Abstract
Robust algorithms have been widely used and intensively studied in the communities of engineering, statistics, and machine learning since such algorithms are less sensitive to outliers and effective in addressing the issue of non-Gaussian noise during the learning process. In this paper we study the learning performance of a distributed robust algorithm with mixing dependent samples, where big data are collected distributively and have a dependence structure. Learning rates are derived by means of an integral operator decomposition technique and probability inequalities in Hilbert spaces. The results show that with a suitable robustification parameter, the performance of the distributed robust algorithm is comparable with that of its non-distributed counterpart, even if the dependent feature restricts the availability and the effective amount of data.
MSC:
62J02
1. Introduction
Regression analysis plays an important role in the framework of supervised learning, which aims at estimating the function relations between input data and output data. The ordinary least-squares (OLS) method is widely employed for regression learning in real applications. However, when the sampling data are contaminated by high levels of noise, OLS behaves poorly since it belongs to two-moment statistical methods and cannot capture the high-moment information contained in the data. To tackle this problem, new learning methods are increasingly developed that are robust to heavy-tailed data or other potential forms of contamination. Among them, various robust loss functions are proposed to replace the least squares loss function, which can overcome the limitation of OLS caused by the characteristic of second-order statistics (see [1,2,3,4,5,6,7,8,9]). In this paper we focus on the robust loss functions of the form
induced by a windowing function and the robustification parameter Here the windowing function G is required to satisfy the following two conditions:
- For any and . In addition, .
- There exists some such that for some constant ,
Some commonly used robust loss functions fall into this category and are listed below.
- Fair loss function: , ;
- Cauchy loss function: ;
- Correntropy loss function: , ;
- Huber loss function: .
We can easily check that the windowing function G has the redescending property [4]. That is, when , the loss is convex and behaves like the least-squares loss; when the loss function tends to be concave and rapidly decreases to be flat as goes far from zero. Therefore, with a suitable chosen robustification parameter h, robust loss can completely reject gross outliers while maintaining a prediction accuracy similar to that of least-squares losses. In this work, we are interested in the application of robust loss in regression problems, linked to the data generation model given as
Here X is the input variable that takes values in a separable metric space and stands for the output variable; is the noise of the model, having a conditional mean of zero with respect to given . The main purpose of the regression problem is to estimate according to a set of sampling data generated by model (3).
Distributed learning has received considerable attention for the rapid expansion of computing capacities in the era of big data. Due to privacy concerns and communication cost, this paper studies a distributed robust algorithm with one communication round, based on the divide-and-conquer principle (DC). DC starts by using a massive data set that is stored distributively in local machines or dividing the whole data set into multiple subsets that are distributed to local machines, then takes a base algorithm to analyze the local data set, and finally averages all local estimators by only one communication to the master machine. It is thus computationally efficient by enabling parallel computing in the local learning process and can preserve data security and privacy without mutual information communications. This scheme has been developed for many classical learning algorithms, including kernel ridge regression, bias correction, minimum error entropy, and spectral algorithms, see [10,11,12,13,14,15,16,17,18].
During the data collection or assignment, the sampling data is generated from some non-trivial stochastic process with memory. In particular, when big data are collected in a temporal order, they display a dependence feature between samples. Typical examples include Monte Carlo estimation in the Markov chain, covariance matrix estimation for Markov-dependent samples, and multiarm bandit problems [19,20,21,22]. In the literature the mixing process is frequently used to model a dependence structure between samples due to its ubiquitousness in stationary stochastic processes [23,24], which will be described in the next section.
With the development of modern science and technology, data collection becomes easier and thus more big data have been obtained and stored. Besides the property of large scale, such data usually have temporal dependence characteristics, such as in economy, finance, biology, medicine, industry, agriculture, transportation, and other fields. It is thus worthy to investigate the learning ability of distributed algorithms in the mixing sampling process. Robust learning is widely employed for regression learning when the sampling data are contaminated by high levels of noise. Therefore, we shall investigate the interplay between the level of robustness, degree of dependence, partition number, and generalization ability. Our works will demonstrate that in robust learning, the distributed method with dependent sampling can obtain statistical optimality while reducing computation cost substantially.
