Abstract
This study introduces the sine unit exponentiated half-logistic distribution, a novel extension of the unit exponentiated half-logistic distribution within the sine-G family. Using trigonometric transformations, the proposed distribution offers flexible density shapes for modeling asymmetric unit-interval data. We derive its statistical properties, including quantiles, moments, and stress–strength reliability, and estimate parameters via classical methods like maximum likelihood and Anderson–Darling. Simulations and real-world applications to fiber strength and burr datasets demonstrate the superior fit of the proposed distribution over competing models, highlighting its utility in reliability engineering and manufacturing.
Keywords:
half-logistic distributions; trigonometric distributions; stress–strength reliability; parameter estimation; data analysis MSC:
60E05; 62G05; 62N05
1. Introduction
The increasing complexity of modern datasets, characterized by diverse and asymmetric patterns, underscores the need for flexible statistical models capable of capturing intricate data structures. Traditional probability distributions often fall short in modeling dynamic or heterogeneous data, prompting the development of innovative distributions to address these challenges. This limitation has driven researchers to create adaptable models tailored to the evolving demands of real-world data. Consequently, the statistical community has focused on enhancing distribution theory to better fit complex empirical datasets.
To tackle the challenges posed by complex data, researchers have developed generated families of distributions that enhance traditional models through transformations or parameter expansions [1,2,3]. These families provide greater flexibility, enabling the modeling of heavy-tailed or skewed datasets prevalent in reliability and survival analysis [4,5]. Techniques such as modifying failure rates, density functions, or applying trigonometric transformations allow new distributions to capture underlying data patterns effectively [6,7]. Such approaches offer a robust framework for overcoming the constraints of classical distributions, paving the way for advanced statistical modeling [8].
The need to model intricate empirical data has spurred significant advancements in distribution theory, particularly for datasets exhibiting heterogeneity and asymmetry. Classical models often fail to reflect the diverse dynamics of contemporary datasets, necessitating sophisticated generated families designed through innovative transformations [9,10,11]. Notable examples include the sine-G family for trigonometric modeling [10,12,13] and exponentiated sine-G for reliability applications [14]. Half-logistic-based families have also gained prominence, such as the beta half-logistic [15], half-logistic xgamma [16], and unit-exponentiated half-logistic [17,18,19,20,21]. Further extensions include the modified half-logistic [22], gamma power half-logistic [23], and half-logistic Kies exponential [24]. Bounded-domain models, such as the odd log-logistic-G [25] and exponentiated Fréchet [26,27], enhance flexibility for unit-interval data. Reliability modeling is advanced through stress–strength analyses [28] and Kumaraswamy-G [29]. Additive models effectively capture bathtub-shaped hazard rates prevalent in reliability engineering [30,31,32,33,34,35]. These models are often combined with half-logistic distributions to enhance flexibility for asymmetric reliability data [36]. Parameter estimation techniques, including maximum likelihood and product-of-spacings methods, ensure accurate fitting of these models to empirical data [37,38,39,40,41,42]. These families collectively provide tailored solutions for complex data structures [43,44,45]. Despite these advancements, existing unit-interval distributions, such as Beta and Topp–Leone, often lack the flexibility to model asymmetric data in reliability engineering [18]. The proposed sine unit exponentiated half-logistic (SUEHL) distribution, inspired by the sine power half-logistic model [13], fills this gap by extending the unit exponentiated half-logistic (UEHL) distribution with trigonometric transformations. This two-parameter model offers diverse density shapes and robust reliability measures, including stress–strength reliability, inverse hazard rate, and mean residual life, making it a powerful tool for reliability applications [11,30].
Building on these developments, this study introduces the SUEHL distribution, a novel extension of the UEHL distribution within the sine-G family. Leveraging trigonometric transformations, the SUEHL enhances flexibility for modeling asymmetric unit-interval data, drawing inspiration from recent trigonometric models. The manuscript explores its statistical properties, estimation methods, and real-world applications, demonstrating its utility in reliability engineering and manufacturing. The subsequent sections are organized as follows: Section 2 defines the SUEHL distribution, Section 3 derives its properties, Section 4 discusses estimation, Section 5 presents simulations, Section 6 provides real-data applications, and Section 7 concludes with future directions.
