1. Introduction
With the rise of online communication, the ability to share information has increased tremendously and surpassed authorized entities. Anyone, anywhere, can easily participate in generating and disseminating information. This comes with the significant consequence of the widespread proliferation of fake news. The sheer volume of information constantly streaming online makes manual verification nearly impossible. Traditional methods of addressing fake news involved employing journalists and editorial teams to verify information against reliable sources before publication. This process, however, proved costly and time consuming, especially when dealing with the vast volume of information requiring verification against a limited number of fact-checkers. This challenge has become particularly evident during critical events, such as the COVID-19 pandemic [
1].
Recent research [
2,
3,
4,
5,
6] has explored utilizing machine learning algorithms to address the shortcomings of manual fact-checking. However, these approaches often face challenges like overfitting, scalability limitations, and difficulties in generalizing to new situations. Additionally, due to their statistical nature, machine learning models might struggle to understand the contextual nuances of continuously evolving fake news content. While the development of deep learning models has been effective in predicting the validity of news, training these models from scratch can be time-consuming and requires large quantities of labeled data.
Pre-trained language (transformer-based) models (PLMs) are a type of language model trained using a self-supervised learning (SSL) approach on large-scale corpora [
7]. These models can then be fine-tuned for specific downstream tasks such as text classification, named entity recognition, and text summarization. Pre-trained language models like BERT have demonstrated promising performance in various NLP tasks, including text classification [
8]. These models require less data for training due to their prior exposure to large unlabeled datasets. The remarkable achievements of transformer-based approaches have encouraged the development of Arabic transformers such as Arabic Bidirectional Encoder Representations from Transformers (AraBERT) [
9], the Arabic Generative Pre-trained Transformer version 2 (AraGPT2) [
10], Arabic Efficiently Learning an Encoder that Classifies Token Replacements Accurately (AraELECTRA) [
11], Arabic Bidirectional Encoder Representations from Transformers (ARBERT), and Multilingual Arabic Bidirectional Encoder Representations from Transformers (MARBERT) [
12], which enabled significant progress in various NLP tasks. These techniques are widely used in text classification [
13], where it has been employed to capture the relationship between labels in multilabel classification through attention. In the field of fake news detection, numerous efforts have been made to address the spread of fake news and enhance the accuracy of detection models. A recent survey [
14] reviewed several studies that proposed solutions and developed fake news detection methods. A comparative analysis of these methods was reported in terms of feature-extraction techniques and classification accuracy. The study demonstrated the superior performance of contextually dependent-based models, particularly transformer models, which outperform other models consistently. Additionally, research suggests that combining multiple feature representation and classification models can yield better performance and reduce computational costs.
In the context of Arabic FND, pre-trained language models have shown significant progress recently, despite challenges like overfitting. Ensemble learning methods can address such issues by leveraging the strengths of multiple transformer models. Ensemble learning is a machine-learning technique that helps to improve the accuracy of poor-performing models by combining several models together into one optimal model [
15]. This approach emerged with the introduction of machine learning and weak learners and continues to proliferate for improving deep learning networks to handle the complexity of data and to enhance accuracy for tasks like speech processing, image recognition, and text classification. By combining predictions from various models, this approach mitigates overfitting and utilizes the diverse knowledge acquired by each individual model [
16]. According to a recent literature review [
17], ensemble learning has been widely used in the field of fault diagnosis and classification. In their comparative analysis, the authors of [
17] compare fault diagnosis models that used different ensemble methods, including bagging, boosting, stacking, and other ensemble models. The evaluation results demonstrate the promising results of ensemble learning strategies for fault diagnosis, outperforming using a single model.
In previous works, the focus has not been on utilizing ensemble learning techniques with Arabic transformer models specifically for the task of Arabic fake news detection (FND). While individual transformer models, such as AraBERT and MARBERT, have demonstrated strong performance in various natural language processing (NLP) tasks, their individual weaknesses and limitations—such as domain biases or overfitting—can hinder their ability to generalize effectively in fake news detection. Ensemble learning, which combines multiple models, has the potential to overcome these challenges by leveraging the diverse strengths of different transformers, thus providing a more robust and accurate solution. However, the use of ensemble techniques for Arabic FND has not been thoroughly investigated, particularly in the context of combining multiple transformer architectures.
This study aims to address this gap by developing an ensemble of state-of-the-art Arabic pre-trained transformer models with the goal of advancing Arabic fake news detection. By integrating multiple pre-trained models, such as AraBERT, MARBERT, and other transformer-based models, into an ensemble framework, we aim to enhance model performance by reducing individual model uncertainties and improving generalizations across various types of fake news. In addition, we combine several standard Arabic fake news datasets into a unified dataset, representing a wide range of domains, such as politics, health, and social issues, and experiment with various ensemble learning techniques including weighted averaging, hard voting, and soft voting. In particular, the contributions of this study are as follows:
A novel ensemble strategy using State-of-the-Art Arabic Pre-Trained Models: We propose and evaluate an ensemble strategy that incorporates state-of-the-art Arabic pre-trained models (e.g., AraBERT and MARBERT) for fake news detection. The ensemble leverages techniques such as weighted averaging, hard voting, and soft voting to enhance the overall performance by combining the strengths of these models. The weights assigned to each model in the ensemble are not fixed or predefined. These weights are dynamically optimized through a search algorithm that identifies the best combination of models to maximize the performance metrics (e.g., accuracy) on the validation set.