The aim of this paper is to study the learning performance of distributed robust algorithms for mixing sequences of sampling data. Our theoretical results will be the capacity-dependent error bounds obtained by using a recently developed integral operator technique and probability inequalities in Hilbert spaces for mixing sequences. We prove that such a distributed learning scheme can obtain optimal learning rates in the regression setting if the robustification parameter is suitably chosen.
2. Main Results
In this section, we state our main results and discuss their relations to the existing works. For this purpose, we first introduce some notations and concepts.
2.1. Preliminaries and Problem Setup
Given the sequence of random variables , let be the sigma-algebra generated by the random variables . The strong mixing condition and uniform mixing condition are defined as follows.
Definition 1.
For two σ-fields and , define the α-coefficient as
and ϕ-coefficient as
A set of random sequences is said to satisfy a strongly mixing condition (or α-mixing condition) if
It satisfies a uniformly mixing condition (or ϕ-mixing condition) if
Remark 1.
When the sampling data are drawn independently, both mixing conditions hold with According to the definitions, the strongly mixing condition is weaker than the ϕ-mixing condition. Many random processes satisfy the strongly mixing condition, for example, the stationary Markov process, which is uniformly purely non-deterministic, the stationary Gaussian sequence with a continuous spectral density that is bounded away from 0, certain ARMA processes, and some aperiodic Harris recurrent Markov processes; see [25,26].
In this work, we study the robust learning algorithm under the framework of reproducing kernel Hilbert space (RKHS) [27]. Let be a Mercer kernel, that is, a continuous, symmetric, and positive semi-definite function. The RKHS associated with K is defined to be the completion of the linear span of the set of functions equipped with the inner product satisfying the reproducing property
Denote [10]. This property implies that Kernel methods provide efficient non-parametric learning algorithms for dealing with nonlinear features and RKHSs are used here as hypothesis spaces in the design of robust algorithms. Define the empirical robust risk over ,
Definition 2.
Given a sample set , the regularized robust algorithm with an RKHS in supervised learning is defined by
where λ is a regularization parameter and h is a robustification parameter.
Distributed learning considered in the paper is applied to two real situations: 1. Data are collected and stored distributively and cannot be shared with each other due to privacy or communication cost. The typical example is continuous monitoring data from hospitals. 2. The collections of data have the time-serial property and the partitioning of data is performed sequentially. The typical example is spot price data. In the following, we describe the implementation of distributed learning in the two situations.
Based on DC, the implementation of (7) with distributed learning is described as follows:
- Decompose the data sets into k disjoint subsets of equal size so that each subset has the sample size .
- Assign to the ℓ-th local machine and produce the local estimator using the base algorithm (7) performing on
- Obtain the final estimator by averaging the local estimators
When a sample set is drawn independently according to the identical distribution, it has been proven that for a broad class of algorithms, distributed learning has the same learning rates as its non-distributed counterpart as long as the local machines do not have too little training data [10,11,12,13]. When data have dependent structures, distributed regularized least-squares methods were shown in [22] to perform as well as the standard least-squares methods via attaining optimal learning rates. Their theoretical analysis is based on the characteristics of the squared losses, which cannot apply to the robust loss directly since it is not necessarily convex. Therefore, the learning performance of distributed robust algorithms under the dependency condition on the sampling data is still unknown.
2.2. Learning Rates
Throughout this paper, we assume that is a Borel probability measure on The joint measure can be decomposed into
where is the conditional distribution on for given and is the marginal distribution of on that describes the input data set . We assume the sample sequence comes from a strictly stationary process, and the dependence will be measured by the strongly mixing condition and uniformly mixing condition.
The goal of this paper is to estimate the learning error between and the target function in the -space, that is ,
We now provide some necessary assumptions with respect to an integral operator associated with the kernel K by
By the reproducing property of for any it can be expressed as
Since K is continuous, symmetric, and positive semi-definite, is a compact positive operator of trace class and is invertible for all .
