
Tensor-Based Sparse Representation for Hyperspectral Image Reconstruction Using RGB Inputs



Abstract
1. Introduction
- (1)
- A novel tensor-based sparse representation framework is proposed for reconstructing HSIs from the corresponding RGB images through making full use of the tensor-wise representations to describe the spectral data, by which the structure of original inputs can be retained in a more flexible way, thus enhancing the spatial contextual relations.
- (2)
- A preprocessing method based on the clustering strategy is devised to reduce the redundancy of spectral training datasets, enhancing the representativeness of the target spectral dictionary.
- (3)
- A spectral enhancement strategy is deployed to further mitigate the spectral distortion in the junction of two different image regions through introducing the regression method.
- (4)
- Extensive quantitative and qualitative experiments are conducted over two benchmark datasets under multiple evaluation metrics, demonstrating the availability of our proposed method.
2. Related Work
2.1. CNN-Based Reconstruction Methods
2.2. Sparse Coding-Based Methods
3. Preliminaries
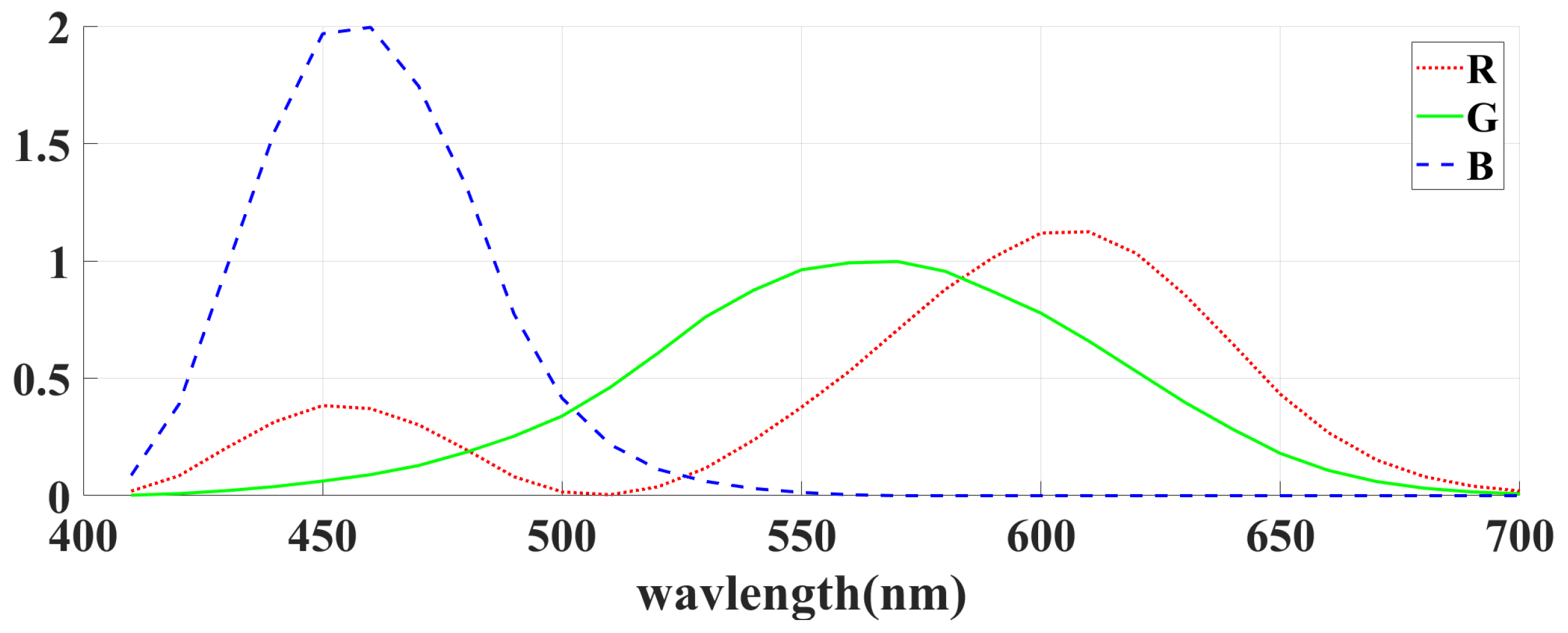
3.1. Problem Formulation
3.2. Tensor Algebra
4. Proposed Method
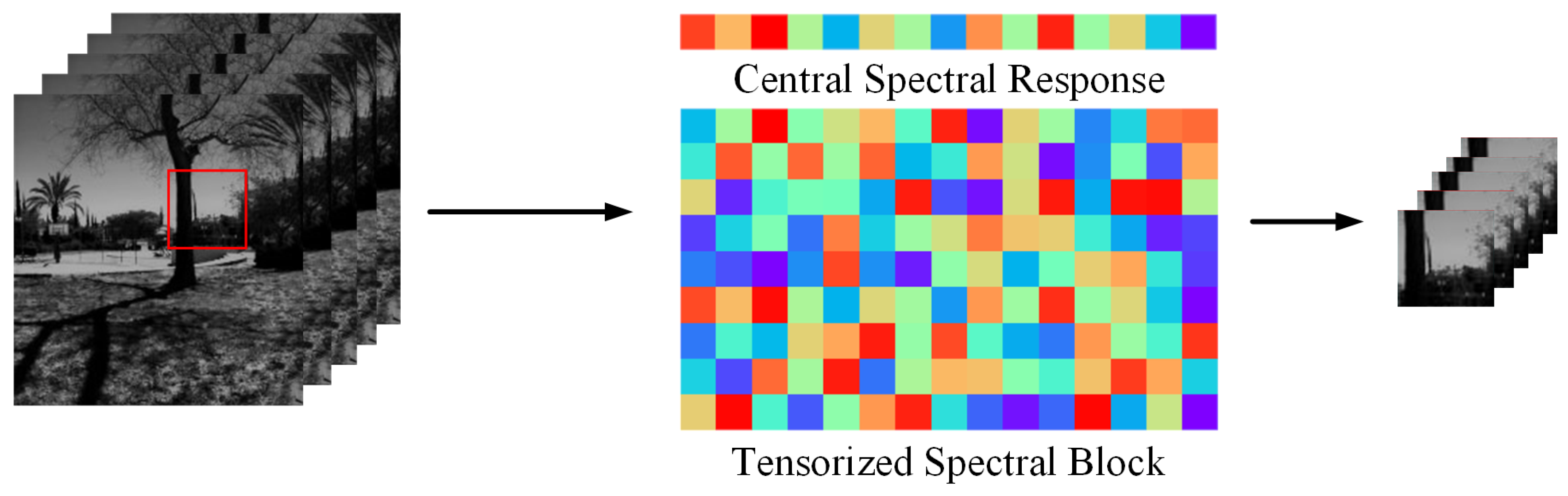
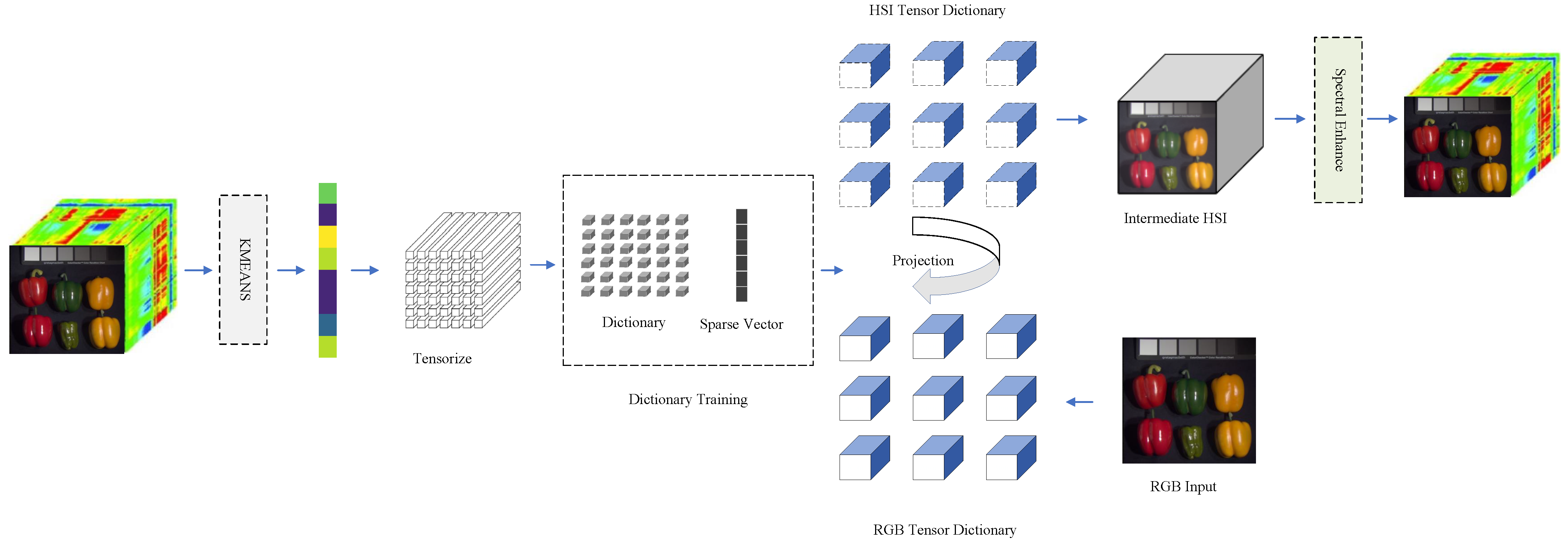
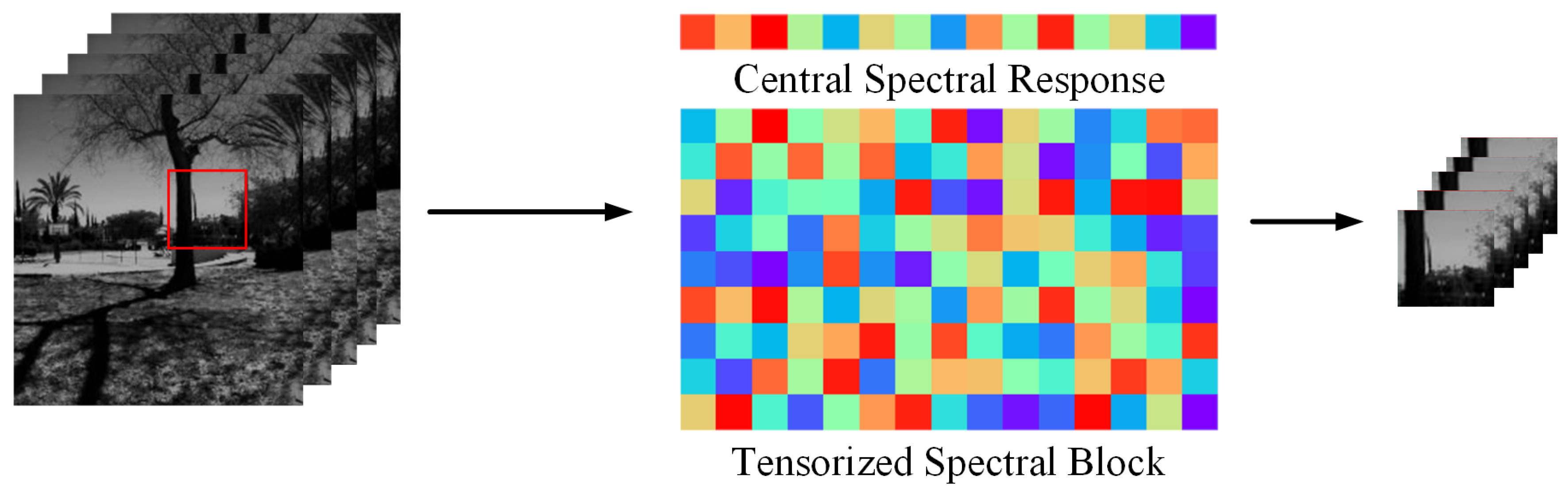
4.1. Data Preprocessing
4.2. Tensor-Based Dictionary Learning
4.3. Tensor-Based Spectral Reconstruction
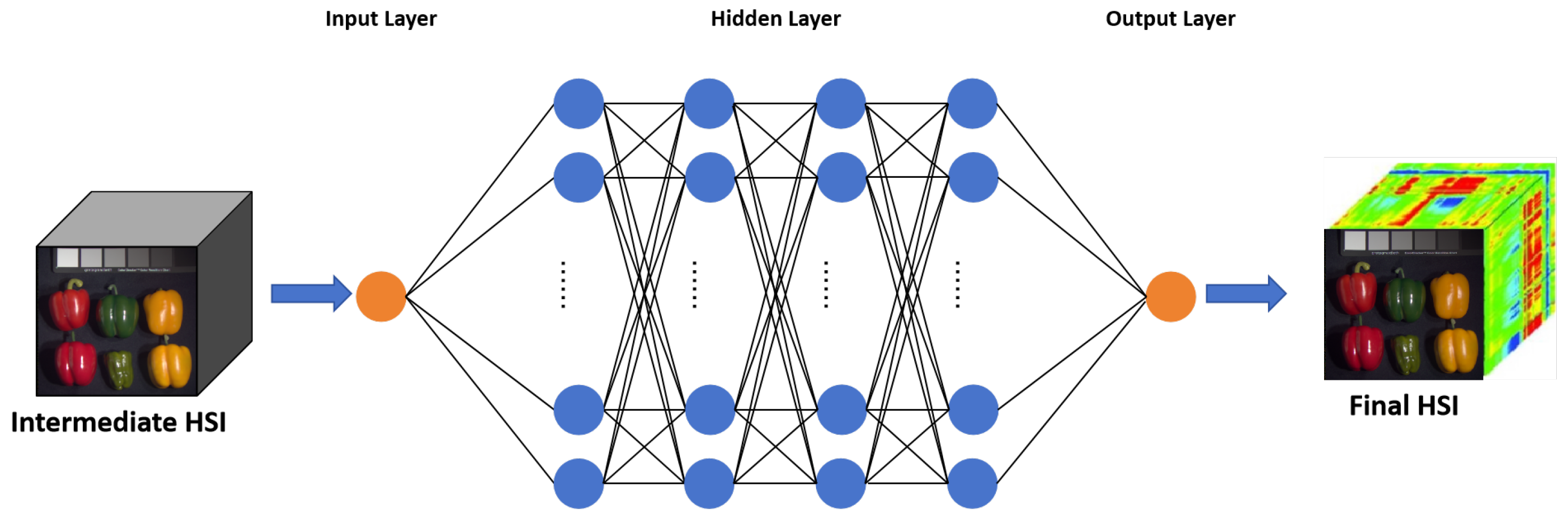
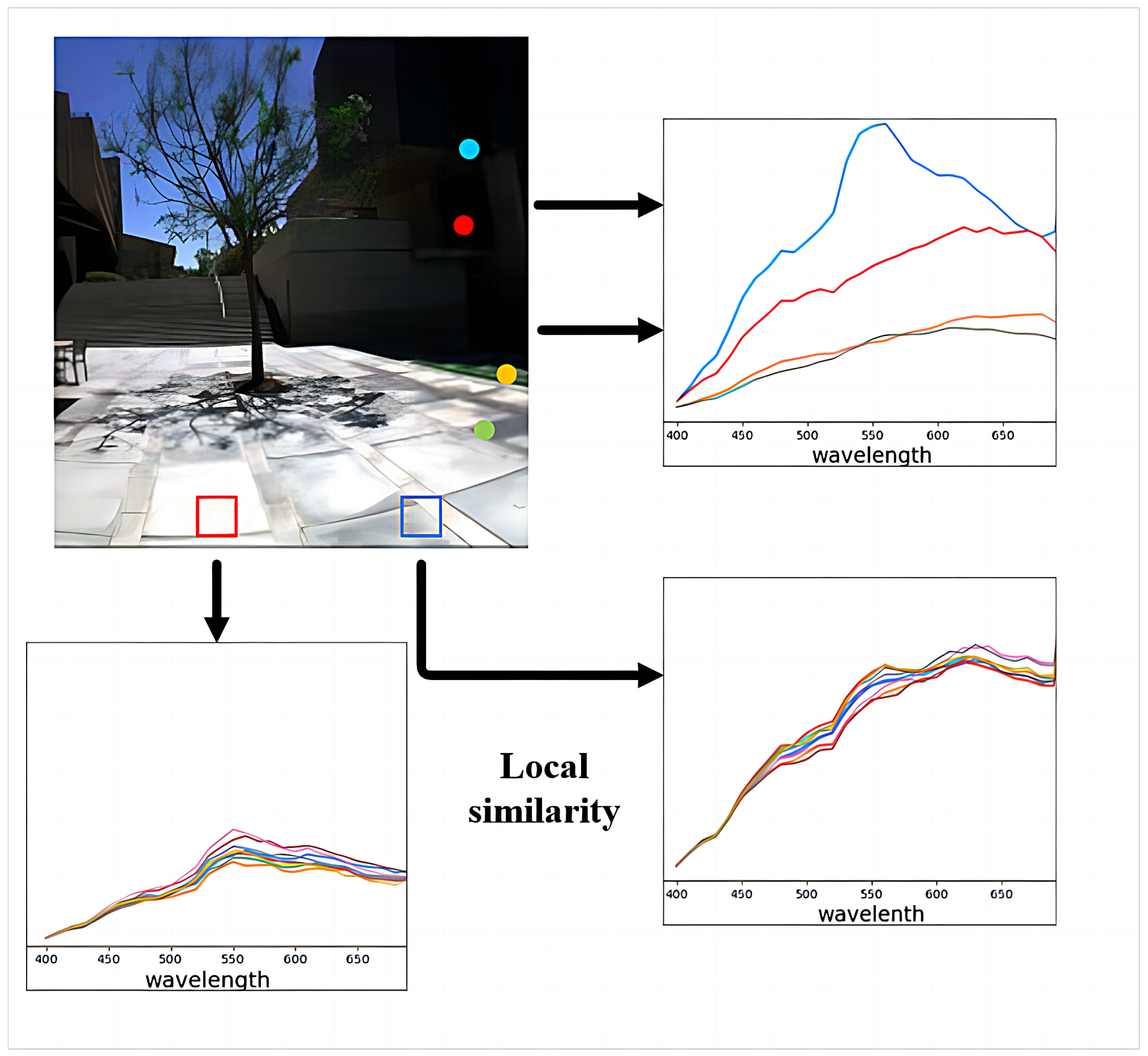
4.4. Spectral Enhancement
5. Experiment
5.1. Experimental Settings
5.1.1. Datasets
