
Brain-Inspired Agents for Quantum Reinforcement Learning



Abstract
1. Introduction
2. Background
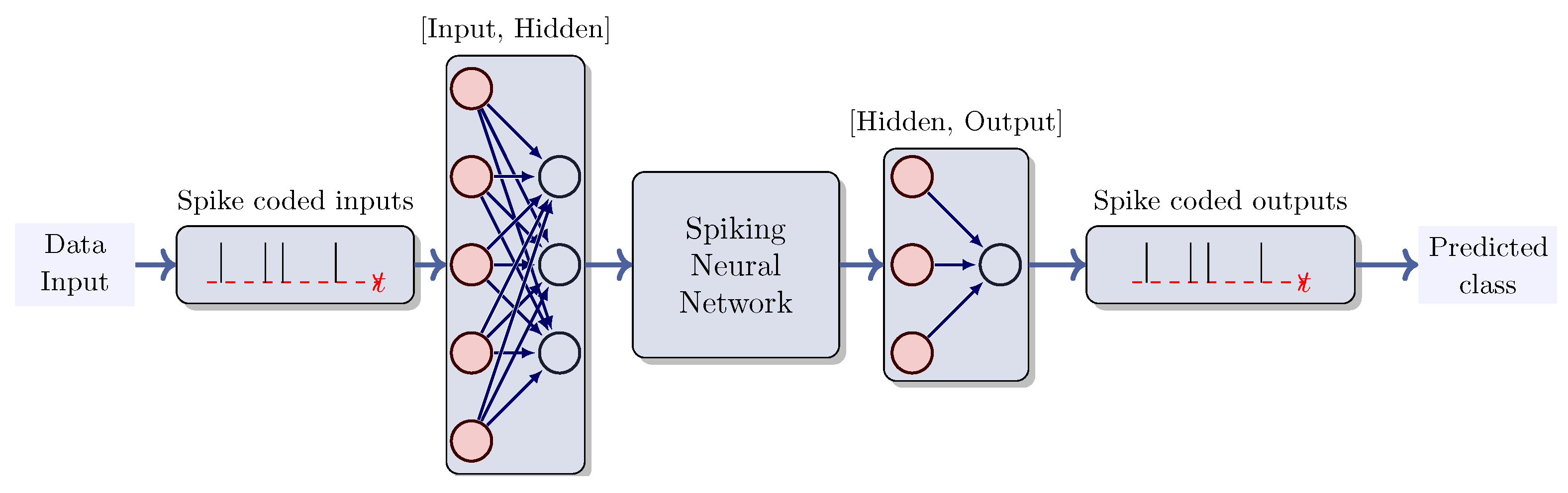
2.1. Spiking Neural Networks
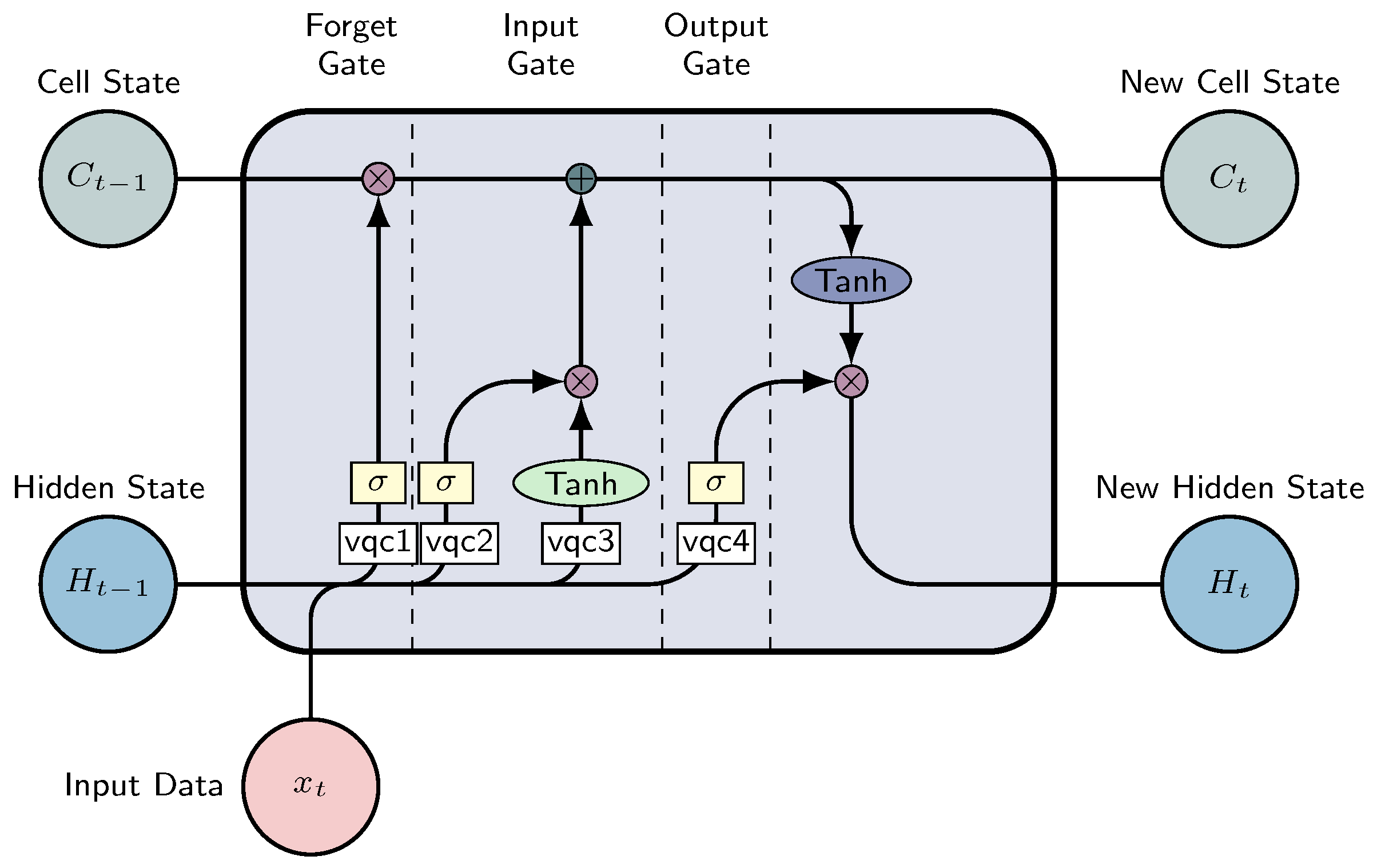
2.2. Long Short-Term Memory
- Cell state: The network’s current long-term memory;
- Hidden state: The output from the preceding time step;
- The input data in the present time step.
- Forget gate: This gate decides what information from the cell state is important, considering both the previous hidden state and the new input data. The neural network that implements this gate is built to produce an output closer to 0 when the input data are considered unimportant, and closer to 1 otherwise. To achieve this, we employ the sigmoid activation function. The output values from this gate are then passed upwards and undergo pointwise multiplication with the previous cell state. This pointwise multiplication implies that components of the cell state identified as insignificant by the forget gate network will be multiplied by a value approaching 0, resulting in a reduced influence on subsequent steps.To summarize, the forget gate determines what portions of the long-term memory should be disregarded (given less weight) based on the previous hidden state and the new input data;
- Input gate: Determines the integration of new information into the network’s long-term memory (cell state), considering the prior hidden state and incoming data. The same inputs are utilized, but now with the introduction of a hyperbolic tangent as the activation function. This hyperbolic tangent has learned to blend the previous hidden state with the incoming data, resulting in a newly updated memory vector. Essentially, this vector encapsulates information from the new input data within the context of the previous hidden state. It informs us about the extent to which each component of the network’s long-term memory (cell state) should be updated based on the new information.It should be noted that the utilization of the hyperbolic tangent function in this context is deliberate, owing to its output range confined to [−1, 1]. The inclusion of negative values is imperative for this methodology, as it facilitates the attenuation of the impact associated with specific components;
- Output gate: The objective of this gate is to decide the new hidden state by incorporating the newly updated cell state, the prior hidden state, and the new input data. This hidden state has to contain the necessary information while avoiding the inclusion of all learned data. To achieve this, we employ the sigmoid function.
