completed probability space with and . The filtration satisfies the usual conditions, and is generated by Brownian motion, i.e.,
where is the totality of -null sets. Denote as the set of random variables , where is -measurable and
Denote as the set of -adapted stochastic processes with norm
The stochastic linear system with exogenous disturbance is given as
where , are coefficient matrices, is the exogenous disturbance, and is the terminal time with . We first review some results of problem for system (1) that will be used later.
Denote the solutions of (1) beginning at with initial state under exogenous disturbance . For every , let
be the output of system (1). Define operator with
where . The norm of is defined as
If there exists a constant such that, for every ,
i.e.,
then (2) and (3) are equivalent to
The following lemma is the bounded real lemma from [34], which is also suitable for the case of problem for system (1).
Lemma 1.
For some given positive scalar , suppose there exists a positive definite matrix such that
where ★ denotes the symmetrical part, and then . Moreover, there also exists
for all and .
3. State-Feedback and Error-Feedback Tracking Control for Linear Systems Based on Partially Observable Data
The following linear control systems are considered:
where , , , , , and are coefficient matrices, is the system state, is the controller, and and are the exogenous disturbances.
Suppose the tracking target of system (5) can be described by the following reference model:
where is the desired reference state tracked by in (5), is the coefficient matrix, and is the exogenous disturbance of reference system (6). In system (6), the system coefficient is unknown, but can be observed at discrete-time with ; i.e., the observation values of can be obtained.
Denote as the tracking errors between and ; i.e.,
Our target is, with the background of reference system coefficients unknown and only based on the obtained discrete-time observation , to find an controller such that, for the given , the tracking performance always satisfies the following inequality in the next coming time given as
for all exogenous disturbances , where is the weighted matrix of tracking errors , is the weighted matrix of controller , is the terminal time of control, and is the attenuation level of external interference on the system.
Denote
In order to obtain the control , the unknown coefficient matrix in system (6) should be estimated first. Because the trajectory of reference system (6) can be observed at discrete-time , in order to overcome the system’s uncertainty regarding (6), the observation values of are used to estimate the unknown matrix . This requires the discrete form of (6) as follows:
i.e.,
where are the fitting errors or residuals of this model. The least-squares method is used to estimate matrix , which satisfies
where TSSE is the total sum of squared errors with
Theorem 1.
Let and ; then, the least-squares estimator of matrix can be presented by
which satisfies (9), where is the Moore–Penrose inverse matrix of .
Proof.
Applying the discrete-time model (8), we can obtain
By the definition of , there exists
So, the least-squares estimator of is given by (11). □
Remark 1.
In Theorem 1, the Moore–Penrose inverse matrix is used. As proposed by the anonymous reviewer, the Moore–Penrose procedure is insufficient. But, if the sample size is large enough, the matrix can be an invertible matrix, which is shown in Examples 1 and 2. If is invertible, then it is equivalent to , where denotes the rank of matrix . Because and is matrix, the necessary condition for to be invertible is . So, if is invertible, the result of (11) can be replaced by
So, based on the results of Theorem 1, the parameter-unknown reference system (6) can be estimated with the observed data form
The augment system of (5) and (12) is written by
where
So, the corresponding performance of (13) is rewritten as
where
Remark 2.
Denote the observations of the reference system (6) at discrete-time as
and then the coefficients of and in (12) depend on such observation data . So, some coefficients of the augment system (13) such as are also data-dependent where the data is only the observations of at discrete-time . Because such data is only the observation of reference system (6) but not including the to-be-controlled system (5), and is only the data at discrete time at but not the continuous interval in , so the to-be-designed control is called partial-data-driven, which depends on such data . Now, we outline the definition of partial-data-driven tracking control of systems (5) and (6) in which the performance is more general than (14).
Definition 1.