A Unified Arabic Multisource Fake News Dataset (AMFND): We create a comprehensive dataset called AMFND by merging several Arabic fake news datasets from different sources, enabling the model to generalize better across various types of misinformation and Arabic dialects. The dataset is curated from various online sources across different domains (e.g., politics, health, sports, and social issues). Unlike many fake news detection datasets that focus primarily on political misinformation, our approach ensures that the model is exposed to different types of fake news, each with distinct language patterns and structures.
The employment of different fine-tuning strategies: we fine-tune our model using both the traditional 80/20 train–test split and cross-validation techniques, ensuring the model is thoroughly evaluated and tuned for generalizability across different fake news contexts.
An extensive baseline comparison and performance evaluation: we rigorously compare the performance of the proposed ensemble models against a strong baseline, demonstrating significant improvements in fake news detection accuracy, precision, recall, and F1 score using the ensemble of pre-trained models.
Given the unique linguistic challenges posed by Arabic fake news detection, such as the complexity of morphological structures and the scarcity of relevant datasets, applying ensemble techniques of pre-trained language models offers a novel contribution to the field. The ensemble method proposed in this paper leverages the strengths of multiple models to address the specific challenges within the Arabic context, which has been relatively underexplored compared to other languages.
2. Related Work
Fake news is not a new phenomenon. In fact, it emerged in the late 19th and early 20th centuries through “yellow journalism”, which sensationalized news concerning crimes, disasters, and rumors [
18]. While traditional forms of fake news relied on print media, the digital age has amplified its prevalence. The sheer volume of information constantly streaming online makes manual verification nearly impossible. This challenge has become particularly evident during critical events, such as the 2016 US election [
19], the Syrian conflict [
20], and the COVID-19 pandemic [
1]. Fake news detection methods have been applied for languages other than Arabic. For example, a recent research study, published in [
21], presented a lexicon-based approach for detecting Italian fake reviews focusing on the cultural heritage domain. In their methodology, the authors explored two types of lexicons including linguistic features and sentiment analyses for classifying deceptive reviews. The key findings proved the effectiveness of lexical modifiers, such intensifiers and downtowners, in the detection of Italian deceptive reviews. The quantitative and qualitative analysis showed a large impact of the sentiment lexicon on the deceptive text. Another study [
22] explored fake news detection utilizing language-independent textual features across multiple languages. These authors targeted news content published in American English, Brazilian Portuguese, and Spanish texts by examining textual complexity and stylometric and psychological features. Four machine learning algorithms, including k-Nearest Neighbors (k-NNs), Support Vector Machines (SVMs), Random Forest (RF), and Extreme Gradient Boosting (XGB), were trained to classify the factuality of news texts. The results obtained show that the curated features successfully discriminate between the fake, satirical, and real news obtained using Random Forest, reporting a classification accuracy of 85.3%.
Research on FND can be organized into two lines of research: transformer approaches and shared tasks and public datasets.
2.1. Transformer Approaches
In the FND literature, there is a large body of research that employs transfer learning solutions and pre-trained-based models for identifying fake news using detection approaches.
The work in [
23] proposes a two-step classification pipeline to predict the factual content of online news for the English language, acknowledging that some news may contain subjective opinions that cannot be definitively labeled as fake or real. In the first step, the authors filtered out opinion-based articles from the dataset to focus solely on factual news prediction. Subsequently, they employed attention-based transformer models, including BERT, DistilBERT, and DeBERTa, to classify the remaining data into “fake” and “real” categories. For training, they utilized two datasets: the ISOT Fake News Dataset and the Combined Corpus Dataset (CC), each containing approximately 45,000 and 80,000 news articles categorized as fake or real. Their experiments demonstrated that removing opinion-based news leads to more accurate predictions compared to including them in the training data. Notably, DeBERTa achieved the best performance, reaching an F1 score of 0.79 in the two-step classification when trained and tested on different datasets. However, despite the significant progress made by transformer-based approaches in NLP tasks like fake news classification, research suggests that a single model can become biased by its training data, potentially hindering its performance when fine-tuned on different datasets.
Another relevant study [
24] constructed a stacking ensemble model comprising five layers of vectorization to effectively determine the truthfulness of texts. They experimented with various feature representations, including manually extracted features, n-grams, and transformer-based contextual features. For the latter, the authors employed embedding tokenizers from three transformers (DistilBERT, RoBERTa, and XLM) using the sentence transformers library. In the final phase, the predictions from all embedding methods were combined and fed into a final decision classifier to generate the classification output. The training data consisted of 10,700 social media posts labeled as fake or real news, provided in the COVID-19 fake news detection shared task. The evaluation results yielded an F1 score of 0.97, demonstrating the proposed stacking approach’s effectiveness, as it emerged as the leader on the challenge leaderboard. Interestingly, the authors observed that individual transformer models like DistilBERT exhibited signs of overfitting on the training data and underperformed compared to the latent space representation achieved by the ensemble model.
