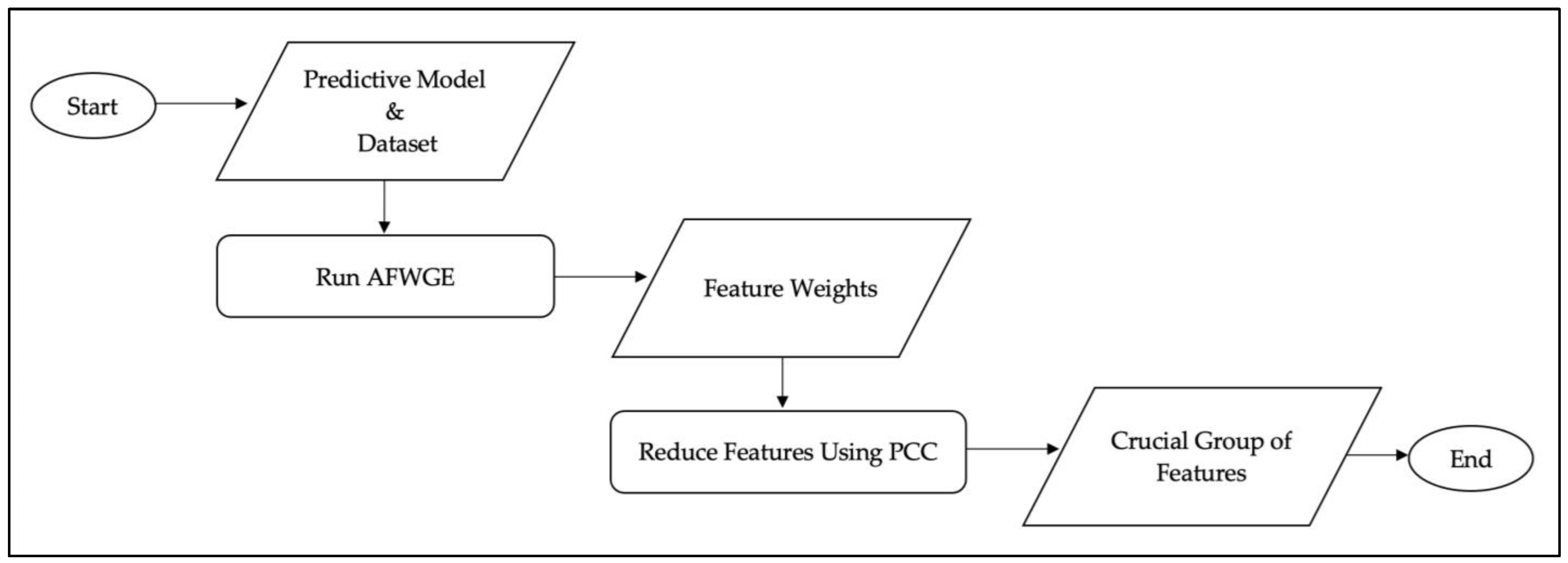
5.2.1. PCC Results
Examining the heatmaps of the Pearson correlation coefficients for the Adult, Breast Cancer, Pima Indians Diabetes, and Iris datasets was crucial for understanding the relationships between features in each dataset. These heatmaps are visual representations of the strength and direction of the linear relationship between two features. These give insights into the relevance of features and possible redundancies. Moreover, the heatmaps demonstrate how the different inputs used to compute the PCC for each method can impact the correlation values for each dataset, as shown next. This comparison highlights how the AFWGE feature weights serve as indicators of feature correlations compared to the number of feature changes in CERTIFAI and the original feature values.
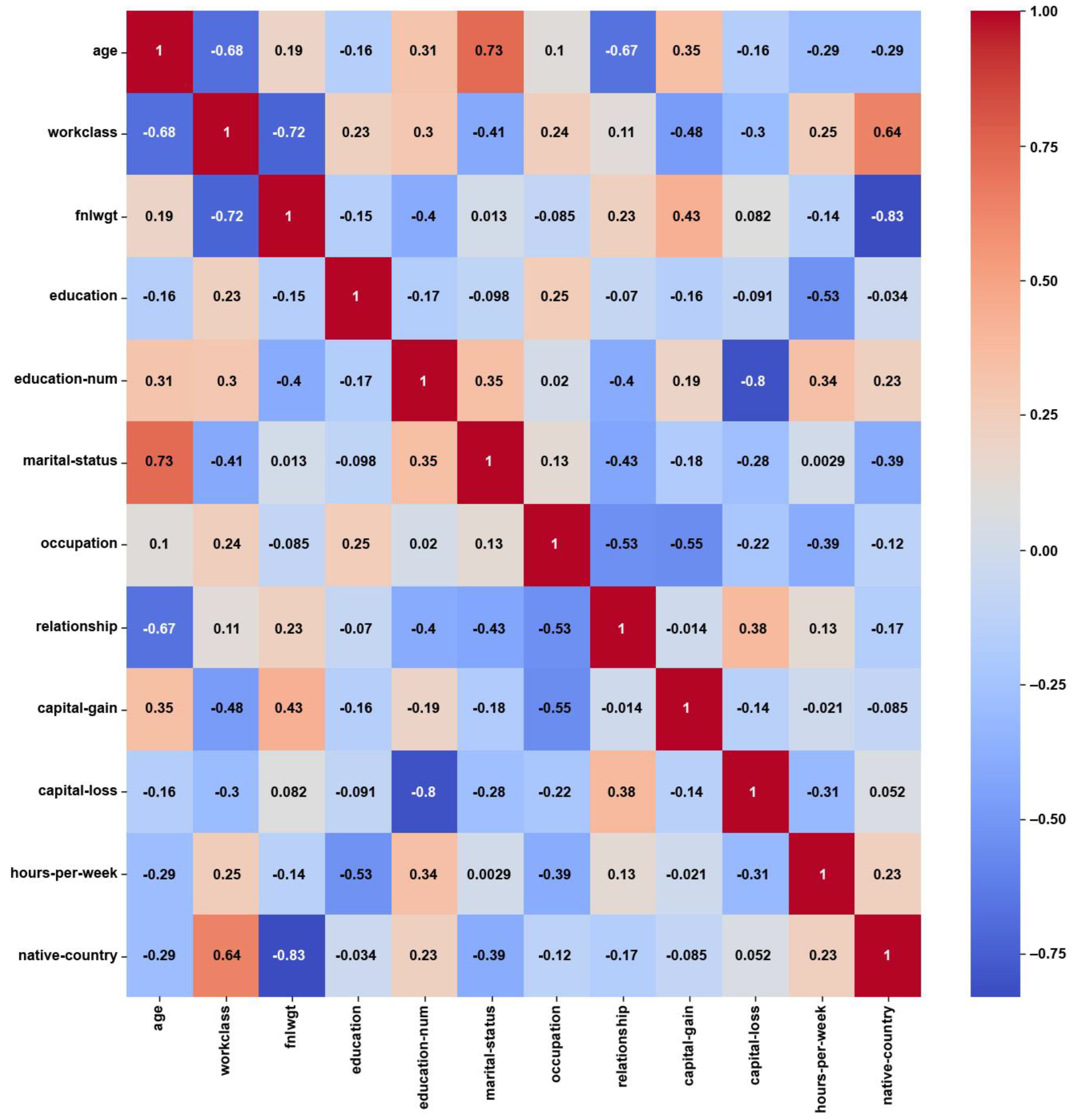
For the Adult dataset, the heatmap in
Figure 3 shows weak correlations, with maximum PCC values of around ±0.3, which might have been caused by the notable class imbalance. About 75% of the instances belong to the ‘income ≤ 50 K’ class, while the remaining 25% belong to the ‘income > 50 K’ class. On the other hand, the feature weights by AFWGE (
Figure 4) and the number of feature changes by CERTIFAI (
Figure 5) show higher correlations, with maximum PCC values of around ±0.8 and ±0.7, respectively. These high correlations are not due to the unified numerical type of features (i.e., the weights by AFWGE or the number of changes by CERTIFAI); rather, the weights of the features by AFWGE and the number of feature changes by CERTIFAI seem to provide more efficient encoding of categorical features and expressing all features, in general, to interpret correlations accurately.