For the given scalar and the observations of reference system (6), if there exists a positive definite matrix P and a control such that the solutions of for augmented system (13) satisfy the following inequality
for all , then is called the partial-data-driven tracking control of systems (5) and (6).
Theorem 2.
For the given positive number , suppose the positive definite matrix satisfies the following Riccati inequality:
Then, the state-feedback control is the partial-data-driven tracking control of systems (5) and (6).
Proof.
Let . Applying Itô’s formula to , we have
Taking expectation on both sides, we get
Since , there exists . So, we have
By completing-squares method, we have
where . Taking and combining with inequality (17), the following inequality is obtained:
i.e.,
for all , . This ends the proof. □
Remark 3.
Let
and then the inequality (16) can be rewritten as
Particularly, if , we have
This is just the performance of (14). Under such situation, we can define the operator as follows:
with , and the norm of satisfies . So, the inequality (16) in Definition 1 is the generalization of the performance given by (16).
Now, we consider the error-feedback control case and suppose the corresponding control will be designed with the form of
where K is a to-be-designed matrix taking values in . Denote
Then, the augmented system of (5) and (12) under control can be described as
So, our target is to find proper matrix K and P to satisfy the following inequality for some given
Theorem 3.
Suppose there exists matrix , and positive matrix satisfies the following Riccati inequality
Then, the error-feedback control satisfies (19).
Proof.
Similar to the proof of Theorem 2, applying Itô’s formula to , we can obtain the following inequality:
where . So, for every , there exists
for all . This ends the proof. □
4. Hybrid Partial-Data-Driven Robust Tracking Control Scheme for Linear Stochastic Systems
Based on the results of Theorems 1–3 in Section 3, the hybrid partial-data-driven robust tracking control scheme for (5) and (6) is proposed in this section. The hybrid control scheme includes three stages, and the interval is divided into three segments with the subintervals of , , and , where . The control input of system (5) is designed with piecewise form for each stage, which is organized in detail as follows:
Stage 1: Observing state of in at .
In this stage, the coefficient of reference system (6) is unknown, but the observation values of can be obtained at . The observations of can rewritten as a matrix
Denote
By results of Theorem 1, the estimator of can be obtained:
Because the main objective is to observe the state of system (6), there are no control inputs in this stage; i.e.,
when .
Stage 2: Designing state-feedback control in .
Based on the estimator of reference system (12), the augmented control system of (5) and (12) can be obtained. For the given positive scalar , by solving the Riccati inequality (17), the positive definite matrix P is obtained corresponding to the augmented system (13). By the results of Theorem 2, the state-feedback control is designed:
when , where and is the state of the augmented system (13), and such control satisfies the following performance:
Stage 3: Designing error-feedback control in .
In order to further decrease the errors between and , the error-feedback control is designed. By solving the Riccati inequality (20), the positive matrix P is obtained, and the corresponding error-feedback is designed:
when , where is a part of the solutions of Riccati inequality (20).
Finally, the three-stage control of (5) and (6) is obtained with piecewise form regarding , which can be written as follows:
This piecewise control satisfies the following performance:
For the profiles of the hybrid control and the corresponding performances are shown in the following Example 1–3.
In summary, the programming evolution of such suggested hybrid 3-stage control is organized in the following Table 1.

Table 1.
The programming evolution of hybrid partial-data-driven control.
5. Examples and Simulation
Example 1.
