Abstract
Competing risks modeling plays a pivotal role in both reliability analysis for scientific and engineering fields and survival analysis within medical research. In real-world scenarios, failure or death (from a biological perspective) often arises from multiple risk factors that compete with one another. To adequately capture these complexities, it is essential to employ a flexible probabilistic framework, such as the competing risks model, which ensures suitability for intricate risk scenarios (e.g., analyzing data from aggressive diseases where treatment response and disease progression are closely interwoven). This study introduces Stacy’s competing risks model, built upon Stacy’s generalized gamma distribution, offering enhanced robustness and flexibility over existing models. The paper first develops the mathematical properties of the proposed model, followed by a detailed exploration of parameter estimation through various estimation methods. A key focus is accurately estimating shape parameters to gain deeper insights into the survival and failure mechanisms associated with the underlying phenomenon. The performance of different estimation approaches is assessed using Monte Carlo simulations, with results indicating that the least square, Cramér–von Mises, Anderson–Darling, right Anderson–Darling, and weighted least square had better performance and stable estimation accuracy compared with maximum likelihood maximum product of spacings methods. The model is applied to two real-world blood cancer datasets to demonstrate practical applicability, showing the superior performance and outstanding fit of the Anderson–Darling method among the other methods. The findings highlight the superior performance of Stacy’s competing risks model, supported by low Kolmogorov–Smirnov statistics and high p-values, affirming its suitability and robustness in modeling blood cancer data compared to other standard models.
Keywords:
competing risks; generalized gamma distribution; maximum likelihood estimation; maximum product of spacing; minimum distance estimation; data analysis MSC:
62-08; 62F10; 62F35
1. Introduction
Human beings are affected by various diseases, such as non-communicable diseases. A well-known example of a non-communicable disease is cancer. A particular type of cancer is blood cancer, which refers to malignant conditions affecting the blood, bone marrow, and lymphatic system. These disorders involve the uncontrolled growth of abnormal blood cells, which disrupt normal blood functions. The primary types of blood cancer are leukemia, lymphoma, and multiple myeloma. Leukemia affects the blood and bone marrow, lymphoma originates in the lymphatic system, and multiple myeloma involves malignant plasma cells. For more comprehensive details, see [1]. Cancer is a major societal, public health, and economic problem. Around 1.24 million blood cancer cases in the world are recorded annually, which represents approximately of all cancer cases. In addition, over 720,000 people die due to blood cancer every year, accounting for more than of cancer deaths [2].
A patient who is diagnosed with blood cancer might have other risk factors, such as diabetes and obesity, among others. Therefore, when the time of death is declared for such a patient, there are at least two risk factors that compete to cause the loss of the patient’s life. This complexity highlights the importance of modeling patient lifetimes precisely. For improving treatment design, clinical trial planning, and healthcare decision-making, reliable statistical models are essential. Selecting the best lifetime modeling leads to a reduction in uncertainty of survival predictions, ultimately contributing to enhanced survival rates and reduced economic burden of cancer care. From a statistical perspective, the time of death declarations are time-to-event data common in reliability and survival analyses. When at least two factors can cause failure (from an engineering perspective) or death (from a medical viewpoint), researchers are dealing with time-to-event data in the context of competing risks. This type of data is in the form of successive failure times, with indicators referring to the cause of each failure.
Various models have been proposed for such data; however, Cox’s competing risks model is often used to analyze competing risks data [3]. For more details and examples about the competing risks model, readers are referred to the monograph of [4]. Cox’s model has the following assumptions:
- The object (or subject) fails only due to any of the k independent causes of failure.
- The lifetimes of the objects (or subjects) under study, , are independent and identically distributed random variables (i.e., a random sample). Also, suppose that for , each lifetime can be redefined as such that are latent failure times corresponding to the j different independent competing risk factors.
Although Cox’s model was introduced over six decades ago, it has garnered significant attention from various researchers. For example, ref. [5] investigated comparative life tests using joint-censoring samples from an exponential competing risks model, whereas ref. [6] considered progressively Type-II-censored competing risks data with lifetimes assumed to follow a linear-exponential distribution. Moreover, ref. [7] investigated estimation for the competing risks model under adaptive progressively Type-II-censored Rayleigh lifetime data. Additionally, ref. [8] examined the statistical inference of competing risks samples under a joint Type-II-censoring plan, assuming that the underlying lifetime distribution is Weibull. Ref. [9] conducted statistical inferences in competing risks models with Akshaya sub-distributions based on a Type-II-censoring scheme. A competing risks model was adopted in [10], assuming a generalized inverted exponential distribution with independent failure modes and partially observed under a Type-II progressive-censoring scheme. In [11], inference for the competing risks model based on the Weibull distribution was examined under an improved adaptive progressive Type-II-censoring scheme.
Furthermore, ref. [12] developed statistical inference for a competing risks model with latent failure times following the Kumaraswamy-G family of distributions under a unified progressive hybrid-censoring scheme. Addressing a masking problem, ref. [13] introduced an expectation–maximization (EM) algorithm for parameter estimation for the Birnbaum–Saunders distribution under competing risks with censored data, while ref. [14] applied a similar algorithm for the inverse Weibull distribution under competing risks. Additionally, ref. [15] proposed a novel competing risks model termed the additive generalized linear-exponential (AGLE) competing risks model. More recently, ref. [16] concentrated on statistical inference for independent competing risks data modeled by the inverse Lomax distribution using a Type-II generalized hybrid-censored dataset, while ref. [17] evaluated the reliability function in competing risks models by employing adaptive progressively Type-II-censored data from small electrical appliances and X-ray-exposed male mice, using the XGamma distribution as the parent model.
In the literature, there are some studies that consider the Gamma distribution as an underlying lifetime distribution in a competing risks model. Ref. [18] provided both classical and Bayesian estimation of the parameters of a competing risk model defined on the basis of the minimum of exponential and gamma failure, where the failures were due to aging or were accidental failures, and as such they considered Gamma with increasing failure rate. They considered the case where the causes were identified but which of the causes lead to failure is unknown. Ref. [19] studied the competing risk model on the basis of the minimum of exponential and gamma failure, considering the case where failure times are classified due to the two causes. Recently, ref. [20] used cardiovascular disease patients’ data for the comparison of parametric competing risk regression models, attempting to study the effect of covariates in the competing risk model. The cause of risks is assumed to follow certain lifetime distributions, such as exponential, Weibull, gamma, and generalized gamma. They used an ML method to estimate the parameters without a proposed simulation study to see the performance of the estimates. The Stacy’s GG distribution proposed by Stacy [21] is widely used not only in classical lifetimes but also extends beyond many advanced models because its multiple shape parameters accommodate a wide range of skewness, tail behavior, and hazard shapes. Models such as frailty models [22], autoregressive moving average (ARMA) model [23], reliability and accelerated life testing [24], stress strength [25], and regression models [26] are included within the stochastic process framework as in [27]. Across diverse applications, the Stacy’s GG distribution provides a good fit of real-life data and sometimes consistently outperforms or competes strongly with traditional models (Gamma, Weibull, lognormal, Gaussian, Generalized Lindley Distribution, etc.) [28,29,30,31,32,33,34,35,36,37]. Theoretically, the GG model extends the exponential, Weibull, and gamma families through two shape parameters, allowing for monotonic and non-monotonic hazard forms. Methodologically, this flexibility permits nested model comparison and provides a unified framework to assess whether simpler models are sufficient. In the context of competing risks, this adaptability ensures more accurate representation of cause-specific hazards in heterogeneous lifetime data such as blood cancer survival.