This dataset is balanced with two classes (malignant and benign), consisting entirely of numerical features related to medical measurements, and is likely to show stronger and more meaningful correlations. The heatmap of the Original Data PCC using the feature values from the Breast Cancer dataset in
Figure 6 shows strong correlations, with maximum PCC values of around 0.9 and PCC values of at least 0.7 for most features; it represents 21% of all feature correlation pairs (92 pairs out of 435). Ambiguity is introduced by the high correlations among the features since feature selection methods might struggle to distinguish which feature to keep when multiple features are highly correlated. This can lead to uncertain decisions about which features are truly significant, potentially leading to the exclusion of valuable features or the inclusion of redundant ones [
37]. On the other hand, the feature weights of AFWGE (
Figure 7) and the number of feature changes of CERTIFAI (
Figure 8) show how these high correlations are filtered by eliminating a number of them. Feature correlation pairs with PCC values of at least 0.7 were eliminated by AFWGE (15 pairs out of 435) and CERTIFAI (20 pairs out of 435). This filtration prevents ambiguity in the feature selection process.
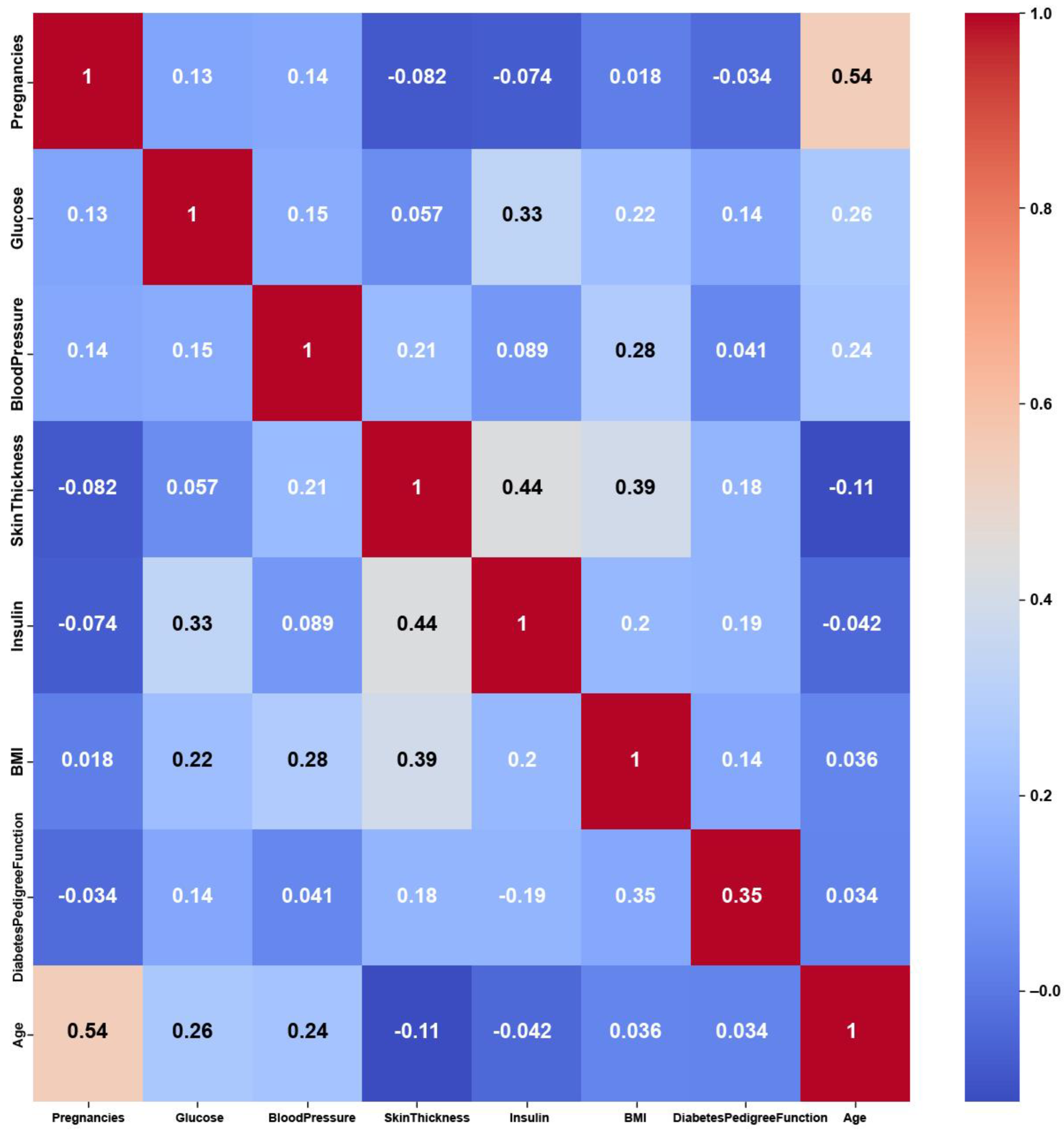
The Pima Indians Diabetes dataset consists of numerical features, yet it shows weak correlations among these features, as shown in