Our first assumption is related to the complexity of the RKHS which can be measured by the concept effective dimension [10], that is, the trace of the operator defined as
Assumption 1.
With a parameter there exists a constant such that
Let be the eigenvalues of the operator ; then the eigenvalues of the operator are and the trace is equal to By the compactness of , we know that Hence, the above assumption is always satisfied with by taking the constant When is a finite rank space, for example, the linear space, the parameter s tends to 0. Furthermore, we assume that decays as for some ; then it is easy to check that In fact, the effective dimension is a common tool in leaning theory and spectral algorithms. It reflects the structure of the hypothesis space and establishes a connection between integral operators and spectral methods. For more details, see [21].
The second assumption is stated in terms of the regularity of the target function
Assumption 2.
For some and
Here denotes the r-th power of , and it is well defined since is compact and positive. By the definition of we know that for any , Then if it implies that lies in This assumption is called the Holder source condition [28] in inverse problems and characterizes the smoothness of the target function
In the sequel, let for simplicity and almost surely for some constant Without loss of generality, let and . Our main results can be stated as follows. Here we assume that each sub-data set has the same size for
Theorem 1.
Define by (8). Under Assumptions 1 and 2 with and if the sample data satisfies the α-mixing condition, let ,
where is a constant depending on the constants (appearing in the previous necessary assumptions), independent of (will be given in the proof).
A consequence of Theorem 1 is that the error bound for the distributed robust algorithm (8) depends on the partition number robustification parameter h, and dependence coefficients . In particular, we have the following learning rates.
Corollary 1.
Under the same conditions as Theorem 1 with , if the α-mixing coefficients satisfy with and
then for any arbitarily small
where is a constant depending on the constants (appearing in the previous necessary assumptions), independent of (will be given in the proof).
Remark 2.
It was shown in [22] that the distributed least-squares method maintains the nearly optimal learning performance for small enough provided the number of local machines k is not so large and samples are drawn according to the α-mixing process. This corollary suggests that as the robustification parameter h increases, the learning rates can improve to the best order , coinciding with the results for the least-squares methods. However, further increasing of h beyond may not help to improve the learning rate. This shows that h should keep a balance between the prediction accuracy and the degree of robustness during the training process.
For example, when is a linear space and lies in , then s goes to 0 and By Corollary 1, we deduce that the generalization error bound for the robust losses (including Huber loss) is on the order of ( is arbitrarily small) by taking h large enough and ϵ small enough.
Next, Theorem 2 concerns the error bound for the distributed robust algorithm (8) under the -mixing process.
Theorem 2.
Define by (8). Under Assumptions 1,2 with and if the sample data satisfies the ϕ-mixing condition, let
where is a constant depending on the constants (appearing in the previous necessary assumptions), independent of (will be given in the proof).
Corollary 2.
Under the same conditions as Theorem 2 with , if the ϕ-mixing coefficients satisfy with some and
then
where is a constant depending on the constants (appearing in the previous necessary assumptions), independent of (will be given in the proof).
Remark 3.
Corollaries 1 and 2 tell us that distributed robust algorithms can achieve the same learning rate as that for independent samples if the mixing coefficients are summable, which was proved in [10]. Therefore, such algorithms have advantages in dealing with the large sample size and noise models.
3. Proofs
Now we are in a position of proving the consistency results stated in Section 2. First, we will give the error decomposition of defined in algorithm (7).
3.1. Expression of
Define the empirical operator by
So for any , . Then we have the following representation for .
Lemma 1.
Proof.
Since is the minimizer of algorithm (7), we take the gradient of the regularized functional on in (7) to give
or equivalently (recall the assumption ),
which is .
The proof is completed. □
The quantity is referred to as the robust error, which is determined by the degree of robustness in the training process and can be estimated as follows. By the definition of in (7), we have that . Recall that . With the fact that for all and considering Taylor expansion,
It follows that
By (2), we see that
This in combination with the bounds (17) gives that
where .