2. Description of the Model
Recently, Özbilen and Genç [18] developed the UEHL distribution, grounded in the omega distribution and categorized within the proportional hazard rate model framework. The cumulative distribution function (CDF) of the UEHL distribution is defined as
with corresponding probability distribution function (PDF)
where and are the shape parameters. The UEHL distribution demonstrates multiple applications in reliability theory, leveraging the exponentiated half-logistic distribution [11,18].
In this section, a novel and flexible distribution, termed the SUEHL, is introduced by integrating the CDF of the UEHL distribution into the sine-G family framework. The CDF of the sine-G family of distributions is defined as
where is the baseline CDF of a continuous distribution and is the parameter vector of the distribution. The approach can be used to leverage the trigonometric transformation to enhance the adaptability of the baseline UEHL model. The CDF of the SUEHL distribution is obtained by substituting from Equation (1) into the sine-G family transformation in Equation (2), yielding
where are the shape parameters. The corresponding probability density function (PDF) of the SUEHL distribution is obtained by differentiating the CDF (3), given by
The SUEHL distribution exhibits remarkable flexibility in capturing various density shapes within the unit interval . Specifically, the PDF can display positively skewed, reverse J-shaped, U-shaped, or unimodal configurations, depending on the parameter values. The behaviors are illustrated in the top row in Figure 1, which visualizes the density for different parameter combinations. To visualize the behavior of the distribution in the three-dimensional case, we present the second and third rows of Figure 1 for specific parameter values while keeping the other parameter fixed. For the special case where , the PDF simplifies to a sine-transformed version of the unit half-logistic distribution, serving as a new sub-model. Also, the survival function (SF) and hazard rate function (HRF) of the SUEHL distribution are derived as
and
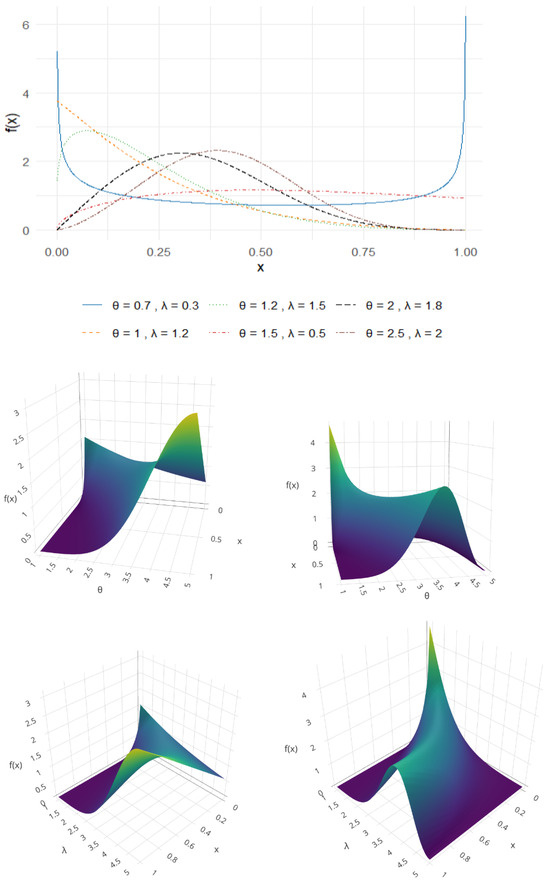
Figure 1.
SUEHL probability density function for various parameter values.
3. Some Statistical Characteristics
3.1. Quantile Function
The quantile function of a statistical distribution provides a critical tool for generating random variates and understanding the distributional properties across different probability levels. The quantile function of the SUEHL distribution is
Some numerical values of the quantiles of the proposed SUEHL model are presented in Table 1.

Table 1.
Some numerical values for the quantiles of the proposed model.
Table 1 shows that, for a fixed , increasing results in smaller quantile values, indicating a concentration of the distribution around lower values. Conversely, for a fixed , increasing shifts the quantiles to the right, suggesting a broader spread and heavier tail toward higher values.
3.2. Moments
Studying the moments of a random variable provides valuable insights into several characteristics of its distribution. In this section, we derive the series expansions for the n-th moment of the SUEHL distribution. The Taylor series expansion of the sine function, used in the derivation, is given by
Let X follow an SUEHL distribution with parameters and . The n-th moment of the random variable X is
which simplifies to
To derive the moments in Equation (8), we employ the Taylor series expansion of the sine function given in Equation (7) and substitute , which yields
Substituting and applying the binomial series expansion, the integral in Equation (9) is evaluated by
where is the beta function. This expression provides an explicit analytic form for the moments.
