
Population Median Estimation Using Auxiliary Variables: A Simulation Study with Real Data Across Sample Sizes and Parameters



Abstract
1. Introduction
- These improved estimators reduce bias and MSE, making median estimates more accurate and reliable. Our estimators use unique transformation techniques that include the inter-quartile range, mid-range, quartile average, quartile deviation, and robust measures (trimean and decile mean) on auxiliary variables to improve precision. This helps estimators handle data variability and enhance efficiency.
- The suggested estimators are flexible to skewed distributions and data sets with outliers, in contrast to many other estimators previously in use. Because of their flexibility, they are especially useful in domains such as environmental research, healthcare, and income analysis.
- The suggested estimators perform well with simple random sampling, which is one of the most often used sampling methods in survey research. Their usefulness across multiple areas can be improved by adapting them to diverse data distributions. This practical applicability makes them valuable tools for policymakers, researchers, and industry professionals.
- By considering additional data characteristics, such as the relationships between the target and auxiliary variable, the new estimators enhance their effectiveness in more complex survey designs, while filling a gap in the existing statistical literature. This contribution not only advances practical applications but also paves the way for future developments in the field.
2. Variables and Notation
3. Previously Proposed Estimators
4. Proposed Family of Estimators
Properties of the Proposed Estimator
5. Comparison of Estimators
6. Analysis and Discussion of Findings
6.1. Simulation Study
- Population 1: Moderate skew and spread Gamma distribution with
- Population 2: Slight skew Log-Normal distribution with
- Population 3: Heavy tails Cauchy distribution with
- Population 4: Baseline Uniform distribution with
- Population 5: High skew Exponential with
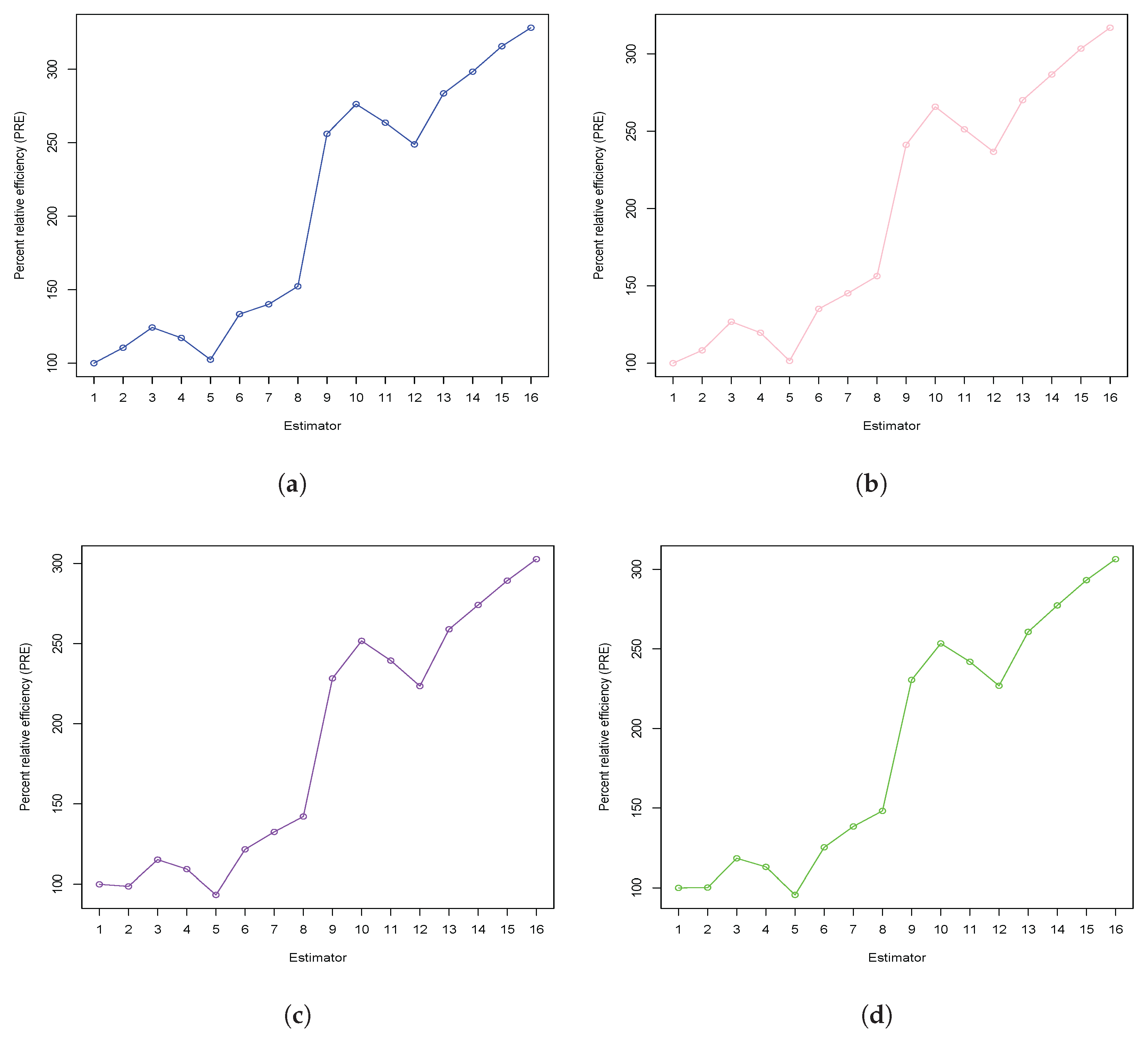