Figure 9, with maximum PCC values of around 0.5. The weak correlations might have been due to dataset imbalance, with 35% labeled as diabetic and 65% of the instances labeled as nondiabetic. Nevertheless, the features might not be strongly correlated with each other, but they are still relevant for predicting diabetes. On the other hand, the feature weights of AFWGE (
Figure 10) and the number of feature changes of CERTIFAI (
Figure 11) show higher correlations than Original Data. However, they still do not have strong PCC values, i.e., not exceeding 0.6 for either AFWGE or CERTIFAI.
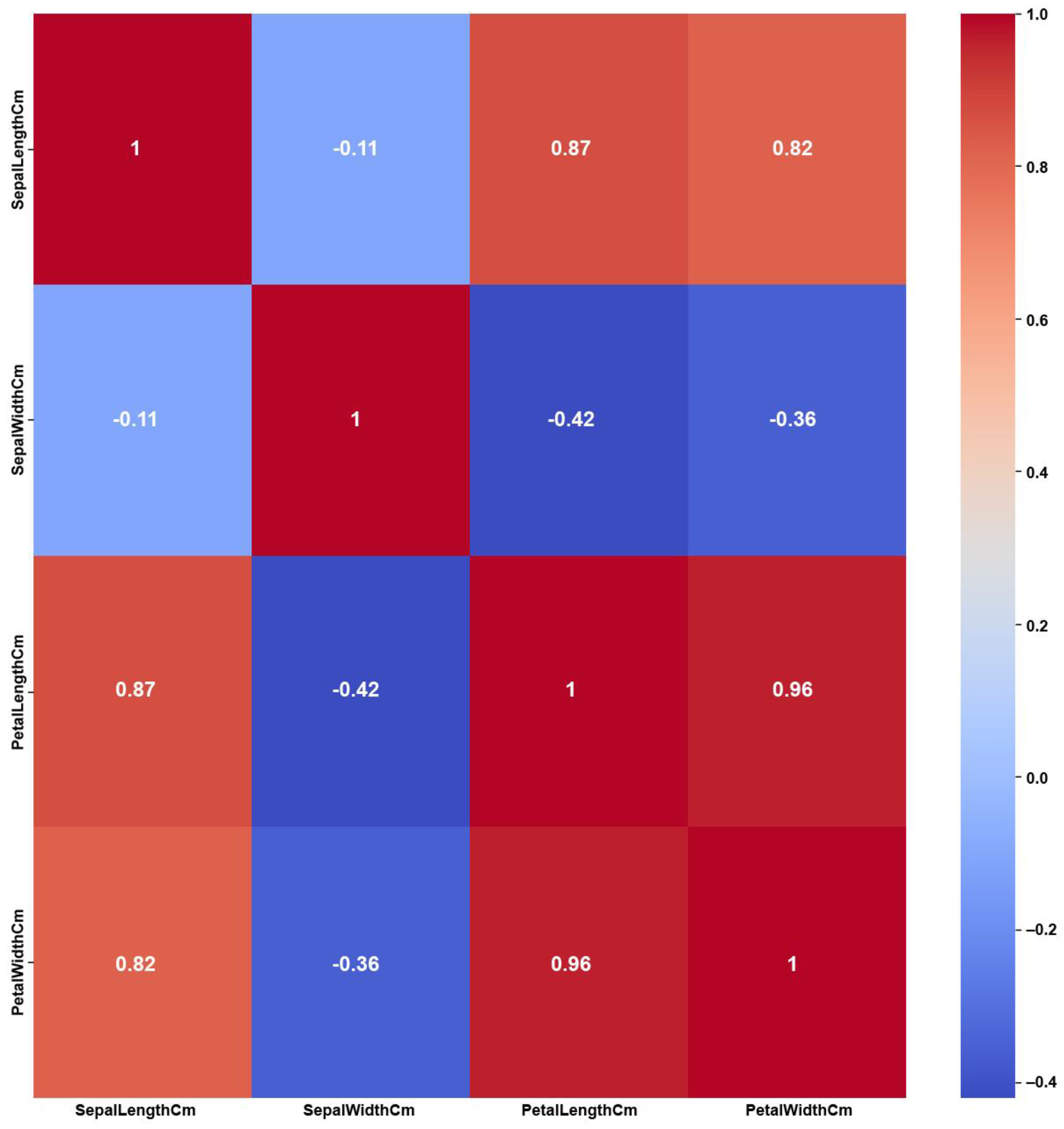
The Iris dataset’s simplicity, having a small number of features and balanced classes, shows clear and strong correlations among the features, as shown in the Original Data heatmap (
Figure 12). The figure shows a maximum PCC value of around 0.9 and PCC values of at least 0.8 for most of the features, i.e., 50% of all feature correlation pairs (three pairs out of six). Again, as previously discussed in the Breast Cancer case, this high amount of feature correlations can lead to ambiguous decisions in feature selection. However, the feature weights of AFWGE (
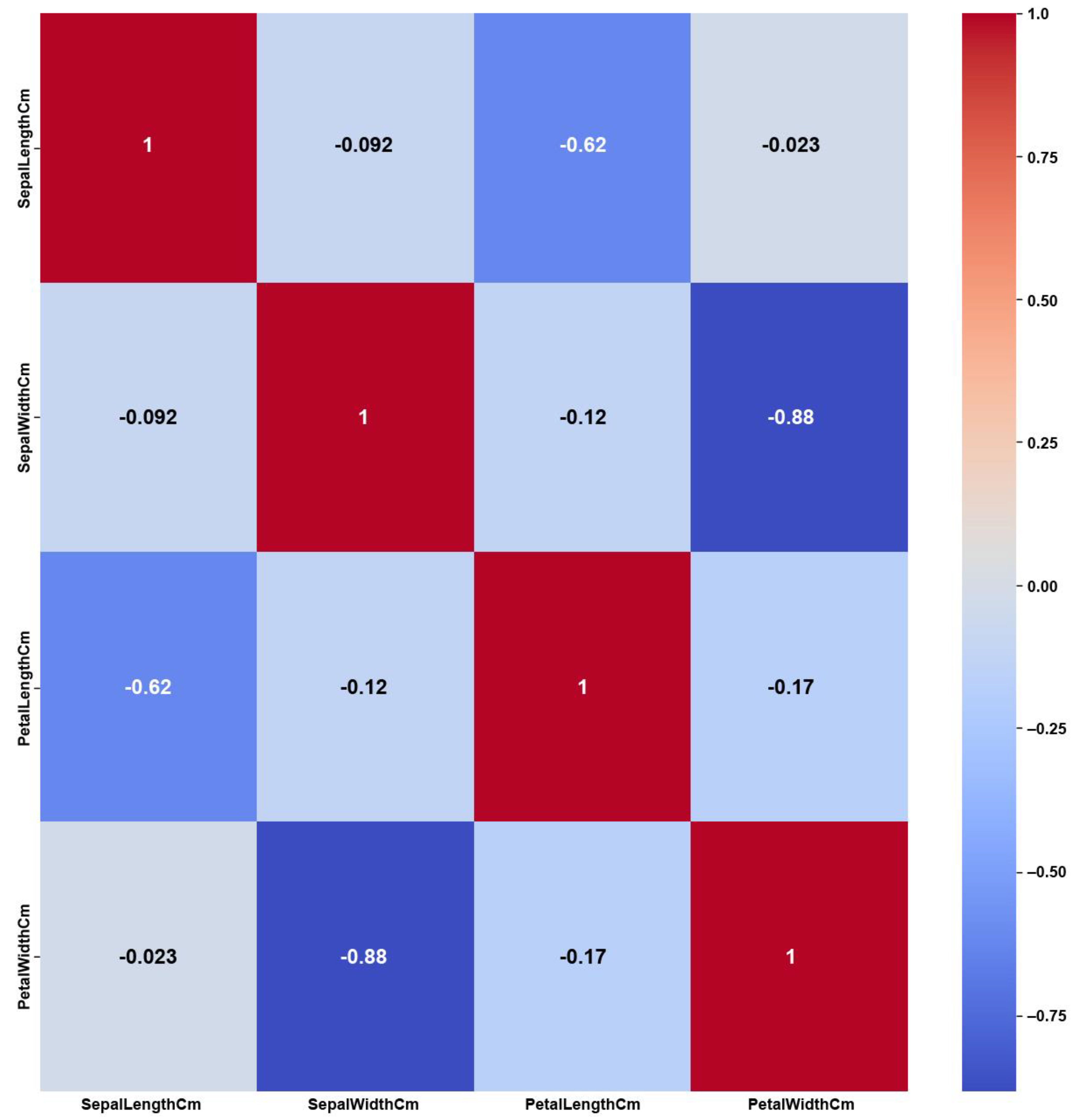
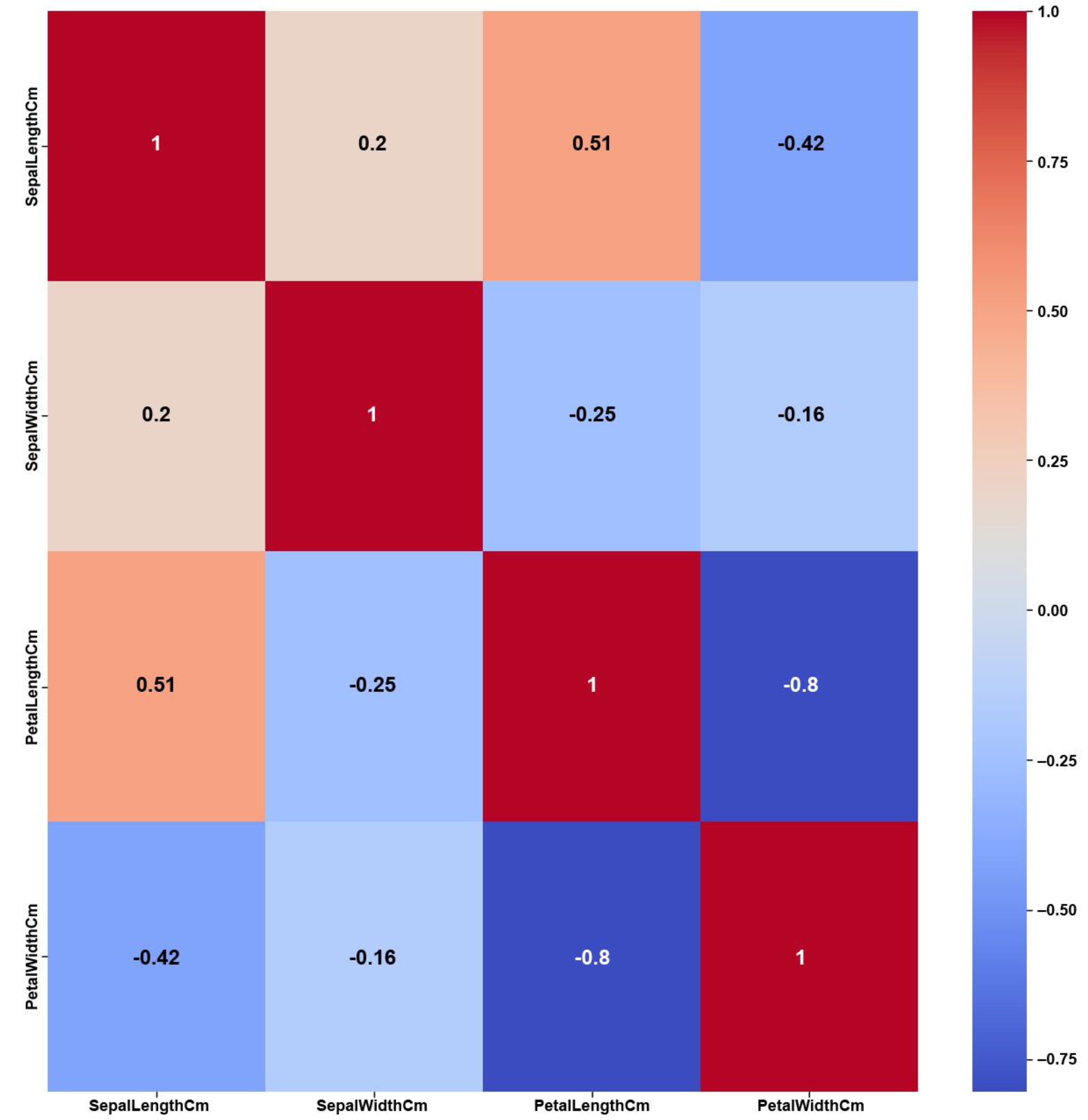
Figure 13) and the number of feature changes by CERTIFAI (
Figure 14) show how these high correlations are filtered by eliminating a number of them, which helps to prevent ambiguity in the feature selection process. Feature correlation pairs with PCC values of at least 0.8 were eliminated in AFWGE and in CERTIFAI (i.e., from three pairs to one pair out of six).