- The initial step involves determining what information to discard or preserve at the given moment in time. This process is facilitated by the utilization of the sigmoid function. It examines both the preceding state and the present input , computing the function accordingly:where and and are weights and biases;
- In this step, the memory cell content undergoes an update by choosing new information for storage within the cell state. The subsequent layer, known as the input gate, comprises the following two components: the sigmoid function and the hyperbolic tangent (tanh). The sigmoid layer decides which values to update; a value of 1, indicates no change, while a value of 0 results in exclusion. Subsequently, a tanh layer generates a vector of new candidate values, assigning weights to each value based on its significance within the range from −1 to 1. These two components are then combined to update the state:
- The third step consists of updating the previous cell state, with the new cell state, , through the following two operations: forgetting irrelevant information by scaling the previous state by and incorporating new information from the candidate :
- Ultimately, the output is calculated through a two-step process. Initially, a sigmoid layer is employed to determine what aspects of the cell state are pertinent for transmission to the output.Subsequently, the cell state undergoes processing via the tanh layer to normalize values between −1 and 1, followed by multiplication with the output of the sigmoid gate.
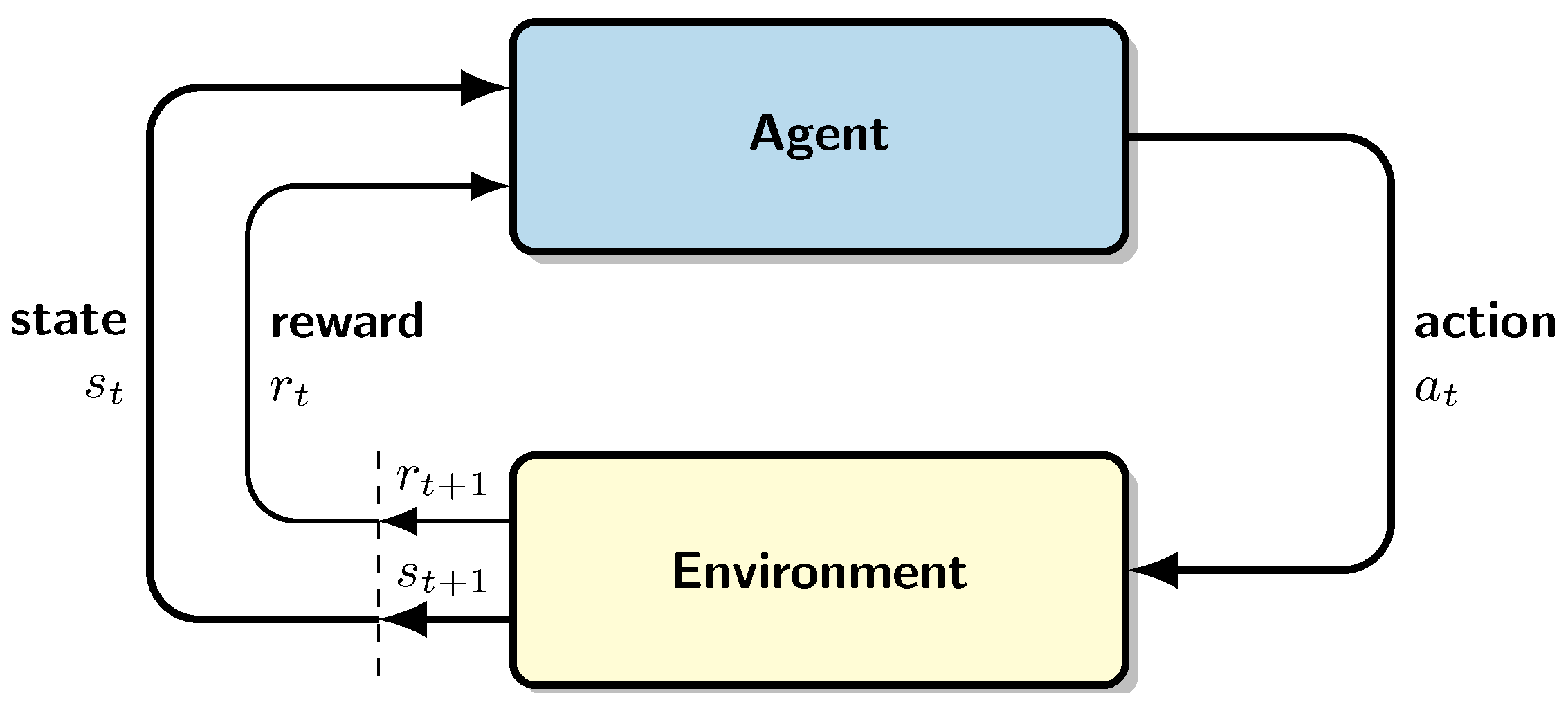
2.3. Deep Reinforcement Learning
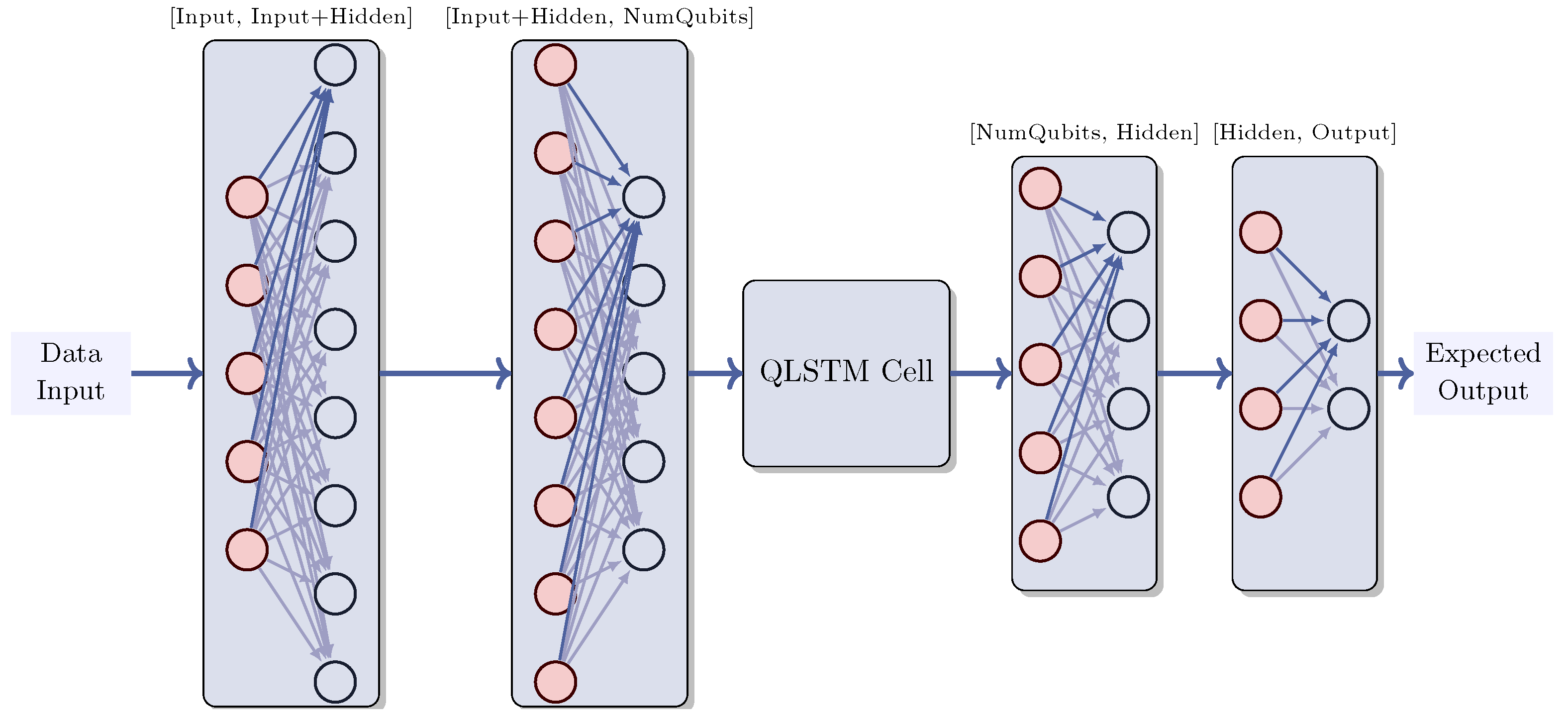
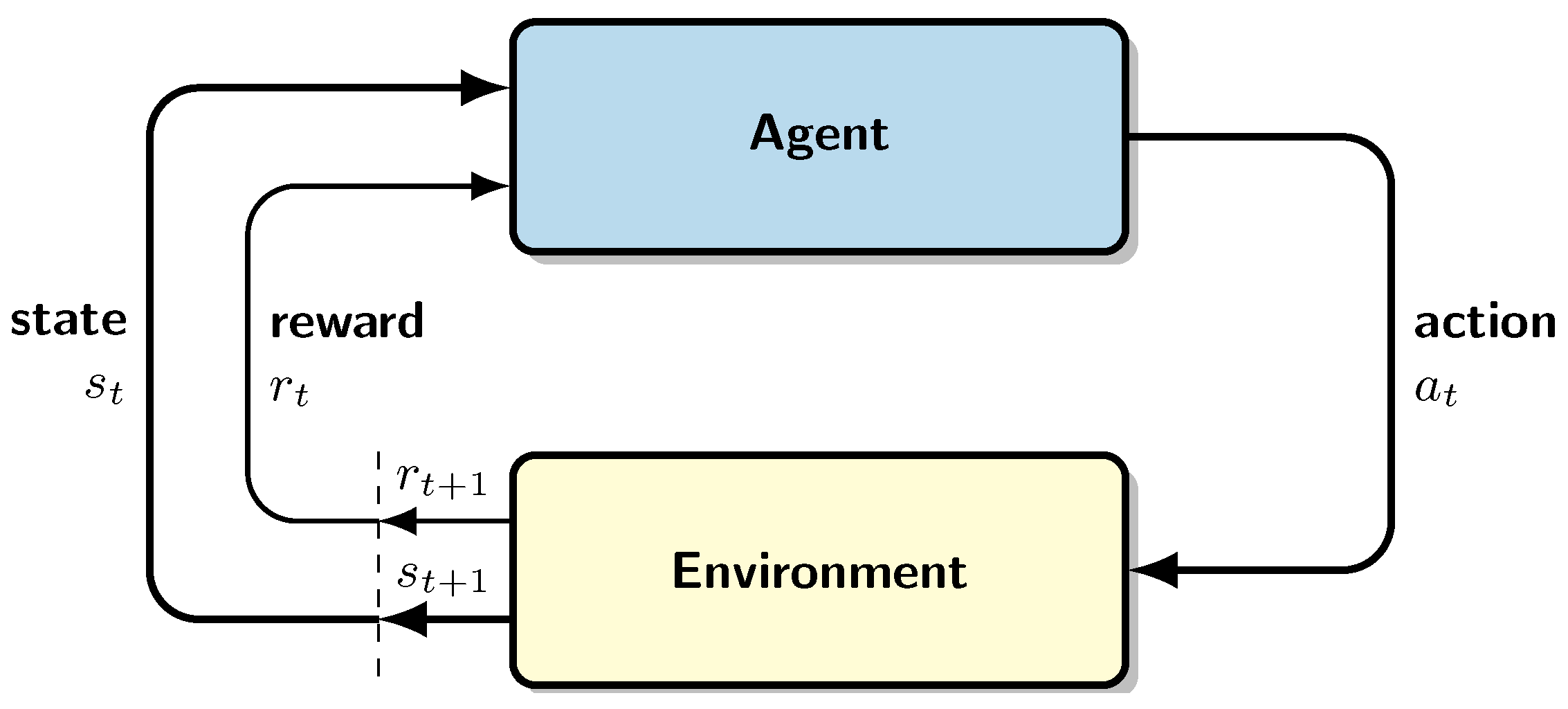
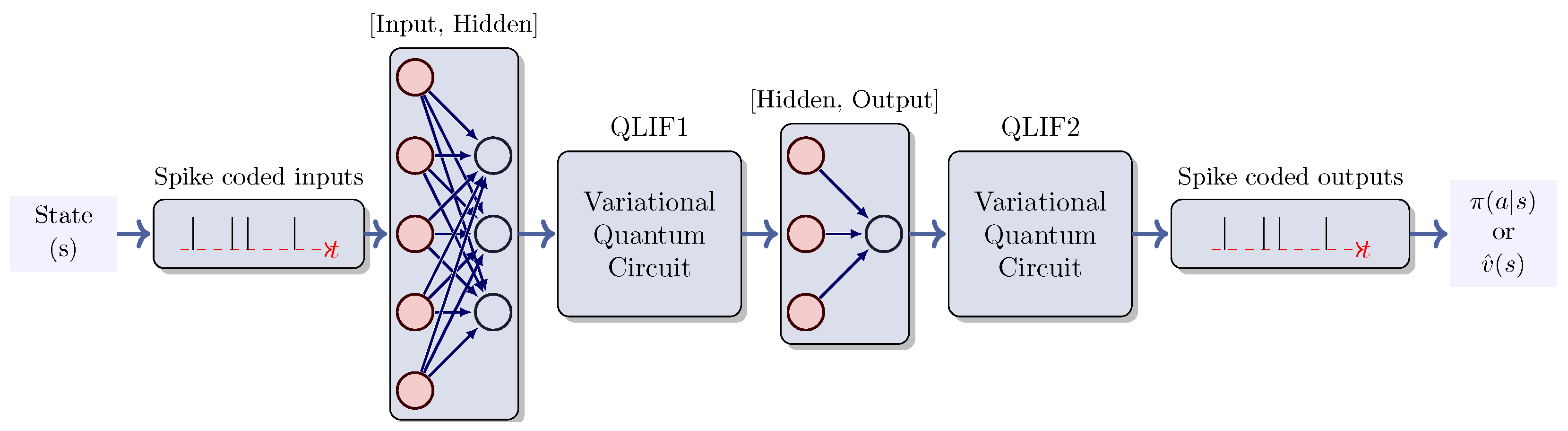
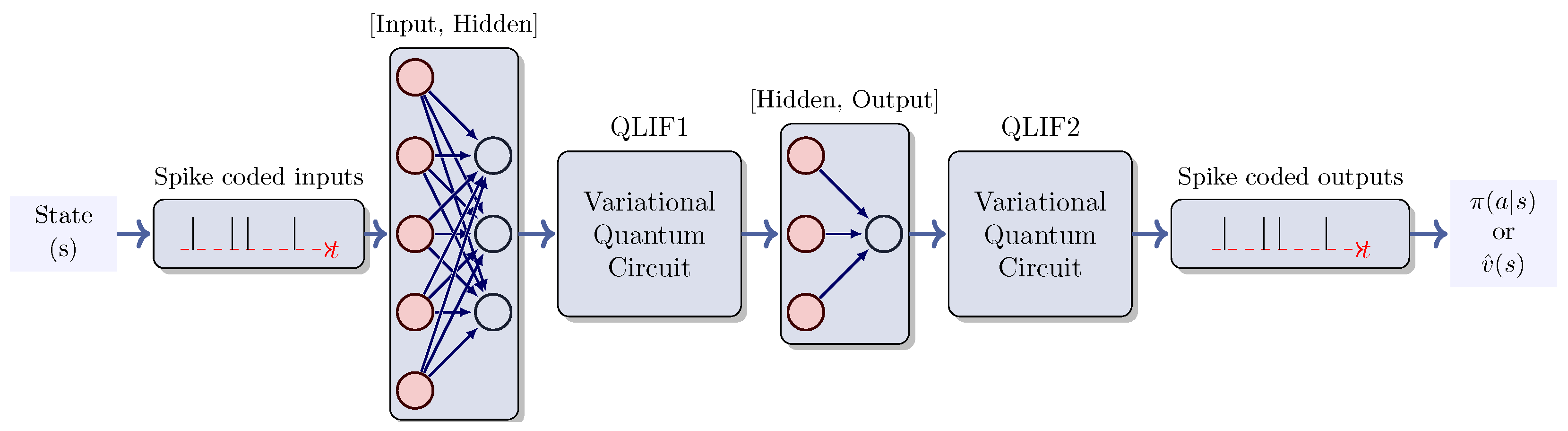
2.4. Quantum Neural Networks
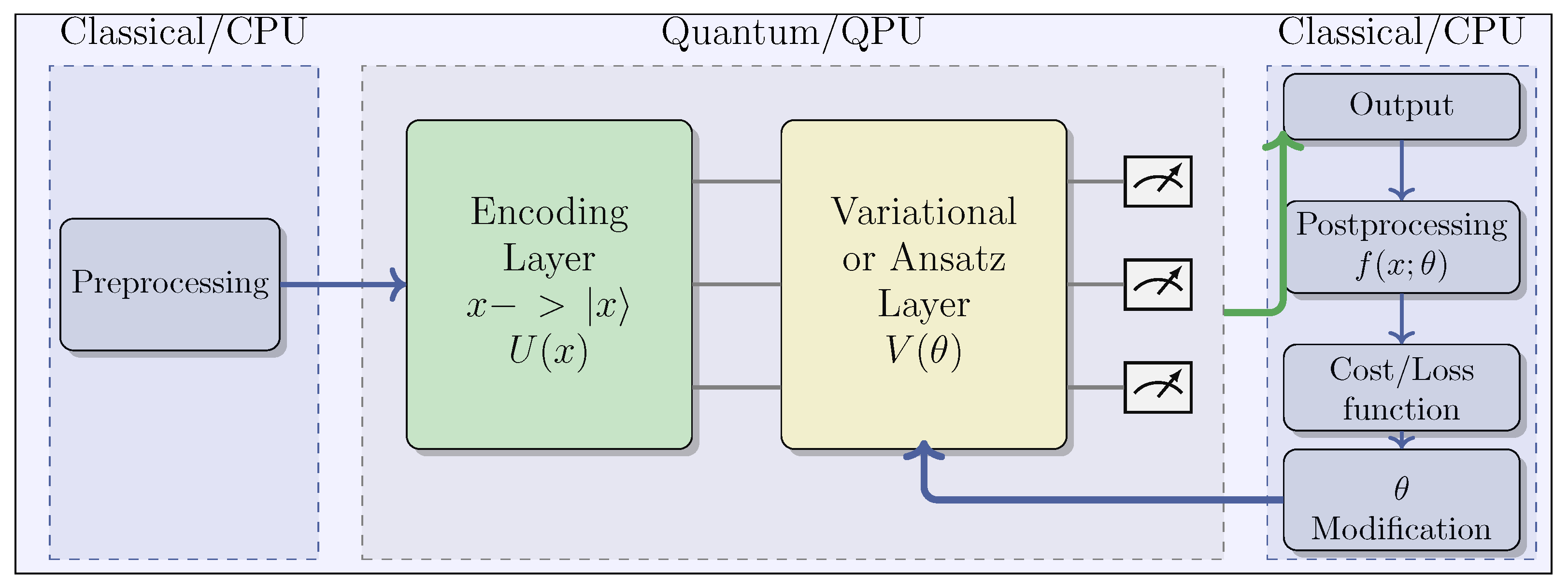
- Pre-processing (CPU): Initial classical data preprocessing, which includes normalization and scaling;
- Quantum Embedding (QPU): Encoding classical data into quantum states through parameterized quantum gates. Various encoding techniques exist, such as angle encoding, also known as tensor product encoding, and amplitude encoding, among others [65];
- Variational Layer (QPU): This layer embodies the functionality of quantum neural networks through the utilization of rotations and entanglement gates with trainable parameters, which are optimized using classical algorithms;
- Measurement Process (QPU/CPU): Measuring the quantum state and decoding it to derive the expected output. The selection of observables employed in this process is critical for achieving optimal performance;
- Post-processing (CPU): Transformation of QPU outputs before feeding them back to the user and integrating them into the cost function during the learning phase;
- Learning (CPU): Computation of the cost function and optimization of ansatz parameters using classic optimization algorithms, such as Adam or SGD. Gradient-free methods, such as SPSA or COLYBA, are also capable of estimating parameter updates.