3.2. Error Decomposition
To derive the explicit learning rate of the distributed algorithm (8), we define the regularization function in ,
where is the expected risk associated with the least-squares loss. It was proved in [29] that
so . Under Assumption 2 with ,
and
Now we state two error decompositions for . By (20), , so
and we obtain the first decomposition
Recall that , so
and we obtain the second decomposition
3.3. Estimates in Distributed Learning
In order to deal with the mixing sequences, we use the following two lemmas, which can be found in [21]. For a random variable with values in a Hilbert space and , denote if and
Lemma 2.
Let ξ and η be random variables with values in separable Hilbert space measurable σ-fields and with finite u-th and v-th moments, respectively. If with then
Lemma 3.
Let ξ and η be random variables with values in separable Hilbert space measurable σ-fields and with finite p-th and q-th moments, respectively. If with then
Next, we define some notations used in this paper.
Lemma 4.
If the sample sequence satisfies the α-mixing condition, then for any
If the sample sequence satisfies the ϕ-mixing condition, then
Proof.
When satisfies the -mixing, the estimates (28)–(32) can be found in [22]. We only consider the situation of -mixing. Define It takes values on , which is the Hilbert space of Hilbert–Schmidt operators on with the inner product . The norm is given by , where is an orthonormal basis on . is a subspace of the space of bounded linear operators on with the norm relations
It was proved in [10] that
Thus, for any we have
For any , by Lemma 3 with
In the rest, denote . Then
Note that by (38) and (39),
Putting the estimate above into (40) yields
Then the estimate (33) holds.
Now we turn to estimating (34).
where the last inequality is obtained by (41). Formula (34) can be obtained directly.
We proceed to estimating (35). Define the random variable It takes values on , and
Denote the empirical form of as . It is easy to check that and . For any , by Lemma 3 with
Following similar procedures in estimating (33) again, we can get (35).
We are in the position of estimating (36). Define . Then for any we have
due to
For any , by Lemma 3 with
Following similar procedures in estimating (33), we can get estimate (36).
For estimating (37), we define Then for any we have
For any , by Lemma 3 with
Following similar procedures in estimating (36), we can get estimate (37).
The proof is finished. □
Proposition 1.
Under Assumptions 1,2 with and we have
Proof.
We split into and First, we use the decomposition (24) and get
By the definition of , we know that for any , ; then
Then by decomposition (25), we have
Therefore, we have
where the last inequality is obtained by the Cauchy inequality. Using (48) with and putting it into the estimate above, we have
This together with (19) and (22) gives the desired conclusion. □
3.4. Proofs of the Main Results
Proof of Theorem 1.
We apply Proposition 1 to prove our main results. With the choice of , by Assumption 1, we get
Similarly, we obtain
Next, by we get
Similarly, we have
□
Proof of Corollary 1.
We shall prove it by Theorem 1. Note that with ; then there exists a constant such that . In addition, with arbitrarily small we choose large enough . By simple calculation,
where is a constant depending only on , independent of m. Note that Putting the estimates above into (10), we get
This together with (14) yields the desired conclusion by letting . □
Proof of Theorem 2.
We also apply Proposition 1 to prove our Theorem 2. With the choice of , by Assumption 1, we get
Similarly, we obtain
Next, by we get
Similarly, we have
Then,
with
and
Putting the estimates into (47) yields the desired conclusion (13).
□
Proof of Corollary 2.
Note that for some due to for . Then following similar procedures to those in the proof of Corollary 1, we get
The restriction of k implies that . Then the desired conclusion holds with .
□
4. Experimental Setup
We consider the non-parametric regression model
where the regression function is chosen as
which is infinitely smooth and therefore satisfies the regularity assumptions of our theory for any . The noise variables are generated independently as and are independent of the covariates .
To instantiate the theoretical rates in a concrete manner, we fix the smoothness, capacity, and robustness indices as
These choices correspond to a moderately smooth regression function, a kernel with effective dimension exponent , and a light-tailed noise regime compatible with the Huber loss used in the algorithm.
Given , the theoretically guided tuning parameters for distributed robust regression are set as
which agree with the convergence theory developed in this paper. All experiments employ the Gaussian kernel with bandwidth parameter and the Huber loss.