5.2.2. Accuracy
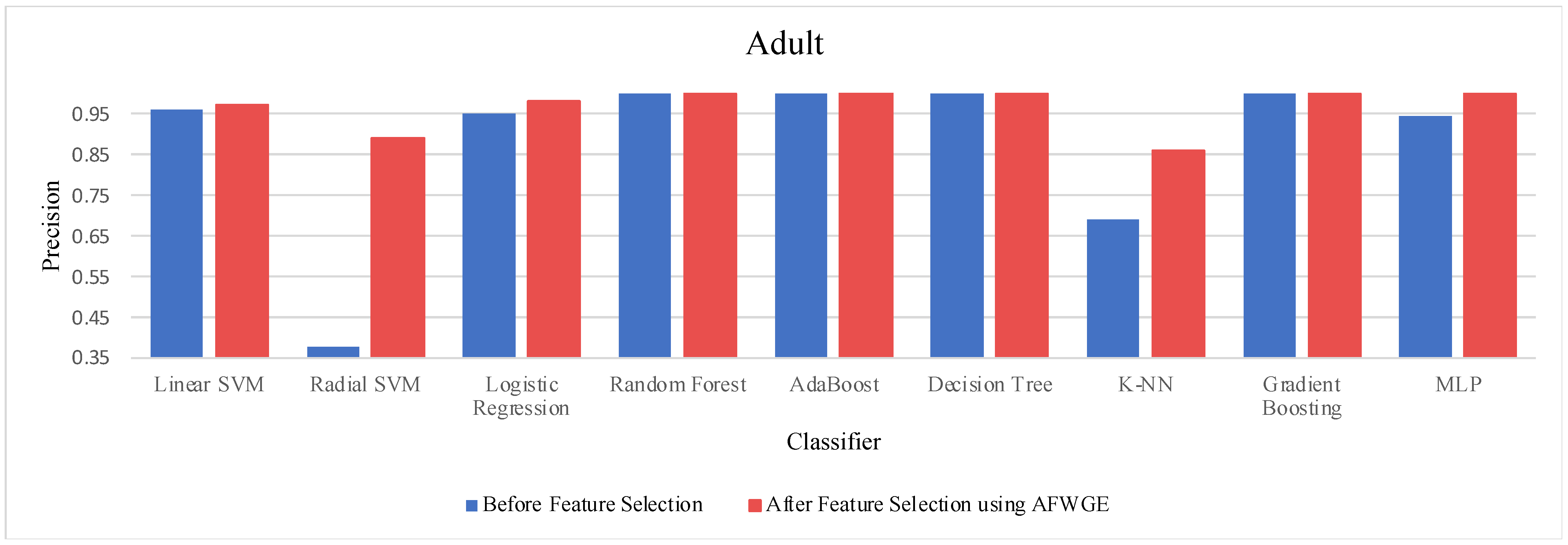
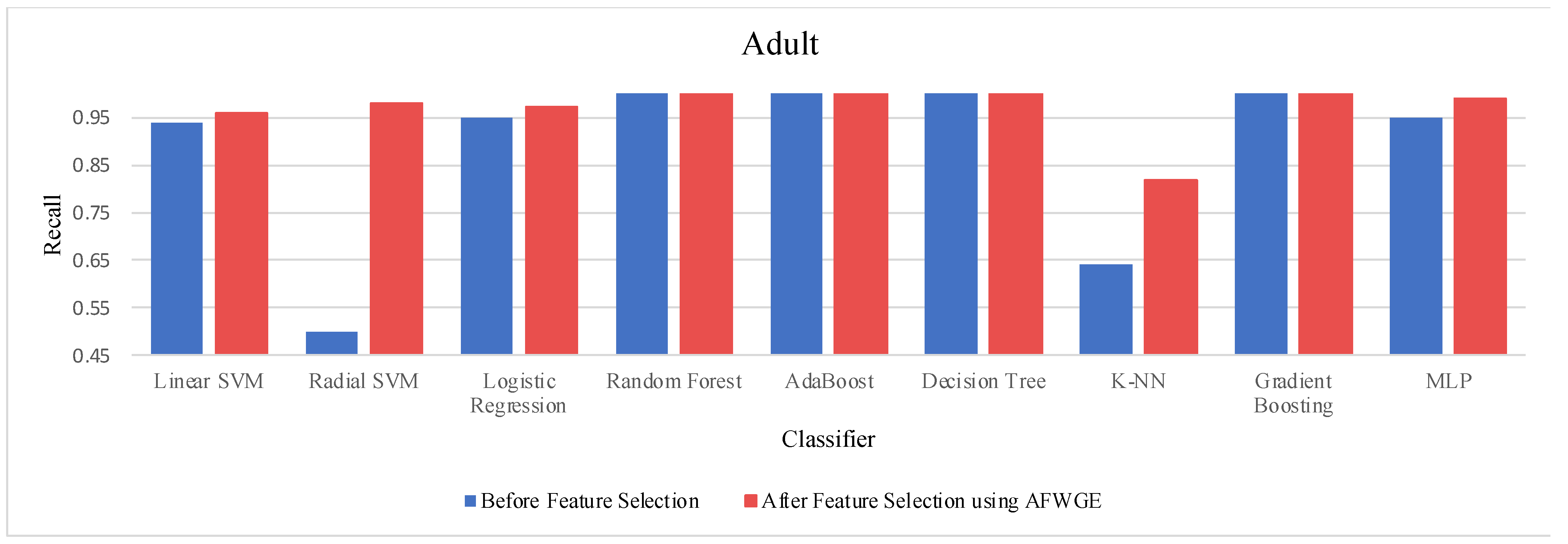
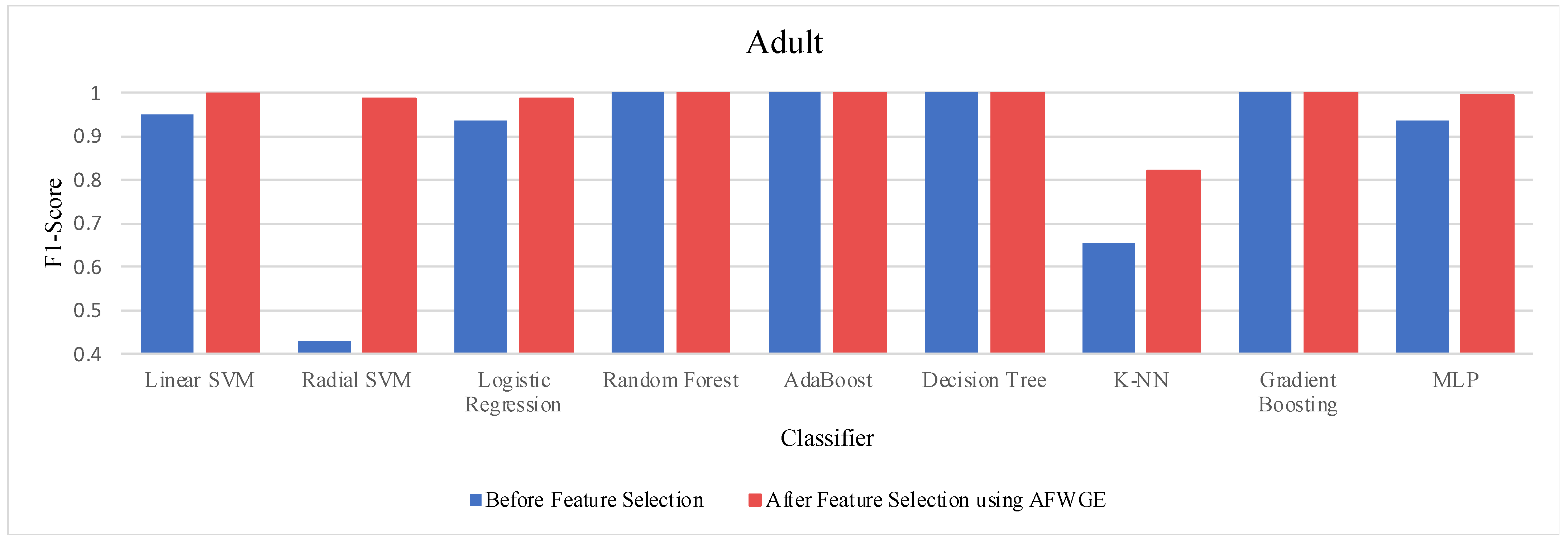
When comparing the performance using all features against the performance using only the important group of features across the three methods—Original Data, CERTIFAI, and AFWGE—on the Adult dataset, we obtained distinct outcomes, as shown in
Table 3. For Original Data, there was no change in the accuracy of any of the nine classifiers. In contrast, the AFWGE method achieved enhanced accuracies for the L-SVM, R-SVM, LR, K-NN, and MLP classifiers, while the accuracies for RF, AdaBoost, DT, and Gradient Boosting remained unchanged. Meanwhile, the CERTIFAI method did not affect the accuracies of most classifiers; however, it led to an improvement in the K-NN classifier’s accuracy and a reduction in the MLP classifier’s accuracy.