Consider the following 1-dimensional controlled system:
and the reference system is also a 1-dimensional system:
where is an unknown number, but the values of are observed at with observation vector as follows:
where , , , and . By Theorem 1, we get the estimator . So, the augmented system is obtained:
The inverse matrix of is , and the corresponding augmented matrices are
For , it is easy to check that the following matrix
satisfies the Riccati inequality (17). Let . By Theorem 2, the corresponding state-feedback control
is designed. Similarly, it is easy to check that the matrix and also satisfy the Riccati inequality (20). By Theorem 3, we can obtain the corresponding error-feedback control
In summary, the control of system (21) is designed in three stages with t in different intervals: , , . So, the control has a piecewise form:
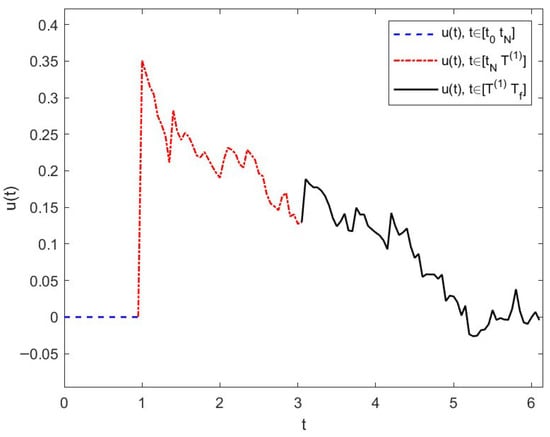
This control is the suggested hybrid control of (21) and (22). The trajectory of with piecewise form is shown in Figure 1.
Figure 1.
Trajectories of in Example 1.
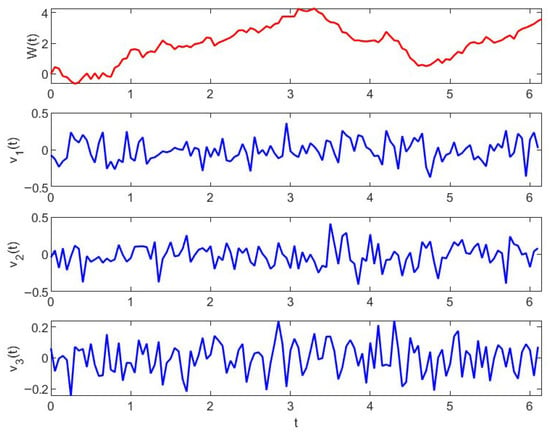
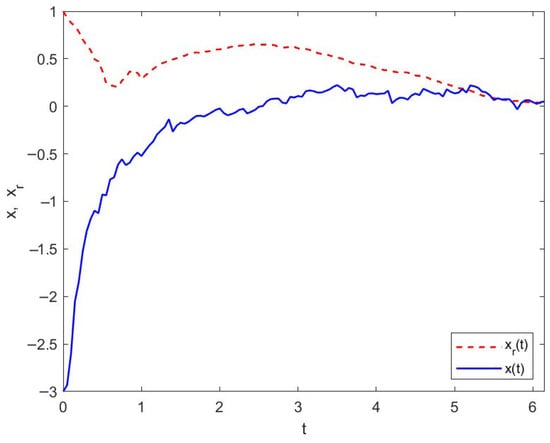
Figure 2 shows the profiles of exogenous disturbances and Brownian motion. The trajectories of and are illustrated in Figure 3, which are the solutions of (21) and (22) under the control given by (24).
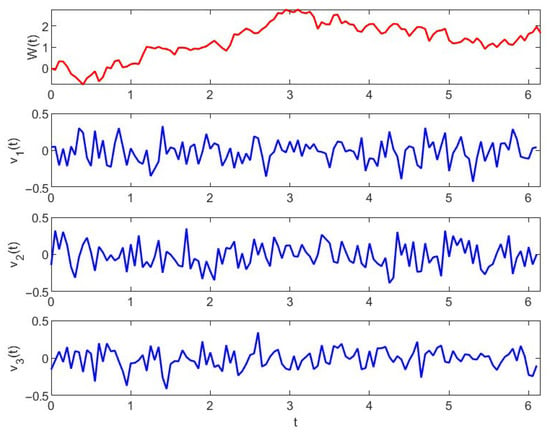
Figure 2.
Profiles of Brownian motion and exogenous disturbance in systems (25) and (26) in Example 1.
Figure 3.
Trajectories of and under the control in Example 1.