Traditionally, researchers consider the exponential, the Rayleigh, or the Weibull distribution, among others, when modeling competing risks. This study focuses on Stacy’s generalized gamma (GG) competing risks model for two main reasons. First, it is a generalization of the aforementioned models, as well as the gamma, the additive gamma, and the additive Weibull models. The two competing risks, both with different failure rates as in Stacy’s GG, cover various practical cases and might fit the available data well. Second, although the generalized gamma distribution has been widely used in reliability, frailty, and regression settings, its explicit formulation as a competing risks model with two GG cause-specific lifetimes and a detailed comparison of several frequentist estimators—particularly in the context of blood cancer survival data—has, to the best of our knowledge, not been systematically investigated. In this study, blood cancer data is utilized as an illustrative application to study the applicability of our proposed model and discover how precise the fitting of lifetimes is for patients. The choice of blood cancers is particularly pertinent, not only because of their high prevalence and increasing burden but also because the complexity of competing risks affects survival outcomes. We apply the competing risks model in this situation, aiming to provide insights that are transferable to other cancer types, supporting broader efforts in oncology.
Let denote the time-to-event datum caused by risk j, such that . If follow the Stacy’s GG distribution [21] with scale parameter and shape parameters and , where , then the probability density function (PDF) and survival function (SF) are given by
and
where is the gamma function, while is the upper incomplete gamma function, respectively. Note that this study considers only two competing risk factors (i.e., ) without loss of generality. A re-parameterized and extended logarithm of the distribution of the GG random variable was developed by [38]. Recently, a new partially linear regression based on a reparametrized generalized gamma distribution with two systematic components that can be easily interpreted was established by [36], while ref. [37] presented the flexible GG distribution with a PDF that can be expressed as an infinite linear combination of generalized gamma densities, and ref. [39] rehabilitated maximum likelihood (ML) estimation for the parameters of the GG distribution via a modified MLE to deal with computational difficulties, including, but not limited to, non-convergence or convergence to the wrong root for the normal equations.
Under the assumption that there are two unknown causes of failure (i.e., k = 2), this study aims to explore the mathematical properties of the Stacy’s GG competing risk model, compare various estimation methods through Monte Carlo simulations, and validate the model’s practical applicability by analyzing real blood cancer data. Comparing estimation methods via Monte Carlo simulation is crucial for numerically evaluating their performance under diverse finite sample and parametric settings, thereby providing a robust framework for assessing their accuracy, consistency, and efficiency. Monte Carlo simulations have become increasingly prevalent as computational technologies have advanced over the past two and a half decades; see [40,41,42,43,44,45,46,47,48] as examples of Monte Carlo simulation comparative studies, among others. In this study, seven frequentist estimation procedures are considered; namely, maximum likelihood estimators (MLEs), least squares estimators (LSEs), weighted least squares estimators (WLSEs), maximum product of spacings estimators (MPSEs), Cramér–von Mises estimators (CVMEs), Anderson–Darling estimators (ADEs), and right-tailed Anderson–Darling estimators (RADEs), assuming that these estimators exist and are unique.
The remainder of this study is organized as follows. Section 2 discusses key distributional aspects of the competing risks model, while Section 3 outlines the seven frequentist estimation procedures under consideration. Section 4 presents simulation studies that compare the performance of these estimation methods. An analysis of an actual dataset is provided to demonstrate the model’s practical applicability in Section 5. Finally, the article is concluded by a discussion and future research direction in Section 6.
2. Model Description
Consider a study or an experiment that has n objects (or subjects) and there are only two causes of failure. By the end of the study or the experiment, the researcher obtained a random sample of lifetimes; say, , such that where represents the latent failure time of the i-th item due to the jth cause of failure. If the latent failure times and are independent, and under the assumption that each follows the Stacy’s GG distributions with scale parameter and shape parameters and , , then the survival function (SF) of the Stacy’s GG competing risks model of according to (2) is given by
where is the vector of model parameters defined on a parameter space . Henceforth, the Stacy’s GG competing risks model is known by this name or is denoted by the additive generalized gamma (AGG) distribution.
2.1. Distributional Properties
The cumulative distribution function (CDF) of the AGG distribution is the complement of the SF (3), i.e.,
The probability density function (PDF) of the AGG distribution is obtained by differentiating (4) with respect to x, i.e.,
Using the CDF (4) and PDF (5), the hazard rate function (HRF) of the AGG distribution is given by
In the competing risks framework with two causes, the cause-specific hazard functions for risks are defined as
where and denote the probability density and survival functions of the jth cause, respectively, and is the overall survival function given in (3). The corresponding sub-distribution hazard for cause j can be written as
where is the cumulative distribution function of the jth cause. These expressions explicitly establish the connection between the proposed AGG formulation and standard competing risks notation.
Figure 1 shows the shape of the PDF for different values of the model parameters , while Figure 2 illustrates the behavior of the corresponding HRFs. As illustrated in the latter figure, the AGG hazard function can display increasing, decreasing, and bathtub-shaped forms depending on the values of the model parameters, which provides additional flexibility compared to standard exponential or Weibull models. The HRF is a fundamental property of life probability distributions, representing the failure rates of subjects, objects, products, or systems over time. While researchers often assume the HRF to be constant or monotonic, in practice, it can exhibit non-monotonic behavior, such as bathtub-shaped patterns, which consist of three distinct phases: early failures (infant mortality), random failures (normal life), and wear-out failures (end-of-life). For more details on bathtub-shaped HRFs, see [49]. Mathematically characterizing the HRF shapes for the AGG distribution is beyond the scope of this study and remains an open problem for future research.
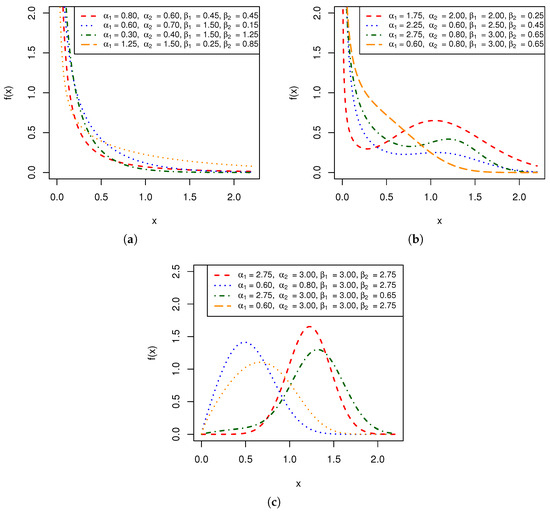
Figure 1.
Different shapes of the PDF of the AGG distribution for different values of the model parameters. (a) Decreasing. (b) Non-monotonic. (c) Unimodal.

Figure 2.
Different shapes of the HRF of the AGG distribution for different values of the model parameters. (a) Decreasing. (b) Non-monotonic bathtub-shaped. (c) Increasing.
2.2. Sub-Models
The AGG distribution is flexible since it comprises various well-known sub-models. In fact, it is a generalization for the exponential, linear-exponential, Rayleigh, Weibull, and gamma distributions. Moreover, it is a generalization of the additive gamma distribution and the additive Weibull distribution. The latter probability distribution belongs to a family of Gurvich’s generalized family of Weibull distributions [50] (see also [51,52] in this connection), and it was initially introduced by [53]. Explicit expressions for the moments and other fundamental distributional properties were considered by [54], who discussed model parameter estimation by the maximum likelihood methodology and obtained the corresponding observed information matrix, while [55] generalized the additive Weibull distribution by exponentiating its CDF, and discussed some statistical properties of the new generalization and maximum likelihood estimation for parameters. Table 1 summarizes the sub-models of the AGG distribution.

Table 1.
The sub-models of AGG distribution.
2.3. Statistical Properties
In this subsection, key statistical properties are obtained, namely, the moments and the quantiles.