3. Methodology
4. Experimentation
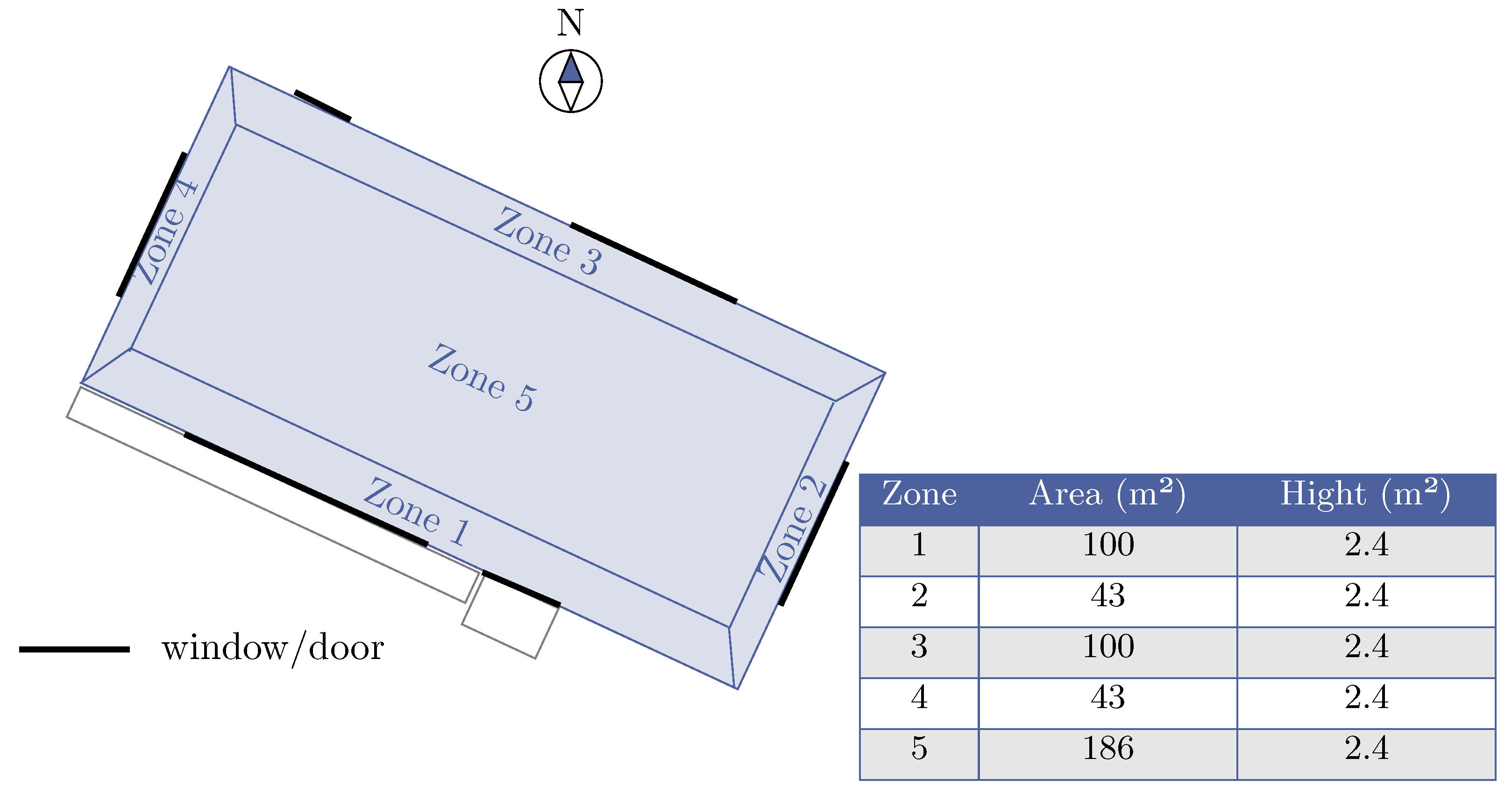
4.1. Problem Statement
- State space: The state space encompasses 17 attributes; with 14 detailed in Table 1, while the remaining 3 are reserved in case new customized features need to be added;
- Action space: The action space comprises a collection of 10 discrete actions as outlined in Table 2. The temperature bounds for heating and cooling are [12, 23.5] and [21.5, 40], respectively;
- Reward function: The reward function is formulated as multi-objective, where both energy consumption and thermal discomfort are normalized and added together with different weights. The reward value is consistently non-positive, signifying that optimal behavior yields a cumulative reward of 0. Notice also that there are two temperature comfort ranges defined, one for the summer period and other for the winter period. The weights of each term in the reward allow to adjust the importance of each aspect when environments are evaluated. Finally, the reward function is customizable and can be integrated into the environment.
4.2. Experimental Settings
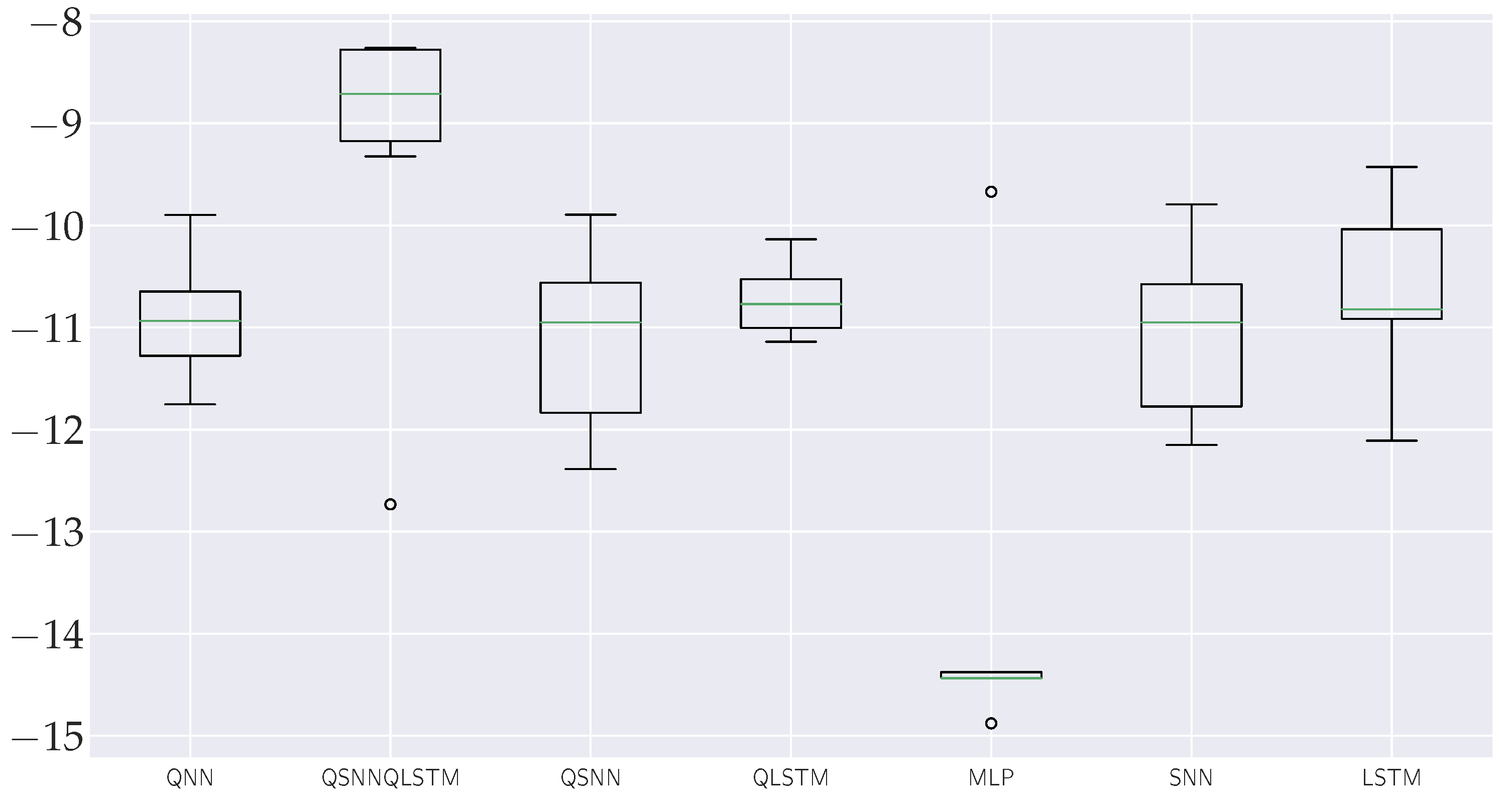
4.3. Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| A2C | Advantage Actor–Critic |
| BPTT | Backpropagation through time |
| BG | Basal Ganglia |
| CPU | Central processing unit |
| DQN | Deep Q-network |
| DRL | Deep reinforcement learning |
| HDC | Hyperdimensional computing and spiking |
| HVAC | Heating, ventilation, air-conditioning |
| KPI | Key performance indicator |
| LIF | Leaky integrate and fired Neuron |
| LSTM | Long/short-term memory |
| LTS | Long-term store |
| mPFC | Medial prefrontal cortex |
| MDP | Markov decision process |
| MLP | Multilayer perceptron |
| NISQ | Noisy, intermediate-scale quantum era |
| PFC | Prefrontal cortex |
| QC | Quantum computing |
| QLIF | Quantum leaky integrate and fired neuron |
| QLSTM | Quantum long/short-term memory |
| QML | Quantum machine learning |
| QNN | Quantum neural network |
| QSNN | Quantum spiking neural network |
| QPU | Quantum processing unit |
| QRL | Quantum reinforcement learning |
| RNN | Recurrent neural networks |
| RL | Reinforcement learning |
| SNN | Spiking neural network |
| S-R | Stimulus-response |
| STS | Short-term store |
| vmPFC | Ventromedial prefrontal cortex |
| VQC | Variational quantum circuit |
References
- Zhao, L.; Zhang, L.; Wu, Z.; Chen, Y.; Dai, H.; Yu, X.; Liu, Z.; Zhang, T.; Hu, X.; Jiang, X.; et al. When brain-inspired AI meets AGI. Meta-Radiology 2023, 1, 100005. [Google Scholar] [CrossRef]
- Fan, C.; Yao, L.; Zhang, J.; Zhen, Z.; Wu, X. Advanced Reinforcement Learning and Its Connections with Brain Neuroscience. Research 2023, 6, 0064. [Google Scholar] [CrossRef]
- Domenech, P.; Rheims, S.; Koechlin, E. Neural mechanisms resolving exploitation-exploration dilemmas in the medial prefrontal cortex. Science 2020, 369, eabb0184. [Google Scholar] [CrossRef]
- Baram, A.B.; Muller, T.H.; Nili, H.; Garvert, M.M.; Behrens, T.E.J. Entorhinal and ventromedial prefrontal cortices abstract and generalize the structure of reinforcement learning problems. Neuron 2021, 109, 713–723.e7. [Google Scholar] [CrossRef]
- Bogacz, R.; Larsen, T. Integration of Reinforcement Learning and Optimal Decision-Making Theories of the Basal Ganglia. Neural Comput. 2011, 23, 817–851. [Google Scholar] [CrossRef]
- Houk, J.; Adams, J.; Barto, A. A Model of How the Basal Ganglia Generate and Use Neural Signals that Predict Reinforcement. Model. Inf. Process. Basal Ganglia 1995, 13. [Google Scholar] [CrossRef]
- Joel, D.; Niv, Y.; Ruppin, E. Actor–critic models of the basal ganglia: New anatomical and computational perspectives. Neural Netw. 2002, 15, 535–547. [Google Scholar] [CrossRef]
- Collins, A.G.E.; Frank, M.J. Opponent actor learning (OpAL): Modeling interactive effects of striatal dopamine on reinforcement learning and choice incentive. Psychol. Rev. 2014, 121, 337–366. [Google Scholar] [CrossRef]
- Maia, T.V.; Frank, M.J. From reinforcement learning models to psychiatric and neurological disorders. Nat. Neurosci. 2011, 14, 154–162. [Google Scholar] [CrossRef]
- Maia, T.V. Reinforcement learning, conditioning, and the brain: Successes and challenges. Cogn. Affect. Behav. Neurosci. 2009, 9, 343–364. [Google Scholar] [CrossRef]
- O’Doherty, J.; Dayan, P.; Schultz, J.; Deichmann, R.; Friston, K.; Dolan, R.J. Dissociable Roles of Ventral and Dorsal Striatum in Instrumental Conditioning. Science 2004, 304, 452–454. [Google Scholar] [CrossRef]
- Chalmers, E.; Contreras, E.B.; Robertson, B.; Luczak, A.; Gruber, A. Context-switching and adaptation: Brain-inspired mechanisms for handling environmental changes. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3522–3529. [Google Scholar] [CrossRef]