3.3. Reliability Analysis
This section explores the reliability properties of the SUEHL distribution, including stress–strength reliability, inverse hazard rate function (IHRF), and mean residual life (MRL), complementing the hazard rate function provided in Equation (4).
3.3.1. Stress–Strength Reliability
The stress–strength reliability model describes the operational lifespan of a component subjected to random stress and possessing random strength. Let represent the strength and the applied stress, where failure occurs if , and the component functions when . For the SUEHL distribution, we assume and with a common shape parameter . The stress–strength reliability, , is computed as
The integral in Equation (10) represents the probability that for all possible values of . To evaluate the integral, we apply series expansions
where is defined as
Substituting and using the binomial series expansion, we obtain
Thus, the stress–strength reliability is
The expression in Equation (11) facilitates computing the reliability for practical applications.
3.3.2. Inverse Hazard Rate and Mean Residual Life
To further characterize the SUEHL’s reliability, we derive the inverse hazard rate function (IHRF) and mean residual life (MRL). The IHRF is defined as , where is the PDF and is the CDF of the relevant distribution. For the SUEHL distribution, it is given by
This function characterizes the probability of immediate failure given survival up to time x, offering insights into reliability for small time increments.
The MRL function represents the expected remaining lifetime given survival past x. It is defined as
where is the survival function and is the PDF. To compute the MRL in Equation (12), we derive its series expansion using the Taylor series of the PDF’s sine term given by Equation (7). The resulting form is
where is the incomplete beta function. This series facilitates numerical evaluation and provides a practical measure for reliability applications, such as predicting component longevity in engineering systems.
3.4. Information Measures
To analyze the uncertainty associated with the SUEHL distribution, we derive the Shannon entropy and residual entropy, providing insights into its information content.
The Shannon entropy, measuring the expected uncertainty, is defined as
where is the PDF. Decomposing into five terms and using the series expansion of the sine term in Equation (7), we express the entropy as
The residual entropy, measuring uncertainty given survival past x, is defined as
where is the survival function. The corresponding series expansion is
where , , and are analogous to , , with integrals from to 1 using the incomplete beta function , and is evaluated numerically. This provides dynamic insights into the SUEHL’s uncertainty over time.
4. Estimation Methods
In this section, we explore various classical estimation techniques to estimate the parameters of the SUEHL distribution. We investigate several methods, including maximum likelihood (ML), Anderson–Darling (AD), ordinary and weighted least-squares (OLS and WLS), and Cramér–von Mises (CVM) [38,39,40], to enhance the straightforward nature of the estimation process with detailed derivations.
4.1. Maximum Likelihood Estimation
In this section, we estimate the SUEHL parameters using the maximum likelihood technique. Let be an observed sample of size n from the PDF (4). The log-likelihood function is given by
The ML estimators can be found by solving the partial differential equations corresponding to Equation (13) with respect to and :
4.2. Anderson–Darling Methods
The AD methods form a specialized class of minimum-distance estimators aimed at optimizing the fit of a distribution to empirical data. In this subsection, we derive three distinct estimators for the parameters of the SUEHL distribution: the Anderson–Darling Estimators (ADEs), Right-Tail Anderson–Darling Estimators (RTADEs), and Left-Tail Anderson–Darling Estimators (LTADEs). Let represent the order statistics of a random sample drawn from the SUEHL distribution.
The Anderson-Darling Estimators (ADEs), denoted as and , are obtained by minimizing the following function with respect to the model parameters
where is the CDF given by Equation (3), is the survival function given by Equation (5), and . Alternatively, the ADEs can be determined by solving the following nonlinear system of equations:
where the partial derivatives of the CDF are defined as
The RTADEs, denoted as and , are obtained by minimizing the function
or equivalently, by solving the nonlinear equations
where is as defined above for .
The LTADEs, denoted as and , are obtained by minimizing
or equivalently, by solving the nonlinear system
The Anderson–Darling-based estimators provide robust methods for estimating the SUEHL distribution parameters, with each method focusing on different aspects of the distribution’s fit to the observed data.
4.3. Ordinary and Weighted Least-Squares
The OLSE and WLSE estimators of the unknown parameters and of the SUEHL distribution are obtained by minimizing the following functions:
where is the CDF of the distribution given by Equation (3). Equivalently, the OLSE and and WLSE and can be obtained by solving the following equations with respect to and :
where and are defined in Equations (16) and (17).