6.2. Real-Life Application
6.3. Discussion
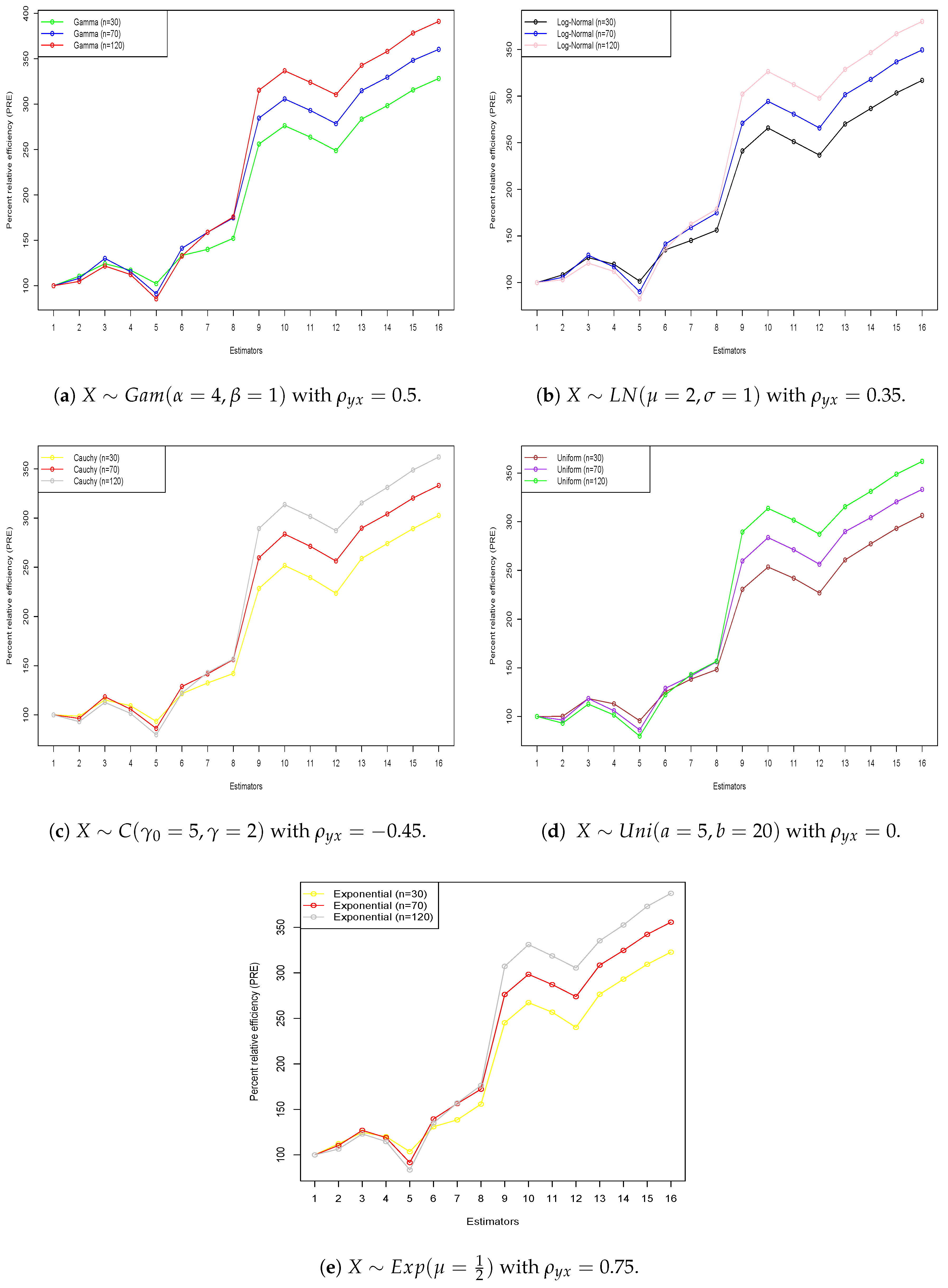
- The values for all new estimators are higher than those of the other existing estimators covered in Section 2, according to the findings of both simulated and real data sets, which are shown in Table 2, Table 3, Table 4 and Table 5. This illustrates the better performance of the newly proposed estimators over existing ones.
- Furthermore, the upward-trending graph lines in Figure 1 and Figure 2 for both five simulated distributions and four real data sets prove that all new estimators have values that are consistently greater than those of existing estimators. The inverse relationship between the values for the new estimators and the existing estimators led to the conclusion that the new family of estimators outperforms existing methods. This proves that the proposed family of estimators performs better than the other estimators, as it shows a reverse relationship between the values for the new and existing approaches.
- Based on the comprehensive simulation results and real-life data analysis presented in Table 2, Table 3, Table 4 and Table 5, the estimator consistently demonstrates the highest percent relative efficiency (PRE) among all proposed and existing estimators. Therefore, we recommend the use of in practice, especially in applications involving skewed or data affected by extreme under simple random sampling.

{kind=link}
{kind=link}
| Estimator | |||||
|---|---|---|---|---|---|
| 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 110.54 | 108.31 | 98.70 | 100.29 | 112.39 | |
| 124.37 | 126.80 | 115.21 | 118.43 | 124.80 | |
| 117.21 | 119.79 | 109.35 | 113.01 | 120.12 | |
| 102.46 | 101.57 | 93.46 | 95.68 | 103.61 | |
| 133.41 | 135.12 | 121.60 | 125.30 | 131.35 | |
| 140.10 | 145.97 | 132.50 | 138.47 | 138.55 | |
| 152.32 | 156.37 | 142.17 | 148.28 | 155.80 | |
| 256.17 | 241.29 | 228.36 | 230.54 | 245.23 | |
| 276.30 | 265.81 | 251.71 | 253.48 | 267.34 | |
| 263.73 | 251.27 | 239.49 | 241.96 | 256.88 | |
| 248.97 | 236.70 | 223.54 | 226.83 | 240.15 | |
| 283.61 | 270.10 | 258.46 | 260.77 | 276.52 | |