The percentage change in accuracy across Original Data, AFWGE, and CERTIFAI reflects how each of the resulting groups of features affects the model’s ability to classify instances correctly. When comparing the values in
Table 3, we can identify which method performs best and which performs worst. A positive percentage change in accuracy (highlighted in purple) indicates improvement, while a negative percentage change (highlighted in orange) indicates a reduction. The method with the highest percentage change (in bold) had the most significant positive impact on accuracy. In
Table 2, the group of features selected by AFWGE shows the highest positive changes across multiple classifiers.
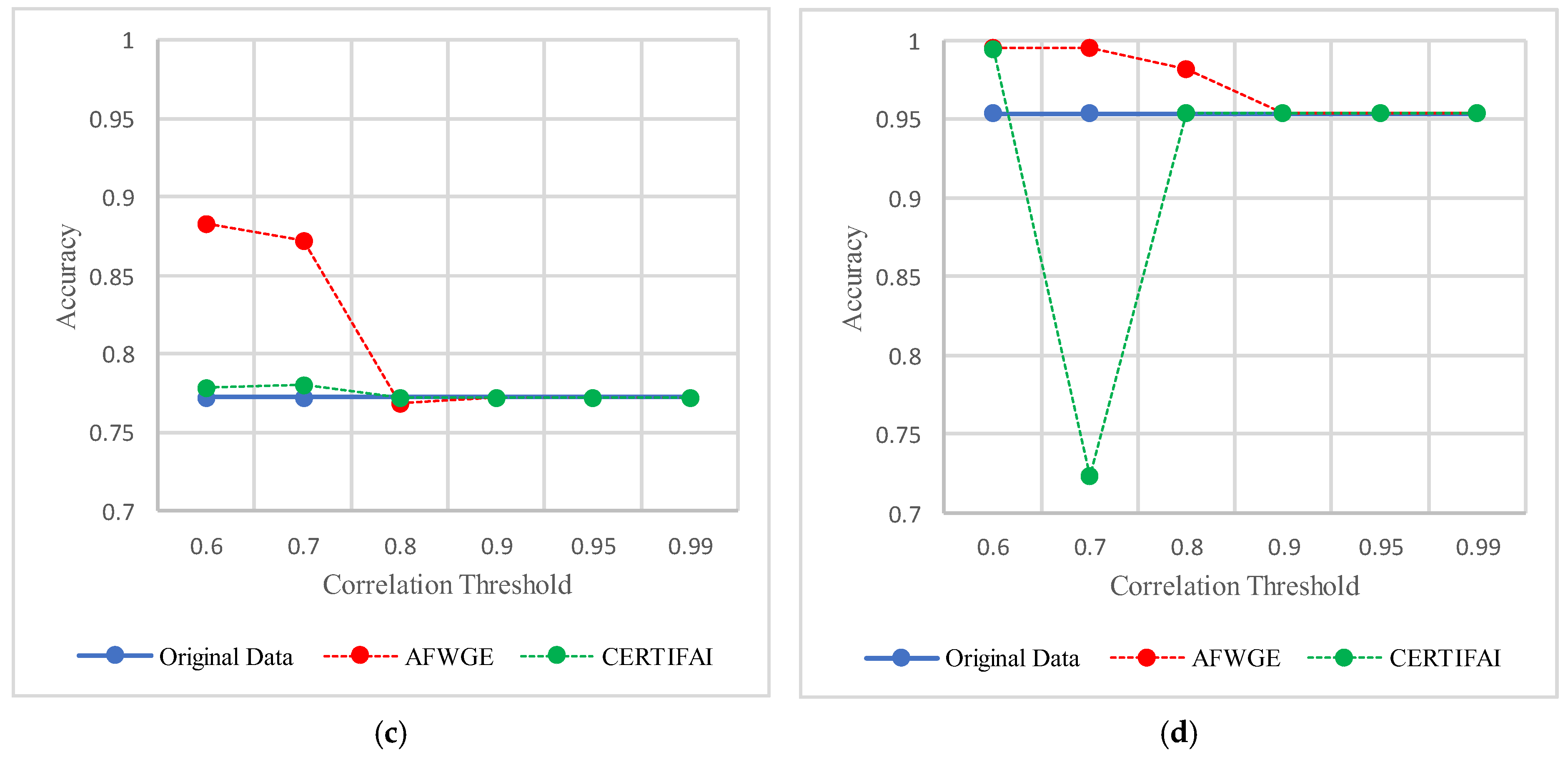
The threshold values for the PCCs were 0.6 and 0.7 for selecting the crucial group of features. The performance in terms of accuracy was the best for the most affected classifiers with the selected features at these thresholds, as shown in
Figure 15. This increase in accuracy suggests that the features chosen at these PCC thresholds capture the main characteristics of the data, leading to the enhanced predictive performance of the classifiers.
Moreover, we conducted a Wilcoxon signed rank test to see if there was a statistically significant difference between the classifiers’ accuracies before and after using the group of features selected by AFWGE. The Wilcoxon test uses the following null (h
0) and alternative (h
A) hypotheses: h
0: the average value of accuracies is equal between the two groups; h
A: the average value of accuracies is not equal between the two groups. The test indicates that there was, indeed, a significant difference (at a significance level of α = 0.05); thus, the null hypothesis was rejected. This is verification that the average value of accuracies after using the selected feature group of AFWGE is significantly better than using all the Adult dataset features (
Figure 16).