For each sample size m, we draw a training sample under the specified dependence structure and compute the distributed estimator using k machines, as described earlier. Each configuration is repeated 100 independent times. For evaluation, we generate an independent test set of size 500 and report the mean test MSE together with standard deviation. The only quantity that varies in Experiment 1 is the dependence structure of the covariates ; all other aspects of the data generating process and all tuning parameters are kept fixed to ensure a fair comparison.
The covariates follow the stationary Gaussian AR(1) model
where the dependence strength is varied by . For , the process is geometrically -mixing, and larger corresponds to slower mixing.
To obtain a process that is provably -mixing, we generate from a finite-state, irreducible, aperiodic Markov chain. Let the state space be five equally spaced points
Given a parameter , the transition matrix is defined as
That is, with probability the chain stays in its current state, and with probability it jumps uniformly to any state in . This construction is well known to yield a uniformly ergodic (hence geometrically -mixing) Markov chain, and the parameter directly controls the dependence strength: larger implies slower mixing. We consider .
4.1. Experiment 1: Effect of Dependence Strength
The sample sizes are
and all aspects of the data generating process and estimator are held fixed, except for the temporal dependence strength of the covariates . For -mixing, the strength is controlled by the AR(1) coefficient ; for -mixing, the strength is controlled by the Markov chain persistence parameter . Each configuration is repeated 100 times, and the test set contains 500 samples.
Figure 1 shows that the test MSE is monotone in the dependence parameter: smaller or produces lower error. This is consistent with the fact that stronger dependence corresponds to slower decay of the mixing coefficients, which enlarges the variance component of the risk.
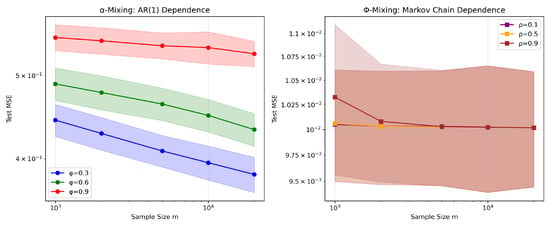
Figure 1.
Experiment 1: Effect of dependence strength under -mixing (left) and -mixing (right). Curves show the mean test MSE over 100 repetitions, and the shaded region shows standard deviation. Stronger dependence leads to larger MSE, while the nearly parallel slopes confirm the theoretical rate .
When plotted against , all curves decay almost linearly, indicating a power-law rate close to the theoretical . That is, dependence modifies only the multiplicative constant while the convergence rate remains unchanged. Although AR(1) processes and finite-state Markov chains generate different types of temporal dependence (-mixing versus -mixing), both exhibit identical qualitative behavior: stronger dependence increases the finite-sample error but does not alter the asymptotic decay rate. This supports the generality of our theory across multiple dependence frameworks.
The tuning parameters depend solely on and do not use any information about the mixing strength. The smooth decay of all curves, despite very different dependence scenarios, demonstrates the practical robustness of this theoretically motivated choice. The parallel slopes in all settings show that the proposed estimator remains stable across a wide range of temporal dependence strengths. Thus, even in moderately or strongly dependent environments, the method retains its theoretical convergence behavior and delivers reliable empirical performance.
4.2. Experiment 2: Effect of the Number of Machines
In this experiment we investigate the scalability of the proposed distributed robust regression estimator as the number of machines increases. We fix the total sample size at
and the data follow the AR(1) model with dependence level . The number of machines is varied over
According to Theorem 1, the distributed estimator remains minimax optimal only if k grows no faster than
which equals approximately under our choice and . When k exceeds this threshold, the local sample size becomes too small to guarantee the stability of the bias and variance terms.
Figure 2 exhibits a clear phase transition: the MSE remains nearly flat for and , both of which lie below the predicted upper bound. Once k exceeds , the error begins to increase and becomes unstable. This is consistent with the theoretical constraint that guarantees statistical optimality only when each local machine receives sufficiently many samples. For large values of k, each local machine receives only observations (e.g., only 500 samples when ). In this regime, the local estimators become significantly more variable, and the averaging step cannot adequately correct for the inflated variance. The resulting oscillatory behavior in the curve reflects precisely this high-variance effect.