In contrast to the aforementioned research, De and Desarkar [
25] proposed a multi-context transformer approach called MiCNA for identifying COVID-19-related fake news. Their approach goes beyond typical single-context training by leveraging rich representations from three transformer models trained in various contexts. MiCNA harnesses the strengths of these models by utilizing representations learned from language contexts, Tweet semantics, and COVID-19 connotations. To address the high dimensionality of the combined representation, MiCNA applies average pooling to the outputs of the three transformers. This resulting average vector is then fed into a feed-forward layer and an activation function before reaching the classification layer for label predictions. The authors evaluated MiCNA on a dataset of 10,700 tweets labeled as fake or real news, which were specifically collected during the COVID-19 pandemic. To demonstrate the model’s effectiveness, they employed an ablation study. This involved removing specific transformer models from MiCNA and evaluating the performance with different combinations. Their findings show that MiCNA achieved the highest accuracy (98.69) and weighted average F1 score (98.64) compared to all combinations of individual or paired transformers.
Another important research direction explores multilingual systems to address fake news detection in low-resource languages. De et al. [
26] investigated the performance of transformer-based models for classifying misleading information across multiple domains and languages. Their system aims to determine whether models can effectively transfer domains and language-agnostic features for the task of fake news classification. These authors conducted several experiments in language-specific, domain-specific, domain-independent, and language-independent settings using a translated Asian language dataset. This dataset was created by translating two English-language datasets, namely, Fake News AMT and Celebrity Fake News datasets, into four Asian languages (Hindi, Vietnamese, Indonesian, and Swahili) using Google Translate. The resulting dataset, encompassing 980 news items across multiple domains, provided a multilingual testbed. This study employed the BERT transformer for unimodal experiments and its multilingual variant (mBERT) for evaluating the multilingual dataset. The results reveal that mBERT achieved impressive zero-shot classification performance on unseen languages. It also significantly enhanced the results for low-resource languages, reaching a peak accuracy of 83%. However, this study has limitations. First, relying solely on Google Translate for language translation is not optimal for languages with complex morphology or dialects. Second, the dataset used in this study might be too small to fully train a language model like BERT, potentially leading to predictions with high variance.
The work in [
27] is closely related to our approach, as it also examines an ensemble of fine-tuned transformer models for fake news detection, specifically focusing on the COVID-19 pandemic. Their methodology employed both hard- and soft-voting ensemble techniques to combine prediction vectors from multiple models, ultimately determining the final “fake” or “real” labels. Additionally, their experiment incorporated two heuristic features: username and URL link domain. The evaluation results demonstrate that soft voting outperformed hard voting, achieving a prediction accuracy of 0.98 (as measured by the F1 score). This result surpasses the performance of individual transformer models.
Recognizing the data limitations in Arabic fake news detection, the work presented in [
28] presented a large-scale dataset called AraNews. Utilizing a novel method, they automatically generated fake news by manipulating genuine news articles. They then fine-tuned large pre-trained models (specifically, AraBERT) on the generated data, achieving an F1 score of 89.25, surpassing previous state-of-the-art results.
In the context of comparative analyses of detection approaches, a comparative analysis of Arabic fake news detection methods was conducted by [
29]. The authors investigated the effectiveness of different neural network and transformer architectures alongside embedding methods for feature extraction. They evaluated their approach on various Arabic corpora, including ANS, COVID-19-Fakes, AraNews, and ArCOV19-rumors. This study revealed that transformers outperformed the best neural networks, with QARiB achieving the highest F1 score of 0.95, followed by GRU (0.83).
In the work of Harrag et al. [
30], a BERT-based transformer model was developed to automatically detect deep fake texts in Arabic languages that were generated using the GPT2 transformer model. In their study, the authors utilized an existing Arabic dataset for human-generated text extracted from Twitter and then generated the fake data using a generative transformer, namely, GPT2. Using the GPT2 pre-trained model, they were able to collect 3512 auto-generated Arabic samples along with 1559 real texts obtained from a public Twitter dataset. Their system was trained to recognize whether a given Arabic text is human or a bot using the encoder–decoder transformer called BERT. In their experimental setting, they investigated the performance of four deep learning networks, including LSTM, GRU, Bi-LSTM, and BI-GRU models, as a baseline compared with the fine-tuned AraBERT Arabic pre-trained model. Their fine-tuned AraBERT transformer showed a competitive classification accuracy of 98.7%, exceeding the baseline line deep learning models in the detection of auto-generated texts. Different from the aforementioned study, we aimed to develop an Arabic transformer to classify genuine and fraudulent Arabic texts generated by humans, which is considered one of the more challenging tasks than detecting fake texts generated by machines.