2.3.1. Moments
To obtain the rth moment of the AGG distribution, one must obtain the rth moment of the GG distribution and apply the Fubini–Tonelli theorem when interchanging the order of integration and infinite summation; see [56,57] for this connection. The rth moment of the GG distribution is given by
According to [58], it is straightforward to show that
Hence,
Thus, the rth moment of the AGG distribution is given by
2.3.2. Quantiles
In the statistical literature, q-quantiles are values that split sorted data or a probability distribution into q parts. They are the general form of quartiles (), deciles (), and percentiles (). They have various applications, such as establishing a goodness-of-fit visualization device called the quantile–quantile (Q-Q) plot. Moreover, they are used to simulate random variates from the underlying probability model. The q-quantile, denoted by , is obtained by solving a nonlinear equation , such that
Since cannot be obtained directly, one can use Newton’s method [59] to solve as follows. Given an initial value , we iterate
for such that , where . For the initial value , one can consider from the physical interpretation of the survival function of the AGG distribution. Moreover, since follows the GG distribution with shape parameters and and a scale parameter , then such that follows the conventional gamma distribution with a shape parameter and a scale parameter equal to 1. Accordingly, , where is the inverse of the CDF of the classical gamma distribution with a shape parameter and a scale parameter equal to 1. Table 2 shows the solutions of assuming various values for q using Brent’s method [60] and the corresponding approximation of Newton’s method for various values of the model parameters assuming without loss of generality.
Table 2.
The q-quantiles assuming Brent’s method () and Newton’s method ().
2.3.3. The Mean Residual Lifetime
The mean residual lifetime (MRLT) is a concept in reliability and survival analyses that describes the expected remaining lifetime of a system, component, object, or species given that it has survived up to a specific time threshold. Under the assumption that the mean residual lifetime (MRLT) model for the failure time is conditioned on the failure of interest, a recent study by [61] considered a mixture regression model for competing risks data, where the logistic regression model is specified for the marginal probabilities of the failure types. Based on Equations (3) and (5), the MRLT is given by
The behavior of the MRLT can be evaluated by rewriting Equation (11) as follows:
where is the HRF (6); see [62]. Figure 3 shows the shape of the MRLT (12) for different values of the model parameters . The latter figure shows that the MRLT behaves oppositely to the HRF; for example, if the HRF is increasing, the MRLT is decreasing.
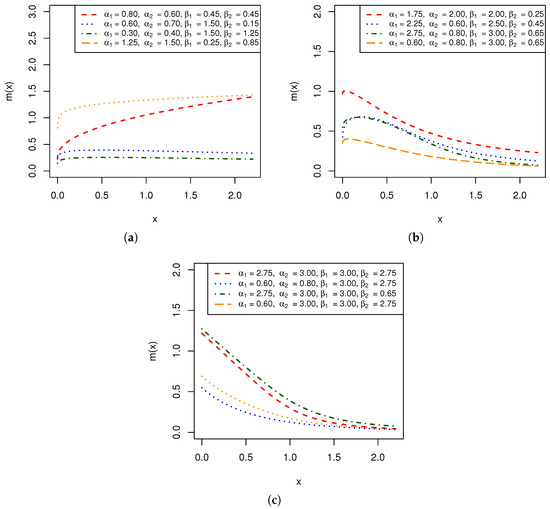
Figure 3.
Different shapes of the MRLT of the AGG distribution for different values of the model parameters. (a) Increasing. (b) Non-monotonic upside-down bathtub-shaped. (c) Decreasing.
3. Estimation Procedures
This section is dedicated to discussing seven estimation methods for the parameters of the AGG distribution. It is essential to mention that it is assumed that all estimators from these methods exist and are unique. Mathematically proving the existence and uniqueness of estimators in the case of the AGG distribution is an open problem, and it is beyond the scope of this study.
3.1. Maximum Likelihood Method
The ML estimation is a statistical inference framework in which model parameters are estimated by maximizing the log-likelihood function with respect to the unknown parameters. It is a widely used approach in many fields. Suppose that is an observed random sample of size n from the GG risk model. Also, suppose that for each i, is an indicator function which indicates that the cause of failure is the first cause, while indicates that the cause of failure is the second risk factor. Finally, assume indicates that the cause of failure is either the first cause or the second cause, but which cause leads to failure is unknown (i.e., unknown cause of failure). Hence, we are under the assumption that some causes are known, and others are unknown. Therefore, in summary, we have the following types of observations: , and . The likelihood contributions from the observations are, respectively, , and . The likelihood function is given by
such that
and
However, we consider the case where all causes of failure are unknown for this method and henceforth. Thus, the corresponding MLEs of , say, , are obtained by maximizing the following objective:
where is the log-likelihood function without the normalized constant term. and are given, respectively, by Equations (1) and (2), where . The first partial derivatives of Equation (14) with respect to and are
where and is the digamma function, respectively. The normal equations are obtained by equating these partial derivatives to 0. Since the resulting equations are nonlinear, the MLEs are obtained numerically using an appropriate optimization approach, assuming the existence and uniqueness of these estimators.
3.2. Maximum Product of Spacing Estimation
Another estimation approach based on maximization is the maximum product of spacings (MPS) framework, which yields MPS estimates (MPSEs). These estimators compete with maximum likelihood estimators (MLEs) in terms of efficiency and asymptotic performance, as demonstrated in [63,64,65,66]. However, ties complicate MPSE computation, as the conventional method cannot be applied directly. To address this issue, ref. [67] introduced a generalized maximum product of spacings method. The idea of the method is to maximize the geometric mean of the differences between the distribution function values at adjacent ordered points. Suppose that are the corresponding observed order statistics based on a random sample of size n from the AGG distribution with an arbitrary CDF with model parameters , say, , such that and . The MPSEs of , say, , are acquired by maximizing
such that
The first partial derivatives of Equation (15) with respect to the model parameters are as follows:
where
such that
and
for . Note that these expressions are frequently used in the following subsections.
3.3. Least Square Estimation
In a study by [68], LSEs were obtained for the beta distribution model parameters. Recall that is an observed random sample, and are the corresponding observed order statistics. Thus, are order statistics from a standard uniform distribution with expected values:
such that [69]. The LSEs of , say, , are obtained by minimizing the following least squares objective function:
The first partial derivatives of Equation (19) with respect to model parameters are given by
and
where and and are defined by (16)–(18).
3.4. Weighted Least Square Estimation
Alongside the LSEs, ref. [68] considered WLSEs for the beta distribution parameters. Recall that are the observed order statistics. From [69], it is known that
since are order statistics from a standard uniform distribution. The WLSEs of are computed after minimizing the objective function:
where are the weights, such that . The first partial derivatives of Equation (20) with respect to model parameters are
and
for .
3.5. Cramér–von Mises Estimation
Some estimators can be acquired under a minimum-distance framework in the statistical literature. Under this framework, the difference between an empirical distribution function and the hypothesized model distribution function is minimized. The first estimation method is per Cramér–von Mises statistic, which is used for the goodness-of-fit test. Recall that the observed order statistics of a random sample of size n with CDF , the CVMEs of , say, , are calculated by minimizing
The first partial derivative of Equation (21) with respect to model parameters, are given by
and
for .
3.6. Anderson–Darling Estimation
Another minimum-distance estimation method is the Anderson–Darling method. This approach may provide robust and efficient estimators; see [70]. Recall that the observed order statistics of a random sample of size n with CDF , the ADEs of , say, , are obtained by minimizing the following objective function:
The first partial derivative of Equation (22) with respect to model parameters are given by
and
for .
3.7. Right-Tailed Anderson–Darling Estimation
Another version of the Anderson–Darling-based estimation method is the right-tailed Anderson–Darling method. Based on the observed order statistics with CDF , the RADEs of , say, , are computed after minimizing the following objective function:
The first partial derivative of Equation (23) with respect to model parameters are given by
and
for .
