
Knowledge Graph Embedding Using a Multi-Channel Interactive Convolutional Neural Network with Triple Attention




Abstract
1. Introduction
- A multi-channel CNN is proposed to ensure interaction between entities and relations across multiple channels, along with a max pooling layer added to each convolutional channel to capture more local features.
- The CNN structure is optimized by introducing a triple attention mechanism during the multi-channel convolutional process, enhancing the extraction of global information for entities and relations across the convolutional channels.
- The feature mapping tensors obtained from the multi-channel convolution are concatenated in the form of a Hadamard product, and traditional inner product operations are abandoned in the complex space. Instead, a more comprehensive Hadamard product is employed to achieve better predictions.
2. Related Work
3. Proposed Model
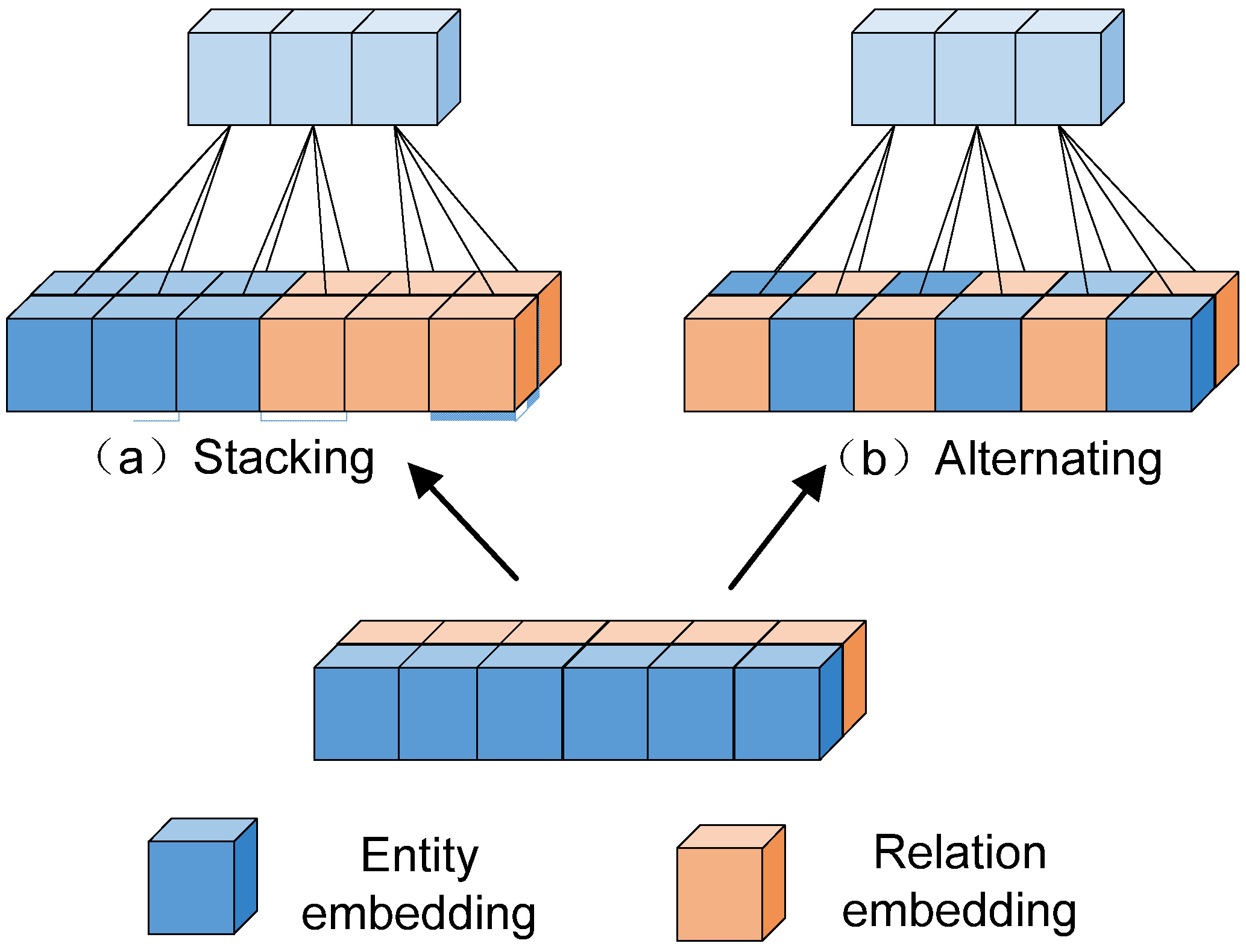
3.1. Embedding Representation Module
3.2. Encoding Module
3.3. Prediction and Scoring Module
3.4. Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Metrics
4.3. SOTA Models for Comparison
4.4. Experimental Setting
4.5. Results and Analysis
4.5.1. Link Prediction
4.5.2. Symmetric Relationship Modeling
4.5.3. Ablation Study
4.5.4. Influence of Convolutional Kernel Size
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saxena, S.; Sangani, R.; Prasad, S.; Kumar, S.; Athale, M.; Awhad, R.; Vaddina, V. Large-Scale Knowledge Synthesis and Complex Information Retrieval from Biomedical Documents. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 2364–2369. [Google Scholar]
- Mouromtsev, D.; Wohlgenannt, G.; Haase, P.; Pavlov, D.; Emelyanov, Y.; Morozov, A. A Diagrammatic Approach for Visual Question Answering over Knowledge Graphs. In The Semantic Web: ESWC 2018 Satellite Events, Proceedings of the 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Gangemi, A., Gentile, A.L., Giovanni Nuzzolese, A., Rudolph, S., Maleshkova, M., Paulheim, H., Pan, J.Z., Alam, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11155, pp. 34–39. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A Core of Semantic Knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2018; pp. 1247–1250. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A Nucleus for a Web of Open Data. In Proceedings of the International Semantic Web Confermahdisoltani, Busan, Republic of Korea, 11–15 November 2007. [Google Scholar]