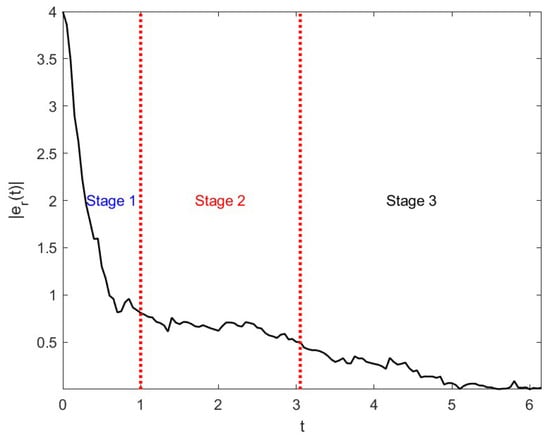
By Figure 3 and Figure 4, we see that, under the control of , the distance between and becomes less and the errors also become smaller when t changes in . Comparing the errors in different stages, Figure 4 illustrates that the values of errors at the third stage () are smaller than in the other two stages, where and .
Figure 4.
The changes in errors under the effect of control in Example 1.
Example 2.
Consider the following 3-dimensional controlled system:
with the matrix coefficients as follows:
and the reference system is also a 3-dimensional system:
where is an unknown matrix. Suppose the interval is divided into three segments, i.e., , , and . Now, we apply the suggested hybrid 3-stage-control method to design the control of (25) and (26), which includes 3 steps:
Stage 1: Observing state of in at .
In this stage, the states of reference system (26) can be observed at . Suppose the observations of reference system (26) at with are arranged as a matrix denoted by , whose values are observed as follows:
where is the sampling period. The inverse matrix of is
Applying the results of Theorem 1 in this stage, the estimator of can be obtained as follows:
In this stage, there is no control input ; i.e., .
Stage 2: Designing state-feedback control in .
Taking , by solving the Riccati inequality (17) corresponding to systems (25) and (26) with observation , we can obtain the positive definite matrix
Furthermore, by Theorem 2, we can get the state-feedback control with
Stage 3: Designing error-feedback control in .
By solving the Riccati inequality (20), the positive definite matrix is obtained as
and, by results of Theorem 3, the corresponding error-feedback control can be obtained, where is solved as
Combining the results of Stage 1, Stage 2, and Stage 3, the input control of system (25) can be rewritten as segmentation form:
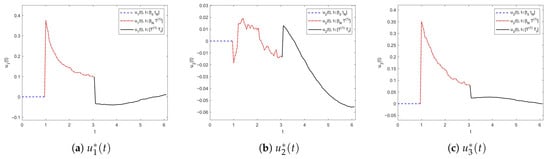
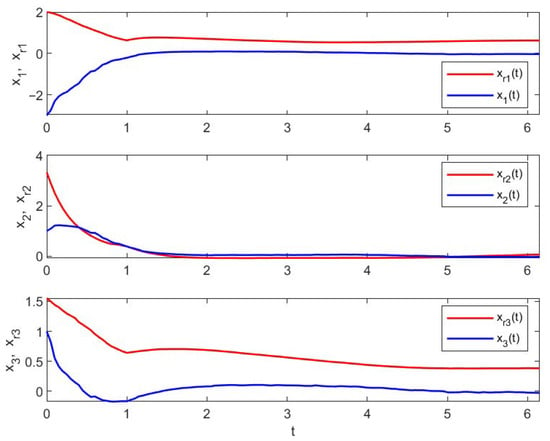
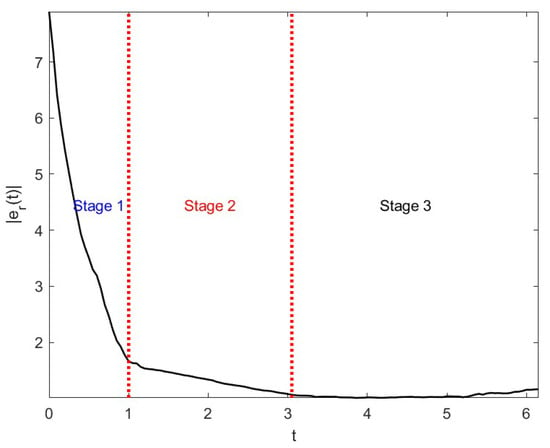