In principle, MLEs and MPSEs are generally preferred because of their asymptotic efficiency. However, for complex survival models, their performance may deteriorate when the likelihood surface is flat, multimodal, or poorly conditioned, leading to convergence failures or unstable estimates, especially in small samples. Moreover, MLEs are sensitive to data contamination and outliers. To overcome these limitations, several alternative estimators are considered in this study. Minimum-distance estimators, such as ADEs, RADEs, and CVMEs, provide robustness by assigning different weights across the distribution. ADEs and RADEs emphasize the tails, which are particularly important in reliability and survival applications, whereas CVMEs offer a more balanced fit across the entire range. Although LSEs and WLSEs are not asymptotically efficient, they may yield stable results when likelihood-based estimators become unreliable. Accordingly, this study adopts a multi-method estimation strategy in which MLEs and MPSEs serve as the primary estimators, while the remaining procedures act as complementary approaches to improve robustness and ensure reliable inference under various data conditions.
4. Monte Carlo Simulation Outcomes
A comprehensive Monte Carlo simulation analysis is conducted to numerically analyze and compare the efficacy of the proposed estimators under different combinations of sample size n and different parameters values of where the parameters , and affect the shape of the distribution while the scale parameters and control the spread of data, stretching the distribution along the x-axis rather than changing its fundamental shape which is basically controlled by the parameter shape. The simulation results are categorized into two sections: the first section assesses the efficiency of estimators, while the second section focuses on goodness-of-fit analysis for each estimation method. In the simulation, the sample size is designated as ; moreover, the parameter values were set as , and with the scale parameters maintained at without loss of generality. The simulation outcomes are based on simulation iterations. All numerical results were obtained using RStudio 2024.12.1 [71], an integrated development environment (IDE) for R 4.4.3 [72], a language and environment designed for statistical computing, visualization, and analysis. Due to its versatility, R includes numerous built-in functions for optimization, in addition to a wide range of contributed packages. One such package is nloptr 2.2.1, which serves as an R interface to NLopt 2.10.0, a free and open-source library for nonlinear optimization. NLopt provides a unified interface to various freely available optimization routines, as well as original implementations of several algorithms [73]. Among these is the Bound Optimization by Quadratic Approximation (BOBYQA) algorithm [74], which demonstrated strong performance in obtaining the estimators.
Each estimation method was implemented using numerical optimization via the BOBYQA algorithm. We determine the stopping criteria when the relative change in the calculated optimized objects from one iteration to the next is less than , or when the maximum number of function evaluations is reached. The initial parameter values were obtained using uniform sampling within of the true parameters for each simulation run. For any of the seven estimation objects, if a failure to converge was detected (e.g., returning infinite values or reaching the maximum number of function evaluations), the optimization was repeated using a newly generated initial value until the convergence criteria were met. The estimation is ensured to be stable across all simulation runs due to adaptive re-initialization, resulting in negligible final non-convergence rates.
To acquire random samples from the underlying model, the following steps are implemented:
- Generate two independent random samples of size n for each cause of failure, i.e., represent a random sample from (failure #1) and form a random sample from .
- Set for all to obtain a random sample from the AGG distribution.
Using the specified simulation settings and procedures described above, 1000 random samples were generated, and the model parameters were estimated using the seven previously discussed methods. As some comparison metrics yielded disproportionately large values, min–max normalization was applied to scale all results between 0 and 1. It is important to note that lower values indicate better performance; thus, an estimation method with metrics closer to 0 is considered superior to its counterparts.
4.1. Estimation Efficiency
The root mean square error (RMSE) is a common metric for assessing the average magnitude of errors between estimated values and actual values. This evaluation is crucial for determining the performance of estimators across various statistical applications. In this study, RMSE is used to compare estimator performance under varying parameter settings. The simulated RMSE is obtained for each estimator as
where is the point estimator of on simulation run i. Table 3, Table 4 and Table 5 include the estimated RMSEs for three cases of parameters selected from simulation results. For a complete visual summary, Figure 4, Figure 5, Figure 6 and Figure 7 illustrate the efficiency of the estimation and provide numerous patterns in RMSE values related to various estimation methods in differing values of parameters and sample sizes. For clarification, Figure 4 is a heatmap that displays the simulated RMSE of the estimator across the seven estimation methods and different sample sizes for all combinations of the parameters , and ; more green is associated with lower values of RMSE. The outcomes of this part of the simulation study are discussed as follows:
Table 3.
Simulation results based on parameters .
Table 4.
Simulation results based on parameters .
Table 5.
Simulation results based on parameters .
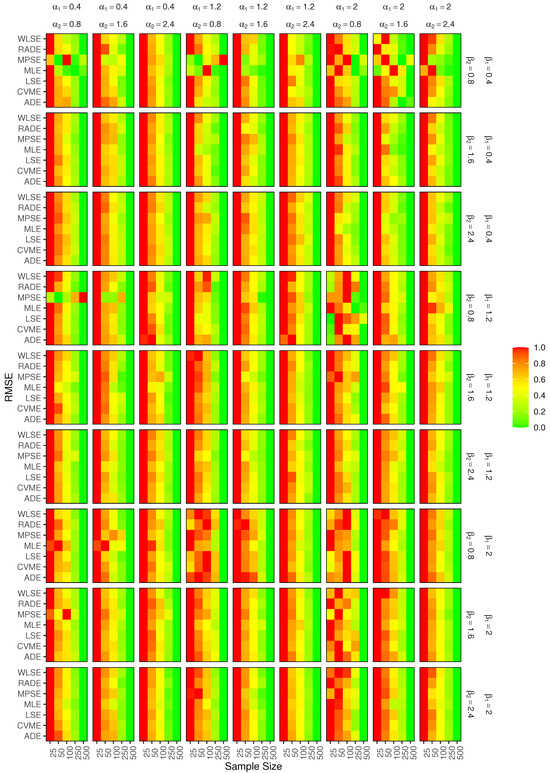
Figure 4.
RMSE of the estimators of for each estimation method and sample size. Color bars include numeric ticks; green indicates better performance (lower RMSE values), red indicates poorer accuracy (higher RMSE values).
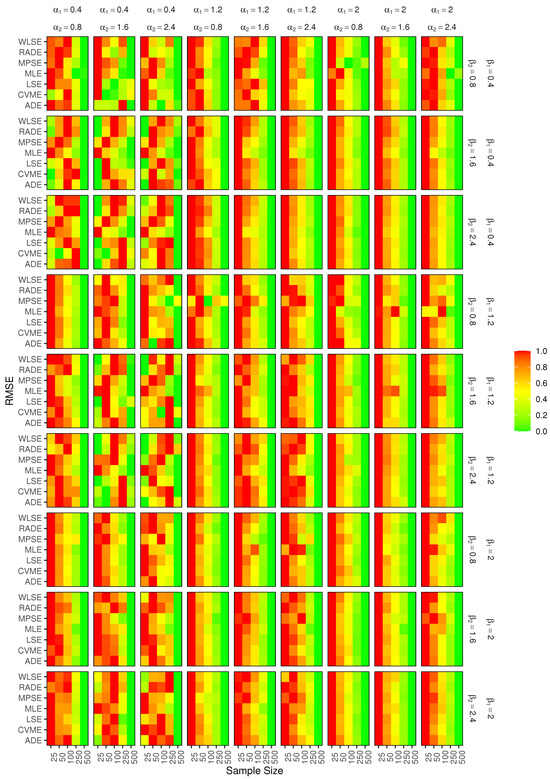
Figure 5.
RMSE of the estimators of for each estimation method and sample size. Color bars include numeric ticks; green indicates better performance (lower RMSE values), red indicates poorer accuracy (higher RMSE values).

Figure 6.