- Miller, G.A. WORDNET: A Lexical Database for English. In Proceedings of the Human Language Technology: Proceedings of a Workshop, Plainsboro, NJ, USA, 21–24 March 1993. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for Modeling Multi-Relational Data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Yang, B.; Yih, S.W.-t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2071–2080. [Google Scholar]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. Rotate: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; pp. 1–18. [Google Scholar]
- Balažević, I.; Allen, C.; Hospedales, T.M. Tucker: Tensor Factorization for Knowledge Graph Completion. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), HongKong, China, 3–7 November 2019; pp. 5185–5194. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Balažević, I.; Allen, C.; Hospedales, T.M. Hypernetwork Knowledge Graph Embeddings. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2019: Workshop and Special Sessions: 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 553–565. [Google Scholar]
- Zhang, Z.; Li, Z.; Liu, H.; Xiong, N.N.; Engineering, D. Multi-Scale Dynamic Convolutional Network for Knowledge Graph Embedding. IEEE Trans. Knowl. 2020, 34, 2335–2347. [Google Scholar] [CrossRef]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association For Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.-P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the Icml—The 28th International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2021; pp. 3104482–3104584. [Google Scholar]
- Gao, C.; Sun, C.; Shan, L.; Lin, L.; Wang, M. Rotate3d: Representing Relations as Rotations in Three-Dimensional Space for Knowledge Graph Embedding. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 385–394. [Google Scholar]
- Dai Quoc Nguyen, T.D.N.; Nguyen, D.Q.; Phung, D. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, NY, USA, 1–6 June 2018. [Google Scholar]
- Jiang, X.; Wang, Q.; Wang, B. Adaptive Convolution for Multi-Relational Learning. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 978–987. [Google Scholar]
- Ren, F.; Li, J.; Zhang, H.; Liu, S.; Li, B.; Ming, R.; Bai, Y. Knowledge Graph Embedding with Atrous Convolution and Residual Learning. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 13–18 September 2020; pp. 1532–1543. [Google Scholar]
- Feng, J.; Wei, Q.; Cui, J.; Chen, J. Novel Translation Knowledge Graph Completion Model Based on 2D Convolution. Appl. Intelligence 2022, 52, 3266–3275. [Google Scholar] [CrossRef]
- Zhang, F.; Qiu, P.; Shen, T.; Cheng, J. Multi-Aspect Enhanced Convolutional Neural Networks for Knowledge Graph Completion. In ECAI 2023; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2023; pp. 2994–3001. [Google Scholar]