Figure 5 shows the profiles of exogenous disturbances , , , and Brownian motion to which systems (25) and (26) are subjected. The trajectories of each component of the suggested control of (25) are illustrated in Figure 6, which is divided into 3 stages. The contrast between and shown in Figure 7 and Figure 8 illustrate the change in errors between and with . In the firs stage, i.e., , system (25) is no control input, where . Figure 7 and Figure 8 illustrate that the distance between and is the farthest; i.e., the values of errors are worst in the first stage. In the second stage, i.e., , the control input of system (25) is state-feedback control. By Figure 7 and Figure 8, we see that, compared with the first stage, the values of errors with become smaller but still not very good. In the third stage, it is easy to see that the errors between and become the smallest when , which is shown in Figure 7 and Figure 8.
Figure 5.
Profiles of Brownian motion and exogenous disturbance , , and in Example 2.
Figure 6.
Trajectories of in Example 2.
Figure 7.
Trajectories of and under the control in Example 2.
Figure 8.
The changes in errors under the effect of control in Example 2.
Example 3.
Consider the system of robot manipulator discussed in [35], whose dynamic equation is given by
where is the vector of generalized coordinates, is the inertia matrix, is the Coriolis and centrifugal torque vector, is the gravitational torque vector, is the generalized control input vector, and is the disturbance.
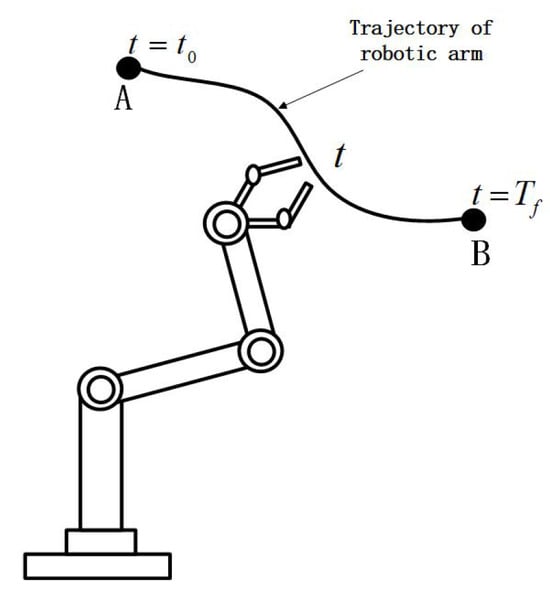
See Figure 9 in order to complete the task of the robot arm moving along with a given trajectory from A to B in the time interval . The control τ in (28) should be designed rationally such that can take proper values at every moment . So, the values of should track a given reference . The error between them is defined as
Figure 9.
Sketch of robot manipulator moving along the given reference trajectory.
Now, suppose is an invertible positive definite constant matrix and and are linear in q and ; i.e., there exist matrices such that and .
Let
Then, system (28) is equivalent to
Now, we extend it to the stochastic case. Denote the control and the exogenous disturbance . Suppose the stochastic system with control input has the following form:
where
In practice, system (29) is seen as a version of (28) subjected to Brownian motion and exogenous disturbances and .
We also suppose the reference trajectory given by
where is unknown, but the values of can be observed at .