2.2. Shared Tasks and Public Datasets
To encourage solutions for detecting COVID-19 misinformation on social media, several publicly shared tasks and datasets have been released. One example is NLP4IF2021, which provides a dataset and challenges participants to develop NLP-based solutions for identifying false information. In [
31], the authors proposed a two-step pipeline utilizing the AraBERT transformer model to analyze misleading Arabic information on Twitter. They achieved an accuracy score exceeding 84%, using various experimental settings.
Another initiative towards combating the COVID-19 infodemic involved a large Arabic Twitter corpus presented in [
32]. These authors collected and manually annotated 7 million tweets as “fake” or “genuine” using fact-checking websites. They then employed supervised learning with six machine learning classifiers, achieving the best F1 score of 93.4% with Logistic regression. This study concluded that additional pre-processing, like stemming or lemmatization, did not improve the results.
Similarly, Ref. [
33] introduced the ARACOVID19-MFH dataset for Arabic COVID-19 fake news and hate speech detection. This dataset comprises 10,828 manually labeled tweets categorized into 10 classes. Baseline models based on pre-trained models (AraBERT, mBERT, and Distil-mBERT) were used to evaluate the annotation process and were fine-tuned for fake news detection. Further pre-training on a large Twitter dataset improved the performance compared to direct fine-tuning. AraBERT and mBERT showcased the best results, exceeding a 0.92 F1 score in various classification tasks.
In addition to the previous research, the work in [
34] introduced a new naturally occurring claims dataset called AraFact for the Arabic language. They used five fact-checking websites to extract the data and normalized its labels into four categories: True, False, Partly False, and Sarcasm. AraFact consists of 6000 claims that were crawled along with metadata information. The constructed dataset covers diverse topics, including topics such as politics, Health, News, Science, social religion, Art and culture, and other topics. The annotation process was implemented using two of the authors, where each of them verified the veracity of the news separately and decided on the final labels in case of disagreements. In addition, a further analysis of the dataset was conducted to analyze the distribution of each feature as well as to demonstrate the use case scenarios to serve relevant research tasks such as claims. The authors presented a new dataset for the verification of Arabic claims. However, they did not evaluate the quality of the dataset for classifying claims automatically using machine learning models.
Similar to the work conducted by [
32], Haouari et al. [
35] presented an Arabic benchmark dataset, named ArCOVID19-Rumors, for misinformation detected on Twitter. ArCOVID19-Rumors was constructed using 138 verified claims scrapped from fact-checking websites and 9.4k tweets related to COVID-19 conversations annotated manually as True, False, and other. The proposed dataset was designed mainly to support the claims verification on Twitter, but it can support free text claims further. To confirm the annotation quality, they implemented several models that leveraged one of the features such as content-based attributes, user profiles, temporal features, and network-based features. The authors examined two Arabic pre-trained models, AraBERT and MARBERT, along with an ensemble of two deep learning architectures, RNN–CNN, and a graph convolution neural network to classify the text into either true or false. The evaluation result reported that MARBERT produced superior results compared to AraBERT, obtaining a 0.74 macro F1 score due to the matching domain of MARBERT, which was pre-trained on Twitter, compared with AraBERT, which was pre-trained on Wikipedia.
The research in [
36] released a novel Arabic dataset called AraStance, which can be used for stance fact-checking tasks. In the AraStance dataset, a group of 4063 pairs of claims (false and true) were collected, where each article had one of the following stance labels: agree, disagree, discuss, and unrelated. The proposed dataset retrieved news from different Arab countries, including Saudi Arabia, the UAE, and Egypt, on different topics, such as politics, health, and sports. Basically, the constructed dataset was designed for stance detection as the main task, but it can also be used for fact-checking or claim veracity. Thus, the unbalanced issue is not a crucial factor for stance detection as for claims verification with two labels. To evaluate the dataset, they investigated the performance of different Arabic transformer models, which include Arabic BERT, MARBERT, ARBERT, and mBERT. The results show that ARBERT and MARBERT achieved better classification results, reaching a macro F1 score of 0.85 and 0.78 in stance detection, which outperforms the other two models. This could be explained by the importance of matching dataset types that the pre-trained models trained on before and the dataset the transformer fine-tuned on. The previous study experimented with the AraStance dataset only for stance detection. However, it is also possible to evaluate the dataset on the claim’s veracity task.
The summary in
Table 1 shows a comparative analysis of the related work in fake news detection across different languages. This review also highlights ongoing efforts to create benchmark datasets and shared tasks and to demonstrate the effectiveness of transformer-based models in addressing this complex issue.