- Robertazzi, F.; Vissani, M.; Schillaci, G.; Falotico, E. Brain-inspired meta-reinforcement learning cognitive control in conflictual inhibition decision-making task for artificial agents. Neural Netw. 2022, 154, 283–302. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhao, F.; Zhao, Y.; Zeng, Y.; Sun, Y. A brain-inspired theory of mind spiking neural network improves multi-agent cooperation and competition. Patterns 2023, 4, 100775. [Google Scholar] [CrossRef]
- Zhang, K.; Lin, X.; Li, M. Graph attention reinforcement learning with flexible matching policies for multi-depot vehicle routing problems. Phys. A Stat. Mech. Appl. 2023, 611, 128451. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019. [Google Scholar] [CrossRef]
- Rezayi, S.; Dai, H.; Liu, Z.; Wu, Z.; Hebbar, A.; Burns, A.H.; Zhao, L.; Zhu, D.; Li, Q.; Liu, W.; et al. ClinicalRadioBERT: Knowledge-Infused Few Shot Learning for Clinical Notes Named Entity Recognition. In Proceedings of the Machine Learning in Medical Imaging; Lian, C., Cao, X., Rekik, I., Xu, X., Cui, Z., Eds.; Springer: Cham, Switzerland, 2022; pp. 269–278. [Google Scholar]
- Liu, Z.; He, X.; Liu, L.; Liu, T.; Zhai, X. Context Matters: A Strategy to Pre-train Language Model for Science Education. In Proceedings of the Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky; Wang, N., Rebolledo-Mendez, G., Dimitrova, V., Matsuda, N., Santos, O.C., Eds.; Springer: Cham, Switzerland, 2023; pp. 666–674. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021. [Google Scholar] [CrossRef]
- Aïmeur, E.; Brassard, G.; Gambs, S. Quantum speed-up for unsupervised learning. Machine Learn. 2013, 90, 261–287. [Google Scholar] [CrossRef]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef]
- Wiebe, N.; Kapoor, A.; Svore, K.M. Quantum Nearest-Neighbor Algorithms for Machine Learning. Quantum Inf. Comput. 2015, 15, 318–358. [Google Scholar]
- Anguita, D.; Ridella, S.; Rivieccio, F.; Zunino, R. Quantum optimization for training support vector machines. Neural Netw. 2003, 16, 763–770. [Google Scholar] [CrossRef]
- Andrés, E.; Cuéllar, M.P.; Navarro, G. On the Use of Quantum Reinforcement Learning in Energy-Efficiency Scenarios. Energies 2022, 15, 6034. [Google Scholar] [CrossRef]
- Andrés, E.; Cuéllar, M.P.; Navarro, G. Efficient Dimensionality Reduction Strategies for Quantum Reinforcement Learning. IEEE Access 2023, 11, 104534–104553. [Google Scholar] [CrossRef]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Li, J.A.; Dong, D.; Wei, Z.; Liu, Y.; Pan, Y.; Nori, F.; Zhang, X. Quantum reinforcement learning during human decision-making. Nat. Hum. Behav. 2020, 4, 294–307. [Google Scholar] [CrossRef]
- Miller, E.K.; Cohen, J.D. An Integrative Theory of Prefrontal Cortex Function. Annu. Rev. Neurosci. 2001, 24, 167–202. [Google Scholar] [CrossRef]
- Atkinson, R.; Shiffrin, R. Human Memory: A Proposed System and its Control Processes. Psychol. Learn. Motiv. 1968, 2, 89–195. [Google Scholar] [CrossRef]
- Andersen, P. The Hippocampus Book; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Olton, D.S.; Becker, J.T.; Handelmann, G.E. Hippocampus, space, and memory. Behav. Brain Sci. 1979, 2, 313–322. [Google Scholar] [CrossRef]
- Eshraghian, J.K.; Ward, M.; Neftci, E.; Wang, X.; Lenz, G.; Dwivedi, G.; Bennamoun, M.; Jeong, D.S.; Lu, W.D. Training Spiking Neural Networks Using Lessons from Deep Learning. Proc. IEEE 2021, 111, 1016–1054. [Google Scholar] [CrossRef]
- McCloskey, M.; Cohen, N.J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. Psychol. Learn. Motiv. 1989, 24, 109–165. [Google Scholar] [CrossRef]
- Raman, N.S.; Devraj, A.M.; Barooah, P.; Meyn, S.P. Reinforcement Learning for Control of Building HVAC Systems. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 2326–2332. [Google Scholar] [CrossRef]
- Wang, Y.; Velswamy, K.; Huang, B. A Long-Short Term Memory Recurrent Neural Network Based Reinforcement Learning Controller for Office Heating Ventilation and Air Conditioning Systems. Processes 2017, 5, 46. [Google Scholar] [CrossRef]
- Fu, Q.; Han, Z.; Chen, J.; Lu, Y.; Wu, H.; Wang, Y. Applications of reinforcement learning for building energy efficiency control: A review. J. Build. Eng. 2022, 50, 104165. [Google Scholar] [CrossRef]
- Hebb, D. The Organization of Behavior: A Neuropsychological Theory; Taylor & Francis: Abingdon, UK, 2005. [Google Scholar]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef]
- Lobo, J.L.; Del Ser, J.; Bifet, A.; Kasabov, N. Spiking Neural Networks and online learning: An overview and perspectives. Neural Netw. 2020, 121, 88–100. [Google Scholar] [CrossRef]
- Lapicque, L. Recherches quantitatives sur l’excitation electrique des nerfs. J. Physiol. Paris 1907, 9, 620–635. [Google Scholar]
- Zou, Z.; Alimohamadi, H.; Zakeri, A.; Imani, F.; Kim, Y.; Najafi, M.H.; Imani, M. Memory-inspired spiking hyperdimensional network for robust online learning. Sci. Rep. 2022, 12, 7641. [Google Scholar] [CrossRef]