| 298.46 | 286.75 | 274.17 | 277.35 | 293.19 | |
| 315.70 | 303.46 | 289.33 | 293.29 | 309.45 | |
| 328.33 | 316.95 | 302.73 | 306.48 | 322.86 |
| Estimator | |||||
|---|---|---|---|---|---|
| 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 108.21 | 105.78 | 96.41 | 97.57 | 110.46 | |
| 130.15 | 129.42 | 118.41 | 120.82 | 127.41 | |
| 115.49 | 116.88 | 105.82 | 109.23 | 119.08 | |
| 91.24 | 90.37 | 86.27 | 88.38 | 91.60 | |
| 141.30 | 141.31 | 128.94 | 132.56 | 139.50 | |
| 158.98 | 158.94 | 141.75 | 147.39 | 156.48 | |
| 174.83 | 174.87 | 156.34 | 161.26 | 172.28 | |
| 284.72 | 270.95 | 259.60 | 261.86 | 276.36 | |
| 305.84 | 294.39 | 283.74 | 285.64 | 298.42 | |
| 293.14 | 280.76 | 271.28 | 272.92 | 287.15 | |
| 278.69 | 265.84 | 256.36 | 259.22 | 273.96 | |
| 314.94 | 301.55 | 289.83 | 292.31 | 308.52 | |
| 329.79 | 317.90 | 304.27 | 307.13 | 324.72 | |
| 348.39 | 336.77 | 320.41 | 323.45 | 342.33 | |
| 360.40 | 349.58 | 333.25 | 337.64 | 355.72 |
| Estimator | |||||
|---|---|---|---|---|---|
| 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| 104.81 | 103.17 | 93.120 | 95.56 | 106.50 | |
| 121.71 | 120.93 | 112.72 | 115.24 | 123.77 | |
| 112.33 | 111.97 | 101.59 | 105.70 | 114.77 | |
| 85.66 | 82.68 | 79.81 | 81.28 | 83.51 | |
| 132.79 | 136.11 | 122.30 | 127.84 | 135.13 | |
| 158.91 | 162.72 | 143.18 | 150.27 | 157.07 | |
| 175.80 | 178.90 | 156.85 | 164.76 | 176.41 | |
| 315.48 | 302.18 | 289.43 | 291.64 | 307.25 | |
| 336.86 | 326.38 | 313.78 | 316.23 | 331.14 | |
| 324.14 | 312.44 | 301.65 | 303.52 | 318.65 | |
| 310.53 | 297.81 | 287.23 | 290.16 | 305.44 | |
| 342.82 | 328.78 | 315.48 | 319.80 | 335.31 | |
| 358.27 | 346.74 | 331.29 | 335.44 | 352.61 | |
| 378.44 | 366.92 | 348.93 | 352.75 | 373.17 | |
| 391.20 | 380.18 | 362.10 | 366.54 | 387.48 |
| Estimator | Data 1 | Data 2 | Data 3 | Data 4 |
|---|---|---|---|---|
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 110.50 | 108.33 | 98.74 | 100.28 | |
| 124.33 | 126.80 | 115.23 | 118.46 | |
| 117.29 | 119.71 | 109.35 | 113.03 | |
| 102.48 | 101.52 | 93.46 | 95.64 | |