Now, let ; i.e., q is a 3-dimensional vector with
Suppose the corresponding matrices of , and G are provided as follows:
and , . Suppose the observations of at are obtained:
where with . By Theorem 1, we can obtain the estimator of :
Construct the augmented system of (29) and (30) with given above. Then, for , applying the results of Theorems 2 and 3, the state-feedback control and error-feedback control are designed, which are given as follows:
where
and
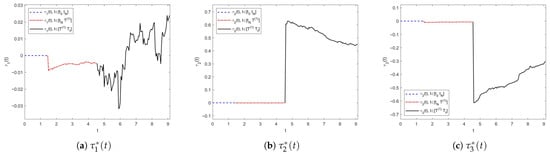
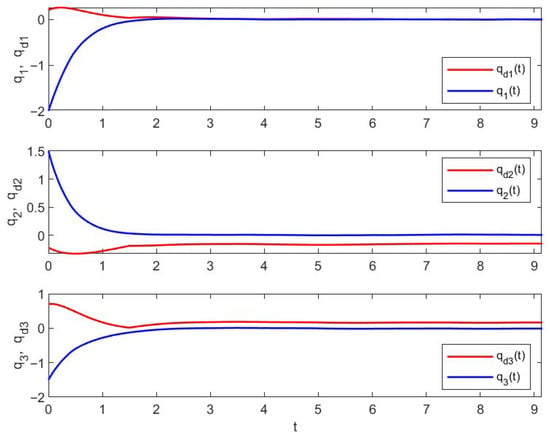
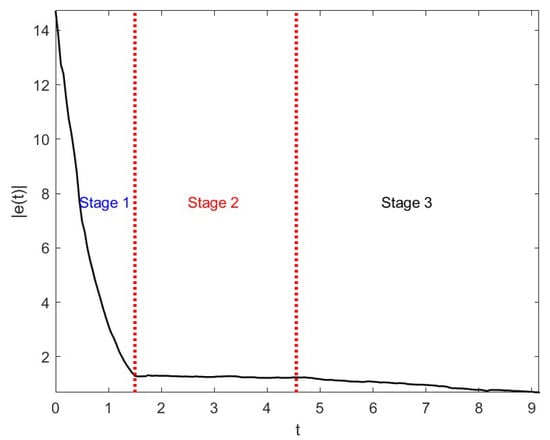
Figure 10 illustrates the trajectories of control with three stages. Figure 11 shows the trajectories of and reference under the control designed above. It is easy to see that each component of performs well regarding the reference . Figure 12 illustrates the error’s changes between and , showing that there exists the smallest error in the third stage, which verifies the effect of the proposed method.
Figure 10.
Trajectories of in Example 3.
Figure 11.
Trajectories of and under the control in Example 3.
Figure 12.
The changes in errors under the effect of control in Example 3.
6. Conclusions
The robust tracking problem is investigated for linear stochastic systems where the parameters of a reference system are unknown but some discrete-time observations are available. A hybrid data-driven tracking-control design scheme is proposed for such problems. By using the least-squares method, the parameters of the reference system are estimated and the corresponding data-dependent augmented systems are established. Based on the solutions of algebraic Riccati inequalities, the state-feedback and error-feedback controls are designed for such tracking problems to enhance system performance and reduce tracking error. Moreover, the programming evolution of the hybrid control method is summarized, which includes data observation, state-feedback control, and error-feedback control.
