

Sentiment Analysis: Predicting Product Reviews for E-Commerce Recommendations Using Deep Learning and Transformers

Abstract
1. Introduction
2. Background and Related Work
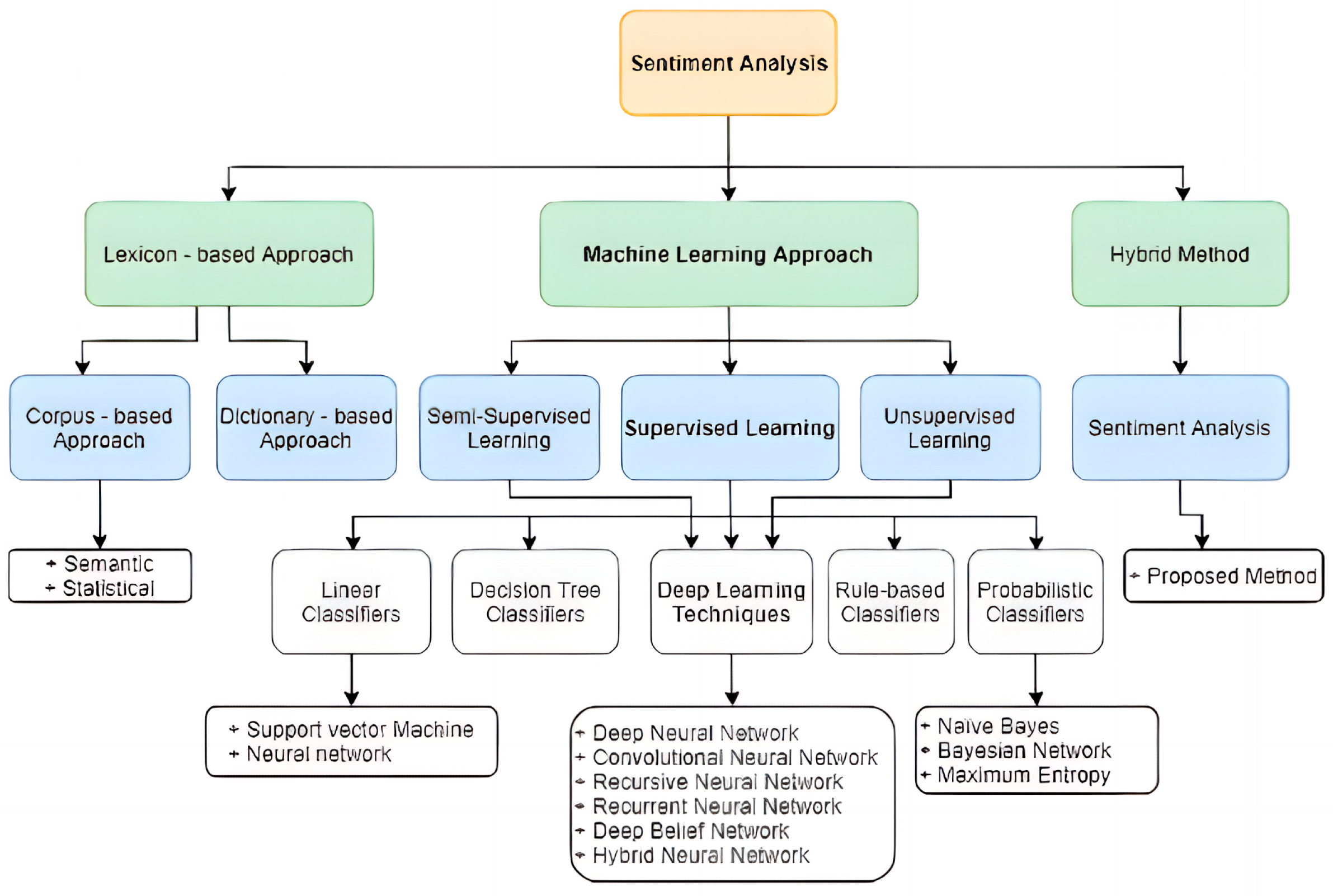
2.1. Sentiment Analysis
- Binary Sentiment Analysis: Positive/negative sentiment. Binary sentiment analysis divides text into positive or negative groups. This approach is used in tasks such as assessing sentiment in product reviews, where the goal is to evaluate whether the expressed attitude is good or negative.
- Ternary Sentiment Analysis: Sentiment: positive, negative, neutral. This style of literature is divided into three different categories: positive, negative, and neutral. This is useful when a more nuanced attitude is required or when a large number of texts express a neutral opinion.
- Multi-Class Sentiment Analysis: Includes multiple sentiment categories. Unlike the three-category approach, multi-class sentiment analysis divides text into several sentiment categories. Sentiment can be categorized as very positive, positive, neutral, negative, or very negative. This strategy allows for a more extensive and sophisticated study of sentiment.
- Ambiguity and situation: Language is inherently ambiguous, and the same words or phrases can have different meanings depending on the situation. Sentences such as “I’m dying of laughter” or “This movie is wicked” provide difficulties in interpretation without context.
- Sarcasm and Irony: Detecting sarcasm, irony, and other forms of figurative language is a significant challenge for sentiment analysis models. This issue arises because the sentiment expressed frequently contradicts the actual meaning of the words.
- Negation: Negations can drastically change the sentiment of a statement. For example, “not bad” is positive while “not good” is negative. Understanding the influence of negations is critical for conducting proper sentiment analysis.
- Emoticons and emojis: Individuals often utilize emojis and emoticons to convey emotions, and these symbols can pose challenges for models to accurately interpret.
- Slang and Informal Language: Sentiment analysis methods may struggle with slang, informal language, and expressions unique to a certain community or subculture. These expressions may not be present in the training data.
- Product Feedback: sentiment analysis may help organizations collect client feedback via reviews, social media, and polls, providing insights into how their products or services are regarded.
- Competitor Analysis: companies can use sentiment analysis to examine the sentiment surrounding their competitors, identifying their strengths and flaws.
- Real-time Feedback: sentiment analysis technologies can actively monitor social media and customer service channels to detect and handle client issues and sentiments.
- Chatbots: integrating sentiment analysis into chatbots allows them to better understand and respond to client emotions and wants.
- Crisis Management: brands can use sentiment analysis to detect and address possible PR disasters on social media and news channels.
- Brand Monitoring: this tool helps firms track how their brand is perceived over time and across locations.
- Feature Prioritization: analyzing consumer sentiment allows organizations to prioritize product innovations and upgrades based on customer value.
- Innovation: sentiment analysis helps to discover developing trends and client requests, which can provide significant assistance for innovation efforts.
- Stock Market Prediction: sentiment analysis of news items and social media discussions can anticipate stock market trends.
- Risk Management: analyzing sentiment in financial reports and news helps to estimate market sentiment and risk.
2.2. Recommendation Systems
- Content-Based Filtering: This technique suggests products based on the user’s past choices or actions. To generate recommendations, it assesses an object’s qualities or attributes and contrasts them with the user’s profile or past. A movie recommendation system might, for instance, make recommendations for similar movies based on the plot, performers, or genre.
- Collaborative Filtering: Products are suggested according to the preferences and actions of other users who have similar tastes. It finds patterns and similarities in user behavior, like ratings and purchases, and suggests products that people with similar interests have found enjoyable. This approach is based more on user behavior than item features.
- Hybrid Approaches: To increase suggestion accuracy, hybrid recommendation systems include a number of methods. In addition to conventional machine learning algorithms, these systems might employ collaborative and content-based filtering techniques to offer more detailed and varied recommendations.