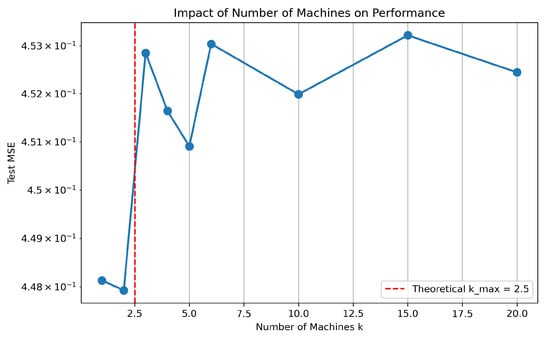
Figure 2.
Experiment 2: Test MSE as a function of the number of machines k. The red dashed line marks the theoretical upper limit . Test error remains stable up to and begins to fluctuate and increase once , in accordance with the theoretical prediction.
The experiment provides a direct empirical confirmation of the theoretical scalability bound: distributing the data across too many machines degrades performance even when the total number of samples is fixed. The fact that the degradation occurs almost exactly beyond the predicted threshold demonstrates that the bound is not merely an artifact of the analysis but accurately characterizes the practical limitation of distributed learning under dependence. The results highlight an important guideline for real-world implementations: to preserve minimax optimality, the number of computational workers must be chosen in accordance with the problem’s smoothness and marginal dimension . The experiment confirms that over-parallelization can harm statistical efficiency, especially in the presence of temporal dependence.
5. Conclusions
Non-Gaussian noise and dependent samples are two stylized features of big data. In this paper we studied the learning performance of distributed robust regression with -mixing and -mixing inputs. Our analysis provides very useful information on the application of distributed kernel-sounding algorithms. It tells us that the number of local machines and robustification parameter should be selected according to the big sample size and mixing coefficients. It is worth mentioning that the selection of the robustification parameter should balance between the learning rates and the degree of robustness.
We should point out that integral operator decompositions are mostly used to analyze ordinary least-squares methods, where the loss functions are convex and derivatives of losses have a linear structure. However, the robust losses in this work are generally not convex and their derivatives do not have linear structures, which brings about essential difficulties in the technical analysis. Therefore, we introduce the robust error term to deal with the technical difficulty caused by non-convexity features of robust algorithms. We notice that the robust error term is vital in analyzing the learning performance of robust algorithms, as shown in Theorems 1 and 2. It helps us understand the difference between robust learning and OLS and explains that robust loss can completely reject gross outliers while keeping a prediction accuracy similar to that of least-squares losses.
Author Contributions
Formal analysis, L.L.; writing—original draft, T.H.; writing—review and editing, B.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Hubei Province Key Laboratory of Systems Science in Metallurgical Process (Wuhan University of Science and Technology) (Grant No. Y202303) and the National Natural Science Foundation of China (Grant No. 12471095), the Natural Science Foundation of Hubei Province in China (Grant No. 2024AFC020), and the Fundamental Research Funds for the Central Universities, South-Central MinZu University (Grant No. CZY23010).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Feng, Y.; Wu, Q. Learning under (1+ϵ)-moment conditions. Appl. Comput. Harmon. Anal. 2020, 49, 495–520. [Google Scholar] [CrossRef]
- Ganan, S.; McClure, D. Bayesian image analysis: An application to single photon emission tomography. Amer. Statist. Assoc. 1985, 12–18. [Google Scholar]
- Hampel, F. A general definition of qualitative robustness. Ann. Math. Stat 1971, 42, 1887–1896. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 523. [Google Scholar]
- Mizera, I.; Müller, C.H. Breakdown points of Cauchy regression-scale estimators. Stat. Probab. Lett. 2002, 57, 79–89. [Google Scholar] [CrossRef]