- Kumarasinghe, K.; Kasabov, N.; Taylor, D. Brain-inspired spiking neural networks for decoding and understanding muscle activity and kinematics from electroencephalography signals during hand movements. Sci. Rep. 2021, 11, 2486. [Google Scholar] [CrossRef]
- Banino, A.; Barry, C.; Uria, B.; Blundell, C.; Lillicrap, T.; Mirowski, P.; Pritzel, A.; Chadwick, M.J.; Degris, T.; Modayil, J.; et al. Vector-based navigation using grid-like representations in artificial agents. Nature 2018, 557, 429–433. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Networks 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. Off. J. Int. Neural Netw. Soc. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. Adv. Neural Inf. Process. Syst. 1996, 9, 473–479. [Google Scholar]
- Triche, A.; Maida, A.S.; Kumar, A. Exploration in neo-Hebbian reinforcement learning: Computational approaches to the exploration–exploitation balance with bio-inspired neural networks. Neural Netw. 2022, 151, 16–33. [Google Scholar] [CrossRef]
- Dong, H.; Ding, Z.; Zhang, S.; Yuan, H.; Zhang, H.; Zhang, J.; Huang, Y.; Yu, T.; Zhang, H.; Huang, R. Deep Reinforcement Learning: Fundamentals, Research, and Applications; Springer Nature: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Sutton, R.S.; Barto, A.G. The Reinforcement Learning Problem. In Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; pp. 51–85. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Shao, K.; Zhao, D.; Zhu, Y.; Zhang, Q. Visual Navigation with Actor-Critic Deep Reinforcement Learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Macaluso, A.; Clissa, L.; Lodi, S.; Sartori, C. A Variational Algorithm for Quantum Neural Networks. In Proceedings of the Computational Science—ICCS 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 591–604. [Google Scholar]
- Benedetti, M.; Lloyd, E.; Sack, S.; Fiorentini, M. Parameterized quantum circuits as machine learning models. Quantum Sci. Technol. 2019, 4, 043001. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, X.S. QDNN: Deep neural networks with quantum layers. Quantum Mach. Intell. 2021, 3, 15. [Google Scholar] [CrossRef]
- Lu, B.; Liu, L.; Song, J.Y.; Wen, K.; Wang, C. Recent progress on coherent computation based on quantum squeezing. AAPPS Bull. 2023, 33, 7. [Google Scholar] [CrossRef]
- Hou, X.; Zhou, G.; Li, Q.; Jin, S.; Wang, X. A duplication-free quantum neural network for universal approximation. Sci. China Physics Mech. Astron. 2023, 66, 270362. [Google Scholar] [CrossRef]
- Zhao, M.; Chen, Y.; Liu, Q.; Wu, S. Quantifying direct associations between variables. Fundam. Res. 2023. [Google Scholar] [CrossRef]
- Zhou, Z.-r.; Li, H.; Long, G.L. Variational quantum algorithm for node embedding. Fundam. Res. 2023. [Google Scholar] [CrossRef]
- Ding, L.; Wang, H.; Wang, Y.; Wang, S. Based on Quantum Topological Stabilizer Color Code Morphism Neural Network Decoder. Quantum Eng. 2022, 2022, 9638108. [Google Scholar] [CrossRef]
- Tian, J.; Sun, X.; Du, Y.; Zhao, S.; Liu, Q.; Zhang, K.; Yi, W.; Huang, W.; Wang, C.; Wu, X.; et al. Recent Advances for Quantum Neural Networks in Generative Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12321–12340. [Google Scholar] [CrossRef]
- Jeswal, S.K.; Chakraverty, S. Recent Developments and Applications in Quantum Neural Network: A Review. Arch. Comput. Methods Eng. 2019, 26, 793–807. [Google Scholar] [CrossRef]
- Wittek, P. Quantum Machine Learning: What Quantum Computing Means to Data Mining; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Weigold, M.; Barzen, J.; Leymann, F.; Salm, M. Expanding Data Encoding Patterns For Quantum Algorithms. In Proceedings of the 2021 IEEE 18th International Conference on Software Architecture Companion (ICSA-C), Stuttgart, Germany, 22–26 March 2021; pp. 95–101. [Google Scholar]
- Zenke, F.; Poole, B.; Ganguli, S. Continual Learning Through Synaptic Intelligence. Proc. Mach. Learn. Res. 2017, 70, 3987–3995. [Google Scholar] [PubMed]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive Neural Networks. arXiv 2016. [Google Scholar] [CrossRef]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual Learning with Deep Generative Replay. arXiv 2017. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.C.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. arXiv 2016. [Google Scholar] [CrossRef]
- Crawley, D.; Pedersen, C.; Lawrie, L.; Winkelmann, F. EnergyPlus: Energy Simulation Program. Ashrae J. 2000, 42, 49–56. [Google Scholar]
- Mattsson, S.E.; Elmqvist, H. Modelica—An International Effort to Design the Next Generation Modeling Language. Ifac Proc. Vol. 1997, 30, 151–155. [Google Scholar] [CrossRef]
- Zhang, Z.; Lam, K.P. Practical Implementation and Evaluation of Deep Reinforcement Learning Control for a Radiant Heating System. In Proceedings of the 5th Conference on Systems for Built Environments, BuildSys ’18, New York, NY, USA, 7–8 November 2018; pp. 148–157. [Google Scholar] [CrossRef]