- Wang, J.; Zhang, Q.; Shi, F.; Li, D.; Cai, Y.; Wang, J.; Li, B.; Wang, X.; Zhang, Z.; Zheng, C. Knowledge Graph Embedding Model with Attention-Based High-Low Level Features Interaction Convolutional Network. Inf. Process. Manag. 2023, 60, 103350. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, W.; Chen, M.; Chen, H.; Cheng, X.; Zhang, W.; Chen, H. Dualde: Dually Distilling Knowledge Graph Embedding for Faster and Cheaper Reasoning. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event, 21–22 February 2022; pp. 1516–1524. [Google Scholar]
- Kazemi, S.M.; Poole, D. Simple Embedding for Link Prediction in Knowledge Graphs. arXiv 2018, arXiv:1802.04868. [Google Scholar]
- Toutanova, K.; Chen, D. Observed Versus Latent Features for Knowledge Base and Text Inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 31 July 2015; pp. 57–66. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F.M. YAGO3: A Knowledge Base from Multilingual Wikipedias. In Proceedings of the Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Agrawal, N.; Talukdar, P. Interacte: Improving Convolution-Based Knowledge Graph Embeddings by Increasing Feature Interactions. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3009–3016. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, J.; Ye, J.; Wu, F. Rethinking Graph Convolutional Networks in Knowledge Graph Completion. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 798–807. [Google Scholar]
- Demir, C.; Ngomo, A.-C.N. Convolutional Complex Knowledge Graph Embeddings. In Proceedings of the Semantic Web: 18th International Conference, ESWC 2021, Virtual Event, 6–10 June 2021; pp. 409–424. [Google Scholar]
- Liu, X.; Tan, H.; Chen, Q.; Lin, G. Ragat: Relation Aware Graph Attention Network for Knowledge Graph Completion. IEEE Access 2021, 9, 20840–20849. [Google Scholar] [CrossRef]
- Li, J.; Su, X.; Zhang, F.; Gao, G. TransERR: Translation-based Knowledge Graph Embedding via Efficient Relation Rotation. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Turin, Italy, 20–25 May 2024; pp. 16727–16737. [Google Scholar]
- Rossi, A.; Barbosa, D.; Firmani, D.; Matinata, A.; Merialdo, P. Knowledge Graph Embedding for Link Prediction: A Comparative Analysis. ACM Trans. Knowl. Discov. Data 2021, 15, 1–49. [Google Scholar] [CrossRef]
- Le, T.; Le, N.; Le, B. Knowledge Graph Embedding by Relational Rotation and Complex Convolution for Link Prediction. Expert Syst. Appl. 2023, 214, 119122. [Google Scholar] [CrossRef]