RMSE of the estimators of for each estimation method and sample size. Color bars include numeric ticks; green indicates better performance (lower RMSE values), red indicates poorer accuracy (higher RMSE values).

Figure 7.
RMSE of the estimators of for each estimation method and sample size. Color bars include numeric ticks; green indicates better performance (lower RMSE values), red indicates poorer accuracy (higher RMSE values).
- Generally, the RMSEs for the estimators of converges to 0 as the sample size increases starting from . Nonetheless, in certain instances, we observe variations. For instance, when , the RMSEs for the MPSEs initially (at ) exhibit small values, subsequently rise at moderate samples, and then decline once more.
- When exceeds 1, the RMSEs for the estimators of are minimal in large samples, indicating that the estimators are efficient, except when , where the RMSEs for LSE, WLSE, and CVME are lower (close to 0) in small samples () than in large samples () where the values substantially increase to 1. In contrast, the RMSEs for ; in the first place, MPSEs exhibit reduced efficiency in certain situations, such as , where at the RMSEs are close to 1.
- When is less than 1, the RMSEs of the estimators of diminish as the sample gets larger, starting from color red . Nevertheless, some methods yield more efficient estimators for small samples than the others. The RMSEs of the LSEs, WLSEs, CVMEs, ADEs, and RADEs are inferior to those of MLEs and MPSEs when , where at , the RMSEs are extremely close to 0.
- Generally, the RMSEs of the estimators of , which decrease with a growth in sample size (starting from , reflect the efficiency of the estimators’ performance. However, in some situations, some estimation approaches provide superior performance in small samples compared to other ones such as MPSEs in case of , and MLEs when , where RMSEs converge to 1 as sample size increases.
- When is more than 1, the estimators of show better performance with increasing sample size, regardless of the methods employed, but in most situations where is less than 1, we observe variations in the RMSE values of estimators, which are initially low at , which subsequently get higher at , and then decrease again at .
- The presence of fluctuations in RMSEs across sample sizes might be attributed to several causes, such as sampling variability, the complexity of the lifetime distribution, and the sensitivity of the estimation methods to the underlying distribution characteristics, sample size, and sample variability. Smaller samples, by coincidence, may sometimes produce estimators with unexpectedly low RMSE; for instance, the sample might resemble the population well enough. As the sample size increases, the estimation procedure might be more susceptible to the specific sample realization and fail to reflect the underlying distribution’s characteristics.
The medians of RMSEs (denoted by ) were used as robust summary measures to compare the overall performance of the estimation methods across parameters and sample sizes. As shown in Table 6, the values consistently decrease as the sample size increases, indicating improved estimation accuracy with larger samples. Among all methods, LS, CVM, AD, RAD, and WLS exhibit relatively low values across parameters, reflecting stable and reliable performance. In contrast, MPS and particularly ML estimators yield considerably higher values, especially for small and moderate sample sizes, suggesting slower or less stable convergence.
Table 6.
Overall median of RMSEs per method across all sample sizes.
Overall, estimation precision improves with sample size, leading to smaller RMSEs. However, the observed fluctuations across estimators and parameters underscore the importance of selecting estimation methods that are suited to both the parameter regime and the available sample size.
4.2. Goodness-of-Fit Analysis
This section of the simulation results presents simulation results based on two simulated goodness-of-fit metrics: the average absolute difference () between the true and estimated cumulative distribution functions (CDFs), and the maximum absolute difference () between the true and estimated CDFs, to evaluate the estimation methodologies. These metrics are defined as
and
where denotes the estimate of the model parameter based on the i-th simulation run. The statistical measures and are used to assess the accuracy of the estimation methods by quantifying the average and maximum absolute differences across all data points and simulation runs. Table 3, Table 4 and Table 5 include the estimated values of and for three cases of parameters selected from simulation results. The simulated goodness-of-fit results are presented in Figure 8 and Figure 9. Both and exhibit a decreasing trend as the sample size increases, regardless of the values of the shape parameters. Moreover, the values of and are consistent across all estimators, indicating independence from the specific values of the shape parameter. While the RMSE values may not exhibit a perfectly monotonic convergence pattern, the comparison criteria based on and indicate that all estimators achieve comparable distributional accuracy. The observed variation in parameter estimates arises because each method optimizes a different objective function. Despite these numerical differences, the resulting fitted distributions exhibit similar overall shapes and goodness-of-fit measures, confirming that the generalized gamma model adequately represents the data. Consequently, for larger sample sizes, all seven estimation procedures demonstrate reliable performance in capturing the underlying lifetime distribution.

Figure 8.
Simulated for each estimation method and sample size. Color bars include numeric ticks; green indicates a better fit (lower values), red indicates a poorer fit (higher values).

Figure 9.
Simulated for each estimation method and sample size. Color bars include numeric ticks; green indicates a better fit (lower values), red indicates a poorer fit (higher values).
5. Data Analysis
This section illustrates the AGG distribution using real data in the health field. These real data are used to investigate the suggested estimation approaches and the practical applicability of the model. In addition to the RMSE, goodness-of-fit criteria such as Kolmogorov–Smirnov (KS) statistic and the corresponding p-value are used when analyzing the data. The preferred distribution is selected based on the lowest calculated criterion alongside the highest p-value. Because of estimating the parameters and existing ties in data, the corresponding p-value is calculated based on 1000 parametric bootstrap samples (see Algorithm 1).
| Algorithm 1 Calculation of p-value |
|
The first dataset in Table 7 consists of the survival times in days of 43 patients with blood cancer obtained from the Ministry of Health Hospital in Saudi Arabia, studied by [75]. The data are transformed from days to years for computational convenience. The second dataset in Table 8 consists of survival times of 30 patients with chronic granulocytic (CG) leukemia, as cited in the National Cancer Institute [76]. Both datasets represent complete samples of uncensored survival times. No additional information was available in the original sources regarding disease subtypes, treatment protocols, or specific causes of death. Consequently, these datasets are interpreted as pure lifetime data, where the observed failures are assumed to result from either disease progression (Cause #1) or other complications (Cause #2), both of which are unknown. The summary statistics of the two datasets are obtained in Table 9. The histogram and box-plot for each dataset are shown in Figure 10.
Table 7.
Survival times in days of blood cancer data.
Table 8.
Survival times of chronic granulocytic leukemia.
Table 9.
Summary statistics for blood cancer and CG leukemia datasets.

Figure 10.
The histogram and box-plot of blood cancer and CG luekemia.
For blood cancer data, the estimated model parameters employing the seven estimation methods are listed in Table 10. The variation in RMSEs is observed across parameters within the same method, with no specific approach providing uniformly optimal estimates for all parameters. ML procedure exhibited the highest RMSE for , while performing well for , , and . MPS approach showed the greatest RMSEs for , , and . AD and RAD methods delivered close estimates as well as close RMSEs for all parameters except where their RMSEs are not the least.
Table 10.
The estimated values of the parameters with their RMSEs based on blood cancer data.
The goodness-of-fit metrics based on the observed blood cancer data are studied and the results are listed in Table 11. The quantile–quantile (Q-Q) plot between the estimated and empirical distribution functions is provided in Figure 11. Obviously, all the estimation methods yielded close test statistics KS, demonstrating a good distributional fit. The p-values for AD, RAD, and ML methods are the highest compared to others. The MCSE refers to how uncertain is because of using a finite number of simulations B. It is the standard error of “successes” that represents the number of bootstrap statistics greater than or equal to the observed statistic. The MCSEs corresponding to AD, RAD, and ML are the least, indicating their p-values are the most confident.
Table 11.
Outcomes of goodness-of-fit statistics based on blood cancer data.