3. Methodology
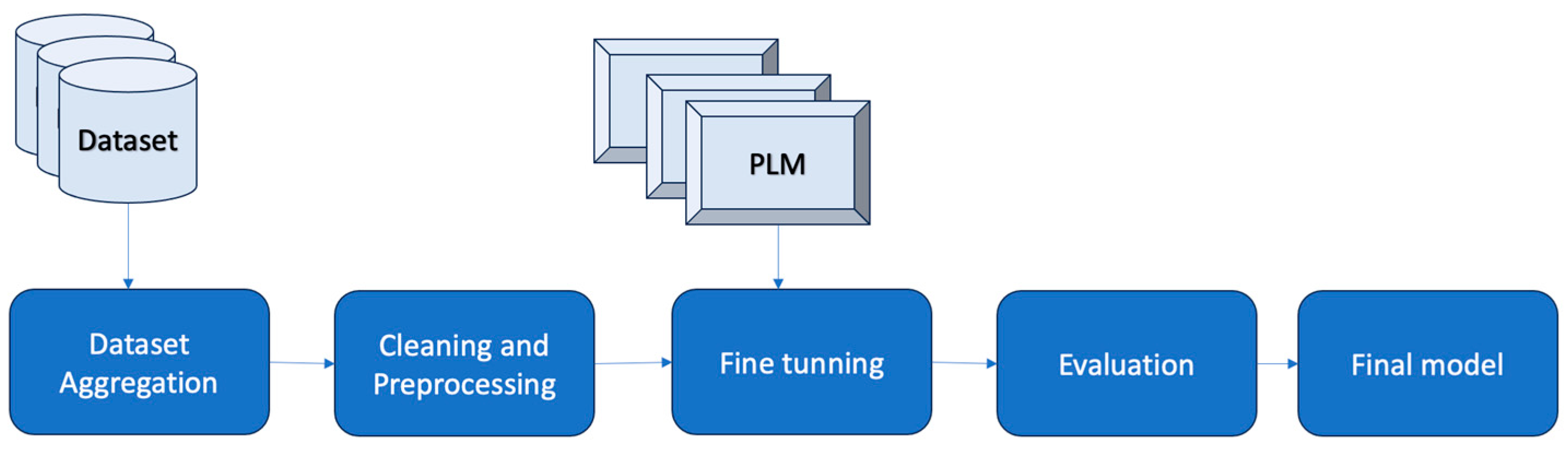
In this study our aim was to investigate to what extent an ensemble model of transformers can improve the performance of Arabic FND. The general approach we adopted is a general machine learning approach (fine-tuning PLM), as depicted in
Figure 1. Here, the datasets were combined, cleaned, and pre-processed. Then, the PLMs were fine-tuned and evaluated to develop the final model. We approached this investigation by building an ensemble of transformer models using standard datasets (details of the datasets are shown in
Table 2). Two of the datasets were collected from a single source written using Modern standard Arabic (MSA). However, the third ArCOV19-rumors dataset is the only dataset that contains news from Twitter, which typically contains dialectal Arabic (DA). Research has shown that models trained on MSA datasets do not perfectly work in dialect datasets [
37]. There is a growing interest in training models on large diverse datasets in order to achieve better results and reduce generalization errors. Therefore, in this study we used a combined dataset, which contains all three datasets, in an AMFND dataset to study its impact on the FND task.
3.1. Arabic Multisource Fake News Dataset (AMFND)
We combine the three Arabic datasets, AraNews, AFND, and AraCOV19-Rumors, into one large dataset, AMFND. The combination of multiple datasets significantly enhances the overall size and diversity of data, which plays a crucial role in improving the generalization ability and enables machine learning models to capture a wide range of patterns and features for detecting fake news. To handle the diversity of labels, we first transformed the labels into one standard schema, in our case, to a binary classification (fake or real). For example, if the dataset contained multiple labels like the AFND dataset, which had the labels credible, not credible, and undecided, we first changed the labels into fake and real labels and removed items with the third label ‘undecided’, as the objective of our task was binary classification. After normalizing the labels, we removed the unnecessary columns element and kept only two columns, one for the text and one for the label. Finally, a unique ID was assigned for each news item. The three datasets were then merged sequentially to construct the final dataset. The resulted AMFND dataset consisted of the following attributes, News_ID, News_Text, and the Label, which is the normalized category of news.
The resulting AMFND dataset is composed of 56769 items classified as fake or real news. In the AMFND dataset, the labels were imbalanced (59% of the dataset was fake and 41% was real). An imbalanced dataset could lead to poor model performance biases against one label. To alleviate this problem, we considered using resampling strategies specifically under the sampling method, whereas the majority class was reduced until it became equal or balanced with the distribution of the other class.
3.2. Text Pre-Processing
Text pre-processing is a challenging task for data scientists and NLP researchers, especially when performed on datasets scrapped from social networks, which contain a lot of noise and unnecessary elements. The cleaning procedures were implemented using mathematical functions like regex and existing Python libraries called NLTK. We performed the following pipeline on all the three datasets before combing them.
Cleaning pipeline
Remove punctuation, diacritics, special characters, and non-Arabic text. Diacritics are vowel marks. As Arabic text does not provide information about pronunciation, the main purpose of diacritics is to provide a phonetic guide for correct pronunciation.