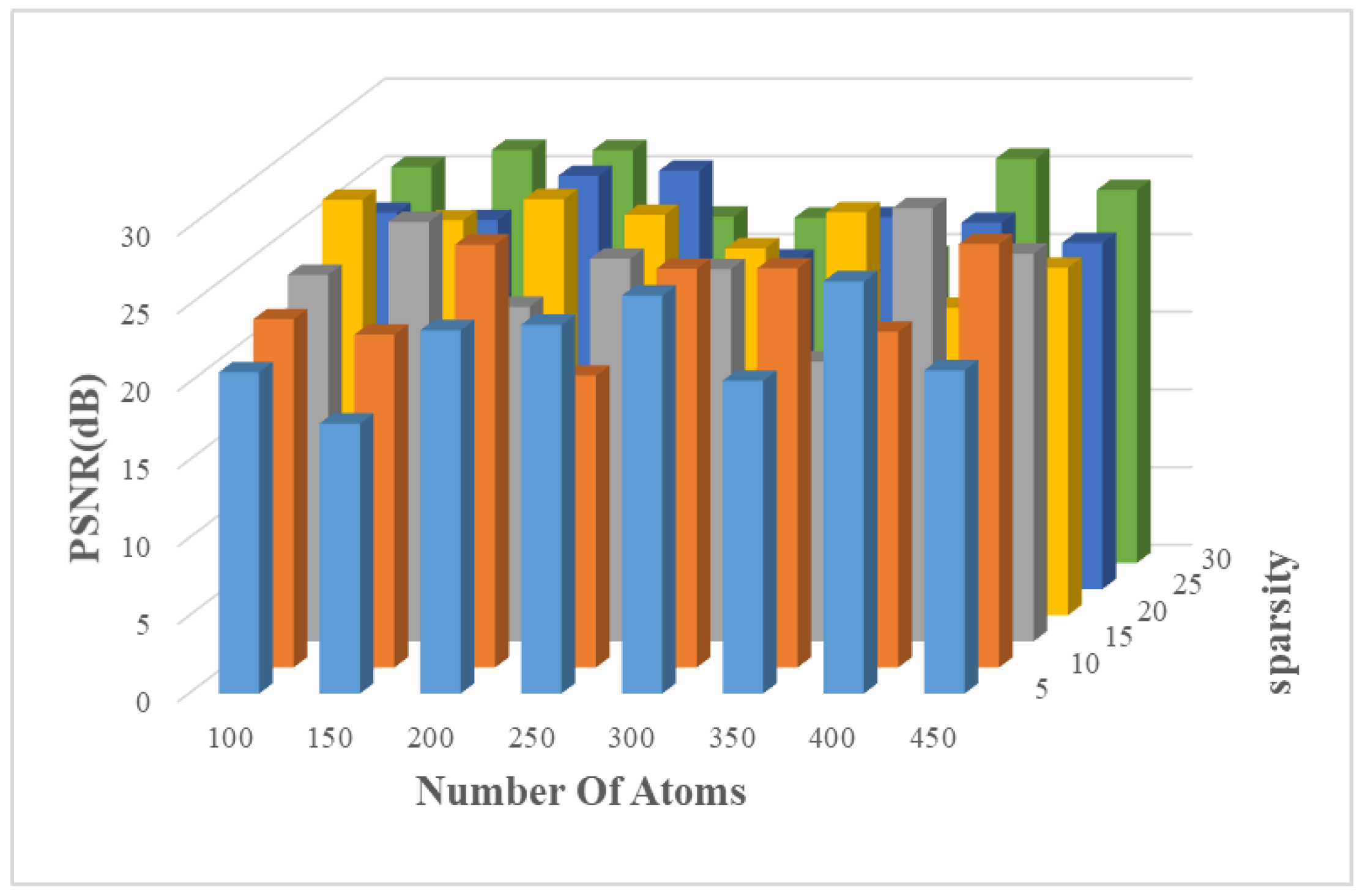
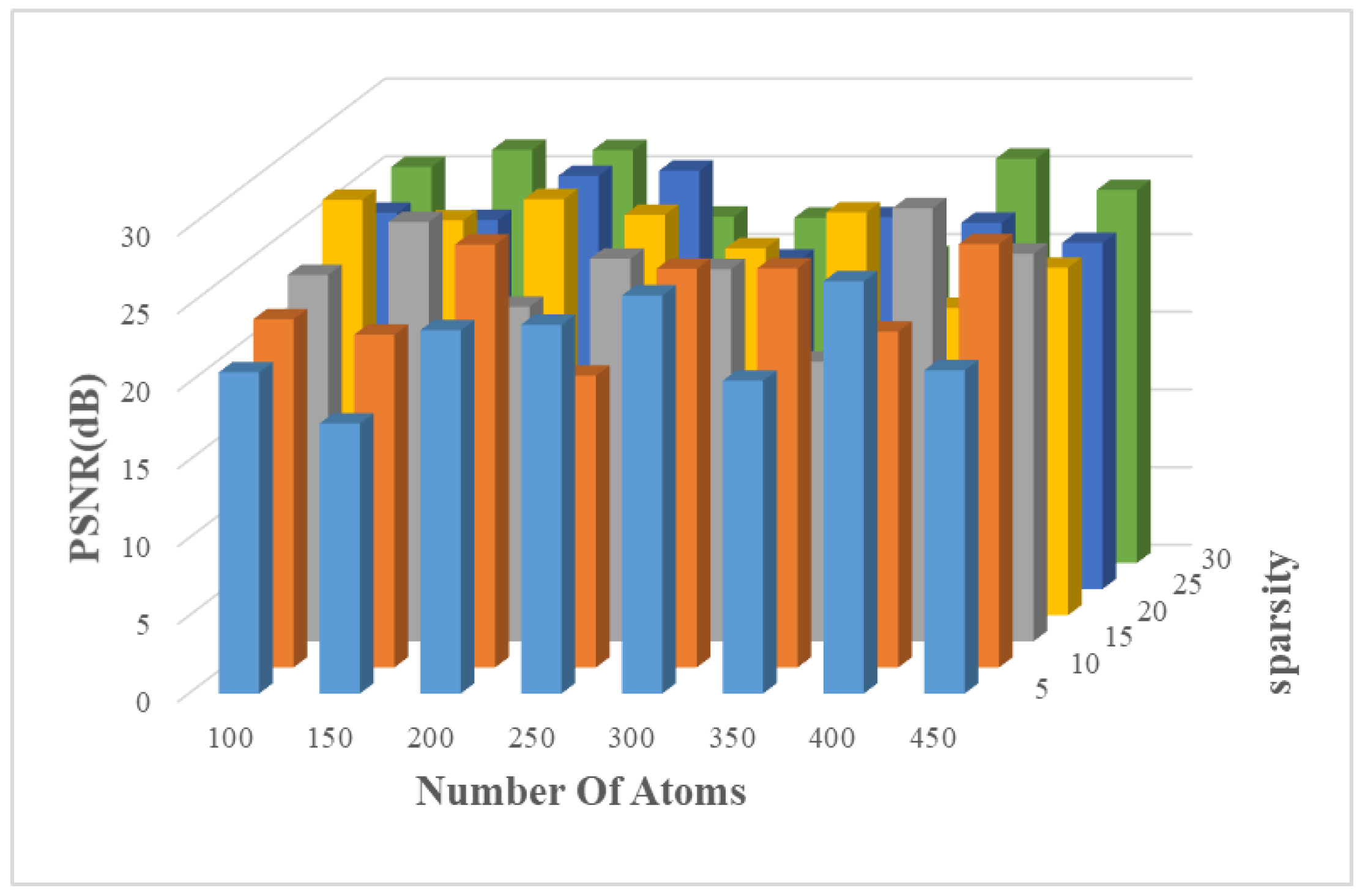
5.1.2. Dictionary Training
5.1.3. Sparse Reconstruction
5.1.4. Experiment Metrics
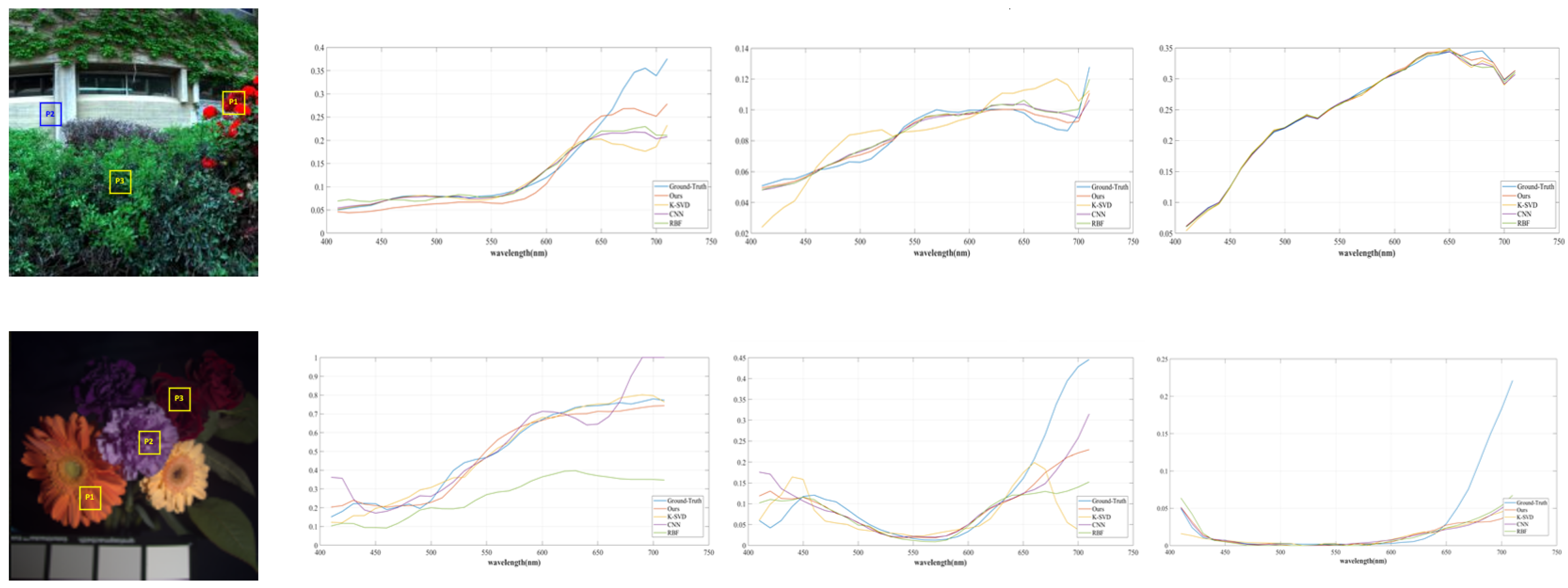
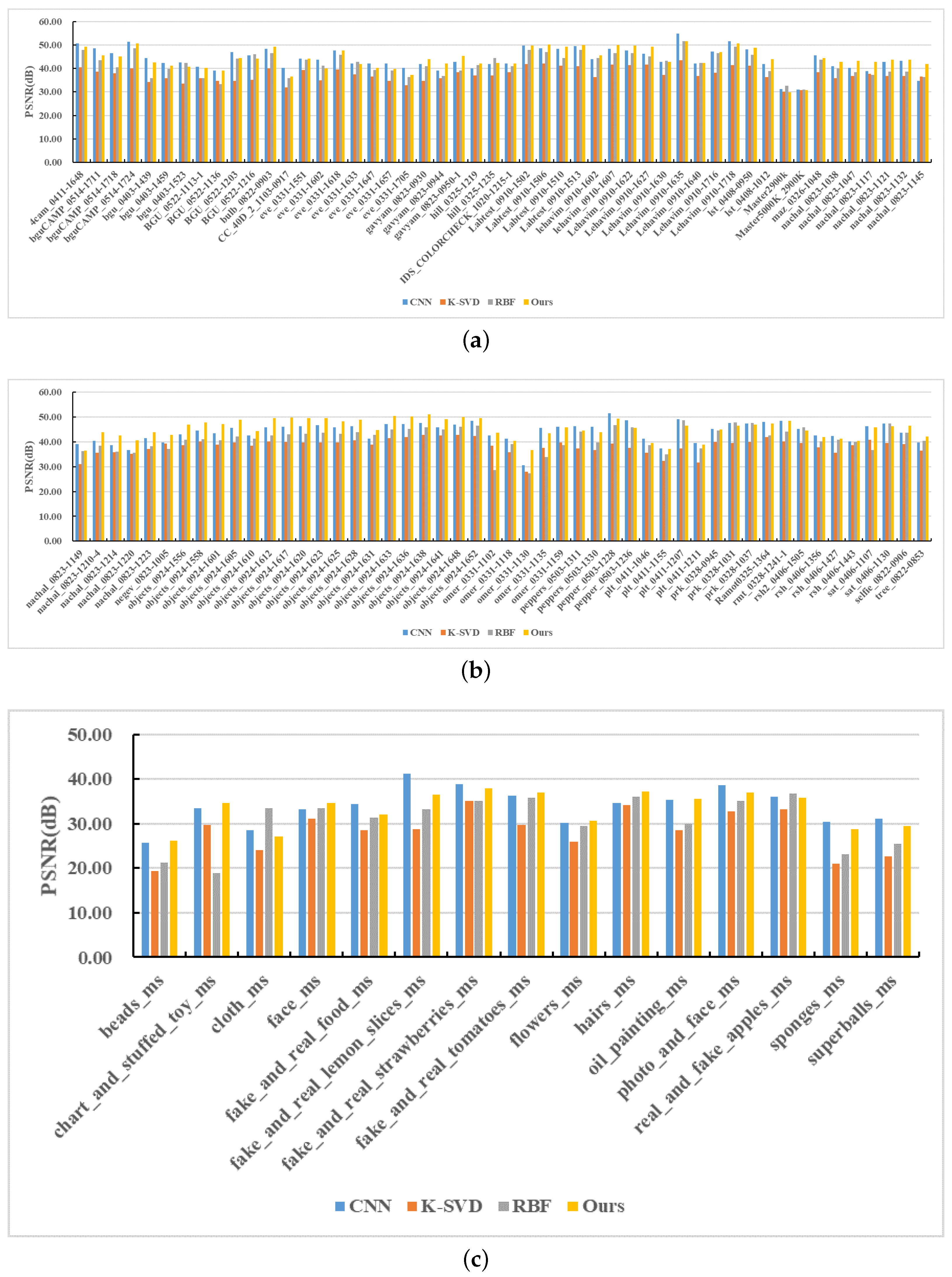
5.2. Quantitative and Qualitative Comparison Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011. [Google Scholar]
- Miao, C.; Pages, A.; Xu, Z.; Rodene, E.; Yang, J.; Schnable, J.C. Semantic segmentation of sorghum using hyperspectral data identifies genetic associations. Plant Phenomics 2020, 2020, 4216373. [Google Scholar] [CrossRef]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 10901. [Google Scholar] [CrossRef] [PubMed]
- Briottet, X.; Boucher, Y.; Dimmeler, A.; Malaplate, A.; Cini, A.; Diani, M.; Bekman, H.; Schwering, P.; Skauli, T.; Kasen, I.; et al. Military applications of hyperspectral imagery. In Targets and backgrounds XII: Characterization and Representation; SPIE: Bellingham, WA, USA, 2006; Volume 6239, pp. 82–89. [Google Scholar]
- Stuart, M.B.; McGonigle, A.J.; Willmott, J.R. Hyperspectral imaging in environmental monitoring: A review of recent developments and technological advances in compact field deployable systems. Sensors 2019, 19, 3071. [Google Scholar] [CrossRef]
- Manolakis, D.; Shaw, G. Detection algorithms for hyperspectral imaging applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Treado, P.; Nelson, M.; Gardner, C., Jr. Hyperspectral Imaging Sensor for Tracking Moving Targets. U.S. Patent 13/199,981, 15 March 2012. [Google Scholar]