| 133.47 | 135.13 | 121.67 | 125.35 | |
| 140.16 | 145.24 | 132.58 | 138.46 | |
| 152.35 | 156.35 | 142.19 | 148.27 | |
| 256.14 | 241.26 | 228.30 | 230.58 | |
| 276.33 | 265.87 | 251.75 | 253.49 | |
| 263.72 | 251.28 | 239.44 | 241.90 | |
| 248.91 | 236.79 | 223.53 | 226.85 | |
| 283.60 | 270.12 | 258.92 | 260.74 | |
| 298.44 | 286.75 | 274.11 | 277.34 | |
| 315.77 | 303.48 | 289.36 | 293.23 | |
| 328.37 | 316.93 | 302.78 | 306.42 |
6.3.1. Limitations of the Proposed Estimator
- Dependence on auxiliary information: The performance improvements depend strongly on the availability and quality of auxiliary variables. If the auxiliary variable exhibits a weak correlation with the study variable, or if its distributional characteristics are poorly understood, the proposed estimators may not yield significant benefits.
- Computational complexity: Unlike traditional estimators such as the sample median or ratio-type estimators, the proposed estimators require more elaborate computations. These include transformation functions and the estimation of tuning parameters (such as and ), which may be less practical in time-constrained or resource-limited survey environments.
- Assumption of known robust parameters: The proposed estimators use robust statistics like the interquartile range, trimean, or decile mean, assuming that such measures are either available from prior knowledge or can be estimated accurately. In scenarios where this information is unavailable or unreliable, the estimator’s effectiveness could be limited.
6.3.2. Applicability of the Proposed Estimators in Practical Scenarios
- Skewed distributions: In surveys involving variables such as income, expenditures, or environmental indicators that typically show non-normal or skewed distributions, the proposed estimators outperform traditional alternatives by offering greater robustness.
- Presence of outliers: In data sets that contain outliers or extreme values, traditional estimators may be heavily influenced, whereas the proposed estimators, which are designed using robust transformations, continue to provide reliable median estimates.