4.4. Cramér–Von Mises
The CVM method is another type of minimum-distance estimator that aims to minimize the weighted sum of squared differences between the empirical distribution function and the theoretical CDF. Suppose are the order statistics of a random sample from the SUEHL distribution. The CVM estimators (CVMEs) and are obtained by minimizing the following function:
where is the CDF of the distribution given by Equation (3). Alternatively, the CVMEs can be determined by solving the following nonlinear equations:
where and are given in Equations (16) and (17).
5. Numerical Simulation
This section compares the performance of several estimation methods for estimating the parameters of the proposed SUEHL model. In the simulation, we utilized the SUEHL quantile function to generate random datasets for various sample sizes (). Here, we investigate the performance and behavior of the model estimators, focusing on seven classical estimation techniques: MLE, ADEs, RTADEs, LTADEs, OLS, WLS, and CVM, detailed in Section 4. We assess the performance of the estimation strategies using several metrics, including the average bias (), mean squared error (MSE = ), standard deviation (SD), and mean absolute deviation (MAD = ), where represents the parameter vector, and is the number of simulation replicates.
The simulation study considers three parameter combinations for the SUEHL distribution: , , and . These values were chosen to explore the behavior of the estimators across different shape and scale configurations of the SUEHL distribution. For each combination and sample size, we generated random samples using the quantile function (6), and applied the seven estimation methods to estimate and . The results are summarized in Table 2, Table 3 and Table 4, corresponding to the three parameter settings, respectively. Overall, ADEs and WLS consistently outperform others, particularly in small sample sizes (), exhibiting low bias, MSE, MAD, and SD across all parameter combinations, indicating more accurate and stable estimates. Conversely, LTADE performs poorly, especially with high parameter values and small samples, producing extreme errors, rendering it unsuitable for such scenarios. CVM also shows suboptimal performance in some cases, with high bias and MSE, particularly for larger parameters.
Table 2.
Simulation results for , across different sample sizes (n).
Table 3.
Simulation results for , across different sample sizes (n).
Table 4.
Simulation results for , across different sample sizes (n).
As sample size increases, error metrics across all methods decrease significantly, yielding more reliable estimates, especially for high parameter values where small-sample errors are substantial. In larger samples, MLE becomes competitive with ADEs and WLS, offering reliable results with computational simplicity. Practically, ADEs or WLS are recommended for small samples, with ADEs excelling in low bias and WLS in low variance (SD) and overall error (MSE). For large samples, MLE is a viable option. These findings highlight the critical influence of sample size and parameter magnitude on method selection, with ADEs and WLS emerging as robust choices across a wide range of scenarios. Ranking the methods based on MSE further clarifies their performance. For in Table 2, MLE and WLS consistently rank among the top for both and , particularly for larger samples (), while ADEs excel for smaller samples (). LTADEs and CVM generally rank lower, especially for . For in Table 3, MLE, ADEs, and WLS lead, with MLE dominating larger samples and ADEs smaller ones; LTADEs ranks lowest. For in Table 4, MLE and WLS perform best for larger samples, with ADEs competitive for smaller samples, while LTADEs show the weakest performance, particularly for . Overall, MLE and WLS are the most reliable across settings, followed by ADEs for smaller samples, with LTADEs consistently underperforming.
Also, the graphical representations of the simulation results given by Figure 2, Figure 3 and Figure 4 strongly support the findings presented in Table 2, Table 3 and Table 4. These figures visually depict the performance of the estimation methods across sample sizes for the parameter settings , , and , respectively. Specifically, they illustrate the trends in bias, MSE, MAD, and SD for and , highlighting how MLE and WLS achieve lower errors in larger samples, while ADEs show superior performance in smaller samples. The figures also underscore the poor performance of LTADEs, particularly for high parameter values, as evidenced by elevated error metrics, providing a clear visual complement to the tabular results.