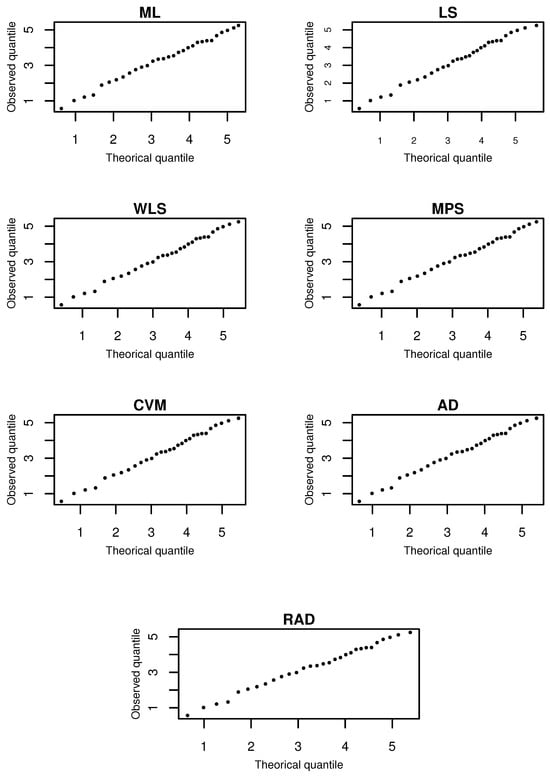
Figure 11.
The Q-Q plot of fitted models based on blood cancer data.
Based on CG leukemia data, the calculated values of the model’s parameters using the previously described approaches are listed in Table 12. The variation in estimates, as well as within the corresponding RMSEs, is obvious. The MPS method produced estimates with the highest RMSEs corresponding to and , while RMSEs of MLEs of and are the least efficient. Although there was no systemic pattern among the performance of estimates that concluded a specific approach that could provide uniformly optimal estimates for all parameters, generally, AD provided more accurate estimates according to their RMSEs, despite the RMSE of and , which provided a slight rise higher than those of RAD.
Table 12.
The estimated values of the parameters with their RMSEs based on CG leukemia.
The results of goodness-of-fit tests are shown in Table 13, while the Q-Q plot is shown in Figure 12. All methods produced adequate distributional fits according to test statistics, but AD showed outstanding performance based on the corresponding p-value and MCSE.
Table 13.
Outcomes of goodness-of-fit statistics based on CG leukemia data.
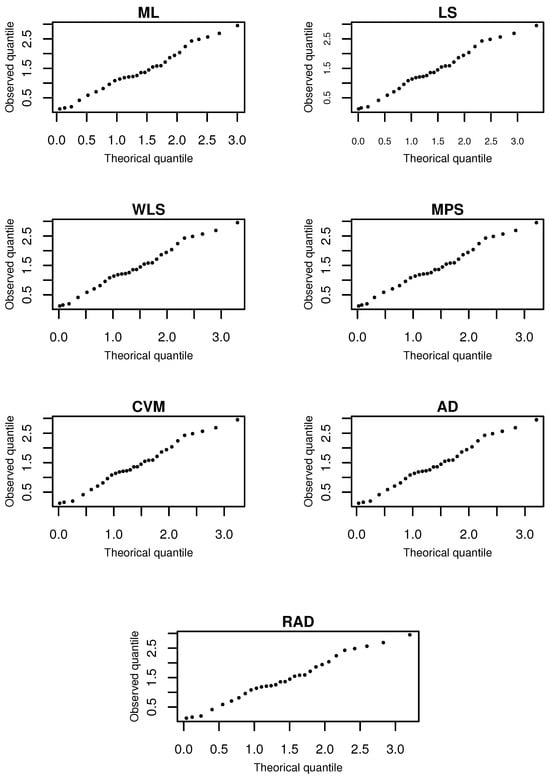
Figure 12.
The Q-Q plot of fitted models based on CG leukemia data.
The evaluations revealed that some approaches provided better parameter estimation accuracy (lower RMSE). At the same time, other methods showed superior distributional approximation (better goodness-of-fit results) as demonstrated in the first application, where ML exhibited goodness-of-fit results and the highest RMSE of . The conflict between the estimation efficiency of the parameters and the performance of the goodness-of-fit test is not a problem to be solved; it is expected, especially when dealing with complex distributions. The results demonstrated the ability of unstable parameters to produce better distributional fits and provide adaptation to limited data. Based on analysis of two datasets, AD achieved a best fit with more accurate estimates. The choice of optimal methods depends on the purpose of the analysis, whether it is parameter inference or distributional modeling. For clinical data analysis, goodness-of-fit tests are the primary recommendation since decisions depend on distributional accuracy, risk evaluation requires accurate distributional behavior, and predictive performance is more critical than parameter precision.
6. Conclusions
In this paper, a competing risks model based on Stacy’s GG distribution is proposed, considering two latent failure times with different shapes and scale parameters. The model parameters are estimated using seven methods, and a free derivative procedure is utilized to optimize the objective functions of these methods. The accuracy of estimates is evaluated through the examination of their RMSEs. The results showed fluctuations in the values of the RMSEs for all estimation approaches, indicating a non-systematic pattern across different sample sizes. The existence and uniqueness of the estimators remain analytically intractable and represent an open problem. The model complexity and potential parameter interactions may lead to flat or multimodal likelihood surfaces. Further research could explore parameter identifiability through profile likelihoods or Fisher information analysis. To assess distributional fit quality, the KS test is considered, and the results revealed that while individual parameter estimates exhibited variations across samples, the overall distributional form remains consistent.
One of the most significant challenges faced by physicians in clinical research is accurately diagnosing diseases to design effective treatment plans, while also considering the factors that interfere with patients’ lives. For the application part, two real datasets from the clinical field are used to study the applicability of the proposed competing risks model (AGG distribution). The different estimation methods yielded substantially different parameter estimates, even with the same initial values as well as RMSEs. The methods, in general, produced adequate distributional fits despite the inaccuracy of their estimates; however, based on data analysis, AD showed superior performance and an excellent fit. It is preferable to consider the method that provides a better distributional approximation, allowing for accurate capture of data patterns and reliable clinical predictions.
Author Contributions
Conceptualization, F.M.A.A.; methodology, D.A.; software, F.M.A.A. and D.A.; validation, A.M.D. and D.A.; formal analysis, D.A.; investigation, F.M.A.A.; data curation, A.M.D.; writing—original draft preparation, D.A.; writing—review and editing, F.M.A.A. and A.M.D.; visualization, D.A.; supervision, F.M.A.A. and A.M.D.; project administration, F.M.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This Project was funded by KAU Endowment (WAQF) at King Abdulaziz University, Jeddah, under grant. The authors, therefore, acknowledge with thanks WAQF and the Deanship of Scientific Research (DSR) for technical and financial support.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to thank the assistant editor and four anonymous reviewers for their helpful comments, suggestions, and recommendations, which greatly strengthened the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Loscalzo, J.; Fauci, A.S.; Kasper, D.L.; Hauser, S.; Longo, D.L. Harrison’s Principles of Internal Medicine, 21st ed.; McGraw-Hill Education: New York, NY, USA, 2022; Volumes 1 and 2. [Google Scholar]
- International Agency for Research on Cancer. Global Cancer Observatory: Cancer Today. 2018. Available online: https://gco.iarc.fr/today (accessed on 3 October 2025).