- Matrix factorization: This is a technique that breaks down user-item interaction matrices to uncover latent components or attributes. Examples include singular value decomposition (SVD) and alternating least squares (ALS). By capturing underlying trends, these systems may forecast missing ratings and then recommend things.
- Deep Learning-Based Methods: Neural networks and other deep learning models can be applied to enhance the performance of recommendation systems. These models can produce more precise recommendations by incorporating complex patterns and representations from huge datasets. For recommendation tasks, methods such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are employed.
- Techniques Based on Natural Language Processing (NLP): Recommendation systems have the capability to utilize natural language processing (NLP) techniques such as sentiment analysis, text classification, or topic modeling to extract insights from textual inputs. Algorithms based on NLP, which can interpret user reviews, feedback, or product descriptions, can subsequently offer recommendations based on sentiment analysis or linguistic resemblance.
2.3. Related Work
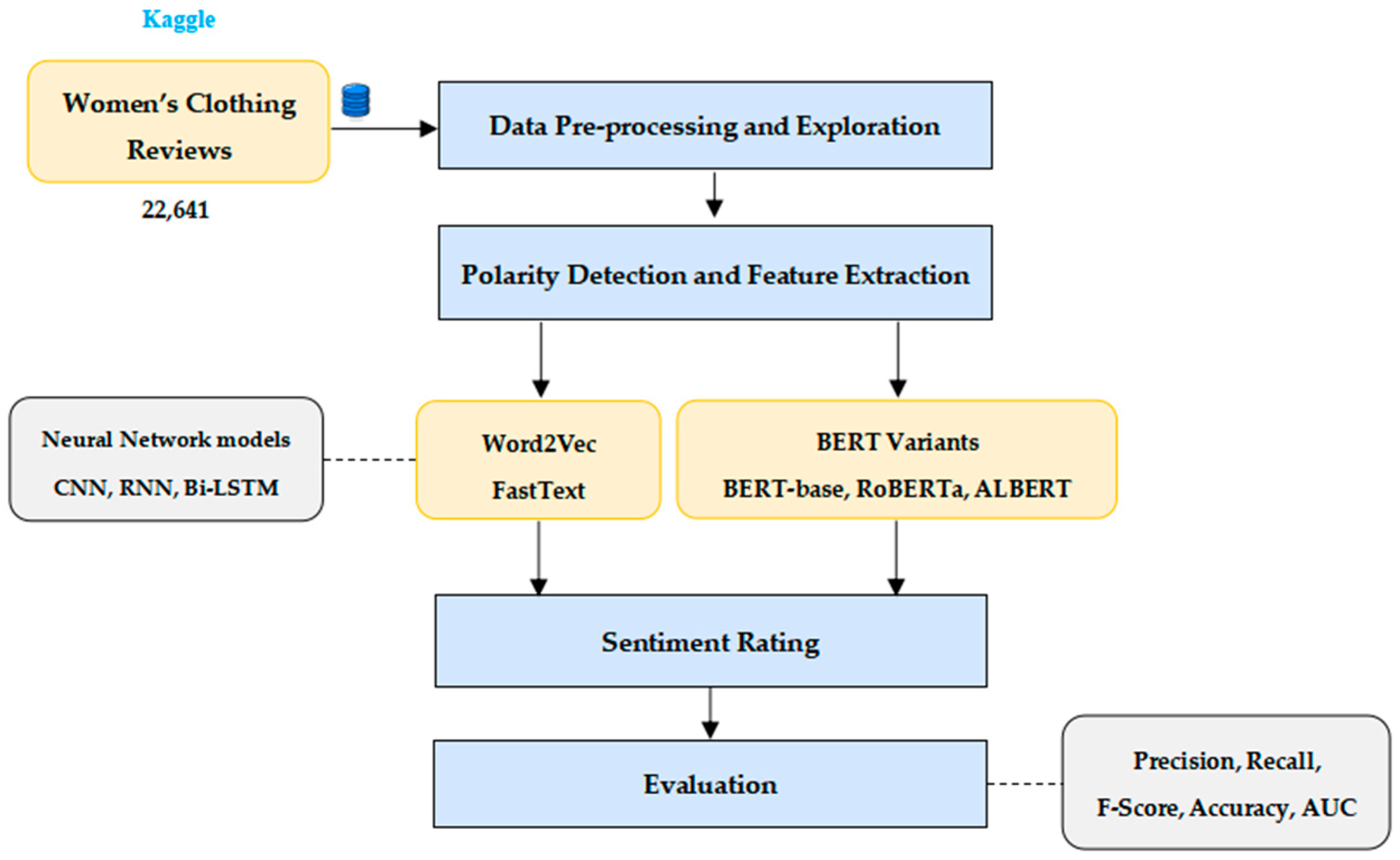
3. Proposed Methodology
3.1. Dataset Description
- Clothing ID: An integer category variable that designates the precise item under examination.
- Age: The age of the reviewer is represented as a positive integer variable.
- Title: A string variable containing the review’s title.
- Review Text: A text variable containing the review’s body.
- Rating: A positive ordinal integer variable, with a range of 1 (worst) to 5 (best), that indicates the client’s product score.
- Recommended IND: A binary variable that indicates if the customer recommends the product (1 = recommended, 0 = not recommended).
- Number of Positive Comments: A positive number signifying how many other consumers thought this review was good.
- Division Name: A categorical name that represents the product’s highest-level division.
- Department Name: A classification name designating the department of products.
- Class Name: Identifies the product class.
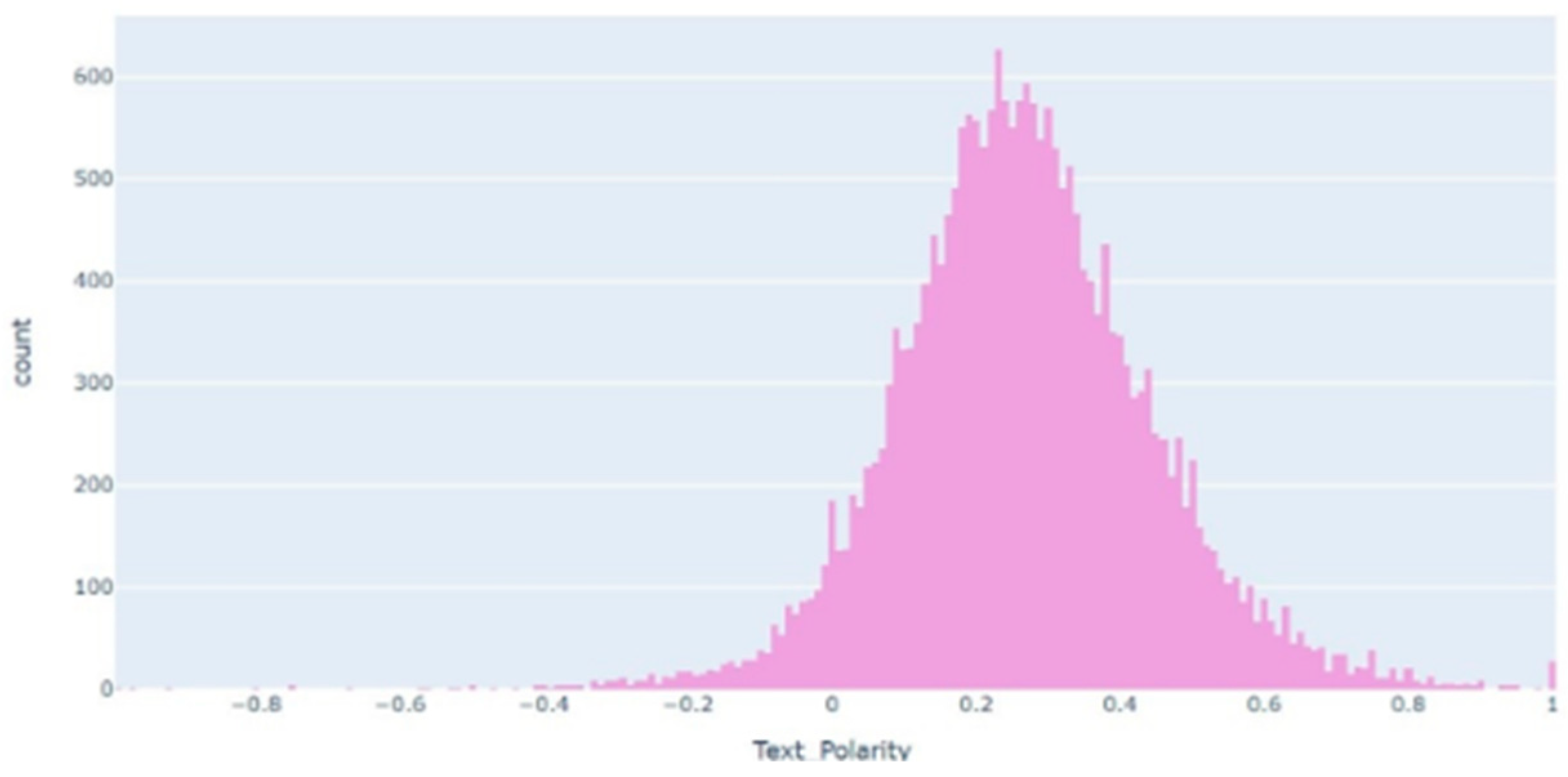
3.2. Data Pre-Processing and Exploration
3.3. Polarity Detection and Feature Extraction
- Word2Vec: a trained model that creates an embedded vector for every word in a text by identifying word associations in a corpus.