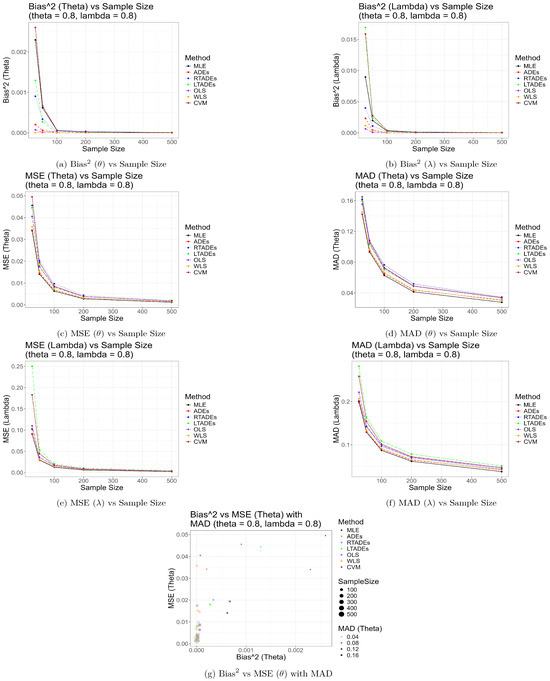
Figure 2.
Graphical representation of simulation results for , .
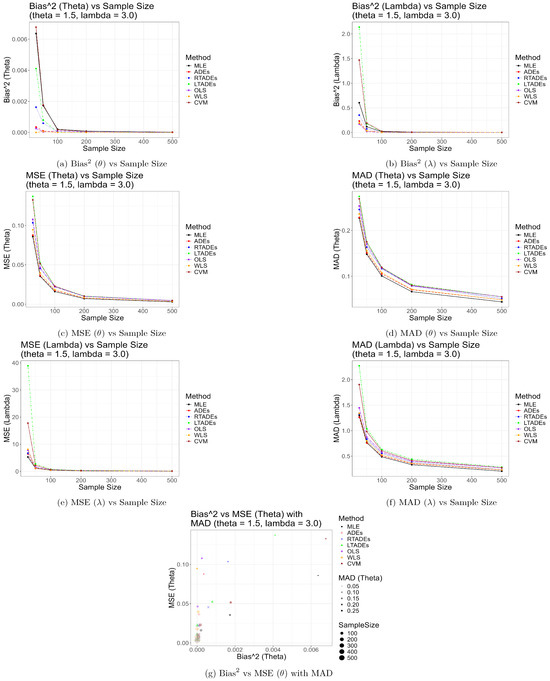
Figure 3.
Graphical representation of simulation results for , .
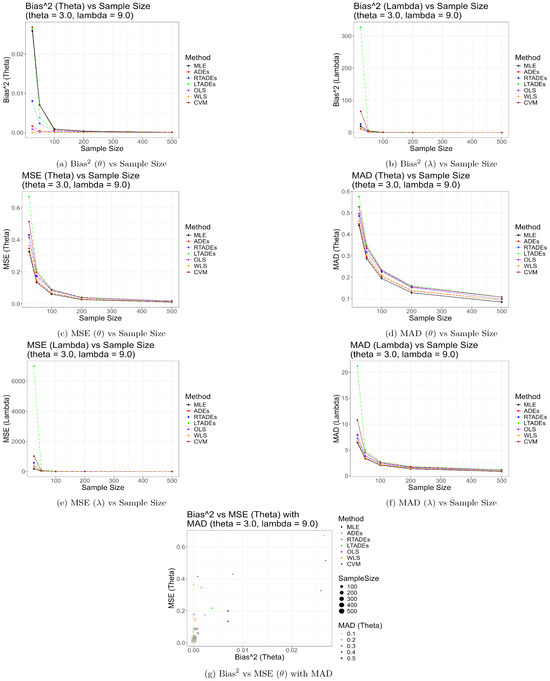
Figure 4.
Graphical representation of simulation results for , .