- Nguyen, H.V.; Banerjee, A.; Chellappa, R. Tracking via object reflectance using a hyperspectral video camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 44–51. [Google Scholar]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chang, C.-I. Hyperspectral Imaging: Techniques for Spectral Detection and Classification; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 1. [Google Scholar]
- Mei, S.; Ji, J.; Hou, J.; Li, X.; Du, Q. Learning sensor-specific spatial-spectral features of hyperspectral images via convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4520–4533. [Google Scholar] [CrossRef]
- Mei, S.; Song, C.; Ma, M.; Xu, F. Hyperspectral image classification using group-aware hierarchical transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Lian, J.; Mei, S.; Zhang, S.; Ma, M. Benchmarking adversarial patch against aerial detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Mei, S.; Jiang, R.; Ma, M.; Song, C. Rotation-invariant feature learning via convolutional neural network with cyclic polar coordinates convolutional layer. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Mei, S. Rethinking transformers for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617515. [Google Scholar] [CrossRef]
- ElMasry, G.; Sun, D.-W. Principles of hyperspectral imaging technology. In Hyperspectral Imaging for Food Quality Analysis and Control; Elsevier: Amsterdam, The Netherlands, 2010; pp. 3–43. [Google Scholar]
- Wei, Q.; Bioucas-Dias, J.; Dobigeon, N.; Tourneret, J.-Y. Hyperspectral and multispectral image fusion based on a sparse representation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3658–3668. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z. Multi-focus image fusion based on sparse representation with adaptive sparse domain selection. In Proceedings of the 2013 Seventh International Conference on Image and Graphics, Qingdao, China, 26–28 July 2013; pp. 591–596. [Google Scholar]