- FastText: a Word2Vec plugin that breaks down words into n-grams, or smaller units, like “application” into “app,” with the goal of teaching word morphology. Every word in the text is converted by the model into a bag of embedded vectors.
3.4. Description of the Models Used for Sentiment Analysis
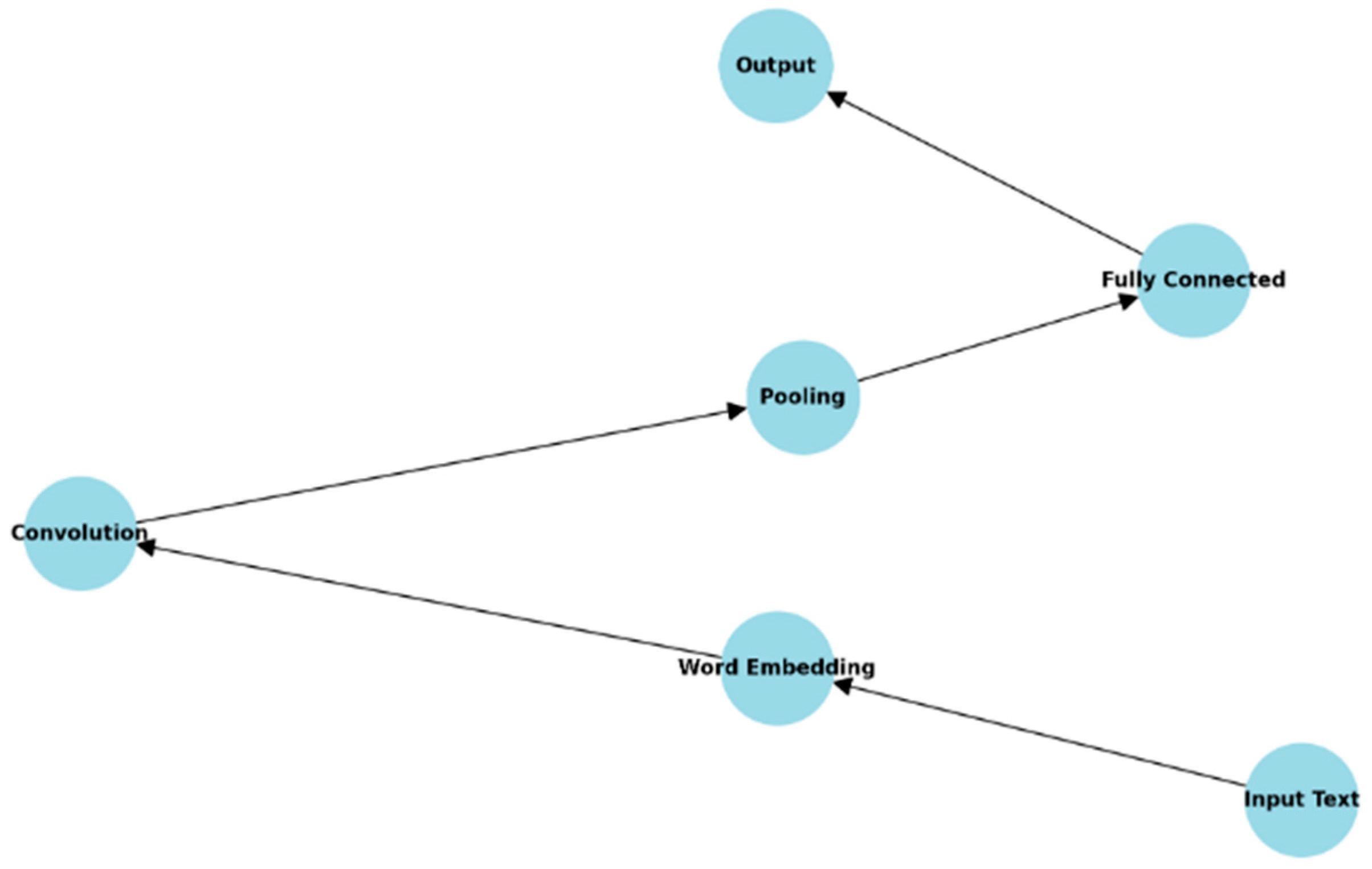
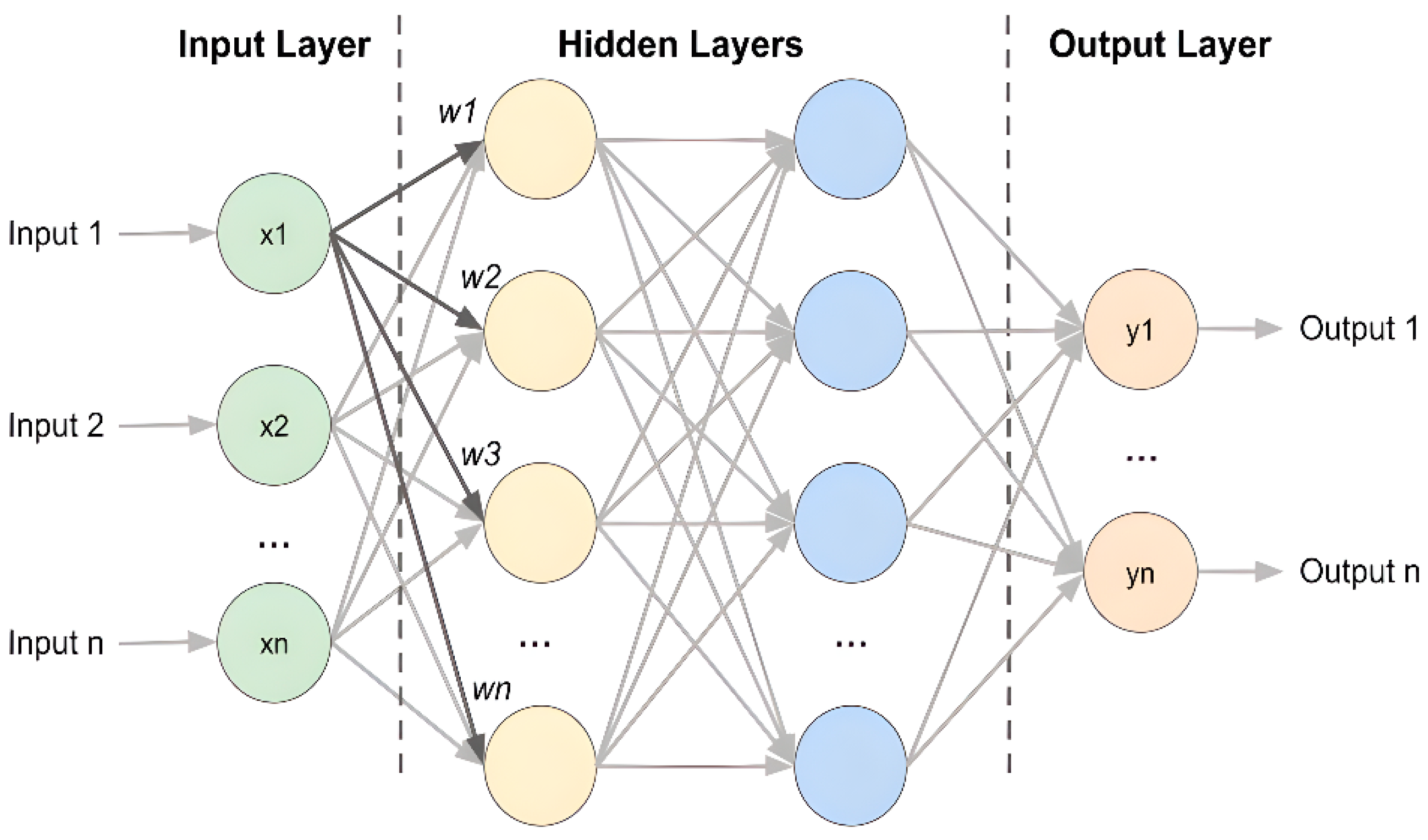
3.4.1. Convolutional Neural Network (CNN)
- Architecture:
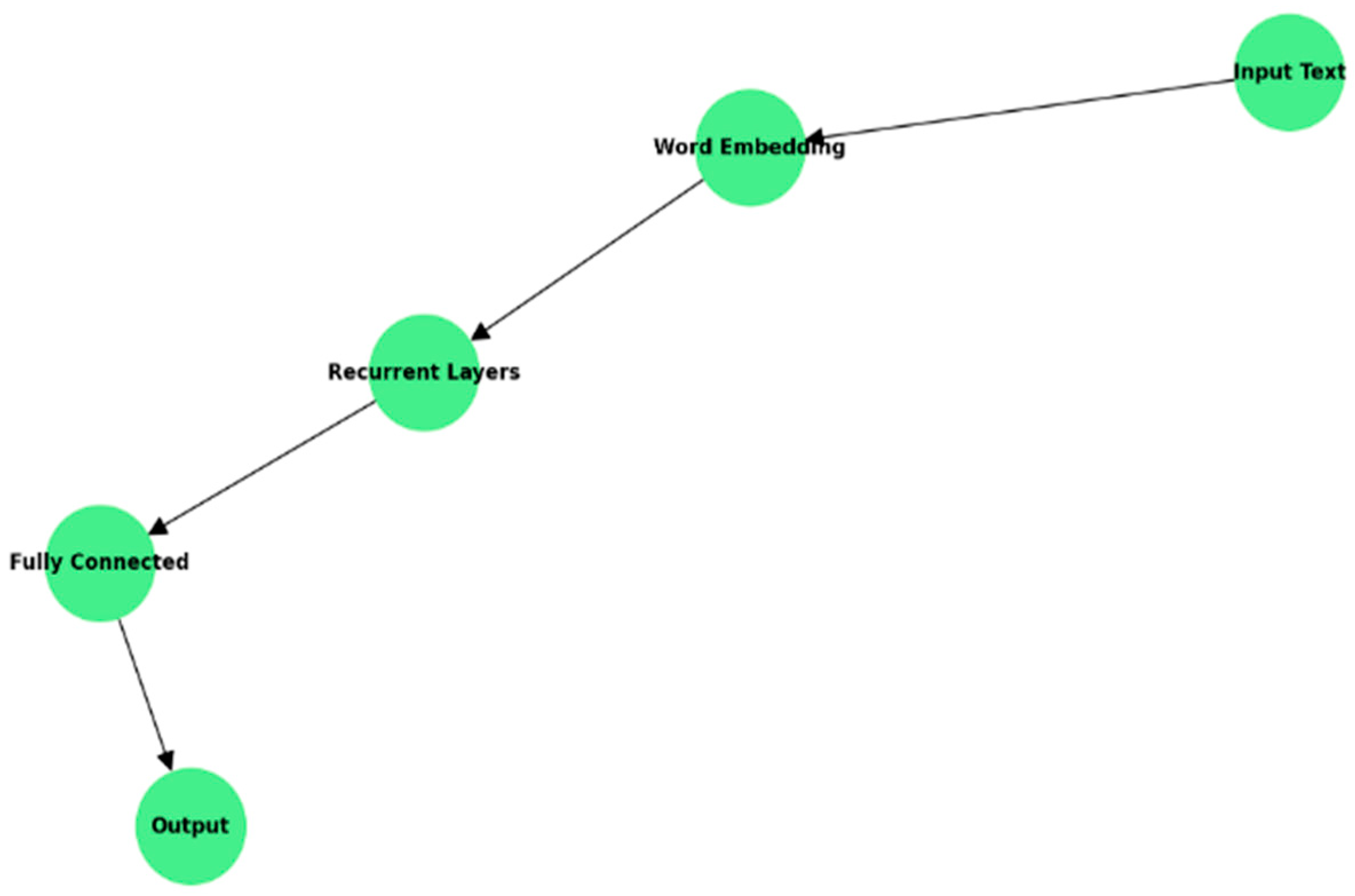
3.4.2. Recurrent Neural Network (RNN)