- Cox, D.R. The Analysis of Exponentially Distributed Life-Times with Two Types of Failure. J. R. Stat. Soc. Ser. B (Methodol.) 1959, 21, 411–421. [Google Scholar] [CrossRef]
- Crowder, M.J. Classical Competing Risks; Chapman and Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar] [CrossRef]
- Almarashi, A.M.; Algarni, A.; Daghistani, A.M.; Abd-Elmougod, G.A.; Abdel-Khalek, S.; Raqab, M.Z. Inferences for Joint Hybrid Progressive Censored Exponential Lifetimes under Competing Risk Model. Math. Probl. Eng. 2021, 2021, 3380467. [Google Scholar] [CrossRef]
- Davies, K.F.; Volterman, W. Progressively Type-II censored competing risks data from the linear exponential distribution. Commun. Stat.—Theory Methods 2020, 51, 1444–1460. [Google Scholar] [CrossRef]
- Nassar, M.; Alotaibi, R.; Dey, S. Estimation Based on Adaptive Progressively Censored under Competing Risks Model with Engineering Applications. Math. Probl. Eng. 2022, 2022, 6731230. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Abd-Elmougod, G.A.; Kundu, D.; Marin, M. Statistical Inference of Jointly Type-II Lifetime Samples under Weibull Competing Risks Models. Symmetry 2022, 14, 701. [Google Scholar] [CrossRef]
- Ramadan, D.A.; Almetwally, E.M.; Tolba, A.H. Statistical Inference to the Parameter of the Akshaya Distribution under Competing Risks Data with Application HIV Infection to AIDS. Ann. Data Sci. 2022, 10, 1499–1525. [Google Scholar] [CrossRef]
- Farghal, A.W.A.; Badr, S.K.; Abu-Zinadah, H.; Abd-Elmougod, G.A. Analysis of generalized inverted exponential competing risks model in presence of partially observed failure modes. Alex. Eng. J. 2023, 78, 74–87. [Google Scholar] [CrossRef]
- Elshahhat, A.; Nassar, M. Inference of improved adaptive progressively censored competing risks data for Weibull lifetime models. Stat. Pap. 2023, 65, 1163–1196. [Google Scholar] [CrossRef]
- Dutta, S.; Ng, H.K.T.; Kayal, S. Inference for Kumaraswamy-G family of distributions under unified progressive hybrid censoring with partially observed competing risks data. Stat. Neerl. 2024, 78, 719–742. [Google Scholar] [CrossRef]
- Park, C.; Wang, M. Parameter Estimation of Birnbaum-Saunders Distribution under Competing Risks Using the Quantile Variant of the Expectation-Maximization Algorithm. Mathematics 2024, 12, 1757. [Google Scholar] [CrossRef]
- Alotaibi, R.; Rezk, H.; Park, C. Parameter estimation of inverse Weibull distribution under competing risks based on the expectation–maximization algorithm. Qual. Reliab. Eng. Int. 2024, 40, 3795–3808. [Google Scholar] [CrossRef]
- Alhidairah, S.; Alam, F.M.A.; Nassar, M. A new competing risks model with applications to blood cancer data. J. Radiat. Res. Appl. Sci. 2024, 17, 101001. [Google Scholar] [CrossRef]
- Ahmed, S.M.; Abdalla, M.; Farghal, A.W.A. Statistical inference for competing risks model with Type-II generalized hybrid censored of inverse Lomax distribution with applications. Alex. Eng. J. 2025, 118, 132–146. [Google Scholar] [CrossRef]
- Alotaibi, R.; Nassar, M.; Khan, Z.A.; Alajlan, W.A.; Elshahhat, A. Analysis and data modelling of electrical appliances and radiation dose from an adaptive progressive censored XGamma competing risk model. J. Radiat. Res. Appl. Sci. 2025, 18, 101188. [Google Scholar] [CrossRef]
- Ranjan, R.; Singh, S.; Upadhyay, S.K. A Bayes analysis of a competing risk model based on gamma and exponential failures. Reliab. Eng. Syst. Saf. 2015, 144, 35–44. [Google Scholar] [CrossRef]
- Ranjan, R.; Upadhyay, S.K. Classical and Bayesian Estimation for the Parameters of a Competing Risk Model Based on Minimum of Exponential and Gamma Failures. IEEE Trans. Reliab. 2016, 65, 1522–1535. [Google Scholar] [CrossRef]
- Jayakodi, G.; Sundaram, N.; Venkatesan, P. Parametric Regression Modeling of Competing Risk Using Cardiovascular Disease Patient’s Survival Data. JP J. Biostat. 2022, 22, 25–47. [Google Scholar] [CrossRef]
- Stacy, E.W. A Generalization of the Gamma Distribution. Ann. Math. Stat. 1962, 33, 1187–1192. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Peng, Y. Generalized gamma frailty model. Stat. Med. 2006, 25, 2797–2816. [Google Scholar] [CrossRef]
- Barkauskas, D.A.; Kronewitter, S.R.; Lebrilla, C.B.; Rocke, D.M. Analysis of MALDI FT-ICR mass spectrometry data: A time series approach. Anal. Chim. Acta 2009, 648, 207–214. [Google Scholar] [CrossRef] [PubMed]
- Khakifirooz, M.; Tseng, S.T.; Fathi, M. Model Mis-Specification of Generalized Gamma Distribution for Accelerated Lifetime Censored Data. Technometrics 2020, 62, 357–370. [Google Scholar] [CrossRef]
- Chang, I.H.; Kim, B.H. Non-informative priors in the generalized gamma stress-strength systems. IIE Trans. 2011, 43, 797–804. [Google Scholar] [CrossRef]
- Ortega, E.M.M.; Bolfarine, H.; Paula, G.A. Influence diagnostics in generalized log-gamma regression models. Comput. Stat. Data Anal. 2003, 42, 165–186. [Google Scholar] [CrossRef]
- Jordanova, P.K.; Savov, M.; Tchorbadjieff, A.; Stehlík, M. Mixed Poisson process with Stacy mixing variable. arXiv 2024, arXiv:2303.10226v1. [Google Scholar] [CrossRef]
- Tahai, A.; Meyer, M.J. A Revealed Preference Study of Management Journals’ Direct Influences. Strateg. Manag. J. 1999, 20, 279–296. [Google Scholar] [CrossRef]
- van Noortwijk, J.M. Bayes Estimates of Flood Quantiles using the Generalised Gamma Distribution. In System and Bayesian Reliability; Essays in Honor of Professor Richard E. Barlow on His 70th Birthday; Hayakawa, Y., Irony, T., Xie, M., Eds.; World Scientific Publishing: Singapore, 2001; pp. 351–374. [Google Scholar]
- Shin, J.W.; Chang, J.H.; Yun, H.S.; Kim, N.S. Voice Activity Detection Based on Generalized Gamma Distribution. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Philadelphia, PA, USA, 23 March 2005; IEEE: New York, NY, USA, 2005; pp. I-781–I-784. [Google Scholar]
- Shanker, R.; Shukla, K.K. On Modeling Of Lifetime Data Using Three-Parameter Generalized Lindley and Generalized Gamma Distributions. Biom. Biostat. Int. J. 2016, 4, 283–288. [Google Scholar] [CrossRef]
- Pending, A.N. Modeling traumatic brain injury lifetime data: Improved estimators for the Generalized Gamma distribution under small samples. PLoS ONE 2019, 14, e0221332. [Google Scholar] [CrossRef]
- Zamani, H.; Shekari, M.; Pakdaman, Z. Modeling insurance data using generalized gamma regression. J. Stat. Model. Theory Appl. 2020, 1, 169–177. [Google Scholar]
- Ulusoy, I.C.; Erdik, T. Marine current energy estimation using the generalized gamma distribution: A case study for the upper layer of the Dardanelles Strait. J. Ocean. Eng. Mar. Energy 2021, 7, 481–492. [Google Scholar] [CrossRef]
- Peng, C. A New Formulation of Generalized Gamma: Some Results and Applications. ESAIM Probab. Stat. 2023, 27, 913–935. [Google Scholar] [CrossRef]
- Fidelis, C.R.; Ortega, E.M.M.; Prataviera, F.; Vila, R.; Cordeiro, G.M. Reparametrized generalized gamma partially linear regression with application to breast cancer data. J. Appl. Stat. 2024, 51, 3248–3265. [Google Scholar] [CrossRef]