Remove duplicated sentences, missing or corrupted values, and handling missing values.
Normalize the Arabic text (transform the text to a unified form, removing elongation. Elongation is used to communicate a long vowel pronunciation) and remove stop words.
Remove hyperlinks, emojis, and Twitter handlers.
Pre-processing pipeline
Used text pre-segmentation requirements using the Farasa segmenter [
38] from the official transformer documentation. Word segmentation involves breaking words into their constituent clitics.
Employ the transformer tokenizer. Tokenizers are essential tools in machine learning, especially in natural language processing (NLP). They break down a text into smaller units called tokens. These tokens can be words, sub-words, or characters. A tokenizer is in charge of preparing the inputs for a specific model.
Perform padding and truncations to handle sequence length inconsistencies. To avoid variable sequence lengths, we used padding and truncation strategies to handle the long input sequence and to ensure that all the sequences were in the same length that the model could accept, which typically adjusted to a maximum of 512 input tokens. The padding handled the short sequence by appending additional tokens or special tokens like [PAD] after the last tokens in the sentence so that all sentences had equal token lengths. The truncations worked differently by removing the end of long sequences in order to avoid mismatched sequence lengths and to reduce the overwhelming computational processing of long sequences.
Table 3 demonstrates the pre-processing steps applied on Arabic fake news using two examples prior to their input into a BERT-based model (e.g., AraBERT). Each text was tokenized into token IDs[‘CLS’] and segmented IDs[‘SEP’] using a BERT tokenizer. This table also shows how the text input was normalized, removing diacritics and standardizing certain characters. Additionally, it shows the text input after removing punctuations and non-alphabetic characters. For padding and truncation, Example 1 required both truncation and padding, whereas Example 2 required only padding. The input representation section shows how the text input was prepared for the model, including the token IDs and attention masks.
3.3. Model Fine-Tuning and Ensemble
Five transformer models were used in our study: AraBERT v1, AraGPT2, AraELECTRA, MARBERT, and ARBERT. Details of these models are presented in
Table 4. They were fine-tunned for Arabic FND, using the three individual datasets, as well as the combined AMFND.
For model evaluation, we performed two resampling approaches to evaluate our system. The first evaluation approach was random sampling, in which we split the dataset into three sets, training–validation–test, with a size ratio equal to 80:10:10, respectively. Additionally, we used a k-fold cross validation (k = 5) to examine the model performance. Evaluating the model using a cross validation usually aids in achieving a more generalized machine learning classifier and avoids the overfitting problem during the training process [
39,
40]. We compared the results of each evaluation approach and selected the best results.
For ensemble methods, the voting ensemble is the most commonly used method in the literature, due to its superior performance achievements in classification and regression tasks [
41]. Essentially, a voting ensemble involves calculating the prediction of each model for a specific class and predicting the label that has the majority vote. There are two policies of voting: hard voting and soft voting. A hard voting is computed by collecting the class voting generated by each model member. Soft voting, on the other hand, relies on predicting the largest probability of the classes obtained from each of the model members.
4. Experiments
For model fine-tuning, we used the transformer library from the huggingface repository to fine-tune the pre-trained models. Here, we ran the training process using the Pytorch library [
42], which supports hardware accelerators such as GPUs and efficient code debugging. Then, we implemented segmentations using the Farasa library [
38] on all models that required pre-processing in their official repo, such as AraBERT, AraELECTRA, and AraGPT2. For tokenization, we used the Auto Tokenizer library from the transformer which included all the models used for training. Using Trainer API from the huggingface library, we determined the training parameters and the model hyperparameters used to train a transformer model. For the training setting, we fine-tuned all the models for 3 to 5 epochs with a learning rate of 2 × 10
−5 and with an Adam optimizer equal to 1 × 10
−8. The evaluation strategy was set according to the number of iterations, and the best model was loaded at the end of the training process. The models were evaluated using a macro F1 score, precision, recall, and accuracy in both the training and testing procedures. For the ensemble experiment, we loaded the model training weights and combined the predictions of the considered models on the test data using the ensemble methods.