- Architecture:
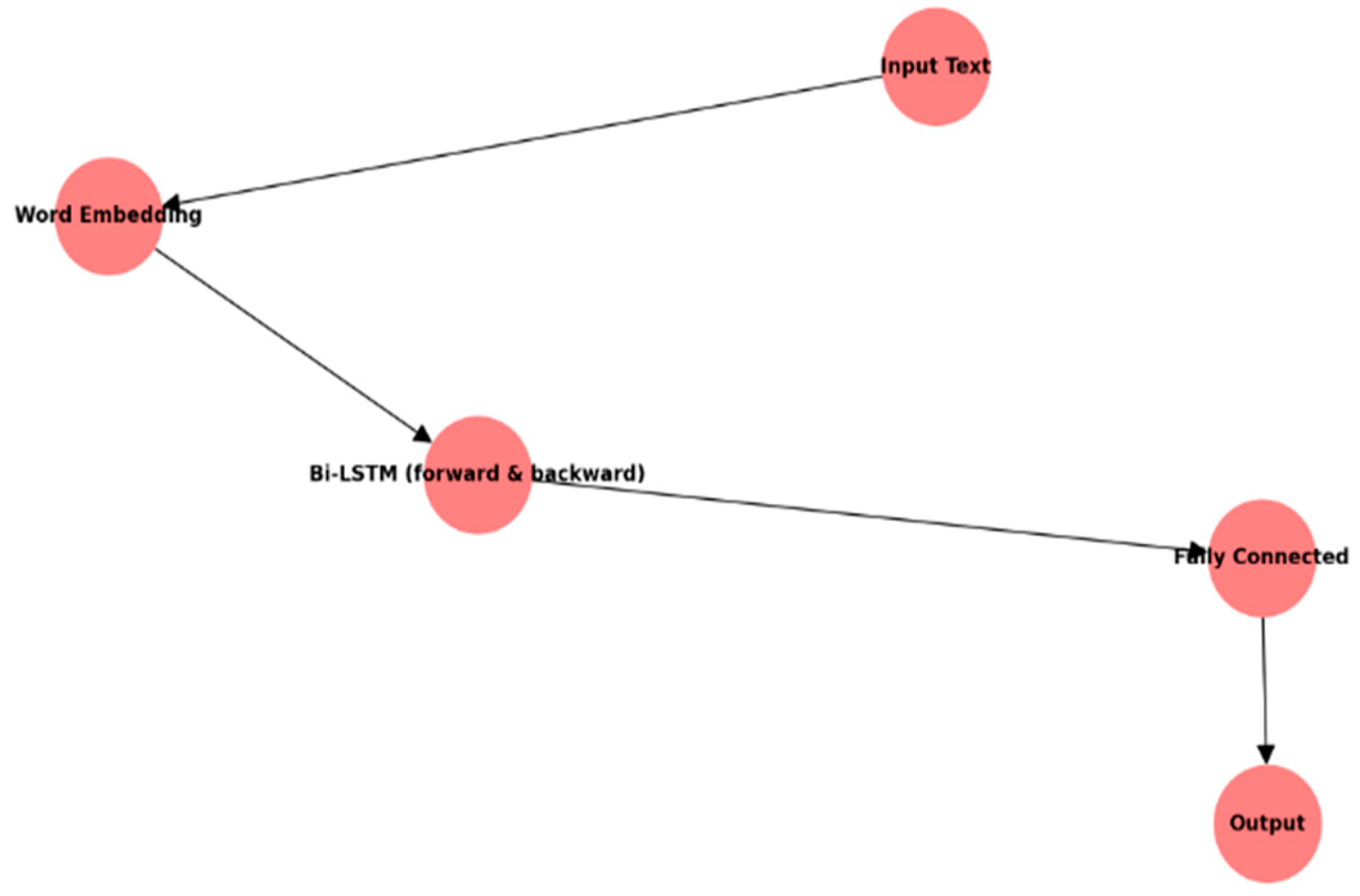
3.4.3. Bi-Directional Long Short-Term Memory (Bi-LSTM)
- Architecture:
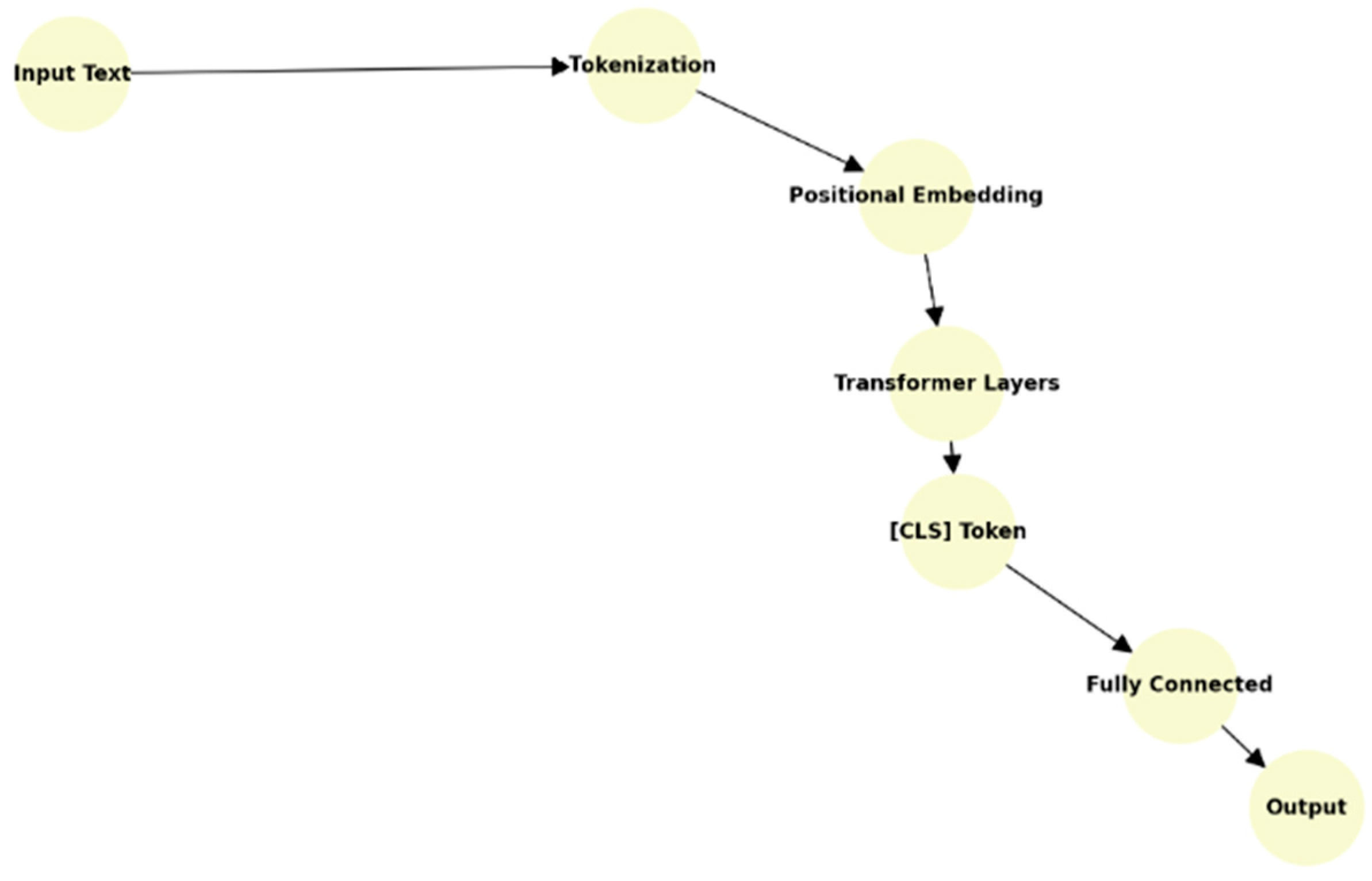
3.4.4. Bidirectional Encoder Representations from Transformers (BERT)
- Architecture:
3.5. Sentiment Analysis Review Predictions with Deep Learning Models
3.6. Machine Learning Models
3.7. Evaluation
4. Experimental Results and Discussion
4.1. Experiment
- 3-class: Combining ratings 1 and 2 indicated negative sentiment, 3 indicated neutral emotion, and combining ratings 4 and 5 indicated positive sentiment [30].
- 5-class: This corresponds to the original rating system, which consisted of five categories: 1 denoting extremely negative, 2 representing negative, 3 indicating neutral, 4 signifying positive, and 5 denoting extremely positive [31].
- Utilization of RNN, CNN, and Bi-LSTM models with Word2Vec and FastText embeddings on the dataset.
- Assessment of BERT variants (including BERT, RoBERTa, and ALBERT) in both 5-class and 3-class configurations.