- Le, T.; Huynh, N.; Le, B. RotatHS: Rotation Embedding on the Hyperplane with Soft Constraints for Link Prediction on Knowledge Graph. In Proceedings of the Computational Collective Intelligence: 13th International Conference, ICCCI 2021, Rhodes, Greece, 29 September–1 October 2021; pp. 29–41. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.-C.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Event, 5–10 July 2020; pp. 6901–6914. [Google Scholar]
- Li, J.; Su, X.; Gao, G. Teast: Temporal Knowledge Graph Embedding via Archimedean Spiral Timeline. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 15460–15474. [Google Scholar]
 denotes the Hadamard product operation).
denotes the Hadamard product operation).
denotes the Hadamard product operation).
denotes the Hadamard product operation).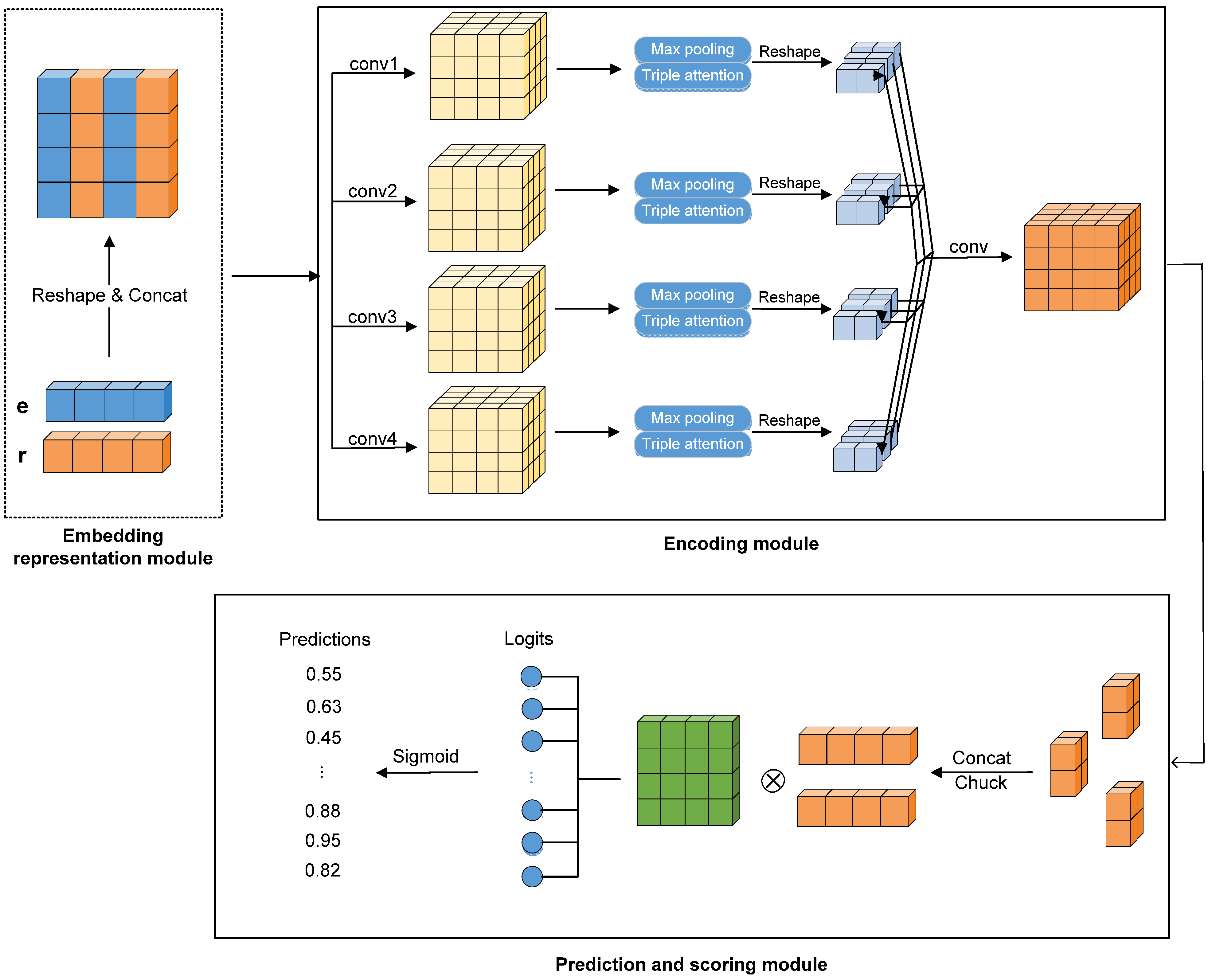


{kind=link}
{kind=link}
{kind=link}
| Model | Scoring Function | Embedding Space | Relationship Parameters |
|---|---|---|---|
| TransE [7] | |||
| DistMult [10] | |||
| ComplEx [11] | |||
| ConvE [14] | |||
| ConvKB [20] | |||
| TuckER [13] | |||
| RotatE [12] | |||
| SimplE [27] | |||
| ConvAMC (proposed) | Re |
| Dataset | Entities | Relations | Triplets | ||
|---|---|---|---|---|---|
| Train | Valid | Test | |||
| FB15k | 14,951 | 1345 | 483,142 | 50,000 | 59,071 |
| WN18 | 40,943 | 18 | 141,442 | 5000 | 5000 |
| FB15k-237 | 14,541 | 237 | 272,115 | 17,535 | 20,446 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| YAGO3-10 | 123,182 | 37 | 1,079,040 | 5000 | 5000 |
| Model | MRR | Hit@1 | Hit@3 | Hit@10 |
|---|---|---|---|---|
| TransE & | 0.230 | - | - | 0.501 |
| DistMult & | 0.430 | 0.390 | 0.440 | 0.490 |
| ComplEx † | 0.440 | 0.410 | 0.460 | 0.510 |
| ConvE [14] | 0.430 | 0.400 | 0.440 | 0.520 |
| InteractE [30] | 0.463 | 0.430 | - | 0.528 |
| TuckER [13] | 0.470 | 0.443 | 0.482 | 0.526 |
| RotatE [12] | 0.476 | 0.428 | 0.492 | 0.571 |
| ConvHLE [25] | 0.469 | 0.437 | 0.482 | 0.532 |
| ConEx [32] | 0.481 | 0.448 | 0.493 | 0.550 |
| ConvEICF [24] | 0.486 | 0.446 | 0.501 | 0.560 |
| RAGAT [33] | 0.489 | 0.452 | 0.503 | 0.562 |
| TransERR [34] | 0.501 | 0.450 | 0.520 | 0.605 |
| ConvAMC (proposed) | 0.438 | 0.470 | 0.514 | 0.559 |
| Model | MRR | Hit@1 | Hit@3 | Hit@10 |
|---|---|---|---|---|
| TransE & | 0.294 | - | - | 0.465 |
| DistMult & | 0.241 | 0.155 | 0.263 | 0.419 |
| ComplEx † | 0.247 | 0.158 | 0.275 | 0.428 |
| ConvE [14] | 0.325 | 0.237 | 0.356 | 0.501 |
| InteractE [30] | 0.354 | 0.263 | - | 0.535 |
| TuckER [13] | 0.358 | 0.246 | 0.380 | 0.544 |
| RotatE [12] | 0.338 | 0.241 | 0.375 | 0.533 |
| ConvHLE [25] | 0.360 | 0.268 | 0.395 | 0.544 |
| ConEx [32] | 0.366 | 0.271 | 0.403 | 0.555 |
| ConvEICF [24] | 0.365 | 0.271 | 0.401 | 0.554 |
| RAGAT [33] | 0.365 | 0.273 | 0.401 | 0.547 |