Author Contributions
Conceptualization, X.L. and R.Z.; methodology, X.L. and Y.Z.; software, X.L. and Y.Z.; validation, X.L., Y.Z., and R.Z.; formal analysis, X.L.; investigation, R.Z.; resources, X.L.; writing—original draft preparation, Y.Z. and X.L.; writing—review and editing, X.L. and R.Z.; visualization, R.Z.; supervision, X.L.; project administration, X.L.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NSF of China, grant number 62273212.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Persis, C.D.; Tesi, P. Formulas for data-driven control: Stabilization, optimality, and robustness. IEEE Trans. Autom. Control 2020, 65, 909–924. [Google Scholar] [CrossRef]
- Shen, D.; Zhang, W.; Wang, Y.; Chien, C. On almost sure and mean square convergence of P-type ILC under randomly varying iteration lengths. Automatica 2016, 63, 359–365. [Google Scholar] [CrossRef]
- Yu, H.; Guan, Z.; Chen, T.; Yamamoto, T. Design of data-driven PID controllers with adaptive updating rules. Automatica 2020, 121, 109185. [Google Scholar] [CrossRef]
- Hou, Z.; Xiong, S. On model-free adaptive control and its stability analysis. IEEE Trans. Autom. Control 2019, 64, 4555–4569. [Google Scholar] [CrossRef]
- Pang, Z.; Ma, B.; Liu, G.; Han, Q. Data-driven adaptive control: An incremental triangular dynamic linearization approach. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4949–4953. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, K.; Cheng, X.; Sun, X. Online data-driven model predictive control for switched linear systems. IEEE Trans. Autom. Control 2025, 70, 6222–6229. [Google Scholar] [CrossRef]
- Wu, W.; Qiu, L.; Rodriguez, J.; Liu, X.; Ma, J.; Fang, Y. Data-driven finite control-set model predictive control for modular multilevel converter. IEEE J. Emerg. Sel. Top. Power Electron. 2023, 11, 523–531. [Google Scholar] [CrossRef]
- Sun, T.; Sun, X.; Sun, A. Optimal output tracking of aircraft engine systems: A data-driven adaptive performance seeking control. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1467–1471. [Google Scholar] [CrossRef]
- Liu, W.; Sun, J.; Wang, G.; Bullo, F.; Chen, J. Data-driven self-triggered control via trajectory prediction. IEEE Trans. Autom. Control 2023, 68, 6951–6958. [Google Scholar] [CrossRef]
- Zhan, J.; Ma, Z.; Zhang, L. Data-driven modeling and distributed predictive control of mixed vehicle platoons. IEEE Trans. Intell. Veh. 2023, 8, 572–582. [Google Scholar] [CrossRef]
- Zhang, W.; Xie, L.; Chen, B.S. Stochastic H2/H∞ Control: A Nash Game Approach; Taylor & Francis: Boca Raton, FL, USA, 2017. [Google Scholar]
- Chen, B.S.; Wang, C.P.; Lee, M.Y. Stochastic robust team tracking control of multi-UAV networked system under Wiener and Poisson random fluctuations. IEEE Trans. Cybern. 2021, 51, 5786–5799. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Ma, T.; Lewis, F.L.; Wan, Y. Robust formation control for multiple quadrotors with nonlinearities and disturbances. IEEE Trans. Cybern. 2020, 50, 1362–1371. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, H.; Song, Y.; Sun, Z.Y.; Yu, D. Fast finite-time consensus protocol for high-order nonlinear multi-agent systems based on event-triggered communication scheme. Appl. Math. Comput. 2026, 508, 129631. [Google Scholar] [CrossRef]
- Boshkovska, E.; Ng, D.W.K.; Zlatanov, N.; Koelpin, A.; Schober, R. Robust resource allocation for MIMO wireless powered communication networks based on a non-linear EH model. IEEE Trans. Commun. 2017, 65, 1984–1999. [Google Scholar] [CrossRef]
- Zames, G. Feedback and optimal sensitivity: Model reference transformations, multiplicative seminorms, and approximate inverses. IEEE Trans. Autom. Control 1981, 26, 301–320. [Google Scholar] [CrossRef]