4.2. Neural Network-Based Models Using Word2Vec and FastText Embeddings
4.3. BERT Variants for Sentiment Review Prediction
4.4. Ensemble Neural Network Models for Sentiment Rating Prediction
4.5. Machine Learning Models for Sentiment Prediction
5. Conclusions, Limitations, and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Zhang, A.; Liu, D.; Bian, Y. Customer preferences extraction for air purifiers based on fine-grained sentiment analysis of online reviews. Knowl.-Based Syst. 2021, 228, 107259. [Google Scholar] [CrossRef]
- Ma, L.; Wang, Y. Constructing a semantic graph with depression symptoms extraction from twitter. In Proceedings of the 16th IEEE International Conference on Computational Intelligence in Bioinformatics and Computational Biology, Siena Tuscany, Italy, 9–11 July 2019; IEEE: New York, NY, USA; pp. 1–5. [Google Scholar]
- Bhowmik, N.R.; Arifuzzaman, M.; Mondal, M.R.H.; Islam, M. Bangla text sentiment analysis using supervised machine learning with extended lexicon dictionary. Nat. Lang. Process. Res. 2021, 1, 34–45. [Google Scholar] [CrossRef]
- Wu, J.J.; Chang, S.T. Exploring customer sentiment regarding online retail services: A topicbased approach. J. Retail. Consum. Serv. 2020, 55, 102145. [Google Scholar] [CrossRef]
- Xu, F.; Pan, Z.; Xia, R. E-commerce product review sentiment classification based on a Naïve Bayes continuous learning framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Kabir, A.I.; Ahmed, K.; Karim, R. Word Cloud and Sentiment Analysis of Amazon Earphones Reviews with R Programming Language. Inform. Econ. 2020, 24, 55–71. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Lok, P.Y.; Rahim, H.A. A semi-supervised approach in detecting sentiment and emotion based on digital payment reviews. J. Supercomput. 2021, 77, 3795–3810. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment analysis for E commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Carosia, A.E.; Coelho, G.P.; Silva, A.E. Investment strategies applied to the Brazilian stock market: A methodology based on sentiment analysis with deep learning. Expert Syst. Appl. 2021, 184, 115470. [Google Scholar] [CrossRef]
- Zad, S.; Heidari, M.; Jones, J.H.; Uzuner, O. A survey on concept level sentiment analysis techniques of textual data. In Proceedings of the 2021 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 10–13 May 2021; IEEE: New York, NY, USA; pp. 0285–0291. [Google Scholar]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]
- Keikhosrokiani, P.; Pourya Asl, M. (Eds.) Handbook of Research on Opinion Mining and Text Analytics on Literary Works and Social Media; IGI Global: Pennsylvania, PA, USA, 2022. [Google Scholar]
- Fang, X.; Zhan, J. Sentiment analysis using product review data. J. Big Data 2015, 2, 5. [Google Scholar] [CrossRef]
- Mukherjee, S.; Bhattacharyya, P. Feature specific sentiment analysis for product reviews. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, New Delhi, India, 11–17 March 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 475–487. [Google Scholar]
- Yadav, A.; Jha, C.K.; Sharan, A.; Vaish, V. Sentiment analysis of financial news using unsupervised approach. Procedia Comput. Sci. 2020, 167, 589–598. [Google Scholar] [CrossRef]
- Zhan, Y.; Han, R.; Tse, M.; Ali, M.H.; Hu, J. A social media analytic framework for improving operations and service management: A study of the retail pharmacy industry. Technol. Forecast. Soc. Change 2021, 163, 120504. [Google Scholar] [CrossRef]
- Taparia, A.; Bagla, T. Sentiment analysis: Predicting product reviews’ ratings using online customer reviews. Soc. Sci. Res. Netw. 2020. [CrossRef]
- Peng, J.; Fung, J.S.; Murtaza, M.; Rahman, A.; Walia, P.; Obande, D.; Verma, A.R. A sentiment analysis of the Black Lives Matter movement using Twitter. STEM Fellowsh. J. 2022, 8, 1–11. [Google Scholar] [CrossRef]
- Colón-Ruiz, C.; Segura-Bedmar, I. Comparing deep learning architectures for sentiment analysis on drug reviews. J. Biomed. Inform. 2020, 110, 103539. [Google Scholar] [CrossRef] [PubMed]
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained sentiment classification using BERT. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019; IEEE: New York, NY, USA. [Google Scholar]
- Wu, F.; Shi, Z.; Dong, Z.; Pang, C.; Zhang, B. Sentiment analysis of online product reviews based on SenBERT-CNN. In Proceedings of the 2020 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 2–15 July 2020; pp. 229–234. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An effective BERT-based pipeline for twitter sentiment analysis: A case study in ITALIAN. Sensors 2021, 21, 133. [Google Scholar] [CrossRef] [PubMed]