- Ma, X.; Hu, S.; Liu, S.; Fang, J.; Xu, S. Remote sensing image fusion based on sparse representation and guided filtering. Electronics 2019, 8, 303. [Google Scholar] [CrossRef]
- Xia, K.-J.; Yin, H.-S.; Wang, J.-Q. A novel improved deep convolutional neural network model for medical image fusion. Clust. Comput. 2019, 22, 1515–1527. [Google Scholar] [CrossRef]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural rgb images. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 19–34. [Google Scholar]
- Nguyen, R.M.; Prasad, D.K.; Brown, M.S. Training-based spectral reconstruction from a single rgb image. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VII 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 186–201. [Google Scholar]
- Aeschbacher, J.; Wu, J.; Timofte, R. In defense of shallow learned spectral reconstruction from rgb images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Stiebel, T.; Koppers, S.; Seltsam, P.; Merhof, D. Reconstructing spectral images from rgb-images using a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 948–953. [Google Scholar]
- Stigell, P.; Miyata, K.; Hauta-Kasari, M. Wiener estimation method in estimating of spectral reflectance from rgb images. Pattern Recognit. Image Anal. 2007, 17, 233–242. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, L.; Li, J.; Wei, W.; Zhang, Y. Accurate spectral super-resolution from single rgb image using multi-scale cnn. In Proceedings of the Pattern Recognition and Computer Vision: First Chinese Conference, PRCV 2018, Guangzhou, China, 23–26 November 2018; Proceedings, Part II 1. Springer: Berlin/Heidelberg, Germany, 2018; pp. 206–217. [Google Scholar]