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Sun, D.; Roth, S.; Black, M.J. Secrets of optical flow estimation and their principles. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2432–2439. [Google Scholar]
- Tukey, J.W. A survey of sampling from contaminated distributions. Contrib. Probab. Stat. 1960, 448–485. [Google Scholar]
- Wang, X.; Jiang, Y.; Huang, M.; Zhang, H. Robust variable selection with exponential squared loss. J. Am. Stat. Assoc. 2013, 108, 632–643. [Google Scholar] [CrossRef]
- Lin, S.B.; Guo, X.; Zhou, D.X. Distributed learning with regularized least squares. J. Mach. Learn. Res. 2017, 18, 1–31. [Google Scholar]
- Muckec, N.; Blanchard, G. Parallelizing spectrally regularized kernel algorithms. J. Mach. Learn. Res. 2018, 19, 1–29. [Google Scholar]
- Hu, T.; Wu, Q.; Zhou, D.X. Distributed kernel gradient descent algorithm for minimum error entropy principle. Appl. Comput. Harmon. Anal. 2020, 49, 229–256. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, L.; Wu, Q. Learning Theory of Distributed Regression with Bias Corrected Regularization Kernel Network. J. Mach. Learn. Res. 2017, 18, 1–25. [Google Scholar]
- Shi, L. Distributed learning with indefinite kernels. Anal. Appl. 2020, 17, 947–975. [Google Scholar] [CrossRef]
- Ouakrim, Y.; Boutaayamou, I.; Yazidi, Y.; Zafrar, A. Convergence analysis of an alternating direction method of multipliers for the identification of nonsmooth diffusion parameters with total variation. Inverse Probl. 2023, 39. [Google Scholar] [CrossRef]
- Liu, J.; Shi, L. Distributed learning with discretely observed functional data. Inverse Probl. 2025, 41. [Google Scholar] [CrossRef]
- Jiao, Y.; Yang, K.; Song, D. Distributed Distributionally Robust Optimization with Non-Convex Objectives. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Allouah, Y.; Guerraoui, R.; Gupta, N.; Pinot, R.; Rizk, G. Robust Distributed Learning: Tight Error Bounds and Breakdown Point under Data Heterogeneity. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Fan, J.; Liao, Y.; Liu, H. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Sun, Q.; Zhou, W.X.; Fan, J. Adaptive Huber Regression. J. Am. Stat. Assoc. 2017, 115, 254–265. [Google Scholar] [CrossRef]
- Sun, H.; Wu, Q. Regularized least square regression with dependent samples. Adv. Comput. Math. 2010, 32, 175–189. [Google Scholar] [CrossRef]
- Sun, Z.; Lin, S.B. Distributed Learning with Dependent Samples. Inf. Theory IEEE Trans. (T-IT) 2022, 68, 6003–6020. [Google Scholar] [CrossRef]
- Li, L.; Wan, C. Support Vector Machines with Beta-Mixing Input Sequences. In International Symposium on Neural Networks; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Mirzaei, E.; Maurer, A.; Kostic, V.R.; Pontil, M. An Empirical Bernstein Inequality for Dependent Data in Hilbert Spaces and Applications. In Proceedings of the 28th International Conference on Artificial Intelligence and Statistics, Mai Khao, Thailand, 3–5 May 2025. [Google Scholar]
- Agarwal, A.; Duchi, J.C. The Generalization Ability of Online Algorithms for Dependent Data. IEEE Trans. Inf. Theory 2011, 59, 573–587. [Google Scholar] [CrossRef]
- Modha, D.S.; Masry, E. Minimum complexity regression estimation with weakly dependent observations. IEEE Trans. Inf. Theory 2002, 42, 2133–2145. [Google Scholar] [CrossRef]
- Aronszajn, N. Theory of reproducing kernels. Trans. Am. Math. Soc. 1950, 68, 337–404. [Google Scholar] [CrossRef]
- Blanchard, G.; Mücke, N. Optimal Rates for Regularization of Statistical Inverse Learning Problems. Found. Comput. Math. 2016, 18, 971–1013. [Google Scholar] [CrossRef]
- Smale, S.; Zhou, D.X. Learning Theory Estimates via Integral Operators and Their Approximations. Constr. Approx. 2007, 26, 153–172. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).