- Qurat, T.A.; Mubashir, A.; Amna, R.; Amna, N.; Muhammad, K.; Babar, H.; Rehman, A. Sentiment Analysis Using Deep Learning Techniques: A Review. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 424–433. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text data augmentation for deep learning. J. Big Data 2021, 8, 101. [Google Scholar] [CrossRef] [PubMed]
- Shuai, Z.; Lina, Y.; Aixin, S. Deep Learning based Recommender System: A Survey and New Perspectives. ACM J. Comput. Cult. Herit. 2017, 52, 1–38. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kobayashi, S. Contextual augmentation: Data augmentation bywords with paradigmatic relations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 452–457. [Google Scholar] [CrossRef]
- Duong, H.T.; Nguyen-Thi, T.A. A review: Preprocessing techniques and data augmentation for sentiment analysis. Comput. Soc. Netw. 2021, 8, 1. [Google Scholar] [CrossRef]
- Alaoui, M.E.; Bouri, E.; Azoury, N. The determinants of the U.S. consumer sentiment: Linear and nonlinear models. Int. J. Financ. Stud. 2020, 8, 38. [Google Scholar] [CrossRef]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Topic-level sentiment analysis of social media data using deep learning. Appl. Soft Comput. 2021, 108, 107440. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Haque, T.U.; Saber, N.N.; Shah, F.M. Sentiment analysis on large scale Amazon product reviews. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10, Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 79–86. [Google Scholar]
- Kaur, W.; Balakrishnan, V. Improving sentiment scoring mechanism: A case study on airline services. Ind. Manag. Data Syst. 2018, 118, 1578–1596. [Google Scholar] [CrossRef]
- Lee, H.; Lee, N.; Seo, H.; Song, M. Developing a supervised learning-based social media business sentiment index. J. Supercomput. 2019, 76, 3882–3897. [Google Scholar] [CrossRef] [PubMed]
- Prabha, M.I.; Srikanth, G.U. Survey of Sentiment Analysis Using Deep Learning Techniques. In Proceedings of the 1st International Conference on Innovations in Information and Communication Technology (ICIICT), Chennai, India, 25–26 April 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Mandhula, T.; Pabboju, S.; Gugalotu, N. Predicting the customer’s opinion on amazon products using selective memory architecture-based convolutional neural network. J. Supercomput. 2019, 76, 5923–5947. [Google Scholar] [CrossRef]
- Al-Dabet, S.; Tedmori, S.; Al-Smadi, M. Enhancing Arabic aspect-based sentiment analysis using deep learning models. Comput. Speech Lang. 2021, 69, 101224. [Google Scholar] [CrossRef]
- Pasupa, K.; Ayutthaya, T.S. Thai sentiment analysis with deep learning techniques: A comparative study based on word embedding POS-tag, sentic features. Sustain. Cities Soc. 2019, 50, 101615. [Google Scholar] [CrossRef]
- Kurniasari, L.; Setyanto, A. Sentiment analysis using recurrent neural network. J. Phys. Conf. Ser. 2020, 1471, 17–18. [Google Scholar] [CrossRef]
- Hameed, Z.; Garcia-Zapirain, B. Sentiment classification using a single-layered BiLSTM model. IEEE Access 2021, 8, 73992–74001. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Bellar, O.; Baina, A.; Bellafkih, M. Application of Machine Learning to Sentiment Analysis. In Proceedings of the 3rd International Conference on Artificial Intelligence and Computer Vision (AICV2023), Marrakesh, Morocco, 5–7 March 2023; Hassanien, A.E., Haqiq, A., Azar, A.T., Santosh, K.C., Jabbar, M.A., Słowik, A., Subashini, P., Eds.; Lecture Notes on Data Engineering and Communications Technologies. Springer: Cham, Switzerland, 2023; Volume 164. [Google Scholar] [CrossRef]
- Bellar, O.; Baina, A.; Bellafkih, M. Sentiment Analysis of Tweets on Social Issues Using Machine Learning Approach. In Proceedings of the 2023 International Conference on Digital Age & Technological Advances for Sustainable Development (ICDATA), Casablanca, Morocco, 3–5 May 2023; pp. 126–131. [Google Scholar] [CrossRef]
- Oumaima, B.; Amine, B.; Mostafa, B. Deep Learning or Traditional Methods for Sentiment Analysis: A Review. In Innovations in Smart Cities Applications Volume 7. SCA 2023; Ben Ahmed, M., Boudhir, A.A., El Meouche, R., Karaș, İ.R., Eds.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2024; Volume 906. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rating | Class_ Name | Recommended_ IND | Text | Text_ Length | Text_ Polarity | Sentiment | |