- Banerjee, A.; Palrecha, A. Mxr-u-nets for real time hyperspectral reconstruction. arXiv 2020, arXiv:2004.07003. [Google Scholar]
- Zhao, Y.; Po, L.-M.; Yan, Q.; Liu, W.; Lin, T. Hierarchical regression network for spectral reconstruction from rgb images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 422–423. [Google Scholar]
- Xiong, Z.; Shi, Z.; Li, H.; Wang, L.; Liu, D.; Wu, F. Hscnn: Cnn-based hyperspectral image recovery from spectrally undersampled projections. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 October 2017; pp. 518–525. [Google Scholar]
- Koundinya, S.; Sharma, H.; Sharma, M.; Upadhyay, A.; Manekar, R.; Mukhopadhyay, R.; Karmakar, A.; Chaudhury, S. 2d-3d cnn based architectures for spectral reconstruction from rgb images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 844–851. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Xie, W.; Ge, C.; Li, B.; Li, Y. Hybrid 2-d–3-d deep residual attentional network with structure tensor constraints for spectral super-resolution of rgb images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2321–2335. [Google Scholar] [CrossRef]
- Peng, H.; Chen, X.; Zhao, J. Residual pixel attention network for spectral reconstruction from rgb images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 486–487. [Google Scholar]