- Moderate to strong auxiliary variable correlation: When the auxiliary variable is moderately or strongly correlated with the study variable, the proposed estimators achieve high percent relative efficiency (PRE), as supported by both simulation results and real-data applications in the manuscript.
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cochran, W.B. Sampling Techniques; John Wiley and Sons: Hoboken, NJ, USA, 1963. [Google Scholar]
- Särndal, C.E. Sample survey theory vs. general statistical theory: Estimation of the population mean. Int. Stat. Rev. Int. Stat. 1972, 40, 1–12. [Google Scholar] [CrossRef]
- Gross, S. Median estimation in sample surveys. In Proceedings of the Section on Survey Research Methods; American Statistical Association Ithaca: Alexandria, VA, USA, 1980. [Google Scholar]
- Sedransk, J.; Meyer, J. Confidence intervals for the quantiles of a finite population: Simple random and stratified simple random sampling. J. R. Stat. Soc. Ser. B 1978, 40, 239–252. [Google Scholar] [CrossRef]
- Philip, S.; Sedransk, J. Lower bounds for confidence coefficients for confidence intervals for finite population quantiles. Commun. Stat. Theory Methods 1983, 12, 1329–1344. [Google Scholar] [CrossRef]
- Kuk, Y.C.A.; Mak, T.K. Median estimation in the presence of auxiliary information. J. R. Stat. Soc. Ser. B 1989, 51, 261–269. [Google Scholar] [CrossRef]
- Rao, T.J. On certail methods of improving ration and regression estimators. Commun. Stat. Theory Methods 1991, 20, 3325–3340. [Google Scholar] [CrossRef]
- Singh, S.; Joarder, A.H.; Tracy, D.S. Median estimation using double sampling. Aust. N. Z. J. Stat. 2001, 43, 33–46. [Google Scholar] [CrossRef]
- Khoshnevisan, M.; Singh, H.P.; Singh, S.; Smarandache, F. A General Class of Estimators of Population Median Using Two Auxiliary Variables in Double Sampling; Virginia Polytechnic Institute and State University: Blacksburg, VA, USA, 2002. [Google Scholar]
- Singh, S. Advanced Sampling Theory with Applications: How Michael Selected Amy; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 2. [Google Scholar]
- Gupta, S.; Shabbir, J.; Ahmad, S. Estimation of median in two-phase sampling using two auxiliary variables. Commun. Stat. Theory Methods 2008, 37, 1815–1822. [Google Scholar] [CrossRef]
- Aladag, S.; Cingi, H. Improvement in estimating the population median in simple random sampling and stratified random sampling using auxiliary information. Commun. Stat. Theory Methods 2015, 44, 1013–1032. [Google Scholar] [CrossRef]
- Solanki, R.S.; Singh, H.P. Some classes of estimators for median estimation in survey sampling. Commun. Stat. Theory Methods 2015, 44, 1450–1465. [Google Scholar] [CrossRef]
- Daraz, U.; Khan, M. Estimation of variance of the difference-cum-ratio-type exponential estimator in simple random sampling. Res. Math. Stat. 2021, 8, 1899402. [Google Scholar] [CrossRef]
- Daraz, U.; Alomair, M.A.; Albalawi, O. Variance estimation under some transformation for both symmetric and asymmetric data. Symmetry 2024, 16, 957. [Google Scholar] [CrossRef]
- Ding, F. Least squares parameter estimation and multi-innovation least squares methods for linear fitting problems from noisy data. J. Comput. Appl. Math. 2023, 426, 115107. [Google Scholar] [CrossRef]
- Shabbir, J.; Gupta, S. A generalized class of difference type estimators for population median in survey sampling. Hacet. J. Math. Stat. 2017, 46, 1015–1028. [Google Scholar] [CrossRef]
- Irfan, M.; Maria, J.; Shongwe, S.C.; Zohaib, M.; Bhatti S., H. Estimation of population median under robust measures of an auxiliary variable. Math. Probl. Eng. 2021, 2021, 4839077. [Google Scholar] [CrossRef]