|---|---|---|---|---|---|---|---|
| 0 | 4 | Intimates | 1 | Absolutely wonderful silky and sexy and comfortable… | 54 | 0.633 | Positive |
| 1 | 5 | Dresses | 1 | Love this dress it’s sooo pretty i happene. | 304 | 0.340 | Positive |
| 2 | 3 | Dresses | 0 | Some major design flaws I had such high hopes for this dress… | 524 | 0.073 | Positive |
| 3 | 5 | Pants | 1 | My favorite buy I love love love this jumpsuit. | 141 | 0.561 | Positive |
| 4 | 5 | Blouses | 1 | Flattering shirt This shirt is very flattering to all due to the adjustable front tie. | 209 | 0.513 | Positive |
| 5 | 2 | Dresses | 0 | Not for the very petite I love tracy reese dresses. | 512 | 0.181 | Positive |
| 6 | 5 | Knits | 1 | Cagrcoal shimmer fun I aded this in my basket at hte last. | 517 | 0.158 | Positive |
| 7 | 4 | Knits | 1 | Shimmer, surprisingly goes with lots I ordered this in carbon. | 519 | 0.230 | Positive |
| 8 | 5 | Dresses | 1 | Flattering I love this dress. i usually get an xs but it runs a little. | 177 | 0.003 | Positive |
| 9 | 5 | Dresses | 1 | Such a fun dress I’m 55 and 125 lbs i ordered. | 378 | 0.202 | Positive |
| 10 | 3 | Dresses | 0 | Dress looks like it’s made of cheap material Dress runs small. | 381 | −0.047 | Negative |
| 11 | 5 | Dresses | 1 | This dress is perfection! so pretty and flattering | 52 | 0.250 | Positive |
| Feature Extraction | Model | Precision | Recall | F-Score | Accuracy | AUC |
|---|---|---|---|---|---|---|
| 3-class | ||||||
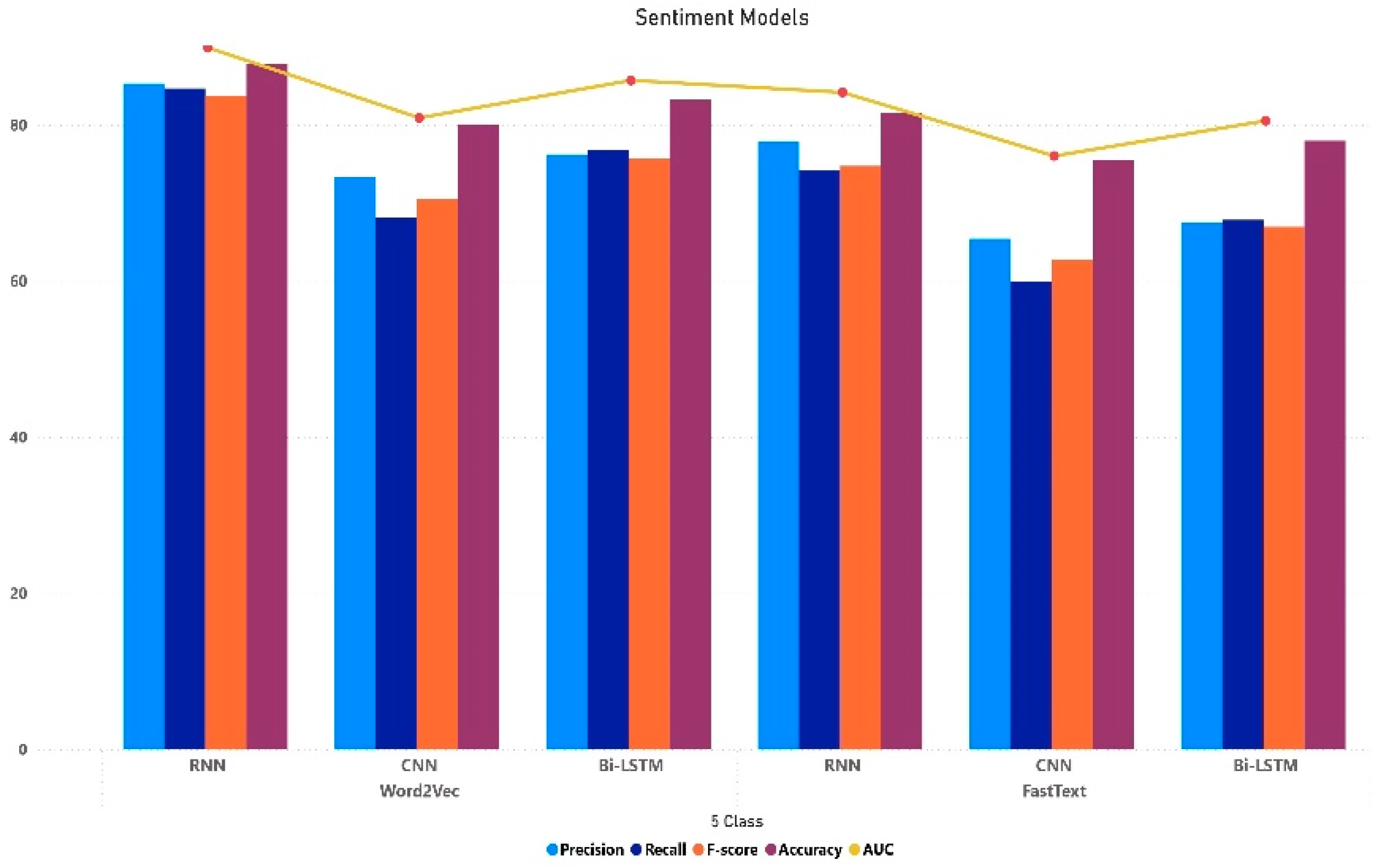
| Word2Vec | CNN | 73.35 | 68.08 | 70.54 | 80.09 | 80.91 |
| RNN | 85.30 | 84.67 | 83.75 | 87.83 | 89.91 | |
| Bi-LSTM | 76.23 | 76.75 | 75.67 | 83.22 | 85.72 | |
| FastText | CNN | 65.42 | 59.97 | 62.72 | 75.45 | 76.03 |
| RNN | 77.89 | 74.15 | 74.76 | 81.53 | 84.17 | |
| Bi-LSTM | 67.48 | 67.85 | 66.96 | 77.99 | 80.54 | |
| 5-class | ||||||
| Word2Vec | CNN | 83.65 | 78.53 | 80.73 | 90.99 | 85.17 |
| RNN | 88.87 | 90.77 | 89.78 | 94.85 | 93.75 | |
| Bi-LSTM | 84.08 | 87.45 | 85.58 | 92.89 | 91.65 | |
| FastText | CNN | 76.07 | 68.39 | 71.45 | 87.61 | 78.19 |
| RNN | 83.76 | 85.28 | 84.47 | 92.37 | 90.12 | |
| Bi-LSTM | 81.89 | 84.15 | 82.95 | 91.75 | 89.57 |
| Class | Model | Precision | Recall | F-Score | Accuracy | AUC |
|---|---|---|---|---|---|---|
| 3-class | BERT | 57.14 | 53.39 | 53.08 | 73.57 | 80.46 |
| ALBERT | 54.79 | 51.57 | 52.51 | 69.08 | 76.37 | |
| RoBERTa | 59.29 | 57.10 | 57.81 | 72.47 | 79.18 | |
| 5-class | BERT | 71.38 | 70.91 | 71.3 | 86.66 | 86.33 |
| ALBERT | 69.29 | 68.53 | 68.84 | 85.59 | 84.55 | |
| RoBERTa | 73.27 | 73.07 | 73.12 | 87.69 | 87.09 |
| Model | Precision | Recall | F-Score | Accuracy | AUC |
|---|---|---|---|---|---|
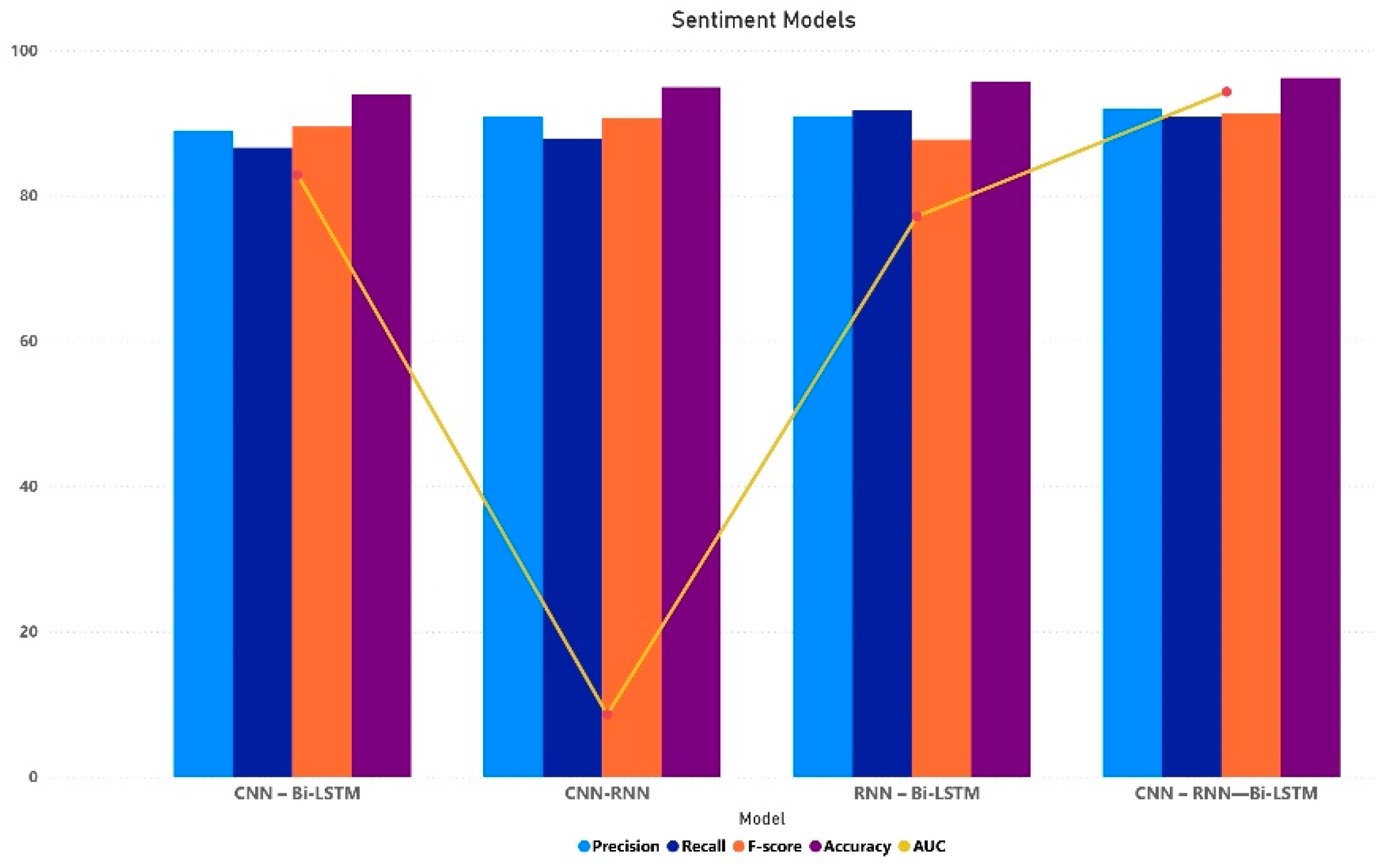
| CNN-RNN | 90.9 | 87.8 | 90.7 | 94.9 | 96.3 |
| CNN–Bi-LSTM | 88.9 | 86.6 | 89.5 | 93.9 | 98.9 |
| RNN–Bi-LSTM | 90.9 | 91.7 | 87.7 | 95.7 | 98.7 |
| CNN–RNN–Bi-LSTM | 91.9 | 90.8 | 91.3 | 96.2 | 99.3 |
| Model | Precision | Recall | F-Score | Accuracy | AUC |
|---|---|---|---|---|---|
| Naïve Bayes | 43.76 | 38.40 | 39.90 | 66.15 | 62.12 |
| Support Vector Machine | 37.71 | 36.21 | 36.82 | 64.23 | 56.11 |
| Logistic Regression | 43.93 | 35.97 | 37.68 | 64.14 | 62.26 |
| Decision Tree | 43.88 | 30.27 | 30.84 | 66.30 | 60.20 |
| Random Forest | 46.15 | 26.27 | 24.80 | 55.02 | 59.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellar, O.; Baina, A.; Ballafkih, M. Sentiment Analysis: Predicting Product Reviews for E-Commerce Recommendations Using Deep Learning and Transformers. Mathematics 2024, 12, 2403. https://doi.org/10.3390/math12152403
Bellar O, Baina A, Ballafkih M. Sentiment Analysis: Predicting Product Reviews for E-Commerce Recommendations Using Deep Learning and Transformers. Mathematics. 2024; 12(15):2403. https://doi.org/10.3390/math12152403
Chicago/Turabian StyleBellar, Oumaima, Amine Baina, and Mostafa Ballafkih. 2024. "Sentiment Analysis: Predicting Product Reviews for E-Commerce Recommendations Using Deep Learning and Transformers" Mathematics 12, no. 15: 2403. https://doi.org/10.3390/math12152403
APA StyleBellar, O., Baina, A., & Ballafkih, M. (2024). Sentiment Analysis: Predicting Product Reviews for E-Commerce Recommendations Using Deep Learning and Transformers. Mathematics, 12(15), 2403. https://doi.org/10.3390/math12152403