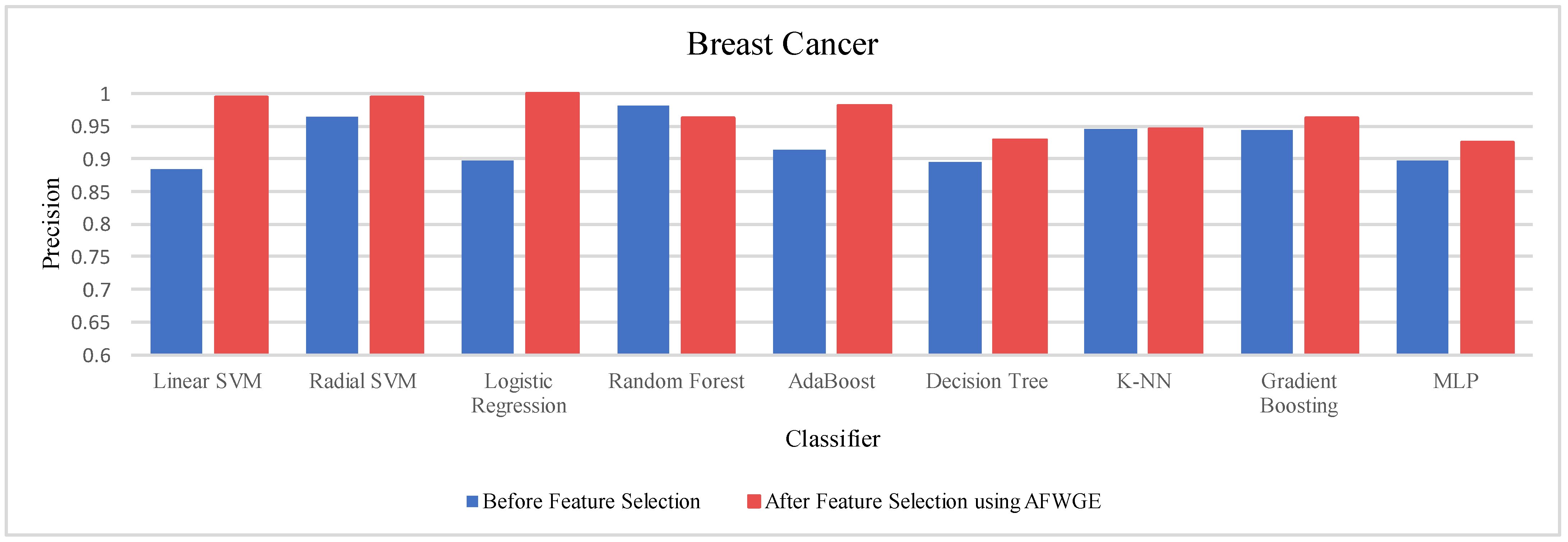
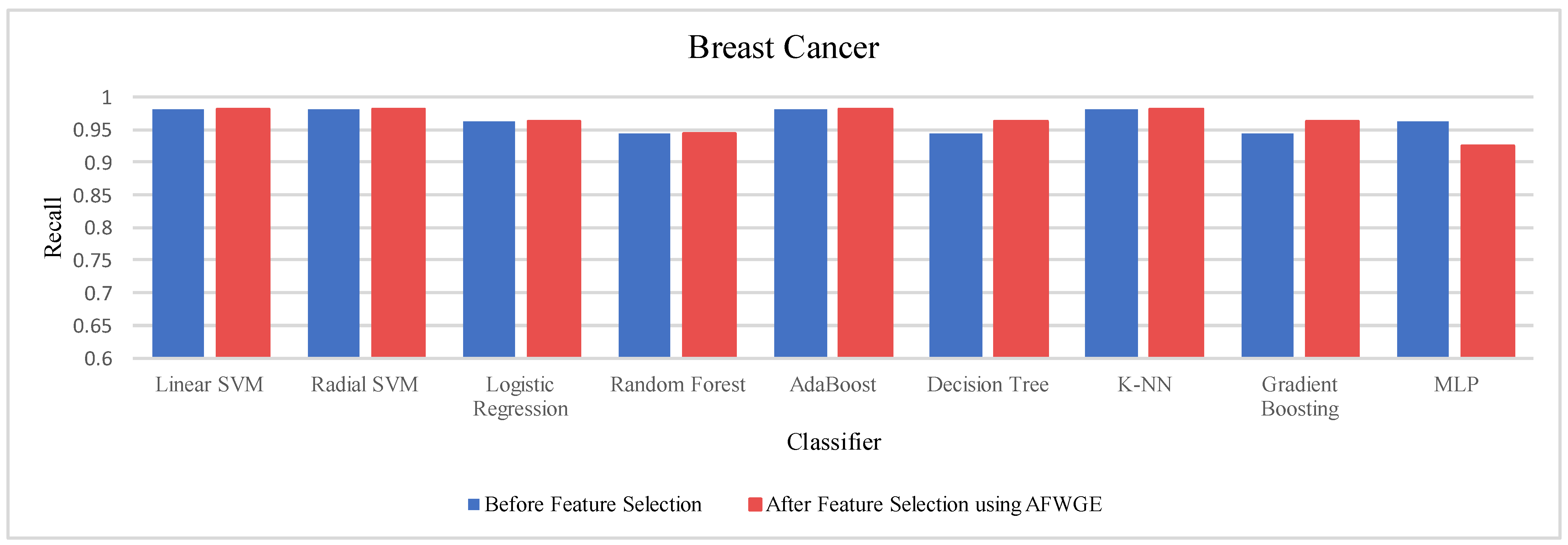
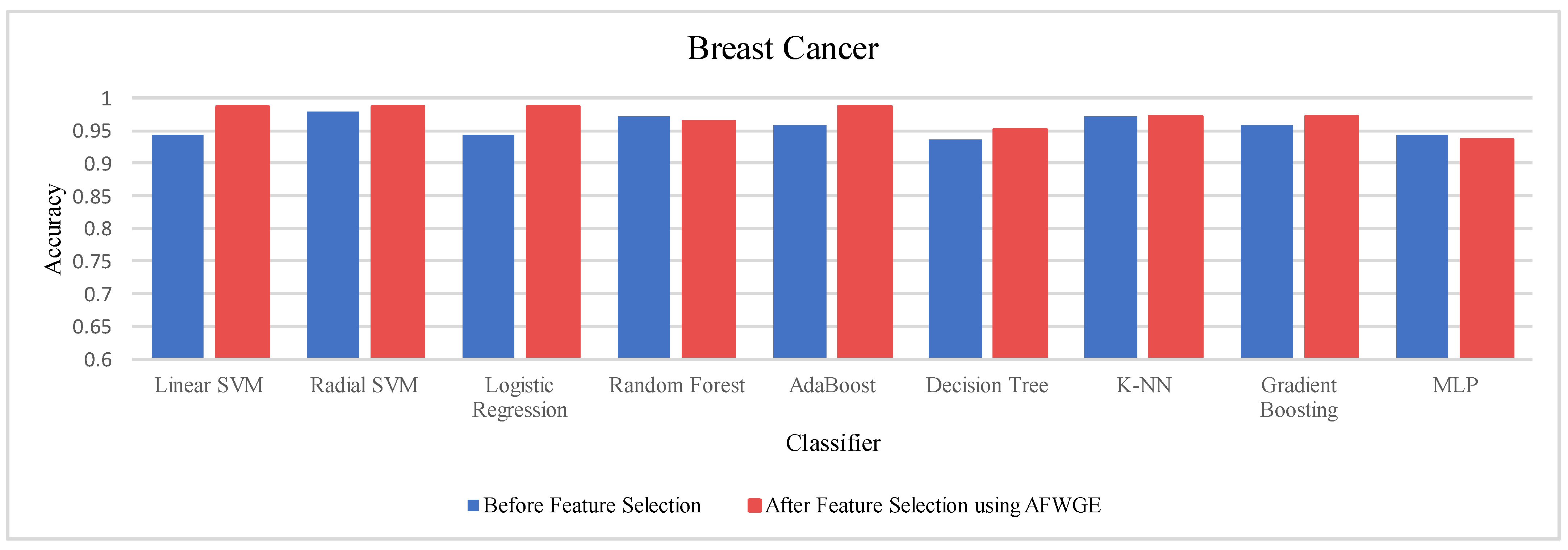
Table 4 shows the performance results of the three methods —Original Data, CERTIFAI, and AFWGE—on the Breast Cancer dataset. The results in
Table 3 reveal the following findings: For Original Data, all nine classifiers, except L-SVM and LR, dropped in accuracy. In contrast, using AFWGE resulted in better accuracies for the L-SVM, R-SVM, LR, AdaBoost, DT, and Gradient Boosting classifiers while that for the K-NN classifier remained the same. However, there was a resultant decrease in accuracy for the RF and MLP classifiers. In contrast, when using the CERTIFAI method, the L-SVM, LR, DT, and Gradient Boosting classifiers showed enhanced accuracy, while there was a decrease in the accuracy of the R-SVM, RF, AdaBoost, K-NN, and MLP classifiers.