- Shabbir, J.; Gupta, S.; Narjis, G. On improved class of difference type estimators for population median in survey sampling. Commun. Stat. Theory Methods 2022, 51, 3334–3354. [Google Scholar] [CrossRef]
- Subzar, M.; Lone, S.A.; Ekpenyong, E.J.; Salam, A.; Aslam, M.; Raja, T.A.; Almutlak, S.A. Efficient class of ratio cum median estimators for estimating the population median. PLoS ONE 2023, 18, e0274690. [Google Scholar] [CrossRef] [PubMed]
- Iseh, M.J. Model formulation on efficiency for median estimation under a fixed cost in survey sampling. Model Assist. Stat. Appl. 2023, 18, 373–385. [Google Scholar] [CrossRef]
- Hussain, M.A.; Javed, M.; Zohaib, M.; Shongwe, S.C.; Awais, M.; Zaagan, A.A.; Irfan, M. Estimation of population median using bivariate auxiliary information in simple random sampling. Heliyon 2024, 10, e28891. [Google Scholar] [CrossRef]
- Almulhim, F.A.; Alghamdi, A.S. Simulation-based evaluation of robust transformation techniques for median estimation under simple random sampling. Axioms 2025, 14, 301. [Google Scholar] [CrossRef]
- Baig, A.; Masood, S.; Ahmed Tarray, T. Improved class of difference-type estimators for population median in survey sampling. Commun. Stat. Theory Methods 2019, 49, 5778–5793. [Google Scholar] [CrossRef]
- Masood, S.; Ibrar, B.; Shabbir, J.; Movaheedil, Z. Estimating neutrosophic finite median employing robust measures of the auxiliary variable. Sci. Rep. 2024, 14, 10255. [Google Scholar] [CrossRef] [PubMed]
- Daraz, U.; Alomair, M.A.; Albalawi, O.; Al Naim, A.S. New Techniques for Estimating Finite Population Variance Using Ranks of Auxiliary Variable in Two-Stage Sampling. Mathematics 2024, 12, 2741. [Google Scholar] [CrossRef]
- Alomair, M.A.; Daraz, U. Dual transformation of auxiliary variables by using outliers in stratified random sampling. Mathematics 2024, 12, 2829. [Google Scholar] [CrossRef]
- Singh, H.P.; Vishwakarma, G.K. Modified exponential ratio and product estimators for finite population mean in double sampling. Austrian J. Stat. 2007, 36, 217–225. [Google Scholar] [CrossRef]
- Murthy, M.N. Sampling Theory and Methods; Statistical Publishing Society: Calcutta, India, 1967. [Google Scholar]
- Koyuncu, K.; Kadilar, C. Family of estimators of population mean using two auxiliary variables in stratified random sampling. Commun. Stat. Theory Methods 2009, 38, 2398–2417. [Google Scholar] [CrossRef]
| Different Classes of | ||||
|---|---|---|---|---|
| 1 | ||||
| 1 | 0 | |||
| 0 | 1 | |||
| 0 | ||||
| 1 | 1 | |||
| 1 | ||||
| 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daraz, U.; Almulhim, F.A.; Alomair, M.A.; Alomair, A.M. Population Median Estimation Using Auxiliary Variables: A Simulation Study with Real Data Across Sample Sizes and Parameters. Mathematics 2025, 13, 1660. https://doi.org/10.3390/math13101660
Daraz U, Almulhim FA, Alomair MA, Alomair AM. Population Median Estimation Using Auxiliary Variables: A Simulation Study with Real Data Across Sample Sizes and Parameters. Mathematics. 2025; 13(10):1660. https://doi.org/10.3390/math13101660
Chicago/Turabian StyleDaraz, Umer, Fatimah A. Almulhim, Mohammed Ahmed Alomair, and Abdullah Mohammed Alomair. 2025. "Population Median Estimation Using Auxiliary Variables: A Simulation Study with Real Data Across Sample Sizes and Parameters" Mathematics 13, no. 10: 1660. https://doi.org/10.3390/math13101660
APA StyleDaraz, U., Almulhim, F. A., Alomair, M. A., & Alomair, A. M. (2025). Population Median Estimation Using Auxiliary Variables: A Simulation Study with Real Data Across Sample Sizes and Parameters. Mathematics, 13(10), 1660. https://doi.org/10.3390/math13101660