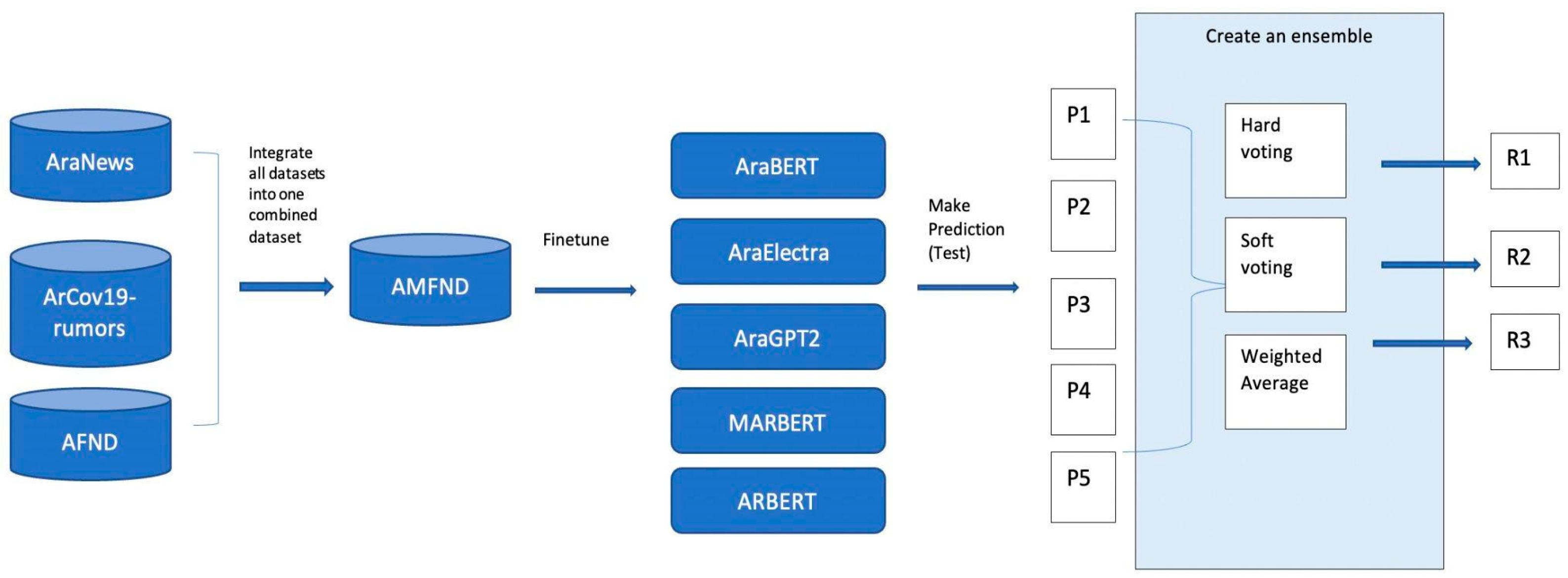
We first developed a baseline using a zero-shot setting. Next, we conducted two major experiments, as shown in
Figure 2.
Experiment 1: five Arabic transformers were fine-tuned on the combined dataset (AMFND).
Experiment 2: Each of the five Arabic transformer models were fine-tuned on the combined AMFND dataset. Then, an ensemble of five, three, and two transformers was created. We experimented with two kinds of ensemble strategies: the weighted-average ensemble and voting ensembles (hard and soft).
5. Results
The baseline results for all five models are shown in
Table 5.
Table 6 shows the performance results after fine-tuning on the combined AMFND dataset using a 5-fold cross validation. The results of experiment 2, fine-tuning each of the five Arabic transformer models on the combined AMFND dataset and then creating an ensemble, are shown in
Table 7.
Table 8 shows the performance results when the number of ensemble models was varied, depicting results using an ensemble of five, three, and two models.
6. Discussion
From the experiments, we observed that training a model using the common 80–20% ratio for training and testing produces lower performance for all models compared to a 5-fold cross validation. This can be explained by multiple reasons, such as the variance in the dataset; therefore, such a model is not able to capture a good representation from the training sample. The second reason for this is due to the sequential integration of the individual dataset into one large dataset, which might make the model biased to a specific dataset. Regarding experiment 1 (
Table 5), among all models, AraELECTRA achieved the best F1 score using the stratified 5-fold cross validation, with a score of 0.92, followed by the AraGPT2 model, which reported 0.90% using the same training strategy. On the other hand, AraBERT recorded the lowest accuracy score of 0.84 under various settings compared to MarBERT and ARBERT. Our intuition for the cause of this result is that AraBERT has been trained on more structured and formal language corpora from Wikipedia, unlike our dataset, which contains a combination of MSA and dialectal texts.
With regards to experiment 2, we further conducted a comparative analysis of the ensemble model over state-of-the-art models reported in the literature, as shown in
Table 9. We can observe that the ensemble model in this study is comparable to those of the literature. It outperformed some of the standalone models, reaching an F1 score of 94% using the weighted-average ensemble. The results show that composing predictions from multiple models yields the best overall performance, if we give the well-performing model the largest weights, which enable them to contribute more to the ensemble result and, therefore, to obtain a better prediction. On the other hand, a voting ensemble performs poorly, in general, with an F1 score equal to 88% and 90% for hard and soft voting, respectively. This is likely because it aggregates the class probabilities from each prediction to vote the final class, considering fair contributions for all ensemble members in the final ensemble prediction.