6. Illustration with Real Data
To evaluate the proposed SUEHL distribution, we analyzed two real datasets with distinct characteristics. The first, from Smith and Naylor [37], consists of fiber strength measurements, exhibiting asymmetric and skewed patterns ideal for testing lifetime distributions. The second, from Dasgupta [45], includes 50 observations of burr measurements with a 9 mm hole diameter and 2 mm sheet thickness, providing a manufacturing context to assess model flexibility. To provide insight into the structures of the datasets, we report their descriptive statistics in Table 5. The fiber strength dataset, scaled by 1/10 to fit the unit interval (0,1), has a mean of 0.151 and a median of 0.159, indicating slight right-skewness. The burr dataset, with a mean of 0.152 and a median of 0.160, shows moderate skewness and higher variability (standard deviation of 0.078), suitable for manufacturing applications. The parameters of the models were estimated using MLE in R (version 4.4.3) [41,42]. For the fiber dataset, the SUEHL estimates are (), and for the burr dataset, (). We compared SUEHL against the beta, UEHL, Topp–Leone, and sine-G distributions using goodness-of-fit metrics: negative twice log-likelihood (), Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Kolmogorov–Smirnov (KS), Anderson–Darling (AD), and Cramér–von Mises (CVM) statistics, with their p-values. These distributions were selected as they are bounded-domain models suitable for unit-interval data, aligning with the SUEHL’s focus on asymmetric reliability engineering applications. Table 6 and Table 7 summarize the results. For the fiber dataset, SUEHL yields the lowest (), AIC (), BIC (), KS (0.15, ), AD (1.14, ), and CVM (0.20, ). For the burr dataset, it achieves , AIC (), BIC (), KS (0.16, ), AD (1.23, ), and CVM (0.19, ). The beta and UEHL distributions are competitive but consistently outperformed, while Topp–Leone and sine-G show poor fits with high test statistics. To visually complement these results, Figure 5 illustrates the empirical cumulative distribution functions (ECDFs) of the datasets alongside the fitted SUEHL CDF, with the fiber strength dataset shown in the left graph and the burr dataset in the right graph, demonstrating the model’s strong alignment with both datasets.
Table 5.
Descriptive statistics of the fiber strength and burr datasets.
Table 6.
Goodness-of-fit results for fiber strength dataset.
Table 7.
Goodness-of-fit results for burr dataset.
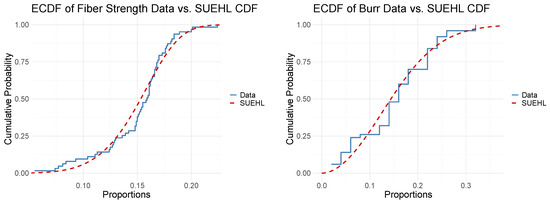
Figure 5.
Empirical CDFs of the datasets compared to the fitted SUEHL CDF, with the fiber strength dataset shown in the left graph and the burr dataset in the right graph.
These results underscore versatility of the SUEHL distribution for applications in reliability engineering and manufacturing, offering a robust two-parameter model that handles diverse, skewed datasets.
7. Conclusions
The SUEHL distribution represents a significant advancement in statistical distribution theory, addressing the need for flexible models to capture intricate patterns in modern datasets. By integrating the UEHL distribution with the sine-G family, this study introduces a versatile two-parameter model capable of accommodating diverse data shapes within the unit interval. Key findings include the comprehensive derivation of statistical properties, such as quantiles, moments, stress–strength reliability, inverse hazard rate, and mean residual life, which enhance the SUEHL’s applicability in reliability engineering. Simulation studies demonstrate the efficacy of various estimation techniques. Real data applications, compared with unit-interval distributions, confirm the SUEHL’s superior fit for the datasets, offering practical implications for decision-making in reliability engineering and manufacturing. The SUEHL’s advantages include its flexible density shapes and robust reliability measures, though its computational complexity may pose challenges for large datasets. Future studies could explore multivariate extensions of the SUEHL to model joint reliability, potentially advancing statistical analysis further. These contributions fill a critical gap in modeling asymmetric unit-interval data, providing a powerful tool for real-world applications.