- Doyle, J.C.; Glover, K.; Khargonekar, P.; Francis, B. State-space solutions to standard H2 and H∞ control problems. IEEE Trans. Autom. Control 1989, 34, 831–847. [Google Scholar] [CrossRef]
- Gahinet, P.; Apkarian, P. A linear matrix inequality approach to H∞ control. Int. J. Robust Nonlinear Control 1994, 4, 21–448. [Google Scholar] [CrossRef]
- Dai, X.; Zuo, H.; Deng, F. Mean square finite-time stability and stabilization of impulsive stochastic distributed parameter systems. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 4064–4075. [Google Scholar] [CrossRef]
- Zhao, J.; Yuan, Y.; Sun, Z.Y.; Xie, X. Applications to the dynamics of the suspension system of fast finite time stability in probability of p-norm stochastic nonlinear systems. Appl. Math. Comput. 2023, 457, 128221. [Google Scholar] [CrossRef]
- Hinrichsen, D.; Pritchard, A.J. Stochastic H∞. SIAM J. Control Optim. 1998, 36, 1504–1538. [Google Scholar] [CrossRef]
- der Schaft, A.J.V. On a state-space approach to nonlinear H∞ control. Syst. Control Lett. 1991, 16, 1–8. [Google Scholar]
- Ball, J.A.; Helton, J.W.; Walker, M.L. H∞ control for nonlinear systems with output feedback. IEEE Trans. Autom. Control 1993, 38, 546–559. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, B.S. State feedback H∞ control for a class of nonlinear stochastic systems. SIAM J. Control Optim. 2006, 44, 1973–1991. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, T.; Zhang, W.; Chen, B.S. New approach to general nonlinear discrete-Time stochastic H∞ control. IEEE Trans. Autom. Control 2019, 64, 1472–1486. [Google Scholar] [CrossRef]
- Chen, B.S.; Yang, C.T.; Lee, M.Y. Multiplayer noncooperative and cooperative minimax H∞ tracking game strategies for linear mean-field stochastic systems with applications to cyber-social systems. IEEE Trans. Cybern. 2022, 52, 2968–2980. [Google Scholar]
- Xin, Y.; Zhang, W.; Wang, D.; Zhang, T.; Jiang, X. Stochastic H2/H∞ control for discrete-time multi-agent systems with state and disturbance-dependent noises. Int. J. Robust Nonlinear Control 2025, preprinted. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Z.; Lv, Y.; Na, J.; Liu, C.; Zhao, Z. Data-driven learning for H∞ control of adaptive cruise control systems. IEEE Trans. Veh. Technol. 2024, 73, 18348–18362. [Google Scholar] [CrossRef]
- Liao, Y.; Zhang, T.; Yan, X.; Jiang, D. Integrated guidance and tracking control for underactuated AUVs on SE(3) with singularity-free global prescribed performance attitude control. Ocean Eng. 2025, 342, 122770. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, Y.; Chai, P.; Tan, J.; Zheng, H. Prescribed-performance time-delay compensation control for UUV trajectory tracking in main-branch water conveyance tunnel transitions under unknown input delays. Ocean Eng. 2025, 342, 122941. [Google Scholar]
- Xu, B.; Dai, Y.; Suleman, A.; Shi, Y. Distributed fault-tolerant control of multi-UAV formation for dynamic leader tracking: A Lyapunov-based MPC framework. Automatica 2025, 175, 112179. [Google Scholar] [CrossRef]
- Luque, I.; Chanfreut, P.; Limón, D.; Maestre, J.M. Model predictive control for tracking with implicit invariant sets. Automatica 2025, 179, 112436. [Google Scholar] [CrossRef]
- Chen, B.S.; Hsueh, C.H.; Wu, R.S. Optimal H∞ adaptive fuzzy observer-based reference tracking control of nonlinear stochastic systems under uncertain measurement function and noise. Fuzzy Sets Syst. 2025, 521, 109597. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, R. H∞ Control for stochastic systems with Poisson jumps. J. Syst. Sci. Complex 2011, 24, 683–700. [Google Scholar] [CrossRef]
- Song, G.; Park, H.; Kim, J. The H∞ Robust stability and performance conditions for uncertain robot manipulators. IEEE/CAA Hournal Autom. Sin. 2025, 12, 270–272. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).