Our experiments show how the number of ensembled models (two, three, and five) affect the performance of Arabic fake news detection (
Table 8). Our results suggest that there is no observed impact of the number of models in improving the accuracy of the ensemble model. Therefore, increasing the number of models in the ensemble may not be helpful, if multiple models produced similar accuracy results. For the first ensemble, we combined the prediction of five transformer models, including AraBERT + MarBERT + ARBERT + AraELECTRA + AraGPT2, using the three ensemble methods, namely, weighted-average ensemble, hard voting, and soft voting. The weighted-average ensemble achieved the best F1 score of 94%, whereas the results of hard and soft voting showed no improvement against the performance of individual models used in the ensemble, reporting similar F1 scores of 86.6% and 86.7%, against the best standalone F1 result of 0.92 achieved by the AraELECTRA model. This is expected, because the voting accuracy is determined by the majority vote of the class predicted by the ensemble members, unlike the weighted-average ensemble, which basically aggregated all the predictions from each model, multiplied by certain weights, according to their performance. For this reason, if three out of five models make incorrect predictions, the voting ensemble will probably result in a lower performance, since it considers all the models equally, meaning that each model in the ensemble will have the same contribution in the prediction.
Similarly, we found that an ensemble of three models, which consists of AraBERT + MARBERT + AraELECTRA, yielded successful improvements in terms of F1 results using all ensemble methods. It achieved similar performance to the five-ensemble model using the weighted-average ensemble. However, the hard-voting and soft-voting results show some improvements, F1 = 0.88 and F1 = 0.87, respectively. As for the last ensemble variant, which comprised two models, which were AraELECTRA and MarBERT, the weighted-average ensemble reached 0.91 in terms of the F1 score, whereas for voting, the highest F1 value was obtained by soft voting, with F1 = 0.88, surpassing the hard-voting result of F1 = 0.85.
Although a perfect comparison is impossible given the disparity of models and resources; however, to enrich the discussion, we considered FND for other languages. For example, the study by [
21] on deceptive text classifications in the Italian Cultural Heritage Dataset showed an accuracy of 81% and a micro F1 of 85% using the Sentita and Sentix lexicons joined together. This result is comparable to our ensemble-model results, however, with a noticeable improvement in the latter. In addition, the reported accuracy for end-to-end transformer models in a comparative study [
14] reached a score of 25% for the Liar dataset (multi-class), 100% for the ISOT dataset (binary), 94% for the COVID-19 dataset (binary), and 99% for the GM dataset (binary). These results are comparable to our work and other Arabic FND results reported in the literature.
7. Conclusions
In this work, we carried out multiple experiments aimed at enhancing Arabic FND by employing transformer-based ensemble models trained on a diverse dataset compiled by combining three publicly available sources. We developed a unified dataset, AMFND, by integrating multiple Arabic fake news datasets from diverse sources. This comprehensive dataset facilitates improved model generalizations across different forms of misinformation and various Arabic dialects. We further conducted a thorough evaluation of the proposed ensemble models against a baseline, showcasing substantial improvements in fake news detection performance across metrics such as accuracy, precision, recall, and F1 score, which were achieved through the use of the pre-trained model ensemble.
To the best of our knowledge, this is the first study to apply an ensemble of pre-trained language models specifically for Arabic FND. The performance of our ensemble models was assessed on the combined dataset, AMFND. Various ensemble methods, including different voting techniques, such as weighted averaging, hard voting, and soft voting, were implemented to aggregate predictions from several transformer models. Additionally, we investigated factors affecting ensemble performance and provided recommendations for the effective implementation of these techniques.
Our findings indicate that the best ensemble result was achieved by implementing the weighted-average ensemble. However, we do acknowledge that the performance of ensemble models can be influenced by factors related to the structure and implementation of an ensemble model. These factors include the performance of individual models in the ensemble and the number of ensemble models, in addition to the extent of diversity between the ensemble members. We observed that integrating an odd number of models can enhance the performance of an ensemble. Moreover, the ensemble strategy used to combine the prediction of individual models together can play an important role in the model performance.
Although constructing an ensemble from multiple transformer models showed improved performance, it is important to analyze the cost of combining more than one model compared to fine-tuning a single transformer model. The cost can be computed according to different factors, which include computational resources, memory usage, development costs, energy consumption, and performance and accuracy. Regarding computational resources, ensemble models require significantly more time to fine-tune multiple transformer models and a high memory consumption for every transformer model used in the ensemble. However, despite the cost, the ensemble can provide better performance compared to a single model. Therefore, in order to leverage the advantage of an ensemble model, considering the cost efficiency is indeed crucial against superior performance.
While the discussed limitations highlight the complexities of Arabic fake news detection, they also unveil exciting opportunities for future research and improvements. Exploring the adaptation of fake news detection models to specific Arabic dialects has potential and is important. This research direction can significantly improve social media detection accuracy by addressing the linguistic variations across different Arab regions. By accounting for dialectal differences, models can become more adept at identifying fake news content, leading to a more robust Arabic FND. Moreover, another avenue for future work is to address the challenge of data scarcity in Arabic languages, and investigating cross-lingual transfer-learning techniques emerges as a promising solution. This approach involves leveraging existing, well-trained fake news detection models from resource-rich languages like English and transferring their knowledge to Arabic models. This strategy has the potential to significantly improve the state of the art in Arabic FND research, particularly in settings with limited annotated data.





{kind=link}
{kind=link}