Author Contributions
Conceptualization, M.G.; Methodology, M.G. and Ö.Ö.; Software, M.G.; Validation, Ö.Ö.; Writing—original draft, M.G.; Writing—review & editing, Ö.Ö.; Visualization, M.G.; Supervision, Ö.Ö. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| CDF | Cumulative Distribution Function |
| CVM | Cramér–von Mises |
| ECDF | Empirical Cumulative Distribution Function |
| MAD | Mean Absolute Deviation |
| MLE | Maximum Likelihood Estimation |
| MSE | Mean Squared Error |
| Probability Density Function | |
| SD | Standard Deviation |
| SUEHL | Sine Unit Exponentiated Half-Logistic |
| UEHL | Unit Exponentiated Half-Logistic |
| ADE | Anderson–Darling Estimator |
| OLS | Ordinary Least-Squares |
| RTADE | Right-Tail Anderson–Darling Estimator |
| LTADE | Left-Tail Anderson–Darling Estimator |
| WLS | Weighted Least-Squares |
References
- Eugene, N.; Lee, C.; Famoye, F. Beta-normal distribution and its applications. Commun. Stat. Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Famoye, F.; Lee, C. A new method for generating families of continuous distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Marshall, A.; Olkin, I. A new method for adding a parameter to a family of distributions with applications to the exponential and Weibull families. Biometrika 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Yegen, D.; Ozel, G. Marshall-Olkin half logistic distribution with theory and applications. Alphanumeric J. 2018, 6, 408–416. [Google Scholar] [CrossRef]
- Elgarhy, M.; Hassan, A.S.; Fayomi, S. Maximum likelihood and Bayesian estimation for two-parameter type I half logistic Lindley distribution. J. Comput. Theor. Nanosci. 2018, 15, 1–9. [Google Scholar] [CrossRef]
- Al-Shomrani, A.; Arif, O.; Shawky, A.; Hanif, S.; Shahbaz, M.Q. Topp-Leone family of distributions: Some properties and application. Pak. J. Stat. Oper. Res. 2016, 12, 443–451. [Google Scholar] [CrossRef]
- Hassan, A.S.; El-Sherpieny, E.A.; El-Taweel, S.A. New Topp Leone-G family with mathematical properties and applications. J. Phys. Conf. Ser. 2021, 1860, 012011. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elgarhy, M.; Haq, M.A.; Alrajhi, S. On type II half logistic Weibull distribution with applications. Math. Theory Model. 2019, 19, 49–63. [Google Scholar] [CrossRef]
- Mohammad, G.S. A new two-parameter modified half-logistic distribution: Properties and Applications. Stat. Optim. Inf. Comput. 2022, 10, 589–605. [Google Scholar] [CrossRef]
- Kumar, D.; Singh, U.; Singh, S.K. A new distribution using sine function-its application to bladder cancer patients data. J. Stat. Appl. Prob. 2015, 4, 417–427. [Google Scholar]
- Cordeiro, G.M.; Alizadeh, M.; Ortega, E.M.M. The exponentiated half logistic family of distributions: Properties and applications. J. Probab. Stat. 2014, 2014, 864396. [Google Scholar] [CrossRef]
- Mahmood, Z.; Chesneau, C.; Tahir, M.H. A new sine-G family of distributions: Properties and applications. Bull. Comput. Appl. Math. 2019, 7, 53–81. [Google Scholar]
- Hassan, A.S.; Alsadat, N.; Elgarhy, M.; Sapkota, L.P.; Balogun, O.S.; Gemeay, A.M. A novel asymmetric form of the power half-logistic distribution with statistical inference and real data analysis. Electron. Res. Arch. 2025, 33, 791–825. [Google Scholar] [CrossRef]
- Muhammad, M.; Alshanbari, H.M.; Alanzi, A.R.A.; Liu, L.; Sami, W.; Chesneau, C.; Jamal, F. A new generator of probability models: The exponentiated sine-G family for lifetime studies. Entropy 2021, 23, 1394. [Google Scholar] [CrossRef]
- Jose, J.K.; Manoharan, M. Beta half logistic distribution: A new probability model for lifetime data. J. Stat. Manag. Syst. 2016, 19, 587–604. [Google Scholar] [CrossRef]
- Bantan, R.; Hassan, A.S.; Elsehetry, M.; Kibria, B.M. Half-logistic xgamma distribution: Properties and estimation under censored samples. Discrete Dyn. Nat. Soc. 2020, 2020, 9136513. [Google Scholar] [CrossRef]
- Hassan, A.S.; Fayomi, A.; Algarni, A.; Almetwally, E.M. Bayesian and non-Bayesian inference for unit-exponentiated half-logistic distribution with data analysis. Appl. Sci. 2022, 12, 11253. [Google Scholar] [CrossRef]
- Özbilen, Ö.; Genç, A.I. A bivariate extension of the omega distribution for two-dimensional proportional data. Math. Slovaca 2022, 72, 1605–1622. [Google Scholar] [CrossRef]