- Yi, C.; Zhao, Y.-Q.; Chan, J.C.-W. Spectral super-resolution for multispectral image based on spectral improvement strategy and spatial preservation strategy. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9010–9024. [Google Scholar] [CrossRef]
- Timofte, R.; Smet, V.D.; Gool, L.V. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Revised Selected Papers, Part IV 12. Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–126. [Google Scholar]
- Mei, S.; Geng, Y.; Hou, J.; Du, Q. Learning hyperspectral images from rgb images via a coarse-to-fine cnn. Sci. China Inf. Sci. 2022, 65, 1–14. [Google Scholar] [CrossRef]
- Mei, S.; Zhang, G.; Wang, N.; Wu, B.; Ma, M.; Zhang, Y.; Feng, Y. Lightweight multiresolution feature fusion network for spectral super-resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Chakrabarti, A.; Zickler, T. Statistics of real-world hyperspectral images. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 20–25 June 2011; pp. 193–200. [Google Scholar]
- Peng, J.; Huang, Y.; Sun, W.; Chen, N.; Ning, Y.; Du, Q. Domain adaptation in remote sensing image classification: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9842–9859. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, J.; Sun, W.; Chen, N.; Du, Q.; Ning, Y.; Su, H. Two-branch attention adversarial domain adaptation network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, J.; Chen, N.; Sun, W.; Du, Q.; Ren, K.; Huang, K. Cross-scene wetland mapping on hyperspectral remote sensing images using adversarial domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2023, 203, 37–54. [Google Scholar] [CrossRef]
- Tominaga, S.; Wandell, B.A. Standard surface-reflectance model and illuminant estimation. JOSA A 1989, 6, 576–584. [Google Scholar] [CrossRef]