- Ferreira, A.A.; Cordeiro, G.M. The Flexible Generalized Gamma Distribution with Applications to COVID-19 Data. Rev. Colomb. Estadística 2024, 47, 453–473. [Google Scholar] [CrossRef]
- Prentice, R.L. A log gamma model and its maximum likelihood estimation. Biometrika 1974, 61, 539–544. [Google Scholar] [CrossRef]
- Arslan, T.; Acitas, S.; Senoglu, B. On the maximization of the likelihood for the generalized gamma distribution: The modified maximum likelihood approach. Soft Comput. 2025, 29, 579–591. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. Generalized exponential distribution: Different method of estimations. J. Stat. Comput. Simul. 2001, 69, 315–337. [Google Scholar] [CrossRef]
- Alkasasbeh, M.R.; Raqab, M.Z. Estimation of the generalized logistic distribution parameters: Comparative study. Stat. Methodol. 2009, 6, 262–279. [Google Scholar] [CrossRef]
- Mazucheli, J.; Louzada, F.; Ghitany, M. Comparison of estimation methods for the parameters of the weighted Lindley distribution. Appl. Math. Comput. 2013, 220, 463–471. [Google Scholar] [CrossRef]
- do Espirito Santo, A.; Mazucheli, J. Comparison of estimation methods for the Marshall–Olkin extended Lindley distribution. J. Stat. Comput. Simul. 2014, 85, 3437–3450. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Alam, F.M.A. Maximum likelihood estimation of the parameters of Student’s t Birnbaum-Saunders distribution: A comparative study. Commun. Stat. Simul. Comput. 2019, 51, 793–822. [Google Scholar] [CrossRef]
- Alam, F.M.A.; Nassar, M. On Modeling Concrete Compressive Strength Data Using Laplace Birnbaum-Saunders Distribution Assuming Contaminated Information. Crystals 2021, 11, 830. [Google Scholar] [CrossRef]
- Moloy, D.J.; Ali, M.A.; Alam, F.M.A. Modeling Climate data using the Quartic Transmuted Weibull Distribution and Different Estimation Methods. Pak. J. Stat. Oper. Res. 2023, 19, 649–669. [Google Scholar] [CrossRef]
- Alosaimi, B.S.; Alam, F.M.; Baaqeel, H.M. Modeling Air Pollution Data Using a Generalized Birnbaum-Saunders Distribution with Different Estimation Procedures. In Mathematical Modeling in Physical Sciences; Springer Nature: Cham, Switzerland, 2024; pp. 587–618. [Google Scholar] [CrossRef]
- Alam, F.M.A. On Modeling X-Ray Diffraction Intensity Using Heavy-Tailed Probability Distributions: A Comparative Study. Crystals 2025, 15, 188. [Google Scholar] [CrossRef]
- Klutke, G.; Kiessler, P.; Wortman, M. A critical look at the bathtub curve. IEEE Trans. Reliab. 2003, 52, 125–129. [Google Scholar] [CrossRef]
- Gurvich, M.R.; Dibenedetto, A.T.; Ranade, S.V. A new statistical distribution for characterizing the random strength of brittle materials. J. Mater. Sci. 1997, 32, 2559–2564. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. On Some Recent Modifications of Weibull Distribution. IEEE Trans. Reliab. 2005, 54, 561–562. [Google Scholar] [CrossRef]
- Lai, C.; Xie, M.; Murthy, D. Reply to “On Some Recent Modifications of Weibull Distribution”. IEEE Trans. Reliab. 2005, 54, 563. [Google Scholar] [CrossRef]
- Xie, M.; Lai, C. Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 1996, 52, 87–93. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M.; Ortega, E.M.M. On the Additive Weibull Distribution. Commun. Stat.—Theory Methods 2014, 43, 2066–2080. [Google Scholar] [CrossRef]
- Ahmad, A.E.B.A.; Ghazal, M. Exponentiated additive Weibull distribution. Reliab. Eng. Syst. Saf. 2020, 193, 106663. [Google Scholar] [CrossRef]
- Friedman, H. A consistent Fubini-Tonelli theorem for nonmeasurable functions. Ill. J. Math. 1980, 24. [Google Scholar] [CrossRef]
- Priestley, H.A. Fubini’s Theorem and Tonelli’s Theorem. In Introduction to Integration; Oxford University Press: Oxford, UK, 1997; pp. 190–200. [Google Scholar] [CrossRef]
- Olver, F.W.J.; Olde Daalhuis, A.B.; Lozier, D.W.; Schneider, B.I.; Boisvert, R.F.; Clark, C.W.; Miller, B.R.; Saunders, B.V.; Cohl, H.S.; McClain, M.A. (Eds.) NIST Digital Library of Mathematical Functions; Release 1.2.3 of 2024-12-15. Available online: https://dlmf.nist.gov/ (accessed on 19 November 2025).
- Kelley, C.T. Solving Nonlinear Equations with Newton’s Method; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2003. [Google Scholar] [CrossRef]
- Brent, R.P. An algorithm with guaranteed convergence for finding a zero of a function. Comput. J. 1971, 14, 422–425. [Google Scholar] [CrossRef]
- Chen, C.M.; Lin, C.C.; Wu, C.C.; Tsai, J.R. Mixture mean residual life model for competing risks data with mismeasured covariates. J. Appl. Stat. 2024, 52, 1361–1380. [Google Scholar] [CrossRef]
- Watson, G.S.; Wells, W.T. On the Possibility of Improving the Mean Useful Life of Items by Eliminating Those with Short Lives. Technometrics 1961, 3, 281–298. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Maximum Product-of-Spacings Estimation with Applications to the Lognormal Distribution; Technical Report 1; Department of Mathematics, University of Wales IST: Wales, UK, 1979. [Google Scholar]
- Cheng, R.C.H.; Amin, N.A.K. Estimating Parameters in Continuous Univariate Distributions with a Shifted Origin. J. R. Stat. Soc. Ser. B Stat. Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ranneby, B. The Maximum Spacing Method. An Estimation Method Related to the Maximum Likelihood Method. Scand. J. Stat. 1984, 11, 93–112. [Google Scholar]
- Ghosh, K.; Jammalamadaka, S. A general estimation method using spacings. J. Stat. Plan. Inference 2001, 93, 71–82. [Google Scholar] [CrossRef]
- Murage, P.; Mung’atu, J.; Odero, E. Optimal Threshold Determination for the Maximum Product of Spacing Methodology with Ties for Extreme Events. Open J. Model. Simul. 2019, 07, 149–168. [Google Scholar] [CrossRef]
- Swain, J.; Venkatraman, S.; Wilson, J. Least squares estimation of distribution function in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- Boos, D.D. Minimum Distance Estimation in Nonlinear Regression. Ann. Stat. 1982, 10, 826–837. [Google Scholar]
- Posit team. RStudio: Integrated Development Environment for R; Posit Software, PBC: Boston, MA, USA, 2025. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2025. [Google Scholar]
- Johnson, S.G. The NLopt Nonlinear-Optimization Package. 2007. Available online: https://github.com/stevengj/nlopt (accessed on 22 July 2025).
- Powell, M. The BOBYQA Algorithm for Bound Constrained Optimization without Derivatives; Technical Report; Department of Applied Mathematics and Theoretical Physics, University of Cambridge: Cambridge, UK, 2009. [Google Scholar]
- Abouammoh, A.; Abdulghani, S.; Qamber, I. On partial orderings and testing of new better than renewal used classes. Reliab. Eng. Syst. Saf. 1994, 43, 37–41. [Google Scholar] [CrossRef]
- Bryson, M.C.; Siddiqui, M. Some Criteria for Aging. J. Am. Stat. Assoc. 1969, 64, 147–161. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).