Again, from
Table 4, the percentage changes in accuracy for the Original Data, AFWGE, and CERTIFAI methods reveal how each method’s resulting group of features impacts the model’s ability to classify instances correctly. From this table, it is obvious that the group of features of AFWGE shows the highest positive changes across multiple classifiers.
For the Breast Cancer dataset, the most important group of features was selected when the PCC threshold was equal to 0.6, 0.7, and 0.8. The selected features at these thresholds provided the best performance in terms of accuracy for the most affected classifiers, as shown in
Figure 17. The selected features at these PCC thresholds capture the important characteristics of the data, enhancing the accuracy performance of the classifiers.
Again, the results were subjected to a Wilcoxon signed rank test to test the statistically significant difference between the classifier’s accuracies before and after using AFWGE’s selected group of features. Additionally, the test indicated that there was a significant difference at a significance level of α = 0.05; thus, the null hypothesis was rejected. This is verification that the average value of accuracy after using AFWGE’s selected crucial features is significantly better than that using all the Breast Cancer dataset features (
Figure 18).
Table 5 demonstrates the accuracy results on the Pima Indians Diabetes dataset for the three compared methods. When evaluating the results in
Table 4, we observed distinct patterns, whereas, for Original Data, there was no change in the accuracy for any of the nine classifiers. In contrast, AFWGE improved the accuracies of the L-SVM, LR, RF, and MLP classifiers, though it had no effect on the R-SVM, AdaBoost, or DT classifiers. However, the accuracies of the K-NN and Gradient Boosting classifiers went down. For the CERTIFAI approach, the accuracy for the LR, AdaBoost, and K-NN classifiers increased, and the accuracy of the L-SVM, R-SVM, RF, DT, Gradient Boosting, and MLP classifiers decreased.
Again, from
Table 5, the most important group of features of AFWGE shows the highest positive changes across multiple classifiers for the Pima Indians Diabetes dataset, indicating the best performance among the three rival methods.
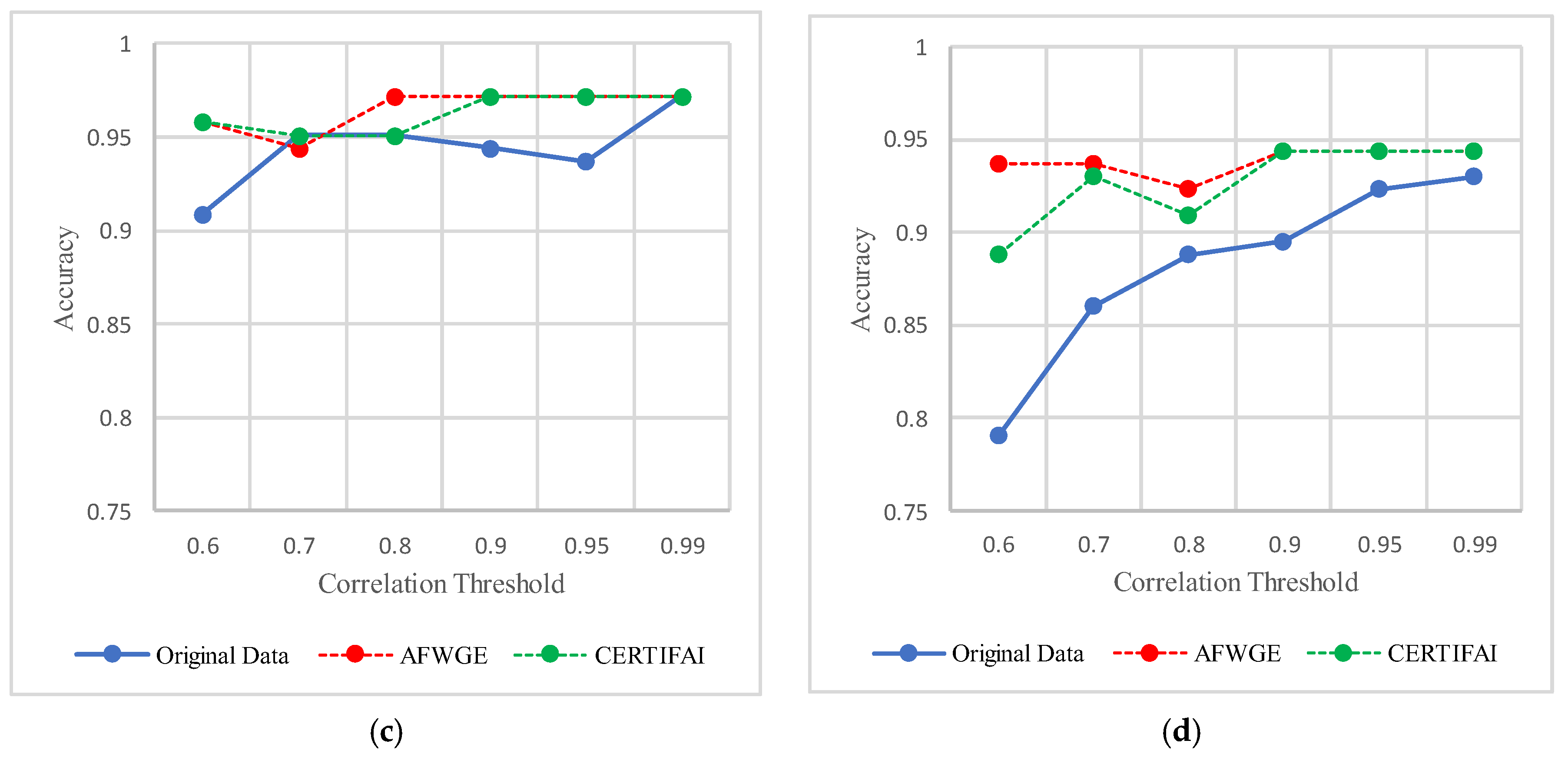
As shown in
Figure 19, the selected features at a PCC threshold of 0.6 provided the best performance in terms of accuracy for the most affected classifiers.
Once more, we performed a Wilcoxon signed rank test between the classifiers’ accuracies before and after using the most important group of features of AFWGE. The results, again, showed that there was a significant difference at α = 0.05; thus, the null hypothesis was rejected. Thus, we can conclude that the average value of accuracy after AFWGE is significantly better than using all the Pima Indians Diabetes dataset’s features (
Figure 20).