- Geng, Y.; Mei, S.; Tian, J.; Zhang, Y.; Du, Q. Spatial constrained hyperspectral reconstruction from rgb inputs using dictionary representation. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3169–3172. [Google Scholar]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Bader, B.W.; Kolda, T.G. Algorithm 862: Matlab tensor classes for fast algorithm prototyping. ACM Trans. Math. Softw. (TOMS) 2006, 32, 635–653. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm as 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-svd: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized assorted pixel camera: Postcapture control of resolution, dynamic range, and spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Arad, B.; Ben-Shahar, O.; Timofte, R.; Gool, L.V.; Zhang, L.; Yang, M. Ntire 2018 challenge on spectral reconstruction from rgb images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; p. 1042. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CAVE | ICVL | |
|---|---|---|
| Camera | Cooled CCD camera | Specim PS Kappa DX4 |
| Resolution | 512 × 512 pixel | 1392 × 1300 pixel |
| Illuminant | CIE Standard Illuminant D65 | Natural sunlight |
| Range of wavelength | 400–700 nm | 400–700 nm |
| Steps | 10 nm | 10 nm |
| Number of bands | 31 | 31 |
| Image format | 16 bit | 12 bit |
| Methods | RMSE | PSNR | SSIM | SAM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| max | mean | std | min | mean | std | min | mean | std | max | mean | std | ||
| ICVL | K-SVD | 0.0404 | 0.0136 | 0.0056 | 27.88 | 37.90 | 3.08 | 0.8804 | 0.9571 | 0.0194 | 0.2038 | 0.1030 | 0.0293 |