- Jiménez-Raboso, J.; Campoy-Nieves, A.; Manjavacas-Lucas, A.; Gómez-Romero, J.; Molina-Solana, M. Sinergym: A Building Simulation and Control Framework for Training Reinforcement Learning Agents. In Proceedings of the 8th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 17–18 November 2021; pp. 319–323. [Google Scholar] [CrossRef]
- Scharnhorst, P.; Schubnel, B.; Fernández Bandera, C.; Salom, J.; Taddeo, P.; Boegli, M.; Gorecki, T.; Stauffer, Y.; Peppas, A.; Politi, C. Energym: A Building Model Library for Controller Benchmarking. Appl. Sci. 2021, 11, 3518. [Google Scholar] [CrossRef]
- Hill, F.; Lampinen, A.; Schneider, R.; Clark, S.; Botvinick, M.; McClelland, J.L.; Santoro, A. Environmental drivers of systematicity and generalization in a situated agent. arXiv 2020. [Google Scholar] [CrossRef]
- Lake, B.M.; Baroni, M. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. arXiv 2018. [Google Scholar] [CrossRef]
- Botvinick, M.; Wang, J.X.; Dabney, W.; Miller, K.J.; Kurth-Nelson, Z. Deep Reinforcement Learning and Its Neuroscientific Implications. Neuron 2020, 107, 603–616. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Units |
|---|---|
| Site-Outdoor-Air-DryBulb-Temperature | °C |
| Site-Outdoor-Air-Relative-Humidity | % |
| Site-Wind-Speed | m/s |
| Site-Wind-Direction | degree from north |
| Site-Diffuse-Solar-Radiation-Rate-per-Area | W/m2 |
| Site-Direct-Solar-Radiation-Rate-per-Area | W/m2 |
| Zone-Thermostat-Heating-Setpoint-Temperature | °C |
| Zone-Thermostat-Cooling-Setpoint-Temperature | °C |
| Zone-Air-Temperature | °C |
| Zone-Air-Relative-Humidity | % |
| Zone-People-Occupant-Count | count |
| Environmental-Impact-Total-CO2-Emissions-Carbon-Equivalent-Mass | Kg |
| Facility-Total-HVAC-Electricity-Demand-Rate | W |
| Total-Electricity-HVAC | W |
| Name | Heating Target Temperature | Cooling Target Temperature |
|---|---|---|
| 0 | 13 | 37 |
| 1 | 14 | 34 |
| 2 | 15 | 32 |
| 3 | 16 | 30 |
| 4 | 17 | 30 |
| 5 | 18 | 30 |
| 6 | 19 | 27 |
| 7 | 20 | 26 |
| 8 | 21 | 25 |
| 9 | 21 | 24 |
| MLP | SNN | LSTM | |
|---|---|---|---|
| Optimizer | Adam(lr = ) | Adam(lr = ) | Adam(lr = ) |
| Batch Size | 32 | 16 | 32 |
| BetaEntropy | 0.01 | 0.01 | 0.01 |
| Discount Factor | 0.98 | 0.98 | 0.98 |
| Steps | - | 15 | - |
| Hidden | - | 15 | 25 |
| Layers | Actor: [Linear[17, 450], ReLU | Actor: [Linear[17, 15] | Actor: [LSTM(17, 25, layers = 5) |
| Linear[450, 10]] | Lif1, Lif2 | Linear[25, 10]] | |
| Linear[15, 10]] | |||
| Critic: [Linear[17, 450], ReLU | Critic: [Linear[17, 15] | ||
| Linear[450, 1]] | Lif1, Lif2 | Critic: [LSTM(17, 25, layers = 5) | |
| Linear[15, 1]] | Linear[25, 1]] |
| QNN | QSNN | QLSTM | QSNN–QLSTM | |
|---|---|---|---|---|
| Optimizer | Adam(lr=) | Adam(lr = ) | Adam(lr = ) | [(Adam(QSNN.parameters, lr = ), |
| Adam(QLSTM.parameters, lr = ))] | ||||
| Batch Size | 128 | 16 | 128 | 128 |
| Pre-processing | Normalization | Normalization | - | Normalization |
| Post-processing | - | - | - | - |
| BetaEntropy | 0.01 | 0.01 | 0.01 | 0.01 |
| Discount Factor | 0.98 | 0.98 | 0.98 | 0.98 |
| Steps | - | 15 | 15 | 15 |
| Hidden | - | 15 | 25 | 15 (QSNN), 125 (QLSTM) |
| Layers | Actor: [[5 QNN] | Actor: [Linear[17, 15] | Actor: [Linear[17, 42] | |
| ReLU | 15 QSNN | Linear[42, 5] | ||
| Linear[, 10]] | Linear[15, 10]] | 4 VQCs | ||
| Linear[25, 5] | ||||
| Linear[5, 25] | ||||
| Linear[25, 10]] | ||||
| Critic: [[5 QNN | Critic: [Linear[17, 15] | Critic: [Linear[17, 42] | 5 QSNN | |
| ReLU | 15 QSNN | Linear[42, 5] | 5 QLSTM | |
| Linear[, 1]] | Linear[15, 1]] | 4 VQC’S | ||
| Linear[25, 5] | ||||
| Linear[5, 25] | ||||
| Linear[25, 1]] | ||||
| Qubits | 5 | 5 | 5 | 5 |
| Encoding Strategy | Amplitude Encoding | Amplitude Encoding | Angle Encoding | Amplitude Encoding |
| Average Tot.Reward | Best Tot.Reward | Worst Tot.Reward | Test Reward | Time (s) | |
|---|---|---|---|---|---|
| MLP | −13.75 | −9.67 | −14.88 | −13.25 | 297.8 |
| SNN | −11.05 | −9.79 | −12.15 | −13.31 | 307.6 |
| LSTM | −10.56 | −9.43 | −12.11 | −12.67 | 302.8 |
| QNN | −10.92 | −9.90 | −11.75 | −12.87 | 326.1 |
| QSNN | −11.12 | −9.89 | −12.39 | −13.32 | 467.4 |
| QLSTM | −10.72 | −10.14 | −11.14 | −12.19 | 335.42 |
| QSNN–QLSTM | −9.40 | −8.26 | −12.73 | −11.83 | 962.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrés, E.; Cuéllar, M.P.; Navarro, G. Brain-Inspired Agents for Quantum Reinforcement Learning. Mathematics 2024, 12, 1230. https://doi.org/10.3390/math12081230
Andrés E, Cuéllar MP, Navarro G. Brain-Inspired Agents for Quantum Reinforcement Learning. Mathematics. 2024; 12(8):1230. https://doi.org/10.3390/math12081230
Chicago/Turabian StyleAndrés, Eva, Manuel Pegalajar Cuéllar, and Gabriel Navarro. 2024. "Brain-Inspired Agents for Quantum Reinforcement Learning" Mathematics 12, no. 8: 1230. https://doi.org/10.3390/math12081230
APA StyleAndrés, E., Cuéllar, M. P., & Navarro, G. (2024). Brain-Inspired Agents for Quantum Reinforcement Learning. Mathematics, 12(8), 1230. https://doi.org/10.3390/math12081230