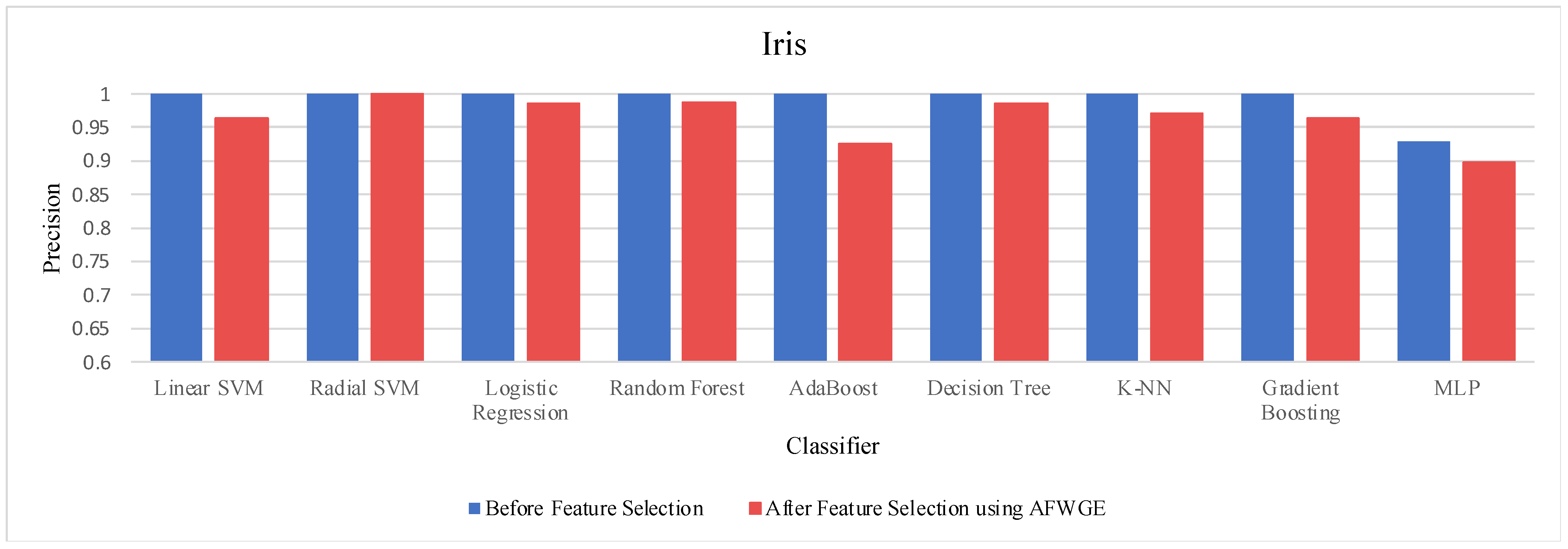
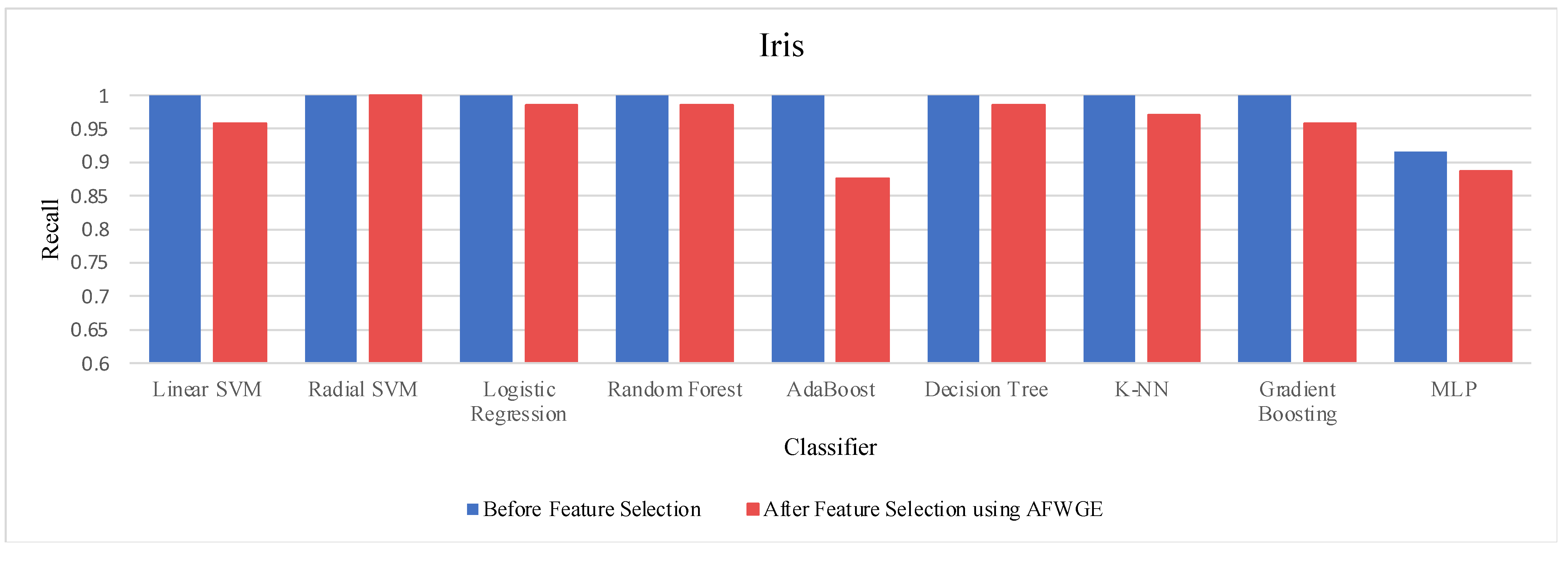
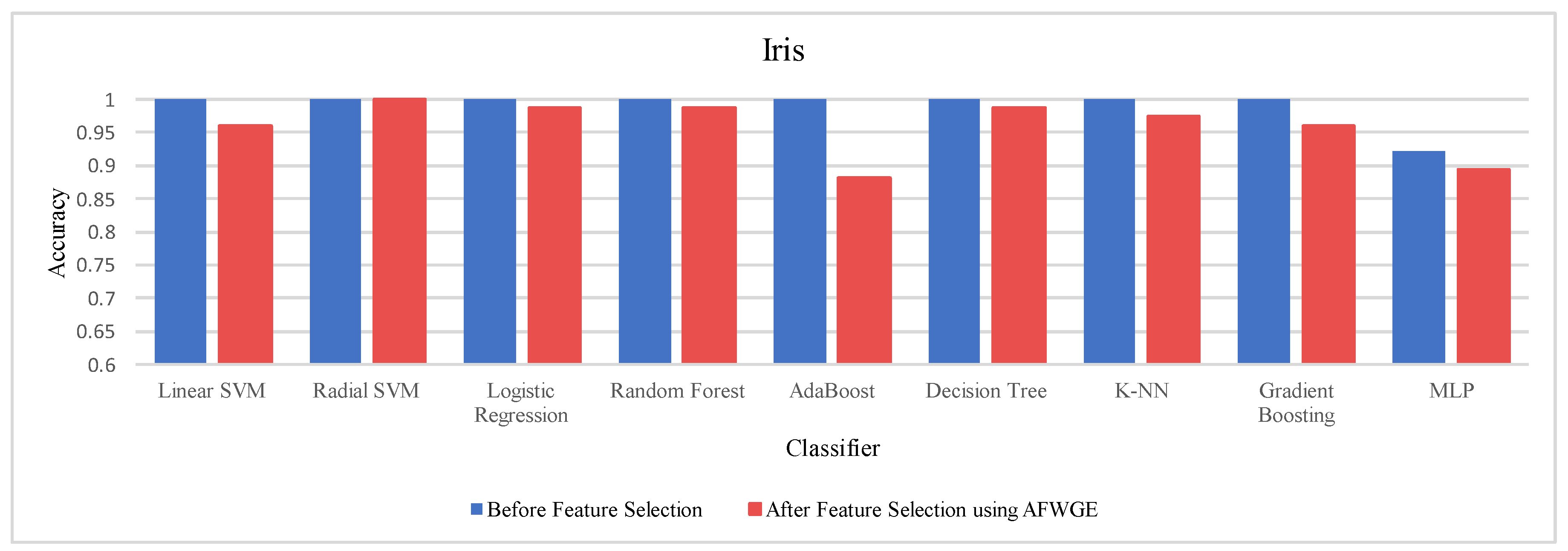
Prior to utilizing the selected group of features, all classifiers employed on the Iris dataset demonstrated exceptionally high accuracies, nearly equivalent to 1.0, often indicating overfitting. Certain characteristics of the Iris dataset, such as its small size, low dimensionality, and distinct class separability, can contribute to overfitting. However, when the Original Data method was used, the accuracies of all nine classifiers were reduced, as shown in
Table 6. Similarly, the AFWGE method resulted in a moderate decrease in accuracies for all nine classifiers, with the exception of the R-SVM classifier, which maintained the same accuracy. The CERTIFAI method also led to reduced accuracies for all nine classifiers. Nevertheless, the results in
Table 6 demonstrate that the most important group of features of AFWGE exhibited the minimum reduction in accuracy across multiple classifiers.
As shown in
Figure 21, the most important group of features was selected when the PCC threshold was equal to 0.9, 0.95, and 0.99. This limited the reduction in accuracy at these PCC thresholds; however, it effectively minimized overfitting, demonstrating that the selected features retained the essential characteristics of the data without allowing the classifiers to overfit. Therefore, the selected features are the most important features, supporting both generalizability and interpretability.
We ran another Wilcoxon signed rank test to check whether there was a statistically significant difference between the classifiers’ accuracies before and after using the most important group of features of AFWGE. Once again, the findings demonstrated a significant difference at a significance level of α = 0.05; thus, the null hypothesis was rejected. Therefore, it can be concluded that the average value of the accuracies after using AFWGE is significantly better than using all the Iris dataset features since it reduces overfitting (
Figure 22).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}