- Usman, R.M.; Haq, A.M.; Talib, J. Kumaraswamy half-logistic distribution: Properties and applications. J. Stat. Appl. Prob. 2017, 6, 597–609. [Google Scholar] [CrossRef]
- Anwar, M.; Bibi, A. The half-logistic generalized Weibull distribution. J. Probab. Stat. 2018, 2018, 8767826. [Google Scholar] [CrossRef]
- Algarni, A.; Almarashi, A.M.; Elbatal, I.; Hassan, A.S.; Almetwally, E.M.; Daghistani, A.M.; Elgarhy, M. Type I half logistic Burr X-G family: Properties, Bayesian, and non-Bayesian estimation under censored samples and applications to COVID-19 data. Math. Probl. Eng. 2021, 2021, 5461130. [Google Scholar] [CrossRef]
- Hashempour, M. An extended type I half-logistic family of distributions: Properties, applications and different method of estimations. Math. Slovaca 2022, 72, 745–764. [Google Scholar] [CrossRef]
- Arshad, R.M.I.; Tahir, M.H.; Chesneau, C.; Khan, S.; Jamal, F. The gamma power half-logistic distribution: Theory and applications. Sao Paulo J. Math. Sci. 2023, 17, 1142–1169. [Google Scholar] [CrossRef]
- Alghamdi, S.M.; Shrahili, M.; Hassan, A.S.; Gemeay, A.M.; Elbatal, I.; Elgarhy, M. Statistical inference of the half logistic modified Kies exponential model with modeling to engineering data. Symmetry 2023, 15, 586. [Google Scholar] [CrossRef]
- Alizadeh, M.; MirMostafee, S.; Ortega, E.; Ramires, T.; Cordeiro, G. The odd log-logistic logarithmic generated family of distributions with applications in different areas. J. Stat. Distrib. App. 2017, 4, 1–25. [Google Scholar] [CrossRef][Green Version]
- Nadarajah, S.; Kotz, S. The exponentiated Fréchet distribution. Interstat 2003, 14, 1–7. [Google Scholar]
- Oliveira, J.; Santos, C.; Xavier, D.; Trindade, D.; Cordeiro, G.M. The McDonald half-logistic distribution: Theory and practice. Commun. Stat. Theory Methods 2016, 45, 2005–2022. [Google Scholar] [CrossRef]
- Xavier, T.; Jose, J.K. A study of stress-strength reliability using a generalization of power transformed half-logistic distribution. Commun. Stat. Theory Methods 2020, 50, 4335–4351. [Google Scholar] [CrossRef]
- Nadarajah, S.; Cordeiro, G.M.; Ortega, E.M.M. General results for the Kumaraswamy-G distribution. J. Stat. Comput. Simul. 2013, 83, 951–979. [Google Scholar] [CrossRef]
- Xavier, T.; Jose, J.K.; Nadarajah, S. An additive power-transformed half-logistic model and its applications in reliability. Qual. Reliab. Eng. Int. 2022, 38, 3179–3196. [Google Scholar] [CrossRef]
- Hjorth, U. A reliability distribution with increasing, decreasing, constant and bathtub-shaped failure rates. Technometrics 1980, 22, 99–107. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M.; Ortega, M.M.E. On the additive Weibull distribution. Commun. Stat. Theory Methods 2014, 43, 2066–2080. [Google Scholar] [CrossRef]
- Xie, M.; Lai, C.D. Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 1995, 52, 87–93. [Google Scholar] [CrossRef]
- Wang, F.K. A new model with bathtub-shaped failure rate using an additive Burr XII distribution. Reliab. Eng. Syst. Saf. 2000, 70, 305–312. [Google Scholar] [CrossRef]
- Hassan, A.H.; Elgarhy, M.; Shakil, M. Type II half logistic family of distributions with applications. Pak. J. Stat. Oper. Res. 2017, 13, 245–264. [Google Scholar] [CrossRef]
- Smith, R.L.; Naylor, J.C. A comparison of maximum likelihood and Bayesian estimators for the three-parameter Weibull distribution. Appl. Stat. 2002, 36, 358–369. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Maximum product-of-spacings estimation with applications to the log-normal distribution. Univ. Wales IST Math Rep. 1979, 79, 103. [Google Scholar]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ranneby, B. The maximum spacing method: An estimation method related to the maximum likelihood method. Scand. J. Stat. 1984, 11, 93–112. [Google Scholar]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Aarset, M.V. How to identify a bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Krishnarani, S.D. On a power transformation of half-logistic distribution. J. Probab. Stat. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Dasgupta, R. On the distribution of burr with applications. Sankhya B 2011, 73, 1–19. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).