| RBF | 0.0432 | 0.0097 | 0.0064 | 27.29 | 41.65 | 4.65 | 0.9130 | 0.9858 | 0.0112 | 0.1187 | 0.0485 | 0.0163 | |
| CNN | 0.0296 | 0.0072 | 0.0047 | 30.57 | 44.03 | 4.42 | 0.9653 | 0.9914 | 0.0063 | 0.1062 | 0.0397 | 0.0137 | |
| Ours | 0.0321 | 0.0067 | 0.0045 | 29.87 | 44.66 | 4.35 | 0.9679 | 0.9907 | 0.0062 | 0.1168 | 0.0407 | 0.0168 | |
| CAVE | K-SVD | 0.1066 | 0.0445 | 0.0268 | 19.44 | 28.33 | 4.81 | 0.7481 | 0.9033 | 0.0630 | 0.5360 | 0.4216 | 0.0702 |
| RBF | 0.1137 | 0.0373 | 0.0300 | 18.89 | 30.61 | 5.78 | 0.7536 | 0.9331 | 0.0585 | 0.4410 | 0.2660 | 0.0782 | |
| CNN | 0.0519 | 0.0226 | 0.0115 | 25.69 | 33.86 | 4.19 | 0.8815 | 0.9556 | 0.0268 | 0.3431 | 0.2017 | 0.0525 | |
| Ours | 0.0495 | 0.0238 | 0.0120 | 26.11 | 33.40 | 3.99 | 0.8973 | 0.9433 | 0.0191 | 0.3107 | 0.2217 | 0.0492 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, Y.; Wang, N.; Zhang, Y.; Song, C. Tensor-Based Sparse Representation for Hyperspectral Image Reconstruction Using RGB Inputs. Mathematics 2024, 12, 708. https://doi.org/10.3390/math12050708
Duan Y, Wang N, Zhang Y, Song C. Tensor-Based Sparse Representation for Hyperspectral Image Reconstruction Using RGB Inputs. Mathematics. 2024; 12(5):708. https://doi.org/10.3390/math12050708
Chicago/Turabian StyleDuan, Yingtao, Nan Wang, Yifan Zhang, and Chao Song. 2024. "Tensor-Based Sparse Representation for Hyperspectral Image Reconstruction Using RGB Inputs" Mathematics 12, no. 5: 708. https://doi.org/10.3390/math12050708
APA StyleDuan, Y., Wang, N., Zhang, Y., & Song, C. (2024). Tensor-Based Sparse Representation for Hyperspectral Image Reconstruction Using RGB Inputs. Mathematics, 12(5), 708. https://doi.org/10.3390/math12050708