| ConvRot [36] | 0.386 | 0.290 | 0.423 | 0.575 |
| TransERR [34] | 0.360 | 0.264 | 0.396 | 0.555 |
| ConvAMC (proposed) | 0.414 | 0.320 | 0.459 | 0.602 |
| Model | MRR | Hit@1 | Hit@3 | Hit@10 |
|---|---|---|---|---|
| TransE & | 0.501 | 0.406 | - | 0.632 |
| ComplEx & | 0.360 | 0.260 | 0.400 | 0.550 |
| ComplEx-N3 ‡ | 0.569 | 0.498 | 0.609 | 0.701 |
| DistMult [10] | 0.501 | 0.413 | - | 0.690 |
| ConvE [14] | 0.440 | 0.350 | 0.490 | 0.620 |
| InteractE [30] | 0.541 | 0.462 | - | 0.687 |
| RotatE [12] | 0.495 | 0.402 | 0.550 | 0.670 |
| RotatHS [37] | 0.551 | 0.468 | 0.603 | 0.699 |
| ConEx [32] | 0.553 | 0.474 | 0.601 | 0.696 |
| M-DCN [16] | 0.505 | 0.423 | 0.587 | 0.682 |
| HypER [15] | 0.533 | 0.455 | 0.580 | 0.678 |
| ConvRot [36] | 0.538 | 0.448 | 0.593 | 0.700 |
| ConvAMC (proposed) | 0.610 | 0.540 | 0.677 | 0.766 |
| Dataset | MRR | Hit@1 | Hit@3 | Hit@10 |
|---|---|---|---|---|
| WN18RR | 0.435 ± 0.003 | 0.470 ± 0.003 | 0.512 ± 0.003 | 0.555 ± 0.003 |
| FB15k-237 | 0.412 ± 0.003 | 0.320 ± 0.003 | 0.457 ± 0.003 | 0.600 ± 0.003 |
| YAGO3-10 | 0.609 ± 0.003 | 0.538 ± 0.003 | 0.673 ± 0.003 | 0.765 ± 0.003 |
| ConvAMC | FB15k-237 | WN18RR | ||||||
|---|---|---|---|---|---|---|---|---|
| MRR | Hit@1 | Hit@3 | Hit@10 | MRR | Hit@1 | Hit@3 | Hit@10 | |
| Without TA | 0.388 | 0.294 | 0.423 | 0.573 | 0.423 | 0.459 | 0.496 | 0.534 |
| Without MP | 0.391 | 0.299 | 0.426 | 0.579 | 0.426 | 0.460 | 0.499 | 0.541 |
| Without MC | 0.386 | 0.296 | 0.422 | 0.576 | 0.436 | 0.464 | 0.498 | 0.538 |
| Full model (with all modules) | 0.414 | 0.320 | 0.459 | 0.602 | 0.438 | 0.470 | 0.514 | 0.559 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, L.; Liu, W.; Wu, Y.; Dai, C.; Ji, Z.; Ganchev, I. Knowledge Graph Embedding Using a Multi-Channel Interactive Convolutional Neural Network with Triple Attention. Mathematics 2024, 12, 2821. https://doi.org/10.3390/math12182821
Shi L, Liu W, Wu Y, Dai C, Ji Z, Ganchev I. Knowledge Graph Embedding Using a Multi-Channel Interactive Convolutional Neural Network with Triple Attention. Mathematics. 2024; 12(18):2821. https://doi.org/10.3390/math12182821
Chicago/Turabian StyleShi, Lin, Weitao Liu, Yafeng Wu, Chenxu Dai, Zhanlin Ji, and Ivan Ganchev. 2024. "Knowledge Graph Embedding Using a Multi-Channel Interactive Convolutional Neural Network with Triple Attention" Mathematics 12, no. 18: 2821. https://doi.org/10.3390/math12182821
APA StyleShi, L., Liu, W., Wu, Y., Dai, C., Ji, Z., & Ganchev, I. (2024). Knowledge Graph Embedding Using a Multi-Channel Interactive Convolutional Neural Network with Triple Attention. Mathematics, 12(18), 2821. https://doi.org/10.3390/math12182821